
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Aspect-level sentiment classification, a significant task of fine-grained sentiment analysis, aims to identify the sentimental information expressed in each aspect of a given sentence The existing methods combine global features and local structures to obtain good classification results. However, the introduction of global features will bring noise and reduce the classification accuracy. To solve this problem, a new method is proposed, named GP-GCN. In our proposed method, the global feature is further simplified to reduce the noise . The local structures and global features obtained by orthogonal feature projection are introduced into aspect-level sentiment classification. First, the simplified global feature structures of text are built. Through orthogonal projection, GCN not only weakens the dependency of the graph node in updating process but also reduces the dependency between node and corpus. Next, syntactic dependency structure and sentence sequence information are utilised to mine the local dependency structure of sentences. A percentage-based multi-headed attention mechanism is proposed to measure the critical output of GCN, which can better represent sentences for given aspects. Finally, location coding is input to simulate aspect-specific representations between each aspect and its context such that the text becomes more discriminative in sentiment classification. The experimental results show that the proposed method effectively improves the accuracy of text sentiment classification.
1. Introduction
At present, sentiment analysis research for the whole text has been relatively perfect (Zhang et al., Citation2021; Zhang et al., Citation2022; Zhou et al., Citation2020) and has obtained good classification results. However, the sentiment analysis of the whole text will cover up its details, so it cannot reflect people's fine-grained sentimental expressions. Therefore, it is necessary to find all aspects of text reviews and determine the sentimental polarity expressed by the text. These can provide strong technical support for text sentiment classification, recommendation systems (Geler et al., Citation2021; Wu et al., Citation2022), question-answering systems, etc. As shown in Figure , in the sentiment sentence ‘computer screen is very good, but the price is not friendly’, ‘computer screen’ and ‘price’ has two aspects. Their views are ‘very good’ and ‘not friendly’ respectively, and their sentimental polarity is positive and negative.
Figure 1. An example of aspect-based sentiment classification.

In recent years, local information has been used to capture rich semantic information (Cai et al., Citation2021; Mansouri-Benssassi & Ye, Citation2021; Zhang et al., Citation2022). Although this work has achieved good results, its limitations are mainly concentrated on the use of local features such as order information and syntactic dependence in a given sentence. The global features of a sentence are not fully considered, so it is difficult to conduct a more complete sentiment analysis of the text. Specifically, global features refer to the global dependency information between words, which is often hidden in the whole corpus to reveal the global relationship between words. Recent studies have shown that using global structural dependence can usually significantly improve the performance of text classification. More and more experts use GCN to learn global features (Zargari et al., Citation2021; Zhou et al., Citation2019) and capture high-order neighbourhood information. However, when considering global dependency information, it is often overdependent on the corpus. Specifically, the existing methods usually model the corpus, resulting in too many interference factors. It lacks effective modelling of global dependence information, so it is difficult to truly mine valuable global dependence information. Different from previous work, the sentiment analysis in this paper is fine-grained aspect-level sentiment analysis. A GCN model integrating simplified global features and local features is constructed based on feature projection.
Given the above problems, effective fine-grained sentiment expression research should fully consider the following two keystones. (1) How to obtain global structural features from the text. The global structural features are hidden in the whole database. When modelling the database, the interference words are eliminated, and the global features in the database are fully excavated, which can reveal the global relationship between words. (2) How to fuse global features and local features effectively. The global features and local dependency information are fused to obtain a complete sentiment features vector for text sentiment classification.
Based on the above considerations, we introduce the local structure and global features obtained by orthogonal feature projection into the aspect-level sentiment classification. Furthermore, a new aspect-level sentiment classification method is proposed.
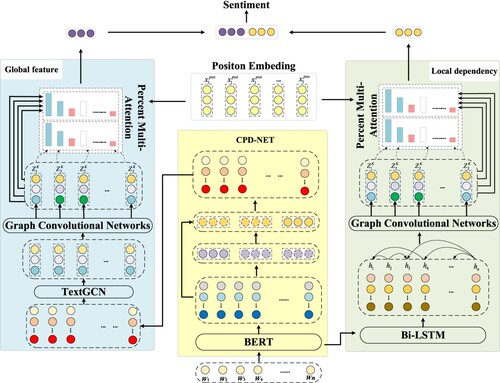
The motivation of this paper is to further simplify the global features from the view of reducing the interference of global features. Furthermore, the accuracy of text sentiment classification can be improved by fusing the global features and local dependency. The framework is shown in Figure . Two GCN networks are used to learn the global features and local dependency information of the text, respectively, and the two features are fused. Thus, the interdependent information can be accurately extracted from the dependency tree. The model framework is divided into two aspects: (1) Modelling the text corpus by GCN to obtain valuable global features (G-GCN). The output of the orthogonal projection is the input of the GCN. (2) Exploring each sentence by fusing GCN to obtain local features dependency information (P-GCN). The input of GCN is the output of BERT and Bi-LSTM. The advantage of G-GCN is to simplify global features by reducing the noise of the global features. The advantage of P-GCN is to make the local features more representative and learn more discriminative features.
Figure 2. The framework of GP-GCN.
The main contributions of this paper are as follows:
The acquisition of global and local features for the text. Global features obtained by orthogonal feature projection and local dependence are better for solving the long-term problem of multi-word dependence. It not only retains the overall attributes of global features but also reduces noise interference for further refining global features. At the same time, the influence of local features is considered on text sentiment classification, and local features are refined. The effective integration of the two improves the accuracy of text sentiment classification.
The fusion of global features and local dependency information. Percentage-based multi-head attention mechanism to accurately measure the key output of GCN and obtain a sentence representation for a given aspect. It can not only capture long-distance dependencies but also prevent over-fitting by setting super parameters. The accuracy of text sentiment classification is improved.
The division of this paper is as follows. In Section 2, we summarise the related work. Then, we detail our GP-GCN model in Section 3. In Section 4, we set up experiments based on the dataset and analyse the results. Finally, we summarise our work and put forward some ideas for future work in Section 5.
2. Related works
This section reviews related research work of traditional learning method and graph neural network method in aspect-level sentiment classification.
2.1. Aspect-based sentiment analysis (ABSA)
The purpose of ABSA is to analyze the sentimental polarity of specific aspect items in a sentence (Cambria, Citation2016; Cambria et al., Citation2022; De Meo et al., Citation2020). Its subtasks mainly include aspect item extraction, opinion item extraction, Explainable Artificial Intelligence (XAI), and aspect item sentiment classification. Zhang et al. (Citation2020) jointly extracted aspect items, opinion items, and sentiment polarity and named it a new subtask in aspect-level sentiment analysis task as opinion triplet extraction (OTE). As shown in Figure , the sentence ‘the screen of computer is very good, but price is unfriendly’, ‘computer screen’ and ‘price’ have two aspects, their views are ‘very good’ and ‘unfriendly’, sentiment polarity is positive and negative. Usually, the task is described as a triad consisting of aspects, opinions, and sentiment polarity. Given the low efficiency of artificial annotation features, early aspect-level sentiment analysis is mainly based on neural networks. Especially, since Tang et al. (Citation2016) proposed the challenge of establishing a semantic correlation between context and aspect words, attention-based and recurrent neural network methods are usually used in ABSA. Chen et al. (Citation2017) introduced an attention mechanism into regular RNN to further solve the long-term dependence problem. At the same time, LSTM based on the attention network has also been proved to identify important sentimental information related to targets. However, due to the lack of a mechanism to explain relevant syntactic constraints and long-distance word dependence in such models, Xiao et al. (Citation2020) composed multiple attention and improved GCN established on the sentence dependence tree for dealing with complex text structures. Zuo et al. (Citation2020) used token semantics and proposed a GCN framework with heterogeneous context, which can better reflect the structural context information.
Although the above work has achieved good results, they mainly focus on the use of local features such as sequence information and syntactic dependence in a given sentence, which is their limitation. So, we need to consider the global features of the sentence to obtain better accuracy.
2.2. Traditional learning method
The traditional deep learning methods mainly include convolutional neural networks, neural memory networks, and circulatory neural networks. Ruder et al. (Citation2016) embed words into sentence-level Bi-LSTM to learn intra-sentence and inter-sentence relationships. Tay et al. (Citation2017) used a binary memory network to optimise memory selection operation and improve binary interaction between aspects and word embedding. However, In the research process, some given aspects are easily ignored. To strengthen attention to given aspects, Wang et al. (Citation2016) set an attention vector for each target based on LSTM to respond to specific targets. Huang et al. (Citation2018) introduced aspect word information into CNN through parameterised filters to effectively obtain the features vector of a given aspect. Wu et al. (Citation2018) combined the target as a feature and its context features to conduct aspect-level sentiment classification. When dealing with the interaction between context and target, LSTM cannot explain the importance of each word in the full text. To address this issue. Yang et al. (Citation2017) introduce an attention mechanism into Bi-LSTM to improve classification results. Li et al. (Citation2017) used a target recognition task to simulate aspectual sentiment interaction. Fan et al. (Citation2018) used the attention mechanism to capture the words and multi-word expressions in the sentence simultaneously, which can more accurately locate the sentiment polarity. To extend the attention model, an attention mechanism with a memory network (Li et al., Citation2021) can capture the importance of each context word for a given target. Inspired by this, Basiri et al. (Citation2021) proposed an attention-based bidirectional CNN-RNN learning model (ABCDM), which can extract past and future contexts in the time dimension and measure the importance of different features.
With the deepening of the research, the sentimental contextual knowledge of specific entities needs to be further explored. (Xue & Li, Citation2018; Zhang et al., Citation2016) used the gating neural network structure to control the propagation deviation and model the interaction between aspect words and context words. (Li et al., Citation2018; Thesia et al., Citation2022) adjusted the input of the convolution layer by using the position correlation between words and aspect words for better input representation. Liu and Zhang (Citation2017) used two attention to sentence-level semantics and context. At the same time, the order and correlation of words are considered. Huang et al. (Citation2018) modelled aspects and sentences jointly and captured the interaction between aspects and context sentences. To solve the problem that implicit sentiments are difficult to be mined, the capsule network is used to extract additional semantic information to obtain high-level feature information (Hussain et al., Citation2021; Yan et al., Citation2021). But Gupta et al. (Citation2022) use an improved binary particle swarm algorithm to improve sentiment classification accuracy by global and local optimisation. Inspired by this, our model is to model the text corpus to obtain valuable global sentiment features and enhance sentiment mining for a given aspect.
2.3. Graph convolutional networks (GCNs)
A graph is a data structure representing the multi-to-multi relationship between objects, covering the representation of a set of one-to-one and one-to-many relationship structures, highlighting the strong representation ability of the graph structure. GCNs can obtain the information of adjacent nodes. It can fully excavate interdependent information from complex relational data.
With the update of sentiment analysis requirements, data in many practical application scenarios are generated from non-European spaces. Traditional deep learning methods have successfully extracted features of Euclidean spatial data, but their performance in dealing with non-European spatial data is still unsatisfactory. GCNs are more competent in this respect, and they capture graph dependency through message passing between graph nodes (Zhang et al., Citation2019; Zhang et al., Citation2020). It can be used to explain the mechanism of related syntactic constraints and long-distance word dependence and better identify context words unrelated to grammar. Many studies applied GCNs to aspect-level sentiment classification. GCNs is a simple and effective deep learning network. It can obtain not only the information of adjacent nodes but also the information of other nodes of adjacent nodes. It can fully excavate the information of interdependence from rich relational data. Hou et al. (Citation2021) selected the GCNs model based on the dependency tree, which used multiple attention to select attention for each word in the sentence. Zhao et al. (Citation2020) used GCNs to capture the sentiment dependence between different aspects of sentences on the bidirectional attention mechanism of location coding. Liang et al. (Citation2022) propose a SenticGCN model, which combines the sentimental dependence of sentences to mine the specific aspects of sentences.
The existing methods often rely too much on the whole corpus when considering the global dependency information, resulting in too many interference factors and a lack of effective modelling of global dependency signals, which makes it difficult to truly mine valuable global dependency information. For example, Zhou et al. (Citation2020) used a syntactic dependency tree and common-sense map to enhance the representation of each given aspect in the sentences, which can effectively incorporate external knowledge into the sentiment classification model to improve the accuracy. Zhu et al. (Citation2021) constructed a document map to model the whole corpus to mine the global dependency between words. Different from the above, our model can effectively obtain global dependence and local features. Specifically, the global features obtained by orthogonal feature projection and local dependence can better solve the long-term problem of multi-word dependence. It not only retains the overall attributes of global features but also reduces noise interference, further refines the global features, and improves the accuracy of text sentiment classification.
3. GP-GCN of our proposed method
To improve the accuracy of text sentiment classification, we further consider the noise interference of global features and refine the global features. Combining the advantages of the BERT model, GCN model, and attention mechanism, we introduce the global features by orthogonal features projection and local structure obtained into the aspect-level sentiment classification (GP-GCN). We use two fusion graph convolution neural networks to learn the global features (G-GCN) and local dependence (P-GCN) information of the text, respectively. The model framework is shown in Figure . It is composed of an embedded layer, convolution layer, pooling layer, attention layer, and full connection layer.
3.1. Embedded layer
The main role of the input embedding layer is to represent the text statement as a word vector matrix and map each word into the vector space of high latitude. In traditional processing tasks, words usually use One-Hot Encoding to represent text with discrete values. However, this method ignores the correlation between words and context information, which is easy to cause data disaster. To solve these problems, researchers proposed to represent words as continuous dense low latitude vectors (Giatsoglou et al., Citation2017). At present, the commonly used methods are Glove (Pennington et al., Citation2014), Word2Vec, and BERT (Devlin et al., Citation2018).
In our model, we use the Glove and BERT pretraining models to obtain word embedding representations. In Glove, is a word embedding matrix, where
is the dimension of a word vector.
represents the size of a vocabulary. Word embedding
is
, And it can be calculated by the word embedding matrix
. In BERT, we use parameters BERTbase as the experimental basis. As the given sentence S = {w1, w2, w3, … , wn}, the input is out = {[CLS], w1, w2, w3, … , wn, [SET]}.
, where
is the size of the hidden dimension. Word embedding
is
, they can map words into high latitude vector spaces. Then sentiment lexicon
(Xu et al., Citation2022) is used to weight the word vector, and the formula is as follows:
(1)
(1) where
is the weighted word vector, the matrix is used as the output of the embedding layer.
3.2. Bi-LSTM
Since Bi-LSTM can process variable-length sequence information (Tang et al., Citation2015; Wei et al., Citation2020), we summarise two directions of information through three gated units that control information transmission to obtain context information more accurately. The calculation formula is shown in Formula (2).
(2)
(2) where
is the parameter of the LSTM model. We connect the hidden state to obtain
. Input word embedding
, we use
to represent the given the word
and get to
. Where
represents the dimension of the hidden state. The word input into GCN is the features matrix of this node.
3.3. Graph convolutional network
GCNs is a multi-layer neural network that is suitable for the convolution operation of nodes in the graph. Formally, we consider a graph G = (V, E, A), |V| and |E| of G denote the order of graph G and the number of edges. is the corresponding adjacency matrix of G. In the Lth layer of GCN,
is Layer L output as the i node. The convolution operation formula is shown in Formula (3).
(3)
(3) Where l∈ {1, … , L},
is the sigmoid function. In the function,
and
is weight and biased, respectively. Through the above operation of GCN, the aggregated information of each node is not only itself but also its direct neighbour. Then the information of adjacent internal nodes was collected by the L+1 layer GCN.
3.4. Neutral word vectors and CPD-NET
In this paper, some words with special meaning are given appropriate weight, that is, by calculating the relevance of the context of neutral words. Then, the selected neutral word vector is projected into the sentimental polarity word vector space, so the neutral word vector is given appropriate weight. When tagging text, there are generally more explicit sentimental features, such as ‘perfect’ representing positive sentiments, ‘bad’ and ‘disgusting’ representing negative sentiments. However, there are also words in the text called neutral words (e.g. ‘general’, ‘normal’, ‘?’). Their sentiment characteristics are not obvious, and there is no ambiguity in the classification. They all belong to the neutral word vector, but the neutral word vector will affect the results of text sentiment classification to some extent. In this paper, we propose a new feature projection method. We project the neutral feature vector to the orthogonal direction of the emotional polarity feature vector to generate the final and more comprehensive features for classification. Obviously, this orthogonal projection is to get rid of common features, so that the model not only pays attention to those distinctive features but also pays attention to neutral features with special significance. The specific projection method is explained later.
Definition 1. The Degree of Word Correlation (DWC). It is used to measure the correlation between sentimental polarity words and neutral words in the context. That is, to calculate the sentimental polarity intensity of neutral words from the context. Words or characters with special significance can be more accurately identified through the semantic correlation between words. The integrity of feature extraction can be improved. The calculation formula is shown in Formula (4).
(4)
(4) where
represents the correlation between neutral words and polar words, and the calculation formula is shown in Formula (5).
(5)
(5) where
represents the average value in the whole review corpus.
represents the correlation between words i and the average value.
represents the initial weight of neutral words and
represents the position of words.
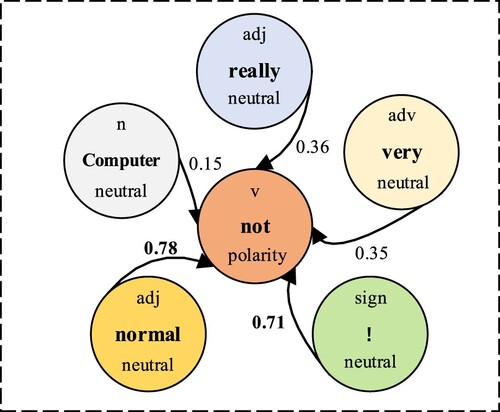
Because only a small part of the neutral words in the text has special significance, we use the LTP tool of the Harbin Institute of Technology to segment the text according to the part of speech. It calculates the semantic association between words and selects the neutral words or symbols with special significance. As Figure shows, ‘This computer is really unusual!’, where ‘computer’, ‘general’ and ‘!’ are all neutral words. By calculating the semantic association between neutral words and polar words, the neutral words ‘general’ and ‘!’ with special significance are screened out. The words greater than the threshold are selected as the screening result to provide data support for subsequent feature projection operations.
Figure 3. Sample description of word relevance.
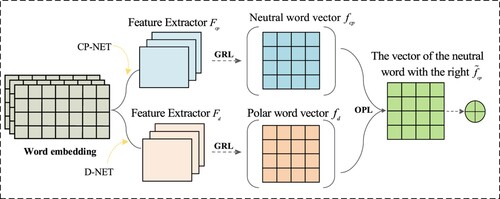
CPD-NET framework is shown in Figure . The framework comprises two parts: the feature projection network (CP-NET) and the sentimental polarity features learning network (D-NET). The model projects the complete information vector of the learned text into a more recognisable semantic space. It can identify special neutral word vectors affecting text sentiment classification, so the global features are simplified. The purpose of CP-NET is to extract the neutral word feature vector with special significance and give appropriate weights. D-NET is to obtain sentiment polarity word vector. CP-NET and D-NET are composed of three parts. The first two layers are the input layer and the feature extraction layer. The input layer has the same input , where
is an input document with the length L. The feature extraction layer uses VD-CNN (Conneau et al., Citation2017). The third layer is the orthogonal projection layer (OPL) and the reverse gradient layer (GRL). The core idea of the model is to project the feature vector
to the orthogonal direction of
,
is projected to a more discriminative semantic space. It can identify the noise interference of the global features and simplify the global features. And the special neutral word vector, which has an impact on text sentiment classification, is given appropriate weight. The CP-NET feature extraction layer is extracted, and the D-NET feature extraction layer is extracted. Next, each proposed orthogonal projection model component is described in detail.
Figure 4. Orthogonal projection (CPD-NET) model.
When the feature extraction layer of CP-NET receives from the Bert model,
is the embedding matrix of
. The advanced features
are extracted in the form of n-grams from
by
. The specific extraction method
is:
(6)
(6) Where
represents the filtering output of
, A convolution operation for filtering is composed of a filter
and a bias
.
can be expressed as:
(7)
(7)
is ReLU, and Maxpooling is applied to feature mapping.
is used as the corresponding feature of the filter
. The same D-NET feature extraction layer also receives advanced features
from the input layer when
is received.
(8)
(8)
(9)
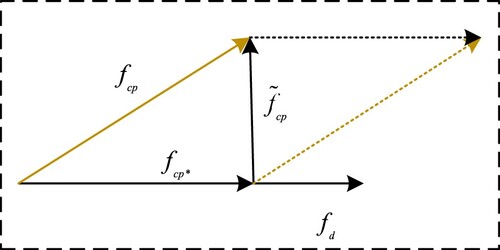
(9) Orthogonal Projection Layer (OPL), As shown in Figure . The two-dimensional space
represents the feature vector of sentiment polarity words.
represents the feature vector of neutral words and
represents the final weighted neutral word feature vector.
Figure 5. Orthogonal projection principle.
The feature vector is set
by GRL, and the formula is shown as:
(10)
(10)
(11)
(11) The purpose of D-NET is to extract sentiment polarity feature vectors
. In the text, sentiment classification tasks can obtain discriminative semantic information. Then, the sentiment classifier uses sentiment polarity words to distinguish different sentiment categories. The purpose of CP-NET is to extract the feature vector
of neutral words, which means to obtain semantic information that is not discriminative in text sentiment classification tasks. And then project it to the semantic space of sentiment polar words for reinforcement learning. This can give the neutral word vector appropriate weight to identify valuable sentiment features. To accurately obtain the feature vector, GRL is added after the feature extractor
and
to reverse the direction of the gradient (Ganin et al., Citation2017). Through this training module, we can obtain the neutral word feature vector with low discrimination and the sentiment polarity feature vector with high discrimination in the text. To identify the valuable sentimental features of neutral words, the extracted feature vector
is projected onto the orthogonal direction of
the sentimental polarity word vector. The feature space orthogonal to the feature vector of sentimental polarity words should contain pure and efficient features for text sentiment classification.
is projected into the orthogonal feature space. It calculates not only the similarity between the neutral word feature vector and the polar word feature vector but also refines according to the orthogonal distance between the two. The special neutral word feature vector is given the appropriate weight, so that valuable sentiment features can be well identified.
In mathematics, the neutral word feature vector is projected onto the sentiment polarity word feature vector
, and it is shown in formula (12).
(12)
(12) where
is a projection function, and it is shown in Formula (13).
(13)
(13) where
are vectors. Then, the orthogonal direction of the projection feature
is projected to obtain the classification feature vector with high discrimination. The calculation formula is shown in Formula (14).
(14)
(14) It can be seen from the above that the feature vector
is equivalent to
. The feature vector
can be obtained by using the neutral word feature vector
projection, and a plane (in 3D) can be constructed. The intersection of this plane and the orthogonal plane of the projection feature vector
is a high-resolution sentimental feature vector.
In addition, the projection in Formula (13) is a constraint on the feature vector of sentimental polarity words. That is, the modulus of sentimental polarity word feature vector is limited when is projected to
. So the semantic information of sentimental polarity word feature vector obtained by projection is the projection feature
. It only contains sentimental polarity semantic information related to the neutral word feature vector. This makes the final high-resolution sentiment feature vector
come from the neutral word feature vector
, rather than the vector on any plane orthogonal to the sentimental polarity feature vector
. Finally, the feature vector
obtained by projection is used for text sentiment classification.
(15)
(15)
(16)
(16) where
function and
function are trained simultaneously, but ADAM and SGD optimiser are used, respectively. The gradient is passed back through the characteristic when the loss function is optimised. Although these two loss functions are opposite in the optimisation objective of the feature extractor
, the influence
is in the orthogonal direction
. This can find a balance point so that the extracted features are closer to the real sentiment polarity features. Algorithm 1 gives the proposed complete training algorithms for CP-NET and D-Net.
Table
3.5. Global structure dependency (G-GCN)
The motivation of this section is to learn global dependency attention weights. So, we need to extract global information of words. We prune the corpus by orthogonal projection to reduce interference factors and give some words with special meanings appropriate weights. When we are committed to extracting the global features of words, a graph of the word co-occurrence and text graph is prevalent. Compared with the construction of the word co-occurrence graph (Peng et al., Citation2018), the text graph (Yao et al., Citation2019) is represented as nodes, which consists of words and sentences. Taking sentence nodes as a bridge, we can capture the long-term word relations in the whole corpus, thus further enhancing word representation learning. Therefore, we choose a text graph to input information into the GCN model.
The original Text-GCN began to learn the sentence representation of test data, which will significantly limit its practical application. Therefore, we train the corpus's matrix of word embedding from the perspective of global dependence, which will be more conducive to the training effect of the model. Formally, the weights i and j of edges between nodes are defined as:
(17)
(17) The PMI value i, j is calculated as:
(18)
(18) where the value of N(i) is the sliding window of i, so is N(j). #N is the sliding windows’ number. It will be considered when the PMI between the word nodes is positive. Two-layer GCN is applied to the text graph. The formula is as follows:
(19)
(19) where output is Y, W0 and W1 are training weight matrices.
In the whole corpus, TextGCN is pre-trained, which can get the embedding matrix of words. Word semantic relationships are reflected by learned word representations from the view of a global feature. Eg is obtained by embedding the original input sentence into the learned word embedding matrix. Then, we combine the output H gate mechanism of Eg using Bi-LSTM.
3.6. Local dependency attention
To obtain aspect-oriented attention, local dependence structures are considered. A GCN is applied in the dependency tree of sentences and used with Bi-LSTM. This process can capture long-term relations. Specifically, according to the words of a given sentence, a dependency tree is constructed at first, and its adjacency matrix is obtained. We apply dependency tree modelling by the graph convolution. A self-loop is used for each node, and the activation is normalised before the nonlinear transformation. The formalisation is as follows:
(20)
(20) where A = A + I, I as an n × n unit matrix,
represents the scope of the ith node. W(l) and b(l) is the training parameters of a specific layer. The GCN layer on the final output dependency tree is
, and the aspect-specific masking layer at the top is further applied, replacing the non-aspect state with zero. In the masking layer,
as an output. So, we can determine the local dependency attention weight α as the following formula.
(21)
(21)
(22)
(22)
3.7. Percentage multiple attention mechanism
To improve the suitability of the weight assignment of the multi-attention mechanism, a pooling is proposed. In most cases, the weighted average method is selected because the average pool performance is better than the maximum pool performance. However, the average pool sometimes misses the optimal choice because it takes the average as the final standard. So, the average sometimes is not robust. To solve these problems, we propose a new method of Percentage Pooling. The motivation of pth percentage is to minimise p% value of the set-in sorting elements. In general, the 50th percentile is more robust than the average and has more advantages than the maximum pool. For example, with large outliers in a set, the maximum pool as output is not the best choice. And the 80h percentage is better to exclude the abnormal value. In this paper, the pth percentage of vector R as function , m can be adjusted as a super parameter. The range of m is between 0 and 100.
4. Experiments
Comparative experiments are carried out on real datasets as shown in to verify that the proposed method is effective. The effectiveness of the proposed GP-GCN is verified by the experimental results..
Table 1. Official link of datasets.
4.1. Experimental data
SemEval dataset is the most commonly used dataset in aspect-level sentiment analysis. Its primary task is to analyse the sentiment of Twitter texts. SemEval datasets links are shown in . The SemEval dataset is used in this experiment, includes 14Res and 14Lap from SemEval-2014, 15 Res from SemEval-2015, and 16 Res from SemEval-2016. In Table , the statistical results of the dataset are shown.
Table 2. Statistics of the datasets.
4.2. Experimental setup and evaluation measurement
Because the proportion of N labels in edge labels is much larger than in other tag categories, the data category is not balanced. To solve the imbalance of data, we set the weighted gate of the relationship distance weight. It is not involved in graph calculation when the relationship distance weight is less than the threshold. In the model training process, different optimisers are selected for optimisation so that it makes the model training to bemore effective and convenient for experimental comparison. The selection of each model parameter and optimiser is shown in Table .
Table 3. Parameter setting.
In this paper, the feature extraction of text sentiment classification combines multiple extraction methods based on orthogonal projection. To verify the classification performance of the proposed GD-GCN model, we conduct experiments on real datasets. The specific experimental steps are as follows.
Step1: Experimental data acquisition. The part of the original AFOE data is used as experimental data. We add sentiment polarity annotation based on the SemEval dataset to obtain sentiment polarity review data. After denoising, 10000 high-quality text reviews are screened.
Step2: Calculate the embedding matrix of text. This paper selects the Skip-gram structure to train the input text and obtain the word vector and embedding matrix, which can better represent the information between characters or words and context.
Step3: Simplifying global features. Eliminating Interference in Global Features by Orthogonal Projection.
Step4: The aspect-level sentiment classification of comment texts. Features with high discrimination are learned by combining simplified global and local features with a multi-headed attention mechanism. So that the text is more discriminative in aspect-level sentiment classification. Acc calculates the accuracy of text sentiment classification, Pre, Rec and F1 are used as evaluation criteria to compare the text sentiment classification results of multiple models.
4.3. Experimental results
Experimental results on Restaurants14, Laptop14, Restaurants15, Restaurants16 and Twitter are shown in . The glove model obtained in each set and the best results based on the BERT model are marked in bold and underlined, respectively.
To verify the effect of different percentage pooling on (PD-GCN) model classification, full connection layer, 30th,50th, 60th, 70th, 80th, 90th, 100th, and average pooling participation graphs were set to calculate and compare.
Table 4. Result of experimenting.
Experimental results in Table show that the maximum pooling operation has achieved good classification results, which is also the reason why it can be widely used. However, compared with the maximum pooling method, the percentile pooling method shows better performance. The experimental results are the best when the percentile pooling is set to 50th. Compared with maximum pooling and average pooling increased by 1.25% and 2.31%, respectively, which indicates that percentile pooling is suitable for the grammar-based GCN model. The experiment shows that the percentile combination can improve the measurement value of microflow in our model by 3.55%.
Table 5. Result of different percentile pooling.
4.4. Experimental discussion
To further demonstrate the superiority of the GP-GCN model, this paper explores the accuracy of the training process of each model on the validation set, as shown in Figures and .
The classification accuracy of this model is higher than other models. AdaRNN and PhraseRNN have similar classification results, but the classification results are relatively low. ContextAvg and TD-LSTM classify text by SoftMax function and bidirectional LSTM, respectively, which is better than RNN, LSTM, and its variants in classification effect. However, the words with significant influence on a given target are not given enough attention, so the classification effect needs to be improved. Compared with LAN and TD-LSTM models, this model not only considers the optimisation of local information extraction but also considers the global dependency between words. Different from PRET + multi model, some interference factors are eliminated by feature projection when dealing with the database to extract the emotional features with higher discrimination. It can be seen from the above experimental results that the GP-GCN model combined with G-GCN and P-GCN can effectively improve the text classification effect.
G-GCN is a more effective method in ABSA. GP-GCN has three modules: G-GCN, P-GCN, and CPD-NET. The ablation experiments on the dataset show that compared with P-GCN and G-GCN (no CPD-NET), G-GCN respectively improves the classification performance by 1.19% and 1.32%. It proves that simplified global dependency information between words plays a vital role in ABSA. The training result of the GP-GCN (Bert) model is the best, which is 0.79 percentage points higher than that of P-GCN, 1.88% higher than that of D-GCN, 2.25% higher than that of the P-GCN + D-GCN hybrid (Glove), and 1.93% higher than that of G-GCN (no CPD-NET).
The parameter optimisation route of this model is more efficient than other models. As shown in Figures and , in the early training (the first ten rounds), the accuracy of each model is low, and the cross-entropy loss is high, but GP-GCN is in a leading position. In the middle of training (10–20 rounds), the accuracy of each model gradually increased. But the accuracy of GP-GCN has tended to be stable. After training (20–50 rounds), the accuracy of other models tends to be stable.
Figure 6. Accuracy curve of calibration set (Baselines).
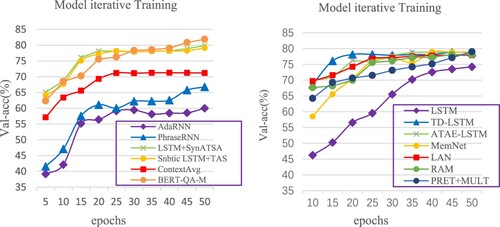
Figure 7. Accuracy curve of calibration set (Ablated Models and Full Models).
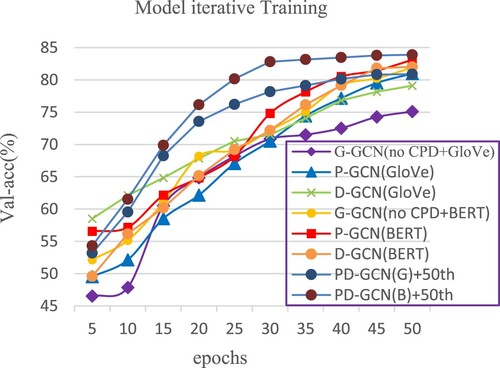
The traditional deep learning model has a significant fluctuation in the early stage of training, and it began to converge in the fifth period. The fluctuation of a single GCN learning model is relatively stable, but the convergence speed is normal. The GP-GCN model proposed in this paper has a fast convergence rate and relatively flat training curve. The training process is stable, the accuracy is high, and it has been in a leading position in the subsequent model training process, reflecting the advantages of the GP-GCN model.
5. Conclusions
To improve the accuracy of text sentiment classification, global features are further simplified from the view of reducing the noise in this paper. An aspect-level sentiment classification method is proposed, named GP-GCN. The local structure and global features obtained by orthogonal feature projection are introduced into the aspect-level sentiment classification. The contribution of this paper mainly includes the following two aspects:
An aspect-level sentiment classification method is proposed. Text sentimental features are effectively extracted. Different from the traditional methods, it not only weakens the noise interference but also refines the global features. In addition, global and local features are introduced into the aspect-level sentiment classification to improve the accuracy of the results.
The percentage multi-headed attention mechanism is proved effective. Compared with the traditional attention mechanism, this method is more robust and insensitive to outliers. It can accurately measure the critical output of GCN and obtain better sentence representation of given aspects. The classification accuracy and generalisation performance of the model are improved, which can provide technical support for text sentiment classification.
The experimental results show that the proposed model can accurately and effectively represent all aspects of sentimental tendencies. The calculation speed can be improved by optimising the global features. This model can help users better understand the fine-grained sentimental tendencies in all aspects. In future work, we will fully consider combining local dependence information and knowledge map to learn more discriminative text sentiment features. At the same time, it is considered to be extended to sentiment analysis and sentiment value calculation to obtain better results.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Basiri, M. E., Nemati, S., Abdar, M., Cambria, E., & Acharya, U. R. (2021). Abcdm: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Generation Computer Systems, 115, 279–294. https://doi.org/10.1016/j.future.2020.08.005
- Cai, J., Zhang, S. X., Zhu, H. Z., & Zhu, G. L. (2021). Building the summarization model of micro-blog topic. Journal of Ambient Intelligence and Humanized Computing, 12(1), 797–809. https://doi.org/10.1007/s12652-020-02078-9
- Cambria, E. (2016). Affective computing and sentiment analysis. IEEE Intelligent Systems, 31(2), 102–107. https://doi.org/10.1109/MIS.2016.31
- Cambria, E., Kumar, A., Al-Ayyoub, M., & Howard, N. (2022). Guest editorial: Explainable artificial intelligence for sentiment analysis. Knowledge-Based Systems, 107920. https://doi.org/10.1016/j.knosys.2021.107920
- Chen, P., Sun, Z., Bing, L., & Yang, W. (2017). Recurrent attention network on memory for aspect sentiment analysis. In Proceedings of the 2017 conference on empirical methods in natural language processing, 452-461. https://doi.org/10.18653/v1/d17-1047.
- Conneau, A., Schwenk, H., Barrault, L., & Lecun, Y. (2017). Very deep convolutional networks for text classification. https://doi.org/10.18653/v1/e17-1104.
- De Meo, P., Levene, M., Messina, F., & Provetti, A. (2020). A general centrality framework-based on node navigability. IEEE Transactions on Knowledge and Data Engineering, 32(11), 2088–2100. https://doi.org/10.1109/TKDE.2019.2947035
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pretraining of deep bidirectional transformers for language understanding. Universal Language Model Fine-tuning for Text Classification, 278. ACL Press.
- Fan, C., Gao, Q. H., Du, J. C., Gui, L., Xu, R. F., & Wong, K. F. (2018). Convolution-based memory network for aspect-based sentiment analysis. In The 41st International ACM SIGIR conference on research & development in information retrieval, 1161-1164. https://doi.org/10.1145/3209978.3210115.
- Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., Marchand, M., & Lempitsky, V. (2017). Advances in computer vision and pattern recognition. The Journal of Machine Learning Research, 17(1), 189–209. https://doi.org/10.1007/978-3-319-58347-1_10
- Geler, Z., Savić, M., Bratić, B., Kurbalija, V., Ivanović, M., & Dai, W. (2021). Sentiment prediction based on analysis of customers assessments in food serving businesses. Connection Science, 33(3), 674–692. https://doi.org/10.1080/09540091.2020.1870436
- Giatsoglou, M., Vozalis, M. G., Diamantaras, K., Vakali, A., Sarigiannidis, G., & Chatzisavvas, K. C. (2017). Sentiment analysis leveraging emotions and word embeddings. Expert Systems with Applications, 69, 214–224. https://doi.org/10.1016/j.eswa.2016.10.043
- Gupta, A., Chhikara, R., & Sharma, P. (2022). Feature reduction of rich features for universal steganalysis using a metaheuristic approach. International Journal of Computational Science and Engineering, 25(2), 211. https://doi.org/10.1504/IJCSE.2022.122207
- Hou, X. C., Huang, J., Wang, G. T., Qi, P., He, X. D., & Zhou, B. W. (2021). Selective attention based graph Convolutional Networks for Aspect-Level sentiment classification. In Proceedings of the fifteenth Workshop on graph-based methods for Natural Language Processing (TextGraphs-15), 83-93. https://doi.org/10.18653/v1/11.textgraphs-1.8.
- Huang, B. X., Ou, Y. L., & Carley, K. M. (2018). Aspect level sentiment classification with attention-over-attention neural networks. In International Conference on social computing, Behavioral-cultural modeling and prediction and Behavior representation in modeling and simulation, 197-206. Springer, Cham. https://doi.org/10.1007/978-3-319-93372-6_22.
- Hussain, A., Cambria, E., Poria, S., Hawalah, A. Y., & Herrera, F. (2021). Information fusion for affective computing and sentiment analysis. Information Fusion, 71(5), https://doi.org/10.1016/j.inffus.2021.02.010
- Li, C., Guo, X., & Mei, Q. (2017). Deep memory networks for attitude identification. In Proceedings of the tenth ACM International Conference on Web search and data mining, 671-680. https://doi.org/10.1145/3018661.3018714.
- Li, X., Bing, L., Lam, W., & Shi, B. (2018). Transformation networks for target-oriented sentiment classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 1, 946-956. https://doi.org/10.18653/v1/p18-1087.
- Li, Z., Li, Q., Zou, X., & Ren, J. (2021). Causality extraction based on self-attentive BiLSTM-CRF with transferred embeddings. Neurocomputing, 423, 207–219. https://doi.org/10.1016/j.neucom.2020.08.078
- Liang, B., Su, H., Gui, L., Cambria, E., & Xu, R. (2022). Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowledge-Based Systems, 235, 107643. https://doi.org/10.1016/j.knosys.2021.107643
- Liu, J. M., & Zhang, Y. (2017). Attention modeling for targeted sentiment. In Proceedings of the 15th Conference of the European chapter of the Association for Computational Linguistics, 2, 572-577. https://doi.org/10.18653/v1/e17-2091.
- Mansouri-Benssassi, E., & Ye, J. (2021). Generalisation and robustness investigation for facial and speech emotion recognition using bio-inspired spiking neural networks. Soft Computing, 25(3), 1717–1730. https://doi.org/10.1007/s00500-020-05501-7
- Peng, H., Li, J., He, Y., Liu, Y., Bao, M., Wang, L., Song, Y., & Yang, Q. (2018). Large-scale hierarchical text classification with recursively regularized deep graph-cnn. In Proceedings of the 2018 world wide web conference, 1063-1072. https://doi.org/10.1145/3178876.3186005.
- Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 1532-1543. https://doi.org/10.3115/v1/d14-1162.
- Ruder, S., Ghaffari, P., & Breslin, J. G. (2016). A hierarchical model of reviews for aspect-based sentiment analysis. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language processing, 999-1005. https://doi.org/10.18653/v1/d16-1103.
- Tang, D., Qin, B., Feng, X., & Liu, T. (2015). International Conference on Computational Linguistics (COLING 2016). Effective LSTMs for target-dependent sentiment classification. Osaka, Japan.
- Tang, D., Qin, B., & Liu, T. (2016). Aspect Level Sentiment Classification with deep memory network. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language processing, 214-224. https://doi.org/10.18653/v1/d16-1021.
- Tay, Y., Tuan, L. A., & Hui, S. C. (2017). Dyadic memory networks for aspect-based sentiment analysis. In Proceedings of the 2017 ACM on Conference on information and Knowledge management, 107-116. https://doi.org/10.1145/3132847.3132936.
- Thesia, Y., Oza, V., & Thakkar, P. (2022). Predicting stock price movement using a stack of multi-sized filter maps and convolutional neural networks. International Journal of Computational Science and Engineering, 25(1), 22–33. https://doi.org/10.1504/IJCSE.2022.120784
- Wang, Y., Huang, M., Zhu, X., & Zhao, L. (2016). Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 conference on empirical methods in natural language processing, 606-615. https://doi.org/10.18653/v1/d16-1058.
- Wei, J. Y., Liao, J., Yang, Z. F., Wang, S. G., & Zhao, Q. (2020). Bilstm with multi-polarity orthogonal attention for implicit sentiment analysis. Neurocomputing, 383, 165–173. https://doi.org/10.1016/j.neucom.2019.11.054
- Wu, S. T., Liu, Y. L., Zou, Z., & Weng, T. H. (2022). S_I_LSTM: Stock price prediction based on multiple data sources and sentiment analysis. Connection Science, 34(1), 44–62. https://doi.org/10.1080/09540091.2021.1940101
- Wu, X., He, R., Sun, Z. N., & Tan, T. N. (2018). A light cnn for deep face representation with noisy labels. IEEE Transactions on Information Forensics and Security, 13(11), 2884–2896. https://doi.org/10.1109/TIFS.2018.2833032
- Xiao, L. W., Hu, X. H., Chen, Y. N., Xue, Y., Gu, D. H., Chen, B. L., & Zhang, T. (2020). Targeted sentiment classification based on attentional encoding and graph convolutional networks. Applied Sciences, 10(3), 957. https://doi.org/10.3390/app10030957
- Xu, H., Zhang, S., Zhu, G., & Zhu, H. (2022). Alsee: A framework for attribute-level sentiment element extraction towards product reviews. Connection Science, 205–223. https://doi.org/10.1080/09540091.2021.1981825
- Xue, W., & Li, T. (2018, July). Aspect based sentiment analysis with gated convolutional networks. In Proceedings of the 56th Annual Meeting of the Association for Computational linguistics, (pp. 2514-2523).ACL Press.
- Yan, Y., Xiao, Z., Xuan, Z., & Ou, Y. (2021). Implicit emotional tendency recognition based on disconnected recurrent neural networks. International Journal of Computational Science and Engineering, 24(1), 1–8. https://doi.org/10.1504/IJCSE.2021.113616
- Yang, M., Tu, W., Wang, J., Xu, F., & Chen, X. (2017, February). In Proceedings of the AAAI Conference on artificial intelligence. Attention based LSTM for target dependent sentiment classification. Arizona, USA.
- Yao, L., Mao, C., & Luo, Y. (2019). Graph convolutional networks for text classification. Proceedings of the AAAI Conference on Artificial Intelligence, 33(1), 7370–7377. https://doi.org/10.1609/aaai.v33i01.33017370
- Zargari, H., Zahedi, M., & Rahimi, M. (2021). Gins: A global intensifier-based N-gram sentiment dictionary. Journal of Intelligent & Fuzzy Systems, 11763–11776. https://doi.org/10.3233/jifs-202879
- Zhang, C., Li, Q., & Song, D. (2019). In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International joint Conference on Natural Language Processing (EMNLP-IJCNLP). Aspect-based sentiment classification with aspect-specific graph convolutional networks. Suzhou, China. https://doi.org/10.18653/v1/D19-1464.
- Zhang, C., Li, Q., Song, D., & Wang, B. (2020). A multi-task learning framework for opinion triplet extraction. In Findings of the Association for Computational Linguistics: EMNLP, 2020, 819–828. https://doi.org/10.18653/v1/2020.findings-emnlp.72
- Zhang, J., Hu, X., & Dai, H. (2020). A graph-voxel joint convolution neural network for ALS point cloud segmentation. IEEE Access, 8, 139781–139791. https://doi.org/10.1109/ACCESS.2020.3013293
- Zhang, M., Zhang, Y., & Vo, D. T. (2016, March). In thirtieth AAAI conference on artificial intelligence. Gated neural networks for targeted sentiment analysis. Arizona, USA.
- Zhang, S. X., Hu, Z. Y., Zhu, G. L., Jin, M., & Li, K. C. (2021). Sentiment classification model for Chinese micro-blog comments based on key sentences extraction. Soft Computing, 25(1), 463–476. https://doi.org/10.1007/s00500-020-05160-8
- Zhang, S. X., Xu, H. Q., Zhu, G. L., Chen, X., & Li, K. C. (2022). A data processing method based on sequence labeling and syntactic analysis for extracting new sentiment words from product reviews. Soft Computing, 26(2), 853–866. https://doi.org/10.1007/s00500-021-06228-9
- Zhang, S. X., Yu, H. B., & Zhu, G. L. (2022). An emotional classification method of Chinese short comment text based on ELECTRA. Connection Science, 34(1), 254–273. https://doi.org/10.1080/09540091.2021.1985968
- Zhao, P. N., Hou, L. I., & Wu, O. (2020). Modeling sentiment dependencies with graph convolutional networks for aspect-level sentiment classification. Knowledge-Based Systems, 193, 105443. https://doi.org/10.1016/j.knosys.2019.105443
- Zhou, J., Huang, J. X., Chen, Q., Hu, Q. V., Wang, T., & He, L. (2019). Deep learning for aspect-level sentiment classification: Survey, vision, and challenges. IEEE ACCESS, 7, 78454–78483. https://doi.org/10.1109/ACCESS.2019.2920075
- Zhou, J., Huang, J. X., Hu, Q. V., & He, L. (2020). Sk-gcn: Modeling syntax and knowledge via graph convolutional network for aspect-level sentiment classification. Knowledge-Based Systems, 205, 106292. https://doi.org/10.1016/j.knosys.2020.106292
- Zhu, X., Zhu, L., Guo, J., Liang, S., & Dietze, S. (2021). GL-GCN: Global and local dependency guided graph convolutional networks for aspect-based sentiment classification. Expert Systems with Applications, 186, 115712. https://doi.org/10.1016/j.eswa.2021.115712
- Zuo, E. G., Zhao, H., Chen, B., & Chen, Q. C. (2020). Context-specific heterogeneous graph convolutional network for implicit sentiment analysis. IEEE Access, 8, 37967–37975. doi:10.1109/ACCESS.2020.2975244