
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The collaborative filtering recommendation technique (CFR) is one of the techniques used in recommended systems, in which the most proximal neighbours to a target user are selected. Their profiles are used to predict rating for items as yet unrated by that target user. However, malicious users inject fake user profiles to destroy the security and reliability of the recommender systems, which is called shilling attacks. Therefore, it is crucial to improve the recommendation technique against shilling attacks. Malicious users use a single method to perform shilling attacks. Intuitively, fusing multiple criteria to construct CFR can effectively resist shilling attacks. A novel CFR is proposed against shilling attacks (called CFR-F). In our approach, a similar interest users’ resource set is obtained first by integrating users’ dynamic interest model and social tags. Then, a similar interest user resource set is selected according to a strategy that selects preference influence weight based on user background. Our experimental results show that our approach can recommend accurate information resources and has a lower Mean Absolute Error (MAE) and Average Prediction Shift (APS) than traditional techniques by 50% and 20%, respectively.
1. Introduction
Information overload is becoming quite serious (Tang et al., Citation2021; Zhang et al., Citation2021). It is a big challenge to use information resources effectively. Information recommendation systems can help users sift through a large amount of information to select items they are interested in (Lian & Tang, Citation2022; Liu et al., Citation2022). However, due to the openness of information recommendation techniques, they are vulnerable to shilling attacks (Gao et al., Citation2011; Gao et al., Citation2010; Li et al., Citation2022). Shilling attacks are when malicious users inject fake user profiles to affect the recommendation’s results (Yu et al., Citation2017). Shilling attacks threaten the recommendation system security and cause losses to the users. Therefore, it is crucial to study recommendation techniques against shilling attacks (Si & Li Citation2020; Arora & Taneja, Citation2021).
Currently, information recommendation techniques are classified into (Adomavicius & Tuzhilin, Citation2005; Yu et al., Citation2020): (1) collaborative filtering recommendation (CFR), (2) content-based recommendation, and (3) hybrid recommendation. The CFR is one of the most popular and successful techniques in the information recommendation community, and it assumes that similar users have similar tastes. A user-based CFR technique makes recommendations by finding their neighbours with similar user profiles, which are assumed to represent the preferences of many different individuals. The profile database contains fake data; these fake profiles would be considered neighbours of target users and eventually result in biased recommendations in shilling attacks (Shah & Bhanderi, Citation2014; Wu et al., Citation2021).
In the event of a shilling attack, the key to CFR techniques is to ensure that the selected neighbours are trusted (Zhang and Kulkarni Citation2013; Zhang et al., Citation2013). A trust mechanism is a common method to solve shilling attacks in CFR. According to the initial trust value, trust can be explicit trust and implicit trust. The former explicitly provides the trust value between users in the system to set the initial trust value and maintains and adjusts its trust list. The latter calculates the initial trust value from the user profile (Mobasher et al., Citation2007). Trust relationships in social networks are combined with traditional recommendation systems to reduce the possibility of attacks. However, the trust relationship is computed by the static user behaviours or user ratings, and they are the object of fraud by the malicious users. It makes the trust relationship entirely dependent on its mining the risk of fraud. At the same time, maintaining user trust relationships in social networks brings a huge amount of extra work to the recommendation system, and the consideration of trust dynamics makes the problem more complicated (Mehta et al., Citation2008a; Arul & Razia, Citation2021).
Generally, a malicious user fakes data based on a single criterion, such as user rating, to perform shilling attacks. A malicious user finds it difficult to fake data based on multi-criteria. Therefore, fusing multiple criteria to construct a novel CFR can effectively resist shilling attacks. Unlike CFR, we fuse the two criteria of dynamic social tagging and user ratings to form user dynamic interests. The user interest is dynamic. User dynamic interests are difficult to be imitated by malicious users. Collaborative filtering recommendations using Fusing criteria increase the difficulty of a malicious user to fake attack data. The approach can improve the ability of the recommendation system to resist shilling attacks. In our approach, user dynamic interest fuses users' interest constructed by dynamic social tagging and user interest based on user ratings. Furthermore, based on the weight of scenario attribute combination in the scenario, the influence weight selection strategy is designed to find the nearest neighbours and set target users to provide reliable recommendations.
The main contribution of our work is as follows: (1) We fuse multi-criteria to construct dynamic interest, which is difficult for malicious users to fake data in user scenarios. (2) We select near neighbours by selection strategy based on attribute combination to exclude malicious user information, and (3) We verified our approach by experiments on the two synthetic datasets Smovie and Slast.fm.
The rest of the paper is organised as follows. Section 2 introduces related works. Section 3 shows the framework of our approach and its details. Section 4 reports the experiment results and analysis. In the last section, we conclude our works.
2. Related work
2.1. Shilling attack framework
The recommendation system has natural noise and artificial noise. In reality, some users who are rigorous and some users who are not rigorous for grading items, the rating of the strict user is a natural noise. The artificial noise mainly refers to the malicious rate for some items. That is called shilling attacks. If, a malicious user, forges a rating vector that is similar to a target user in a recommendation system, it can affect the result of recommendation for the target user. For a shilling attack, a malicious user attempts to manipulate the system recommendation results by injecting fake profile information close to other individuals. The general model of shilling attacks is shown in Figure (Adomavicius & Tuzhilin, Citation2005), and its scoring vector (user profile information) usually consists of four parts:, where
is a selected item,
is the filler item,
is the unrated item,
is a singleton target item. In the target item, the attacker tries to improve or reduce the recommendation frequency. The malicious user uses the filler item to disguise himself as a regular user and uses the selected item to disguise himself as the nearest neighbour of as many normal users as possible. Meanwhile, the filler item and the selected item enhance the attack efficiency.
Figure 1. Shilling-attack scoring vector model.
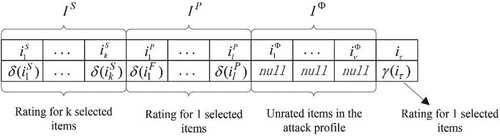
Shilling attacks can be generally divided into three categories (Mehta et al., Citation2008b; Jiang et al., Citation2016): push attacks, nuclear attacks, and malicious disruption attacks. If the attack is intended to increase the recommended frequency of the target item, it is called a push attack, whereas a nuclear attack is an attempt to reduce the recommendation ranking of the target item and an attempt to disable the recommendation system is called a malicious disruption attack.
There are two common forms of anti-attack: attack detection (Hao et al., Citation2021; Julio et al., Citation2021) and attack defence. Attack detection is generally based on mathematical statistics. Defend against attacks, such as using user relationships in social networks to exclude attackers as much as possible. For the former, a lot of work has been done. Most detectors model shilling attacks detection as a classification problem, including three detection algorithms based on supervised learning, unsupervised learning and semi-supervised learning, divided from the perspective of machine learning. We mainly focus on the techniques for defending against shilling attacks.
2.2. CFR against shilling attacks
The CFR is to recommend resources that may be of interest to target users based on the interests of the most similar neighbours (Deldjoo et al., Citation2020). User rating similarity and user interest similarity jointly determine user similarity (Ma et al., Citation2009). By injecting fake user profile information (such as user rating) close to other individuals, the attacker attempts to influence user similarity calculation tomanipulate system recommendation results. The presentation of user interests is derived from multiple dimensions, including user interaction with the environment and user context. User social behaviours, including user tagging, interact between users and the environment. Social tagging refers to the labelling of resources in the social community from users' perspective. In the social labelling system, the content information and labelling time reflect the user’s interest preference and its changing trend. As the result of users’ labelling behaviours, social tags can dynamically reflect users’ real interests (Eleftherios et al., Citation2011). Dynamic tags expressing social behaviours can reflect the similarity of users’ interests from the perspective of behaviour. Such interest actively displayed by users is difficult for others to track and grasp, especially in semantically rich labels (Xi et al., Citation2014). It is even harder for the attackers to forge and fill the data.
Based on the potential of users’ dynamic interest and the weight selection of users’ situation on preferences, we propose an information resource recommendation method integrating dynamic interest with selection strategy to resist shilling attacks.
3. Our approach
3.1. Framework
Our idea that defends shilling attacks is to obtain candidate user sets of similar interests by fusing dynamic social tags and user ratings, and then apply preference influence weighted ranking to candidate user sets of similar interests using the selection strategy, and finally determine the nearest neighbour recommendation set of target users.
Our CFR technique is illustrated in Algorithm 1. The approach has two phases: (1) Generating a neighbour set. In this phase, the dynamic interests are computed by fusing criteria. User similarity obtained no longer depends entirely on the user rating. It makes its difficult to generate the target user’s nearest neighbours manipulated by malicious users (lines 2-6). (2) Resource items recommendation. In this phase, the nearest neighbours are screened based on the preference selection strategy and formed the nearest neighbour set for target users (lines 8-9). Next, we discuss the two phases. The recommendation technique is described as follows:
Table
3.2. Generating neighbour set
3.2.1. Dynamic interest model
Label information and time weight
When users use social tags to label resources, the frequency of usage reflects the user’s preference for related resources. If the frequency of tag usage is high, it has a great influence on the user’s interest preference, and the related tags should have a higher weight. This paper uses the TF-IUF method to calculate the weight of a single label. The calculation equation is shown in Equation (1):
(1)
(1) where
is the weight of tag i in user labels, fi is the frequency of tag ti, N is the total number of users in the test set, and ni is the number of times that tag ti appears in different user tag sets.
In general, recently labelled tags have a greater impact on users’ interests and preferences, and corresponding tag resources should have a higher weight than those labels earlier. Cheng et al. proposed an adaptive exponential decay function to calculate the time weight in labels, and the calculation equation is shown in Equation (2) (Cheng et al., Citation2008):
(2)
(2) where
is the time weight of the label that represents the attenuation degree of user preferences,
and
. When
, it indicates the last annotation time of the user
to the resource
. When
, it indicates the time of the penultimate annotation of the resource by the user, and so on. The
is the half-life of the user
, whose value varies with the user’s life cycle.
Dynamic label weight
User-label pseudo-matrix is defined as , where the value of matrix
represents the total score for the user
on the tag
, which can be obtained by weighting tag information and time weight. The calculation equation is shown in Equation (3):
(3)
(3) where the parameter
is a harmonic factor and
, label weight reflects user preference, and time weight reflects the change in user preferences. Therefore, the value of
can be adjusted according to the importance of
and
. If the two factors are equally important, we set
. If annotation information has a more important influence on user preference,
takes a larger value. Conversely,
takes a smaller value.
3.2.2. Neighbour set generation
For the similarity based on user labels, cosine similarity is used in our approach to calculating, as shown in Equation (4):
(4)
(4)
Tthe equation indicates the resource set annotated by users
and
.
Assume that the user set is and the resource item set is
, the
represents the behaviour of the user u towards resource item
(such as purchase or rating behaviour). When the user does nothing,
is set as 0. The behaviour of all users towards resource items is represented as a matrix of
, denoted as
, where the value of
represents the rating of the user
to resource item
.
The Pearson correlation coefficient is adopted to calculate the resource item set jointly evaluated by users
and
, and the similarity between users and each other is calculated according to Equation (5):
(5)
(5) where the
is the user rating of
for resource item
,
is the user rating of the user
for the resource item
,
is the average score of the user a, and
is the average score of the user b. The weighted calculation equation of user similarity is shown in Equation (6):
(6)
(6) where
is the comprehensive similarity of the integration,
and
are the weights of
and
similarity, respectively, and
,
,
. The first
candidate neighbour sets of the target user are found by calculating user comprehensive similarity. The user dynamic interests fusing criterion makes the candidate neighbours of target users no longer depend entirely on a single criterion, such as user ratings. This reduces the weight of user ratings and reduces the likelihood that fake filling items enter the recommended target user’s nearest neighbour set.
3.3. Resource items recommendation
Different attribute combinations have different influences on user preferences. Therefore, the selection strategy for user preference weight should give by different situational instances. The influence weight of user preference is set according to the similarity between target users and neighbours recommended in a specific attribute combination. The scenario instance (reflected by a specific attribute) with a high similarity degree will have a significant weight. If the preference influence weight is small, the similarity degree is low.
Therefore, our selection strategy is as follows: First, according to the application needs, select several situational attributes as a combination of situational attributes. Then, the influence weight of the attribute combination on user preference in different situation instances is set. Finally, according to the given weight of the situational similarity between the target user and the candidate neighbour user, the weighted sorting is performed again to select the Top-N neighbour, which, in the candidate neighbour set, have of the target user with a similar interest.
Generally, for an application rely more on user background, such as watching movies, user preference is closely related to the factors such as gender, age, occupation, and education. The influence weight of user preferences is given according to different situational instances and the influence degree of combination attribute on user preferences. For watching movies, the user background can select two attributes: “age” and “occupation”. Among them, the influence of attribute “occupation” on the preference for watching movies is higher than that of “age”. We take target users and
to be recommended as examples to illustrate the influence of weight selection strategy.
The attributes “occupation” and “age” have four situational instances. For example, if the user and
are of the same occupation and age, the recommended users should have the highest preference weight for watching movies, and the weight should be
. If the user
and
are of the same occupation but different ages, the weight of user preference for watching movies should be recommended next, and the weight should be
. If the users
and
are of different occupations and the same age, the weight of user preference for watching movies should be recommended next again, and the weight should be
. If users
and
are of different occupations and ages, the recommended users have the lowest preference weight for watching movies, and the weight is taken
. The selection strategy of preference influences weight is shown in Table . The preference weight
of the recommended neighbour selected by the target user and the user to be recommended in different situations is given.
Table 1. An Example of influence weights of user preference.
After the top-k neighbour for a target user is obtained, corresponding information recommendations are provided for the target user. The rating of the target user is predicted according to the weighted average equation of scoring difference, and the predicted item is obtained. The calculation equation is shown in Equation (7):
(7)
(7) where
is the predicted score of the user
for the item
,
is the average user score
,
is the nearest neighbour set of the user
,
is the similarity of similar users
and
,
is the weight of the attribute and attribute combination of user background selected in the selection strategy on user
and
preference, and
(8)
(8) where
. Finally, top-k recommended items for predicting target users are selected.
In our selection strategy, we consider the attribute combination for a target user, and similar candidate neighbours selected are different from the normal candidate neighbour set. After reordering candidate neighbours, it reduces the possibility of the malicious attacker to forge score dynamic tags and shields the fake user data into the target user's nearest neighbours set.
4. Empirical study
We implement our approach called CFR-F. We used the CFR-F tool to conduct an empirical study on two datasets, synthesised based on MovieLens and last.fm. We present an empirical evaluation of the effectiveness of CFR-F for different scenarios that have a shilling attack and have not it. Notably, we seek answers to the following four research questions:
RQ1. How does choosing fusion weights of our CFR-F
RQ2. How well does our CFR-F work without shilling attacks?
RQ3. How effective is our CFR-F approach under different filling scales and attack injection scales?
RQ4. How effective is our CFR-F approach under different shilling attack models?
4.1. Data synthesis and description
There exist several public datasets for social networks and product users. However, there is no suitable dataset available to validate a CFR using fusing criterion against shilling attacks. Inspired by Yu et al. (Citation2021), we design an approach to construct synthetic datasets based on MovieLenFootnote1 and last.fm,Footnote2 which have been widely used in the CFR community.
MovieLens haa two datasets: MovieLens_D1 and MovieLens_D2. MovieLens_D1 contains 1Mb public data, including 6040 subscribers in 2000. MovieLens_D2 contains 10Mb public data including 71,567 subscribers, 10,681 movies, and 95,580 tabs. MovieLens_D1 contains user background and user rating information, and MovieLens_D2 has a user rating, a social label that users freely add tags, and time attribute of label tags. By obtaining similarities between user ratings, similar user classes are obtained as a bridge to construct a new synthetic dataset. Last.fm is an Internet radio and music community based in the UK. It has over 15 million active listeners in 232 countries. The dataset includes 2100 users, 18,745 artists, and 12,648 tags; Data items include user ID, timestamp, artist ID, artist, song ID, song name, etc. Specifically, the number of times users listened to artists from 2005 to 2011, users’ tags on different artists, and the friendship relationship between users. The Last.fm dataset does not directly provide user rating or user background. Considering that film and music belong to entertainment and film contains music, it is reasonable to combine these two datasets. Therefore, dataset Last.fm needs to be pre-processed and combined with MovieLens_D1. The pre-processing takes the listening frequency range as the artist's rating, and the higher listening frequency corresponds to the higher rating.
The construction process of synthetic dataset SMovie is as follows: (1) According to the similarity between user ratings, we conclude the similar user classes; (2) User background information in MovieLens_D1 to MovieLens_D2 for a synthetic dataset (contained users-project evaluation, film category, background information, label) in which the user project evaluation dataset contains: user ID, project, score values, and timestamp; The tag dataset contains: user ID, item, tag, and timestamp.
The construction process of synthetic SLast.fm is as follows: First, the number of times users listen to artists is divided into scores 1-5 according to different intervals. Then, the data of last.fm and Movielens are scored and matched according to the data records to construct a new synthetic dataset. If the score of Movie Lens is the same as that of last.fm, the two score records are matched successfully. Form a new record containing user background information for the corresponding record in Movielens_D1 for the composite dataset. If the two scores are different, the match fails, and the score is deleted.
Through the above construction process, the two synthetic datasets, SMovie and SLast.fm, have user scores, user background, social tags, time stamps and other data attributes. The synthetic dataset was randomly divided into the training dataset and the test dataset.
4.2. Evaluation criteria
To evaluate the effectiveness of our recommendation technique, we evaluate the performance of our approach using mean absolute error (MAE) and average prediction shift (APS).
Mean Absolute Error
The accuracy of the recommendation system is measured by calculating the absolute value between the user’s actual score and the score predicted by the recommendation technique. If MAE is smaller, the system’s recommendation accuracy is higher. Conversely, the higher its value, the worse its recommendation accuracy.
Assuming that the predicted user evaluation set is and the corresponding actual user evaluation set is
, the calculation equation of
is shown in Equation (9):
(9)
(9) where n represents the number of scoring items of the test algorithm,
represents the predicted score of the test algorithm, and
represents the real score of users in the test set.
Average Prediction Shift (
)
The robustness of the recommendation technique is measured by the average prediction shift. and
are the test user set and the target item set, respectively.
represents the real score of the user
for item
,
defines the score after being affected by the shilling attack, and the predicted increment
describes the difference between user u’s predicted score for the item
after and before the attack.
, then the
is defined as Equation (10):
(10)
(10) The larger the average prediction offset, the more vulnerable the CFR is to perform shilling attacks. The closer the value is to 0, the stronger the robustness of the CFR.
4.3. Analysis of experimental results
In the mean absolute error experiment, the synthetic dataset comprises 80% training set and 20% test set. In the average predictive deviation experiment, the performance of our approach with shilling attacks is tested by inserting fake user profiles. Two attack strategies are proposed: push attack and nuclear attack. In push attacks and nuclear attacks, the target items of forged fake user profiles are assigned the highest and lowest ratings, respectively. The profile size of the forgery attack is important to affect the performance of the recommendation algorithm. The experiment intends to investigate the anti-attack capability of the system under the attack scale of 1%, 2%, 5%, 10% and 20%.
4.3.1. Analysis of experimental results without shilling attacks
To verify the effectiveness of our method without attack, the synthetic dataset is conventionally divided into 80% training set and 20% test set; we perform experiments to answer RQ1 and RQ2.
Answer RQ1
In our approach, we fuse two criteria to improve CFR. Therefore, the weights for two criteria would influence the effectiveness of our approach. We assume the weight is the weight of user similarity based on dynamic social tagging
is the weight of user rating similarity. We set fusion weight
,
, and
on the same experiment, a setting to compare
our approach with traditional CFR. The results on dataset SMovie are shown in Table , and on dataset SLast.fm is shown in Table .
Table 2. MAE on different fusing weights on dataset SMovie.
Table 3. MAE on different fusing weights on dataset SLast.fm.
Table shows that in the case of the same number of neighbour on the dataset SMovie, the recommendation accuracy of our approach is higher than that of the traditional CFR. Due to the different selection of similarity weight, the corresponding recommendation efficiency is also different, and the recommendation efficiency of our approach reaches the best when . Similarly, Table shows that in dataset SLast.fm, the recommendation efficiency reaches the best when
. Therefore,
are taken as similarity weights to compare the recommendation performance of our approach with other CFRs.
Answer RQ2
To answer this question, our approach is compared with the traditional CFR, including CFR based on scoring (called CFR-T), CFR based on social tags (called CFR-S), and CFR based on user background (CFR-B). The result is shown in Figures and .
Figure 2. Comparison of MAE among CFRs(SMovie).
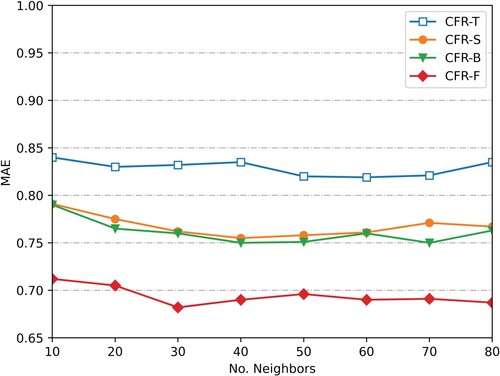
Figure 3. Comparison of MAE among CFRs (SLast.fm).
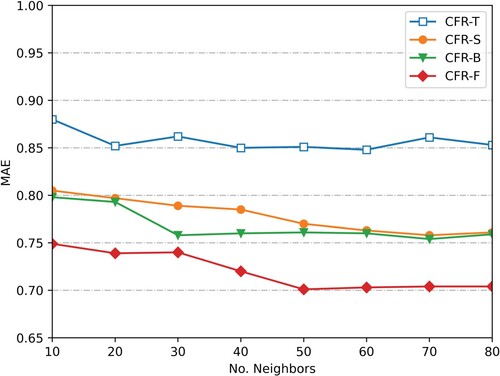
When the similarity weight , the
change curve of the algorithm in our approach on dataset Smovie is shown in Figure , and the
change curve on dataset SLast.fm is shown in Figure . In Figure , when the nearest neighbour number is less than 30,
becomes smaller as the number of neighbours increases, indicating that the recommendation accuracy of the algorithm is improved as the number of neighbour increases, and the recommendation quality is affected by the number of neighbours. When the number of neighbour is 30, the recommendation efficiency of the algorithm is the highest. When the neighbour number is larger than 30 and gradually increases, the
curve of the proposed algorithm tends to be stable. It improves the recommendation accuracy significantly compared with the other three recommendation algorithms. In Figure , on dataset Slast.fm, the recommendation accuracy of the algorithm also increases with the increase of the number of neighbours and gradually tends to be stable.
4.3.2. Analysis of experimental results with shilling attacks
To verify the effectiveness of our CFR-F approach with shilling attacks, we perform experiments to answer RQ3 and RQ4.
Answer RQ3
To investigate the robustness of our approach, is used to evaluate the effectiveness of our CFR-F and the three CFR approaches in the above experiments under the injection of attack data of different sizes. The closer
is to 0, the less impact the attack has on the recommended system. Figures show the push attack and nuclear attack with a 5% population size of the user profile on dataset Smovie and Slast.fm, respectively.
Figure 4. APS changes with a 5% push attack scale (Smovie).
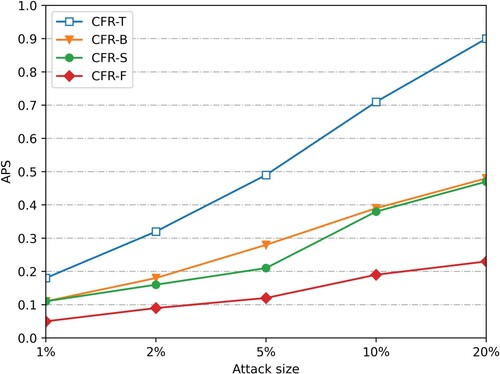
Figure 5. APS changes with a 5% nuclear attack scale (Smovie).
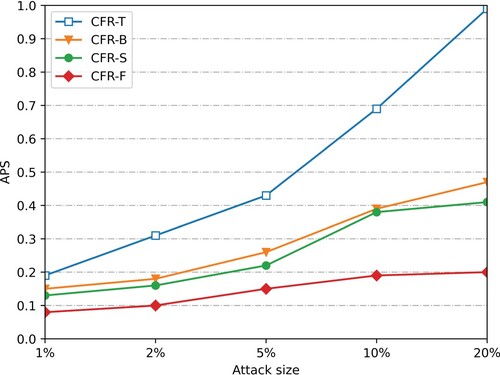
Figure 6. APS changes with a 5% push attack scale (Slast.fm).
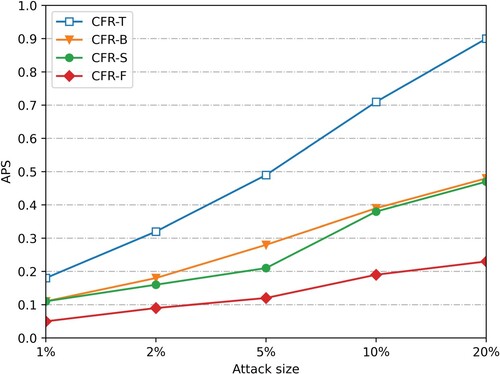
Figure 7. APS changes when filling the 5% nuclear attack scale (Slast.fm).
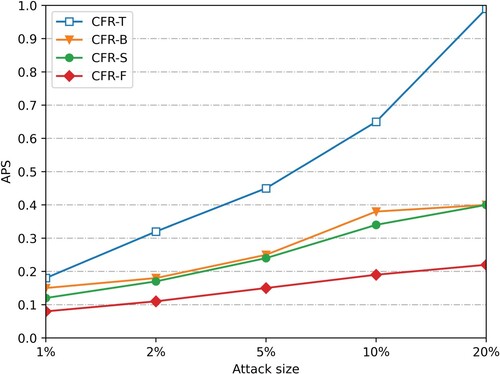
After the attack data of 1%, 2%, 5%, 10%, and 20% scales are injected (considering that the attack is easy to be discovered manually when the attack scale is large), the average offset of the four recommended algorithms changes. Figure , Figure 9, Figures and show the
changes after the attack data of 1%, 2%, 5%, 10% and 20% scales are injected into the push attack and nuclear attack with the padding scale of 10% on dataset SMovie and dataset SLast.fm. (Figure ).
Answer RQ4
Figure 8. APS changes with a 10% push attack scale (Smovie).
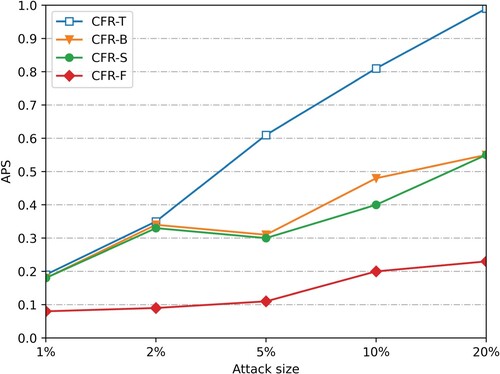
Figure 9. APS changes when filling the 10% nuclear attack scale (Smovie).
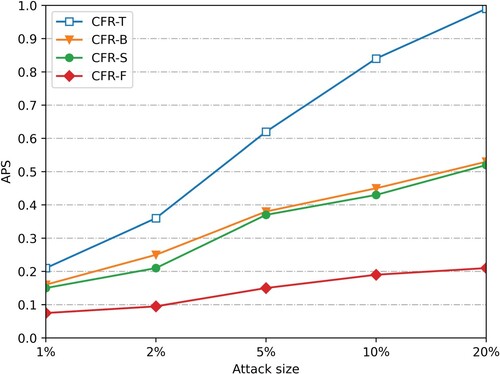
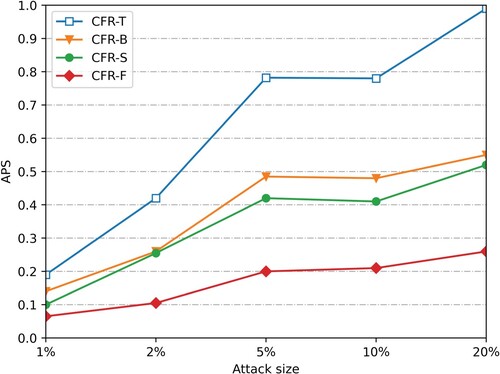
As can be seen from Figures and and Figure and Figure , under the push attack of the same filling scale on the dataset SMovie and SLast.fm, the average offset values of the four recommended algorithms increase with the increase of the attack scale. Therefore, the more attacking users, the lower the stability of the recommendation system. In addition, when injecting attack data of the same scale, compared with CFR-T, CFR-B and CFR-S, the average offset value of the prediction score of this algorithm is reduced by nearly 50%, and its offset value is more stable with the increase of attack scale. When injecting attack data with a 10% filling scale and 20% attack scale, the average offset value of the algorithm prediction score is still lower than 0.3. As shown in Figures and and Figure and Figure , our CFR-F also performs well in the nuclear attack mode, indicating that it has a strong anti-attack ability.
Figure 10. APS changes with a 10% push attack.
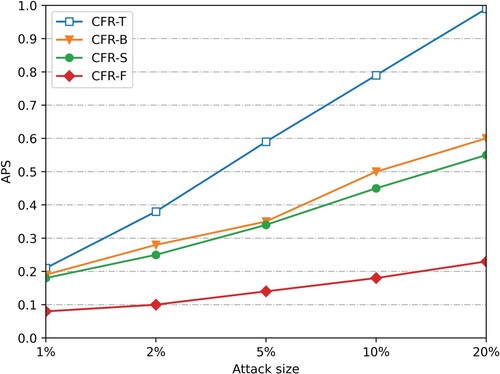
Figure 11. APS changes when filling a 10% nuscale (Slast.fm) clear attack scale (Slast.fm).
5. Conclusion and our future works
How to improve the reliability and accuracy of recommendation systems has become a very important research problem. A trust mechanism is a conventional means to resist attacks, but the workload of maintaining the dynamic trust relationship between users is large, and the trust relationship obtained by mining users’ historical behaviour and the score has the risk of being forged. Since it is difficult for attackers to grasp the user’s interest in social tag modelling, and the selection strategy of the influence weight of scenario attributes or attribute combinations on preferences, we propose an information resource recommendation approach based on fusing criteria against shilling attacks. Experimental results show that compared with the traditional recommendation methods, our approach can effectively improve the reliability and accuracy of recommendations. Despite the effectiveness of our approach, they need more information consumption due to fusing multiple-view data. In our future work, we will focus on how to collect multiple data to support our proposed methods.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
References
- Adomavicius, G., & Tuzhilin, A. (2005, June). Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Transactions on Knowledge and Data Engineering, 17(6), 734–749. https://doi.org/10.1109/TKDE.2005.99.
- Arora, A., & Taneja, A. (2021). Research issues, innovation and associated approaches for recommendation on social networks. International Journal of Performability Engineering, 17(12), 10271036. https://doi.org/10.23940/ijpe.21.12.p7.10271036
- Arul, J. J. A., & Razia, S. A. (2021). A review on the literature of fashion recommender system using deep learning. International Journal of Performability Engineering, 17(8), 695702. https://doi.org/10.23940/ijpe.21.08.p5.695702
- Cheng, Y., Qiu, G., Bu, J. J., Liu, K. M., Han, Y., Wang, C., & Chen, C. (2008). Model bloggersinterests based on forgetting mechanism[C] // Proceedings of the 17th International Conference on World Wide Web. New York: ACM Press, 1129–1130. https://doi.org/10.1145/1367497.1367690
- Deldjoo, Y., Noia, T. D., & Merra, F. A. (2020). A survey on adversarial recommender systems: From attack/defense strategies to generative adversarial networks. ACM Computing Surveys (CSUR), 54(2), 1–38. https://doi.org/10.1145/3439729
- Eleftherios, T., Yannis, M., & Panagiotis, S. (2011). Product recommendation and rating prediction based on multimodal social networks[C] // Poceedings of the 5th ACM Conference on Recommender Systems. New York: ACM Press: 61–68. https://doi.org/10.1145/2043932.2043947
- Gao, M., Liu, K., & Wu, Z. F. (2010). Personalisation in web computing and informatics: Theories, techniques, applications, and future research. Information Systems Frontiers, 12(5), 60729. https://doi.org/10.1007/s10796-009-9199-3
- Gao, M., Wu, Z. F., & Jiang, F. (2011). Userrank for item-based collaborative filtering recommendation. Information Processing Letters, 111(9), 4406. https://doi.org/10.1016/j.ipl.2011.02.003
- Hao, L., Min, G., Feng, T. Z., Yue, Y. W., Qi, L. F., & Lin, D. Y. (2021). Fusing hypergraph spectral features for shilling attack detection. Journal of Information Security and Applications, 63(2021), 103051. https://doi.org/10.1016/j.jisa.2021.103051
- Jiang, F., Gao, M., Xiong, Q. Y., Wen, J. H., & Zhang, Y. (2016). Robust social recommendation techniques: A review[C] //International Conference on Informatics and Semiotics in Organisations. Springer International Publishing: 53–58. https://doi.org/10.1007/978-3-319-42102-56
- Julio, B., Leandro, G. M. A., Filipe, B., & Geraldo, Z. (2021). Simulating real profiles for shilling attacks: A generative approach[J]. Knowledge-Based Systems, 230, 107390. https://doi.org/10.1016/j.knosys.2021.107390
- Li, T. Y., Su, X., Liu, W., Liang, W., Hsieh, M.-Y., Chen, Z. H., Liu, X. C., & Zhang, H. (2022). Memory-augmented meta-learning on meta-path for fast adaptation cold-start recommendation. Connection Science, 34(1), 301–318. https://doi.org/10.1080/09540091.2021.1996537
- Lian, S. X., & Tang, M. D. (2022). API recommendation for Mashup creation based on neural graph collaborative filtering. Connection Science, 34(1), 124–138. https://doi.org/10.1080/09540091.2021.1974819
- Liu, X. Y., Wang, G. J., et al. (2022). Personalised context-aware re-ranking in recommender system. Connection Science, 34(1), 319–338. https://doi.org/10.1080/09540091.2021.1997915
- Ma, H., King, I., & Lyu, M. R. (2009). Learning to recommend with social trust ensemble[A]. Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval[C]. New York, USA: ACM. 203–210. https://doi.org/10.1145/1571941.1571978
- Mehta, B., & Nejdl, W. (2008a). Attack resistant collaborative filtering[C]. //Proceedings of the 31st International Conference on Research and Development in Information Retrieval. New York: ACM, 75–82. https://doi.org/10.1145/1390334.1390350
- Mehta, B., & Nejdl, W. (2008b). Unsupervised strategies for shilling detection and robust collaborative filtering[J]. User Modeling and User-Adapted Interaction, 19, 65–97. https://doi.org/10.1007/s11257-008-9050-4
- Mobasher, B., Burke, R., Bhaumik, R., & Williams, C. (2007). Toward trustworthy recommender systems: An analysis of attack models and algorithm robustness. ACM Transactions on Internet Technology, 7(4), 23–38. https://doi.org/10.1145/1278366.1278372
- Shah, N. J., & Bhanderi, S. D. (2014). A survey on recommendation system approaches. Data Mining and Knowledge Engineering, 6(4), 151–156. https://doi.org/10.1111/j.1432-1033.1984.tb08464.x
- Si, M., & Li, Q. (2020). Shilling attacks against collaborative recommender systems: A review. Artificial Intelligence Review, 53, 291–319. https://doi.org/10.1007/s10462-018-9655-x
- Tang, B., Tang, M. D., Xia Y, M., et al. (2021). Composition pattern-aware web service recommendation based on depth factorisation machine. Connection Science, 33(4), 870–890. https://doi.org/10.1080/09540091.2021.1911933
- Wu, F., Gao, M., Yu, J., Wang, Z., Liu, K., & Xu, W. (2021). Ready for emerging threats to recommender systems? A graph convolution-based generative shilling attack. Information Sciences, 2021, 578. https://doi.org/10.1016/j.ins.2021.07.041
- Xi, W. Y., Yang, G., Yong, L., & Harald, S. (2014). A survey of collaborative filtering based social recommender systems. Computer Communications, 41, 1–10. https://doi.org/10.1016/j.comcom.2013.06.009
- Yu, D., Chen, R., & Chen, J. (2020). Video recommendation algorithm based on knowledge graph and collaborative filtering. International Journal of Performability Engineering, 16(12), 1933–1940. http://doi.org/10.23940/ijpe.20.12.p9.19331940
- Yu, J., Gao, M., Rong, W., Li, W., Xiong, Q., & Wen, J. (2017). Hybrid attacks on model-based social recommender systems. Physica A: Statistical Mechanics and its Applications, 483, 171. https://doi.org/10.1016/j.physa.2017.04.048
- Yu, L., Duan, Y. C., & Li, K. C. (2021). A real-world service mashup platform based on data integration, information synthesis, and knowledge fusion. Connection Science, 33(3), 463–481. https://doi.org/10.1080/09540091.2020.1841110
- Zhang, S. W., Yao, T. T., et al. (2021). A novel blockchain-based privacy-preserving framework for online social networks. Connection Science, 33(3), 555–575. https://doi.org/10.1080/09540091.2020.1854181
- Zhang, X. L., Lee, T. M. D., & Pitsilis, G. (2013). Securing recommender systems against shilling attacks using social-based clustering[J]. Journal of Computer Science and Technology, 28(4), 616–624. https://doi.org/10.1007/s11390-013-1362-0
- Zhang, Z., & Kulkarni, S. R. (2013). Graph-based detection of shilling attacks in recommender systems. 2013 IEEE International Workshop On Machine Learning for Signal Processing, Southapmton, UK, 2013:22–25. https://doi.org/10.1109/MLSP.2013.6661953