
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
With the development of deep learning, neural networks are widely used in various fields, and the improved model performance also introduces a considerable number of parameters and computations. Model quantisation is a technique that turns floating-point computing into low-specific-point computing, which can effectively reduce model computation strength, parameter size, and memory consumption but often bring a considerable loss of accuracy. This paper mainly addresses the problem where the distribution of parameters is too concentrated during quantisation aware training (QAT). In the QAT process, we use a piecewise function to statistics the parameter distributions and simulate the effect of quantisation noise in each round of training, based on the statistical results. Experimental results show that by quantising the Transformer network, we lose less precision and significantly reduce the storage cost of the model; compared with the full precision LSTM network, our model has higher accuracy under the condition of a similar storage cost. Meanwhile, compared with other quantisation methods on language modelling task, our approach is more accurate. We validated the effectiveness of our policy on the WikiText-103 and PENN Treebank datasets. The experiments show that our method extremely compresses the storage cost and maintains high model performance.
1. Introduction
The Transformer-based models have surpassed most LSTM-based models in the field of natural language processing. Meanwhile, the recent researches on Transformer network have been widely used in the field of computer vision (Brock et al., Citation2021; Riquelme et al., Citation2021; Zhai et al., Citation2021), and its accuracy in some datasets have approached the model performance of CNN-based network (Ning et al., Citation2021; Ning, Gong, et al., Citation2021; Qi et al., Citation2021). However, Transformer architecture itself has a large number of parameters, which makes it limited in low computational devices. Therefore, in order to trade-off the high-precision and large storage cost of Transformer network and make it enable to be used in low computing power edge devices, many model compression methods under Transformer network include pruning (Dong & Yang, Citation2019; Wang, Wohlwend, et al., Citation2020; Zhu et al., Citation2021) and quantisation (Chung et al., Citation2020; Prato et al., Citation2020; Zhang et al., Citation2020) have been widely explored.
In this paper, we mainly explore the quantisation under the framework of Transformer. This paper explored the problem of decreased model accuracy caused by the over-concentration of model parameters around the mean after quantisation. In this work, we consider quantisation as a kind of noise added to the full precision model parameters; we simulate such noise in the quantisation Aware Training (QAT) to improve the robustness during the model training, as mentioned in Section 3.3. Inspired by Yan et al. (Citation2021), Wang, Li, et al. (Citation2021), Ning, Duan, Li, Shi, et al. (Citation2020), Zhou et al. (Citation2020) and Bai et al. (Citation2018), we introduce a regular term to loss function to quantify the performance of the model in the STE process, as mentioned in Section 3.4. A suitable quantisation method should simultaneously solve the problems of uneven weight distribution after quantisation and the significant performance gap between the full-precision model and which correspond to two contradictory points in the quantisation.
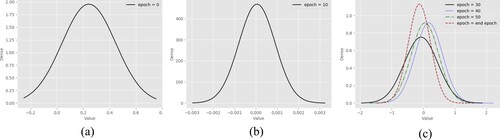
The distribution of the model's parameters during the quantisation-Aware Training has a significant impact on the accuracy of the model. In Han et al. (Citation2016) pointed out that the distribution of the model obeys the Bell distribution and the long-tail distribution instead of the binomial distribution. In Miyashita et al. (Citation2016), activation of the model also obeys this distribution too. Williams (Citation1993) matches the distribution of the model parameters, assigns more quantisation levels (higher resolution) for the peak of the distribution and fewer levels (lower resolution) for the tails. However, during QAT the parameters in the model are often in different distributions at different training stages, as depicted by Figure . Therefore, the training method of the model needs to be dynamically adjusted in the QAT process.
Figure 1. The experimental results show that the model parameters obey different data distributions in different training stages. At the beginning of training (epoch = 0), the model parameters are initialised randomly and follow uniform distribution. At the middle stage of training (epoch = 10), the model parameters follow binomial distribution. After 20 iterations (epoch = 30), model parameters follow a bell-shaped and long-tailed distribution and keep this data distribution until model convergence. (a) Epoch = 0, (b) epoch = 10 and (c) epoch = 30, 40, 50, end epoch.
Reducing the accuracy gap between the quantised model and the corresponding full precision model. In the work of scalar quantisation (Williams, Citation1993), the floating-point parameters in the model are compressed into low dimension space directly, with a significant decline in accuracy. The introduction of QAT class methods like (Jacob et al., Citation2018) solves part of the problem of this accuracy degradation. It regards quantisation as a kind of noise and introduces such noise into all full-precision parameters of the model, to improve the robustness of the quantised. However, the parameter distribution of the model is not taken into account in the above quantisation method. Our method adds quantisation noise to QAT according to the distribution of model parameters, as shown in Figure .To this end, we propose Multi-Distribution Noise (MDN) quantisation to resolve these two contradictories; our contribution can be as follow:
According to the weight distribution of different training stages, a piecewise function is used to quantify the model's subset parameters in the QAT process. In the quantisation process, Iterator Product quantisation (IPQ) (Stock et al., Citation2020) is used to further avoid the parameter concentration near the average value. We set different compression rates for different layers for further accuracy increase.
We introduce a quantised regularisation term into the loss function to make the performance of the quantised model approach that of the full-precision model in the training process.
Experimental results show that our method dramatically reduces the storage cost of the model under the condition of only losing part of the accuracy under the Transformer network. Compared to a full precision model, our approach compresses the model size significantly with only a partial loss of precision, as mentioned in Section 4.3. Meanwhile, our method is a better trade-off between storage costs and model accuracy than other quantisation methods on language modelling task, as mentioned in Section 4.4. In the WikiText-103 dataset, we compressed it to 35.92 M and maintained 19.9 ppl. In the smaller Penn Treebank (PTB) dataset, we achieved a ppl of 41.2 and compressed it to 46.2 M.
Figure 2. Schematic diagram of local quantisation of the model. (a) represents the model weight under full accuracy. (b) demonstrates clipping weight matrix into blocks. (c) represents the quantisation weight of the Product quantisation (PQ) algorithm, where different colours represent different codewords. (d) shows that the random quantisation subset MDN method. (a) Initial weight, (b) weight blocks, (c) weight blocks represent by codewords and (d) weight with distribution noise.

2. Related work
In this section, we first analyse the technical development direction of quantisation and the limitations of various quantisation methods. We summarised the quantisation technology as Post-Training quantisation (PTQ) and quantisation-Aware quantisation (QAT) and reviewed the works closest to ours of these two aspects for a comprehensive overview.
2.1. Quantisation development and limitations
Due to the high storage cost of the full-precision model, it is difficult to migrate to low computational devices (Bai et al., Citation2021; Wang, Wang et al., Citation2021). In Jégou et al. (Citation2011) lower-precision representation replaces used to replace floating-point weights of a trained network. However, when the model parameters compress to fixed-width integers is often accompanied by great model performance degradation. The errors made by these approximations accumulate in the computations operated during the forward pass, inducing a significant drop in performance (Stock et al., Citation2020). The Product Quantiser (PQ) is used to alleviate such errors accumulation (Ge et al., Citation2013; Jegou et al., Citation2010; Norouzi & Fleet, Citation2013; Xu et al., Citation2021), The idea is to decompose the original high-dimensional space into a cartesian product of subspaces that are quantised separately with a joint codebook (Stock et al., Citation2020). However, this type of PQ algorithm often suffers from a large loss of accuracy in models of high complexity, like VGG network (Simonyan & Zisserman, Citation2015), Transformer network (Vaswani et al., Citation2017) and other high storage cost networks (Ning, Ning, Li & Zhang, Citation2020; Ning, Nan et al., Citation2020; Wang, Bai et al., Citation2020). The QAT (Jacob et al., Citation2018) solves this problem and makes quantisation schemes on complex models feasible. Quant-Aware Training simulates low precision representation in the forward pass while updating the full-precision representation of model weights in backpropagation. This makes model parameters more robust to quantisation and makes the model process almost lossless. Due to the characteristics of Transformer's high accuracy and high storage cost, the research on transformer quantification has attracted more and more attention, including Prato et al. (Citation2020), Chung et al. (Citation2020), Bhandare et al. (Citation2019), Bie et al. (Citation2019) and Boo and Sung (Citation2020).
2.2. Post-training quantisation
Post-Training quantisation has gained more and more attention from the industry because it does not require retraining. Recent work (Nagel et al., Citation2019) proposed an offline 8-bit quantisation method that does not need extra data to finetune the recovery accuracy, which makes full use of the sizing equivalent scaling feature of the RELU function to adjust the weight range of different channels, and at the same time, it can correct the deviation introduced in the quantisation process. In Lee et al. (Citation2018), a simple method for channel level distribution recognition is proposed to reduce the loss of accuracy caused by quantisation and minimise the data sample required for analysis. In order to solve the problem of outliers in the distribution of model parameters, Karayiannis (Citation1999) proposes Outlier Channel Splitting, which can reduce the magnitude of outliers without retraining.
2.3. Quantisation-aware training
While Post-Training quantisation can significantly reduce the quantisation time overhead of a model; it also comes with a significant accuracy decrease. To solve this problem, Han et al. (Citation2016) proposed a new quantisation framework, in which the quantisation noise is introduced in the training process to simulate the error caused by the quantisation process. Due to the unstable during quantisation-Aware quantisation easily occurred, Stock et al. (Citation2021) quantised subset of weights randomly, in which most of the weights are updated with unbiased gradients. Zhang et al. (Citation2018) developed LQ-Nets, quantisation model, and quantisation level are trained together instead of fix-point quantisation. This considerably narrowed the gap between the quantised model and the full-precision model. Li et al. (Citation2020) assigned higher resolution around the mean by adding a clipping function so that the quantisation levels can match weights and activations distribution dynamically.
3. Preliminaries
Quantising neural networks In our work, we split the weights in the model into fix-size blocks and use a codebooks to represent quantisation vector. For example, weight matrix , We split W into
blocks
:
(1)
(1) We adopt the algorithm mentioned in Carreira-Perpiñán and Idelbayev (Citation2017) to map the weight matrix into the codebook. Weight matrix was first divided into subvectors, then a codebook with K centroid
was calculated by K-means algorithm, a total of K codewords are used to represent the weight matrix, where K-means algorithm is used to find the clustering centres present in the weight matrix. Each subvector of W was represented by a codeword from codebook with formulation:
(2)
(2) After quantisation, each weight block in weight matrix is represent by a codebook vector indice I, such that
. The blocks in the model is represented by the subvector in the codebook:
(3)
(3) Iterative PQ To prevent the accumulation of errors across layers, Stock et al. (Citation2020) minimised loss reconstruction error for in-domain inputs. The method focuses on the Euclidean distance between the activation values before and after the quantisation instead of the Euclidean distance between the weights before and after the quantisation in tradition PQ (Jégou et al., Citation2011), Codebook
is a training parameter updated by formulation:
(4)
(4) Where
, Loss is the loss function, η is learning rate. By introducing the vector in the codebook into the loss function, the iterative update of the codebook in the process of model backpropagation is introduced.
4. Methods
4.1. Overview
In the training phase of MDN, we refer to the IPQ algorithm to quantise the embedding layer, transformer layer, and fully connected layer in the model layer by layer from bottom to top as shown in Algorithm 1. At the beginning of each training iteration, we construct the codewords of the weight blocks of the unquantised layer and calculate the weight distribution of the codewords corresponding to these blocks. According to this distribution, we introduce a piecewise function to achieve local quantisation under different distributions by adding distribution noise to the unquantised weight as shown in Equation (Equation5(5)
(5) ). A simple visualisation of this computational flow is provided in Figure . Meanwhile, we add a regular term in the loss function to introduce the Euclidean distance between the quantised and pre-trained full-precision weights as shown in Equation (Equation7
(7)
(7) ).

Figure 3. To briefly illustrate the steps of the algorithm, this figure explains the flow of the algorithm when epoch = 1. The model training is divided into a weight pre-processing phase and a forward propagation phase. The pre-processing phase uses the IPQ algorithm to quantise the weights of the specified layers according to the training dataflow, while the codebooks of the unquantised weights are calculated but do not map this unquantised weights into codewords. Instead, the MDN algorithm is used to add quantised noise to the full precision weights so that these layers of weight include both code block and weight itself.
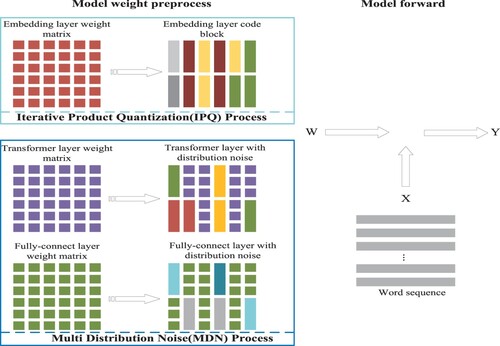
4.2. Multi-distribution noise
Model weight distribution varies considerably under different training stages, this affects the quantisation performance (Zhang et al., Citation2018). We tackle this problem by introducing a piecewise function to judge the different distributions of weights and then introduce noise to the full-precision parameters in the model according to different distributions:
(5)
(5) b represents the code blocks calculated by Equation (Equation3
(3)
(3) ) and the p denotes the dropout rate of the Bernoulli function. The model first initialises and obeys uniform distribution. Hopkin function is used as the judgment condition for the uniform distribution. After that, the model will gradually obey the binomial distribution to the long-tail, bell distribution (Han et al., Citation2016). We introduce confidence-spaced intervals as a judgment condition. When the confidence space is less than 1.0 and greater than 0.9544, this represents the weight is too concentrated near the mean, and the MDN algorithm is used to generate the quantise noise:
(6)
(6) Hyperparameter τ is used to control the quantisation ratio of long-tailed distribution and bell distribution. In our training strategy, we add more random quantisation ratios in the case of long-tailed distribution to improve the model's ability to fit outlier factors.
4.3. Regular setting
In backpropagation, we update the codebooks of the model. Meanwhile, the STE algorithm is used to update the full-precision weight of the unquantised layer. In order to reduce the performance gap between the quantised model and the pre-trained full-precision model, we introduce a regularisation term into the loss function:
(7)
(7) We use cross-entropy as the loss function, where N denotes the length of the sentence,
and
represent label and output respectively, where V is the vocabulary dictionary length. layer represents the weight of the layer to be quantised.
and
represent the pre-trained full precision weight and the unquantised model weight, respectively. In the backpropagation of the model, the quantised weights are fixed, and the unquantised full-precision weights are iterated to simulate the impact of the quantisation process on the performance of the model.
5. Experiment
In this section, we validate our proposed method Multi-Distribution Noise on WikiText-103 (Bradbury et al., Citation2016) and Penn Treebank (Marcus et al., Citation1994) Language modelling benchmarks. WikiText-103 contains more than 100 million tokens and is widely used in the modelling of natural language processing. There are 103,227,021 training, 217,646 validation, and 245,569 test tokens. Meanwhile, to verify our method's performance in small sample learning, we use Penn tree bank to test the effectiveness of our method, which includes 929,590 training, 73,761 validation, and 82,431 test tokens from the Wall Street Journal. Before the word sequence sends into the model, there is not any preprocess on the dataset. We extensively compared full-precision modelling methods with the same storage cost as well as other quantisation methods on the two datasets mentioned above. Then we conduct an ablation study for important components.
Results of all the language modelling task experiments are presented in Tables . We compared the experimental results extensively with the full precision model results and the experimental results of other quantisation methods.
Table 1. MDN performance vs different full-precision models.
Table 2. MDN performance vs. other quantisation methods.
Table 3. With different drop rate.
Note that, although algorithm needs to statistic the weight distribution during the model training phase, which causes additional computational cost. However, in the model validation phase, our model does not require statistics on the weight distribution. It takes 0.0072 s per word sequence in the training stage and only 0.0029 s per word sequence in the validation phase.
5.1. Implementation details
We trained a total of 60 epochs on the dataset, compressing the embedding layer of the model when epoch = 0, set 8 for block size and 256 for centroids. Compress the transformer layer of the model when epoch = 20, set 4 for block size and 256 for centroids. Compress the fully connected layer of the model when epoch = 40, set 4 for block size and 256 for centroids. We used p = 0.2 to quantise the blocks for all model layers. Meanwhile, We use , thus introducing a larger outlier factor into the model training. We trained on a 16 layers transformer (Vaswani et al., Citation2017), and using Fairseq framework (Ott et al., Citation2019).
5.2. Evaluation metric
Perplexity (PPL) is a metric used in natural language processing to measure the degree of convergence of the model. We use perplexity when evaluating language models to estimate the training effect and make judgments and analyses. We leverage the same loss algorithm mentioned in Stock et al. (Citation2021). PPL is defined:
(8)
(8) Where N denotes the length of the whole sentence.
denotes the ith token of a sentence.
denotes the ith word probability of occurrence under the premise of the i−1 tokens probability.
5.3. Compare with full-precision language modelling results
Table shows the difference in accuracy as well as storage cost between our method and the full precision method under each model structure.
We compare with the full precision Transformer-based method. On the WikiText-103 dataset, decrease +16%/+12%/−10% accuracy than kNN-LM/Transformer-XL/BERT-Large-CAS with reduction in storage costs. On the PENN Treebank dataset, our approach decrease +19% accuracy than BERT-Large-CAS with storage compression 10.69×. The results show that we have significantly reduced the model storage cost compared to other full-precision Transformer-based models, with only a partial loss of precision.
Meanwhile, we have significantly improved the model's performance compared to the full-precision LSTM architecture with comparable storage costs. On the Wikitext-103 dataset, our quantisation method has a accuracy increase compared to LSTM-RMC/char3-MS-vec with less storage cost. Meanwhile, on the PENN Treebank dataset, Our approach increases the storage cost by only
than char3-MS-vec/AWD-LSTM/Mogrifier-LSTM while outperforming all the methods in terms of performance. The results show that Our approach is better in terms of performance by compressing the model size of LSTM architecture.
5.4. Compare with quantisation language modelling results
We compared other work on model quantisation in the language modelling task, and the results are presented in Table . On the dataset of WikiText-103, we compared with the transformer-based model quant noise (Stock et al., Citation2021), our method has an accuracy increase of 9.9% with a nominal storage cost. Meanwhile, compared with the transformer-based model DIFQQ (Défossez et al., Citation2021), although 4.5% decreases the accuracy of our model, the storage overhead is one-fifth of its occupancy. Both quant noise (Stock et al., Citation2021) and DIFQQ (Défossez et al., Citation2021) are transformer-based quantisation methods, which researches are closer to ours and are based on quantisation methods within the Transformer structure. On the dataset of PENN Treebank, Compared to the LRLSTM-1500 method, our method increases the storage overhead by 55.6% and improves the model accuracy 2×.
5.5. Ablation study
Our approach consists of two techniques, MDN to fit the bell-shaped and long-tailed distribution; a regular term to narrow the gap between the full-precision model and quantisation model. In this section, we conduct an ablation study for these two techniques. We compare the effect of quantisation on a subset of the model parameters under different τ in formulation (5). Also, we use different values of η to investigate the effect of the value of hyperparameters on the performance of the model in formulation (6).
In order to investigate the effect of the outlier factor on model accuracy in model quantisation, we set different values of τ, as well as different p without regularisation term, as shown in Table . The paper (Karayiannis, Citation1999) proposed that unless outliers are identified and suppressed or eliminated, they can influence the formation of clusters by competing with the rest of the feature vectors to attract the prototypes. Inspired by this, we used a larger τ to quantise the outlier points in the model, thus eliminating the effect of the outlier factor on the accuracy of the model. The experimental results show that the MDN method gives the most significant performance improvement to the model when p = 0.2, .
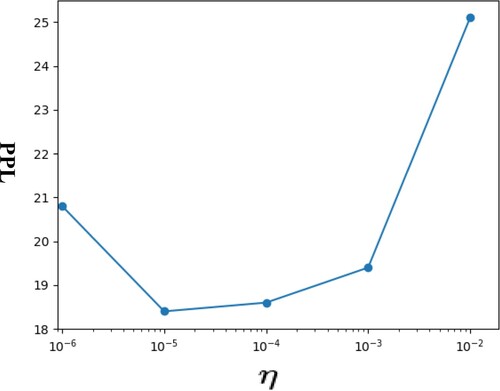
For verifying the effectiveness of the regularisation, ablation experiments were taken in the experiment. The results show that the addition of the regularisation term improves the model performance (increase 4% performance as shown in Table ). Meanwhile, to investigate the effect of our proposed regularisation term on model performance, we conducted extensive experiments on multiple sets of different values of η, as shown in Figure . The model has higher accuracy when η is taken as 0.00001.
Figure 4. Correlation of model performance metrics with hyperparameters η taken after adding regular terms to the loss function.
6. Discussion
In this paper, we use MULTI-DISTRIBUTION NOISE (MDN) to quantise the parameters into codewords. During quantisation Aware Training (QAT), we use a piecewise function to randomly quantise the model parameters under different distributions to simulate the noise generated by the quantisation operation. Meanwhile, a regular term is introduced into the loss function to make the quantisation model accuracy approximate the full precision model accuracy. Our approach can compress complex model (Transformer-based) to the same storage cost and take fuller advantage of complex structures than simple ones (with higher accuracy). Meanwhile, the experiment shows that our approach can excellent trade-off between model accuracy and storage overhead compared with other state-of-art quantisation methods.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Bai, X., Wang, X., Liu, X., Liu, Q., Song, J., Sebe, N., & Kim, B. (2021). Explainable deep learning for efficient and robust pattern recognition: A survey of recent developments. Pattern Recognition, 120, 108102. https://doi.org/10.1016/j.patcog.2021.108102
- Bai, X., Yan, C., Yang, H., Bai, L., Zhou, J., & Hancock, E. R. (2018). Adaptive hash retrieval with kernel based similarity. Pattern Recognition, 75(9), 136–148. https://doi.org/10.1016/j.patcog.2017.03.020
- Bhandare, A., Sripathi, V., Karkada, D., Menon, V., Choi, S., Datta, K., & Saletore, V. (2019). Efficient 8-bit quantization of transformer neural machine language translation model. CoRR abs/1906.00532. http://arxiv.org/abs/1906.00532
- Bie, A., Venkitesh, B., Monteiro, J., Haidar, M. A., & Rezagholizadeh, M. (2019). Fully quantizing a simplified transformer for end-to-end speech recognition. CoRR abs/1911.03604. http://arxiv.org/abs/1911.03604
- Boo, Y., & Sung, W. (2020, May 4–8). Fixed-point optimization of transformer neural network. In 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020 (pp. 1753–1757). IEEE. https://doi.org/10.1109/ICASSP40776.2020.9054724
- Bradbury, J., Merity, S., Xiong, C., & Socher, R. (2016). Quasi-recurrent neural networks. arXiv preprint arXiv:1611.01576.
- Brock, A., De, S., Smith, S. L., & Simonyan, K. (2021, July 18–24). High-performance large-scale image recognition without normalization. In M. Meila & T. Zhang (Eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event (Vol. 139, pp. 1059–1071). PMLR. http://proceedings.mlr.press/v139/brock21a.html
- Carreira-Perpiñán, M. Á., & Idelbayev, Y. (2017). Model compression as constrained optimization, with application to neural nets. Part II: Quantization. CoRR abs/1707.04319. http://arxiv.org/abs/1707.04319
- Chung, I., Kim, B., Choi, Y., Kwon, S. J., Jeon, Y., Park, B., Kim, S, & Lee, D. (2020, November 16–20). Extremely low bit transformer quantization for on-device neural machine translation. In T. Cohn, Y. He, & Y. Liu (Eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, EMNLP 2020, Online Event (Vol. EMNLP 2020, pp. 4812–4826). Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.findings-emnlp.433
- Défossez, A., Adi, Y., & Synnaeve, G. (2021). Differentiable model compression via pseudo quantization noise. CoRR abs/2104.09987. https://arxiv.org/abs/2104.09987
- Dong, X., & Yang, Y.. (2019, December 8–14). Network pruning via transformable architecture search . In H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alch á-Buc, E. B. Fox, & R. Garnett (Eds.), Advances in neural information processing systems 32: Annual conference on Neural Information Processing Systems, Vancouver, BC, Canada (pp. 759–770). PMLR.
- Ge, T., He, K., Ke, Q., & Sun, J. (2013). Optimized product quantization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(4), 744–755. https://doi.org/10.1109/TPAMI.2013.240
- Grachev, A. M., Ignatov, D. I., & Savchenko, A. V. (2019). Compression of recurrent neural networks for efficient language modeling. Applied Soft Computing, 79(8), 354–362. https://doi.org/10.1016/j.asoc.2019.03.057
- Han, S., Mao, H., & Dally, W. J. (2016, May 2–4). Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. In Y. Bengio & Y. LeCun (Eds.), 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, Conference Track Proceedings. http://arxiv.org/abs/1510.00149
- Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A. G., Adam, H., & Kalenichenko, D. (2018, June 18–22). Quantization and training of neural networks for efficient integer-arithmetic-only inference. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018 (pp. 2704–2713). IEEE Computer Society.
- Jegou, H., Douze, M., & Schmid, C. (2010). Product quantization for nearest neighbor search. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(1), 117–128. https://doi.org/10.1109/TPAMI.2010.57
- Jégou, H., Douze, M., & Schmid, C. (2011). Product quantization for nearest neighbor search. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(1), 117–128. https://doi.org/10.1109/TPAMI.2010.57
- Karayiannis, N. B. (1999). An axiomatic approach to soft learning vector quantization and clustering. IEEE Transactions on Neural Networks, 10(5), 1153–1165. https://doi.org/10.1109/72.788654
- Khandelwal, U., Levy, O., Jurafsky, D., Zettlemoyer, L., & Lewis, M. (2020, April 26–30). Generalization through memorization: Nearest neighbor language models. In 8th International Conference on Learning Representations, ICLR 2020. OpenReview.net. https://openreview.net/forum?id=HklBjCEKvH
- Krause, B., Kahembwe, E., Murray, I., & Renals, S. (2019). Dynamic evaluation of transformer language models. CoRR abs/1904.08378. http://arxiv.org/abs/1904.08378
- Lee, J. H., Ha, S., Choi, S., Lee, W., & Lee, S. (2018). Quantization for rapid deployment of deep neural networks. CoRR abs/1810.05488. http://arxiv.org/abs/1810.05488
- Li, Y., Dong, X., & Wang, W. (2020, April 26–30). Additive powers-of-two quantization: An efficient non-uniform discretization for neural networks. In 8th International Conference on Learning Representations, ICLR 2020. OpenReview.net. https://openreview.net/forum?id=BkgXT24tDS
- Marcus, M., Kim, G., Marcinkiewicz, M. A., MacIntyre, R., Bies, A., Ferguson, M., Katz, K., & Schasberger, B. (1994, March 8–11). The Penn treebank: Annotating predicate argument structure. In Human Language Technology: Proceedings of a Workshop, Plainsboro. Morgan Kaufmann.
- Melis, G., Kociský, T., & Blunsom, P. (2020, April 26–30). Mogrifier LSTM. In 8th International Conference on Learning Representations, ICLR 2020. OpenReview.net. https://openreview.net/forum?id=SJe5P6EYvS
- Miyashita, D., Lee, E. H., & Murmann, B. (2016). Convolutional neural networks using logarithmic data representation. CoRR abs/1603.01025. http://arxiv.org/abs/1603.01025
- Nagel, M., van Baalen, M., Blankevoort, T., & Welling, M. (2019). Data-free quantization through weight equalization and bias correction. CoRR abs/1906.04721. http://arxiv.org/abs/1906.04721
- Ning, X., Duan, P., Li, W., Shi, Y., & Li, S. (2020). A CPU real-time face alignment for mobile platform. IEEE Access, 8, 8834–8843. https://doi.org/10.1109/Access.6287639
- Ning, X., Duan, P., Li, W., & Zhang, S. (2020). Real-time 3D face alignment using an encoder-decoder network with an efficient deconvolution layer. IEEE Signal Processing Letters, 27, 1944–1948. https://doi.org/10.1109/LSP.97
- Ning, X., Gong, K., Li, W., & Zhang, L. (2021). JWSAA: Joint weak saliency and attention aware for person re-identification. Neurocomputing, 453(9), 801–811. https://doi.org/10.1016/j.neucom.2020.05.106
- Ning, X., Gong, K., Li, W., Zhang, L., Bai, X., & Tian, S. (2021). Feature refinement and filter network for person re-identification. IEEE Transactions on Circuits and Systems for Video Technology, 31(9), 3391–3402. https://doi.org/10.1109/TCSVT.2020.3043026
- Ning, X., Nan, F., Xu, S., Yu, L., & Zhang, L. (2020). Multi-view frontal face image generation: A survey. Concurrency and Computation: Practice and Experience, e6147. https://doi.org/10.1002/cpe.6147
- Norouzi, M., & Fleet, D. J. (2013). Cartesian k-means. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3017–3024). IEEE Computer Society.
- Ott, M., Edunov, S., Baevski, A., Fan, A., Gross, S., Ng, N., Grangier, D., & Auli, M. (2019). fairseq: A fast, extensible toolkit for sequence modeling. In W. Ammar, A. Louis, & N. Mostafazadeh (Eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Demonstrations (pp. 48–53). Association for Computational Linguistics. https://doi.org/10.18653/v1/n19-4009
- Prato, G., Charlaix, E., & Rezagholizadeh, M. (2020, November 16–20). Fully quantized transformer for machine translation. In T. Cohn, Y. He, & Y. Liu (Eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, EMNLP 2020, Online Event (Vol. EMNLP 2020, pp. 1–14). Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.findings-emnlp.1
- Qi, S., Ning, X., Yang, G., Zhang, L., Long, P., Cai, W., & Li, W. (2021). Review of multi-view 3D object recognition methods based on deep learning. Displays, 69, 102053. https://doi.org/10.1016/j.displa.2021.102053
- Riquelme, C., Puigcerver, J., Mustafa, B., Neumann, M., Jenatton, R., Pinto, A. S., Keysers, D., & Houlsby, N. (2021). Scaling vision with sparse mixture of experts. CoRR abs/2106.05974. https://arxiv.org/abs/2106.05974
- Santoro, A., Faulkner, R., Raposo, D., Rae, J. W., Chrzanowski, M., Weber, T., Wierstra, D., Vinyals, O., Pascanu, R., & Lillicrap, T. P. (2018). Relational recurrent neural networks. CoRR abs/1806.01822. http://arxiv.org/abs/1806.01822
- Simonyan, K., & Zisserman, A. (2015, May 7–9). Very deep convolutional networks for large-scale image recognition. In Y. Bengio & Y. LeCun (Eds.), 3rd International Conference on Learning Representations, ICLR 2015, Conference Track Proceedings. http://arxiv.org/abs/1409.1556
- Stock, P., Fan, A., Graham, B., Grave, E., Gribonval, R., Jégou, H., & Joulin, A. (2021, May 3–7). Training with quantization noise for extreme model compression. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event. OpenReview.net. https://openreview.net/forum?id=dV19Yyi1fS3
- Stock, P., Joulin, A., Gribonval, R., Graham, B., & Jégou, H. (2020, April 26–30). And the bit goes down: Revisiting the quantization of neural networks. In 8th International Conference on Learning Representations, ICLR 2020. OpenReview.net. https://openreview.net/forum?id=rJehVyrKwH
- Takase, S., Suzuki, J., & Nagata, M. (2019). Character n-gram embeddings to improve RNN language models. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, pp. 5074–5082). AAAI Press.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In Advances in Neural Information Processing Systems (pp. 5998–6008). MIT Press.
- Wang, C., Bai, X., Wang, X., Liu, X., Zhou, J., Wu, X., Li, H., & Tao, D. (2020). Self-supervised multiscale adversarial regression network for stereo disparity estimation. IEEE Transactions on Cybernetics, 51(10), 4770–4783. https://doi.org/10.1109/TCYB.2020.2999492
- Wang, C., Li, M., & Smola, A. J. (2019). Language models with transformers. arXiv preprint arXiv:1904.09408.
- Wang, D., Gong, C., & Liu, Q. (2019, June 9–15). Improving neural language modeling via adversarial training. In K. Chaudhuri & R. Salakhutdinov (Eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA (Vol. 97, pp. 6555–6565). PMLR. http://proceedings.mlr.press/v97/wang19f.html
- Wang, G., Li, W., Zhang, L., Sun, L., Chen, P., Yu, L., & Ning, X. (2021). Encoder-X: Solving unknown coefficients automatically in polynomial fitting by using an autoencoder. IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2021.3051430
- Wang, X., Wang, C., Liu, B., Zhou, X., Zhang, L., Zheng, J., & Bai, X. (2021). Multi-view stereo in the deep learning era: A comprehensive review. Displays, 70, 102102. https://doi.org/10.1016/j.displa.2021.102102
- Wang, Z., Wohlwend, J., & Lei, T. (2020, November 16–20). Structured pruning of large language models. In B. Webber, T. Cohn, Y. He, & Y. Liu (Eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online (pp. 6151–6162). Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.emnlp-main.496
- Williams, J. (1993). Narrow-band analyzer [Unpublished doctoral dissertation]. Dept. Elect. Eng., Harvard Univ.
- Xu, S., Chang, C. C., & Liu, Y. (2021). A novel image compression technology based on vector quantisation and linear regression prediction. Connection Science, 33(2), 219–236. https://doi.org/10.1080/09540091.2020.1806206
- Yan, C., Pang, G., Bai, X., Liu, C., Xin, N., Gu, L., & Zhou, J. (2021). Beyond triplet loss: Person re-identification with fine-grained difference-aware pairwise loss. IEEE Transactions on Multimedia. https://arxiv.org/pdf/2009.10295.pdf
- Zhai, X., Kolesnikov, A., Houlsby, N., & Beyer, L. (2021). Scaling vision transformers. CoRR abs/2106.04560. https://arxiv.org/abs/2106.04560
- Zhang, D., Yang, J., Ye, D., & Hua, G. (2018, September 8–14). LQ-Nets: Learned quantization for highly accurate and compact deep neural networks. In V. Ferrari, M. Hebert, C. Sminchisescu, & Y. Weiss (Eds.), Computer vision -- ECCV 2018 -- 15th European Conference, Proceedings, Part VIII (Vol. 11212, pp. 373–390). Springer. https://doi.org/10.1007/978-3-030-01237-3_23
- Zhang, W., Hou, L., Yin, Y., Shang, L., Chen, X., Jiang, X., & Liu, Q. (2020, November 16–20). TernaryBERT: Distillation-aware ultra-low bit BERT. In B. Webber, T. Cohn, Y. He, & Y. Liu (Eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online (pp. 509–521). Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.emnlp-main.37
- Zhou, L., Bai, X., Liu, X., Zhou, J., & Hancock, E. R. (2020). Learning binary code for fast nearest subspace search. Pattern Recognition, 98(1), 107040. https://doi.org/10.1016/j.patcog.2019.107040
- Zhu, M., Han, K., Tang, Y., & Wang, Y. (2021). Visual transformer pruning. CoRR abs/2104.08500. https://arxiv.org/abs/2104.08500