
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The existing Emotion-Cause Pair Extraction (ECPE) has made some achievements, and it is applied in many tasks, such as criminal investigations. Previous approaches realised extraction by constructing different networks, but they did not fully exploit the original information of the data, which led to low extraction precision. Moreover, the extraction precision will also be decreased when the model is attacked by adversarial samples. To address the above problems, a new model CL-ECPE is proposed in this article to improve the extraction precision through contrastive learning. First, contrastive sets are constructed by adversarial samples. The contrastive sets are used as the raw data of adversarial training and the test data of the pilot experiment. Then, adversarial training is used to get contrastive features according to the training target. The acquisition of contrastive features can improve extraction precision. Experimental results on the benchmark emotion cause corpus show our method outperforms the state-of-the-art method by over 12.49%, as well as demonstrates the strong robustness of CL-ECPE.
1. Introduction
As an emotional reason extraction task, Emotion-Cause Pair Extraction (ECPE) (Xia & Ding, Citation2019) is different from sentiment classification(Wang et al., Citation2020; Wei et al., Citation2021; Yan et al., Citation2021; Zhang et al., Citation2022), which can provide technical support for many tasks, such as criminal investigations. The current models of the ECPE task have obvious show shortcomings. These methods do not fully consider the impact of the data itself on the extraction results. When encountering adversarial attacks, the extraction precision of ECPE model decreases rapidly.
In recent work, ECE and ECPE are constructing different networks to avoid limitations and improve extraction precision (Cheng et al., Citation2021; Fan, Zhu, et al., Citation2021; Singh et al., Citation2021; Xu et al., Citation2021). They did not consider that their model would deteriorate the precision of extraction results due to data changes. When attacked by adversarial samples, the robustness of these models is extremely poor. Different from the previous work, this paper applies the original data information and adversarial samples for feature learning. For raw data, subtle differences in data can lead to lower extraction precision, which verifies the poor robustness of models according to Section 3.
An ECPE model using contrastive learning method to improve the extraction precision and enhance model robustness needs to consider the following two points: (1) Select the appropriate adversarial sample generation method to generate adversarial samples for contrastive sets construct. (2) Select the appropriate data proportion of contrastive sets for contrastive feature learning. The change in the model by adversarial attack determines the data composition ratio of the contrastive sets. Therefore, we need to grasp this change. The pilot experiment is conducted to observe the extraction precision decline of existing models by adversarial attacks (Section 3). The motivation of this paper is to improve extraction precision and enhance model robustness by generating adversarial samples for adversarial training. This work proposed CL-ECPE: Contrastive Learning with Adversarial Samples for Emotion-Cause Pair Extraction. The framework of CL-ECPE is shown in Figure :
Figure 1. CL-ECPE framework.
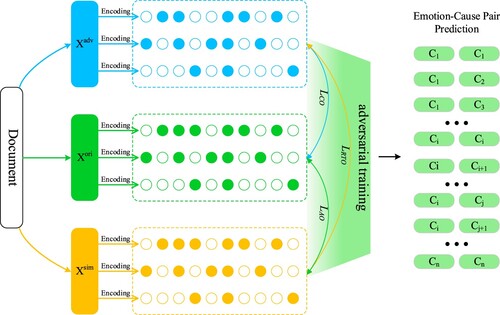
CL-ECPE is a simple method. Generate adversarial samples and
according to the original input data
. Among them,
and
represent the sentences generated by two different adversarial sample generation methods. This paper uses synonym and antonym substitutions to generate two different adversarial samples. After encoding sentences, the contrastive sets and adversarial sets are constituted as per a certain proportion. The adversarial sets consist of all adversarial samples with a word substitution. The contrastive sets were composed of the original data and the adversarial samples with a word substitution. The adversarial training is conducted with the adversarial and original samples to minimise contrastive loss. The contrastive loss function is added to the ECPE model, and the emotion-cause pair is extracted as the extraction result. To summarise, this work main contributions are two-fold as follows:
This paper integrates the contrastive learning method into the Emotion-Cause pairs extraction. Through the contrastive learning method, the features of ECPE tasks can be better learned. Contrastive learning is used to improve the extraction precision of ECPE tasks.
Contrastive and adversarial sets are constructed by using the adversarial sample generation method. According to the original data features, the adversarial samples are generated to construct the contrastive and adversarial sets. Furthermore, the robustness of the model is enhanced by adversarial training with adversarial samples.
CL-ECPE is a simple but effective method that can improve ECPE task extraction precision. The first advantage is to build adversarial samples by using synonyms and antonyms. The positive examples formed by synonyms and negative examples constituted by antonyms can strengthen the contrastive learning effect. This method calculates the most likely Emotion-Cause pairs in the sample by replacing the emotional words. The second advantage is using the replacement of allographs to enhance the model robustness for Chinese data. Experiments were conducted on standard emotion-cause pair extraction datasets to verify the effectiveness of CL-ECPE. Specifically, CL-ECPE could enhance the robustness and improve the extraction precision of the model.
The structure of this paper is as follows: Section 2 briefly introduces the related work. Section 3 introduces the pilot experiment to verify the impact of adversarial samples. Section 4 details the method and training objectives of this paper. Section 5 introduces the relevant experimental settings and makes a detailed analysis. And summarises this work and looks forward to future work in Section 6.
2. Related works
The main component of this work is contrastive learning of the ECE and ECPE tasks, so the survey of previous work mainly focuses on these two parts.
2.1. ECE and ECPE
The task of ECE (Emotion-Cause Extraction) was presented in 2010 (Lee et al., Citation2010). Lee et al. (Citation2010) constructed a small Chinese corpus and annotated it. The extraction methods mainly include rule-based methods (Gui et al., Citation2016; Hu et al., Citation2021a; Li, Zhao, et al., Citation2021) and machine learning-based methods (Diao et al., Citation2020; Turcan et al., Citation2021; Xu et al., Citation2021). ECE does not consider the correlation between emotion and cause. Due to the apparent limitation of the ECE and improving the precision of extraction results, Xia and Ding (Citation2019) proposed the Emotion-Cause Pair Extraction (ECPE) task. Some researchers studied the correlation between the two steps of ECPE (Ding et al., Citation2020a; Yu et al., Citation2021) to improve its extraction precision. Some scholars from the end-to-end perspective (Chen et al., Citation2020; Fan, Wang, et al., Citation2020) research ECPE tasks. They extracted Emotion-Cause pairs from different perspectives such as emotion and cause, which improved extraction precision. According to the classification of research clauses, ECE and ECPE tasks can be divided into Span-level (Li, Zhao, et al., Citation2021; Li, Gao, et al., Citation2021; Fan, Yuan, et al., Citation2021), Clause-level (Tang et al., Citation2020; Hu et al., Citation2021b), and Multi-level (Tang et al., Citation2020; Yu et al., Citation2019).
2.2. Contrastive learning
Contrastive learning constructs positive and negative examples for adversarial training to minimise contrast loss. The positive examples are close, and the negative examples are far away to enhance model learning ability and robustness. Existing studies have shown (Li et al., Citation2022) that contrastive learning by adversarial training can improve extraction precision and enhance model robustness in text and image. For the contrastive learning work in Chinese, the contrast effect of negative examples is more pronounced. Due to the particularity of Chinese data and improving the learning ability, the positive and negative examples should be structured differently. There are three common construction methods, namely inserting and replacing keywords (Chen et al., Citation2021; Giorgi et al., Citation2021; Wang et al., Citation2021), using adversarial samples (Hu et al., Citation2021), and directly constructing from the original document (Liu & Liu, Citation2021). These methods have advantages in constructing positive and negative examples, and different ways are selected according to different task types.
The ECPE task was based on different extraction methods or labelling methods. That is different from our work. We suggest that when extracting emotional cause pairs, the impact of adversarial samples should be considered. We recommend using contrastive learning to enhance model robustness and improve extraction precision. When generating a contrastive learning sample set, we should consider the features of the data. Constructing the appropriate sample set directly from the original document can enhance the correlation between raw data. In this paper, we take a method of directly constructing contrastive sets from the original document adopted.
3. Pilot experiment and analysis
Pilot experiments and results analysis are carried out in this section to study the robustness of the existing models on the adversarial set and the contrastive set.
3.1. Model and datasets
We want to construct adversarial and contrastive sets, and it is necessary to analyze the data. In our work, the adversarial samples of synonyms generated by the TextBugger (Li et al., Citation2019) model as the positive samples, and the adversarial samples of antonyms generated by the IG algorithm (Alzantot et al., Citation2018) as the negative samples. Moreover, the robustness of the model is tested by substituting allographs. Based on this, adversarial sets with both antonym substitution and generic substitution and contrastive sets with both synonyms and antonyms are obtained. The data were selected Benchmark ECE corpus (Gui et al., Citation2016) and NTCIR-13ECE (Singh et al., Citation2021), labelled with emotional words and emotional labels. An example of adversarial attacks is shown in Figure . When the core sentiment words are replaced by different methods (synonyms and antonyms replacement), the final extraction results of ECPE have changed. Adversarial sample attacks will change the emotion and causality of sentences, which will deteriorate the extraction results.
Figure 2. An adversarial sample of emotion-cause pair extraction.

We use several different Emotion-Cause Pair Extraction task methods: ECPE-2Steps (Xia & Ding, Citation2019), ECPE-MLL (Ding et al., Citation2020b), Trans-ECPE (Fan, Yuan, et al., Citation2020), RANKCP (Wei et al., Citation2020), ECPE-2D (Ding et al., Citation2020a), E2E-PExtE (Singh et al., Citation2021) as Pilot Experiment model. Evaluate those methods effect on adversarial sets and contrastive sets. Those methods have achieved good results in the recent ECPE task and representatives of the industry's latest achievements. By comparing the results of those models on the adversarial sets and the contrastive sets, the disadvantages of those methods tasks can be shown more clearly.
3.2. Result and analysis
Table shows the comparison results of different models on the adversarial sets and contrastive sets, where the original set is the precision value corresponding to the highest F1 value of each model. The results show that the extraction precision of the six models on the benchmark ECE corpus is not much different. The precision is significantly reduced on the adversarial and contrastive sets, which shows poor robustness. The extraction precision of ECPE-2D and Trans-ECPE decreased by more than 30% on the adversarial sets. That is related to the vulnerability of the original dataset to attack and the poor robustness of the existing model. In addition, the precision of E2E-PExtE in the contrastive sets increased by 1.40%. We believe that the result of the original method was trained on English data, which is inconsistent with the current task test on the Chinese data set.
Table 1. Precision (%) on the adversarial sets compared to the contrastive sets of different models.
When encountering adversarial attacks, the precision of existing model extraction decreases. Comparing the data in Table , we found that the precision of the model decreases very little or even may increase slightly on the contrastive sets. The contrastive sets contain both adversarial samples and raw samples, and the model learns the features of adversarial samples. We found that the contrastive sets contain different data, which has played a certain role in promoting the original model. Therefore, adversarial training can try contrastive learning to strengthen the extraction precision and the model's robustness.
4. Method
As stated in the pilot experimental result in Section 3, we explore strategies that could enhance the robustness of the ECPE task. This section mainly focuses on our method CL-ECPE, a simple but effective method that can construct contrastive sets and learn from them. Different adversarial samples for contrastive learning construct adversarial and contrastive sets. Firstly, the ECPE task is briefly introduced in 4.1. Then, the adversarial samples are generated, and the contrastive sets are constructed in section 4.2. Section 4.3 introduces the learning objectives of CL-ECPE.
4.1. Description of ECPE task
The input document D contains multiple clauses . The task goal of ECPE is to extract Emotion-Cause pairs from D:
(1)
(1) where
represents the emotional clause and
represents the corresponding cause clause. There is no difference in order.
4.2. Generation of contrastive sets
Contrastive learning is the core of CL-ECPE, and the construction of contrastive sets is crucial. We hope that compared with sentences with similar and opposite emotional words, the model can become more sensitive to the implicit emotion in the original sentence, thus better learning the contrastive features. For this reason, we adopt positive and negative examples with opposite meanings from contrastive sets. Based on this, the idea of contrastive learning is more suitable for learning the different features of positive and negative examples. Therefore, the choice of positive and negative examples is essential. To better learn the features of positive and negative examples, we describe positive and negative examples as follows: positive examples (synonym replacement samples), negative examples (antonym replacement samples), and contrastive sets (raw data and negative examples). We can use contrastive learning to better achieve the ideal goal by learning negative example features.
The adversarial sample is generated by substituting antonyms as a negative example, making the emotion in the substitution sentence irrelevant to or opposite the original text. For the ECPE task, the implicit emotion in the uncorrected sentence can be extracted, which helps to improve the precision. At the same time, the replacement of antonyms as adversarial samples can make the emotions stronger. As shown in Figure , given the input sample: “①男子发现未婚妻与他人玩暧昧, (The man found that his fiancee was ambiguous with others) ②愤怒约战情敌将其捅成重伤。 (He was angry fighting with the enemy, and the enemy was stabbed badly.) ③因涉嫌故意伤害罪, (On suspicion of intentional injury,) ④郭某被抓获。 (Guo was arrested.)”. The adversarial sample generation method performs the following actions, replacing “愤怒 (anger)” with “开心 (happy)”, turning “重 (badly)” into “轻 (easily)”, and “捅 (stab)” was replaced by the allograph “通 (pass)”. Finally, the clause “①男子发现未婚妻与他人玩暧昧, (The man found that his fiancee was ambiguous with others) ②开心约战情敌将其通成轻伤。 (He was happy to fight with the enemy, and the enemy was passed easily.) ③因涉嫌故意伤害罪, (On suspicion of intentional injury,) ④郭某被抓获。 (Guo was arrested.)” was obtained, which is irrelevant to and contradictory to the original. The former sentence contradicts the latter sentence, and the latter constitutes a negative example – the two sentences as a set of basic in the contrastive sets.
Figure 3. An illustration of the relationship between our model training objectives. (The original sample translation is: The man found that his fiancee was ambiguous with others, he angry fighting with the enemy and the enemy was stabbed badly. On suspicion of intentional injury, Guo was arrested.)
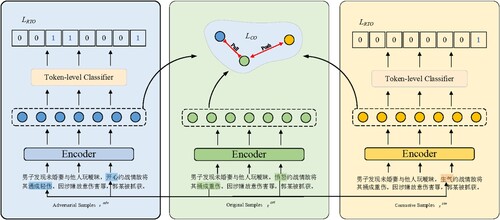
Two adversarial sample clauses are generated by the original input sample . The sub-sentences in which the adversarial samples are far from
in both semantics and glyphs are denoted as
, and the sub-sentences in which the adversarial samples are similar in meaning are denoted as
. Specifically, we used some adversarial sample generation methods (Alzantot et al., Citation2018; Li et al., Citation2019) to generate adversarial samples.
generated by antonym substitution and allograph substitution of the original sentence,
generated by synonym substitution of the original sentence. To better play the effect of contrastive learning, the replacement ratios of tokens in
and
are different. The
only replace the core emotional words, and
replace the original sentences as much as possible. In short,
only replaces emotional words with synonyms. There are a few emotional words that will be replaced in a sentence. The
replaces all the words in the sentence that conform to the
substitution rule. In this way, the contrast between
and
is more obvious.
4.3. Training objectives
The core of the ECPE task is to find the emotional cause pairs. Adversarial sample attacks will change the emotional and emotion-cause pair of sentences. There are three main training objectives of CL-ECPE: replaced token objective, adversarial objective, and contrastive objective. Training objectives are to make the model more sensitive to the causal relationship caused by the change of sentence emotion in the adversarial training stage. The training goal is mainly to map the input sequence to the representation sequence tokens
through
to the parameter encoder
, where the range of
, d is determined by Formula (2):
(2)
(2)
4.3.1. Replaced token objective
Based on the generated and
, classifier C is used to classify the generated two sequences, and the sigmoid output layer is used to determine which token is changed:
(3)
(3)
(4)
(4)
The loss function, denoted as , which calculated by Formula (5):
(5)
(5) Where
indicates that the position token is replaced, otherwise
indicates it is not replaced.
4.3.2. Adversarial objective
In the extraction of emotional causes, the preferred goal of CL-ECPE is to tell the model what is wrong. In other words, the measurement distance between and
must be far enough. We use
to represent the part different from
in
, then
represents the word before
has not been modified, and
represents the modified word. The measure between the two modifiers is calculated as the dot product embedded in
and
:
(6)
(6)
The loss function, denoted as , which calculated by Formula (7):
(7)
(7)
4.3.3. Contrastive objective
In the CL-ECPE method, the task is to determine whether the semantics change when the original sentence changes. In the feature space, and
metric distance is close enough,
and
metric distance is far enough (the same as Adversarial Objective). Therefore, positive pair (
,
) and negative pair (
,
) are set in contrastive learning. Where the modification was represented by
. The measure between sentences calculates the dot product between
embeddings:
(8)
(8)
The loss function, denoted as , which calculated by Formula (9):
(9)
(9)
To simultaneously improve the extraction precision and model robustness, CL-ECPE uses generated by multiple groups for training. Eventually, the training loss function can be obtained:
(10)
(10)
Where is the task weight at training.
The process of training objectives is shown in algorithm 1.
Table
5. Experiments and analysis
In this section, multiple sets of experiments were conducted and analyzed to verify the effectiveness of CL-ECPE. Firstly, the experimental setup and data set (Section 5.1) are introduced. Then, the experiments of the contrastive sets (Section 5.2) and the adversarial sets (Section 5.3) are introduced, respectively. Finally, the ablation study and the robust detection (Section 5.4) are carried out.
5.1. Implementation
For easier task execution without training data from scratch, we conduct adversarial training based on ECPE-2Steps (Xia & Ding, Citation2019). The experiment is implemented on the local device with python. Need to provide some hardware support. Device information includes CPU, hard disk, operating system information, and memory. CPU is “Intel (R) Core (TM) i9-10850 K CPU @ 3.60GHz”, RAM is 32.0 GB, hard disk is 2 T, GPU is “MAX SUN MS-GeForce RTX3060 i-Craft OC 12G”,and operating system is Win10 education edition. The word vector dimension is set to 300, and the relative position dimension is 60. An Adam optimiser with an initial learning rate of 3e-5 is used without scheduler and weight attenuation to optimise the proposed method. For all data sets, the epoch is 500, and the batch size is set to 1024. Our model was evaluated against six similar models on the ECPE benchmark dataset.
5.2. Experiments on contrastive sets
The generated samples construct the contrastive sets, and the model is trained on the contrastive sets. The trained model was compared with six existing ECPE models:
ECPE-2Steps is the first interactive multi-task learning model of two-step emotional cause pair extraction (Xia & Ding, Citation2019).
ECPE-MLL is a new multi-label learning model based on a sliding window, which solves the problem of morbid emotional cause extraction and error transfer in the pipeline (Ding et al., Citation2020b).
Trans-ECPE adopts a directed graph with marked edges and identifies emotions with corresponding reasons (Fan, Yuanet al., Citation2020).
RANKCP adopts a graph attention network to model the relationship between sub-sentences in the document to learn clause representation. And it enhances clause pair representation by embedding relative positions based on the kernel to rank effectively (Wei et al., Citation2020).
ECPE-2D is based on an end-to-end method to generate emotional cause pairs directly (Ding et al., Citation2020a).
E2E-PExtE adapts the NTCIR-13 ECE corpus and establishes a baseline for the ECPE task (Singh et al., Citation2021).
According to the contrast consistency principle (Gardner et al., Citation2020), qualified models do not cause any changes to the raw data, that is, to validate our model against the original task test set. The ratio of positive to negative in the contrastive text set is 5:5. The results are shown in Tables and :
Table 2. Precision (%) on the Chinese original test set and chinese contrastive test set. (“♣” denotes the model in our work)
The data in Table is more intuitive in Figure .
Figure 4. Precision (%) on different Chinese test sets.
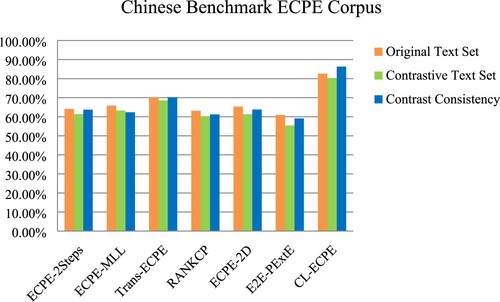
Our results are far superior to the existing model. Based on Table and Figure , the precision of CL-ECPE on the original text set was 12.49%−21.71% higher than that of the control group; the precision on the contrastive sets decreased significantly, while CL-ECPE only decreased by 2.32%, which was 11.78%−24.94% higher than other groups. From contrast consistency, our model is 3.68% higher than that in the original text set and 16.09%- 27.19% higher than that in other groups. The verification on the comparison test set means that our model is susceptible to changes in emotion or semantics rather than simply extracting features from the dataset. On the other hand, our model is superior to the existing models on the original test set. Our method can improve the precision of existing ECPE extraction.
The data in Table is more intuitive in Figure .
Table 3. Precision (%) on the english original test set and english contrastive test set. (“♣” denotes the model in our work)
Figure 5. Precision (%) on different English test sets.
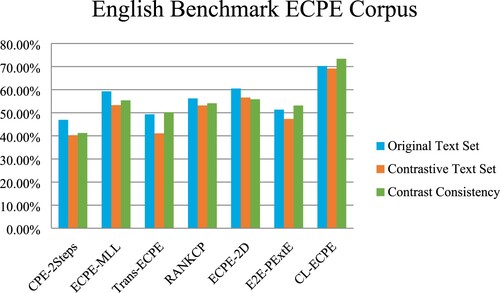
The verification results in the English dataset also show that our model is superior to the existing model. On the English Contrastive Text Set, the precision of CL-ECPE is 12.53%–28.86% higher than that of the existing model. Similarly, it is superior to other models in Original Text Set and Contrast Consistency. This verifies that CL-ECPE also has excellent performance on English data sets. The extraction precision of CL-ECPE on the English dataset is lower than that of the Chinese dataset because of the limitation of English grammatical structure.
Our model achieves high extraction precision on Chinese and English data sets. It is proven that adversarial training based on data generated by the adversarial sample generation method is effective.
5.3. Experiments on adversarial sets
Given that the Chinese data change will change the results, we can have better results in robustness verification on Chinese data sets. We compare this work model with several other models in the adversarial test set to test our model robustness. We do not use the common white-box attack method to attack our model. In CL-ECPE, which used the existing adversarial sample generation method (Gao et al., Citation2018; Nuo et al., Citation2020; Tong et al., Citation2020; Wang et al., Citation2019), generated the adversarial as the test set. The adversarial sets contain 2000 adversarial samples generated by the attack method to test the robustness of the model. The experimental results are as follows Table shows:
Table 4. Precision (%) on the adversarial test set (“♣” denotes the model in our work)
The data in Table is more intuitive in Figure .
Figure 6. The precision of adversarial sets under different generation methods. (Among them, Wang et al., Tong et al., Gao et al., and Nuo et al.correspond to different confrontation sample generation methods)
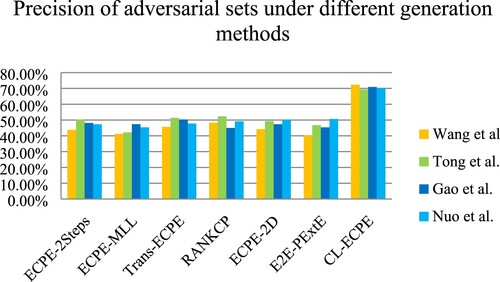
The existing models have no defence ability against adversarial sample attacks and have poor robustness. Adversarial attacks make the extraction precision has dramatically reduced. When dealing with different attacks, our model has far less decline than other models and shows strong robustness. In the tests of different adversarial methods, WordHandling (Wang et al., Citation2019) was used to test CL-ECPE and other contrastive models. Compared with the original test set, our model decreased by 10.26%, and other models decreased by 14.8%−24.61%. When using CWordAttacker (Tong et al., Citation2020) to test our model, the decrease was 13.27%, and that of other models was 10.81%−23.63%. Using DeepWordBug (Gao et al., Citation2018) to test our model, the decline was 11.72%, and the decline of other models was 15.6% −19.83%. WordChange (Nuo et al., Citation2020) was used to test our model, the decline was 12.3%, and the other models decreased by 10.28% −22.39%.
5.4. Ablation study
We want to verify the influence of the proportion of concentrated samples on the experimental results, and the ablation study was set for verification. Set the feedback ablation study to w/o RT on the contrastive text set: Remove the replacement target to verify that our model depends primarily on the replacement target. According to positive and negative combinations into contrastive sets, we generated 2000 adversarial samples. We also set the ablation group with the ratio of the contrastive test set as 1:9, 2:8, 3:7, 4:6, 5:5, 6:4, 7:3, 8:2, and 9:1. Whether the contrastive sets formed under different proportions significantly impacts the experimental results. The optimal composition ratio can better carry out contrastive learning. The experimental results are shown in Table :
Table 5. Ablation study on the contrastive text set of CL-ECPE.
It proves that the replacement target can further improve the data sensitivity of the model. From Table , we found that our model is optimal on the contrastive text set when the ratio of positive and negative cases is 5:5. Moreover, it can be seen from w/o RT that the precision rate of the model with the removal of the replacement target reaches the highest at 5:5 in different proportions, with a decline of 11.95%; when the minimum decline is 6.16%, and the ratio of positive to negative is 3:7.
5.5. Robust detection
For the CL-ECPE model, CLEVER (Weng et al., Citation2018) is used for robustness detection. The robustness of the model is measured by using the CLEVER method. CLEVER estimates the lower bound of robustness by sampling the norm of the gradient and fitting the limit distribution by extreme value theory. CLEVER is consistent with the and
robustness specification and measures robustness by scoring. CLEVER does not rely on attack-agnostic to measure model robustness. The adversarial training data in this paper comes from different adversarial sample generation methods, and CLEVER can better measure the robustness of CL-ECPE. Compare CL-ECPE with the latest methods. The test results are shown in Table :
Table 6. Comparison of the average and
distortions under CLEVER. (“♣” denotes the model in our work)
Compared with other models, CL-ECPE is robust. It can be found from Table that the and
values of CL-ECPE are the lowest than those of other models. The data in Table compares the paradigm values of several models. The data show that the local Lipschitz constant is used to estimate the lower boundary of the shortest adversarial distance. A small value indicates that the shortest adversarial distance is short, proving the model is robust. CL-ECPE through adversarial training method to improve the generalisation ability of the model. Based on training objectives (Section 4.3), CL-ECPE learns the difference between different adversarial samples. Moreover, the minimisation of the loss function
ensures the minimum confrontation distance, which ensures the strong robustness of our model.
6. Conclusions
This paper focuses on the ECPE task. Compared with the existing models, this paper fully considers the impact of adversarial samples on raw data. When encountering simple adversarial attacks, it causes a small disturbance to the data, and the extraction precision of CL-ECPE is more stable. This reveals the strong robustness of our model. Therefore, we conclude that CL-ECPE can improve the extraction accuracy and has strong robustness. In the training phase, positive, negative, and contrastive sets are generated by constructing adversarial samples. Different methods generate these adversarial samples. Through the respective train of training objectives, make full use of the original information of the different data sets. The main contributions of this paper are:
An ECPE extraction method based on contrastive learning is proposed, improving extraction precision. This method can effectively learn the features of emotion-cause pairs from the contrastive data sets. These features can improve extraction precision.
The robustness of the model is enhanced by adversarial training. The adversarial training sets are constructed by data generated from different adversarial sample generation methods with rich features. Adversarial training enables CL-ECPE to learn more features from adversarial samples. The model learns more adversarial samples feature can enhance robustness.
In the future ECPE tasks, we will consider integrating causality into adversarial training to improve the sensitivity of the extraction task. Want to improve the extraction precision from the perspective of the relationship.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Alzantot, M., Sharma, Y., Elgohary, A., Ho, B. J., Srivastava, M., & Chang, K. W. (2018). Generating natural language adversarial examples. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2890–2896. https://doi.org/10.18653/v1/D18-1316
- Chen, T., Shi, H., Tang, S., Chen, Z., Wu, F., & Zhuang, Y. (2021). CIL: Contrastive instance learning framework for distantly supervised relation extraction. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 1, 6191–6200. https://doi.org/10.18653/v1/2021.acl-long.483
- Chen, Y., Hou, W., Li, S., Wu, C., & Zhang, X. (2020). End-to-end emotion-cause pair extraction with graph convolutional network. Proceedings of the 28th International Conference on Computational Linguistics, 198–207. https://doi.org/10.18653/v1/2020.coling-main.17
- Cheng, Z. F., Jiang, Z. W., Yin, Y. F., Li, N., & Gu, Q. (2021). A unified target-oriented sequence-to-sequence model for Emotion-Cause pair extraction. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 2779–2791. https://doi.org/10.1109/TASLP.2021.3102194
- Diao, Y., Lin, H., Yang, L., Fan, X., & Xu, B. (2020). Multi-granularity bidirectional attention stream machine comprehension method for emotion cause extraction. Neural Computing and Applications, 32(12), 8401–8413. https://doi.org/10.1007/s00521-019-04308-4
- Ding, Z., Xia, R., & Yu, J. (2020a). ECPE-2D: Emotion-cause pair extraction based on joint two-dimensional representation, interaction and prediction. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 3161–3170. https://doi.org/10.18653/v1/2020.acl-main.288
- Ding, Z., Xia, R., & Yu, J. (2020b). End-to-end emotion-cause pair extraction based on sliding window multi-label learning. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 3574–3583. https://doi.org/10.18653/v1/2020.emnlp-main.290
- Fan, C., Yuan, C., Du, J., Gui, L., Yang, M., & Xu, R. (2020, July). Transition-based directed graph construction for emotion-cause pair extraction. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 3707–3717. https://doi.org/10.18653/v1/2020.acl-main.342
- Fan, C., Yuan, C., Gui, L., Zhang, Y., & Xu, R. (2021). Multi-task sequence tagging for emotion-cause pair extraction via tag distribution refinement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 2339–2350. https://doi.org/10.1109/TASLP.2021.3089837
- Fan, R., Wang, Y., & He, T. (2020). An End-to-End multi-task learning network with scope controller for Emotion-Cause pair extraction. In X. Zhu, M. Zhang, Y. Hong, & R. He (Eds.), Natural Language Processing and Chinese computing. NLPCC 2020 (pp. 764–776). Springer Press.
- Fan, W., Zhu, Y., Wei, Z., Yang, T., Ip, W. H., & Zhang, Y. (2021). Order-guided deep neural network for emotion-cause pair prediction. Applied Soft Computing, 112, 107818. https://doi.org/10.1016/j.asoc.2021.107818
- Gao, J., Lanchantin, J., Soffa, M. L., & Qi, Y. (2018). Black-Box generation of adversarial Text sequences to evade deep learning classifiers. 2018 IEEE Security and Privacy Workshops (SPW), 50–56. https://doi.org/10.1109/spw.2018.00016
- Gardner, M., Artzi, Y., Basmov, V., Berant, J., Bogin, B., Chen, S., … Zhou, B. (2020). Evaluating models’ local decision boundaries via contrast sets. Findings of the Association for Computational Linguistics: EMNLP, 2020, 1307–1323. https://doi.org/10.18653/v1/2020.findings-emnlp.117
- Giorgi, J., Nitski, O., Wang, B., & Bader, G. (2021). Declutr: Deep contrastive learning for unsupervised textual representations. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 1, 879–895. https://doi.org/10.18653/v1/2021.acl-long.72
- Gui, L., Wu, D. Y., Xu, R. F., Lu, Q., & Zhou, Y. (2016). Event-Driven emotion cause extraction with corpus construction. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 1639–1649. https://doi.org/10.18653/v1/D16-1170
- Hu, G., Lu, G., & Zhao, Y. (2021a). Bidirectional hierarchical attention networks based on document-level context for emotion cause extraction. Findings of the Association for Computational Linguistics: EMNLP, 2021, 558–568. https://doi.org/10.18653/v1/2021.findings-emnlp.51
- Hu, G., Lu, G., & Zhao, Y. (2021b). FSS-GCN: A graph convolutional networks with fusion of semantic and structure for emotion cause analysis. Knowledge-Based Systems, 212, 106584. https://doi.org/10.1016/j.knosys.2020.106584
- Hu, Q., Wang, X., Hu, W., & Qi, G. J. (2021). Adco: Adversarial contrast for efficient learning of unsupervised representations from self-trained negative adversaries. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1074–1083. https://doi.org/10.1109/cvpr46437.2021.00113
- Lee, S. Y. M., Chen, Y., & Huang, C. R. (2010, June). A text-driven rule-based system for emotion cause detection. Proceedings of the NAACL HLT 2010 workshop on computational approaches to analysis and generation of emotion in text (pp. 45-53). Association for Computational Linguistics Press.
- Li, J., Ji, S., Du, T., Li, B., & Wang, T. (2019, February 24-27). Textbugger: Generating adversarial text against real-world applications. 2019 network and distributed system security symposium, San diego, CA, USA.
- Li, M., Zhao, H., Su, H., Qian, Y., & Li, P. (2021). Emotion-cause span extraction: A new task to emotion cause identification in texts. Applied Intelligence, 51(10), 7109–7121. https://doi.org/10.1007/s10489-021-02188-7
- Li, X., Gao, W., Feng, S., Wang, D., & Joty, S. (2021). Span-Level emotion cause analysis by BERT-based graph attention network. Proceedings of the 30th ACM International Conference on Information & Knowledge Management, 3221–3226. https://doi.org/10.1145/3459637.3482185
- Li, Y., Dai, H. N., & Zheng, Z. B. (2022). Selective transfer learning with adversarial training for stock movement prediction. Connection Science, 34(1), 492–510. https://doi.org/10.1080/09540091.2021.2021143
- Liu, Y., & Liu, P. (2021). Simcls: A simple framework for contrastive learning of abstractive summarization. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2, 1065–1072. https://doi.org/10.18653/v1/2021.acl-short.135
- Nuo, C., Chang, G. Q., Gao, H., Pei, G., & Zhang, Y. (2020). Wordchange: Adversarial examples generation approach for Chinese Text classification. IEEE Access, 8, 79561–79572. https://doi.org/10.1109/ACCESS.2020.2988786
- Singh, A., Hingane, S., Wani, S., & Modi, A. (2021, April). An End-to-End network for Emotion-Cause pair extraction. Proceedings of the eleventh workshop on computational approaches to subjectivity, sentiment and social media analysis (pp. 84-91). Association for Computational Linguistics Press.
- Tang, H., Ji, D., & Zhou, Q. (2020). Joint multi-level attentional model for emotion detection and emotion-cause pair extraction. Neurocomputing, 409, 329–340. https://doi.org/10.1016/j.neucom.2020.03.105
- Tong, X., Wang, L., Wang, R., & Wang, J. (2020). A generation method of wordlevel adversarial samples for Chinese Text classification. Netinfo Security, 20(9), 12–16. https://doi.org/10.3969/j.issn.1671-1122.2020.09.003
- Turcan, E., Wang, S., Anubhai, R., Bhattacharjee, K., Al-Onaizan, Y., & Muresan, S. (2021). Multi-Task learning and adapted knowledge models for Emotion-Cause extraction. In Findings of the Association for Computational Linguistics: Acl-IJCNLP, 2021, 3975–3989. https://doi.org/10.18653/v1/2021.findings-acl.348
- Wang, D., Ding, N., Li, P., & Zheng, H. (2021). Cline: Contrastive learning with semantic negative examples for natural language understanding. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 1, 2332–2342. https://doi.org/10.18653/v1/2021.acl-long.181
- Wang, Q., Zhu, G., Zhang, S., Li, C., Chen, X., & Xu, H. (2020). Extending emotional lexicon for improving the classification accuracy of Chinese film reviews. Connection Science, 33(2), 153–172. https://doi.org/10.1080/09540091.2020.1782839
- Wang, W. Q., Wang, R., Wang, L. N., & Tang, B. X. (2019). Adversarial samples generation approach for tendency classification on Chinese texts. Journal of Software, 30(8), 2415–2427. https://doi.org/10.13328/j.cnki.jos.005765
- Wei, P., Zhao, J., & Mao, W. (2020). Effective inter-clause modeling for end-to-end emotion-cause pair extraction. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 3171–3181. https://doi.org/10.18653/v1/2020.acl-main.289
- Wei, Z., Liu, W., Zhu, G., Zhang, S., & Hsieh, M. Y. (2021). Sentiment classification of Chinese weibo based on extended sentiment dictionary and organisational structure of comments. Connection Science, 409–428. https://doi.org/10.1080/09540091.2021.2006146
- Weng, T. W., Zhang, H., Chen, P. Y., Yi, J. F., Su, D., Gao, Y. P., Hsieh, C., & Daniel, L. (2018, April 30-May 3). Evaluating the robustness of neural networks: An extreme value theory approach. Proceedings of the sixth international conference on learning representations (ICLR 2018). vancouver, BC, Canada.
- Xia, R., & Ding, Z. (2019). Emotion-cause pair extraction: A new task to emotion analysis in texts. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 1, 1003–1012. https://doi.org/10.18653/v1/P19-1096
- Xu, B., Lin, H., Lin, Y., & Xu, K. (2021). Two-stage supervised ranking for emotion cause extraction. Knowledge-Based Systems, 228, 107225. https://doi.org/10.1016/j.knosys.2021.107225
- Yan, Y., Xiao, Z., Xuan, Z., & Ou, Y. (2021). Implicit emotional tendency recognition based on disconnected recurrent neural networks. International Journal of Computational Science and Engineering, 24(1), 1–8. https://doi.org/10.1504/IJCSE.2021.113616
- Yu, J., Liu, W., He, Y., & Zhang, C. (2021). A mutually auxiliary multitask model With self-distillation for Emotion-Cause pair extraction. IEEE Access, 9, 26811–26821. https://doi.org/10.1109/ACCESS.2021.3057880
- Yu, X., Rong, W., Zhang, Z., Ouyang, Y., & Xiong, Z. (2019). Multiple level hierarchical network-based clause selection for emotion cause extraction. IEEE Access, 7, 9071–9079. https://doi.org/10.1109/ACCESS.2018.2890390
- Zhang, S., Yu, H., & Zhu, G. (2022). An emotional classification method of Chinese short comment text based on ELECTRA. Connection Science, 34(1), 254–273. https://doi.org/10.1080/09540091.2021.1985968