
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In order to effectively use differential evolution (DE) to solve multi-objective optimisation problems, it is necessary to consider how to ensure the search ability of DE. However, the search ability of DE is affected by related parameters and mutation mode. Based on decomposition, this paper proposed a hybrid differential evolution (HMODE/D) for solving multi-objective optimisation problems. First, when generation satisfies a certain condition, the local optimum is selected using the information of neighbour individual objective values to produce mutation offspring. Then, the heuristic crossover operator is established by using a uniform design method to produce better crossover individuals. Next, an external archive is set for each individual to store the individuals beneficial to the optimisation objective functions. Then, the individual is selected from the external archive to generate mutation offspring. In addition, considering that the performance of DE is determined by parameters, using the relevant information of the objective space function value, the self-adaptive adjustment strategy is adopted for the relevant parameter. Finally, a series of test functions with 5-, 10-, and 15-objectives are performed in the experiments to evaluate the superiority of HMODE/D. The results show that HMODE/D can solve the multi-objective optimisation problem very well.
1. Introduction
Multi-objective optimisation problems (MOPs) widely exist in real life and industrial applications, such as the design of complex systems (Ramirez et al., Citation2016), water reservoir (Giuliani et al., Citation2014), optimisation of risk design optimisation (Gang & Hao, Citation2014), shop scheduling problem (J. Li et al., Citation2020), environmental-economic load dispatch (Yalcinoz & Rudion, Citation2020), and optimisation of engineering systems (Falahiazar & Shah-Hosseini, Citation2018). It usually consists of more than three objectives, which conflicts with each other. In general, the model of a multi-objective optimisation problem (MOP) is as follows:
(1)
(1) where m is the number of objectives, x is n-dimensional decision variable vector and Ω is the decision (variable) space. Unlike single-objective optimisation problem, MOP does not find the optimal of a single objective, but to reach a reasonable trade-off for every objective in the objective space to produce a set of solutions. The set is called the Pareto set (PS), and the set of all the objective vectors corresponding to the PS is called Pareto front (PF) (Mardle & Miettinen, Citation1999). It is challenging to optimised conflicting objectives concurrently by using traditional methods. Evolutionary algorithms can produce a set of solutions in parallel and a set of approximate Pareto optimal can be obtained by multiple iterations. Therefore, evolutionary algorithms (MOEAs) are widely used to solve multi-objective optimisation problems.
Classical MOEAs include NSGAII (Deb et al., Citation2002) and MOEA/D (Q. Zhang & Li, Citation2007). NSGAII uses non-dominated sorting approach to select offspring, which can ensure the uniform distribution of Pareto optimal. However, the corresponding selection pressure increases with the increasing number of objectives, which worsens the convergence of the algorithm. In order to reduce the pressure of selection, NSGAII variants have been proposed to solve MOPs in Deb and Jain (Citation2014). Moreover, MOPs were solved by adjusting the dominance relationship of Pareto to improve the dominance region, such as M. Li et al. (Citation2014).
MOEA/D decomposes a multi-objective optimisation problem into several scalar optimisation subproblems and optimises them simultaneously. Compared with NSGAII, MOEA/D has better convergence when the number of objectives increases; however, the uniformity of PF is relatively worse, combining the advantages and disadvantages of MOEA/D, many improved algorithms based on MOEA/D have been proposed to solve MOPs in Y. Yuan et al. (Citation2016), Lotfi and Karimi (Citation2017), Hui et al. (Citation2018) and Farias and Araujol(Citation2019).
The following two principal aspects should be considered while using MOEAs to solve MOPs. (1) How to ensure the convergence of the algorithm so that the objective values of individuals converge to true PF as close as possible. (2) How to ensure the diversity of the populations so that PF is uniformly distributed in the objective space. Researchers designed some algorithms through analysing the above problems from a different perspective and the specific work is summarised as follows.
In recent years, some researchers utilised use user preferences or reference points to select offspring individuals in the search process. For example, a preference-based weight vector was designed in X. Zhang et al. (Citation2016) to enable the algorithm to search in the region of interest of decision-makers. On the contrary, Zhang considered that there is no preference between each objective, but a point, called knee point, which is selected from a set of non-inferior solutions, can accelerate the convergence of the populations. Therefore, an evolutionary algorithm based on knee point was designed in X. Zhang et al. (Citation2015). However, Cheng pointed out that some algorithms, including the above algorithms, will face the problem that the population might not converge to the true PF while the amount of objective increased. Therefore, a multi-objective evolutionary algorithm based on reference vector guidance was proposed in Cheng et al. (Citation2016), which used the angle penalty distance to balance the convergence and diversity of solutions. Moreover, the convergence-diversity balanced fitness evaluation mechanism is proposed in J. Liu et al. (Citation2019), which can evaluate each solution's quality and then increase the selection pressure. A novel interactive preference based on a multi-objective evolutionary algorithm is proposed in Guo et al. (Citation2019) to solve bolt supporting network, which updates dynamically these preference regions based on satisfactory candidates during the evolution.
In order to ensure that the algorithm converges to Pareto optimal as close as possible, different optimisation operators were designed to improve the performance of algorithms, such as particle swarm optimisation proposed in Lin et al. (Citation2018); ant colony optimisation proposed in Ning et al. (Citation2018); genetic algorithm proposed in He et al. (Citation2017); differential evolution (DE) proposed in Yi Elsayed et al. (Citation2013), where DE was proposed by Price and Storn (Storn & Price, Citation1997) in 1997, which can exploit and explore population searching. Therefore, DE has attracted attention in recent years to solve single objective problems, such as Tang et al. (Citation2015), X. Wang and Tang (Citation2016) and C. Wang et al. (Citation2019). Zhang proposed an algorithm (MOEA/D-DE) in 2009, which uses DE to produce offspring and combines multi-objective decomposition to solve MOPs in Hui and Zhang (Citation2009). Considering that the performance of DE is related to mutation operator and related parameters to solve MOPs, the adaptive differential evolutionary and the decomposition with variable neighbourhood size are combined in Z. Liu et al. (Citation2014), where the neighbourhood size is determined by the ensemble of neighbourhood size, and the differential strategy is selected from the differential strategy pool. In the same way, the DE strategy is chosen from a candidate pool according to a probability that depends on its previous experience in Venske et al. (Citation2014). Moreover, based on the decomposition approach, a modified mutation and crossover operation of DE are presented in Jin and Tan (Citation2015) to solve continuous MOPs. A novel DE is proposed in Xie et al. (Citation2020), where mutation operator and parameter can be, respectively, adaptive dynamic selected by using the search information of the current population and population evolution state. Nayak et al. (Citation2018) present an elitism-based multi-objective DE for feature selection, and a multi-objective clustering algorithm has been proposed based on DE in Nayak et al. (Citation2019) to solve data clustering. In addition, Other algorithms combined with DE to build hybrid evolution algorithm, which can solve MOPs, such as K. Li et al. (Citation2014), X. Zhang et al. (Citation2016), X. Zhang et al. (Citation2018) and Guerrero-Peña and Araújo (Citation2019).
However, in Tanabe and Ishibuchi (Citation2019), the influence of different mutation strategies on algorithm MOEA/D-DE is analysed in detail, and it is pointed out that a reasonable mutation strategy and parameters can improve the performance of the MOEA/D-DE, which means that the convergence speed of DE is affected by mutation operation and parameters. Therefore, it is essential for DE to select reasonable mutation operation and relevant parameters to solve MOPs. Although some optimisers use different strategies to adjust the parameter F of DE, it is rare to use the size of the decision space to adjust the parameter. In addition, according to the characteristics of MOEA/D-DE and the feedback information of the function values, the external archive and rank sum are established, and the local optimal is selected to produce offspring individuals according to the above results, this process can improve the convergence of DE. It is worth noting that the binomial crossover operation of DE is the recombination of parental and offspring individual, which has certain randomness. Obviously, if each component of the crossover individual is selected according to some heuristic information, this operation is better than binomial crossover. Therefore, this paper did the following work based on MOEA/D-DE.
The norm values of vectors satisfying certain conditions are used to self-adaptively adjust parameter F.
The gambling wheel is used to select local optimal individual and to execute the mutation operator, which can ensure the convergence of DE.
An external archive must be set for each individual; this archive is formed by individuals whose weights are relatively smaller. Then an individual is selected from the external archive to execute the mutation operator.
A heuristic crossover operator is established based on a uniform design.
An improved DE based on decomposition is developed by implanting different operations of mutation and heuristic crossover and the self-adaptive adjustment for relevant parameter, which can solve real-world optimisation for industrial problems, such as operation of distributed energy systems, operation of natural gas pipeline networks, crash safety design of vehicles, greenhouse gas emissions from ships, land use allocation in high flood risk areas, etc. The rest of this paper is organised as follows. Section 2 briefly explains the related work. Section 3 introduces improved schemes, including selecting local optimal to produce mutation operator and heuristic crossover operation based on a uniform design, the self-adaptive adjustment for relevant parameter, mutation operation using an external archive, and the framework of HMODE/D. The simulation computation and comparison between HMODE/D and other algorithms are presented in Section 4. Finally, the conclusion is presented in Section 5.
2. Related work
The section introduces some basic algorithmic approaches, including classical DE and multi-objective differential algorithm based on decomposition.
2.1. Classical DE
The classical DE was proposed by Price and Storn to effectively solve the single-objective optimisation problem, which uses mutation, crossover, and selection operators to evolve the population. The basic procedure of DE is described as follows.
NP individuals are randomly generated in D-dimensional space, the jth decision variable of the ith individual at the initial generation is noted as
, where
.
Mutation operation is performed on the parent individuals to produce offspring. Different ways of mutation have distinct characteristics. Some common mutation operations are listed below:
(2)
DE/rand/1 and DE/rand/2 use random vectors to provide mutation direction for the population, which can almost cover the region of the potential optimal solution. However, the random search of the above two mutation methods lacks the exploit ability of DE, which cannot guarantee the convergence of DE. In contrast, DE/best/1 and DE/best/2 use the global optimal solution to provide the mutation direction for the population, which can improve the convergence of DE. However, the above two mutation methods lack the exploration ability of DE, which makes DE easy to fall into the local optimal. Different from the above mutation methods, DE/current-to-best/1 and DE/current-to-rand/1 have a better compromise between convergence of DE and diversity of population.
Crossover operation is selected for each component from the parent and mutation individual by a certain probability CR, and this process is named binary crossover, i.e.
(8)
(8) where
.
is an integer randomly chosen in
;
is a random number in [0,1], the parameter CR is called the crossover probability.
The selection operation is a one-to-one selection from the parent and mutation individual. In this operation, the fitness value of each parent individual and the corresponding crossover individual are compared to select the next generation individual.
2.2. Multi-objective DE based on decomposition (MOEA/D-DE)
DE can overcome the defect of simulated genetic operators generating inferior offspring. Therefore, Hui and Zhang proposed a multi-objective differential algorithm based on decomposition in Hui and Zhang (Citation2009), which uses DE to produce offspring. The detailed procedure of MOEA/D-DE is described as follows.
Step 1: Initialisation
Step 1.1 Randomly generate an initial population and uniformly generate the weight vectors
;
Step 1.2 Calculate the Euclidean distances between any two weight vectors and then output T closest weight vectors to each weight vector. For , if the nearest T weight vectors of
are
, then the neighbourhood indexes of the corresponding individuals
are
;
Step 1.3 Calculate the objective value for each individual
and the minimum value for each objective, noted as
, where
.
Step 2 Update: For i = 1:N do
Step 2.1 Select mating range:
where rand is a random value that is uniformly distributed on
; δ is the probability that parent solutions are selected from the neighbourhood.
Step 2.2 Perform mutation and crossover
Randomly select two indexes and
from P, generate an individual v using the following equation
(9)
(9) Then, crossover operation is executed for
to produce a new individual
by Equation (Equation8
(8)
(8) ) and repair the component that exceeds the boundary for
.
Step 2.3 Update z: for each , if
, then
replaces
.
Step 2.4 Update individuals: set c = 0 and let be a parameter
(1) If , randomly pick an index q from P;
(2) If , set
,
and c = c + 1;
(3) Remove q from P and go back to (1) until the condition is not satisfactory.
Where ,
, this is named the Tchebycheff approach (Q. Zhang & Li, Citation2007).
Some algorithms, including MOEA/D-DE and WVMOEAP (X. Zhang et al., Citation2016), use Equation (Equation9(9)
(9) ) to generate mutation individual, which is a random search mechanism. If the above mutation operation is adopted in the whole evolutionary process, the convergence of DE may worsen. Moreover, some potential solutions may not be obtained when the parameters F and CR are invariable. Therefore, in order to solve the above problems, this paper performs some improvements on DE. The relevant work of this paper will be described in the next section in detail.
3. Handling method and proposed algorithm
This section mainly introduces some handling techniques to improve the convergence of DE, including adjustment strategy of related parameter, mutation operation based on the local optimum, external archive, and heuristic crossover operation based on a uniform design.
3.1. Adjustment for mutation factor
In order to ensure that DE has a strong searching ability, the mutation individuals should be produced in the early stage of the evolution and distributed as widely as possible in the decision space, while individuals of higher quality should be produced in the late stage of evolution. In order to solve the above problem, it is feasible to adjust the mutation factor using the size of the decision space. If the difference vector is standardised, i.e.
, the mutation factor F is set as
, where ρ is a parameter,
and
are the decision variables that guarantee the maximum Euclidean distance in the decision space. Obviously, if ρ is larger, individual offspring may be close to the decision boundary and explore the unknown area in the decision space; if ρ is smaller, individual generated by mutation operation may be close to the best individual.
MOEA/D-DE generates mutation individual by making use of the neighbour individuals, in which the scaling factor keeps constant in whole iterations. In this paper, the mutation scheme is improved, in which the information of neighbourhood individuals is used to adaptively tune the scaling factor. In addition, in order to save the computational cost, only part of the objective functions are selected randomly to determine the extreme variable values, and
. The specific process is described as follows.
First, randomly select an objective function in the objective space for individual . Then, calculate the objective values of the neighbour individuals for
and find individual sets corresponding to the maximum and minimum values of the objective function in neighbour individuals, which are noted as
and
, respectively.
Then, calculate the Euclidean distance between individuals in set and
; find the individuals
and
that satisfy the largest Euclidean distance.
Next, randomly select two indexes and
from the neighbour individuals, the corresponding individuals are noted as
and
.
Finally, calculate the norms of vector and
, the norms are denoted as
and
, the mutation parameter
for
as follows by using the above norm values
(10)
(10) where control parameter ρ is set to
; τ is a number in [0,1]; G and Gmax represent current and maximum generation, respectively.
It is worth noting that in order to ensure the rationality of the parameter values, the parameter is adjusted as follows:
(11)
(11) where
represents the lower bound of
and if
is small, the algorithm is easy to fall into local optimal.
represents the upper bound of
and if
is large, the algorithm approximates random search, which will affect the convergence of the algorithm.
3.2. Mutation operation based on local optimum and external archive
Two different mutation methods are proposed in this section to improve the convergence of DE. One is to select the local optimal individual from the neighbourhood individuals to generate an offspring individual, and the other is to select an individual from the external archive to generate an offspring individual.
3.2.1. Mutation operation based on local optimum
MOEA/D-DE decomposes MOP into a group of single-objective optimisation problems and evolves sub-populations to obtain the optimal solutions to the original problem. If a single mutation strategy is used throughout the evolution of DE, it is difficult to balance the exploration and exploitation abilities of DE. In order to overcome the shortcoming, an improved mutation operator based on the rank of objective values is developed. It distinguishes from DE/best/1, because the roulette wheel selection selects the best individual. The procedure can be described as follows.
First, for individual , the corresponding subpopulation is set
.
Then, rank all individuals of the subpopulation using each dimension of the objective vector; in this way, each individual obtains an order vector. Calculate the sum of each order vector, the sum is called as rank value, denoted by
.
Finally, get the selection probability as follows:
(12)
(12)
(13)
(13) Once the selection probability is determined, a potential better individual
can be obtained by roulette wheel selection, and a new mutation operation can be executed:
(14)
(14) where
are different individuals selected from the subpopulation
and F satisfies Equation (Equation10
(10)
(10) ).
Obviously, an individual with a smaller ranking is closer to PF in the domain. Therefore, such an individual should have a greater probability of being selected and become the local optimal.
3.2.2. Mutation operation based on external archive
MOEA/D compares the weight values of neighbour individuals with offspring to update parent individuals using the Tchebycheff approach. If the offspring replaces the neighbour individual, i.e. the weight value of offspring does not exceed the corresponding weight value of a neighbour individual. It suggests that the offspring individual is beneficial for optimising some objective functions. On the contrary, the parent individual is more favourable. Therefore, an external archive is set for each weight vector; this archive can store individuals whose corresponding weight is relatively insignificant. Then, an individual can be selected from the corresponding external archive to perform a mutation operation, which is beneficial to the convergence of the algorithm. The detailed process is described as follows.
At first, an empty external archive with a certain size is set for each weight vector
to store individuals and weight values.
Then, the weight value of the neighbour of the ith individual
and the weight value
of the offspring are compared one by one, where q is selected from the neighbourhood indexes P. If
, the individual u and the weight value
are stored in the external archive
of the corresponding weight vector
. Otherwise, the individual
and the weight value
are stored in the external archive
.
At last, randomly select two indexes and
from the neighbourhood indexes P. Then, an individual
can be randomly selected from the external archive
to generate mutation offspring. i.e.
(15)
(15) Unfortunately, the calculation cost is high while each group of weights are compared to store the relatively good individuals. Therefore, some groups are selected in this paper for comparison to ensure that the external archive of each individual is not empty, which can reduce the calculation cost.
3.3. Heuristic crossover operation based on uniform design
The binomial crossover operation of DE is the recombination of parental and offspring individual based on crossover probability CR to maintain the diversity of the population. This means that the binomial crossover operator does not have the characteristic of heuristic. Considering that uniform design has the advantage of obtaining global information to solve some optimisation problems. Therefore, the heuristic crossover operator is established in this section using the uniform design to produce better offspring, i.e. the parent individual and the mutation individual
perform the following recombination process.
First, generate an orthogonal matrix of elements 0 and 1 by using Latin square, where
indicates that the jth component of the ith recombined individual is selected from the parent individual
and
indicates that the jth component of the ith recombined individual is selected from the mutation individual
. It is obvious that N recombinant individuals are formed.
Then, randomly select an index j from neighbourhood indexes P and calculate the weight values of above N recombinant individuals.
Next, select some recombined individuals to form optimal individual set using the weight values and correspondingly select ranks from matrix .
Finally, calculate the probability value of 1 in the ith column of matrix
. If
satisfies with
, select the ith component of crossover individual from the parent individual. Otherwise, select the ith component from the mutation individual, where
.
However, if the crossover operator is designed by the above process, the number of fitness evaluations of individual function values is . The calculation is expensive. Therefore, in order to ensure the effectiveness of the crossover operator and reduce the amount of computation, only some components of the individual, instead of the whole individual, are executed by the heuristic crossover operator, and the rest are generated using the binomial crossover operator in this paper.
3.4. The proposed algorithm
A hybrid different evolution HMODE/D is introduced in this section, which is based on the framework of MOEA/D-DE. In the proposed algorithm, the iteration is divided into two criteria for evaluation, including evolutionary generation and the maximum times of functions evaluations (MaxFEs). The first criterion is that the evolutionary generation G satisfies and
; HMODE/D performs mutation operation based on the local optimum described in Section 3.2.1 and the heuristic crossover operation based on a uniform design in Section 3.2. Because the heuristic crossover operation based on uniform design is used frequently in each iteration, the computation of HMODE/D is increased. Therefore, the heuristic crossover operation based on the uniform design is periodically executed in the iteration process of populations. This procedure obtains a trade-off between computation cost and potential better individuals. The second criterion is that the evolutionary generation G does not satisfy
; HMODE/D performs mutation operation described in Section 3.2.2 and classical crossover operation. In addition, in order to ensure the effectiveness of HMODE/D, the self-adaptive adjustment strategy is adopted in the whole process of evolution, which is described in Section 3.1. If the stop criterion is satisfied, we output the optima. The procedure of HMODE/D is presented in Algorithm ??.



4. Experimental study
Twenty-two acknowledged test functions DTLZ1-DTLZ7 and MaF1-MaF15 with diverse properties are used to test the performance of HMODE/D. The properties of the above test functions include linear, concave, multimodal, degenerate, nonseparable, etc. The number of objective for above test functions are 5-objective (M = 5), 10-objective (M = 10), and 15-objective(M = 15), respectively. The number of variables is set to M + 4 for DTLZ1, M + 19 for DTLZ7, and M + 9 for other DTLZ problems. The number of variables for MaF1-MaF15 is related to the number of position variables and distance variables. A detailed description of these test functions can be found in Deb et al. (Citation2002) and Cheng et al. (Citation2017). Six state-of-the-art EMO algorithms, MOEA/D-DE (Hui & Zhang, Citation2009), WVMOEAP (X. Zhang et al., Citation2016), AMPDEA, KnEA (X. Zhang et al., Citation2015), RVEA (Cheng et al., Citation2016) and CVEA3, are involved in the comparison, where MOEA/D-DE, WVMOEAP, and AMPDEA are based on DE, the rest belong to non de category. RVEA and CVEA3 rank as the first and second in the competition on CEC2018. The relevant codes are obtained from PlatEMO and detailed materials are listed in Tian et al. (Citation2017).
4.1. Parameter settings and performance metric
For fair comparisons, all compared algorithms adopt the original parameter values. The relevant parameters of five comparative algorithms are introduced briefly in this section. The parameters of MOEA/D-DE include , nr = 2, F = 0.5 and CR = 1, where δ is the probability that parent solutions are selected from the neighbourhood; nr is the maximum number of solutions replaced by each offspring; F and CR are the mutation factor and the crossover probability. The parameter of WVMOEAP is b = 0.05, which is the extent of the preferred region. The parameters of AMPDEA are nPer = 50 and nPerGroup = 35, where nper is the number of perturbations on each solution for decision variable clustering; nPerGroup is the group size for separative variables. The parameter of KnEA is r = 0.5, which is the rate of knee points in the population. The parameters of RVEA include fr = 0.1 and
, where α represents the number of the reference points; fr represents the frequency of a random population. The parameters of CVEA3 include the crossover probability
, distribution index
, the mutation probability
and the probability of crossover between each region. The parameters of HMODE/D include
, nr = 2, CR = 0.9,
,
,
,
and
, where K represents the dimensions of the heuristic crossover operation, and
, respectively, represent the lower and upper bounds of F.
In order to fairly evaluate the performance of HMODE/D, the population size and stopping criterion are equal for all seven algorithms (MOEA/D-DE, WVMOEAP, AMPDEA, KnEA, RVEA, CVEA3, and HMODE/D). The population size NP is, respectively, set to 100, 150, and 200 for M = 5, M = 10, and M = 15. Moreover, the maximum number of function evaluations (MaxFEs) is considered as the stopping criterion and the MaxFEs is set to for all the test functions. In addition, each algorithm is run 20 times independently.
In order to compare the performance of the different algorithms, the inverted generational distance (IGD) (Coello & Cortes, Citation2005) and hypervolume (HV) (Zitzler & Thiele, Citation1999) are used to evaluate the performance of these algorithms. A lower value of IGD implies that the Pareto front must be very close to the true Pareto front; The hypervolume metric measures the size of the region, which is dominated by the obtained Pareto front. Therefore, the higher value of HV-metric is preferred. In addition, two statistical methods, the Friedman test and the multiple-problem Wilcoxon test are used to analyse the performance of these algorithms. At last, the convergence figures of some test functions are illustrated to verify the effectiveness of the compared algorithms.
4.2. Experimental results and analysis on DTLZ1-DTLZ7
This paper improves the MOEA/D-DE algorithm by the following four schemes, i.e.
adjustment for mutation factor;
mutation operation based on local optimum;
mutation operation based on external archive;
heuristic crossover operation based on uniform design.
In order to test the influence of the above schemes on the performance of HMODE/D, some comparison algorithms are established by bowdlerising the corresponding schemes of HMODE/D, for example, the same HMODE/D version without adjustment for mutation factor, is fixed at 0.5 and this version can be called HMODE/D-1. The same HMODE/D version does not use mutation operation based on local optimum, but uses DE/rand/1 of DE, this version can be called HMODE/D-2. The same HMODE/D version does not use mutation operation based on external archive, but uses DE/rand/1 of DE, this version can be called HMODE/D-3. The same HMODE/D version does not use heuristic crossover operation based on uniform design, but uses binomial crossover of DE, this version can be called HMODE/D-4.
Tables and , respectively, show the average value (Mean) and variance (Std) of IGD and HV via 20 independent runs on DTLZ1-DTLZ7. The parts in bold represent the best performance values of all compared algorithms, and the last three rows of these tables enumerate the comparison results of HMODE/D with each compared algorithm, where “+”, “−”, and “≈” indicate the result of the corresponding competition algorithm is better, worse, and equal than HMODE/D, respectively. Moreover, the results of the Friedman test are summarised in Table , in which HMODE/D and other algorithms are ranked by the Friedman test on the functions with DTLZ1-DTLZ7 in terms of Mean values of IGD and HV. Finally, the results of the multi-problem Wilcoxon test are summarised in Tables –, which are used to test whether HMODE/D is significantly different from the comparison algorithms.
Table 1. Experimental results of HMODE/D and abridged versions on DTLZ1-DTLZ7 in terms of Mean values and Std of IGD.
Table 2. Experimental results of HMODE/D and abridged versions on DTLZ1-DTLZ7 in terms of Mean values and Std of HV.
Table 3. Ranking of HMODE/D and abridged versions by the Friedman test on the functions with DTLZ1-DTLZ7 in terms of Mean values of IGD and HV.
Table 4. Results of the multiple problem Wilcoxon test on the functions with DTLZ1-DTLZ7 in terms of Mean values of IGD.
Table 5. Results of the multiple problem Wilcoxon test on the functions with DTLZ1-DTLZ7 in terms of Mean values of HV.
Obviously, the results in Tables and highlight the superiority of algorithm HMODE/D. Moreover, HMODE/D achieves the first rank in the Friedman test on DTLZ1-DTLZ7 for the Mean values of both IGD and HV in Table . Finally, all the values are more significant than the
values in Table and all the
values are smaller than the
values in Table , which reflects that HMODE/D is better than the four competitors. There is no doubt that the better experimental results obtained by algorithm HMODE/D are mainly attributed to four schemes proposed in this paper, which can improve the exploitation and exploration ability of DE. Unfortunately, the performance of HMODE/D is almost equal to HMODE/D-4. The main reason is that the heuristic crossover operator needs a larger amount of computation. Therefore, in order to balance the performance of HMODE/D and the cost of computation, the number of executions of the heuristic crossover operator proposed in this paper is finite.
The following section evaluates the advantage of HMODE/D compared with MOEA/D-DE, WVMOEAP, AMPDEA, KnEA, RVEA, and CVEA3 in solving test function DTLZ1-DTLZ7. As shown in Table , HMODE/D can beat apart compared algorithms on DTLZ2, DTLZ3, and DTLZ6, except for DTLZ3(10M), and the result of the last row in Table show that HMODE/D performs better than MOEA/D-DE, WVMOEAP, AMPDEA, KnEA, RVEA, CVEA3 on 16, 20, 13, 15, 10, and 15 test functions, respectively. Moreover, compared with RVEA, which is ranked second, HMODE/D performs better on DTLZ2, DTLZ3, and DTLZ6, where DTLZ2 is used to test the uniformity of the Pareto optimal distribution; DTLZ3 is used to test an algorithm's ability to converge the global Pareto optimal front; DTLZ5 is used to test an algorithm's ability to converge a degenerated curve; DTLZ6 is used to test an algorithm's ability to maintain subpopulation in different Pareto optimal regions. The best performance of HMODE/D in the above test functions is attributed to the different mutation strategies used in the evolution process to ensure that the algorithm has a strong searching ability. However, the results in Table also show that HMODE/D performs poorly in DTLZ4, which is used to test an algorithm's ability to maintain a good distribution of solutions. The main reason is that the mutation strategies of HMODE/D cannot well maintain the diversity of the population.
As shown in Table , HMODE/D outperforms the competing algorithms on 7 functions in terms of HV. HMODE/D performs better than or equal to MOEA/D-DE, WVMOEAP, AMPDEA, KnEA, RVEA, CVEA3 on 11, 17, 13, 16, 12, and 13 test functions, respectively. In addition, HMODE/D stands out in DTLZ2, DTLZ3 and DTLZ6, whereas RVEA stands out in DTLZ1 and DTLZ4.
Table 6. Experimental results of HMODE/D and other algorithms on DTLZ1-DTLZ7 in terms of Mean values and Std of IGD.
Table 7. Experimental results of HMODE/D and other algorithms on DTLZ1-DTLZ7 in terms of Mean values and Std of HV.
As shown in Table , HMODE/D both achieves the first rank in the Friedman test on DTLZ1-DTLZ7 for the Mean values of IGD and HV. In addition, in order to further test the convergence of these algorithms, Figures describe the convergent speed of compared algorithms when solving DTLZ1 (5M), DTLZ3 (5M), DTLZ5 (5M) and DTLZ7 (5M), respectively. Obviously, HMODE/D has better convergence than other compared algorithms when solving DTLZ3 (5M) and DTLZ5 (5M).
The above results show that HMODE/D is better than other comparative algorithms, which means that HMODE/D can solve complex multi-objective optimisation problems.
Figure 1. The convergent speed of compared algorithms on DTLZ1.
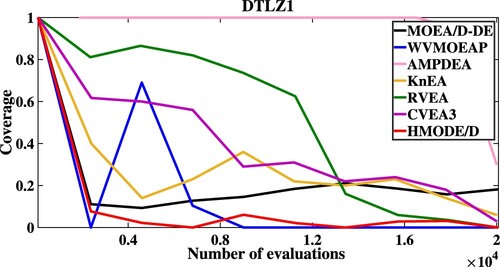
Figure 2. The convergent speed of compared algorithms on DTLZ3.
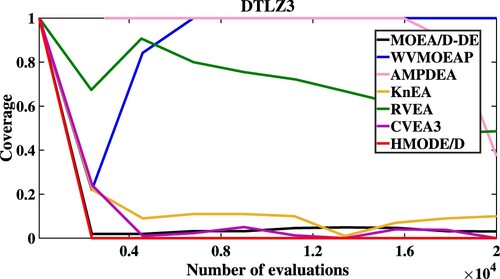
Figure 3. The convergent speed of compared algorithms on DTLZ5.
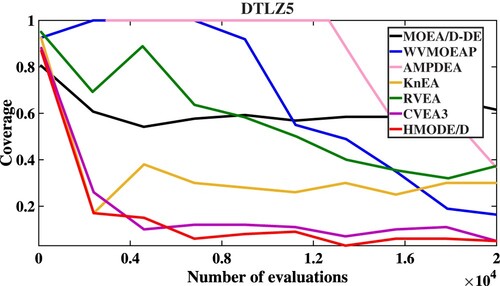
Figure 4. The convergent speed of compared algorithms on DTLZ7.
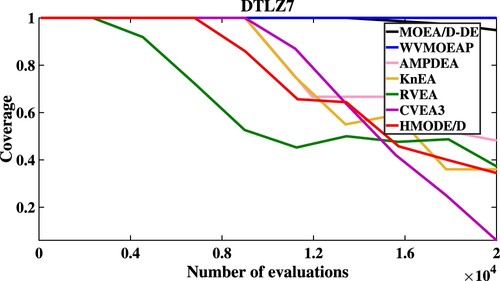
Table 8. Ranking of HMODE/D and other algorithms by the Friedman test on the functions with DTLZ1-DTLZ7 in terms of Mean values of IGD and HV.
4.3. Experimental results and analysis on MaF1-MaF15
In order to comprehensively evaluate the performance of HMODE/D, HMODE/D and the six compared algorithms (MOEA/D-DE, WVMOEAP, AMPDEA, KnEA, RVEA and CVEA3) to solve the test function MaF1-MaF15. Tables and , respectively, show the average value (Mean) and variance (Std) of IGD and HV via 20 independent runs on MaF1-MaF15.
Table 9. Experimental results of HMODE/D and other algorithms on MaF1-MaF15 in terms of Mean values and Std of IGD.
Table 10. Experimental results of HMODE/D and other algorithms on MaF1-MaF15 in terms of Mean values and Std of HV.
The results in Table show that HMODE/D outperforms the other comparison algorithms on MaF3, MaF8, MaF9 and MaF14 for IGD, except for MaF3 (5M), where MaF3 has a convex PF, and there are a large number of local fronts. HMODE/D uses local optimal to generate mutant offspring, which can improve the local convergence of the HMODE/D. The Pareto optimal region of MaF8 and MaF9 is manifold, HMODE/D uses parameter adaptive and local optimal to generate offspring individuals, which can improve the search ability of the algorithm. MaF14 has a larger scale of decision variables, HMODE/D adaptively adjusts the mutation parameters by using the decision space, which ensures that the algorithm has a strong searching ability. In addition, the result of the last row in Table shows that HMODE/D is better than MOEA/D-DE, WVMOEAP, AMPDEA, KnEA, and RVEA. However, it is regrettable that HMODE/D does not surpass CVEA3 on MaF4, MaF5, MaF12 and MaF13, the characteristic of these four types of test functions is that their PF is convex, which means that HMODE/D has some defects in solving the above problems.
The results in Table show that HMODE/D can beat all the comparison algorithms on MaF3, MaF4, MaF8, MaF9, and MaF13-MaF15 in terms of HV, except for MaF3 (5M), MaF8 (5M), MaF9 (15M), and MaF13 (15M). It is worth noting that for each comparison algorithm, the proportion of HMODE/D with better or equivalent performers exceeds two-thirds, except for CVEA3.
Although HMODE/D has poor performance compared with CVEA3, the results in Table show that HMODE/D both achieves the first rank in the Friedman test, which means that the algorithm proposed in this paper has strong comprehensive ability to deal with various complex multi-objective optimisation problems.
Moreover, Figures describe the convergent speed of compared algorithms when solving MaF3 (5M), MaF6 (5M), MaF9 (5M) and MaF12 (5M), respectively. HMODE/D has better convergence than other compared algorithms when solving MaF9 (5M) and MaF12 (5M).
Figure 5. The convergent speed of compared algorithms on MaF3.
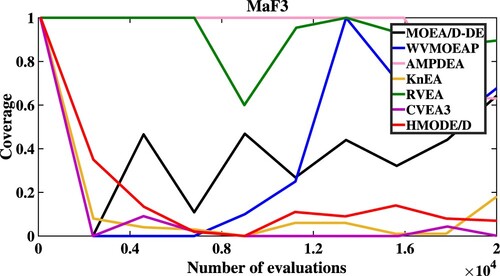
Figure 6. The convergent speed of compared algorithms on MaF6.
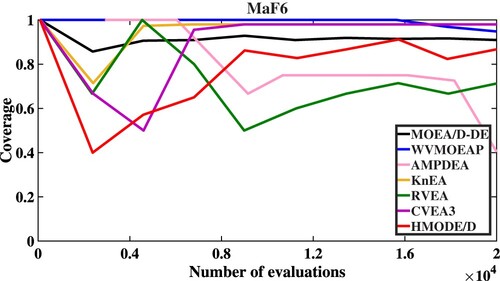
Figure 7. The convergent speed of compared algorithms on MaF9.
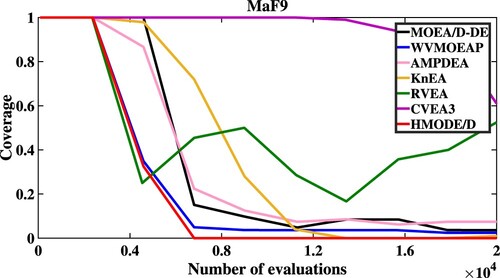
Figure 8. The convergent speed of compared algorithms on MaF12.
Table 11. Ranking of HMODE/D and other algorithms by the Friedman test on functions with MaF1-MaF15 in terms of Mean values of IGD and HV.
5. Conclusion
In order to solve multi-objective optimisation problems by using DE effectively, a hybrid multi-objective differential evolution (HMODE/D), based on decomposition, is proposed in this paper. The handling schemes of HMODE/D include (1) the probability value for every neighbour individual is set by using the rank sum, and the local optimal is selected by the roulette wheel. Then, one mutation operator is designed by the local optimal. Besides, one heuristic crossover operator is constructed by using the method of uniform design. (2) The search ability of HMODE/D is improved using the self-adaptive adjustment strategy; the mutation factor is adjusted by the norms of vectors satisfying certain conditions. (3) Parent individuals are updated using decomposition; during the decomposition external archive for each individual can be constructed, i.e. the weight values of neighbourhood individuals are compared with those of offspring, during which individual with less significant weight value is selected and stored in the archive of the corresponding individual. Then, an individual, which is beneficial to the convergence of DE, is selected from the external archive to execute the mutation operation. The effectiveness of HMODE/D is verified by comparing it with the latest algorithm. The related experimental results show that the performance of HMODE/D has advantages compared with other algorithms.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
References
- Cheng, R., Jin, Y., Olhofer, M., & Sendhoff, B. (2016). A reference vector guided evolutionary algorithm for many-objective optimization. IEEE Transactions on Evolutionary Computation, 20(5), 773–791. https://doi.org/10.1109/TEVC.2016.2519378
- Cheng, R., Li, M., Tian, Y., Zhang, X., & Yao, X. (2017). A benchmark test suite for evolutionary many-objective optimization. Complex & Intelligent Systems, 3(1), 67–81. https://doi.org/10.1007/s40747-017-0039-7
- Coello, C. A. C., & Cortes, N. C. (2005). Solving multiobjective optimization problems using an artificial immune system. Genetic Programming & Evolvable Machines, 6(2), 163–190. https://doi.org/10.1007/s10710-005-6164-x
- Deb, K., & Jain, H. (2014). An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: Solving problems with box constraints. IEEE Transactions on Evolutionary Computation, 18(4), 577–601. https://doi.org/10.1109/TEVC.2013.2281535
- Deb, K., Pratap, A., Agarwal, S., & Meyarivan, T. (2002). A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation, 6(2), 182–197. https://doi.org/10.1109/4235.996017
- Deb, K., Thiele, L., Laumanns, M., & Zitzler, E. (2002). Scalable multi-objective optimization test problems. In IEEE (Ed.), Congress on Evolutionary Computation. Evolutionary Computation, 2002. CEC '02 (pp. 825–830).
- Falahiazar, L., & Shah-Hosseini, H. (2018). Optimisation of engineering system using a novel search algorithm: The spacing multi-objective genetic algorithm. Connection Science, 30(3), 326–342. https://doi.org/10.1080/09540091.2018.1443319
- Farias, L., & Araujol, A. (2019). Many-objective evolutionary algorithm based on decomposition with random and adaptive weights. In IEEE (Ed.), 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC). IEEE (pp. 3746–3751).
- Gang, L., & Hao, H. (2014). Risk design optimization using many-objective evolutionary algorithm with application to performance-based wind engineering of tall buildings. Structural Safety, 48(1), 1–14. https://doi.org/10.1016/j.strusafe.2014.01.002
- Giuliani, M., Galelli, S., & Soncini-Sessa, R. (2014). A dimensionality reduction approach for many-objective Markov decision processes: Application to a water reservoir operation problem. Environmental Modelling & Software, 57, 101–114. https://doi.org/10.1016/j.envsoft.2014.02.011
- Guerrero-Peña, E., & Araújo, A. F. R. (2019). Multi-objective evolutionary algorithm with prediction in the objective space. Information Sciences, 501, 293–316. https://doi.org/10.1016/j.ins.2019.05.091
- Guo, Y., Zhang, X., Gong, D., Zhang, Z., & Yang, J. (2019). Novel interactive preference-based multi-objective evolutionary optimization for bolt supporting networks. IEEE Transactions on Evolutionary Computation, 99(4), 1–10. https://doi.org/10.1109/TEVC.2019.2951217
- He, C., Tian, Y., Jin, Y., Zhang, X., & Pan, L. (2017). A radial space division based evolutionary algorithm for many-objective optimization. Applied Soft Computing, 61, 603–621. https://doi.org/10.1016/j.asoc.2017.08.024
- Hui, L., Sun, J., Wang, M., & Zhang, Q. (2018). MOEA/D with chain based random local search for sparse optimization. Soft Computing, 22(1), 1–16. https://doi.org/10.1007/s00500-016-2442-1.
- Hui, L., & Zhang, Q. (2009). Multi-objective optimization problems with complicated Pareto sets, MOEA/D and NSGA-II. IEEE Transactions on Evolutionary Computation, 13(2), 284–302. https://doi.org/10.1109/TEVC.2008.925798
- Jin, K., & Tan, K. (2015). An opposition-based self-adaptive hybridized differential evolution algorithm for multi-objective optimization (OSADE). In Proceedings of the 18th Asia Pacific Symposium on Intelligent and Evolutionary Systems (Vol. 1, pp. 447–461).
- Li, J., Deng, J., Li, C., Han, Y., Tian, J., Zhang, B., & Wang, C. (2020). An improved Jaya algorithm for solving the flexible job shop scheduling problem with transportation and setup times. Knowledge-Based Systems, 200, 106032–106048. https://doi.org/10.1016/j.knosys.2020.106032
- Li, K., Fialho, A., Kwong, S., & Zhang, Q. (2014). Adaptive operator selection with bandits for a multiobjective evolutionary algorithm based on decomposition. IEEE Transactions on Evolutionary Computation, 18(1), 114–130. https://doi.org/10.1109/TEVC.2013.2239648
- Li, M., Yang, S., & Liu, X. (2014). Shift-based density estimation for Pareto-based algorithms in many-objective optimization. IEEE Transactions on Evolutionary Computation, 18(3), 348–365. https://doi.org/10.1109/TEVC.4235
- Lin, Q., Liu, S., & Zhu, Q. (2018). Particle swarm optimization with a balanceable fitness estimation for man-objective optimization problems. IEEE Transactions on Evolutionary Computation, 2, 32–46. https://doi.org/10.1109/TEVC.2016.2631279
- Liu, J., Wang, Y., Fan, N., Wei, S., & Tong, W. (2019). A convergence diversity balanced fitness evaluation mechanism for decomposition based many-objective optimization algorithm. Integrated Computer Aided Engineering, 26(3), 1–26. https://doi.org/10.3233/ICA-180594
- Liu, Z., Gao, Y., Zhang, W., & Wang, X. (2014). Decomposition with ensemble neighborhood size multi-objective adaptive differential evolutionary algorithm. Control Theory & Applications, 11(31), 1492–1501. https://doi.org/10.7641/CTA.2014.40371
- Lotfi, S., & Karimi, F. (2017). A hybrid MOEA/D-TS for solving multi-objective problems. Journal of Artificial Intelligence and Data Mining, 5(2), 183–195. https://doi.org/10.22044/jadm.2017.886
- Mardle, S., & Miettinen, K. M. (1999). Nonlinear multiobjective optimization. Journal of the Operational Research Society, 51(2), 246–247. https://doi.org/10.2307/254267
- Nayak, S. K., Rout, P. K., & Jagadev, A. K. (2019). Multi-objective clustering: A kernel based approach using differential evolution. Connection Science, 31(3), 294–321. https://doi.org/10.1080/09540091.2019.1603201
- Nayak, S. K., Rout, P. K., Jagadev, A. K., & Swarnkar, T. (2018). Elitism-based multi-objective differential evolution with extreme learning machine for feature selection: a novel searching technique. Connection Science, 30(4), 1–26. https://doi.org/10.1080/09540091.2018.1487384
- Ning, J., Zhang, C., Sun, P., & Feng, Y. (2018). Comparative study of ant colony algorithms for multi-objective optimization. Information (Switzerland), 10(1), 11–19. https://doi.org/10.3390/info10010011
- Ramirez, A., Raul Romero, J., & Ventura, S. (2016). A comparative study of many-objective evolutionary algorithms for the discovery of software architectures. Empirical Software Engineering, 21(6), 1–55. https://doi.org/10.1007/s10664-015-9399-z
- Storn, R., & Price, K. (1997). Differential evolution: A simple and efficient heuristic for global optimization over continuous spaces. Journal of Global Optimization, 11, 341–359. https://doi.org/10.1023/A:1008202821328
- Tanabe, R., & Ishibuchi, H. (2019). Review and analysis of three components of the differential evolution mutation operator in MOEA/D-DE. Soft Computing, 23, 12843–12857. https://doi.org/10.1007/s00500-019-03842-6
- Tang, L., Yun, D., & Liu, J. (2015). Differential evolution with an individual-dependent mechanism. IEEE Transactions on Evolutionary Computation, 19(4), 560–574. https://doi.org/10.1109/TEVC.2014.2360890
- Tian, Y., Cheng, R., & Zhang, X. (2017). Platemo: A matlab platform for evolutionary multi-objective optimization. IEEE Computational Intelligence Magazine, 12(4), 73–87. https://doi.org/10.1109/MCI.2017.2742868.
- Venske, S., Goncalves, R., & Delgado, M. (2014). ADEMO/D: Multiobjective optimization by an adaptive differential evolution algorithm. Neurocomputing, 127, 65–77. https://doi.org/10.1016/j.neucom.2013.06.043
- Wang, C., Liu, Y., Zhang, Q., Guo, H., Liang, X., & Chen, Y. (2019). Association rule mining based parameter adaptive strategy for differential evolution algorithms. Expert Systems with Applications, 123, 54–69. https://doi.org/10.1016/j.eswa.2019.01.035
- Wang, X., & Tang, L. (2016). An adaptive multi-population differential evolution algorithm for continuous multi-objective optimization. Information Sciences, 348, 124–141. https://doi.org/10.1016/j.ins.2016.01.068
- Xie, Y., Qiao, J., Wang, D., & Yin, B. (2020). A novel decomposition-based multiobjective evolutionary algorithm using improved multiple adaptive dynamic selection strategies. Information Sciences, 556(5), 472–494. https://doi.org/10.1016/j.ins.2020.08.070
- Yalcinoz, T., & Rudion, K. (2020). Multi-objective environmental-economic load dispatch considering generator constraints and wind power using improved multi-objective particle swarm optimization. Advances in Electrical and Computer Engineering, 20(4), 3–10. https://doi.org/10.4316/aece
- Yi Elsayed, S. M., Sarker, R. A., & Essam, D. L. (2013). An improved self adaptive differential evolution algorithm for optimization problems. IEEE Transactions on Industrial Informatics, 9(1), 89–99. https://doi.org/10.1109/TII.2012.2198658
- Yuan, Y., Xu, H., Wang, B., Zhang, B., & Yao, X. (2016). Balancing convergence and diversity in decomposition based many-objective optimizers. IEEE Transactions on Evolutionary Computation, 20(2), 180–198. https://doi.org/10.1109/TEVC.2015.2443001
- Zhang, Q., & Li, H. (2007). MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Transactions on Evolutionary Computation, 11(6), 712–731. https://doi.org/10.1109/TEVC.2007.892759.
- Zhang, X., Jiang, X., & Zhang, L. (2016). A weight vector based multi-objective optimization algorithm with preference. Acta Electronica Sinica, 44(11), 2639–2645. 10.3969/j.issn.0372-2112.2016.11.011
- Zhang, X., Tian, Y., & Jin, Y. (2015). A knee point driven evolutionary algorithm for many-objective optimization. IEEE Transactions on Evolutionary Computation, 19(6), 761–776. https://doi.org/10.1109/TEVC.2014.2378512
- Zhang, X., Zheng, X., Cheng, R., Qiu, J., & Jin, Y. (2018). A competitive mechanism based multi-objective particle swarm optimizer with fast convergence. Information Sciences, 427, 63–76. https://doi.org/10.1016/j.ins.2017.10.037
- Zitzler, E., & Thiele, L. (1999). Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Transactions on Evolutionary Computation, 3(4), 257–271. https://doi.org/10.1109/4235.797969