
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Finding a good compiler autotuning methodology, particularly for selecting the right set of optimisations and finding the best ordering of these optimisations for a given code fragment has been a long-standing problem. As the rapid development of machine learning techniques, tackling the problem of compiler autotuning using machine learning or deep learning has become increasingly common in recent years. There have been many deep learning models proposed to solve problems, such as predicting the optimal heterogeneous mapping or thread-coarsening factor; however, very few have revisited the problem of optimisation phase tuning. In this paper, we intend to revisit and tackle the problem using deep learning techniques. Unfortunately, the problem is too complex to be addressed in its full scope. We present a new problem, called reduced O3 subsequence labelling – a reduced O3 subsequence is defined as a subsequence of O3 optimisation passes that contains no useless passes, which is a simplified problem and expected to be a stepping stone towards solving the optimisation phase tuning problem. We formulated the problem and attempted to solve the problem by using genetic algorithms. We believe that with mature deep learning techniques, a machine learning model that predicts the reduced O3 subsequences or even the best O3 subsequence for a given code fragment could be developed and used to prune the search space of the problem of the optimisation phase tuning, thereby shortening the tuning process and also providing more effective tuning results.
1. Introduction
An optimising compiler performs a sequence of optimising transformation techniques, which are implemented as optimisation passes (or optimisation phases) and aim to transform a program to a semantically equivalent program that uses fewer computing resources or instructions. However, some passes are correlated and have positive or negative impacts to each other. For example, a program might not be vectorised if the licm pass (which performs loop invariant code motion) is not used (Kruse & Grosser, Citation2018). Therefore, how to determine the best sequence of passes for a program is a big research problem of compiler optimisations. In past research, evolution algorithms were used to solve this problem. However, since there are many optimisation passes in a compiler, the search space for the best sequence of passes is too large to be explored in reasonable time. There have been many kinds of research that use machine learning techniques to improve the speed of compiler optimisation tuning. The biggest challenge of such research is how to present program sources for machine learning models. With the rapid progress of deep learning technology, applying deep learning techniques to compilers has become a new research hotspot.
It seems that we can use the deep learning technique to find a way to present program structures more accurately and to predict the best sequences of passes for programs, but deep learning methods require an adequately large amount of training data. Unfortunately, preparing those training data could be time-consuming for the problem of optimisation phase tuning (OPT) because we have to tune the compiler optimisations for many programs, and this involves lots of compilation and running processes. A trivial solution is to use a brute-force search method to find the best sequence of passes for a program, but it takes a huge amount of time to explore all sequences even for a single program. Perhaps, as a result, recent researches have seldom focused directly on optimisation pass analysis and prediction but rather on simpler compilation tuning problems, such as tuning for heterogeneous mapping or the thread coarsening factor (Ben-Nun et al., Citation2018b; Cummins et al., Citation2017).
An alternative approach to brute-force search is to use evolutionary computation as a tool for generating good sequences of passes for a program so as to speed up the process of collecting training data. However, evolutionary computation is used to seek a good enough solution rather than the optimal one, so the sequences produced by an evolutionary computation-based tuning algorithm are likely the best sequence. Unfortunately, optimisation passes are not guaranteed to be effective in improving the program execution performance, so there might be useless passes in an optimisation sequence. These useless passes are considered noises for machine learning. It is as if we use sentences that are full of redundant words as training data for building a machine learning model for language translation. Simplifying sentences by word properties is an important trick in natural language processing, so for compiler tuning with machine learning, we also need a technique to simplify optimisation sequences to eliminate possible noises of machine learning.
In view of the aforementioned problems, we attempt to reduce both the noises and the variations in order to improve machine learning performance. We attempt to change the objective of machine learning from predicting the best optimisation options of a program to predicting the reduced O3 subsequences of the program. We believe that optimisation-level three (i.e. O3) is a combination of optimisation options that are selected and ordered by compiler experts. The O3 optimisation sequence might not be the best for a program, but for most programs the O3 option results in acceptable performance improvement. However, the O3 optimisation sequence may also contain useless optimisations. A reduced O3 subsequence is thus defined as an O3 optimisation subsequence that contains no useless optimisations. We expect to use machine learning techniques to predict reduced O3 subsequences of a program, and then use the reduced O3 subsequences as the basis (as a reduced search space) for compiler autotuning.
2. Optimisation phase tuning and its difficulties
2.1. Problem formulation
The OPT problem is to select the right set of compiler optimisation passes and find the best ordering of these passes for a given program so that the program achieves the best performance. The solution of the problem involves searching the best sequence from arbitrary lengths of sequences of repeatable optimisation passes, though not all optimisation passes are considered repeatable. The search space of the problem is extremely huge for a modern compiler, which is commonly equipped with many optimisation passes.
Suppose a compiler C has n distinct optimisation passes: , and
is a multiset containing the n distinct optimisation passes:
, where M is a sequence of positive integers
and
denotes the number of repetitions of
in the multiset; that is, optimisation pass
occurs
time(s) in the multiset. A possible optimisation sequence, with
being used at most
time(s), in compiler C is a k-permutation of
, a sequence of length k of elements of
, where k can be any positive integer that is smaller than or equal to the size of the multiset (
, which equals to
). In other words, all possible optimisation sequences form a set
, where
denotes the permutation group of x and
denotes the power set of x. For simplicity we denote
as
, as indicated in Equation (Equation1
(1)
(1) ).
(1)
(1) The number of all possible optimisation sequences is expected to be huge when n is large. According to Jurić and Šiljak's formula of number of permutations of multisets (Željko & Šiljak, Citation2011), the number of k-permutations of
can be written as
(2)
(2) where
max
, and
is the number of numbers
that are not smaller than i, where
are integers, and
. Consequently, the number of all possible optimisation sequences, with
being used at most
time(s), in compiler C can be written as
(3)
(3) which summarises the numbers of permutations of optimisation sequences whose length ranges from 1 to
. For example, considering a compiler with a set of optimisation passes
and
– and thereby
–, all possible optimisation sequences can be derived in Table . As listed in Table , with only five optimisation passes and three of them being used for at most twice, the number of all possible optimisation sequences [or
, which equals
] is truly large. More specifically, there are 14, 457 possible optimisation sequences in the set of
, which represents the search space of the OPT problem.
Table 1. All possible optimisation sequences of , which form the set
;
, the number of k-permutations of
.
Suppose Compiler is a function that generates the executable of a given program prog with an optimisation sequence being applied by using compiler C, and Evaluator is another function that evaluates the performance of a given executable exec with specific input data in on a specific hardware platform, as indicated in Equation (Equation4
(4)
(4) ). The definition of performance can refer to a metric, such as the time elapsed (or the energy consumed) during the execution, the size of the executable, or even the combination of multiple metrics; in most scenarios, execution time is regarded as the performance metric, where the lower execution time, the higher performance. By taking the result of Compiler into Evaluator, we can derive a fitness function
that judges how good an optimisation sequence is for a given program prog with specific inputs in, as shown in Equation (Equation5
(5)
(5) ). Finally, the OPT problem can be defined in Definition 2.1, and it is considered an optimisation problem which can be solved using evolutionary computation.
(4)
(4)
(5)
(5)
Definition 2.1
The problem of optimisation phase tuning
Given a program prog with inputs in together with a multiset , find an optimisation sequence
, which belongs to
, such that
is maximised, as shown in Equation (Equation6
(6)
(6) ).
(6)
(6)
2.2. Optimisation phase tuning using machine learning
As indicated in Equation (Equation3(3)
(3) ), the search space of the OPT problem defined in Equation (Equation6
(6)
(6) ) can be very large even when
is moderate. Machine learning techniques, which allows machine to learn from past tuning experiences, have been used to directly or indirectly solve the OPT problem. Many prior studies reshaped the problem and used machine learning results to guide tuning actions and reduce the search space. Most of these studies focused on building two predictors: optimisation sequence predictors and speedup predictors (Ashouri et al., Citation2018, september). An optimisation sequence predictor is built upon a machine learning model that yields the best set of optimisation passes or sequences for a given program (Cavazos et al., Citation2007; Fursin et al., Citation2011; Kulkarni et al., Citation2004; Park et al., Citation2011), whereas a speedup predictor is based on a machine learning model that predicts the amount of speedup that can be obtained when an optimisation sequence is applied (Ashouri et al., Citation2016, Citation2017; Dubach et al., Citation2007).
No matter which problem a prediction model targets at, a difficult challenge is how to transform a sequence of program code into numerical features usable for machine learning. Many prior studies (e.g. Milepost GCC (Fursin et al., Citation2011)) extracted features from a program based on some statistics of static or dynamic instructions of the program and provided adequate results. However, the feature extractor in such studies does not consider the execution order of instructions as a program feature and thus likely fails to distinguish two programs with almost identical computation tasks but slightly different computation orders, which may determine whether a specific optimisation pass should be applied. For example, functions slp_vectorizable and less_slp_vectorizable listed in Figure are semantically equivalent but have slight differences in the order of the operations in lines 2 and 9. The effect of the slp-vectorize optimisation pass (Lattner & Adve, Citation2004) on these two functions are significant different, where slp_vectorizable is fully vectorised. One may design a feature extractor that also considers the sequence or the structure of a program, but it is likely to be a challenging task. Moreover, there might be more features to be developed in order to capture the important characteristics of the program for better machine learning results.
Figure 1. An example in which two functions that are semantically equivalent but slightly different in the order of operations are interpreted differently by the slp-vectorize compiler optimiser (Lattner & Adve, Citation2004), thereby resulting in different optimisation results.

With the development of deep learning techniques, automatic feature extraction has been made feasible (Cummins et al., Citation2017; Park et al., Citation2012), and therefore end-to-end prediction models have become possible. Nevertheless, past researches that utilised deep learning techniques rarely focused on the OPT problem but the problem of parameter tuning for specific optimisation passes, such as finding the optimal heterogeneous compute device mapping or the optimal thread coarsening factor (Ben-Nun et al., Citation2018a; Cummins et al., Citation2017). This is attributed to fact that the parameter tuning problems usually have a smaller search space, whereas the OPT problem is too complex to be effectively solved using deep learning techniques.
2.3. Useless optimisation passes
Despite the absence of a practical optimiser sequence predictor, compiler designers have done extensive work to determine some fixed optimisation sequences and provide compilation options (e.g. -O1, -O2, and -O3) for compiler users to optimise their programs with these optimisation sequences. It is well-known that the fixed optimisation sequences, especially the O3 sequence, can yield good results in terms of performance for many programs, and sometimes it can be quite difficult to find another optimisation sequence that delivers better results. Nevertheless, some passes of the optimisation sequences may fail to transform the programs or even transform the programs negatively. These optimisation passes are considered useless for the programs since they provide no benefit to the programs. The fact that a pass might be useless for a program seems intuitive – otherwise selecting the right set of compiler optimisation passes is unnecessary, but such fact has a significant impact on solving the OPT problem. For example, if someone attempts to use a naïve genetic algorithm to find the best optimisation sequence, the genetic algorithm is probably not effective. The genetic algorithm is likely to be stuck at a local optimum sequence since a sequence might just evolve one with some useless passes to another with some other useless passes during the evolutionary process; it is like someone randomly walks into a basin and is trapped in the basin.
To address the possible issues that can arise from useless passes when solving the OPT problem, we introduce a concept of the effectiveness of passes to quantify the strength of a pass on a specific program and input. The effectiveness of a pass on a program prog with inputs in is defined as the maximum benefit in the performance of the program execution that results from the pass for all possible optimisation sequences that contain the pass, as indicated in Equation (Equation7
(7)
(7) ).
(7)
(7) where
represents the set of all possible optimisation sequences that contain
for the given
, and
is a sequence that is derived from
and contains no
. The concept of effectiveness of a pass is trivial: the more the performance benefit the pass can deliver, the more effective the pass is. Of course, determining the effectiveness of a pass on a program will take a long process by evaluating the program with all possible optimisation sequences that involve the pass being applied, as well as the corresponding optimisation sequences in which the pass is removed. Nevertheless, one may still get a rough figure of how effective a pass is by a sampling methodology. For example, Table listed the estimated effectiveness of some LLVM passes on two programs (loop_unroll and stepanov_abstraction from the LLVM test suite), where the estimated effectiveness of each pass is obtained by running a program with 100 different subsequences (randomly sampled) of the LLVM O3 optimisation sequence being applied. According to Table , we found that passes like inline, instcombine, and instcombine had a significant impact on stepanov_abstraction, while passes like globalopt, deadargelim, argpromotion, and correlated-propagation seemed useless for stepanov_abstraction.
Table 2. Estimated effectiveness of some LLVM passes on programs loop_unroll and stepanov_abstraction.
A possible solution to the aforementioned problem is to use a genetic algorithm to generate appropriate, effective training data (or the golden labels) for machine learning, but nevertheless, a naïve genetic algorithm will probably fail to achieve this goal as mentioned earlier in this section. We believe this is perhaps why previous studies on the OPT problem using machine learning have often focused on only the performance gain but not the accuracy of the machine learning models. We boldly conclude that the OPT problem is difficult to solve because not only is the problem space huge but also useless passes act as a barricade against successfully solving the problem.
Table 3. The execution times (in seconds) of matmul4x4 and recursive when some sampled optimisation sequences were applied. A bit vector represents the optimisation sequence that was applied to a program, and each bit of a vector represents whether the corresponding optimisation pass was applied. The corresponding optimisation passes of a vector are memtoreg, simplifycfg, tailcallelim, memcpyopt, sroa, loop-rotate, and slp-vectorize.
3. Reduced O3 subsequence labelling
In order to cope with the two problems (i.e. a vast problem space and annoying useless optimisation passes) concluded in Section 2.3, we introduce a new problem, called reduced O3 subsequence labelling (RO3SL), which aims to discover reduced O3 subsequences that are considered as key hints for obtaining appropriate training data to model an effective, accurate optimisation sequence predictor. In this sense, RO3SL can be regarded as a subproblem of OPT from two main perspectives, which address the two aforementioned problems: (1) RO3SL has a smaller problem space than OPT, and (2) RO3SL is designed to assist in solving the OPT problem by eliminating annoying useless passes. As indicated by its name, the RO3SL problem has a problem space that is formed by O3 subsequences, which are subsequences of the O3 optimisation sequence, rather than all possible optimisation sequences. As we have discussed in Section 2.3, in practice the O3 optimisation sequence typically perform well for a wide range of different programs; therefore, it seems reasonable to use only the subsequences of the O3 optimisation sequence as the training data to get around the issue of the enormous problem space. Furthermore, RO3SL is designed to identify all the reduced O3 subsequences for a given program and inputs, where a reduced sequence is defined as an optimisation sequence that does not contain any useless passes, thereby eliminating possible training noises that are caused by useless passes.
3.1. Investigation on O3 subsequences
Despite the reduced problem space, the number of possible O3 subsequences can still be huge when the length of the O3 optimisation sequence is long. Taking LLVM compiler infrastructure, whose O3 optimisation sequence consists of 92 passes, as an example, the number of possible O3 subsequences (i.e. the size of set ) exceeds
, as indicated in Equation (Equation8
(8)
(8) ).
(8)
(8) where
and
represent the O3 optimisation sequence and the set of all possible O3 subsequences of the LLVM compiler infrastructure, respectively.
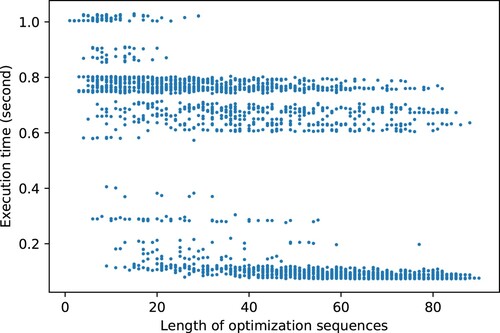
For a better understanding of how many useless passes may occur in an O3 subsequence, we conducted an experiment, in which we randomly sampled 2700 sequences from all possible O3 subsequences and applied each of these sequences to three programs (loop_unroll, matmul4x4, and recursive) and executed the programs, respectively. Figure illustrates the execution times of program loop_unroll for 2700 distinct O3 subsequences, where the x-axis represents the length of an optimisation sequence, and the y-axis represents its corresponding execution time. This figure indicates that many O3 subsequences, with different lengths of optimisation sequences, resulted in the same execution performance. This is likely attributed to fact that these optimisation sequences are variants of a reduced sequence, which contain different numbers of useless passes. Such a phenomenon also occurred for matmul4x4 and recursive.
Figure 2. Execution times of program loop_unroll for 2700 distinct O3 subsequences. Each dot represents the result of an O3 subsequence.
To further perceive the dependencies and interactions among different optimisation passes, we investigated the relevance between optimisation sequences and their corresponding execution results for matmul4x4 and recursive. Tables and display the execution times of programs matmul4x4 and recursive for some particular optimisation sequences. Table indicates that pass slp-vectorize was necessary for matmul4x4 and the execution performance of matmul4x4 could be better improved if passes memcpyopt and sora were applied before slp-vectorize, while other O3 optimisation passes provided almost no contribution to growth in performance. By contrast, Table reveals that both early-cse-memssa and mem2reg produced good results for program recursive, but the combination of the two did not produce a synergistic effect. In addition, although the sequence of itself did not perform well, pass tailcallelim transformed the recursive structure of the program into the form of loops, which were later optimised by pass loop-rotate. Instead, the sequence with a prepended pass mem2reg achieved the best performance.
Table 4. Execution times of program matmul4x4 for four particular O3 subsequences.
Table 5. Execution times of program recursive for seven particular O3 subsequences.
If we attempt to build a optimisation sequence prediction model, we will naturally treat sequences and
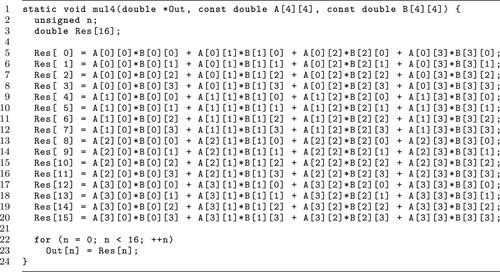
as labels for programs matmul4x4 and recursive, respectively. However, if we take a close look at the effect of the desired O3 subsequence on the code snippet of matmul4x4, which is shown in Figure , we can see that the
sequence effectively optimised the memory copy loop (lines 22–23), whereas the matrix computations (lines 5–20) could be optimised only by
. If the machine-learning methods we intend to use can extract features that describe the characteristics of these two parts of the code snippet and we demand the machine learning model to be more general, the two O3 subsequences should be preserved and treated as labels for training the model. Therefore, identifying as many O3 subsequences that do not contain any useless passes (or reduced O3 subsequences) as possible is a crucial step towards resolving the OPT problem.
Figure 3. Code snippet of program matmul4x4.
3.2. Problem formulation
As defined earlier in this section, a reduced sequence is an optimisation sequence that does not contain any useless passes, which have no benefit to a program with specific inputs; nevertheless, the passes may profit another program or even the same program with other inputs. Consequently, the set of reduced sequences varies from program to program and even input to input. The formal definitions of the set of all reduced sequences and the set of all reduced O3 subsequences with a specific program and inputs are given in Equations (Equation9(9)
(9) ) and (Equation13
(13)
(13) ), respectively.
(9)
(9)
(10)
(10) where δ represents a measurement error. The condition of
is used to determine whether
is a useless pass as
belongs to
, but not
, which is derived from
. The RO3SL problem is in fact an optimisation problem that aims to collect the set of reduced O3 subsequences and can be roughly formulated in Equation (Equation11
(11)
(11) ).
(11)
(11) where
denotes the length of vector
. In this optimisation problem, the objective is to find out as many reduced O3 subsequences as possible using the fact that a short sequence that delivers the same performance as a longer sequence contains fewer useless passes. As a result, the need to check whether a pass is useless in a certain sequence can be eliminated.
However, by the definition of the reduced sequences, two sequences that contain no useless passes and optimise different program fragments with less benefit will not be included in the set of reduced sequences. These two sequences will be indistinguishable if we use Equation (Equation11(11)
(11) ) to solve the RO3SL problem; hence, Equation (Equation11
(11)
(11) ) should be revised to address such issue. In evolutionary computation, this type of problem is called a multimodal task (Tanabe & Ishibuchi, Citation2020), which distinguishes different elements in the solution space by the distance between them – in this case, two sequences are distinguished by the distance between the two sequences, where the distance should be clearly defined.
Since a sequence can be encoded as a bit vector (as we have done in Table ), it makes intuitive sense to consider the Hamming distance (Hamming, Citation1950) to distinguish two sequences. However, the Hamming distance is not an appropriate measure for distinguishing two optimisation sequences. For example, Table gives an example of two similar Hamming distances for two distinct pairs of sequences. The first pair of sequences are similar sequences, both of which turn on the six passes except the third one, and they are different by the decisions made on the last two passes, so the Hamming distance of three is calculated. By contrast, the second pair of sequences are quite different because they turn on two distinct passes, respectively, but the Hamming distance between the two sequences is only two. It would be difficult to determine the similarity between two sequences by using the Hamming distance. Fortunately, the Jaccard distance (Jaccard, Citation1912), which measures the similarity between two bit vectors, as indicated in Equation (Equation12(12)
(12) ), fits our needs.
Table 6. The Hamming and Jaccard distances between optimisation sequences. ,
, the Hamming distance between sequences
and
;
,
, the Jaccard distance between sequences
and
.
With the consideration of the sequence distance, now, we have a well-defined optimisation problem, which is defined in Definition 3.1 and aims to collect reduced O3 subsequences.
Definition 3.1
The problem of reduced O3 subequence labelling
Given a program prog with inputs in together with the O3 optimisation sequence , find the set of reduced O3 subsequences
, which is defined in Equation (Equation13
(13)
(13) ).
(13)
(13) where
is defined in Equation (Equation14
(14)
(14) ).
(14)
(14)
3.3. Genetic algorithm for reduced O3 subsequence labelling
The optimisation problem defined in Definition 3.1 is not a simple problem; it is a typical multi-modal, multi-objective problem. This optimisation problem is obvious a multi-objective problem since multiple objectives, such as the length and the result (i.e. the execution time of a program after a sequence is applied when compiling the program) of a sequence, should be considered to find a reduced O3 subsequence. The problem is also a multi-modal because multiple reduced O3 subsequences are expected to discover in order to be applied to different parts of a program. It is worth noting that in the past a multi-modal optimisation was not necessary if the objective was to seek the best sequence of a whole program. With the rapid growth of deep learning techniques, especially more and more sophisticated feature extraction techniques, it is essential to decompose a program and optimise its decompositions individually. Therefore, a multi-modal optimisation must be considered to meet this need in Definition 3.1.
A multi-modal, mulit-objective optimisation problem is difficult to solve, so many new techniques and approaches have been tried in recent years (Tanabe & Ishibuchi, Citation2020). In this study, we adopted the technique of SPEA2+ (Kim et al., Citation2004), which is an improved version of SPEA2 (Zitzler et al., Citation2001), to solve the RO3SL problem. We propose a new crossover operator (Algorithm ??) and a new mutation operator (Algorithm ??) upon the operators defined in SPEA2+ so as to generate better sequences with respect to the objective of the RO3SL problem. More specifically, the crossover operator is basically based on the one-point crossover (Poli & Langdon, Citation1998). When performing the crossover operation, if the given two sequences are indistinguishable (i.e. their Jaccard distance is smaller than ), it is likely that the two sequences are variants of the same reduced sequence but contain different numbers of useless passes. In this case, the crossover operation can be performed in a more aggressive way by producing a new sequence that is the intersection or union of the two sequences. Moreover, a fully random mutation is likely not a favourable mutation method for the RO3SL problem since the mutation operation may just lead to an unproductive result, just like randomly walking the floor of a basin and get trapped as we have discussed in Section 2.3. The proposed mutation operator intends to guide the mutation process to move towards the same direction by setting or unsetting a number of bits within a given bit vector (or the optimisation sequence). By using the SPEA2+ algorithm along with the proposed crossover and mutation operators, we are now able to generate approximate reduced O3 subsequences, which can be treated as the key training data for resolving the OPT problem.


4. Experimental results and discussion
4.1. Evaluation environment
All of the evaluations in this study were conducted on a platform whose hardware and system details are indicated in Table . Processor affinity was used to ensure that each program or application stayed in the same processor during the whole execution in order to reduce cache interference. Meanwhile, there were no other processes running except the system processes in order to reduce any possible interference. The benchmarks we used to evaluate the modified SPEA2+ algorithm were collected from the test suite of the LLVM compiler infrastructure (Lattner & Adve, Citation2004), including loop_unroll from Adobe-C++ and two applications: libSVM and Hexxagon.
Table 7. Hardware and system information of the evaluation platform.
4.2. Evaluation results
In order to demonstrate the effectiveness of the modified SPEA2+ algorithm, we implemented four different genetic algorithms to solve the RO3SL problem: naïve genetic algorithm (GA), SPEA2, SPEA2, and modified SPEA2+ (with customised crossover and mutation operators listed in Algorithms ?? and ??, respectively). All of the four genetic algorithms were implemented based on DEAP, an evolutionary computation framework (Fortin et al., Citation2012), and Table lists the details about the implementation of the genetic algorithms. As the goal of the genetic algorithms is to generate reduced O3 subsequences, the effectiveness of a genetic algorithm is assessed by how closely the generated sequences resemble the reduced O3 subsequences, which contain no useless passes. In other words, the assessments could be based upon the degree of similarity (i.e. the Jaccard distance) between the generated sequences and the reduced O3 subsequences. Figure illustrates the average Jaccard distances between the generated sequences and the reduced O3 subsequences for the four genetic algorithms during the evolutionary process from ten runs of the genetic algorithms. It indicates that as the generation number became larger, the sequences generated by the modified SPEA2+ algorithm gradually resembled the reduced O3 subsequences, whereas the sequences generated by the other three algorithms contained about 50% or even more of useless passes for all generations. Table lists the average Jaccard distances between the generated sequences (for final generation) and the reduced O3 subsequences for program loop_unroll and applications libSVM and Hexxagon from 10 runs of the genetic algorithms. Our proposed algorithm (modified SPEA2+) produced the best results against the other three algorithms.
Figure 4. Jaccard distances between the generated sequences and the reduced O3 subsequences by generations for program loop_unroll.
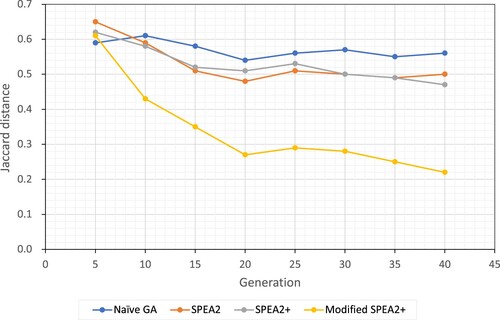
Table 8. Genetic algorithms used to solve the problem of reduced O3 subsequence labelling.
Table 9. Jaccard distances between the generated sequences (final generation) and the reduced O3 subsequences for program loop_unroll and applications libSVM and Hexxagon.
5. Conclusion
Compiler tuning using machine learning techniques is moving to the next level, where more accurate code feature models are required with more detailed optimisation information. We have presented a new problem, called reduced O3 subsequence labelling, to simplify the compiler autotuning problem and expected to be a stepping stone towards solving the optimisation tuning problem. We have also implemented a modified SPEA2+ genetic algorithm to address the problem of reduced O3 subsequence labelling. The experimental results demonstrate that the proposed genetic algorithm generated optimisation sequences with less useless passes. We believe that mature deep learning techniques combined with evolutionary optimisation algorithms that generate reduced O3 subsequences can enable an effective prediction model that predicts reduced O3 subsequences or even the best O3 subsequence for an individual code fragment; this will be a major step towards solving the problem of optimisation phase tuning.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Ashouri, A. H., Bignoli, A., Palermo, G., & Silvano, C. (2016). Predictive modeling methodology for compiler phase-ordering. In Proceedings of the 7th workshop on parallel programming and run-time management techniques for many-core architectures and the 5th workshop on design tools and architectures for multicore embedded computing platforms (pp. 7–12). Association for Computing Machinery. https://doi.org/10.1145/2872421.2872424.
- Ashouri, A. H., Bignoli, A., Palermo, G., Silvano, C., Kulkarni, S., & Cavazos, J. (2017). MiCOMP: Mitigating the compiler phase-ordering problem using optimization sub-sequences and machine learning. ACM Transactions on Architecture and Code Optimization, 14(3), Article 29. https://doi.org/10.1145/3124452.
- Ashouri, A. H., Killian, W., Cavazos, J., Palermo, G., & Silvano, C. (2018, September). A survey on compiler autotuning using machine learning. ACM Computing Surveys, 51(5), Article 96. https://doi.org/10.1145/3197978.
- Ben-Nun, T., Jakobovits, A. S., & Hoefler, T. (2018a). Neural code comprehension: A learnable representation of code semantics. CoRR. http://arxiv.org/abs/1806.07336.
- Ben-Nun, T., Jakobovits, A. S., & Hoefler, T. (2018b). Neural code comprehension: A learnable representation of code semantics. In Proceedings of the 32nd international conference on neural information processing systems (pp. 3589–3601). Curran Associates Inc.
- Cavazos, J., Fursin, G., Agakov, F., Bonilla, E., O'Boyle, M. F. P., & Temam, O. (2007). Rapidly selecting good compiler optimizations using performance counters. In Proceedings of the international symposium on code generation and optimization (pp. 185–197). IEEE Computer Society. https://doi.org/10.1109/CGO.2007.32.
- Cummins, C., Petoumenos, P., Wang, Z., & Leather, H. (2017, October). End-to-end deep learning of optimization heuristics. In Proceedings of parallel architectures and compilation techniques, PACT 2017 (vol. 2017-September, pp. 219–232). Institute of Electrical and Electronics Engineers Inc. doi:10.1109/PACT.2017.24.
- Dubach, C., Cavazos, J., Franke, B., Fursin, G., OBoyle, M. F., & Temam, O. (2007). Fast compiler optimisation evaluation using code-feature based performance prediction. In Proceedings of the 4th international conference on computing frontiers (pp. 131–142). Association for Computing Machinery. doi:10.1145/1242531.1242553.
- Fortin, F. A., De Rainville, F. M., Gardner, M. A., Parizeau, M., & Gagné, C. (2012, July). DEAP: Evolutionary algorithms made easy. Journal of Machine Learning Research, 13, 2171–2175.
- Fursin, G., Kashnikov, Y., Memon, A. W., Chamski, Z., Temam, O., Namolaru, M., & O'Boyle, M. (2011). Milepost GCC: Machine learning enabled self-tuning compiler. International Journal of Parallel Programming, 39(3), 296–327. https://doi.org/10.1007/s10766-010-0161-2
- Hamming, R. W. (1950). Error detecting and error correcting codes. The Bell System Technical Journal, 29(2), 147–160. https://doi.org/10.1002/bltj.1950.29.issue-2
- Jaccard, P. (1912). The distribution of the flora in the alpine zone. 1. New Phytologist, 11(2), 37–50. https://doi.org/10.1111/nph.1912.11.issue-2
- Kim, M., Hiroyasu, T., Miki, M., & Watanabe, S. (2004). SPEA2+: Improving the performance of the strength pareto evolutionary algorithm 2 SPEA2+: Improving the performance of the strength pareto evolutionary algorithm 2. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 3242, pp. 742–751. https://doi.org/10.1007/978-3-540-30217-9_75.
- Kruse, M., & Grosser, T. (2018). DeLICM: Scalar dependence removal at zero memory cost. In Proceedings of the 2018 international symposium on code generation and optimization. https://doi.org/10.1145/3168815.
- Kulkarni, P., Hines, S., Hiser, J., Whalley, D., Davidson, J., & Jones, D. (2004). Fast searches for effective optimization phase sequences. In Proceedings of the ACM sigplan 2004 conference on programming language design and implementation (pp. 171–182). Association for Computing Machinery. https://doi.org/10.1145/996841.996863.
- Lattner, C., & Adve, V. (2004). LLVM: A compilation framework for lifelong program analysis & transformation. In Proceedings of the international symposium on code generation and optimization: Feedback-directed and runtime optimization (p. 75). IEEE Computer Society.
- Park, E., Cavazos, J., & Alvarez, M. A. (2012). Using graph-based program characterization for predictive modeling. In Proceedings of international symposium on code generation and optimization, CGO 2012 (pp. 196–206). https://doi.org/10.1145/2259016.2259042.
- Park, E., Kulkarni, S., & Cavazos, J. (2011). An evaluation of different modeling techniques for iterative compilation. In Proceedings of the 14th international conference on compilers, architectures and synthesis for embedded systems (pp. 65–74). Association for Computing Machinery. https://doi.org/10.1145/2038698.2038711.
- Poli, R., & Langdon, W. B. (1998). Genetic programming with one-point crossover. In P.K. Chawdhry, R. Roy, & R.K. Pant (Eds.), Soft computing in engineering design and manufacturing (pp. 180–189). Springer.
- Tanabe, R., & Ishibuchi, H. (2020, February). A review of evolutionary multimodal multiobjective optimization. Transactions on Evolutionary Computation, 24(1), 193–200. https://doi.org/10.1109/TEVC.4235
- Željko, J., & Šiljak, H. (2011). A new formula for the number of combinations of permutations of multisets. Applied Mathematical Sciences, 5(19), 875–881.
- Zitzler, E., Laumanns, M., & Thiele, L. (2001). SPEA2: Improving the strength pareto evolutionary algorithm [Tech. Rep.]. Computer Engineering and Communication Networks Lab (TIK), Swiss Federal Institute of Technology (ETH) Zurich.