
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Concept blending – a cognitive process which allows for the combination of certain elements (and their relations) from originally distinct conceptual spaces into a new unified space combining these previously separate elements, and enables reasoning and inference over the combination – is taken as a key element of creative thought and combinatorial creativity. In this article, we summarise our work towards the development of a computational-level and algorithmic-level account of concept blending, combining approaches from computational analogy-making and case-based reasoning (CBR). We present the theoretical background, as well as an algorithmic proposal integrating higher-order anti-unification matching and generalisation from analogy with amalgams from CBR. The feasibility of the approach is then exemplified in two case studies.
1. Introduction: computational creativity and concept blending
Boden (Citation2003) identifies three forms of creativity: exploratory, transformational, and combinatorial. The label exploratory refers to creativity which arises from a thorough and persistent search of a well-understood domain (i.e. within an already established conceptual space), while transformational creativity either involves the removal of constraints and limitations from the initial domain definition, or the rejection of characteristic assumptions forming part of the specification of the creative problem (or both). Combinatorial creativity shares traits of both other forms in that it arises from a combinatorial process joining familiar ideas (in the form of, for instance, concepts, theories, or artworks) in an unfamiliar way, by this producing novel ideas.
Computationally modelling the latter form of creativity turns out to be surprisingly complicated: although the overall idea of combining preexisting ideas into new ones seems fairly intuitive and straightforward, when looking at it from a more formal perspective at the current stage neither can a precise algorithmic characterisation be given, nor are the details of a possible computational-level theory describing the process(es) at work well understood. Footnote1 Still, in recent years a proposal by Fauconnier and Turner (Citation1998) called concept blending (or conceptual integration) has influenced and reinvigorated studies trying to unravel the general cognitive principles operating during creative thought. In their theory, concept blending constitutes a cognitive process which allows for the combination of certain elements (and their relations) from originally distinct conceptual spaces into a new unified space combining these previously separate elements, and then enables reasoning and inference over the combination. Nevertheless, Fauconnier and Turner (also in their later works) remain mostly silent concerning details needed for a proper computational modelling of concept blending as cognitive capacity – neither do they provide a fully worked out and formalised theory themselves, nor does their informal account capture key properties and functionalities as, for example, the retrieval of input spaces, the selection and transfer of elements from the input spaces into the blend space, or the further combination of possibly mutually contradictory elements in the blend. In short: up until today, the theory does not specify how the blending process is supposed to work.
These shortcomings notwithstanding, several researchers in artificial intelligence (AI) and computational cognitive modelling have used the provided conceptual descriptions as starting point for suggesting possible refinements and implementations: Goguen and Harrell (Citation2010) propose a concept blending-based approach to the analysis of the style of multimedia content in terms of blending principles and also provide an experimental implementation, Pereira (Citation2007) tries to develop a computationally plausible model of several hypothesised sub-parts of concept blending, Thagard and Stewart (Citation2011) exemplify how creative thinking could arise from using convolution to combine neural patterns into ones which are potentially novel and useful, and Veale and O'Donoghue (Citation2000) present a computational model of conceptual integration.
Another attempt at developing a computationally feasible, cognitively inspired formal model of concept creation, grounded on a sound mathematical theory of concepts and implemented in a generic, creative computational system had been undertaken in the EU-FP7 “Concept Invention Theory” (COINVENT) project.Footnote2 One of the main goals of the COINVENT research programme was the development of a computational-level and algorithmic-level account of concept blending based on insights from psychology, AI, and cognitive modelling, the heart of which are made up by results from cognitive systems studies on computational analogy-making and knowledge transfer and combination (i.e. the computation of so-called amalgams) from case-based reasoning (CBR). In the following, we present an analogy-inspired perspective on the resulting COINVENT core model for concept blending and show how the respective mechanisms and systems interact.
2. Cognitive task and theoretical commitments
The cognitive task targeted by COINVENT was the blending of conceptual theories, i.e. of logic-based representations of real-world concepts in finite axiomatisations. Contrary to accounts of mathematical theory blending as, e.g. presented by Martinez et al. (Citation2014), a conceptual theory is not necessarily a (modulo logical equivalence) unique and unambiguous description of a concept. Mathematical theories can offer both properties due to the axiomatic nature of mathematical concepts, making them conceivable as being made up exclusively by the set of defining axioms (or the deductive closure thereof). In contrast, conceptual theories as descriptive results of a formalisation process in most cases represent a certain partial perspective (among several possible ones) on the described concept, instantiating what Bou et al. (Citation2015) call a conceptual space:
Conceptual spaces are partial and temporary representational structures which are constructed on the fly when talking about a particular situation, which are informed by the knowledge structures associated with a domain. These are influenced by Boden's idea of a concept space which is mapped, explored and transformed by transcending mapped boundaries (Boden, Citation1977) (…). (Bou et al., Citation2015, p. 56)
Still, with respect to the computational-level account of the cognitive task addressed by our theory and system, strong parallels exist to the work on mathematical theory blending. The system is presented with two input theories formalised as finite axiomatisations in possibly different logic-based languages (in the case of the algorithmic-level system description in Section 4.3: many-sorted first-order logics), and produces as output another theory describing the blend between the formalised input concepts again as finite axiomatisation in a logic-based language.
In terms of the corresponding account of creativity, we thereby aim to automatise an important mechanism as part of combinatorial creativity in Boden's sense. Approaching this (family of) task(s) via theory blending allows to accommodate for several theoretical characteristics we perceive to be central to blending on the level of real-world concepts:
Concept blending: Blending happens on the knowledge level. While people as cognitive agents in most cases might not be aware of it, the blending process crucially relies on knowledge about the input concepts available to the cogniser. The blending process is then guided by similarities between the input concepts, as characteristics of concepts are not arbitrarily combined during the blending process, but the blending process is guided by shared properties/elements of the input concepts. These similarities also define the basic structure of the resulting blend(s).
Similarities, analogy, and amalgams: Similarities between input concepts are accessible via meaningful generalisation between concepts. On the level of conceptual theories, this corresponds to the anti-unification of theories (see Section 3.1 for details). As such, generalisation-based analogy-making is a suitable approach for identifying and subsequently (via analogical transfer) carrying over these similarities into the basic structure of the blend. The combination of further properties from both input theories can then be conceived of as generalisation-based amalgamation, maintaining the basic structure introduced by the analogy process.
Constraints on the blending process: On the system side, further external constraints imposed by the environment and/or task, and internal properties of the cognitive agent (such as, e.g. expertise) can be taken into account through heuristics and knowledge-sensitive methods during the computation of the blend(s) and the subsequent selection of the final output theory.
Given the central role generalisation, analogy-making, and amalgamation play in our understanding and computational-level theorising of the blending of conceptual theories, we proceed with fairly detailed introductions to the accounts of computational analogy-making and the computation of amalgams used in our theory and system (which are then described in detail in Section 4).
3. Computational models of analogy and amalgams
As analogy seems to play a crucial role in human cognition (see, for instance, the overview provided by Gentner & Smith, Citation2013), researchers on the computational side of cognitive science and in AI also very quickly got interested in the topic and have been creating computational models of analogy-making basically since the advent of computer systems, among others giving rise to Falkenhainer, Forbus, and Gentner (Citation1989)'s well-known Structure-Mapping Engine. One of the latest entries in the long series of computational analogy engines, and the system applied in COINVENT, is the Heuristic-Driven Theory Projection (HDTP) framework (Schmidt, Krumnack, Gust, & Kühnberger, Citation2014), a generalisation-based symbolic analogy engine discussed in detail in Section 3.1.
In a conceptually related, but mostly independently conducted line of work researchers in CBR have been trying to develop problem-solving methodologies based on the principle that similar problems likely tend to have similar solutions. As described by Aamodt and Plaza (Citation1994), CBR tries to solve problems by retrieving one or several relevant cases for the current issue at hand from a case-base with already solved previous problems, and then reusing the knowledge to also tackle the new task. While the retrieval stage has received significant attention over the last two decades, the transfer and combination of knowledge from the retrieved case to the current problem has been studied only to a lesser extent, with Ontañón and Plaza (Citation2012) outlining a recent attempt at also gaining insights on this part of the CBR cycle by suggesting the framework of amalgams (originally introduced by Ontañón & Plaza, Citation2010) as a formal model. Section 3.2 gives an overview of amalgams as used in the COINVENT model.
3.1. Representing and computing generalisation-based analogies using HDTP
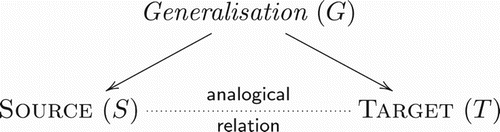
HDTP has been conceived as a mathematically sound theoretical model and implemented engine for computational analogy-making, computing analogical relations and inferences for domains which are presented in (possibly different) many-sorted first-order logic languages: source and target of the analogy-making process are defined in terms of axiomatisations, i.e. given by a finite set of formulae. HDTP follows a generalisation-based approach to analogy-making: given both domains, a common generalisation encompassing structurally shared elements common to both input domains is computed (mapping phase) and this generalisation then guides the analogical alignment and knowledge transfer process of unmatched knowledge from the source to the target domain used for establishing new hypotheses (transfer phase). See Figure for a conceptual overview of the entire analogy mechanism.
Figure 1. A schematic overview of HDTP's generalisation-based approach to analogy.
3.1.1. Representing domain theories and generalisation steps between domains in HDTP
More precisely, HDTP uses many-sorted term algebras to define the input conceptual domains (i.e. one source and one target domain for the later analogy). A term algebra requires two ingredients: a signature and a set of variables.
Definition 3.1
A many-sorted signature is a tuple containing a finite set Sort of sorts, and a finite set Func of function symbols. An n-ary function symbol
is specified by
, where
. We will consider function symbols of any non-negative arity, and we will use 0-ary function symbols to represent constants.
Definition 3.2
Let be a many-sorted signature, and let
be an infinite set of sorted variables, where the sorts are chosen from Sort. Associated with each variable
is an arity, analogous to the arity of function symbols above. For any
, we let
be the variables of arity i. The set
and the function
are defined inductively as follows:
If
, then
If
We refer to the structure as a term algebra, often suppressing sort.
As an example for a domain representation using HDTP's language, Table reproduces a possible formalisation of the concept of “horse” using some of a horse's key characteristics (this formalisation reoccurs below as part of a bigger case study demonstrating the concept blending capacities of the framework combining analogy and amalgams in Section 4.4).
Table 1. Example formalisation of a stereotypical characterisation of a horse.
Given two input domains, HDTP uses anti-unification (firstly studied in a first-order setting by Plotkin, Citation1970) to compute a generalisation of both domains. In this process, terms are generalised resulting in an anti-instance, where differing subterms are replaced by variables; the original terms can be restored by inverting the procedure, i.e. by replacing the new variables by appropriate subterms. These “replacements” can be formalised as substitutions:
Definition 3.3
Given term algebra . A term substitution is a partial function
mapping variables to terms, formally represented by
provided each of the
is unique and the sorts of the variables and terms match. An application of a substitution σ on a term is defined inductively by:
Given two terms and a substitution σ such that
, then we call
an instance of t and t an anti-instance of
. We will often shorten
to
, or
if the substitution is clear from context.
Using substitutions, generalisations can formally be characterised, with the least general generalisation (LGG) playing a special role as most specific anti-unifier (i.e. as minimal with respect to the instantiation order):
Definition 3.4
Let f,g be terms from a term algebra . A generalisation of f and g is a triple
where
and
are substitutions such that
and
. The generalisation
is called the (LGG) if for any generalisation
of f,g, there exists a substitution φ such that
.
As shown by Plotkin (Citation1970), the LGG is unique when considering only first-order anti-unification between terms.
3.1.2. Computing LGGs using restricted higher-order anti-unification as basis for analogies in HDTP
Against this background, Schwering, Krumnack, Kühnberger, and Gust (Citation2009) describe a restricted form of higher-order anti-unification applied in HDTP, defined as using the composition of a number of unit substitutions operating on higher-order terms (also see Figure for concrete examples of the defined substitution operations).
Figure 2. A reproduction of the examples originally given by Schwering et al. (Citation2009) for the different types of higher-order anti-unifications applied in HDTP: a renaming (a), two different forms of fixation (b and c), an argument insertion (d), and a permutation (e).
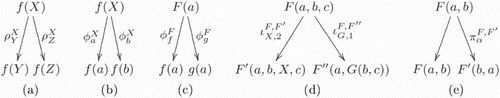
Definition 3.5
The following are the types of unit substitutions allowed in restricted higher-order anti-unification.
A renaming
A fixation
An argument insertion
A permutation
A restricted substitution is a substitution which results from the composition of any sequence of unit substitutions transforming t into
.
Clearly, restricted substitutions are strictly more general than mere (first-order) term substitutions. While for a given term t there are (up to renaming) still only finitely many anti-instances (i.e. terms s with ), this generality unfortunately, among others, causes the LGG to be no longer necessarily unique. Therefore, HDTP ranks generalisations according to a complexity order on the complexity of generalisation (based on a complexity measure for substitutions), and finally chooses the least complex generalisations as preferred ones.
From a practical point of view, it is also necessary to anti-unify not only terms, but formulae: HDTP extends the notion of generalisation also to formulae by basically treating formulae in clause form and terms alike (as positive literals are structurally equal to function expressions, and complex clauses in normal form may be treated component wise).
Furthermore, analogies in general not only rely on an isolated pair of formulae from source and target, but on two sets of formulae, making it necessary to extend the notion of anti-unification accordingly:
Definition 3.6
Let denote the set of all formulae that can be syntactically derived from a set of axioms Ax, i.e.
, and let G be a finite set of formulae.
G is an anti-instance of a set of formulae F if and only if there exists a substitution σ such that . Given substitutions σ and τ,
is a generalisation of two sets of formulae S and T if and only if
and
.
As a simple example, we take the “horse” formalisation from Table and the stereotypical characterisation of a dog given in Table , and generalise them into the shared generalisation in Table .
Table 2. Example formalisation of a stereotypical characterisation of a dog.
Table 3. Shared generalisation of the “horse” and “dog” formalisations from Tables and , respectively.
When processing sets of formulae, a heuristic is applied for iteratively selecting pairs of formulae to be generalised: coherent mappings outmatch incoherent ones, i.e. mappings in which substitutions can be re-used are preferred over isolated substitutions, as they are assumed to be better suited to induce the analogical relation.
Finally, HDTP in its heuristics also aims to maximise the coverage of generalisations:
Definition 3.7
Given a generalisation of two sets of axioms S and T,
is said to be covered by G, and for T accordingly.
The degree to which G covers is called the coverage of G, with a generalisation
having at least the same coverage as
if there exists a substitution θ for which it holds that
,
, and
(inducing a partial order over generalisations).
In general, while there are some constraining factors which have to be taken into account (details on this have been given by Schwering et al., Citation2009), maximising the coverage of an analogy seems meaningful as this also automatically increases the domain support for the corresponding analogy.
Once obtained, the generalised theory and the substitutions specify the analogical relation, and formulae of the source for which no correspondence in the target domain can be found may, by means of the already established substitutions, be transferred to the target, constituting a process of analogical transfer between the domains.
3.2. Representing and guiding the combination of conceptual theories using amalgams
Ontañón and Plaza (Citation2010) developed the notion of amalgams in the context of CBR, where new problems are tackled based on previously solved problems (or cases, residing on a case base). Solving a new problem often requires more than one case from the case base, so their content has to be combined in some way to address the new problem. The notion of an “amalgam” of two cases (two descriptions of problems and their solutions) is a proposal to formalise the ways in which cases can be combined to produce a new, coherent case.
Formally, amalgams can be defined in any representation language for which a subsumption relation
between the formulae (or descriptions) of
can be defined. We say that a description
subsumes another description
(
) when
is more general (or equal) than
.Footnote3 Additionally, we assume that
contains the infimum element ⊥ (or “any”), and the supremum element ⊺ (or “none”) with respect to the subsumption order.
Next, for any two descriptions and
in
we can define their unification, (
), which is the most general specialisation of two given descriptions, and their anti-unification, (
), defined as the LGG of two descriptions, representing the most specific description that subsumes both. Intuitively, a unifier is a description that has all the information in both the original descriptions; when joining this information yields to inconsistency this is equivalent to say that
, i.e. they have no common specialisation except “none”. The anti-unification
contains all that is common to both
and
; when they have nothing in common then
. Depending on
anti-unification and unification might be unique or not.
Amalgams can be conceived of as a generalisation of the notion of unification: as “partial unification” (see the description given by Ontañón and Plaza, Citation2010 for details). Unification means that what is true for or
is also true for
; e.g. if
describes “a red vehicle” and
describes “a German minivan” then their unification yields a common specialisation like “a red German minivan”. Two descriptions may possess information that yields an inconsistency when unified; for instance “a red French sedan” and “a blue German minivan” have no common specialisation except ⊺. An amalgam of two descriptions is a new description that contains parts from each of the two original descriptions. For instance, an amalgam of “a red French sedan” and “a blue German minivan” is “a red German sedan”; clearly there are always multiple possibilities for amalgams, like “a blue French minivan”.
For the purposes of this article we can define an amalgam of two input descriptions as follows:
Definition 3.8
Amalgam
A description is an amalgam of two inputs
and
(with anti-unification
) if there exist two generalisations
and
such that (1)
, (2)
, and (3)
.
When and
have no common specialisation then trivially
, since their only unifier is “none”. For our purpose we will only be interested in non-trivial amalgams.
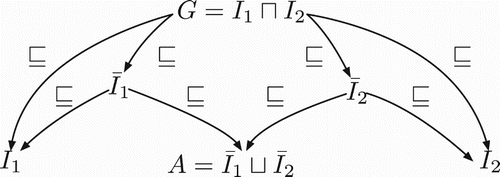
This definition is illustrated in Figure , where the anti-unification of the inputs is indicated as G, and the amalgam A is the unification of two concrete generalisations and
of the inputs. Equality here should be understood as
-equivalence: X=Y iff
and
. Conventionally, we call the space of amalgams of
and
the set of all amalgams A that satisfy the definition above (i.e. all descriptions that are consistent and can be defined as the unification of two generalisations of the inputs).
Figure 3. A diagram of an amalgam A from inputs and
where
.
Usually we are interested only in maximal amalgams of two input descriptions, i.e. those amalgams that contain maximal parts of their inputs that can be unified into a new coherent description. Formally, an amalgam A of inputs and
is maximal if there is no other non-trivial amalgam
of inputs
and
such that
. The reason why we are interested in maximal amalgams is very simple: a non-maximal amalgam
preserves less compatible information from the inputs than the maximal amalgam A; conversely, any non-maximal amalgam
can be obtained by generalising a maximal amalgam A, since
.
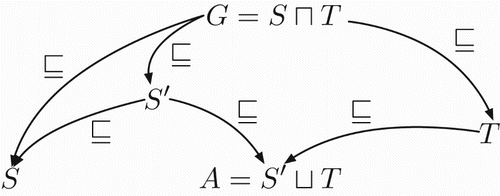
There is a special case of particular interest that is called asymmetric amalgam, in which the two inputs play different roles. The inputs are called source and target, and while the source is allowed to be generalised, the target is not. As we shall see, asymmetric amalgams share important properties with analogical inference: while the source can be relaxed and thus lose information, the target is fixed, so all information belonging to the target will be present in the final (asymmetric) amalgam.
Definition 3.9
Asymmetric Amalgam
An asymmetric amalgam of two inputs S (source) and T (target) satisfies that
for some generalisation of the source
.
As shown in Figure , the content of target T is transferred completely into the asymmetric amalgam, while the source S is generalised. The result is a form of partial unification that preserves all the information in T while relaxing S by generalisation and then unifying one of those generalisations
with T. As before, we will usually be interested in maximal amalgams: in this case, a maximal amalgam corresponds to transferring as much content from S to T while keeping the resulting amalgam A consistent. For this reason, asymmetric amalgams can be seen as a model of analogical inference, where information from the source is transferred to the target by creating a new amalgam A that enriches the target T with the content of
(Ontañón & Plaza, Citation2012).
Figure 4. A diagram that transfers content from source S to a target T via an asymmetric amalgam A.
4. The COINVENT account of analogy-based concept blending
The previous section gave an introduction to computational analogy-making using HDTP and to the combination of conceptual theories within the framework of amalgamation. Both theories and the corresponding mechanisms underlie the COINVENT model for concept blending and its proof-of-concept implementation described in this section. Naturally, ours is not the only attempt at modelling and automatising concept blending capacities in a computational system. In addition to those already mentioned in Section 1, a short overview of other efforts aiming to achieve similar goals is given in Section 5.
The following Section 4.1 provides an introduction to the COINVENT model, starting with a computational-level description before pushing towards the level of detail needed for the algorithmic-level implementation described in Section 4.3. Section 4.2 gives an example for the computational-level dynamics, by this grounding the previous mostly abstract descriptions, while Section 4.4 and 4.5 detail two prototypical application case studies for the proposed implementation of the COINVENT model.
4.1. The COINVENT model of concept blending
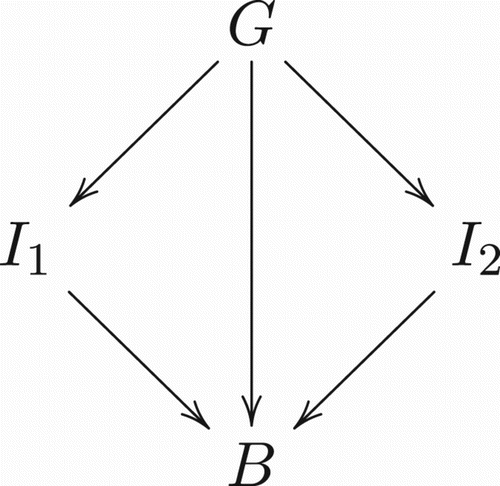
One of the early formal accounts on concept blending – which is especially influential to the approach in COINVENT – is the classical work by Goguen (Citation2006) using notions from algebraic specification and category theory. This version of concept blending can be described by the diagram in Figure , where each node stands for a representation an agent has of some concept or conceptual domain. As stated in Section 2, we consider these representations to be conceptual theories, corresponding to conceptual spaces, and in some cases abuse terminology by using the word “concept” to really refer to its representation by the agent. The arrows stand for morphisms, that is, functions that preserve at least part of the internal structure of the related conceptual theories (and associated spaces). The idea is that, given two conceptual theories and
as input, we look for a generalisation G and then construct a blend space B in such a way as to preserve as many as possible of the structural alignments between
and
established by the generalisation. As an example, consider Goguen (Citation2006)'s houseboat blend depicted in Figure .
Figure 5. Schematic overview of the houseboat blend as conceptualised by Goguen (Citation2006): the conceptual theories for house and boat are generalised to a theory describing some object used by a person resting on some medium, and then combined to a houseboat theory featuring an object which is at the same time house and boat, resting on water, with residents living in it (who are at the same time passengers riding on it).
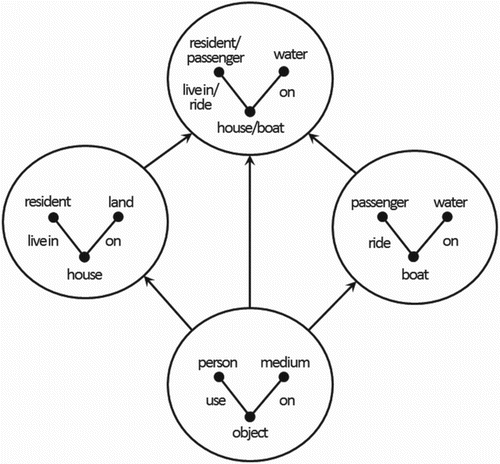
Figure 6. A conceptual overview of Goguen (Citation2006)'s account of concept blending.
This may involve taking the functions to B to be partial, in that not all the structure from and
might be mapped to B. Again using an example by Goguen (Citation2006), this would for example become relevant in the case of blending a house and a boat into a boat used as a land-based shelter: given the input theories in Figure , in that case the blend theory would have to omit axioms putting the house/boat on water, and stating that a passenger rides aboard the house/boat. In any case, as the blend respects (to the largest possible extent) the relationship between
and
, the diagram will commute. Clearly, this approach is structurally similar to the mechanism underlying generalisation-based analogy-making in HDTP (with the latter only missing the blending capabilities; also compare Figures and ).
Concept invention by concept blending can then be phrased as the following task: given two axiomatisations of two domain theories and
, we need first, to compute a generalised theory G of
and
(which codes the commonalities between
and
) and second, to compute the blend theory B in a structure preserving way such that new properties hold in B. Ideally, these new properties in B are considered to be (moderately) interesting properties. In what follows, for reasons of simplicity and without loss of generality we assume that the additional properties are just provided by one of the two domains, i.e. we align the situation with a standard setting in computational analogy-making by renaming
and
: the domain providing the additional properties for the concept blend will be called source S, the domain providing the conceptual basis and receiving the additional features will be called target T.Footnote4
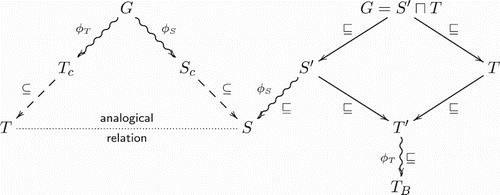
Provided with S and T, according to the just given task description, the following steps have to be accounted for:
Find a joint generalisation G between the input domains S and T, accounting for the shared structure between both.
Building on G, fully generalise S.
Combine the generalised version of S in an asymmetric amalgam with T to obtain the blend
Assure consistency of
In the first step, the reasoning process is triggered by the computation of the generalisation G (generic space). When using an analogy engine for this purpose, for concept invention we will only need the mapping mechanism and replace the transfer phase (which is characteristic for analogy-making) by a new blending algorithm. In the case of HDTP, the mapping is achieved via the usual generalisation process between S and T, in which pairs of formulae from the source and target theories are anti-unified resulting in a generalised theory that reflects common aspects of both spaces. The generalised theory can be projected into the original ones by substitutions which are computed during anti-unification. In what follows, we will say that a formula is “covered” by the analogy, if it is in the image of this projection ( and
, respectively), otherwise it is “uncovered” (also see Section 3.1). While in analogy-making the analogical relations are used in the transfer phase to translate additional uncovered knowledge from the source to the target space, blending combines additional (uncovered) facts from one or both spaces. Therefore the process of blending can build on the generalisation and substitutions provided by the analogy engine, but has to include a new mechanism for transfer and concept combination. Here, amalgams naturally come into play: in the second step, the set of substitutions can be inverted and applied to generalise the original source theory S into a more general version
(forming a superset of the shared generalisation G, also including previously uncovered knowledge from the source) which then can be combined in the third step into an asymmetric amalgam with the target theory T, forming the (possibly underspecified) proto-blend
of both. Concluding this step and also the blending process itself,
is then completed into the blended theory and output of the process
by applying corresponding specialisation steps stored from the generalisation process between S and T (see also Figure ). In the final step, the resulting blend theory
then is checked for consistency in the logical sense and regarding potentially available world knowledge, since inconsistencies of either type could have been introduced when transfering axioms into the blend. If inconsistencies are detected, repair mechanisms are triggered until a consistent blend theory is returned as final output of the blending process.
Figure 7. A conceptual overview of the COINVENT model of concept blending as described in Section 4.1: the shared generalisation G from S and T is computed with . The relation
is subsequently re-used in the generalisation of S into
, which is then combined in an asymmetric amalgam with T into the proto-blend
and finally, by application of
, completed into the blended output theory
. (⊆ indicates an element-wise subset relationship between sets of axioms and
indicates subsumption between theories in the direction of the respective arrows.)
At this point a remark concerning the selection of good blends among the many possible ones is in place. As should also become obvious from the conceptual overview, there are several stages in the process where implementation details will significantly influence the precise outcome of the blending process (e.g. a change in HDTP's heuristics could significantly change the outcome of the selection of and
, and consequently all subsequent steps). Assessing the quality of a blend is generally considered a hard task since the evaluation strongly depends, among others, on the context and the purpose of the blending process. The selection of particularly good blends – or, more generally, of specific types of blends over others – has therefore not been in the focus of this work. Still, it has been treated in other places both within the COINVENT project, as well as by other researchers. A first set of informal and heuristic style optimality principles for concept blends had been postulated by Fauconnier and Turner (Citation1998). Unfortunately, while being helpful especially in the evaluation of linguistic blends, they lack the precision as to directly be algorithmically realisable. Pereira and Cardoso (Citation2003) attempted to fill this gap by proposing one possible implementation. As part of COINVENT, Confalonieri, Corneli, Pease, Plaza, and Schorlemmer (Citation2015) suggested to use computational argumentation for evaluating concept blends (as well as other forms of combinatorial creativity). In their approach, concept blends are evaluated in an open-ended and dynamic discussion, allowing for the improvement of blends and the explicit representation of the reasons behind an evaluation. Relatedly, Schorlemmer, Confalonieri, and Plaza (Citation2016) discussed how newly invented concepts can be evaluated with respect to a background ontology of conceptual knowledge, checking which can be added to the system of familiar concepts, and how the previously given conceptualisation might be altered.
4.2. Example: following trees and signposts into the sign forest
In this first example, originally introduced by Besold and Plaza (Citation2015), we want to illustrate the overall approach to generalisation-based blending using analogy and amalgamation. In this section we therefore leave aside the representational and algorithmic characteristics imposed by the use of HDTP as specific generalisation mechanism and analogy engine (which will be elaborated upon in detail in the actual account of the system given in Section 4.3, and also in the later case studies in Sections 4.4 and 4.5), but focus exclusively on the high-level dynamics. To this end, an ontology-driven approach to generalisation is taken instead, allowing for intuitive and straightforward “semantic” generalisations and analogies within a common concept hierarchy.
We reconstruct the sign forest blend discussed in Kutz, Mossakowski, Hois, Bhatt, and Bateman (Citation2012), providing an interpretation of the concept from a metaphor-centred perspective, and show how the general COINVENT model can serve for modelling the blending process. In what follows we consider sign forest equivalent to the (interpretation of the concept detailed by the) expression “a forest of signs”, that shows more clearly its metaphorical nature.
The concept of tree (and, thus, our corresponding conceptual theory) is typically conceived as a plant having roots, a trunk and a crown (even if there may be plants categorised as trees that do not have a trunk, this is ignored as it does not belong to the bundle of properties that are typical); this view is depicted as in the bottom right of Figure , where other properties are included, like plants being not mobile and the roots fixing the (typical) tree to the ground. Finally, a forest is commonsensically defined as a group of trees. The second concept, (traffic) sign, may come in many forms (as we know from own experience), but the first that comes to mind is the most typical one: the signpost. The signpost is typically fixed on the ground near a road, and has a post supporting a surface panel depicting some traffic-related information (labelled
in the lower left corner of Figure ). The cognitive advantage of a signpost is that it has a recognisable physical structure, while “traffic sign” is so generic as to be a merely functional-based concept: any kind of surface panel depicting some traffic-related information is a traffic sign.
Figure 8. Blending schema for “Sign Forest” when inputs are typical concepts for “Sign” (traffic signpost) and “Forest” (forest of typical trees); the arrows indicate subsumption () as in Figure .
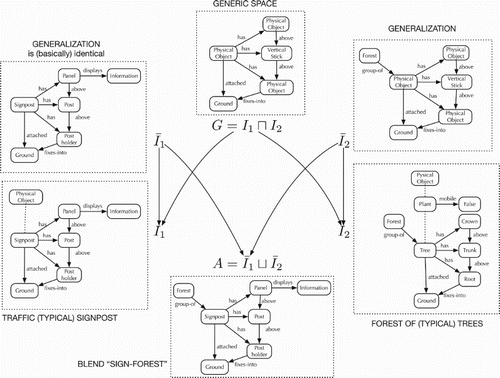
The generic space G of concept blending corresponds to the anti-unification shown as in Figure ; G depicts common structure between a signpost and a tree: a stick-like object, fixed to the ground, and supporting another object on top. As discussed later, this common structure is the basis for a metaphor like “a forest of signs” to make sense – in contradistinction to a metaphor that does not make sense such as “a forest of chairs”, even when a typical chair is made of wood.
Now, the construction of the blended metaphor for sign forest can be interpreted easily in the combined generalisation-based analogy and amalgam framework: the input spaces can be generalised in different ways (although always satisfying what they already have in common, namely G). Different generalisations would yield different amalgams, but the one we are considering here can be seen as generalising into
, as shown in Figure . Now this generalisation
can directly be unified with
, since
is identical to
; this unification yields the amalgam
that, as shown in Figure , represents a “forest of signposts”. Moreover, since
, this model is an asymmetric amalgam, as evidenced by the fact that we generalise the source (forest) until it unifies with the target (signpost), while the latter remains fixed (i.e. is not generalised).
4.3. Implementing the model's mechanism(s) using HDTP and asymmetric amalgams
Besides the theoretical developments, one of the project aims of COINVENT was an implementation of the developed general model of concept blending into a system producing novel and useful output theories, fully integrating HDTP and the amalgam framework. In what follows, we present an intermediate version on the way to this goal: a blend is taken to be novel if it is not a subset of or equal to the source or the target domain, usefulness is defined as consistency of the resulting theory, the generalisation step uses a further constrained variant of restricted higher-order anti-unification, applying only fixations and renamings, the amalgamation uses higher-order unification as combination mechanism, and logical semantic consequence serves as ordering relationship:
Find joint generalisation G of input theories S and T: Given two input domain theories S and T, the (set of) common generalisation(s)
In COINVENT, HDTP is used for this step: in the present version of the algorithm, only renamings and fixations are used as admissible types of unit substitutions. As the LGG under restricted higher-order anti-unification is (still) not unique (also see Section 3.1), the anti-unification itself returns several possible LGGs out of which the system choses one generalisation
Reuse set of anti-unifications to get complete generalised source theory
Here, if
Compute asymmetric amalgam between
Subsequently, the remaining axioms from both theories are added as additional elements to the resulting set of axioms
Fully instantiate proto-blend
Check for consistency of blend
The resulting blend theory is based on T (consistently) enriched by imported “unaffected” axioms and (via generalisation from S to
, and re-instantiation from
to
) adapted structural elements from S. This blend forms the (in a certain concept-theoretical sense) “closest” blend to T and can presumably play an important role in different contexts: for instance it can account for the addition of new solution elements to a solution idea at hand in problem-solving scenarios, and in creativity tasks the addition of novel features and elements to existing concepts can be achieved.
Clearly, this remains only a partial solution on the way to completely solving computational concept blending (even when already restricted to the case of logic-based domain theories), requiring further algorithmic and conceptual development: the inconsistency resolution in step 5 can probably be made significantly more efficient by developing heuristics for efficiently selecting axioms for removal, the simple identification between usefulness and consistency might not be enough for many contexts, and methods for assessing the novelty of the resulting blend (also allowing for comparisons between different possible blends) have to be developed and integrated.
In the following sections, we want to further exemplify our approach in two application cases: a concept blending account of Pegasus as combination between a horse and a bird in classical mythology, and a re-creation of the concept of a foldable toothbrush. While being structurally similar to each other, the application domains vastly differ – mythology and imaginative thought versus product development with high practical relevance – and give evidence of both, the pervasiveness of concept blending as cognitive phenomenon and the generality and domain-independence of the described approach.Footnote7 Additionally, besides exemplifying the functioning of the just described algorithm, the two examples (together with the reconstruction of the classical Rutherford analogy given by Besold, Kühnberger, and Plaza, Citation2015) thereby show that the newly conceived model for concept blending truly constitutes a conservative extension of the accounts of generalisation-based analogy and amalgamation integrated into it (logically resulting from the central roles assigned to both theories in the conceptual commitments in Section 2).
4.4. Case study 1: Pegasus as mythological concept blend
One of the best known concept blends is Pegasus, the winged divine stallion and son of Poseidon and the Gorgon Medusa from classical Greek mythology. From a concept blending perspective, Pegasus constitutes a blend between a stereotypical horse and a stereotypical bird, maintaining all the horse characteristics but adding bird-like features such as, for instance, the wings and the ability to fly. In what follows, we will reconstruct the blending process underlying Pegasus' concept formation as second application example for the analogy-based perspective on blending in COINVENT.
Contrary to the Rutherford analogy and several other examples from the cognitive AI literature, in the Pegasus case analogy-making alone would not be sufficient to model the genesis of the concept of a winged horse: Rutherford's achievement was to recognise the structural similarities between a schematic account of the solar system (the sun in the centre, celestial bodies with lesser mass revolving around it) and his conception of the structure of the atom (the nucleus in the centre, lightweight electrons in the surrounding), and to use the more precise understanding of the solar system to also sharpen his theory about the atom (introducing the idea of the revolution of the electrons along stable orbits around the nucleus). Accordingly, computational accounts of the Rutherford analogy focus on transferring the governing laws from the (better informed) solar system domain to the (up to that point law-free) atom model domain. But compiling the Pegasus blend between conceptual theories for birds and horses requires the combination of qualitatively equally informed, with respect to the context fairly complete conceptual theories, most likely also involving inconsistency handling in the resulting blend (due to conflicting defining characteristics of the input domains). In this example we, thus, expect the model to produce a knowledge-rich but initially inconsistent conceptual theory as blend, forcing itself into inconsistency resolution before returning the final output.
We start with the conceptual theories (i.e. stereotypical characterisations) of a horse and a bird in a many-sorted first-order logic representation (as used by HDTP) from Table .
Table 4. Example formalisations of stereotypical characterisations for a bird S and a horse T.
Given these characterisations, HDTP can be used for finding a common generalisation of both (Table ),Footnote8 basically describing an entity of some clade, having a torso and legs, and being able to walk – a characterisation covering (at least) most land-based vertebrates except for limbless or limb-reduced reptiles and amphibians.
Table 5. Abbreviated representation of the shared generalisation G based on the stereotypical characterisations for a horse and a bird, constituted by generalisations
/, /, /, and / (i.e. and ).
Subsequently, the anti-unifications inversely corresponding to are re-used for generalising the entire source theory S (and not only
, i.e. the part covered by the original generalisation G) into
as given in Table . The resulting theory has the shared generalisation from Table as a real subset, adding the abilities to fly and lay eggs, as well as wings as part of the body, to the mix.
Table 6. Abbreviated representation of the generalised source theory based on the stereotypical characterisations for a horse and a bird, including additional axioms
, , and obtained from generalising the remaining axioms from .
This conceptual theory of a, among others, winged, oviparous entity of some clade, is now used for computing the asymmetric amalgam with the (fixed) target theory T, consisting of descriptions of stereotypical features of a horse. As a result we obtain the proto-blend
from Table , featuring the axioms describing the horse (which, as part of the amalgamation process, have been unified with the corresponding axioms from
, namely those giving the entity some clade, legs, a torso, and the ability to walk) and additionally the as yet unmatched axioms from
assigning wings, and the abilities to fly and to lay eggs to some entity.
Table 7. Abbreviated representation of the proto-blend obtained from computing the asymmetric amalgam between and T.
Therefore, as still features said axioms containing non-instantiated variables, the set of substitutions
is applied to the theory resulting in the (with respect to
) fully instantiated blend theory
from Table – the description of a mammal with legs, torso, and wings, being able to walk fly, and lay eggs.
Table 8. Abbreviated representation of .
In a concluding step, a consistency check of the blended theory is performed. As already initially expected, taking into account world knowledge about mammals identifies a clash with the ability to lay eggs asserted in axiom
, as mammals generally are not oviparous (except for the subclass Prototheria as precisely defined special case, with no class member ever having been observed to have wings or be able to fly). Thus, returning to the start of the procedure, the algorithm is re-initiated, for example, with
, and finally returns the (with respect to
fully instantiated and consistent) version of
given in Table as output: a mammal with torso, legs, and wings, being able to walk and fly.
Table 9. Abbreviated representation of the final blended theory giving a characterisation of Pegasus after inconsistency check and repair (i.e. based on ).
4.5. Case study 2: the folding toothbrush
Folding toothbrushes are a conceptual combination between a typical stick-like toothbrush and a hinge-folding mechanism like that of a pocketknife (see Figure ).
Figure 9. A folding toothbrush like the one from the example in Section 4.5, characteristically featuring a hinge allowing the brush head to be folded back into the handle.

As such, they represent a combination of two actual industry products subject to all the limitations and demands practicality and real-world applicability impose. In order to reconstruct the concept blending process at the heart of the invention of folding toothbrushes, analogous to the Pegasus case in the previous section, we start with the stereotypical characterisations of a standard toothbrush and a pocketknife in a many-sorted first-order logic representation from Table .
Table 10. Example formalisations of stereotypical characterisations for a pocketknife S and a toothbrush T.
Given these characterisations, HDTP can be used for finding a common generalisation of both, for instance (due to the syntactic similarities and the system's heuristics) aligning and generalising the axioms with
(respectively asserting that the knife and the brush each have a handle), the blade
with the brush head
, and the functionality to cut things
with the functionality to be used for brushing
, resulting in some entity having a handle and (at least) one more part and a function (Table ).
Table 11. Abbreviated representation of the shared generalisation G based on the stereotypical characterisations for a pocketknife and a toothbrush, constituted by generalisations /, /, and / (i.e. and ).
Subsequently, reusing the same anti-unifications applied in finding G (more precisely the ones inversely corresponding to the substitutions in ), the source theory S is generalised into
as given in Table :
form the joint generalisation G, and the additional axioms
and
are obtained by generalising
and
, respectively. The resulting generalised source theory
describes an entity with a handle, a hinge, and some additional part, which can be folded, and has some additional function.
Table 12. Abbreviated representation of the generalised source theory based on the stereotypical characterisations for a toothbrush and a pocketknife, including additional axioms and obtained from generalising the remaining axioms from .
Computing the asymmetric amalgam of this generalised source theory with the (fixed) target theory T (describing a toothbrush), we obtain the proto-blend
from Table : the characterisation of an object with a handle, a brush head, and a hinge, which can be used for brushing, together with an additional object describing some foldable entity.
Table 13. Abbreviated representation of the proto-blend obtained from computing the asymmetric amalgam between and T.
As still features axiom
containing non-instantiated variables, the substitutions from
(obtained in the original generalisation step from T to G) are applied to the theory resulting in the (with respect to
) fully instantiated blend theory
from Table , describing an entity with a handle, a brush head, and a hinge, which can be folded and is usable for brushing: the concept of a hinge-equipped toothbrush that can be folded.
Table 14. Abbreviated representation of .
5. Conclusion: related work and future directions
In the previous sections we presented the analogy-inspired COINVENT model and a corresponding working algorithm for the blending of conceptual theories. The main contributions are the combination of generalisation-based analogy instantiated in (a restricted version of) the HDTP system with a well-founded formal model and mechanism for knowledge transfer and concept combination in form of the amalgam framework: building upon HDTP's approach to generalisation and domain matching asymmetric amalgams allow to soundly compute the concept blend of two input theories in a controlled fashion.
As should have become clear from the presentation of the model, and the discussion of its corresponding components, analogy plays a crucial role for COINVENT's take on concept blending. Still, there are also significant differences which may not be overlooked, with the distinct “power” of both mechanisms in our opinion being the most salient but also most important one. Analogy in most accounts is taken as a cognitive mechanism transfering knowledge from a better informed source domain into a sufficiently structurally similar target domain in a coherent fashion. Concept blending goes beyond this fairly conservative form of transfer in that the most general case does not recognise one domain as source and the other as target (with only the source contributing additional information to the target domain), but that both domains contribute information to the resulting blend, allowing for more combinatorial options – and consequently possible outcomes – than obtainable in the analogy setting.Footnote9 A dedicated discussion of the relationship between concept blending – and more precisely, COINVENT's account thereof – and analogy has, for instance, been provided by CitationBesold (Citationin press).
Also, ours is by far not the only current attempt at the computational modelling of concept blending. For instance Kutz, Bateman, Neuhaus, Mossakowski, and Bhatt (Citation2015) give an account and a system model for the computer-based blending of ontologies (i.e. the conceptual theories involved as inputs for blending are ontological descriptions). The ontology-based approach views a concept as an ontological specification: a specification that is ideally so general as to cover all possible instances or occurrences of the concept. As such, certain properties and relations are selected to form these specifications that are useful for an ontology framework. In contrast, in its conceptual layout our approach is inspired by an idea also underlying Rosch (Citation1988)'s prototype theory, namely the notion that concepts in human cognition can be characterised up to a high level of precision by bundles of their most typical properties (albeit typicality may certainly be context-dependent). This view is also taken in examples by Fauconnier and Turner (Citation1998) that are used to show how conceptual blend works: a boathouse has typical properties of boat and house – but not other properties that may appear in an ontological specification of boat and house.
Martinez et al. (Citation2014) presented an approach for the algorithmic blending of mathematical theories, trying to model the combination of previously independent mathematical concepts as basis for mathematical concept invention. Contrary to our setting, dealing with mathematical conceptual theories limits the range to unambiguous and logically unique axiomatisations, also removing the need for “semantic” consistency checks of the resulting blends within output theories or against world knowledge. The approach taken by Martinez et al. (Citation2014) is similar to ours in that it also builds upon Goguen (Citation2006)'s ideas and uses HDTP for finding shared generalisations between mathematical input theories. Still, the blending mechanism works differently in that it basically relies on a simple generate-and-test approach to step-wise building up increasingly complex logically consistent combinations of the axioms from the input theories.
Compared to the earlier work by Martinez et al. (Citation2012) on blending as general cognitive mechanism, our addition of amalgamation as formal description and guiding framework and the integration with the generalisation-based analogy mechanism goes beyond the work reported there. Moreover, Martinez et al. (Citation2012) do not provide an algorithmic account but restrict themselves to outlining a fairly general computational-level description of the envisioned mechanism.
Another recent report of work on concept blending was described by Li, Zook, Davis, and Riedl (Citation2012), who provide case studies of systems taking into account goals and contexts in the blending-based production of creative artefacts. They emphasise the context-dependent aspects of concept blending, moving focus away from the attributes of the input domains to the role the context plays in blend generation. In their model, the situational relevance and the communicative goal of a blend as metaphor-like speech element determine the blending process and outcome to a huge extent. While Li et al. (Citation2012)'s work is similar to our general account in its emphasis on (cognitive representations of) real-world concepts and a certain influence from computational analogy-making in the described systems, their approach differs in that it relies on selective projections from the input spaces into the blend space without generalisation playing a prominent role. Also, again a clear description of the systems applied in the presented examples is lacking.
Based on this short comparison we think that the COINVENT model and system constitutes a valuable contribution to the ongoing discourse and a big step towards a computationally feasible model of concept blending. Its virtues lie, among others, in combining the generality of modelling introduced by HDTP's use of many-sorted first-order logic languages with the formal soundness and solid theoretical foundations of the underlying generalisation model and the amalgam framework, offering a computational- and algorithmic-level account for blending general conceptual theories.
Concerning the next steps of development of our concept blending framework, on the formal side the restriction on the substitutions used in HDTP has to be weakened and finally removed in order to access the frameworks full generality and expressivity (i.e. allowing for applications of all four types of substitutions admissible in restricted higher-order anti-unification). If this constraint is lifted, a replacement for the semantic consequence relationship ⊧ as basis for the subsumption ordering will have to be found as the former does not hold anymore between successive generalisation steps as soon as permutations or argument insertions are applied. Here, we hope that providing a semantics to the syntax-based operations in HDTP and restricted higher-order anti-unification – for instance by an approach similar to the derived signature morphisms discussed by Mossakowski, Krumnack, and Maibaum (Citation2015) – will allow us to subsequently construct a suitable substitute.
A more system-oriented open question is the further integration of heuristic and knowledge-sensitive methods during blend computation and selection for modelling contextual constraints or internal properties of the cognitive agent (as also described in the overview of conceptual commitments in Section 2). Heuristics can be applied at different points of the proposed concept blending: they form essential part of HDTP's computation of the LGG between the input domains and also promise to make the inconsistency resolution as final step before outputting a blended theory more efficient. Still, they can also be used for modelling a cogniser's expertise or similar individual features. For instance, already during the computation of generalisations certain combinations of elements from the respective input domains could be favoured over others, and during inconsistency resolution focus could not only be put on efficiency in finding a consistent conceptual theory but content-related aspects could be taken into account. Moreover, also the integration of background knowledge about the environment or the task as guiding forces for the blending process and its output clearly would be desirable. While this seems fairly straightforward during inconsistency resolution, whether and how to already inform the earlier steps of the algorithm remains an open question.
Finally, resonating with the corresponding remark at the end of Section 4.1, a more general challenge not only relevant for our system but for a significant part of computational creativity as a research discipline concerns theories and computationally feasible methods for evaluating the usefulness and the novelty of the output of a computational system from either an agent-centric or a general perspective. While our current approach (i.e. simply equating usefulness with consistency) falls short of the requirements in most application scenarios or contexts, alternative proposals are either highly specific to a domain or task, or make recourse to external means of evaluation shifting the burden away from the cognitive system. As can be expected, focusing on the degree of novelty instead of usefulness as dimension further complicates the question.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
Tarek R. Besold http://orcid.org/0000-0002-8002-0049
Additional information
Funding
Notes
1 In the title and throughout the article, the terms “algorithmic characterisation”, “computational-level theory”, etc. refer to the corresponding conceptualisations in Marr (Citation1982)'s tri-level hypothesis.
3 In machine learning terms, means that A is more general than B, while in description logics it has the opposite meaning, since it is seen as “set inclusion” of their interpretations.
4 In the case where additional properties are provided by both domains the same general principles as described below apply. It just becomes necessary to also treat the target domain T similar to the current source S, expanding the conceptual overview in Figure with a second “generalisation triangle” to the right of the “blending diamond”, computing a generalisation of T and using the latter for the blending process (for which only minor and quite straightforward changes become necessary, assuring that all terms in the resulting blend are grounded and no variables introduced during the generalisation steps remain uninstantiated).
5 The maximality of the outcome is rooted in HDTP's previously mentioned coverage maximisation.
6 Note that the unifications and addition of axioms conserve the ⊧ relation between theories and, thus, the subsumption ordering as indicated in Figure .
7 The conceptual theories used in both examples for the sake of clarity have been reduced to what the authors think are the most basic characterisations of the involved concepts. Of course, for each of the conceptual spaces much richer formalisations would be possible, e.g. adding a beak to the characterisation of a bird, or a tail to the horse theory. Still, these additions would not impede the functioning of the proposed mechanism in a principled way, but instead would combinatorially increase the complexity of the reasoning process (for instance most likely resulting in a higher number of competing candidate theories in the generalisation step). Still, this complexity would be counteracted by the respectively corresponding selection heuristics assuring the effective functioning of the algorithm.
8 As stated previously, when using HDTP the required subsumption relation between theories currently is given by logical semantic consequence ⊧, i.e. if
for any two theories A and
. In order to make sure that this relationship is preserved by HDTP's syntax-based operations, the range of admissible substitutions for restricted higher-order anti-unifications has to be further constrained to only allow for fixations and renamings.
9 Recall that the choice for asymmetric amalgams in the presentation of the COINVENT model had been motivated by considerations of simplicity. As explained in the corresponding footnote in Section 4.1, the required expansion of the model (and subsequently also the algorithm) is straightforward and basically consist of a doubling of already existing structures.
References
- Aamodt, A., & Plaza, E. (1994). Case-based reasoning: Foundational issues, methodological variations, and system approaches. AI Communications, 7(1), 39–59.
- Besold, T. R. (In press). The relation of conceptual blending and analogical reasoning. In R. Confalonieri et al. (Eds.), Concept invention: Foundations, implementation, social aspects and applications. Springer.
- Besold, T. R., Kühnberger, K.-U., & Plaza, E. (2015). Analogy, amalgams, and concept blending. Proceedings of the third annual conference on advances in cognitive systems (poster collection). Cogsys.org.
- Besold, T. R., & Plaza, E. (2015). Generalize and blend: Concept blending based on generalization, analogy, and amalgams. Proceedings of the sixth international conference on computational creativity (ICCC 2015) (pp. 150–157). Provo, UT: Brigham Young University.
- Boden, M. (1977). Artificial intelligence and natural man. Hassocks, Sussex: Harvester Press.
- Boden, M. A. (2003). The creative mind: Myths and mechanisms. London: Routledge.
- Bou, F., Schorlemmer, M., Corneli, J., Gomez Ramirez, D., Maclean, E., Smaill, A., & Pease, A. (2015). The role of blending in mathematical invention. Proceedings of the sixth international conference on computational creativity (ICCC 2015) (pp. 55–62). Park City, UT: Brigham Young University.
- Confalonieri, R., Corneli, J., Pease, A., Plaza, E., & Schorlemmer, M. (2015). Using argumentation to evaluate concept blends in combinatorial creativity. Proceedings of the sixth international conference on computational creativity (ICCC 2015) (pp. 174–181). Park City, UT: Brigham Young University.
- Falkenhainer, B., Forbus, K. D., & Gentner, D. (1989). The structure-mapping engine: Algorithm and examples. Artificial Intelligence, 41(1), 1–63. doi: 10.1016/0004-3702(89)90077-5
- Fauconnier, G., & Turner, M. (1998). Conceptual integration networks. Cognitive Science, 22(2), 133–187. doi: 10.1207/s15516709cog2202_1
- Gentner, D., & Smith, L. A. (2013). Analogical learning and reasoning. In D. Reisberg (Ed.), The Oxford handbook of cognitive psychology (pp. 668–681). Oxford: Oxford University Press.
- Goguen, J. (2006). Mathematical models of cognitive space and time. Reasoning and cognition; proceedings of the interdisciplinary conference on reasoning and cognition (pp. 125–128). Tokyo: Keio University Press.
- Goguen, J. A., & Harrell, D. F. (2010). Style: A computational and conceptual blending-based approach. In S. Argamon, K. Burns, & S. Dubnov (Eds.), The structure of style (pp. 291–316). Heidelberg: Springer.
- Kutz, O., Bateman, J., Neuhaus, F., Mossakowski, T., & Bhatt, M. (2015). E pluribus unum. In T. R. Besold, M. Schorlemmer, & A. Smaill (Eds.), Computational creativity research: Towards creative machines (Vol. 7, pp. 167–196). Berlin: Atlantis Press.
- Kutz, O., Mossakowski, T., Hois, J., Bhatt, M., & Bateman, J. (2012). Ontological blending in DOL. Proceedings of the 1st international workshop on “computational creativity, concept invention, and general intelligence”. Osnabrück: Institute of Cognitive Science.
- Li, B., Zook, A., Davis, N., & Riedl, M. (2012). Goal-driven conceptual blending: A computational approach for creativity. Proceedings of the third international conference on computational creativity (pp. 9–16). ComputationalCreativity.net.
- Marr, D. (1982). Vision: A computational investigation into the human representation and processing of visual information. New York, NY: Henry Holt.
- Martinez, M., Besold, T. R., Abdel-Fattah, A., Gust, H., Schmidt, M., Krumnack, U., & Kühnberger, K.-U. (2012). Theory blending as a framework for creativity in systems for general intelligence. In P. Wang & B. Goertzel (Eds.), Theoretical foundations of artificial general intelligence (pp. 219–239). Berlin: Atlantis Press.
- Martinez, M., Krumnack, U., Smaill, A., Besold, T. R., Abdel-Fattah, A. M., Schmidt, M., & Pease, A. (2014). Algorithmic aspects of theory blending. In G. Aranda-Corral, J. Calmet, & F. Martín-Mateos (Eds.), Artificial intelligence and symbolic computation (Vol. 8884, pp. 180–192). Cham: Springer.
- Mossakowski, T., Krumnack, U., & Maibaum, T. (2015). What is a derived signature morphism? In M. Codescu, R. Diaconescu, and I. Tutu (Eds.), Recent trends in algebraic development techniques: 22nd international workshop, WADT 2014, Sinaia, September 4–7, 2014, Revised selected papers (pp. 90–109). Springer.
- Ontañón, S., & Plaza, E. (2010). Amalgams: A formal approach for combining multiple case solutions. In I. Bichindaritz & S. Montani (Eds.), Case-based reasoning: Research and development (Vol. 6176, pp. 257–271). Heidelberg: Springer.
- Ontañón, S., & Plaza, E. (2012). On knowledge transfer in case-based inference. In B. D. Agudo & I. Watson (Eds.), Case-based reasoning research and development (Vol. 7466, pp. 312–326). Berlin: Springer.
- Pereira, F. C. (2007). Creativity and AI: A conceptual blending approach. Berlin: Mouton de Gruyter.
- Pereira, F. C., & Cardoso, A. (2003). Optimality principles for conceptual blending: A first computational approach. AISB Journal, 1(4), 351–369.
- Plotkin, G. D. (1970). A note on inductive generalization. Machine Intelligence, 5, 153–163.
- Rosch, E. (1988). Principles of categorization. In A. Collins & E. E. Smith (Eds.), Readings in cognitive science, a perspective from psychology and artificial intelligence (pp. 312–322). San Mateo, CA: Morgan Kaufmann.
- Schmidt, M., Krumnack, U., Gust, H., & Kühnberger, K.-U. (2014). Heuristic-driven theory projection: An overview. In H. Prade & G. Richard (Eds.), Computational approaches to analogical reasoning: Current trends (pp. 163–194). Berlin: Springer.
- Schorlemmer, M., Confalonieri, R., & Plaza, E. (2016). Coherent concept invention. Proceedings of the workshop on computational creativity, concept invention, and general intelligence (C3GI 2016). CEUR-WS.org.
- Schwering, A., Krumnack, U., Kühnberger, K.-U., & Gust, H. (2009). Syntactic principles of heuristic-driven theory projection. Journal of Cognitive Systems Research, 10(3), 251–269. doi: 10.1016/j.cogsys.2008.09.002
- Thagard, P., & Stewart, T. C. (2011). The aha! experience: Creativity through emergent binding in neural networks. Cognitive Science, 35(1), 1–33. doi: 10.1111/j.1551-6709.2010.01142.x
- Veale, T., & O'Donoghue, D. (2000). Computation and blending. Cognitive Linguistics, 11(3/4), 253–281.