
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Differential evolution (DE), as an extremely powerful evolutionary algorithm, has recently been widely employed within complex reality optimisation problems. However, the DE algorithm mainly focuses on strengthening the adaptability of exploitation, which allows the sensitivity of the DE algorithm to be solved in cases where the effects of solving various types of problems are quite different. Moreover, the local search ability and population diversity have not been solved properly. Therefore, an adaptive DE algorithm using fitness distance correlation and a neighbourhood-based strategy (FNADE) is proposed. FNADE introduces the fitness distance correlation (FDC) as the basis for judging the difficulty of the problem, utilises a Voronoi diagram to increase the population diversity for complex multimodal problems and adopts the neighbourhood-based mutation strategy to strengthen the local search capability. FNADE is committed to solving unconstrained single-objective optimisation problems. The proposed algorithm is compared with six advanced DE algorithms in terms of CEC2017 benchmark functions. The experimental results show that the adaptive DE algorithm using FNADE is superior to other DE algorithms with regard to the accuracy and population diversity of the solution.
1. Introduction
Evolutionary algorithms (EAs) are global optimisation methods that simulate the process of biological evolution (Jiang et al., Citation2018). EAs work on the set of populations which are also called natural heuristic algorithms. Since EAs do not rely on the mathematical properties and are easy to be implemented (Wang et al., Citation2019), EAs are widely used. Many improved evolutionary algorithms have become promising methods to solve complex optimisation problems (Liu et al., Citation2018). Differential evolution algorithm (DE) is an evolutionary algorithm that was first proposed by Storn and Price (Citation1997). Their excellent performance attracted the attention of a large number of scholars at the first IEEE International Conference on Evolutionary Computation (CEC). The improved version of the DE algorithm became known as one of the top four algorithms in the CEC competition since 2005 (Pant et al., Citation2020). It is also applied to optimise problems in clustering (Nayak et al., Citation2019b), feature selection (Hancer, Citation2019; Nayak et al., Citation2019a), large-scale global optimisation (Liu et al., Citation2020a), electrical engineering (Dos Santos Coelho et al., Citation2013), network planning (Liu et al., Citation2014) and other fields.
With the rapid development of information science, the increasing complexity of optimisation problems has created considerable challenges to DE algorithm, which has been developed in many aspects by many scholars. Montgomery and Chen (Citation2010) analysed how the adaptive parameters affect the performance of the DE algorithm. Liu and Lampinen (Citation2005) introduced the fuzzy adaptive differential evolution algorithm (FADE), which employs fuzzy logic controllers to adapt the search parameters of mutation and crossover operations. Tanabe and Fukunaga (Citation2013) employed a historical record of control parameters on successful individuals to guide the future selective control parameter values. Liu et al. (Citation2010) proposed an improved MOEA/D algorithm. This algorithm using a monotonic increasing function to transform each individual objective function into the shape to find the uniformly distributed solutions. Zhao et al. (Citation2016) presented a differential evolution algorithm with a self-adaptive strategy and control parameters (SLADE). The experimental vector generation strategy from the strategy candidate database could adaptively match different stages according to the previous successful experience of each individual target. Liu et al. (Citation2009) proposed the MSEA algorithm by the maximum value of the weighted normalised objectives using a min–max strategy. This algorithm overcomes the shortcoming of algorithms using the weighted sum of the objectives. Guo et al. (Citation2014) proposed an enhanced self-adaptive differential evolution algorithm (ESADE) as an initial control parameter of the next generation. Although these algorithms perform adaptive control on the parameters of DE, they ignore the relationship between individuals. In this paper, the neighbourhood-based mutation strategy and Voronoi diversity strategy are adopted to remedy this deficiency.
Furthermore, evolutionary algorithms have been improved by some scholars in terms of population diversity (Liu et al., Citation2019; Wang et al., Citation2021b), cooperative coevolution (Wang et al., Citation2018), filled function method (Lin et al., Citation2018) and local search (Xue & Wang, Citation2015). Montgomery and Chen (Citation2012) compared each new solution to the member of the population to which it is most likely to be closest. Zhan et al. (Citation2019) proposed an adaptive distributed differential evolution algorithm (ADDE). In ADDE, different populations select their mutation strategies adaptively and estimate the evolutionary state accordingly. Their proposed algorithm made full use of the feedback information from the individuals and corresponding populations. Shen and Zhu (Citation2019) drew on the best individuals in the neighbourhood to maintain a balance between development and exploration. Zhao and Cai (Citation2018) presented an intelligent parents selection strategy to improve the efficiency of the DE algorithm in solving complex problems. Choudhary et al. (Citation2016) proposed a novel differential evolution algorithm using stochastic mutation (DESMU) to enhance the exploitation capability by incorporating inspiration from Levy flight random walks with the DE algorithm. Qin et al. (Citation2008) employed trial vector generation strategies to adapt different phases of strategies and parameters and created a differential evolution algorithm with strategy adaptation (SaDE). Mohamed and Suganthan (Citation2018) introduced a triangular mutation operator to strengthen the balance between global exploration capabilities and local development trends and improve the convergence speed of the algorithm. Mohamed and Mohamed (Citation2019a) proposed the DE/current-to-grbest/1 mutation strategy. The scheme adapts to the two most important control parameters to improve its performance. Cui et al. (Citation2018) used different trial vector generation strategies for each individual at the same time and generated two candidate solutions accordingly. Then, the best one is used to enter the next generation to deal with stagnation and premature convergence. Wu et al. (Citation2018) divided the population into four subpopulations, and each DE variant had an indicator subgroup. After each iteration, the most promising DE variants are determined and additional rewards are given. In this way, the most efficient DE variant obtains the most computing resources in the evolution process. Hadi et al. (Citation2021) proposed the ELSHADE-SPACMA algorithm by controlling the greedy degree of the mutation strategy in LSHADE-SPACMA, which further enhanced its performance. ElQuliti and Mohamed (Citation2016) introduced a new search mutation, a new binary mutation rule, an adaptive crossover rate, and a random scale factor to enhance the balance of the algorithm and efficiently solve constrained optimisation problems. Based on the convex combination vector of the triangle and the difference vector between the best and worst individuals, Mohamed (Citation2017) proposed a new triangle mutation method, which effectively improved the effect of the mutation. Hadi et al. (Citation2019) emphasised the concept of dividing and conquering, dividing the dimensions of the problem into groups, and each group is solved separately, which greatly reduces the complexity of large-scale optimisation problems. Mohamed et al. (Citation2019b) used the information of good individuals and bad individuals in the population to propose a mutation method that can effectively maintain the balance between exploration and exploitation. Zhao et al. (Citation2021) combined DE with the invasive weed algorithm to improve population diversity and enhance the exploration ability in the iterative process.The above-mentioned DE variants contribute to the development of DE in many ways, but the evolutionary state has not been accurately judged. In view of this shortcoming, evolution is divided into three cases by fitness distance correlation in this paper, and different strategies are adopted in different cases.
To date, the DE variants developed by some scholars have achieved excellent performance. However, there are still some shortcomings to DE, such as its lack of accuracy in judging the evolution state and the higher sensitivity to the type of problem. In addition, it is difficult to choose the appropriate strategy within different optimisation problems. For example, the current variants for the problem of data clustering exist the shortcoming of premature convergence due to their inaccurate diversity control methods (Xiang et al., Citation2015). Moreover, differential evolution variants that can be used for data clustering are difficult to employ to train other models such as fuzzy neural networks (Hou et al., Citation2018). Therefore, the above shortcomings need to be solved urgently, and the combination of strategies based on the problem in the differential evolution algorithm is a channel that can be tried. In this paper, an adaptive differential evolution algorithm using fitness distance correlation and a neighbourhood-based strategy is proposed. FNADE employs the fitness distance correlation to judge the difficulty of the problem and uses Voronoi technology to adaptively increase the population diversity on account of the problem difficulty. In addition, the improved population initialisation method and the neighbourhood-based strategy are developed to enhance the convergence performance and local search ability. The main contributions of this paper are summarised as follows:
Improved the opposition-based learning population initialisation method to make the population more dispersed.
Used fitness distance correlation as the basis for strategy selection to effectively improve the convergence speed of the algorithm.
Improved the neighbourhood-based mutation strategy to improve the accuracy of the solution.
Designed the Voronoi diversity strategy to maintain the diversity of the population.
The organisational structure of the rest of this paper is as follows: Section 2 introduces the related work, including the basic DE, fitness distance correlation, neighbourhood-based mutation strategy and Voronoi. Section 3 describes the innovation of this paper and the process of the FNADE algorithm in detail. Section 4 focuses on comparing the analysis results between the proposed algorithm and other advanced algorithms. Section 5 summarises this paper and points out further research directions.
2. Relevant work
2.1. Basic DE
DE algorithm begins to initialising a population, where the NP refers to the population size and D represents the problem dimension. Then the fitness sequence
can be obtained by fitness of function f while the next population is generated by differential mutation, crossover and selection which are described extensively in the following.
Mutation
The Gth generation individuals
are transformed into
Crossover
Target vector
Selection
After performing the mutation and crossover, the next generation individuals are selected between the target vector X and the trial vector U by the greedy method.
2.2. Initialisation
The population of evolutionary algorithms is uniformly distributed, however, some scholars have mentioned that improving the initialisation process can be conducive to improving the performance of the algorithm (Liu et al., Citation2020b). Li et al. (Citation2020) divided the initial population into several subpopulations. They used the average learning strategy based on dynamic segmentation to construct learning samples, leading to information sharing and coevolution among the populations. Wang et al. (Citation2021a) employed a mixed-variable encoding scheme to initialise two types of populations for continuous variables and discrete variables. Pant et al. (Citation2009) pointed out that a good initialisation scheme not only helps to obtain a better final solution but also improves the convergence rate of the algorithm, as well as proposing an initialisation scheme to generate the initial population by using quadratic interpolation. Rahnamayan et al. (Citation2008) used an opposition-based learning (OBL) strategy to initialise the population and generate jumping, while proposing the opposition-based DE algorithm (ODE). The population initialisation based on the OBL method (Rahnamayan et al., Citation2008) is as shown in Equation (Equation8(8)
(8) ).
(8)
(8)
where
and
is the lower limit of the dimension,
is the upper limit.
Each individual of population X is executed in Equation (Equation8(8)
(8) ) to obtain an opposite population
, and then the fitness values of the two populations are calculated. Finally, the first NP individuals with the best fitness values are selected from
to form the initial population. After executing all the individuals of population X in Equation (Equation8
(8)
(8) ), an opposite population
would be elaborated and then the fitness of the two populations can be evaluated accordingly. Finally, the first NP individuals with the best fitness are selected from
to form the initial population.
2.3. Neighbourhood-based mutation strategy
The classical DE algorithm uses three random individuals to participate in mutation; however, some scholars realise that the search ability of the algorithm can be enhanced by the population topology operation. Tian and Gao (Citation2019) presented a novel differential evolution algorithm for numerical optimisation by designing the neighbourhood-based mutation strategy. Kennedy and Mendes (Citation2006) tried to change the method of interaction between individuals and their neighbours in the paper swarm optimisation algorithm. They found that the paper swarm optimisation algorithm with good topology is more effective than the basic version. Das et al. (Citation2009), inspired by the PSO algorithm, proposed a DE/target-to-best/1/bin mutation strategy based on the neighbourhood concept, which could balance the exploration and development capabilities of DE. Sun and Cai (Citation2017) proposed a novel neighbourhood-dependent mutation operator for the DE algorithm (NDE). A population topology pool was employed to define multiple neighbourhood relations for each individual in the NDE (Sun & Cai, Citation2017) algorithm, and the neighbourhood relations of the function of the required solution were adaptively selected in the evolution process. According to the different connectivity between individuals in the population, the NDE (Sun & Cai, Citation2017) algorithm selects four common population topologies.
Small world – There is a ring composed of NP vertices in the small world topology where each vertex is connected to its Kth neighbour vertices. Each edge is reconnected to a randomly and evenly selected vertex on the whole ring with a probability p, where
Cellular – Neighbourhoods are arranged in a ring grid in the cellular topology where the individuals only interact with their neighbours in a breeding loop.
Ring – The individuals in the population are organised into a ring, and the neighbourhood is defined in this way, that is, each individual only interacts with the next and previous individuals within the radius of its neighbourhood in the ring.
Random – Random graph topology, in which each individual randomly chooses its Kth neighbour vertices to be selected completely where all the neighbour's vertices have equal probability.
Individual ranking, topology selection, neighbourhood definition and parent selection are four steps in the neighbourhood-dependent mutation operator.
Individual ranking – All individuals are ranked on the basis of the fitness of each generation.
Topology selection – The population topology selection for the ith individual is as shown in Equation (Equation9
Neighbourhood definition – Based on the selected population topology, the ith individual can form its neighbourhood. In the evolution process, individual i will only interact with individuals in its neighbourhood.
Parent selection – Individual r1 is randomly selected from the neighbourhood of the current individual; then, the individuals in the neighbourhood are divided into a good group and a worst group based on r1. Finally, two individuals from both groups were selected randomly to participate in the mutation.
2.4. Fitness distance correlation
Some scholars have attempted to solve problems by drawing on the characteristics of environmental change. Jones and Forrest (Citation1995) introduced a method to measure the search difficulty, namely fitness distance correlation, and studied the prediction ability of the FDC on the performance of the genetic algorithm (GA). The research concluded that the FDC can be used to predict the performance of GA on a large number of problems in terms of known global maxima. Tomassini et al. (Citation2005) employed the FDC as an index of problem difficulty, as well as what was achieved by some achievements. The ruggedness of landscapes was analysed by Huang et al. (Citation2020) to estimate whether the local landscape presents a unimodal or multimodal topology. The optimal probability distribution of the search strategy set was determined by a combination of the outcomes with a reinforcement learning strategy. Li et al. (Citation2019) proposed a self-feedback differential evolution algorithm to select the optimal mutation strategy by extracting the local fitness landscape characteristics of each generation population. They combined unimodal and multimodal probability distributions in each local fitness landscape. Li et al. (Citation2021) quantitatively analysed the fitness distance correlation information, and consequently, the difficulty of the problem in terms of the search space for obtaining the classification of the correlation degree was evaluated.
Assume that is the fitness of the population, whose population size is n, and
is a set of distances between the individuals of the population and the globally optimal individuals. The FDC of the
generation can be evaluated as follows.
Generally, the genetic algorithm (maximisation problems) can be divided into three categories on the basis of the FDC (Jones & Forrest, Citation1995).
(10)
(10)
(11)
(11)
Misreading
Difficulty
Straight forward
2.5. Parameter adaptive
The main parameters of the DE algorithm are the population size NP, crossover rate CR and scaling factor F. Many investigations have been performed by other scholars to find the best setting method of these parameters. Wang et al. (Citation2011) proposed a new method to combine several kinds of effective trial vector generation strategies with appropriate control parameter settings. Brest et al. (Citation2006) proposed an effective parameter adaptation method and combined it with the DE algorithm (jDE).They applied it in six practical applications that obtained good performances. Zhang and Sanderson (Citation2009) proposed a new differential evolution algorithm (JADE) to adapt and update the control parameters into appropriate values automatically, which avoids the usage of prior knowledge of the relationship between the parameter settings and the characteristics of optimisation problems.
In the gth generation of the JADE algorithm (Zhang & Sanderson, Citation2009), the cross rate and the scaling factor F of each individual
are generated by
(12)
(12)
(13)
(13)
(14)
(14)
(15)
(15)
(16)
(16)
(17)
(17)
where C is a normal number between 0 and 1, meanA is the commonly used arithmetic mean, meanL is the Lehmer average value, and
and
are the sets of F and CR of all successful individuals in the gth generation, respectively.
2.6. Voronoi diagram
In a Voronoi diagram, a plane is divided according to the nearest neighbour of points in a given plane. Each point is associated with the plane region that is closest to the point (Aurenhammer, Citation1991). Figure shows schematic details of the Voronoi diagram (Song et al., Citation2013). In Figure , the initial data are the coordinates of the blue point, all edges do not coincide with any point, and each point is surrounded by edges, so the edges constitute a Voronoi diagram.
Figure 1. Voronoi schematic diagram.
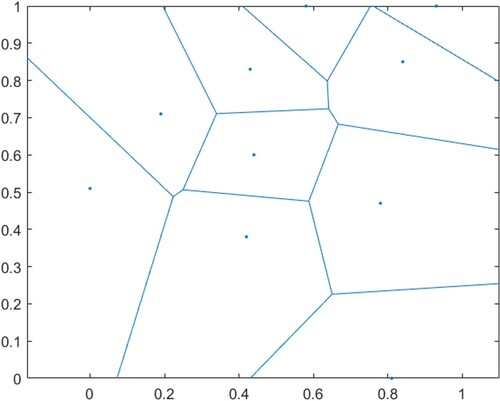
A Voronoi diagram consists of a set of continuous polygons composed of vertical bisectors connecting two adjacent points. In the Voronoi diagram, there is a generator in each polygon and the distance from the interior point to the generator is shorter than the distance to other generators. The distance from the point on the polygon boundary to the generator generating this boundary is equal. Where there is a group of discrete points on the plane region B. if the region B is divided into
adjacent polygons by a group of straight-line segments, then:
Each polygon contains and only contains one discrete point.
If any point
If the point
The generated polygon is called a Voronoi diagram. A combination of Voronoi and evolutionary algorithms is not common; however, some scholars have employed this method. Tong et al. (Citation2019) employed a Voronoi diagram to boost the performance of surrogate-assisted evolutionary algorithms. They proposed a framework for the Voronoi-based efficient surrogate assisted evolutionary algorithm (VESAEA).
3. Proposed approach
The FNADE algorithm adaptively adjusts the mutation strategy and changes the population diversity according to the difficulties of the problems. To enhance the local search ability, the improved mutation strategy is implemented at the beginning of the algorithm. The FDC is calculated every 100 generations, and the difficulty of the problem is judged on the basis of the correlation. If the problem is complex and if the effect of the performance of the current population is poor, the Voronoi diversity strategy proposed in this paper can be employed to increase the population diversity. Otherwise, the mutation strategy would be used. In addition, the proposed algorithm adds an initialisation strategy to accelerate the convergence.
3.1. Population initialisation based on OBL
An enhancement in the initialisation rules of the population can effectively improve the convergence rate, as well as the accuracy enhancement of the algorithm to a certain extent. This paper improves the OBL-based initialisation strategy (Rahnamayan et al., Citation2008) to set up a population initialisation operation more suitable within the proposed algorithm.
(18)
(18)
(19)
(19)
where
is the value of the optimal individual in the jth dimension of the original population and
and
represent the lower and upper limits of the jth dimension respectively. Similar to ODE algorithm, the population initialisation based on OBL strategy is applied to the initialisation. The improved population initialisation will further narrow the search area. However, this method cannot improve the overall effect of the population, where it generally makes the effect of the optimal individual of the population better than that of the ODE initialisation method, which is conducive to accelerating the convergence rate of the proposed algorithm.
3.2. NDE/current-to-tbest/1
The NDE algorithm (Sun & Cai, Citation2017) combines several topologies to coordinately promote population evolution. Although it enhances the local search ability of the algorithm, its basic mutation mode is still DE/rand/1, which does not consider the influence of the optimal individual on the convergence rate. This paper enhances the mutation strategy of the NDE algorithm (Sun & Cai, Citation2017) as shown in Equation (Equation20(20)
(20) ).
(20)
(20)
where
is the best individual within the topology of the current mutation individual i. The participation of individuals
and
in the mutation are randomly selected from the topology of individual i. The mutation strategy of the NDE is called
. The improved mutation strategy is called
. The improved mutation strategy further enhances the local search ability on the basis of the original strategy. The improved mutation strategy is implemented after population initialisation based on OBL to replace the original mutation strategy if it meets the conditions of the FDC.
3.3. Voronoi diversity strategy
Voronoi is generally used in path optimisation. We found that this strategy can also be applied to swarm intelligence. The strategy in this paper uses Voronoi to generate multiple individuals to replace overly clustered individuals, thereby enhancing the diversity of the population. As far as we know, this paper applies Voronoi to control the diversity of the population for the first time. This operation is implemented after the FDC of the population is calculated and the threshold condition is met. First, suppose a group of points , according to the requirements set out in Section 2.6. Then, the set of points from the set X within a Voronoi diagram
can be considered. Figure shows a schematic diagram of the Voronoi evaluation. The
in Figure represents the values of the 10 individuals' first dimension, and these values are used as initial data to obtain Voronoi edges. vp1–vp8 are the intersection points of the edges, which are also the points required by the Voronoi diversity strategy. Perform this operation on each dimension to obtain some individuals who can maintain diversity. The calculation method for defining VP is as shown in Equation (Equation21
(21)
(21) ).
(21)
(21)
Figure 2. Schematic diagram of Voronoi calculation.
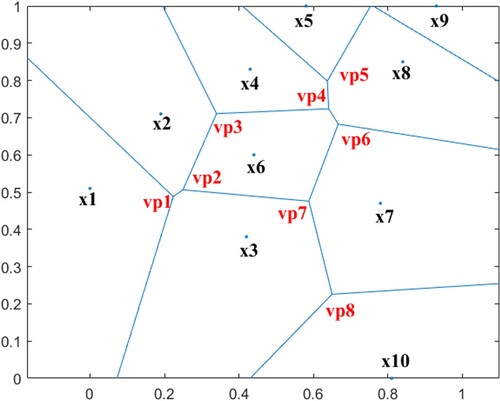
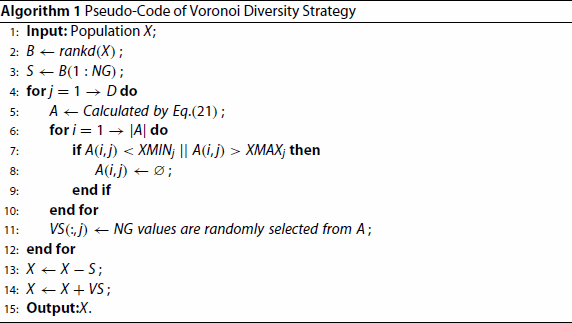
The process of the Voronoi diversity strategy is shown in Algorithm 1. As a brief description, the Voronoi diversity strategy sorts the individuals (line 2) and selects the NG individuals within the worst effect (line 3). Then the process finds the set of Voronoi points, which is composed of the point set of each dimension from these individuals. Later, it selects the NG points from the set of Voronoi points to form a new individual (lines 4–12), which confirms the specifications. Finally, the NG worst individuals of the population are replaced by the new NG individuals (lines 13–14). The Voronoi diversity strategy provides a new idea to enhance diversity. The method not only maintains diversity but also deletes individuals with poor performance in the population and speeds up the convergence rate to a certain extent.
3.4. The process of FNADE
Differential evolution algorithm is an efficient global optimisation algorithm, but its local search ability is slightly inferior to its global search ability. moreover, there is often insufficient diversity in the later stages of the algorithm. The proposed FNADE algorithm introduces FDC as the basis for judging the difficulty and evolution state, utilises Voronoi diversity strategy and population initialisation based on OBL strategy for enhancing the population diversity to improve the global search ability, and adopted neighbourhood-based mutation strategy to enhance the local search ability.
The proposed algorithm considers the FDC as a basis for judging the difficulty of the problem and decides whether to implement the diversity strategy accordingly and then changes the mutation strategy adaptively. The population initialisation and mutation strategies can be enhanced by the proposed algorithm to speed up the convergence rate. To avoid setting the parameters artificially, the parameter of adaptive strategy based on historical success information is adopted by the proposed algorithm. The process of the FNADE algorithm is shown in Algorithm 2.

After inputting the fitness function f, upper bound, lower bound, and
which are used in parameter adaptation (line1), the FNADE executes the improved population initialisation strategy to obtain population X (lines 2–6). Then, CR and F are generated for each individual to be strengthened by the parameter adaptive strategy (lines 9–10); then, the
mutation strategy is implemented to obtain V. The FDC of the population is then calculated every 100 generations (lines 11–12). If the FDC is less than or equal to −0.15, the fitness would be decreased by increasing the diversity. Therefore, the diversity of the population (lines 13–14) is increased by implementing the Voronoi diversity strategy to update X. The FDC within the range of [−0.15,0.15] indicates that the diversity has little relation with the change in fitness. The mutation vector V is obtained by the
strategy (lines 15–16). If the FDC is greater than or equal to 0.15, X would evolve in the right direction where no operation should be done (lines 17–18). Finally, the FNADE algorithm carries out crossover and selects to obtain U and updated X, respectively, and updates
and
(lines 23–25).
4. Experimental study
Three groups of experiments are used to discuss the performance of the proposed algorithms and strategies in this section. In the first group of experiments, FNADE was compared with six advanced DE variants. The second group of experiments discussed the convergence and stability of FNADE. The third group of experiments examined the effects with different strategies.
4.1. Compare with DE variants
To verify the effectiveness of the algorithm proposed in the paper, FNADE is compared with CoDE (Wang et al., Citation2011), SaDE (Qin et al., Citation2008), jDE (Brest et al., Citation2006), ODE (Rahnamayan et al., Citation2008), RNDE (Peng et al., Citation2018) and NBOLDE (Deng et al., Citation2021) on CEC2017 benchmark functions. The CEC2017 benchmark functions consist of 30 functions, of which f1 to f2 are unimodal functions, and the rest are multimodal functions. Among the multimodal functions, f3 to f9 are simple multimodal functions, f10 and f19 are the hybrid functions, and f20 to f30 are composition functions. The population sizes of both the proposed and the comparison algorithms are 100, which generates a maximum evaluation times, where D is the dimension of the problem, while all other parameters of the comparison algorithm are considered the original parameters. The experimental setup is an Intel (R) Core i5-6300HQ CPU @ 2.30 GHz with 8 GB RAM, using Windows 10, and the simulation environment is Matlab 2019b.
To reduce the experimental error, the 7 algorithms are run independently to measure the performance of the algorithm 51 times in the cases of 10, 30, 50 and 100 dimensions, where the optimal value , mean value (mean) and standard deviation value (std) of the results are obtained from running the algorithms 51 times. Tables – list the comparison results in different dimensions between the proposed and comparison algorithms. The best-performing algorithms in Table are in bold format. The results of the Wilcoxon rank sum test (Corder & Foreman, Citation2009) under the significance level set to 0.05 are listed in Table . The sign “+” means that the proposed algorithm is more effective than the comparison algorithm, the sign “−” means that the proposed algorithm is less effective than the comparison algorithm, and the sign “≈” means that the effectiveness of both the proposed and comparison algorithms is equivalent.
Table 1. Comparison of results of CEC2017 benchmark functions with 10 variables.
Table 2. Comparison of results of CEC2017 benchmark functions with 30 variables.
Table 3. Comparison of results of CEC2017 benchmark functions with 50 variables.
Table 4. Comparison of results of CEC2017 benchmark functions with 100 variables.
Table 5. Test results of Wilcoxon rank sum test.
In 10-dimensional problems, the overall effect of FNADE is equivalent to that of RNDE. The mean and variance of the effects of the FNADE algorithm are better than those of other algorithms. In 30-dimensional problems, the variance of the effect of FNADE is reduced to some extent; however, the improvement of the overall effect of FNADE is more than that of the 10-dimensional problem. In 50-dimensional problems, even though the stability of the proposed algorithm compared with other algorithms is further reduced, it achieves higher optimal and mean values. In 100-dimensional problems, FNADE reaches more obvious advantages than other algorithms. In summary, with the increase in dimensions, FNADE shows a trend of increasingly better performance. On the whole, FNADE is not very effective in solving simple and low-dimensional problems, but it achieves high accuracy in solving complex and high-dimensional problems.
Through the above analysis, we realised that the stability of the FNADE algorithm would be declined by increasing the dimensionality of the problems; however, the overall performance of the proposed algorithm is higher than that of the other algorithms. Therefore, we conclude that the FNADE algorithm is faster than the others in solving high-dimensional problems. But in the case of high dimensions, the stability of FNADE is poor, which is its limitation.
4.2. Convergence and stability
To further analyse the convergence of FNADE, this section discusses the convergence curves of the algorithm in different dimensions. The convergence of the seven algorithms in different dimensions is shown in Figures , , , and , accordingly.
Figure 3. Convergence effect of 7 algorithms on CEC2017 benchmark functions with 10 variables.

Figure 4. Convergence effect of 7 algorithms on CEC2017 benchmark functions with 30 variables.

Figure 5. Convergence effect of 7 algorithms on CEC2017 benchmark functions with 50 variables.

Figure 6. Convergence effect of 7 algorithms on CEC2017 benchmark functions with 100 variables.

The FNADE algorithm has achieved fast convergence speed in unimodal functions, multimodal functions, hybrid functions and compositions functions. The convergence effect is better than other algorithms. This algorithm benefits from the use of neighbourhood mutation strategies. However, while FNADE outperforms other algorithms in every dimension, this advantage decreases as dimensionality increases. This is because the Voronoi diversity strategy and the population initialisation based on OBL can prolong the speed of convergence while avoiding premature convergence.
This paper also carries out a statistical analysis on the results of 7 algorithms running within the CEC2017 benchmark functions 51 times to verify the stability of the proposed algorithm. The results are shown in Figure , where the overline of the rectangular box shows the upper quartile of the data, and the underscore line shows the lower quartile; the red line and ‘+’ sign in the rectangle represent the median and the outlier respectively.
Figure 7. Box diagram of 7 algorithms on CEC2017 benchmark functions with 30 variables.
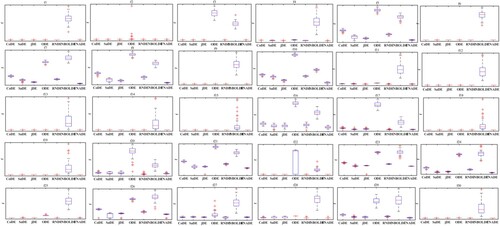
As shown in Figure , the FNADE algorithm leaves abnormal points in f4, f20, f26, and f28, where its stability is slightly poor. The stability of the FNADE algorithm in f4, f11, f20 and f28 is lower than those of the other algorithms. It is worth nothing that the stability effect of the FNADE algorithm in other nonmentioned functions is higher than that of other algorithms. Overall, the FNADE algorithm ranks first in terms of stability.
4.3. Influence of strategies
This paper improved the NDE algorithm by proposing three modifications: (1) population initialisation based on OBL, (2) NDE/current-to-tbest/1 and (3) the Voronoi diversity strategy. In this section, FNADE is divided into three versions in such a parametric analysis.
FNADE-1 uses a random initialisation method to replace the initialisation strategy to test the individual effect of the population initialisation based on OBL on the performance of the FNADE algorithm.
FNADE-2 uses the DE/rand/1 strategy instead of the NDE/current-to-tbest/1 strategy to test the effect of the proposed NDE/current-to-tbest/1 on the performance of the FNADE algorithm.
FNADE-3 does not use the Voronoi diversity strategy to test the individual effect of the Voronoi diversity strategy on the performance of the FNADE algorithm.
The comparison results and statistical results of the three versions and FNADE when the number of dimensions is 30 are shown in Table . Similarly, each version of the algorithm runs 51 times independently on each function in CEC2017.
Table 6. Comparison results and Wilcox test of three versions with FNADE.
Table shows that the three modifications of the FNEADE algorithm are indispensable. FNADE has higher accuracy than FNADE-2 in all functions. This finding shows that NDE/current-to-tbest/1 is the most important contributor to the performance improvement of the algorithm. On the other hand, the population initialisation method based on OBL and the Voronoi diversity strategy are both used to balance the powerful local search capabilities of the NDE/current-to-tbest/1 strategy. Abandoning the NDE/current-to-tbest/1 strategy will lead to the algorithm's failure. The search is more randomised and unbalanced. Compared with FNADE, FNADE-3 is at a disadvantage in seven functions, indicating that the Voronoi diversity strategy effectively enhances the diversity of the population, and its importance to FNADE is inferior to that of the NDE/current-to-tbest/1 strategy. The effect of FNADE-1 on most functions is the same as that of FNADE, but it is undeniable that the effect on three functions is still worse than in the case of FNADE, indicating that the population initialisation method based on OBL further balances the exploration and exploitation of FNADE.
5. Conclusion
To reduce the sensitivity of the DE algorithm to the problems, an adaptive differential evolution algorithm using fitness distance correlation and a neighbourhood-based strategy is proposed. The method judges the difficulty of the problem through the FDC, adaptively controls the population diversity on the basis of the difficulty of the problem and dynamically changes the mutation strategy. In addition, the population initialisation strategy and mutation strategy are enhanced to accelerate the convergence of the algorithm. According to the results of experimental investigations, the proposed algorithm reflects strong competitiveness in terms of accuracy and stability. It is worth mentioning that, as far as we know, this is the first combination of Voronoi and the DE algorithm. The method proposed in this paper proves that Voronoi method is effective for the population. However, the effect of the diversity strategy is not stable enough. This leads to the fact that FNADE cannot always maintain its advantages in convergence and stability. Future work will focus on the neighbourhood-based mutation strategy and the application of Voronoi technology.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Aurenhammer, F. (1991). Voronoi diagrams – A survey of a fundamental geometric data structure. ACM Computing Surveys (CSUR), 23(3), 345–405. https://doi.org/10.1145/116873.116880
- Brest, J., Greiner, S., Boskovic, B., Mernik, M., & Zumer, V. (2006). Self-adapting control parameters in differential evolution: a comparative study on numerical benchmark problems. IEEE Transactions on Evolutionary Computation, 10(6), 646–657. https://doi.org/10.1109/TEVC.2006.872133
- Choudhary, N., Sharma, H., & Sharma, N. (2016). Differential evolution algorithm using stochastic mutation. In Paper presented at the 2016 international conference on computing, communication and automation (ICCCA). IEEE.
- Corder, G. W., & Foreman, D. I. (2009). Nonparametric statistics for non-statisticians (a step-by-step approach) | Nonparametric statistics: an Introduction. pp. 1–11. John Wiley & Sons, Inc.
- Cui, L., Li, G., Zhu, Z., Lin, Q., Wong, K. C., Chen, J., & Lu, J. (2018). Adaptive multiple-elites-guided composite differential evolution algorithm with a shift mechanism. Information Sciences, 422, 122–143. https://doi.org/10.1016/j.ins.2017.09.002
- Das, S., Abraham, A., Chakraborty, U. K., & Konar, A. (2009). Differential evolution using a neighborhood-based mutation operator. IEEE Transactions on Evolutionary Computation, 13(3), 526–553. https://doi.org/10.1109/TEVC.2008.2009457
- Deng, W., Shang, S., Cai, X., Zhao, H., Song, Y., & Xu, J. (2021). An improved differential evolution algorithm and its application in optimization problem. Soft Computing, 25(7), 5277–5298. https://doi.org/10.1007/s00500-020-05527-x
- Dos Santos Coelho, L., Mariani, V. C., Da Luz, M. V. F., & Leite, J. V. (2013). Novel gamma differential evolution approach for multiobjective transformer design optimization. IEEE Transactions on Magnetics, 49(5), 2121–2124. https://doi.org/10.1109/TMAG.2013.2243134
- ElQuliti, S. A. H., & Mohamed, A. W. (2016). A large-scale nonlinear mixed-binary goal programming model to assess candidate locations for solar energy stations: an improved real-binary differential evolution algorithm with a case study. Journal of Computational and Theoretical Nanoscience, 13(11), 7909–7921. https://doi.org/10.1166/jctn.2016.5791
- Guo, H., Li, Y., Li, J., Sun, H., Wang, D., & Chen, X. (2014). Differential evolution improved with self-adaptive control parameters based on simulated annealing. Swarm and Evolutionary Computation, 19, 52–67. https://doi.org/10.1016/j.swevo.2014.07.001
- Hadi, A. A., Mohamed, A. W., & Jambi, K. M. (2019). LSHADE-SPA memetic framework for solving large-scale optimization problems. Complex and Intelligent Systems, 5(1), 25–40. https://doi.org/10.1007/s40747-018-0086-8
- Hadi, A. A., Mohamed, A. W., & Jambi, K. M. (2021). Single-objective real-parameter optimization: enhanced LSHADE-SPACMA algorithm. In Heuristics for optimization and learning (pp. 103–121). Springer.
- Hancer, E. (2019). Fuzzy kernel feature selection with multi-objective differential evolution algorithm. Connection Science, 31(4), 323–341. https://doi.org/10.1080/09540091.2019.1639624
- Hou, Y., Zhao, L., & Lu, H. (2018). Fuzzy neural network optimization and network traffic forecasting based on improved differential evolution. Future Generation Computer Systems, 81, 425–432. https://doi.org/10.1016/j.future.2017.08.041
- Huang, Y., Li, W., Tian, F., & Meng, X. (2020). A fitness landscape ruggedness multiobjective differential evolution algorithm with a reinforcement learning strategy. Applied Soft Computing, 96, 106693. https://doi.org/10.1016/j.asoc.2020.106693
- Jiang, J., Xue, Y., Ma, T., & Chen, Z. (2018). Improved artificial bee colony algorithm with differential evolution for the numerical optimisation problems. International Journal of Computational Science and Engineering, 16(1), 73–84. https://doi.org/10.1504/IJCSE.2018.089584
- Jones, T. C., & Forrest, S. (1995). Fitness distance correlation as a measure of problem difficulty for genetic algorithms. In Paper presented at the Proceedings of the sixth international conference on genetic algorithms. Santa Fe Institute.
- Kennedy, J., & Mendes, R. (2006). Neighborhood topologies in fully informed and best-of-neighborhood paper swarms. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 36(4), 515–519. https://doi.org/10.1109/TSMCC.2006.875410
- Li, W., Li, S., Chen, Z., Zhong, L., & Ouyang, C. (2019). Self-feedback differential evolution adapting to fitness landscape characteristics. Soft Computing, 23(4), 1151–1163. https://doi.org/10.1007/s00500-017-2833-y
- Li, W., Meng, X., Huang, Y., & Fu, Z. (2020). Multipopulation cooperative ppaper swarm optimization with a mixed mutation strategy. Information Sciences, 529, 179–196. https://doi.org/10.1016/j.ins.2020.02.034
- Li, W., Meng, X., & Huang, Y. (2021). Fitness distance correlation and mixed search strategy for differential evolution. Neurocomputing, 458, 514–525. https://doi.org/10.1016/j.neucom.2019.12.141
- Lin, H., Wang, Y., Gao, Y., & Wang, X. (2018). A filled function method for global optimization with inequality constraints. Computational and Applied Mathematics, 37(2), 1524–1536. https://doi.org/10.1007/s40314-016-0407-8
- Liu, J., & Lampinen, J. (2005). A fuzzy adaptive differential evolution algorithm. Soft Computing, 9(6), 448–462. https://doi.org/10.1007/s00500-004-0363-x
- Liu, H., Wang, Y., & Cheung, Y. (2009). A multi-objective evolutionary algorithm using min-max strategy and sphere coordinate transformation. Intelligent Automation and Soft Computing, 15(3), 361–384. https://doi.org/10.1080/10798587.2009.10643036
- Liu, H. L., Gu, F., & Cheung, Y. (2010). T-MOEA/D: MOEA/D with objective transform in multi-objective problems. In 2010 international conference of information science and management engineering, Vol. 2 (pp. 282–285). IEEE.
- Liu, H. L., Gu, F., Cheung, Y. M., Xie, S., & Zhang, J. (2014). On solving WCDMA network planning using iterative power control scheme and evolutionary multiobjective algorithm. IEEE Computational Intelligence Magazine, 9(1), 44–52. https://doi.org/10.1109/MCI.2013.2291690
- Liu, H., Wang, Y., Liu, L., & Li, X. (2018). A two phase hybrid algorithm with a new decomposition method for large scale optimization. Integrated Computer-Aided Engineering, 25(4), 349–367. https://doi.org/10.3233/ICA-170571
- Liu, J., Wang, Y., Fan, N., Wei, S., & Tong, W. (2019). A convergence-diversity balanced fitness evaluation mechanism for decomposition-based many-objective optimization algorithm. Integrated Computer-Aided Engineering, 26(2), 159–184. https://doi.org/10.3233/ICA-180594
- Liu, H., Wang, Y., & Fan, N. (2020a). A hybrid deep grouping algorithm for large scale global optimization. IEEE Transactions on Evolutionary Computation, 24(6), 1112–1124. https://doi.org/10.1109/TEVC.4235
- Liu, J., Wang, Y., Wei, S., Sui, X., & Tong, W. (2020b). A filled flatten function method based on basin deepening and adaptive initial point for global optimization. International Journal of Pattern Recognition and Artificial Intelligence, 34(4), 2059011. https://doi.org/10.1142/S0218001420590119
- Montgomery, J., & Chen, S. (2010). An analysis of the operation of differential evolution at high and low crossover rates. In Paper presented at the IEEE congress on evolutionary computation. IEEE.
- Montgomery, J., & Chen, S. (2012). A simple strategy for maintaining diversity and reducing crowding in differential evolution. In Paper presented at the 2012 IEEE congress on evolutionary computation. IEEE.
- Mohamed, A. W. (2017). Solving stochastic programming problems using new approach to differential evolution algorithm. Egyptian Informatics Journals, 18(2), 75–86. https://doi.org/10.1016/j.eij.2016.09.002
- Mohamed, A. W., & Suganthan, P. N. (2018). Real-parameter unconstrained optimization based on enhanced fitness-adaptive differential evolution algorithm with novel mutation. Soft Computing, 22(10), 3215–3235. https://doi.org/10.1007/s00500-017-2777-2
- Mohamed, A. W., & Mohamed, A. K. (2019a). Adaptive guided differential evolution algorithm with novel mutation for numerical optimization. International Journal of Machine Learning and Cybernetics, 10(2), 253–277. https://doi.org/10.1007/s13042-017-0711-7
- Mohamed, A. W., Mohamed, A. K., Elfeky, E. Z., & Saleh, M. (2019b). Enhanced directed differential evolution algorithm for solving constrained engineering optimization problems. International Journal of Applied Metaheuristic Computing, 10(1), 1–28. https://doi.org/10.4018/IJAMC
- Nayak, S. K., Rout, P. K., & Jagadev, A. K. (2019a). Elitism-based multi-objective differential evolution with extreme learning machine for feature selection: a novel searching technique. Connection Science, 30(4), 362–387. https://doi.org/10.1080/09540091.2018.1487384
- Nayak, S. K., Rout, P. K., & Jagadev, A. K. (2019b). Multi-objective clustering: a kernel based approach using differential evolution. Connection Science, 31(3), 294–321. https://doi.org/10.1080/09540091.2019.1603201
- Pant, M., Ali, M., & Singh, V. P. (2009). Differential evolution using quadratic interpolation for initializing the population. In Paper presented at the 2009 IEEE international advance computing conference. IEEE.
- Pant, M., Zaheer, H., Garcia-Hernandez, L., & Abraham, A. (2020). Differential evolution: a review of more than two decades of research. Engineering Applications of Artificial Intelligence, 90, 103–479. https://doi.org/10.1016/j.engappai.2020.103479
- Peng, H., Guo, Z., Deng, C., & Wu, Z. (2018). Enhancing differential evolution with random neighbors based strategy. Journal of Computational Science, 26, 501–511. https://doi.org/10.1016/j.jocs.2017.07.010
- Qin, A. K., Huang, V. L., & Suganthan, P. N. (2008). Differential evolution algorithm with strategy adaptation for global numerical optimization. IEEE Transactions on Evolutionary Computation, 13(2), 398–417. https://doi.org/10.1109/TEVC.2008.927706
- Rahnamayan, S., Tizhoosh, H. R., & Salama, M. M. (2008). Opposition-based differential evolution. IEEE Transactions on Evolutionary Computation, 12(1), 64–79. https://doi.org/10.1109/TEVC.2007.894200
- Shen, D., & Zhu, L. (2019). Differential evolution with spatially neighbourhood best search in dynamic environment. International Journal of Computational Science and Engineering, 19(1), 104–111. https://doi.org/10.1504/IJCSE.2019.099644
- Song, J., Li, S., Zhao, Z., & Wu, S. (2013). Research on application of thiessen polygon to spatial distribution characteristics of settlement: a case study of Lingao county. Journal of Hainan Normal University (Natural Science), 2.
- Storn, R., & Price, K. (1997). Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. Journal of Global Optimization, 11(4), 341–359. https://doi.org/10.1023/A:1008202821328
- Sun, G., & Cai, Y. (2017). A novel neighborhood-dependent mutation operator for differential evolution. In Paper presented at the 2017 IEEE international conference on computational science and engineering (CSE) and IEEE international conference on embedded and ubiquitous computing (EUC). IEEE.
- Tanabe, R., & Fukunaga, A. (2013). Success-history based parameter adaptation for differential evolution. In Paper presented at the 2013 IEEE congress on evolutionary computation. IEEE.
- Tian, M., & Gao, X. (2019). Differential evolution with neighborhood-based adaptive evolution mechanism for numerical optimization. Information Sciences, 478, 422–448. https://doi.org/10.1016/j.ins.2018.11.021
- Tomassini, M., Vanneschi, L., Collard, P., & Clergue, M. (2005). A study of fitness distance correlation as a difficulty measure in genetic programming. Evolutionary Computation, 13(2), 213. https://doi.org/10.1162/1063656054088549
- Tong, H., Huang, C., Liu, J., & Yao, X. (2019). Voronoi-based efficient surrogate-assisted evolutionary algorithm for very expensive problems. In Paper presented at the 2019 IEEE congress on evolutionary computation (CEC). IEEE.
- Wang, Y., Cai, Z., & Zhang, Q. (2011). Differential evolution with composite trial vector generation strategies and control parameters. IEEE Transactions on Evolutionary Computation, 15(1), 55–66. https://doi.org/10.1109/TEVC.2010.2087271
- Wang, Y., Liu, H., Wei, F., Zong, T., & Li, X. (2018). Cooperative coevolution with formula-based variable grouping for large-scale global optimization. Evolutionary Computation, 26(4), 569–596. https://doi.org/10.1162/evco_a_00214
- Wang, F., Li, Y., Zhou, A., & Tang, K. (2019). An estimation of distribution algorithm for mixed-variable newsvendor problems. IEEE Transactions on Evolutionary Computation, 24(3), 479–493. https://doi.org/10.1109/TEVC.2019.2932624
- Wang, F., Zhang, H., & Zhou, A. (2021a). A particle swarm optimization algorithm for mixed-variable optimization problems. Swarm and Evolutionary Computation, 60, 100808. https://doi.org/10.1016/j.swevo.2020.100808
- Wang, F., Liao, F., Li, Y., & Wang, H. (2021b). A new prediction strategy for dynamic multi-objective optimization using Gaussian mixture model. Information Sciences, 580, 331–351. https://doi.org/10.1016/j.ins.2021.08.065
- Wu, G., Shen, X., Li, H., Chen, H., Lin, A., & Suganthan, P. N. (2018). Ensemble of differential evolution variants. Information Sciences, 423, 172–186. https://doi.org/10.1016/j.ins.2017.09.053
- Xue, X., & Wang, Y. (2015). Using memetic algorithm for instance coreference resolution. IEEE Transactions on Knowledge and Data Engineering, 28(2), 580–591. https://doi.org/10.1109/TKDE.2015.2475755
- Xiang, W. L., Zhu, N., Ma, S. F., Meng, X. L., & An, M. Q. (2015). A dynamic shuffled differential evolution algorithm for data clustering. Neurocomputing, 158, 144–154. https://doi.org/10.1016/j.neucom.2015.01.058
- Zhan, Z., Wang, Z., Jin, H., & Zhang, J. (2019). Adaptive distributed differential evolution. IEEE Transactions on Cybernetics, 50(11), 4633–4647. https://doi.org/10.1109/TCYB.6221036
- Zhao, Z., Yang, J., Hu, Z., & Che, H. (2016). A differential evolution algorithm with self-adaptive strategy and control parameters based on symmetric Latin hypercube design for unconstrained optimization problems. European Journal of Operational Research, 250(1), 30–45. https://doi.org/10.1016/j.ejor.2015.10.043
- Zhao, M., & Cai, Y. (2018). Intelligent selection of parents for mutation in differential evolution. International Journal of Computational Science and Engineering, 17(2), 133–145. https://doi.org/10.1504/IJCSE.2018.094924
- Zhao, F., Du, S., Lu, H., Ma, W., & Song, H. (2021). A hybrid self-adaptive invasive weed algorithm with differential evolution. Connection Science, 1–25. https://doi.org/10.1080/09540091.2021.1917517
- Zhang, J., & Sanderson, A. C. (2009). JADE: adaptive differential evolution with optional external archive. IEEE Transactions on Evolutionary Computation, 13(5), 945–958. https://doi.org/10.1109/TEVC.2009.2014613