
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Personalised recommendation is a difficult problem that has received a lot of attention to academia and industry. Because of the sparse user–item interaction, cold-start recommendation has been a particularly difficult problem. Some efforts have been made to solve the cold-start problem by using model-agnostic meta-learning on the level of the model and heterogeneous information networks on the level of data. Moreover, using the memory-augmented meta-optimisation method effectively prevents the meta-learning model from entering the local optimum. As a result, this paper proposed memory-augmented meta-learning on meta-path, a new meta-learning method that addresses the cold-start recommendation on the meta-path furthered. The meta-path builds at the data level to enrich the relevant semantic information of the data. To achieve fast adaptation, semantic-specific memory is utilised to conduct the model with semantic parameter initialisation, and the method is optimised by a meta-optimisation method. We put this method to the test using two widely used recommended data set and three cold-start scenarios. The experimental results demonstrate the efficiency of our proposed method.
1. Introduction
Recommendation systems (Dacrema et al., Citation2019; Tang et al., Citation2021; Wang et al., Citation2019) have become increasingly important to the industry due to the rapid development of mobile applications. The core goal is to solve the problems of user information overload, which comes with a slew of challenges. Although there are several kinds of recommendation systems, traditional recommendation methods based on matrix factorisation (Jiang et al., Citation2021; Xu et al., Citation2021) or deep learning (D'Angelo et al., Citation2021) have been efficient, cold-start (Kumar et al., Citation2020; Zhang et al., Citation2019) is an unavoidable problem in most recommendation systems. Because of the absence of user–item interaction, the recommendation system frequently fails to recommend appropriately for new users. The issue of the cold-start is broken into two parts: user cold-start and item cold-start, which refer to the situation in which the recommendation system is unable to deal with the presence of new users or items because of the absence of user–item interaction. To deal with the issue of cold-start, an effective solution is to enrich new users and new items with auxiliary data, such as recommendation systems based on user or item content (Li & She, Citation2017; Wei et al., Citation2016). Furthermore, a heterogeneous information network (HIN) (Pham & Do, Citation2020; Shi et al., Citation2016) is used to supplement user–item interaction with complementary heterogeneous information.
Because the cold-start problem is a natural data sparsity concern, increasing the data can address the cold-start strain significantly. On the basis of these works (Dong et al., Citation2020; Lu et al., Citation2020), we combined the data level method with the model level method and proposed memory-augmented meta-learning on meta-path (MAMP) method for cold-start recommendation. The proposed approach first develops the appropriate initial embedding for the user's semantic context and the items, a meta-optimisation-based strategy is advised. In particular, introducing the user's semantics and items into a specific user's task will be significant, and by establishing two layers of fully connected neural networks, utilising previously studied semantics and items, learning new semantic embedding and new item embedding, the last meta-optimisation approach will be used to update parameters. Then, to solve the local optimisation problem, MAMP creates a semantic-specific memory that generates a customised bias item while parameters of model are initialised. The following is the specific procedure: semantic adaptation learns each aspect's unique semantic priors, updates each user's preference for task adaptation learning from diverse semantic priors and, lastly, uses semantic-specific memory to guide the initialisation of semantic priors with individualised parameters.
To conclude, the main contributions of MAMP are as follows:
We introduce HIN to meta-embedding, which is able to learn new semantics embeddings and new items embeddings to solve the cold-start problem more effectively.
We present semantic memory improvement to aid the co-adaptation meta-learner (Lu et al., Citation2020), which significantly improves the co-adaptation meta-learner's performance measure.
Experiments using DBook and MovieLens data sets to demonstrate the performance effectiveness of our meta-learning technique.
2. Related work
2.1. Cold-start recommendation
There may be a different proportion of new users and new items in the recommendation system, and interaction between these users and items is sparse. As a result, personalised recommendation for new users is challenging due to the cold-start problem. Deep learning (Liang, Xie, et al., Citation2020) has achieved great results in a variety of artificial intelligence domains. However, in order to obtain significant generalisation, a large number of examples must be trained. Deep learning becomes ineffective when used in a cold-start recommendation scenario with sparse user–item interactions. Data augmentation at the data level or the provision of auxiliary data (Zhu et al., Citation2019) are the most typical solutions to cold-start recommendations. There are also some methods involving the high-level representation of the data, such as capturing the rich heterogeneous data (Chang et al., Citation2021) of the items and the users, using the data representation of the heterogeneous information network, in addition to considering the basic characteristics of the data. Alternatively, a semantic network can be built using a knowledge graph, in which nodes represent entities and edges to reflect various semantic relationships between items. There are also cross-domain recommendations based on mapping of neighbour user attributes, or recommendations based on mining friend lists on social networks. These techniques rely largely on data and have a number of drawbacks.
2.2. Meta-learning
The purpose of meta-learning is to acquire meta-knowledge, which can be regarded as the most basic general knowledge needed to solve similar learning tasks, as a result of which it would swiftly adapt to new target tasks according to several learning tasks. Due to its characteristic of cross-task learning, meta-learning is also regarded as one of the key technologies to open up general artificial intelligence. According to different research contents, meta-learning can be divided into three types (Hospedales et al., Citation2020). Metrics-based approaches (Hu et al., Citation2018; Snell et al., Citation2017; Vinyals et al., Citation2016) to compare and classify by calculating measurement or approximation, while model-based approach (Munkhdalai & Yu, Citation2017; Santoro et al., Citation2016) wraps internal learning steps in the feed-forward transfer stage of a single model, so as to generalise tasks quickly. Finally, the optimisation-based method focuses on acquiring meta-knowledge to improve the optimisation performance of the model, including the optimisation of the model's initialisation parameters (Finn et al., Citation2017).
2.3. Meta-learning for cold-start recommendation
Wang et al.’s work (Citation2019) demonstrated the effectiveness of meta-learning on the few-shot problem, and the issue of cold-start could be thought as a subset of the few-shot problem. As a result, it is possible to incorporate meta-learning into a cold-start recommendation system. These papers (Chen, Luo, et al., Citation2018; Zhao et al., Citation2019) make some progress in introducing the meta-learning paradigm from the model level of recommendation systems.
Lu et al. (Citation2020) began to address the issue of cold-start on the levels of data and model. It is the first time meta-learning has been used to address cold-start recommendation on HIN, while it can make effective recommendations, it also has flaws. On the one hand, although the link between two objects sequence meta-path (Sun et al., Citation2011), such figure forms can effectively capture the semantic context on the data level, but on the various semantic (i.e. meta-path) to integrate the user history record embed into a single implicit, thus strongly relies on collaborative filtering technology, fine structure is difficult to adjust to individual new users. Some characteristics or items may lose their relevance, causing multidimensional semantic fusion to perform poorly. On the other hand, the author uses an optimisation-based meta-learning technique called model-agnostic meta-learning (MAML) (Finn et al., Citation2017) at the model level. It is frequently recommended for the user as a learning task since it performs well in learning configuration initialisation for new tasks. The central concept is to learn a global parameter that will be used to set the parameters of the personalised recommendation model. Personalisation parameters are updated locally to comprehend a user's preferences, global parameters are updated by reducing training task loss between users and learnt global parameters are then utilised to guide model settings for subsequent users. Although these methods based on the MAML method and its derivatives have a significant capacity to deal with data sparsity, they have a number of flaws, including instability, sluggish convergence and poor generalisation ability. When dealing with users who have different gradient descent directions than the bulk of users, which are included in the data set of training, they are more likely to be influenced by gradient degradation, which can lead to local optimisation. Starting at the model level, to offer a customised bias item while initialising parameters of the model and to gain knowledge to catch the commonality of prospective user preference shared across items, Dong et al. (Citation2020) created a feature-specific memory and a task-specific memory. It effectively solves the problem that the MAML technique and its variants are easy to optimise locally, but without considering the level of auxiliary data, the model would become inefficient when the interaction data is sparse.
At present, most traditional cold-start recommendation systems try to initialise the basic model by learning the global meta-parameter
by the meta-learner; therefore, the global meta-parameter
is also called the global prior. Global prior
is optimised in several tasks and quickly adapts to a target task after one or several gradient stages, given the limited number of instances. Specifically, meta-learning divides tasks into meta-training tasks and meta-testing tasks, for each task of meta-training and meta-testing, it also includes support set and query set, which are mutually exclusive. First, during meta-training, the meta-learner adjusts the global prior
to suit the specific parameters of the task by using the loss w.r.t support set. In the query set, the loss w.r.t the specific parameters of the task are calculated and propagated backwards to update the global prior
. Second, during meta-testing, the meta-learner adapts the
updated in meta-training to the task by one or several gradient steps on the support set, and then applies the adjusted parameters to predict the results of the query set.
2.4. Memory neural networks
In general, after the training parameters have been trained, the neural network will put the samples directly into the trained model for calculation, and then retrieve the results without interacting with the memory. For few-shot learning with sparse data, or models with human–computer interaction, it is difficult to achieve the goal only by connecting calculation between parameters within the model. Weston et al. (Citation2014) first implemented the memory-augmented network using the neural Turing machine model, which consists of a controller and a memory module. The controller writes data to the memory module with a writing head and reads data from the memory module with a reading head. In the memory-augmented network, the feature information is closely associated with the corresponding label in the writing process, and the feature vector is accurately classified in the reading process.
2.5. Memory-augment neural network for recommendation
Neural Turing machine (Graves et al., Citation2014) is the foundation of a significant subsidiary of memory neural networks: extract and update information from memory. These features make NTM a good example of few-shot learning or meta-learning. Based on this idea, Santoro et al. (Citation2016) proposed a Memory-Augmented Neural Network (MANN), which applied NTM to few-shot learning, retained sample feature information by displaying external memory modules and optimised the reading and writing process of NTM by using meta-learning algorithm, and finally realised effective small sample classification and regression. Chen, Xu, et al.’s work (Citation2018) is one of the first batches of work to integrate man into recommendation task, proposed the idea of integrating MANN with collaborative filtering (Lian & Tang, Citation2021) to recommend, with the help of external memory matrix, the model can store and update the user's history, which effectively improves the presentation ability of the model. Dong et al. (Citation2020) further propose two kinds of global shared memory, to deal with the cold-start recommendation.
3. Proposed approach
In this section, a meta-learning method called MAMP based on memory augmented and meta-path is proposed to solve the cold-start recommendation.
3.1. Overview
Which can be seen in Figure , the suggested model of this paper mainly consists of three parts: the first part is semantic enhancement task constructor that extracts meta-paths from profiles. The second part is meta-learning recommendation and semantic co-adaptation models for prediction. The third part is memory-augment optimiser to help recommendation model initialisation parameters.
Figure 1. The training phase of MAMP.
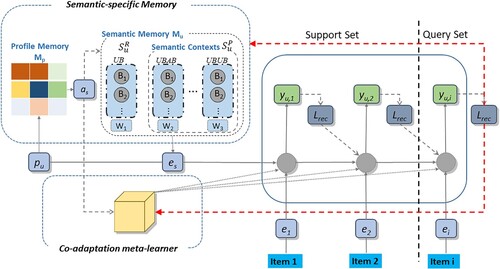
3.2. Semantic-enhanced task constructor
In a cold-start recommendation task, a node's neighbours on the meta-path have different importance. The focus is on substituting the various levels of semantic context of meta-path into tasks. The definition of the task involves one user
follows Lu et al.’s work (Citation2020), that is
(1)
(1) where
represents the semantic-enhanced support set,
represents the semantic-enhanced query set. The support and query sets to every task
are mutually exclusive and they comprise items randomly selected from item sets that user
has rated. Similarly, the semantic-enhanced support and query set are defined as follows:
(2)
(2) where
and
are sets of items that the user
has rated,
and
represent a semantic context according to a collection of meta-paths
.
Firstly, is used to encode the multidimensional semantics of predicted rating
. Specifically, in the recommendation, it is assumed that user
has not rated item
, but the rated items
have some relationship with unrated item
or the users with some relationship with the user
has relation with item
.
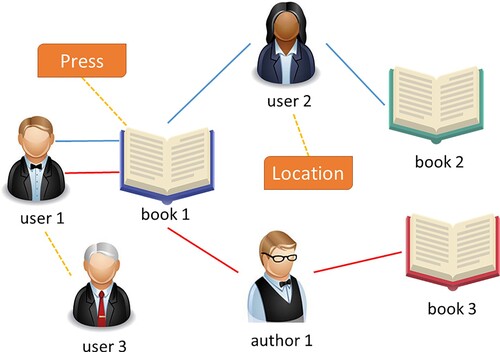
These relationships are defined as multifaceted semantics here. For example, in Figure , the multifaceted semantics can be defined as follows:
(3)
(3) where capital letters represent a type of node, such as `U’ for user, `B’ for book and `A’ for author. The multifaceted semantics are a collection of meta-paths, such as `UBAB’ and `UBUB’, that define different semantic contexts induced by meta-paths: books written by the same author or books purchased separately by the same user. Since there are multiple interactions for user
in each task, a specific meta-path
semantic context is built for task
, as follows:
(4)
(4) where
represents the items reachable along the meta-path
starting from the user
and rated item
.
Figure 2. An example meta-path of Book. The blue line represents the meta-path {UBUB}, while the red line represents the meta-path {UBAB}. In addition, the broken yellow lines represent the attributes associated with the node.
Secondly, we formulate personalised recommendation as a task in the context of meta-learning. Given the user set and its profile
, the item set
and its profile
, and the corresponding rating set
, then the task of the recommendation system is to predict the rating
of an item
for a user
then the recommendation system’s goal is to anticipate a user
’s rating of an item, under the conditions
and
, where
and
represent support set and query set, respectively. Under the cold-start recommendation scenario, to construct a support set for rated items, the data include only users with 13–100 items, we take the below equation
(5)
(5) as the rated condition to construct, the number of ratings for a user
is indicated by
.
Using the same method above, these steps can continue to make and
.
3.3. Recommendation model and co-adaptation meta-learner
3.3.1. Recommendation model
Based on the initial embedding of a certain user
and the embedding
of a certain item
to be rated, we predict
’s rating for
.
The semantic-enhanced user encoder creates a user's embedding based on the embeddings of the p-related items
that are reachable through meta-path p rooted from
, as follows:
(6)
(6) where
represents the collection of items that are related by a user
through either direct interaction (i.e. rated items) or meta-paths (i.e. induced indirect items).
is the context aggregation function, with
as the parameter.
is a d-dimensional dense vector, mainly used to embed multiple features of the users.
is the feature embedding matrix.
represents the activation function which is defined as follows:
(7)
(7) where
is a fixed parameter in the interval of
.
Using an embedding of user
as well as an embedding
of item
in the prediction of preferences, to learn better initial embedding to adapt to new users,
and
are relearned by building two multi-layers fully connected neural networks, which is defined as Equation (8)
(8)
(8) where
represents the fully connected layer, which will be used as the generator of semantic embedding and item embedding;
and
represent the full-connection layer parameters of learning semantic embedding and item embedding, respectively, which will be optimised by meta-leaning.
The preference prediction function predicts user ’s rating on item
, which is defined as follows:
(9)
(9) where
is implemented by a multi-layer perceptron parametrised by
and
stands for the concatenation of the two real-valued vectors.
Finally, we denote the recommendation model by the below equation
(10)
(10) where
.
3.3.2. Co-adaptation meta-learner
The objective of a co-adaptive meta-learner is to learn global prior so that it can swiftly adjust to a new task with only sparse interactions. The co-adaptation meta-learner includes semantic-based adaptation and task-based adaptation procedures, which will be described as follows.
3.3.2.1. Semantic-based adaptation
Using of task
, the semantic adaptor evaluates the loss based on the semantic context caused by a particular meta-path
, and uses a gradient descent step to get global context prior
w.r.t a specific
. It not only encodes how to use contextual semantics in a heterogeneous information network, but also adapts to the semantic space induced by meta-path
.
In general, given task of a particular user
, the support set
is enhanced by the semantic context
. Then given
, the semantic embedding
in the semantic space of
can be calculated by the below equation
(11)
(11)
Then the loss of the rated item in task
is further calculated by the below equation
(12)
(12) which
represent meta-path
induced semantic space used for
on the item
predicted rating. Finally, to get the semantic prior of various aspects
, the loss of task
in each semantic space can be calculated after gradient descent follows the below equation
(13)
(13) where
is the adapted model parameter when given a user
and semantic context
, and
represents the semantic learning rate. The adaptation is achieved by a single-step gradient descent based on the gradient of the supervised loss computed on a support set (defined in Equation (12)) w.r.t the semantic-enhanced user representation
while freezing the gradient to
.
3.3.2.2. Task-based adaptation
Based on the that we got before, task-based adaptation further adapts the global prior
to the task
through multiple gradient descent, the prior parameter
of the rating prediction function
is also adapted by using given a user and semantic context in a similar way.
First, on the support set is updated through Equation (10)
(14)
(14) next, we convert the global priors
into the same space which follows the below equation
(15)
(15) where
is the product of elements,
can be regarded as a transformation function realised by several full-connection layer networks. Then the
is adapted to task
using gradient descent which follows the below equation
(16)
(16)
Finally, the main optimisation is achieved by the gradient descent of the sum of the task-specific loss over the users’ query sets.
3.4. Memory-augmented meta-learning
Referring to the single-initialisation problem in Dong et al.’s work (Citation2020), this paper introduced sentiment-specific Memory. That is, by semantic embedding memory and profile memory
, the personality parameter
is effectively initialised. The information that profile memory
associated with profile
to provide the retrieval attention value
.
is used to extract key information from
, where each row of
holds the corresponding. These matrices of memory will aid with in construction of a customised bias term
when initialising
, that is,
.
is a hyper-parameter that controls the degree of personalisation when initialising
, which is the set of
and
.
Specifically, given the semantic profile , which is the set of
. Semantics are a two-dimensional vector representation, the first dimension of semantic vectors for different users is not necessarily consistent, therefore, consider the profile memory is represented by a three-dimensional vector, that is,
, where
is the common dimension of the first dimension of different semantic vectors.
Then calculate semantic attention value . Firstly, the semantic profile vector is extended to the same dimensional space as
, that is, Equation (17)
(17)
(17)
Cosine similarity is used to calculate the degree of correlation between and
which follows the below equation
(18)
(18)
Finally, the semantic attention value can be obtained by the normalisation of SoftMax function.
Semantic embedding memory saves any of the rapid gradients which have the same shape as parameters that belong to semantic embedding model,
represents the dimension of parameters that belong to
. Then get a personalised bias term
, through the below equation
(19)
(19)
During the initialisation phase, the two memories are randomly initialised and updated during the training process. will be updated with the following equation
(20)
(20) where
is a hyper-parameter that controls how much new profile information is added. Similarly,
will also be updated with the following equation
(21)
(21) where
represents the loss of training task,
and
are hyper-parameters that regulate what more new data are kept.
3.5. Optimisation
Optimise the global prior across different semantic tasks is the purpose of co-adaptation meta-learner, which will be optimised by the back propagation of the loss of query set for the meta-training task
as follows:
(22)
(22)
There is no direct update the global prior with the data of
, memory
and
will be updated by formulas (20) and (21), semantic prior
and task prior
will be updated by formulas (13) and (16). In addition, semantic embedding prior and item prior will also be updated through the following equation
(23)
(23) where
is a hyper-parameter, and
represents the recommendation model.
4. Experiments
In this section, the performance of MAMP is verified by detailed experiments: through recommendation system commonly used three evaluation indicators, the model of this paper compared with the previous models.
4.1. Data sets
4.1.1. Data sets
This paper mainly conducts experiments and evaluations on two widely used standard data sets, DBook and MovieLens-1M, which contain both user information and item information from open-source data sets. MovieLens has about 1 million ratings, with over 3000 movies rated by about 6000 users, including attributes such as gender, age, occupation, zip-code and movies including attributes such as genre, with ratings ranging from 1 to 5. In addition, DBook contains about 650,000 ratings and 20,000 books are rated by about 10,000 users. Users include address attributes, and books contain information such as the year, the author, the publisher, with ratings ranging from 1 to 5. Unlike previous efforts (Lee et al., Citation2019; Lu et al., Citation2020) to add extra information for MovieLens, such as adding information about the director and actors for the movie, here we use a native data set, Table outlines some essential statistics for the two data sets.
Table 1. Essential statistics of the data sets. The underlined edge type is the recommended target item type.
4.1.2. Data preprocessing
For each data set, we divided users and items into two groups: existing and new, roughly based on user joining time (or first user operation time) and item release time. In particular, for DBook, since there is no time information of users, we randomly select 80% of users as existing users and the other 20% as new users according to Lu et al.’s work (2020). In addition, each data set is divided into meta-training and meta-testing. (1) Meta-training only contains the ratings of existing items by existing users, of which 10% that the verification set choose at random, and the corresponding task is to recommend existing items for existing users, that is, warm scenario. (2) The remaining is spent on meta-testing, which is broken into three parts to correspond to three different cold-start scenario. (CW) The corresponding task is to recommend existing items for new users; (WC) the corresponding task is to recommend new items for existing users; (CC) the corresponding task is to recommend the new item to the new user.
Rated in order to construct the sets of and
, we follow the previous work (Lee et al., Citation2019). Specifically, the users in the task should include the number of rated items between 13 and 100, that is, Equation (5). The items that a user has rated, will be randomly selected 10 items as
, and the rest of the items as
. In addition, to construct the sets of
and
, we consider any meta-paths
, beginning with user–item and concluding with items up to 2 in length.
4.2. Evaluation metrics
This paper mainly verifies the model performance under three evaluation indexes. The mean squared error (MAE) and root mean squared error (RMSE) and normalised discounted cumulative gain (NDCG)
(23)
(23)
(24)
(24)
(25)
(25)
(26)
(26)
MAE and RMSE are utilised to indicate the error between the predicted and actual values, with lower value indicates better performance of the model. N is the number of predictions for each user in the query set. NDCG@N accounts for the observed predictions sorting performance of the query set, with higher values indicating better performance of the model.
4.3. Comparison
4.3.1. Model comparison
To compare performance with MAMP, we select various representative advanced technologies. Among them, there is the traditional feature-based method, namely FM; and there are also HIN-based methods HEREC, MetaHIN; the rest are cold-start based methods, namely, MeLU, MAMO and MetaHIN.
FM (Rendle et al., Citation2011): a feature-based model that makes use of a variety of auxiliary information. FM can be used to solve the classification problem (to predict the probability of each rating) and can be used to solve the regression problem (to predict the size of each rating).
HEREC (Shi et al., Citation2018): a heterogeneous information network embedding method was proposed, which combined embeddings and matrix decomposition (MF) model to optimise the recommendation effect.
MeLU (Lee et al., Citation2019): a typical approach to applying meta-learning to cold-start recommendations. Rating predictions are obtained by providing user and item embedding links into a fully connected network, and MAML method is used to update the parameters locally and globally.
MAMO (Dong et al., Citation2020): the authors designed two memory matrices, which offer a customised bias item while initialising parameters of the model and assist the model to quickly predict user preferences.
MetaHIN (Lu et al., Citation2020): a method based on the thorough capture of HIN-based semantics allows learner to readily adapt to basic knowledge of multidimensional semantics in a meta-learning, combining meta-learning model at the model level with a heterogeneous information network at the data level.
4.3.2. Comparison results
4.3.2.1. Cold-start scenario
The performance indexes of various models under the three cold-start schemes are listed in detail in Table and Figure provides a more intuitive comparison. Overall, our meta-learning model has achieved relatively ideal performance in all indicators of the two data sets. For example, on the MovieLens-1M data set, our meta-learning model improved 1.65%, 2.48%, and 1.12% on nDCG@5, respectively, compared to the best model. Generally speaking, the performance of traditional methods such as FM is poor, mainly because it is difficult for traditional methods to deal with the high-order graph structure such as meta-path and fail to integrate richer semantic features. In contrast to traditional methods, HIN-based methods such as HEREC performs better because they include meta-paths and incorporate richer semantic features. However, the problem of sparse data interaction exists on various scenarios of cold-start. In the case of insufficient training data, these models cannot further improve their performance. Furthermore, MeLU, MAMO and MetaHIN using meta-learning can effectively deal with the problem of sparse data interaction. MeLU only integrates heterogeneous information into content characteristics, while MetaHIN captures multifaceted semantics from higher-order structures and performs co-adaptation of semantics and tasks, so MetaHIN outperforms MeLU in most performance metrics. In addition, MAMO relies on personalised bias terms to enhance the generalisation ability of meta-learning and alleviate the disadvantage of being unable to capture deeper semantic data to a certain extent. However, these meta-learning methods based on MAML variants are still lower than our model, mainly because the training set is prone to confrontation data, and the problem of gradient degradation often occurs when dealing with users with different gradient descent directions, and the poor robustness leads the model to enter the local optimal state. MAMP not only performs semantic and task co-adaptation, but also effectively improves the robustness of the model by designing a semantically specific memory that provides a personalised bias item when initialising model parameters.
Figure 3. Performance comparison of the six models under four recommendation scenarios.
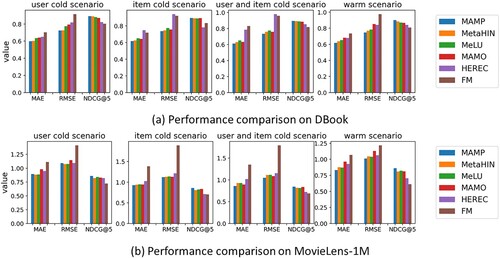
Table 2. The performance of various representative models and MAMP in various recommendation scenarios.
4.3.2.2. Warm scenario
In the W–W section of Table , we also examine traditional recommendation scenarios. Statistically, the MAMP model is still ahead of other models in terms of performance. This is mainly due to the sparse samples and interactive data sparsity will still exist in a traditional recommendation scenario. MetaHIN and other meta-learning models need to be updated by combining the gradient results of the loss generated on the inner task of the test set of each task, so each iteration is targeted at a batch of data. MAMP, on the other hand, provides a personalised offset entry through semantic memory, which only updates a set of input parameters, effectively achieving fast adaptation.
4.4. Model analysis
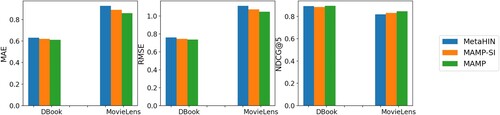
To show the severity of the single-initialisation problem and the advantage of the proposed memory-based technique, we conducted ablation studies. Intuitively, we consider MAMP without memory-based initialisation as a trivial baseline, which is called MAMP-SI. We just present the performance in CC, which is the most difficult scenario, because the various cold-start scenarios showed similar results.
The performances of MetaHIN, MAMP-SI and MAMP in all data sets are readily seen in Figure . First, the performance of MAMP-SI is better than MetaHIN, which is mainly due to the better adaptability of meta-embedding to new tasks; second, due to the single-initialisation problem, the performance of MAMP-SI is worse than MAMP, which also proves the advantages of the proposed memory-based technology.
Figure 4. Performance comparison of the three models under user–item cold-start scenarios.
4.5. Parameter analysis
MAMP has two memories, including profile memory and semantic embedding memory
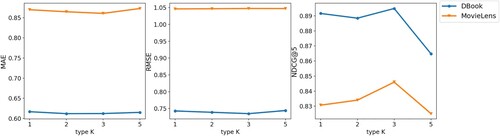
, whose function is used to generate customised bias terms when initializing local parameters. During the construction of semantic memory, we predefined K user types and built a three-dimensional common semantic embedding. For predefined user types, the effect of appropriate values of K values on model performance is investigated, and for the Semantic Common Embedding, we discuss the impact of the specific value of the second dimension on the model performance. For a clearer display effect, we only show the results in the C–C scenario, as shown in Figures and .
Figure 5. Impact of memory embedding dimensions.
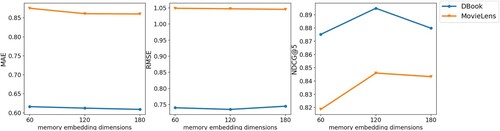
Figure 6. Impact of type K.
4.6. Limitations and future work
Data sparsity is a natural problem in cold-start recommendation, so auxiliary data are critical to solving the cold-start problem. However, in practice, auxiliary information is not always able to be imported successfully, in which case, data enhancement becomes an alternative. In this work, we use the fusion of multiple meta-paths in heterogeneous information network to enhance data, and some results have been obtained. However, we preliminarily find that meta-paths may not be the best way to describe rich semantics, because the construction of meta-path is cumbersome. In future work, we will use meta-graph (Zhao et al., Citation2017) to replace meta-path. Compared with meta-path, which requires continuous structure, meta-graph only requires one starting node and one ending node, and the intermediate structure is not restricted. But how to calculate the similarity of the meta-graph and how to integrate the meta-graph into meta-learning can be an interesting challenge. In addition, data fusion (Liang, Xiao, et al., Citation2021) is also a direction worth considering.
5. Conclusion
In this article, we propose MAMP, a new meta-learning recommendation method, for fast adaptation cold-start recommendation. Specifically, we use the idea of meta-optimisation to learn embedding to better fit the recommendation model and new tasks. In addition, a semantic-specific memory is proposed to assist the co-adaptation meta-learner, which generates a personalised bias term through the history record to greatly improve the performance index of the co-adaptation meta-learner. Experiments on DBook and MovieLens data sets show that our meta-learning method has significant advantages in terms of effectiveness and performance in various scenarios.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data sets of this paper is available at https://book.douban.com and https://grouplens.org/datasets/movielens/.
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
References
- Chang, F., Ge, L., Li, S., Wu, K., & Wang, Y. (2021). Self-adaptive spatial-temporal network based on heterogeneous data for air quality prediction. Connection Science, 33(3), 427–446. https://doi.org/10.1080/09540091.2020.1841095
- Chen, F., Luo, M., Dong, Z., Li, Z., & He, X. (2018). Federated meta-learning with fast convergence and efficient communication. arXiv preprint arXiv:1802.07876.
- Chen, X., Xu, H., Zhang, Y., Tang, J., Cao, Y., Qin, Z., & Zha, H. (2018, February 5–9). Sequential recommendation with user memory networks. The 11th ACM International Conference on Web Search and Data Mining, Los Angeles, CA, pp.108–116.
- Dacrema, M. F., Cremonesi, P., & Jannach, D. (2019, September 16–20). Are we really making much progress? A worrying analysis of recent neural recommendation approaches. The 13th ACM Conference on Recommendaer Systems, Copenhagen, Denmark, pp.101–109.
- D'Angelo, G., Palmieri, F., Robustelli, A., & Castiglione, A. (2021). Effective classification of android malware families through dynamic features and neural networks. Connection Science, 33(3), 786–801. https://doi.org/10.1080/09540091.2021.1889977.
- Dong, M., Yuan, F., Yao, L., Xu, X., & Zhu, L. (2020, August 23–27). MAMO: Memory-augmented meta-optimization for cold-start recommendation. The 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, California, USA, pp. 688–697.
- Finn, C., Abbeel, P., & Levine, S. (2017, July 6–11). Model-agnostic meta-learning for fast adaptation of deep networks. International Conference on Machine Learning (ICML), Sydney, NSW, pp. 1126–1135.
- Graves, A., Wayne, G., & Danihelka, I. (2014). Neural turing machines. arXiv preprint arXiv:1410.5401.
- Hospedales, T., Antoniou, A., Micaelli, P., & Storkey, A. (2020). Meta-learning in neural networks: A survey. arXiv preprint arXiv:2004.05439.
- Hu, H., Gu, J., Zhang, Z., Dai, J., & Wei, Y. (2018, June 18–23). Relation networks for object detection. The IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, USA, pp. 3588–3597.
- Jiang, Y., Liang, W., Tang, J., Zhou, H., Li, K. C., & Gaudiot, J. L. (2021). A novel data representation framework based on nonnegative manifold regularisation. Connection Science, 33(2), 136–152. https://doi.org/10.1080/09540091.2020.1772722
- Kumar, R., Bala, P. K., & Mukherjee, S. (2020). A new neighbourhood formation approach for solving cold-start user problem in collaborative filtering. International Journal of Applied Management Science, 12(2), 118–141. https://doi.org/10.1504/IJAMS.2020.106734
- Lee, H., Im, J., Jang, S., Cho, H., & Chung, S. (2019, July 4–8). MeLU: Meta-learned user preference estimator for cold-start recommendation. The 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AL, pp. 1073–1082.
- Li, X., & She, J. (2017, August 13–17). Collaborative variational autoencoder for recommender systems. The 23th ACM ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, pp. 305–314.
- Lian, S., & Tang, M. (2021). API recommendation for mashup creation based on neural graph collaborative filtering. Connection Science. https://doi.org/10.1080/09540091.2021.1974819.
- Liang, W., Xiao, L., Zhang, K., Tang, M., He, D., & Li, K. C. (2021). Data fusion approach for collaborative anomaly intrusion detection in blockchain-based systems. IEEE Internet of Things Journal. https://doi.org/10.1109/JIOT.2021.3053842
- Liang, W., Xie, S., Zhang, D., Li, X., & Li, K. C. (2020). A mutual security authentication method for RFID-PUF circuit based on deep learning. ACM Transactions on Internet Technology, 22(2), 1–20.
- Lu, Y., Fang, Y., & Shi, C. (2020, August 23–27). Meta-learning on heterogeneous information networks for cold-start recommendation. The 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, California, USA, pp. 1563–1573.
- Munkhdalai, T., & Yu, H. (2017, July 6–11). Meta networks. International Conference on Machine Learning (ICML), Sydney, NSW, pp. 2554–2563.
- Pham, P., & Do, P. (2020). Topic-driven top-k similarity search by applying constrained meta-path based in content-based schema-enriched heterogeneous information network. International Journal of Business Intelligence and Data Mining, 17(3), 349–376. https://doi.org/10.1504/IJBIDM.2020.109295
- Rendle, S., Gantner, Z., Freudenthaler, C., & Schmidt-Thieme, L. (2011, July 24–28). Fast context-aware recommendations with factorization machines. The 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, pp. 635–644.
- Santoro, A., Bartunov, S., Botvinick, M., Wierstra, D., & Lillicrap, T. (2016, June 10–13). Meta-learning with memory-augmented neural networks. International Conference on Machine Learning (ICML), Jeju Island, South Korea, pp. 1842–1850.
- Shi, C., Hu, B., Zhao, W. X., & Yu, P. S. (2018). Heterogeneous information network embedding for recommendation. IEEE Transactions on Knowledge and Data Engineering, 31(2), 357–370. https://doi.org/10.1109/TKDE.2018.2833443
- Shi, C., Li, Y., Zhang, J., Sun, Y., & Yu, P. S. (2016). A survey of heterogeneous information network analysis. IEEE Transactions on Knowledge and Data Engineering, 29(1), 17–37. https://doi.org/10.1109/TKDE.2016.2598561
- Snell, J., Swersky, K., & Zemel, R. S. (2017). Prototypical networks for few-shot learning. arXiv preprint arXiv:1703.05175.
- Sun, Y., Han, J., Yan, X., Yu, P. S., & Wu, T. (2011). Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. Proceedings of the VLDB Endowment, 4(11), 992–1003. https://doi.org/10.14778/3402707.3402736
- Tang, B., Tang, M., Xia, Y., & Hsieh, M. Y. (2021). Composition pattern-aware web service recommendation based on depth factorisation machine. Connection Science, 33(4), 1–21. https://doi.org/10.1080/09540091.2021.1911933.
- Vinyals, O., Blundell, C., Lillicrap, T., & Wierstra, D. (2016). Matching networks for one shot learning. Advances in Neural Information Processing Systems, 29, 3630–3638.
- Wang, X., He, X., Wang, M., Feng, F., & Chua, T. S. (2019, July 21–25). Neural graph collaborative filtering. The 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, pp. 165–174.
- Wang, Y., & Yao, Q. (2019). Few-shot learning: A survey. arXiv preprint arXiv:1904.05046.
- Wei, J., He, J., Chen, K., Zhou, Y., & Tang, Z. (2016, August 8–12). Collaborative filtering and deep learning based hybrid recommendation for cold start problem. 2016 IEEE 14th Intl Conf on Dependable, Autonomic and Secure Computing, 14th Intl Conf on Pervasive Intelligence and Computing, 2nd Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Auckland, New Zealand, pp. 874–877.
- Weston, J., Chopra, S., & Bordes, A. (2014). Memory networks. arXiv preprint arXiv:1410.3916.
- Xu, J., Xiao, L., Li, Y., Huang, M., Zhuang, Z., Weng, T. H., & Liang, W. (2021). NFMF: Neural fusion matrix factorisation for QoS prediction in service selection. Connection Science, 33(3), 1–16. https://doi.org/10.1080/09540091.2021.1889975.
- Zhang, Y., Yin, G., & Chen, D. (2019). A dynamic cold-start recommendation method based on incremental graph pattern matching. International Journal of Computational Science and Engineering, 18(1), 89–100. https://doi.org/10.1504/IJCSE.2019.096948
- Zhao, H., Yao, Q., Li, J., Song, Y., & Lee, D. L. (2017, August 13–17). Meta-graph based recommendation fusion over heterogeneous information networks. The 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , Halifax, NS, pp. 635–644.
- Zhao, L., Wang, Y., Dong, D., & Tian, H. (2019). Learning to recommend via meta parameter partition. arXiv preprint arXiv:1912.04108.
- Zhu, Y., Lin, J., He, S., Wang, B., Guan, Z., Liu, H., & Cai, D. (2019). Addressing the item cold-start problem by attribute-driven active learning. IEEE Transactions on Knowledge and Data Engineering, 32(4), 631–644. https://doi.org/10.1109/TKDE.2019.2891530