
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Mobile Crowd Sensing (MCS) typically assigns sensing tasks in the same target area to many participants considering data quality and the diversity of sensing devices. However, participant selection is based on the individual in many research. The efficiency of individual recruitment is low. Individuals need higher transportation costs to go to the task location alone, and the data quality perceived by individuals is difficult to guarantee. This paper proposes a team-based multitask data acquisition scheme under time constraints to address these challenges. The scheme optimised the number of participants, traffic cost, and data quality and designed four team-based multitask allocation algorithms under time constraints in the MCS: T-RandomTeam, T-MostTeam, T-RandomMITeam, and T-MostMITeam. The team size is associated with the number of participants required for the first task or the vehicle capacity to perform the task. We conducted extensive experiments based on a real large-scale dataset to evaluate the four algorithms' performances compared to two baseline algorithms (T-Random and T-most). The efficiency of the four algorithms has been significantly improved by team recruitment. The transportation cost can be multiplicatively reduced by carpooling. Data quality can be improved by at least 2% through reputation screening and team members' communication.
1. Introduction
Successful social and urban management depends on the effective positioning (Zhu et al., Citation2020) and monitoring (Z. Liu et al., Citation2020) of urban and community resources (e.g. vehicle Cui et al., Citation2020, ‘convenience store Estrada et al., Citation2020)’ to make appropriate decisions. To achieve this, traditional sensing technologies, such as sensor networks (Qiu et al., Citation2017), typically use distributed sensors to obtain real environmental information (Liang et al., Citation2020). Traditional sensor networks have high installation costs and insufficient space coverage (Guo et al., Citation2015). To overcome the drawbacks of the traditional sensor networks, Mobile Crowd Sensing (MCS) exploits sensors embedded in mobile devices and the mobility of participant users to sense surroundings and achieve an unprecedented level of spatial-temporal coverage for a target area without significant cost and time consumption (L. Wang et al., Citation2019). The emergence of MCS has expanded the scope of the Internet of Things (IoT) (Mahmud et al., Citation2018; Yong et al., Citation2020), where “things” are not limited to physical objects but also include people and the mobile devices they carry (J. Wang, et al., Citation2018). To use MCS, people must carry relevant mobile devices in the target region to complete tasks, increasing labour and transportation costs. Moreover, sensor data quality tends to be spotty because of people's participation. Therefore, how to optimise the number of participants, cost, and perceived data quality of MCS has become a hot topic (Y. Li et al., Citation2019).
Multitask allocation is a key problem in MCS. At present, there is some research on multitask allocation in MCS. Y. Liu et al. (Citation2016) studied the multitask allocation with more tasks and fewer participants, requiring each participant to complete multiple tasks. The optimisation goal is to maximise the total number of completed tasks and minimise the total moving distance. Guo et al. (Citation2017) studied the multitask participant selection problem in two cases. Time-sensitive multitask is to select participants who move intentionally, and the goal is to minimise the total distance of movement. Delay-tolerant multitask is to select participants who move unintentionally, and the goal is to minimise the total number of participants. J. Wang, et al. (Citation2018) consider the interdependence between multiple tasks. As the number of tasks increases, the perceived quality of a single task may deteriorate. The task-specific minimal sensing quality thresholds is introduced to redefine the multitask assignment problem. The goal is to assign a group of appropriate tasks to each participant to maximise the utility of the whole system. Niu et al. (Citation2020) considered the impact of participant speed on time-sensitive multitask allocation, aiming to minimise the total distance of user movement based on minimising the number of participants in the participant selection process. Maximise the reward value of participants by completing multiple tasks within a specified time.
In these existing MCS multitask allocation research, the choice of participants is based on individuals. The efficiency of individual recruitment is very low. It requires higher transportation costs for individuals to go to the task site alone, and it isn't easy to guarantee the data quality perceived by individuals. Considering the data quality and the diversity of sensing equipment, MCS usually assigns sensing tasks in the same target area to an appropriate number of participants, which creates conditions for team-based multitask allocation. Moreover, many tasks have time constraints, and the available time of participants is limited. Therefore, time effectiveness is crucial for both tasks and participants. To meet these challenges, this paper proposes a team-based multitask allocation problem with time constraints. This problem studies the impact of time constraints on multitask allocation to minimise the number of participants in MCS tasks, minimise traffic costs and maximise perceived data quality.
Team formation is critical in the field of organisational theory (Hamrouni et al., Citation2020). Based on the team form (e.g. carpooling), the proposed MCS task assignment algorithms solve the relatively high travel cost when participants go to a target area alone to complete their task. The quality of perception data can also be improved through interaction between team participants. Many studies (Y. Liu et al., Citation2016, Citation2017), which are based on the fact that participants go to a target area alone to complete their task, ignored the characteristics of MCS tasks; the perception task of the same target area is assigned to an appropriate number of participants to complete together to ensure the quality and diversity of data. The significance of building a team lies in reducing transportation costs by carpooling and improving data quality by completing tasks together.
The number of people in a team must be determined. Simple tasks require less diverse, more similar team members and simple communication and coordination among team members; thus, more team members can be. Conversely, for complex tasks, team members must have more differences, less consistency, and more complex communication and coordination; thus, the number of team members should be smaller. Thus, simple tasks can use large teams, but complex tasks require small teams. The number of team members required for cooperation should not be too small or too large, with 3–9 people typically being appropriate (B. Liu & Zou, Citation2004).
This study proposes four algorithms to build a team based on the number of participants required for the first task (e.g. 5) or associate the team size with the capacity of the vehicle to perform the task. If the next task requires fewer participants than the number of team members, the team members with the least or insufficient time left will be eliminated first, allowing a team can complete more tasks. Thus, it is essential to choose the first task purposefully. Typically, choosing a task that requires the largest number of participants to form a team can avoid the situation where the number of team members is too small to complete other tasks. Because a task requires several participants to complete, if the number of team members is too small, a task will be executed by multiple teams, which will result in low efficiency and high cost. The team leader is the member with the best reputation on the team, and a dynamic leader mechanism is used. If there is only one team member, he is the team leader. If multiple members have the same reputation, the leader will be randomly selected among these members.
We now consider an example case to demonstrate the problem of team-based time-limited multitask allocation in the MCS. We assume that there are certain registered users on the MCS platform and that users can complete multiple sensing tasks at any time. The proposed algorithms can randomly choose the first task and then select the nearest participants (e.g. 4) based on the first task's location to form a team. The platform requires each participant to execute many tasks for 2 hours and each task for 5 min. The first task requires all team members (A, B, C, D) to arrive at the task site at 3:10 pm. Moving A to the task's location requires 15 min, B to the task's location requires 18 min, C to the task's location requires 20 min, and D to the scene of the task requires 22 min. Thus, to reach the task site at 3:10 pm, A should start at 2:55 pm, B should start at 2:52 pm, C should start at 2:50 pm, and D should start at 2:48 pm. At 3:10 pm, A, B, C, D can perform tasks over the next 105, 102, 100, 98 min, respectively. After the first task, the team can carpool to the next location to perform the next task. Assuming that it takes 20 min to go from the first task site to the second task site, 25 min from the second task site to the third task site, and 32 min from the third task site to the fourth task site, the team can disband after executing four tasks. The travel cost is calculated in terms of time spent, which is 15 + 18 + 20 + 22 + 20 + 25 + 32 = 152 min for the team-based multitask allocation algorithm compared to the travel costs of a single-user-based multitask allocation algorithm ( min). The proposed algorithm can thus reduce travel costs by about 2.5 (383/152) times in this case.
Specifically, this paper makes the following contributions:
A team-based multitask data acquisition scheme under time constraints in MCS is proposed, which solves the problems of low efficiency, high traffic cost, and difficulty guaranteeing data quality of individual-based multitask recruitment system.
Four team-based multitask allocation algorithms under time constraints in MCS are designed: T-RandomTeam, T-MostTeam, T-RandomMITeam, T-MostMITeam. The team size is associated with the number of participants required for the first task or the vehicle capacity to perform the perception task; thus, team members can effectively reduce travel costs by carpooling. Using the team member reputation screening system, the team leader responsibility system, and paying the team leader and members the saved travel cost, the data quality of the perception task is effectively improved.
Through the experimental evaluation of four designed algorithms and two baseline algorithms (T-Random and T-Most) on a real large-scale data set, our algorithm's distribution efficiency, traffic cost, and data quality are improved compared with the baseline algorithm.
2. Related work
2.1. Multitask allocation
To date, many multitask allocation algorithms have been designed for MCS. In a multitask allocation, tasks can be homogeneous or heterogeneous. Typically, homogeneous tasks have different task positions. Apart from this, heterogeneous tasks have different standards (e.g. different tasks have different perceptive time or spans and different sensors) (Guo et al., Citation2018). L. Wang et al. (Citation2019) proposed and implemented an essential heterogeneous multi-task assignment (HMTA) problem in the MCS to maximise data quality and minimise the total incentive budget. They proposed a two-stage HMTA problem-solving method to effectively manage multiple concurrent tasks in a shared resource pool through the implicit temporal and spatial correlation between heterogeneous tasks. All these studies are based on the fact that participants go to a target area alone to complete their task,which can result in high transportation costs, especially in remote areas. W. Jiang et al. (Citation2021) studied the participant selection scheme on the multitask condition in MCS. According to the tasks completed by the participants in the past, the accumulated reputation and willingness of participants are used to construct a quality of service model (QoS). The purpose is to select the most suitable set of participants to ensure the QoS as far as possible to improve the platform's final revenue and the benefits of participants.
The previous research has substantially contributed to multitask allocation in MCS. However, all of these research selected participants based on the individuals and ignored a critical characteristic of MCS tasks. The critical characteristic of MCS is that the perception task of the same target area is assigned to an appropriate number of participants to complete together to ensure the quality and diversity of data. The efficiency of individual recruitment is very low. It requires higher transportation costs for individuals to go to the task site alone, and it isn't easy to guarantee the data quality perceived by individuals.
2.2. Team-based or group-based task allocation
Currently, a few studies have investigated team-based or group-based MCS task allocation; however, some have investigated team-based general crowdsourcing task allocation.
Mizouni et al. (Citation2016) propose a group-based recruitment model based on a genetic algorithm that selects the most appropriate group of participants using three types of parameters: areas of interest (AoI)-related, device-related, and user-related. The group-based system's performance is compared to an individual-based quality-assessment system that employs a greedy algorithm to recruit participants. The evolution of the provided quality by the available participants is analysed, and the least amount of resources to achieve the best possible quality is determined. Tan et al. (Citation2021) propose a three-phase approach named group-oriented cooperative crowdsensing to tackle the multiple cooperative task allocation (MCTA) problem in social MCS. Phase 1 selects a subset of users on the social network as initial leaders and directly pushes sensing tasks to them. Phase 2 utilises the leaders to search for their socially connected users to model groups. Phase 3 presents the process of group-oriented task allocation for solving the MCTA problem. Zeng et al. (Citation2019) focussed on a popular Multiplayer Online Battle Arena (MOBA) collaboration team game. They showed that teams composed of friends performed more actively than those composed of strangers. However, the increase in social connections did not uniformly improve player performance; for example, social relationships are good for low-skilled players but harmful for high-skilled players. The mixed impact of social relationships on performance was thus described in detail and provided a new perspective for virtual team management and behavioural motivation. In a non-cooperative social network, W. Wang et al. (Citation2017) designed a team-building mechanism based on distributed negotiation, in which the requester decides which employee to hire, the employee decides which team to join, and how much to pay for providing skill services. The proposed approach to form social teams can always be achieved by letting team members form a connection diagram to build the collaboration team, enabling them to work together effectively. All the teams in these literatures are not based on carpooling, nor did they choose the team leader responsible for data quality.
2.3. Data quality control
Data quality is sometimes referred to as data credibility. MCS data quality can be measured with multiple criteria: the coverage of the perception area, the duration of perception, data granularity, quantity, clarity, diversity, perceived user skill level, etc.
Two important factors that affect MCS data quality are the degree of accuracy of sensors and participants' reputations. Gao et al. (Citation2019) first introduce a mathematical model for characterising the quality of sensing data. W. Li et al. (Citation2017) proposed a user recommender system where the users' data qualities for sensing tasks are derived from historical statistical data to filter out the non-interested and malicious users in the current task. In Zhang and Kamiyama (Citation2020), smart device users' quality of data is considered by incorporating smart device users' long-term factor reputation. Sun and Tao (Citation2019) studied the participant selection problem of data quality perception in MCS. By introducing active factors, they proposed the participant reputation model of quality perception and proposed a Multi-Stage Decision-making scheme based on the Greed strategy (MSD-G). On the premise of satisfying certain data quality constraints, solving problems is performed. Hui-hui et al. (Citation2020) used the open collection mode to provide the collected data information to participants, help participants adjust the collection strategy and improve data collection quality and efficiency. They also used two incentive mechanisms (traditional payment and reverse auction) to effectively reduce the data redundancy rate and improve the data quality of difficult tasks. Luo et al. (Citation2021) refine the generalised data quality into the fine-grained ability requirement. To stimulate the workers with long-term high quality, they design two ability reputation systems to assess workers' fine-grained abilities online. Federated Learning (FL) (Zheng et al., Citation2021) is a promising approach to MCS systems, and the incorporation of FL into MCS can measure the quality of data collected by mobile users (Y. Jiang et al., Citation2020). Thus, the data quality of most literature is evaluated based on the reputation or ability of users.
3. Problem definition
3.1. Problem analysis
Because the participant selection problem is NP-hard (Y. Liu et al., Citation2017), a task-centred greedy heuristic algorithm is used to solve a time-limited multitask allocation optimisation problem.
The selected participants are required to complete as many tasks as possible within a specified time. The positions of participants change with the positions of the tasks, and we can choose appropriate participants based on the distances between the participants and tasks. We determine the first task's location first, then the second, closest to the first task, etc., until the tasks set closest to the initial task are selected. The participant can complete the tasks set within the specified time.
The strategy to select participants based on the team is described next. We must build teams by choosing users closest to the first task based on the required number of participants. If users at the same distance exceed the required number of participants, users with the highest reputation can be screened to perform the task. Because the initial position of the participant closest to the first task position may be different, all participants in the team at the beginning must go to the first task position (team meeting point) to gather at the appointed time. Because the time spent per team member on the way and the mobile distance may be different, the time of the team's task execution is determined by the participant closest to the first task position; the nearest participant can perform more tasks and stay on the team for the longest time.
3.2. Problem description
This section presents a formal definition of team-based time-limited multitask allocation optimisation in MCS. In this definition, we require participants to perform multiple tasks during a limited period and within the nearest region. For the demonstration below, we list the symbols commonly used in this article in Table .
Table 1. Frequently used symbols.
We first define the tasks of the MCS platform.
Definition 3.2.1
Task
Set as m tasks registered on the MCS platform to be assigned to execute. Each task
has six attributions, and
is the position of task
,
is the execution time of task
,
is the number of participants required by task
,
is a set of participants performing task
, and
is the number of participants performing task
(
).
is the data quality of task
.
The factors yielding differences in task data quality include human factors, equipment factors, and the accuracy and clarity of perceived task instruction information.
In this paper, data quality assessment begins with human factors. It is based on the selected user's reputation: the higher the user's reputation, the higher the user-perceived data quality. The first consideration is the user's location: if multiple users are in the same location, users with a high reputation should be selected first to perform the task. The data quality of task
is formally defined as follows:
(1)
(1)
where
is a traversal judgment function,
is a set,
is an element.
= 1 means that
is in the set
, and
= 0 means that
is not in the set
.
represents the participant
's reputation. The data quality
is equal to the average reputation of the
participants performing the task
.
Next, we define the user in the MCS platform, which is selected in the user set to perform the task.
Definition 3.2.2
User
We set as q user participants registered in the MCS platform who are willing to perform tasks. Each user participant
have eight properties.
's initial position is
.
is the available time for user
,
is
's total execution of time,
is user's moving speed,
is a set of user
performing tasks,
is the number of tasks performed by user
,
is the reputation value of the user participant
,
is the sum of the distance that the user moves while performing the tasks
. The formal definition is as follows:
(2)
(2)
where
consists of two parts:
is the distance of user
from the initial position
to the first task position
, and
is the sum of the distance user
moves to perform
tasks.
We ask the user to complete as many tasks as possible within the specified time
. The total execution time
of user
consists of two parts: the time spent moving a certain distance to the task location
, and the time spent by user
to complete multiple tasks
. Therefore, the user
total execution time
is formally defined as follows:
(3)
(3)
when the time
is greater than 0, the user
must execute the task unconditionally after he is assigned to the task. When the time
is below or equal to
, the user
must complete as many tasks as possible within the specified time
.
Finally, we define the team in the MCS platform, and the size of the team is based on the number of participants required for the first task or the vehicle capacity to perform the perceptual task.
Definition 3.2.3
Team
Set as s teams formed on the MCS platform to perform tasks together. Each team
has nine attributes.
is the dynamic leader of team
, and
is the total execution time.
is the set of team
members.
is the number of team
members.
is the set of tasks executed by team
, and
is the number of tasks executed by team
.
The team's execution time
is formally defined as follows:
(4)
(4)
Equation (Equation4
(4)
(4) ) indicate that the execution time
of team
is equal to the user with the longest execution time among all team
members.
For team , it is necessary to move a certain distance to complete multiple tasks. This distance consists of two parts. We can obtain one part of
by calculating the sum of the distance from the initial position
of each member in the team to the initial position
of the team (the position of
team's first task ). We can obtain the other part of
by calculating the sum of the distance between
and
of each sequential task in the team.
is the key to optimising the cost in this paper. The formal definition is as follows:
(5)
(5)
(6)
(6)
The cost primarily includes transportation cost, labour cost (participant incentive), and mobile devices' energy consumption; however, we only consider transportation cost and labour cost. Transportation cost is
, where b is the coefficient of travel distance converted to transportation cost. The labour cost is
, where
is the sum of the time the team task
is executed, c is the coefficient that the number of tasks performed by team members is converted into labour cost,
is the cost of team
to complete tasks, and
is a function of the team member
, task
, and time
. The formal definition of cost is as follows:
(7)
(7)
(8)
(8)
For the MCS platform, the first goal is to minimise the number of participants. Particularly when many tasks emerge or the target area's optional users are reduced, the platform requires the user to complete multiple tasks during a given period to ensure task completion. For the user, this process also can improve the personal income and participation enthusiasm in a given period completing more tasks. The second goal is to minimise the total cost. Under the condition that all tasks' labour costs are fixed and minimising all tasks' cost is equivalent to minimising the transportation cost, we aim to minimise the moving distance required to perform all tasks. The minimum total costs to complete all tasks is the task costs accumulation of each team; transportation costs can be saved and thus serve as an additional incentive for participants, encouraging participants to carpool. The third goal is to maximise data quality. Low-quality data will undermine the effectiveness and prospects of the platform. The platform thus must ensure the quality of the collected data. Therefore, the objective function of the team-based urgent multi-task allocation optimisation problem is formally defined as follows:
(9)
(9)
(10)
(10)
(11)
(11)
subject to:
(7) (12)
(7) (12)
(13)
(13)
(14)
(14)
(15)
(15)
(16)
(16)
where the time
indicates that the user
must execute the task unconditionally after he is assigned to the task. The execution time of the members of the team
is below or equal to the execution time of the team
, and the execution time of the team
is below or equal to all team members' available time. Equation (Equation13
(13)
(13) ) ensures that any task can be performed by
participants. In Equation (Equation14
(14)
(14) ), the union of the set of tasks executed by all users is assumed to be equal to the union of the set of tasks executed by all teams equal to the task set. In Equation (Equation15
(15)
(15) ), the union of all user sets performing tasks should be equal to the union of all user sets performing tasks by the team and below or equal to the user set.
4. Proposed algorithms
Four team-based time-limited task-centric multi-task allocation algorithms were proposed in the MCS environment: T-RandomTeam, T-MostTeam, T-RandomMITeam, T-MostMITeam. In T-RandomTeam and T-MostTeam, the number of team members is equal to the number of participants required by the first task executed by the team. In T-RandomMITeam and T-MostMITeam, the maximum number of team members is initialised to the specified vehicle capacity (e.g. taxi capacity can be set to 4).
4.1. Algorithm 1: T-RandomTeam
T-RandomTeam is an optimisation algorithm that minimises the number of participants as the primary objective, minimises the team's movement distance as the secondary objective, and maximises the task's data quality as the third objective. T-RandomTeam requires each participant to complete as many tasks as possible in a limited amount of time and considers minimising the movement distance and maximising task data quality.

First, we set each user to complete as many tasks as possible in a given timeframe and then randomly select a task as the initial task. Next, based on the participants' initial task, we select users to form a team. Users should have a higher reputation and be closest to the initial task. The team-building strategy is described as follows. Suppose many users meet the team's requirements (i.e. the number of users meeting the requirements exceeds the number of participants required by the task). In that case, we select the nearest users, and users with the same distance will be selected by reputation. If there are insufficient qualified users (i.e. if the number of qualified users does not exceed the number of participants required for this task), all qualified users will be selected. Because the user cannot complete the same task multiple times in the same place, we then select the nearest task as the second task based on the first task's location after the first task is completed. After completing the first task, there are two scenarios. In one case, the team will automatically disband if all the team members do not have sufficient time to complete the second task. In another case, certain team members will automatically quit the team after completing the first task because there is not sufficient time to complete the second task. Simultaneously, certain team members have sufficient time to complete the second task, record the completion status, and continue to the next task. When the team has completed the second task, the nearest task is selected as the third task based on the second task's location, excluding tasks completed, etc. Based on this method, the team is disbanded only when all team members quit. Thus, we can select the set of tasks completed by the team and the set of tasks completed by each team member. The completed tasks and users with unusable remaining time are eliminated when the first team is done. Based on the above algorithm, we can select the set of tasks completed by the team and the set of tasks completed by each team member in turn until all tasks are completed.
4.2. Algorithm 2: T-MostTeam
The experimental results with the T-RandomTeam algorithm are not stable and may be different each time the algorithm is run. This result likely occurs because the initial task is randomly selected each time, and the initial task has a significant impact on the result. Tasks are randomly distributed on different base stations, and the initial task location determines the combination of tasks. Therefore, we designed the next algorithm called T-MostTeam. Unlike the T-RandomTeam's random selection of the initial task, the T-MostTeam algorithm selects the task requiring the most participants as the initial task in the set of unfinished tasks. Because the task selection is based on the maximum number of participants, the algorithm can ensure that each task may be selected as the initial task, avoiding situations where certain tasks are never selected. Because there is a benchmark for selecting the initial task, the algorithm is stable.

The difference between these two algorithms is in the first step. The first step of T-MostTeam is to select the task requiring the most participants among the unfinished tasks as the initial task. The other steps of T-MostTeam follow those of T-RandomTeam and are thus not reiterated here.
4.3. Algorithm 3: T-RandomMITeam
Some tasks often require large numbers (up to thousands) of participants. Thus, building a team based on the number of participants required for the task can be ill-advised. Because a team moves together, it must use vehicles to move and complete tasks together. Therefore, vehicle capacities limit team size. For example, a taxi carries four people, an ordinary car carries five people, and a commercial car may carry seven people. Considering these factors, we design the T-RandomMITeam algorithm. Unlike the T-RandomTeam algorithm, creating a team size is not based on the number of participants required for the initial task. Still, it is instead based on the number of teams the system sets, and the threshold size is set based on the vehicle's capacity. For example, a taxi can transport four people. The remainder of the algorithm is similar to the T-RandomTeam algorithm.

At first, the T-RandomMITeam algorithm selects a random task as the initial task and then selects the users to set up the team and complete the task. The team members are closest to the initial task, and the team size does not exceed the team number threshold. The team-building strategy is as follows:
4.3.1. the team number threshold does not exceed the number of participants required for the initial task
If the team number threshold does not exceed the number of participants required for the initial task, the team will be built with the nearest users based on the threshold of team number. When the number of qualified users exceeds the team size threshold, the team is formed based on the nearest and higher reputation users whose number is the team size threshold. When eligible users are below the team size threshold, all nearest users are selected to form the team.
4.3.2. the team number threshold exceeds the number of participants required for the initial task
If the team number threshold exceeds the number of participants required by the initial task, the number of participants required by the task is used as the basis, and the nearest users are selected to form the team. The number of participants required for the initial task is small; thus, the number of participants cannot be set as the team size threshold to form a team to avoid wasting resources. When the number of qualified users is greater than the number of participants required by the task, the team is formed based on the nearest and higher reputation users whose number is the number of participants required by the task. When the number of eligible users does not exceed the number of participants required for the task, all nearest users are selected to form the team.
Because the user cannot complete the same task multiple times in the same place, we select the nearest task as the second task after the first task is completed based on the first task's location. When completing the second task, there are two scenarios. In one case, the team will automatically disband if all the team members do not have sufficient time to complete the second task. In another case, certain team members will automatically quit the team after completing the first task because there is not sufficient time to complete the second task. Simultaneously, certain team members have sufficient time to complete the second task, record the completion status, and continue to the next task. When the team has completed the second task, the nearest task is selected as the third task based on the second task's location, excluding tasks completed, etc. Based on this method, the team is disbanded only when all members of the team quit. Thus, we can select the set of tasks completed by the team and the set of tasks completed by each team member. The completed tasks and users with unusable remaining time are eliminated when the first team is done. Based on the above algorithm, we can select the set of tasks completed by the team and the set of tasks completed by each team member in turn until all tasks are completed.
4.4. Algorithm 4: T-MostMITeam
The T-MostMITeam algorithm is designed based on the T-RandomMITeam algorithm. The T-MostMiteam algorithm also builds teams based on a set threshold.

The flow of T-MostMITeam and T-RandomMITeam is only different in the first step. The first step of T-MostMITeam is to select the task requiring the most participants as the initial task among the unfinished tasks. The other steps of T-MostMITeam follow those of T-RandomMITeam and are thus not reiterated here.
4.5. Time complexity analysis of the algorithm
The time complexity of these four algorithms is mainly composed of three parts: Part 1 is the total execution times of m tasks. For m tasks, each task requires n participants. Assuming that m tasks are completed, the total execution times of m tasks is . Part 2 is the time complexity for all teams to select the n participants closest to the initial task. The platform has a total of q user candidates. Assuming that the average number of people in each team is K and the average number of tasks performed by each team member within a limited time is E, the number of team establishment times is
. Selecting the n participants closest to the initial task for each team requires a sorting algorithm (Java sorting algorithm timsort), which has an average time complexity of
. The time complexity for all teams to select the n participants closest to the initial task is
. Part 3 is the time complexity of task sorting. When each team executes the next task, it needs to find the nearest task and use the sorting algorithm (Java sorting algorithm timsort). Its average time complexity is
, and m is the number of tasks involved in sorting. However, with fewer sorting tasks, m decreases, and the number of tasks ordered is related to the required participants' size and the team's size. If the maximum number of team members allowed is not below the number of participants in the task, it is typically considered to be sorted once to complete a task. If the required number of participants is greater than the maximum number of team members, tasks must be sorted approximately twice. Thus, the task sorting algorithm's time complexity is
, where
. thus, these four types of algorithm's time complexity is
. The time complexity of these four algorithms is mainly different from the team size in part 2 and Part 3: the larger the team is, the smaller the time complexity is. The time complexity of the two baseline algorithms is
. The time complexity of the four algorithms proposed is significantly lower than that of the baseline algorithm in parts 2 and 3.
5. Experimental evaluation
5.1. Dataset and experimental setup
5.1.1. Dataset
In this paper, we use the D4D dataset (Blondel et al., Citation2012) to evaluate the proposed algorithms. The D4D dataset is a collection of phone records from Cote d' Ivoire, an African country of more than 20 million people, provided by the Orange Group. The data set primarily contains two types of data: base station location information, which includes the base station's ID, the base station's longitude and latitude; and user's detailed call records, including the user's ID, the call time, and the base station ID where the user is. The dataset contains the call records of 50,000 anonymous users from Cote d 'Ivoire between December 1, 2011, and April 28, 2012. Due to many base stations (1231) in the dataset, we select Abidjan (405), the capital of Cote d' Ivoire, for experiment convenience. The distribution location of base stations is shown in Figure .
Figure 1. Location of Abidjan base stations.
5.1.2. Experimental setup
In the D4D data set, the user's location by the base station's location corresponds to the user's call record. We can associate the user with the base station by assuming the user's location is where the call is currently being made. We also associate the task location with the base station for experimental convenience. In this process, the distance between the user and the task is converted to the distance between the two base stations. When the user and the task are associated with the same base station, their distance is 0.
We set the users' reputation to obey a Gaussian distribution (0.8, ) in the experiment. Each task requires five users to complete (
), and each task requires 5 min to complete (
). The participant selection problem proposed in this paper is primarily aimed at urgent tasks. Considering the MCS platform's insufficient users or the emergence of concurrent tasks on the platform, each participant must complete as many tasks as possible within one hour (
min) by driving (v = 500 m/min).
5.2. Experimental evaluation index
To solve the problem based on the team's time-limited multitask participant selection, this paper proposes four algorithms in the MCS environment: T-RandomTeam, T-MostTeam, T-RandomMITeam, and T-MostMITeam. All these algorithms select participants based on the task. The number of team members in T-RandomTeam and T-MostTeam equals the number of participants required by the team's first task. The difference between the two algorithms is whether the algorithm chooses the task randomly or the task is selected based on the largest number of participants. The maximum number of team members in T-RandomMITeam and T-MostMITeam is initialised to a specified threshold, determined by the vehicle's capacity. The difference lies in whether the algorithm randomly chooses the task or chooses the task requiring the most participants. The four algorithms have different solutions in task selection and team size. Therefore, we must experiment and verify the four algorithms' performances.
From the participants' perspective, we hope to complete as many tasks as possible within the specified time. Because in the case of a certain number of tasks, the total number of participants is inversely proportional to the number of tasks completed by each participant on average; thus, the fewer participants you want to select, the more tasks each person completes on average. From the perspective of the crowdsensing platform, all tasks should be executed. When the number and location of tasks are specific, the total distance moved to complete tasks should be minimised to minimise travel costs. Data quality acquired should be improved as much as possible.
The following experiment evaluates experimental results from the number of participants selected, algorithm running time, algorithm team number, total distance moved to complete the task (travel cost), carpool incentive, team leader management incentive, data quality, etc.
5.3. Experimental results
In this experiment, we consider Abidjan's call records from 14:55:00, December 20, 2011, to 15:00:00 December 20, 2011, as the experiment dataset; users who made phone calls in the base station in the region during this period are candidates. There are 570 candidates, and other variables are held static, while the number of tasks is varied. Multiple tasks are selected based on distance.
5.3.1. Comparison of the number of participants
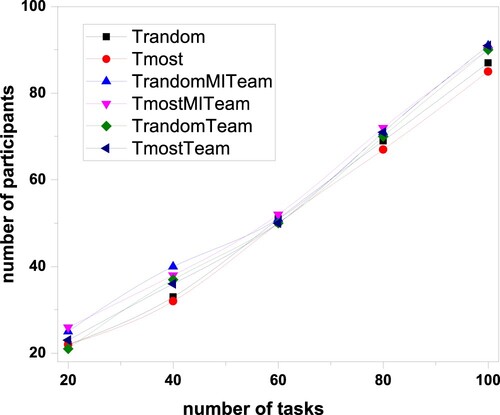
Figure shows that as the number of tasks increases, the number of participants selected by each algorithm increases more rapidly. There is little difference in the number of participants selected by each algorithm because the four proposed algorithms and the two baseline algorithms' primary optimisation goal is the number of participants.
Figure 2. The relationship between the number of participants and the number of tasks.
5.3.2. Comparison of the running time
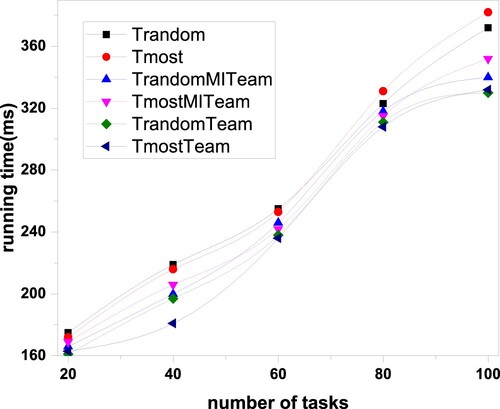
The six algorithms are considered (T-RandomTeam, T-MostTeam, T-RandomMITeam, T-MostMITeam, T-Random, and T-Most). Their time complexity is O() based on task scale and user scale. If the team is large, T-RandomTeam, T-MostTeam, T-RandomMITeam, and T-MostMITeam have a better time complexity than T-Random and T-Most because the team algorithm distributes tasks in batches based on the number of team members. Figure shows little difference in the running time between the four proposed algorithms and the two baseline algorithms because the four proposed algorithms' team size is relatively small. T-RandomTeam and T-MostTeam require five people, and T-RandomMITeam and T-MostMITeam require four people. As the number of tasks increases, the running time also increases.
Figure 3. The relationship between the running time of algorithm and the number of tasks.
5.3.3. Comparison of the number of teams
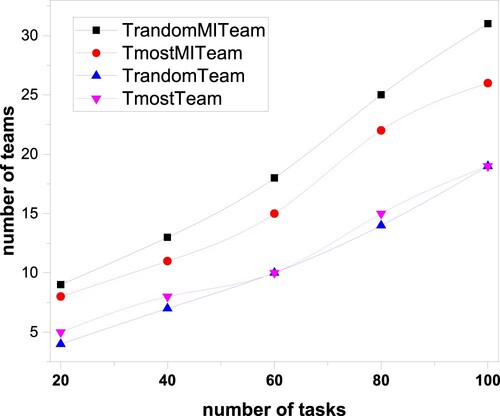
Figure shows that as the number of tasks increases, the number of teams calculated by the four proposed algorithms also increases. The numbers of teams from T-RandomTeam and T-MostTeam are below the teams from T-RandomMITeam and T-MostMITeam. Because the number of team members in T-RandomTeam and T-MostTeam is equal to the number of participants required for the first task (5), and the maximum number of team members in T-RandomMITeam and T-MostMITeam is initially four, so there are more teams in T-RandomMITeam and T-MostMITeam.
Figure 4. The relationship between the number of teams and the number of tasks.
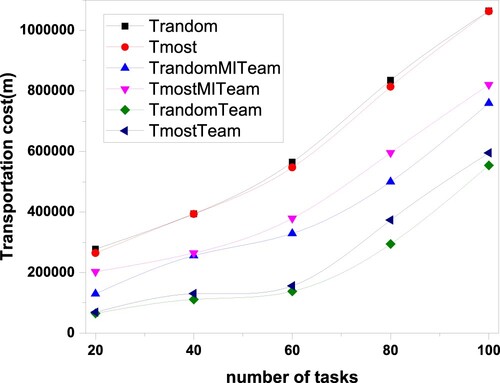
5.3.4. Comparison of transportation costs
Figure shows that as the number of tasks increases, each algorithm's transportation cost increases more quickly. As the number of tasks increases, participants must move longer distances to perform their tasks. However, the four proposed algorithms' transportation costs increase more slowly than the two baseline algorithms. The transportation costs of T-RandomTeam and T-MostTeam are lower than T-RandomMITeam and T-MostMITeam because T-RandomTeam and T-MostTeam have five members. In comparison, T-RandomMITeam and T-MostMITeam have four members. We thus select the appropriate algorithm based on the vehicle capacity of the specific scene.
Figure 5. The relationship between travel cost and task number.
5.3.5. Comparison of participants' average carpooling incentives
The experiment assumes that the travel cost per kilometre is 5 yuan. The participants' average carpooling incentives equal two-thirds of all travel costs saved divided by the number of participants in all tasks, providing motivation for participants to carpool. Figure shows that the platform has fewer optimal users to select with the increasing tasks' number, which will lead to an increased initial movement distance for participants. The larger the distance is, the fewer tasks users will perform within the specified time, and the less the transportation cost can be saved.
Figure 6. The relationship between the average carpool incentive of participants and the number of tasks.
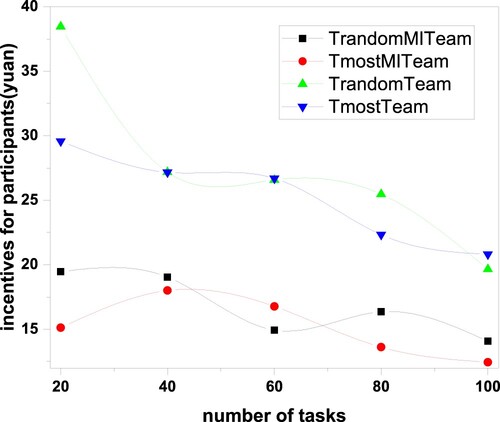
The average carpool incentives of T-RandomTeam and T-MostTeam participants are greater than RandomMITeam and T-MostMITeam because the number of team members in the two algorithms equal the number of participants required by the first task (5), which saves more transportation costs. However, the maximum number of team members of the two algorithms of T-RandomMITeam and T-MostMITeam is initialised to 4, resulting in a task that can be completed by two teams, yielding a relatively high cost. Thus, the participants of the T-RandomMITeam and T-MostMITeam algorithms are less motivated.
5.3.6. Comparison of average management incentives of team leaders
Team leaders' average management incentive equals one-third of the saved travel costs divided by the number of team leaders for all tasks, motivating team leaders to manage their team well (e.g., preventing data reuse, checking data formatting, analyzing data, uploading data). Figure shows the average management incentive of the leaders. For example, the average management incentive of the leaders of T-RandomMITeam is 25.95 yuan for 20 tasks. Because different team leaders manage different numbers of tasks, T-RandomMITeam leaders can obtain a maximum incentive of 81.22 yuan or a minimum incentive of 6.77 yuan for 20 tasks.
Figure 7. The relationship between the average management incentives of team leaders and the number of tasks.
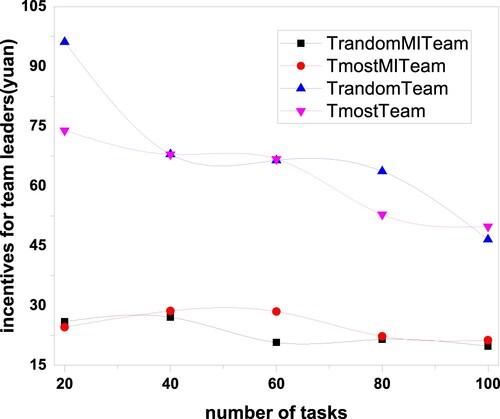
Figure shows that the average management incentives of the leaders of T-RandomTeam and T-MostTeam are greater than that of T-RandomMITeam and T-MostMITeam because the numbers of team members of T-RandomTeam and TMostTeam are equal to the numbers (five) of participants required by the first task, which saves more transportation costs and reduces the number of team leaders. The maximum number of team members of T-RandomMITeam and TMostMITeam is four. Completing a task requiring two teams, the moving distance is relatively longer, and the number of team leaders is larger, which results in less average management incentive for the two algorithms.
5.3.7. Data quality comparison
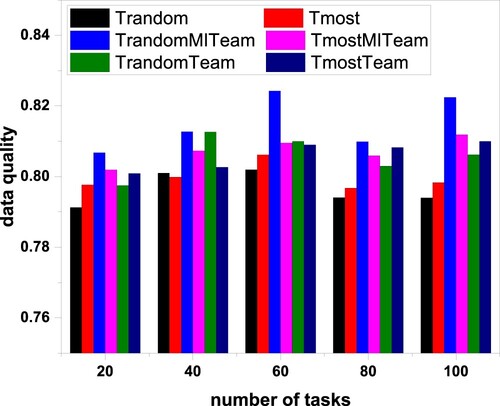
There are two schemes to evaluate data quality in the proposed experiment: ranking by distance and reputation (priority method) and ranking by distance and reputation weight (linear weighted sum method).
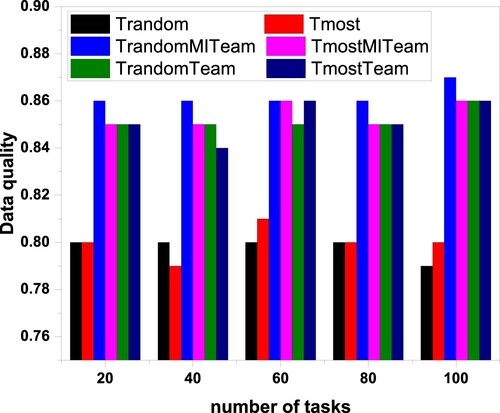
Figure , the ranking way by distance and reputation (priority method) considers the users' location when selecting users. If multiple users are in the same location, we prefer to select users with a high reputation to perform tasks. When too few users perform tasks on the platform, this method's ability to improve data quality is limited. Normally, data quality can be improved by at least 2% compared to two baseline algorithms. Figure shows that the average data quality of T-RandomMITeam is the highest because the number of participants selected by the algorithm is below the number of participants required by the task, and there are higher reputation users to choose from.
Figure 8. Data quality relations sorted by distance and reputation.
To improve data quality more effectively, we plan to combine the distance and reputation to select users (linear weighted sum method). The calculation formula is as follows:
(17)
(17)
Figure shows the data quality assessment results when we set the weight of distance and reputation as 0.5, respectively. With the weight of 0.5, data quality can be improved by 7%. The data qualities of the four proposed algorithms are significantly higher than that of two baseline algorithms that select users only based on location.
Figure 9. Data quality relations sorted by distance and reputation proportion.
6. Conclusions and future work
This paper proposes a scheme to optimise time-limited multitask allocation based on team. We designed four team-based algorithms (T-RandomTeam, T-MostTeam, T-RandomMITeam, and T-MostMITeam) that select participants based on tasks. In T-RandomTeam and T-MostTeam, team members are equal to the number of participants required to complete the first task. The difference between these two algorithms lies in how the task is chosen: randomly or by the largest number of participants. In T-RandomMITeam and T-MostMITeam, the maximum number of team members is initialised to the specified vehicle capacity. The difference between them is whether the algorithm chooses the task randomly or the task is selected based on the largest number of participants. We evaluate the four algorithms using the D4D dataset. The experimental results show that T-RandomTeam and T-MostTeam yield better performance if each participant is expected to complete as many tasks as possible and move the shortest distance. However, the two algorithms require that the number of participants should not exceed the vehicle's capacity. The four proposed algorithms effectively improve perceived tasks' data quality using team-member reputation screening and team-leader responsibility. The data quality can be improved by at least 2% compared to two baseline algorithms. This study thus provides valuable knowledge about the relationship between team participant's selection and various factors, such as movement mode, task execution time, and participants' reputation, that will help improve mobile crowdsourcing.
In the future, we can study the impact of user available time on the number of participants in emergency tasks. We can also study the team formation of mixed movement modes of participants, such as walking to perform near tasks teams and carpooling to perform far tasks teams. A reasonable update plan for the reputation value of participants is also researchable. Next, we can also study an FL-based MCS quality model approach to help participants improve local data quality to get better ML training results.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Blondel, V., Esch, M., Chan, C., Clerot, F., Deville, P., Huens, E., Morlot, F., Smoreda, Z., & Ziemlicki, C. (2012). Data for development: The D4D challenge on mobile phone data. CoRR. abs/1210.0137.
- Cui, M., Han, D., Wang, J., Li, K. C., & Chang, C. C. (2020). Arfv: An efficient shared data auditing scheme supporting revocation for fog-assisted vehicular ad-hoc networks. IEEE Transactions on Vehicular Technology, 69(12), 15815–15827. https://doi.org/10.1109/TVT.25
- Estrada, R., Mizouni, R., Otrok, H., Ouali, A., & Bentahar, J. (2020). A crowd-sensing framework for allocation of time-constrained and location-based tasks. IEEE Transactions on Services Computing, 13(5), 769–785. https://doi.org/10.1109/TSC.4629386
- Gao, H., Liu, C. H., Tang, J., Yang, D., Hui, P., & Wang, W. (2019). Online quality-aware incentive mechanism for mobile crowd sensing with extra bonus. IEEE Transactions on Mobile Computing, 18(11), 2589–2603.
- Guo, B., Liu, Y., Wang, L., Li, V. O. K., Lam, J. C. K., & Yu, Z. (2018). Task allocation in spatial crowdsourcing: Current state and future directions. IEEE Internet of Things Journal, 5(3), 1749–1764. https://doi.org/10.1109/JIOT.2018.2815982
- Guo, B., Liu, Y., Wu, W., Yu, Z., & Han, Q. (2017). Activecrowd: A framework for optimized multitask allocation in mobile crowdsensing systems. IEEE Transactions on Human-Machine Systems, 47(3), 392–403. https://doi.org/10.1109/THMS.2016.2599489
- Guo, B., Wang, Z., Yu, Z., Wang, Y., & Zhou, X. (2015). Mobile crowd sensing and computing: The review of an emerging human-powered sensing paradigm. Acm Computing Surveys, 48(1), 1–31. https://doi.org/10.1145/2794400
- Hamrouni, A., Ghazzai, H., Alelyani, T., & Massoud, Y. (2020). A stochastic team formation approach for collaborative mobile crowdsourcing. IEEE. https://doi.org/10.1109/ICM48031.2019.9021910
- Hui-hui, C., Bin, G., & Zhi-wen, Y. (2020). Research on the method to collect high-quality crowdsourced data in open mode. Journal of Chinese Computer Systems, 41(1), 78–84.
- Jiang, W., Chen, J., Liu, X., Liu, Y., & Lv, S. (2021). Participant recruitment method aiming at service quality in mobile crowd sensing. Wireless Communications and Mobile Computing, 2021(3), 1–14. https://doi.org/10.1155/2021/6621659
- Jiang, Y., Cong, R., Shu, C., Yang, A., & Min, G. (2020). Federated learning based mobile crowd sensing with unreliable user data. 2020 IEEE 22nd international conference on high performance computing and communications, Fiji, December 14–16.
- Li, W., Fan, L., Sharif, K., & Yu, W. (2017). When user interest meets data quality: A novel user filter scheme for mobile crowd sensing. 2017 IEEE 23rd International Conference on Parallel and Distributed Systems (ICPADS), Shenzhen, China, December 15–17.
- Li, Y., Li, F., Yang, S., Wu, Y., Chen, H., Sharif, K., & Wang, Y. (2019). Mp-coopetition: Competitive and cooperative mechanism for multiple platforms in mobile crowd sensing. IEEE Transactions on Services Computing, 14(6), 1864–1876. https://doi.org/10.1109/TSC.2019.2916315.
- Liang, W., Huang, W., Long, J., Zhang, K., Li, K., & Zhang, D. (2020). Deep reinforcement learning for resource protection and real-time detection in iot environment. IEEE Internet of Things Journal, 7(7), 6392–6401. https://doi.org/10.1109/JIoT.6488907
- Liu, B., & Zou, Z. (2004). An experimental study on the efficiently individual quantity in cooperating team. Industrial Engineering And Management, 9(6), 89–94. https://doi.org/10.2174/0929866043478455
- Liu, Y., Guo, B., Wang, Y., Wu, W., Yu, Z., & Zhang, D. (2016). TaskMe: Multi-task allocation in mobile crowd sensing. 2016 ACM international joint conference on pervasive and ubiquitous computing, Heidelberg, Germany, September 12–16.
- Liu, Y., Guo, B., Wu, W.-L., Yu, Z.-W., & Zhang, D.-Q. (2017). Multitask-oriented participant selection in mobile crowd sensing. Jisuanji Xuebao/Chinese Journal of Computers, 40, 1872–1887. https://doi.org/10.11897/SP.J.1016.2017.0187
- Liu, Z., Liu, X., & Li, K. (2020). Deeper exercise monitoring for smart gym using fused rfid and CV data. 2020 IEEE 39th conference on computer communications (INFOCOM), Toronto, Canada, July 6–9.
- Luo, Z., Xu, J., Zhao, P., Yang, D., Xu, L., & Luo, J. (2021). Towards high quality mobile crowdsensing: Incentive mechanism design based on fine-grained ability reputation. Computer Communications, 180, 197–209. https://doi.org/10.1016/j.comcom.2021.09.026
- Mahmud, R., Kotagiri, R., Buyya, R., Di Martino, B., Li, K., Yang, L., & Esposito, A. (2018). Internet of things (Technology, Communications and Computing) (Vol. 103, pp. 1–130). Springer.
- Mizouni, R., Otrok, H., Singh, S., Azzam, R., & Ouali, A. (2016). Grs: A group-based recruitment system for mobile crowd sensing. Journal of Network and Computer Applications, 72(sep.), 38–50. https://doi.org/10.1016/j.jnca.2016.06.015
- Niu, H., Liu, W., Wang, Z., & Sun, S. (2020). Multitask-oriented partipant selection in mobile crowd sensing. Journal of Chinese Computer Systems, 41(8), 1707–1712.
- Qiu, T., Zhao, A., Xia, F., Si, W., & Wu, D. O. (2017). Rose: Robustness strategy for scale-free wireless sensor networks. IEEE/ACM Transactions on Networking, 25(5), 2944–2959. https://doi.org/10.1109/TNET.2017.2713530
- Sun, H., & Tao, D. (2019). Data-quality-aware participant selection mechanism for mobile crowdsensing. Wireless Sensor Networks.
- Tan, W., Zhao, L., Li, B., Xu, L. D., & Yang, Y. (2021). Multiple cooperative task allocation in group-oriented social mobile crowdsensing. IEEE Transactions on Services Computing, PP(99), 1–13. https://doi.org/10.1109/TSC.4629386
- Wang, J., Wang, L., Wang, Y., Zhang, D., & Kong, L. (2018). Task allocation in mobile crowd sensing: State-of-the-art and future opportunities. IEEE Internet of Things Journal, 5(5), 3747–3757. https://doi.org/10.1109/JIoT.6488907
- Wang, J., Wang, Y., Zhang, D., Feng, W., & Qiu, Z. (2018). Multi-task allocation in mobile crowd sensing with individual task quality assurance. IEEE Transactions on Mobile Computing, 17(9), 2101–2113. https://doi.org/10.1109/TMC.7755
- Wang, L., Yu, Z., Zhang, D., Guo, B., & Liu, C. H. (2019). Heterogeneous multi-task assignment in mobile crowdsensing using spatiotemporal correlation. IEEE Transactions on Mobile Computing, 18(1), 84–97. https://doi.org/10.1109/TMC.2018.2827375
- Wang, W., Jiang, J., An, B., Jiang, Y., & Chen, B. (2017). Toward efficient team formation for crowdsourcing in noncooperative social networks. IEEE Transactions on Cybernetics, 47(12), 4208–4222. https://doi.org/10.1109/TCYB.2016.2602498
- Yong, B., Wei, W., Li, K. C., Shen, J., & Damaeviius, R. (2020). Ensemble machine learning approaches for webshell detection in internet of things environments. Transactions on Emerging Telecommunications Technologies, (e4085). https://doi.org/10.1002/ett.4085.
- Zeng, Y., Sapienza, A., & Ferrara, E. (2019). The influence of social ties on performance in team-based online games. IEEE Transactions on Games, 13(4), 358–367. https://doi.org/10.1109/TG.2019.2923223.
- Zhang, C., & Kamiyama, N. (2020). Data quality maximization for mobile crowdsensing. 2020 IEEE/IFIP Network Operations and Management Symposium (NOMS), Budapest, Hungary, 20–24 April.
- Zheng, Z., Zhou, Y., Sun, Y., Wang, Z., Liu, B., & Li, K. (2021). Applications of federated learning in smart cities: Recent advances, taxonomy, and open challenges. Connection Science 33(5). https://doi.org/10.1080/09540091.2021.1936455
- Zhu, X., Qu, W., Qiu, T., Zhao, L., Atiquzzaman, M., & Wu, D. O. (2020). Indoor intelligent fingerprint-based localization: Principles, approaches and challenges. IEEE Communications Surveys & Tutorials, 22(4), 2634–2657. https://doi.org/10.1109/COMST.9739