
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In search for better technological solutions for education, we adapted a principle from economic game theory, namely that giving a help will promote collaboration and eventually long-term relations between a robot and a child. This principle has been shown to be effective in games between humans and between humans and computer agents. We compared the social and cognitive engagement of children when playing checkers game combined with a social strategy against a robot or against a computer. We found that by combining the social and game strategy the children (average age of 8.3 years) had more empathy and social engagement with the robot since the children did not want to necessarily win against it. This finding is promising for using social strategies for the creation of long-term relations between robots and children and making educational tasks more engaging. An additional outcome of the study was the significant difference in the perception of the children about the difficulty of the game – the game with the robot was seen as more challenging and the robot – as a smarter opponent. This finding might be due to the higher perceived or expected intelligence from the robot, or because of the higher complexity of seeing patterns in three-dimensional world.
1. Introduction
The mainstream recent developments in the field of social and assistive robotics utilise on designing micro- and short-term interactions to create socially believable and engaging robots. We argue that the uptake of robots as social companions depends as much on the design of long-term interactions and grounding these interactions in the robot behaviour and propose a game-theoretic approach to achieve such grounding.
The micro- and short-term interactions include social signals and cognitive behaviours that are seen on a timescale of milliseconds to few minutes. For the design of these interactions methods, theories and heuristics from social signal processing, affective computing, social and cognitive psychology, and neuroscience have been adopted. To develop the global plot of the interaction, game-based scenario design is often used, and this approach is promising since it combines the advantages of providing realistic interactions and still keeping these interactions to be confined by the set of game rules. Although the advantages of the interactive plot (story) of the game are broadly explored in human–robot interactions, game design based on economic game-theoretic strategies, that have been shown useful to build complex social skills as collaboration, and for promoting long-term interactions (Barakova, Gorbunov, & Rauterberg, Citation2015; Gorbunov, Barakova, Ahn, & Rauterberg, Citation2011; Gorbunov, Barakova, & Rauterberg, Citation2013), have not been used in social robotics research and practice.
A recent review by Leite, Martinho, and Paiva (Citation2013) conclude that robots need to be able to simulate more complex and diverse social behaviours and that the diversity of micro interactions is a way to achieve long-term interactions. In other studies a multi-activity approach is proposed to cope with situations when repetitive encounters with the robot are needed (Coninx et al., Citation2016). The study of Barakova, Bajracharya, Willemsen, Lourens and Huskens (Citation2015) uses game design to motivate multiple encounters; nevertheless, principles from economic game theory have not been exploited as well.
In the current paper, we make the first step towards applying strategies from collaborative games by combining a game and a social strategy against either a robot or a computer agent. We developed an interaction around a board game, since it is already known how to use these games for monitoring and stimulating long-term interactions (Barakova, Gorbunov, et al., 2015; Gorbunov et al., Citation2011, Citation2013). In an attempt to find out if a direct mapping from the computer to a robot game that uses collaborative strategies will be effective, we designed a social strategy in the game within the existing game strategy by offering help by a robot or by a computer agent who pretend not to have seen the right move and make a move that gives an advantage to the child. The experimental design is outlined in detail in Section 2.
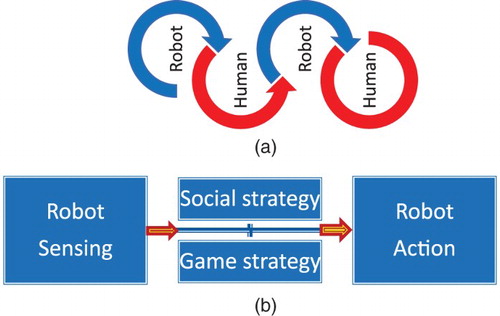
We look at the human–robot interaction as taking turns between a human and a robot, as seen in Figure (a) and each turn takes place of sensing the game situation, deciding the move the robot needs to take, and acting, as depicted in Figure (b) . The division made in Figure (b) makes explicit where our contribution is: most attention in the field of social robotics has taken place of creating expressive robots in terms of Robot Actions – what the robot will say or how it will move, and some work has been done on how the robot perceives the opponent, i.e. on the Robot Sensing, while the Robot Strategy or the decision-making mechanisms are not exploited in the design and grounding of the interactions with social robots.
Figure 1. The human–robot interaction process in games. (a) The human–robot interaction process as taking turns between a human and a robot. (b) An individual turn of a robot consists of sensing/perception of the state of the game, strategy module that consists of a game strategy and a social strategy, and action towards the human. Different from existing studies in this study we ground social interaction via the strategy module, and not by adding social features to the observable action or by perception of social cues by the robot.
To summarise, in this paper we search for a game design method that will encourage engagement across encounters. The design combines the robot interaction using physical objects, its intelligence for winning the game and its social strategy. In other words, the trade-off of different types of design and implementation complexity is resolved by optimising the user (child) engagement. For this purpose, we make the following contributions:
We model the human–robot interaction as continuous turn-taking between a human and a robot where each turn consists of three components (modules): perception module – in Figure (b) Robot Sensing, game strategy module Robot Strategy and physical interaction moduleRobot Actions. While each of these modules has an instrumental and a social behavioural component, we for the first time in human–robot interaction research we use the Social Strategy to ground the interaction in the robot with the aim to achieve long-term engagement and bonding.
We use as an inspiration approaches from economic game theory adapted to game scenarios appropriate for the age group of school children. We design interactions that combine the robot physical interaction skills, intelligence and social strategy with the aim to enhance the user engagement. We optimise the complexity and the tradeoffs of the implementation of these modules using engagement criteria, obtained through a pilot user test.
We identify and propose a future direction for the design of the game module, that the social and game strategy needs to be adapted to the age/level of the player. For this purpose, a dynamic neural fields (DNF) model is proposed.
Obviously, there is a high complexity in the implementation of such a game which caused a number of compromises. We attempted to achieve an optimal combination of the three interaction components (modules), as a measure of optimality we used the engagement of the children while playing a game of checkers against the robot. To validate our choices we conducted a pilot test to identify which interaction components will contribute mostly to the engagement.
2. Related work
Games with physical objects is a promising way to include robots in general and special education since it can engage children in physical interaction in contrast to the interaction that is offered by computer games. As discussed Section 1, most studies with robots in this context do not include physical interaction beyond social gestures, and the long-term interactions are achieved through designing and improving the expressive social cues of the robot. The robots that have been used in long-term interaction studies, as recent review by Leite et al. (Citation2013) conclude, rely on the ability of the designer to simulate more complex and diverse social behaviours as a way to achieve engaging longer term interactions. A similar line of reasoning is proposed in Wada, Shibata, Asada, and Musha (Citation2007) and Kanda, Shiomi, Miyashita, Ishiguro and Hagita (Citation2010). de Graaf, Allouch, and van Dijk (Citation2017) analysed why their social robot was not used and proposed to create robots that are enjoyable and easy to use to capture users in the short-term, and are functionally relevant to keep those users in the longer term. Gockley et al. (Citation2005) propose that the new story-telling mechanism, person identification and personalisation and inclusion of emotions could be a solution for long-term engagement, while Coninx et al. (Citation2016) argue that a multi-activity approach is needed to cope with situations when repetitive encounters with the robot are needed. Barakova, Bajracharya, et al. (2015) proposed a design of a collaborative game in which the game plot continued over several sessions, which indeed can promote long-term interaction for a number of sessions. None of these approaches have made use of game-theoretic approaches for promoting a long-term interactions.
The design approaches using economic game theories have shown to be a promising tool for establishing and monitoring long-term relations since they may include many different aspects of real-life interactions between people. For instance, they can be used to learn the rules of collaboration. Many game designers are currently exploring the added value of cooperative strategies within their games (El-Nasr et al., Citation2010) such as reaching a goal with limited resources. Gorbunov et al. (Citation2011, Citation2013) redesigned and tested a game which utilises on collaborative patterns to induce cooperation within the game. The game was designed to be played multiple times – each time a player would choose to help or ask for a help expecting that during the next game instance the chosen partner may help back or request a help.
It has been shown that humans respond to computer agents differently depending on the game strategies embedded into the agent (van Wissen, van Diggelen, & Dignum, Citation2009). In particular, collaborative, altruistic behaviour in agents induces more collaborative and altruistic behaviour in human players. We expect that this may be true not only for computer agents but also for robots. Human-to-human interaction in game environments has been formalised in different models, including models that include retrospective and prospective thinking. These models include humans' memories of previous behaviour of other players as well as certain expectations about the future behaviour of these players (Gal & Pfeffer, Citation2007). With this approach long-term reciprocal behaviour of humans can be modelled and these models can also be applied to human–robot interactions. The computer games are of particular interest in the context of the monitoring interpersonal relations since they cover many different aspects of real-life interactions between people. Collaboration is one of the aspects of computer games, which is of a particular interest in monitoring interpersonal relations in goal-oriented teams. Many game designers and producers are currently exploring the addition of cooperative patterns within their games. A special attention was given to the identification of design patterns of cooperative games (El-Nasr et al., Citation2010). It has also been demonstrated that people do not play like game-theoretical rational players. In particular, it has been shown that the behaviour of humans in game environments can be better described if social factors such as altruism, self-interest and fairness are taken into account (Gal & Pfeffer, Citation2006; Gal, Pfeffer, Marzo, & Grosz, Citation2004). The influence of social factors on the game strategies of humans makes the behaviour of human players dependent on social relations with other players – it has been demonstrated that humans way of playing depends on whom they are playing with and “friends” and “strangers” are treated differently (Marzo, Gal, Grosz, & Pfeffer, Citation2004).
Moreover, it has been shown that humans treat computer agents differently depending on the game strategies embedded into these agents (van Wissen et al., Citation2009) and that collaborative, altruistic behaviour in agents induces more collaborative and altruistic behaviour in human subjects. Different models of reciprocity have been developed to describe the human-to-human interaction in a game environment. For example, relations of human subjects to other players can be modelled by retrospective and prospective thinking which reflects humans' memories about the past behaviour of other players as well as certain expectations about the future behaviour of these players (Gal & Pfeffer, Citation2007).
The models describing human–human interactions in game environments were proven to improve the performance of computer agents when interacting with human subjects. We hypothesise that human–robot relationships might also be impacted. However, the games that are used in the reviewed studies have been developed for adults. Children may not be able to understand or appreciate these strategies, lacking life experience. Therefore, we propose to use some elements of these games in board games that are liked by children. We choose a checkers game and implement an altruistic social strategy, which was shown (Gorbunov et al., Citation2011) to promote collaboration between players. To adapt the economic game strategy to the checkers game, we simply made the robot make mistakes by using least favourable for itself strategy and thus making the child have a lucky turn.
3. Technical approach and implementation
There have been several projects in which robots are playing board games. A checkers playing robot is presented in Bailey and Lewis (Citation2004). These methods do not include elements of collaborative and social behaviour that usually takes place during games. We have chosen to restrict the robot gestural behaviour to only functional and not expressive gestures, so we can isolate and test only the impact of the social strategy of the robot on the engagement of the children. In our case, the robot behaviour at each turn is designed according to the see–think–act cycle, as shown in Figure (b) . The Robot Sensing consists of a vision module that estimates the state of the game, which is used by the Game and Social Strategy-module to determine the next move to be executed by the Robot Action-module.
3.1. Game state estimation
The goal of the Robot Sensing-module is to calibrate the NAO's lower camera and infer the state of the game after each move of the human opponent. The state of the game consists of the position of each checker piece on the checkerboard. The current move is inferred as a combination of the game state before and after the human turn. In summary, NAO uses the difference in the captured image to infer the move of the human and then update its “mental” representation of the state of the game. An online update of the state also allows the robot to keep track of the kings as well as to guarantee that the rules of the game are followed.
(1)
(1)
(2)
(2)
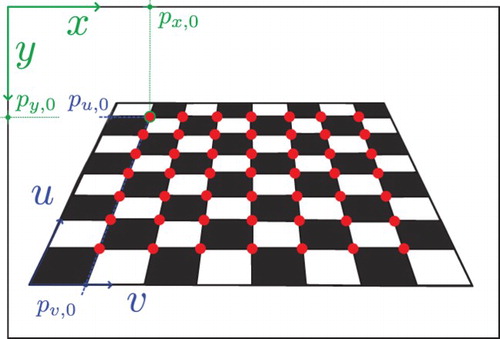
Calibration. The calibration is performed only at the beginning of the game. The objective of this is to find the relation between the camera's 2D coordinate system (pixels) and the coordinate system of the checkerboard (centimetres). The calibration is done by defining the mapping between both coordinate systems using Equations (Equation1
(1)
(1) ) and (Equation2
(2)
(2) ), where x,y and u,v are defined as presented in Figure .
are the coefficients to be estimated, these are estimated using a least-squares method which is applied to the checkerboard inner corners as denoted in Figure . The exogenous variables
and
are the coordinates in x and y, respectively. The endogenous variables
and
are the corresponding coordinates in the board, which are a consequence of the checkerboard geometry, these variables are known a priori. Once the parameters have been estimated, Equations (Equation1
(1)
(1) ) and (Equation2
(2)
(2) ) can be used to relate the board coordinates (v,u) to the pixel coordinates (x,y).
Figure 2. Relation between the reference frames of the camera and the position of the checkboard.
Game state dynamics. Once the calibration is done, the next challenge is to be able to track the changes in the state of the game. Let us assume as an initial condition that is NAO's turn and the availability of the current state, denoted as . Using the rules of the game and the strategy explained in Section 3.2 it is possible for the NAO robot to plan its move and update with total confidence its state to
. At this point, the opponent must choose a move which introduces uncertainty in the robot knowledge about the state
. We rely on the vision of the robot to identify the decision of the opponent, and then update the state. The colours of the checker pieces were chosen to be red and green, to improve the detection reliability of the pieces. The hue saturation value colour space is used to increase the robustness to small illumination changes.
Once the human finishes its turn, it has to notify the robot by touching the tactile head sensor. NAO uses the knowledge before the opponents turn and the rules of the game to find the set of legal moves of the human opponent
. The challenge is to find
, such that
applied to
matches the image in front of NAO. To accomplish this, the Robot Sensing module finds the green and red pieces in the frame coordinates and summarises each of them as an ellipse. The centroid of each ellipse is mapped to the board coordinates, using the calibration function. If the robot makes a mistake, two scenarios are likely – either the state of the game found by the Robot Sensing module is wrong, or the child did not make a legal move. To avoid wrong game state estimation, NAO tries several times to identify the opponents move with small variations of its head position. If no move is detected the child is notified about the detected inconsistency and asked to make his/her move.
3.2. Game strategy
The robot strategy consists of a game and a social strategy. When the robot has to execute its turn it has full knowledge about the current game state, provided by the Robot Sensing-module. The goal of the robot, according to the game strategy, is to decide which move, based on quantitative criteria, will lead it to achieve his objective, i.e. win against the human opponent. The social strategy aims to increase the child engagement by causing the robot to deliberately make a mistake. An important fact at this point is that checkers is a deterministic, observable and a zero-sum board game. Deterministic, because given a state the same decision will never lead to different results. Observable means that if the robot's vision capabilities are robust the robot will always understand the state of the game, and zero-sum means that the each possible move is modelled by a function in which the gains of one player are the looses of the other (Figure ).
Figure 3. Pieces detection and state estimation example. (a) Image captured with NAO camera. All pieces of the robot and of the opponent are detected and their centers are estimated. (b) representation of the state of the game in the robot “mind”. The robot plays with the black pieces, denoted with b and the opponent pieces are denoted with w (for white). On the color prints and in the designed game red and green colors are used instead of black and white, since the colors might be more enjoyable for the children.

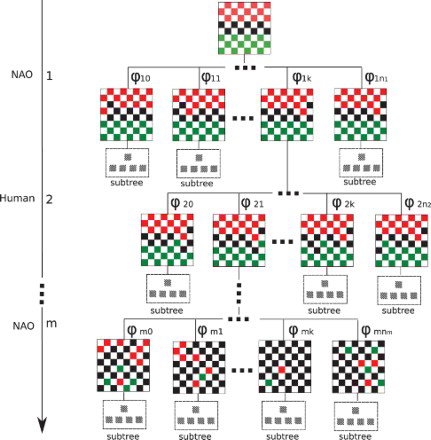
With this in mind, and following previous research about board games, each turn of NAO is formulated as a min–max search tree, on which each node is a possible state and its branches are the possible legal moves resulting from the previous action. The root of the tree is the current state of the game which is observable by assumption. Figure illustrates the min–max decision tree at the beginning of the game. Each row of the diagram represents the reachable states at a particular depth level, and the lines connecting each node and its children are the legal decisions , where i is the depth and j the index of the decision. The vertical axis is the search depth and m is the maximum searchable depth. For instance, at the beginning of the game the robot has
possible decisions and reachable states at depth 1. For illustrative purposes, and given the large game space, Figure only expands with one decision per level. The remaining consequences are illustrated with a label “subtree”. Notice that the second level is the opponent turn, which the robot simulates using its own objective function and assuming that the opponent goal is to win, i.e. to minimise its value.
Figure 4. Illustrative example of the decision tree on which NAO base its decisions.
In order to take its decision, the robot traverses the decision tree, finds the sequence of moves that maximise its objective function, and uses the first element of the sequence as its current move. For this purpose, robot must evaluate all the leaves at a depth level lower than m as well as the reachable states at depth m. As is clear from the figure, the game space quickly grows and a full traversal is computationally expensive. To alleviate this problem the search tree is pruned using an alpha–beta traversal strategy, on which only the branches that could potentially be selected, given the previously evaluated nodes are explored. This pruning strategy considerably reduces the number of nodes to be evaluated. For more information about the alpha–beta pruning algorithm, please refer to Ertel (Citation2011).
As explained before, the cornerstone of a good automatic player is its objective function. According to the literature, there are several possibilities, particularly when the main goal is to beat professional checker players. In our case we use a linear combination of six variables, namely: number of own pieces (p), number of own kings (k), number of opponent pieces (op), number of opponent kings (ok), number of pieces and kings lost between the original state and the evaluated state (lp, lk). In the experiments, we have used Equation (Equation3(3)
(3) ) as the objective function.
To accomplish the social strategy, we multiply the objective function by with the expectation to increase the engagement of the child on a short term and promote bonding on a long term. In this way, the robot would help the human opponent to find a complex move and conquer more than 1 piece
(3)
(3)
3.3. Robot motion and interaction control
Numerous approaches exist for controlling the movements of robots. For the control of robotic manipulators Vidyasagar, Spong, and Hutchinson (Citation2006) contain theory for (i) force control, (ii) geometric non-linear control and (iii) vision-based control. In Stramigioli and Duindam (Citation2009) another control approach is presented which is based on a virtual spring, connected between the end-effector of the robot and the desired position of the end-effector in space. The forces and torques applied by that virtual spring on the robot are calculated and distributed across the joints of the robot according to the manipulator Jacobian.
In our experiment, the focus will be on controlling the arms of the NAO robot. An inverse kinematic-control strategy is already implemented in the NaoQi Developer Framework (Softbank Robotics, Citation2012) for the NAO robot. This approach, however, uses a Jacobian iterative approximation method. This kind of methods might get stuck in local minima and provide poor handling of singular configurations. In Kofinas (Citation2012) and Lagoudakis, Kofinas, and Orfanoudakis (Citation2013) a closed-form inverse kinematic solution to the NAO robots arms motion is presented. This solution was found by a combination of (i) manipulating the forward kinematic equations until expressions for the joint angles were obtained and (ii) using geometry and/or trigonometry. Another solution to control for grasping purposes is presented in Muller, Frese, and Rofer (Citation2012), the presented approach pre-calculates the workspace using forward kinematics and saves the solutions in a look-up table, which is used in the motion planner.
We need an approach with is sufficiently accurate, while the calculation of the accurate movement is nearly real time. The overall goal of Robot Action-module is to control the NAO robot to execute its move or if this is not possible to ask for a help and provide detailed instructions to the human opponent where to move the piece of the robot. To design this module that can have a positive influence on user engagement, we try to mimic human behaviour as closely as possible, but we restricted the movement to only instrumental movements so in the experiment we can test only the impact of the game strategy and not of the social gestures. Humans move checker pieces using their hands and have grasping capabilities provided by their fingers. NAO is equipped with fingers as well, which enables grasping. Its grasping capabilities were found to be limited (Muller et al., 2012), if an accurate pointing is needed. Therefore, before grasping, a correct position and orientation of NAO's hand has to be achieved. The control approach chosen for this purpose is an inverse kinematic algorithm which follows a point-to-point trajectory. The inverse kinematic algorithm provides the joint angles for a certain position and orientation. The forward and inverse kinematic algorithms will be presented elsewhere since they do not contribute to the line of arguments provided in this paper. Here, we will only discuss the constraints of the implementation. Using the forward kinematics equations we found that the reachable space of NAO's arm is quite restricted due to the length of the arms, which makes it unfeasible to grasp all checker pieces on the checkerboard. This is indicated in Figure , which shows all the reachable positions by an arbitrary orientation of the robot. These positions are denoted by dots, between 3 and 7 cm above the checkerboard.
Figure 5. Reachable space for the NAO robot on the checkerboard.

For () points in a grid in the joint space. For each of these points it is determined whether they are between 3 and 7 cm from the checkerboard. This range will be the size of the extruded pieces which would allow NAO to grasp them. Note that for this experiment the surface height of the board was set to 5 cm beneath the NAO's torso frame, the board was 8 cm removed from the NAO's torso frame in
-direction. The sides of the checker squares have a length of 3 cm. The selected control approach has a twofold drawback concerning implementation. First, as mentioned before, to make full use of NAO's grasping capabilities the positioning of the hand has to be exactly above the checker piece. The position is known because the position of the checkerboard is fixed with respect to the robot in the calibration stage. The robot is able to grasp the checker pieces even though its hand is not perfectly aligned with the piece. The set of orientations with which NAO is able to grasp the piece successfully is limited by a set of constraints on the roll, pitch and yaw of the hand with respect to NAO's torso frame.
As a second limitation because the arms of NAO robot have five degrees of freedom, not every point in the reachable workspace of the robot can be reached.
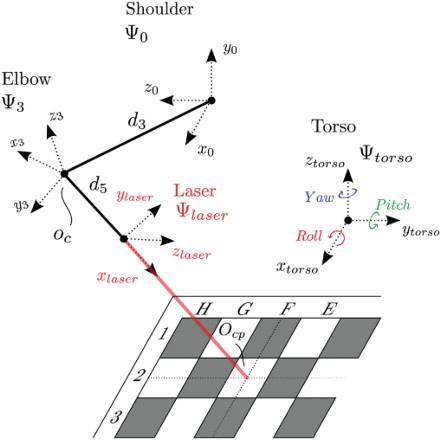
To solve both of the implementation constraints, NAO is equipped with a laser pointer. With this laser pointer, NAO is going to point and provide instructions to the human opponent about the move it intends to make. For practical purposes the laser is attached exactly in line from the wrist centre to the coordinate frame of the hand allowing us to build the solution as an extension of the already derived decoupled inverse kinematics. This solution is schematically represented in Figure . If the laser is placed in a different position, for example, on top of the hand, it would act as a sixth prismatic joint. This will increase the complexity of the inverse kinematic algorithm as the conditions for a spherical wrist are no longer satisfied. From the Game Strategy module an input will be received in the form of a certain coordinate on the checkerboard, for example . The position of this checker piece
with respect to NAO torso frame is known as the position of the checkerboard with respect to the robot is fixed in the calibration stage. Using the derived inverse position kinematics we position the wrist centre at a fixed point
. Note that once the wrist centre is positioned, only the inverse orientation kinematics have to be executed. As the laser is oriented along the x-axis of the
frame, it has to be coincide with the vector
. Together with a vector oriented close to
for all positions, the frame
can be artificially constructed using Marschner, Shirley, and Ashikhmin (Citation2009). The transformation matrix between this new basis and the torso frame is the input to the inverse kinematic algorithm.
Figure 6. Schematic representation of the NAO robot equipped with a laser pointer.
4. Results and validation
In this section we will present the validation process of the software modules described above and the results achieved. This section is structured in the same way as that used to present our plan of approach. At the end of this section we also present the process and results of the pilot study with children.
4.1. Validation of game strategy module
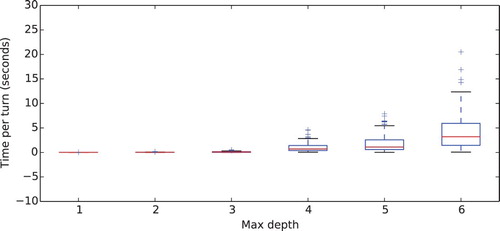
To validate the performance of the Game Strategy-module we focus on two important aspects: (i) it should not take too much time for the robot to find its next move and (ii) it should make a move that not only aims to win the match but also to engage the human opponent. Figure shows the distributions of the time required to explore the tree at different depth levels. For practical purposes, we found that a maximum depth of 5 offers a good balance between computation time and a challenging match. Finally, to improve the engagement of the opponent, the objective function is inverted with a chance of 0.5, which means that NAO frequently works to design advantageous moves for the opponent. During these moves, the opponent would be able to capture several pieces in one turn. During the study case, we found that the children found these moves rewarding and their engagement was significantly increased. This will be further elaborated on in Section 5.
Figure 7. The computation time required to calculate the next move plotted to the depth used.
4.2. NAO motion control and interaction control
To validate the performance of the NAO Control-module, the inverse kinematic algorithm was executed for 6250 different positions and orientations in the cartesian space. The ground truth in this validation is provided by the joint angles which were used by the forward kinematic algorithm to generate the different positions and orientations in the cartesian space. This process did not yield any inconsistencies and the error was kept low.
Another way in which we wanted to test this module was to measure the accuracy of the laser point with respect to the centre of the checker square. During these validation tests, we have found however that due to the extra weight (the laser pointer) attached to NAO's hand the joint control is disturbed. Results show that the laser point is sometimes off by one checker square, therefore these results have not been documented.
5. User study with children
We performed a pilot test to find out whether children are engaged with the game and whether there is a difference between the play with the robot and with the computer. Twelve children aged on average M=8.13 () were involved. The children played one game with the robot and one with the computer. After both games the children were asked to fill in a questionnaire. This questionnaire was based on the Immersive Experience Questionnaire (Jennett et al., Citation2008). We selected of 12 questions that related either to the engagement of the children with the game or to the empathy with the partner (computer or robot) and translated the questions to Dutch and simplified them for the children (Table ). These questions can be divided into two categories relating to: (i) the engagement with the game and (ii) the empathy the child had with the robot or the computer. For every question, the children had to answer on a 4-point rating scale (totally disagree, slightly disagree, slightly agree, or totally agree) or fill in that they did not know. A neutral rating was excluded so the children had to choose whether they agree or not. The nonverbal behaviour of the children was also recorded with a video recorder. This was done with the aim to analyse how the children would react on the interaction with the robot – several studies show that engagement could be detected from the nonverbal behaviour of the children.
Table 1. The questionnaire for the children (English version).
We compared the frequency of the children's turns towards the computer and the robot, their gaze at the robot and the children's answers on the questionnaire. We only compared the frequency count of 10 children and excluded 2 children from the data because the data were incomplete for the frequency count.
5.1. Turns
A paired-samples t-test was conducted to compare the frequency of turns in playing against the robot and the computer. The children took significantly more turns when playing against the robot (M=19.6, ) than when playing with the computer (M=16.2,
);
, p=0.05.
5.2. Gaze
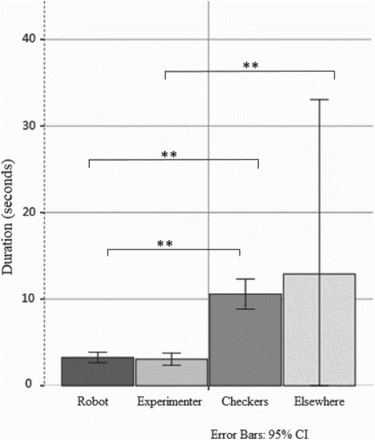
A one-way repeated measures analysis of variance was conducted to evaluate the null hypotheses that there is a significant difference between the children's gaze, , p=0.00,
. Follow-up comparisons indicated that pairwise differences were significant between gaze towards the robot and elsewhere and the game, between gaze towards the experimenter and elsewhere and the game (see Figure for a visual representation).
Figure 8. The gaze duration of the children across all conditions.
5.3. Questionnaire
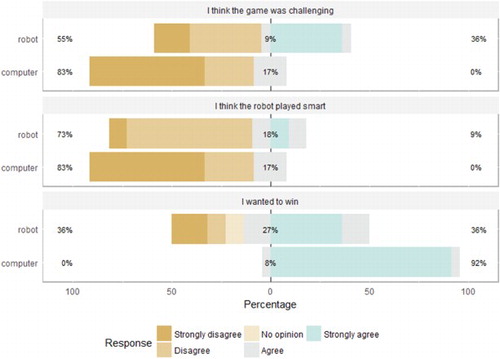
A Wilcoxon signed-ranks test was used to compare the results from the questionnaire. Only for the questions: “I think the computer/robot played smart, I wanted to win against the computer/robot and I found the game challenging” a significant difference was found between the answers for the game with the robot and the game with the computer. Table shows the p and Z values, and Figure shows the actual answer percentages for the three significant results. While the children thought that both the computer and the robot were not so smart, they considered the robot as much smarter. Another comparison shows that the children found the game more challenging with the robot, which confirms the belief of the children that the robot was a smarter and challenging partner. This coincided with the results from the mean duration of the play against the robot and the computer – the children took significantly more turns to win against the robot. In addition, they minded much less to lose against the robot, which implies that they see the robot more as a partner than the computer.
Figure 9. The children's answers on the questionnaire.
6. Conclusions and future work
In this paper we have presented the design, the implementation and the testing of an embodied game between a robot and a child and a non-embodied variant of the same game in which the child plays against a computer. We compared the engagement of the children when they played with the robot or with a computer, both equipped with the same game strategy. The design of the embodied game was based upon a combination of robot skills for physical interaction, robot intelligence that was shown in combining game-theoretic strategy with a social strategy. The same combination of game and social strategy was also implemented on the computer variant of the game. By adding social strategy we aimed to enhance the user engagement and possibly enhance the bonding with the robot partner, which might be useful as a step towards creating long-term relationship with the robot.
Serious games are good means for embodying the combination of social and educational or therapeutic goals in robot behaviour, since the games naturally include components such as interactive story line, long- and short-term goals and other rewards that trigger engagement and emotions. Games with physical objects and board games in particular provide more opportunities to naturally experience social engagement and interaction in addition to the game-specific goals, because of the continuous confrontation with the physical presence and the interacting qualities of the two players.
The architecture designed for the embodied game (with the robot) consists of three interaction modules, and in each module there has been an implementation challenge. To make the robot capable of grasping or at least reaching for a game piece, the inverse kinematics of the robot need to be solved for this particular robot (NAO) which has not been solved with such a quality (or report on that is not available) yet. Our method achieves a good speed of the motor planning, which is one aspect of keeping the game engaging for the children. The game strategy module is the main innovation for the purpose of this paper, because it combines a strategy which chooses between the optimal game-theoretical solution and the socially appropriate choice that need to be made. However, the main goal of the study is to make the first from a series of experiments that show the potential of games with robots for monitoring and grounding and building long-term interaction between a robot and humans. For computer agents, who lack embodiment it has been shown that humans treat these agents differently depending on the game strategies embedded into these agents. This is particularly true for cooperative games (Gorbunov et al., Citation2013), and have not been explored with zero-sum games. We tested whether if implementing social game strategy next to the game strategy that gives an obvious advantage to the human player at some moves in the competitive zero-sum board game as checkers game is equally well accepted as it was done in a game against computer agents. The choice of the checkers game was made because the human participants were children and economic game strategies (as proposed for instance in Gorbunov et al., Citation2013) are likely to add complexity which children are not ready to deal with.
We created questionnaire that concerned the engagement of the children during the game with the computer or with the robot and the empathy with the same opponent. More significant results were found with regards to the empathy and the relational behaviour between the child and the robot/computer agent. With regards to the engagement, there were no significant differences when child played with a computer or a robot, except that the children found the game with the robot more challenging. The children did wanted to win the game against the computer, but when playing with the robot they were much less eager to win, they rather wanted to play. The results also show that the children found both the robot and the computer not so smart, since they were giving the advantage of the child to make a very smart move in 50 % of the cases. However, the children found the robot significantly smarter than the computer, even though both used exactly the same algorithm. The children also answered that they found the game more challenging with the robot than with the computer. We believe that this is related to the higher expectations about the smartness of the robot which likely stems from its humanoid appearance and embodiment. In addition, the robot talked to the children to ask them for a help to move the pieces, which influenced the perception of smartness.
With regard to engagement, there were mostly not significant differences between the answers of the children in both cases. The only question that brought to a significant difference in the answers of the children was “I think the game was challenging”, where the robot was found to be the more challenging opponent. This indicates that although the question is in principle targeting to find out how challenging is the game, and formally is in the category of questions that relate to engagement, the question actually concerns more the social relations with the robot or the computer, considering the game with the same difficulty much more difficult if played against the robot. This result can have an alternative explanation. If we look at the number of turns that the children took to win the game, it was significantly higher in the robot condition. This could be explained by the fact that in a three-dimensional game it is more difficult to see some patterns. In addition, it might be that part of the attention of the children goes to the robot, as also shown in Figure . If judging from the nonverbal behaviour of the children captured by the video recordings, it could be seen that the children smiled whenever they could touch the robot. They smiled less when playing with the computer. The videos also show that the children look and act more engaged when they were able to capture more than one piece from the robot in a turn.
The described experiments were performed with the robot choosing at random when to make a mistake and give an advantage to the human player. A more socially intuitive decisions could be made if the robot uses a good model of when a mistake should be made. For this purpose we propose to use the signs of engagement and empathy as an input to a dynamic model of game behaviour that enhances the social strategy of the robot. For this purpose we propose to use the DNF model proposed as a simplified mathematical model for neural processing (Amari, Citation1977). The DNF model has been used to model the decision-making, for multimodal integration (Schauer & Gross, Citation2004) and imitation (Sauser & Billard, Citation2006). The model was also used for action selection when different sensorymotor cues have temporal delays (Barakova & Chonnaparamutt, Citation2009). Applications feature biologically convincing methods that can optimise more than one behavioural goal, which makes it interesting for choosing between the optimal according to the game-theoretic outcome of the game and the social goals of the robot to keep the game with the robot engaging for the children.
Overall, our study showed that by combining the social and game strategy the children (average age of 8.3 years) had more empathy and social engagement with the robot. This conclusion is made because the children did not want to win against the robot as much as they wanted to win against the computer. This finding is promising for using social strategies for creation of long-term-relations between robots and children and making educational tasks more engaging. It especially can be exploited in teaching social skills. An additional outcome from the study was the significant difference in the perception of the children about the difficulty of the game – the game with the robot was seen as more challenging and the robot – as a smarter opponent. This finding might be due to the higher perceived or expected intelligence from the robot, or because of the higher complexity of seeing patterns in three-dimensional world.
As an additional contribution of this paper, each of the three interaction modules can also be used by other researchers, requiring for example: (game) object detection, solving a game of checkers, or solving the eye-arm coordination of NAO robot in an exact way. The software used in this research is made available on GIT Drive.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Amari, S. (1977). Dynamics of pattern formation in lateral-inhibition type neural fields. Biological Cybernetics, 27(2), 77–87.
- Bailey, D., & Lewis, D. (2004, November). A checkers playing robot. Proceedings of the eleventh electronics New Zealand conference, ENZCon'04, Palmerston North (pp. 218–222).
- Barakova, E. I., Bajracharya, P., Willemsen, M., Lourens, T., & Huskens, B. (2015). Long-term lego therapy with humanoid robot for children with asd. Expert Systems, 32(6), 698–709.
- Barakova, E. I., & Chonnaparamutt, W. (2009). Timing sensory integration. IEEE Robotics & Automation Magazine, 16(3), 51–58.
- Barakova, E. I., Gorbunov, R., & Rauterberg, M. (2015). Automatic interpretation of affective facial expressions in the context of interpersonal interaction. IEEE Transactions on Human–Machine Systems, 45(4), 409–418.
- Coninx, A., Baxter, P., Oleari, E., Bellini, S., Bierman, B., Henkemans, O. B., ... Espinoza, R. R. (2016). Towards long-term social child–robot interaction: Using multi-activity switching to engage young users. Journal of Human–Robot Interaction, 5(1), 32–67.
- de Graaf, M., Allouch, S. B., & van Dijk, J. (2017). Why do they refuse to use my robot?: Reasons for non-use derived from a long-term home study. Proceedings of the 2017 ACM/IEEE international conference on human–robot interaction, Vienna, Austria (pp. 224–233). ACM.
- El-Nasr, M. S., Aghabeigi, B., Milam, D., Erfani, M., Lameman, B., Maygoli, H., & Mah, S. (2010). Understanding and evaluating cooperative games. Proceedings of the 28th international conference on human factors in computing systems, Atlanta, Georgia, USA (pp. 253–262).
- Ertel, W. (2011). Introduction to artificial intelligence, Undergraduate Topics in Computer Science, London: Springer.
- Gal, Y., & Pfeffer, A. (2006). Predicting people's bidding behavior in negotiation. Proceedings of the 5th international joint conference on autonomous agents and multiagent systems, Hakodate, Japan (pp. 370–376).
- Gal, Y., & Pfeffer, A. (2007). Modeling reciprocal behavior in human bilateral negotiation. Proceedings of the 22nd national conference on artificial intelligence, Vancouver, British Columbia, Canada (Vol. 1, pp. 815–820).
- Gal, Y., Pfeffer, A., Marzo, F., & Grosz, B. J. (2004). Learning social preferences in games. Proceedings of the 19th national conference on artificial intelligence, San Jose, California (pp. 226–231).
- Gockley, R., Bruce, A., Forlizzi, J., Michalowski, M., Mundell, A., Rosenthal, S., ... Wang, J. (2005). Designing robots for long-term social interaction. 2005 IEEE/RSJ international conference on intelligent robots and systems, Edmonton, Alberta, Canada (pp. 1338–1343).
- Gorbunov, R., Barakova, E. I., Ahn, R. M. C., & Rauterberg, M. (2011). Monitoring interpersonal relationships through games with social dilemma. IJCCI (ECTA-FCTA), Paris, France (pp. 5–12). Citeseer.
- Gorbunov, R., Barakova, E. I., & Rauterberg, M. (2013). Design of social agents. Neurocomputing, 114, 92–97.
- Jennett, C., Cox, A. L., Cairns, P., Dhoparee, S., Epps, A., Tijs, T., & Walton, A. (2008). Measuring and defining the experience of immersion in games. International Journal of Human–Computer Studies, 66(9), 641–661.
- Kanda, T., Shiomi, M., Miyashita, Z., Ishiguro, H., & Hagita, N. (2010). A communication robot in a shopping mall. IEEE Transactions on Robotics, 26(5), 897–913.
- Kofinas, N. (2012). Forward and inverse kinematics for the NAO humanoid robot (M.S. thesis). Technical University of Crete, Chania.
- Lagoudakis, M. G., Kofinas, N., & Orfanoudakis, E. (2013). Complete analytical inverse kinematics for NAO. 13th international conference on autonomous robot systems (Robotica), Lisbon, Portugal.
- Leite, I., Martinho, C., & Paiva, A. (2013). Social robots for long-term interaction: A survey. International Journal of Social Robotics, 5(2), 291–308.
- Marschner, S., Shirley, P., & Ashikhmin, M. (2009). Fundamentals of computer graphics. Natick, MA: A K Peters/CRC Press.
- Marzo, F., Gal, Y., Grosz, B. J., & Pfeffer, A. (2004). Social preferences in relational contexts. Proceedings of the 4th conference in collective intentionality.
- Muller, J., Frese, U., & Rofer, T. (2012, November). Grab a mug – Object detection and grasp motion planning with the NAO robot. 12th IEEE-RAS international conference on humanoid robots (Humanoids), Osaka, Japan (pp. 349–356).
- Sauser, E. L., & Billard, A. G. (2006). Biologically inspired multimodal integration: Interferences in a human–robot interaction game. 2006 IEEE/RSJ international conference on intelligent robots and systems, Beijing, China.
- Schauer, C., & Gross, H.-M. (2004). Design and optimization of amari neural fields for early auditory–visual integration. Proceedings 2004 IEEE international joint conference on neural networks, Budapest, Hungary (Vol. 4, pp. 2523–2528).
- Stramigioli, S., & Duindam, V. (2009). Modeling and control for efficient bipedal walking robots: A port-based approach. Berlin: Springer.
- Softbank Robotics. (2012). NAO software 1.14.5 documentation – Cartesian control.
- van Wissen, A., van Diggelen, J., & Dignum, V. (2009). The effects of cooperative agent behavior on human cooperativeness. Proceedings of the 8th international conference on autonomous agents and multiagent systems, Budapest, Hungary (Vol. 2, pp. 1179–1180).
- Vidyasagar, M., Spong, M. W., & Hutchinson, S. (2006). Robot modeling and control. Hoboken, NJ: John Wiley & Sons.
- Wada, K., Shibata, T., Asada, T., & Musha, T. (2007). Robot therapy for prevention of dementia at home. Journal of Robotics and Mechatronics, 19(6), 691.