
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The recognition of English texts in teaching scenes is a practical research direction. English text recognition can be widely used in English teaching scenes, such as assisting teachers to recognise students’ English homework, text positioning before text translation, developing outdoor classrooms, assisting junior students in scene understanding and so on. To identify English information in different scenes as accurately as possible, identifying the corresponding text content is the key. Based on a deep neural network, this paper proposes GCN-Attention English recognition algorithm. The experiment adopts the deep learning framework Tensorflow, which combines 104 × 104 size GCN with an attention mechanism for training. The output of GCN is used to train the cyclic neural network to continuously predict the next most likely letter in the sequence. The goal of training is to match the output words with the expected words as much as possible. The test results show that the model can have a good recognition accuracy for the scene image data set used in teaching.
1. Introduction
Text with arbitrary direction and shape in teaching practice refers to a collection of text with different directions and shapes in the same image. The existing algorithms are difficult to recognise the text with arbitrary shape features efficiently and accurately. Coupled with the complex background information in the text image, it is difficult to recognise. Character recognition is the key link of character extraction technology. According to the different macro understanding and detection mechanism of the algorithm (Cai et al., Citation2021a; Wang et al., Citation2022a). We summarise most of the recognition algorithms into the following two categories: one is character-based character recognition algorithm, the other is vocabulary-based character recognition algorithm. The following analyses the research status of the two categories.
The character-based recognition algorithm (Bai et al., Citation2022) was originally used in the recognition of Latin characters. Its recognition process generally requires three processes. First, segment the characters in the image, then locate the characters in the detected area, and then use the classifier to recognise the character part. Finally, the recognised characters are collected together through the improved combined recognition algorithm to form a complete string or word group, to achieve the purpose of text recognition. HOG (Bai et al., Citation2016) proposed to use HOG feature (Dalal & Triggs, Citation2005) to construct stroke feature blocks for recognition and use a random classifier to complete text recognition. Literature (Tao et al., Citation2013; Wang et al., Citation2022b) uses Convolutional Neural Network (CNN) to recognise a single character. The PhotoOCR system (Bissacco et al., Citation2013) uses the fusion of the above two methods to realise character segmentation. The difference is that finally, the Beam search algorithm of multilingual framework is used to obtain the probability distribution, and the path with the highest combination probability is selected as the recognition result. Reference (Jaderberg et al., Citation2014) uses CNN as a single character classifier. One (Alsharif & Pineau, Citation2013) chooses to build two CNN for character recognition. One CNN is used to segment different regions in the image, and the other CNN classifies these different regions and then uses a Markov algorithm for character recognition. This method is a successful case of the successful integration of Markov algorithm and deep learning correlation network. This method not only improves the quality of the extracted text image but also analyses the correlation parameters of features between different regions based on Markov algorithm. The experiment also proves that this method has good robustness in practical recognition. There is another method, that is, using the Extreme Region (ER) (Matas et al., Citation2004) to find the candidate region of characters for recognition. Considering that the ER-related recognition algorithm has some special properties for the image itself, including the invariance of projection transformation and the improvement of recognition accuracy across resolutions, Neumann et al. systematically improved the ER recognition algorithm shortly after the method was proposed and proposed the maximum stable extremum region algorithm. This method intersects with the detection method proposed by Neumann, which will not be repeated here.
Character-based recognition algorithm can not only recognise any number of single character text but also recognise phrase text with different lengths and is not limited in the recognition of letter arrangement (Wang, Du, et al., Citation2022; Yu et al., Citation2022). It is a flexible and exquisite recognition method. Because this kind of recognition method recognises one character each time, its disadvantage is also visible to the naked eye, that is, its accuracy of character recognition in the image depends too much on the advantages and disadvantages of character segmentation. As mentioned above, the text background in the image is relatively complex and changeable, and there will be some restrictions if the character-based recognition algorithm is used for recognition.
Due to the problems of the above methods, a vocabulary-based recognition algorithm (Cai et al., Citation2021) is proposed. The vocabulary-based recognition algorithm directly regards each detected phrase as a whole and carries out the recognition operation according to the overall characteristics. The advantage of this kind of method is that it does not need to segment characters before character recognition but uses the overall characteristics of the text region in the image to represent the text region by vector. The use of this kind of recognition algorithm can effectively improve the efficiency of text recognition, and the frequent occurrence of improved methods makes the recognition accuracy improve steadily.
As a representative of vocabulary-based methods, Jaderberg et al. (Citation2016) migrated the problem of character recognition in images to the problem of classification. Its essence is to directly apply the deep learning neural network to the text image to be detected and recognise the lexical feature blocks in the text. Lexical feature block is a convolution divided into 90,000 different kinds. In the convolution, a word is a kind. After classifying different words, it is divided into about 90,000 words and combined into a vocabulary library. The use of this algorithm does not need to deal with the problem of segmented region (Du et al., Citation2020), which improves the recognition efficiency and achieves good recognition effect. After system analysis, it can be found that the training model parameters of this kind of method are huge, and the problem of overfitting often occurs. Considering the continuous expansion of vocabulary, the calculation model will only increase. For the treatment of the above problems, researchers have given different solutions, and their subsequent research is based on the original intention of this kind of method. One (Su & Lu, Citation2014) performed HOG extraction on the input image according to the lexical features. After extracting the corresponding features of the characteristic vocabulary, they used the Recurrent Neural Network (RNN) to process the extracted lexical features and then used the Connectionist Temporal Classification (CTC) (Graves et al., Citation2006) to recognise the text. As a combination method for the first time, its recognition effect is still excellent, but its deficiency is obvious compared with CNN. The extracted HOG features cannot accurately represent the text features. The convolution end of the neural network is named as Convolutional Recurrent Neural Networks (CRNN) by Shi et al. (Citation2016). This method consists of three parts: convolution layer, circulation layer and transcription layer. The convolution layer of crnn extracts text features from the input image, the circulation layer makes probability prediction for the features extracted from the convolution layer, and the transcription layer then converts the result value of the probability prediction of the circulation layer through a series of parameter settings, and finally generates the recognition result. Compared with traditional CNN, this method has better effect. It can directly learn feature information from the pixel data contained in the image. Its advantage is that there is no restriction on the length of sequence objects, and more text data can be accommodated in the recognition process. The DTRN network model proposed by Huang (He et al., Citation2016) is used for character recognition. The network model uses CNN to extract sequence features and recognises all feature sequences through Long Short-Term Memory (LSTM), so as to recognise the vocabulary text in the image. One (Lee C & Osindero, Citation2016) immediately put forward the improved network model, which is different from the former in that the attention mechanism is introduced into the network before recognition, and then some design improvements are made in feature extraction and recognition algorithms. The introduction of recursive convolutional neural network enables it to achieve the purpose of extraction more accurately under the same parameters. The implantation of RNN avoids redundant steps such as redundant parameter analysis. The attention mechanism enables the whole recognition model to accurately select picture features and avoid unnecessary retrieval and learning time.
To solve the problem of edge recognition, One (Cheng et al., Citation2017) proposed an automatic alignment method. The difference between this method and the above is that a focus attention network module is added. The function of this module can increase the accuracy of feature extraction, make the distribution of extracted feature sequence more concentrated, improve the accuracy and improve the robustness of the recognition system. The fledgling Graph Convolutional Network (GCN) (Jiang Z et al., Citation2022; Li et al., Citation2019) has made breakthroughs in many application fields (Chen et al., Citation2019; Yan et al., Citation2021; Ye et al., Citation2020). One (Yao et al., Citation2019) proved with experimental data that GCN can obtain high robustness with less training data.
According to the above problems, this paper designs the text feature extraction, graph attention model, gating loop unit and so on, and proposes a GCN attention network for text recognition.
2. Network model design
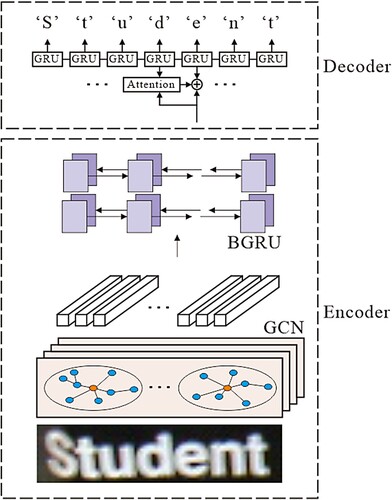
The character recognition model proposed in this paper consists of two parts: encoding and decoding. The input of the encoding part is the original image. It obtains the feature sequence through the convolution network and then sends the feature sequence to the BGRU network to extract the image features. The decoding part first allocates the structural attributes of the image feature sequence through the attention model and then outputs the recognised characters through the GRU network. The structure of GCN-Attention recognition model is shown in Figure . It is worth noting that there are six groups of attention when identifying “Student” in the example of Figure .
Figure 1. GCN-Attention network model.
2.1 Character feature extraction
To avoid the inconsistency of feature extraction data caused by different size character blocks, all character images are normalised in advance. Specifically, the corrected character blocks are uniformly adjusted to 104 × 104 size. At the same time, to reduce the redundancy of feature information and reduce the time complexity, uniform sampling is a good choice (Chen et al., Citation2021). The two features extracted from the sampling points are integrated to express the character features. The specific operations are as follows.
The normalised square character image is uniformly sampled, the initial distance between rows and columns is set to 2, and the spacing step of adjacent sampling points is set to 10. Its essence is to set 10 × 10 uniform mesh sampling points, so that a total of 100 sampling points are extracted on 104 × 104 character blocks.
The features of sampling points are counted by the interval feature capture template as shown in Figure (a). The template is successively used for 100 sampling points in the character block, as shown in the Yellow feature capture template in Figure (b). Retrieve the centre position of area in advance and set it as the initial sampling point. According to the subsequent operations, the histogram of the gradient direction from
to this point is counted, and the vertical direction of the maximum value in the histogram is set as the positive direction of the
axis of the sampling point.
Figure 2. Texture feature: (a) feature extraction template and (b) feature point sampling.
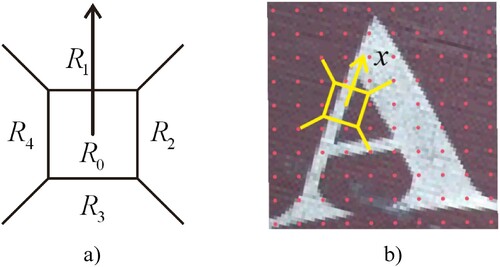
In the process of feature extraction, taking the center of the feature capture template as the axis, it is divided into 36 directions, that is, 36 parts within the range of . Then integrate the features of each copy to generate a gradient histogram. Each direction is divided into sections, which are specifically divided into
,
. Take the middle value of each direction vector and set it as the quantisation direction.
For a sampling point, after defining 36 quantisation directions and the positive direction of the sampling point, point the arrow of the feature capture template to the positive direction. Name the five areas of the template in the following order:
,
,
,
and
.
Calculation of local features. For one of the sampling points, first rotate the initial quantisation direction of the position to the position consistent with the positive direction of axis. This is equivalent to rotating each sampling point in the image by the same angle. Then, the local features of eight intervals are described by the HOG value. This value is used to effectively input the described local features, and the distance between intervals is set to
.
Through the above operations, the features of each sampling point are extracted by 5 × 8 = 40 vector eigenvalue. Then the remaining 99 relative sampling features of each sampling point are fused, which is equivalent to 99 feature fusion vector groups with a dimension of 80. Finally, these vector groups are used as the combined texture features of the sampling point.
This method sets the radius of the innermost feature capture range in the feature capture template to 1. The outermost feature snap range radius is set to 6. Texture feature capture is performed every 1 unit. After performing the same operation on each sampling point in the image, 100 × 99 80-dimensional sampling point combined texture features can be obtained, with a total of 792,000 feature data.
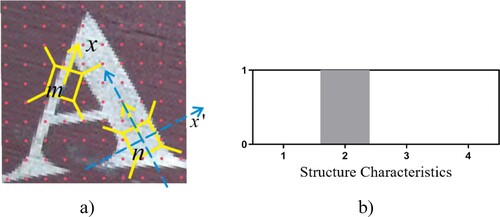
The structural feature reflects the position structure between two sampling points. In practice, it is expressed by looking for the quadrant relationship between two sampling points and expressed by four-dimensional vector counting board. As shown in Figure (a), through the design modelling in the previous part, the sampling templates of two marking directions are obtained. After the rectangular coordinate system is established on the template , the structural relationship between other templates and template
is obtained through calculation. The characteristics of its structural part are expressed by the vector counting board. For example, if the coordinate of template
relative to template
is the second quadrant, the position information is recorded as 1. Similarly, if the relative position is in other quadrants, the structural feature is recorded 1 in the corresponding dimension, as shown in Figure (b). When counting the structural characteristics of the other 98 sampling points relative to the sampling points where the template
is located, the corresponding position relationship is also recorded through the counting board, and the second is used as the representation method of the structural characteristics. It should be noted that in the representation of structural features, when the centre of a reference point is in the area with a small plus or minus 10 degrees of the coordinate axis of another reference point, such points shall be specified uniformly. Make them belong to two quadrants at the same time, and record 0.5 in two dimensions of location information at the same time. To sum up, 9900 structural features can be extracted from each character image.
Figure 3. Structure characteristics: (a) examples of structural features and (b) structural characteristics representation.
After the integration input of texture features and structural features, the overall probability of the integrated features of each character image will be evaluated, that is, the probability of belonging to a character is predicted to be , where
is the character feature,
is the character type and
. To avoid the disharmony of the spatial location features of the sampling template, the word bag model is introduced to remove this potential trouble. Word bag model is a commonly used word storage and memory method in the field of information retrieval. In the retrieval and call of information, we do not consider the word order and grammatical characteristics of a single character in the whole text. Only regard it as a character set to retrieve or call, that is, the word bag contains several characters. The appearance of each character in the text is independent and does not depend on whether the order of other characters is uniform. This corresponds to the intention of the character feature capture template and meets the needs of the method of character level feature recognition. Finally, the statistical character features are compared with the word bag character features, and the word bag character with the highest probability is selected to represent the character. The algorithm will use the principle of learning features to integrate character features into feature centres in the training process, which constitute the word bag model. The word bag model used in this experiment divides the
features of character pixels into fixed
characters, that is, the integrated feature centre is classified as
. In this paper,
represents the number of character features, which is obtained through GCN training, and its value is relatively large.
refers to the number of characters in the dictionary, where
= 62, including 26 English uppercase letters, 26 English lowercase letters and 10 Arabic numerals. The essence of feature integration centre is to map the extracted character feature classification to the feature dictionary to form a
-dimensional feature vector.
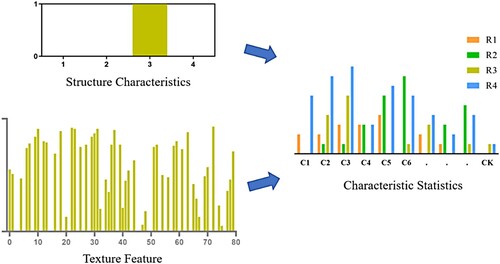
In model training, the sampling feature information of combined texture features is divided into classes by K-means clustering method. Then cluster each feature belonging to the same character into a feature centre. Finally, the
feature centres are combined into a feature character dictionary. In the training process, we should also do the following points. When extracting combined texture features, we do cumulative statistics. Therefore, the process of extracting feature vectors needs to be carried out from left to right and from top to bottom. When expressing the relationship between structural features, the corresponding structural features need to be accumulated behind the texture features to realise feature fusion. As shown in Figure , the feature fusion part is expressed by histogram. The fused histogram is formed by the fusion of
-dimensional vector and corresponding
-dimensional structural features, that is, each type of character library includes
feature groups. In the subsequent recognition, a one-to-many SVM classifier is used, and the histogram cross kernel (Maji et al., Citation2013) is used to estimate the posterior probability
of characters. Obtain the maximum value in the posterior probability, mark it as the character
, and output the character category as the recognition result.
Figure 4. Feature fusion.
2.2 Attention mechanism
The Attention mechanism (Huang et al., Citation2019) is mainly proposed to solve a series of problems such as text information ambiguity in the decoding process. The model structure is shown in Figure .
Figure 5. Attention mechanism model.
Attention mechanism is just like the attention effect of the human visual field. When observing things, people filter unnecessary information in the visual field, connect useful information in series, and then transmit it to our brain through the optic nerve. This process is the result of automatic coding of the brain and the mechanism formed by continuous learning and training in the process of growing up. This is just like the encoding and decoding mechanisms of Attention. The mechanism learns the importance of each feature from the retrieved character sequence, then divides the level according to the importance and combines the feature information of different importance to be applied to the next learning or retrieval (Badrinarayanan et al., Citation2017). Furthermore, the Attention mechanism is a connecting channel between encoding and decoding in the recognition task. It can learn the importance of each layer of implicit information and transmit it to the next layer of information. After passing it to each other, it discards the low-quality information and retains the relatively important high-quality information. This can be applied to identify the underlying semantic information between characters and then determine the directionality of the characters in the connected string.
Under the action of the Attention mechanism, the character connection order will become the focus. The code is no longer a separate input, but the weighted sum of the characteristics of each character according to the importance. The weighted code can be expressed as
(1)
(1) Among them, the parameter
represents the time,
represents the
characteristic element,
represents the character characteristic length and
represents the coding of element
.
is the probability value, indicating the importance of element
to
, which can be expressed as
(2)
(2) where
indicates the matching degree between the feature to be encoded and other features. The matching degree is the similarity ratio of the weighted sum value of the feature importance to the feature importance in the training set. The higher the matching degree, the greater the
value. In the decoding structure with Attention mechanism, each semantic code
will automatically select the most appropriate context information for the current output
.
When using graph convolution neural network for scene graph learning, this paper designs the following graph attention network model. Let the eigenvectors corresponding to each sampling point in the graph be
,
.
represents the characteristic dimension of the sampling point. Through the Attention network, the output is the new eigenvector of the sampling point,
,
.
represents the dimension of the eigenvector of the output sampling point. Considering the characteristics of the GCN network model, the feature dimension of the input node is set to 2048. The feature dimension output in this paper is 1000. The specific process is as follows.
Assuming that the central node is and the weight coefficient from neighbour nodes
to
is
(3)
(3) where
is the weight parameter of the node feature transformation of this layer and
is the function of calculating the correlation degree of two nodes.
The correlation function used here is the full connection layer of a single layer. After the node features are spliced, the output is
after passing through the full connection layer and activation function.
(4)
(4) Among them, the weight parameter
and the activation function are designed
.
In the experiment, to better distribute the weight, Softmax normalisation will be used, which is expressed as
(5)
(5) where
is the weight coefficient. Through the processing of Equation (5), it is ensured that the sum of the weight coefficients of all neighbour nodes is 1. The complete weight coefficient calculation formula is:
(6)
(6)
The specific process of adaptive weight allocation of different neighbour nodes is shown in Figure .
Figure 6. Adaptive weight allocation process of different neighbour nodes.
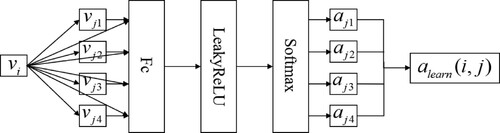
After the above calculation of the weight coefficient and weighting through the attention mechanism, the feature vector of the new sampling point is expressed as
(7)
(7) where
is all neighbour nodes of node
, that is, adjacent characters in the scene graph.
2.3 Gating recurrent unit
Here, the structural model of Bidirectional Gating Recurrent Unit (BGRU) is used, which is shown in Figure . This part includes two series of double-layer GRU networks in different directions. The number of hidden nodes in the hidden layer of each GRU layer is 256. By using the coding strategy of bidirectional BGRU, the obtained coded character sequence contains more features between character contexts. Its function is to put “I” and “L”, “O” and “0”, “U” and “V” on characters that are easy to recognise errors. In the process of single GRU coding, the information expression is insufficient, and the effect of recognition is not ideal. Both correct and wrong recognition occur. BGRU is introduced here, which combines two-way scores and generates results according to two feature codes, which can make the recognised results more accurate.
Figure 7. BGRU model.
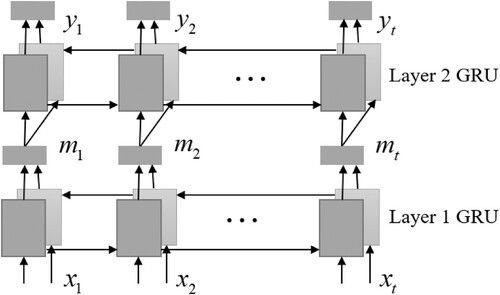
The feature map of GCN network is transmitted to BGRU, and the features of each symbol in the feature map are extracted by BGRU in turn, arranged into a feature vector and formed a feature sequence. The sequence length is the width
of the input characteristic graph, and the dimension of the vector in the sequence is the product of the height
and the depth
of the characteristic graph. The character feature sequence
is output to the intermediate sequence
after bidirectional processing at the first layer of BGRU. Then the intermediate sequence is used as input for two-way processing. The output vector
is a complete character feature group, which includes the prediction probability of each feature of the sequence. The high probability result finally output by BGRU is output as recognition character.
In the process of recognition, first, the corrected text image is taken as the input and transformed into a fixed-length vector for coding. Then the characters corresponding to the high probability value of vector features are output through feature comparison, and decoding is realised. The feature vectors in the coding model are compared with the word bag model to output the most relevant vectors, which effectively improves the recognition performance.
3. Experiment
3.1 Environment configuration
The main hardware configurations used are as follows: the system platform is Windows 10 professional edition, the processor is Interl (R) Core (TM) i9-9900k, the main frequency is 3.4 GHz, the core 16 thread has faster event processing speed, and the graphics card adopts GTX 1080Ti with 11GB video memory. The methods mentioned later are implemented in this environment.
The software environment used is configured as follows: Python(3.7) programming language is selected, PyCharm compiler is used for network model establishment and parameter learning and training, CUDA(10.2) is selected as the operation platform, and cuDNN(7.6) is configured as the acceleration library. Tensorflow algorithm tool is selected. Tensorflow is a framework based on flow structure, which has strong flexibility and high portability. While optimising performance and efficiency, it supports the saving and reading of graph and other data forms.
3.2 Evaluation index
The evaluation index used in the experiment is the character recognition rate index. Character recognition rate is the ratio of the number of correctly recognised characters in the recognition result to the total number of recognised characters.
It is worth mentioning that the word bag model designed in the recognition algorithm contains the case of English letters, so the network we trained is case sensitive, and the recognition rate is also case sensitive.
3.3 Comparative experiments
From the effective role of Attention mechanism. To prove the effectiveness of the Attention model, we also conducted a comparative experiment. This section trains two models. One model contains GRU decoder with graph Attention model, and the other model's decoder is an ordinary GRU network. The network is tested on CUTE80, IIIT5K, SVT and ICDAR2015.
According to the comparison results in Table , the effect of Attention mechanism on character recognition is significantly improved. Especially in CUTE80 and SVT data sets with more irregular text, the accuracy is improved by 3.1% and 3.2% respectively. At the same time, the recognition accuracy in IIIT5K and ICDAR2015 data sets is improved by 1.7% and 1.2% respectively. It is worth mentioning that some characters with different meanings after rotation are easy to cause recognition confusion, and the introduction of attention mechanism solves the above problems.
Table 1. Text recognition accuracy with or without Attention mechanism.
To make a comparative analysis from different recognition models and data sets, we must first screen the data sets. Because the word bag model is used in the recognition algorithm in this paper, we use CUTE80, ICDAR2015, IIIT5K and SVT to test the recognition. The experimental results of the 5 recognition algorithms after 5000 iterations are shown in Table .
Table 2. Recognition rate of comparison between recognition algorithm and data set.
From the recognition rate in Table , we know that GCN + AEN has high recognition accuracy in the five comparison algorithms. The recognition rate results on ICDAR2015 and SVT are the best or one of the best. Especially in CUTE80 data set, the recognition rate is at least 4% higher than other algorithms.
It can be seen that compared with the traditional RCNN model, the GCN model which extracts the graph features on the two-dimensional topology has a better effect on text recognition. Moreover, Attention mechanism can significantly improve the accuracy of text recognition. The reason is that when recognising fuzzy characters, the graph Attention model can improve the probability of correct recognition, to improve the recognition rate as a whole.
Figure shows the comparison curve of recognition rate results under different iteration times. The following conclusions can be drawn from the comparison of the recognition rate results in various data of different iterations. When the number of iterations exceeds 3000, the recognition accuracy gradually tends to be stable. Under the same number of iterations, GCN is generally better than traditional CNN in the recognition accuracy of irregular fonts.
Figure 8. Comparison curve of recognition rate results under different iteration times: (a) SVT Data Set; (b) CUTE80 Data Set; (c) IIIT5K Data Set.
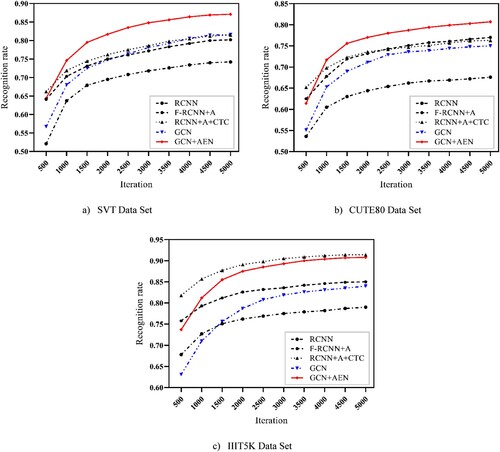
Comparing different data sets, we can draw the following conclusions. The recognition algorithm in this paper has no obvious advantage in the recognition effect of Regular Fonts (the recognition rate of RCNN + AEN + CTC is better on IIIT5K data set). The more accurate the GCN is in the recognition of irregular characters, the more obvious the advantage is in the recognition rate of irregular characters. This is reflected in the CUTE80 dataset and SVT dataset with large degree of shape arbitrariness. Under the same iteration times of the two sets of data sets, the recognition rate of this method is about 5% higher.
The experimental results of multiple sets of recognition data sets show that the establishment of graph Attention model can further improve the recognition accuracy in the recognition network. In the field of text extraction, compared with the latest methods, this method has enough competitiveness, and GCN has more valuable exploration space.
4. Conclusion
In this paper, a recognition network based on GCN and graph Attention model is designed. It effectively solves the correctness of the direction of recognising characters with different meanings after rotation in English teaching scene. By introducing BGRU, the problems of text information loss and slow training speed are solved. Through experimental verification, the recognition algorithm GCN-Attention proposed in this paper has a high recognition rate in multiple sets of data sets. Compared with other algorithms, this method has better recognition accuracy.
Data availability declaration
The data used to support the findings of this study are available from the corresponding author upon request.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Alsharif, O., & Pineau, J. (2013). End-to-end text recognition with hybrid HMM maxout models. Computer Science, 276–283. https://doi.org/10.48550/arXiv.1310.1811
- Badrinarayanan, V., Kendall, A., & Cipolla, R. (2017). Segnet: A deep convolutional encoder–eecoder architecture for image segmentation. IEEE Transactions on Pattern Analysis & Machine Intelligence, 39(12), 2481–2495. https://doi.org/10.1109/TPAMI.2016.2644615
- Bai, X., Yao, C., & Liu, W. (2016). Strokelets: A learned multi-scale mid-level representation for scene text recognition. IEEE Transactions on Image Processing, 25(6), 2789–2802. https://doi.org/10.1109/TIP.2016.2555080
- Bai, X., Zhou, J., Ning, X., & Wang, C. (2022). 3D data computation and visualization. Displays, 102169. https://doi.org/10.1016/j.displa.2022.102169
- Bissacco, A., Cummins, M., Netzer, Y., & Neven, H.. (2013). PhotoOCR: Reading text in uncontrolled conditions. IEEE International Conference on Computer Vision (pp. 785–792). https://doi.org/10.1109/ICCV.2013.102
- Cai, W., Liu, D., Ning, X., Wang, C., & Xie, G. (2021a). Voxel-based three-view hybrid parallel network for 3D object classification. Displays, 69, 102076. https://doi.org/10.1016/j.displa.2021.102076
- Cai, W., Zhai, B., Liu, Y., Liu, R., & Ning, X. (2021). Quadratic polynomial guided fuzzy C-means and dual attention mechanism for medical image segmentation. Displays, 70, 102106. https://doi.org/10.1016/j.displa.2021.102106
- Chen, Z., Huang, J., Ahn, H., & Ning, X.. (2021, July). Costly features classification using monte carlo tree search. In 2021 International Joint Conference on Neural Networks (IJCNN) (pp. 1–8). IEEE. https://doi.org/10.1109/IJCNN52387.2021.9533593
- Chen, Z. M., Wei, X. S., Wang, P., & Guo, Y. (2019). Multi-label image recognition with graph convolutional networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5177–5186). IEEE. https://doi.org/10.1109/CVPR.2019.00532
- Cheng, Z., Fan, B., Xu, Y., Zheng, G., Pu, S., & Zhou, S.. (2017). Focusing attention: Towards accurate text recognition in natural images. In Proceedings of the IEEE international conference on computer vision (pp. 5076–5084). IEEE. https://doi.org/10.1109/ICCV.2017.543
- Dalal, N., & Triggs, B.. (2005, June). Histograms of oriented gradients for human detection. In 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05) (Vol. 1, pp. 886–893). IEEE. https://doi.org/10.1109/ICCV.2017.543
- Du, X., Tang, S., Lu, Z., Wet, J., Gai, K., & Hung, P. C. K.. (2020, October). A novel data placement strategy for data-sharing scientific workflows in heterogeneous edge-cloud computing environments. In 2020 IEEE International Conference on Web Services (ICWS) (pp. 498–507). IEEE. https://doi.org/10.1109/ICWS49710.2020.00073
- Graves, A., Fernández, S., & Gomez, F. (2006). Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In International conference on machine learning, Dalian, China (pp. 492–501). IEEE.
- He, T., Huang, W., Qiao, Y., & Yao, J. (2016). Text-attentional convolutional neural networks for scene text detection. IEEE Transactions on Image Processing, 25(6), 2529–2541. https://doi.org/10.1109/TIP.2016.2547588
- Huang, L., Wang, W., Chen, J., & Wei, X. Y. (2019). Attention on attention for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 4634–4643). https://doi.org/10.48550/arXiv.1908.06954
- Jaderberg, M., Simonyan, K., Vedaldi, A., & Zisserman, A. (2016). Reading text in the wild with convolutional neural networks. International Journal of Computer Vision, 116(1), 1–20. https://doi.org/10.1007/s11263-015-0823-z
- Jaderberg, M., Vedaldi, A., & Zisserman, A.. (2014, September). Deep features for text spotting. In D. Fleet, T. Pajdla, B. Schiele, & T. Tuytelaars (Eds.), Computer Vision – ECCV 2014. ECCV 2014. Lecture Notes in Computer Science (Vol. 8692). Springer. https://doi.org/10.1007/978-3-319-10593-2_34
- Jiang Z, Y., Huang, L., & Chen, S. (2022). Text recognition in natural scenes based on deep learning. Multimedia Tools and Applications, 81(8), 10545–10559. https://doi.org/10.1007/s11042-022-12024-w
- Lee C, Y., & Osindero, S.. (2016). Recursive recurrent nets with attention modeling for ocr in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2231–2239). IEEE. https://doi.org/10.1109/CVPR.2016.245
- Li, Q., Peng, X., Qiao, Y., & Peng, Q. (2019). Learning category correlations for multi-label image recognition with graph networks. arXiv preprint arXiv:1909.13005. https://doi.org/10.48550/arXiv.1909.13005
- Maji, S., Berg A, C., & Malik, J. (2013). Efficient classification for additive kernel SVMs. IEEE Transactions on Pattern Analysis & Machine Intelligence, 35(1), 66–77. https://doi.org/10.1109/TPAMI.2012.62
- Matas, J., Chum, O., Urban, M., & Pajdla, T. (2004). Robust wide-baseline stereo from maximally stable extremal regions. Image & Vision Computing, 22(10), 761–767. https://doi.org/10.1016/j.imavis.2004.02.006
- Shi, B., Xiang, B., & Cong, Y. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Transactions on Pattern Analysis & Machine Intelligence, 39(11), 2298–2304. https://doi.org/10.1109/TPAMI.2016.2646371
- Su, B., & Lu, S. (2014). Accurate scene text recognition based on recurrent neural network. In Asian Conference on Computer Vision (pp. 35–48). Springer. https://doi.org/10.1007/978-3-319-16865-4_3
- Tao, W., Wu, D., Coates, A., & Ng, Y.. (2013). End-to-end text recognition with convolutional neural networks. In Proceedings of the 21st international conference on pattern recognition (ICPR2012) (pp. 3304–3308). IEEE.
- Wang, C., Wang, X., Zhang, J., et al. (2022a). Uncertainty estimation for stereo matching based on evidential deep learning. Pattern Recognition, 124, 108498. https://doi.org/10.1016/j.patcog.2021.108498
- Wang, M., Sun, T., Song, K., Li, S., Jiang, J., & Sun, L. (2022b). An efficient sparse pruning method for human pose estimation. Connection Science, 34(1), 960–974. https://doi.org/10.1080/09540091.2021.2012423
- Wang, Y., Du, X., Lu, Z., Duan, Q., & Wu, J. (2022). Improved LSTM-based time-series anomaly detection in rail transit operation environments. IEEE Transactions on Industrial Informatics, https://doi.org/10.1109/TII.2022.3164087
- Yan, C., Pang, G., Bai, X., Liu, C., Xin, N., Gu, L., & Zhou, J. (2021). Beyond triplet loss: Person re-identification with fine-grained difference-aware pairwise loss. IEEE Transactions on Multimedia, 24, 1665–1677. https://doi.org/10.1109/TMM.2021.3069562
- Yao, L., Mao, C., & Luo, Y. (2019). Graph convolutional networks for text classification. World Wide Web-Internet & Web Information Systems, 33(01), 7370–7377. https://doi.org/10.1609/aaai.v33i01.33017370
- Ye, J., He, J., Peng, X., Wu, W., & Qiao, Y. (2020). Attention-driven dynamic graph convolutional network for multi-label image recognition. In European Conference on Computer Vision (pp. 649–665). Springer. https://doi.org/10.1007/978-3-030-58589-1_39
- Yu, Z., Li, S., Sun, L., Liu, L, & Haining, W (2022). Multi-distribution noise quantisation: An extreme compression scheme for transformer according to parameter distribution. Connection Science, 34(1), 1–15. https://doi.org/10.1080/09540091.2021.2024510