
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Image event recognition is different from object recognition, behaviour recognition and scene recognition. Event is a more advanced concept than object, behaviour and scene. Regarding semantics loss in image event recognition, this paper first proposes a WordNet-based optimization algorithm for concept semantics similarity and describes the semantics relations between different concepts by taking account of such following four impact factors in the WordNet tree as concept semantics distance, concept node depth, concept node density and concept semantics overlap ratio. On that basis, an image event recognition algorithm (CS-IER) based on concept score is proposed, while multi-view learning is applied to fuse concept score and inter-conceptual semantics relations. However, if a higher erroneous concept score is given using CNN, multi-view learning will also augment the concept score approximate to its erroneous concept semantics, thereby leading to the distortion of image representation information. To address this problem, CNN is used to extract channel information to obtain the local features of the image, and it is further fused with the optimized concept score features, so as to form the final image representation information and complete the image event recognition. In experiments, the effectiveness of the proposed algorithm on three datasets is verified.
1. Introduction
With the growth of population and the diversity of social activities, the event scenario has become more common. At the same time, the popularity of social media and smartphones has flooded every corner of people's daily life with image data. To avoid manual data processing, there is a growing need for automatic collection and identification of unstructured multimedia data. How to recognise image events, automatically and effectively model, analyze and discover valuable information and knowledge from them are important research topics in today's intelligent era. Figure shows some examples of image event. Image event recognition can provide technical support and more optimised solutions for many important project applications, such as abnormal event monitoring, automatic driving, intelligent monitoring and so on.
Figure 1. Examples of the image event.

Traditional image event recognition methods use multi-classification and feature extraction methods and widely use different types of information including visual, audio and text. Visual feature is the most widely used information. However, current studies show that the recognition performance of image recognition methods based on shallow traditional features is inadequate. Traditional features cannot fully express the spatial information of images and semantic relations between objects, while CNN has better performance in image recognition. However, compared with traditional methods, the CNN model of training event recognition needs a large amount of training data related to events. Although there are many data sets available, the vast majority are not sufficient for retraining depth models. To solve the problems related to data set, the current mainstream methods are transfer learning and data enhancement. In transfer learning, models are pre-trained and fine-tuned on their associated datasets for different recognition tasks using large-scale datasets. In data enhancement, images in the training set are pruned or rotated to generate new images (DeVries & Taylor, Citation2017).
The main methods to realise image event recognition are supervised learning, semi-supervised learning and unsupervised learning. Traditional image event recognition methods require the data of training samples and test samples to ensure that the samples are independent of each other, and many training samples are required to build a recognition model with good performance. However, with the explosive growth of image data, it is expensive to filter data by manual annotation. Therefore, the method of image recognition with only a small amount of annotation information or external knowledge has become one of the current mainstream methods. For example, transfer learning and concept as the minimum unit to describe information and information matching, the semantic similarity between concepts plays an important role in semantic ambiguity, text classification, information retrieval and machine translation (Pan et al., Citation2022). The recognition performance of the model can be improved by using the image recognition task based on the inherent knowledge of real life.
Due to the particularity of the event, different concepts in the event have potential semantic relationships. How to use the potential semantic relationship information between concepts and the information extracted from CNN to represent the event features in a more comprehensive way is also one of the current research hotspots. In this work, inspired by the successful application of multi-view representation learning in various fields, we aim to employ multi-view representation learning to capture multiple view data features so that the prediction model can obtain different view information in an image event recognition task. Data from different views often complement each other, and multi-view representation learning takes advantage of this to learn a more comprehensive representation than single-view learning approaches. Multi-view representation fusion is the main way of learning multi-view representation, which integrates features extracted from multiple views into a sufficient representation, and makes use of the supplementary knowledge contained in multi-view representation to obtain more comprehensive representation data.
In this paper, we propose a novel Conceptual Semantic enhanced Image Event Recognition method (named CS-IER). Specifically, we first propose a semantic similarity measurement algorithm based on WordNet to measure the semantic relationship between concepts. Then, an image event recognition method based on concept score is proposed based on concept semantic similarity. The semantic similarity between different concepts is calculated by external knowledge (WordNet), and the semantic relationship between different concepts in the image is integrated into the image features by the semantic similarity of concepts and multi-view representation learning. Finally, the recognition results are obtained by combining multi-class SVM classifier. The multi-view representation is used to learn and integrate depth features and concept semantic similarity information. To solve the problem that multi-view representation learning may amplify the concept score similar to its false concept and distort the image representation information, image representation is formed by combining CNN channel information to realise image event recognition. The effectiveness of the proposed method is verified on three datasets. The remaining parts of this paper are organised as follows. The main ideas of related works are summarised in Section 2. We discuss the proposed model in detail in Section 3. Section 4 presents the performed experiments and detailed result analysis. Lastly, Section 5 concludes our work and future works are discussed.
In a nutshell, this work makes the following main contributions:
We develop a concept semantic similarity measurement algorithm based on WordNet, which selects semantic distance, node depth, node density and semantic overlap degree of concepts in WordNet tree to measure semantic similarity among different concepts.
We propose a novel image event recognition model CS-IER, which takes advantage of multi-view representation learning to achieve deep feature fusion, leading to better representations and accuracy.
We conduct extensive experiments on three benchmark datasets to demonstrate the advantages of our CS-IER on the effectiveness of image event recognition compared with the state-of-the-art methods.
2. Related work
General events involve multiple objects and behaviours and lack consistent and continuous information flow, so it is difficult to realise event recognition in a single image. However, the current mainstream method is to extract image features or establish a discriminative classification paradigm (Tzelepis et al., Citation2016), and at the same time use information related to image data (Dao et al., Citation2014), such as tag, title, owner, upload date and other information to achieve image event recognition. Although such additional information in the form of metadata has proven to be effective in event identification, it also has certain limitations (Liu & Huet, Citation2013). For example, the camera time zone is set incorrectly or not set, resulting in the image time stamp error, lack of time stamp and unclear label meaning. At present, the event recognition algorithm based on visual information has achieved good results. This is because visual information contains sufficient event characteristic information, so many image recognition algorithms based on visual information have been produced. Due to the rise of deep network, CNN model also shows good performance in the field of computer vision and proves the inefficiency of traditional manual visual feature algorithm (Ahmad et al., Citation2016b).
At present, the mainstream image event recognition method is to fine-tune the pre-trained model on the event-related images to avoid wasting resources by using large-scale image data sets to retrain the CNN model. The model pre-trained on ImageNet has been widely used (Deng et al., Citation2009). Ahmad pre-trained AlexNet model on ImageNet and then fine-tuned the data set covering 14 different types of social events to realise image event recognition (Adhikari et al., Citation2018; Krizhevsky et al., Citation2017). Liu fine-tuned the existing pre-training models VGGNet and GoogLeNet in 2015 to realise cultural event recognition (Liu et al., Citation2015; Simonyan & Zisserman, Citation2015; Ballester & Matsumura, Citation2016). There are also methods to retrain existing and newly designed CNN models for event recognition. Literature retrained AlexNet and NIN models on image data set UIUC and video data set, respectively, and then performed later fusion of classification scores obtained by the two models to realise event recognition (Rachmadi et al., Citation2016; Lin et al., Citation2014; Li & Li, Citation2007). In addition to the post-fusion method, we can also train the features extracted from the model to carry out the fusion method in the early stage. Park extracted many specific regional features from images related to cultural events and used them to train CNN model (Park & Kwak, Citation2015). This method is mainly inspired by literature to realise the recognition of a single image event in a specific region of the image, extract a specific region through selective search and achieve object positioning and segmentation through selective search (Girshick et al., Citation2014; Jasper et al., Citation2013). Then the CNN model is trained on the extracted specific regions, and the classification decision is realised based on a majority voting algorithm.
According to the general features of the existing pre-trained CNN model, image event recognition methods are also commonly used at present. Ahmad realised the significant event recognition method based on image region by extracting features in ImageNet pre-trained VGGNet-16 (Ahmad et al., Citation2018). The image is divided into multiple regions through selective search, and the region most relevant to the event is selected among the divided regions (Jasper et al., Citation2013). Then, the related regions extracted are classified by using the multi-example learning (MIL) paradigm. In the depth model pre-trained on ImageNet is used to extract image features, while the model is also used to extract features after fine-tuning on images related to cultural events, and the features extracted from the two models are integrated to achieve image classification (Salvador et al., Citation2015).
Wang adopted a similar approach to realise event recognition by integrating object-level information with scenario-level information, reflecting the complementarity of object-level information and scenario-level information (Wang et al., Citation2017). To study the event recognition method realised by complementary fusion of different information, literature pre-trained three different CNN models on ImageNet and Places data sets and then used post-processing fusion method based on IOWA to fuse features extracted from different models (Ahmad et al., Citation2017; Yager & Filev, Citation1999). These depth models include AlexNet, GoogLeNet and VGGNet. In 2015, Grez proposed a language for describing complex events and used a formal selection strategy as an extension of the existing framework (Grez et al., Citation2021).
The description of an event is extremely complex because it is highly related to the many visual cues it contains. Current methods mainly use CNN to extract a global representation of images or fuse multiple visual cues in images to realise image event recognition. Wang et al. (Citation2015) proposed an OS-CNN algorithm, which comprehensively considers objects, behaviours and scenes to realise image event recognition. Hasan et al. (Citation2020) proposed a framework with active learning ability, constructed a conditional random field to encode the context and used entropy and mutual information of nodes to calculate the maximum query set of information labelled by thermal endoscope to realise the situational awareness of activities in tag-free videos. Wang et al. (Citation2018) used depth representations learned from target and scene datasets to solve image event recognition and confirmed the correlation between object, scene and event concepts. An iterative selection method is proposed to identify object and scene categories in subsets and transfer the most relevant representations. This paper proposes an image recognition method that integrates concept semantics. According to the diversity and complexity of events, image event recognition is realised by using CNN's good image representation ability and integrating concept semantic relations in the existing knowledge base.
One of the keys to image event recognition is to seek effective image representation and to highlight the internal structure and specific feature information of the image (Li et al., Citation2021). Convolutional Neural Network (CNN) has become an effective method for image representation (Akilandeswari et al., Citation2021; Bhavana et al., Citation2021). The description of the image event is tremendously complex in that it is not only highly correlated with numerous visual clues contained wherein but also incorporates some specific inter-conceptual logical semantics relations. On that account, representation information of image event cannot be fully extracted via CNN. However, multi-view learning can improve the representation capacity by effectively correlating with different view data (Dingchao et al., Citation2021; Kai et al., Citation2021). In this paper, multi-view learning fused with image visual features and inter-conceptual semantics relations are adopted, while external knowledge rich in concept semantics information is fused into image representation information, in an effort to materialise image event recognition.
In the above methods, if the statistical attributes of multi-view representation data are inconsistent in a certain learning scenario, the representation after learning may reduce learning performance (Wei et al., Citation2019). Such as speech recognition with audio and video data, it is difficult to correlate the raw pixels with the audio waveform, while the data of the two views is correlated between intermediate representations (such as phonemes and opemes). Inspired by deep learning, the limitation of high-level association of different data is overcome to some extent (Shaokang et al., Citation2022; Yan et al., Citation2021). However, when the statistical attributes of multi-view representation data are inconsistent in a certain learning scene, the weakness of semantic correlation still affects the representation performance.
The algorithm in this paper uses external knowledge to study the semantic interaction between features and proposes a semantic similarity measurement method based on semantic distance, node depth, node density and semantic coincidence degree in WordNet tree. Then, multi-view representation learning is used to map semantic similarity information and image visual features to the same feature space to realise semantic correlation mining of different feature information in the image and enhance the semantic understanding ability of the recognition model.
3. Proposed method
3.1. Concept semantic similarity measurement algorithm based on WordNet
When measuring concept similarity based on node density factor, only the number of sibling nodes of the concept itself is considered when considering concept node density, but the density of concept node is also affected by node local density. As shown in Equation (1), and
represent the sum of sibling nodes of concept X and concept Y, respectively.
represents the maximum sibling nodes in all branches of the WordNet tree structure. When measuring the similarity of the same concept, the result may not be 1, but that's not the case.
(1)
(1) To solve this problem, we consider the density of common grandfather nodes when measuring semantic similarity based on conceptual node density, as shown in the following equation.
(2)
(2)
represents the nearest common ancestor node density of concept x and concept y,
and
represent the number of sibling nodes of concept x and concept y, respectively, and
represents the maximum number of sibling nodes in all branches of the entire WordNet tree structure. When measuring concept similarity based on semantic coincidence factor above, only the number of common ancestor nodes of concepts is considered, and the influence of common ancestor nodes of different concepts is different. The closer the common ancestor node is to the concept, the greater the influence of ancestor nodes on the concept. It can be seen from the above that when measuring the similarity of concepts based on semantic coincidence degree, considering the number of common ancestor nodes of concepts and the distance between common ancestor nodes and concepts can better represent the semantic relations between concepts. For concept nodes A and B and their grandfather node C, the distance between the nodes is calculated to determine the significance of semantic coincidence degree of the concept, which is expressed by the difference between the depth of concept nodes A and B and their grandfather node. The significance calculation of semantic coincidence degree between grandfather concept node C and concept node A and B is shown in the following equation.
(3)
(3) Through the whole WordNet tree, the importance of all ancestor nodes is calculated, and the sum of semantic overlap degree of common nodes in the WordNet tree is formed.
The above analysis only considers the influence of one concept node on its semantic similarity, but the number of common grandparent nodes of the concept node in WordNet tree also contains semantic similarity information between concepts. This paper divides the related nodes of concept node into two types for analysis (common grandparent node and independent grandparent node). The importance calculation method of the independent grandfather node of concepts A and B is shown in the following equations.
(4)
(4)
(5)
(5)
Based on the factors considered above, the final calculation method of conceptual semantic similarity based on the factor of conceptual semantic coincidence is formed, as shown in the following equation.
(6)
(6) All grandfather nodes of concepts A and B in the WordNet tree are defined as
, respectively.
represents the independent grandparent concept node of concept A in the WordNet tree, and
represents the independent grandparent concept node of concept B in the WordNet tree.
Semantic similarity is measured based on semantic coincidence degree, and the value range of semantic similarity is also 0–1. After comprehensively considering the above four influencing factors, the WordNet-based concept semantic similarity algorithm (CSS) is shown in the following equation.
(7)
(7) The empirical parameters
are assigned to different influencing factors of concept semantic similarity.
. The above factors were combined to measure the semantic similarity of concepts.
3.2. Image event recognition algorithm based on concept score
The core idea of the proposed image event recognition algorithm based on concept scoring (CS-IER) is that the occurrence of events must contain some specific concepts and semantic relations between concepts, while CNN can only extract the features of the image itself. Once the visual features that are easily confused appear, the accuracy of recognition will be greatly reduced. Therefore, the potential semantic relations of different concepts in image event recognition are integrated into the recognition algorithm, see Figure .
Concept score extraction
Figure 2. Illustration of event recognition.
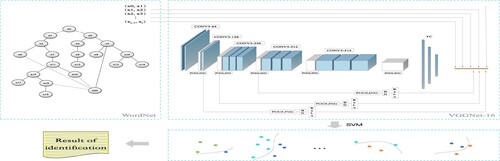
In general, the output results of CNN's output layer (SoftMax layer) are taken as concept scores, and each dimension of the extracted concept score vector corresponds to a specific concept in the real world. For a given image I, the concept score result is .
is the concept score vector of image I, and
is the scoring value of 1000 selected concepts.
CNN channel information extraction
The multi-scale information of feature graph comes from different CNN convolution layers. Then, dimension reduction sampling is carried out for this multi-scale information to obtain the same dimension feature vector as SoftMax layer. Finally, the feature vector after dimension reduction sampling is added to the output of SoftMax layer. The output of the -th branch is shown in the following equation.
(8)
(8)
is the input of the convolution layer,
is the down-sampling function, the output of the branch is
and the input of the SoftMax layer is
, as shown in the following equation.
(9)
(9)
When the width and depth of CNN are increased, the problem of gradient explosion also appears. To solve the gradient explosion problem, each branch is processed by activation function (ReLU), as shown in the following equation.
(10)
(10)
3.2.1. Overview of our CS-IER
WordNet tree is used to calculate the semantic similarity between different concepts, and multi-view representation learning is used to make the concept scores of concepts with similar semantic meanings similar. However, this algorithm has shortcomings. For example, when CNN gives a high score to a false concept when extracting the concept score, this algorithm may amplify the score of the false concept with similar semantics at the same time. Therefore, CNN channel information is simultaneously extracted and fused with the optimised CS features to solve the above problems to a certain extent. The overview of our proposed CS-IER is shown in Figure .
Figure 3. Overview of our proposed CS-IER.
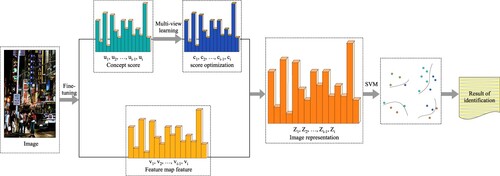
Firstly, the concept score vector () of the image and the feature vector (
) formed by the feature map are extracted. Considering the potential semantic relationships among different concepts in the image and integrating such potential semantic relationships into the extracted concept score vector, we optimise the concept score vector (
) by using the proposed CS-MVL algorithm (See Section 3.2.2). The optimised concept score vector (
) is obtained. Then the feature vector formed by the feature map and the optimised concept score vector are fused to form the final representation vector of the image (
), as shown in the following equation.
(11)
(11) Finally, a linear classifier
is constructed using the resulting image representation vector
. w is the weight of the linear classifier. LIBSVM is selected as the classifier learning weight w, where the equalisation regularisation parameter C and loss are both set to 1 (Chang & Lin, Citation2011). Vectors need to be normalised before they are used to build linear classifiers, and then input to LIBSVM for training. The feature vector
is normalised by L2 and the feature vector
is normalised by BN.
3.2.2. Concept semantic similarity-based multi-view representation learning
In this section, we propose a multi-view representation learning algorithm (CS-MVL) based on semantic similarity. The core idea of this algorithm is to optimise the recognition results of CNN by using external knowledge. If two concepts in external knowledge have very similar semantic meaning, it is also expected that the score of concepts extracted from CNN will be closer. The extracted concept score and the calculated semantic similarity information of the concept are mapped to a new feature space. The new feature space maps the two feature spaces to the new feature space from the concept score view and the similarity information view and retains the information of different views at the same time.
Concept score extracted by CNN forms the corresponding similarity matrix
formed by WordNet-based concept semantic similarity measurement algorithm, as shown in the following equation.
(12)
(12) Firstly, the objective function
is constructed, and the new feature space is assumed to be
. The similarity matrix is mapped into the new feature space
, and the objective function is minimized, as shown in the following equation.
(13)
(13)
(14)
(14)
is concept similarity; the larger the concept similarity is, the smaller the distance between concepts is.
is also smaller to realise the objective function optimisation step by step.
is Laplace matrix
.
In addition, a loss function is constructed to map the concept score and concept similarity into the new feature space, minimising the loss function and smoothing the loss values.
(15)
(15)
is the Laplace matrix, as shown in the above equation
or
. According to the concept of algorithm stability in literature, when
, the stability of the algorithm can be guaranteed or the regularisation problem can be transformed into a constraint function with a mean value of 0 to determine the corresponding generalisation boundary of the function. The fusion parameter
was determined experimentally.
According to Equation (16), the new feature space is created after linear transformation when the derivative of the loss function
is 0.
(16)
(16)
(17)
(17)
is the diagonal matrix, and
is the unit vector.
controls the stability of a function such that
is orthogonal to 1. Function
is shown in Equation (19).
(18)
(18)
(19)
(19)
(20)
(20)
3.2.3. Algorithm analysis of CS-IER
The proposed multi-view learning based on semantic similarity is based on the hierarchy of real-world concepts. Each dimension of the 1000-dimension descriptor vector generated by the output layer of CNN (FC8 layer) corresponds to a real concept. Therefore, we combine multi-view representation learning to integrate conceptual semantic information. In addition, each dimension of the feature vectors of FC6 and FC7 layers in CNN does not conform to the concept of the real world. Therefore, the CS-IER algorithm cannot be used for eigenvectors generated by these layers. Traditional low-level-based approaches, such as the BoW feature, also fail to produce a conceptual representation; they are based on low-level features and ignore middle-level concepts. The algorithm proposed in this section based on concept level representation is based on concept hierarchy, so it can better explore the semantic association of concepts at different levels. The overall steps of the algorithm are shown in Algorithm 1.
Table
4. Experiments
We perform our experiments on three benchmark datasets and we aim to answer the following questions:
RQ1: How does our CSS perform as compared with the baseline similarity measurement methods on WordNet tree?
RQ2: How is the parameter sensitivity and noise resistance of our CS-MVL?
RQ3: How does CS-IER perform as compared with the state-of-the-art methods on the selected three datasets?
The main motivation of RQ1 is to be different from the existing similarity measurement methods. This paper considers several influencing factors in similarity calculation and proposes a similarity measurement method based on WordNet to measure semantic similarity between different concepts in events. As a key upstream task of cultural event recognition method, semantic similarity measurement of nodes in wordNet tree is the basis of our model. Therefore, we compared with the existing similarity calculation methods to verify the validity of the semantic similarity calculation method proposed in this paper.
Our motivation for setting RQ2 is that considering the importance of model parameter changes to the proposed model, we conducted sensitivity analysis on relevant important parameters of the model to verify the impact of model performance with parameter changes.
The motivation of RQ3 is to highlight the overall performance comparison between the proposed method and the existing event recognition method, so as to verify the effectiveness of the proposed method combining visual features and conceptual semantics.
4.1. Datasets and evaluation metric
4.1.1. Datasets
In this paper, Chalearn cultural event dataset, WIDER dataset and PECD dataset are used to realise event recognition (Escalers et al., Citation2015; Yang et al., Citation2016; Bossard & Guillaumin, Citation2013; Ahmad et al., Citation2016a).
Chalearn cultural event data is mainly derived from two data search engines (Google Images and Bing Images). There are 100 categories of cultural events from different countries in the dataset (99 categories are cultural events and 1 category is scene). Images of cultural events are very complex. Clothing, human body posture, special objects and special scenes in the images can all become important clues to identify cultural events. Meanwhile, the data set was also divided into three parts: training set (14,332 images), test set (5704 images) and evaluation set (8669 images). Since the labels of the images in the evaluation set could not be obtained, we use the training set to fine-tune the algorithm model, and then verified the validity of the algorithm on the test set.
The WIDER dataset contains 50,574 images and 61 event categories. The whole dataset is divided into 25,275 training images and 25,299 test images. The dataset focuses more on events in daily life, such as parades, dances, conferences, press conferences, etc. Thus, from the point of view of event categories, is a complement to the Chalearn cultural event recognition dataset.
The PEC dataset consists of 807 photo albums, is annotated with 14 social event categories and contains a total of 61,000 photos. In the experiment, 30 albums contained in each category are formed into a training set, and 10 albums are formed into a test set. Albums level labels are directly assigned to each image contained in the album, and the image itself is simply used for event recognition without using any original information (such as time information).
4.1.2. Evaluation metric
In this paper, average precision (AP) and mean average precision (mAP) are mainly used. AP value is the accuracy and recall rate curve of each category in the data set based on the algorithm, and the integral of the curve is used as the evaluation index of the algorithm's recognition of each category of events. mAP value is the average AP value of each class in the event class. mAP is used as the final evaluation index of the algorithm. Therefore, AP values of each category and mAP values of all classes in the evaluation dataset will be calculated in the experimental results to evaluate the effect of the algorithm.
4.2. Implementation details
In the experiment, VGGNet-16 is adopted as the network structure of CNN. The network is pre-trained on ImageNet. The network is then fine-tuned using a set of images from the dataset. The learning method was stochastic gradient descent (SGD), and the small batch size was set to 128 samples. To speed up learning, set the momentum to 0.9 and use L2 weight attenuation 0.0005 to reduce the training error. To reduce overfitting, the dropout strategy is employed. The initial learning rate is set to 0.01. Fine-tuning will run for about 10 batches and the model converges. The output results of VGGNet-16's output layer (SoftMax layer) are used as the concept score vector (global feature) of the image, and the features of the convolutional layer (conv 5-1, conv 5-2, conv 5-3, conv 5-4) are extracted to form feature vector (local feature).
The classification of SVM uses the LIBSVM library. Choose the one-for-one approach (the default for LIBSVM developers) for multi-class classification. Two different categories are selected to construct sub-classifiers. For k categories, there are classifiers. For the two different categories,
, the training samples are set as 1 and −1 respectively for training. At the same time, the feature vectors extracted from j are normalised.
4.3. Experimental results and analysis
4.3.1. Performance of our similarity measurement (RQ 1)
We select the concept fragment of poison in WordNet tree as an example to verify the effectiveness of the algorithm in this section. See Figure .
Figure 4. Diagram of poison concept fragment in WordNet tree.
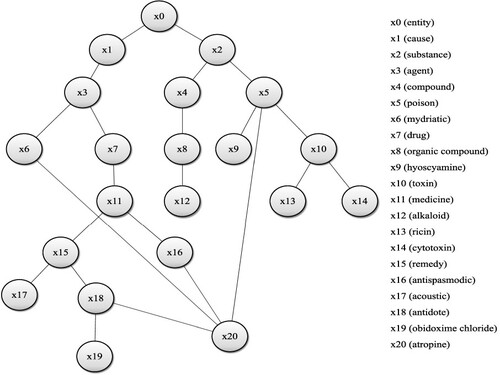
Figure shows a fragment of the poison concept captured in the WordNet tree. In Figure , represents the 20 concepts contained in the concept tree. Since only the concepts
have actual physical significance, only these 10 concepts are selected to consider the semantic similarity of concepts.
Experimental results of conceptual node density
Table 1. Experimental results of semantic similarity based on node density.
It can be seen from Table that the algorithm in this paper is always 1 when calculating concept similarity based on the concept density factor, while the algorithm in literature (Wang et al., Citation2015) is not always 1 when calculating concept similarity based on the concept density factor. Obviously, our algorithm better reflects the semantic relationship of concepts. At the same time, it can be observed that the semantic similarity of concept node pairs ,
,
is the same, so only considering the impact factor of concept node density cannot fully reflect the semantic relationship between concepts. To solve the above problems, we select semantic distance, depth of concept node, density of concept node and semantic coincidence degree of concept in WordNet tree to calculate semantic similarity between different concepts.
Experimental results of semantic consistency of concepts (RQ 1)
Table 2. Experimental results of semantic coincidence degree.
As seen in Table , when the algorithm in literature (Ouyang & Hu, Citation2017) calculates concept similarity based on semantic coincidence factor, only the number of common grandparent nodes of concepts is considered. The semantic similarity of node pairs of concepts ,
and
is the same. However, our algorithm considers the influence of common ancestor nodes of different concepts and better expresses the semantic relationship of the above concept node pairs.
Experimental results of concept semantic similarity (RQ 1)
Table 3. Experimental results of concept semantic similarity.
As seen from Table , compared with the current classical algorithm for calculating the semantic similarity of concepts, the value of semantic similarity of the same concept calculated by the algorithm in this section is always 1, and the values of four different impact factors are also within the interval of [0,1]. Let’s look at concept node pairs ,
,
for example. The classical algorithm for computing concept semantic similarity obtained the same concept semantic similarity, while our algorithm can more reasonably express the semantic similarity between concepts.
The semantic similarity measurement algorithm proposed in this paper considers that the density of concept nodes is also affected by the local density of nodes, the influence of common ancestor nodes of different concepts on concepts is different, and the number of common grandfather nodes of concept nodes in WordNet tree also contains the information of semantic similarity between concepts. After comprehensively considering the above factors, the semantic similarity algorithm in this paper is proposed to better express the semantic relationship of semantic similarity between concepts.
4.3.2. Performance of our CS-MVL (RQ 2)
As shown in Figure , cultural event data sets are selected in the experiment, and different fusion parameters are used to realise image event recognition.
Figure 5. Effect of different fusion parameters for our CS-MVL.
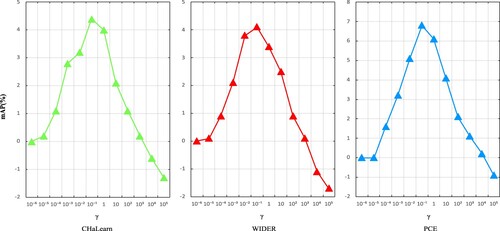
The parameter is a marker of semantic association between concepts. As shown in Figure , the multi-view representation learning algorithm based on semantic similarity is tested on Chalearn cultural event dataset, WIDER dataset and PEC dataset. The algorithm performance can be continuously improved by adjusting the parameter
value. As seen from Equation (13), with the constant increase of parameter values, the weight of conceptual semantic similarity also increases. The image representation information formed gradually deviates from the original image information, and the algorithm effect will gradually decline. We proposed the semantic similarity-based multi-view learning method which can achieve better performance when
.
Generally, noise has a negative effect on multi-view representation learning, and even reduces the recognition accuracy in the case of multi-view representation learning. Figure shows the effect of multi-view representation learning on CS.
Figure 6. Effect of noise data on multi-view representation learning.
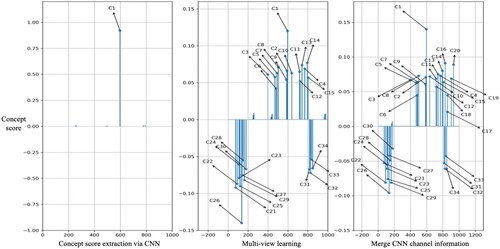
The first picture on the left of Figure shows the distribution of concept score in the image, where multi-view representational learning optimisation is not used. Concept C1: Maximum concept score for golf parking Spaces. This is due to the inadequacy of the video noise or CNN concept score extraction model, which assigns an extremely large score to an unrelated concept.
The second figure in Figure shows the processing effect of concept score optimisation using multi-view representation learning. When concept scores were optimised by multi-view representation learning, it was observed that concept scores were more evenly distributed. In addition to C1 to C4, scores for C5: Garden car, C6: tandem bicycle, C7: taxi, C8: convertible, C9: fire truck, C10: limousine, C11: motorcycle, C12: passenger car, C13: snowmobile, C14: tram, C15: tram also improved. These concepts are vehicles, and they have nothing to do with the holiday theme. Although the multi-view representation learning algorithm can make the concept score more uniform to solve the problem of data sparsity, it may reduce the accuracy of event recognition to a certain extent, mainly because the multi-view representation learning algorithm will increase the score of the concepts with similar semantics. For example, when CNN extracts false concept information from images, multi-view representation learning amplifies the error information. CNN channel information can be regarded as a local feature of the image, which can be fused to solve the above problems.
The last figure in Figure shows the processing effect of CNN channel information fusion. After the integration of CNN channel information, C16: lawn, C17: pedestrian, C18: seats, C19: trees, C20: flowers and other concepts related to image themes increase significantly, and the problem of data sparseness is also solved.
Compared with the traditional multi-view representation learning algorithm, the proposed CS-MVL algorithm uses the inter-concept semantic association marker γ to map the visual features and inter-concept semantic information to the same space. At the same time, considering that multi-view representation learning will amplify the concept score similar to its false concept at the same time, which will cause the distortion of image representation information, image representation is formed by combining CNN channel information to realise image event recognition.
4.3.3. Performance comparison on Chalearn dataset (RQ 3)
In the Cultural event data set of Chalearn, to verify the effectiveness of our algorithm, SoftMax layer, convolution layer and full connection layer in the network are, respectively, taken as feature vectors of images. The concept score vector extracted by SoftMax layer is optimised, and then tested on the cultural event data set. The experimental results are shown in Table .
Table 4. Experimental results of image event recognition algorithm (mAP).
In Table , algorithm 1 directly uses VGGNet-16 for image event recognition without pre-training or fine-tuning the network. Algorithm 2 pre-trains VGGNet-16 on ImageNet. Algorithm 3 pre-trains VGGNet-16 on ImageNet and fine-tunes it by using the training set of cultural event data set. Algorithms 4, 5 and 6 pre-train and fine-tune VGGNet-16, but select different features in the network as feature vectors of the image. The experimental results in Tables and show that:
The features of VGGNet-16 after pre-training and fine-tuning (Algorithm 3) are better than the features directly output by SoftMax layer of original VGGNet-16 (Algorithm 1). This situation is caused by the fact that VGGNet-16 is easier to overfit the training samples when there are fewer images in the training set.
By comparing the features of VGGNet-16 after pre-training and fine-tuning (Algorithm 3) with those of VGGNet-16 after pre-training only (Algorithm 2), pre-training and fine-tuning of VGGNet-16 can improve the recognition performance of the model.
Compared with convolutional layer features in VGGNet-16 (Algorithm 4) and CS features in SoftMax layer after pre-training and fine-tuning of VGGNet-16 (Algorithm 5), CS features have a better recognition effect.
After pre-training and fine-tuning of VGGNet-16, CS features (global features) of SoftMax layer and convolution layer features (local features) of VGGNet-16 are fused (Algorithm 6). Features of each layer in VGGNet-16 have abstract representations of different image features and complement each other so that the fused features can effectively improve the performance of event recognition.
The proposed multi-view representation learning is based on the hierarchy of real-world concepts. Each dimension of the 1000-dimension concept score vector generated by the output layer (SoftMax layer) of VGGNet-16 corresponds to a real concept, so the concept semantic information is fused with the CS-MVL algorithm. In addition, the different dimensions of feature vectors generated by FC6 and FC7 do not conform to real-world concepts. Therefore, our CS-MVL algorithm cannot process the feature vectors generated by these layers. As seen from Table , the recognition performance of the algorithm is greatly improved after the 1000-dimension concept score vector generated by the output layer (SoftMax layer) of VGGNet-16 is optimised by concept semantic similarity. This also shows that it is effective to integrate conceptual semantic information into an image event recognition algorithm.
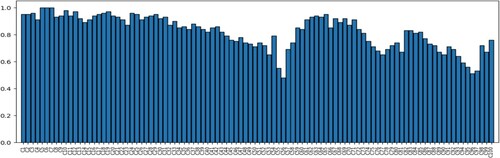
Figure shows the AP values for all event classes in cultural events. From all the calculated AP values, the average recognition accuracy (AP) of cultural event monkey festival category (C5) and cultural event orange Fight category (C6) is 100%, which is due to the existence of specific objects in these two cultural events. Meanwhile, the average accuracy (AP) of cultural events such as Halloween (C56), Candlemas (C96) and Pirate Day (C97) is low. Such cultural events contain only a small number of specific objects and scenes, and these different cultural event classes are easily confused with other classes.
Figure 7. Experimental results of cultural events (AP).
4.3.4. Performance comparison on WIDER and PEC datasets (RQ 3)
Further, we compare the proposed algorithm with the current mainstream deep learning method on WIDER. As shown in Table , Xiong et al. (Citation2015) adopted CNN for image event recognition in the early stage and proposed a multi-layer framework that took into account the visual features of images and the interactive information between objects, with a recognition rate of 60.2%. Subsequently, CNN channel information was fused to optimise the algorithm. The algorithm performance improved from 60.2% to 62.1%, which also showed that CNN channel information fusion effectively improved the model performance. CNN is pre-trained and fine-tuned on ImageNet, and the recognition performance is greatly improved, reaching 69.6% (Zhou et al., Citation2014). Meanwhile, the image event recognition algorithm that integrates visual features and scene label information realises event recognition by fully combining diverse information in the data set. It achieved 72.2% recognition performance on GoogLeNet.
Table 5. Experimental results on WIDER dataset (mAP).
The WIDER data set comes from daily life, and there is large noise information in the image data. The recognition performance of the algorithm far exceeds that of the baseline algorithm compared in this paper after integrating the conceptual semantics and CNN channel information. The recognition performance of our algorithm improved by 15.9% and 15% respectively compared with the earlier algorithms that only apply to CNN and integrate CNN channel information. Compared with ImageNet CNN algorithm, the recognition performance of this algorithm improved by 6.5%. Compared with GoogLeNet GAP algorithm, the recognition performance improved by 3.9%.
In Table , our algorithm compares with the traditional event recognition algorithm (Bossard & Guillaumin, Citation2013) and aggregates four methods, Aggregated SVM, Bag of sub-events, HMM, and SHMM, and experimental results on PEC dataset. In the experiment, the original image without time information is simply used for image-level event recognition. To ensure the integrity of the experiment, several event recognition algorithms using timestamp information, such as SVM, HMM and SHMM, are selected. Among the traditional image event recognition algorithms, SHMM algorithm achieved good results. This algorithm uses the improved hidden Markov model to extract potential sub-event information to realise image event recognition. Our proposed CS-MVL algorithm adopts the current mainstream deep network and integrates the event semantic information, which improves the recognition performance by 6.5% compared with the traditional SHMM algorithm. At the same time, aiming at the problems existing in multi-view representation learning, CS-IER algorithm adds CNN channel information to form image representation to realise image event recognition and has a more obvious improvement in recognition effect on PEC data set. Compared with SHMM and CS-MVL algorithm, the recognition performance improved by 8.8% and 2.3%. respectively.
Table 6. Experimental results on PEC dataset (mAP).
4.4. Analysis of experimental results
This paper proposes a semantic similarity measurement algorithm based on WordNet, which measures the semantic relationship between concepts by WordNet tree and different influencing factors. Experimental results on “poison” concept fragment in WordNet tree show that the proposed algorithm can more accurately measure the semantic relationship between concepts. After obtaining the semantic similarity of concept, an image event recognition algorithm based on concept score was proposed for the event recognition task. Multi-view representation is used to learn fusion concept semantics, and CNN channel information is used to form a more discriminative image semantic representation to realise image event recognition.
Experiments show that the semantic similarity of the WordNet-based concept semantic similarity measurement algorithm proposed in this chapter is always 1 when the concept density factor is considered to calculate the semantic similarity, while the traditional algorithm cannot ensure that the semantic similarity of the same concept is 1. The algorithm in this chapter comprehensively considers the semantic distance, node depth, node density and semantic overlap of concepts, and fully expresses the semantic relations between concepts.
At the same time, the CS-MVL algorithm was verified in Chalearn, WIDER and PECD datasets, and the optimal value of parameter γ in the algorithm was determined to be 0.1. Taking wedding video data as an example, the effect of integrating concept semantics and CNN channel information on improving the discrimination ability of image representation was analyzed and demonstrated. Then verify the effectiveness of CS-IER algorithm in the above three data sets.
5. Conclusion
In this paper, a semantic similarity measurement algorithm based on WordNet is proposed to measure the semantic relationship between concepts. Then, an image event recognition algorithm based on concept score (CS-IER) is presented based on concept semantic similarity. Multi-view representation is used to learn and integrate depth features and concept semantic similarity information (CS-MVL).
In the experiment, the concept fragment of “poison” in WordNet tree is selected as an example to verify the effectiveness of the algorithm. The proposed WordNet-based concept semantic similarity measurement algorithm is always 1 when the concept density factor is considered to calculate the semantic similarity, while the traditional algorithm cannot ensure the semantic similarity between the same concepts is 1. Our algorithm also considers the semantic distance, node depth, node density and semantic coincidence degree of concepts and calculates the influence of common ancestor nodes of different concepts on concepts to express the semantic relations between concepts.
In the experiment of image event recognition, the semantic similarity-based multi-view representation learning algorithm was first verified in Chalearn, WIDER and PECD datasets. The optimal value of parameter in the algorithm was determined to be 0.1. At the same time, taking wedding video data as an example, the effect of integrating conceptual semantics and CNN channel information on image representation discrimination is analyzed and demonstrated. Then, the effectiveness of CS-IER algorithm is verified in the above three data sets. In the Chalearn cultural event dataset, our algorithm is compared with the OS-CNN algorithm. OS-CNN is close to the core idea of the algorithm in this paper, which uses the deep network to extract image objects and form image representation after the fusion of scene features to realise the recognition of image events. Compared with OS-CNN algorithm, the recognition performance of this algorithm improved by 3.2%. In the WIDER dataset, our algorithm is compared with the current mainstream deep network algorithm. Compared with GoogLeNet GAP algorithm, the recognition performance of the proposed algorithm improved by 3.9%. At the same time, we compare with the traditional event recognition algorithm, and our algorithm has obvious improvement effect. Compared with Bag of sub-events and SHMM, the recognition performance improved by 14.1% and 8.8%.
Although the algorithm in this paper has achieved good results, there are still some problems to be solved. The semantic identification parameter γ of CS-MVL algorithm proposed in this paper is determined by several experiments, and the parameter value needs to be verified repeatedly for different application fields. If we can find more suitable semantic identification parameters through some learning mechanism, the model performance can be better improved. We will consider a more advanced technique or feature for improving image event recognition in the future work.
Acknowledgements, avoiding identifying any of the authors prior to peer review
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Adhikari, A., Dutta, B., Dutta, A., Mondal, D., & Singh, S. (2018). An intrinsic information content-based semantic similarity measure considering the disjoint common subsumers of concepts of an ontology. Journal of the Association for Information Science and Technology, 69(8), 1023–1034. https://doi.org/10.1002/asi.24021
- Ahmad, K., Conci, N., Boato, G., & Francesco, G. D. N. (2016a). USED: A large-scale social event detection dataset. Proceedings of the International Conference on Multimedia Systems(MMSys), 50, 1–6. https://doi.org/10.1145/2910017.2910624
- Ahmad, K., Conci, N., & FGB, D. N. (2018). A saliency-based approach to event recognition. Signal Processing: Image Communication, 60, 42–51. https://doi.org/10.1016/j.image.2017.09.009
- Ahmad, K., Mekhalfi, M., Conci, N., Boato, G., Melgani, F., & FGB, D. N. (2017). A pool of deep models for event recognition. Proceedings of the IEEE International Conference on Image Processing(ICIP), 2886–2890. https://doi.org/10.1109/ICIP.2017.8296810
- Ahmad, K., Natale, F. D., Boato, G., & Rosani, A. (2016b). A hierarchical approach to event discovery from single images using MIL framework. Proceedings of the IEEE Global Conference on Signal and Information Processing (Global SIP) (pp. 1223–1227). https://doi.org/10.1109/GlobalSIP.2016.7906036
- Akilandeswari, J., Jothi, G., Naveenkumar, A., Sabeenian, R. S., Iyyanar, P., & Paramasivam, M. E. (2021). Detecting pulmonary embolism using deep neural networks. International Journal of Performability Engineering, 17(3), 322–332. https://doi.org/10.23940/ijpe.21.03.p8.322332
- Ballester, P., & Matsumura, R. (2016). On the performance of GoogLeNet and AlexNetApplied to sketches. Proceedings of the Association for the Advance of Artificial Intelligence (AAAI) (pp. 1124–1128). http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12278
- Bhavana, D., Kishore, K. K., Chandra, M. B., Joy, S. D., & Mohan, G. G. (2021). Hand sign recognition using CNN. International Journal of Performability Engineering, 17(3), 314–321. https://doi.org/10.23940/ijpe.21.03.p7.314321
- Bossard, L., & Guillaumin, M. (2013). Event recognition in photo collections with a stopwatch HMM. Proceedings of the IEEE International Conference on Computer Vision(ICCV), 1193–1200. https://doi.org/10.1109/ICCV.2013.151
- Chang, C., & Lin, C. (2011). LIBSVM: A library for support vector machines. ACM TIST, 2(3), 27. https://doi.org/10.1145/1961189.1961199
- Dao, M., Tien, D., Nguyen, D., & Francesco, G. D. N. (2014). Robust event discovery from photo collections using signature image bases(SIBs). Multimedia Tools and Applications, 70(1), 25–53. https://doi.org/10.1007/s11042-012-1153-6
- Deng, J., Dong, W., Socher, R., Li, L., Li, K., & Li, F. (2009). Imagenet: A large-scale hierarchical image database. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 248–255). https://doi.org/10.1109/CVPR.2009.5206848
- DeVries, T., & Taylor, G. W. (2017). Dataset augmentation in feature space. Proceedings of the International Conference on Learning Representations (ICLR) (pp. 78–86). https://openreview.net/forum?id =HyaF53XYx
- Dingchao, J., Hua, Q., Jihong, Z., Jianlong, Z., & Meng-Yen, H. (2021). Aggregating multi-scale contextual features from multiple stages for semantic image segmentation. Connection Science, 33(3), 605–622. https://doi.org/10.1080/09540091.2020.1862059
- Escalers, S., Fabian, J., Pardo, P., Baro, X., Gonzlez, J., Escalante, H. J., Misevic, D., Steiner, U., & Guyon, I. (2015). Chalearn looking at People 2015: Apparent age and cultural event recognition datasets and results. Proceedings of the IEEE International Conference on Computer Vision (ICCV) (pp. 243–251). https://doi.org/10.1109/ICCVW.2015.40
- Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (pp. 580–587). https://doi.org/10.1109/CVPR.2014.81
- Grez, A., Riveros, C., Ugarte, M., & Vansummeren, S. (2021). A formal framework for complex event recognition. ACM Transactions on Database Systems, 46(4), 1–49. https://doi.org/10.1145/3485463
- Hasan, M., Paul, S., Mourikis, A. I., & Roy-Chowdhury, A. K. (2020). Context-Aware query selection for active learning in event recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(3), 554–567. https://doi.org/10.1109/TPAMI.2018.2878696
- Jasper, R. R. U., Koen, E. V. D. S., Theo, G., & Arnold, W. S. (2013). Selective search for object recognition. International Journal of Computer Vision, 104(2), 154–171. https://doi.org/10.1007/s11263-013-0620-5
- Kai, X., Peng, W., Xue, C., Xiangfeng, L., & Jiangqi, G. (2021). Causal event extraction using causal event element-oriented neural network. International Journal of Computational Science and Engineering, 24(6), 621–628. https://doi.org/10.1504/IJCSE.2021.119985
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). Imagenet classification with deepconvolutional neural networks. Communications of the Acm, 60(6), 84–90. https://doi.org/10.1145/3065386
- Li, D., Wong, W. E., Wang, W., Yao, Y., & Chau, M. (2021). Detection and mitigation of label-flipping attacks in federated learning systems with KPCA and K-means. In 2021 8th International Conference on Dependable Systems and Their Applications (DSA) (pp. 551–559). https://doi.org/10.1109/DSA52907.2021.00081
- Li, J., & Li, F. (2007). What, where and who? Classifying events by scene and object recognition (2007). Proceedings of the International Conference on Computer Vision (ICCV) (pp. 1–8). https://doi.org/10.1109/ICCV.2007.4408872
- Lin, M., Chen, Q., & Yan, S. (2014). Network in network. Proceedings of the International Conference on Learning Representations (ICLR) (pp. 224–233). https://arxiv.53yu.com/abs/1312.4400
- Liu, M., Liu, X., Li, Y., Chen, X., Hauptmann, A. G., & Shan, S. (2015). Exploiting feature hierarchies with convolutional neural networks for cultural event recognition. Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV) (pp. 274–279). https://doi.org/10.1109/ICCVW.2015.44
- Liu, X., & Huet, B. (2013). Heterogeneous features and model selection for event-based media classification. Proceedings of the ACM Conference on International Conference on Multimedia Retrieval (ICMR) (pp. 151–158). https://doi.org/10.1145/2461466.2461493
- Ouyang, L., & Hu, P. (2017). An improved similarity computation module based on basic semantics and influencing factors of concepts in domain ontology. Proceedings of the 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (pp. 2880–2885). https://doi.org/10.1109/FSKD.2017.8393238
- Pan, X., Ding, M., & Yang, M. (2022). A geometrical perspective on image style transfer with adversarial learning. IEEE Transaction on Pattern Analysis and MachineIntelligence (TPAMI), 44(1), 63–75. https://doi.org/10.1109/TPAMI.2020.3011143
- Park, S., & Kwak, N. (2015). Cultural event recognition by subregion classification with convolutional neural network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 45–50). https://doi.org/10.1109/CVPRW.2015.7301335
- Rachmadi, R. F., Uchimura, K., & Koutaki, G. (2016). Combined convolutional neural network for event recognition. Proceedings of the Korea-Japan Joint Workshop on Frontiers of Computer Vision (FCV) (pp. 85–90).
- Salvador, A., Zeppelzauer, M., Manchon-Vizuete, D., Calafell, A., & Nieto, X. G. (2015). Cultural event recognition with visual convnets and temporal models. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 36–44). https://doi.org/10.1109/CVPRW.2015.7301334
- Shaokang, C., Dezhi, H., Xinming, Y., Dun, L., & Chin-Chen, C. (2022). A hybrid parallel deep learning model for efficient intrusion detection based on metric learning. Connection Science, 34(1), 551–577. https://doi.org/10.1080/09540091.2021.2024509
- Simonyan, K., & Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. Proceedings of the International Conference on Learning Representations (ICLR). http://arxiv.org/abs/1409.1556
- Tzelepis, C., Ma, Z., Mezaris, V., Ionescu, B., Kompatsiaris, I., Boato, G., Sebe, N., & Yan, S. (2016). Event-based media processing and analysis: A survey of the literature. Image and Vision Computing, 53, 3–19. https://doi.org/10.1016/j.imavis.2016.05.005
- Wang, L., Wang, Z., Guo, S., & Qiao, Y. (2015). Better exploiting OS-CNNs for better event recognition in images. Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV) (pp. 287–294). https://doi.org/10.1109/ICCVW.2015.46
- Wang, L., Wang, Z., Qiao, Y., & Gool, L. V. (2017). Transferring deep object and scene representations for event recognition in still images. International Journal of Computer Vision, 390–409. https://doi.org/10.1007/s11263-017-1043-5
- Wang, L., Wang, Z., Qiao, Y., & Gool, L. V. (2018). Transferring deep object and scene representation. International Journal of Computer Vision, 126(2-4), 390–409. https://doi.org/10.1007/s11263-017-1043-5
- Wei, Z., Wei, L., & Zhaoquan, C. (2019). High-dimensional Arnold inverse transformation for multiple images scrambling. International Journal of Computational Science and Engineering, 20(3), 362–375. https://doi.org/10.1504/IJCSE.2019.103941
- Xiong, Y., Zhu, K., Lin, D., & Tang, X. (2015). Recognize complex events from static images by fusing deep channels. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 1600–1609). https://doi.org/10.1109/CVPR.2015.7298768
- Yager, R. R., & Filev, D. P. (1999). Induced ordered weighted averaging operators. IEEE Transactions on Systems(Cybernetics), 29(2), 141–150. https://doi.org/10.1109/3477.752789
- Yan, J., Wei, L., Jintian, T., & Hongbo, Z. (2021). A novel data representation framework based on nonnegative manifold regularisation. Connection Science, 33(2), 136–152. https://doi.org/10.1080/09540091.2020.1772722
- Yang, S., Luo, P., Loy, C. C., & Tang, X. (2016). WIDER FACE: A face detection benchmark. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 5525–5533). https://doi.org/10.1109/CVPR.2016.596
- Zhou, B., Lapedriza, A., Xiao, J., Torralba, A., & Oliva, A. (2014). Learning deep features for scene recognition using places database. Proceedings of the Conference and Workshop on Neural Information Processing Systems (NIPS) (pp. 487–495). https://proceedings.neurips.cc/paper/2014/hash/3fe94a002317b5f9259f82690aeea4cd-Abstract.html.