
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Process discovery usually analyses frequent behaviour in event logs to gain an intuitive understanding of processes. However, there are some effective infrequent behaviours that help to improve business processes in real life. Most existing studies either ignore them or treat them as harmful behaviours. To distinguish effective infrequent sequences from noisy activities, this paper proposes an algorithm to analyse the distribution states of activities and the strong transfer relationships between behaviours based on maximum probability paths. The algorithm divides episodic traces into two categories: harmful and useful episodes, namely noisy activities and effective sequences. First, using conditional probability entropy, the infrequent logs are pre-processed to remove individual noisy activities that are extremely irregularly distributed in the traces. Effective sequences are then extracted from the logs based on the state transfer information of the activities. The algorithm is based on a PM4Py implementation and is validated using synthetic and real logs. From the results, the algorithm not only preserves the key structure of the model and reduces noise activity, but also improves the quality of the model.
1. Introduction
The goal of process mining is to convert data logged as events into actionable objects (W. M. van der Aalst, Citation2016). There are three core branches in process mining: process discovery, consistency checking, and process enhancement. In process discovery, a well-structured model is expected to be found in the event log. To check whether the event log is consistent with the model, consistency checking techniques are applied to the models and logs. Finally, some event logging information is used to improve or enhance the existing process model during process enhancement. And process discovery plays a crucial role in process mining because this step transforms event logs into easy-to-understand visual graphics. All these event logs are recorded and stored by various information systems (Pecchia et al., Citation2020), such as movie websites (Wang et al., Citation2020), financial systems (Alizadeh et al., Citation2018), etc. But the reality is that not all information is useful.
In the last few years, most of the research has focused on analysing frequent behaviours to study the main part of the business process (Vázquez-Barreiros et al., Citation2015). However, real-world logs are often mixed with infrequent behaviours, which makes the process of discovery less straightforward. One of these is noisy activity (Xiao et al., Citation2021), which adds complexity to the system and should be filtered out. Another type of infrequent behaviour is important for improving business systems, such as network intrusions, credit card fraud and airbag pop-ups during car crashes, and ignoring them will lead to major system vulnerabilities. Therefore, not all infrequent behaviours should be treated as noisy activities. However, existing studies (Gúnther & Van Der Aalst, Citation2007; S. J. Leemans et al., Citation2013b; Maggi et al., Citation2012) do not distinguish between effective infrequency and ordinary infrequency. They either assume that this is done in configurations without infrequent noise, or they treat all infrequent behaviour equally. Such an assumption simplifies the analysis, but leads to the loss of important information in it. Thus, it is necessary to distinguish between noise and effective infrequent sequences.
We propose a process discovery algorithm based on maximum probability paths that aim to identify valid infrequent sequences based on the path with the highest probability of occurrence for each trace. Unlike previous methods based on frequency filtering, we aim to analyse strong transfer relationships between activities, which allows us to distinguish between valid and harmful infrequent behaviour. The algorithm uses conditional probability entropy to analyse the operational state of activities and identify noisy activities, allowing for a simplified model structure. Subsequently, we construct state transition matrices for infrequent traces to analyse the correlation between effective low frequencies and the body of the model. This leads to the discovery of effective infrequent behaviours from the logs that have not been attended to. Experiments on synthetic and real logs have shown that it retains not only the major high-frequency components but also the effective infrequent sequences, effectively optimising business processes.
The article structure is organised as follows. We reviewed some related work in Section 2. Section 3 illustrates the motivation of this article with a specific example introduces relevant background knowledge. Section 4 introduces the technology proposed in this paper. We evaluate the algorithm through synthetic logs and real cases in Section 5. Section 6 summarises the algorithm and points out the future research direction.
2. Related work
Existing studies generally focus on frequent behaviour only or treat infrequent behaviour as anomalous. Therefore, the research relevant to this paper is divided into infrequent behaviours in process discovery and the detection of abnormal behaviour.
2.1. Infrequent behaviours in process discovery
Interest in process discovery continues to rise in the field of process mining (dos Santos Garcia et al., Citation2019). Process discovery enables stakeholders to help understand the most frequent behaviours in business processes, thus early research focused more on frequent behaviours. As one of the pioneers in the field, the alpha algorithm obtains a reasonable network structure from the complete log (W. Van der Aalst et al., Citation2004). Over the next nearly two decades, a variety of more refined methods have emerged. For example, ILP miner (Van der Werf et al., Citation2008) algorithm based on regions, Inductive miner algorithm (S. J. Leemans et al., Citation2013a) based on block structure, Maximal Pattern Mining algorithm (Liesaputra et al., Citation2016) based on causal network (Augusto et al., Citation2019), and the discovery algorithm that processes large logs through random sampling (Sani et al., Citation2021).
There are also studies that consider some infrequent behaviours in real logs, including incomplete executions, noisy activities, error cases, etc. Some of them discovery models from such logs through built-in filters. S. J. Leemans et al. (Citation2013b) expands on S. J. Leemans et al. (Citation2013a) and is able to effectively remove low frequency behaviour. And another variant of it, which analyses incomplete logs through probabilistic behavioural relationships, is able to use very small logs to obtain high-quality results (S. J. Leemans et al., Citation2014). M. Leemans and van der Aalst (Citation2017) are able to cope with incomplete logs in another scenario caused by cancellation or incorrect processing. van Zelst et al. (Citation2018) filter some undesirable behaviours through built-in sequence coding diagrams. By deleting sequences lower than the set frequency, it ensures the accuracy and fitness of the algorithm. Sun et al. (Citation2019) synthesis of a hybrid dependency with fine-grained filtering of noisy events based on statistical probabilities.
Most existing process discovery techniques work offline, using static historical data stored in event logs. These techniques cannot be implemented when logs are not available for political reasons. So the emergence of online process mining arises at the historic moment. These research methods analyse real-time data flows and provide immediate insight into business processes as they are being executed. In this context, some algorithms have emerged that can handle infrequent behaviours online. Awad et al. (Citation2020) processes online events by buffering or speculative processing so that online data can be analysed. In van Zelst et al. (Citation2020), an event handler is proposed to filter infrequent behaviour from the real-time event stream. Chapela-Campa et al. (Citation2020) focus on the abstraction of infrequent behaviours with which to simplify process models. Mannhardt, de Leoni, Reijers, and van der Aalst (Citation2017) proposes a heuristic data-aware mining method (DHM). It uses a classification method based on frequency-based data attributes to distinguish infrequent trace and random noise.
2.2. Detection of abnormal behaviour
There are anomalous activities that occur relatively infrequently but have a nasty impact. This is why anomalous activity is specifically dealt with in some studies. Ghionna et al. (Citation2008) uses a two-step method to detect outliers in infrequent logs. By calculating log clusters and obtaining their average size, individuals that are hardly part of any cluster or actually smaller than the average size are considered as noise activities. In Sani et al. (Citation2018), a sequence mining algorithm is used to discover the flow relationship between sequential patterns and rules as well as long-distance activities. This filtering method can more accurately detect the removal of abnormal behaviour, especially for event data with severe parallel and long-term dependencies. A new technology derived from information theory and Bayesian statistics in Tax et al. (Citation2019) is proposed to filter out chaotic activities from event logs. Experiments show that the filtering technology is superior to the frequency-based algorithm, but the performance of the four active filtering technologies is highly dependent on the characteristics of event logs. Krajsic and Franczyk (Citation2020) performs unsupervised anomaly detection on event streams in an online scenario, resulting in a better model.
These studies simply either consider only frequent behaviours or look at all infrequent behaviours as one category. The quality of the logs directly affects the effectiveness of the model (Cheng & Kumar, Citation2015), so as much information as possible about the correct behaviour should be retained in the logs.
3. Preliminaries
3.1. Motivation
The synthetic logs in Table are records that simulate multiple users browsing a web site. We first used FHM algorithm (Weijters & Ribeiro, Citation2011) for analysis and obtained a causal network. FHM (Flexible heuristics Miner) is a new representation language combination mining algorithm. Its most important feature is the representation of segmentation and connection semantics. This makes the process model easy to understand even in the presence of non-trivial structures, low domains and noise. But FHM can only mine simple remote dependencies, and the implementation of remote mining is not perfect. As a result, the FHM algorithm filters out some existing cases of X, but does not delete X completely, and at the same time leads to incomplete mined models, as shown in Figure . iDHM (Interactive Data-aware Heuristics Miner) mining method is improved on the basis of existing heuristic discovery methods. It interactively sets the frequency threshold and dependency to filter logs containing noise (Mannhardt, de Leoni, & Reijers, Citation2017). Although iDHM effectively filters out noise activity X and obtains a causal network (as shown in Figure ), there is no guarantee that the deletion does not contain important information.
Figure 1. Process model mined by FHM algorithm.
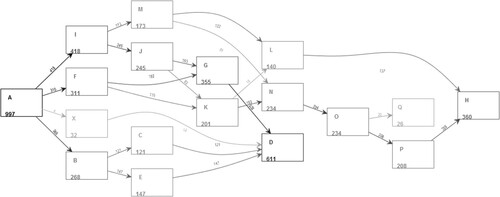
Figure 2. Process model mined by iDHM algorithm.
Table 1. 1000 logs containing noise activity x and the meaning of the activity.
3.2. Background
is a finite active set.
represents the power set on A, i.e. the set of all possible subsets of A.
represents the set of all series on A.
represents a sequence of length n, subsequence
is a subset of sequence A. Empty sequence is marked as ε. The connection of sequence
and
is marked as
. One occurrence of an activity forms an event e. And a sequence of events
is the trace in the log. Event
represents a multi-set of traces (Deshmukh et al., Citation2020).
Each time a subsequence appears in the log, we count it one time. Therefore, we introduce the concept of subsequence frequency.
Definition 3.1
(Subsequence frequency) (Tax et al., Citation2019)
L is an event log based on activity set A. The frequency of the subsequence with respect to L is denoted as:
(1)
(1)
Example 3.2
Let has 40 traces.
Then, ,
.
Considering the behavioural relationships between the different activities in the log, we introduce the following concept.
Definition 3.3
(Log behaviour profile) (Cao et al., Citation2018)
Let ,
be a log in the process model
, and a pair of transitions
has at most one of the following two relationships, namely these two relationship are mutually exclusive.
strict order relation:
, iff
interleaving order relation:
Definition 3.4
(Conditional Occurrence Probability) (Sani et al., Citation2017)
L is an event log over and is a subsequence of L. For activity
, then a's conditional probability with
in L, expressing as
is defined as follows.
(2)
(2)
Conditional Occurrence Probability is the probability (W. Yu et al., Citation2020) that a subsequence will occur in succession with an activity, reflecting the following relationship between the two. If an activity always occurs after a subsequence, then its probability value tends to 1. Conversely, if the activity never occurs after the subsequence, the value is 0.
4. Mining effective infrequent behaviour sequences
Our Effective Infrequent Sequence Miner (EIM) algorithm extracts effective infrequent sequences from logs containing complex. This technique distinguishes effective infrequent from noise by two processes. Since we aim to analyse different types of activity in the infrequent part, we first separate the infrequent from the high-frequency logs. In the first stage, EIM identifies the noise from the infrequent logs by analysing the operational patterns of the activities through Conditional probability entropy to simplify the logs. Subsequently, based on the state transition matrix, EIM calculates the path with the highest probability of occurrence for each trace and retains the traces that meet the filtering criteria.
4.1. Process a single noisy activity in the log
Some activities may occur spontaneously at any moment of process execution. This situation affects the quality of the process model obtained by using process discovery technology (Tax et al., Citation2019). Not only does the model become more complex, but many mining algorithms cannot get satisfactory results. So our first task is to clear the noisy activity in the log. There are currently two solutions to deal with noise. Delete the corresponding event from the trace: event-level filtering. Delete the trace as a whole: trace-level filtering (Sani et al., Citation2017). Since trace-level filtering may cause the loss of important information in infrequent logs, we choose event-level filtering.
Due to strict ordering relationships between log activities, e.g. and
correspond to different sequence, we define two new concepts: precursor conditional probability set and successor conditional probability set. They are based on conditional behavioural probability (Definition 3.4). Here, we only consider the previous activity x of activity a. For the sake of convenience, we will directly record the sequence with only one activity as the activity name.
Definition 4.1
Precursor conditional probability set
The precursor conditional probability of activity a is the conditional probability of in the log, which refers to the probability that activity x occurs before activity a:
(3)
(3)
Denoting the subsequence by , we denote it as a tuple when considering the pattern of occurrence of activity a with all activities in the subsequence, denoted as Precursor conditional probability set.
(4)
(4)
Successor conditional probability considers the case where it is inverse to Equation (Equation3(3)
(3) ). In this case, it reflects the probability that a binding to x occurs and that a is followed by x.
Definition 4.2
Successor conditional probability set
The subsequent conditional probability of activity a is the conditional probability of in the log, which can be expressed as:
(5)
(5)
Successor conditional probability set of activity a is a tuple composed of n successor conditional probabilities, defined as:
(6)
(6)
Information entropy (Yin et al., Citation2020) enables the quantification of information and describes the uncertainty of information (Gleick, Citation2011). In order to apply it to the analysis of the stochastic nature of activities, while integrating the strict-order and inverse-strict-order relationships between activities, we define conditional probability entropy of activity based on conditional entropy in L. Yu et al. (Citation2020).
Definition 4.3
Conditional probability entropy of activity
Hereinafter referred to as entropy, it is used to describe the time and space uncertainty of the activity.
(7)
(7)
Conditional probability entropy reflects the uncertainty degree of known random event y under the condition of activity set X. In the log, the higher the conditional entropy value of activity y is, the higher the uncertainty degree of the time and position of y with respect to the elements of the activity set is. On the contrary, the more random the time and position of y is, the higher the conditional entropy of y. Therefore, we filter the elements with the highest conditional entropy in the log trace to obtain a relatively stable system structure.
Example 4.4
Taking the log in Example 3.2 as an input, activity A is the starting event in the log, so
So A's precursor conditional probability set is:
Similarly, the following conditional probability set of A can be calculated as:
We use Conditional probability entropy for the analysis of infrequent logs and formalise the algorithmic idea as follows.

Algorithm 1: According to the log threshold, the log is divided into high-frequency traces and infrequent traces. We choose the infrequent part of the log. To identify and filter the noise activity, we process the log based on conditional probability entropy. After that, there is no noise activity in the log. We initialise a conditional probability entropy list H and log set Q at first (Algorithm 1:2). And save the log whose frequency is lower than the threshold to the new log set Q (Algorithm 1:3–7). According to Definition 4.3, we calculate the conditional probability entropy of each activity. Under the guidance of entropy, noise activity is identified (Algorithm 1:8–11). The algorithm outputs an infrequent log set without noise activity.
4.2. Mining effective infrequent sequences in logs
The method of filtering infrequent behaviour based on threshold can improve the quality of the model to a certain extent. However, the infrequent behaviour in real life is not necessarily completely noise. Because it may contain some infrequent sequences useful for perfecting the system. This section will analyse the infrequent trace obtained from Algorithm 1. The robustness of the system is enhanced by selecting traces that are highly transferable to the main activity.
In the log sequence , suppose the system is in the x state at the time m and in the y state at the time n. The change from time m to time n is called state transition, and the probability from state x to state y is the corresponding transition probability. The state transition matrix is a matrix composed of transition probabilities.
Definition 4.5
State transform matrix
(8)
(8)
Wherein, it is expressed as the transition probability that the Markov chain is in the state at the time m and is transferred to the
at the time m + 1.
Definition 4.6
string editing distance, string editing similarity
Let s and t be two strings, and represents the number of characters in a string x.
represents the editing distance of two strings.
(9)
(9)
It refers to the minimum number of times needed to edit (including modify, insert, delete) a single character when changing one string s to another string t. The similarity of string editing between s and t reflects the degree of association between the two.

Algorithm 2: Obtain the index j of each activity Z in the infrequent log activity set in turn, and divide all activities into predecessor and successor
with Z as the dividing point (Algorithm 2: 4–19). Then start from Z and traverse backwards to obtain the set of activities Priori that are most likely to occur from Z (Algorithm 2: 7–10). In the same way, starting from Z and traversing forward, get the most likely set of activities Follow to reach Z. Combine the predecessor set Priori, Z, and the successor set Follow, which is the most likely path through the activity Z in the log (Algorithm 2:11–14). The third step is to use string editing similarity to verify, save the traces less than the threshold, and finally get a processed
(Algorithm 2: 16–20).
5. Evaluation
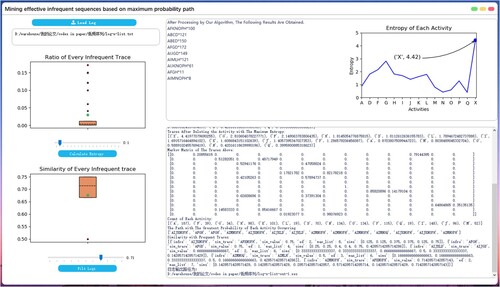
In this section, we design three experiments to evaluate the correctness of the algorithm proposed in this paper. The first two experiments used synthetic logs, and in the third experiment we analysed actual cases. To measure the quality of the algorithm, we implemented the algorithm of this article based on the open-source project PM4Py.Footnote1 Besides, we developed an EIM software (Figure ) to verify the validity of the algorithm.
Figure 3. Screenshot of the program running interface.
5.1. Experimental design
In this experiment, we will answer the following two questions:
Can the algorithm identify a single noise activity?
Can the algorithm reduce the complexity of the model while ensuring the accuracy of the model?
In response to problem (1), we designed experiment 1. The input data is a synthesised logs, including frequent traces and infrequent traces. Then we injected different numbers of noise activities into the log randomly. To answer question (2), we designed experiment 2 and experiment 3. In the first two experiments, YasperFootnote2 was used to generate artificial logs. The log has 17 activities, 5068 events, 1000 traces, and the trace frequency is between 1 and 172. The synthetic log has strong controllability, which is convenient for verifying the expected effect. In Experiment 3, the open-source data set BPI Challenge 2020: Request For PaymentFootnote3 was used to verify the algorithm. The open-source data set has 19 activities, 36,796 events, 6886 traces, and the frequency is between 1 and 3011.
Generally, the frequency of noise occurrence is lower than the normal trace. Therefore, in Experiment 1, the log is divided into high-frequency traces and infrequent traces to be processed separately. To explore the impact of different log thresholds on the results, we use different thresholds (log thresholds ) to split the log. Then we inject noise activity in the infrequent log randomly. In this synthetic log, the ratio of traces is between 0.01 and 0.17. Thus, the threshold (noise threshold
) range is set in this interval, the step size is set to 0.01, and there are 17 values in total. Since we have separated the high-frequency traces from the infrequent traces, and these infrequent activities account for a small proportion in the log. So injecting a lot of noise will not affect the high-frequency traces. Hence the range of injected noise is set between 0 and 1, the step size is 0.1, and there are 10 values in total. Besides, the location of noise injection has uncertainty, and different locations result in different entropy values. To reduce the error, we take the method of taking the average of multiple experiments. We repeat the experiment 10 times for each setting. In this way, a total of
identifications is performed in Experiment 1.
In Experiment 2, the value range is reduced and set between 0 and 0.1, and the step size is set to 0.02. The setting of X is the same as in experiment 1. Let us consider the third threshold involved in the experiment, the similarity threshold. To investigate the impact of the similarity threshold on the results fully, we take 0.1 as the step size, and take values from 0 to the largest value of the infrequent trace similarity in turn. Repeat 10 times as in Experiment 1 and take the average value. After algorithm processing, a log that does not contain noise and contains effective infrequent sequences is obtained. We mine the logs processed by the method of frequency-based filter (FBF) and the Effective Infrequent Sequence miner(EIM) of this article. The mining algorithms used here are Inductive Miner (S. J. Leemans et al., Citation2013b), Heuristic Miner (Weijters et al., Citation2006) and Directly-Follows Graph Miner (S. J. Leemans et al., Citation2015). Then we use fitness F, accuracy P, generalisation G and conciseness S to evaluate the quality of the mining model.
Finally, in Experiment 3, we took a real-life log as input, and set the range of S as the smallest ratio and the largest ratio of the trace. But this experiment will no longer inject noise activity. Since the noise activity characteristics in the example are not as obvious as in the controllable situation, interactive operations with users are provided in the experiment. So we allow users to choose whether to delete suspected noise activities according to the threshold distribution of activities (the box plot in the lower-left corner of Figure ). The experiment starts with the smallest similarity of the trace and ends with the largest similarity of the trace. A total of 90 experiments are carried out.
5.2. Result analysis
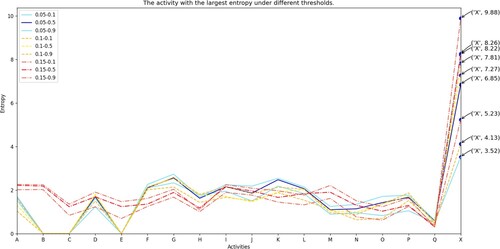
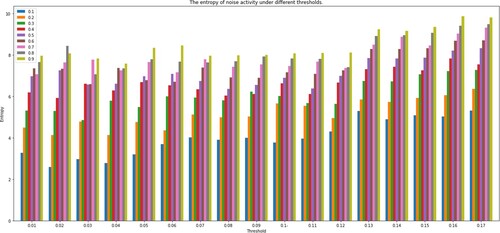
In Experiment 1, under different threshold settings, the average recognition accuracy of the algorithm for injected noise activities reached 99.73%. We plot some of the results in Figure . The first number in the legend represents , and the second number represents
. The horizontal and vertical coordinates of each polyline represent each activity and its entropy in different thresholds. It can be seen that the original activity A Q entropy in the log fluctuates slightly. Even in different threshold settings, the difference between the largest value and the smallest value is less than 2. And the entropy value of other activities is not significantly different. Yet, the injected noise activity X is more prominent, and its entropy value changes more widely. Besides, the entropy value of X in each broken line is also significantly higher than the value of other activities. Let us further analyse the entropy of X.
Figure 4. The entropy of activities under different threshold settings.
Explanation of Figure 5: Figure shows the average change of X in 10 repeated experiments. Divide the entropy of X into 17 groups. Looking at the trend, as the threshold for dividing the high frequency and low frequency of the log increases, the entropy value of each group X gradually increases. This is because as increases, more and more traces are classified as infrequent traces. The amount of noise injected increases accordingly, so the entropy value of X will increase slightly. Within each group, as the proportion of injected noise increases, the entropy value of X increases almost linearly. This will give it a clear advantage in comparison with other activities. So we confirmed the effectiveness of the algorithm to identify a single noise activity.
Figure 5. The change of entropy of noise activity in different thresholds.
In Experiment 2, IM, HM, and DFC mining algorithms are used to mine models from logs processed by FBF and EIM. Figures shows the experimental results of the above three algorithms at different thresholds. The abscissa represents the set threshold. The three numbers on the x-axis scale represent the log threshold , noise threshold
and similarity threshold
. We first analyse the results from the trend. The results show that the same index of the same mining algorithm is less affected by the change of the threshold. Thus, we conclude that the log mining results after EIM processing are stable.
Figure 6. IM mines the model quality of manual logs under the threshold ().
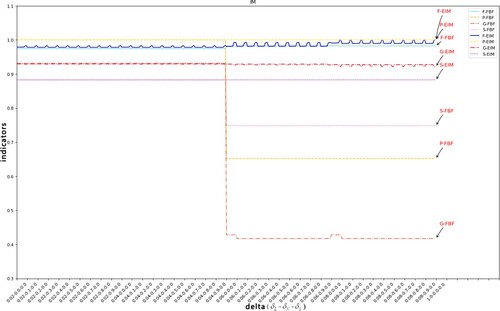
Explanation of Figures 6–8. As shown in Figure , the degree of fitness (F-EIM) is less than 0.25 during the whole experiment, which is always above 0.95 and is always higher than F-FBF. The accuracy has been stabilised at 1.0 from the original unstable state, even reaching a smallest of 0.65. As shown in Figure , the original accuracy P-FBF is lower than 0.2 (the smallest value of the ordinate in the figure is 0.2, so P-FBF does not appear in the figure). It is higher than 0.9 after EIM treatment. When the HM algorithm in Figure mines the EIM processed log, the simplicity is lower than the original value. Because the EIM algorithm retains part of the effective low frequency, and retains as much as possible to benefit the structure of the business process. Compared with the effective low frequency and useless low frequency as a whole and direct filtering, the EIM processed log retains more structure. Next, we will group by to analyse the effect of different
in each group on the results. The quality index in Figure fluctuates, so we take the DFG algorithm as an example and take four groups for analysis.
Figure 7. HM mines the model quality of manual logs under the threshold ().
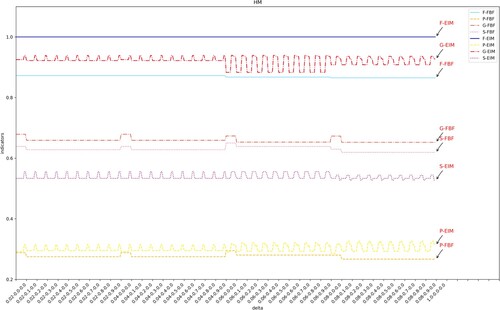
Figure 8. DFG mines the model quality of manual logs under the threshold ().
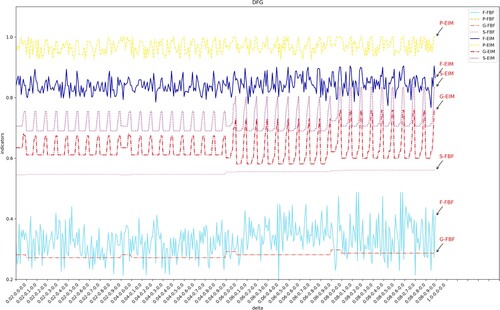
We take (a),
(b),
(c),
(d), a total of 40 data (Figure ). The results show that with the increase of
, the model's suitability, accuracy, generalisation and simplicity all show an increasing trend.
Figure 9. Partial results of DFG mining synthetic logs.
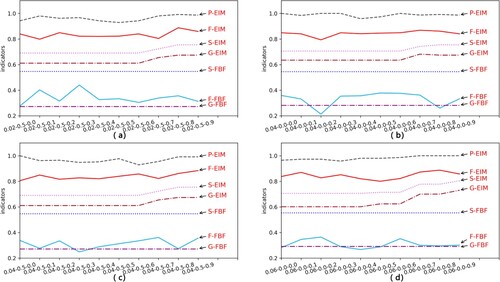
In Experiment 3, the above three algorithms were used to analyse the real log. Part of the results of the experiment is shown in Table . Compare the quality of the model mined using EIM processed logs with the quality of the model mined using original logs (the third row in Table ). The experimental results show that the logs processed by the EIM algorithm can improve the quality of IM algorithm mining, especially the accuracy and simplicity. The second is the DFG algorithm. The accuracy and conciseness are generally higher than (or remain stable) the original indicators, and the suitability and generalisation are improved when each threshold reaches half or more. Yet, the mining quality improvement ability of HM is limited, and only when the log threshold and the similarity threshold are high, there is a certain improvement. This is because the HM algorithm itself has the ability to deal with noise, it can make trade-offs on the log and remove part of the noise. But as we mentioned earlier, there is no guarantee that the relevance between the retained trace and the model is higher than that of the deleted trace.
Table 2. Model quality metrics under different threshold settings.
In summary of the three experiments, our algorithm effectively filters out noisy activities at the level of model structure and behaviour distribution, and is able to distinguish effective infrequent behaviour from harmful infrequent behaviour, improving the quality of process discovery.
6. Conclusion
Noisy activities often lead to inefficiencies or induce safety problems. The accuracy of process models can be affected by infrequent activities. However, removing all infrequent behaviours as useless sequences would result in the loss of important information. Accordingly, we propose a new approach to identify valid infrequent behaviours in event logs.
We define a two-stage approach EIM.
We consider the execution relationships between activities and remove the noise without reducing the quality of the mining. In this phase, we focus only on the low-frequency part of the logs, reducing the amount of data to be analysed. By using a method based on conditional probability entropy, irregular activities can be correctly judged as noise. The algorithm then removes the selected noisy activities for the purpose of cleaning up the dataset.
We were able to distinguish between effective infrequent sequences and useless infrequent sequences. The effective infrequent sequences were obtained by analysing each trace with the proposed maximum probability path algorithm, using the strong transfer relationship between activities.
We validated the algorithm using synthetic logs and real logs. The results show that the algorithm can retain as many key behaviours as possible and improve the quality of the findings.
Although the algorithm improves the quality of the mining model to a certain extent, it does not perform well when there is a loop structure in the model. So the loop structure will be considered in the future to expand the application range of the algorithm. At the same time, make full use of the time in the log, user role information and other attributes for further research. Besides, the traditional quality metrics cannot fully reflect the effect of effective infrequent behaviour when measuring mining results. In the future, therefore, we need to explore more reasonable measures of quality.
Acknowledgments
We also gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
References
- Alizadeh, M., Lu, X., Fahland, D., Zannone, N., & van der Aalst, W. M. P. (2018). Linking data and process perspectives for conformance analysis. Computers & Security, 73(1), 172–193. https://doi.org/10.1016/j.cose.2017.10.010
- Augusto, A., Conforti, R., Dumas, M., La Rosa, M., & Polyvyanyy, A. (2019). Split miner: Automated discovery of accurate and simple business process models from event logs. Knowledge and Information Systems, 59(2), 251–284. https://doi.org/10.1007/s10115-018-1214-x
- Awad, A., Weidlich, M., & Sakr, S. (2020). Process mining over unordered event streams. In 2020 2nd International Conference on Process Mining (ICPM) (pp. 81–88). IEEE. https://doi.org/10.1109/ICPM49681.2020.00022
- Cao, R., Fang, X. W., Wang, L. L., & Fang, H. (2018). Mining and optimization of conditional infrequent behavior based on data consciousness. Computer Integrated Manufacturing Systems, 24(7), 1671–1679. https://doi.org/10.13196/j.cims.2018.07.008.
- Chapela-Campa, D., Mucientes, M., & Lama, M. (2020). Understanding complex process models by abstracting infrequent behavior. Future Generation Computer Systems, 113(4), 428–440. https://doi.org/10.1016/j.future.2020.07.030
- Cheng, H. J., & Kumar, A. (2015). Process mining on noisy logs—Can log sanitization help to improve performance? Decision Support Systems, 79(9), 138–149. https://doi.org/10.1016/j.dss.2015.08.003
- Deshmukh, S., Agarwal, M., Gupta, S., & Kumar, N. (2020). MOEA for discovering Pareto-optimal process models: An experimental comparison. International Journal of Computational Science and Engineering, 21(3), 446–456. https://doi.org/10.1504/IJCSE.2020.106067
- dos Santos Garcia, C., Meincheim, A., Junior, E. R. F., Dallagassa, M. R., Sato, D. M. V., Carvalho, D. R., & Scalabrin, E. E. (2019). Process mining techniques and applications – a systematic mapping study. Expert Systems with Applications, 133(2), 260–295. https://doi.org/10.1016/j.eswa.2019.05.003
- Ghionna, L., Greco, G., Guzzo, A., & Pontieri, L. (2008). Outlier detection techniques for process mining applications. In International symposium on methodologies for intelligent systems (pp. 150–159). Springer. https://doi.org/10.1007/978-3-540-68123-6_17
- Gleick, J. (2011). The information: A history, a theory, a flood. Vintage.
- Gúnther, C. W., & Van Der Aalst, W. M. (2007). Fuzzy mining – adaptive process simplification based on multi-perspective metrics. In International conference on business process management (pp. 328–343). Springer.
- Krajsic, P., & Franczyk, B. (2020). Lambda architecture for anomaly detection in online process mining using autoencoders. In International Conference on Computational Collective Intelligence (pp. 579–589). Springer. https://doi.org/10.1007/978-3-030-63119-2_47
- Leemans, S. J., Fahland, D., & van der Aalst, W. M. (2013a). Discovering block-structured process models from event logs-a constructive approach. In International Conference on Applications and Theory of Petri Nets and Concurrency (pp. 311–329). Springer. https://doi.org/10.1007/978-3-642-38697-8_17
- Leemans, S. J., Fahland, D., & van der Aalst, W. M. (2013b). Discovering block-structured process models from event logs containing infrequent behaviour. In International Conference on Business Process Management (pp. 66–78). Springer. https://doi.org/10.1007/978-3-319-06257-0_6
- Leemans, S. J., Fahland, D., & van der Aalst, W. M. (2014). Discovering block-structured process models from incomplete event logs. In International Conference on Applications and Theory of Petri Nets and Concurrency (pp. 91–110). Springer. https://doi.org/10.1007/978-3-319-07734-5_6
- Leemans, S. J., Fahland, D., & van der Aalst, W. M. (2015). Scalable process discovery with guarantees. In Enterprise, Business-Process and Information Systems Modeling (pp. 85–101). Springer. https://doi.org/10.1007/978-3-319-19237-6_6
- Leemans, M., & van der Aalst, W. M. (2017). Modeling and discovering cancelation behavior. In OTM Confederated International Conferences on the Move to Meaningful Internet Systems (pp. 93–113). Springer. https://doi.org/10.1007/978-3-319-69462-7_8
- Liesaputra, V., Yongchareon, S., & Chaisiri, S. (2016). Efficient process model discovery using maximal pattern mining. In International Conference on Business Process Management (pp. 441–456). Springer. https://doi.org/10.1007/978-3-319-23063-4_29
- Maggi, F. M., Bose, R. J. C., & van der Aalst, W. M. (2012). Efficient discovery of understandable declarative process models from event logs. In International Conference on Advanced Information Systems Engineering (pp. 270–285). Springer. https://doi.org/10.1007/978-3-642-31095-9_18
- Mannhardt, F., de Leoni, M., & Reijers, H. A. (2017). Heuristic mining revamped: An interactive, data-aware, and conformance-aware miner. In Bpm (demos).
- Mannhardt, F., de Leoni, M., Reijers, H. A., & van der Aalst, W. M. (2017). Data-driven process discovery-revealing conditional infrequent behavior from event logs. In International conference on advanced information systems engineering (pp. 545-560). Springer. https://doi.org/10.1007/978-3-319-59536-8_34
- Pecchia, A., Weber, I., Cinque, M., & Ma, Y. (2020). Discovering process models for the analysis of application failures under uncertainty of event logs. Knowledge-Based Systems, 189(1), 105054. https://doi.org/10.1016/j.knosys.2019.105054
- Sani, M. F., van Zelst, S. J., & van der Aalst, W. M. (2021). The impact of biased sampling of event logs on the performance of process discovery. Computing, 103(6), 1085–1104. https://doi.org/10.1007/s00607-021-00910-4
- Sani, M. F., van Zelst, S. J., & van der Aalst, W. M. (2017). Improving process discovery results by filtering outliers using conditional behavioural probabilities. In International Conference on Business Process Management (pp. 216-229). Springer. https://doi.org/10.1007/978-3-319-74030-0_16
- Sani, M. F., van Zelst, S. J., & van der Aalst, W. M. (2018). Applying sequence mining for outlier detection in process mining. In OTM Confederated International Conferences on the Move to Meaningful Internet Systems (pp. 98–116). Springer. https://doi.org/10.1007/978-3-030-02671-4_6
- Sun, X., Hou, W., Yu, D., Wang, J., & Pan, J. (2019). Filtering out noise logs for process modelling based on event dependency. In 2019 IEEE International Conference on Web Services (ICWS) (pp. 388–392). IEEE. https://doi.org/10.1109/ICWS.2019.00069
- Tax, N., Sidorova, N., & van der Aalst, W. M. P. (2019). Discovering more precise process models from event logs by filtering out chaotic activities. Journal of Intelligent Information Systems, 52(1), 107–139. https://doi.org/10.1007/s10844-018-0507-6
- van der Aalst, W. M. (2016). Process mining: Data science in action. Springer.
- W. Van der Aalst, Weijters, T., & Maruster, L. (2004). Workflow mining: Discovering process models from event logs. IEEE Transactions on Knowledge and Data Engineering, 16(9), 1128–1142. https://doi.org/10.1109/TKDE.2004.47
- Van der Werf, J. M. E., van Dongen, B. F., Hurkens, C. A., & Serebrenik, A. (2008). Process discovery using integer linear programming. In International conference on applications and theory of petri nets (pp. 368–387). Springer. https://doi.org/10.1007/978-3-540-68746-7_24
- van Zelst, S. J., Sani, M. F., Ostovar, A., Conforti, R., & M. La Rosa (2020). Detection and removal of infrequent behavior from event streams of business processes. Information Systems, 90(10), 101451. https://doi.org/10.1016/j.is.2019.101451
- van Zelst, S. J., van Dongen, B. F., van der Aalst, W. M. P., & Verbeek, H. M. W. (2018). Discovering workflow nets using integer linear programming. Computing, 100(5), 529–556. https://doi.org/10.1007/s00607-017-0582-5
- Vázquez-Barreiros, B., Mucientes, M., & Lama, M. (2015). ProDiGen: Mining complete, precise and minimal structure process models with a genetic algorithm. Information Sciences, 294(3), 315–333. https://doi.org/10.1016/j.ins.2014.09.057
- Wang, Q., Zhu, G., Zhang, S., Li, K. C., Chen, X., & Xu, H. (2020). Extending emotional lexicon for improving the classification accuracy of Chinese film reviews. Connection Science, 33(2), 153–172. https://doi.org/10.1080/09540091.2020.1782839
- Weijters, A., & Ribeiro, J. (2011). Flexible heuristics miner (FHM). In 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM) (pp. 310–317). IEEE. https://doi.org/10.1109/CIDM.2011.5949453
- Weijters, A. J. M. M., van Der Aalst, W. M., & De Medeiros, A. A. (2006). Process mining with the heuristics miner-algorithm. Technische Universiteit Eindhoven, Tech. Rep. WP, 166, 1–34 . https://research.tue.nl/nl/publications/process-mining-with-the-heuristicsminer-algorithm
- Xiao, L., Xie, S., Han, D., Liang, W., Guo, J., & Chou, W. K. (2021). A lightweight authentication scheme for telecare medical information system. Connection Science. https://doi.org/10.1080/09540091.2021.1889976
- Yin, H., Zhang, J., & Qin, Z. (2020). A malware variants detection methodology with an opcode-based feature learning method and a fast density-based clustering algorithm. International Journal of Computational Science and Engineering, 21(1), 19–29. https://doi.org/10.1504/IJCSE.2020.105209
- Yu, L., Duan, Y., & Li, K. C. (2020). A real-world service mashup platform based on data integration, information synthesis, and knowledge fusion. Connection Science. https://doi.org/10.1080/09540091.2020.1841110
- Yu, W., Xiong, Z., Rong, S., Liu, Y., Wang, S., Xu, Y., & Liu, A. X. (2020). Unambiguous discrimination of binary coherent states. International Journal of Computational Science and Engineering, 22(2–3), 313–319. https://doi.org/10.1504/IJCSE.2020.107353