
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Model incremental updating enhances the initial model by analysing discrepancy parts of the system to improve the model's adaptability for new scenarios. These discrepancy components originate from the deviation between the increasing business process operational state and the outdated original planning model. Considerable domain-specific knowledge is required to determine the threshold points for selecting appropriate activities, but process analysts rarely know each scenario's domain knowledge. Moreover, most analytical processes only focussed on the control flow level. Aiming at these issues, this paper proposes a Hybrid Behavioural and Resource Trusted intervals Updating algorithm (BI&RI Updating) for model enhancement based on control level and resource level of online event streams. First, analyse the reference model to construct multi-perspective trusted interval constraints in the offline stage. From a control-flow perspective, the behavioural relationships between activities are researched using a deep clustering approach. Moreover, from a data-flow standpoint, resource co-occurrence relationships are analysed based on association rules. Next, the incremental update algorithm in online scenarios is proposed to update the model by filtering the event streams and iteratively optimising the trusted intervals. Finally, the proposed algorithm is implemented based on the PM4PY framework and evaluated using real logs with both outcome model quality and execution efficiency. The results show that the algorithm can execute quickly and improve the quality of the model even in a non-ideal state where the logs contain noise.
1. Introduction
As an essential research direction of process mining, model enhancement analyses the actual behaviour of business processes for repairing/extending the process model to optimise its adaptability and decision-making capability (van der Aalst, Citation2016). Furthermore, as a critical Technology for model enhancement, the incremental updating technique enriches the original model structure by selecting a sound new process sequence. So, the original structure is retained (Thakur et al., Citation2020), effectively using industry-proven models and avoiding reconstructing them from scratch. Existing techniques mainly rely on consulting domain experts or researchers' practical experience to determine appropriate threshold points for sequence selection. Therefore, this operation relies on the domain knowledge or practice, which increases the difficulty of business process analysis. Moreover, many studies have considered only control flow-level constraints, rarely incorporating data flow information in logs. Since data flow information such as resources, time, and roles can influence the control flow structure. For example, the airport security process will be adjusted because of the hazardous items carried. So the data flow level information also needs attention.
Regarding the study of model augmentation, previous work has proposed a domain-based invisible transition mining approach. It constructs an initial interaction process model by behavioural profile theory and maps submodels containing invisible transitions to the initial model for model optimisation based on domain theory (Fang et al., Citation2018). Fang et al. identify the effective low frequencies by log automata for optimising the model (Fang et al., Citation2020). Lu et al. propose an effective infrequent sequence mining method (EIM) to improve the model quality in offline scenarios (K. Lu et al., Citation2022). The technique filters noisy activities based on conditional probability entropy. It constructs a state transfer matrix to identify effective infrequent sequences, which can distinguish effective infrequent sequences from noisy sequences in the logs that are beneficial for model enhancement. Wang et al. consider combining data flow with control flow to identify effective low-frequency and optimise the model by considering frequent patterns and interaction behaviour profiles (Wang et al., Citation2021). Zhu et al. developed a model for assessing popular Weibo topics that assists users in comprehending the subjects through a multisubject bilayer network (MSBN) based on feature co-occurrence and semantic community division (Zhu et al., Citation2020). Unlike previous work, this paper focusses on constructing hybrid trusted intervals from the execution logs and enhancing the model quality based on online event streams to enhance the reference model structure. The novelty of this paper lies in the construction of trusted intervals that combine control flow and data flow. Then the hybrid trusted intervals can assist online decision-making by filtering undesired event flow sequences.
Based on the previous works and the above considerations, we propose a Hybrid Behavioural and Resource Trusted intervals Updating algorithm (BI&RI Updating) framework for model enhancement based on multi-perspective trusted intervals, which mainly consists of the following two stages (as shown in Figure ).
Figure 1. logical structure of the study.
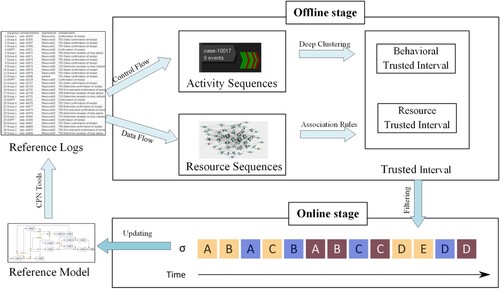
Constructing multi-perspective trusted interval constraints in the offline phase: First, event sequences and resource information are extracted from the reference model to construct a training set. Second, from the control-flow perspective, we use a deep clustering technique to construct the trusted behavioural intervals based on the activity sequences for the behavioural relationships among the analysed activities in the log sequences. Finally, from the data flow perspective, the resource relationships in the events are studied, and the association rule analysis method is applied to calculate the trusted resource intervals.
Analyse event streams in the online phase to perform incremental model updates: First, the online event streams are constructed as event stream sequences. then, the online event streams are analysed based on the hybrid trusted intervals obtained in the previous stage, and the real-time event streams whose behaviours and resource relations do not satisfy the constraints are filtered. Finally, the initial model is updated using the event stream of constraints, and the conditions are iteratively updated.
This paper divides the model incremental update framework into two parts. The offline phase constructs a trusted interval constraint from both control and data flow levels. It has the advantage of considering conditions concurrently at different levels, which improves the utilisation of log features and the algorithm's reliability. Moreover, obtaining decision guidance from historical execution logs reduces the reliance on subjective factors such as domain knowledge, which benefits the robustness of the constraints. The online phase filters the non-compliant event streams under the guidance of hybrid trusted intervals, facilitating timely updating of the reference model. In addition, iterative updating of constraints enables continuous and reliable model enhancement in online scenarios.
We organise the remainder of the article as follows. Section 2 presents the related work. The basics used in the paper, i.e. the meaning of some concepts and notations, are explained in Section 3. Section 4 presents the approach in this paper to construct hybrid trusted intervals based on the behaviour of events and resource relations. Moreover, the process to update the reference model in real-time increments based on event streams is introduced in Section 5. Section 6 evaluates the methods proposed in this paper using real logs. Section 7 concludes the paper and indicates future works.
2. Related work
Process mining is a data-driven technology that combines business process management (using information technology and management science knowledge to understand and operate business processes), data mining, and machine learning. Many current information systems record the execution of business processes in great detail and data information (Xu et al., Citation2022). From this structured or unstructured data, process mining gains insights about business processes through process discovery, consistency checking, and model enhancement (van der Aalst, Citation2016; Zhang et al., Citation2022). As the first stage, process discovery conducts models based on event logs. Conformance checking seeks to assess how well the process models conform to the behaviour in the event logs. Multiple perspectives, such as business process organisers and data flows, are included, and model enhancements use them to improve business processes (Pika et al., Citation2017).
Traditional process discovery focusses on building models from scratch using information from event logs, and many algorithms for discovering models have been proposed. For example, the series of inductive mining algorithms use a divide-and-conquer approach to extract relationships between process activities and construct concurrent process models that can effectively handle noise simultaneously (Brons et al., Citation2021). A series of methods based on domain mining can explicitly discover dependencies between activities from event logs to build process models that are free of redundant information and more declarative (van Zelst et al., Citation2018). Split Miner ensures a deadlock-free and well-structured process model by filtering out directly following relationships and replacing gateway (Augusto et al., Citation2019).
One form of the existing approach for process enhancement is to adapt and improve the process model by consistency checking. Another way is to use additional behaviours to extend the existing process model. However, they do not apply them iteratively to a given event log for incremental process model discovery. Kindler et al. presented an incremental process discovery architecture, which automates merging newly discovered process models into existing models (Kindler et al., Citation2006). Armas et al. proposed a method to repair the deviations of the process model concerning a given event log in an incremental manner (Armas Cervantes et al., Citation2017). It can correct the deviations manually according to the guidance of the algorithm. A model enhancement method that improves process performance is constructed in Dees et al. (Citation2017), which focusses on repairing the model by selecting behaviours that comply with laws and regulations and improve process performance. Nguyen et al. visualised the evolution of process features to enable timely identification of process bottlenecks (Nguyen et al., Citation2016). Along with incremental process discovery algorithms, some scholars have proposed methods based on interactive process mining. Dixit et al. presented an interactive process discovery algorithm based on continuous user feedback and constructed a well-structured process model (Dixit et al., Citation2018). Nevertheless, these methods have not real-time analysed online event streams. Most of the threshold settings in the quantitative analysis process rely on domain-specific knowledge.
Most methods are currently based on static and offline historical event logs. The majority of which are used for a posteriori analysis. However, with the rapid development of the big data era, the data magnitude has increased quickly. Traditional process mining techniques are incapable of meeting the demand for online event log processing. Dealing with online large-scale event streams has become a hot topic for many scholars. Therefore, some scholars have proposed studies dealing with online process discovery (Burattin et al., Citation2015; Leno et al., Citation2018; van Zelst et al., Citation2018). Barbon et al. introduced a preliminary implementation of online process mining based on cognitive computing (Barbon Junior et al., Citation2018). Tavares et al. focus on event flow to create and maintain a process model (Tavares et al., Citation2018). Some studies focus on conformance checking in online scenarios (Al-Ali et al., Citation2018; Burattin & Josep, Citation2018). Bose et al. propose a series of approaches to deal with conceptual drift in business processes in online strategies (Bose et al., Citation2013). However, these approaches solve the problem based on the control flow in the online event streams but ignore the property relationships accompanying events.
3. Preliminaries
The approach proposed in this paper focusses on behavioural relationships between activities and dependencies between attributes, including the offline phase for event log analysis and the online phase for event flow analysis. Consequently, we briefly introduce some related basics in this section.
3.1. Event log and event stream
Individual executions of a process are called process instances. They are linked to the execution of a specific case identifier i. Table illustrates a business process fragment for software product registration. Each time of the process is considered a case c. The information system's database maintains a record of the process's execution. We use a row describing an individual execution of an activity a and denote it as an event e, which is unique and corresponds to i. An event consists of a case identifier i, an executed activity a, a timestamp t, and a resource for executing the activity r, i.e. an event is a quaternion (Deshmukh et al., Citation2020). For example, considering the 361-st event in Table consists of
. Let
be a universal set of unique identifiers,
be a universal set of cases,
be a universal set of activities, and
be a universal set of resources. Here, the universal set of events is denoted as
. We concentrate on the case's activities and the resources required to carry them out in this paper. To extract each constituent of an event, we introduce a projection function Π (X. Lu et al., Citation2020).
Table 1. Example of storage events in a business process.
The sequence of events extracted for a particular case is called a trace σ. It keeps track of the status of activities that occur in a specific process instance, as ordered by the timestamp of the event trigger. All these traces constitute an event log L.
Definition 3.1
Event log
Given a set of traces , the event log is denoted as
.
As shown in Table , multiple activities share the same resources in a case. So we sequence them in order of their timestamps when describing the case traces, i.e.
(1)
(1) In business process systems, the activities that have occurred are stored in the database in the form of event logs. When the focus shifts to online scenarios, this static data does not meet the needs at this time. Accordingly, we consider the event stream a potentially infinite sequence of events. Assume that a case arrives at the unit time and the timestamp orders the activities. So, there are 3 cases in Table , but none of the cases have ended. The formal presentation of the event stream is shown below as follows Awad et al. (Citation2020).
Definition 3.2
Event stream
Let be the universal set of events and the event stream be an infinite sequence of events. Given
,
is the ith event in the stream of events, where each event in the event stream is unique, i.e. S is bijectionary.
Figure depicts an example graph of event streams arriving in a time sequence according to Table . It is important to note significant differences between event streams and event logs. The event log records the final information of the case, and each trace is completed. So the knowledge of the case will not change over time. While in the event streams, the information of the cases will be changed over time. Besides, we consider an event log is terminable, while the event streams is infinite sequences of events. Therefore, when handling event streams, we need to provide methods to store the observed event streams as traces.
Figure 2. Example of event streams.
3.2. Behavioural relationships
The concepts of event log and event stream in the process are introduced in the above section. Still, in the actual execution of the process, it is also necessary to consider the behavioural relationships between each event.
Definition 3.3
Behaviour profile
Let L be an event log and be a successor relationship corresponding to the activities in the log. The behaviour relations of the event log consist of a 3-tuple array
, in which:
Strict order relation:
iff
Interleaving relation:
Exclusiveness order relationship:
Inverse strict order relation:
The behaviour profile captures the dependencies between business process activities that are directional. We use a directed edge between and
to present a relationship between them. Therefore, the activity relationship in the business process event log L can be described as a weighted directed graph. The weight is defined as the frequency of the activities. The definition of the log-based business process graph is formalised as follows.
Definition 3.4
Log-based business process graph, Yongsiriwit et al., Citation2015
It is defined as a weighted directed graph constructed from the business process log L:
(2)
(2) in which
is a universal set of activities,
is a universal set of directed edges, and W is a universal set of weight.
4. Contructions of trusted intervals based on behaviour and resource relationships
Process mining research entails a significant amount of quantitative analysis, such as assessing if a process exhibits anomalous behaviour when a threshold value is exceeded. A critical challenge in this case is how to determine an adequate threshold. Certain studies establish thresholds based on domain knowledge, which presents a barrier for process analysers, since processors cannot be experts in every basin. Certain research use a high number of experiments to explore thresholds, which may result in resource waste. In addition, fixed threshold constraints are susceptible to noise, and the analysis process may become more complicated. Therefore, extracting features from the process itself and setting looser interval constraints is crucial to break the limitations of accuracy thresholds and reduce the dependence of thresholds on domain knowledge.
Some studies have also focussed on online event streams, but most of them only focus on the process's control-flow perspective, and few combine the control flow and data flow perspectives. While online event streams are always accompanied by various attribute information, ignoring the information between attributes will miss critical dependencies and even misjudge the process structure. Although some event streams have a suitable structure at the control flow level, these structures may subsequently change when considering information about their data flow aspects. In this context, we propose a method for online incremental updating of reference models based on behavioural and resource trusted intervals to improve the quality of process models, reduce the dependence on domain knowledge, and avoid repetitive and redundant modelling efforts.
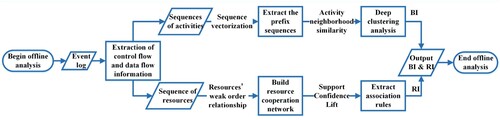
Achieving a decreased dependence on domain knowledge implies that we can only receive guiding information from existing reference models and event logs. For a thorough investigation of the large amount of static data collected by the information system, we analyse it at both the data flow and control flow levels. The work in this section is divided into two phases (Figure ).
Analyse behaviour relations to construct behavioural trusted intervals. In this step, existing reference models are analysed to extract activity and resource information. And we explore the behavioural relationships among activities from the perspective of control flow using deep clustering techniques.
Capture resource co-occurrence relationships to extract resource trusted intervals. We quantify and analyse the resource attributes in events using association rules.
Figure 3. Steps for constructing behaviour- and resource-based trusted intervals in the offline phase.
4.1. Behavioural trusted intervals construction
Business process analysts usually focus on control flow level dependencies, such as strict order, cross order, and exclusive order of activities captured by behavioural profiles. Analysing this behavioural information can help business process researchers understand the process structure and enhance the business logic.
As the reference model conforms to legal specifications and is instructive for process modelling, we build a knowledge repository from it. To facilitate the relationship between the model and event stream, we simulate the model by CPN ToolsFootnote1 to obtain a reference log. Subsequently, we extracted attribute pairs (activity, resource) for each event, shorthanded as . Since log sequences are from a mature initial model, they are reliable and accurate.
First, all activities are encoded based on the extracted log sequences. Moreover, feature vectors are defined based on all activities, named activity vectors. The activity vector takes the set of all activities and the target trace as input and returns a vector containing the number of occurrences of all activities in that trace. In this paper, encoding activity vectors based on frequencies, for example, the -dimensional activity vector of the trace σ is defined as
, or
, in which,
denotes the number of times the activity
occurs in the sequence σ. Then, extracted log sequences are encoded by traces based on the prefix sequence method.
Definition 4.1
Prefix sequence
Given a trace σ, in which and the positive integer
, then
(3)
(3)
Clustering techniques can divide similar data together (Du et al., Citation2021). By encoding all the traces in the log sequence with prefix sequences according to the above definition, obtained trace encoding can be represented in matrix form. Afterward, applying the deep clustering technique, clustering the trace encoding can get the clusters of trace encoding in the log sequence (the cluster centre is composed of (a, r) pairs).
We refer to the deep clustering approach (Xie et al., Citation2016) and adjust it to make it suitable to the event log control flow. This clustering phase is implemented in two steps:
For each sample point, its similarity to the predefined cluster centre is calculated by soft specifying using the t-distribution.
To make the sample points in the cluster clustered around the cluster centre as much as possible, KL scatters loss is used as an auxiliary objective distribution function:
Next, interval constraints on the trusted behaviour of the activity are computed based on the cluster centre. The following relevant definitions are given as follow:
Definition 4.2
Activity neighbourhood context graph, Chan et al., Citation2014
Activity neighbourhood context graph of an activity is a vertex layer and edge zone number based extension of
, represented by
. The shortest route length from
to
is indicated by the layer number of a vertex
, which is denoted by
. The zone number of an edge
is indicated by
.
Definition 4.3
kth neighbour, Chan et al., Citation2014
a is the kth neighbour of b, iff . A set of kth neighbours
for activity
is denoted as
.
The number of layers and regions in the neighbourhood context graph reflects the proximity between activities, while the edge weights in the log-based graph indicate the intensity of the interaction between them.
Furthermore, we analyse the similarity between activities based on the common edges in the zones of the kth neighbours of the activities.
(7)
(7) Where
denotes the vector of weights of the joint edges.
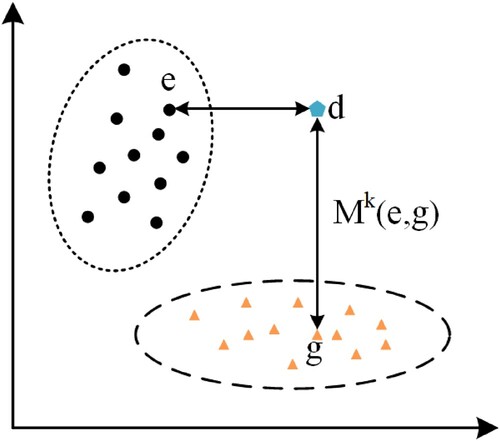
As shown in Figure , the similarity of two events is measured by the weight vector of their common kth neighbour. With this similarity, we quantify the distance of each activity in the log sequence relative to the cluster centre. Furthermore, the lower bound of the behavioural trusted interval is defined as the minimum value of the non-zero distance Min(M). And the maximum value of the non-zero distance Max(M) is the upper bound of the behavioural credible interval. In this way, we can obtain the behaviour-based credible interval (abbreviated as BI below) in the log sequence. Then we will describe how to derive attribute relationship-based resource credible intervals in log sequences.
Figure 4. Visual interpretation of activity similarity. The events are dimensioned into a 2D vector and the distance between two events is measured by M metric.
As the process mining research progresses, researchers realise that there are some limitations in considering only control flow level constraints. Because some data flow information may affect the reasonableness of the control flow. For example, some reasonable behaviours in banks are detected as illegal behaviours that exceed the authority after considering the data flow level constraints (Alizadeh et al., Citation2018).
4.2. Resource trusted intervals construction
To strengthen the constraints by resource information at the data level, we perform association rule analysis on the reference logs. The resource-based trusted interval constraint (r) was obtained by extracting the set of frequent items of resource information (Hamdad et al., Citation2020).
First, we introduce the weak order relationship among resources:
Definition 4.4
Resource weak order relationship, van Zelst et al., Citation2018
For an event log L and a tuple of resources , for an arbitrary trace
, the formula is as follows:
(8)
(8) The symbol
denotes the number of transfers from resource
to resource
within σ.
In general, reacts to a local relationship. For the global relationship, we use the definition as follow:
(9)
(9) For example, assume in Table that case
and case
are the only two traces. The case
has only one activity, and no transfer of resources has occurred. However, adding the case does not affect the results, so the case
is not considered. Consider only the transfer of resources in case
, i.e.
, and consider the transfer of resources in case
, i.e.
. Thus, when considering the relationship with a handover distance of 1 for resources, it can be observed that:
. Similarly we can observe that:
. According to the resource-based relationships in Definition 4.4, we can merge relationships between longer-distance resources. Still, for simplicity in this paper, only relationships with a transfer distance of 1 between resources are considered.
To analyse the dependencies between resources in an event, we further investigate the resources weak order relationship by association rules. It consists of two item sets: the antecedent and consequent item set. Simplistically, an association rule is an outcome that can be inferred if the antecedent holds. Three metrics are commonly used to measure an association rule: support, confidence, and lift.
Support measures how well an association rule applies to a dataset. Namely, what part of the data it applies to. And it represented the number of resources containing it to the total number of resources. For example, given a pair of resources , the support of the resource
is:
(10)
(10) Similarly, to calculate the support for the co-occurrence of resources
and
, we use
. It represents the co-occurrence probability of resources
and
.
Confidence measures the possibility that an association rule will correctly predict when its antecedent term set is satisfied, i.e. the ratio of the number of co-occurring resources and
to the number of contained resources
, expressed by the following formula:
(11)
(11) Lift measures the degree of dependence between antecedents and outcomes, which in this paper refers to the probability of occurrence of resources
and
together. But also considers the probability of occurrence of each of these two resources, expressed by the following formula:
(12)
(12) Lift reflects the relevance of resources
and
in the association rule, if the value of Lift>1 and higher indicates positive relevance between resources, if the value of Lift<1 and lower indicates negative relevance between resources if the value of Lift = 1 indicates no relevance between resources.
Based on the above association rules among resources, the lift of each resource in the log sequence concerning the resources in the mass centre can be calculated. From the lifting degree of each resource for the resource in the mass centre, the non-zero minimum lifting degree is taken as the lower bound of the current resource trusted interval. The non-zero maximum lifting degree is taken as the upper bound of the current resource trusted interval. So far, the resource-based trusted intervals (abbreviated as RI in the following) can be obtained.
4.3. Output multi-perspective trusted intervals
The previous two sections show the basics of construction behaviour and resource trusted intervals and the construction steps. In this section we formalise the construction steps as the following Algorithm 1, described as follows.
Algorithm 1 formally describes extracting trusted intervals based on behaviours and resources. Lines 3–12 represent obtaining behaviour-based trusted intervals from event activities. The traces of each case are first obtained based on the log sequences transformed from the reference model, which are converted into activity vectors based on the frequency of each activity occurring. Then, it is clustered by the deep clustering technique to obtain the cluster centre, which contains the activities and the resources for executing the current activity. The minimum and maximum behavioural distances are then compared with the behavioural distances between each activity and the cluster centre to obtain the trusted intervals based on the activity behaviour (the detailed calculation steps are described in Section 3.1). The trusted intervals based on the activity behaviour are returned in line 13. The resource-based association rule analysis in the log sequence is described in lines 15–26. Furthermore, the lift of each resource relative to the centre-of-mass resource is calculated, and the resource-based trusted interval constraints are obtained. The resource-based trusted intervals are returned in line 27.

5. Online model incremental updating based on event streams
Many algorithms in process discovery are based on static historical data sources in the event log and work offline. Traditional process mining algorithms have not considered the real-time event streams in management systems, which are dynamic and changing in real-time, and mainly analyse offline logs. Most offline-based event logs create models from scratch, limited by log completeness and business completion time. In practice, additional staff needs to repeat the modelling work when analysing the process, which increases the cost and may cause anomalies. An incremental updating can update the difference part based on the reference model compared with the existing structure, which can be partially updated based on the original model to adapt to new scenarios. This technology avoids reconstructing the model from scratch and effectively reduces errors and redundant work.
In the above section, the behaviour- and resource-based trusted intervals are derived based on the activities and resources in the log sequence, and Algorithm 1 does not require excessive reliance on domain knowledge from the reference model. In this section, the reference model will be updated incrementally based on real-time event streams, refer to Figure . Moreover, the behaviour- and resource-based trusted intervals output in Algorithm 1 will change after each update is completed to adapt to the new events that arrive, thus further enhancing the utility and flexibility of the algorithm.
Figure 5. Steps for updating the reference model in the online phase.

An event stream is an infinite sequence generated while the system is running, so manipulating it is different from an offline event log. To cope with such scenarios, we analyse the event streams by a sliding window. Specifically, a window view with a time span w is used to observe the sequence of event streams that occurred during this period. The window is gradually slid backward over time, thus enabling continuous analysis of the real-time event streams in the order of triggering. Using the sliding window to observe the event streams occurring at the current time reflects well on the current execution. In this paper, we assume the case that starts first ends first. The complete triggering of a case is taken as a time unit. When observing the next case triggers, it indicates that the previous case has ended. The sequence of event streams in a specific time period can be obtained by observing the sliding window. We formalise the method in this section as Algorithm 2, which is shown in the following.
Online incremental update of model structure for model enhancement. First, the online event streams are cached as sequences using the sliding window mechanism. Then the online event streams are analysed using a multi-view trusted interval guide. This step includes filtering the real-time event streams whose behaviours and resource relationships do not satisfy the constraints. Finally, we use the sequences of conforming event streams to update the reference model while iterating over the constraints.
First, by extracting the events with the same case identifier in the sliding window w and generating them into activity vectors, the behavioural distance between the current event activity and the prime activity is calculated (Algorithm 2:1–6). Next, to determine whether the behavioural distance of the current new event satisfies the activity behaviour-based trusted interval obtained from the log sequence transformed by Algorithm 1 from the reference model (Algorithm 2:7):

If satisfied, continue to calculate the lift of the current resource of the new event with respect to the resource of the cluster centre, and judge whether the current lift satisfies the resource-based trusted interval obtained in Algorithm 1 (Algorithm 2:8–9), which will be discussed herein two scenarios:
When the resource of the new event exists in the reference model database, if the lift of the resource of the new event satisfies the resource-based trusted interval obtained in Algorithm 1, the current event is retained to add it to the reference model and update the reference model (Algorithm 2:10–12). If not, the event is deleted, and the sliding window is moved (Algorithm 2:14).
When the resource for the new event does not exist in the reference model database, add the current event and the edge between it and the previous event and update the reference model (Algorithm 2:17)
If not satisfied, the current event is not retained, and the sliding window is moved to the next new case.
Then continue the execution of Algorithm 1 to update the conditions to determine if the new event is satisfied, i.e. update the trusted intervals based on behaviour and resources (Algorithm 2:22). Finally, output the updated model (Algorithm 2:23).
6. Experiments
We implement the algorithm of this paper based on the scikit-learn (Pedregosa et al., Citation2011) interface (i.e. the Hybrid Behavioural and Resource Trusted intervals Updating algorithm, briefly called BI & RI updating in the following) and analyse the model quality under the trusted behavioural interval constraints and the efficiency under incremental updates using publicly available datasets. Section 6.1 describes the relevant setup of the experiments, and then the results of the experiments are shown in Section 6.2, as well as the related discussion in Section 6.3.
6.1. Experimental setup
A real log titled “Receipt phase of an environmental permit application process (‘WABO’), CoSeLoG project”Footnote2 (denoted as Receipt) is used in this section to evaluate the effectiveness and performance of the proposed algorithm. The project has a complex process structure and a rich set of case attributes.
Receipt: The log records the execution of some building permit application processes in the Netherlands, with 1434 traces, 8577 events, 27 activities, 48 resources, and a complex structure (including order, concurrency, and loops).
To evaluate the reliability of BI & RI Updating under general conditions, we use a small portion of logs to mine a simple initial reference model to replace the industry reference model. The reference model is mined from a part of the logs as a starting point by a process discovery algorithm in the process mining domain. Subsequently, the logs are transformed into the form of event streams, and then multiple cases of system processes are simulated in the process to run in real-time based on the idea of threads. The performance and effectiveness of the algorithms in this paper in online scenarios are evaluated by analysing such simulated real-time cases.
The experiment was divided into three steps, and the specific experiment-related settings are as follows:
Analyse the structure of the reference model and perform association rule analysis and cluster analysis on the resources and activities of the reference logs respectively to obtain trusted interval constraints.
First, 10% of the data from the logs are randomly selected as the reference logs (named reference sets), and a simple initial reference model is obtained using Split Miner. Then the events of the reference logs are clustered and analysed using a deep clustering algorithm. In which, the number of clusters k of the clusters is determined using the elbow method (Marutho et al., Citation2018). Meanwhile, the resource properties of the reference logs are analysed using FrequentPattern Tree (FP-Tree). FP-Tree, as a common association rule algorithm, adopts the idea of divide-and-conquer, which has well adaptability and high efficiency for rules of different lengths. After this stage, we can obtain the trusted interval constraints and reference models based on the reference logs.
Evaluate the impact of the proposed algorithm on model quality under online event streams.
To evaluate the enhancement of the model under the trusted interval constraint, we randomly injected 5%, 10%, and 15% noise in the remaining logs using the ProMFootnote3 plugin Add Noise to Log Filter. Subsequently, the four logs were analysed using BI & RI Updating and Split MinerFootnote4 to obtain the models, and the metric was used to measure the obtained models. Besides, some processing of the logs is needed: we cache the event streams as sequence sets at specific points in time.
Split Miner: As the first automated process discovery method, which is a more advanced discovery algorithm. It is not only to discover various behavioural structures but also to have a faster execution speed. Therefore, in this paper, we use it to obtain the initial reference model.
Metrics: In the field of process mining, four types of metrics are commonly used:
Fitness: responds to the extent to which the model obtained by the process discovery technique is able to replay the behaviour in the event log.
Precision: reflects the degree to which the discovered model does not allow irrelevant behaviour to appear in the event log.
Generalisability: reacts to the ability of the model to describe behaviours that do not yet appear in the event log.
Simplicity: According to Aum's razor principle, discovered models should be as simple as possible. This indicator reflects the simplicity of the model.
These four metrics are not positively correlated; on the contrary, some of them may be negatively correlated. In this paper, we are more concerned with the Fitness of the model to the event log, so we adopt a common practice: using the reconciled average of Fitness and Precision, i.e. the F1-score as the metric:
Compare the efficiency of incremental mining with trusted interval constraints with that of traditional process mining.
In this experiment, the efficiency of the algorithm is analysed by comparing the length of time taken by the algorithm in this paper and the traditional process mining algorithm to obtain a model when processing a new event stream occurs. We use the incremental set as the online data source and set the sliding window to 10, i.e. after every 10 events, 1 incremental update processing as well as model discovery operation is performed.
6.2. Experimental results
In this section, we present and analyse the results of the different phases of the experiment.
6.2.1. Reference logs analysis
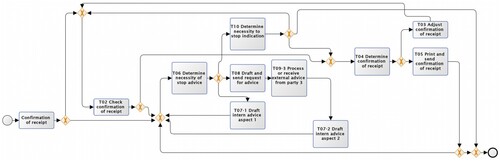
Firstly, we assume that all logs are legal and randomly select a portion of logs to set a reference model. Figure shows the model mined from a random 10% fraction of the event logs using Split Miner. Due to the small size of the selected logs, the structure of the obtained model is simple, and the dependencies between activities and events are not complete. For example, “T04 Determine confirmation of receipt” and “T05 Print and send confirmation of receipt” are separated only by a simple strict order relationship of the “XOR split” gateway, which is one of the closing activities in the model.
Figure 6. Reference model from 10% of the logs using Split Miner.
Then, using the reference model as a starting point, analyse the activity dependencies and resource attribute relationships among the activities in the model.
Figure shows the association rule relationships between the resource pairs in the reference logs. The X-axis represents the different resource pairs in the reference logs, the left y-axis represents the Support and Confidence values (between 0 and 1), and the right y-axis represents the lift values (0–25). As can be obtained from this figure, the differences between the different resource pairs are large. All lift values are higher than 1, indicating different degrees of positive correlation between resources in this example. The higher the lift value, the stronger the positive correlation between the two resources, e.g. , indicating that Resource12 will appear together to a large extent when Resource10 appears.
Figure 7. Support, confidence and lift of resource pairs in the reference logs.
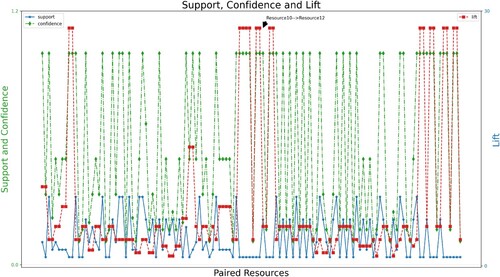
Figure 8. Reference logs clustering scatter jittering plot.
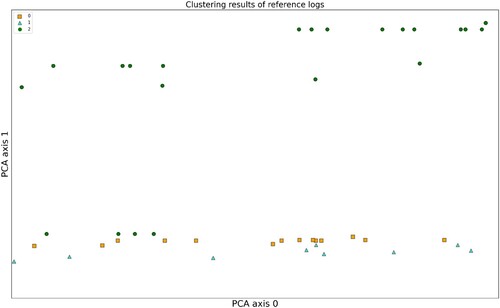
shows the clustering results of the reference logs. Based on the elbow method, to determine the number of clusters as 3, and then apply the deep clustering method in this paper to process the reference logs to obtain the clustering results. The log vector is downscaled into a 2-dimensional vector using the PCA technique, and the jitter plot is used to expand the horizontal axes of similar points to make them easier to observe. The results show that the discriminability between clusters is better, which provides a foundation for the subsequent calculation of trusted intervals.
6.2.2. Model quality metrics
In this phase of the experiments, we aim to analyse the effectiveness of the algorithm running with different noise logs levels and the difference in efficacy with existing models. We use Split Miner and the algorithm in this paper to process the event streams with 0–15% noise, and the Precision, Fitness, and F1-score values obtained are shown in Table . Firstly, analyse the metrics with the same noise levels and take the log “receive” without noise as an example. The Precision of the model obtained using this paper's algorithm is 0.783, and the Precision of the model got using Split Miner is 0.676, an increase of 15.8%; however, the Fitness obtained by this paper's algorithm is slightly lower than the value obtained by Split Miner, a decrease of 0.6%. This is the reason why the F1-score metric was introduced. In this case, the F1-score obtained by the algorithm in this paper is 0.873, and the value obtained by Split Miner is 0.804, which is an improvement of 8.6% in comparison. This situation is intuitive during the incremental update. The algorithm in this paper not only dynamically updates the model but also filters the event streams based on the trusted intervals. By definition of each metric given earlier, since we remove some behaviours that do not fit the trusted intervals, the obtained model is more accurate, and therefore the Precision value is higher. While the deleted logs cannot be replayed in the model, i.e. there are some logs that cannot be replaced by the model, the Fitness value is low.
Table 2. Model quality measures under different noises.
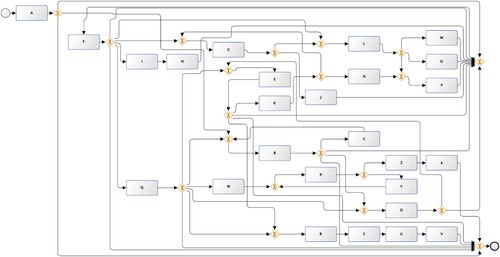
When the noise injected in the logs is 10%, the F1-score of the model is higher than that of the case without noise. We attempted to further analyse the less intuitive results in Table by visualising the model for these two cases as Figures and . In this context, it can be found that although the F1-score value of the model containing 10% noise is slightly higher, a large number of silent transitions are introduced into the model, which reduces the simplicity and readability of the model and leads to model overfitting. Therefore, the algorithm in this paper is able to achieve incremental updates of the model in online scenarios and obtain a model with balanced indicators (as shown in Figure ).
Figure 9. Model obtained using the algorithm of this paper after injecting 10% of noise.
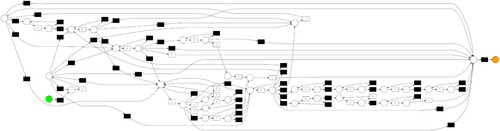
Figure 10. Resulting model.
6.2.3. Running time analysis
Discovery algorithms applied in offline scenarios lag far behind the actual execution time of the process, and if only timeliness is considered, the online processing event streams algorithm of this paper has a clear advantage, and no additional comparison is needed. Therefore, this section aims to compare the duration of the algorithm implementation (still compared with Split Miner).
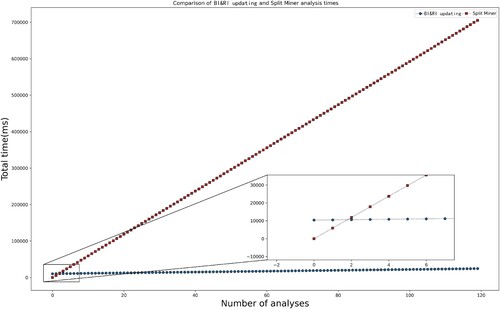
The duration of the algorithm in this paper is mainly divided into two parts: the pre-processing part of the reference logs and the incremental update part under the online event streams. And the Split Miner duration is also in two parts: the aggregated part of the event streams within the sliding window and the process model discovery part. In Figure , it is shown the total duration spent by both algorithms at each execution. The BI & RI updating algorithm requires only one pre-processing operation for the reference log, but this phase takes relatively longer (in seconds). The starting point is higher than that of the Split Miner algorithm. Subsequently, the analysis time for the added event streams is shorter (milliseconds), and the number of event streams added each time is less different and proportionally more minor compared to the starting pre-processing time, so the total time increase is smooth and stable. While Split Miner needs to re-mining the model after aggregating the event streams in the sliding window, the new part has a slight increase compared to the existing structure, so it has little impact on the single processing, and all the total time increases almost linearly. We show the whole time from the start to the fifth update in the vignette section of Figure and can see that the time spent by Split Miner is less than the total time for BI & RI updates at the start position. However, with the online event streams, the time required for Split Miner has surpassed the BI & RI updating at only the second analysis and is multiplying.
Figure 11. Running time comparison.
6.3. Discussion
Through experimental evaluation on real logs, we validate the approach's effectiveness in this paper. Trusted interval constraints at the control and resource flow levels are extracted from the reference logs. The latter is used to aid decision-making in the former, guiding incremental model updates in the online stage. High-quality models can be obtained based on mixed trusted interval constraints even without relying on domain knowledge or repetitive experiments.
In addition, the method in this paper has higher efficiency. Traditional process mining methods cannot cope with the continuous growth of execution logs. They need to collect logs and re-mine the model from scratch every time a new event stream occurs. With the system's continuous running, the event streams' size constantly increases, so each mining time will always be larger than the previous execution time, and the total time spent tends to overgrow. The computation time of the incremental update algorithm proposed in this paper is mainly consumed in the initial analysis phase of the reference logs. Then, for the algorithm in this paper, the model structure before the current analysis state has been frozen, and the object of each analysis is only a newly added part. Therefore, the increasing size of the event stream has a slight fluctuation in the computation time of the algorithm in this paper. The minor change of the computation time is mainly reflected in the different structures of the newly added parts, so the time consumed in updating the model varies slightly.
Finally, the algorithms generate a new event log while updating the reference model incrementally. Therefore, these logs can be used as input to the traditional process discovery algorithm, i.e. this algorithm in the pre-processing phase of the offline algorithm and can improve the quality of the process mining.
The limitation of the algorithm is in the processing part of the resource flow, and currently, we use association rules to analyse the relationship between resource pairs. Limited by the characteristics of association rules, the analysis of resource pairs at this time is based on the absence of sequential relationships between entries. In future work, we will analyse resources at a deeper level to study the impact of structural relationships between resources on the control flow.
7. Conclusions
The BI & RI Updating algorithm is proposed to adopt the outdated reference model for new business processes with rapid iterations. It implements incremental model updates for model enhancement based on multi-perspective trusted behaviour intervals for online event streams. And deep clustering and association rules are applied to compute trusted behaviour intervals from both control and data streams, respectively. The paper achieves two main objectives.
A multi-view hybrid trusted interval under offline logs is effectively constructed, which effectively combines control flow features and data flow features and reduces the dependence on domain knowledge. The reference logs are first extracted from the reference model in the offline phase. Then the activities in the control flow and the resources in the data flow are analysed based on the deep clustering method and the association rule method, respectively, so as to construct the hybrid trusted intervals.
Continuous model enhancement in online scenarios is achieved to improve the quality of the reference model. A multi-perspective trusted interval-guided online event stream detection and model incremental updating method is proposed, and the filtered event stream is used to enhance the reference model.
We implemented this paper's algorithm based on an open-source framework for simulation experiments. By experimenting and discussing, the contributions are concluded below.
The approach can progressively update the model structure without depending on domain knowledge, while without diminishing the quality of the model. This helps to increase the dependability of current related approaches and lessen the need on domain expertise.
The algorithm has a quick reaction time and execution cycle for live event stream, which helps developing the model structure while the business system activity is in progress.
In addition, the approach may be employed in the pre-processing phase of classic process discovery algorithms, which is advantageous for increasing the flexibility and analysis quality of offline models.
We will consider techniques such as sequence mining to explore further the resource level's impact on the control flow level to obtain more instructive interval constraints.
Acknowledgments
We also gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
References
- Al-Ali, H., Damiani, E., Al-Qutayri, M., Abu-Matar, M., & Mizouni, R. (2018). Translating BPMN to business rules. In P. Ceravolo, C. Guetl, & S. Rinderle-Ma (eds.), International symposium on data-driven process discovery and analysis (pp. 22–36). Springer International Publishing. https://doi.org/10.1007/978-3-319-74161-1_2
- Alizadeh, M., Lu, X., Fahland, D., Zannone, N., & van der Aalst, W. M. (2018, March). Linking data and process perspectives for conformance analysis. Computers & Security, 73, 172–193. https://doi.org/10.1016/j.cose.2017.10.010
- Armas Cervantes, A., van Beest, N. R. T. P., La Rosa, M., Dumas, M., & García-Bañuelos, L. (2017). Interactive and incremental business process model repair. In On the move to meaningful internet systems. OTM 2017 conferences (pp. 53–74). Springer International Publishing.
- Augusto, A., Conforti, R., Dumas, M., La Rosa, M., & Polyvyanyy, A. (2019). Split miner: automated discovery of accurate and simple business process models from event logs. Knowledge and Information Systems, 59(2), 251–284. https://doi.org/10.1007/s10115-018-1214-x
- Awad, A., Weidlich, M., & Sakr, S. (2020). Process mining over unordered event streams. In International conference on process mining (ICPM) (pp. 81–88). IEEE.
- Barbon Junior, S., Tavares, G. M., Da Costa, V. G. T., Ceravolo, P., & Damiani, E. (2018). A framework for human-in-the-loop monitoring of concept-drift detection in event log stream. In Companion proceedings of the the web conference 2018 (pp. 319–326). ACM Press.
- Bose, R. J. C., Van Der Aalst, W. M., V Z Liobait E, I. E., & Pechenizkiy, M. (2013). Dealing with concept drifts in process mining. IEEE Transactions on Neural Networks and Learning Systems, 25(1), 154–171. https://doi.org/10.1109/TNNLS.2013.2278313
- Brons, D., Scheepens, R., & Fahland, D. (2021). Striking a new balance in accuracy and simplicity with the probabilistic inductive miner. In International conference on process mining (ICPM) (pp. 32–39). IEEE.
- Burattin, A., Cimitile, M., Maggi, F. M., & Sperduti, A. (2015). Online discovery of declarative process models from event streams. IEEE Transactions on Services Computing, 8(6), 833–846. https://doi.org/10.1109/TSC.2015.2459703
- Burattin, A., & Josep, C. (2018). A framework for online conformance checking. In International conference on business process management (pp. 165–177). Springer International Publishing.
- Chan, N. N., Yongsiriwit, K., Gaaloul, W., & Mendling, J. (2014). Mining event logs to assist the development of executable process variants. In Advanced information systems engineering (Vol. 8484, pp. 548–563). Springer.
- Dees, M., de Leoni, M., & Mannhardt, F. (2017). Enhancing process models to improve business performance: A methodology and case studies. In H. Panetto, et al. (Eds.), On the move to meaningful internet systems. OTM 2017 conferences (pp. 232–251). Springer International Publishing.
- Deshmukh, S., Agarwal, M., Gupta, S., & Kumar, N. (2020). MOEA for discovering pareto-optimal process models: an experimental comparison. International Journal of Computational Science and Engineering, 21(3), 446. https://doi.org/10.1504/IJCSE.2020.106067
- Dixit, P. M., Verbeek, H., Buijs, J., & Aalst, W. (2018). Interactive data-driven process model construction. In International conference on conceptual modeling (pp. 251–265). Springer International Publishing.
- Du, H., Hao, Y., & Wang, Z. (2021). An improved density peaks clustering algorithm by automatic determination of cluster centres. Connection Science, 34(1), 857–873. https://doi.org/10.1080/09540091.2021.2012422.
- Fang, X. W., Cao, R., Liu, X., & Wang, L. (2018). A method of mining hidden transition of business process based on region. IEEE Access, 6, 25543–25550. https://doi.org/10.1109/ACCESS.2018.2833450
- Fang, X. W., Li, J., Wang, L. L., & Fang, H. (2020). Log automaton under conditions of infrequent behaviour mining. International Journal of Information Technology and Management, 19(4), 292–304. https://doi.org/10.1504/IJITM.2020.110239
- Hamdad, L., Ournani, Z., Benatchba, K., & Bendjoudi, A. (2020). Two-level parallel CPU/GPU-based genetic algorithm for association rule mining. International Journal of Computational Science and Engineering, 22(2/3), 335. https://doi.org/10.1504/IJCSE.2020.107366
- Kindler, E., Rubin, V., & Schäfer, W. (2006). Incremental workflow mining based on document versioning information. In Unifying the software process spectrum (pp. 287–301). Springer.
- Leno, V., Armas-Cervantes, A., Dumas, M., La Rosa, M., & Maggi, F. M. (2018). Discovering process maps from event streams. In Proceedings of the 2018 international conference on software and system process (pp. 86–95). ACM.
- Lu, K., Fang, X., Fang, N., & Asare, E. (2022). Discovery of effective infrequent sequences based on maximum probability path. Connection Science, 34(1), 63–82. https://doi.org/10.1080/09540091.2021.1951667
- Lu, X., Gal, A., & Reijers, H. A. (2020). Discovering hierarchical processes using flexible activity trees for event abstraction. In International conference on process mining (pp. 145–152). IEEE.
- Marutho, D., Hendra Handaka, S., Wijaya, E., Muljono, (2018). The determination of cluster number at k-mean using Elbow method and purity evaluation on headline news. In International seminar on application for technology of information and communication (pp. 533–538). IEEE.
- Nguyen, H., Dumas, M., ter Hofstede, A. H. M., La Rosa, M., & Maggi, F. M. (2016). Business process performance mining with staged process flows. In S. Nurcan, P. Soffer, M. Bajec, & J. Eder (Eds.), Advanced information systems engineering (pp. 167–185). Springer International Publishing.
- Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., & Duchesnay, E. (2011). Scikit-learn: machine learning in python. Journal of Machine Learning Research, 12, 2825–2830. https://doi.org/10.1007/978-1-4842-3913-1_8
- Pika, A., Leyer, M., Wynn, M. T., Fidge, C. J., Ter Hofstede, A. H. M., & Van Der Aalst, W. M. P. (2017). Mining resource profiles from event logs. ACM Transactions on Management Information Systems, 8(1), 1–30. https://doi.org/10.1145/3041218
- Tavares, G. M., da Costa, V. G. T., Martins, V. E., Ceravolo, P., & Barbon, S. (2018). Anomaly Detection in Business Process Based on Data Stream Mining. In Proceedings of the XIV Brazilian symposium on information systems. Association for Computing Machinery.
- Thakur, H. K., Gupta, A., Nag, S., & Shrivastava, R. (2020). Multi-class instance-incremental framework for classification in fully dynamic graphs. International Journal of Computational Science and Engineering, 21(1), 69. https://doi.org/10.1504/IJCSE.2020.105214
- van der Aalst, W. (2016). Process mining data science in action (2nd ed.). Springer.
- van Zelst, S. J., van Dongen, B. F., & van der Aalst, W. M. P. (2018). Event stream-based process discovery using abstract representations. Knowledge and Information Systems, 54(2), 407–435. https://doi.org/10.1007/s10115-017-1060-2
- Wang, L. l., Fang, X. w., Asare, E., & Huan, F. (2021). An optimization approach for mining of process models with infrequent behaviors integrating data flow and control flow. Scientific Programming, 2021, 1–17. https://doi.org/10.1155/2021/8874316.
- Xie, J., Girshick, R., & Farhadi, A. (2016). Unsupervised deep embedding for clustering analysis. In Proceedings of machine learning research (Vol. 48, pp. 478–487). PMLR.
- Xu, H., Zhang, S., Zhu, G., & Zhu, H. (2022). ALSEE: a framework for attribute-level sentiment element extraction towards product reviews. Connection Science, 34(1), 205–223. https://doi.org/10.1080/09540091.2021.1981825
- Yongsiriwit, K., Chan, N. N., & Gaaloul, W. (2015). Log-based process fragment querying to support process design. In Hawaii international conference on system sciences (pp. 4109–4119). IEEE.
- Zhang, S., Yu, H., & Zhu, G. (2022). An emotional classification method of Chinese short comment text based on ELECTRA. Connection Science, 34(1), 254–273. https://doi.org/10.1080/09540091.2021.1985968
- Zhu, G., Pan, Z., Wang, Q., Zhang, S., & Li, K. C. (2020). Building multi-subtopic bi-level network for micro-blog hot topic based on feature co-occurrence and semantic community division. Journal of Network and Computer Applications, 170, 1–10. https://doi.org/10.1016/j.jnca.2020.102815