
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In the field of image segmentation in industrial production. When using depth neural network to extract features from image information. Deep neural network can not effectively use the feature information between different levels. The accuracy of image semantic segmentation is damaged. To solve this problem, we present an image semantic segmentation with hierarchical feature fusion based on deep neural network (ISHF). It can be widely used in image perception and recognition of various living and industrial backgrounds. This algorithm uses convolution structure to extract the shallow low-level features with pixel level and the deep semantic features with image level, fully obtaining the hidden feature information in the shallow low-level features and deep semantic features. Then, after thinning the shallow low-level feature information by up-sampling operation, all feature information is merged and fused. Finally, the image semantic segmentation of hierarchical feature fusion is realised. Experimental results shows that our proposed method not only get better performance of image semantic segmentation, but also achieve faster running speed than SegNet, PSPNet, and DeepLabV3.
1. Introduction
Image processing mainly involves image enhancement and restoration (Ibrahim et al., Citation2022; Zhai et al., Citation2022; Chen et al., Citation2017b), image semantic segmentation (Wang et al., Citation2019), and image recognition (Guo et al., Citation2022). Among them, image semantic segmentation as an important part of image processing has received more and more attention from researchers. As a key step from image processing to image analysis, it is of great significance to extract the key information of the image. Meanwhile, image semantic segmentation still has great application prospects in related fields such as target detection, image recognition and target tracking. For example, in the field of unmanned vehicle driving (Deng & Ye, Citation2022; Nahavandi et al., Citation2022), obstacles in the input image are obtained by image segmentation, which provides security for unmanned vehicles. In the field of earth survey (He et al., Citation2019; Lin et al., Citation2018), the landmark buildings in remote sensing images are analyzed by image segmentation, which helps researchers to complete identification. Therefore, it is of great significance and practical value to study image segmentation.
At present, image semantic segmentation methods are mainly divided into four categories, namely, methods based on threshold, edge (Du et al., Citation2020), region and deep learning. Among them, the threshold-based segmentation algorithm (Choy et al., Citation2017; Yamini & Sabitha, Citation2017; Yang et al., Citation2015; Ying-ming & Feng, Citation2005 ) divides the information in the grey image according to the set threshold, mainly including Otsu method, maximum entropy method and clustering method. These methods have the advantages of simple operation, easy realisation and stable performance, but they also have the disadvantages of excessive information loss and noise sensitivity. The segmentation method based on edge detection (Coates & Ng, Citation2012) realises the region segmentation of the image according to the significant boundary region of the image, mainly including first-order Sobel, Robert and second-order Laplacian differential operators. This kind of method has good segmentation effect for images with clear edge structure. However, for images with excessively slow edge, edge detection can not provide regional structure well. The region based segmentation method (Jinling & Zhaohui, Citation2012; Zeng et al., Citation2021; Zhang et al., Citation2021) converts the regions with large similarity into a whole according to the similarity of local regions to realise image segmentation, mainly including region growth method (Hojjatoleslami & Kittler, Citation1998), graphcut (Boykov & Jolly, Citation2001), etc. These methods are robust to noise, but they need to provide corresponding region segmentation criteria, which often leads to over segmentation of the image. Although these methods can realise image segmentation, they only realise image segmentation through the spatial structure, colour features, edge structure and other information of the image itself, and can not make use of the semantic information of the image, which greatly restricts the effect of image segmentation.
With the rapid development of deep learning (Park et al., Citation2022; Zhou et al., Citation2022; Chen et al., Citation2017b), the image semantic segmentation method based on deep learning has been widely used(Zhu, Citation2022). Because the deep learning method can be trained from massive samples, the essential expression of image content can be learned. Therefore, the deep learning method shows excellent segmentation performance. Among them, the image segmentation method based on convolutional neural network (CNN) (Hinton & Salakhutdinov, Citation2006; Sharif Razavian et al., Citation2014; Wang et al., Citation2022) is the current research hotspot. Convolutional Neural Network extracts different levels of image features from training samples through convolution, learns the semantic information in the image content from training samples, constructs the mapping relationship between the learning image and the target content, and finally realises the image segmentation task. For example, Long et al. first proposed fully convolutional networks (FCN) (Long et al., Citation2015), which realised the semantic segmentation of images by replacing the full connection layer in the convolutional neural network with full convolution layer. Its advantage is that it can output images of any size, and its efficiency is high, but its disadvantage is that the segmentation can not be completed accurately, and the segmentation results will have the problems of blurred edges and lost details. In order to better reflect the details of objects, Noh et al. replaced bilinear interpolation with deconvolution, and proposed DeconvNet (Noh et al., Citation2015) symmetric network architecture, which achieved fine segmentation of target content. This method adopts deconvolution and uppooling operation, which avoids the loss of details and unclear boundaries in segmentation, restores the spatial dimension of the image and the position information of pixels, and solves the problem that the resolution of the feature map decreases after pooling operation. However, compared with FCN, its network training parameters are too many and the calculation amount is larger. Lin et al. put forward RefineNet method by multi-path upsampling low-resolution feature maps of different levels and fusing multi-layer high-resolution feature maps (Lin et al., Citation2017) to realise multi-feature fused image segmentation. Its advantage is that by capturing context information, it solves the problems of large amount of calculation and memory consumption caused by using probability map model (Xu et al., Citation2019). But its disadvantage is that there will be the loss of boundary information in the process of obtaining segmentation results. Chen et al. use hole convolution to enlarge the receptive field of the feature map, and use the fully connected conditional random field to optimise the segmentation boundary. The DeepLabV1 method (Chen et al., Citation2014) is proposed to optimise the segmentation boundary. Its advantage is that multi-scale information can be obtained by hole convolution and has high invariance for spatial transformation, but the disadvantage is that the resolution of the feature image is not clear and the location accuracy is not obvious. To improve the above problems, a DeepLabV3 method was proposed (Chen, Papandreou et al. Citation2017a). An improved atrous spatial pyramid pooling (ASPP) (Chen, Papandreou et al. 2017) method is used to better capture image context information by cascading multiple convolutional modules with holes. The advantage is that feature maps of different receptive fields can be obtained and integrated in a spatial pyramid pooling mode. The shortcoming is that the segmentation of small scale objects is not obvious. Although the above methods can achieve image semantic segmentation well, the feature information between different levels of convolutional neural network cannot be deeply mined and utilised in the process of processing.
In order to make better use of the feature information among different levels and further improve the segmentation accuracy of image semantics, this paper proposes an image semantic segmentation with hierarchical feature fusion based on deep neural network (ISHF). In this method, the shallow low-level feature information and deep semantic feature information of the image are extracted respectively through the infrastructure with depth separable convolution blocks. And the feature information among different levels is mined step by step to make full use of the feature information among different levels. In addition, the shallow and low-level feature information is preferentially integrated with the deep semantic feature information, which enriches the feature information of the image, deepens the network learning of the image content, and realises more accurate semantic segmentation of the image.
We summarise our contributions as follows:
We propose an image semantic segmentation with hierarchical feature fusion based on deep neural network (ISHF) to fully utilise more feature information of different levels of image, improving the segmentation accuracy of image semantics.
We propose a deep semantic feature extraction to extract multi-level features of image and to learn the mapping of next-level feature, ensuring the richness and integrity of the deep semantic feature information.
Experimental results show that our proposed methods outperform other comparison methods and achieve better performance.
2. Related work
Segmentation targets in complex scenes have the characteristics of multi-scale. In order to realise feature learning for each scale target, DeepLab series methods have appeared, which adopt different ratios of cavity convolution to realise multi-scale structure, and PSPNET uses spatial pyramid pooling (SPP) to extract multi-scale target features, but the cavity convolution and pyramid pooling may lead to the loss of pixel positioning information. Another solution is to adjust the input images to various resolutions and send them to the network for training respectively, and fuse the output feature maps to achieve the effect of multi-scale learning, such as ICNet and other structures. However, a large number of calculations and the limitation of the network on the size of image input also become the disadvantages of this kind of methods. With the deepening of convolution network layers, the feature map obtained by the network layer becomes more abstract, and the reduction of resolution leads to the loss of a large amount of spatial information, that is, detail information. In order to rebuild the resolution until the feature map is restored to the size of the input image, a U-shaped structure of encoder and decoder appears. U-Net was proposed by Ronneburger et al. In the decoding process, the upsampled feature map of each stage is fused with the corresponding stage feature map of the previous encoder, and the shallow feature map is used to help the deep feature map recover the detailed information. However, the direct fusion operation may lead to inconsistent classification results of the same target by the network. Similar encoding and decoding networks, such as Refinnet, GCN and DDSC, all design complex decoding modules to improve the segmentation effect in the process of resolution reconstruction, but also increase the learning complexity of the networks. Other lightweight U-shaped structures such as Segnet, Enet and Deconvnet have a relatively balanced structure of encoder and decoder, but they can only achieve moderate segmentation effect. In order to extract semantic features and spatial detail features at the same time, two-branch networks such as Bisenet also appeared.
In this paper, we present an image semantic segmentation with hierarchical feature fusion based on deep neural network (ISHF), which uses convolution structure to extract the shallow low-level features with pixel level and the deep semantic features with image level, further mining the feature information between different levels, and fully obtaining the hidden feature information in the shallow low-level features and deep semantic features.
3. Image semantic segmentation with hierarchical feature fusion based on deep neural network
The purpose of image semantic segmentation is to achieve accurate localisation and classification of the content contained in an image. Due to the different model structures and extraction methods, shallow low-level features and deep-level semantic features become the main factors affecting the accuracy of image segmentation. In this paper, by fusing the feature information between different levels, the feature information can be fully utilised to achieve the purpose of improving the accuracy of image semantic segmentation.
3.1. Hierarchical feature extraction based deep neural network
When deep neural network is used for feature extraction in image semantic segmentation, the frequent use of maximum pool operation and downsampling operation will lead to the decrease of feature map resolution. As a result, the loss of image context information makes the segmentation results lose the sensitivity to the target location. In addition, using a single way to capture feature mapping will reduce the combination rate of image context information and previous feature information, and these features also contain detailed information and semantic information in the network path. Therefore, this paper uses the idea of classification to extract the feature information step by step so that it can be fully utilised.
In order to obtain the image feature information, this paper takes lightweight xception (Chen, Papandreou et al. 2017) as the main architecture to realise the hierarchical feature extraction. Hierarchical feature extraction mainly realises the extraction of shallow low-level feature information and deep semantic feature information. The process is divided into three classes, and the extraction structure of each class remains the same. The extraction class mainly includes three parts: Entry Flow, Middle Flow and Exit Flow. The Entry Flow part is mainly responsible for obtaining the shallow low-level feature information. The Middle Flow part is responsible for the transmission of the feature information and the feature information mining between different levels. The Exit Flow part is mainly responsible for obtaining the deep semantic feature information and merging the feature information into the channel information of the decoder through the full connection layer.
3.2. Feature processing and aggregation
Feature aggregation mainly realises the merging of shallow low-level feature information and deep semantic feature information. Among them, the shallow low-level feature information contains a large amount of structure and edge information, and some feature information that can help recover image boundaries will be discarded due to redundancy after direct fusion by up-sampling operation. Therefore, this paper uses the idea of first refinement and then fusion for the shallow low-level feature information in the feature fusion part, while the deep semantic feature information at each level is the optimal result obtained by level-by-level mining, so it is reserved for direct use.
3.2.1. Refine shallow low-level features
Conventional decoders generally use bilinear interpolation upsampling operation to convert rough segmentation results to fine results. The process is shown in formula (1):
(1)
(1) Where
denotes the extracted feature information,
denotes the label. However, conventional bilinear upsampling doesn't consider the correlation between each pixel, which limits the ability of accurately recovering pixel prediction, and reduces the utilisation rate of shallow low-level feature information. Therefore, in the decoding stage, this paper replaces bilinear upsampling by improving the upsampling of real-time data (Tian et al., Citation2019), so as to improve the utilisation rate of shallow and low-level feature information in the aggregation process.
Real-time data upsampling is to transform the structural information contained in into a new feature map
. The shallow low-level feature information output by encoder to decoder is
, and the final refinement is realised by calculating the difference between it and the reproduced
. Firstly, the step size of output feature information is defined as
, and
is divided into
squares with feature map of
size; then, the divided squares are constructed into a small three-dimensional window
, and a new vector
is generated by
(the sum of small three-dimensional windows with feature maps); finally, the vector
is transformed into the required low-dimensional vector
, and the vector
is rearranged from the horizontal and vertical directions to form the final
, which makes the information of the feature map rearranged, thus realising the transformation from
to
.
The specific forms of some vectors involved in the conversion process are shown in formula (2):
(2)
(2) Where
is used to transform
into a low-dimensional vector
;
is the opposite transformation, and
is the reconstructed space vector
.
And and
are obtained by minimising the error between
and
, and are formally expressed by formula (3):
(3)
(3) The replacement process of the final real-time data upsampling and bilinear interpolation is shown in formula (4):
(4)
(4) Where
represents a new feature mask graph, and the loss of
dimension is calculated after the transformation from
to
is realised; then, the output
of the encoder is upsampled by the transformed
, and the upsampling is applied to every shallow low-level feature of
(the output of the encoder); finally, the loss of
and
is calculated, thus realising the replacement of real-time data upsampling and bilinear interpolation upsampling, that is, the thinning of shallow and low-level feature information.
3.2.2. Feature aggregation
The realisation of feature aggregation is shown in Figure (the black dotted box in the figure indicates the fusion process of shallow low-level features and deep semantic features). After refinement, the shallow low-level feature information extracted by Entry Flow is convoluted to facilitate the fusion with deep semantic feature information. Hierarchical structure can not only ensure that shallow low-level features get enough local contour details, but also ensure that deep features get enough high-level semantic information. After the two kinds of feature information are merged and fused, the final prediction result is obtained by up-sampling processing.
Figure 1. Feature fusion process.
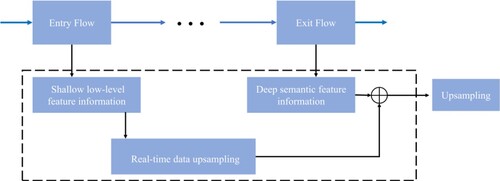
3.3. Deep neural network structure
Figure shows the complete process of this paper. The input image is processed by the first convolution to get the feature information, and then by Block2A, Block3A, Block4A containing depth-separable convolution blocks (the size is 1/2, 1/4, 1/8 of the input image size in turn). Each depth-separable convolution block is 3 × 3, and the step length of each convolution block is 2. The full connection attention-A (FCA-A) layer (with dimensions consistent with Block4A) uses the learned feature mappings to match the features from the extracted backbone. Block2B, BlockK3b and Block4B containing depth separable convolution blocks are used as the second feature extraction stage. The output features of Block2A are input as new features and the feature information of the second stage is obtained through BlockK3b and Block4B (the size is 1/2 and 1/4 of the input size in turn). Each depth separable convolution block is 3 × 3, and the step size of each convolution block is 2. The features are integrated into the channel information of the decoder through the full connection attention-B (FCA-B) (the size is consistent with that of Block4B). The output features of Block2B are used as the input features of Block2C to start the third stage of extraction, and the feature information of this stage is obtained by Block3C and Block4C containing depth-separable convolutional blocks (the size of which is 1/2 and 1/4 of the input size in turn). Each depth-separable convolutional block is 3 × 3, and the step length of each convolutional block is 2. The feature information is integrated into the channel information of the decoder through FCA-C (full connection attention-C) (the size is consistent with that of Block4C). The above is the extraction process of feature information. In the process of feature aggregation, the shallow low-level feature information is upsampled by real-time data, then processed by convolve Conv1, and merged with the deep semantic feature information processed by Conv X2, Conv X4 and Conv X8. Finally, high-resolution image semantic segmentation is realised by upsampling operation (X4).
Figure 2. Deep Neural Network structure of hierarchical feature fusion.
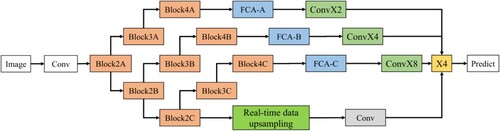
In order to obtain as much low-level feature information of the image as possible, such as colour, line, texture and other information, the extraction is carried out at the beginning. The final information of deep semantic feature extraction is output by the fully connected layer of each stage. Because each sub-stage of the whole feature extraction stage is mutually influenced, the black arrow from top to bottom indicates the feature mining at the corresponding position among all levels. This process is learned at the beginning of each stage, which not only retains the receptive field of the feature map of the previous level, but also can learn the new mapping of the feature map of the next level, which also ensures the richness and integrity of the finally obtained deep semantic feature information.
4. Experiment
4.1. Dataset
The dataset used in this paper is a public dataset containing a total of 20 categories of objects and 1 background category, and its semantic segmentation dataset contains a training set (1,464 images), a validation set (1,449 images) and a test set (1,464 images). In this paper, we select 874 samples as the validation set and 216 samples as the test set and visualise the experimental results to validate the method.
4.2. Implement details
The input picture size of this experiment is 512 × 512, and the initial learning rate is an important parameter that affects the training of neural network. If it is too large, the model will easily oscillate, and if it is too small, the model will not converge and the training time will be prolonged. In this experiment, we set the learning rate to 0.0001 and the batch size to 32. The deep learning framework used in this experiment is Pytorch, the programming language is Python3.6, and the GPU is RTX2080Ti. In the training process, the training samples are enhanced by mirror image, etc. The loss function used in training is cross entropy loss function, and the training method uses the method of small batch random gradient descent.
4.3. Ablation study
We conducted ablation research on four different fusion situations, and the experimental results are shown in Table .
Table 1. Influence of fusion of feature information at all levels on results.
It can be seen from Table that when there is only shallow low-level feature information, the segmentation result (MIOU) at this time is 24.2310%, and the segmentation result (MIOU) obtained after thinning the shallow low-level feature information is 29.4203%. Compared with the original shallow low-level feature information, the precision of the refined shallow low-level feature information is improved by 5.1893%. This shows that the improved real-time data upsampling can effectively improve the colour, texture, edge and other feature information contained in the shallow low-level feature information. The segmentation result (MIOU) obtained when there is only deep semantic feature information is 60.4025%, and the segmentation result (MIOU) obtained when the shallow low-level feature information and deep semantic feature information are fused is 68.8254%. Compared with only deep semantic feature information, the segmentation accuracy is improved by 8.4229%, which shows that shallow low-level feature information can promote the improvement of semantic segmentation accuracy. When the refined shallow low-level feature information is fused with the deep-level semantic feature information, the segmentation result (MIOU) is 70.9014%, and the segmentation accuracy is increased by 2.076% compared with that without refinement. This shows that the information such as object contour and edge texture contained in the refined shallow low-level feature information can be better used by the deep-level semantic feature information when it is fused, which can effectively refine the boundary of the object, promote the improvement of segmentation accuracy, and get better results.
4.4. Comparison with state-of-the-arts
In order to further verify the effectiveness of this method, under the condition that the input picture size and the experimental environment are completely consistent, this method is compared with three mainstream methods, SegNet, PSPNet and DeepLabV3. The results are shown in Table .
Table 2. MIOU of SegNet, PSPNet, DeepLabV3 and our proposed method.
Because Deepplabv3 lacks the full use of shallow low-level feature information, PSPNet method does not discriminate between shallow low-level feature information and deep semantic feature information, and SegNet method uses feature information in a single way, so the accuracy of this method is improved by 2.6% compared with Deepplabv3 method, 7.4% compared with PSPNet method and 12.9% compared with SegNet method, which shows that this method has a good segmentation result. This is mainly due to the cascade structure consisting of convolution layers with depth separable, which extracts the shallow low-level feature information and deep semantic feature information in stages, excavates the hidden information among levels step by step, refines the shallow low-level feature information to improve the definition of the object outline in the picture. At the same time, the cascade structure improves the utilisation ratio in the process of merging and fusing with deep semantic feature information, greatly enriches the feature information of the image, makes the segmentation of the object edge more detailed, and effectively improves the accuracy of image semantic segmentation.
Finally, in order to further verify the effectiveness of this method, this paper makes further experiments with PASCAL VOC 2012 data set, and selects some visual segmentation results, as shown in Figure , which verifies that this method can achieve the results of image semantic segmentation.
Figure 3. Partial segmentation results of PASCAL VOC 2012 dataset.
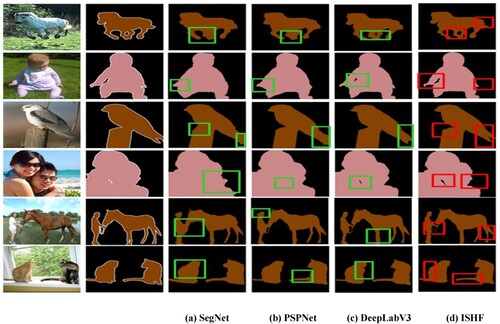
From the six segmentation results from the running horse to the cat on the balcony in the picture, we can see that the objects segmented by SegNet method are incomplete and the details of the objects are not very clear. The segmentation of object details in PSP method is not prominent either. The method of DeepLabV3 has relatively complete segmentation results for objects, but the processing of contour details is not sufficient. In this method, the segmentation of each object has a clear and complete outline, and the processing of edge details is smoother. Taking the running horse in Figure as an example, the SegNet method gets the rough outline of the horse, and the segmentation of the head is rather vague. The PSPNet method obtains a more recognisable outline result, but the detail segmentation of the legs is not outstanding. The DeepLabV3 method obtains a complete outline of the stallion, but the detail segmentation of the tail and legs of the stallion is also less obvious. The method of this paper has a clear segmentation of the outline of the whole stallion, especially the detail segmentation of the legs and the tail is very clear. For the children on the lawn, SegNet method and PSPNet method get a rough outline, and the segmentation of children's left hand is vague. The method of DeepLabV3 gets complete segmentation, but the segmentation of children's feet and hands is rough. This method can clearly segment children's hands and feet. For people and horses on the lawn, SegNet method is to realise the basic segmentation of people and horses; The PSPNet method and DeepLabV3 method are relatively clear for the contour segmentation of human and horse, but they are not very good for the contour details of objects. This method highlights the outline of people and horses more completely, and the rope is segmented more finely, and the overall segmentation result is smoother and more detailed. To sum up, this method has effectively improved the accuracy of image semantic segmentation.
4.5. Analysis of running speed
In order to analysis the running speed of this method, we test the speed of SegNet, PSPNet, DeepLabV3, and our proposed method on PASCAL VOC 2012 dataset. The results are shown in Table .
Table 3. Speed of SegNet, PSPNet, DeepLabV3 and our proposed method.
As we can see, compared to SegNet, PSPNet, and DeepLabV3, our proposed method have faster running speed and less GFlops calculation. The reason is that our proposed method uses hierarchical feature fusion to perform image semantic segmentation based on deep neural network.
5. Conclusion
In this paper, we propose a hierarchical feature fusion image semantic segmentation based on deep neural network method. This method combines image contextual information with the previous level of features in the process of feature extraction, gradually improves the prediction results of deep high-level feature information in the final output of each level. The refines shallow low-level feature information in the upsampling process, and enriches feature information by merging. Fusing multiple layers of features to achieve high-resolution image semantic segmentation. It can be widely used in image perception and recognition of various living and industrial backgrounds. However, how to improve the segmentation speed while ensuring the segmentation accuracy is a problem that needs to be addressed in the next work.
Declaration of interest statement
We declare that we have no financial and personal relationships with other people or organisations that can inappropriately influence our work, there is no professional or other personal interest of any nature or kind in any product, service and/or company that could be construed as influencing the position presented in, or the review of, the manuscript entitled.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Boykov, Y. Y., & Jolly, M.-P. (2001). Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, IEEE, 1, 105–112. https://doi.org/10.1109/ICCV.2001.937505
- Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. (2014). Semantic image segmentation with deep convolutional nets and fully connected crfs.” arXiv preprint arXiv:1412.7062.
- Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. (2017a). Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(4), 834–848. https://doi.org/10.1109/TPAMI.2017.2699184
- Chen, L.-C., Papandreou, G., Schroff, F., & Adam, H. (2017b). Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587.
- Choy, S. K., Lam, S. Y., Yu, K. W., Lee, W. Y., & Leung, K. T. (2017). Fuzzy model-based clustering and its application in image segmentation. Pattern Recognition, 68, 141–157. https://doi.org/10.1016/j.patcog.2017.03.009
- Coates, A., & Ng, A. Y. (2012). Learning feature representations with k-means. Neural Networks: Tricks of the Trade, 7700, 561–580. https://doi.org/10.1007/978-3-642-35289-8_30
- Deng, X., & Ye, J. (2022). A retinal blood vessel segmentation based on improved D-MNet and pulse-coupled neural network. Biomedical Signal Processing and Control, 73, 103467. https://doi.org/10.1016/j.bspc.2021.103467
- Du, X., Tang, S., Lu, Z., Wet, J., Gai, K., & Hung, P. C. K. (2020). A novel data placement strategy for data-sharing scientific workflows in heterogeneous edge-cloud computing environments. 2020 IEEE International Conference on Web Services (ICWS), 498–507. https://doi.org/10.1109/ICWS49710.2020.00073
- Guo, C., Lin, Y., Chen, S., Zeng, Z., Shao, M., & Li, S. (2022). From the whole to detail: Progressively sampling discriminative parts for fine-grained recognition. Knowledge-Based Systems, 235, 107651. https://doi.org/10.1016/j.knosys.2021.107651
- He, J., Deng, Z., & Qiao, Y. (2019). Dynamic multi-scale filters for semantic segmentation. Proceedings of the IEEE/CVF International Conference on Computer Vision, 3562–3572. https://doi.org/10.1109/ICCV.2019.00366
- Hinton, G. E., & Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. science, 313(5786), 504–507. https://doi.org/10.1126/science.1127647
- Hojjatoleslami, S., & Kittler, J. (1998). Region growing: A new approach. IEEE Transactions on Image Processing, 7(7), 1079–1084. https://doi.org/10.1109/83.701170
- Ibrahim, R. W., Jalab, H. A., Karim, F. K., Alabdulkreem, E., & Ayub, M. N. (2022). A medical image enhancement based on generalized class of fractional partial differential equations. Quantitative Imaging in Medicine and Surgery, 12(1), 172–183. https://doi.org/10.21037/qims-21-15
- Jinling, S., & Zhaohui, W. (2012). An image segmentation method based on graph cut and super pixels in nature scene. Journal of Soochow University (Natural Science Edition), 2, 108–132.
- Lin, D., Ji, Y., Lischinski, D., Cohen-Or, D., & Huang, H. (2018). Multi-scale context intertwining for semantic segmentation. Proceedings of the European Conference on Computer Vision (ECCV), 603–619. https://doi.org/10.1007/978-3-030-01219-9_37
- Lin, G., Milan, A., Shen, C., & Reid, I. (2017). Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1925–1934. https://doi.org/10.1109/CVPR.2017.549
- Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3431–3440. https://doi.org/10.1109/CVPR.2015.7298965
- Nahavandi, D., Alizadehsani, R., Khosravi, A., & Acharya, U. R. (2022). Application of artificial intelligence in wearable devices: Opportunities and challenges. Computer Methods and Programs in Biomedicine, 213, 106541. https://doi.org/10.1016/j.cmpb.2021.106541
- Noh, H., Hong, S., & Han, B. (2015). Learning deconvolution network for semantic segmentation. Proceedings of the IEEE International Conference on Computer Vision, 1520–1528. https://doi.org/10.1109/ICCV.2015.178
- Park, T. J., Kanda, N., Dimitriadis, D., Han, K. J., Watanabe, S., & Narayanan, S. (2022). A review of speaker diarization: Recent advances with deep learning. Computer Speech & Language, 72, 101317. https://doi.org/10.1016/j.csl.2021.101317
- Sharif Razavian, A., Azizpour, H., Sullivan, J., & Carlsson, S. (2014). Cnn features off-the-shelf: An astounding baseline for recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 806–813. https://doi.org/10.1109/CVPRW.2014.131
- Tian, Z., He, T., Shen, C., & Yan, Y. (2019). Decoders matter for semantic segmentation: Data-dependent decoding enables flexible feature aggregation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3126–3135. https://doi.org/10.1109/CVPR.2019.00324
- Wang, C., Ning, X., Sun, L., Zhang, L., Li, W., & Bai, X.,et al. (2022). Learning Discriminative Features by Covering Local Geometric Space for Point Cloud Analysis. “ IEEE Transactions on Geoscience and Remote Sensing. https://doi.org/10.1109/TGRS.2022.3170493
- Wang, Y., Zhang, H., & Huang, H. (2019). A survey of image semantic segmentation algorithms based on deep learning. Application of Electronic Technique, 45(6), 23–27.
- Xu, J., Du, X., Cai, W., Zhu, C., & Chen, Y. (2019). Meurep: A novel user reputation calculation approach in personalized cloud services. PLoS ONE, 14(6), e0217933. https://doi.org/10.1371/journal.pone.0217933
- Yamini, B., & Sabitha, R. (2017). Image steganalysis: Adaptive color image segmentation using otsu’s method. Journal of Computational and Theoretical Nanoscience, 14(9), 4502–4507. https://doi.org/10.1166/jctn.2017.6767
- Yang, H., Lijun, G., & Rong, Z. (2015). Integration of global and local correntropy image segmentation algorithm. Journal of Image and Graphics, 12(12), 1619–1628.
- Ying-ming, H., & Feng, Z. (2005). Fast algorithm for two-dimensional Otsu adaptive threshold algorithm. Journal of Image and Graphics, 4, 484–485. http://dx.doi.org/10.1360/aas-007-0968
- Zeng, N., Li, H., Wang, Z., Liu, W., Liu, S., Alsaadi, F. E., & Liu, X. (2021). Deep-reinforcement-learning-based images segmentation for quantitative analysis of gold immunochromatographic strip. Neurocomputing, 425, 173–180. https://doi.org/10.1016/j.neucom.2020.04.001
- Zhai, S., Ren, C., Wang, Z., He, X., & Qing, L. (2022). An effective deep network using target vector update modules for image restoration. Pattern Recognition, 122, 108333. https://doi.org/10.1016/j.patcog.2021.108333
- Zhang, Q., Wang, Z., Heidari, A. A., Gui, W., Shao, Q., Chen, H., Zaguia, A., Turabieh, H., & Chen, M. (2021). Gaussian Barebone Salp Swarm algorithm with stochastic fractal search for medical image segmentation: A COVID-19 case study. Computers in Biology and Medicine, 139, 104941. https://doi.org/10.1016/j.compbiomed.2021.104941
- Zhou, T., Wu, W., Peng, L., Zhang, M., Li, Z., Xiong, Y., & Bai, Y. (2022). Evaluation of urban bus service reliability on variable time horizons using a hybrid deep learning method. Reliability Engineering & System Safety, 217, 108090. https://doi.org/10.1016/j.ress.2021.108090
- Zhu, H. (2022). Application research of image semantic segmentation algorithm based on deep learning. Electronic Components and Information Technology, https://doi.org/10.19772/j.cnki.2096-4455.2022.2.075