
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Selecting suitable web services based on the quality-of-service (QoS) is essential for developing high-quality service-oriented applications. A critical step in this direction is acquiring accurate, personalised QoS values of web services. As the number of web services is enormous and the QoS data are highly sparse, improving the accuracy of QoS prediction has become a challenging issue recently. In this study, we propose a novel QoS prediction model, called neural fusion matrix factorisation, wherein we combine neural networks and matrix factorisation to perform non-linear collaborative filtering for latent feature vectors of users and services. Moreover, we consider context bias and employ multi-task learning to reduce prediction error and improve the predicted performance. Furthermore, we conducted extensive experiments in a large-scale real-world QoS dataset, and the experimental results verify the effectiveness of our proposed method.
1. Introduction
The emergence of service-oriented computing (SOC) has provided users with a dynamic, elastic, and reliable computing paradigm (Huhns & Singh, Citation2005). With the evolution of cloud computing and edge computing, technologies such as the Internet of things (Liang et al., Citation2020a), software-as-a-service, and blockchain (Liang et al., Citation2021, Citation2020d) are being developed and broadly employed. Generally, a match between the user and service depends on functional requirement. Nevertheless, some services are non-functional and constrained. Thus, making it increasingly challenging for users to select the right service from various candidate services due to the ever-growing service marketplace. In light of this, quality-of-service (QoS) has emerged as a crucial criterion for service selection (Liu & Chen, Citation2019; Shao et al., Citation2007). Hence, with the number of services available to users expanding, the demand for QoS-based service selection is rising.
Since QoS values, such as response time, throughput, and invocation failure rate, may vary when different users invoke non-identical services, obtaining accurate, reliable, and personalised QoS values requires the deployment of QoS monitors on both the server side and client side (users). However, owing to various factors related to performance, time, and cost, it is unrealistic for service providers to do so on a large scale. Typically, only critical services are monitored. Likewise, it is infeasible for each user to invoke all services to obtain the QoS values due to the time-consuming nature of the process. Therefore, the QoS observation matrix is often highly sparse. In some cases, users will not even invoke a single service, leading to cold-start problem.
In recent years, deep learning has experienced explosive growth and reached milestone achievements in many fields, such as natural language processing, image recognition (Liang et al., Citation2020b), security authentication (Liang et al., Citation2020c), and recommender systems (Schmidhuber, Citation2015). These networks offer various advantages, which include effectively learning features by stacking multiple layers and fusing the features at various levels. They also have the potential of approximating extremely complex functions. Moreover, deep neural network can very well free us from feature engineering. Additionally, multi-task learning can be easily employed using the branching structure. Inspired by these deep learning techniques, in this study, we propose a novel approach called neural fusion matrix factorisation (NFMF) to predict personalised QoS more effectively. The core idea of NFMF is to apply neural networks to construct complex relationships among users, services, and their contexts. Therefore, we first apply embedding lookup to transform contexts. After obtaining feature vectors, we employ a context encoder to incorporate a high-order combination of multiple contextual factors. Next, we introduce a neural network-based collaborative filtering model to predict QoS. Bias modules fine tune the prediction from both the user side and service side. Finally, stacking the task-specific layer enables our model to predict different QoS attributes. By extending matrix factorisation in deep learning, we fit our model in the service selection scenario.
The main contributions of this study are summarised as follows:
We replace inner product modelling by a neural network combined with contextual information to enhance the prediction accuracy of QoS and alleviate the difficulties of introducing side information to collaborative filtering.
We improved the prediction robustness, particularly in root mean square error (RMSE), which enables a more robust and stable performance in QoS prediction, by introducing a context-aware bias term.
We conducted extensive experiments relying on a large-scale real-world dataset, which demonstrates the effectiveness of NFMF for QoS prediction.
The remainder of this paper is organised as follows. Section 2 discusses related work. Section 3 details our model. Section 4 presents the experimental results. Finally, Section 5 draws the conclusion and discusses future work.
2. Related works
Neighbourhood-based collaborative filtering methods rely on discovering similar users or services to predict QoS values. These methods can be divided into two categories: user-based and service-based. Shao et al. (Citation2007) and Linden et al. (Citation2003) proposed the user Pearson correlation coefficient (UPCC) and item Pearson correlation coefficient(IPCC), respectively. Zheng et al. (Citation2011) proposed a mixed model integrating the UPCC and IPCC by assigning different weights, and proved that the mixed model performed better than two models did individually. Follow-up works mainly concentrate on improving similarity metrics to quantify the correlations of users or services, and these methods require the discovery of similarity from data. When data are highly sparse, their performance declined due to cold-start issues. Therefore, neighbourhood-based models have limited accuracy.
Matrix factorisation approaches put accuracy and scalability in the center stage, and hence are widely used for QoS prediction. Zheng & Lyu (Citation2013) used probabilistic matrix factorisation (PMF) to perform decomposing data matrix for QoS prediction. To further improve accuracy, other methods exploit additional information (e.g. spatial, temporal). He et al. presented a hierarchical matrix factorisation (HMF) model exploiting geographic information. It divides users into multiple groups, constructs local matrices within these groups, and then combines local and global information for the prediction of QoS values via matrix factorisation. Yu et al. (Citation2014) proposed MF with bias terms to incorporate geographic location information.
In addition to geographic location information, other factors may affect the prediction accuracy of QoS values, such as IP addresses and autonomous systems (Wu et al., Citation2018a, Citation2018b; Xu et al., Citation2016). Xu et al. (Citation2016) suggested an ensemble model that utilised both the users and services' affiliation information. Wu et al. (Citation2018a) exploited both implicit and explicit contextual information and achieved state-of-the-art performance. Since context factors are discrete for these model-based methods, they all face difficulties in vectorising context information or quantifying them. Additionally, they may not be robust and stable enough as manual similarity metric design is inevitable.
In recent years, some researchers have performed QoS prediction through deep learning inspired by deep learning. Wu et al. (Citation2018b) presented the deep neural model (DNM) method using the superior feature–learning capabilities of deep learning. They not only introduced the context information but also considered the interaction between different context informations. DNM constructs a multi-task learning prediction model using neural networks, providing a general framework for deep learning to predict QoS. The previous collaborative filtering methods cannot sufficiently learn complex feature representations. It also suffers from the limitations imposed by inner product modelling. To solve this problem, He et al. (Citation2017) presented neural matrix factorisation (NeuMF), which can address the limitation of inner product and generalised matrix factorisation. DNM differs from our model in that we aim to enhance collaborative filtering and model user, service latent vector directly, whereas DNM predicts multi-QoS attributes based on multilayer perceptron (MLP), which mixes all latent vectors. However, DNM performs well for MAE but is relatively weak for some metrics that measure variance (e.g. RMSE, MSE), which may indicate an unstable QoS experience.
In this study, we further exploit the ability of neural collaborative filtering in NeuMF and enable it to adapt to complicated cases of QoS prediction. Then, we proposed the user-side and service-side context-aware bias terms to enable a more robust and stable prediction performance. Additionally, stacked task-specific layers help us to reduce parameters and take advantage of other related QoS attributes.
3. Our model
3.1. Problem description
Let be a set of users and
be a set of services. For each
, let
be their user side context where UAS denotes User Autonomous System while URE denotes User REgion(to be specific, their nationality). Similiarly, for service
, let
be their user side context where SAS denotes Autonomous System, REgion and Service Provider of service. The context of service j invoke by user i represented by
. Let interested QoS attributes be
. For QoS records, we use a sparse tensor
to store all qos record with different timestamps. In this paper, we assume qos value will not change through time, therefore Q can be simplify to be a 3-dimension tensor
.
Let qos record of an invocation between service j and user i at timestamp t be a tuple :.
Embedding Layer widely used in mapping discrete context feature into latent representation. For convenience, we still use to represent them in latent space where k denotes dimension of latent space.
Let f be the abstract function of our model, since we are aiming at predict the qos value through given context as well as user and service, it can be further described as
A naive matrix factorisation with bias term predict qos value by
We implement and extended matrix factorisation by modifying the equation above:
where
denotes Nerual Fusion Collaborative Filtering and
is our bias interaction module. Both of them will be detailed later.
3.2. Prediction framework
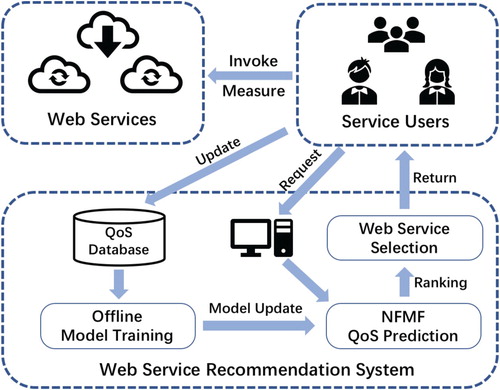
The overview of our QoS-based web service selection system is shown in Figure , which includes three main functions:
Data Collection and Update. Users collect existing information of users and services in invocation process. Then all existing web services invocation records tuple I will be submited and update a global user-service matrix in database.
Offline Model Training. While providing prediction service, the model need to periodically retrain or continue to optimise based on the latest QoS data. After the offline training completed, the serving model will be replaced.
QoS-Based Service Selection. Users request for service selection suggestions via web service recommendation system server. The server predict the QoS value by NFMF model, rank and return selection result to users.
Figure 1. The QoS prediction framework in service selection.
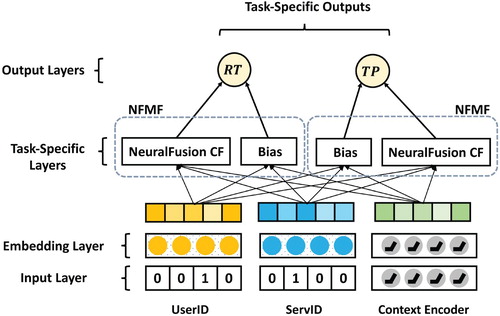
3.3. Model architecture
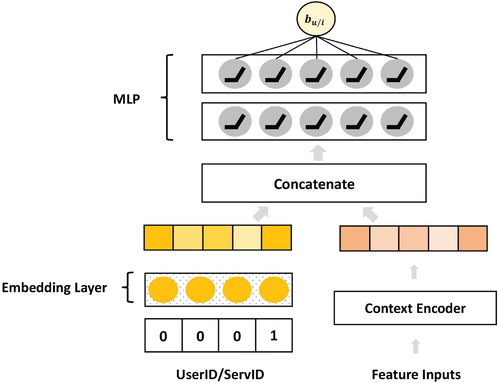
Figure shows the overall architecture of our model, consisting of three parts: input layer, embedding layer, and task-specific layer. The input layer contains UserID, ServID, and Context Encoder. In the embedding Layer, we establish embedding for users and services along with other context features, and then, discuss how to encode and construct context features using the context encoder. In the task-specific layer, we calculate the user bias term with the context and predict QoS attributes, such as response time (RT) and throughput (TP). Multi-task learning is implemented by organising different task-specific layers, which include neural fusion collaborative filtering (NFCF) and bias interaction.
Figure 2. The overall architecture of our model.
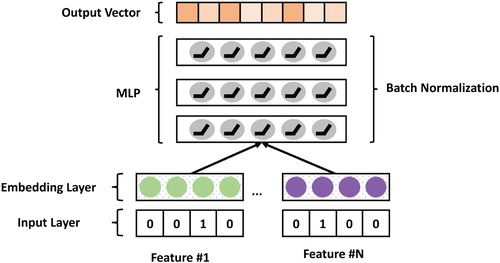
3.4. Context encoder of input layer
For feature interaction, we present a context encoder network shown in Figure . Our context information interaction method is fulfilled using the context encoder module, which helps us process all features through a neural network that results in outputing a context information vector representing the features. We stack multiple fully connected layers to allow various features to interact in high-order. We did not artificially construct a second-order feature interaction and input it into the neural network, because there is a certain overlap between these features, for example, the user autonomous system and the region where the user autonomous system is determined will determine the country in which it is located. Another reason is that we rely on feature encoders to reduce the dimensionality of multiple high-dimensional sparse features to reduce network parameters and allow element-wise operations between context and feature vectors of users or services.
Figure 3. The context encoder network.
3.5. Embedding layer
Embedding is an approach used to turn the sparse vector into a dense vector. Because the contextual information (e.g. User AS) will be first encoded to one-hot representation, which may take up massive space for large-scale data due to its sparsity, the embedding technique was put forward to map sparse vectors into the dense representation. That is, embedding involves assigning vector representations to discrete features. In matrix factorisation, we decompose the scoring matrix, , into two small matrices,
and
, where m denotes the number of users, n denotes the number of services, and l denotes the latent dimension; both matrices U and S can be considered as embeddings.
3.6. Neural fusion matrix factorisation
In the task-specific layers, we present NFMF that contains neural fusion collaborative filtering (NFCF) and bias interaction.
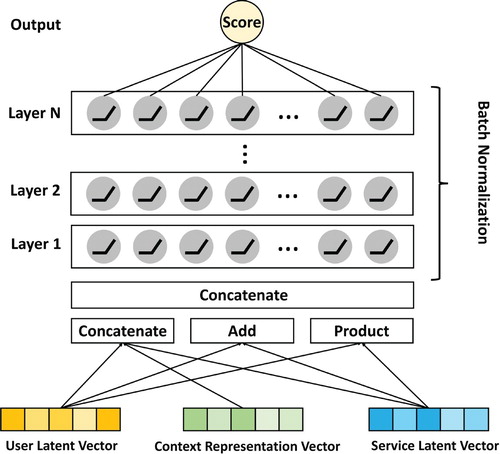
3.6.1. Neural fusion collaborative filtering
The conventional matrix factorisation is completed by an inner product modelling method between the latent vector of user and service. We realised that the model expression ability of inner product modelling is affected by linearisation, and we cannot learn more complex user-hidden vectors and complex interactions between the service-hidden vectors. To solve this problem, we propose applying a neural network instead of the inner product to complete the prediction. Additionally, to tackle the difficulty in constructing a collaborative filtering model with the context and make full use of the advantages of the neural network, we present an NFCF module. The module employs the concatenate method to merge the features. Thus, the input of the network can be directly targeted at user vectors, service vectors, and contextual information. Moreover, to increase the diversity of input features, we applied element-wise product and element-wise add operations. Figure presents the architecture of the NFCF module.
Figure 4. The architecture of neural fusion collaborative filtering.
3.6.2. Bias interaction
Figure shows the architecture of the bias interaction module in the task-specific layer. By using the means demonstrated, we first query the embeddings of users, and then, concatenate them with context vectors. Finally, the bias value can be obtained through the perceptions.
Figure 5. The architecture of bias interaction module.
Considering the matrix factorisation with bias terms, we introduce bias terms to improve the performance and power of the model, especially in BiasedMF (Yu et al., Citation2014). This is because the influence of geographic information is considered in the calculation of the offset term, which successfully helps the model obtain certain advantages over other methods in terms of the RMSE. The formulation of the basic matrix factorisation with bias term is as follow:
(1)
(1) where
indicates the estimation of the observed matrix, R,
denotes the latent vector of
, and
represents the latent vector of
.
and
indicate the effect biases of
and
, respectively. μ expresses the overall average of R.
As we use a neural network instead of the inner product of and
, let F denote the NFCF function,
represent the context information for the combination of
and
, and λ indicate the weight assign to all biases, the estimation of R can be modified to:
(2)
(2) Then, the user bias,
, and service bias,
, can be calculated using a context-sensitive neural network.
(3)
(3)
(4)
(4) Our NFMF model is related to the matrix factorisation method since we model users and services and similarly calculate bias terms. Meanwhile, we use the deep neural network entirely to encode context features, process users, service latent vectors, and generate personalised bias terms. Hence, our model can be viewed as an extension of matrix factorisation.
3.7. Multi-task learning
Since there is no significant difference between the prediction models based on a neural network, and the main difference is the data distribution for the neural network to learn. Therefore, when the prediction model transforms from one QoS attribute to another (e.g. from RT to TP), it does not need to make any adjustments on the neural network structure, but need to change the dataset. Based on this, we suggest employing multi-task learning methods to share parameters for the prediction model. We have observed that multi-task learning can enable the network to acquire a better generalisation ability by introducing other tasks related to the main task, which can improve the performance of the main task to a certain extent (Zhang & Yang, Citation2017).
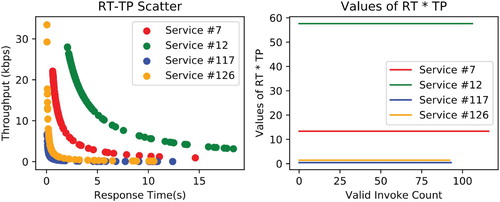
One prerequisite of employing multi-task learning is the correlation among the tasks. In Figure , we visualise four randomly selected services to demonstrate the relation between RT and TP via a scatter plot on the left. Then, we visualise RT multiplied by TP of each service on the right. We discover that services with a short RT are of a larger TP, while those with a long RT are of a smaller TP. The value of RT times TP for each service remains the same which indicate an inverse proportional relationship. We presume that . Since different users have different experiences when invoking available services, θ could be different and remain unknown. Thus, we apply multi-task learning in the hard-sharing pattern instead of inferencing the other attritube by θ. Each Task-specific layer independently calculates and outputs its prediction.
Figure 6. Relationship between RT and TP with different services.In the left figure, it is clear that RTs and TPs have a strong correlation. In the right figure, we can further discover this relation is inverse proportional by multiplying RT and TP from service side.
4. Experiments
In the experimental part, we will mainly answer the following questions:
Is deep learning good for QoS prediction? To what extent can the model improve the performance?
Which part of the network structure is related to the improvement of the model performance? Does the bias term reduce errors?
How does the model's parameters affect the performance?
How important is contextual information? What can we learn from it?
4.1. Dataset
We selected the WS-DREAM dataset for this study. WS-DREAM (Zheng et al., Citation2012), collected by Zheng et al, contains a QoS matrix of 339 users and 5825 services, and includes two QoS attributes, RT and TP. The basic statistics of this dataset are listed in Table .
Table 1. Statistics of dataset#1.
4.2. Data preprocessing
Since users did not invoke this service, some vacant entries in the QoS matrix marked as −1 need to be removed. In terms of the embedding layer, it is necessary to encode user autonomous system (UserAS), IP address, and other textual information (e.g. WSDL) into one-hot representation. Considering the international regulations of the category of IP addresses, we divided the IP address into five sections: 0–126, 128–191, 192–223, 224–239, and 240–255, corresponding to classes A–E, respectively. The daily used IP address belongs to classes A, B, and C, whereas classes D and E are for scientific research or other purposes. Further, we extract some additional information from the dataset as input features of a neural network, such as the longitude and latitude. The longitude and latitude features are directly input as numerical features after normalisation. From the statistics of the dataset (Table ), we have perceived that the observed matrix is dense, whereas in the actual scene, the matrix would be much more sparse. For a better simulation of the performance of the actual scene, we use low matrix density from 2.5% to 10% with a stepping value of 2.5%. From the data matrix, we randomly take 2.5% of the data as the training set and the rest as the test set. Subsequently, we generate all matrix subscripts and samples after random permutation.
4.3. Evaluation metrics
We evaluate the model performance of our proposed model in comparison with other existing approaches by using the following metrics.
Since QoS values are of large variance, it is better to focus on relative error metrics that reflect prediction robustness, i.e. MRE and NPRE. As it is widely used in other paper to evaluate performance,we also included MAE and RMSE for comparison.
| • | MAE (Mean Absolute Error). It is commonly used in evaluating the performance in recommender systems. | ||||
| • | RMSE (Root Mean Squared Error). RMSE is used to illustrate the degree of dispersion of the sample. For non-linear fittings, the smaller the dispersion, the better the RMSE. | ||||
| • | MRE (Median Relative Error). MRE is used to take the median value of pair-wise error. Similar to RMSE, it can reflect whether the majority of relative errors distribute in a wide range. | ||||
| • | NPRE (Ninety-Percentile Relative Error). NPRE is used to metric the distribution of relative errors. A robust and stable recommender system should have low NPRE which indicates the system seldom give prediction that vary a lot from ground truth. | ||||
4.4. Compared methods
To demonstrate the prediction performance of our proposed model, we compare the following models. In terms of neighbourhood-based methods, PMF uses neighbourhood information for the QoS matrix. We select BiasedMF and HMF as representative methods for location-based methods. For context-aware models, we choose CSMF and DNM. Specifically, DNM is also a neural network–based method.
PMF (Zheng & Lyu, Citation2013) performs a probabilistic model in matrix factorisation.
BiasedMF (Yu et al., Citation2014) is a matrix factorisation method that uses bias terms to quantify the location impact.
HMF (Lee & Seung, Citation1999) structures location information and QoS data hierarchically in matrix factorisation.
CSMF (Wu et al., Citation2018a) is a context-sensitive matrix factorisation model that exploits interactions of users-to-services and environment-to-environment.
DNM (Wu et al., Citation2018b) is a state-of-the-art deep learning model for multiple QoS attribute prediction.
4.5. Parameters setting
We implemented our model in PyTorch 1.4 with Python 3.7. Both the NFCF and bias interaction module adopt four linear layers of shape { InputSize, 64, 32, 1 }.
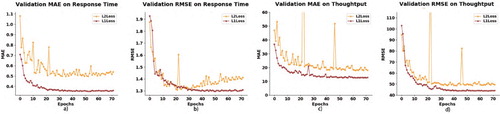
In terms of model settings, we select 64 as the hidden dimension for embedding. For the gradient descent algorithm, we selected adaptive moment estimation (Kingma & Ba, Citation2014) algorithm (Adam). The initial learning rate is set to 0.004, and weight decay at 0.0001. For the training process, we adopt a batch size of 256 and accept L1Loss (also known as MAE) as our criterion instead of L2Loss (also known MSE). All loss functions share the same weight. The reason for selecting L1Loss as the loss function is that we have evaluated two criteria, as shown in Figure , and discovered that L2Loss is relatively slower than L1Loss in optimisation and achieves more unsatisfactory results than L1Loss when converging.
Figure 7. Validation accuracy on the training process with different loss functions. As shown in this figure, using L2Loss as the loss function, MAE and RMSE are significantly inferior to those obtained using L1Loss, and the unstable fluctuations of the model can be observed during the training process.
4.6. Performance evaluation (RQ1)
In this section, we mainly focus on Question1. According to Tables and , we learn that BiasedMF has smaller RMSE values compared to NMF, PMF, and DNM when the matrix density is 2.5%. The deep neural network-based methods, DNM and NFMF, have significant advantages over the non-deep learning models. Moreover, we have observed that as the matrix density increases the RMSE values drop rapidly, whereas for deep neural network-based methods, the RMSE values drop more slowly. Remarkably, the DNM model has better performance in terms of MAE, whereas other approaches display better performance in terms of RMSE. Conversely, the single-task model we set up outperformed the DNM on both metrics. By introducing multi-task learning, we have found that generally, multi-task learning shows better performance, especially in terms of TP, both of which are substantially ahead of single-task one.
Table 2. Performance comparisons of QoS prediction models on response-time.
Table 3. Performance comparisons of QoS prediction models on throughput.
4.7. Ablation experiment (RQ2)
In this section, we mainly concentrate on Question 2. To verify the effectiveness of the module, we propose and attempt to test whether it can bring the performance improvement in the model, and to this end, we design an ablation experiment. We denote NFCF as the non-linear collaborative filtering module. Context denotes whether considering context information or not and Bias as the bias interaction module. The complete model consisting of NFCF, context, and bias is denoted by “Full”. We estimated these models under the multi-task mode. Table presents the experiment result. By introducing NFCF, our model achieves significantly better performance compared with other matrix factorisation approaches. This indicates that the NFCF module has effectively solved the limitations of inner product modelling. The prediction performance of the model can be noticeably improved using context information and NFCF, whereas the model may be enhanced once again using multi-task learning.
Table 4. Performance comparisons of QoS prediction models on attritubes response-time and throughput.
4.8. Impact of dimensionality (RQ3)
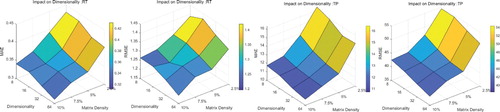
As we exploited neural networks in our model, the main hyper-parameter of this model is the dimension of embedding layers. The dimension determines the number of the latent factors, which ranges from 8 to 64 multiplied by 2 each time. In Figure , the performance gains in most cases with dimension and matrix density increases. When the dimensionality is close to 64, the values of MAE and RMSE are the smallest, and then they slowly increase. Moreover, for MAE and RMSE at different densities, their values drop as the dimensions increase.
Figure 8. Prediction performance of NFMF(Multi-Task) with different dimensionalities and matrix density.
4.9. Impact of contextual information (RQ4)
We investigated different context factors to establish their importantance. In this experiment, we concentrate on AS (autonomous system), RE (regions), SP (services provider), and IP (IP address and classes). For each factor, we remove others except the one we are investigating from NFMF-Full. The experiment results are presented in Table .
Table 5. Performance with different context.
We can summarise that prediction accuracy drops sharply without context (e.g. NFMF w/o context, Density=2.5%). Notably, although all of them can improve performance, different factors are of different importance. AS is the most crucial factor, and indicates that services provided in the same AS are more likely to be similar. Despite services provider (SP) being the only service sided feature, it is significant; however, it is not as important as AS. This may because SP is a broader concept since a variety of ASs shares the same SP. We also noted that regions play a part, suggesting the difference of QoS among countries.
5. Conclusion
In this study, we presented NFMF for personalised QoS prediction. The proposed method employs a neural network to perform collaborative filtering with contextual information, providing a framework for introducing contextual information and cross features in QoS collaborative filtering. Then, we proposed a bias interaction model to improve personalised prediction accuracy. Next, we recommended a multi-task model to improve the performance by exploiting the association between multiple QoS attributes. Finally, the experiments based on a large-scale real-world web service dataset indicate that our method outperforms existing methods and achieves state-of-the-art performance. We also realised that for QoS prediction, data preprocessing is crucial to improve the quality of the prediction. Additionally, selecting the correct loss function can help optimise the model.
In future work, we intend to utilise temporal features to adapt our model to a dynamic QoS prediction scene. Furthermore, we plan to extend our model to meet the requirement of large-scale web service recommendations.
Acknowledgments
This research was financially supported by the National Natural Science Foundation of China (No. 61702318), the Shantou University Scientific Research Start-up Fund Project (No. NTF18024), 2018 Provincial and Municipal Vertical Coordination Management Science and Technology Planning Project (No. 180917124960518), 2019 Guangdong province special fund for science and technology (“major special projects + task list”) project (No. 2019ST043), 2020 Li Ka Shing Foundation Cross-Disciplinary Research Grant (No. 2020LKSFG08D), and in part by Guangdong Provincial Youth Innovative Talents Program for Universities in 2020 (Project No. 2020KQNCX110).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Correction Statement
This article has been corrected with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
References
- He, X., Liao, L., Zhang, H., Nie, L., Hu, X., & Chua, T.-S. (2017). Neural collaborative filtering. Proceedings of the 26th International Conference on World Wide Web, 173–182. https://doi.org/10.1145/3038912.3052569
- Huhns, M. N., & Singh, M. P. (2005). Service-oriented computing: Key concepts and principles. IEEE Internet Computing, 9(1), 75–81. https://doi.org/10.1109/MIC.4236
- Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Lee, D. D., & Seung, H. S. (1999). Learning the parts of objects by non-negative matrix factorization. Nature, 401(6755), 788–791. https://doi.org/10.1038/44565
- Liang, W., Huang, W., Long, J., Zhang, K., & Zhang, D. (2020a). Deep reinforcement learning for resource protection and real-time detection in iot environment. IEEE Internet of Things Journal, 7(7), 6392–6401. https://doi.org/10.1109/JIoT.6488907
- Liang, W., Long, J., Li, K.-C., Xu, J., Ma, N., & Lei, X. (2020b). A fast defogging image recognition algorithm based on bilateral hybrid filtering. ACM Transactions on Multimedia Computing, Communications, and Applications, 0(JA), 1–1. https://doi.org/10.1145/3391297
- Liang, W., Xiao, L., Zhang, K., Tang, M., He, D., & Li, K.-C. (2021). Data fusion approach for collaborative anomaly intrusion detection in blockchain-based systems. IEEE Internet of Things Journal, 1–1. https://doi.org/10.1109/JIOT.2021.3053842
- Liang, W., Xie, S., Zhang, D., Li, X., & Li, K. (2020c). A mutual security authentication method for rfid-puf circuit based on deep learning. ACM Transactions on Internet Technology, 1–1. https://doi.org/10.1145/3426968
- Liang, W., Zhang, D., Lei, X., Tang, M., & Zomaya, A. (2020d). Circuit copyright blockchain: Blockchain-based homomorphic encryption for ip circuit protection. IEEE Transactions on Emerging Topics in Computing, 1–1. https://doi.org/10.1109/TETC.2020.2993032
- Linden, G., Smith, B., & York, J. (2003). Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Computing, 7(1), 76–80. https://doi.org/10.1109/MIC.2003.1167344
- Liu, J., & Chen, Y. (2019). Hap: A hybrid qos prediction approach in cloud manufacturing combining local collaborative filtering and global case-based reasoning. IEEE Transactions on Services Computing. https://doi.org/10.1109/TSC.2019.2893921
- Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural Networks, 61, 85–117. https://doi.org/10.1016/j.neunet.2014.09.003
- Shao, L., Zhang, J., Wei, Y., Zhao, J., Xie, B., & Mei, H. (2007). Personalized Qos prediction forweb services via collaborative filtering. IEEE International Conference on Web Services (ICWS 2007), 439–446. https://doi.org/10.1109/ICWS.2007.140
- Wu, H., Yue, K., Li, B., Zhang, B., & Hsu, C.-H. (2018a). Collaborative qos prediction with context-sensitive matrix factorization. Future Generation Computer Systems, 82, 669–678. https://doi.org/10.1016/j.future.2017.06.020
- Wu, H., Zhang, Z., Luo, J., Yue, K., & Hsu, C.-H. (2018b). Multiple attributes qos prediction via deep neural model with contexts. IEEE Transactions on Services Computing. , 1–1. https://doi.org/10.1109/TSC.2018.2859986
- Xu, Y., Yin, J., Deng, S., Xiong, N., & Huang, J. (2016). Context-aware QoS prediction for web service recommendation and selection. Pergamon Press.
- Yu, D., Liu, Y., Xu, Y., & Yin, Y. (2014). Personalized Qos prediction for web services using latent factor models. In 2014 IEEE international conference on services computing (pp. 107–114). IEEE.
- Zhang, Y., & Yang, Q. (2017). A survey on multi-task learning. arXiv preprint arXiv:1707.08114.
- Zheng, Z., Hao, M., Lyu, M. R., & King, I. (2011). Qos-aware web service recommendation by collaborative filtering. IEEE Transactions on Services Computing, 4(2), 140–152. https://doi.org/10.1109/TSC.2010.52
- Zheng, Z., & Lyu, M. R. (2013). Personalized reliability prediction of web services. Acm Transactions on Software Engineering & Methodology, 22(2), 12.1–12.25. https://doi.org/10.1145/2430545.2430548
- Zheng, Z., Zhang, Y., & Lyu, M. R. (2012). Investigating qos of real-world web services. IEEE Transactions on Services Computing, 7(1), 32–39. https://doi.org/10.1109/TSC.2012.34