
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
A pre-trained neural language model (LM) is usually used to generate texts. Due to exposure bias, the generated text is not as good as real text. Many researchers claimed they employed the Generative Adversarial Nets (GAN) to alleviate this issue by feeding reward signals from a discriminator to update the LM (generator). However, some researchers argued that GAN did not work by evaluating the generated texts with a quality-diversity metric such as Bleu versus self-Bleu, and language model score versus reverse language model score. Unfortunately, these two-dimension metrics are not reliable. Furthermore, the existing methods only assessed the final generated texts, thus neglecting the dynamic evaluating the adversarial learning process. Different from the above-mentioned methods, we adopted the most recent metric functions, which measure the distributional discrepancy between real and generated text. Besides that, we design a comprehensive experiment to investigate the performance during the learning process. First, we evaluate a language model with two functions and identify a large discrepancy. Then, several methods with the detected discrepancy signal to improve the generator were tried. Experimenting with two language GANs on two benchmark datasets, we found that the distributional discrepancy increases with more adversarial learning rounds. Our research provides convicted evidence that the language GANs fail.
1. Introduction
Text generation based on neural language models (LM) (e.g. LSTM Hochreiter & Schmidhuber, Citation1997) has received much attention and has been used for news generation (Zellers et al., Citation2019), text summarisation (Lin et al., Citation2022) and image captioning (Xu et al., Citation2015). However, the generated sentences are still of low quality with regards to semantics and global coherence and are often imperfect grammatically speaking (Caccia et al., Citation2020).
These issues give rise to a large discrepancy between generated text and real text. Two underlying reasons are the architecture and the number of parameters of the LM itself (Radford et al., Citation2019; Santoro et al., Citation2018). Many researchers attribute this to exposure bias (Bengio et al., Citation2015) because an LM is trained with a maximum likelihood estimate (MLE) and predicts the next word conditioned on words from the ground truth during training. However, an LM only uses words that it has generated during the reference.
Statistically, this discrepancy means the two distributional functions of real texts and generated texts are different. Reducing this distributional difference may be a practicable way to improve text generation.
Some researchers try to reduce this difference with GAN (Goodfellow et al., Citation2014) as the success in image generation (Wu et al., Citation2021), image classification (Cao et al., Citation2021) and stock prediction (Li et al., Citation2022; Wu et al., Citation2022). They used a discriminator to detect the discrepancy between real samples and generated samples, and fed the signal back to upgrade the generator (an LM). To solve the non-differential issue that arises by the need to handle discrete tokens, reinforcement learning (RL) (Williams, Citation1992) was adopted by SeqGAN (Yu et al., Citation2017), RankGAN (Lin et al., Citation2017), and LeakGAN (Guo et al., Citation2018). The Gumbel-Softmax is also introduced by GSGAN (Jang et al., Citation2017) and RelGAN (Nie et al., Citation2019) to solve this issue. These language GANs pre-train both the generator (G) and the discriminator (D) before adversarial learning.Footnote1 During adversarial learning, for each round, the G is trained several epochs and the D is trained tens of epochs. The learning process will not stop until the model converges. Furthermore, considering the generated texts' quality and diversity simultaneously (Shi et al., Citation2018), MaskGAN (Fedus et al., Citation2018), DpGAN (Xu et al., Citation2018) and FMGAN (Chen et al., Citation2018) are proposed. They evaluate the generated text with Bleu (Papineni et al., Citation2002) versus self-Bleu (Zhu et al., Citation2018) or LM score versus reverse LM score (Cífka et al., Citation2018), and claim these GANs improve the performance of the generator.
However, some questions have been recently raised over these claims. Semeniuta et al. (Citation2019) and Caccia et al. (Citation2020) showed that by more precise experiments and evaluation, these considered GAN variants are outperformed by a well-adjusted language model. They draw a performance line in a quality-diversity space by adjusting the softmax temperature. Bleu and language model scores are usually used for measuring local and global quality, respectively; self-Bleu and reverse language model scores are used for measuring local and global diversity, respectively. To overcome these two-dimension metrics, de Masson et al. (Citation2019) proposed a single metric Fréchet embedding distance (FED). It computes the Fréchet distance between two Gaussian distributions. However, Cai et al. (Citation2021) showed that all metrics are not appropriate to evaluate an un-conditional text generator and proposed a novel metric. In short, whether these language GANs fail or not is still an open problem.
We investigate this issue in depth. For language GANs, several critical issues are still not clear, such as whether D detects the discrepancy, whether the detected discrepancy is severe, and whether the signals from D can improve the generator. In this paper, we try to solve these problems by investigating GAN in both pre-training and the adversarial learning processes. Theoretically analysing the signal from D, we employ approximate discrepancy and absolute discrepancy (Cai et al., Citation2021) to measure the distributional discrepancy. With these two functions, we first measure the discrepancy between the real text and the faked text, which is generated by an MLE-trained language model (pre-train). Second, we attempt some methods to update the generator with a feedback signal from D. Then, we use these metric functions to evaluate the updated generator. Finally, we analyse the performance of two typical language GANs during adversarial learning with these two functions across two benchmark datasets.
Our contributions are as follows:
We are the first to measure the variation of the distributional discrepancy between real text and generated text during the training of language GANs by using a discriminator to design and implement two equations.
Although this discrepancy could be detected by a discriminator (D), the feedback signal from D cannot improve G using existing methods. This manifests as an increase in the discrepancy with adversarial learning.
Experimenting on two existing language GANs, SeqGAN and RelGAN, the distributional discrepancy between real text and generated text increases with more adversarial learning rounds. This demonstrates that existing adversarial learning does not work. Thus, the industrial systems need not try in this way.
The rest of the paper is organised as follows. Section 2 describes the related work. Section 3 introduces the proposed method to measure the distributional discrepancy. The next section presents the experimental procedure in detail. The experiments and analysis are shown in Section 5. Finally, we give a short summary in Section 6.
2. Related work
Many GAN-based models were proposed to improve neural language models. SeqGAN (Yu et al., Citation2017) attacked the non-differential issue by resorting to RL. By applying a policy gradient method (Sutton et al., Citation2000), they optimised the LSTM generator with rewards received through Monte Carlo (MC) sampling. Many researchers such as RankGAN and MailGAN (Che et al., Citation2017) also used this technique, although it is ineffective in MC search. The RL-free model, e.g. GSGAN, contained continuous application of the approximating softmax function and working on latent continuous space directly. TextGAN (Salimans et al., Citation2016) added Maximum Mean Discrepancy to the original objective of GAN based on feature matching. Considering the drawbacks of pre-training a neural language model, Nie et al. (Citation2019) proposed a RelGAN that uses the relation memory (Santoro et al., Citation2018), which allows for interactions between memory slots by using the self-attention mechanism (Vaswani et al., Citation2017). Gu & Cheung (Citation2018) optimised GAN by evolutionary algorithms. We selected SeqGAN and RelGAN as representatives for this study. The results show that the adversarial learning does not work for either of these models.
Caccia et al. (Citation2020) argued the current evaluation measures correlate with human judgment (Cífka et al., Citation2018) was treacherous. They furthermore proposed a temperature sweep, which evaluates model at many temperature settings rather than only one. By drawing lines in a quality-diversity space such as Bleu versus self-Bleu, or language model score versus reverse language model score, they show that a well-adjusted language model can beat those considered language GANs. Unfortunately, the limitations of Bleu vs self-Bleu were shown by training a 5-gram language model and its scores were even better than the training data (de Masson et al., Citation2019). Cai et al. (Citation2021) also revealed that they were unreliable and proposed a novel metric to evaluate unconditional text generation by calculating the distributional discrepancy between two text sets. This single metric could simultaneously measure both the diversity and quality. We adopt it and propose a simpler version. Semeniuta et al. (Citation2019) and He et al. (Citation2021) also argued GAN-based models were weaker than LM, because they observed a less severe impact of exposure bias. The latter furtherly quantified the exposure bias by using conditional distribution. Obviously, the existing methods only assessed the final generated texts, thus neglecting the dynamic evaluating the adversarial learning processes. Different from the above-mentioned methods, we investigate the mechanism of language GANs and quantify the discrepancy between real texts and generated texts both after the pre-training and the whole adversarial learning process.
3. Method
In GAN, the generator implicitly defines a probability distribution
to mimic the real data distribution
. θ is the parameters of the language model
and is the parameter of the value function V, which is listed as follow.
is the distributional function of
.
(1)
(1) Alternating optimisation of
and
is used to resolve the above equation. Given θ, to detect the discrepancy between
and
, we optimise
as follows:
(2)
(2) Assuming
is the optimal solution for a given θ, according to Goodfellow et al. (Citation2014), it will be,
(3)
(3) and it is obvious to get the follow formula:
(4)
(4) Because the real distribution
cannot be obtained in practice, it is impossible to directly measure the discrepancy according to Equation (Equation3
(3)
(3) ). Fortunately, we have massive real sentences and each x could be a sample from
. Based on real samples and the above equation, we obtain a way to estimate the distributional discrepancy.
3.1. Approximate discrepancy
Let,
(5)
(5) Therefore,
,
,
. With Equation (Equation5
(5)
(5) ), we can get a constraint and an approximate measure of distributional function. Figure (a) illustrates the relationship between
and
.
Figure 1. Illustration of two measures. (a) The yellow area denotes the negative, and the green one denotes the positive. (b) Half of the shaded area equals the result of Equation (Equation10(10)
(10) ). (a) Approximate discrepancy. (b) Absolute discrepancy.
 ). (a) Approximate discrepancy. (b) Absolute discrepancy.](/cms/asset/e5413b4d-3b45-4445-9fdb-77fabf3e0fa8/ccos_a_2080182_f0001_oc.jpg)
Let,
(6)
(6) These are two equations for these two statistics, which are the expectation of the
's predictions on real text and on generated text. From the above equation, it is easy to obtain the following equation:
(7)
(7) The results give a constraint for
converging to
. We should take this constraint into account when estimating the ideal function
. From Equation (Equation3
(3)
(3) ), the optimisation process for the discriminator increases
and decreases
to as small a value as possible. So, we can estimate the distributional discrepancy according to the following function.
Intuitively, using and
, we get a metric function to measure the discrepancy between
and
,
(8)
(8) We call this approximate discrepancy. It is the difference in the average score that a well-trained discriminator (denoted as
) makes in the predictions on real samples compared to generated samples. It reflects the discrepancy between these two sets to some degree. From Equations (Equation5
(5)
(5) ), (Equation6
(6)
(6) ) and (Equation8
(8)
(8) ), we get Equation (Equation9
(9)
(9) ),
(9)
(9) The range of
is
. The bigger its value is, the larger the discrepancy. When
, namely there is no discrepancy, there will be
. On the contrary,
if
. Figure (a) illustrates the discrepancy between two distributional functions
and
. Both of them are systematic to the line of q = 0.5.
Cai et al. (Citation2021) proposed a novel metric that is more complete than ours because there are a positive part and also a negative part, as presented in Figure (b), and it is defined as absolute discrepancy . This is represented by the following equation:
(10)
(10) The range of
is also
. The drawback of this metric is that it needs more computation than ours. Both metrics are used in this paper.
3.2. Using  to improve
to improve
Given an instance x generated by , if
is larger, it means the possibility of x in real data is larger. For an instance x, if
, there will be
according to Equation (Equation3
(3)
(3) ). So, we should update
to increase the probability density
. It may improve the performance of
. Based on this, we can select some generated instances by the value of
to update the generator. In fact, we find it improves the performance a little when compared with the random selection. However, this method is still worse than without it. Experiment 5.3 shows the results.
4. Implementation procedure
The optimal function is an ideal function that can only be statistically estimated by an approximated function. We can design a function
and sample from real data and generated data; then, we train
according to Equation (Equation2
(2)
(2) ). When the results convergence, we get
, which is the approximated function of
. The degree of approximation is mainly determined by three factors: the structure and the number of the parameters number of
, the volume of training data, and the settings of hyper-parameters.
Based on the above analysis, we obtain two metric functions to measure the distributional discrepancy between dataset A and B (for example, A is composed of real sentences while B consists of machine-generated sentences). The implementation procedure is described as follows:
Step 1: Design a discriminator .
Step 2: Sets A and B are, respectively, divided into a training set and
, a validation set
and
, and a test set
and
. The partition should be as equal an amount of instances as possible for classification training.
Step 3: is optimised with
and
according to the Equation (Equation2
(2)
(2) ). Validating with
and
, we can judge whether
convergences or not and then get
.
Step 4: According to Equation (Equation8(8)
(8) ) and (Equation10
(10)
(10) ), with two test datasets, we can estimate the discrepancy of two distributional functions between dataset A and B.
denotes the absolute discrepancy, and
denotes the approximate discrepancy, respectively.

Algorithm 1 illustrates the procedure. Generally speaking, there should be . Because
cannot be obtained, it is hard to get the degree of the approximation of
to
. Many research results have shown that discriminators with deep neural networks are very powerful, some of which can even exceed human performance on tasks such as image classification (He et al., Citation2016) and text classification (Kim, Citation2014). So, if
with CNN, and an attention mechanism is well trained,
will be a meaningful approximation of
. Therefore, we can obtain the meaningful approximation of
and
via
.
5. Experiment
We select SeqGAN and RelGAN as representative models for our experiment, and the benchmark datasets are also the same as used by these models previously. Then, we show that the well-trained discriminator can measure the discrepancy between the real and generated texts, and then point out that the existing GAN-based methods does not work. Finally, a third-party discriminator is used to evaluate the performance of adversarial learning with incremental training iterations.
5.1. Datasets and model settings
Both SeqGAN and RelGAN used a relatively short sentences dataset (COCO image caption)Footnote2 and a long sentences dataset (EMNLP2017 WMT news).Footnote3 For the former dataset, the sentences' average length is about 11 words. There are, in total 4682-word types, and the longest sentence consists of 37 words. Both the training and test data contain 10,000 sentences. For the latter dataset, the average length of sentences is about 20 words. There are in total 5255-word types and the longest sentence consists of 51 words. All training data, about 280 thousand sentences, is used and there are 10,000 sentences in the test data. According to Section 3, each test data is divided into two parts. Half is the validation set and the remaining half is the test set. We always generate the same number of sentences to compare with the two test datasets, respectively.
For these two models, all hyper-parameters, including word embedding size, learning rate and dropout, are set the same as in their original papers. For RelGAN, the standard GAN loss function (the non-saturating version) is adopted because the relative standard loss which is used in (Nie et al., Citation2019) does not meet the constraints of Equation (Equation7(7)
(7) ). But, when measuring RelGAN's discrepancy during the adversarial stage, its own loss function is still a relatively standard loss. A critical hyper-parameter, temperature, is set to 100, which is the best result in their paper. During the process of training
, we always train 10,000 epochs and observe performance on the validation dataset.
5.2. Distributional differences in pre-training
We estimate the distributional differences caused by the MLE-based generators. We first train the generator for N epochs and then until it converges (this needs 10,000 epochs). For example, following Nie et al. (Citation2019), we train
for 150 epochs, and select the one whose perplexity (PPL) is the smallest by measuring on the validation set. Then,
is trained following the procedure in Section 4.
Figure shows the discrepancy between real and generated texts. The discrepancy increases with more training for discriminator until the training is stable.
Figure 2. Discrepancy between real and generated texts with two pre-training generators after 80 epochs across two datasets. Red lines denote absolute discrepancy, and blue ones mean approximate discrepancy. Pale lines denote batch instances' discrepancy, and the curve is the exponential moving average on this sampled batch for each epoch. (a) Discrepancy of SeqGAN on EMNLP. (b) Discrepancy of SeqGAN on COCO. (c) Discrepancy of RelGAN on EMNLP. (d) Discrepancy of RelGAN on COCO.
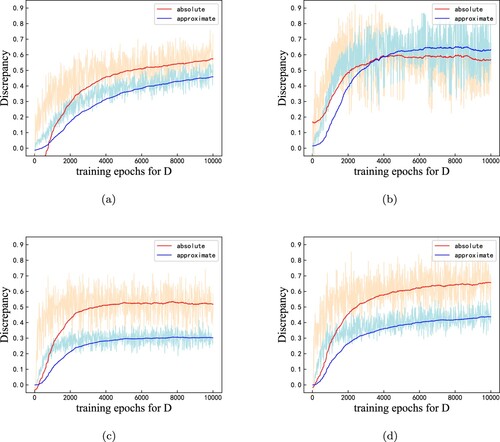
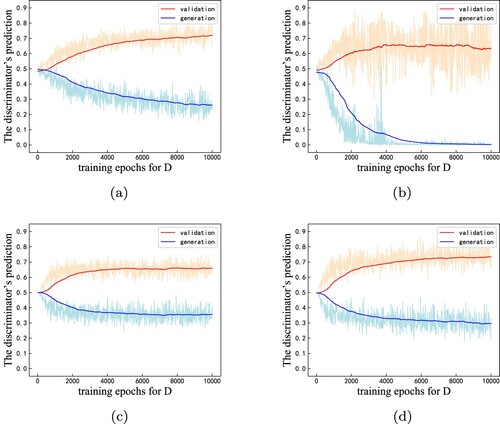
Figure shows the discriminator's prediction on real and machine-generated texts, respectively. The more difference between the scores on these two datasets, the distributional discrepancy is larger. From this figure, we can see convergences after about 3000 epochs for RelGAN, but SeqGAN needs more epochs to train the discriminator because the latter used an LSTM as the generator.
Figure 3. Discriminator scores on real and generated texts with pre-training two generators after 80 epochs across two datasets. Red lines denote the score on the real validation set, and blue ones mean the score on the machine-generated validation set. Pale lines denote batch instances' discrepancy, and the curve is the exponential moving average on this sampled batch for each epoch. (a) Accuracy with SeqGAN on EMNLP. (b) Accuracy with SeqGAN on COCO. (c) Accuracy with RelGAN on EMNLP. (d) accuracy with RelGAN on COCO.
Considering the smoothed value on one batch rather than the prediction on the whole data, we use the convergence discriminator to predict on the all validation data and generated data.Footnote4 Table summarises the discrepancy across two models and two datasets. It shows that the difference between real text and generated text does exist and it is huge.
Table 1. Discrepancy across two models and two datasets after pre-training.
5.3. Detected discrepancy by cannot improve the generator
We explore the improvement of with the discrepancy detected by
at the end of pre-training. We select the best pre-train epochs for
. It should be noted that
is well-trained with sufficient real sentences and generated ones by
. Then,
is updated according to the signals from the
. To verify the effect of the feedback signals, we generate many rather than only several batch-size instances to adjust θ.
Then, fixing , we re-train
with 10,000 epochs to get a new convergence discriminator to compute two distributional functions according to Equations (Equation9
(9)
(9) ) and (Equation10
(10)
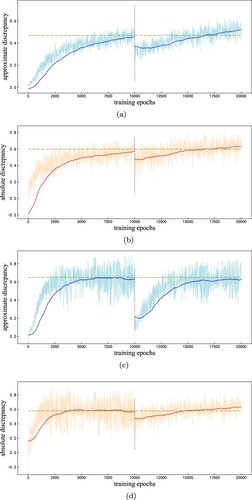
(10) ). Unfortunately, in the view of both absolute and approximated discrepancy, the discrepancy always exceeds the original value computed in pre-training. It demonstrates that the generator is not improved further. Figure illustrates the comparison.
Figure 4. The comparison of the discrepancy between pre-train and the generator is updated with the feedback signals from , which is obtained from pre-train. The vertical dash line represents the end of pre-training. (a) Approximate discrepancy on EMNLP. (b) Absolute discrepancy on EMNLP. (c) Approximate discrepancy on COCO. (d) Absolute discrepancy on COCO.
Besides following Zhu et al. (Citation2018), we also propose a new method to update in the adversarial way. Rather than using all the generated instances to update
, only the ones, which are assigned relatively high scores by
, are used. We denote it as HW. The reason is that we assume that the higher score instances may be more informative than the lower ones. The method that only the relatively low scores samples are used to adjust the generator is also experimented with. Regretfully, all of them fail. Table lists the discrepancy across two datasets with different settings. The discrepancy is always larger than that of the pre-training.
Table 2. Comparison between the absolute discrepancy in pre-training and updated by
's feedback signal.
5.4. A third-party discriminator evaluates these language GANs
In order to evaluate different adversarial learning's GANs, we use a third-party discriminator , which is a clone of the discriminator in its counterpart language GAN except for the parameters' values. For each adversarial round, we train
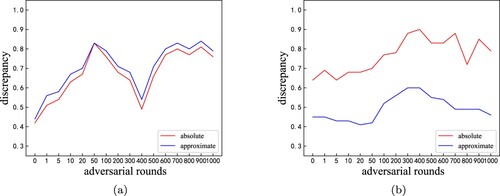
from scratch many epochs (verifying its convergence) with real text and generated text. Then, two distributional functions are computed according to its prediction. Figure shows the dynamic evaluation result. In view of both approximate discrepancy and absolute discrepancy, the distribution difference on the real text and generated text does not decrease when more adversarial learning rounds are adapted. Once again, the results show that the approach of the existing language GANs cannot improve text generation.
Figure 5. A third party discriminator evaluates two GANs' performance on COCO. (a) SeqGAN. (b) RelGAN.
6. Conclusion and future work
Unconditional text generation is the step-stone of conditional text generation such as news generation and text summarisation. It is not clear that GAN can improve the unconditional text generation. We present two metric functions to measure the discrepancy between real text and generated text. Numerous experiments show that this discrepancy does exist. We use various methods to update the generator parameters according to the detected discrepancy signals. Unfortunately, the distributional difference between real data and generated data does not decrease, indicating the difficulty of generator improvement with these signals. Finally, we use a third-part discriminator to evaluate the effectiveness of GAN and find that with more adversarial learning epochs, the discrepancy increases rather than decreases. Our study provided valuable information for the industry by analysing the existing language GANs do not work in-depth.
Many studies could be done in the future. First, the novel method used to facilitate the reward signals to improve the generator is worth further study. Besides the constraints from intrinsic language characteristics, common sense and logic should be introduced to improve text generation. Finally, diversity, such as conversation generation in chat platforms, should be further investigated.
Acknowledgments
We thank the anonymous reviewers for their valuable comments.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 An exception is RelGAN which does not need to pre-train D.
4 According to Section 3, we sample generated instances as much as test instances.
References
- Bengio, S., Vinyals, O., Jaitly, N., & Shazeer, N. (2015). Scheduled sampling for sequence prediction with recurrent neural networks. International Conference on Neural Information Processing Systems, (pp. 1171–1179). https://dl.acm.org/doi/10.5555/2969239.2969370
- Caccia, M., Caccia, L., Fedus, W., Larochelle, H., Pineau, J., & Charlin, L. (2020). Language GANs falling short. International Conference on Learning Representation. https://openreview.net/pdf?id=BJgza6VtPB
- Cai, P., Chen, X., Jin, P., Wang, H., & Li, T. (2021). Distributional discrepancy: A metric for unconditional text generation. Knowledge-Based Systems, 2021(217), 1–9. https://doi.org/10.1016/j.knosys.2021.106850
- Cao, Z., Zhou, Y., Yang, A., & Peng, S. (2021). Deep transfer learning mechanism for fine-grained cross-domain sentiment classification. Connection Science, 33(4), 911–928. https://doi.org/10.1080/09540091.2021.1912711
- Che, T., Li, Y., Zhang, R., Hjelm, D., & Bengio, Y. (2017). Maximum-likelihood augmented discrete generative adversarial networks. https://arxiv.org/abs/1804.07972
- Chen, L., Dai, S., Tao, C., Shen, D., Gan, Z., Zhang, H., Zhang, Y., & Carin, L. (2018). Adversarial text generation via feature-mover's distance. International Conference on Neural Information Processing Systems, (pp. 4671–4682). https://dl.acm.org/doi/10.5555/3327345.3327377
- Cífka, O., Severyn, A., Alfonseca, E., & Filippova, K. (2018). Eval all, trust a few, do wrong to none: Comparing sentence generation models. https://arxiv.org/abs/1804.07972
- de Masson, C., Rosca, M., Rae, J., & Mohamed, S. (2019). Training language GANs from scratch. International Conference on Neural Information Processing Systems, (pp. 4300–4311). https://dl.acm.org/doi/10.5555/3454287.3454674
- Fedus, W., Goodfellow, I., & Dai, A. (2018). MaskGAN: Better Text Generation via Filling in the ______. International Conference on Learning Representation. https://openreview.net/pdf?id=ByOExmWAb
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. International Conference on Neural Information Processing Systems, (pp. 2672–2680). https://dl.acm.org/doi/10.5555/2969033.2969125
- Gu, F., & Cheung, Y. (2018). Self-Organizing Map-Based Weight Design for Decomposition-Based Many-Objective Evolutionary Algorithm. IEEE Transactions on Evolutionary Computation, 22(2), 211–225. https://doi.org/10.1109/TEVC.2017.2695579
- Guo, J., Lu, S., Han, C., Zhang, W., & Wang, J. (2018). Long text generation via adversarial training with leaked information. AAAI Conference on Artificial Intelligence, (pp. 5141–5148). https://dlnext.acm.org/doi/10.5555/3504035.3504665
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. IEEE Conference on Computer Vision and Pattern Recognition, (pp. 770–778). https://doi.org/10.1109/CVPR.2016.90
- He, T., Zhang, J., Zhou, Z., & Glass, J. (2021). Exposure bias versus self-Recovery: Are distortions really incremental for autoregressive text generation? https://arxiv.org/abs/1905.10617
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
- Jang, E., Gu, S., & Poole, B. (2017). Categorical reparameterization with Gumbel-Softmax. International Conference on Learning Representation. https://openreview.net/pdf?id=rkE3y85ee
- Kim, Y. (2014). Convolutional neural networks for sentence classification. Conference on Empirical Methods in Natural Language Processing, (pp. 1746–1751). https://doi.org/10.3115/v1/D14-1181
- Li, Y., Dai, H., & Zheng, Z. (2022). Selective transfer learning with adversarial training for stock movement prediction. Connection Science, 34(1), 492–510. https://doi.org/10.1080/09540091.2021.2021143
- Lin, K., Li, D., He, X., Zhang, Z., & Sun, M. (2017). Adversarial ranking for language generation. International Conference on Neural Information Processing Systems, (pp. 3158–3168). https://dl.acm.org/doi/10.5555/3294996.3295075
- Lin, N., Li, J., & Jiang, S. (2022). A simple but effective method for Indonesian automatic text summarisation. Connection Science, 34(1), 29–43. https://doi.org/10.1080/09540091.2021.1937942
- Nie, W., Narodytska, N., & Patel, A. (2019). RelGAN: Relational generative adversarial networks for text generation. International Conference on Learning Representation. https://openreview.net/pdf?id=rJedV3R5tm
- Papineni, K., Roukos, S., Ward, T., & Zhu, W. (2002). Bleu: A method for automatic evaluation of machine translation. . Annual Meeting of the Association for Computational Linguistics, (pp. 311–318). https://doi.org/10.3115/1073083.1073135
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners (Technical Report). OpenAI.
- Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved techniques for training GANs. International Conference on Neural Information Processing Systems, (pp. 2234–2242). https://dl.acm.org/doi/10.5555/3454287.3454674
- Santoro, A., Faulkner, R., Raposo, D., Rae, J., Chrzanowski, M., Weber, T., Wierstra, D., Vinyals, O., Pascanu, R., & Lillicrap, T. (2018). Relational recurrent neural networks. International Conference on Neural Information Processing Systems, (pp. 7299–7310). https://dl.acm.org/doi/epdf/10.5555/3327757.3327832
- Semeniuta, S., Severyn, A., & Gelly, S. (2019). On accurate evaluation of GANs for language generation. https://arxiv.org/pdf/1806.04936
- Shi, Z., Chen, X., Qiu, X., & Huang, X. (2018). Toward diverse text generation with inverse reinforcement learning. International Joint Conference on Artificial Intelligence, (pp. 4361–4367). https://dl.acm.org/doi/abs/10.5555/3304222.3304376
- Sutton, R., McAllester, D., Singh, S., & Mansour, Y. (2000). Policy gradient methods for reinforcement learning with function approximation. International Conference on Neural Information Processing Systems, (pp. 1057–1063). https://dl.acm.org/doi/10.5555/3009657.3009806
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need. International Conference on Neural Information Processing Systems.
- Williams, R. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3), 229–256. https://doi.org/10.1007/BF00992696
- Wu, Q., Zhu, B., Yong, B., Wei, Y., Jiang, X., Zhou, R., & Zhou, Q. (2021). ClothGAN: Generation of fashionable Dunhuang clothes using generative adversarial networks. Connection Science, 33(2), 341–358. https://doi.org/10.1080/09540091.2020.1822780
- Wu, S., Liu, Y., Zou, Z., & Weng, T. (2022). S_I_LSTM: Stock price prediction based on multiple data sources and sentiment analysis. Connection Science, 34(1), 44–62. https://doi.org/10.1080/09540091.2021.2021143
- Xu, J., Ren, X., Lin, J., & Sun, X. (2018). Diversity-promoting GAN: A cross-entropy based generative adversarial network for diversified text generation. Conference on Empirical Methods in Natural Language Processing, (pp. 3940–3949). https://doi.org/10.18653/v1/D18-1428
- Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., Zemel, R., & Bengio, Y. (2015). Show, attend and tell: Neural image caption generation with visual attention. International Conference on Machine Learning, (pp. 2048–2057). https://dl.acm.org/doi/10.5555/3045118.3045336
- Yu, L., Zhang, W., Wang, J., & Yu, Y. (2017). SeqGAN: Sequence generative adversarial nets with policy gradient. AAAI Conference on Artificial Intelligence, (pp. 2852–2858). https://dl.acm.org/doi/10.5555/3298483.3298649
- Zellers, R., Holtzman, A., Rashkin, H., Bisk, Y., Farhadi, A., Roesner, F., & Choi, Y. (2019). Defending against neural fake news. International Conference on Neural Information Processing Systems, (pp. 9054–9065). https://dl.acm.org/doi/10.5555/3454287.3455099
- Zhu, Y., Lu, S., Lei, Z., Guo, J., Zhang, W., Wang, J., & Yu, Y. (2018). Texygen: A benchmarking platform for text generation models. International ACM SIGIR Conference on Research & Development in Information Retrieval, (pp. 1097–1100). https://doi.org/10.1145/3209978.3210080