
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Data deduplication can solve the problem of resource wastage caused by duplicated data. However, due to the limited resources of Internet of Things (IoT) devices, applying data deduplication to IoT scenarios is challenging. Existing data deduplication frameworks for the IoT are prone to inefficiency or trust crises due to the random allocation of edge computing nodes. Furthermore, side-channel attacks remain a risk. In addition, after IoT devices store data in the cloud through data deduplication, they cannot share their data efficiently. In this paper, we propose a secure and efficient data deduplication framework for the IoT based on edge computing and blockchain technologies. In this scheme, we propose a model based on parallel use of three-layer and two-layer architectures and introduce the RAndom REsponse (RARE) scheme to resist side-channel attacks. We also design a label tree to realise one-to-many data-sharing, which improves efficiency and meets the needs of the IoT. In addition, we use blockchain to resist collusion attacks. Experiments were conducted to demonstrate that our framework has advantages over similar schemes in terms of communication cost, security and efficiency.
1. Introduction
The Internet of Things (IoT) is an extended network based on the Internet that is an essential part of the new generation of information technology (Afzal et al., Citation2008). IoT devices collect, process and share relevant data (Karati et al., Citation2021; Lin et al., Citation2021), and store it in a cloud service provider (CSP) (Cui et al., Citation2015; C. Zhang et al., Citation2018; Z. Zhang et al., Citation2017). However, in the data collected by IoT devices, there are increasing amounts of duplicate data. A large amount of duplicate data results in a massive waste of resources, bringing enormous cost pressures to CSPs (Stanek & Kencl, Citation2016). Data deduplication (Bolosky et al., Citation2000) is a data storage optimisation technology that retains a single physical copy of data in the cloud to avoid storing duplicates, which saves storage costs (Hovhannisyan et al., Citation2018; Y. Tian et al., Citation2014, Citation2014?). Therefore, data deduplication is widely used in IoT scenarios and has been a topic of much research. However, there are still many problems to be solved.
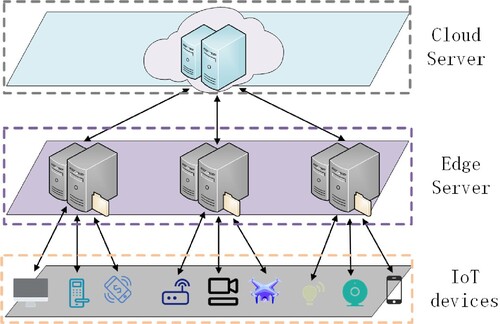
Firstly, almost all existing research schemes use a two-layer architecture that allows IoT devices to interact directly with CSPs (as shown in Figure ) or a three-layer architecture that allows IoT devices to interact with CSPs via edge computing platforms (as shown in Figure ). However, in the two-layer architecture, many IoT devices interact directly with a remote CSP, which often leads to an extended response delay and reduces the system's overall efficiency. In order to improve the overall efficiency of such systems, Ming et al. (Citation2022) used a three-layer architecture. This scheme uses edge computing nodes for data deduplication. However, the trust crisis caused by the random allocation of edge computing nodes to IoT devices is rarely considered in studies on three-layer architectures. Edge computing platforms are not usually wholly trusted by users; moreover, their resources are limited (Ming et al., Citation2022). Directly performing block-level data deduplication at edge computing nodes will impose considerable burdens on them.
Figure 1. Schematic diagram of a two-layer IoT architecture.
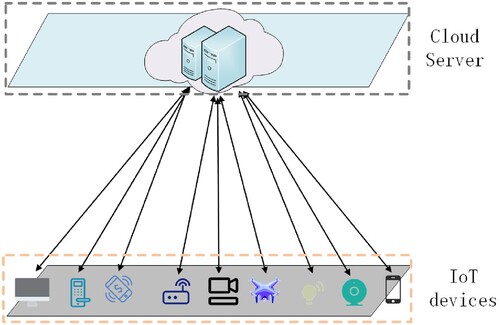
Figure 2. Schematic diagram of a three-layer IoT architecture.
Secondly, after a data deduplication operation between an IoT device and CSP is conducted, the IoT data is stored in the cloud and the IoT device deletes its local copy. Therefore, when IoT devices outsource their data to a CSP, they lose direct control over their data. At the same time, after data deduplication, a CSP only stores one copy of the data. Therefore, IoT devices need to update cloud data ownership by requesting CSPs to allow data sharing, making it difficult for IoT devices to realise dynamic ownership management of their data and efficiently share data with other IoT devices. G. Tian et al. (Citation2020) used a dynamic Key-Encrypting Key (KEK) tree to assist in data re-encryption, enabling users to share data smoothly while ensuring security. However, to improve security, the scheme requires users to pay for more computing resources, which is not suitable for one-to-many data sharing. In the field of IoT, especially in large organisations that have deployed a large number of IoT devices, data sharing between IoT devices is very frequent. Therefore, IoT devices with limited resources are not suitable for use with this cumbersome one-to-one data sharing mode.
Finally, convergent encryption is a common technology used to realise the deduplication of encrypted data. However, a data deduplication scheme based on convergent encryption is vulnerable to side-channel attacks. Halevi et al. (Citation2011) first discovered side-channel attacks in the process of data deduplication and used a random threshold to resist them. Based on this research, Lee and Choi (Citation2012) proposed a data deduplication scheme with a dynamic randomised threshold. However, these schemes are restricted by the threshold value and have difficulty resisting side-channel attacks. In the IoT scenario, side-channel attacks also occur in the process of data deduplication. Although most schemes do not consider side-channel attacks, it is still essential to resist them.
To solve the above problems, we propose a three-layer and two-layer, parallel, secure, efficient deduplication framework for the IoT. A local manager is added as an edge computing node in a large organisation (an organisation that deploys many IoT devices). For the IoT devices deployed within the organisation, the local manager is secure and trusted, thus reducing the system's security threat from edge nodes. The local manager is responsible for data deduplication within the organisation to reduce the workload of the CSP. Moreover, the local manager only does file-level data deduplication, which can reduce the pressure of the local manager. The local manager also needs to add labels to the internal IoT devices and build a label tree, thereby improving the data sharing efficiency of IoT devices. In addition, we introduce the RAndom REsponse (RARE) system (Pooranian et al., Citation2018) to resist side-channel attacks. At the same time, we store the operation records on a blockchain and use its traceability to improve the resistance to collusion attacks. The main contributions of our work are as follows:
We propose a secure multi-mode data deduplication framework for the IoT. In our framework, three-layer and two-layer architecture patterns are used in parallel. The three-layer architecture model comprises IoT devices, local managers (edge computing nodes), and a CSP. The local manager only serves the IoT devices within its organisation and is secure and trusted, so the framework has high security. Moreover, the local manager only needs to do perform file-level data deduplication, thus reducing its storage requirements.
We design a label tree to improve file sharing efficiency. The local manager adds labels to the label tree of the IoT devices deployed by the organisation. IoT devices with limited resources can share data via labels.
We use the RARE scheme for block-level data deduplication, which effectively improves the ability of the system to resist side-channel attacks. We introduce a blockchain to record the interaction information between users (the IoT devices in this paper) and the CSP, which improves the ability of the system to resist collusion attacks.
1.1. Organisation
The rest of this paper is organised as follows. In Section 2, we focus on a survey of related work. In Section 3, we introduce the preliminary knowledge. In Section 4, we describe the system model, threat model, and security goals. In Section 5, we present a secure and efficient data deduplication framework for the IoT based on edge computing and blockchain technologies. In Section 6, we analyse the security of the proposed scheme and offer performance evaluations. In Section 7, we conclude the paper.
2. Related work
According to the content of this study, we divide the work related to data deduplication into general and IoT scenarios. Table shows the comparison of several schemes.
Table 1. Comparison of several schemes.
2.1. Data deduplication in in general scenarios
Data deduplication is an effective method for helping CSPs save storage space and reduce network bandwidth requirements (Shakarami et al., Citation2021). However, as users become more aware of privacy and confidentiality, data uploaded to the cloud is more often encrypted (Harnik et al., Citation2010; Paulo & Pereira, Citation2014; Wu et al., Citation2021), which creates challenges for data deduplication. In order to successfully deduplicate encrypted data, Douceur et al. (Citation2002) proposed the convergent encryption approach. Convergent encryption is a type of deterministic encryption that ensures that the same file can only be encrypted into the same ciphertext, with the plaintext content only determining the ciphertext. However, convergent encryption is vulnerable to brute-force attacks. In order to improve the resistance to these, message-locked encryption (MLE) and the DupLESS system have been proposed (Bellare et al., Citation2013; Keelveedhi et al., Citation2013). The DupLESS system (Citation2013) uses a separate key server to generate keys. The key is jointly determined by the data itself and a system key, so it can improve the resistance to brute-force attacks. Also, to fight brute-force attacks, G. Zhang et al. (Citation2021) proposed a blockchain-based deduplication scheme. Based on the improvement offered by convergent encryption, the scheme replaces the third-party auditor with an intelligent contract and proposes a hierarchical-role hash tree for authorisation. This scheme can resist brute-force attacks and complicity attacks. Aparna et al. (Citation2021) also used a blockchain to record the file tag and user operation process. A smart contract replaces the CSP in conducting data duplication-checking and data management. This scheme reduces the bandwidth consumption of the system; however, over-reliance on the efficiency and performance of smart contracts can easily cause system instability.
Halevi et al. (Citation2011) first discovered the side-channel risk of client data de-emphasis in the process of request and response. To solve this problem, they proposed the Random Threshold (RT) solution. As long as users do not know the deduplication threshold, side-channel attacks cannot be used to deduce the existence state of files. Based on the research in article (Halevi et al., Citation2011), Lee and Choi proposed a data deduplication scheme that dynamically randomises the threshold (Lee & Choi, Citation2012). Pooranian et al. (Citation2018) proposed the RARE approach, which uses the simultaneous upload of hashes of two data blocks and uses the number of data blocks that should be uploaded as a response message. The RARE approach also introduces the dirty block mechanism, which is primarily guaranteed not to reveal the existing state of the data block. The proposed approach references the RARE approach for block-level deduplication.
2.2. Data deduplication in the IoT
With the rapid development of IoT technology, a large amount of IoT data is stored on cloud storage servers, making data deduplication a focus of attention. Gao, Xian, and Yu (Citation2020) judged the security requirements of IoT data according to its popularity. The deduplication scheme is dynamically adjusted according to the security requirements of the data, and an ideal threshold is introduced to improve the rationality and security of the system. To protect the data security of group users, Gao, Xian, and Teng (Citation2020) divided the attributes of users and then dynamically adjusted the data deduplication scheme according to the similarity of users.
In a cloud storage system, we should not only pay attention to data security but also to the efficiency and resource allocation of the system. Centralised cloud computing technology has attracted large numbers of users. Accordingly, if the cloud platform is not handled well, it may face the problems of over-configuration or insufficient configuration (Shahidinejad, Ghobaei-Arani, & Esmaeili, Citation2020). Shahidinejad, Ghobaei-Arani, and Masdari (Citation2020) used workload analysis to solve the resource provisioning issue in cloud computing. In order to improve the service quality of cloud computing, we should not only optimise its resource provisioning but also use edge computing to improve the efficiency of the system. Abdellatif et al. (Citation2021) used edge computing to improve the efficiency of medical data collection. Lang et al. (Citation2020) designed an edge-IoT encrypted data deduplication scheme that supports dynamic ownership management and privacy protection. The scheme realises fine-grained access control and dramatically reduces the communication overhead. Ming et al. (Citation2022) stored file labels on a blockchain to realise the cross-domain data deduplication of edge nodes. However, the scheme does not consider the security threats of edge nodes, and the data labels are stored in the blockchain, which may affect the system's efficiency. Moreover, when the IoT, edge computing, and blockchain are combined, rules for storing data on the blockchain (Shaikh et al., Citation2021) and the authentication of IoT devices (Shahidinejad et al., Citation2021) are critical.
3. Preliminaries
In this section, we introduce some symbols and preliminary knowledge involved in the framework of our proposed scheme.
3.1. Notations
Table lists the main symbols used in the framework and their corresponding definitions.
Table 2. Notation and definitions used in this study.
3.2. Convergent encryption
The convergent encryption method proposed by Douceur et al. (Citation2002) is a deterministic encryption mechanism. Message-locked encryption algorithm (MLE) (Bellare et al., Citation2013) is widely used in data deduplication. The main idea of convergent encryption is to use data D to generate a key , then use
to symmetrically encrypt data D to obtain ciphertext C, and then use data D to generate the tag T. A CSP can perform data duplication checks according to the tag T. Because the key used for convergent encryption is the hash value of the data, as long as the hash algorithm used to generate the key is determined, the ciphertext corresponding to the data can be determined. After convergent encryption, the same data can generate the same ciphertext, and the CSP can quickly identify the ciphertext of the same data when the data is deduplicated. Therefore, convergent encryption can ensure the efficiency of data deduplication on the premise of protecting data privacy. Convergent encryption has been widely used in the field of data deduplication. Its specific algorithm is as follows:
Convergent Key Generation:
. The algorithm extracts the convergent key
Encryption:
Decrypt:
Generate Tag:
3.3. Proof of ownership
Proof of ownership (PoW) is an algorithm completed by an interaction between a prover (in this paper, a prover is an IoT device requesting to store a file in a CSP) and a verifier (the CSP). The main idea of PoW is that the certifier proves that they have complete documents to realise trusted storage in an untrusted environment. The algorithm includes three main processes: generate a challenge, return proof, and check the proof. The verifier challenges the certifier and the certifier produces the corresponding proof according to the challenge. The verifier verifies whether the certifier's proof is equal to the standard answer by comparison. If the verification is passed, it indicates that the certifier does have complete documents; otherwise, it means that the certifier does not. The specific process is as follows:
Generate Challenge: The verifier generates a challenge value CG according to document F and sends it to the certifier.
Return Proof : The certifier generates a relevant proof
Check Proof : The verifier calculates the standard answer
3.4. Blockchain
Satoshi Nakamoto proposed the Bitcoin cryptocurrency in 2008 (Nakamoto, Citation2008). As the technology underlying Bitcoin, blockchain has received extensive research attention. Blockchain is a distributed ledger technology, which is decentralised, tamper-proof, and traceable.
All nodes in the blockchain system jointly maintain the same ledger in a point-to-point network, and the transaction records cannot be tampered with without a central authority. This decentralised model allows the system to effectively avoid the risk of a single point of failure. Blockchain is a chained data structure composed of blocks linked in chronological order. Each block is divided into a block header and block body. The block header mainly includes a version number, the hash value of the parent block (previous block), and a Merkle tree root, timestamp, difficulty value, and nonce. The block mainly contains the transaction content packaged by miners. Timestamps ensure that data must exist at a particular time. Each block header contains the hash value of the previous block. If a malicious user wants to tamper with the data of any block, they need to recalculate that block and all its subsequent blocks, which ensures that the blockchain is tamper-proof. The system will dynamically adjust the difficulty value. Miners need to find a nonce that meets the difficulty value and package the transaction data into blocks. Miners broadcast their packaged blocks for verification, and the blocks that pass verification are added to the main chain of the blockchain. All data from the genesis block to the current block can be tracked and queried on the main chain.
3.5. RAndom REsponse (RARE)
In the process of data deduplication, a user needs to send a data label to a CSP for data duplication-checking. The CSP returns the duplication checking results to the user. The channel through which the user and CSP interact is called a side channel. An attacker can try to detect the existing state of the data from feedback from the CSP through the side-channel to understand the privacy data of the attacked object. To solve the privacy risk of a side channel, Pooranian et al. (Citation2018) proposed the RARE scheme, which strengthens the security of the side channel and reduces privacy disclosures. We apply RARE to our framework for block-level data deduplication. The specific steps of the RARE scheme are as follows:
A user divides a file into n data blocks
The user uses a specific algorithm to fill blocks of insufficient length to length ϕ and ensure that n is even.
Starting from the first data block, the user sends the hash values
The CSP does not directly send the specific result of the data block duplication check to the user but sends 1 or 2 to the user. If neither block exists, it sends 2. If one or both of the two blocks exist, 1 or 2 will be sent to the user with a probability of
The user uploads data according to the received result. If the user receives 1, the user needs to send the XOR value of two data blocks
The CSP adds the data blocks that are not uploaded to the dirty block list.
In the RARE scheme, it is not emphasised that the uploaded data is ciphertext. In our solution, the uploaded data needs to be encrypted into ciphertext before uploading.
4. Problem statement
4.1. System model
Our system model includes six entities: Key Distribution Center (KDC), Cloud Service Provider (CSP), Local Manager (LM), Member Equipment (ME), Personal Equipment (PE) and Blockchain. The system model is shown in Figure .
Figure 3. Diagram of the proposed system model.
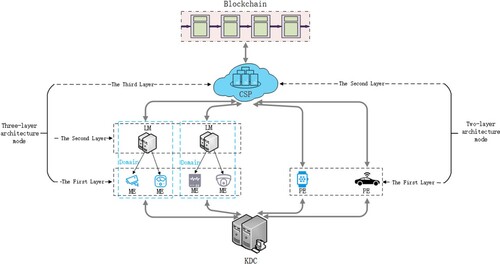
Key Distribution Center (KDC): Responsible for assigning IDs to entities and managing the keys of the entities in the system.
Cloud Service Provider (CSP): Provides services such as storage, access, and authorisation of IoT data. To save data storage costs, the CSP needs to delete duplicate data.
Local Manager (LM): An edge computing platform deployed within large organisations. We define a large organisation as a domain. The LM is responsible for deleting duplicate data in the domain, delivering messages to member devices and CSPs as an intermediate layer, setting the label tree in the domain, and managing file sharing in the domain.
Member Equipment (ME): An IoT device deployed by an organisation and managed by the LM. A ME uploads encrypted files to CSP via the LM. The ME needs to cooperate with the LM and CSP to deduplicate data and generate file tags.
Personal Equipment (PE): An IoT device for individual users that does not belong to a large organisation. To store data in the CSP, a PE directly interacts with it and needs to cooperate with it for data deduplication.
Blockchain: Records the specific processes of file uploading, file sharing and file downloading.
The system framework proposed in this paper implements a parallel two-layer architecture and three-layer architecture. In the two-layer architecture, the PE is the first layer, and the CSP is the second layer. The PE does not belong to any organisation and interacts directly with CSP to store, download and share data. In the three-layer architecture, the first layer is the ME, the second layer is the LM of the corresponding organisation of the ME, and the third layer is the CSP. Any interaction between the ME and CSP needs to pass information through the LM. The LM is also responsible for managing the ME in the domain and deduplicating data in the domain. In the rest of this paper, IoT devices (MEs and PEs) are sometimes referred to as users for the convenience of description.
4.2. Threat model
The edge computing nodes randomly assigned to serve users are often not fully trusted. In our framework, we introduce LMs within large organisations. The LM is fully trusted by member devices within the organisation and does not interact with IoT devices outside of it. Therefore, we assume that the LM is fully trusted.
According to the above assumptions, we consider two types of attackers in our system: external and internal.
External Attacker: A malicious user who illegally obtains other people's file information. Malicious users can make exhaustive guesses by making violent attacks to obtain the content of data blocks. Malicious users can also understand the status of files through side-channel attacks. When performing a side-channel attack, the malicious user sends the hash value of the guessed data block to the CSP. The CSP uses that hash value as a data tag for the data duplicate check and sends the results to malicious users. The malicious user confirms whether the guessed data exists based on the duplicate check result provided by the CSP.
Internal Attacker: This is usually a CSP. A CSP will honestly store and deduplicate data according to a protocol; however, it may damage or delete some infrequently used data to save storage space. A CSP may also be curious about a user's stored data. In this case, the CSP checks the plaintext content of these data and may disclose it to an external malicious user to seek illegal interests.
4.3. Security goals
Data reliability: Honest users can ensure that files will not be deleted or modified by verifying the data integrity. This prevents a malicious CSP from damaging user files.
Data confidentiality: A malicious user cannot obtain the contents of a file through a violent attack, or the status of a file from a CSP through a side-channel attack.
Traceability: During information interactions between entities, the identity of an information sender can be accurately traced. Each process of storing, authorising, and downloading files can be effectively tracked for verification.
5. Scheme description
We propose a secure and efficient data deduplication approach for the IoT based on a parallel three-layer and two-layer architecture (Figure ). We combine the idea of edge computing with the introduction of LMs into large organisations. As an edge computing platform, the LM is responsible for managing member equipment (ME) within the organisation and delivering information to the CSP and MEs. The interaction between the MEs and CSP needs to be executed via the LM. To facilitate expression, it is directly described as the interaction between the ME and CSP. The ME, LM and CSP form a three-layer architecture. In edge computing systems, personal equipment (PE) is usually assigned to the nearby edge computing platform; however, these randomly assigned edge computing platforms bring additional risks to PE. In our scheme, the PE and CSP interact directly; therefore, they can be regarded as forming a two-layer architecture. For the convenience of using the LM to manage the MEs and improve file-sharing efficiency, we make the LM responsible for building a hierarchical label tree. The label of the tree is assigned to the MEs by the LM, and the IoT devices can share the file based on the label. The operation of the whole system includes three main processes: file uploading, file sharing and file downloading.
In this section, we introduce our proposed framework in detail, in terms of setup, label assignment, file uploading, file sharing and file downloading.
5.1. Setup
In this scheme, the CSP, LM, ME and PE are all assigned unique identifiers. The unique identifiers (IDs) corresponding to each entity are as follows: ,
,
, and
.
The key distribution centre (KDC) generates key pairs for each entity. Specifically, the KDC selects a random integer for each entity as the private key sk = n of the corresponding entity. We than set
as a bilinear map, where
and
are multiplication groups with the same prime order p, and g is the generator of
. The public key of the corresponding entity can be calculated as
. The KDC sends (sk, pk) to the corresponding entity through the secure channel.
5.2. Assignment of labels
Our framework uses a three-layer architecture and two-layer architecture to run in parallel. In the three-layer architecture, the MEs are the first layer, the LM is the second layer, and the CSP is the third layer. As the second layer in the three-layer architecture, the LM needs to manage the MEs and transmit information to the MEs and CSP.
The LM first constructs a label tree, as shown in Figure , and sends it to the CSP for storage. Each node of the label tree represents a label. The root node represents the LM, which distributes the label to the corresponding ME. In the label tree scheme, there is a hierarchical relationship between labels. The label level of any node is lower than that of its parent node and higher than that of its child node. For example, the hierarchical relationships corresponding to nodes 1, 4, 9 and 15 are 1>4>9>15, 14 and 15 have no explicit hierarchical relationship.
Figure 4. Example of a label tree.
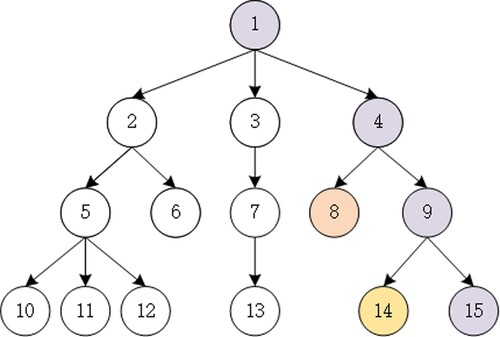
The LM adds a label for each ME according to the label tree. Different MEs can be added to the same label, similar to the way that different MEs are added to the same department or given the same identity. represents the complete ID of MEs, where
and
is the ID assigned by the KDC to the ME and LB is the label assigned by the LM to the ME.
5.3. File upload
When IoT devices upload files, they need to cooperate with a CSP for data deduplication. To save bandwidth and cloud storage resources, only data that the CSP has not stored needs to be uploaded. The PE interacts directly with the CSP for data deduplication. The ME needs to perform an intra-domain duplication with the LM to check whether other MEs in the organisation have stored the same data. If there is no duplicate data in the domain, the ME also needs to deduplicate the data with the CSP and check whether there are IoT devices outside the organisation that store the same data. Next, we describe the file upload processes of the ME and PE separately in detail.
5.3.1. Member equipment upload files
When an ME wants to upload and store a file F to the CSP, they need to interact with the LM and CSP for data deduplication (as shown in Figure ). Firstly, the ME interacts with the LM for file-level data deduplication. When the LM has stored file F, the LM performs PoW verification with the ME as described in Section 2.3. After the ME passes PoW verification, they obtain the file pointer to access cloud file F. When the LM has not stored F, the ME performs data deduplication with the CSP. If the CSP has stored F, the ME needs to interact with the CSP to perform PoW verification. Otherwise, the ME executes the RARE scheme with the CSP for block-level data deduplication. Finally, the process of ME uploading F is recorded on the blockchain.
Figure 5. File uploading process of Member Equipment (ME).
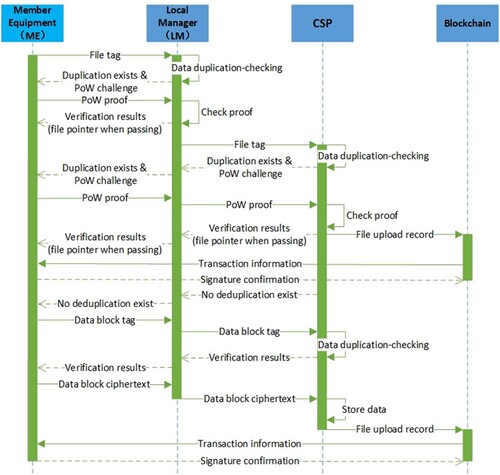
Generate file tag: The ME calculates the file tag
Data deduplication and uploading: The ME sends
Case I: LM has stored the
PoW verification: When the LM has stored
Record the interaction process: The interaction process needs to be stored on the blockchain. The CSP sets
Case II: LM has not stored the
CSP performs file-level data deduplication-checking: When the LM has not stored the
Block-level data deduplication-checking: In order to upload F, the ME also needs to interact with the CSP for block-level data deduplication. We perform block-level data deduplication according to the RARE scheme (Pooranian et al., Citation2018), as shown in Section 3.5. The ME first divides the file F into data blocks
Data uploading: The ME uploads the data block based on the duplication-checking results of the CSP. Before uploading data, the ME needs to encrypt the data block with the convergent encryption algorithm, as shown in Section 3.2. The specific steps used by the ME to upload data blocks are as follows:
Generate a convergent key: The ME runs a convergent key generation algorithm to calculate the convergent key
Data encryption: The ME runs an encryption algorithm to generate ciphertext
Upload the data blocks: The ME packages the ciphertext of the data blocks to be uploaded based on the duplication-checking results of the CSP.
Storage data: The CSP stores ciphertext that has not been stored. Then, the CSP sends the file pointer
Record the interaction process: The data uploading process is still stored on the blockchain. The specific process is the same as that described above. Moreover, if the ME does not upload data blocks according to the rules within the specified time, the CSP blacklists the corresponding data blocks and records this illegal operation by the ME and LM.
5.3.2. Personal equipment upload files
When a PE wants to upload and store file F to the CSP, it also needs to cooperate with the CSP for data deduplication (as shown in Figure ). The difference between a PE and an ME is that a PE interacts directly with the CSP. Firstly, the PE sends the tag of F to the CSP, who checks whether the file has been stored based on the file tag. If the CSP has stored the F, it must also execute the PoW algorithm with the PE. Otherwise, the PE interacts with the CSP according to the rules of the RARE scheme for block-level data deduplication. Finally, the process of PE uploading F is stored on the blockchain. The specific process is as follows:
Figure 6. File uploading process of Personal Equipment (PE).
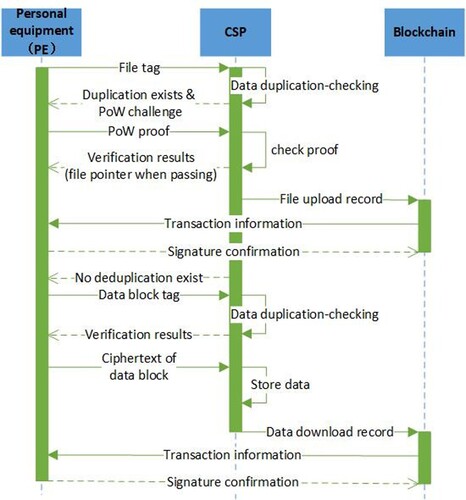
Generate file tag: The PE first calculates the file tag
Data deduplication and uploading: The PE sends
Case I: The CSP has stored
PoW verification: When the CSP has stored
Record the interaction process: The interaction process needs to be stored on the blockchain. The specific process is similar to that described in Section 5.3.1.
Case II: The CSP has not stored
Block-level data deduplication: When the CSP has not stored
Recording the interaction process: The data uploading process is also stored on the blockchain. The specific process is the same as that described above. Moreover, if the PE does not upload data blocks according to the rules within the specified time, the CSP blacklists the corresponding data blocks and records this as an illegal operation by the PE.
5.4. File sharing
In order to share cloud files, IoT devices first need to generate authorisation information. Then, the IoT devices send the authorisation information to the CSP, which uses it to perform ownership verification. When the CSP finds that the IoT device has ownership of the file, it allows the IoT device to share the file. Finally, the file-sharing process of IoT devices is stored on the blockchain. In this scheme, files can be shared to specific equipment or to specified labels. After sharing a file with a specified label, an ME with that label can access that file.
In our scheme, the LM is responsible for constructing the label tree. The labels corresponding to each node in the label tree have a clear hierarchical relationship. The MEs with high-level labels can access the files of MEs with low-level labels. As shown in Figure , an ME with a label corresponding to node 9 can have their files on the CSP accessed by MEs with labels corresponding to node 4 and LMs corresponding to node 1. For example, within a company, department members often need to send working documents to department heads. Within the same organisation, high-level MEs have the right to directly access the files of low-level MEs, thus improving the efficiency of initial file sharing.
There are also differences between MEs and PEs when sharing files, which we now describe separately.
5.4.1. Member equipment file shareing
The interaction process of a member equipment entity sharing a file F is shown in Figure .
Figure 7. File sharing process of Member Equipment (ME).
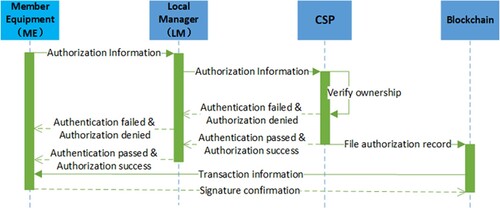
Generate authorisation information: When
Ownership verification:
Record the interaction process: The interaction process needs to be stored on the blockchain. The CSP sets
5.4.2. Personal equipment file sharing
The interaction process of a personal equipment entity sharing a file F is shown in Figure .
Figure 8. File sharing process of Personal Equipment (PE).
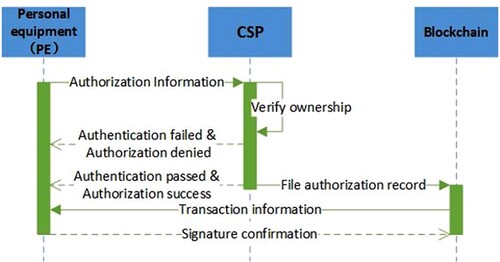
Generate authorisation information: When
Ownership verification:
Recording the interaction process: The file-sharing process is also stored on the blockchain. The specific process is similar to that described in Section 5.4.1 and will not be repeated here.
5.5. File downloading
When an IoT device wants to download a file from the CSP, it must send a file download request. The CSP performs ownership verification based on the information requested for file download. When the CSP finds that the IoT device has ownership of the file, it allows the IoT device to download the file. Finally, the file-sharing process of IoT devices is stored on the blockchain.
There is not much difference between MEs and PEs in downloading files. The main difference is that a ME needs to interact with CSP through an LM. Therefore, we do not describe the ME and PE separately in this section. The interaction process by which downloads file F is shown in Figure while that for
is shown in Figure . The specific process by which IoT devices download files from a CSP is as follows:
Figure 9. File downloading process of Member Equipment (ME).
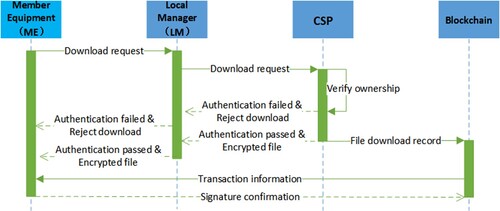
Figure 10. File downloading process of Personal Equipment (PE).
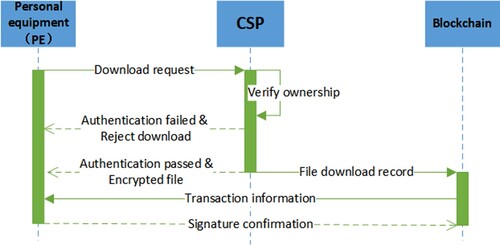
Generate file download request: When IoT device
Ownership verification:
Validation and Recording of the interaction process: The CSP sets
6. Security analysis and performance evaluation
6.1. Security analysis
The framework of this paper is designed to resist internal and external system attackers to achieve data reliability, data confidentiality, and traceability. In the framework's construction, we use some basic cryptographic primitives, such as convergent encryption, proof of ownership, bilinear maps, and so on. In order to describe the security of this scheme, it is assumed that these tools are secure. Then, we illustrate the security of this framework from the following three aspects.
Theorem 6.1
The proposed data deduplication framework satisfies the data reliability criterion.
Proof.
Data reliability means that users (IoT devices) can effectively detect whether their data has been tampered with or deleted. After a user uploads the file F to the cloud for storage, the user needs to store the file pointer and file tag
. For example, when user
downloads file F, the user first sends file pointer
to the CSP. The CSP sends the corresponding file
to
according to file pointer
.
calculates the tag
of
and compares
with its own stored
. According to the anti-collision property of the hash algorithm, the probability of calculating the same file tag for different files is negligible and can be ignored. If
is equal to
, it indicates that the CSP has not tampered with or deleted file F. Otherwise, the CSP has tampered with or deleted it.
Theorem 6.2
The proposed data deduplication framework satisfies the data confidentiality criterion.
Proof.
In order to prevent malicious users from obtaining the content of a file without actually having the file, our system has a PoW ownership verification mechanism. When a malicious user only has the tag of a file but no data block from it, it is difficult for them to pass PoW ownership verification. In this case, the malicious user cannot obtain the file content. Moreover, suppose that malicious users want to deduce the plaintext content from the file tag. In this case, they need to process the one-way hash function, which has been proven to be computationally infeasible.
To resist a side-channel attack, we refer to the RARE scheme (Pooranian et al., Citation2018), where malicious users cannot analyse the existing state of a file from the duplication-checking result returned by the CSP. The RARE scheme adopts the method of uploading and verifying two data blocks at once and returns either 1 or 2 instead of direct duplication-checking results. When the CSP finds out that neither data block has been stored, it returns 2. If only one or both of data blocks have been stored, it return s 1 or 2 with a 50% probability. The malicious users cannot directly determine whether the data block is stored based on the results returned by the CSP. However, they may use other analysis methods. For example, if a malicious user wants to know whether the CSP has stored data block (i.e. whether data block
exists). The malicious user can send the hash values
of randomly guessed data blocks
and
to the CSP. If the CSP returns 2,
and
may not be stored by the CSP. However, the malicious user may not upload data block ciphertext as required and send
to the CSP many times. If the value returned by the CSP is always 2, the malicious user can speculate that
and
are not stored. Then, the malicious user uploads
or
to the CSP for duplication-checking. If 1 appears in the result returned by CSP, it indicates that data block
exists. To resist this attack, the RARE scheme uses a blacklist mechanism. If the data blocks have been queried but is not uploaded to CSP by the user within the specified time, the CSP includes the data blocks in the blacklist. After receiving the duplication-checking request, the CSP will first check whether the two data blocks in the current duplicate check request are in the blacklist. As long as more than one data block is in the blacklist, the CSP always returns 2 to the user. Therefore, malicious users cannot determine the existence of a particular data block.
Theorem 6.3
The proposed data deduplication framework satisfies the traceability criterion.
Proof.
Our framework introduces a blockchain to record the interactions between users and CSPs, including file uploading, file sharing, and file downloading. Blockchain has the characteristics of being tamper-proof and traceable and allowing information regarding interactions between users and CSPs to be effectively queried. Moreover, the interaction information stored on the blockchain needs to be verified and signed by users, which ensures its accuracy. Therefore, the interaction processes between users and CSPs are traceable, which improves the system's security.
6.2. Performance evaluation
In this section, we provide a performance evaluation of our scheme, which was carried out on a test computer with the following configurations: CPU = AMD Ryzen 7 4800U with Radeon Graphics, 3200 MHz, RAM = 16.0 GB; operating system = 64-bit. The SHA-256 secure hash algorithms were used in the experiment.
6.2.1. Functionality comparison
To improve the efficiency of the data-deduplication system, many schemes combine it with edge computing. Ming et al. (Citation2022) used edge computing to improve the efficiency of data deduplication, with edge nodes completing the primary process of data deduplication. To achieve data deduplication across edge computing nodes, the scheme stores file tags on the blockchain. The edge nodes obtain data from the blockchain for data deduplication inspection to prevent repeated data uploads. The scheme uses the blockchain to store file tags, which reduces the storage pressure on edge nodes while avoiding the duplication of cross-domain data. This scheme does not solve the trust problem between users and edge nodes and stores file tags on the blockchain, which causes an additional communication overhead in the process of data-duplication checking. Aparna et al.'s scheme (Aparna et al., Citation2021) also incorporates edge computing. The blockchain is introduced as a middle layer between the user and CSP. Data deduplication is mainly completed by interactions between the smart contract and user. File labels and user operations are recorded on the blockchain. This scheme reduces the bandwidth loss of the system. However, it relies excessively on the efficiency and performance of the smart contract, which can easily cause system instability due to the shortcomings of the blockchain itself.
In our scheme, we adopt a new model based on the parallel use of three-layer and two-layer architectures. The LM within the organisation acts as an edge node to provide system efficiency. The LM only serves member devices within the organisation. The member devices fully trust the local manager to solve the trust crisis between users and edge nodes. The LM performs file-level deduplication, which reduces the computing and storage pressures on edge nodes. We use RARE to improve resistance to side-channel attacks. The interaction process can be traced on the blockchain.
Table compares the proposed scheme with those of Ming et al. (Citation2022) and Aparna et al. (Citation2021).
Table 3. Comparison of the proposed scheme with two existing schemes.
6.2.2. Computational overhead in label tree construction
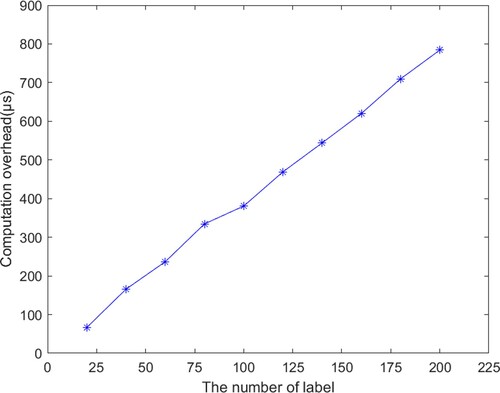
We evaluated the computational overhead of our framework in building the label tree. As shown in Figure , the computational overhead increases with the increase in the number of labels. In order to fit the complex relationship between entities within the organisation and facilitate the construction of a label tree by the organisation's LM, the label tree used in this framework is an ordinary tree rather than a binary tree. Each node in the label tree represents a label, and multiple different MEs can have the same label. Therefore, the number of nodes in a label tree built by a large organisation will be within a reasonable range. In particular, even when the number of label nodes reaches 200 (close to the number of labels required by large enterprises), the time needed to build the label tree is still only 784.15 microseconds.
Figure 11. Computational overhead used in the label tree construction.
6.2.3. Computational overhead in sharing files
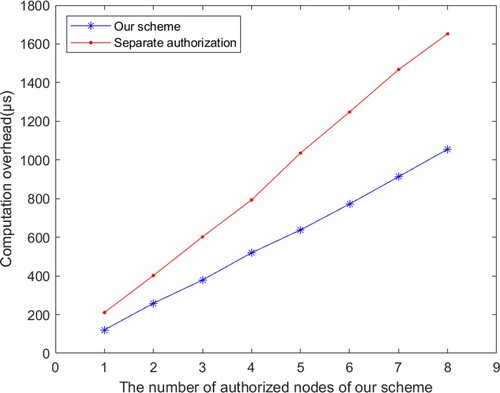
Our proposed framework can share files by authorising specific IoT devices via labels deployed by the organisation. In addition, during label authorisation, to adapt to the file's use-mode and interaction possibility, all the ancestor label nodes of the authorised label in the corresponding label tree will have corresponding permissions for the authorised file. On the premise of ignoring the communication overhead, we mainly conduct an experimental evaluation for label authorisation. To evaluate the computational cost of the proposed label authorisation method, we compare it with a separate label authorisation method in which each label requires separate authorisation. Firstly, we construct a label tree with a height of 7, select the leaf node of the seventh layer in the label tree, authorise it with the method proposed in this scheme, and gradually increase the number of authorised nodes. At the same time, we use the method of single-node authorisation to authorise and compare all label nodes with the rights obtained after authorisation by the proposed method. The experimental results are shown in Figure . It can be seen that the proposed authorisation method has efficiency advantages over the single-label node-authorisation method.
Figure 12. Computational overhead in file sharing through labels and nodes authorised by our framework at a unified height in the label tree in comparison with the single-authorisation method.
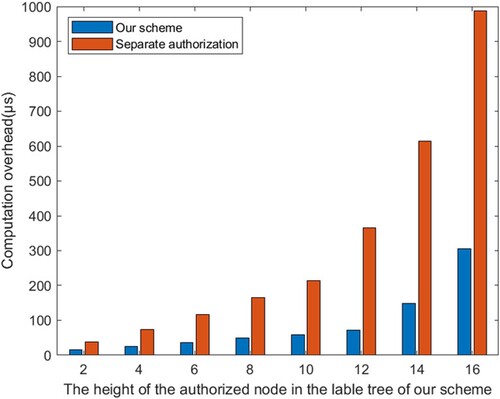
To make the experiment more rigorous, we reconstructed a label tree with a height of 16 layers. By changing the number of layers of authorised nodes, we gradually increased the height of the authorised nodes from the second layer. Similarly, we conducted single-node authorisation of all label nodes and compared them with the rights obtained after authorisation by the proposed method. This was done to explore whether the proposed authorisation method still has efficiency advantages over the method of authorising single nodes with different heights one by one. The experimental results are shown in Figure , which shows that even if the height of an authorised node is changed, the proposed label authorisation method still has advantages. This also reflects the universality of the proposed method.
Figure 13. Computational overhead in file sharing through labels, with the height of the authorised node in the label tree used as the experimental variable. The proposed scheme is compared with single-authorisation.
6.2.4. Computation overhead in data deduplication-checking
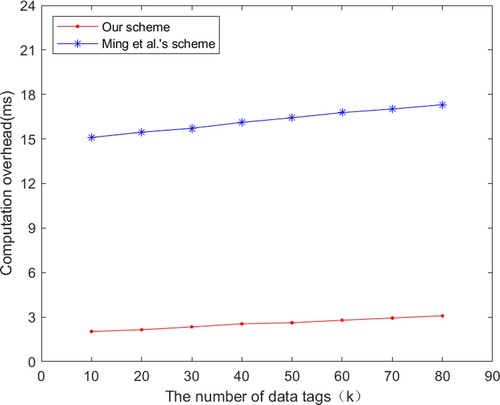
We evaluated the computational overhead of our scheme in comparison with Ming et al.'s scheme (Ming et al., Citation2022) in data deduplication-checking. As shown in Figure , the computational overhead increases with the number of file tags stored in the system. Ming et al.'s scheme stores file tags in a blockchain, while our scheme stores them in a local database. Hence, our scheme has no additional communication overhead in the data duplication-checking process, so the computational overhead is lower.
Figure 14. Computational overhead of data deduplication-checking according to the number of data tags. Comparison of the proposed scheme with Ming et al.'s scheme.
7. Conclusion and future work
This paper proposes a secure and efficient data-deduplication framework for the IoT based on edge computing and blockchain technologies. The framework uses a parallel three-layer and two-layer architecture, with the introduced edge nodes only serving member devices within an organisation. This approach improves efficiency while ensuring that the system is not vulnerable to new threats due to the addition of edge computing. At the same time, the edge nodes are only responsible for file-level data deduplication, which reduces the calculation and storage pressures on edge nodes. The label tree proposed in this paper can adapt to the characteristics of IoT devices and improve the efficiency of the process. In addition, we adopt the RARE scheme to resist side-channel attacks and the blockchain to resist collusion attacks. We store crucial interactive information in the blockchain through smart contracts to enhance the system's security. The tamper-proof interactive information on the blockchain can be used as evidence to protect the user's data security. Finally, security analysis shows that our proposed framework can resist external malicious users and internal CSP attacks. Performance evaluation shows that our proposed framework is more efficient than similar schemes due to its limited computational overhead.
Our scheme assumes that the LM is secure to MEs, which trust the LM completely. However, the LM may be attacked, which can pose risks to the system. Moreover, although the use of the RARE scheme in our scheme can resist side-channel attacks, it will also lead to additional bandwidth consumption. In future work, we plan to study ways to limit malicious attacks and strengthen system security through effective reward and punishment mechanisms. In the meantime, we need to study better methods to resist the side-channel attack.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Abdellatif, A. A., Samara, L., Mohamed, A., Erbad, A., Chiasserini, C. F., Guizani, M., O'Connor, M. D., & Laughton, J. (2021). Medge-chain: Leveraging edge computing and blockchain for efficient medical data exchange. IEEE Internet of Things Journal, 8(21), 15762–15775. https://doi.org/10.1109/JIOT.2021.3052910
- Afzal, M. K., Zikria, Y. B., Mumtaz, S., Rayes, A., Al-Dulaimi, A., & Guizani, M. (2008). Unlocking 5G spectrum potential for intelligent IoT: Opportunities, challenges, and solutions. IEEE Communications Magazine, 56(10), 92–93. https://doi.org/10.1109/MCOM.2018.8493125
- Aparna, R., Sanjay Raj, R., Bandopadhyay, S., Anu Vikram, K., & Pandey, S. (2021). BlockDrive: A Deduplication framework for cloud using edge-level blockchain. In 2021 international conference on communication information and computing technology (ICCICT) (pp. 1–6). IEEE.
- Bellare, M., Keelveedhi, S., & Ristenpart, T. (2013). Message-locked encryption and secure deduplication. In Annual international conference on the theory and applications of cryptographic techniques (pp. 296–312). Springer.
- Bolosky, W. J., Corbin, S., Goebel, D., & Douceur, J. R. (2000). Single instance storage in Windows 2000. In Proceedings of the 4th USENIX Windows Systems Symposium (pp. 13–24). USENIX.
- Cui, B., Liu, Z., & Wang, L. (2015). Key-aggregate searchable encryption (KASE) for group data sharing via cloud storage. IEEE Transactions on Computers, 65(8), 2374–2385. https://doi.org/10.1109/TC.2015.2389959
- Douceur, J. R., Adya, A., Bolosky, W. J., Simon, P., & Theimer, M. (2002). Reclaiming space from duplicate files in a serverless distributed file system. In Proceedings 22nd international conference on distributed computing systems (pp. 617–624). IEEE.
- Gao, Y., Xian, H., & Teng, Y. (2020). User similarity-aware data deduplication scheme for IoT applications. In International conference on frontiers in cyber security (pp. 44–52). Springer.
- Gao, Y., Xian, H., & Yu, A. (2020). Secure data deduplication for internet-of-things sensor networks based on threshold dynamic adjustment. International Journal of Distributed Sensor Networks, 16(3), 155–162. https://doi.org/10.1177/1550147720911003
- Halevi, S., Harnik, D., Pinkas, B., & Shulman-Peleg, A. (2011). Proofs of ownership in remote storage systems. In Proceedings of the 18th ACM conference on computer and communications security (pp. 491–500). ACM.
- Harnik, D., Pinkas, B., & Shulman-Peleg, A. (2010). Side channels in cloud services: Deduplication in cloud storage. IEEE Security & Privacy Magazine, 8(6), 40–47. https://doi.org/10.1109/MSP.2010.187
- Hovhannisyan, H., Qi, W., Lu, K., Yang, R., & Wang, J. (2018). Whispers in the cloud storage: A novel cross-user deduplication-based covert channel design. Peer-to-Peer Networking and Applications, 11(2), 277–286. https://doi.org/10.1007/s12083-016-0483-y
- Karati, A., Amin, R., Mohit, P., Sureshkumar, V., & Biswas, G. (2021). Design of a secure file storage and access protocol for cloud-enabled internet of things environment. Computers & Electrical Engineering, 94(1), Article 107298. https://doi.org/10.1016/j.compeleceng.2021.107298
- Keelveedhi, S., Bellare, M., & Ristenpart, T. (2013). DupLESS: Server-aided encryption for deduplicated storage. In 22nd USENIX Security Symposium (USENIX Security 13) (pp. 179–194). USENIX.
- Lang, W., Ma, W., Zhang, Y., Wei, S., & Zhang, H. (2020). EdgeDeup: An Edge-IoT data deduplication scheme with dynamic ownership management and privacy-preserving. In 2020 IEEE 4th information technology, networking, electronic and automation control conference (ITNEC) (Vol. 1, pp. 788–793). IEEE.
- Lee, S., & Choi, D. (2012). Privacy-preserving cross-user source-based data deduplication in cloud storage. In 2012 International conference on ICT convergence (ICTC) (pp. 329–330). IEEE.
- Lin, J. W., Arul, J. M., & Kao, J. T. (2021). A bottom-up tree based storage approach for efficient IoT data analytics in cloud systems. Journal of Grid Computing, 19(1), 1–19. https://doi.org/10.1007/s10723-021-09553-3
- Ming, Y., Wang, C., Liu, H., Zhao, Y., Feng, J., Zhang, N., & Shi, W. (2022). Blockchain-enabled efficient dynamic cross-domain deduplication in edge computing. IEEE Internet of Things Journal, 1–1. https://doi.org/10.1109/JIOT.2022.3150042
- Nakamoto, S. (2008). Bitcoin: A peer-to-peer electronic cash system. Decentralized Business Review.
- Paulo, J., & Pereira, J. (2014). A survey and classification of storage deduplication systems. ACM Computing Surveys (CSUR), 47(1), 1–30. https://doi.org/10.1145/2611778
- Pooranian, Z., Chen, K. C., Yu, C. M., & Conti, M. (2018). RARE: Defeating side channels based on data-deduplication in cloud storage. In IEEE INFOCOM 2018-IEEE conference on computer communications workshops (INFOCOM wkshps) (pp. 444–449). IEEE.
- Shahidinejad, A., Ghobaei-Arani, M., & Esmaeili, L. (2020). An elastic controller using colored petri nets in cloud computing environment. Cluster Computing, 23(2), 1045–1071. https://doi.org/10.1007/s10586-019-02972-8
- Shahidinejad, A., Ghobaei-Arani, M., & Masdari, M. (2020). Resource provisioning using workload clustering in cloud computing environment: A hybrid approach. Cluster Computing, 24(1), 319–342. https://doi.org/10.1007/s10586-020-03107-0
- Shahidinejad, A., Ghobaei-Arani, M., Souri, A., Shojafar, M., & Kumari, S. (2021). Light-edge: A lightweight authentication protocol for IoT devices in an edge-cloud environment. IEEE Consumer Electronics Magazine, 11(2), 57–63. https://doi.org/10.1109/MCE.2021.3053543
- Shaikh, M., Shibu, C., Angeles, E., & Pavithran, D. (2021). Data storage in blockchain based architectures for internet of things (IoT). In 2021 IEEE international IoT, electronics and mechatronics conference (IEMTRONICS) (pp. 1–5). IEEE.
- Shakarami, A., Ghobaei-Arani, M., Shahidinejad, A., Masdari, M., & Shakarami, H. (2021). Data replication schemes in cloud computing: A survey. Cluster Computing, 24(3), 2545–2579. https://doi.org/10.1007/s10586-021-03283-7
- Stanek, J., & Kencl, L. (2016). Enhanced secure thresholded data deduplication scheme for cloud storage. IEEE Transactions on Dependable and Secure Computing, 15(4), 694–707. https://doi.org/10.1109/TDSC.8858
- Tian, G., Ma, H., Xie, Y., & Liu, Z. (2020). Randomized deduplication with ownership management and data sharing in cloud storage. Journal of Information Security and Applications, 51(5), 1–9. https://doi.org/10.1016/j.jisa.2019.102432.
- Tian, Y., Khan, S. M., Jiménez, D. A., & Loh, G. H. (2014). Last-level cache deduplication. In Proceedings of the 28th ACM international conference on supercomputing (pp. 53–62). ACM.
- Wu, X., Gao, J., Ji, G., Wu, T., Tian, Y., & Al-Nabhan, N. (2021). A feature-based intelligent deduplication compression system with extreme resemblance detection. Connection Science, 33(3), 576–604. https://doi.org/10.1080/09540091.2020.1862058
- Zhang, C., Zhu, L., Xu, C., & Lu, R. (2018). PPDP: An efficient and privacy-preserving disease prediction scheme in cloud-based e-Healthcare system. Future Generation Computer Systems, 79(2), 16–25. https://doi.org/10.1016/j.future.2017.09.002
- Zhang, G., Yang, Z., Xie, H., & Liu, W. (2021). A secure authorized deduplication scheme for cloud data based on blockchain. Information Processing & Management, 58(3), Article 102510. https://doi.org/10.1016/j.ipm.2021.102510
- Zhang, Z., Dong, M., Zhu, L., Guan, Z., Chen, R., Xu, R., & Ota, K. (2017). Achieving privacy-friendly storage and secure statistics for smart meter data on outsourced clouds. IEEE Transactions on Cloud Computing, 7(3), 638–649. https://doi.org/10.1109/TCC.6245519