
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Recommender systems can help correlate information and recommend personalised services to users as a general information filtering tool. However, contextual factors significantly affect user behaviour, especially in the Internet of Things (IoT), which brings difficulties to modelling user preferences. In this paper, we propose a personalised context-aware re-ranking algorithm (p-CAR) in IoT. Our primary purpose is to improve the recommender performance from multiple metrics, such as precision, recall, diversity, and popularity. The core idea is to re-rank the ranking list using the user's preference behaviour under different contexts. The re-ranking process is an iterative selection process; each time an optimal item that meets the target criteria is selected from the candidate items and added to the re-ranked list. The selection of items depends on the given context and the user's interest in that context. User's preference and interest in contexts are both expressed by probability in our algorithm. In addition, we use a weight parameter to control the influence of contexts and model the contextual personalisation of different users through local personalisation parameters. We verify our algorithm through experiments on the real Movielens 100K dataset and show the performance advantage with the existing algorithm.
1. Introduction
As a new network model, the Internet of Things (IoT) can be used as integrating physical objects, the Internet, and semantics. In IoT, various types of devices are used to perceive and collect a large amount of information in the physical world, such as sound, temperature, heat, location, etc., through available networks. This information provides a solid foundation for people to enjoy various services through the processing of information technology. As an essential information filtering tool, the recommender system can help establish the association between objects and services, and it has become a key technology in various solutions of the IoT. We have entered the era of recommendation. Nowadays, recommender systems are widely used in existing commercial systems, such as Taobao, YouTube, Amazon, etc.
The two most fundamental algorithms in the recommender system are content-based recommendation (Pazzani & Billsus, Citation2007) and collaborative filtering (Linden et al., Citation2003). By applying the recommendation technology to IoT, services in the physical world can be moved to the network platform and pushed to relevant users in real-time. The recommender system plays an essential role in smart cities, smart homes, and event monitoring. With the help of recommended technologies, users who are not familiar with the configuration of the IoT platform can perform practical configurations based on the configuration results of similar users. At the same time, the recommendation of applications and devices in the IoT platform can significantly save users' time. For the field of health monitoring, a recommender system can match user groups with similar health statuses and then recommend diet and fitness activities for target users based on their interaction history. Due to the gradual maturity of indoor positioning technology, when a user is shopping in a large shopping mall, the recommender system can promptly recommend nearby commodities according to their location.
Unlike the traditional recommender system environment, there are many uncertain factors in IoT, which leads to significant uncertainty in the recommended results. There are two main reasons. First, the data collected in the IoT environment is uncertain due to noise, sensor errors, transmission errors, etc. Second, user behaviour and habits are greatly affected by contextual factors, and user preferences in different contexts may be completely different. Due to this uncertainty, the recommendation list generated by the ranking algorithm may not be satisfactory. We can re-rank the ranked list according to the context to improve the performance of the recommended list as much as possible. As a post-filtering strategy, re-ranking is widely used to enhance specific system goals, such as diversity and novelty.
In this paper, we propose a personalised context-aware re-ranking algorithm. The primary consideration of our algorithm is that the performance of the recommender system in the IoT environment is highly dependent on contexts, including the user's location, state, mood, etc., and the results of recommendation in different contexts are different. In addition, the user's historical interaction records are generated in different contexts. The predicted result may not be the user's true intention if they are treated equally during the training process. In addition, each user has different preferences for items in different contexts, which requires the recommendation results to meet the user's personalised, contextual needs. We use a probability model to model the user's preferences and the user's contextual preferences. At the same time, we use a global and local parameter to measure the weight of contextual factors and the user's personalised weight. The construction of the re-ranked list is an iterative selection process that is, each time, an optimal item that meets the goal of re-ranking is selected from the candidate item set and added to the re-ranked list.
The contributions of our paper are threefold.
Firstly, we propose a context-aware re-ranking algorithm (CAR). Our algorithm takes the ranked list generated in the ranking stage as input and iteratively selects the best items that meet the objective requirements through a greedy strategy and puts them into the re-ranked list. The optimisation of the goal is expressed by a linear weighting of user preference and user context preference, and preference is expressed by probability.
Secondly, considering the differences in contextual preferences of different users, a personalised context-aware re-ranking algorithm (p-CAR) is further proposed. The p-CAR algorithm distinguishes users through a personalised factor, and its setting is based on the information entropy of the user under the context set.
Thirdly, through the verification of our proposed algorithm by the actual movie data set, we show the performance of our algorithm under different parameter values from multiple performance metrics and offer our performance advantage over the existing algorithm.
This paper is organised as follows. Section 2 reviews related work. The problem description and solution are presented in Section 3. Section 4 clearly explains the context-aware re-ranking algorithm. Section 5 shows the personalised context-aware re-ranking algorithm. Experiments and result analysis are conducted in Section 6. Section 7 concludes this paper.
2. Related works
The content-based recommendation (Reddy et al., Citation2019) is the most basic algorithm in the recommender system. As one kind of content, web service recommendation has received widespread attention from researchers (Tang et al., Citation2021; Xu et al., Citation2021; Yu et al., Citation2021). The core of the recommendation system is ranking, and the quality of the ranked result directly affects the quality of the recommendation (H. Wang et al., Citation2019; Xiao et al., Citation2021). Common content features also include the item's content attributes (Guo et al., Citation2020), user comments (Fu et al., Citation2019), tags (B. Chen et al., Citation2020; X. Chen et al., Citation2020) and the semantic relations of content (T. Liu et al., Citation2019; C. Wang et al., Citation2019). In addition, contextual information as unique content plays a significant role in the recommender system.
For the processing of contextual information, Han et al. (Citation2020) proposed a new framework for Point-of-Interest(POI) recommendation, which explicitly utilises similarity with contexts. Specifically, they categorise the contexts into global and local contexts and develop different regularisation terms to incorporate them for the recommendation. Aims at the same problem, a model to exploit spatial-temporal contexts in a POI-guided attention mechanism was proposed by H. Wang et al. (Citation2020) and a technique named fuzzy areas-based collaborative filtering to provide personalised POI recommendations for users of location-based social networks was proposed by Tourinho and Rios (Citation2021). A position-aware context attention (PACA) model has been proposed as a remedy, which improves the recommendation performance by taking into account both the positions and the contexts of items (Cao et al., Citation2020). To solve the problem of web service QoS prediction, Z. Chen et al. (Citation2019) proposed a unified matrix factorisation model that fully capitalises on the advantages of both location-aware neighbourhood and latent factor approach. Parallel (Richa & Bedi, Citation2019), fast, and scalable (Gautam & Bedi, Citation2019) methods were also proposed for improvement on computational time. The collaborator recommendation problem has been studied by Z. Liu et al. (Citation2018), which aims to recommend high-potential new collaborators for people's context-restricted requests. Their paper designed a novel recommendation framework consisting of the Collaborative Entity Embedding network (CEE) and the Hierarchical Factorisation Model (HFM). Contextual information has been paid more and more attention in recommender systems in recent years (Gu et al., Citation2021; Maio et al., Citation2021; Unger et al., Citation2020; Zhou et al., Citation2020).
Aims at the re-ranking with contexts, Lathia et al. (Citation2010) took into account the dynamic needs of users for diversity and proposed the idea of exchanging and selecting different re-ranking algorithms at different periods to improve temporary diversity. The selection of re-ranking algorithms is based on the system and individual users are treated differently. Combination theory has been studied by Zhang et al. (Citation2013), Swezey and Charron (Citation2018), and they proposed several risk-based re-ranking strategies. The reward and risk of the item are considered in the re-ranking process. Lu and Tintarev (Citation2018) proposed a personalised diversity re-ranking algorithm for the diversification of music recommendation. The algorithm's core is the Maximal Marginal Relevance (MMR) method, which was originally used in information retrieval. X. Wang et al. (Citation2018) took into account the differences in user preferences for different directories and proposed a personalised diversity algorithm based on the greedy re-ranking strategy to optimise relevance and diversity jointly. Different content feature as context information are widely studied in Di Noia et al. (Citation2014), R. Liu et al. (Citation2017), Elsafty et al. (Citation2018), Eberhard et al. (Citation2019), Zhao et al. (Citation2016), and Katariya et al. (Citation2018). As for the edge recommendation, Y. Gong et al. (Citation2020) proposed a context-aware re-ranking strategy which used the behavioural attention network to re-rank on the user terminal to achieve real-time goals.
3. Problem description and solution
This section mainly introduces the problems to be solved and our solutions. Table lists the main symbols used in this paper.
Table 1. Notation in this paper.
3.1. Problem description
In the IoT recommender system, there is significant uncertainty in the collected data due to the influence of environmental noise, transmission errors, and sensor errors. What's more, the user's behaviour is affected by different contexts, bringing many uncertain factors to the system. In this section, we describe these uncertainties in the IoT recommender system. The data uncertainty problem is described in Figure .
Figure 1. Data uncertainty. (a) Data noise. (b) Sensor errors and (c) Transmission errors.
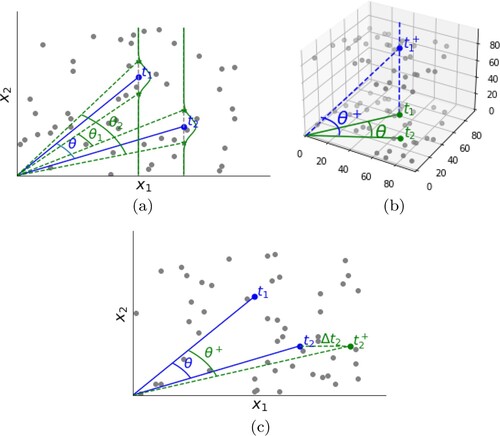
Training data is essential for constructing a recommender model. Even for the same model, changes in the training data set may cause substantial changes in evaluation metrics. For example, in a matrix factorisation model, rating noise may calculate implicit factors inaccurately. Suppose we have many items whose features are two-dimensional, which are represented by scattered points in Figure (a). We want to calculate the cosine similarity between the target and
. The true similarity between targets is determined by the angle θ of their feature vectors, and a smaller θ indicates greater similarity between the targets. When there is no noise, the calculated angle is the blue θ. After adding Gaussian noise, the angle between the targets changes, and the angle changes in
.
Only when the data noise accumulates to a certain amount will it affect the final recommendation. The loss of features caused by sensor errors is a serious problem. The loss of a certain feature, especially the contextual feature, will make the recommendation results utterly different in the IoT recommender system. Taking recipe recommendation as an example, the system recommends suitable recipes for the user based on the user's diet in the past few days, the dietary preferences of similar neighbours, and the types of food available in the refrigerator. Generally speaking, this recommendation will bring satisfactory results. But if the sensor loses the critical feature of the food expiration date, this recommendation will need to be re-evaluated. For another example, the user's blood glucose and blood pressure metrics are too high, but the health sensor has lost these characteristics, so it is not appropriate to recommend meat recipes. Due to the loss of the third feature, as shown in Figure (b), the similarity between the targets has changed, and this change will ultimately affect the recommendation.
In addition to data noise and sensor errors, transmission errors also need to be considered in the IoT recommender system. We map the transmission error to the change of a specific characteristic value. The actual similarity is represented by blue θ in Figure (c). When a transmission error occurs, the first expected value of the target object changes, triggering an increment of , and then
becomes
, and the angle between them becomes
. The change of the included angle will eventually cause a difference in the recommended results.
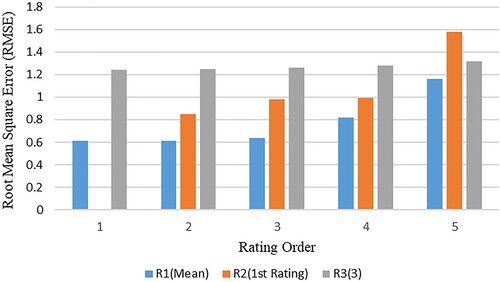
In a system experiment (Jasberg & Sizov, Citation2018), experiment participants were asked to rate movie trailers and TV shows 5 times. After statistics, 27% of users showed consistent rating behaviour, 73% of users gave at least two different ratings, and 39% of users gave at least three different ratings. Based on these rating data, three simple recommendation algorithms are constructed for each experiment, and the performance of each algorithm is evaluated through RMSE. Among them, the first algorithm uses the average value of multiple ratings for prediction, the second recommendation algorithm uses the value of the first rating for prediction, and the prediction of the third recommendation algorithm is always 3. Figure shows the performance of each algorithm in multiple predictions. It can be seen from this that the second recommendation algorithm has the best and worst performance in multiple predictions. This illustrates the impact of user behaviour inconsistency in the recommender system.
Figure 2. User uncertainty.
Due to the existence of uncertainty in the IoT recommender system, when recommending items to users to improve user satisfaction and the system's overall goal, in addition to recommending related items, we should also make the recommendation list more diversified. Aiming at the importance of contextual factors in the IoT recommender system, we can concretise general diversification problems into contextual diversification problems. In the IoT recommender system, various contexts are integrated into it, including time, location, mood, and so on. Users have different requirements for recommendation results in different contexts. Take music as an example. People choose different music when reading and running. People are more inclined to listen to slow-paced music when reading. Therefore, when recommending items to users, the recommender system should maximise the relevance of items and consider the diversity of contexts.
The problem of contextual diversity can naturally be seen as a balance between recommending related items and contextually diverse items. It can be described as follows. Given a user set , an item set
and an initial recommendation list
of the user u, our task is to re-rank
to generate a re-ranked list
composed of K different items, Making it meet the requirements of relevance and contextual diversity at the same time. For an item v,
is the context of the item. Among them,
is a set of contexts.
3.2. Solution
This multi-objective optimisation problem can be reduced to a p-dispersion problem, and this problem is NP-hard. There are a series of approximate algorithms that can be solved and have perfect results in practice for this problem. Our task becomes the formalisation of each optimisation goal and finding optimisation criteria. In this section, we use a probabilistic mixed model to represent relevance and contextual diversity. Our inspiration mainly comes from the diversified probability framework eXplicit Query Aspect Diversification (xQuAD) in search engine (Santos et al., Citation2010). The framework explicitly specifies multiple aspects related to the query and describes them with a probabilistic model.
In our paper, our solution is described as follows. Given a user u and an initial recommendation list for this user, we construct a re-ranked list
by iteratively selecting items in
, the selected rules are based on the following probabilistic mixed model.
(1)
(1) Where,
is the relevance preference of the user
on the item
, which is predicted by the initial recommendation algorithm.
is the contextual diversity preference of user
for items v that are not in the re-ranked list
. λ is a weight parameter. After giving the criteria, our context-aware re-ranking algorithm is shown in Algorithm 1.

4. Context-aware re-ranking algorithm (CAR)
4.1. Probabilistic model
In this section, we mainly describe the contextual diversity, which is . To get
, we consider a set of contexts related to users and items
, generated by the user's marginal probability on contextual variables. For convenience, we use
instead of
for description. The calculation method is shown in Equation (Equation2
(2)
(2) ).
(2)
(2) Where,
can be regarded as user u's preference for context c, and
. This probability can reflect the number of users who prefer the context c.
After each iteration, the items in the re-ranked list S are fixed. We assume that the items to be predicted are independent with the items in S, so that we can further decompose as follows.
(3)
(3) In this way,
can be regarded as the coverage of the item under the context c, and
can be regarded as a consideration of contextual diversity, Which measures the importance of the context c that is not covered by the re-ranked list S.
This independence assumption is significant. It changes the calculation of contextual diversity from the comparison between items to marginal probability under contexts. In other words, different from the traditional method that compares the items to be predicted with all items in the re-ranked list S. Given the coverage of the context of the re-ranked list S, we make a choice by measuring the importance of the items under different contexts. Although the goal is the same, our method is more efficient because we don't need to get the context of each item in R and then calculate them in pairs. We only need to update the importance estimation under the given context after obtaining the context's re-ranked list S coverage.
In order to calculate , we further assume that the importance estimation of the items in the re-ranked list S for the same context are independent of each other. This assumption is reasonable because we need to calculate the probability that the re-ranked list S does not meet the given context. Under this assumption, our calculation method is as follows.
(4)
(4) Put Equations (Equation2
(2)
(2) ), (Equation3
(3)
(3) ) and (Equation4
(4)
(4) ) into Equation (Equation1
(1)
(1) ), and our final selection criteria is shown in Equation (Equation5
(5)
(5) ).
(5)
(5)
4.2. Module design
In our context-aware re-ranking algorithm, we decompose the probabilistic mixed model into many independent probability modules, here we estimate each module. These modules are summarised as follows.
User preference for items,
Contextual diversity,
° The generation of the context set, C
° User preference for context,
° The probability that the item belongs to the context,
° The coverage of the re-ranked list on the context,
The design of each module is not unique, and different strategies will have different effects on the evaluation metrics of the system. Our selection criteria for strategies are mainly based on intuitive rationality.
User preference for items. In the recommender system, which takes precision as the goal, it can be divided into two recommendation methods: score prediction and top-k recommendation. In a sense, these two methods rank the items and then select the top item set to recommend to the target user. The score prediction will predict a score for each item that the user has not visited, and the range depends on the requirement of the system. The top-k recommendation gives a relevant score for each item, and different calculation methods have different scores. In our probabilistic model, we use the ranking score generated by the initial recommendation list to represent the user's preference for items. In order to adapt to our model, we need to standardise the score to be normalised to (0, 1). We use the Min-Max standardisation method for processing, as shown in Equation (Equation6(6)
(6) ).
(6)
(6) Where
is the predicted value of the item v by the user u, given by the initial ranking algorithm.
and
represent the maximum and minimum values of prediction.
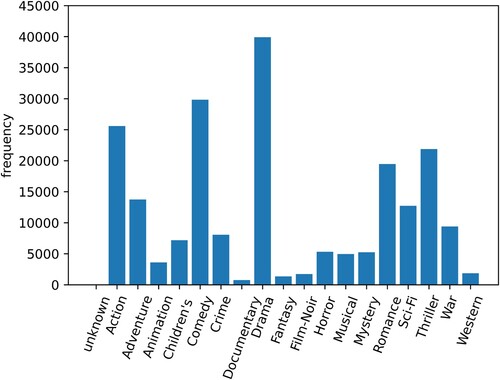
The generation of the context set. There are two main ways to generate context sets. The explicit context is the direct use of existing user or item characteristics, such as time, genre, label, etc. The other is the implicit context; this way is mainly through the dimensionality reduction technology to obtain the implicit context set. Our paper uses the first method because it is easy to understand and interpretable for the recommended results. The second method is not easy to set the size of the context set. Take the Movielens-100K data set as an example. We use genre information as the context, and we get a context set of size 19.
Figure shows the distribution of user preferences in each context in the data set. It can be seen that this distribution is not uniform, and the user's preference for Drama, Comedy, and Action is higher than other contexts.
Figure 3. The distribution of user preferences in different contexts.
User preference for context. The most basic method for estimating context preference is to assume that context preference obeys a uniform distribution, that is, for all context c, their preferences are the same.
(7)
(7) where,
represents the total number of contexts.
This method does not take into account the differences in preferences of different contexts. From Figure we know that this preference is unbalanced in reality, and we need to model this difference. We can derive the number of items visited by the user in different contexts from the user's historical record to measure the difference in the context from the difference in this amount. Based on this consideration, our contextual preference estimation adopts the following method.
(8)
(8) where
refers to the number of items under the context c.
The probability that the item belongs to the context. The relationship between the item and the context is deterministic, either it is contained in the context or it is not. So we can estimate it in the following way.
(9)
(9)
The coverage of the re-ranked list on the context. In order to model the diversity of context, we first need to know the coverage of re-ranked list S on each context. A natural idea is that if an item v in the re-ranked list S covers the context c, then the items in this context will not be considered first when the selection is made next time. In this way, it can be estimated in a deterministic way.
(10)
(10) In this way, when all the items in the re-ranked list S do not cover the context c, the currently selected item
will maximise the contribution to the context.
(11)
(11) The other way is to process more smoothly, that is, to measure the coverage of the re-ranked list on the context through the proportion of items in the list that cover the context c. In our paper, we experimented with both ways.
(12)
(12) Where,
refers to the number of items covered by the context c in the re-ranked list S.
5. Personalised context-aware re-ranking algorithm
In the CAR, we consider the overall preference of user under contexts, and it is aimed at improving broad preference diversity. In the actual situation, each user has his preference and diversity needs. Based on this consideration, we propose a personalised solution p-CAR. We introduce the personalisation factor in the contextual diversity module to model the contextual personalisation needs of different users. The selection criteria for items are shown in Equation (Equation13
(13)
(13) ).
(13)
(13) Where,
is the probability that the user
is interested in the item
, predicted by the initial recommendation algorithm.
is the probability that the user u is interested in the item v that is not in the re-ranked list S. λ is a weight parameter.
is the personalised weight of the user u.
Weight setting. When we set the personalisation weight to 0, that is, , then the re-ranked list
will take the top-k of the initial recommendation list R with the same order. When
, the user's personalisation factor disappears, and its personalisation depends on the settings of the system. Here, we obtain
by learning the user's historical data. We get the probability distribution of the user in each context through the distribution of the items interacted by the user in each context and express this personalised weight through Shannon's information entropy.
To calculate the user's personalised preference , we first calculate the user's preference
for each context
. The calculation method is as follows.
(14)
(14) Where,
is the rating of the user u on the item v,
is an indicator function when condition A is true, its value is 1. Otherwise, it is 0.
represents the user's interest in each context, and
. Some users may be interested in a certain context, while others may have similar preferences for all contexts. To capture this characteristic, we use information entropy to represent the user's personalised weight, that is,
(15)
(15) where the larger the value of
, the greater the diversity of users' preferences for contexts.
The personalised context-aware re-ranking algorithm is shown in Algorithm 2. The algorithm takes the initial recommendation list R as input. Given a user u, the length of the re-ranked list K, and the user's personalisation weight , the best items that meet the conditions are selected from the initial recommendation list each time through the greedy strategy and put into the re-ranked list until the re-ranked list meets the demand.

6. Experimental evaluation
6.1. Data set
We use a movie rating data set published by the Grouplens team at the University of Minnesota in the United States. This data set contains 100,000 rating data for 1682 movies by 943 users, and each user has rated at least 20 movies. It also contains some characteristic information of users and movies. Such as the user's age, gender, occupation, and movie genre. The data set comes from the 7-month visit of the MovieLens website from September 1997 to April 1998. Table shows the field information of the main rating data. Table gives some statistical information in the data set. Unless specified, we divide the data set into five parts during the experiment, 4 of which are used as the training set and one as the testing set, and the average value is taken through 5 experiments.
Table 2. Data set description.
Table 3. Data set statistic.
6.2. Experiment analysis
Precision. We first measure the performance of the proposed algorithm on precision. The definition is as follows.
(16)
(16) where U is the set of all users,
is the set of movies recommended to the user u, and
is the set of movies that the user u has visited in the testing set.
We use user-based collaborative filtering to generate the initial recommendation list. In this algorithm, parameters are set as follows: the number of similar users M = 10, the length of the recommendation list N = 20, and the length of the re-ranking list K = 10. For comparison, when measuring the precision of the initial algorithm, we also take the top 10 items in the recommended list for calculation. The experimental results are shown in Figure .
Figure 4. The impact of the re-ranking algorithms on precision.
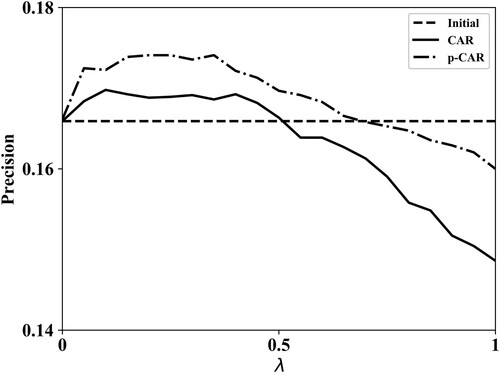
The results show that our proposed re-ranking algorithm can improve recommendations' performance to a certain extent. Compared with the initial recommendation list, our CAR algorithm has better performance. When , the precision of the CAR algorithm is the same as the initial recommendation list, and the CAR algorithm improves by 1% compared to the basic algorithm at the maximum. After introducing the user's personalised parameters, the performance of the p-CAR algorithm is further improved. When
, it is equivalent to the performance of the basic algorithm. In addition, the precision of the p-CAR algorithm at the maximum is improved by 5% compared to the basic algorithm.
When estimating the coverage of the re-ranked list on the context, we mentioned two processing methods: an indicator function and a smoothing process. We measure its impact on the performance of p-CAR respectively. For the indicator function method, we named it p-CAR-binary, and for the smooth method, we named it p-CAR-smooth. The experimental results are shown in Figure .
Figure 5. The influence of the indicator function and smoothing method on performance.
We conclude that the smoothing method is generally better than the indicator function. This is easy to understand because in the existing re-ranked list, there is a difference between single and multiple items covering the same context, and the processing method of the indicator function treats it as the same.
Recall and popularity. We then measure the impact of the re-ranking algorithm on recall and popularity. The recall reflects the percentage of the items visited by the user that the recommender system has discovered. In many commercial systems, the recall is used as an indicator to measure precision. Popularity measures how many people have visited the items. We hope that the recommended items are less popular items because the long-tail items can genuinely reflect the personalised needs of users. The calculation methods of these two metrics are as follows.
(17)
(17)
(18)
(18) where
refers to the set of users who have visited the item i.
The performance of our CAR algorithm and p-CAR algorithm on these two metrics is shown in Figure . We can see that, for the recall, when λ is small, our CAR algorithm and p-CAR algorithm are better than the benchmark algorithm. For popularity, when the value of λ is larger, our CAR algorithm and p-CAR algorithm can better recommend unpopular items, that is, have a better ability to discover long tails. In both metrics, the performance of p-CAR is better than that of CAR, which shows the advantages of the smooth processing method, which is also in line with our intuitive ideas and expectations.
Figure 6. The impact of the re-ranking algorithms on recall and popularity. (a) Recall and (b) Popularity.
Contextual coverage. We measure the coverage of the context of the p-CAR algorithm under different weight parameters. The experimental results are shown in Figure . From this figure, we can see that, compared with the coverage of the initial recommendation list, the coverage of our re-ranking algorithm is more inclined to consider the user's preference for the context because our algorithm covers more high-frequency contexts. With the increase of the weight parameter λ, the preference of the re-ranking algorithm to the user context becomes more obvious; this can be derived from the frequency difference of context recommendation.
Figure 7. Contextual coverage of the re-ranking algorithm. (a) . (b)
. (c)
. (d)
. (e)
. (f)
. (g)
. (h)
and (i)
.
The influence of the number of neighbours. In the user-based collaborative filtering algorithm, an important parameter is the number of neighbours. Here, we set the range of neighbours as [10, 100], and the experimental results are shown in Figure . We can see that, for the initial algorithm and the re-ranking algorithm, the precision begins to increase with the increase in the number of neighbours, and when it grows to a certain level, the precision begins to decrease. It can be understood that when the number of neighbours increases to a certain extent, those neighbours with low similarity begin to harm precision. The precision of the CAR algorithm is slightly better than that of the initial algorithm, and the precision of the p-CAR algorithm is improved more obviously, which illustrates the importance of the personalisation factor.
Figure 8. The impact of the number of neighbours on precision.
Comparison with existing algorithm. Here, we compare with Sim-PoF, a re-ranking method based on context proposed in B. Gong et al. (Citation2020). We chose this algorithm because the work is most similar to the idea we put forward. The difference is that we use a heuristic algorithm with continuous selection instead of calculating the context score of the item at once. We do this because when the user selects an item, its context will change with the selection. The Sim-PoF method linearly weights the initial prediction score of the item and the similarity score between the item and the user context vector, and its calculation method is shown in Equation (Equation19(19)
(19) ).
(19)
(19) Where,
is the context vector of the item,
is the user's personalised context vector, and
is the initial score,
is a similarity calculation method based on Euler distance.
Our algorithm adopts a smooth processing method to cover the context and set the weight parameter in the two methods. We compare the performance of the algorithm in terms of precision, recall, popularity, and diversity. The calculation method of diversity is shown in Equation (Equation20
(20)
(20) ). It measures the dissimilarity between items in the recommended list, and the similarity calculation adopts the Jaccard similarity calculation method.
(20)
(20) The experimental results are shown in Table . From this table, we can see that the p-CAR algorithm we proposed is better than the Sim-PoF method in all metrics, and the improvement in precision and diversity is more obvious. Compared with the Sim-PoF method, the popularity value of p-CAR algorithm is smaller, which shows that our proposed algorithm is more capable of recommending unpopular items, and therefore has better personalisation capabilities. The advantage of the p-CAR algorithm in diversity mainly depends on our probability framework, which contains the user's preference for context diversity. In the Sim-PoF method, the context uses the similarity calculation between the context vector and the user context preference vector, limiting the algorithm's diversity performance.
Table 4. Performance comparison with existing algorithm.
7. Conclusion
In this paper, in response to the uncertainty problem of recommender systems in IoT, we propose CAR, a context-aware re-ranking algorithm. Further considering the impact of user diversity, we propose p-CAR, a personalised context-aware re-ranking algorithm. Our algorithms model user preferences and contextual preferences from the perspective of a probability framework. The core of both algorithms is a process of greedy selection. For the existing recommendation list, an optimal item is selected from it and added to the re-ranked list each time until the size of the re-ranked list meets the demand. In our experiments, we use the public Movielens-100K data. That is not only to measure the performance from commonly used recommendation metrics, such as precision, recall, popularity, diversity, etc. but also to verify the contextual coverage of our proposed algorithms. Because the work we do is based on context-aware re-ranking, contextual information is difficult to obtain; this will bring certain limitations to our algorithms. However, we can solve this problem by manually or automatically setting some contextual categories.
Acknowledgments
I would like to express my gratitude to all those who helped me during the writing of this paper. I gratefully acknowledge the help of my supervisor, Professor Guojun Wang, who has offered me valuable suggestions in academic studies. In preparing the paper, he has spent much time reading through each draft and provided me with inspiring advice. Without his patient instruction, insightful criticism, and expert guidance, the completion of this paper would not have been possible.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Cao, Y., Zhang, W., Song, B., Pan, W., & Xu, C. (2020). Position-aware context attention for session-based recommendation. Neurocomputing, 376, 65–72. https://doi.org/10.1016/j.neucom.2019.09.016
- Chen, B., Guo, W., Tang, R., Xin, X., Ding, Y., He, X., & Wang, D. (2020). TGCN: Tag graph convolutional network for tag-aware recommendation. In Proceedings of the 29th ACM international conference on information and knowledge management (pp. 155–164), Virtual, Online, Ireland.
- Chen, X., Du, C., He, X., & Wang, J. (2020). JIT2R: A joint framework for item tagging and tag-based recommendation. In Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval (pp. 1681–1684), Virtual, Online, China.
- Chen, Z., Shen, L., You, D., Ma, C., & Li, F. (2019). A location-aware matrix factorisation approach for collaborative web service QoS prediction. International Journal of Computational Science and Engineering, 19(3), 354–367. https://doi.org/10.1504/IJCSE.2019.10022721
- Di Noia, T., Ostuni, V. C., Rosati, J., Tomeo, P., & Di Sciascio, E. (2014). An analysis of users' propensity toward diversity in recommendations. In Proceedings of the 8th ACM conference on recommender systems (pp. 285–288), Foster City, CA, USA.
- Eberhard, L., Walk, S., Posch, L., & Helic, D. (2019). Evaluating narrative-driven movie recommendations on Reddit. In Proceedings of the 24th international conference on intelligent user interfaces (pp. 1–11), Marina Del Ray, CA, USA.
- Elsafty, A., Riedl, M., & Biemann, C. (2018). Document-based recommender system for job postings using dense representations. In Proceedings of the 16th annual conference of the North American chapter of the association for computational linguistics: Human language technologies (pp. 216–224), New Orleans, LA, USA.
- Fu, W., Peng, Z., Wang, S., Xu, Y., & Li, J. (2019). Deeply fusing reviews and contents for cold start users in cross-domain recommendation systems. In Proceedings of the 33rd AAAI conference on artificial intelligence (pp. 94–101), Honolulu, HI, USA.
- Gautam, A., & Bedi, P. (2019). FS-CARS: Fast and scalable context-aware news recommender system using tensor factorisation. International Journal of Computational Science and Engineering, 18(2), 118–129. https://doi.org/10.1504/IJCSE.2019.097949
- Gong, B., Kaya, M., & Tintarev, N. (2020). Contextual personalized re-ranking of music recommendations through audio features. Preprint. arXiv:2009.02782.
- Gong, Y., Jiang, Z., Feng, Y., Hu, B., Zhao, K., Liu, Q., & Ou, W. (2020). EdgeRec: Recommender system on edge in mobile Taobao. In Proceedings of the 29th ACM international conference on information and knowledge management (pp. 2477–2484), Virtual, Online, Ireland.
- Gu, P., Han, Y., Gao, W., Xu, G., & Wu, J. (2021). Enhancing session-based social recommendation through item graph embedding and contextual friendship modeling. Neurocomputing, 419, 190–202. https://doi.org/10.1016/j.neucom.2020.08.023
- Guo, G., Chen, B., Zhang, X., Liu, Z., & He, X. (2020). Leveraging title-abstract attentive semantics for paper recommendation. In Proceedings of the 34th AAAI conference on artificial intelligence (pp. 67–74), New York, NY, USA.
- Han, P., Li, Z., Liu, Y., Zhao, P., Li, J., Wang, H., & Shang, S. (2020). Contextualized point-of-interest recommendation. In Proceedings of the 29th international joint conference on artificial intelligence (pp. 2484–2490), Yokohama, Japan.
- Jasberg, K., & Sizov, S. (2018). Human uncertainty and ranking error: Fallacies in metric-based evaluation of recommender systems. In Proceedings of the 33rd annual ACM symposium on applied computing (pp. 1358–1365), Pau, France.
- Katariya, S., Bose, J., Reddy, M. V., Sharma, A., & Tappashetty, S. (2018). A personalized health recommendation system based on smartphone calendar events. In Proceedings of the 16th international conference on smart homes and health telematics (pp. 110–120), Singapore.
- Lathia, N., Hailes, S., Capra, L., & Amatriain, X. (2010). Temporal diversity in recommender systems. In Proceedings of the 33rd annual international ACM SIGIR conference on research and development in information retrieval (pp. 210–217), Geneva, Switzerland.
- Linden, G., Smith, B., & York, J. (2003). Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Computing, 7(1), 76–80. https://doi.org/10.1109/MIC.2003.1167344
- Liu, R., Rong, W., Ouyang, Y., & Xiong, Z. (2017). A hierarchical similarity based job recommendation service framework for university students. Frontiers of Computer Science, 11(5), 912–922. https://doi.org/10.1007/s11704-016-5570-y
- Liu, T., Wang, Z., Tang, J., Yang, S., Huang, G. Y., & Liu, Z. (2019). Recommender systems with heterogeneous side information. In Proceedings of the web conference 2019 (pp. 3027–3033), San Francisco, CA, USA.
- Liu, Z., Xie, X., & Chen, L. (2018). Context-aware academic collaborator recommendation. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1870–1879), London, UK.
- Lu, F., & Tintarev, N. (2018). A diversity adjusting strategy with personality for music recommendation. In Proceedings of the 12th ACM conference on recommender systems (pp. 7–14), Vancouver, BC, Canada.
- Maio, C. D., Gallo, M., Hao, F., & Yang, E. (2021). Who and where: Context-aware advertisement recommendation on Twitter. Soft Computing, 25(1), 379–387. https://doi.org/10.1007/s00500-020-05147-5
- Pazzani, M. J., & Billsus, D. (2007). Content-based recommendation systems. In The adaptive web (pp. 325–341). Springer.
- Reddy, S., Nalluri, S., Kunisetti, S., Ashok, S., & Venkatesh, B. (2019). Content-based movie recommendation system using genre correlation. In Smart intelligent computing and applications (pp. 391–397). Springer.
- Richa, N. A., & Bedi, P. (2019). Parallel context-aware multi-agent tourism recommender system. International Journal of Computational Science and Engineering, 20(4), 536–549. https://doi.org/10.1504/IJCSE.2019.104440
- Santos, R. L., Macdonald, C., & Ounis, I. (2010). Exploiting query reformulations for web search result diversification. In Proceedings of the 19th international conference on world wide web (pp. 881–890), Raleigh, NC, USA.
- Swezey, R. M., & Charron, B. (2018). Large-scale recommendation for portfolio optimization. In Proceedings of the 12th ACM conference on recommender systems (pp. 382–386), Vancouver, BC, Canada.
- Tang, B., Tang, M., Xia, Y., & Hsieh, M. Y. (2021). Composition pattern-aware web service recommendation based on depth factorisation machine. Connection Science, 33(4), 870–890. https://doi.org/10.1080/09540091.2021.1911933
- Tourinho, I. A. D. S., & Rios, T. N. (2021). FACF: Fuzzy areas-based collaborative filtering for point-of-interest recommendation. International Journal of Computational Science and Engineering, 24(1), 27–41. https://doi.org/10.1504/IJCSE.2021.113636
- Unger, M., Tuzhilin, A., & Livne, A. (2020). Context-Aware Recommendations Based on Deep Learning Frameworks. ACM Transactions on Management Information Systems, 11(2), 1–15. https://doi.org/10.1145/3386243
- Wang, C., Zhou, T., Chen, C., Hu, T., & Chen, G. (2019). CAMO: A collaborative ranking method for content based recommendation. In Proceedings of the 33rd AAAI conference on artificial intelligence (pp. 5224–5231), Honolulu, HI, USA.
- Wang, H., Shen, H., & Cheng, X. (2020). Modeling POI-specific spatial-temporal context for point-of-interest recommendation. In Proceedings of the 24th Pacific-Asia conference on knowledge discovery and data mining (pp. 130–141), Virtual, Online, Singapore.
- Wang, H., Yu, X., Zhao, J., & Zheng, Y. (2019). Detecting sparse rating spammer for accurate ranking of online recommendation. International Journal of Computational Science and Engineering, 19(1), 121–131. https://doi.org/10.1504/IJCSE.2019.099646
- Wang, X., Qi, J., Ramamohanarao, K., Sun, Y., Li, B., & Zhang, R. (2018). A joint optimization approach for personalized recommendation diversification. In Proceedings of the 22nd Pacific-Asia conference on advances in knowledge discovery and data mining (pp. 597–609), Melbourne, VIC, Australia.
- Xiao, T., Han, D., He, J., Li, K. C., & de Mello, R. F. (2021). Multi-Keyword ranked search based on mapping set matching in cloud ciphertext storage system. Connection Science, 33(1), 95–112. https://doi.org/10.1080/09540091.2020.1753175
- Xu, J., Xiao, L., Li, Y., Huang, M., Zhuang, Z., Weng, T. H., & Liang, W. (2021). NFMF: Neural fusion matrix factorisation for QoS prediction in service selection. Connection Science, 33(3), 753–768. https://doi.org/10.1080/09540091.2021.1889975
- Yu, L., Duan, Y., & Li, K. C. (2021). A real-world service mashup platform based on data integration, information synthesis, and knowledge fusion. Connection Science, 33(3), 463–481. https://doi.org/10.1080/09540091.2020.1841110
- Zhang, W., Wang, J., Chen, B., & Zhao, X. (2013). To personalize or not: A risk management perspective. In Proceedings of the 7th ACM conference on recommender systems (pp. 229–236), Hong Kong, China.
- Zhao, Y., Liang, S., & Ma, J. (2016). Personalized re-ranking of tweets. In Proceedings of the 17th international conference on web information systems engineering (pp. 70–84), Shanghai, China.
- Zhou, J. P., Cheng, Z., Pérez, F., & Volkovs, M. (2020). TAFA: Two-headed attention fused autoencoder for context-aware recommendations. In Proceedings of the 14th ACM conference on recommender systems (pp. 338–347), Virtual, Online, Brazil.