
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In response to the call for implementing national waste classification, this paper proposes an intelligent waste classification system based on the improved MobileNetV3-Large, which can raise the national awareness of waste classification through the combination of software and hardware. The software module is based on WeChat applet and offers functions for image recognition, text recognition, speech recognition, points-based quiz and so on. The hardware module is based on Raspberry Pi and covers image shooting, image recognition, automatic classification with automatic announcement and so on. The algorithm model applied to the image classification adopts a network model based on MobileNetV3-Large. This network model is enabled to classify garbage images through deep separable convolution, inverse residual structure, lightweight attention structure and the hard_ swish activation function. The text classification model adopts a network model based on LSTM, extracts text features through word embedding, enhancing the effect of garbage text classification. After testing, the system can leverage deep learning to realise intelligent garbage classification. The image recognition accuracy of the algorithm model was found to reach 81%, while the text recognition accuracy was as high as 97.61%.
1. Introduction
China produces nearly 1 billion tons of garbage every year, and with an annual multiplier of 5% to 8%, about 2/3 of the country’s cities are surrounded by a “sea” of garbage. Yet about 30% to 40% of China’s domestic waste can be turned into treasure (Wu et al., Citation2020). By properly sorting waste, the land area it occupies and environmental pollution associated with waste can be reduced. It is well known that the traditional ways of landfills and incineration are not the best means of disposing waste. By sorting waste, however, we can vastly improve our utilisation of waste resources. Most people lack a comprehensive understanding of garbage classification systems, with even their awareness of garbage classification likely being weak. Typical garbage classification bins require users to have a certain understanding of garbage classification, yet these bins are not efficient for classifying garbage. Furthermore, they are unlikely to improve a user’s awareness of the classification system, resulting in a less than ideal effect in terms of classifying garbage.
In response to these issues, this paper proposes an intelligent garbage classification system that relies on a combination of software and hardware. The software module is based on the WeChat applet, which is divided into the applet side and server side. The applet side mainly encompasses the front-end interface display, whereas the server side is mainly responsible for interacting with the applet side. This interaction governs several functions: online image recognition, text recognition, voice recognition and points-based quiz. Such functions enable users to understand the garbage classification in the network and improve their classification awareness. The hardware module is based on Raspberry Pi (Hosny et al., Citation2021) and is divided into Raspberry Pi and the garbage bin itself. The former acts as the “brain” of the garbage bin. It is responsible for identifying the garbage, putting into the bin and controlling the garbage bin for intelligent classification. Furthermore, it can achieve image shooting, image recognition, automatic classification with automatic announcement and other functions, thus allowing users to classify garbage without needing to understand the garbage classification system. This design can classify garbage accurately without the knowledge of garbage classification and informs users of the specific classification of garbage they put in through an announcement function, which can effectively boost the user’s knowledge of garbage classification.
The deep learning technology adopted in this system is divided into two main models: the image recognition model and text recognition model (Zhao et al., Citation2021). Both the image recognition model and the text recognition model extract the associated attributes of garbage classification features via images and texts. The models then match them with their domain rules. The image recognition model is built based on the MobileNetV3-Large (Howard et al., Citation2019; Liu & Wang, Citation2020) model, which uses a combination of deep separable convolution, inverse residual structure, lightweight attention structure, and hard_swish activation function to recognise the images of the garbage input by users. Through the prediction of the image recognition model, the specific classification result of this image is effectively fed back by the prediction of the image recognition model. The text recognition model is built based on the LSTM model (Ahuja Sanjay et al., Citation2021; Sherratt et al., Citation2021), and the word_embedding technique (a function for mapping relationships that can map the integer index of text to a dense vector (Zhao et al. 2018), effectively extracting the relationship between words and enhancing the extraction of text feature information). This approach is used to achieve the recognition of garbage text that a user inputs. Through the prediction of the text recognition model, we can effectively feedback the specific classification consequence of this text.
This system adopts a multimodal approach compared to traditional garbage sorting systems, and includes not only traditional image recognition functions, but also text recognition and voice recognition of garbage. In addition, this system also combines software and hardware technologies to develop a set of WeChat-based applets and Raspberry Pi-based garbage bins, and achieves data interoperability between software and hardware. With the advancement of technology, this system has also improved in terms of accuracy, providing the better guarantee for garbage identification and classification, and achieving the purpose of improving people’s awareness of garbage classification in a subtle way.
2. Related jobs
In recent years, research related to intelligent waste sorting system has mainly included the following aspects:
Implementation of a waste classification system based on cloud development and WeChat applets (Li et al., Citation2021). This area of research adopts the WeChat applet’s cloud development technology, called the Baidu AI interface to recognise generic objects and scenes. The Tencent map API interface is applied to obtain the location information and process route planning for recycling stations.
Intelligent garbage bin recognition and classification system based on deep learning (Vujovic & Maksi movic, Citation2014). The designs seen in the literature thus far mainly use Raspberry Pi equipped with TensorFlow trained CNN garbage recognition and classification algorithm coupled with a speech recognition module as the main components of the bin and integrate technologies such as the STM32 microcontroller as a microcontroller, infrared and touch module to assist with the system’s sensors.
Intelligent garbage bin based on Raspberry Pi and Arduino (Ubeda, Citation2019). Studies have proposed an intelligent garbage bin can be based on Raspberry Pi and Arduino, with Raspberry Pi as the main controller and Arduino as the secondary controller. This approach achieves accurate garbage sorting by manipulating the servo and motor.
Implementation of the ResNet network for garbage classification image recognition (Wen-Jie et al., Citation2020). Some projects have utilised ResNet152 as a network structure to build a neural network for garbage image recognition, then combined with the Android system to develop a garbage classification APP.
At present, the research on intelligent garbage sorting systems mostly focuses on the design of a single structure for a garbage bin or applet. This, however, lacks a combined structure that brings the two together. A garbage sorting technology designed with the structure of applet is aimed at people online, which can effectively enhance their awareness of garbage sorting. A garbage classification technology designed with the structure of garbage bin is for users in daily life, which can effectively enhance users’ awareness of garbage classification. For this paper, the software and hardware of the applet and the bin have been combined, and users of the system not only on the Internet, but also in daily life, which can increase the scale of users and enhance the awareness of waste sorting for all people.
Using a STM32 microcontroller (Demirtas et al., Citation2021) as the controller of the bin, this design can effectively reduce development costs. However, if we would like to realise the development of higher-level applications, STM32 is not a viable option. In this paper, we opt for using Raspberry Pi as the controller of the bin, which has similar IO pins as STM32 and can directly control the functions of other underlying hardware. It can also accomplish more complex task management and scheduling. With the operating system, it is able to leverage Raspberry Pi to build a small server and deploy the code for a deep neural network.
Normally, when a neural network is deeper, the model can accommodate for more complex consequences. However, in the actual training process, a deeper model does not necessarily yield a better consequence, and it is likely to produce a poor fitting effect and gradient disappearance (Li et al., Citation2020; Li et al., Citation2020; Zhao et al., Citation2021). The ResNet (Hu et al., Citation2021) residual network can effectively solve this kind of issue and improve the accuracy of the model (Hao et al. 2018). However, the network structure of ResNet is huge, featuring numerous operations, and requires high hardware support. In this study, we chose the MobieNetV3 as the basis of the image recognition model, which invokes deep separable convolution and 1 × 1 lifting dimensional layers. It also offers high accuracy with a low number of parameters and operations and can be easily deployed in environments with insufficient hardware such as Raspberry Pi. Meanwhile, the attention mechanism has been introduced to gain high adaptation for the output weight of different layers, which improves the accuracy of the model to a certain extent.
3. System architecture
The system is a combination of software and hardware models. The server side of the software module and the Raspberry Pi of the hardware module operate with the same MySQL for data storage, and the specific structure is shown in the following figure (Figures ).
Figure 1. Structure diagram of intelligent waste classification system.
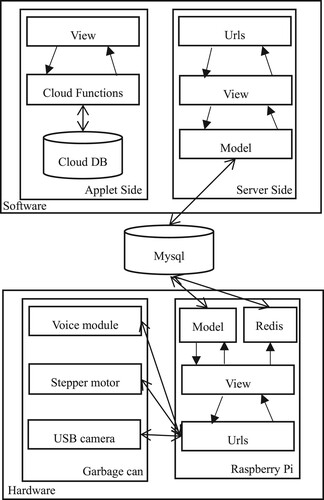
Figure 2. Function of software module.
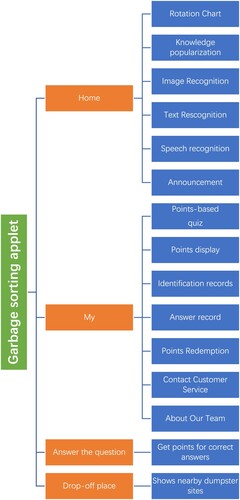
Figure 3. Flow chart of hardware module.
Figure 4. Wiring diagram of camera module.

Figure 5. Motor module wiring diagram.

Figure 6. Voice module wiring diagram.

Figure 7. DW.
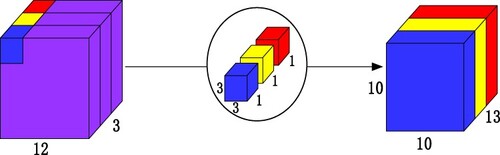
Figure 8. Inverse residual structure.
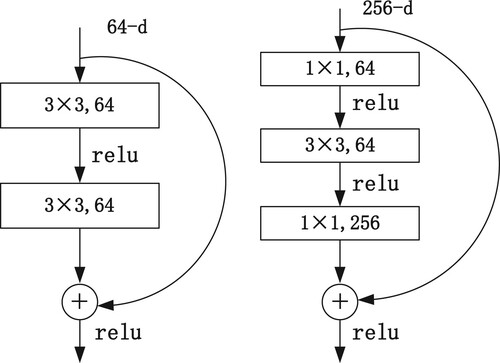
Figure 9. Attention mechanism.
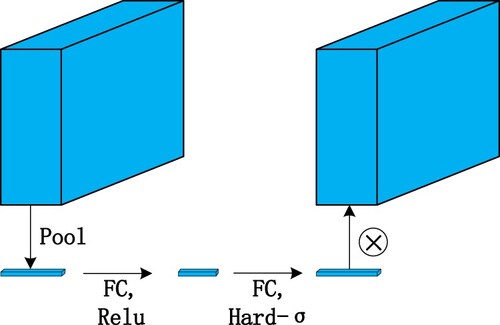
Figure 10. bneck.
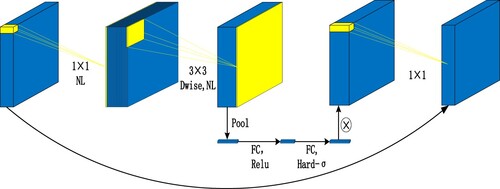
Figure 11. Comparison diagram of sigmoid and hardsigmoid.
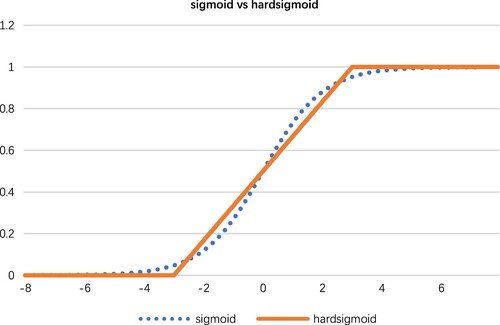
Figure 12. Comparison between swish and hardwish.
Figure 13. Image reacognition model accuracy.
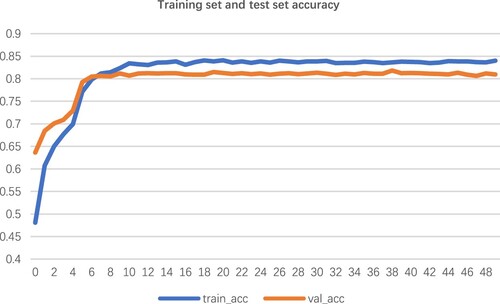
Figure 14. Image reacognition model loss.
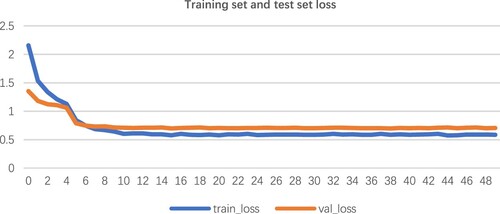
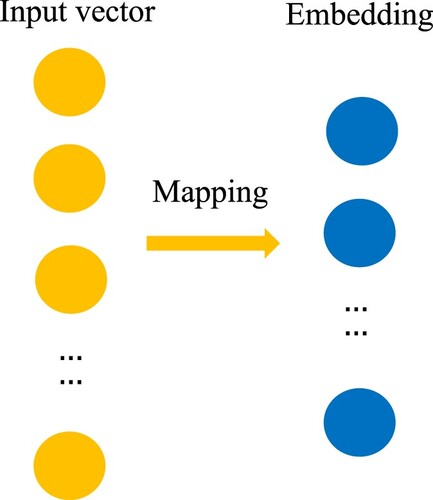
Figure 15. Embedding mapping.
4. System module design
4.1. Software modules
We chose WeChat applet as the carrier for the waste classification application. WeChat applet is an application that does not need to be downloaded and installed, instead relying on the background of big data from WeChat. Compared with native app, it is convenient for WeChat applet to use internal functions without installed application.
In this paper, we divided the software module into applet side and server side. In doing so, we achieved several functions: image recognition, text recognition, speech recognition and points-based quiz.
4.1.1. Applet side
The applet side of the system was quickly built from the cloud development technology offered by WeChat applets and a set of lightweight UI component library based on Vue (Chusho et al., Citation2000). Compared with the traditional development model, cloud development technology provides numerous advantages. It is highly available, allows for automatic elastic expansion and contraction of back-end cloud services, including computing, storage, hosting and other serverless capabilities. This approach effectively assists developers with building and managing back-end services and cloud resources in a unified manner, thus avoiding cumbersome server construction and operation and maintenance in the application development process. We adopted modular development to achieve the separation of the system’s frontend and backend.
4.1.2. Server side
We adopted a python backend developed from the Django framework (Magdalena) as the server side and MySQL as the database, which is mostly applied to the training and the prediction of garbage images along with garbage text. MySQL is also responsible for receiving information from the applet side and giving feedback. We adopted Keras, tensorflow, and the pytorch framework to build neural network models, which create rich neural network modules and greatly facilitate our training and prediction with deep learning methods.
4.1.3. Function Implementation
The software modules have the following functional points.
The main function points include image recognition, text recognition, speech recognition and points-based quiz. The first three of those function points need to interact between the applet side and the server side.
Image recognition: the user selects a picture to be recognised in the recognition interface, and the applet side obtains the picture, converts it into base64 encoding format and sends it to the image recognition interface on the server side. After receiving the image, the server-side interface recognises it and returns the classification consequence and classification probability to the applet side, and displays the consequence on the applet side at last.
Text recognition: The user inputs a paragraph of text to be recognised via the recognition interface. After that, the applet side acquires the text and sends it to the text recognition interface on the server side. After receiving the text, the server-side interface recognises it and returns the classification consequence and similar consequence to the applet side, and then displays the consequence on the applet side.
Speech recognition: This function mainly works through a combination of the “Tencent Cloud Intelligent Speech” plug-in and text recognition function. The user inputs speech that needs to be recognised in the recognition interface, and the Applet side captures the speech and translates it into text through the plug-in. Subsequently, it obtains the classification consequences and similar consequences in the form of text recognition.
Points-based quiz: This function is mainly realised through the cloud database of the cloud development technology. The cloud database establishes questions and user collections. The questions collection is used to store the question bank, and the user collection is used to record users’ points. Users answer questions in the question interface. After that the applet side randomly selects ten questions from the stored question database for users to answer. The system will record the answers and reward users with points.
4.2. Hardware modules
We chose Raspberry Pi as the server for the bin. Raspberry Pi is a card-sized microcomputer, compared with the common 51 microcontrollers and embedded microcontrollers, such as the STM32. It not only has IO pin to control, but also runs the corresponding operating system. It can complete complex task management and scheduling. In addition, it can support the development of upper layer applications.
The hardware module in this paper is composed of a garbage bin and a Raspberry Pi, which allows for image capture, image recognition, automatic classification with automatic announcement function. The workflow of the specific hardware module is shown in the following illustration.
The image information saved in the MySQL database will be used as the training set for the algorithm model after manual review, and the recognition accuracy will be improved through continuous training.
4.2.1. Raspberry Pi
A python backend developed with the Django framework was integrated with Raspberry Pi. The “fswebcam” and RPI (Anggraini et al., Citation2020). GPIO libraries (Zhang et al., Citation2004) were also adopted. The “fswebcam” library utilises Raspberry Pi to control the USB camera to capture images, whereas the RPI. GPIO library was used to control the Raspberry Pi io pins. Moreover, MySQL was used as the database for python backend, and Redis caching technology was chosen for storing image information captured by the dumpster camera.
4.2.2. Garbage can
We adopted hardware including the power supply, USB camera, “PhantomEr” voice synthesis module, TB6600 driver and 42 stepper motor 0.7 N with Raspberry Pi to assemble the trash bin. The wiring connection of the bin is mainly divided into the camera module, motor module and voice module.
Camera module: The USB camera can be plugged into the Raspberry Pi. The wiring diagram is shown in the following figure.
Motor module: There are three input signals for the 42-stepper motor: step pulse signal PUL+ and PUL−, direction level signal DIR+ and DIR−, and offline signal EN+ and EN−. We adopted the common cathode connection: PUL-, DIR-, EN- are connected to the GND port of the Raspberry Pi; the pulse input signal PUL+ is connected to the GPIO of the Raspberry Pi (for port 18), and the direction signal DIR+ is connected to the GPIO port of the Raspberry Pi (for port 12). The wiring diagram is shown below.
Voice module: The “PhantomEr” speech synthesis module can be inserted into the Raspberry Pi. The wiring diagram is as shown in the following figure.
4.2.3. Function Implementation
The main function points of the hardware module include image capture, image recognition, automatic classification with automatic announcement.
Image capture: The user puts the garbage on the garbage bin’s tray. The USB camera monitors the tray in real time and functions as a frequency conversion camera. By taking a picture every 3 s when no physical object is detected on the tray to discern whether a physical object has been placed on the tray. When an object is detected, it increases the camera frequency to 0.5 s. Finally, the captured images are saved to Redis.
Image recognition: The python backend deployed in the Raspberry Pi continuously acquires images in Redis and determines whether there is a physical object on the tray. If a physical object is present, then the image will be identified as garbage at which the image and the identification consequence will be saved to the MySQL database, while simultaneously increasing the camera frequency of the USB camera.
Automatic classification: Raspberry Pi calculates the angle of the stepper motor to be rotated by the image recognition consequence. It controls the stepper motor to drive the trash to rotate to the specified category. When the position of the corresponding category of garbage cans is aligned, the callback function of the control servo will be executed to control the rotation of the tray so as to drop the garbage, thus realising automatic classification.
Automatic announcement: Raspberry Pi calls the voice synthesis module through the image recognition consequence and broadcasts the consequence of garbage classification and lights up its corresponding garbage classification light.
5. Algorithm model
5.1. Knowledge construction for garbage classification identification
Constructed garbage classification domain knowledge includes the concept of garbage classification, garbage classification rules and garbage classification features. Through the image feature extraction algorithm and text feature extraction algorithm, the extracted features of both image and text correspond to the associated attributes of garbage classification features.
The knowledge of the waste classification domain was learned from previous works. This body of literature outlines the concept of waste sorting and the rules for each waste sorting field. The concept of garbage sorting is to classify the garbage into different categories and to convert it into resources by sorting and recycling. The sorting standards are generally based on the composition of the garbage, the amount of garbage generated, and the resource utilisation and treatment methods for local garbage. In Japan, garbage is basically classified into burnable, non-burnable garbage, recyclable and large-sized garbage. In Australia, garbage is classified into compostable, recyclable and non-recyclable garbage. In China, garbage is mainly classified into four categories: recyclable garbage, food garbage, hazardous garbage and other garbage. The table below shows examples of garbage classification rules (Tables ).
Table 1. Garbage classification table.
Table 2. Parameters of each layer of image recognition model.
Table 3. Text recognition model parameter setting.
5.2. Image recognition model
5.2.1. Datasets for image recognition model
In this paper, part of the image classification datasets for garbage is derived from Baidu open datasets, and the other part comes from data produced via crawling technology by Baidu Segou and other major search engines. In addition to the four categories of recyclable garbage, food waste, hazardous garbage and other garbage, the image classification also classifies each major category into 158 sub-categories. Although the Baidu open dataset has been screened to some extent, there are still unavailable images, which is true for the crawler as well, the most common being truncated images. Therefore, data cleaning is still required, including manual screening of the images obtained by the crawler.
5.2.2. Implementation of the image recognition model
The image recognition model in this paper uses MobileNetV3-Large as the basic model. This study combines NAS and NetAdapt techniques for searching the network structure. The former is used to search each module in the network with a certain amount of computation and several parameters, whereas the latter is meant for fine-tuning the network layers if each module is determined. MobileNetV3 introduces the deep separable convolution of MobileNetV1; MobileNetV2 combined with linear MobileNetV3 introduces the deep separable convolution of MobileNetV1, the inverted residual structure with the linear bottleneck of MobileNetV2, the lightweight attention model based on the squeeze and excitation structure introduced by MnasNe. It also adds hard_sigmoid and hard_swish activation functions.
Depth wise Convolution. DW convolution kernel is equal to the number of input channels, i.e. a convolution kernel alone convolves a feature map of the previous layer to obtain the number of output channels equal to the number of input channels, which can be saved by 1/3 compared with conventional convolution DW parameters. The number of parameters can be made deeper while maintaining the same number. The number of layers of the neural network can be made deeper with the same number of parameters. The following figure illustrates this concept.
Inverse residual structure. When the network is made deep enough, it often encounters the issue of gradient disappearance and gradient explosion. Gradience can be solved by batching normalisation regularisation, but this consequences in a decrease in network performance, and the model can no longer acquire new information. Experimentally, it has been proved that one layer alone does not work. Therefore, the residual network is replaced with 1 × 1 + 3 × 3 + 1 × 1 for two 3 × 3 convolutional layers with consideration to computational optimisation. This approach can reduce the number of parameters by 16.94 times. The first 1 × 1 ascends the dimension of the convolutional layer, while the second reducts the dimension of the convolutional layer. The reduced channels should be equal to the number of input channels and summed with the input x to obtain the output y as seen in the following figure.
Lightweight attention structure. The idea behind the SE block is to start from the weight of spatial information and use the FEATURE MAP to obtain the weights of each layer after BP optimisation through a series of CONV operations. First, the feature map of H × W × C is turned into a 1 × 1 × C vector via pool, and then the 1 × 1 × C weight is obtained by two 1 × 1 convolutions. Finally, the feature map of each channel of the input is multiplied with this vector to obtain the final output as seen in the following figure.
A B-Neck is shown in the figure below. First, a 1 × 1 dimensional elevation of the input is performed, followed by a 3 × 3 deep separable convolution, after which the SE structure is added and its 1 × 1 dimensional reduction is performed. This process keeps the number of channels equal to the input. Finally, the output is obtained by summing with the input x.
The hard_swish activation function is obtained by hard_sigmoid, which is a segmented linear approximation of the logistic_sigmoid activation function. It is easier to compute and enables learning to proceed faster.
The input is the input feature map size and the number of channels; operator is the operation performed; exp_size is the number of channels after 1 × 1 dimensional elevation; out is the number of output channels; AT is whether to join the attention structure; AF (Activation function) represents the activation function used (hard_swish function (HW) and ReLU function (RE)), and the s is the number of steps.
5.2.3 Effect of the image recognition model
The datasets of the image classification model were divided into a training set and a test set, where the training set had 23,690 training samples and the test set had 5872 test samples. Before putting the data into the model training, the training set needed to be enhanced by flipping the images horizontally and vertically, as well as (0,30) degrees of random dithering, and cropping images to a random size of 224 pixels. There was also random dithering for saturation, brightness, contrast and hue. Finally, image data was normalised. The above image classification model was trained for 50 iterations after importing ImageNet weights, and accuracy was adopted as the evaluation index to judge the model. The consequences of each iteration were output to tensor board to obtain the diagram between accuracy and loss values of the training and test sets, which can be seen in the figure below.
It can be seen that when the number of iterations of the model training reached 10, its accuracy reached more than 80% and the loss value decreased to the middle of the interval of 0.5–0.6. As the number of iterations increased, the accuracy of the model gradually tended to grow flat and finally stabilised at 81%.
5.3 Text recognition model
5.3.1 Datasets for the text recognition model
The datasets for the garbage text classification model uses more than 4000 pieces of garbage text data collected on “gitee”. The content of the original dataset is uneven, and there is a certain amount of obfuscated data, which was not conducive for training the model. Therefore, it was necessary to perform data cleaning on the collected original dataset. The data that did not meet the requirements in the text or classification labels were removed, while the numbers, English and punctuation marks in the text were deleted or modified. Only the data containing Chinese characters was retained. The final data obtained was used as the dataset for the garbage text classification model.
5.3.2 Implementation of text recognition model
For this paper, the structure of “Embedding + LSTM + Linear + softmax” was used to build the garbage text classification model. The word Embedding was added on the basis of the original LSTM to improve the classification accuracy. The garbage text classification model was constructed by taking text as a form of data to input, using text serialisation to transform texts into a list of numbers indexed by words, while performing fixed-length processing. This process is followed by word embedding (Zhao 2018) to represent the list of numbers as a vector, which is passed through the LSTM layer (Razia Sulthana et al., Citation2021), the Linear fully connected layer, and ultimately a softmax function to obtain a quadratic probability vector of text. The specific process is as follows.
Input a text. Through text serialisation, it can be converted from a n-word text to a list of numbers consisting of n-word index values. The LSTM requires the input length to be of a fixed value, so the list of numbers must be fixed in length. The overly short text will be complemented with zeroes, and the overly long text will be intercepted.
The fixed-length processed list of numbers by word Embedding. As shown in the figure below.
Word Embedding is able to embed the list of numbers into another vector space. This method is more effective than the traditional one-hot coding for discrete features and can better judge the relationship between words to improve classification accuracy. And effectively solve the issue of large dimensionality of ont-hot which has caused expensive calculation.
We used the above word embedding vector mapping as the input to the LSTM. LSTM (Shengting et al., Citation2021) is used for extracting text features. In this paper, LSTM model was selected as the neural network architecture. Compared with the classical RNN model, LSTM introduces three gates, namely the input gate, forget gate and output gate. It also introduces the cell status, which saves long-term memory, and hidden status, which saves short-term memory. The LSTM includes the excellent characteristics of RNN and can resolve defects associated with RNN, which is the inability to remember over a long term. It also adds a function for filtering the past state information to select more favourable information. The state shift of the LSTM memory cell is calculated as shown in .
Figure 16. Illustration of LSTM neuron network mode.
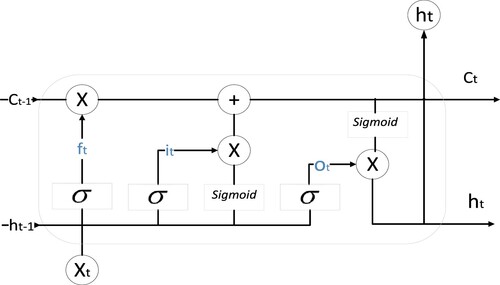
Given the input sequence (which the word embedding obtained after mapping) at time step t and the hidden state
at the previous time step, the input gate
, the forgetting gate
and the output gate
at time step t are calculated as follows.
(1)
(1)
(2)
(2)
(3)
(3)
The and
are weight parameters, and
,
,
are deviation parameters. And sigmoid is adopted as the activation function (Figures ).
Figure 17. Text recognition model architecture diagram.
Figure 18. Text recognition model accuracy.
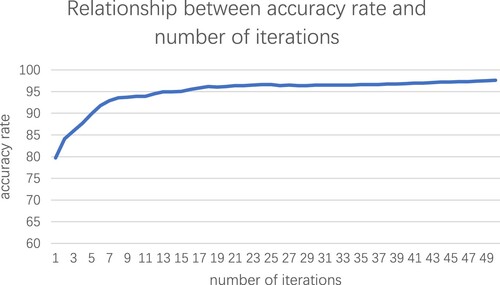
Figure 19. Different embedding_size effect.
The next step is to calculate the candidate cell state, which mainly serves to update the cell state.
(4)
(4)
The and
are weight parameters.
is a deviation parameter, and tanh is adopted as the activation function.
Finally, it needs to update the cell state with the hidden state. The new cell state combines the information from the cell state of the previous time step with the candidate cell state and controls the information flow via the forgetting and input gates.
(5)
(5)
The new hidden state combines the information of the cell state, using the tanh activation function to ensure that the element values of the hidden state are between (−1, 1) and controls the information flow by using the output gates.
(6)
(6)
Softmax regression normalisation. Softmax regression is a linear regression with the softmax normalised exponential function formed in structure. Linear is used to flatten the data, which linearly transform a feature space to another feature space. The target space of any one dimension is related to the original space. Sofemax function is commonly adopted in classification problems, and it primarily maps an n-dimensional vector to another n-dimensional vector so that the range of each element is between (0, 1), and the sum of all elements is one.
Softmax regression is calculated as follows.
The linear regression receives the output hidden state
of the LSTM as the input sequence.
(7)
(7)
The W_n is a weight parameter.
Finally obtained the classification probability by softmax normalisation function.
(8)
(8)
The architecture of the text recognition model is shown in the following diagram.
In this paper, the parameter settings of the LSTM model used were sequence_len sentence length, hidden_dim LSTM hidden layer parameters, embedding_size word vector dimension, learning_rate model learning rate and target_classes garbagegarbage classification classes, and these parameters were set as follows.
5.3.3. Effect of text recognition model
The text datasets were divided into the training set and the test set in the ratio of 7:1, which can be divided into more than 3500 training samples and 500 test samples. The training samples were used to train the garbage text classification model by continuously inputting data, and the test samples were used to test the model. The model was trained for 50 iterations and then tested after each iteration, with accuracy being applied as the evaluation index to judge the model. The relationship between the model accuracy and the number of iterations is shown in the following figure.
From the above figure, it can be concluded that the number of iterations of garbage text classification model training and the accuracy rate are positively correlated. After the number of iterations of model training reached 5 times, its accuracy rate could reach over 90%. As the number of iterations increased, the number of newly learned features by the model also kept decreasing. Thus, the accuracy rate of the model gradually tended to level off and finally stabilised at 97.61%. It meant that the data features were sufficiently learned by the model and the model was able to fit the actual data well.
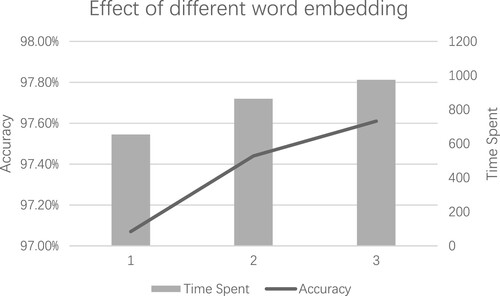
When we set the word vector dimension to 100, 200, and 300, it could obtain the comparison of accuracy and time spent for the garbage text classification model as shown in the following figure.
The ES1 represents embedding_size = 100, ES2 represents embedding_size = 200, and ES3 represents embedding_size = 300. Increasing the word vector dimension of embedding could enable word embedding to better extract key features of text in mapping and improved the accuracy of the model, but it also brought the shortage of time and space. From the above figure, it can be concluded that the accuracy of the model trained by setting the hyperparameter to ES3 is higher than the accuracy of the model trained by the other two parameters, but the cost of time spent on training is higher. For the ES3, accuracy improved by nearly 0.17 percentage points over ES2, but time spent increased by a factor of 1.13. The accuracy of ES3 improved by nearly 0.54 percentage points over ES1, but the time cost increased by a factor of 1.49.
6. Conclusion
In this paper, we proposed an intelligent garbage classification system based on deep learning for the field of garbage classification. By combining hardware and software, we created a software platform based on WeChat applet and hardware bin based on Raspberry Pi with deep learning technology. The image recognition technology adopts MobileNetV3-Large model to analyze the image information and come up with four primary garbage categories, such as recyclable garbage, food waste, hazardous garbage, other garbage along with 158 secondary garbage categories. The text recognition technique adopts LSTM model, combined with the word embedding word embed, to derive four first-level garbage classification consequences by analyzing the text information. But this system still has some limitations, in terms of data we can further increase the amount of data. In terms of classification, we can also refine the secondary classification to classify the waste more accurately and specifically. In terms of model, we can also optimise the current existing model to further improve the accuracy rate. In the future, we will increase the amount of text and image data and further refine the secondary garbage classification. More importantly in terms of modelling, we will try to change the attention mechanism adopted in the MobileNet model of image recognition model to the more powerful mobile network attention mechanism Coordinate Attention, increase the number of layers of the network with increasing the number of parameters, improve the accuracy of the image recognition model, and enrich the garbage category. In the text recognition model, we will adopt Bi-LSTM model (bi-directional LSTM model, which can capture more information about the context between sentences than one-way LSTM) or a multi-layer LSTM model (increasing the depth of the model can capture more information about the features of sentences) instead of the one-layer forward LSTM model in this paper. Moreover, an attention mechanism to improve the accuracy of the text recognition model can be added. In 2010, the national urban domestic waste production was 221 million tons. By 2015, the national urban domestic waste production increased to 258 million tons, with an average annual growth of 3% in six years. The increasing urban domestic waste year by year puts forward higher requirements for clearance, transportation and end-of-end disposal. In 2016, the domestic waste removal and transportation volume has reached 270 million tons, including 203 million tons of urban domestic waste. The domestic waste removal and transportation volume in the county is 67 million tons, and is rising year by year at an annual growth rate of 4–5%. According to the 2018 China Statistical Yearbook, the removal and transportation volume of urban domestic waste reached 215 million tons in 2017. Garbage classification has attracted more and more attention in China. At present, this industry is a labour-intensive industry, which not only has high cost and low efficiency, but also will cause great harm to the health of employees. Therefore, it is a general trend to develop intelligent recycling robots to replace traditional manual garbage recycling This paper discusses the screening efficiency of the intelligent waste classification system proposed in this paper from the aspects of the demand of China’s environmental protection industry, the status of waste classification industry and the market of intelligent robot technology.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Ahuja Sanjay, K., Manoj Kumar, S., & Kiran Kumar, R. (2021). Optimized deep learning framework for detecting pitting corrosion based on image segmentation. International Journal of Performability Engineering, 17(7), 627–637. https://doi.org/10.23940/ijpe.21.07.p7.627637
- Anggraini, N., Rahman, D. F., Wardhani, L. K., et al. (2020). Mobile based monitoring system for an automatic cat feeder using Raspberry Pi. 18(2), 10–38.
- Chen, H., Dou, Q., Yu, L., Qin, J., & Heng, P.-A. (2018). Voxresnet: Deep voxelwise residual networks for brain segmentation from 3d mr images sciencedirect. NeuroImage, 170, 446–455. https://doi.org/10.1016/j.neuroimage.2017.04.041
- Chusho, T., Ishigure, H., Konda, N., & Iwata, T. (2000). Component-based application development on architecture of a model, UI and components. Proceedings Seventh Asia-Pacific Software Engeering Conference, 349–353.
- Demirtas, M., Calgan, H., Toufik, A., & Sedraoui, M. (2021). Small-signal modeling and robust multi-loop PID and H∞ controllers synthesis for a self-excited induction generator. ISA Transactions, 117(11), 234–250. https://doi.org/10.1016/j.isatra.2021.01.059
- Hosny, K. M., Darwish, M. M., Li, K., Salah, A., Raja, G. (2021). COVID-19 diagnosis from CT scans and chest X-ray images using low-cost Raspberry Pi. PLOS ONE, 16(5), 1–18. https://doi.org/10.1371/journal.pone.0250688
- Howard, A., Sandler, M., Chu, G., et al. (2019). Searching for mobilenetv3. Proceedings of the IEEE/CVF International Conference on Computer Vision, 1314–1324.
- Hu, W. J., Xue, P. P., He, G. Y., & Tang, H. Y. (2021). Few shot object detection for headdresses and seats in Thangka Yidam based on ResNet and deformable convolution. Connection Science, 2021(1), 732–748.
- Li, F., Tang, T., Tang, B., et al. (2020). Deep convolution domain-adversarial transfer learning for fault diagnosis of rolling bearings. Measurement, 169(5), 108339.
- Li, J., Chen, J., Sheng, B., et al. (2021). Automatic detection and classification system of domestic waste via multi-model cascaded convolutional neural network. IEEE Transactions on Industrial Informatics, 5(1), 99–108.
- Li, Y., & Chen, L. (2020). Improved LSTM data analysis system for IoT-based smart classroom. Journal of Intelligent and Fuzzy Systems, 39(4), 5141–5148. https://doi.org/10.3233/JIFS-179999
- Liu, J., & Wang, X. (2020). Early recognition of tomato gray leaf spot disease based on MobileNetv2-YOLOv3 model. Plant Methods, 16(1), 83–99. https://doi.org/10.1186/s13007-020-00624-2
- Milanowska, K., Rother, M., Puton, T., Jeleniewicz, J., Rother, K., & Bujnicki, J. M. (2011). ModeRNA server: An online tool for modeling RNA 3D structures. Bioinformatics (oxford, England), 27(17), 2441–2442. https://doi.org/10.1093/bioinformatics/btr400
- Razia Sulthana, A., Jovith, A., & Jaithunbi, A. (2021). LSTM and RNN to predict COVID cases: Lethality’s and tests in GCC nations and India. International Journal of Performability Engineering, 17(3), 299–306. https://doi.org/10.23940/ijpe.21.03.p5.299306
- Shengting, W., Yuling, L., Ziran, Z., & Weng, T.-H. (2021). S_I_LSTM: Stock price prediction based on multiple data sources and sentiment analysis. Connection Science, 2021(1), 44–62.
- Sherratt, F., Plummer, A., & Iravani, P. (2021). Understanding LSTM network behaviour of IMU-based locomotion mode recognition for applications in prostheses and wearables. Sensors, 21(4), 12–64. https://doi.org/10.3390/s21041264
- Ubeda, J. (2019). Beginning robotics with Raspberry Pi and Arduino: Using python and OpenCV. Computing Reviews, 60(5), 188–188.
- Vujovic, V., & Maksi movic, M. (2014). Raspberry Pi as a wireless sensor node: Performances and constraints, international convention on information & communication technology. Electronics & Microelectronics, 1013–1018.
- Wen-Jie, L. V., Wei, X. H., Chen, Z. F., et al. (2020). The implementation of garbage classification software based on convolutional neural network. Computer Knowledge and Technology, 35(5), 30–34.
- Wu, Y., Tao, Y., Deng, Z., Zhou, J., Xu, C., & Zhang, B. (2020). A fuzzy analysis framework for waste incineration power plant comprehensive benefit evaluation from refuse classification perspective. Journal of Cleaner Production, 258, 120734. https://doi.org/10.1016/j.jclepro.2020.120734
- Zhang, J. M., Shen, S. Y., Song, T. Q., et al. (2004). Design and implementation of general purpose interface controller GPIO_WB IP core. Microelectronics & Computer, 21(6), 194–198.
- Zhao, Y., He, K., & Qiao, Y. (2018a). ST-LDA: High quality similar words augmented LDA for service clustering. 18th International Conference, ICA3PP, 15–17.
- Zhao, Y., Qiao, Y., & He, K. (2019). A novel tagging augmented LDA model for clustering. International Journal of Web Services Research, 16(3), 59–77. https://doi.org/10.4018/IJWSR.2019070104
- Zhao, Y., Wang, C., Wang, J., & He, K. (2018b). Incorporating LDA with word embedding for web service clustering. International Journal of Web Services Research (IJWSR), 15(4), 29–44. https://doi.org/10.4018/IJWSR.2018100102
- Zhao, Y., Xiaohong, P., Yan, W., Jingwei, S., & Xing, D. (2021). A prediction and discovery method of cloud API based on the multimodal compact LSTM model. Journal of Nonline and Convex Analysis, 22(10), 2267–2282.
- Zhao, Y., & Zhen, C. (2021). Design method of intelligent classification garbage bin based on deep learning. Science Wind, 32(1), 1671–7341.