
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
With the increase of open APIs appeared on the Web, reusing or combining these APIs to develop novel applications (e.g. Mashups) has attracted great interest from developers. However, to quickly find a suitable one among a huge number of APIs to meet a developer’s requirement is basically a non-trivial issue. Therefore, a high-quality API recommendation system is desirable. Although a number of collaborative filtering methods have been proposed for API recommendation, their recommendation accuracy is limited and needs to be further improved. Based on the neural graph collaborative filtering technique, this paper proposes an API recommendation method that exploits the high-order connectivity between APIs and API users. To evaluate the proposed method, extensive experiments are conducted on a real API dataset and the results show that the proposed method outperforms the state-of-the-art methods in API recommendation.
1. Introduction
With the emergence of new software technologies, such as cloud computing, mobile computing and blockchain (Liang et al., Citation2019), APIs (Application Programming Inter-faces) are playing an increasingly important role in software development. Driven by the API economy, many enterprises, such as Google, Amazon and Microsoft, have published open APIs (typically Web-based) to let the third parties to access their key resources in a programmable way. Consequently, the number of open APIs on the Internet grows rapidly. According to the latest statistics of the largest Web API portal, ProgrammableWeb.com, the number of open Web APIs has exceeded 24,000. With such abundant Web APIs, it become very popular for developers to reuse or combine them to develop value-added services or new applications, such as Mashups (Tang et al., Citation2016; Tang et al., Citation2019a). Mashups represent the web applications that integrate multiple data sources or APIs into one interface (Zang & Rosson, Citation2008). The prevalence of Mashups has raised the API-Mashup ecosystem, which consists of APIs, Mashups, providers, developers, etc. Figure is a toy example of the API-Mashup ecosystem built on ProgrammableWeb.com, which shows that Web APIs from different providers can be combined into Mashups by developers.
Figure 1. The API-Mashup ecosystem: a toy example.
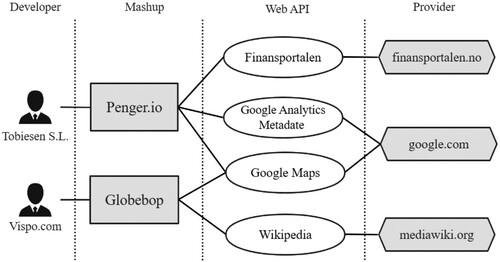
The rapid increase in the number of APIs, however, has posed serious challenges to efficient API discovery and reuse. In addition, since most Web APIs are described using plain text or HTML, instead of structured language, it makes the automatic API discovery task even hard. To address this issue, API recommendation has attracted considerable attention from the academia, and a number of API recommendation methods have been proposed for automatic API discovery.
API recommendation usually relies on users’ requirements and historical data of API invocations to estimate the probability of users choosing an API (Zhang et al., Citation2017b). Like many other recommender systems, Collaborative Filtering (CF) is also very popular in API recommendation. Usually, a CF model has two key components: (1) Embedding module, which converts users and items into vector representations; (2) Interactive modelling module, which reconstructs historical interactions based on the embedding between users and items. For example, matrix factorisation (MF) uses a latent feature vector of real values to represent each user and item, and models the interactions between users and items using the internal product (Koren et al., Citation2009). Collaborative deep learning extends the MF embedding function via learning the deep representation and integration of user/item preference in rich auxiliary information (Wang et al., Citation2015); Neural collaborative filtering uses a multi-layer perceptron (MLP) to learn the user-item interaction function, which unifies the potential structures of user and item modelling (He et al., Citation2017a).
Previous CF methods for API recommendation usually exploit only the direct interactions between users and APIs, but ignore the deeper collaborative signals behind the interactions. As such, most of existing API recommendation methods may be not accurate enough for embedding representations of users and APIs. To further improve the accuracy of API recommendation, this work attempts to exploit the high-order connectivity of the user-API bipartite graph, and overcome the shortcomings of previous embedding representations.
In summary, the contributions of this paper are as follows:
We are the first to integrate high-order connectivity and CF for API recommendation, aiming at mining deeper collaborative signals from the messy interactions between users and APIs to assist API recommendation.
Based on neural graph collaborative filtering, we propose a method which can effectively capture more semantic information from user/API interactions and thus promotes the embedding representation for more accurate API recommendation.
Through experiments on the data set of Programmableweb.com, we show that the proposed API recommendation method outperforms the other state-of-the-art recommendation methods.
The rest of this article is organised as follows: Section 2 surveys related work on API recommendation. Section 3 introduces the motivation and research issue of this work. Section 4 presents the details of the proposed method. Section 5 describes the experimental evaluation and analysis. Finally, Section 6 concludes this paper and outlines future work.
2. Related work
Web API or service recommendation is crucial for users to efficiently finding suitable ones in their application development (Liang et al., Citation2021a; Tang et al., Citation2021). Previous API recommendation methods can be roughly divided into two categories: content-based and CF-based.
Content-based methods usually rely on the requirement of user and the functional description of Web API to calculate their matching degree, and recommend Web APIs with the highest matching degrees to user. Gu et al. (Citation2016) divide the description of the user’s demand into sentence blocks through the discourse parser, and then calculates the similarity between the sentence blocks and the API’s description to predict the user’s preference score. Tang et al. (Citation2019b) use TF/IDF technology to mine keywords in the API function description to expand the API tag set and make API recommendation based on word-level similarity. In addition, Zhang et al. (Citation2017a) use linguistic analysis to extend synonyms for keywords that match user needs. Li et al. (Citation2013) adopt the topic model LDA to obtain the topic feature of Web API description and user requirement, and then accomplish the recommendation task by calculating the matching degree of their two topics.
CF-based methods complete API recommendation task by taking account to the historical data of the other users and APIs, in addition to the target user and the target API. Furthermore, CF-based methods have been widely used for QoS-aware service or API recommendation (Liang et al., Citation2021b; Liu et al., Citation2016; Tang et al., Citation2016; Zhang et al., Citation2019a; Zhang et al., Citation2019b; Zheng et al., Citation2020), with a focus on recommending service or APIs with optimal QoS. Different from them, this paper focuses on recommending APIs that meet the user’s functional requirements. In the following we survey some related work addressing the similar issue. Cao et al. (Citation2017) propose a CF-based API recommendation method which firstly calculates the similarity between user needs and Mashup application based on text mining, and then recommend the APIs in the most similar mashups to users. Yao et al. (Citation2015) propose a CF method that integrates implicit API correlations regularisation and matrix factorisation for API recommendation. Fletcher (Citation2019) incorporates the user’s implicit preferences (i.e. invocation history) into a matrix factorisation model to improve the accuracy and diversity of recommendations. Ma et al. (Citation2020) employ the Node2Vec technology to decompose the Mashup-service invocation matrix into Mashup latent representation and service latent representation, and then integrate them to predict user preference scores of API. Xu et al. (Citation2013) fuse multiple attributes of Mashups and APIs with the Mashup-API invocation matrix in matrix decomposition to derive the representation of users and APIs. Hao et al. (Citation2017) incorporate the API popularity degree into CF-based model to recommend API based on the user’s Mashup development needs.
There are also some studies which employ network or graph models to represent the data of users (or applications) and APIs, and based on which make API recommendations. For instance, He et al. (Citation2017b) model the API cooperative relationships as a network, and formulate API recommendation as an optimal Steiner tree problem. Liang et al. (Citation2016) construct a heterogeneous network by jointly using API, Mashup, tag and API provider attributes, and adopt meta-paths to calculate the similarity between Mashups.
Although previous CF-based methods have exploited direct or indirect connections among user and API for API recommendation, they ignore or fail to explore the high-order connectivity of user and API. This work fills this gap by exploring the higher-order connectivity from the user-API bipartite graph.
3. Problem definition
The Web API recommendation task studied in this paper can be defined as follows: Given a set of APIs and a set of API users (e.g. Mashup developers) as well as a set of invocation records of users on APIs, for any target user, recommend new APIs to him/her as accurate as possible.
To address the above problem, we firstly model the interactions between users and APIs as a bipartite graph, and then explore the higher-order connectivity of the user-API bipartite graph for API recommendation. Figure illustrates the research problem and motivation of this work. The left part of Figure is a bipartite graph illustrating the interactions between APIs and API users. The link between a user u and an API indicates that the user has used the API to create a Mashup. The right part of Figure shows the high-order connectivity between API and users. For example,
and
are with the first-order connectivity for they are directly connected in the user-API bipartite graph, while
and
are with the second-order connectivity for they are connected by at least two edges. The collaborative relationships between users and APIs are also referred to collaborative signals. Typical CF-based recommendation systems usually adopt the collaborative relationships between a user and its first-order neighbours to make recommendation. Therefore, they fail to exploit the second-order or higher-order collaborative signals between APIs and users, which are certainly useful. By extracting the necessary collaboration signals and explicitly encoding key features into the API and user embeddings, we can optimise the user and API representation for recommendation task.
Figure 2. Motivating example. On the left is a bipartite representation of the interactions between users and APIs. The right diagram shows the high-order connectivity between users and APIs (Suppose that u1 is the active user who needs recommendation).
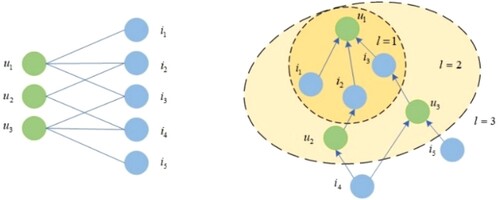
Let’s further use Figure as an example to explain how to explore the high-order connectivity of the user-API bipartite graph. As Figure illustrates, the high-order connectivity sub-graph originated from the active user has a tree-like structure, where
denotes the number of hops for the other users/APIs to reach
. In this setting, the preference scores of
for APIs can be inferred. Intuitively, since there are two paths from
to
(
), while only one path from
to
(
, and both cases are with the same length
, it is reasonable to infer that the interest of user
in
is probably greater than that in
. Besides the number of paths between a user and an API, path length also plays an important part in determining how likely the API will be used by the user. Although the one-hop, i.e. first-order connections are the most important, high-order connections also have rich semantic information. Therefore, we introduce them into the representation of APIs/users, thus optimising the node embedding in the user-API bipartite graph.
4. The proposed method
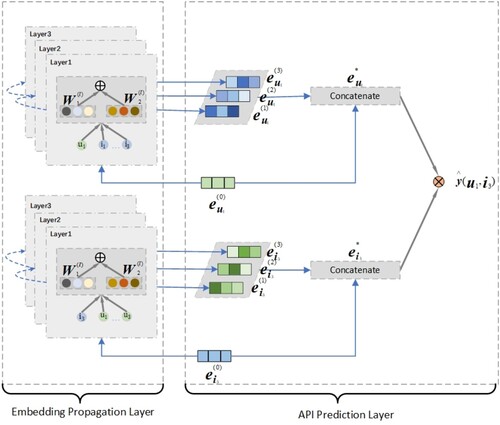
Our proposed Web API recommendation method is inspired by the neural graph collaborative filtering model (Wang et al., Citation2019). The model of the proposed method is overviewed in Figure . The model mainly consists of two components: (1) Embedding propagation layer, which initialises the embedding of APIs and users, and then optimises the multiple embedding propagation layers between APIs and users by high-order connectivity; (2) API Prediction layer, which integrates the embedding of multiple propagation layers and calculate the user preference scores for all target APIs. The details of the proposed method are presented as follows.
Figure 3. Model overview of the proposed method.
4.1 Embedding propagation layer
The user and API embedding vectors are represented as and
respectively, where d represents the size of the embedding vector. In this setting, we construct a parameter matrix as a lookup table for embedding purpose:
(1)
(1)
(2)
(2)
It is worth mentioning that this lookup table is used as the initial state of embeddings for API and user, so that it can be optimised as an end-to-end way.
Next, based on the message passing structure of GNNs (Xu et al., Citation2018), we plan to capture the collaborative signals along the graph structure and optimise the embedding of users and APIs. We first introduce the propagation rules with only one layer, and then extend it to multiple stacked layers.
4.1.1 One-order propagation
In the API recommendation scenario, an API called by a user can be regarded as a collaborative feature of the API, which can be used to measure the similarity between different APIs. Based on this consideration, our embedding propagation can be performed between connected users and APIs, and the process can be formulated through the two main operations of message construction and message aggregation.
Message Construction: For user u and API i that have an interactive relationship , we define the message from
to
as follows:
(3)
(3) where
represents the message embedding (i.e. the information from API to user).
is a message encoding function with two embeddings and a coefficient as input, where the coefficient
control the decay factor of each propagation on the edge
.
In this paper, we implement as:
(4)
(4) where
are trainable weight matrices that are used to extract useful propagation information, and ⊙ denotes the element-wise product operator. The traditional graph convolutional network only considers the contribution of
, different from which we encode the interaction between
and
into the message passing through
⊙
. This operation makes the message depend on the affinity between
and
, which can convey more information from similar APIs. This improves not only the model representation ability, but also the recommendation performance.
Following the parameter settings of the graph convolutional network (Kipf & Welling, Citation2016), we set the graph Laplacian norm to
, where
and
represent the first-hop neighbour of user
and API
respectively. From the perspective of representation learning,
reflects how much the historical item. contributes the user preference. From the perspective of message passing,
can be interpreted as a discount factor, considering that the messages being propagated should decay with the path length.
Message Aggregation: In this step, the neighbour node information near user u will be integrated into the new user representation u′ through an aggregation operator. The aggregation function is defined as follows:
(5)
(5) where
represents the embedding representation of
, which is obtained after the first embedding propagation layer.
is the activation function, which can solve the “gradient disappearance” problem and speed up the convergence. In addition to considering the message propagated from the neighbour
to the user u, we also consider the self-connection of
:
, which allows the original feature information to be preserved. Similar to the user aggregation method, we can obtain the representation of API
by gathering information from its connected users. From the above, it can be seen that the embedding propagation layer has advantages in explicitly using first-order connectivity information to associate users with API representations.
4.1.2 High-order propagation
Here we explore higher-order connectivity information by stacking multiple embedding propagation layers. The high-order connectivity between users and APIs is actually important for encoding the collaborative signal to calculate the correlation scores.
After stacking one embedding propagation layers, users or APIs can receive messages propagated by their l-hop neighbour. As shown in Figure , in the -th layer, the representation of user u can be recursively represented as:
(6)
(6) Among them, the definition of the message being propagated is defined as follows:
(7)
(7) where
are trainable transformation matrices,
is a low-dimension representation of the API generated from the previous message-passing steps, which used to store messages from its
hop neighbour. It helps to further obtain the representation of user
on layer
. Similarly, we can obtain the representation of API
at the layer
.
Based on the high-order connectivity representation between users and APIs (as shown in Figures and ), we can capture collaboration signals like ←
←
←
during the embedding propagation process. And the message from
can be explicitly encoded as
. In this way, the cooperative signals can be seamlessly injected into the representation learning process through the stacking of multiple embedding propagation layers.
Rule of Matrix Propagation: In order to clarify the embedding propagation and enable batch training, we provide a matrix form of hierarchical propagation rules, which is equivalent to formula (6) and (7):
(8)
(8) where
is the embedding of the user or API which after
step propagation, and
represents an identity matrix. In the initial message passing phase, we set the iteration
to
, and let the initial representation of user and API be
and
. The notation
is the Laplacian matrix of the user-API graph, and its formula is:
(9)
(9) Where
denotes the diagonal degree matrix,
represents the adjacency matrix, and
is the user-API interaction matrix. The tth diagonal element is denoted by
. Thus, the non-zero, non-diagonal term
is equal to
used in Equation (3).
Through the implementation of the above matrix propagation rules, the representation of all users and APIs can be updated at the same time. Meanwhile, it allows us to discard the node sampling procedure when training graph convolutional networks on large graphs(Berg et al., Citation2017).
4.2 API Prediction layer
After the -layers message propagating, we can obtain multiple representations of user u, denoted by
. Since the representations obtained by users in different layers emphasise the messages delivered by different connections, they play different roles in reflecting user preferences. Therefore, we connect multiple representations of different layers in series to form the final embedding of the user. Then, we perform the same operation on the API to cascade the representations learned at different layers to obtain the final API embedding:
(10)
(10) where
is a concatenation operator. In this way, not only the initial embedding can be enriched, but also the propagation range can be controlled by adjusting the number of propagation layers
. The advantage of using concatenate operations has also been proved in previous work of graph neural network (Xu et al., Citation2018). In addition to being simple to use and easy to understand, the concatenate operations do not involve the learning of other parameters, and play a crucial role in the layer aggregation mechanism.
After obtaining the final embeddings for users and APIs according to Equation (10), they will be used for recommendation score prediction. Since our focus is optimising the embedding learning by exploiting high-order connectivity, we simply adopt the inner product for user’s preference prediction:
(11)
(11)
For model parameter training, we use the paired BPR loss function which is widely applied in recommender systems (Rendle et al., Citation2012). Specifically, BPR assumes that observed interactions (than unobserved interactions) should reflect higher predictive values, and thus should reflect the user preferences better. The objective function is defined as follows:
(12)
(12) Where
represents paired training data, and among them,
are the observed interactions, while
are the unobserved interactions. Notation
denotes the sigmoid function,
represents all trainable model parameters, and
is used to control the intensity of
regularisation to prevent overfitting. We use mini-batch Adam (Kingma & Ba, Citation2014) to adjust the prediction model and renew the model parameters.
5. Experimental evaluation
5.1 Dataset description
In our experiments, we use the most popular online web API repository, Prgram-mableweb.com (PW for short), to evaluate our method. PW is a website that collects the meta-data about web APIs and corresponding applications (e.g. mashups) that use them. We crawled all web APIs and Mashups from PW, and analysed the interactions between web APIs and API users (Mashups). The dataset includes 21,900 APIs, 6,435 Mashups and 13,340 interactions between Mashups and APIs. Some details of our experimental dataset are shown in Table . For the sake of evaluation, we remove the API users (i.e. Mashups) that have only one API invocation in the dataset. Eventually, 80% of interaction records are used as the training set, and 20% of the rest are used as the test set.
Table 1. Statistics of the dataset.
5.2 Evaluation metrics
For all users in the test set, we treat each API that the user has not invoked with as a negative item. Each model can output user preferences for all APIs. In order to estimate the effectiveness of Top-K recommendation and user preference ranking, we use two evaluation indicators, Recall@K and nDCG@K, which have been widely used in various recommendation systems (Yang et al., Citation2018). In this experimental evaluation, we set K = 5, 10, 15, 20, 25, respectively. After calculating the evaluation metrics in our test set, average metrics of all users will be calculated.
Recall@K is the ratio of the actual APIs in the top-K API recommendation list to the actual APIs used by the user requirements. It can be defined as:
(13)
(13)
nDCG@K assigns different weights to each API in the top-K recommendation list, and the highly ranked APIs should have larger weights. One of its frequently used definitions is:
(14)
(14)
(15)
(15)
(16)
(16) where
is a binary value that indicates whether the user has used the candidate APIs. If true,
, otherwise
. Notation c is the number of APIs that are truly used by the user in the top-K candidate list. The metric nDCG@K is implemented by standardising DCG@K (
) to evaluate the recommendation accuracy.
5.3 Baseline methods
In order to validate the effectiveness of our proposed method, we choose the following methods to compare with our proposed method:
MF (Koren et al., Citation2009): MF (matrix factorisation) is a ranking-oriented recommendation algorithm proposed for implicit feedback scenarios. This method explores the direct interaction of nodes (first-order connectivity) on the user-API bipartite graph.
NeuMF (He et al., Citation2017a): This method adopts Deep Neural Network to implement CF, using multi-layer perceptron (MLP) to learn user and API’s interaction features, and modelling the implicit feedback(first-order connectivity) of user-APIs by using linear capabilities of MF. Here we use a two-layer architecture with fixed hidden layer size.
GCN (Kipf & Welling, Citation2016): This method adopts a local first-order approximation of spectral convolution to represent the convolutional network structure of users and APIs. It makes current node contains the information of direct neighbours, and the 2-step neighbour’s information can be included when calculating the next layer.
GC-MC (Berg et al., Citation2017): This recommendation method employs a user-item bipartite graph and uses a graph autoencoder framework to make recommendations from the perspective of link prediction.
5.4 Experimental results
In this subsection, we compare the performance of our method and the baseline methods mentioned previously. The experimental results are shown in Tables and , and we explain them as follows:
According to Tables and , it is illustrated that our method consistently performs better than the baselines in all cases. More specifically, when Recall@K is compared, our method improves the best baseline by 7.22–26.10%; while nDCG@K is compared, our proposed method improves the best baseline by 20.96–36.77%. It is usual that a user needs less than 5 APIs to create a Mashup, thus, when the number of recommended APIs increases, the improvement in the recall rate gradually decreases. The experimental results indicate that exploiting high-order connectivity information can significantly improve recommendation performance.
We can also observe that MF and NueMF have the worst performance. This indicates that simply using the inner product in the MF models is not enough to exploit the deep interactions between APIs and users. GCN performs better than MF and NeuMF for it explicitly encodes the connections between users and APIs in embedding learning. Among all baselines, GC–MC has the best performance. This indicates that introduction of the first-order neighbourhood and differentiable graphs self-encoding framework can improve the embeddings of users and APIs to some extent.
Table 2. Comparison of different methods in Recall@k.
Table 3. Comparison of different methods in nDCG@k.
5.5 Hyperparameters analysis
In this subsection, we discuss the impact of the model’s hyperparameters used for data training on recommendation performance. We fixed the other parameters and only vary the hyperparameters to carry out the experiments. The hyperparameters include user or API embedding dimensions, L2 regularisation impact factor λ, node loss rate, and message loss rate on the model during training.
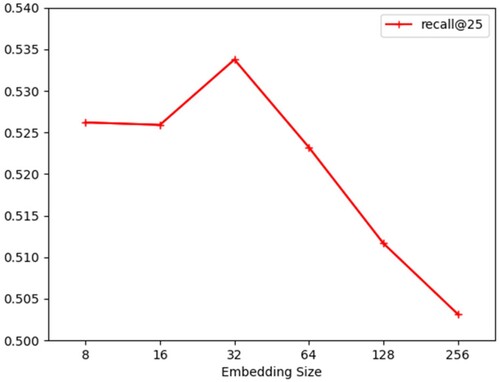
Figure shows the impact of embedding sizes of users and APIs on Recall@25. We can observe, increasing the embedding size of users and APIs initially improves the recommendation performance. More specifically, when the embedding size grows from 16 to 32, Recall@25 increases from 0.5259 to 0.5338. However, when the embedding size exceeds 32, the Recall@25 values begin to decline rapidly. This observation indicates that a moderate embedding size can provide enough information storage space during training. If the embedding size is too small, it may result in the information loss of some users or APIs in the embedding. On the contrary, if the embedding size is too large, it may cause information redundancy and increase the time overhead of model training.
Figure 4. Impact of different embedding size.
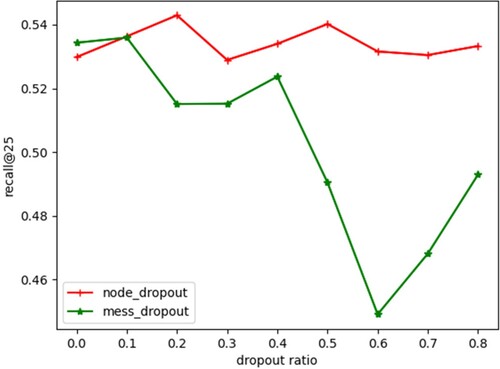
Node dropout and message dropout techniques can be used to prevent model overfitting (Berg et al., Citation2017). Figure shows the impact of node dropout ratio r1 and message dropout rate r2 on Recall@25. Of the two dropout strategies, node dropout performs better than message dropout in most cases, as we can observe from the figure. Moreover, node dropout seems to have less impact than message dropout on Recall@25 when varying their values. For example, when the node dropout ratio increases from 0 to 1, Recall@25 only changes slightly within a small range, and there is no consistency tendency. In contrast, when the message dropout ratio increases to 0.6, the value of Recall@25 declines significantly. However, when the dropout ratio continues to increase from 0.6, the Recall@25 value rises. Overall, it seems that smaller dropout ratio is more appropriate for the proposed method.
Figure 5. Impact of node dropout and message dropout.
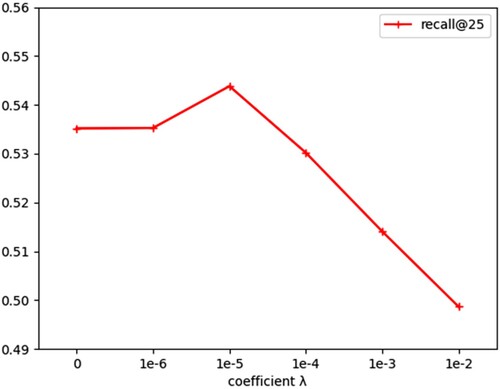
Besides the embedding size and dropout rate, the most important hyperparameter is the coefficient of L2 regularisation. Regularisation is a commonly used technique in machine learning. Its main purpose is to control model complexity and decompose over-fitting. The basic regular method is to add a penalty term to the original target (cost) function to “punish” the model with high complexity. Here, we will explore the impact of different
on model performance. As shown in Figure , when
is set to 1e-5, Recall@25 reaches the optimal value. When λ is greater than 1e-5, the performance of API recommendation will decline rapidly, which indicates that excessive regularisation will adversely affect the normal training of the model.
Figure 6. Impact of different regularisation coefficient .
6. Conclusion and future work
This paper proposes an API recommendation method based on neural graph collaborative filtering, which exploits the historical user-API interactions. The key to the proposed method lies in the embedding propagation which mines the deeper interactions between users and APIs to obtain richer collaborative signals, so that the embedding representation of APIs and users is improved. The experiments on a real dataset demonstrated that introducing the user-API interaction graph into the embedding learning and extracting more collaborative signals of users and APIs can indeed improve the performance of API recommendation.
In the future, we will consider integrating content and connections of APIs to recommend APIs. We will also consider incorporating the QoS of APIs (such as reputation) into API recommendation.
Acknowledgment
The work described in this paper was supported by the National Natural Science Foundation of China (61976061) and the Opening Project of Guangdong Key Laboratory of Big Data Analysis and Processing (202003).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Berg, R. v. d., Kipf, T. N., & Welling, M. (2017). Graph convolutional matrix completion. arXiv preprint arXiv:1706.02263.
- Cao, B., Liu, X. F., Liu, J., & Tang, M. (2017). Domain-aware Mashup service clustering based on LDA topic model from multiple data sources. Information and Software Technology, 90, 40–54. https://doi.org/10.1016/j.infsof.2017.05.001
- Fletcher, K. (2019). Regularizing matrix factorization with implicit user preference embeddings for Web API recommendation. 2019 IEEE International Conference on Services Computing (SCC).
- Gu, Q., Cao, J., & Peng, Q. (2016). Service package Recommendation for Mashup Creation via Mashup Textual description mining. 2016 IEEE International Conference on Web Services (ICWS).
- Hao, Y., Fan, Y., Tan, W., & Zhang, J. (2017). Service recommendation based on targeted reconstruction of Service descriptions. 2017 IEEE International Conference on Web Services (ICWS).
- He, Q., Zhou, R., Zhang, X., Wang, Y., Ye, D., Chen, F., Grundy, J. C., & Yang, Y. (2017a). Keyword search for building service-based systems. IEEE Transactions on Software Engineering, 43(7), 658–674. https://doi.org/10.1109/tse.2016.2624293
- He, X., Liao, L., Zhang, H., Nie, L., Hu, X., & Chua, T.-S. (2017b). Neural collaborative filtering. Proceedings of the 26th international conference on world wide web.
- Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Kipf, T. N., & Welling, M. (2016). Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907.
- Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems. Computer, 42(8), 30–37. https://doi.org/10.1109/MC.2009.263
- Li, C., Zhang, R., Huai, J., Guo, X., & Sun, H. (2013). A probabilistic approach for web service discovery. 2013 IEEE International Conference on Services computing.
- Liang, T., Chen, L., Wu, J., Dong, H., & Bouguettaya, A. (2016). Meta-path based service recommendation in heterogeneous information networks. International Conference on service-oriented computing.
- Liang, W., Li, Y., Xu, J., Zheng, Q., Zhang, D., & Li, K.-C. (2021a). Accurate and robust QoS prediction for large-scale distributed services via neural network. IEEE Transactions on Computers.
- Liang, W., Tang, M., Long, J., Peng, X., Xu, J., & Li, K.-C. (2019). A secure fabric blockchain-based data transmission technique for industrial internet-of-things. IEEE Transactions on Industrial Informatics, 15(6), 3582–3592. https://doi.org/10.1109/TII.2019.2907092
- Liang, W., Xie, S., Cai, J., Xu, J., Hu, Y., Xu, Y., & Qiu, M. (2021b). Deep neural network security collaborative filtering scheme for Service recommendation in intelligent cyber-physical systems. IEEE Internet of Things Journal. https://doi.org/10.1109/JIOT.2021.3086845
- Liu, J., Tang, M., Zheng, Z., Liu, X., & Lyu, S. (2016). Location-aware and personalized collaborative filtering for web service recommendation. IEEE Transactions on Services Computing, 9(5), 686–699. https://doi.org/10.1109/tsc.2015.2433251
- Ma, Y., Geng, X., & Wang, J. (2020). A deep neural network with multiplex interactions for cold-start service recommendation. IEEE Transactions on Engineering Management, 68, 1, 105–119. https://doi.org/10.1109/tem.2019.2961376
- Rendle, S., Freudenthaler, C., Gantner, Z., & Schmidt-Thieme, L. (2012). BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618.
- Tang, B., Tang, M., Xia, Y., & Hsieh, M.-Y. (2021). Composition pattern-aware web service recommendation based on depth factorisation machine. Connection Science, 1–21. https://doi.org/10.1080/09540091.2021.1911933
- Tang, M., Xia, Y., Tang, B., Zhou, Y., Cao, B., & Hu, R. (2019a). Mining collaboration patterns between APIs for Mashup creation in web of things. IEEE Access, 7, 14206–14215. https://doi.org/10.1109/access.2019.2894297
- Tang, M., Xie, F., Liang, W., Xia, Y., & Li, K.-C. (2019b). Predicting new composition relations between web services via link analysis. International Journal of Computational Science and Engineering, 20(1), 88–101. https://doi.org/10.1504/IJCSE.2019.103256
- Tang, M., Zheng, Z., Kang, G., Liu, J., Yang, Y., & Zhang, T. (2016). Collaborative web service quality prediction via exploiting matrix factorization and network map. IEEE Transactions on Network and Service Management, 13(1), 126–137. https://doi.org/10.1109/TNSM.2016.2517097
- Wang, H., Wang, N., & Yeung, D.-Y. (2015). Collaborative deep learning for recommender systems. Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining.
- Wang, X., He, X., Wang, M., Feng, F., & Chua, T.-S. (2019). Neural graph collaborative filtering. Proceedings of the 42nd International ACM SIGIR Conference on research and development in information retrieval.
- Xu, K., Li, C., Tian, Y., Sonobe, T., Kawarabayashi, K.-i., & Jegelka, S. (2018). Representation learning on graphs with jumping knowledge networks. International Conference on machine learning.
- Xu, W., Cao, J., Hu, L., Wang, J., & Li, M. (2013). A social-aware Service recommendation Approach for Mashup creation. 2013 IEEE 20th International Conference on Web Services.
- Yang, J.-H., Chen, C.-M., Wang, C.-J., & Tsai, M.-F. (2018). HOP-rec: high-order proximity for implicit recommendation. Proceedings of the 12th ACM Conference on recommender systems.
- Yao, L., Wang, X., Sheng, Q. Z., Ruan, W., & Zhang, W. (2015). Service recommendation for Mashup composition with implicit correlation regularization. 2015 IEEE International Conference on Web Services.
- Zang, N., & Rosson, M. B. (2008). What’s in a mashup? And why? Studying the perceptions of web-active end users. 2008 IEEE symposium on visual languages and human-centric computing.
- Zhang, N., Wang, J., & Ma, Y. (2017a). Mining Domain knowledge on Service goals from Textual Service descriptions. IEEE Transactions on Services Computing, 13, 1–1. https://doi.org/10.1109/tsc.2017.2693147
- Zhang, N., Wang, J., & Ma, Y. (2017b). Mining domain knowledge on service goals from textual service descriptions. IEEE Transactions on Services Computing, 13(3), 488–502. https://doi.org/10.1109/TSC.2017.2693147
- Zhang, Y., Wang, K., He, Q., Chen, F., Deng, S., Zheng, Z., & Yang, Y. (2019a). Covering-based web service quality prediction via neighborhood-aware matrix factorization. IEEE Transactions on Services Computing. https://doi.org/10.1109/TSC.2019.2891517
- Zhang, Y., Yin, C., Wu, Q., He, Q., & Zhu, H. (2019b). Location-aware deep collaborative filtering for service recommendation. IEEE Transactions on Systems, Man, and Cybernetics: Systems. https://doi.org/10.1109/TSMC.2019.2931723
- Zheng, Z., Xiaoli, L., Tang, M., Xie, F., & Lyu, M. R. (2020). Web Service QoS Prediction via collaborative filtering: A survey. IEEE Transactions on Services Computing, 1–1. https://doi.org/10.1109/tsc.2020.2995571