
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In the era of big data, there are numerous duplicate code snippets on the Internet, it is especially necessary to make use of them to build new software projects. In this paper, we present a toolkit (KG4Py) for generating a knowledge graph of Python files in GitHub repositories and conducting semantic search with the knowledge graph. In KG4Py, we remove all duplicate files in 317 K Python files and perform static code analyses of these files by using a concrete syntax tree (CST) to build a code knowledge graph of Python functions. We integrate a pre-trained model with an unsupervised model to generate a new model, and combine this new model with a code knowledge graph for the purpose of searching code snippets with natural language descriptions. The experimental results show that KG4Py achieves good performance in both the construction of the code knowledge graph and the semantic search of code snippets.
1. Introduction
Software reusability is an important part of software engineering. Software reuse not only reduces the duplicate efforts in software development, but also improves the quality of project development (Wang et al., Citation2019). The core of software reuse is the utilisation of duplicate code snippets, and code search just solves this problem. Traditional code search is mainly based on keywords, and it is impossible to mine the deep semantic information of search statements. Currently, searching for code snippets on GitHub is limited to the keyword search, and this is based on users being able to predict what keywords might be in the comments around the code snippets they are looking for. However, this approach suffers from poor portability and interpretability, and it is impossible to conduct a semantic search on the code snippets. For these reasons, we try to introduce knowledge graphs to solve various challenges faced in code semantic search.
Knowledge Graph (KG) was formally introduced by Google in 2012, which is a symbolic representation of the physical world as a graph to describe real-world entities (people, objects, concepts) and a network-like knowledge base connected by entities and relationships. Numerous different knowledge graphs, such as Freebase (Kurt et al., Citation2008), YAGO (Manu et al., Citation2012), Wikidata (Denny & Markus, Citation2014) and OpenKG (Chen et al., Citation2021) have been built in recent years. These knowledge graphs have brought convenience to people in different fields, such as search engines (Zhao et al., Citation2021), recommendation systems (Arul & Razia, Citation2021; Xie et al., Citation2021; Yu et al., Citation2020), intelligent question and answer (Zhang et al., Citation2018) and decision analysis (Hao et al., Citation2021; Qiao et al., Citation2020).
Inspired by these knowledge graphs, researchers have thought about how to build knowledge graphs in software engineering. Big data of code provides data sources for knowledge graph construction, and deep learning-based methods provide assistance for automatic knowledge graph construction (Wang et al., Citation2020a).
With the growth of open-source software in the past few years, more and more software projects are appearing on major code hosting platforms such as GitHub, Gitlab and Bitbucket. In order to leverage these source codes, APIs, documents, etc., researchers have built various knowledge graphs in software domains. Meng et al. (Citation2017) constructed an Android applications knowledge graph for automatic analysis. Wang et al. (Citation2020b) used Wikipedia taxonomy to build a software development knowledge graph. Inspired by these knowledge graphs, we thought about how to create a knowledge graph of Python functions.
For knowledge graph search systems, we can dig more hidden information about what we want. Wang et al. (Citation2019) proposed and implemented a knowledge graph-based interface for natural language queries in projects. It took the meta-model from the knowledge base and built the inference subgraph associated with the questions, and then automatically converted the natural language questions into structured query statements and returned the relevant answers. This also provides inspiration for our code semantic search.
For the selection of graph databases, knowledge graphs typically use Neo4j, GraphDB and other graph databases to store data and use specific statements to retrieve the data. In this paper, we choose Neo4j to store the data, because it supports rich semantic tag descriptions, it reads and writes data faster, has readable query statements and also represents semi-structured data easily. This gives us the possibility to build code knowledge graphs and code semantic search.
The structure of this paper is as follows: In Section 2, we review the research related to knowledge graph construction and search. In Section 3, we present the general framework and each component of our proposed method in details. In Section 4, we introduce the steps of the experiment and analyse the results. In Section 5, We discuss some of the limitations of our toolkit. In Section 6, we briefly summarise our work and the prospects for the future work.
The main work and contributions of this study are listed below:
We develop a lightweight static code parser to extract the information of Python files for building knowledge graphs.
We construct an unsupervised model for parsing sentence-level semantic information and use it for code search.
2. Related work
In recent years, researchers have made researches on knowledge graphs in the field of software engineering, but there are relatively few studies have combined programming language knowledge graphs with question-and-answer (Q&A) systems.
2.1. Knowledge graphs for programming languages
Knowledge graphs in programming languages domains usually focus on code analysis and apply them to tasks such as code search, question and answer, and recommendation. Liu et al. (Citation2019) crawled the structural and descriptive knowledge of API documents from Java and Android official documents to construct API knowledge graphs and applied to the comparison between APIs. Abdelaziz et al. (Citation2020, Citation2021) used machine learning methods to build the first large-scale code knowledge graph. They analysed Python codes on GitHub and posts on StackOverflow, and demonstrated one application of this knowledge graph, which was a code recommendation engine for programmers within an IDE. Although their model works well in some ways, they ignore semantic information between code snippets and the models do not work well for code semantic search tasks. In this work, we extend KG4Py to the Python programming language, and use concrete syntax trees which enable the model to better extract the code snippets.
2.2. Knowledge graphs for question-and-answer systems
Researchers typically use knowledge graphs to enhance the understanding and inference of users’ queries in Q&A systems. Feng et al. (Citation2021) crawled the data of the business incubation domain to build the knowledge graph, and used a pattern matching algorithm that combined the natural language and entities from the knowledge base to parse the query. Li and Zhao (Citation2021) crawled the physical fitness dataset matched with the template to build a physical fitness knowledge graph question and answer system. Wang et al. (Citation2020b) used Wikipedia taxonomy to create an open-source community-based software knowledge graph, and linked entities and relationships from query statements to this knowledge graph to get the answers. With their models, we further understand the steps to build a semantic search of the code snippets.
3. Method
In this section, we introduce the methods of building the code knowledge graph and constructing the semantic search of the code snippets.
3.1. Building the code knowledge graph
Before building the code knowledge graph, we need to perform code analysis on Python files. Thus, we use the LibCSTFootnote1 (a concrete syntax tree parser and serializer library for Python) to parse the code instead of the abstract syntax tree (AST). The AST does a great job of preserving the semantics of the original code, and the structure of the tree is relatively simple. However, much of the semantics of the code is difficult to understand and extract. Given only the AST, it would not be possible to reprint the original source code. Like a JPEG, the abstract syntax tree is lossy, it cannot capture the annotation information we leave. Concrete syntax tree (CST) retains enough information to reprint the exact input code, but it is hard to implement complex operations. LibCST takes a compromise between the two formats outlined above. Like an AST, LibCST parses the source code into nodes that represent the semantics of the code snippets. Like a CST, LibCST retains all annotation information and can be accurately reprinted. The differences in code analysis between AST, CST and LibCST are shown in Figure .
Figure 1. The differences in code analysis between AST, CST and LibCST.
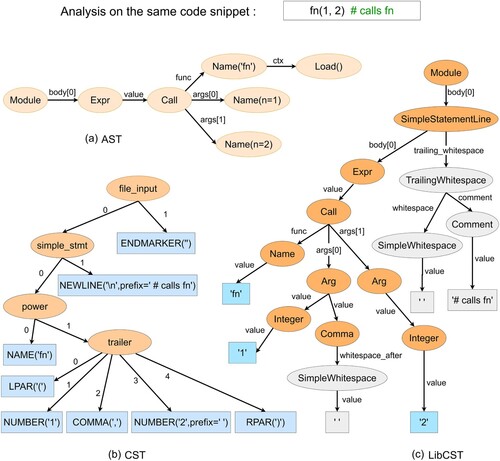
We use the LibCST to do a static code analysis of the Python files and identify the “import”, “class” and “function” in each file. For each function, we also need to identify its parameters, variables and return values. To make the search results more accurate, we use the codeT5 (Wang et al., Citation2021) model to generate a description for each function, which is similar to text summarisation (Fang et al., Citation2020; Lin et al., Citation2022). Finally, we save them in JSON-formatted files. The pipeline we used is shown Figure .
Figure 2. Overview of static code analysis and function summaries pipeline.
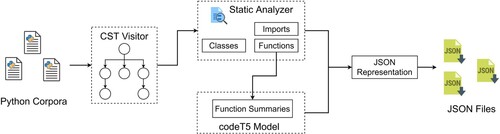
We extract the relevant entities and attributes from the processed JSON-format files and use them to build the code knowledge graph.
3.2. Knowledge graph-based search system
3.2.1. Semantic search in the model
Traditional search engines only retrieve answers by matching the keywords, while semantic search systems retrieve answers by dividing and understanding sentences. Before semantic search, the questions and answers in the database are embedded in a vector space. When searching, we embed the divided and parsed question into the same vector space, and calculate the similarity between the vectors to display the answers with high similarity. Next, we introduce the selection of the semantic search model.
Researchers have begun to input individual sentences into BERT (Devlin et al., Citation2018) and derive fixed-size sentence embeddings. The Bert model has shown to be a strong player in all major Natural Language Processing (NLP) tasks. It is no exception in the semantic similarity computation task. However, the BERT model specifies that two sentences need to be entered into the model at the same time for information interaction when computing semantic similarity, which causes a large computational overhead.
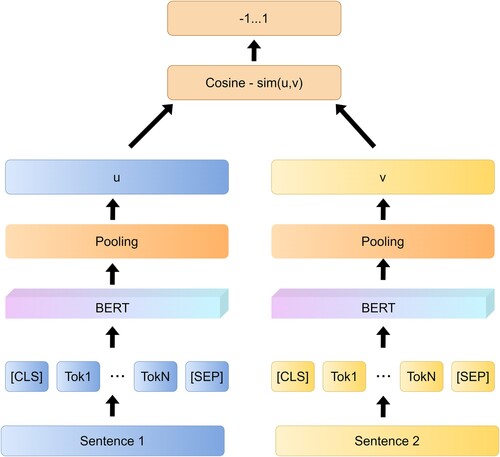
Therefore, we choose and fine-tune the Sentence-BERT (Reimers & Gurevych, Citation2019) model to perform the code semantic search, as shown in Figure . In simple and general terms, it draws on the framework of twin network model to input different sentences into two BERT models (but these two BERT models share parameters, which can also be understood as the same BERT model) to obtain the sentence representation vector of each sentence, and the final sentence representation vector obtained can be used for semantic similarity calculation or unsupervised clustering task. For the same 10,000 sentences, we only need to compute them 10,000 times to find the most similar sentence pairs, which takes about 5 s to compute them completely while BERT takes about 65 h.
Figure 3. Sentence-BERT model.
3.2.2. Encoders in the semantic search model
We use the maximum value pooling strategy, which is to maximise all the word vectors in the sentence obtained by the sentence through the BERT model. The maximum vector is used as the sentence vector of the whole sentence.
For Cross-encoders, they connect questions and answers by full self-attention, so they are more accurate than Bi-encoders. Cross-coders need to take a lot of time to compute the contextual relationship between each question and answer, while Bi-encoders save much time by encoding separately. What’s more, Cross-encoders do not scale when the number of questions and answers is large. Therefore, we use it to parse query statements. The structure of Cross-encoders is shown in Figure .
Figure 4. The structure of Cross-encoders.
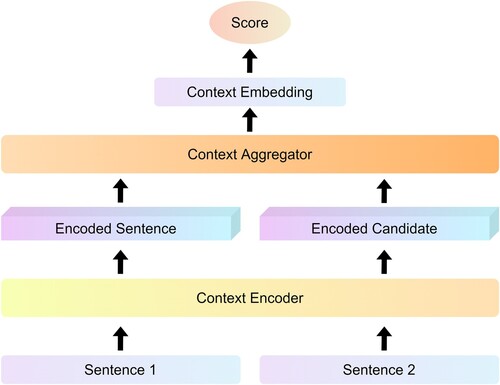
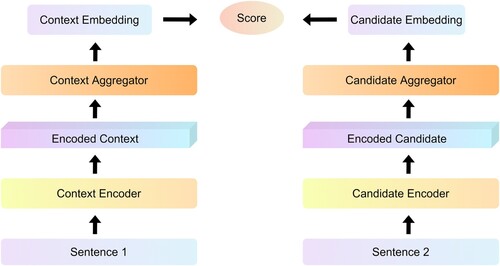
We use Bi-encoders to perform self-attention on the input and candidate labels separately, map them to a dense vector space, and then combine them at the end to obtain the final representation. The Bi-encoders are able to index the encoded candidates and compare these representations for each input, thus speeding up the prediction time. The time reduction from 65 h (using Cross-encoders) to about 5 s for the same complexity of clustering 10,000 sentences.Footnote2 Therefore, we combine it with unsupervised methods to train label-free question and answer pairs. The structure of Bi-encoders is shown in Figure .
Figure 5. The structure of Bi-encoders.
3.2.3. Distribution of encoders
In case of regression tasks, such as asymmetric semantic search, we compute sentence embeddings ,
and the cosine similarity of the respective pairs of sentences, then multiply them by a trainable weight
. We use Mean Squared Error (MSE) loss as an objective function:
(1)
(1)
In asymmetric semantic search, the user provides a query like some keywords or a question, but wants to retrieve a long text passage that provides the answer (Do & Nguyen, Citation2021). So, we use unsupervised learning methods to solve asymmetric semantic search tasks such as using natural language descriptions to search code snippets. These methods have in common that they do not require labelled training data. Instead, they can learn semantically meaningful sentence embeddings just from the text itself. Cross-encoders are only suitable for reranking a small set of natural language descriptions. For retrieval of suitable natural language descriptions from a large collection, we have to use Bi-encoders. These queries and descriptions are independently encoded as fixed-size embeddings in the same vector space. Relevant natural language descriptions can then be found by calculating the distance between vectors. Therefore, we combine Bi-encoders with unsupervised methods to train tasks in the field of label-free code search, use Cross-encoders to receive user input and compute the cosine similarity between the question and the natural language description.
4. Experiment
4.1. Data de-duplication
We take the dataset used by Mir et al. (Citation2021a, Citation2021b), Jiang et al. (Citation2021), Feng et al. (Citation2020), Guo et al. (Citation2020) and Lu et al. (Citation2021), which is a JSON-formatted file containing the URLs of repositories for Python projects in GitHub ranked by Star. We use 3065 Python projects and perform static code analyses on them.
Before training a Machine Learning (ML) model, it is essential to de-duplicate the code corpus (Allamanis, Citation2019). Therefore, we tokenise Python files, use Term Frequency-Inverse Document Frequency (TF-IDF) to vectorise the files, and perform a k-nearest neighbour search to identify candidate duplicate files.Footnote3 We spend more than 4 h detecting duplicate files and writing the results in a text file. We remove the files in the text file that correspond to the file path for the purpose of de-duplication, and perform all the experiments on an Ubuntu 16.04 server with an NVIDIA Tesla P100 GPU. The duplication information is shown in Table .
Table 1. The duplication information of Python repositories.
4.2. Code analysis
We construct a pipeline to implement code information extraction, which is divided into two parts:
generating structured information of the code with concrete syntax trees;
analysing and integrating the extracted structured information.
Table 2. The field definitions in each JSON-formatted file.
4.3. Building the knowledge graph
After defining the entities and relationships in the code knowledge graph, as shown in Table and Table , we extract the relevant information from the JSON-formatted files and save them in the CSV-formatted files. We use Cypher statements to build the knowledge graph, as shown in Figure . The number of entities is shown in Table .
Figure 6. A part of the code knowledge graph.
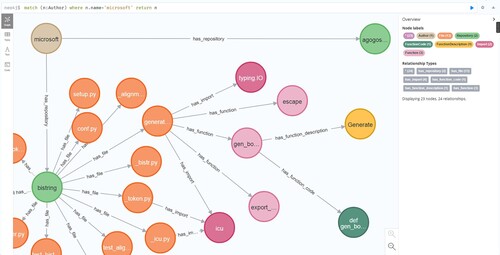
Table 3. The entities in the code knowledge graph.
Table 4. The relationships in the code knowledge graph.
Table 5. The entities in the code knowledge graph.
The Cypher statements used to create entities are as follows:
LOAD CSV WITH HEADERS FROM “file:///author- repository.csv” AS line
CREATE (: Author { author_id: line.author_id, name: line.author })
CREATE (: Repository { repos_id: line.repos_id, name: line.repository })
The Cypher statements used to create relationships are as follows:
LOAD CSV WITH HEADERS FROM “file:///author- repository.csv” AS line
MATCH (author: Author{ name: line.author })
MATCH (repository: Repository{ name: line.repository })
CREATE (author)-[: has_repository ]->(repository)
4.4. Steps of the search system
The knowledge graph-based search system is divided into three modules: query analysis, information retrieval and answer extraction (Feng et al., Citation2021). Our search model is also divided into three parts as shown in Figure .
The query analysis module pre-processes the query statement and vectorises it.
The information retrieval module translates the results of question understanding into query statements for the graph database.
The answer extraction module (Zhang et al., Citation2020) outputs the similarity scores based on the matching vectors and returns them.
Figure 7. Flowchart of the search model.
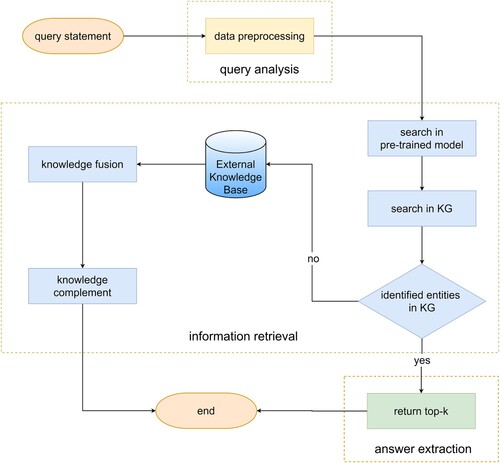
When searching, the model conducts semantic analysis of the question asked by the user, and then puts them into the knowledge graph for recognition. If the query entities are identified, we will connect these entities in the questions to the particular entities in KG, or else carry out the expansion of the knowledge graph and replenish it. The information retrieval module generates specific query statements by matching the query templates of the graph database to get the results. Finally, the answer extraction module sorts the results by their similarity and returns them.
4.5. Training and fine-tuning the search system
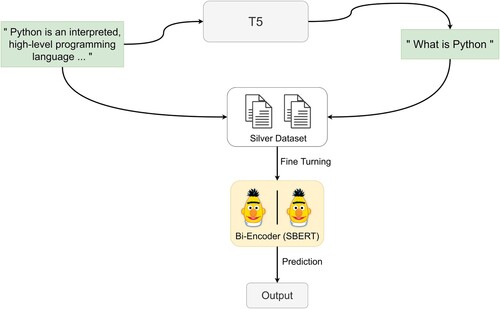
We use the Python dataset in CodeSearchNet (Husain et al., Citation2019) to rebuild a dataset on code search. We select 138 K (124 K training and 14 K test samples) code snippets with their natural language descriptions, and then use the T5 model (Thakur et al., Citation2021) to generate interrogative sentences for each natural language description, and for each natural language description we generate three of these interrogative-natural language description pairs. The maximum length of each query statement is 64, and the length of the answer to each query statement is 100. Finally, we save the generated 276 K statement pairs in a TSV-formatted file. The T5 model is shown in Figure .
Figure 8. The T5 model in SBERT.
For the Multiple Negatives Ranking Loss, it is important that the batch does not contain duplicate entries, i.e. no two equal queries and no two equal answers. We de-duplicate these generated pairs (query, relevant_answer) and put them into the Bi-encoders in the Sentence-Transformer for training. Finally, we fine-tune the parameters of the model to make it suitable for semantic search.
4.6. Evaluation results of the search model
We use Normalised Discounted Cumulative Gain (NDCG), Mean Average Precision (MAP) and Mean Reciprocal Rank (MRR) as the evaluation metrics, which have been widely used in various search and recommendation systems (Lian & Tang, Citation2022). The results are shown in Table .
Table 6. The evaluation results of the code search model
4.7. Performance on the search model
The search steps of our model are listed below:
We need to convert the relevant function names and natural language descriptions into vectors and input them into the model.
Inspired by Tang et al. (Citation2021), we use NLTKFootnote4 to remove stop words from the query statement such as “???” or some strange words, convert it into vectors and input them into the model as well.
We compute the cosine similarity among the query statement and the natural language description of the interrogative in the model and return the Top-K function names and natural language descriptions that are most similar to it.
We convert the Top-K function names into Cypher statements and display them in the knowledge graph.
Figure 9. The results of the knowledge graph search.
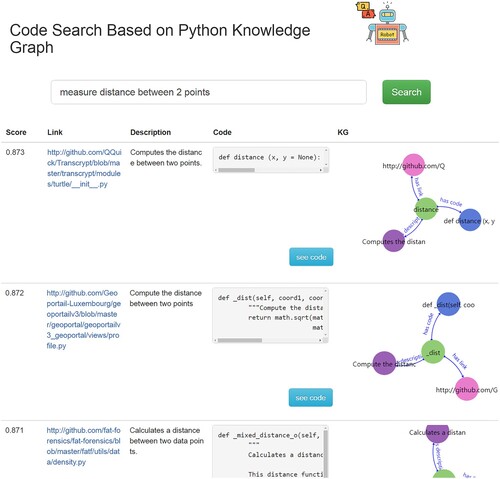
Table 7. A part of the search results and time in our model.
5. Discussion
5.1. Industrial values
The main work of this paper is to do a semantic search of code snippets by building a knowledge graph about Python functions. During the code analysis phase, we find a large number of duplicate code snippets in GitHub, which not only cause a waste of resources, but also increase the development costs of the software companies. These problems can be solved easily by our toolkit, and the industrial values of our toolkit can be divided into two parts:
For individual developers, our toolkit can be used not only to search for code, but also to deepen the understanding of code snippets through our code knowledge graph.
For software companies, our toolkit can be used to find the similar code snippets in the enterprise code base by understanding the semantics of the function’s annotation, and recommends them to developers if they exist. In this way, it not only reduces the duplication of developers’ work, but also cuts down the development costs of software companies.
5.2. Threats to validity
The first threat to validity is the limitation of programming languages. Our toolkit only performs static code analysis for Python among programming languages, but does not work for others. Therefore, our toolkit only supports the code search in Python.
Another threat is the depth of code analysis. We want to build an enterprise code base to reduce software development costs. But we only analyse the attributes of the code snippets such as the return value, return type, and function parameters, which are not sufficient to compare the similarity between the two functions. In the future, we will analyse the data flow and control flow of code snippets and use them to determine the similarity of code snippets instead of text similarity.
In addition, the third threat is the accuracy of search results. We only remove the stop words from the query, but do not subdivide it according to its lexical nature. In the future, we will sub-phrase the query statement and set the corresponding weight according to the word nature to improve the accuracy of the search system.
6. Conclusion
In our research, we perform a static code analysis on the Python-based repositories in GitHub, extract the functions from the files and build a code knowledge graph based on these functions. We construct an unsupervised model, and combine this model with the code knowledge graph for semantic search of code snippets. In the future, we will integrate the data flow and control flow of the function into the code knowledge graph to give the users a deeper understanding of the function. For semantic search, there is still room for improving the speed of question retrieval and matching. We will study these issues deeply in the hope of parsing query statements in a simpler way while reducing the retrieval time of the search model.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
References
- Abdelaziz, I., Dolby, J., McCusker, J., & Srinivas, K. (2021). A toolkit for generating code knowledge graphs. In Proceedings of the 11th on knowledge capture conference (pp. 137–144). https://doi.org/10.1145/3460210.3493578
- Abdelaziz, I., Srinivas, K., Dolby, J., & McCusker, J. P. (2020). A demonstration of CodeBreaker: A machine interpretable knowledge graph for code. In ISWC (Demos/Industry). http://ceur-ws.org/Vol-2721/paper568.pdf
- Allamanis, M. (2019). The adverse effects of code duplication in machine learning models of code. In Proceedings of the 2019 ACM SIGPLAN international symposium on new ideas, new paradigms, and reflections on programming and software (pp. 143–153). https://doi.org/10.1145/3359591.3359735
- Arul, J. J. A., & Razia, S. A. (2021). A review on the literature of fashion recommender system using deep learning. International Journal of Performability Engineering, 17(8), 695–702. https://doi.org/10.23940/ijpe.21.08.p5.695702
- Chen, H., Hu, N., Qi, G., Wang, H., Bi, Z., Li, J., & Yang, F. (2021). Openkg chain: A blockchain infrastructure for open knowledge graphs. Data Intelligence, 3(2), 205–227. https://doi.org/10.1162/dint_a_00095
- Denny, V. C., & Markus, K. (2014). Wikidata: A free collaborative knowledgebase. Communications of the Acm, 57(10), 78–85. https://doi.org/10.1145/2629489
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv, 1810, 04805.
- Do, T. T. T., & Nguyen, D. T. (2021). A computational semantic information retrieval model for Vietnamese texts. International Journal of Computational Science and Engineering, 24(3), 301–311. https://www.inderscienceonline.com/doi/abs/10.1504/IJCSE.2021.115657
- Fang, W., Jiang, T., Jiang, K., Zhang, F., Ding, Y., & Sheng, J. (2020). A method of automatic text summarisation based on long short-term memory. International Journal of Computational Science and Engineering, 22(1), 39–49. https://doi.org/10.1504/IJCSE.2020.107243
- Feng, S., Chen, H., Huang, M., & Wu, Y. (2021). Intelligent question answering system based on entrepreneurial incubation knowledge graph. In 2021 4th international conference on pattern recognition and artificial intelligence (PRAI) (pp. 207–212). IEEE. https://doi.org/10.1109/PRAI53619.2021.9551028
- Feng, Z., Guo, D., Tang, D., & Gong, M. (2020). Codebert: A pre-trained model for programming and natural languages. arXiv preprint arXiv:2002.08155.
- Guo, D., Ren, S., Feng, Z., Tang, D., & Liu, S. (2020). Graphcodebert: Pre-training code representations with data flow. arXiv preprint arXiv:2009.08366.
- Hao, J., Zhao, L., Milisavljevic-Syed, J., & Ming, Z. (2021). Integrating and navigating engineering design decision-related knowledge using decision knowledge graph. Advanced Engineering Informatics, 50. https://doi.org/10.1016/j.aei.2021.101366
- Husain, H., Wu, H. H., Gazit, T., Allamanis, M., & Brockschmidt, M. (2019). Codesearchnet challenge: Evaluating the state of semantic code search. arXiv preprint arXiv:1909.09436.
- Jiang, X., Zheng, Z., Lyu, C., Li, L., & Lyu, L. (2021). TreeBERT: A Tree-Based Pre-Trained Model for Programming Language. arXiv preprint arXiv:2105.12485.
- Kurt, B., Colin, E., Praveen, P., Tim, S., & Jamie, T. (2008). Freebase: A collaboratively created graph database for structuring human knowledge. In SIGMOD conference (pp. 1247–1250). https://doi.org/10.1145/1376616.1376746
- Li, G., & Zhao, T. (2021). Approach of intelligence question-answering system based on physical fitness knowledge graph. In 2021 4th international conference on robotics, control and automation engineering (RCAE) (pp. 191–195). IEEE. https://doi.org/10.1109/rcae53607.2021.9638824
- Lian, S., & Tang, M. (2022). API recommendation for Mashup creation based on neural graph collaborative filtering. Connection Science, 34(1), 124–138. https://doi.org/10.1080/09540091.2021.1974819
- Lin, N., Li, J., & Jiang, S. (2022). A simple but effective method for Indonesian automatic text summarisation. Connection Science, 34(1), 29–43. https://doi.org/10.1080/09540091.2021.1937942
- Liu, M., Peng, X., Marcus, A., Xing, Z., Xie, W., Xing, S., & Liu, Y. (2019). Generating query-specific class API summaries. In Proceedings of the 2019 27th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering (pp. 120–130). https://doi.org/10.1145/3338906.3338971
- Lu, S., Guo, D., Ren, S., Huang, J., Svyatkovskiy, A., Blanco, A., … Liu, S. (2021). CodeXGLUE: A machine learning benchmark dataset for code understanding and generation. arXiv preprint arXiv:2102.04664.
- Manu, S., Julian, D., Satish, C., Max, S., & Frank, T. (2012). Correlation tracking for points-to analysis of JavaScript. In ECOOP 2012 – object-oriented programming – 26th European conference, Beijing, China, June 11–16, 2012. Proceedings (lecture notes in computer science, vol. 7313). Springer, pp. 435–458. https://doi.org/10.1007/978-3-642-31057-7_20
- Meng, G., Xue, Y., Siow, J. K., Su, T., Narayanan, A., & Liu, Y. (2017). Androvault: Constructing knowledge graph from millions of android apps for automated analysis. arXiv preprint arXiv:1711.07451.
- Mir, A. M., Latoskinas, E., & Gousios, G. (2021a). ManyTypes4Py: A benchmark python dataset for machine learning-based type inference. arXiv preprint arXiv:2104.04706.
- Mir, A. M., Latoskinas, E., Proksch, S., & Gousios, G. (2021b). Type4py: Deep similarity learning-based type inference for Python. arXiv preprint arXiv:2101.04470.
- Qiao, X., Luo, L., Yang, J., & Hu, Z. (2020). Intelligent recommendation method of sous-vide cooking dishes correlation analysis based on association rules mining. International Journal of Performability Engineering, 16(9), 1443–1450. https://doi.org/10.23940/ijpe.20.09.p13.14431450
- Reimers, N., & Gurevych, I. (2019). Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084.
- Tang, B., Tang, M., Xia, Y., & Hsieh, M. Y. (2021). Composition pattern-aware web service recommendation based on depth factorisation machine. Connection Science, 33(4), 870–890. https://doi.org/10.1080/09540091.2021.1911933
- Thakur, N., Reimers, N., Rücklé, A., Srivastava, A., & Gurevych, I. (2021). BEIR: A heterogenous benchmark for zero-shot evaluation of information retrieval models. arXiv preprint arXiv:2104.08663.
- Wang, F., Liu, J. P., Liu, B., Qian, T. Y., Xiao, Y. H., & Peng, Z. Y. (2020a). Survey on construction of code knowledge graph and intelligent software development. Journal of Software, 31(1), 47–66. http://www.jos.org.cn/1000-9825/5893.htm
- Wang, J., Shi, X., Cheng, L., Zhang, K., & Shi, Y. (2020b). SoftKG: Building a software development knowledge graph through wikipedia taxonomy. In 2020 IEEE world congress on services (SERVICES) (pp. 151–156). IEEE. https://doi.org/10.1109/SERVICES48979.2020.00042
- Wang, M., Zou, Y., Cao, Y., & Xie, B. (2019). Searching software knowledge graph with question. In International conference on software and systems reuse (pp. 115–131). Springer. https://doi.org/10.1007/978-3-030-22888-0_9
- Wang, Y., Wang, W., Joty, S., & Hoi, S. C. (2021). CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. In Proceedings of the 2021 conference on empirical methods in natural language processing (pp. 8696–8708). https://doi.org/10.18653/v1/2021.emnlp-main.685
- Xie, L., Hu, Z., Cai, X., Zhang, W., & Chen, J. (2021). Explainable recommendation based on knowledge graph and multi-objective optimization. Complex & Intelligent Systems, 7(3), 1241–1252. https://doi.org/10.1007/s40747-021-00315-y
- Yu, D., Chen, R., & Chen, J. (2020). Video recommendation algorithm based on knowledge graph and collaborative filtering. International Journal of Performability Engineering, 16(12), 1933–1940. https://doi.org/10.23940/ijpe.20.12.p9.19331940
- Zhang, X., Lu, W., Li, F., Zhang, R., & Cheng, J. (2020). A deep neural architecture for sentence semantic matching. International Journal of Computational Science and Engineering, 21(4), 574–582. https://doi.org/10.1504/IJCSE.2020.106870
- Zhang, Y., Dai, H., Kozareva, Z., Smola, A. J., & Song, L. (2018). Variational reasoning for question answering with knowledge graph. In Thirty-second AAAI conference on artificial intelligence. https://ojs.aaai.org/index.php/AAAI/article/view/12057
- Zhao, X., Chen, H., Xing, Z., & Miao, C. (2021). Brain-inspired search engine assistant based on knowledge graph. IEEE Transactions on Neural Networks and Learning Systems, 1–15. https://doi.org/10.1109/tnnls.2021.3113026