
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Nowadays, we greatly depend on Internet mass transmission, of all kinds of data, including critical information among them. Therefore, secure communication is an important topic. Data hiding can embed critical information into carriers, such as images, videos, and so on. Efficiently embedding information into images is the goal of this research. Image steganography techniques utilise a cover image to hide secret data and produce a stego-image by modifying pixel values. After modification, the stego-image is distorted with respect to the cover image. Vector quantisation (VQ) is a lossy image compression technique. The image recovered from the VQ compressed code has distortion compared to the original image. Based on the VQ image, we can hide secret data by modifying the pixel value in a way that the distortion is compensated. The embedding rate of the proposed scheme is adjustable. Experimental results show that our scheme can achieve a high embedding rate in comparison with related works. For low-quality VQ images, embedding can improve the visual quality of the stego-image at the same time.
1. Introduction
In this rapid developing age of the Internet, people are increasingly focusing on information security. Many methods have been proposed to secure private information (Schafer & Lilian, Citation2017). Data hiding is one such protection approach. Data hiding (Artz, Citation2001; Du & Hsu, Citation2003; Cheng & Huang, Citation2001; Yang et al., Citation2008; Lin et al., Citation2009; Khan et al., Citation2014; Chang et al., Citation2014; Chang et al., Citation2018; Chang et al., Citation2019a; Chang et al., Citation2019b) embeds important data into carriers, preventing the data from been noticed to achieve the goal of data protection. This process is different from encryption, which converts the secret information into unrecognisable data. The most commonly applied carriers for data are texts, images, and videos. Recently, the application domain has been extended to various other media, such as computer software (Alrehily & Thayananthan, Citation2018; Wang et al., Citation2018), remote sensing data (Carpentieri et al., Citation2019), and DNA microarray images (Pizzolante et al., Citation2018).
Data hiding techniques can be categorised into reversible and irreversible and are widely used in cloud applications for accessorial information embedding (Xiao et al., Citation2021), such as embedding keywords for image retrieval (Ying et al., Citation2021). The payload in reversible data hiding is very low; however, the carrier can be perfectly recovered after the secret data has been extracted. Irreversible data hiding can achieve a higher payload, but the carrier is distorted and cannot be recovered. Both methods have advantages and disadvantages. The advantage of irreversible data hiding is the high payload. Therefore, improving the payload with the lowest distortion is a major concern.
Like other block-based image compression methods, such as block truncation coding (Chen et al., Citation2020), vector quantisation (VQ) is a lossy image compression technique (Linde et al., Citation1980; Nasrabadi & King, Citation1988). VQ can be divided into three phases: codebook training, image compression, and decompression. The conventional codebook design is to leverage the Lindo-Buzo-Gray (LBG) algorithm (Linde et al., Citation1980). Researches have been proposed to accelerate the codebook design (Chang & Hu, Citation1998; Lai & Liaw, Citation1996; Lin & Tai, Citation1998) and index code search (Hu et al., Citation2008; Hu & Chang, Citation2003; Lu & Chang, Citation2009). Based on the codebook, an image can be compressed into an index table. In the decompression phase, the index table is converted back to an image according to the same codebook. Details will be discussed in Section 2.
As mentioned earlier, VQ is a lossy image compression. Method where the image converted back from the index table is not exactly the same as the original image (Xu et al., Citation2021). Hiding data into a cover image also produces a distorted stego-image. Some research works have been proposed to utilise VQ-compressed images to hide secret data. In 2019, Lee et al. published a survey of data hiding based on VQ (Lee et al., Citation2019). Secret data can be embedded into the index (Manohar & Kieu, Citation2018; Qin & Hu, Citation2016; Rahmani et al., Citation2016; Rahmani & Dastghaibyfard, Citation2018a), the codebook (Pan & Wang, Citation2018; Rahmani & Dastghaibyfard, Citation2018b), or the image reconstructed from the compressed code (Huang et al., Citation2018; Huang et al., Citation2019). In 2018, Huang et al. proposed a data hiding scheme based on the image recovered from the VQ compressed code (Huang et al., Citation2018). By storing the index, the decompressed image can be recovered after the secret data extraction. In the following year, they proposed an improved version of their scheme (Huang et al., Citation2019). By comparing with the original image, the secret data is embedded in such a way that the stego-image is closer to the original image than the input. The details are presented in Section 2.
This paper is organised as follows. The vector quantisation and Huang et al.’s (Citation2019) strategy are introduced in Section 2. The newly proposed error compensation data hiding scheme is presented in Section 3. Experimental results are given in Section 4. Discussions and conclusions are given in the last section.
2. Related works
In this section, we will introduce the VQ image compression technique and the VQ-based data hiding scheme proposed by Huang et al.
2.1. VQ image compression
VQ is a lossy image compression technique (Linde et al., Citation1980; Nasrabadi & King, Citation1988) that can be applied to compress different types of data. Here, we will apply VQ to compress gray-level images. The original image is divided into nonoverlapping blocks of size first. Then, applying a codebook training algorithm to obtain
different matrices, called codewords, of size such that these matrices best represent the blocks of the original image. In the compression phase, each block of the original image is represented by the index of its best fitted codeword. Thus, an image can be compressed into an index table together with a codebook. In the decompression phase, the image is recovered by tiling up the codewords according to the index table and the codebook.
Typically, the LBG algorithm proposed by Linde et al. (Linde et al., Citation1980) is utilised to obtain the codebook. The LBG algorithm is based on -means clustering and can produce satisfactory compressed images. In most image applications, the size of a codeword is
, and the length of an index is
, which means the codebook contains
codewords.
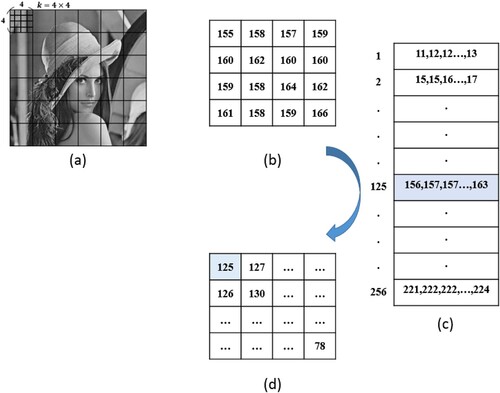
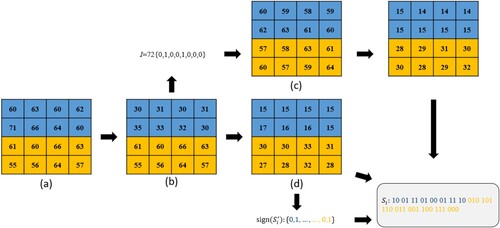
An illustrative example is shown in Figure . The original image (a) is divided into nonoverlapping blocks. The example block at the upper left corner is shown in (b). Then, check the codebook to find the best matching, i.e. minimum square error, codeword, as shown in (c). Finally, represent the block by the index of the matched codeword.
Figure 1. An illustration of Vector Quantization.
2.2. Huang et al.’s data hiding scheme
In 2019, Huang et al. proposed a data hiding scheme based on VQ (Huang et al., Citation2019). The main idea of their scheme is to embed secret data by shrinking the errors between the image reconstructed from the VQ-compressed code and the cover image.
In their data hiding scheme, each decompressed block is compared with its corresponding original block
. Secret data is then embedded in a way that each pixel value
is modified with a dynamic amount of secret data
such that
(1)
(1) subject to
(2)
(2) where
is a predefined threshold of error tolerance.
By saving the index of the codeword
, we can extract secret data
by subtraction
. A problem arises where, since the amount of modification is dynamic, the number of embedded bits also varies from pixel to pixel. Therefore, to avoid ambiguity, each segment of data
should be led with “1”. In cases of “0” leading bits, the whole segment is flipped and the flipping marker is checked, i. e.
.
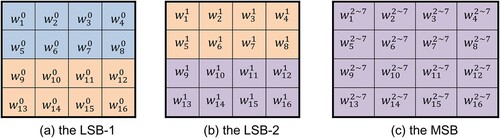
The data structure of a stego-image block is shown in Figure , where ,
, and
are the least significant bit (LSB-1), the second least significant bit (LSB-2), and the six most significant bits (MSB) of the stego-block. The blue region stores the index of the codeword, i.e.
; the green region stores the flip marker, i.e.
; and the yellow region serves as
for embedding secret data.
Figure 2. The data structure of Huang et al.’s scheme (Huang et al., Citation2019).
Huang et al.’s data hiding scheme produces a stego-image of good visual quality at low payloads. However, the flipping marker bit is not worth the sacrifice in high error tolerance.
3. The proposed error compensation strategy
Based on the same framework as Huang et al.’s data hiding scheme, we propose an error compensation strategy to improve the embedding capacity of a VQ-based approach. In the first subsection, we define three types of secret data mapping tables. According to the mapping table, the binary secret bit stream can be converted to signed decimal values. In the second subsection, we propose a data hiding scheme to embed the signed decimal secret digits.
3.1. Three types of mapping tables
Before data embedding, we map the secret bits into signed decimal values. To embed an adjustable amount of secret data, three types of mapping tables are designed as shown in Table . For Type I in (a), two bits of binary data can be mapped to signed decimal values of to
; for Type II in (b), three bits are mapped to values of
to
; for Type III in (c), four bits are mapped to values of
to
. Thus, the required bits of data can be embedded with a minimum amount of absolute values with a signed bit.
Table 1. Three types of mapping tables.
These mapping tables reveal a slight defect, where the maximum value is asymmetric for positive and negative signs. To make the mapping table symmetric, we further design an extended version as shown in Table . For Type I+ in (a), the case of “11” is split into “110” and “111”. Therefore, there are five total cases that map into a symmetric range of to
. In a similar manner, we split the last case of Types II and III and the newly generated cases are arranged in both ends of the tables as shown in (b) and (c), to produce a mapping table of Types II+ and III+. In applying the extended mapping table, the embedding rate is a variable depending on the data value.
Table 2. Three types of extended mapping tables.
3.2. The VQ-based data embedding scheme with error compensation
The framework of the proposed scheme is similar to Huang et al.’s scheme, as introduced in Section 2.2 (Huang et al., Citation2019). The cover image is divided into non-overlapping blocks of size first. Then, each image block is represented by an index of the VQ codebook to produce the VQ compressed image. The decompressed image can be obtained by replacing each index with its corresponding codeword. Our main idea is to compute the pixel values of the stego-image block
based on its corresponding VQ decompressed image block
, where
and
are the corresponding index and codeword of the
-th image block.
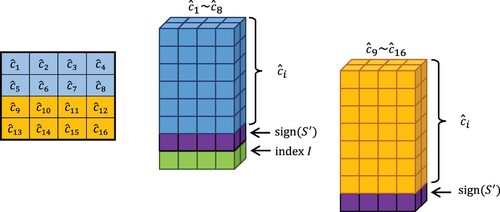
A stego-image block is shown in Figure , where the data structure of the proposed data hiding scheme is illustrated. The block is divided into upper half and lower half sub-blocks. The eight bit planes of both sub-blocks are displayed in the vertical direction. The bits in the green region are used to store the block index, i.e.
; the bits in the purple region are used to store the sign bits, i.e.
; while the MSBs in the blue and yellow regions are applied to embed the absolute value of a decimal encoded data.
Figure 3. The data structure of a stego-image block.
Before embedding, we have to decide the embedding rate first. Since the available MSBs for the upper half and the lower half sub-blocks are not equal, different embedding rates are suggested. We take an example of embedding 2 bits per pixel in the upper half block and embedding 3 bits per pixel in the lower half block. Thus, the embedding process should refer to Type I and Type II tables, as shown in Table (a) and (b). For embedding of each pixel, the segment of secret bits is mapped to a decimal value
according to the mapping table first. Then, the decimal value
is embedded by Equation (3) for a pixel in the upper half sub-block.
(3a)
(3a)
(3b)
(3b)
While the decimal value is embedded by Equation (4) for a pixel in the lower half sub-block.
(4a)
(4a)
(4b)
(4b)
The LSBs of the upper half sub-block are reserved to record the VQ index of the current block. The data embedding algorithm with mapping tables of Type I and II is summarised as follows.
3.2.1. Data embedding algorithm with mapping table Types I and II
Input: cover image , binary secret stream, VQ codebook with size 256
Output: stego-image
| Step 1: | Partition the cover image of size | ||||
| Step 2: | For each image block | ||||
| Step 3: | Obtain the decompressed block | ||||
| Step 4: | Index | ||||
| Step 5: | For each pixel | ||||
| Step 6: | Retrieve 2 bits of binary stream | ||||
| Step 7: | Store the sign of | ||||
| Step 8: | Embed the absolute value | ||||
| Step 9: | For each pixel | ||||
| Step 10: | Retrieve 3 bits of binary stream | ||||
| Step 11: | Store the sign of | ||||
| Step 12: | Embed | ||||
| Step 13: | Go to Step 2, until all blocks are processed. | ||||
For each pixel , its
-th lowest bit is denoted as
. The truncated pixel
of length 6 is applied to embed 2 bits of secret data by referring to mapping table Type I for the upper half sub-block, while
of length 7 is applied to embed 3 bits by referring to mapping table Type II.
Due to the extra space reserved for storing the index value, the truncated pixel lengths are different for the upper and the lower half sub-blocks. To obtain evenly modified pixels throughout the image, we tend to embed more bits in the lower half sub-block. Different mapping table type combinations are possible. In applying the plus (+) series of mapping tables given in Table , the splitting occasions should be checked at Steps 6 and 10. If that happens, one additional bit should be retrieved before mapping to . As a consequence, the embedding capacity of applying the extended mapping table is slightly larger than its original version.
In Steps 8 and 12, the MSB of the processing pixel is compared to the corresponding cover image pixel with the same bit-length and is modified to always compensate the error between them. Since the step size of the compensation is determined by the secret bits, it may result in over or under compensation. However, this strategy is always better than direction modification based on the original pixel value of the cover image.
Another possible variation of the embedding scheme is to alter the codebook to a version with different number of codewords , where typical numbers other than 256 are 128 and 512. Under such circumstances, the index bit-length
is determined first by
. At Step 4, the index insertion is given by
; the execution arrangement of Steps 5–8 and Steps 9–12 are altered by
and
, respectively.
3.3. Data extraction
The data extraction process can be devised according to the embedding process. The stego-image is divided into blocks of size . For each block, truncate the bit planes which store the index and the sign bits. According to the index value, get the corresponding codeword to construct the decompressed image block and truncate in the same way with the stego-block. Each truncated pixel value in the stego-image block is compared with its corresponding pixel in the decompressed block to extract the secret data. The algorithm is summarised as follows.
3.3.1. Data extraction algorithm
Input: stego-image, VQ codebook with size 256
Output: secret binary stream
| Step 1: | Partition the stego-image of size | ||||
| Step 2: | For each image block | ||||
| Step 3: | According to | ||||
| Step 4: | For each pixel | ||||
| Step 5: | For each pixel | ||||
| Step 6: | Go to Step 2, until all blocks are processed. | ||||
3.4. Example of embedding and extraction
An example of the proposed embedding scheme is shown in Figure . Figure (a) is a VQ decompressed block, and Figure (b) is the corresponding original image block. The LSB of the upper half sub-block in (a) is truncated to obtain (c), and the LSB plane of the whole block is truncated once more to get (d). The original image block (b) does repeats process to get (b’).
Figure 4. An example of data hiding.
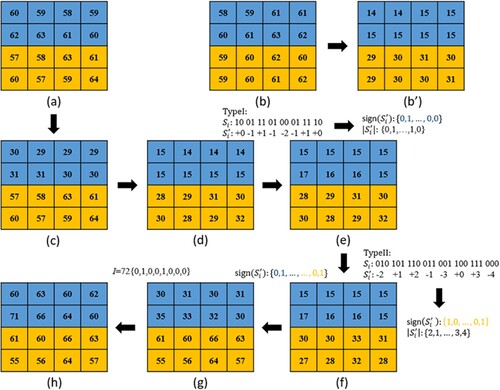
As shown in the figure, the secret data is mapped to
by referring to Type I table. The absolute values are
. Comparing the blue region of (d) with (b’), we add an absolute value when the corresponding pixel value in (d) is lower than (b’); subtract otherwise. The upper sub-block
becomes
.
For the lower sub-block, the secret data is first transferred to
according to the Type II table. Then, compare the orange region of (e) and (b’) to embed the absolute values. The sub-block
is modified to become
as shown in (f). Next, the sign bits
are inserted into the LSB plane to get (g), and the index
is inserted into the LSB of the upper sub-block to get the final stego-image block (h).
The extraction process is shown in Figure . The upper half of stego-image block (a) is truncated into (b) and obtains index . According to the index, the corresponding codeword is obtained as shown in (c). The LSB plane of (b) is truncated again to get sign bits and result in (d). The truncated stego-image block and truncated codeword are compared to obtain the absolute values of
. Combine the absolute values and sign bits to get
, and the secret binary stream can be recovered by referring to the corresponding embedding mapping tables.
Figure 5. An example of data extraction.
4. Experimental results
We use an Intel® Core™ i7-4790 [email protected] GHz and 10GB RAM PC as the platform to execute our experiments. Nine gray level standard test images of size were used in our experiments, as shown in Figure . We randomly selected the four images (b) Baboon, (f) Goldhill, (g) Lena, and (h) Peppers as the input of LBG algorithm (Linde et al., Citation1980) introduced in Section 2.1 to get codebooks of three different sizes, including 128, 256, and 512 codewords. The secret binary stream was generated by a random number generator provided by the MATLAB programming language.
Figure 6. Nine standard test images of size 512×512 applied in our experiments.

4.1. Background analysis
The proposed data hiding scheme is based on the VQ decompressed image. To understand the visual quality of the VQ decompressed image, we adopted the measure of peak signal to noise ratio (PSNR), which is defined as
(5)
(5)
(6)
(6) where
is the original test image,
is the VQ decompressed image, and
is the image size. The PSNR values of nine VQ decompressed images are listed in Table , where the experimental values corresponding to the three different codebook sizes are provided. It can be observed that the PSNR value degrades with a decreasing codebook size. However, the PSNR level mostly relies on the inherent characteristics of the test image. The image “Baboon” is the worst case, while the image “Zelda” is best approximated by the VQ decompressed image.
Table 3. PSNR of VQ decompressed images with different codebook sizes.
Based on the VQ image of three different codebook sizes, we can embed the secret data with different types of mapping tables. According to the proposed embedding algorithm, the upper half block and the lower half block are embedded with different types of mapping tables. The only basic rule is that the lower half block is capable of hiding more bits with the same visual quality degradation level. In our experiment, five mapping table combinations are applied, including (1) Type I and Type II, (2) Type I+ and Type II+, (3) Type II and Type II, (4) Type II and Type III, and (5) Type II+ and Type III+.
For the typical codebook size of 256, case (1) can hide 2 bits per pixel (bpp) in the upper half block and 3 bits per pixel in the lower half block. This results in an average embedding rate (ER) of 2.5 bits per pixel. The embedding rate of cases (3) and (4) can be derived in the same way to get 3 and 3.5 bits per pixel, respectively. Let’s now turn to the more complicated case of (2). Referring to the mapping table of Type I+ in Table (a), the four 2-bit combinations of data “00”, “01”, “10”, and “11” have equal probability of occurring. Therefore, their probabilities are all 1/4. In the special situation that “11” occur, we embedded an additional bit. The average embedding rate can be calculated by:
(7)
(7)
In the same way, we can calculate the average embedding rate of mapping table Type II+ by:
(8)
(8)
Finally, we average the ER of two portions to get:
(9)
(9)
The ER of case (5) can be derived in a similar way to get 3.59 bpp.
4.2. Performance evaluation
The PSNR values for different embedding rates based on the 256 codebook size are listed in Table . The corresponding figure is shown as Figure . As shown in the figure, the PSNR degrades with increasing ER. The only test image that violates this rule is “Baboon”. Since the VQ decompressed image is largely deviated from the original image as indicated by the PSNR value, the error compensation embedding strategy can shrink the deviation. Therefore, the PSNR increases after embedding the secret data. This phenomenon does not happen in the test images where the VQ decompressed image well approximates the original image. The embedding may over compensate the approximation error.
Figure 7. PSNR for different embedding rates (codebook size: 256).
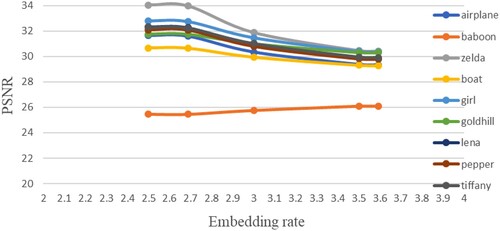
Table 4. PSNR for different embedding rates (codebook size: 256).
Another viewpoint is that the PSNR of case (1) is very close to case (2), and case (4) is very close to case (5). This phenomenon can be explained by referring to Tables and , where the embedding of an additional bit does not alter the absolute value of the pixel value modification. The only change is the sign bit, which is located at the lower bit and has a minor effect on the image quality.
Similar phenomena can be found in the experimental data of codebooks sized 128 and 512 shown in Tables and as well as Figures and . The only difference is the slight change of ER. Due to the change of codebook size, the required index length changed. Thus, the upper half block contains 7 pixels for size 128 and 9 pixels for size 512. The ER for all cases is recalculated as listed in the tables.
Figure 8. PSNR for different embedding rates (codebook size: 128).
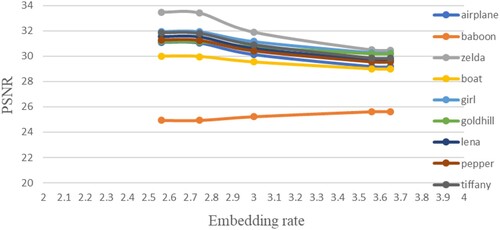
Figure 9. PSNR for different embedding rates (codebook size: 512).
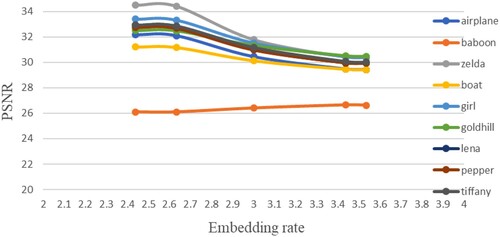
Table 5. PSNR for different embedding rates (codebook size: 128).
Table 6. PSNR for different embedding rates (codebook size: 512).
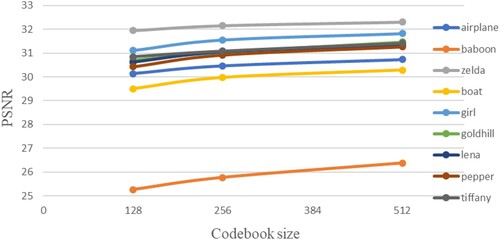
To assess the influence of data embedding on the visual quality of the stego-images, the experimental results are shown in Figure . Two typical test images “Lena” and “Baboon”, are given for different codebook sizes with the largest ER of the experiment. For all cases, the stego-image cannot be distinguished from the original image by human vision. The effect of the codebook size on the PSNR value is shown in Figure . For each test image, the PSNR is obtained by averaging the PSNR of different ERs under the same codebook size. As shown in the figure, the PSNR increases with an increasing codebook size on average.
Figure 10. Stego-images for different codebook sizes.

Figure 11. Comparison of average PSNR for different codebook sizes.
4.3. Comparison with related works
The proposed data hiding scheme is compared with Rahmani et al.’s scheme (Rahmani et al., Citation2016), Rahmani and Dastghaibyfard’s scheme (Rahmani & Dastghaibyfard, Citation2018b), and Huang et al.’s two schemes (Huang et al., Citation2018) and (Huang et al., Citation2019) for different codebook sizes as shown in Tables and . Since secret data is embedded by modifying the index table in the first two schemes, embedding capacities for these schemes are relatively low. Besides, modification of the index value changes all pixel values in the whole reconstructed image block and thus severely degrades the visual quality of stego-image. Huang et al.’s adaptive embedding scheme can hide secret data with good PSNR performance. However, the proposed scheme can embed much more data while maintaining an acceptable visual quality of the stego-images. At very low embedding rate, our scheme suffers from insufficient error compensation and PSNR cannot be further improved.
Table 7. Comparison with related works (codebook size: 256).
Table 8. Comparison with related works (codebook size: 512).
4.4. Steganalysis
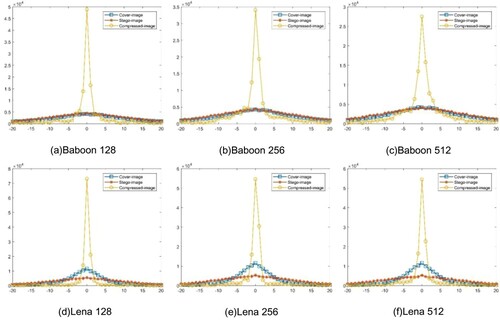
To know how the security of the proposed scheme compares against a pixel value differencing steganalysis (Zhang et al., Citation2004), the pixel value differencing histograms are given in Figure . An analysis of two typical test images, each with three VQ images of different codebook sizes, are presented. In comparison with the VQ-decompressed images, the histogram of the fully embedded stego-image is much closer to that of the cover image. The data embedding error compensation effect is very significant.
Figure 12. The PDH analysis of the stego-images and VQ-decompressed images.
The RS steganalysis (Fridrich et al., Citation2002) was also applied to assess the security of our scheme. The analysed results are shown in Table . Again, the fully embedded stego-images for three different codebook sizes of two test images are analysed. The image name “128-Baboon-stego” represents the fully embedded Baboon image with a codebook size of 128; while “256-Baboon-decom” is the VQ-decompressed Baboon image with a codebook size of 256. The experimental data indicates that the stego-images are robust under RS steganalysis.
Table 9. The RS steganalysis of stego-images and VQ-decompressed images.
5. Conclusions
We propose a VQ-oriented data hiding scheme based on an error compensation strategy. By compensating for the error between the VQ decompressed image and the original image, the resulting stego-image shrinks the error in low embedding rates. However, it may over compensate in high embedding rates. Besides, the proposed scheme is not advantageous in comparison with the related work (Huang et al., Citation2019) at low embedding rates.
Referring to the experimental data, the stego-image is closer to the original image than the VQ decompressed version in a low PSNR case. As the codebook size is reduced to an even lower size, the proposed scheme can embed a greater amount of secret data with improved visual quality in comparison with the VQ image before data hiding.
Although the proposed VQ-oriented data hiding scheme can achieve a high embedding capacity and successfully compensate the approximation error of the VQ-decompressed image, the compensation effect is significant only when the VQ-based image largely deviates from the cover image. A more sophisticated and adaptive design is required to gain a better stego-image than the current scheme.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Alrehily, A., & Thayananthan, V. (2018). Computer security and software watermarking based on return-oriented programming. International Journal of Computer Network and Information Security, 5(5), 28–36. https://doi.org/10.5815/ijcnis.2018.05.04
- Artz, D. (2001). Digital steganography: Hiding data within data. IEEE Internet Computing, 5(3), 75–80. https://doi.org/10.1109/4236.935180
- Carpentieri, B., Castiglione, A., Santis, A. D., Palmieri, F., & Pizzolante, R. (2019). One-pass lossless data hiding and compression of remote sensing data. Future Generation Computer Systems, 90, 222–239. https://doi.org/10.1016/j.future.2018.07.051
- Chang, C. C., & Hu, Y. C. (1998). A fast codebook training algorithm for vector quantization. IEEE Transactions on Consumer Electronics, 44(4), 1201–1208. https://doi.org/10.1109/30.735818
- Chang, C. C., & Li, C. T. (2019b). Algebraic secret sharing using privacy homomorphisms for IoT-based healthcare systems. CDATA[Mathematical Biosciences and Engineering, 16(5), 3367–3381. https://doi.org/10.3934/mbe.2019168
- Chang, C. C., Li, C. T., & Chen, K. (2019a). Privacy-preserving reversible information hiding based on arithmetic of quadratic residues. IEEE Access, 7, 54117–54132. https://doi.org/10.1109/ACCESS.2019.2908924
- Chang, C. C., Li, C. T., & Shi, Y. Q. (2018). Privacy-aware reversible watermarking in cloud computing environments,”. IEEE Access, 6, 70720–70733. https://doi.org/10.1109/ACCESS.2018.2880904
- Chang, C. C., Liu, Y., & Nguyen, T. S. (2014). A novel turtle shell based scheme for data hiding. Proceedings of 2014 International conference on Intelligent Information Hiding and Multimedia Signal processing, Kita Kyushu, Japan, 27–29 August 2014, 89–93.
- Chen, Y. H., Chang, C. C., & Hsu, C. Y. (2020). Content-based image retrieval using block truncation coding based on edge quantization. Connection Science, 32(4), 431–448. https://doi.org/10.1080/09540091.2020.1753174
- Cheng, Q., & Huang, T. S. (2001). An additive approach to transform-domain information hiding and optimum detection structure. IEEE Transactions on Multimedia, 3(3), 273–284. https://doi.org/10.1109/6046.944472
- Du, W. C., & Hsu, W. J. (2003). Adaptive data hiding based on VQ compressed images. IEE Proceedings of vision, image and Signal processing, 150(4), August, 233–238.
- Fridrich, J., & Goljan, M. (2002). Practical steganalysis of digital images: State of the art. Proceedings of SPIE, 4675, 1–13. https://doi.org/10.1117/12.465263
- Hu, Y. C., & Chang, C. C. (2003). An effective codebook search algorithm for vector quantization. The Imaging Science Journal, 51(4), 221–233. https://doi.org/10.1080/13682199.2003.11784428
- Hu, Y. C., Su, B. H., & Tsou, C. C. (2008). Fast VQ codebook search algorithm for grayscale image coding. Image and Vision Computing, 26(5), 657–666. https://doi.org/10.1016/j.imavis.2007.08.001
- Huang, C. T., Lin, L. C., Yang, C. H., & Wang, S. J. (2019). Dynamic embedding strategy of VQ-based information hiding approach. Journal of Visual Communication and Image Representation, 59, 14–32. https://doi.org/10.1016/j.jvcir.2018.12.018
- Huang, C. T., Tsai, M. Y., Lin, L. C., Wang, W. J., & Wang, S. J. (2018). VQ-based data hiding in IoT networks using two-level encoding with adaptive pixel replacements. The Journal of Supercomputing, 74(9), 4295–4314. https://doi.org/10.1007/s11227-016-1874-9
- Khan, A., Siddiqa, A., Munib, S., & Malik, S. A. (2014). A recent survey of reversible watermarking techniques. Information Sciences, 279(20), 251–272. https://doi.org/10.1016/j.ins.2014.03.118
- Lai, J. C., & Liaw, Y. C. (1996). Fast searching algorithm for VQ codebook generation. Journal of Visual Communication and Image Representation, 7(2), 163–168. https://doi.org/10.1006/jvci.1996.0016
- Lee, C. F., Chang, C. C., Shih, C. S., & Agrawal, S. (2019). A survey of data hiding based on vector quantization. Advances in Intelligent Information Hiding and Multimedia Signal Processing, Smart Innovation, Systems and Technologies, 156, 65–72. https://doi.org/10.1007/978-981-13-9714-1_7
- Lin, C. C., Chen, S. C., & Hsueh, N. L. (2009). Adaptive embedding techniques for VQ-compressed images. Information Sciences, 179(1-2), 140–149. https://doi.org/10.1016/j.ins.2008.09.001
- Lin, Y. C., & Tai, S. C. (1998). A fast Linde-Buzo-Gray algorithm in image vector quantization. IEEE T. Circuits and Systems II: Analog and Digital Signal Processing, 45(3), 432–435. https://doi.org/10.1109/82.664257
- Linde, Y., Buzo, A., & Gray, R. M. (1980). An algorithm for vector quantizer design. IEEE Transactions on Communications, 28(1), 84–95. https://doi.org/10.1109/TCOM.1980.1094577
- Lu, T. C., & Chang, C. C. (2009). An improved full-search scheme for the vector quantization algorithm based on triangle inequality. International Journal of Innovative Computing, Information and Control, 5(6), 1625–1632.
- Manohar, K., & Kieu, T. D. (2018). An SMVQ-based reversible data hiding technique exploiting side match distortion. Multimedia Tools and Applications, 77(10), 11727–11750. https://doi.org/10.1007/s11042-017-4814-7
- Nasrabadi, N. M., & King, R. A. (1988). Image coding using vector quantization: A review. IEEE Transactions on Communications, 36(8), 957–971. https://doi.org/10.1109/26.3776
- Pan, Z., & Wang, L. (2018). Novel reversible data hiding scheme for two-stage VQ compressed images based on search-order coding. Journal of Visual Communication and Image Representation, 50, 186–198. https://doi.org/10.1016/j.jvcir.2017.11.020
- Pizzolante, R., Castiglione, A., Carpentieri, B., Santis, A. D., & Palmieri, F., & Castiglione, A. (2018). A. On the protection of consumer genomic data in the Internet of living things. Computers & Security, 74, 384–400. https://doi.org/10.1016/j.cose.2017.06.003
- Qin, C., & Hu, Y. C. (2016). Reversible data hiding in VQ index table with lossless coding and adaptive switching mechanism. Signal Processing, 129, 48–55. https://doi.org/10.1016/j.sigpro.2016.05.032
- Rahmani, P., & Dastghaibyfard, G. (2018a). Two reversible data hiding schemes for VQ-compressed images based on index coding. IET Image Processing, 12(7), 1195–1203. https://doi.org/10.1049/iet-ipr.2016.0618
- Rahmani, P., & Dastghaibyfard, G. (2018b). An efficient histogram-based index mapping mechanism for reversible data hiding in VQ-compressed images. Information Sciences, 435, 224–239. https://doi.org/10.1016/j.ins.2017.12.041
- Rahmani, P., Norouzzadeh, M. S., & Dastghaibyfard, G. (2016). A novel legitimacy preserving data hiding scheme based on LAS compressed code of VQ index tables. Multidimensional Systems and Signal Processing, 27(2), 433–452. https://doi.org/10.1007/s11045-014-0309-0
- Schafer, B., & Lilian, E. (2017). “I spy, with my little sensor”: fair data handling practices for robots between privacy, copyright and security. Connection Science, 29(3), 200–209. https://doi.org/10.1080/09540091.2017.1318356
- Wang, Y., Gong, D., Lu, B., Xiang, F., & Liu, F. (2018). Exception handling-based dynamic software watermarking. IEEE Access, 6, 8882–8889. https://doi.org/10.1109/ACCESS.2018.2810058
- Xiao, T., Han, D., He, J., Li, K. C., & de Mello, R. F. (2021). Multi-Keyword ranked search based on mapping set matching in cloud ciphertext storage system. Connection Science, 33(1), 95–112. https://doi.org/10.1080/09540091.2020.1753175
- Xu, S. Y., Chang, C. C., & Liu, Y. J. (2021). A novel image compression technology based on vector quantisation and linear regression prediction. Connection Science, 1–18. https://doi.org/10.1080/09540091.2020.1806206
- Yang, C., Weng, C., Wang, S., & Sun, H. (2008). Adaptive data hiding in edge areas of images with spatial LSB domain systems. IEEE Transactions on Information Forensics and Security, 3(3), 488–497. https://doi.org/10.1109/TIFS.2008.926097
- Ying, L., Qiqi, L., Jiulun, F., Fuping, W., Jianlong, F., Qingan, Y., Kiang, C. T., & Nam, L. (2021). Tyre pattern image retrieval–current status and challenges. Connection Science, 1–19. https://doi.org/10.1080/09540091.2020.1806207
- Zhang, X., & Wang, S. (2004). Vulnerability of pixel-value differencing steganography to histogram analysis and modification for enhanced security. Pattern Recognition Letters, 3(25), 331–339. https://doi.org/10.1016/j.patrec.2003.10.014