
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Sentiment classification can provide the decision support of social applications such as trend judgment, public opinion monitoring, etc. However, the accuracy of sentiment classification for Chinese Weibo is still not satisfactory due to the complexity of Chinese. In addition, affected by the different organisational structure levels, the sentiment tendency of fewer Weibo Comments may be judged to be the opposite. To solve the problem above, this paper presents a Chinese sentiment classification model based on extended sentiment dictionary and organisational structure of comments. First, the sentiment dictionary can be extended by using seven dictionaries, which include the base sentiment dictionary and six additional dictionaries. Then, the sets of rules are constructed, which include inter-sentence rules and organisational structure rules. Finally, comments on three hot topics are crawled and used to make the data sets for sentiment calculation. Accordingly, based on the result of sentiment calculation, sentiment classification is completed. The effectiveness of the proposed model is verified through comparison experiments, and the experimental results are also discussed.
1. Introduction
As the most influential platform in Chinese social media, Weibo generates a large amount of data every moment. The exchange of these data containing information and emotion (Jia et al., Citation2019) is more dynamic and impactful than traditional communication platforms such as television and newspapers. At the same time, these data obtained from Weibo comments can be helpful to fulfil sentiment classification. The result of sentiment classification can be applied to many fields such as prediction of changes in market conditions (Yu et al., Citation2021), consumer decision-making (Dai & Wang, Citation2021), corporate crisis public relations, and the monitoring of social public opinion by relevant government departments (Xu et al., Citation2019). Therefore, performing tendency analysis on Weibo comments (Tang et al., Citation2012), and thus completing the sentiment classification of Weibo comments (Qiu et al., Citation2021), are currently important research tasks for most researchers conducting sentiment calculation of Chinese information.
Weibo comments have the characteristics of short length (Zhang et al., Citation2017a), diverse content forms (Zhang, Hu, Zhu, Jin, & Li, Citation2021b), strong opinions, colloquial expression (Zhang, Zhu, & Xu, Citation2017b), and lack of context information (Zhang, Liu, Deng, Xu, & Choo, Citation2018a), that increase the difficulty of sentiment classification. There are various forms of expression in Weibo comments, such as emoticons (Cao et al., Citation2021), network neologisms, negatives, degree adverbs, inter-sentence rules, and organisational structure, that also can affect the accuracy of sentiment classification. Among them, the organisational structure of Weibo comments is often overlooked. Most standard datasets for sentiment classification of Weibo comments usually have only two columns of data, which are described as “Review” and “Label”. “Review” is the column heading of the comments data, while “Label” is the manually labelled column heading of the sentiment classification. Those research focused on calculating the value of the “Review” column and then matching it with the value of the “Label” column, but this approach ignores the organisational structure of these comments in reality. Actually, Comments on Weibo are usually ranked in order of popularity and represented in a tree structure, and not all of the comments are on the topic, they also include comments information on comments, that would lead to a mistake in classifying sentiment. For example, when User-A gives the comment “This blog post is awful, it's a mess!” and then User-B gives a comment that says “Great, I totally agree with you!” by “Reply to User-A”, most sentiment classification algorithms will judge User-B's comment as positive, but it should be classified as negative, depending on how these comments are organised in reality.
This paper proposes a method for sentiment classification of Weibo comments based on the extended sentiment dictionary, inter-sentence rule and organisational structure rule, as shown in Figure .
Figure 1. Sentiment classification method for Chinese Weibo comments incorporating.
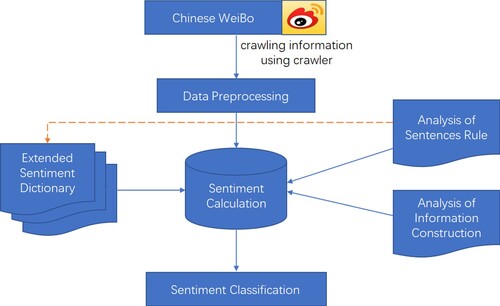
Figure depicts a schematic diagram of sentiment classification by fusing the extended sentiment dictionary and the organisational structure of Weibo comments. Firstly, the targeted data sets of comments from Weibo were collected, mainly consisting of a positive-oriented data set, a negative-oriented data set and a more controversial data set. Secondly, these data are pre-processed, including separating emoticons and sentences from the original comments and segmenting sentences. Finally, the weights of words and sentences were calculated and the comments were classified according to different rules.
The main points of the contribution in this paper are as follows.
Extensions to the basic sentiment dictionary. Multiple sentiment dictionaries are one of the key factors to effectively solve the complexity of Chinese semantics, and there are seven sentiment dictionaries used in this method. A variety of extended dictionaries have been added to the basic sentiment dictionary, including a dictionary of emoticons, a dictionary of network neologisms, a dictionary of negation words, a dictionary of degree adverbs, a dictionary of declared words, and a dictionary of relational conjunctions.
The construction of two rule sets. An inter-sentence rule set was constructed for the relationship between the sentences of a segmented Weibo comment, and an organisational structure rule set was constructed for the organisational structure of Weibo comments. Both rule sets can improve the accuracy of sentiment classification to a certain extent.
A sentiment classification method for Chinese Weibo comments that incorporates sentiment dictionary and organisational structure of comments. By crawling relevant data, processing data cleaning, and then matching dictionaries as well as rule sets, the weight of sentiment words is calculated and sentiment classification is performed.
2. Related work
In this section, we briefly review two aspects of the related work including dictionary-based text sentiment classification and machine learning-based text sentiment classification (Hashimoto et al., Citation2012).
2.1. Dictionary-based sentiment classification
Before the popularity of machine learning, semantic sentiment analysis based on dictionaries was the mainstream method of sentiment computing. Most of these methods are based on the rearranged sentiment dictionary or the rules between words to judge the emotional tendency, especially using the extended dictionary of seed words and domain words for matching calculation (Shi et al., Citation2013).
Based on the basic sentiment dictionary, Zhao et al. (Citation2016) added the analysis and expansion of Weibo expression elements and then set the calculation rules by weighting Weibo expression elements and text sentiment elements to complete Weibo sentiment calculation, which improved the sentiment judgment results of Weibo comments information with expression elements to a certain extent. Zhang, Wei, Wang, and Liao (Citation2018b) used the sentiment dictionary of Dalian University of technology as the basic dictionary, and then extended it by adding related domain dictionaries, such as Internet words, emoticons, etc., finally, the sentiment extremum of Weibo comments information is calculated by transforming the unified weight to complete the sentiment classification of Weibo comments information. Zhu and Li (Citation2020) proposed a method to analyze the sentiment of Chinese Weibo based on semantic rules and weighted expressions, that completed the sentiment classification of Chinese Weibo comments effectively. Qiu et al. (Citation2020) constructed a new expression-based Chinese sentiment dictionary for sentiment classification of Chinese pop-up messages, specifically targeting the heavily used facial expressions that appear in Chinese pop-up messages, improving the accuracy of sentiment classification within this domain, while considering the role of Chinese tone words in semantic expressions and enhancing the overall effectiveness of pop-up sentiment classification. Wan and Du (Citation2020) proposed a fine-grained sentiment classification model incorporating sentiment dictionaries and semantic rules. By expanding sentiment dictionaries and analyzing the text semantic rules, fine-grained analysis of text sentiment was achieved and the accuracy of sentiment classification was improved. Liu et al. (Citation2020) constructed a new sentiment scoring method based on traditional sentiment classification methods, which can classify user categories into VIP users and Normal users according to the number of their followers. And then, a custom social relationship influence coefficient is derived, by combining the number of current users followed and the number of that user's own being followed. Finally, a short text sentiment score is calculated using the social relationship influence coefficient and the SentiWordNet dictionary to derive sentiment tendencies.
2.2. Machine learning-based sentiment classification
Machine learning-based sentiment classification mostly uses supervised learning methods (Li et al., Citation2020), so these methods require manual labelling of text sentiment data with various categories, such as “positive”, “negative” and other classification labels to build a training data set. The machine can learn a model based on the training set and then use the model on the test set to get text classification results.
Li (Citation2020) completed the sentiment classification of Chinese topic texts by constructing a word vector matrix using Word2Vec and training the labelled samples based on a plain Bayesian approach to efficiently train the text classifier. Then the sentiment knowledge graph was constructed based on the classified sentiment texts, and the dominant core nodes were analyzed. These works provide a new research model for the study of sentiment mapping in social media. Zhang, Ma, Zhou, and Guo (Citation2021a) completed the positive and negative Chinese sentiment classification by using the Chinese natural language processing tool SnowNLP to extract the sentiment tendency of the information generated by COVID-19 in Weibo, then the text corpus was clustered and analyzed based on the Single-Pass clustering algorithm to explore the hot topics of the epidemic, and finally, the Louvain association discovery algorithm was used to achieve information mining of public opinion. Liang et al. (Citation2020) first used multiple methods to cleanse the data and then applied the support vector machine classification algorithm to the sentiment classification of Weibo. This method was effective in improving the performance of Weibo sentiment classification. Rahat et al. (Citation2019) did the same extensive pre-processing work on the dataset and then performed text classification operations, by using support vector machines and Naive Bayes. Li et al. (Citation2017) proposed a novel hybrid learning model for Chinese Weibo sentiment classification, which first computes the sentiment score of the entire dataset using an improved Chinese-oriented sentiment dictionary classification method, and then labels the data using a combined support vector machine and KNN classification method to enhance the discriminative power of the selected features effectively.
The above content in this section shows that sentiment classification of Chinese Weibo comments is constantly evolving and improving (Dai et al., Citation2020), it is also very rewarding to use various methods to accomplish sentiment classification (Zhang et al., Citation2016). Considering that the effect of comment organisational structure on the accuracy of sentiment classification is rarely mentioned, this paper gives the comparative approach in the next section.
3. The proposed model
3.1. Extending the dictionary
Using sentiment dictionary (Wang & Alfred, Citation2020) for Chinese sentiment classification (Zhu et al., Citation2020) is an effective method, but there is no universally accepted and well-established dictionary in China. Therefore, the construction of a relatively well-established dictionary for the data of Chinese Weibo, has been a hot topic of research in the area of Chinese sentiment classification (Zhang et al., Citation2020). This section constructs a multi-perspective extended set of sentiment dictionaries (Wang et al., Citation2020), extends the basic dictionary, and then uses it to perform sentiment computation and complete sentiment classification.
3.1.1. Basic sentiment dictionary
A basic sentiment dictionary is an essential part of sentiment classification and it can help researchers get into work more quickly without more effort. There are several commonly used Chinese basic sentiment dictionaries, HowNet (Xu et al., Citation2015), BosonNLP (Tao et al., Citation2019) with sentiment scoring, and Dalian University of Technology Chinese Sentiment Dictionary (Liu & Chen, Citation2015). The basic sentiment dictionary used in this paper is from the Dalian University of Technology Chinese Sentiment Dictionary, it Contains 27466 commonly used Chinese sentiment words. These sentiment words were manually annotated and divided into three categories: neutral words, positive words, and negative words (Zhu et al., Citation2020b). In the sentiment dictionary, neutral words are identified by 0, positive words are identified by 1, negative words are identified by 2, and words that may have both positive and negative aspects in certain contexts by are identified 3. The intensity of sentiment words is divided into five levels: 1, 3, 5, 7, and 9, with increasing intensity of sentiment polarity indicated. To facilitate the subsequent uniform calculation of sentiment values, we modify polarity and intensity by changing polarity*intensity to weight. The example of a specific basic sentiment dictionary is shown in Table .
Table 1. Example of the basic sentiment dictionary.
In Chinese sentiment classification, the classification of neutral words is complex and not very informative, so this paper focuses on positive comments and negative comments from Weibo. In a common operation of Chinese sentiment calculation (Pang et al., Citation2012), First, perform word segmentation operation on a Weibo comment, and store the result of word segmentation into a set named by S. When the word that needs to be calculated appears in the basic sentiment dictionary, its respective sentiment value
can be expressed as:
, where
is the relative weight value of
in the sentiment dictionary. The steps of performing a sentiment calculation using a basic sentiment dictionary are shown in Algorithm 1.
3.1.2. Weibo emoticons dictionary
The Weibo emoticons dictionary is mainly constructed using the built-in emoticons provided on the Weibo platform (Wang, Citation2020). When posting a Weibo comment, the user clicks on the “ ” directory to display the corresponding built-in emoticons. In this paper, some emojis that are used relatively frequently in the mobile Weibo app were selected to build the emoticons dictionary. Relatively repetitive emojis are removed because some emojis are different but have similar meanings. The 132 emojis were retained and divided into five categories according to their meanings, and each category was reassigned a respective weight in the sentiment calculation. The example of Weibo emoticons dictionary is shown in Table .
” directory to display the corresponding built-in emoticons. In this paper, some emojis that are used relatively frequently in the mobile Weibo app were selected to build the emoticons dictionary. Relatively repetitive emojis are removed because some emojis are different but have similar meanings. The 132 emojis were retained and divided into five categories according to their meanings, and each category was reassigned a respective weight in the sentiment calculation. The example of Weibo emoticons dictionary is shown in Table .
Table 2. Example of Weibo emoticons dictionary.
3.1.3. Network neologisms dictionary
With the development of the Chinese online language, new words for the representation of online emotions (Zhu et al., Citation2020a) have emerged. When these words or characters are present in a sentence that does not conform to the Chinese expression regulations, it will seriously affect the effectiveness of the division of the latter sentence. For example, when a comment, “This ball is 666!” appears in a report on a football match, it may mean that the pass or shot was well-performed and was appreciated by the commenter, so the comment should be classified as positive. But if it is understood from a computer perspective, it will be interpreted as the price of this ball is 666, resulting in this comment may turn out to be neutral. Therefore, it is necessary to build a network neologisms dictionary by collecting common internet words to make some necessary conversions and substitutions for these special words. In this paper, 135 new internet words were obtained by searching for the keywords “latest internet words in 2020” and “commonly used internet words”. These words were divided into four classes and given corresponding weights to calculate a uniform sentiment tendency. The example of network neologisms dictionary is shown in Table .
Table 3. Example of network neologisms dictionary.
3.1.4. Negative words dictionary
Because of the peculiarities of Chinese, negation can be expressed in two ways: the first is a negative word, such as “not” etc., which can be very intuitive to the word it modifies, and the other is a rhetorical word, such as “why not” etc., which can present negation from another perspective. Both of these alter the polarity of the phrase being modified, adding to the complexity of the sentiment classification so that treatment of this part is necessary. In the negation words dictionary, the collection of negation is made up of 71 negation words and 12 rhetorical words, which are specially compiled for dealing with Chinese messages. Considering that both of these words can change the sentiment tendency of a sentence, we set the weighting multiplier of the negative words to −1 and set the weighting multiplier of rhetorical words to −2, depending on the intensity of the expressed tone. The example of negative words dictionary is shown in Table .
Table 4. Example of negative words dictionary.
3.1.5. Degree adverbs dictionary
The degree adverb plays an emphatic role in Chinese commentary. For example, a comment “Your opinion is good” becomes “Your opinion is very good” after adding the degree adverb “very”, the sentiment value of the latter sentence must be sensorially greater than that of the former, so setting the appropriate degree adverb weight is the key to building a dictionary of degree adverbs. This paper uses the degree adverbs dictionary from HowNet, which classifies degree adverbs into a total of four categories, and then resets the weight multipliers of degree adverbs, setting the intensity multipliers of the four categories to 3x, 2x, 1x, and 0.5x for the sentiment word they modify. The example of degree adverbs dictionary is shown in Table .
Table 5. Example of degree adverbs dictionary.
3.1.6. Declared words dictionary
Declared words can strengthen the tone of voice and indicate stronger emotions. In this paper, the declared words dictionary is used from CNKI, in which there are two categories of declared words and a total of 35 on the data. The example of declared words dictionary is shown in Table .
Table 6. Example of declared words dictionary.
3.1.7. Relational conjunctions dictionary
Relational conjunctions connect two sentences and play a progressive and turning role in the two sentences, it can operate the calculation of sentiment between sentences. The sentiment polarity of two sentences in a Weibo comment message is sometimes the same as a progressive relationship, and sometimes the opposite as a turning relationship. The relational conjunctions in the commonly used Weibo comment messages were extracted and the resulting relational conjunctions were divided into two parts, progressive relationship, and turning relationship. Relational conjunctions are used in inter-sentence rules by determining whether the word appearing in the comment message is a pre-connector or a post-connector. The example of relational conjunctions dictionary is shown in Table .
Table 7. Example of relational conjunctive dictionary.
3.2. Inter-sentence rules
A Weibo comment can be divided into several sentences by separators, and we can choose the rules for calculating sentiment values among the sentences by setting inter-sentence rules. This paper considers only two common inter-sentence relations: turning relationship and progressive relationship, by using the relational conjunctions dictionary for the effective calculation of relations among sentences. The set {S(0), S(1), … , S(j) … } is defined as the set of sentences, and VS(j) denotes the sentiment weight computed for sentence S(j).
3.2.1. Rules of turning relationship
A turning relationship generally indicates a flip in sentiment between the preceding and following sentences, where the information in the preceding sentence is used primarily to highlight the information in the sentence that appears subsequently. We define the rules of calculation as follows:
If there is a turning preposition appears in sentence S(j), such as “although”, the sentence weight VS(j) of S(j) is set to 0, and the sentiment value of sentence S(j+1) is continued.
If there is a turning suffix appears in sentence S(j), such as “but”, so the weight VS(j-1) of sentence S(j-1) needs to be subtracted.
3.2.2. Rules of progressive relationship
In contrast to turning relationship, progressive relationship generally indicates a progressive increase in the sentiment of the preceding and following sentences. Considering the overall composition of the comment message, here we define the rules for calculating progressive relationship as follows: If there is progressive conjunction appears in a sentence such as “moreover”, the weight of the sentence S(j) is set to 1.5x.
Algorithm 2 is described as follows. Step 0 is the pre-processing of the input Weibo comment, including the extraction of Weibo emoticons, the processing of Weibo comment content that is divided into some sentences stored into the set R by separators and relational conjunctions. In step 1, the sentiment value of the word in the sentence is denoted by Vi, the sentiment value of the sentence is denoted by V(j), and V denotes the sentiment value of the Weibo comment. Step 2 uses the word splitting tool to split the sentences in the set R and store the n-words into the set S after splitting the sentences. Steps 3–44 describe the sentiment calculation process, adding the calculation of the elements in the set R in each extended sentiment dictionary and the calculation of the inter-sentence rule set. Steps 45–50 complete the determination of sentiment tendencies for the values of V. For the time complexity of algorithm 2, that can be expressed as O(n3).3.3. Description of the organisational structure of comments
It was found that the organisational structure of comments on Weibo was hierarchical in the research. When someone posts a personal blog on a hot topic, comments appear below it, and these comments are displayed in a tree structure, as shown in Figure .
Figure 2. Organisational structure of the comments.
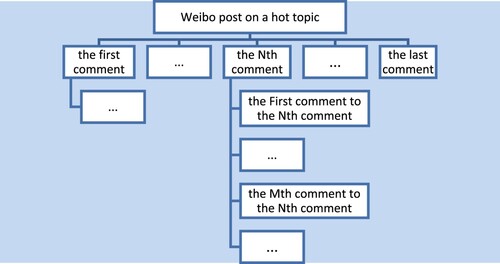
In most Chinese sentiment classification processes, all comments are extracted, and then the sentiment data is calculated and classified according to the corresponding matching rules for the comment information, however, such processing may result in some mistakes. For example, the Nth comment is, “This blog post is awful, it's a mess!”. Then, the first comment to the Nth comment is, “Good point, I agree with you totally!”. The sentiment classification of the Nth comment at this time can generally be classified as a negative tendency. If the structure of the comment message is not considered, the next comment will be classified in the positive tendency, thus generating an error. In this paper, the interference arising from the organisational structure of Weibo comments is corrected by using Algorithm 3, which was shown below.
Algorithm 3 is described as follows. Step 0 is the pre-processing of the input Weibo comment, add the building owner tag and the value of it to each comment message based on Algorithm 2’s pre-processing. In step 1, V denotes the sentiment value of the Weibo comment. In steps 2–8, determine if the username and the building owner tag are the same. If the field values are the same, the calculated value is placed in the sentiment value field denotes as Vu, and it is also placed in the added field value denoted as Vd. If the field values are different, the calculated value is simply placed in the sentiment value field and denotes as Vu. In steps 9–14, rules are set to process the values of the two fields to complete the correction of the sentiment values. Steps 15–20 complete the determination of sentiment tendencies for the values of V. For the time complexity of algorithm 3, that can be expressed as O(n3).4. Experiment
4.1. Experimental methods
In this section, three algorithms are used to classify the sentiment of Chinese Weibo comments, and then the effect of classification is analyzed. Algorithm 1 used only the basic sentiment dictionary from Dalian University of Technology, algorithm 2 additionally extended the sentiment dictionary and inter-sentence rules, and in algorithm 3, the influence of organisational structure is considered and modified for different situations in the calculation of sentiment weight. The experimental steps are as follows:
Experimental data acquisition. The crawler software “Octopus Collector” was used to crawl the data of three topics on Weibo: “#How harmful is it to your body if you sleep late all the time#”, “#How important is it for women to make money after marriage#” and “#Is it reliable to find a date on social networking apps#”. These data were pre-processed by three different algorithms.
Manual labelling of affective polarity. To verify the accuracy of the algorithm, We organised a pre-processing of the three topics by the subject members. In this work, the sentiment was also labelled using a manual labelling method, divided into three levels, positive, neutral, and negative.
Different algorithms are used to calculate the sentiment weights of the comments on Weibo, determine their sentiment tendency.
4.2. Experimental results and discussion
The following experiments were conducted for the three topics according to the experimental steps described in section 4.1.
Experiment 1: The sentiment weights were calculated using algorithm 1, algorithm 2, and algorithm 3 for 1371 Weibo comments on the topic #How harmful is it to your body if you sleep late all the time#, and the experimental results are shown in Figure .
Figure 3. Accuracy of the topic #How harmful is it to your body if you sleep late all the time#.
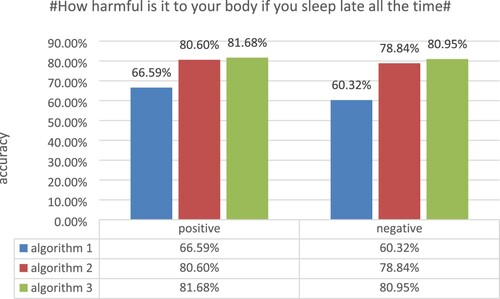
From the results of experiment 1, it is clear that the classification accuracy of the Weibo comments with the topic #How harmful is it to your body if you sleep late all the time# can be seen with the three algorithms. For the positive classification accuracy, algorithm 1 achieves 66.59%, algorithm 2 achieves 80.60% and algorithm 3 achieves 81.68%. For the negative classification accuracy, algorithm 1 achieves 60.32%, algorithm 2 achieves 78.84% and algorithm 3 achieves 80.95%. The data from experiment 1 shows that each improvement in the algorithm has improved the classification accuracy of this dataset to some extent.
Experiment 2: The sentiment weights were calculated using algorithm 1, algorithm 2, and algorithm 3 for 967 Weibo comments on the topic #How important is it for women to make money after marriage#, and the experimental results are shown in Figure .
Figure 4. Accuracy of the topic #How important is it for women to make money after marriage#.
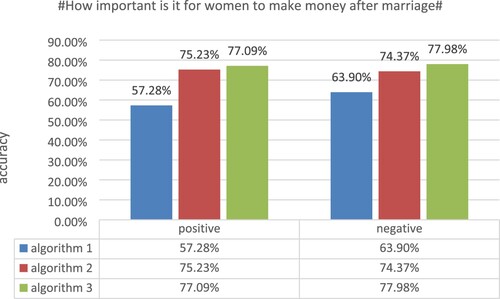
From the results of experiment 2, it is clear that the classification accuracy of the Weibo comments with the topic #How important is it for women to make money after marriage# can be seen with the three algorithms. For the positive classification accuracy, algorithm 1 achieves 57.28%, algorithm 2 achieves 75.23% and algorithm 3 achieves 77.09%. For the negative classification accuracy, algorithm 1 achieves 63.90%, algorithm 2 achieves 74.37% and algorithm 3 achieves 77.98%. The data from experiment 2 shows that each improvement in the algorithm has improved the classification accuracy of this dataset to some extent.
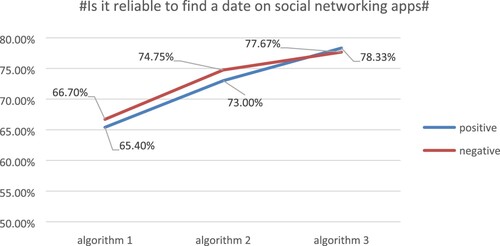
Experiment 3: The sentiment weights were calculated using algorithm 1, algorithm 2, and algorithm 3 for 1934 Weibo comments on the topic #Is it reliable to find a date on social networking apps#, and the experimental results are shown in Figure .
Figure 5. Accuracy of the topic #Is it reliable to find a date on social networking apps#.
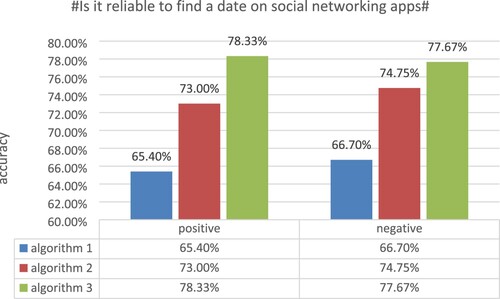
From the results of experiment 3, it is clear that the classification accuracy of the Weibo comments with the topic #Is it reliable to find a date on social networking apps# can be seen with the three algorithms. For the positive classification accuracy, algorithm 1 achieves 65.40%, algorithm 2 achieves 73.00% and algorithm 3 achieves 78.33%. For the negative classification accuracy, algorithm 1 achieves 66.70%, algorithm 2 achieves 74.75% and algorithm 3 achieves 77.67%. The data from experiment 3 shows that each improvement in the algorithm has improved the classification accuracy of this dataset to some extent.
The comparison between algorithm 1 and algorithm 2 in the three graphs (Figures ) shows that using only the basic sentiment dictionary for sentiment classification of Weibo comments is less accurate, as the text in Weibo is constantly evolving and it is necessary to expand the sentiment dictionary. Also, considering the complexity of Chinese, the inter-sentence rules need to be constantly subdivided and improved.
It was found in research that the accuracy improvement results of these data derived from comparing algorithm 2 and algorithm 3 differed across the data sets, as shown in Figures .
Figure 6. Topic #How harmful is it to your body if you sleep late all the time# accuracy comparison.
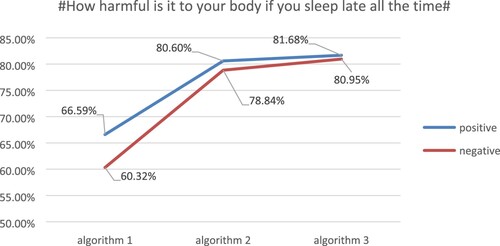
Figure 7. Topic # How important is it for women to make money after marriage# accuracy comparison.
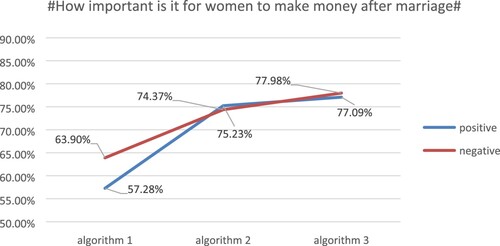
Figure 8. Topic # Is it reliable to find a date on social networking apps# accuracy comparison.
The dataset for the first set of experiments came from the topic # How harmful is it to your body if you sleep late all the time#, which had a majority of positive comment messages. The increase in positive comments in algorithm 3 came mainly from negative misjudgments, while the negative messages were underrepresented, and thus its accuracy rate only increased from 80.60% to 81.68%. The low number of negative information also leads to no significant improvement in the accuracy of negative information, which only increased from 78.84% to 80.95%.
The second experimental dataset came from the topic # How important is it for women to make money after marriage#. The proportion of positive and negative comments in the labelled comment messages was about the same, and the complexity increased, making the overall judgment more difficult, and the accurate recognition rates of positive and negative sentiment judgments improved by 1.86% and 3.61% respectively.
The third dataset, from the topic #Is it reliable to find a date on social networking apps#, had more negative comments among the annotated comment messages, so algorithm 3 made more corrections to the classification of the comment messages, resulting in an increase of 5.33% and 2.92% for positive and negative comments, respectively.
In summary, algorithm 3 proposed in this paper is relatively insensitive to a high proportion of positive comment data information, as well as relatively balanced positive and negative comment information, but it has good results in correcting negative comment information. We also note that the accuracy of positive topics is identified relatively high, while the accuracy of identification is low when there are more controversial or negative comments.
4.3. Feasibility of the method
In the description of algorithm 3 in Section 3.3, the time complexity of the algorithm is expressed as O(n3), which does not seem satisfactory. In this algorithm, a Weibo comment is first divided into several sentences, and then each sentence is cut into several words. Considering the special limitation of Chinese Weibo comments, where each comment message contains at most 140 characters, the above processing does not take much time. The data set selected in experiment 3 was tested with different data sizes, and the results are shown in Table .
Table 8. Running time of method.
The Top N pieces of data are selected from the 1934 Weibo messages on the Weibo topic #Is it reliable to find a date on social networking apps#, and the value of N is displayed in the 1st column. Five round tests were performed for each data volume, resulting in the running times shown in columns 2–6. In the last column, an average processing time is calculated for each Weibo comment and it can be seen that the average processing time is less than 0.01 s. (The CPU of the test environment is 11th Gen Intel(R) Core(TM) i5-1135G7 2.40 GHz, and the memory capacity is 16GB.) This processing time meets the requirements of a real-time application.
From the last row in the table, we can also see that this method takes more than 12 s to process nearly 2000 pieces of data, so this method is still lacking when processing large-scale data.
5. Conclusion and future work
Chinese Weibo comments contain a large number of sentiment elements which can be mined and provided for many applications, such as opinion analysis and information prediction, etc.
Considering the incompleteness of the sentiment dictionary leading to poor classification accuracy, and the organisational structure of Weibo comments leading to misclassification, this paper did three works for the Weibo comments sentiment classification task. (1) On the basis of the basic sentiment dictionary, another six dictionaries were constructed to complete the extension of the sentiment dictionary, including the declared words dictionary rarely mentioned in other research. (2) Considering the interrelationship of sentences in Weibo comments, rules for inter-sentence are defined; considering the organisational structure of Weibo comments, rules for the modification of comment tendencies are defined. (3) By crawling Weibo comments data, conducting data pre-processing and comparison experiments on three topics, a Chinese Weibo comments sentiment classification model integrating sentiment dictionary and organisational structure of Weibo comments was designed. The comparison experiments proved the effectiveness of the model, especially for the correction of negative comments.
There is still much space for improvement in dictionary-based Weibo sentiment classification research, such as the setting of weights in defining the dictionary, more detailed corrections in structural features, fine-grained sentiment classification, and so on. The next step in the work could also be to consider dictionaries combined with machine learning or deep learning to improve accuracy.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Cao, Z., Zhou, Y., Yang, A., & Peng, S. (2021). Deep transfer learning mechanism for fine-grained cross-domain sentiment classification. Connection Science, 33(4), 911–928. https://doi.org/10.1080/09540091.2021.1912711
- Dai, Y., & Wang, T. (2021). Prediction of customer engagement behaviour response to marketing posts based on machine learning. Connection Science, 33(4), 891–910. https://doi.org/10.1080/09540091.2021.1912710
- Dai, Y., Wang, Y., Xu, B., Wu, Y., & Xian, J. (2020). Research on image of enterprise after-sales service based on text sentiment analysis. International Journal of Computational Science and Engineering, 22(2/3), 346–354. https://doi.org/10.1504/IJCSE.2020.107367
- Hashimoto, T., Chakraborty, B., & Shirota, Y. (2012). Social media analysis – determining the number of topic clusters from buzz marketing site. International Journal of Computational Science and Engineering, 7(1), 65–72. https://doi.org/10.1504/IJCSE.2012.046181
- Jia, R., Li, R., & Gao, M. (2019). Study on data sparsity in social network-based recommender system. International Journal of Computational Science and Engineering, 20(1), 15–20. https://doi.org/10.1504/ijcse.2019.103245
- Li, F., Wang, H., Zhao, R., Liu, X., Wang, Y., & Zou, B. (2017). Chinese micro-blog sentiment classification through a novel hybrid learning model. Journal of Central South University, 24(10), 2322–2330. https://doi.org/10.1007/s11771-017-3644-0
- Li, J. (2020). A study on the sentiment map of university opinion users in social media: An example of “anti-academic misconduct” topic on sina weibo. Intelligence Science, 38(7), 100–104. https://doi.org/10.13833/j.issn.1007-7634.2020.07.014
- Li, J., Ren, T., & Lu, L. (2020). A comparative study of text big data mining methods for visitor sentiment computing. Journal of Zhejiang University (Science Edition), 47(4), 507–520. https://doi.org/10.3785/j.issn.1008-9497.2020.04.014
- Liang, Y., Liu, H., & Zhang, S. (2020). Micro-blog sentiment classification using Doc2vec + SVM model with data purification. The Journal of Engineering, 2020(13), 407–410. https://doi.org/10.1049/joe.2019.1159
- Liu, S., & Chen, J. (2015). A multi-label classification based approach for sentiment classification. Expert Systems with Application, 42(3), 1083–1093. https://doi.org/10.1016/j.eswa.2014.08.036
- Liu, S., Wang, L., Wu, J., & Xu, L. (2020). A short text sentiment analysis method based on social relationship enhancement. Journal of Wuhan University (Engineering Edition), 53(9), 838–846. https://doi.org/10.14188/j.1671-8844.2020-09-013
- Pang, L., Li, S., & Zhou, G. (2012). Sentiment classification method of Chinese micro-blog based on emotional knowledge[J]. Computer Engineering, 38(13), 156–158. https://doi.org/10.3969/j.issn.1000-3428.2012.13.046
- Qiu, L., Sai, S., & Tian, X. (2021). TsFSIM: A three-step fast selection algorithm for influence maximisation in social network. Connection Science, 33(4), 854–869. https://doi.org/10.1080/09540091.2021.1904206
- Qiu, Q., Cui, Z., & Yu, J. (2020). Emotion dictionary based on expression and one for popup sentiment analysis. Computer Technology and Development, 30(8), 178–182. https://doi.org/10.3969/j.issn.1673-629X.2020.08.031
- Rahat, A. M., Kahir, A., & Masum, A. (2019). Comparison of Naive Bayes and SVM Algorithm based on Sentiment Analysis Using Review Dataset. 2019 8th International Conference System Modeling and Advancement in Research Trends (SMART) (pp. 266-270). https://doi.org/10.1109/SMART46866.2019.9117512
- Shi, W., Wang, H., & He, S. (2013). Sentiment analysis of Chinese microblogging based on sentiment ontology: A case study of ‘7.23 wenzhou train collision’. Connection Science, 25(4), 161–178. https://doi.org/10.1080/09540091.2013.851172
- Tang, J., Zhang, Y., Sun, J., Rao, J., & Yu, W. (2012). Quantitative study of individual emotional states in social networks. IEEE Transactions on Affective Computing, 3(2), 132–144. https://doi.org/10.1109/T-AFFC.2011.23
- Tao, Y., Zhang, F., Shi, C., & Chen, Y. (2019). Social media data-based sentiment analysis of tourists’ Air quality perceptions. Sustainability, 11(18), 5070. https://doi.org/10.3390/su11185070
- Wan, Y., & Du, Z. (2020). Fine-grained sentiment analysis of microblog comments by fusing sentiment lexicon and semantic rules. Intelligence Inquiry, no. (11), 34–41. https://doi.org/10.3969/j.issn.1005-8095.2020.11.005.
- Wang, D., & Alfred, R. (2020). A Review on Sentiment Analysis Model for Chinese Weibo Tex. International Conference on Advanced Electronic Materials, Computers and Software Engineering (pp. 456-463). http://doi.org/10.1109/AEMCSE50948.2020.00105
- Wang, Q., Zhu, G., Zhang, S., Li, K., Chen, X., & Xu, H. (2020). Extending emotional lexicon for improving the classification accuracy of Chinese film reviews. Connection Science, 33(2), 153–172. https://doi.org/10.1080/09540091.2020.1782839
- Wang, Y. (2020). Iteration-based naive Bayes sentiment classification of microblog multimedia posts considering emoticon attributes. Multimedia Tools and Applications, 79(27a28), 19151–19166. https://doi.org/10.1007/s11042-020-08797-7
- Xu, G., Yao, H., Wu, D., Li, Y., Ouyang, D., & Chen, G. (2019). Public opinion classification and text alignment based on Chinese and Tibetan corpus. Cluster Computing, 22(S4), 10263–10274. https://doi.org/10.1007/s10586-017-1267-8
- Xu, J., Liu, J., & Zhang, Y. (2015). Word similarity Computing based on hybrid hierarchical structure by HowNet. Journal of Information Recording, 31(6), 2089–2101. https://doi.org/10.6688/JISE.2015.31.6.15
- Yu, L., Duan, Y., & Li, K. (2021). A real-world service mashup platform based on data integration, information synthesis, and knowledge fusion. Connection Science, 33(3), 463–481. https://doi.org/10.1080/09540091.2020.1841110
- Zhang, C., Ma, X., Zhou, Y., & Guo, R. (2021a). Analysis of the evolution of public opinion on the new crown epidemic based on user sentiment changes. Journal of Geoinformation Science, 23(2), 341–350. https://doi.org/10.12082/dqxxkx.2021.200248
- Zhang, S., Du, Y., & Lu, K. (2016). A dynamic window split-based approach for extracting professional terms from Chinese courses. International Journal of Computational Science and Engineering, 12(4), 341–351. https://doi.org/10.1504/IJCSE.2016.076948
- Zhang, S., Hu, Z., Zhu, G., Jin, M., & Li, K. (2021b). Sentiment classification model for Chinese micro-blog comments based on key sentences extraction. Soft Computing, 25(1), 463–476. https://doi.org/10.1007/s00500-020-05160-8
- Zhang, S., Liu, W., Deng, X., Xu, Z., & Choo, K. R. (2018a). Micro-blog topic recommendation based on knowledge flow and user selection. Journal of Computational Science, 26, 512–521. https://doi.org/10.1016/j.jocs.2017.10.021
- Zhang, S., Wei, Z., Wang, Y., & Liao, T. (2018b). Sentiment analysis of Chinese micro-blog text based on extended sentiment dictionary. Future Generations Computer Systems, 81, 395–403. https://doi.org/10.1016/j.future.2017.09.048
- Zhang, S., Zhang, S., Yen, N. Y., & Zhu, G. (2017a). The recommendation System of micro-blog topic based on user clustering. Mobile Networks & Applications, 22(2), 228–239. https://doi.org/10.1007/s11036-016-0790-9
- Zhang, S., Zhu, H., & Xu, Z. (2017b). The extraction method of new logining word/term for social media based on statistics and n-increment. Journal of Ambient Intelligence and Humanized Computing. https://doi.org/10.1007/s12652-017-0638-6
- Zhang, Y., Sun, J., Meng, L., & Liu, Y. (2020). Sentiment analysis of e-commerce text reviews based on sentiment dictionary. IEEE International Conference on Artificial Intelligence and Computer Applications (pp. 1346-1350). http://doi.org/10.1109/ICAICA50127.2020.9182441
- Zhao, T., Yao, H., Fang, C., Zhang, J., & Zhang, P. (2016). Micro blog emotion analysis method based on the integration of semantic rules and expression weighting. Journal of Chongqing University of Posts and Telecommunications (NATURAL SCIENCE EDITION), 28(4), 503–510. https://doi.org/10.3979/j.issn.1673-825X.2016.04.010
- Zhu, G., Liu, W., Zhang, S., Chen, X., & Yin, C. (2020a). The method for extracting new login sentiment words from Chinese micro-blog based on improved mutual information. International Journal of Computer Systems Science and Engineering, 35(3), 223–232. https://doi.org/10.32604/csse.2020.35.223
- Zhu, G., Wang, Q., Liu, H., & Zhang, S. (2020b). The mining method of trigger word for food nutrition matching. International Journal of Computational Science and Engineering, 23(3), 205–213. https://doi.org/10.1504/IJCSE.2020.111423
- Zhu, H., Yin, X., Zhang, S., Wei, Z., Zhu, G., & Hsieh, M. (2020). A discovery method for new words from mobile product comments. Computer Systems Science and Engineering, 35(6), 399–410. https://doi.org/10.32604/csse.2020.35.399
- Zhu, J., & Li, W. (2020). Sentiment analysis of Chinese microblogs based on semantic rules and expression weighting. Journal of Light Industry, 35(2), 74–82. https://doi.org/10.12187/2020.02.010W