
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Automatic text summarisation (ATS) (therein two main approaches–abstractive summarisation and extractive summarisation are involved) is an automatic procedure for extracting critical information from the text using a specific algorithm or method. Due to the scarcity of corpus, abstractive summarisation achieves poor performance for low-resource language ATS tasks. That’s why it is common for researchers to apply extractive summarisation to low-resource language instead of using abstractive summarisation. As an emerging branch of extraction-based summarisation, methods based on feature analysis quantitate the significance of information by calculating utility scores of each sentence in the article. In this study, we propose a simple but effective extractive method based on the Light Gradient Boosting Machine regression model for Indonesian documents. Four features are extracted, namely PositionScore, TitleScore, the semantic representation similarity between the sentence and the title of document, the semantic representation similarity between the sentence and sentence’s cluster center. We define a formula for calculating the sentence score as the objective function of the linear regression. Considering the characteristics of Indonesian, we use Indonesian lemmatisation technology to improve the calculation of sentence score. The results show that our method is more applicable.
1. Introduction
Thanks to the development of Internet technology, we can get access to a vast amount of information easily. However, it also causes such problems as information redundancy, rumours spreading (Zhao et al., Citation2020), making it hard for people to obtain valuable information from the Internet in a short time (Fang et al., Citation2020). Hence, it has become an urgent problem to extract effectively the essential and critical knowledge from the Internet.
Artificial intelligence (AI) is a novel technological science used to simulate human intelligence, and its emergence is to change and facilitate people’s lives. As one of the important directions of AI, automatic text summarisation aims at solving “information explosion”, which can automatically generate a shorter version of the source document, retaining its core idea, with some algorithms.
The task has received much attention in natural language processing since it can be used in various fields. Alternatives to achieve Automatic text summarisation (ATS) can be classified into two main approaches, abstractive summarisation and extractive summarisation. One of the critical issues of abstractive summarisation is that it needs a great scale of natural language corpus to train a model. For abstractive summarisation, the ideal summary contains sentences not used in the original text. It usually requires text rewriting to generate a summary, while extractive approaches generate a summary by selecting the most meaningful sentences from the documents. Therefore, the summaries yielded by this kind of method contain some sentences in the source documents without any modification. Apart from the abstractive summarisation and the extractive summarisation, there are many other mature approaches used in universal languages such as English, Chinese, etc. The existing extractive summarisation methods mainly rely on deep learning methods, such as seq2seq. Most of these methods need a great scale of sequence-to-sequence corpus. Owing to the scarcity of corpus, there are few abstractive summarisation approaches used for low-resource language ATS task. Therefore, in this study, we focus on extractive summarisation in the Indonesian ATS task to help Indonesian obtain core information effectively.
A method on the basis of the Light Gradient Boosting Machine (LightGBM Model) (Meng et al., Citation2016) is proposed here to extract important sentences from Indonesian Documents as summaries, using four contributive features, PositionScore, TitleScore, the semantic representation similarity between the sentence and the title of document (SRST), and the semantic representation similarity between the sentence and sentence’s cluster center (SRSC). Being regarded as a linear regression task in relation to the characteristics of Indonesian, Indonesian ATS is defined as a formula to calculate sentence score as the target function. Moreover, some experiments are conducted to find out the most suitable value of the maximum length of the summary. In these experiments, we not only compared our approach with some advanced ATS models but also compared different regression models with LightGBM.
The main contributions of our research are:
A method for the Indonesian automatic text summarisation task is introduced. The experiments conducted reveal that our model could perform what deep Learning methods and LightGBM could for solving extractive summarisation problem in that our model provides a simple but effective way to solve the Indonesian ATS problem.
While using the indexes of
score of ROUGE-1,
With the experiment result, we extracted from the characteristics of Indonesian news briefs the fact that Indonesian media prefer using the first and the last sentence of news as the brief.
The sentence score is verified by lemmatisation to represent better the correlation between the sentence from the source document and the summarisation.
Last but not least, our simple but effective method can be easily and quickly applied to actual industrial scenarios.
2. Previous research
Recently, approaches that use neural network have become a popular trend in extractive summarisation research, which accounts for the majority of the document summaries. Kageback et al. used a recursive autoencoder for the ATS task, achieving the best results on the Opinosis dataset (Kågebäck et al., Citation2015). On multi-document extractive summarisation task, Yin and Pei (Citation2015) chose the CNN (Convolutional Neural Networks) model to represent the semantic information of the text, using sentences by reducing the cost and considering their “prestige” and “diverseness”. For the multi-document extractive summarisation task, Padmapriya and Duraiswamy (Citation2020) proposed an algorithm to associate different algorithms such as particle swarm optimisation, genetic algorithm, and the deep learning algorithm. Moreover, methods based on feature analysis are also commonly used in the research of extractive summarisations (Osman & Salim, Citation2020; Patel & Chhinkaniwala, Citation2018). Text features commonly used include word frequency etc. Baxendale (Citation1995) proposed a feature-based summarisation method in 1995 and Edmundson (Citation1969) added three factors: pragmatic words, title and heading words, and structural indicators to the procedure of extracting features. Kupiec et al. (Citation1995) used a subjective weight combination of features as opposed to training a model to get the weights of features with a corpus. Yu et al. (Citation2016) presented a method based on improved TextRank from PageRank algorithm, to extract features. Scholars also try to use regression algorithms in extractive summarisation. A linear model-based extractive approach by Osborne (Citation2002) considered the connection among various features. A method proposed by Conroy and O’leary (Citation2001) uses a stealth Markov model with some text features to achieve weight computing on sentences. Mani (Citation2016) used MLP and ridge regression to extract summaries, and Sabuna used the decision tree regression method to extract summaries (Sabuna & Setyohadi, Citation2018). All of them regard extractive summarisation as a logistic regression problem rather than a linear regression problem. For the ATS task, Yadav et al. proposed a hybrid model, which combines statistic theories with semantic theories. This model extracts multiple statistical features, such as sentence position, TF-IDF, etc. (Yadav & Sharan, Citation2015; Yadav et al., Citation2016). What is more, they suggested two new approaches used in selecting sentences and proposed the entropy-based summary evaluation criteria in the automatic text document summarisation task (Yadav & Sharan, Citation2018).
The methods of extractive summarisations are relatively simple to implement, and this kind of solution does not need a large number of resources. Nevertheless, the results incompletely cover the core ideas delivered by the texts. Therefore it is also of great concern that there are redundancies in the summary extracted by these approaches.
The abstractive summarisation ordinarily depends on deep learning methods which have different neural network structure. The well-known Seq2seq model (Cho et al., Citation2014) is composed of the encoder and the decoder, which are consisted of several layers of RNN and LSTM. Afterwards, Chorowski et al. (Citation2015) introduced the attention mechanism to natural language processing. With the inspiration of Bahdanau’s work, Paulin et al. (Citation2017) initiated using the CNN model in Encoder and Decoder in 2017 and proposed a multi-step attention mechanism. These methods enhanced the performance of the deep learning method. The generative summarisation can convey the main thought of a text without information redundancy. However, this kind of approach requires a major number of corpus for training, and it costs a lot of time in the training process.
At the present, there are more and more researches concentrating on Indonesian ATS task. Fachrurrozi et al. (Citation2013) scored and used the sentences with TF-IDF to reorganise them, and then generated the summaries of news. Silvia et al. (Citation2014) used the LDA method and genetic algorithm to extract summarisations for news texts. Naive Bayes was also used for finishing the task of Indonesian news summarisation (Najibullah, Citation2015). A study (Gunawan et al., Citation2017) used the TextTeaser algorithm with some statistical features in extracting news summaries. Slamet et al. (Citation2018) used the TF-IDF method to encode the sentences and scored the similarities against another vector obtained from keywords of the document. These similarity scores were used to obtain sentences as the summary, which was conducive to convey the main thought of the document. Massandy and Khodra (Citation2015) achieved state-of-the-art on TAC 2011 competition. The method’s ROUGE-2 score is approximate to human performance. However, the scale of their dataset with only 56 articles, is limited and is not open to the public. A work done by Fajri Koto (Citation2016) makes it possible for the public to get an Indonesian summarisation dataset. They collected a chat dataset along with two versions of the summaries, which could be considered as a milestone work in Indonesian text summarisation research. Kurniawan and Louvan (Citation2019) also constructed a dataset called INDOSUM and performed some experiments using several models. The result demonstrates that the NEURALSUM (Nallapati et al., Citation2017) method achieved the best performance.
3. Approach
3.1. Feature extraction
In our feature extraction model, we considered four characteristics of the sentence: position, word similarity between the sentence and the title, semantic similarity between the sentence and the title and semantic similarity to other sentences in the text. With this in mind we designed four-sentence features:
PositionScore is the score calculated according to the sentence’s position, TitleScore is the number of words that appear in the sentence and the title simultaneously, SRST is the semantic representation similarity between the sentence and the title, SRSC, which is the semantic representation similarity between the sentence and the center of an article sentences cluster.
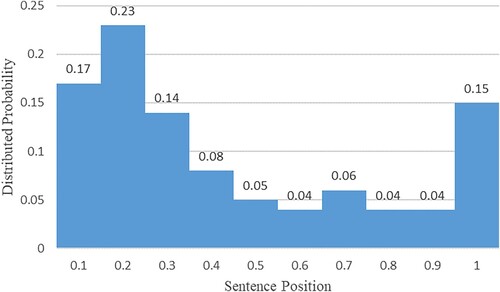
PositionScore: It is generally considered that in news articles, the closer the sentence to the beginning or the end of the news, the higher the importance of the sentence. For this reason, the topic sentence or the sentence at the end of the news gets a higher score than sentences that appear in the middle of the article. The sentence position score named PositionScore is computed by using the following formula:
(1)
(1)
is the position of the sentence in the article and
is the total number of sentences.
is on the basis of Figure which refers to the Textteaser, a summary extraction algorithm (Gunawan et al., Citation2017). According to the probability distribution of the sentence position in (Gunawan et al., Citation2017) and the sentence position distribution in Figure , we calculated the PositionScore.
Figure 1. Indonesian summarisation extraction.
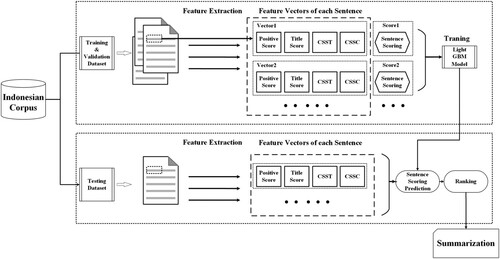
Figure 2. Sentence position score.
TitleScore: TitleScore is determined by calculating the number of words that appear in the sentence and the title simultaneously since the news titles remain the core information of the news. TitleScore can be calculated by using the below formula. is the word collection in a sentence
, and
is the word collection in an article title
.
(2)
(2) SRST: The TitleScore is only considered by the relationship between title and sentences at the lexical level. We converted sentences and title into vectors by the doc2vec model (Le & Mikolov, Citation2014), which was trained by ourselves. Doc2Vec algorithm could be exploited to deeply mine and obtain a document’s semantic representation (Wen et al., Citation2020). We used AntaraFootnote1 news to train the doc2vec model. The cosine similarity between vectors of sentences and title can represent the similarities between the title and each sentence at the semantic level. SRST is calculated by using the following formula:
(3)
(3)
represents the text’s title and
stands for sentence in the text.
SRSC: In the following experiments, we regarded sentences in one article as a cluster and the distance between each sentence and the cluster center could represent the correlation between the sentence and the topic of the article. The cluster center is the average of all the sentences’ vectors. And we used the same doc2vec model trained in SRST to calculate the cosine similarity. SRSC can be evaluated by using the following formula:
(4)
(4)
stands for the cluster center of the sentences and
represents sentence in the text.
3.2. Sentence score
The sentence score (defined as the maximum value of the similarity between one sentence and other sentences in the summarisation) represents the correlation between the sentence from the source document and the summarisation. As a mildly agglutinative language, the morphemes within Indonesian words are loosely arranged (Larasati et al., Citation2011). In Indonesian, two main methods to constitute a new word are affixation and reduplication. Because Indonesian is an agglutinative language, its feature is to generate new words by adding or deleting affixes. For the sentence score to represent the correlation between the sentence from the source document and the summarisation better, we perform lemmatisation to pre-process Indonesian sentences. Generally, lemmatisation is the process of transforming a derivative to its original form based on rules. We choose the Indonesian lemmatisation method, proposed by Lin et al. (Citation2018) to finish the lemmatisation task. We define the formulas (5) and (6) to compute the sentence score. refers to the sentence which needs to be scored and
is the sentence score of this sentence.
is a function to calculate relevance between this sentence
and other sentences in the summary.
is the total number of sentences in the summarisation and
refers to the sentence in the summarisation.
(5)
(5)
(6)
(6)
represents the union of words in two sentences,
represents the intersection of words in two sentences.
3.3. Light gradient boosting machine model
To solve the sentence scoring problem, we describe the automatic summarisation task as a regression problem. In this solution, we regard the result of the regression function
as the sentence score which can cover all the features of one sentence. And then, we sort the sentence score in descending order so that we can obtain the most significant sentences with high scores, as text summary.
We used LightGBM model to finish the logistic regression analysis between four features of the sentence and the sentence score. LightGBM, which released by Meng et al. (Citation2016), is a GBDT (Gradient Boosting Decision Tree) algorithm with Gradient based One-Side Sampling (GOSS) and Exclusive Feature Bundling (EFB). GOSS updates the gradients of all samples with large gradients, and operates random sampling on the samples with small gradients. When calculating the information gain, GOSS proposes a constant multiplier for the data instances with small gradients to minimise the impact on the data distribution. GOSS first sorts the data according to the absolute value of the gradient and selects top instances. Then it randomly samples
instances from the remaining data. Next, when calculating the information gain, GOSS multiplies the sampled small gradient data by
, so that the algorithm will pay more attention to the under-trained instances. EFB regards many exclusive features as one feature to effectively evade needless computation of features whose eigenvalues are zero.
A histogram-based algorithm (Alsabti et al., Citation1998; Jin & Agrawal, Citation2003) is used to accelerate and optimise the training process. The algorithm splits the training data into multiple pieces, and each piece of data is used to train a model. Each model conducts local voting to select the top-k attributes. Then the results of all models are integrated and used to select the top-2k attribute. LightGBM finds a leaf with the largest splitter gain by using the leaf-wise strategy.
Given the training set , LightGBM takes searching an approximation
to a certain function
as the goal.
(7)
(7) The function
minimises the value of the loss function
. LightGBM fuses a great deal of
regression trees
to make up the final model:
(8)
(8) where
is the number of base models. We further determine the base model in the LightGBM model.
The regression trees can be expressed as , where
denotes the total number of leaf nodes,
is the decision rules of the tree and
is the vector representation of the weight of leaf node instances. In step
, the model uses the additive form as (9) for training. In LightGBM, it uses Newton’s method to fit the objective function. For simplicity, we removed the constant term in (9) and transformed the formulation as (10).
In formula (10), and
denote the first-order and second-order gradient statistics of the loss function. Let
represents the sample set of leaf
, and (10) could be converted as (11).
(9)
(9)
(10)
(10)
(11)
(11)
For a certain tree structure , each leaf node
’s optimal leaf weight scores and the extreme value of
could be calculated as follows:
(12)
(12)
(13)
(13) where
could be considered as the quality assessment function that evaluated the performance of the tree structure
. Finally, the objective function after adding the split is
(14)
(14) where
and
are the instance sets of the left and right branches respectively.
3.4. Summary extraction
In the preprocessing process, we split the text sentence by sentence. Considering that Indonesian is an agglutinative language, which creates new words to express different meanings by adding or removing affixes, automatic text summarisation does not depend on features at the affix level. As a result, we decide to process the Indonesian texts in the same way as English texts. With the prediction of the LightGBM model trained in 3.4, all sentences in the article can get their scores that are the symbols of the relevance between sentences and the news topic. The sentence ranking in the summarisation task is very important. Two common methods are based on the original position of the sentence and the sentence score. In this paper, we sort the sentences in the summary according to the scores of the sentences. We sort the sentences in descending order of sentences scores and unify the result in a collection, . Here
refers to a sentence and
is the score of the relevance of this sentence. Then we use the method in Table to extract the summary. It selects sentences that obtain the best score among others. As a result, the computation is performed sentence by sentence. While extracting the summary, we suppose a length threshold
. The threshold
is the maximum length of the summarisation, which affects the quality of the summarisation.
Table 1. Abstract extraction pseudo code.
4. Data and results
In this section, we introduce our implementation, the summarisation datasets and our evaluation indicator, and our results.
4.1. Data
We used the INDOSUM (Kurniawan & Louvan, Citation2019), a dataset constructed by Kemal Kurniawan and Samuel Louvan, consisting of 18,774 news and summaries. There are title, category, source, URL and an abstractive summary written manually by Indonesian native speakers. We used five-fold cross validation to validate our model and finished five experiments to train and validate our model. During each experiment, we split the dataset into five-folds, then we used four-folds as the train set while the remaining fold was the test set. With the experiment results, we took the average result of the experiments as the final result. Nowadays, there are two main measurement systems (score of ROUGE and score of ROUGE) for evaluating the quality of summaries extracted by algorithms. Although ROUGE is a recall-based metric, there is an option to report precision and
scores with each ROUGE metric. The precision score takes the overlapping word units with reference to the word units of the Candidate summary. The
score is the harmonic mean of the recall and precision score. In this paper, we used
score of ROUGE-1,ROUGE-2,and ROUGE-3 as the evaluation indices.
4.2. Parameters
When extracting the features, we constructed a Doc2vec model to extract the semantic representation of the text. During the training process, we conducted an experiment on a combination of different values for each parameter in the LightGBM model and got the model parameters (as shown in Table ) under the best performance.
Table 2. The parameters of the model.
“max_bin” represents the maximum number of the bin and its default value is 255. LightGBM uses it to compact memory automatically. “learning_rate” stands for the shrinkage step size in the update process. “num_leaves” represents the number of leaf nodes. “feature_fraction” refers to the ratio of randomly selected features to all features in each iteration. “bagging_fraction” refers to choose the part of data randomly with no resampling. “bagging_freq” is the bagging frequency. “min_data_in_leaf” constrains the minimum number of samples for a leaf node. The larger the “min_sum_hessian_in_leaf” parameter, the better the generalisation ability while the smaller the “min_sum_hessian_in_leaf” parameter, the purer the leaf nodes, and the easier it is to overfit.
4.3. Result
In this research, we found that the threshold of the length of the summary, , would affect the performance of the model. Therefore we conducted an experiment with different values of the
to get the optimal parameter value. Table illustrates that when the
took 350, the
of ROUGE-1 reached the optimal status and when the
took 400, the
of ROUGE-2 and the
of ROUGE-3 got the highest score. We also analysed the length of the texts in the dataset, and the result shows that the average length of summaries is 422.6 characters. And when we took 400 as the
, our model achieved the best performance because 400 is the number closest to the average length. With this experiment result, we decide to choose 400 as the optimal value of thred.
Table 3. F1 SCORE OF ROUGE-1, ROUGE-2, ROUGE-3 of our model with different values of thred.
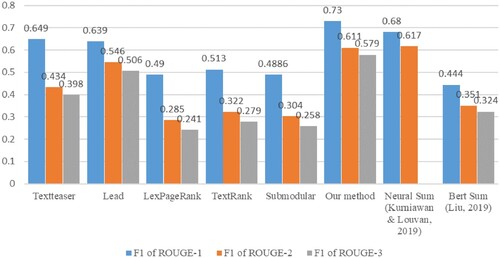
In the experiment, we made the comparison between our approach and five machine learning algorithms: Textteaser (Gunawan et al., Citation2017), Lead, LexPageRank (Erkan & Radev, Citation2004), TextRank (Mihalcea & Tarau, Citation2004) and Submodular (Lin et al., Citation2018). Textteaser algorithm is implemented by the tool Textteaser.Footnote2 Others are implemented by the PKUSUMSUMFootnote3 tool. At the same time, our method was compared with the two most advanced abstract extraction methods Neural Sum (Najibullah, Citation2015) and Bert Sum (Liu, Citation2019), which are based on deep learning. Figure introduces the compare results of all the tested models.
Figure 3. SCORE OF ROUGE-1, ROUGE-2 and ROUGE-3 of all models. *This figure lacks the
of ROUGE-3 of Neural Sum because
of ROUGE-3 is not adopted in Kurniawan and Louvan, (Citation2019).
We not only compared our method with other summary extraction methods but also compared the LightGBM model we used with other regression models to verify the validity of the GBM model as a regression model in our method. We used SVM, Ridge and MLP (Multi-Layer Perception) as comparison models. The result of the experiment is presented in Table .
Table 4. F1 SCORE OF ROUGE-1, ROUGE-2, ROUGE-3 of all the regression models.
As experiment results shows adopting the GBM model is better than using other regression models. Moreover, our model achieved a better performance in score of ROUGE-1,ROUGE-3 than other abstract extraction models and only slightly weaker than the neural model in
score of ROUGE-2.
We also completed an experiment for evaluating the influence of using lemmatisation in the sentence scoring process. Table illustrates that using lemmatisation can represent the relationship between sentences better and have better performance on the three indicators.
Table 5. Comparison of different sentence scoring methods.
What’s worth mentioning is that we explored the extent to which different features influence the result of the task in order to understand how Indonesian users write abstracts for news. After removing a feature, we used other features for regression experiments. Table demonstrates that the parameter PositionScore has the greatest impact on Indonesian feature extraction. It suggests that Indonesian users pay more attention to the first and last sentences in the news text when writing news abstracts. Table demonstrates that all the features we extract from the texts are helpful to get better summaries. Both TitleScore and SRST are much more helpful to disclose the relationship between sentence and title at the lexical level and the semantic level.
Table 6. The result of features’ affect experiments.
5. Conclusion
We have proposed here a multi-featured extractive summarisation algorithm based on the LightGBM regression model for Indonesian language. We utilise sentence position information and title information by using the features we extract. In this paper, there are comparisons between the method we propose and other ATS methods. At the same time, the maximum length of the summarisation is adjusted. During the process of the experiment, we find that the optimal value is determined to be 400. In evaluation, our method achieves a better performance in score of ROUGE-1, ROUGE-3 than other abstract extraction models and only slightly weaker than the neural model in
score of ROUGE-2. The
score of ROUGE-1 of our method reaches 0.730,
score of ROUGE-2 achieves 0.611, and
score of ROUGE-3 comes up to 0.579. We also explore the extent to which different features affect the task.
The weakness of our method is that the features we use are defined by ourselves. Moreover, the method proposed here only uses the method based on similarity calculation to extract semantic feature. Due to scarcity of the corpus, abstractive summarisation achieves poor performance for the Indonesian automatic text summarisation task. For future research, it is suggested to use deep learning to extract features with the target to extract features automatically. Utilising the deep learning method to extract semantic feature of the text or use a transfer learning model, we’ll try to train with a large scale of English corpora to assist the Indonesian automatic summarisation task.
Disclosure statement
The authors declare that they have no known potential conflicts of interest that may have influenced the work presented in this paper.
Additional information
Funding
Notes
References
- Alsabti, K., Ranka, S., & Singh, V. (1998). Clouds: A decision tree classifier for large datasets. 4th Knowledge discovery and Data Mining Conference.
- Baxendale, P. B. (1995). Machine-Made index for technical literature – an experiment. IBM Journal of Research and Development, 2(4), 354–361. https://doi.org/10.1147/rd.24.0354
- Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. EMNLP 2014 - 2014 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference.
- Chorowski, J., Bahdanau, D., Serdyuk, D., Cho, K., & Bengio, Y. (2015). Attention-based models for speech recognition. Advances in Neural Information Processing Systems, 1, 577–585. https://doi.org/10.5555/2969239.2969304
- Conroy, J. M., & O’leary, D. P. (2001). Text summarization via hidden Markov models. SIGIR Forum (ACM Special Interest Group on information retrieval).
- Edmundson, H. P. (1969). New methods in automatic extracting. Journal of the ACM, 16(2), 264–285. https://doi.org/10.1145/321510.321519
- Erkan, G., & Radev, D. R. (2004). Lexpagerank: Prestige in multi-document text summarization. Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Fachrurrozi, M., Yusliani, N., & Yoanita, R. U. (2013). Frequent term based text summarization for Bahasa Indonesia. International Conference on Innovations in Engineering and Technology.
- Fang, W., Jiang, T., Jiang, K., Zhang, F., Ding, Y., & Sheng, J. (2020). A method of automatic text summarisation based on long short-term memory. International Journal of Computational Science and Engineering, 22(1), 39–49. https://doi.org/10.1504/IJCSE.2020.107243
- Gunawan, D., Pasaribu, A., Rahmat, R. F., & Budiarto, R. (2017). Automatic text summarization for Indonesian language using TextTeaser. IOP Conference Series: Materials Science and Engineering, 190, 012048. https://doi.org/10.1088/1757-899X/190/1/012048
- Jin, R., & Agrawal, G. (2003). Communication and memory efficient parallel decision tree construction. Proceedings of the 2003 SIAM International Conference on Data Mining. https://doi.org/10.1137/1.9781611972733.11
- Kågebäck, M., Mogren, O., Tahmasebi, N., & Dubhashi, D. (2015). Extractive summarization using continuous vector space models. Proceedings of the 2nd Workshop on Continuous Vector Space Models and their Compositionality (CVSC). https://doi.org/10.3115/v1/w14-1504
- Koto, F. (2016). A publicly available Indonesian corpora for automatic abstractive and extractive chat summarization. Proceedings of the 10th International Conference on Language Resources and Evaluation, LREC 2016.
- Kupiec, J., Pedersen, J., & Chen, F. (1995). Trainable document summarizer. SIGIR Forum (ACM Special Interest Group on information retrieval). https://doi.org/10.1145/215206.215333
- Kurniawan, K., & Louvan, S. (2019). Indosum: A new benchmark dataset for Indonesian text summarization. Proceedings of the 2018 International Conference on Asian Language Processing, IALP 2018. https://doi.org/10.1109/IALP.2018.8629109
- Larasati, S. D., Kuboň, V., & Zeman, D. (2011). Indonesian morphology tool (MorphInd): Towards an Indonesian corpus. Communications in Computer and Information Science, 119–129. https://doi.org/10.1007/978-3-642-23138-4_8
- Le, Q., & Mikolov, T. (2014). Distributed representations of sentences and documents. 31st International Conference on Machine Learning, ICML 2014.
- Lin, N., Fu, S., Jiang, S., Chen, C., Xiao, L., & Zhu, G. (2018). Learning Indonesian frequently used vocabulary from large-scale news. 2018 International Conference on Asian Language Processing (IALP), pp. 234–239. https://doi.org/10.1109/IALP.2018.8629227
- Liu, Y. (2019). Fine-tune BERT for extractive summarization. CoRR, abs/1903.1. Retrieved from http://arxiv.org/abs/1903.10318
- Mani, K. B. (2016). Text summarization using deep learning and Ridge regression. CoRR.
- Massandy, D. T., & Khodra, M. L. (2015). Guided summarization for Indonesian news articles. Proceedings - 2014 International Conference on advanced informatics: Concept, theory and application, ICAICTA 2014. https://doi.org/10.1109/ICAICTA.2014.7005930
- Meng, Q., Ke, G., Wang, T., Chen, W., Ye, Q., Ma, Z. M., & Liu, T. Y. (2016). A communication-efficient parallel algorithm for decision tree. Advances in Neural Information Processing Systems, 1, 1279–1287. https://doi.org/10.5555/3157096.3157239
- Mihalcea, R., & Tarau, P. (2004). Textrank: Bringing order into texts. Proceedings of EMNLP.
- Najibullah, A. (2015). Indonesian Text Summarization based on naïve Bayes method. International seminar and Conference 2015: The golden triangle (Indonesia-India-Tiongkok).
- Nallapati, R., Zhai, F., & Zhou, B. (2017). SummaRuNNer: A recurrent neural network based sequence model for extractive summarization of documents. 31st AAAI Conference on Artificial Intelligence, AAAI 2017.
- Osborne, M. (2002). Using maximum entropy for sentence extraction. Proceedings of the ACL-02 Workshop on automatic summarization. https://doi.org/10.3115/1118162.1118163
- Osman, A., & Salim, N. (2020). Extracting useful reply-posts for text forum threads summarisation using quality features and classification methods. International Journal of Data Mining, Modelling and Management, 12(3), 330–349. https://doi.org/10.1504/IJDMMM.2020.108725
- Padmapriya, G., & Duraiswamy, K. (2020). Multi-document-based text summarisation through deep learning algorithm. International Journal of Business Intelligence and Data Mining, 16(4), 459–479. https://doi.org/10.1504/IJBIDM.2020.107546
- Patel, D., & Chhinkaniwala, H. (2018). Fuzzy logic-based single document summarisation with improved sentence scoring technique. International Journal of Knowledge Engineering and Data Mining, 12(3), 330–349. https://doi.org/10.1504/IJDMMM.2020.108725
- Paulin, M., Mairal, J., Douze, M., Harchaoui, Z., Perronnin, F., & Schmid, C. (2017). Convolutional patch representations for image retrieval: An unsupervised approach. International Journal of Computer Vision, 121(1), 149–168. https://doi.org/10.1007/s11263-016-0924-3
- Sabuna, P. M., & Setyohadi, D. B. (2018). Summarizing Indonesian text automatically by using sentence scoring and decision tree. Proceedings - 2017 2nd International conferences on information technology, Information Systems and Electrical Engineering, ICITISEE 2017. https://doi.org/10.1109/ICITISEE.2017.8285473
- Silvia, R., Aprilia, P., Suhartono, V. R., Wongso, D., & & Meiliana, R. (2014). Summarizing text for Indonesian language by using latent Dirichlet allocation and genetic algorithm. International Conference on Electrical Engineering, Computer Science and Informatics (EECSI). https://doi.org/10.11591/eecsi.1.364
- Slamet, C., Atmadja, A. R., Maylawati, D. S., Lestari, R. S., Darmalaksana, W., & Ramdhani, M. A. (2018). Automated text Summarization for Indonesian article using vector space model. IOP Conference Series: Materials Science and Engineering, 288, 012037. https://doi.org/10.1088/1757-899X/288/1/012037
- Wen, Y., Ye, H., Geng, J., & Cao, B. (2020). Web services classification via combining doc2vec and line model. International Journal of Computational Science and Engineering, 23(3), 250–261. https://doi.org/10.1504/IJCSE.2020.111433
- Yadav, C. S., & Sharan, A. (2015). Hybrid approach for single text document summarization using statistical and sentiment features. International Journal of Information Retrieval Research, 5(4), 46–70. https://doi.org/10.4018/ijirr.2015100104
- Yadav, C. S., & Sharan, A. (2018). A New LSA and entropy-based approach for automatic text document summarization. International Journal on Semantic Web and Information Systems (IJSWIS), 14(4), 1–32. https://doi.org/10.4018/IJSWIS.2018100101
- Yadav, C. S., Sharan, A., Kumar, R., & Biswas, P. (2016). A new approach for single text document summarization. Advances in Intelligent Systems and Computing, 1, 401–411. https://doi.org/10.1007/978-81-322-2523-2_39
- Yin, W., & Pei, Y. (2015). Optimizing sentence modeling and selection for document summarization. IJCAI International joint Conference on Artificial intelligence.
- Yu, S., Su, J., & Li, P. (2016). Improved TextRank-based method for automatic summarization. Computer Science, 43(6), 240–247. https://doi.org/10.11896/j.issn.1002-137X.2016.06.048
- Zhao, J., Song, Y., Liu, F., & Deng, Y. (2020). The identification of influential nodes based on structure similarity. Connection Science, 33(2), 201–218. https://doi.org/10.1080/09540091.2020.1806203