
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In multi-objective bilevel optimisation problems, the upper-level performance of different lower-level optimal solutions may be very different, even though they belong to the same lower-level problem. It may lead to poor optimisation results. Therefore, the lower-level search should search lower-level non-dominated solutions that are also non-dominated in the upper-level objective space. In this paper, we use two populations in the lower-level search. The first population maintains non-dominance and diversity in the lower-level objective space and provides the second population with convergence pressure from the lower level. The second population selects the upper-level non-dominated solutions that are not dominated by the first population in the lower-level objective space, which make the second population maintain the non-dominance at both upper and lower levels. Besides, to improve the search efficiency, we set up the upper-level mating pool to generate the upper-level vectors of offsprings near the upper-level vectors of the better individuals in the current population. To balance convergence and diversity, the selection operator of a decomposition based multi-objective evolutionary algorithm is adopted. The proposed algorithm has been evaluated on a set of benchmark problems and a real-world optimisation problem. Experimental results demonstrate that the proposed algorithm is efficient and effective.
1. Introduction
In multi-objective bilevel optimisation problems, the upper-level performance of different optimal solutions may be very different, even though they belong to the same lower-level problem. The existing multi-objective bilevel optimisation algorithms ignore this point and may only find the lower-level non-dominated solutions with poor upper-level performance in the lower-level search, resulting in a poor quality upper-level Pareto front (PF). To solve this problem, we proposed a dual populations lower-level search to get those lower-level non-dominated solutions with good upper-level performance in this paper. In addition, we generate the upper-level vectors of offsprings near the upper-level vectors of the better individuals in the current population, which can effectively reduce the computational overhead.
In engineering design and business decision-making, there are a lot of applications of multi-objective bilevel optimisation problems (Cai et al., Citation2018; Chen et al., Citation2022; Kamal et al., Citation2019; Kolak et al., Citation2018; Lin et al., Citation2010; Lv et al., Citation2016; Ni et al., Citation2020; Shaikh et al., Citation2020; Yanhong et al., Citation2011; Zhang, Citation2014). For example, in a manufacturing corporation, the chief executive officer (CEO) aims to maximise the profits and the quality of the products. The CEO sends the design parameters (such as material and appearance), quantity and delivery date of the product to several branch heads working under him. According to these requirements of the CEO, branch heads plan the number of production lines and the scheduling of workers to manufacture one or more components of the final product, maximising their branch profits and the worker satisfaction. Obviously, a CEO's possible decisions must consider the reactions of the heads, which makes the decision-making a multi-objective bilevel optimisation problem by nature and can be described by the following general model of multi-objective bilevel problem:
(1)
(1) where
is the upper-level optimisation task (e.g. the profits and the quality of the products), and
is the lower-level optimisation task (e.g. branch profits and the worker satisfaction). The functions
and
are lower-level constraints, which define the feasible space of the lower-level optimisation task. The decision vector
of the upper-level optimisation task consists of two smaller vectors, i.e.
, where
is the upper-level vector (e.g. the design parameters, quantity and delivery date of the product), which is defined in the upper-level variable space
, while
is the lower-level vector (e.g. number of production lines and the scheduling of workers), which is defined in the lower-level variable space
. It is noteworthy that the lower-level optimisation task only optimises
, while
is fixed as parameters. Hence, the optimal solutions of the lower-level optimisation task can be expressed as functions of
. Then, the feasible space of the upper-level optimisation task is defined by the upper-level unequal constraints
and the upper-level equal constraint
as well as the lower-level multi-objective optimisation. In other words, a feasible solution of the upper-level optimisation task must not only satisfy
and
but also belong to the Pareto optimum solution set (PS) of the lower-level optimisation task. Both the nested structure of bilevel problems and the characteristics of multiple optimum solutions of multi-objective optimisation problems make the multi-objective bilevel optimisation problems computationally demanding and difficult to be solved. In addition, although some representative multi-objective methods of multi-objective evolutionary algorithms (MOEAs) have achieved remarkable results in large-scale multi-objective and multi-objective optimisation problems (Ma et al., Citation2021) as well as feature selection problem (Zhang et al., Citation2017), due to the lack of consideration of nested structure, these methods may not be effective for multi-objective bilevel problems.
Given the difficulty of solving multi-objective bilevel optimisation problems, there are few related researches. In addition to the design of test problems (Deb & Sinha, Citation2010) and special multi-objective bilevel problems (Sinha et al., Citation2016), most of the existing researches focus on methods to reduce the computational overhead (i.e. the number of real function evaluations (FEs), especially the lower-level FEs). These methods can be classified into:
Single-level reduction methods
The idea of the single-level reduction to transform the multi-objective bilevel problem into a simple single-level problem has achieved some results, but these methods often need to meet some extremely harsh conditions, which are difficult to apply in practical problems. For example, based on the theoretical progress of establishing the relationship between bilevel optimisation and multi-objective optimisation in recent years, Ruuska and Miettinen (Citation2012) transform the multi-objective bilevel optimisation problem into a multi-objective optimisation problem and then solve it, but this method is only applicable to optimistic multi-objective bilevel optimisation problems. Pieume et al. (Citation2013) show how to construct two artificial multi-objective programming problems so that any point which is Pareto efficient solution to the two problems is an efficient solution to the multi-objective bilevel optimisation problem, and some necessary and sufficient conditions are given for the results to be applicable. He and Lv (Citation2017) use Kuhn–Tucker optimality condition to replace the lower-level problem of a class of multi-objective bilevel optimisation problems, and the perturbed Fischer–Burmeister function is used to smooth the complementary condition. On this basis, a particle swarm optimisation algorithm is used to solve the smooth multi-objective programming problem.
Surrogate-model-based methods
Surrogate-model-based methods usually adopt an approximated surrogate model to approximate the mapping from the upper-level vector to the optimal solution set of its corresponding lower-level problem. Sinha et al. (Citation2017) introduce an approximated set-valued mapping to obtain approximate lower-level PS for any upper-level vector, greatly reducing the number of evaluations for lower-level tasks.
Population migration methods
Learning from the idea of transfer learning (Cao et al., Citation2021; Li et al., Citation2022; Sundar & Sumathy, Citation2022), population migration methods are to migrate the PS of the adjacent lower-level problem to the population of the current lower-level problem, so as to speed up the search of the current lower-level problem. For example, Deb and Sinha (Citation2010) established an archiving set to store the currently found upper-level non-dominated individuals. When searching for the lower-level optimal solutions corresponding to a new upper-level vector, the lower-level initialised population is selected from the archive set according to the distance in the upper-level decision space. Said et al. (Citation2020) study the bilevel combinatorial optimisation problem. They reduced the computational cost through multi-population strategy and migration mechanism, and introduced an index in the lower level optimisation to measure the performance of the lower-level non-dominated solution in the upper-level problem. Although it improves the searching efficiency to some extent using the information of individuals that have been the searched, this method only simply transfers the existing data without summarising, extracting and utilising the knowledge contained in the data, so the effect may not be satisfactory.
Variable decomposition (grouping) methods
Variable decomposition (grouping) methods adopt divide-and-conquer framework. Recently, Cai et al. (Citation2022) use an interaction matrix to represent the variable interactions. Based on the interaction matrix, the variables are divided into different groups and are optimised in a collaborative way.
Others
There are also some other methods. For example, Tao et al. (Citation2012), Zhang et al. (Citation2012) and Zhang et al. (Citation2013) adopt the framework of alternately executing fixed upper-level vector for lower-level optimisation and fixed lower-level vector for upper-level optimisation. It simplifies the optimisation process of the bilevel problem and reduces the computational cost to a certain extent, and also changes the nested structure of the bilevel problem. Therefore, the solution obtained by the algorithm is only a rough approximation of the optimal solution of the bilevel problem, and the accuracy is not good
As shown in (), although the above algorithms can greatly reduce the computational overhead, they only use the lower-level objective value as the basis for environment selection in the lower-level search, and the result is to obtain a set of solutions evenly distributed on the lower-level PF. However, the upper-level performance of different optimal solutions may be very different, even they belong to the same lower-level problem. For example, Figure shows the performance of the PS of a lower-level problem in the lower-level objective space and the upper-level objective space, respectively. We can see that only those diamonds remains non-dominant in both the upper-level and lower-level objectives. If the proportion of such points in the lower-level PS is further reduced, the lower-level search of the above algorithm is difficult to obtain these points, which may result in a poor quality upper-level PF. Therefore, the lower-level search should not only ensure the non-dominance of the final individuals in the lower-level objective space but also ensure their non-dominance in the upper-level objective space. In this paper, we propose a multi-objective bilevel optimisation evolutionary algorithm with dual populations lower-level search (MOBEA-DPL), which adopts a dual populations (population and
) lower-level search strategy in the lower-level search. In the early stage of lower-level search, the members of the two populations are consistent and evolve towards lower-level PF. However, in the later stage, the first population continue to select individuals according to the convergence and diversity in the lower-level objective space, providing the second population with convergence pressure from the lower level , while the second population is selected according to the upper-level objective on the premise that they are not dominated by the first population. In this way, the second population not only meet the lower-level optimality constraints but also have a good performance in the upper-level objective space.
Figure 1. In the upper-level objective space, the performance of different optimal solutions belonging to the same lower-level problem may be very different. (a) There are different optimal solutions belonging to the same lower-level problem and (b) only three lower-level non-dominated solutions can remain non-dominated in the upper-level objective space.
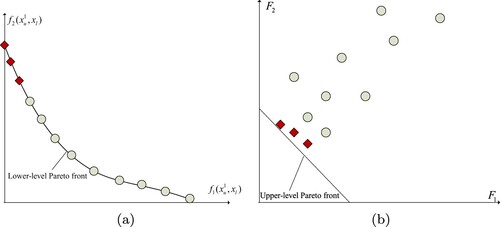
Table 1. The pros and cons of existing works.
In addition, in order to improve the search efficiency, we set up the upper-level mating pool according to the performance of the current generation of individuals in the upper-level task. Compared with the previous practice of treating all upper-level vectors equally and ignoring the quality differences of sub-populations corresponding to different upper-level vectors, it is obviously more reasonable and efficient that the upper-level vector with higher quality sub-population should have more opportunities to produce offspring. However, due to the nested structure of bilevel problems, it is likely to lead to the loss of diversity of the mating pool if the upper-level vector is selected to join the mating pool according to the principle of convergence first, resulting in the population can only search the part of the upper-level PF or even premature convergence. Therefore, we adopt the principle of diversity first in MOEA/D-multi-objective to multi-objective (M2M) proposed by Liu et al. (Citation2014) to improve the search efficiency and maintain diversity at the same time.
As shown in Table , the contributions of this paper are as follows:
We design a dual populations lower-level search strategy. Individuals obtained by means of this strategy not only meets the lower-level optimality constraints but also have good performance in the upper-level objective space.
We select the upper-level mating pool according to the performance of the current generation of individuals in the upper-level objective space using the principle of diversity first, so that the upper-level vector with good performance can obtain more mating opportunities. Then, the upper-level vectors of offsprings are generated near the upper-level vectors of the better individuals in the current population, which greatly improves the search efficiency and maintain diversity at the same time.
Table 2. The contributions of this paper.
The remainder of this paper is organised as follows. In Section 2, we describe the proposed MOBEA-DPL in detail. Experimental settings and the results on test problems with varying complexities and a real-world optimisation problem are presented in Section 3. Finally, conclusions are drawn in Section 4.
2. Proposed algorithm
The overall framework of the proposed MOBEA-DPL is presented in Algorithm 1. First, a set of upper-level vectors of size
are randomly initialised. Next, the dual populations lower-level search is executed to optimise the lower-level multi-objective task for all
in
. Then, the upper-level population Pop are selected from lower-level sub-population SP through upper-level environment selection. Finally, offspring reproduction, upper-level environment selection and refine search are repeated until the termination criteria is met.

2.1. Dual populations lower-level search
In the initialisation and offspring reproduction operations, for each upper-level vector, the corresponding optimal lower-level vectors would be obtained through lower-level search. It should be noted that not all lower-level non-dominated solutions can remain non-dominated in the upper-level objective space. In the upper-level objective space, the performance of different optimal solutions may be very different, even they belong to the same lower-level problem. Thus, the lower-level search should not only ensure the non-dominance of the final individuals in the lower-level objective space but also ensure their non-dominance in the upper-level objective space. Therefore, we propose a dual populations lower-level search in this paper, which is shown in Algorithm 2.

First, a set of lower-level vectors of size
are randomly initialised and
has the same members, which is shown as ). Second, the offspring (SQ) of
are reproduced through differential evolution (DE) operator (Song & Li, Citation2022; Zhao et al., Citation2021). Then,
, SQ and
are merged into r and all members in r are sorted using non-dominated sorting approach according to their lower-level objectives. Next,
is updated by the best
individuals from r using reference-point-based non-dominated sorting approach (Jain & Deb, Citation2014) according to their lower-level objective value, which is followed by the update of
. If the number of lower-level non-dominated individuals in r is no more than
()),
is updated by
; otherwise,
is updated by the best
individuals from lower-level non-dominated individuals in r using reference-point-based non-dominated sorting approach according to their upper-level objective value. Finally, offspring reproduction and the update of
and
are repeated until the termination criteria are met .
Figure 2. The proposed dual populations lower-level search. (a) In the early stage of lower-level search, the members of the two populations are consistent and evolve towards lower-level PF and (b) In the later stage, uniformly converges to the whole lower-level PF, and
converges to the part of the lower-level PF that remains non-dominated in the upper-level objective space.
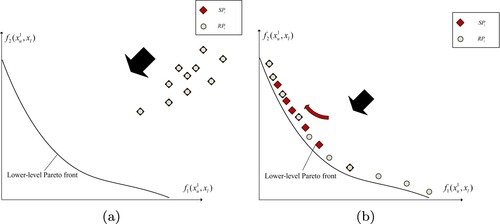
It is worth noting that the proposed dual populations lower-level search can adaptively select the upper-level objectives or the lower-level objectives for optimisation. In the early stage of lower-level search, the number of lower-level non-dominated individuals in r is no more than , and the search focuses on optimising the lower-level objectives. The members of the two populations are consistent and evolve towards lower-level PF. As the search progresses, the number of lower-level non-dominated individuals increased gradually. Once the number of lower-level non-dominated individuals exceeds
, the evolutionary direction of the two populations will differ.
continue to select individuals according to the convergence and diversity in the lower-level objective space, providing
with convergence pressure from the lower level, while
is selected according to the upper-level objectives on the premise that it is not dominated by
. In this way,
is a group of points evenly distributed on the lower-level PF, while
not only meet the lower-level optimality constraints but also have a good performance in the upper-level objectives space.
2.2. Upper-level environment selection
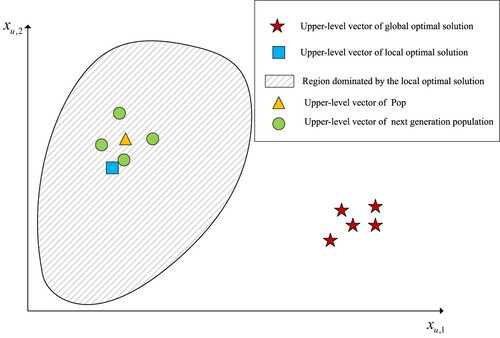
The purpose of the upper-level environment selection proposed in this paper is to update the upper-level population Pop, lower-level populations Archive and the lower-level reference points set RP. It is worth noting that Pop are the individuals with the best upper-level performance. In the next section, we will generate the upper-level vectors of offsprings around the upper-level vectors of Pop to speed up convergence and reduce computational overhead. However, it may cause the population to fall into local optimisation. As shown in Figure , there is a upper-level vector of a local optimal solution in the upper-level variable space and the region dominated by the local optimal solution is quite large. If the selection is based on the principle of convergence first, the upper-level vectors of Pop will converge to the local optimal upper-level vector with a high probability. If we continue to generate the upper-level vectors of offsprings near the upper-level vector of Pop at this time, individuals in Archive will completely fall into local optimisation. Therefore, we should select individuals to consist Pop based on the principle of diversity first, keeping the diversity of upper-level vectors of Pop and Archive as much as possible to avoid falling into local optimisation. The selection operator in MOEA/D-M2M is exactly the selection operator with diversity first.
Figure 3. The population fall into local optimisation.
MOEA/D-M2M is a variant of MOEA/D (Zhang & Li, Citation2007). Different from MOEA/D's method of transforming a multi-objective optimisation problem into multiple single objective optimisation problems, MOEA/D-M2M transforms a multi-objective optimisation problem into multiple multi-objective optimisation problems. Specifically, MOEA/D-M2M divides the candidate solutions into multiple sub-populations according to the diversity of them in the objective space, and then selects individuals in each sub-population according to convergence and diversity to form the next generation population. Therefore, the next generation population has good convergence while retaining excellent diversity. Such solutions are suitable for us to accelerate convergence and avoid the search falling into local optimisation.

The details of upper-level environment selection are shown in Algorithm 3. First of all, k reference weight vectors are uniformly generated, and the size of sub-population (s) is set. Next, the best
individuals are selected from R to update Pop according to the selection operator of MOEA/D-M2M, and the upper-level vectors of individuals in Pop are grouped and stored in
according to their matching relationship with
. Then, the individuals in R that have the same upper-level vectors as the individuals in Pop are eliminated. After that, we start updating the Archive. In the beginning, an empty set
is created to record the upper-level vectors corresponding to individuals that will be stored in the updated Archive. Then, for each reference weight vector
, do the following to fill
different upper-level vectors into
.
First, the set of the upper-level vectors of the individuals associated with
in Pop is assigned to
. Next, duplicate upper-level vectors and the same upper-level vectors from
as in
are deleted. When the number of upper-level vectors in
is less than s, we need to supplement
. If there are individuals associated with
in R, the optimal individual
is selected according to the upper-level objective value; otherwise,
is picked out from R randomly. The upper-level vector of
is added into
, and individuals with the same upper-level vector as
in R are deleted. After supplementing
,
merges
.
After is filled with
upper-level vectors, Archive is updated with individuals in Archive and SQ that have the same upper-level vectors as
, and RP is updated with individuals in RP and RQ that have the same upper-level vectors as
. So far, we have updated Archive and RP, and obtained mating pools
and
.
2.3. Offspring reproduction
After obtaining mating pools Pu and Au, offspring reproduction is executed, which is shown in Algorithm 4. For each , each upper-level vector (
) in
and two randomly selected upper-level vectors (
and
) in
generate a new upper-level vector (
) through DE operator. Then, the dual populations lower-level search is executed to optimise the lower-level multi-objective task for
.

2.4. Refine search
To ensure that each individual in Pop satisfies the lower-level optimality constraint, refine search is executed for upper-level vectors in Pop before the end of each round of upper-level search. It is worth noting that the proposed refine search is consistent with the dual populations lower-level search in design concept. While searching for better lower-level solutions, it prefers individuals that perform better in the upper-level objective space. The details of refine search are shown in Algorithm 5.

First, the upper-level vectors corresponding to the individuals in Pop are extracted without repetition as the upper-level vectors that need refine search, which are recorded as . For each upper-level vector
in
, each corresponding individual in Pop and any two corresponding individuals in Archive generate a new lower-level offspring
through DE operator. Next,
and all corresponding individuals in Archive and RP are merged into r. Then, the best
individuals are picked out from r using reference-point-based non-dominated sorting approach according to their lower-level objective value and denoted as rp. After that, individuals corresponding to
in RP are replaced by rp. If the number of lower-level non-dominated individuals in r is no less than
, the lower-level dominated members are eliminated from r; otherwise, r is updated by rp. Subsequently, individuals corresponding to
in Archive are replaced by r. After all vectors in
have completed the above operations, upper-level environment selection is executed to update Pop, Archive, Pu and Au. It should be noted that the number of individuals corresponding to an upper vector in Archive may exceed
, which needs to be reduced. For each upper-level vector with more than
corresponding individuals in Archive, its corresponding individuals in Archive are sorted using reference-point-based non-dominated sorting approach according to their upper-level objective value. The best
individuals are retained, while the others are eliminated.
2.5. Termination criteria
We adopt a hypervolume-based termination criterion proposed by Sinha et al. (Citation2017) at both levels. At the lower-level, the maximum () and minimum (
) hypervolume are calculated according to the lower-level objective value of
in every generation from the previous
generations (with the worst encountered lower-level objective value in the previous
generations used as reference points). The
-metric is computed as follows:
(2)
(2) If
, then the lower-level optimisation task is terminated indicating adequate convergence. A similar measure is used for the upper-level termination as well, except that the upper-level objective value of Pop are used to compute the hypervolumes. We have used
,
,
and
in our study.
3. Experimental results and discussion
To empirically examine the performance of the proposed MOBEA-DPL, we evaluate MOBEA-DPL on the DS test problems proposed by Deb and Sinha (Citation2009).
There are five test problems in the DS series. In DS1, DS2 and DS3, the dimension of both upper and lower-level problems can be increased by increasing the parameter K. The parameter γ can be adjusted to cause a small proportion of lower-level Pareto-optimal points to be responsible for the upper-level Pareto-optimal front. Besides, conflict between two levels of optimisation can be introduced by choosing . Moreover, the lower-level problem of DS1 is difficult to be solved to Pareto-optimality due to multi-modalities, and it can make an algorithm difficult to locate the true Pareto-optimal points of DS1 by adjusting parameter α. While the upper-level problem of DS2 has multi-modalities, thereby causing an algorithm difficulty in finding the upper-level Pareto-optimal front. DS3 is the most challenging of these three with following properties: first, the Pareto-optimal fronts for both the lower and upper levels lie on constraint boundaries, thereby requiring good constraint handling strategies to solve both problems optimally. Second, not all lower-level Pareto-optimal solutions qualify as upper-level Pareto-optimal solutions. Third, every lower-level front has an unequal contribution to the upper-level Pareto-optimal front. When it comes to DS4 and DS5, the problem complexity in converging to the appropriate lower and upper-level fronts can be increased by increasing K and L. Only one Pareto-optimal point from each participating lower-level problem qualifies to be on the upper-level front in DS4. DS5 has similar difficulties as in DS4, except that only a finite number of
qualifies at the upper-level PF and that a consecutive set of lower-level Pareto-optimal solutions now qualify to be on the upper-level PF (Deb & Sinha, Citation2009).
In the remainder of this section, we first present a brief introduction to the experimental settings of all the compared algorithms. Then, the results from 21 runs of each algorithm for each test problem are presented. A comparative study of the computational expense required by different approaches is also provided.
3.1. Experimental settings
Genetic operators: In this paper, the DE (Vesterstrom & Thomsen, Citation2004; Vishwakarma & Sisaudia, Citation2020) is adopted in all algorithms in the experiments for offspring generation. The parameters of DE in all algorithms in the experiments are default values, which are set to
and F = 0.5, while the expectation of number of bits doing mutation is set to proM = 1 and the distribution index of polynomial mutation is set to disM = 20. Such parameter setting is also adopted by Cai et al. (Citation2022).
Population size: In all algorithms in the behaviour study of the MOBEA-DPL, the upper-level population size is set to
The test problems: The parameters setting of the test problem is shown in Table . In order to shorten the running time, we set the parameter k of the control variable dimension in DS1, DS2 and DS3 to 5 in the behaviour study of the MOBEA-DPL, while other parameters related to the problem characteristics are consistent with Sinha et al. (Citation2017). While in the comparisons of MOBEA-DPL with other approaches, all parameters are consistent with Cai et al. (Citation2022).
Table 3. Benchmark functions used in the behaviour study of the MOBEA-DPL.
3.2. Behaviour study of the MOBEA-DPL
In this section, there are three comparison algorithms. The first one, denoted as MOBEA-nl, considers the quality differences of sub-populations corresponding to different upper-level vectors as MOBEA-DPL, but loses sight of the fact that the lower-level non-dominated solutions may not remain non-dominated in the upper-level objective space, which uses an evolutionary many-objective optimization algorithm usingreference-point based nondominated sorting approach (NSGAIII) proposed by Jain and Deb (Citation2014) as the optimiser for the lower-level search. Other parts of MOBEA-nl are consistent with MOBEA-DPL. Different from MOBEA-nl, the second one, denoted as MOBEA-nr, treats each upper-level vector in Archive equally when generating the upper-level vector of offspring. Each upper-level vector in Au and other two randomly selected vectors generate a new upper-level vector through DE operator, which ignores the quality differences of sub-populations corresponding to different upper-level vectors. Other parts of MOBEA-nr are consistent with the proposed MOBEA-DPL. The third algorithm is a combination of the first two, which is denoted as MOBEA-nrl. When generating the upper-level vectors of offsprings, MOBEA-nrl, like MOBEA-nr, only uses Au as the mating pool. In the lower-level search, NSGAIII is used as the optimiser like MOBEA-nl. Other parts of MOBEA-nrl are consistent with MOBEA-DPL.
3.2.1. Comparison results in IGD
Table presents the comparison results of the four algorithms in inverted generational distance (IGD) on problems proposed by Deb and Sinha, Citation2009 (the DS series), including the results of Wilcoxon rank-sum test calculated at a significance level of , where “+”, “=” and “−” indicate that the compared algorithm is better than, similar to and inferior to the proposed MOBEA-DPL, respectively. We can see that several comparison algorithms have no great difference in the quality of upper-level PF in the first three problems. This is because for DS1 and DS2, the entire lower-level PS can remain non-dominated in the upper-level objective space. Although not all lower-level Pareto-optimal solutions qualify as upper-level Pareto-optimal solutions (Deb & Sinha, Citation2009), the proportion of qualified ones is still relatively large, which is not enough to make a significant difference in the results. Therefore, MOBEA-nl and MOBEA-nrl using the usual lower-level search strategy can also obtain the lower-level most of non-dominated solutions with good upper-level performance. However, when it comes to DS4 and DS5, the algorithms with dual populations lower-level search strategy (i.e. MOBEA-DPL and MOBEA-nr) have obvious advantages. We uniformly take five points on the upper-level decision variable space (i.e.
) of the two problems, which are
,
,
,
and
. Then, we use the two different lower-level search strategies used in the comparison algorithms to solve the lower-level tasks corresponding to these five upper-level variables, and the results are shown in Figures and . The left column subgraphs are the distributions of the solutions in the lower-level objective space, while the right column subgraphs are the distributions of the solutions in the upper-level objective space. We can see that although they are points on the same lower-level PF, their performance in the upper-level objective space are very different. NSGAIII in the experiment is the same as the lower-level search strategy of the existing algorithms, which only uses the lower-level objectives as the basis for the lower-level environment selection. They can find the solutions in the lower-level PS, but they cannot further screen the solutions in the lower-level PS. However, the proposed dual population lower-level search strategy not only searches the lower-level PS but also converges to those solutions with good upper-level performance in the lower-level PS. Therefore, with dual populations lower-level search strategy, MOBEA-DPL and MOBEA-nr obtain significantly better results in IGD, which proves the effectiveness of the proposed dual populations lower-level search.
Figure 4. Performance difference between two lower-level search strategies on DS4. (a) Non-dominated solutions of , where
. (b) The performance of non-dominated solutions of
in the upper-level objective space, where
. (c) Non-dominated solutions of
, where
. (d) The performance of non-dominated solutions of
in the upper-level objective space, where
. (e) Non-dominated solutions of
, where
. (f) The performance of non-dominated solutions of
in the upper-level objective space, where
. (g) Non-dominated solutions of
, where
. (h) The performance of non-dominated solutions of
in the upper-level objective space, where
. (i) Non-dominated solutions of
, where
. (j) The performance of non-dominated solutions of
in the upper-level objective space, where
.

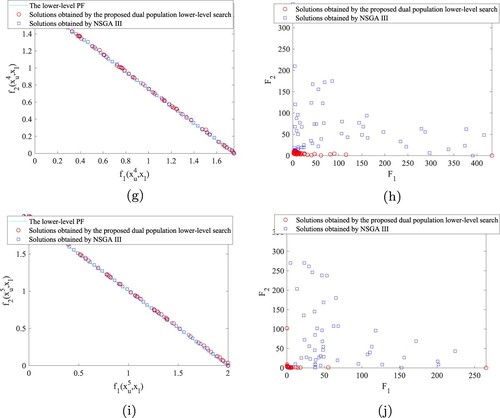
Figure 5. Performance difference between two lower-level search strategies on DS5. (a) Non-dominated solutions of , where
. (b) The performance of non-dominated solutions of
in the upper-level objective space, where
. (c) Non-dominated solutions of
, where
. (d) The performance of non-dominated solutions of
in the upper-level objective space, where
. (e) Non-dominated solutions of
, where
. (f) The performance of non-dominated solutions of
in the upper-level objective space, where
. (g) Non-dominated solutions of
, where
. (h) The performance of non-dominated solutions of
in the upper-level objective space, where
. (i) Non-dominated solutions of
, where
. (j) The performance of non-dominated solutions of
in the upper-level objective space, where
.
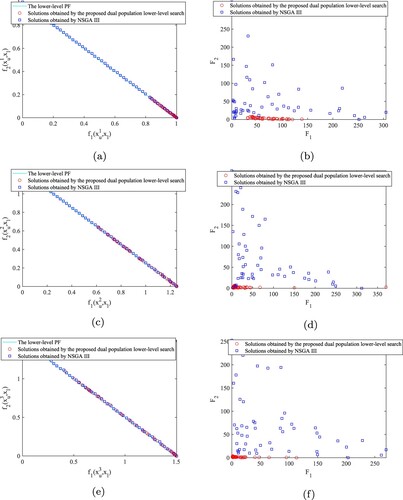
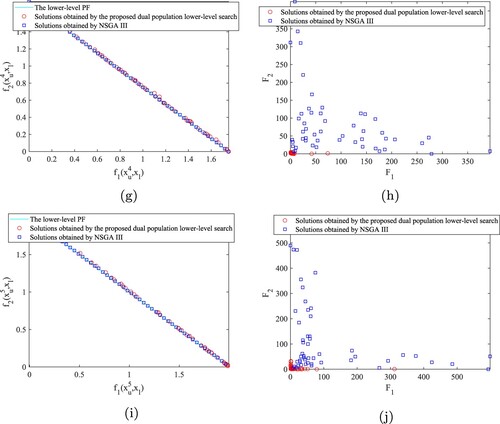
Table 4. The comparison results of the IGD averages of the four algorithms running 21 times independently on DS series.
3.2.2. Comparison results in FEs
Table shows the minimum, maximum and average number of FE required for the upper and lower-level objectives from 21 runs of the compared algorithms. At the same time, Table also gives the ratio of average FEs, where the numerator is the average FEs of the comparison algorithm and the denominator is the average FEs of MOBEA-DPL.
Table 5. The total function evolution by the compared algorithms and their statistical comparison results in 21 independent runs for benchmark problems.
Comparing MOBEA-DPL and MOBEA-nl, MOBEA-nr and MOBEA-nrl, respectively, we can see that the proposed dual population lower-level search not only increases the upper-level (UL) FEs on all the test problems but also increases the lower-level (LL) FEs on the test problems (i.e. DS1, DS2 and DS3) where all or most lower-level Pareto-optimal solutions qualify as upper-level Pareto-optimal solutions. As for the test problems (i.e. DS4 and DS5) where only a smaller part of lower-level Pareto-optimal solutions qualify as upper-level Pareto-optimal solutions, the proposed dual population lower-level search can reduce their lower-level FEs. The growth rate of upper-level FEs on all the test problems is between 1.47 and 12.7. In bilevel optimisation algorithms, the lower-level FEs are often more than one order of magnitude than the upper-level FEs, so the computational overhead is mainly to count the lower-level FEs. Therefore, the increase of upper-level FEs is acceptable. On DS1, DS2 and DS3, there are obvious differences in lower-level FEs. Due to the proposed dual population lower-level search, the lower-level FEs have increased slightly on DS1 and DS3, but more than doubled on DS2. This is because the upper-level task and lower-level task of DS2 are conflict (i.e. ), which means that when dual population lower-level search selects individuals according to their upper-level objective value to form the next generation population, solutions far from the lower-level PF among the lower-level non-dominated solutions are preferred. Therefore, it leads to slower convergence and more lower-level FEs. When it comes to DS4 and DS5, the proposed dual population lower-level search can effectively find the upper-level Pareto-optimal solutions in the lower-level Pareto-optimal solutions, which makes each upper-level vector obtain the correct evaluation and avoid the search misled by the wrong evaluation, so MOBEA-DPL and MOBEA-nr have less lower-level FEs. However, only one Pareto-optimal point from each participating lower-level problem qualifies to be on the upper-level PF in DS4 (Deb & Sinha, Citation2009), which makes DS4 a more difficult problem than DS5. Without dual population lower-level search, MOBEA-nl and MOBEA-nrl are difficult to find better solutions on DS4, so premature convergence take place. Therefore, the reduction of lower-level FEs on DS4 is much less than that on DS5.
Comparing MOBEA-DPL and MOBEA-nr, MOBEA-nl and MOBEA-nrl, respectively, we can see that the proposed upper-level vector generation strategy has no effect on those problems with low-dimension upper-level decision space (i.e. DS4 and DS5, whose upper-level decision space dimension is only 1), because the upper-level vectors are easy to converge quickly in such a low-dimensional space. When it comes to problems with high-dimension upper-level decision space (i.e. DS1, DS2 and DS3, whose upper-level decision space dimension is 5), the situation is a little complicated. On DS1 and DS2, algorithms with the proposed upper-level vector generation strategy (i.e. MOBEA-DPL and MOBEA-nl) achieve smaller upper-level FEs and smaller lower-level FEs with a decrease of between 19% and 30%. However, MOBEA-DPL achieved 10% less upper-level FEs and 11% less lower-level FEs than MOBEA-nr on DS3, MOBEA-nl achieved 3% more upper-level FEs and 4% more lower-level FEs than MOBEA-nrl on DS3. That is because not all lower-level Pareto-optimal solutions qualify as upper-level Pareto-optimal solutions in DS3. With the proposed dual population lower-level search, MOBEA-nr can continuously improve the quality of the upper-level PF by converging the population to those qualified lower-level Pareto-optimal solutions. Therefore, even if the probability of generating a promising upper-level vector is low, MOBEA-nr can avoid premature convergence on DS3. However, with a low probability of generating a promising upper-level vector and without the proposed dual population lower-level search, MOBEA-nrl inevitably converges prematurely on DS3. With the proposed upper-level vector generation strategy, MOBEA-nl is more likely to generate promising upper-level vectors and continuously improve the upper-level PF, so MOBEA-nl also avoids premature convergence on DS3. MOBEA-nrl has obtained the worst IGD and the least FEs on DS3, which provide evidence for this claim.
Overall, the experimental results demonstrate that the proposed dual population lower-level search can effectively improve the quality of upper-level PF of problem where not all lower-level Pareto-optimal solutions qualify as upper-level Pareto-optimal solutions and greatly increased the computational overhead for problems with conflicting upper and lower-level objectives. In order to obtain a better solution, the overhead of computing resources is acceptable. In addition, the experimental results also show that the proposed upper-level vector generation strategy can effectively reduce the computational overhead for problems with high-dimension upper-level decision space. Thus, the proposed MOBEA-DPL is efficient and effective.
3.3. The comparisons of MOBEA-DPL with other approaches
In this section, we conduct experiments to compare the performance of MOBEA-DPL with a nested strategy (NS), a state-of-the-art hybrid bilevel evolutionary multi-objective optimisation (H-BLEMO) algorithm (Deb & Sinha, Citation2010) and a state-of-the-art cooperative coevolution with knowledge-based dynamic variable decomposition optimisation algorithm (BLMOCC) (Cai et al., Citation2022). The settings of test problems and comparison algorithms are the same as those in BLMOCC (Cai et al., Citation2022). It should be noted that we do not have the original codes of H-BLEMO and BLMOCC. We do not think we can reproduce their algorithms perfectly according to their papers. Therefore, we extract the data of IGD and FEs in the original BLMOCC. For IGD, 1000 reference points are uniformly sampled from the true PFs on all the problems, which is the same as that in BLMOCC. Similarly, the scale of the non-dominated solutions used to calculate IGD is also consistent with that in BLMOCC. Thus, it can be reflected for a fair comparison. Table presents the comparison results of the mean and standard deviation values of IGD of MOBEA-DPL with other approaches on DS series, and the best mean results of individual test instances are highlighted, while the comparison results of FEs of MOBEA-DPL with other approaches are shown in Table .
Table 6. The comparison results of the mean and standard deviation values of IGD of MOBEA-DPL with other approaches on DS series.
Table 7. The total function evolution by the compared algorithms and their statistical comparison results in 21 independent runs for benchmark problems.
We can see that the proposed MOBEA-DPL achieves the best IGD on all problems. The reason is that the proposed dual population lower-level search strategy and the refine search enable more upper-level non-dominated solutions to be found. However, the FEs required for the upper and lower-level objectives of MOBEA-DPL are still large. Compared with NS, although the lower-level FEs of MOBEA-DPL is reduced by more than half, it is still far more than that of algorithms with computational overhead reduction methods (i.e. H-BLEMO and BLMOCC). Therefore, the dual population lower-level search strategy and upper-level vector generation strategy proposed in this paper are complementary to the existing researches. Combined with the existing computational overhead reduction methods, MOBEA-DPL can obtain better quality upper-level PF and consumes less computing resources.
3.4. Application on a real-world optimisation problem
In this section, MOBEA-DPL is applied to the real-world decision-making problem we mentioned in the introduction, which is about the CEO making decisions considering the reactions of branch heads. A fuzzy version of this problem is addressed by Zhang et al. (Citation2007), and a deterministic version of this problem can be mathematically formulated as follows:
(3)
(3) where
is the CEO's decision variables, and
are the branch heads' decision variables. The CEO aims to maximise the net profits and the quality of products produced in the company, while the objectives of the branch heads are to maximise both the worker satisfaction and their branch profits. They are all subject to constraints such as the requirements of material, marking cost, labour cost and working hours.
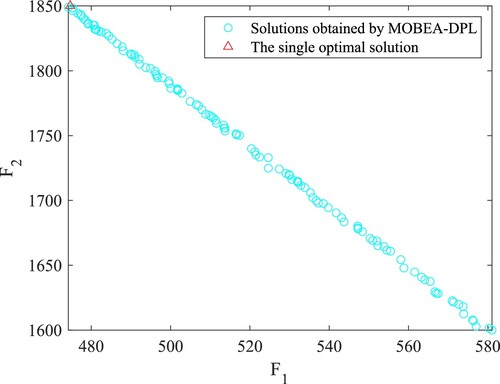
It is not possible to solve this problem analytically. Zhang et al. (Citation2007) solved this problem by converting the two objectives into a single objective with the weighted sum approach for obtaining one optimal solution. Figure shows the final non-dominated set obtained by MOBEA-DPL on this problem. The single optimal solution obtained by Zhang et al. (Citation2007) has also been presented in Figure (marked in triangle). It can be observed that MOBEA-DPL is able to well-approximate the whole PF, including the optimal solution obtained by Zhang et al. (Citation2007). The results further verify the effectiveness of MOBEA-DPL for a real-world multi-objective bilevel optimisation problem.
Figure 6. The obtained PF of MOBEA-DPL on a practical problem. The point marked with a triangle is obtained by Zhang et al. (Citation2007).
4. Conclusion
Multi-objective bilevel optimisation problems are difficult optimisation problems with two levels of multi-objective optimisation tasks. Both the nested structure of bilevel problems and the characteristics of multiple optimum solutions of multi-objective optimisation problems make the multi-objective bilevel optimisation problems computationally demanding and difficult to be solved.
Most of the existing researches focus on methods to reduce the computational overhead. Although the above algorithms can greatly reduce the computational overhead, they only use the lower-level objective value as the basis for environment selection in the lower-level search, and the result is to obtain a set of solutions evenly distributed on the lower-level PF. However, the upper-level performance of different optimal solutions may be very different, even they belong to the same lower-level problem. Not all lower-level Pareto-optimal solutions qualify as upper-level Pareto-optimal solutions. If the proportion of such points in the lower-level PS is further reduced, the lower-level search of the above algorithm is difficult to obtain these points, which may result in a poor quality upper-level PF. Therefore, we propose a MOBEA-DPL, which use two populations ( and
) in the lower-level search.
always maintains non-dominance and diversity in the lower-level objective space throughout the lower-level search process, which provides
with convergence pressure from the lower level.
is consistent with
in the early stage of lower-level search. But in the later stage,
searches for the upper-level non-dominated solutions that is not dominated by
in the lower-level objective space. In this way,
not only meets the lower-level optimality constraints but also have a good performance in the upper-level objective space.
In addition, to improve the search efficiency, we set up the upper-level mating pool according to the performance of the current generation of individuals in the upper-level task. Compared with the previous practice of treating all upper-level vectors equally and ignoring the quality differences of sub-populations corresponding to different upper-level vectors, it is obviously more reasonable and efficient that the upper-level vector with higher quality sub-population should have more opportunities to produce offspring.
The proposed algorithm has been evaluated on five test problems with different kinds of complexities. The experimental results demonstrate that the proposed dual population lower-level search can effectively improve the quality of upper-level PF of problem where not all lower-level Pareto-optimal solutions qualify as upper-level Pareto-optimal solutions and greatly increased the computational overhead for problems with conflicting upper and lower-level objectives. In order to obtain a better solution, the overhead of computing resources is acceptable. In addition, the experimental results also show that the proposed upper-level vector generation strategy can effectively reduce the computational overhead for problems with high-dimension upper-level decision space. Thus, the proposed MOBEA-DPL is efficient and effective. Meanwhile, MOBEA-DPL is also applied to the real-world decision-making problem and successfully obtained the whole PF, including the optimal solution obtained by Zhang et al. (Citation2007). It further verifies the effectiveness of MOBEA-DPL for a real-world multi-objective bilevel optimisation problem.
However, the FEs required for the upper and lower-level objectives of the proposed MOBEA-DPL are still large. In general, the dual population lower-level search strategy and upper-level vector generation strategy proposed in this paper are complementary to the existing researches. Combined with the existing computational overhead reduction methods, MOBEA-DPL can obtain better quality upper-level PF and consume less computing resources. In addition, due to the existence of extreme points and the reference-point-based non-dominated sorting approach used in the upper-level environment selection, the proposed MOBEA-DPL is difficult to obtain uniformly distributed points on the upper-level PF of problems DS4 and DS5. These problems need to be solved in the next research.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Cai, X., Sun, Q., Li, Z., Xiao, Y., Mei, Y., Zhang, Q., & Li, X. (2022). Cooperative coevolution with knowledge-based dynamic variable decomposition for bilevel multiobjective optimization. IEEE Transactions on Evolutionary Computation. Advance online publication. https://doi.org/10.1109/TEVC.2022.3154057
- Cai, Y., Rong, Q., Yang, Z., Yue, W., & Qian, T. (2018). An export coefficient based inexact fuzzy bi-level multi-objective programming model for the management of agricultural nonpoint source pollution under uncertainty. Journal of Hydrology, 557(2), 713–725. https://doi.org/10.1016/j.jhydrol.2017.12.067
- Cao, Z., Zhou, Y., Yang, A., & Peng, S. (2021). Deep transfer learning mechanism for fine-grained cross-domain sentiment classification. Connection Science, 33(4), 911–928. https://doi.org/10.1080/09540091.2021.1912711
- Chen, Z., Wang, C., Jin, H., Li, J., Zhang, S., & Ouyang, Q. (2022). Hierarchical-fuzzy allocation and multi-parameter adjustment prediction for industrial loading optimisation. Connection Science, 34(1), 687–708. https://doi.org/10.1080/09540091.2022.2031887
- Deb, K., & Sinha, A. (2009). An evolutionary approach for bilevel multi-objective problems. In International conference on multiple criteria decision making (pp. 17–24). Springer.
- Deb, K., & Sinha, A. (2010). An efficient and accurate solution methodology for bilevel multi-objective programming problems using a hybrid evolutionary-local-search algorithm. Evolutionary Computation, 18(3), 403–449. https://doi.org/10.1162/EVCO_a_00015
- He, Q., & Lv, Y. (2017). Particle swarm optimization based on smoothing approach for solving a class of bi-level multiobjective programming problem. Cybernetics and Information Technologies, 17(3), 59–74. https://doi.org/10.1515/cait-2017-0030
- Jain, H., & Deb, K. (2014). An evolutionary many-objective optimization algorithm using reference-point based nondominated sorting approach, part ii: Handling constraints and extending to an adaptive approach. IEEE Transactions on Evolutionary Computation, 18(4), 602–622. https://doi.org/10.1109/TEVC.2013.2281534
- Kamal, M., Gupta, S., Chatterjee, P., Pamucar, D., & Stevic, Z. (2019). Bi-level multi-objective production planning problem with multi-choice parameters: A fuzzy goal programming algorithm. Algorithms, 12(7), 143. https://doi.org/10.3390/a12070143.
- Kolak, O. I., Feyzioglu, O., & Noyan, N. (2018). Bi-level multi-objective traffic network optimisation with sustainability perspective. Expert Systems with Applications, 104(August), 294–306. https://doi.org/10.1016/j.eswa.2018.03.034
- Li, Y., Dai, H.-N., & Zheng, Z. (2022). Selective transfer learning with adversarial training for stock movement prediction. Connection Science, 34(1), 492–510. https://doi.org/10.1080/09540091.2021.2021143
- Lin, Y., Pan, S., Jia, L., & Zou, N. (2010). A bi-level multi-objective programming model for bus crew and vehicle scheduling. In 2010 8th world congress on intelligent control and automation (pp. 2328–2333). IEEE.
- Liu, H., Gu, F., & Zhang, Q. (2014). Decomposition of a multiobjective optimization problem into a number of simple multiobjective subproblems. IEEE Transactions on Evolutionary Computation, 18(3), 450–455. https://doi.org/10.1109/TEVC.4235
- Lv, T., Ai, Q., & Zhao, Y. (2016). A bi-level multi-objective optimal operation of grid-connected microgrids. Electric Power Systems Research, 131(6), 60–70. https://doi.org/10.1016/j.epsr.2015.09.018
- Ma, L., Huang, M., Yang, S., Wang, R., & Wang, X. (2021). An adaptive localized decision variable analysis approach to large-scale multiobjective and many-objective optimization. IEEE Transactions on Cybernetics. Advance online publication. https://doi.org/10.1109/TCYB.2020.3041212
- Ni, S., Zhang, L., Wu, G., Shi, P., & Zheng, J. (2020). Multi-objective bi-level optimal dispatch method of active distribution network considering dynamic reconfigurations. In 2020 5th Asia conference on power and electrical engineering (ACPEE) (pp. 2077–2082). IEEE.
- Pieume, C. O., Marcotte, P., Fotso, L. P., & Siarry, P. (2013). Generating efficient solutions in bilevel multi-objective programming problems. American Journal of Operations Research, 3(2), 289–298. https://doi.org/10.4236/ajor.2013.32026
- Ruuska, S., & Miettinen, K. (2012). Constructing evolutionary algorithms for bilevel multiobjective optimization. In 2012 IEEE congress on evolutionary computation (pp. 1–7). IEEE.
- Said, R., Bechikh, S., Louati, A., Aldaej, A., & Said, L. B. (2020). Solving combinatorial multi-objective bi-level optimization problems using multiple populations and migration schemes. IEEE Access, 8(2169-3536), 141674–141695. https://doi.org/10.1109/Access.6287639.
- Shaikh, P. W., El-Abd, M., Khanafer, M., & Gao, K. (2020). A review on swarm intelligence and evolutionary algorithms for solving the traffic signal control problem. IEEE Transactions on Intelligent Transportation Systems, 23(99), 1–16. https://doi.org/10.1109/TITS.2020.3014296
- Sinha, A., Malo, P., & Deb, K. (2017). Approximated set-valued mapping approach for handling multiobjective bilevel problems. Computers & Operations Research, 77(0305-0548), 194–209. https://doi.org/10.1016/j.cor.2016.08.001.
- Sinha, A., Malo, P., Deb, K., Korhonen, P., & Wallenius, J. (2016). Solving bilevel multicriterion optimization problems with lower level decision uncertainty. IEEE Transactions on Evolutionary Computation, 20(2), 199–217. https://doi.org/10.1109/TEVC.2015.2443057
- Song, E., & Li, H. (2022). A hybrid differential evolution for multi-objective optimisation problems. Connection Science, 34(1), 224–253. https://doi.org/10.1080/09540091.2021.1984396
- Sundar, S., & Sumathy, S. (2022). Transfer learning approach in deep neural networks for uterine fibroid detection. International Journal of Computational Science and Engineering, 25(1), 52–63. https://doi.org/10.1504/IJCSE.2022.120788
- Tao, Z., Hu, T., Yue, Z., & Guo, X. (2012). An improved particle swarm optimization for solving bilevel multiobjective programming problem. Journal of Applied Mathematics, 2012(1110-757X), 359–373. https://doi.org/10.1155/2012/626717
- Vesterstrom, J., & Thomsen, R. (2004). A comparative study of differential evolution, particle swarm optimization, and evolutionary algorithms on numerical benchmark problems. In Congress on evolutionary computation (pp. 1980–1987).
- Vishwakarma, V. P., & Sisaudia, V. (2020). Self-adjustive de and kelm-based image watermarking in DCT domain using fuzzy entropy. International Journal of Embedded Systems, 13(1), 74–84. https://doi.org/10.1504/IJES.2020.108286
- Yanhong, L., Dong, W., Xiaonian, S., & Zhenzhou, Y. (2011). Research on allocation and optimization of passenger structure within comprehensive transportation corridor based on bi-level multi-objective programming. In Proceedings 2011 international conference on transportation, mechanical, and electrical engineering (TMEE) (pp. 240–247). IEEE.
- Zhang, G., Lu, J., & Dillon, T. (2007). Decentralized multi-objective bilevel decision making with fuzzy demands. Knowledge-Based Systems, 20(5), 495–507. https://doi.org/10.1016/j.knosys.2007.01.003 Intelligent Knowledge Engineering Systems.
- Zhang, Q., & Li, H. (2007). Moea/d: A multiobjective evolutionary algorithm based on decomposition. IEEE Transactions on Evolutionary Computation, 11(6), 712–731. https://doi.org/10.1109/TEVC.2007.892759
- Zhang, T., Hu, T., Chen, J. W., Wan, Z., & Guo, X. (2012). Solving bilevel multiobjective programming problem by elite quantum behaved particle swarm optimization. Abstract & Applied Analysis, 2012, 97–112. https://doi.org/10.1155/2012/102482
- Zhang, T., Hu, T., Guo, X., Chen, Z., & Zheng, Y. (2013). Solving high dimensional bilevel multiobjective programming problem using a hybrid particle swarm optimization algorithm with crossover operator. Knowledge-Based Systems, 53(0950-7051), 13–19. https://doi.org/10.1016/j.knosys.2013.07.015.
- Zhang, Y., Gong, D.-W., & Cheng, J. (2017). Multi-objective particle swarm optimization approach for cost-based feature selection in classification. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 14(1), 64–75. https://doi.org/10.1109/TCBB.2015.2476796
- Zhang, Z. (2014). A modm bi-level model with fuzzy random coefficients for resource-constrained project scheduling problems. In 2014 seventh international joint conference on computational sciences and optimization (pp. 666–669). IEEE.
- Zhao, F., Du, S., Lu, H., Ma, W., & Song, H. (2021). A hybrid self-adaptive invasive weed algorithm with differential evolution. Connection Science, 33(4), 929–953. https://doi.org/10.1080/09540091.2021.1917517