
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Text classification refers to labelling text with specified labels, and it is widely used in public opinion supervision, spam detection, and other fields. However, due to the complex semantics of natural language and the difficulty of extracting semantic features, users of traditional methods encounter difficulties when trying to achieve better classification results. In response to this problem, a text classification method based on the CBM (Convolutional and Bi-LSTM Model) model, which can extract shallow local semantic features and deep global semantic features, is proposed. First, the text is vectorised using the Glove model in the embedding layer. Then, the vector text is sent to the Multiscale Convolutional Neural Network (MCNN) and the Bidirectional Long Short-Term Memory network (Bi-LSTM) respectively. The Bi-LSTM layer is also designed in the present work with use of mixed attention to extract deeper semantic features. Finally, the MCNN features and Bi-LSTM features are fused and sent to the softmax layer for classification. Experimental results show that the model can significantly improve the accuracy of text classification.
1. Introduction
The goal of text classification which is one of the basic tasks of natural language processing, is to assign labels to text. It has a wide range of applications, including sentiment analysis (Qiaoyun et al., Citation2021; Zhongliang et al., Citation2022; Shunxiang et al., Citation2022; Zhao, Citation2017), question and answer classification (Zhang & Lee, Citation2003), and topic classification (Cho et al., Citation2014). Traditional text classification methods use sparse vocabulary features to represent documents, and treat words as the smallest unit, such as support vector machine model, naive Bayes, N-gram model (Kontorovich, Citation2004), etc. Documents represented by such methods generally exhibit the characteristics of high dimensionality and sparse data, so the classification accuracy is low. Later, with the rise of distributed representation, the use of high-dimensional dense vector representation documents gradually becomes the mainstream, such as the word2vec (Mikolov, Citation2013) or Glove (Global Vectors for Word Representation) (Pennington et al., Citation2014) models. The word vectors trained by using this type of method represent the contextual semantic information of the text. With the emergence of deep learning in recent years, more researchers use deep learning neural networks for text classification, such as convolutional neural network (CNN) and recurrent neural network (RNN). CNN-based methods all use convolution kernels of the same size to extract features, which can effectively extract local features of text, but also prevents this type of method from being able to extract multi-scale features, and it cannot capture context dependencies between words. RNN-based methods can extract contextual information, but such methods cannot capture key information in the text and are difficult to extract local features in the text. Traditional classification methods are unable to solve more complex classification problems (Jair et al., Citation2014). To address the shortcomings of CNN and RNN, a CBM model is proposed for complete text classification.
1.1. Main contributions
A CBM model for text classification tasks is proposed. Firstly, a multiscale convolutional neural network (MCNN) module is designed to obtain the shallow local semantic features of the article, making up for the CNN feature extraction. Meanwhile, bidirectional long short-term memory (Bi-LSTM) is employed to obtain a global representation of the article to overcome the problem whereby CNN fails to capture the contextual dependencies between words. Secondly, in view of the problem that the Bi-LSTM model cannot capture key information, a MIX attention scheme is designed, and the fusion matrix is adopted to mix each head attention, which can extract key information from different perspectives: the effect thereof is better than that when using a pure attention mechanism. The contributions of this article can be summarised thus:
Proposing a MCNN module. The MCNN can use multiple convolution kernel windows of different sizes to capture shallow features more flexibly, adapt to the diversity of word features, increase the efficiency of the network in extracting shallow features, and improve the accuracy of text classification on multiple data sets.
Proposing the MIX attention module. MIX attention can allow fusion of various header information to capture more comprehensive key information, so that the classification accuracy is further improved.
The rest of this article is organised as follows: Section 2 covers related research methods of existing text classification; Section 3 describes the specific implementation process of the proposed method; Section 4 presents the experimental work; Section 5 concludes.
2. Related work
In 2014, Kim et al. proposed the text convolutional neural network (TextCNN) (Kim, Citation2014) using CNN as a sentence feature encoder for text classification for the first time. Zhang et al. established character-level convolutional networks (Char-CNN) for text classification in 2015 (Zhang et al., Citation2015). The network does not consider the intrinsic meaning of words and obtains a more fine-grained representation of text based on a single character; however, Char-CNN improves the computational complexity of the network and increases the difficulties in practical applications. In 2017, Johnson et al. established the deep pyramid convolutional neural network (DPCNN) for text classification (Johnson & Zhang, Citation2017). DPCNN uses a pyramid-shaped network architecture to achieve the best accuracy by increasing the network depth (this does not increase computational complexity of the network).
RNN treats the text as a set of word sequences and understands the structure of the text by determining the dependencies between the words to acquire semantic information (Miyamoto & Cho, Citation2016). The traditional RNN model has the phenomenon of gradient disappearance and gradient explosion. Hochreiter et al. proposed a long short-term memory (LSTM) network (Hochreiter & Jürgen, Citation1997), which avoided this problem through a set of special gate structures. On this basis, Zhou et al. proposed a Bi-LSTM network combined with two-dimensional maximum pooling to capture text features (Zhou et al., Citation2016). Bi-LSTM consists of forward LSTM and backward LSTM. The composition can better capture the two-way semantic dependence. Since CNN cannot capture the contextual dependencies between words. To solve this problem, Zhou et al. proposed convolutional LSTM (C-LSTM) (Zhou et al., Citation2015) in 2015. C-LSTM first uses CNN to extract semantic features at phrase level, and then feeds it to the LSTM to determine the context dependency between words. In 2016, Li et al. proposed a deep stochastic computing convolutional neural network (DSCNN) (Li et al., Citation2016). DSCNN uses CNN to extract features from the hidden state of LSTM, which captures the context dependency between words to a certain extent. In 2018, Zhao et al. developed a new sandwich structure adaptive learning of local global (ALLG) to learn local semantic representation and global structure representation (Zhao et al., Citation2018) and proposed two strategies to cope with the feature fusion problem.
The attention mechanism (Vaswani & Shazeer, Citation2017) can describe the dependency of the context and capture the key information. In 2019, Chia proposed Transformer to CNN (Trans-CNN) method (Chia et al., Citation2019). Trans-CNN is a hybrid model based on CNN and a self-attention mechanism, which is trained through the distillation process of a large-scale pre-training model, that is, using a large-scale “teacher model”. The language model trains a small-scale “student model” structure, which reduces the model scale and computational cost. In 2020, Gu et al. proposed a method based on the attention mechanism (Gu & Peng, Citation2020), which uses a convolution operation to extract attention signals, highlighting the emotional words and turning words of the focus of the text. Li et al. established the LSTM_CNN Hybrid model (Li & Ning, Citation2020), which first uses LSTM to learn the long-term dependence of the text, and then designs a shallow convolution structure to extract the semantic features of the text, and finally uses the maximum pooling operation to filter useful and important features for classification. In 2021, Deng et al. constructed an attention-based gating mechanism network (Deng et al., Citation2021), citing the gating mechanism to assign weights to Bi-LSTM and CNN output features to acquire text fusion features that are conducive to classification. In the same year, Tam et al. proposed the convolutional bidirectional long short-term memory (ConvBiLSTM) deep learning model (Tam & Said, Citation2021), which integrates CNN and Bi-LSTM to realise sentiment analysis. In recent years, due to the rise of large-scale pre-training models, Sun et al. proposed an enhanced representation through knowledge integration (ERNIE) pre-training model based on knowledge enhancement (Sun et al., Citation2019). The ERNIE model predicts semantic units such as words and entities so that the model can learn the semantic representation of complete concepts. On this basis, Cheng et al. established the bidirectional gate recurrent unit (ERNIE_ BiGRU) model (Cheng et al., Citation2021). This model uses ERNIE to model the prior semantic knowledge unit directly, which enhances the semantic representation ability of the model, and then uses BiGRU to capture the contextual dependencies between words. Inspired by hierarchical attention networks (Yang et al., Citation2016), Deng and Ren established a hierarchical emotion recognition model based on label embedding (Deng & Ren, Citation2021). The model trains the label embedding matrix through joint learning to learn the contextual information while determining the emotional representation of the sentence.
3. Method
The overall structure of the CBM network is illustrated in Figure . The dotted line part represents the main contribution of the present work. The bottom of the figure is the Glove word vector, the left half is the MCNN, and the right half is Bi-LSTM and MIX attention. First, the model loads the Glove word vector to vectorise the original corpus. Then, the parallel structure of the MCNN and Bi-LSTM is designed to extract text features. The MCNN module captures the local features of the text; the Bi-LSTM module is employed to extract the global information of the article. MIX attention is adopted to capture the key information in the global information, and further improve the weight of key features in text classification; finally, the two are combined and the softmax function is used for classification.
Figure 1. CBM network.
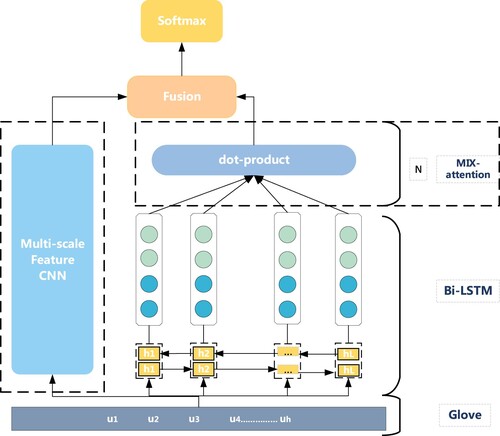
3.1. Shallow feature extraction module
3.1.1. Word vector model Glove
The Glove method is employed to extract and express language features [6]. It is a word characterisation tool based on global word frequency statistics, which can express a word as a vector composed of real numbers. Glove can calculate the semantic similarity between two words by operating on the vector. Compared with word2vec, it considers contextual information in the global scope and uses the co-occurrence matrix to introduce global information; compared to the previous method, the Glove model introduces a weight function to control the relative weight of words.
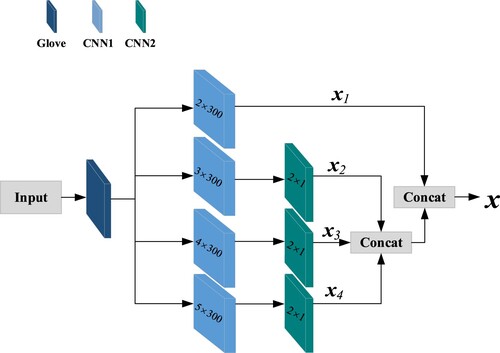
3.1.2. Multiscale CNN
CNN has good position invariance (Kim, Citation2014), so the model uses the convolution kernel window to slide on the document representation matrix, which can extract the phrase-level features of the document and use it for the text to determine the local feature representation thereof (Jincheng & Wang, Citation2022; Suruchi, Citation2021). The internal structure of the MCNN is displayed in Figure . The input in the figure is the vector text that has gone through the Glove model. The module consists of four parallel channels. Channel 1 uses a convolution kernel with a window size of 2 × 300 to undertake convolution operations on the input signal to extract local features . Channels 2–4 use convolution kernels with window sizes of 3 × 300, 4 × 300, and 5 × 300 to conduct convolution operations on the input signal. The signal undergoes a convolution operation, then a convolution kernel with a window size of 2 × 1 is used to perform a convolution operation on the convolved signals from Channel 2 to Channel 4 again to further extract local features
. This design enables the text information to be gathered after initial feature extraction, so that the network can learn both “sparse” (3 × 300, 4 × 300, and 5 × 300) local features and “non-sparse” (2 × 1) local features. That is, features of different scales are extracted through receptive fields of different sizes. Finally, the CONCAT operation is adopted to fuse the local features extracted from the four channels to obtain the final shallow local feature representation
.
Figure 2. Internal structure of the MCNN.
If the sentence has words,
represents the 300-dimensional vector representation of the ith word in the sentence, and
is the concatenation of
words from the word
to the word
. The convolution operation on the window from the word
to
is adopted to generate the feature vector
. The specific convolution calculation formula is as follows:
In formula (1),
denotes the parameter matrix,
is the bias term, and relu represents the activation function. The convolution operation is applied to the entire text representation matrix to obtain the feature
, and then all obtained features
are spliced to produce a feature map
:
(2)
(2)
3.2. Deep feature extraction module
3.2.1. Bi-LSTM network
The Bi-LSTM is used (Zhou et al., Citation2016), which overcomes the problems of gradient disappearance and gradient explosion that are easy to appear in RNNs through a set of gate structures. A single LSTM unit contains three gates (Hochreiter & Jürgen, Citation1997): a forget gate , an input gate
, and an output gate
. Its internal structure is illustrated in Figure .
Figure 3. Single LSTM internal unit.
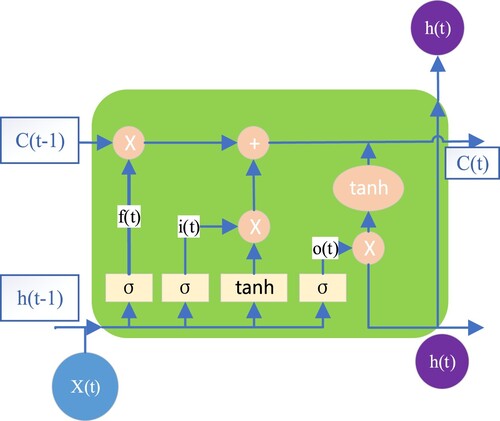
Among them, represents the storage state unit at time
;
is the output produced by the LSTM at time
, and
denotes the input of the model at time
. The forget gate determines how much the cell state
at the previous moment is retained to the current state
, the input gate determines how much of the network input
at the current moment is saved to the cell state
, and the output gate how much of the control unit state
is output to the current output value
of the LSTM. The formulae for input gate
, forget gate
, and output gate
are expressed as follows:
(3)
(3)
(4)
(4)
(5)
(5)
The current state is updated by
, and finally
and
are employed to calculate the current output value
. The calculation formulae are as follows:
(6)
(6)
(7)
(7)
(8)
(8)
Among them, and
are the biases of each gate, and
and
are cycle weights. The symbol ⊙ represents the Hadamard product operator, denoting element-wise multiplication; tanh refers to the hyperbolic tangent function, and σ is the sigmoid activation function.
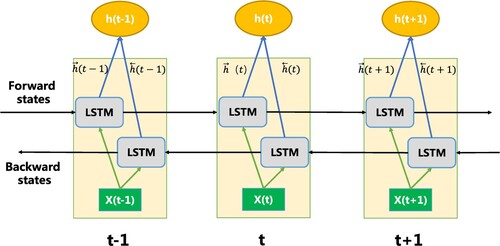
The internal structure of Bi-LSTM is shown in Figure . There are two LSTM units in each module, which are adopted to calculate the forward hidden sequence and the backward hidden sequence
. Through iterations, the forward hidden layer state from time
to
and from time
is spliced to the backward hidden layer state with
to produce output sequence
. As shown in formula (9), the state information of a single hidden layer is:
(9)
(9) ⊕ is the concatenation operator, that is, addition of element-by-element.
Figure 4. Bi-LSTM internal structure diagram.
3.2.2. MIX attention scheme
Since the attention mechanism can capture the key information in the sentence (Vaswani & Shazeer, Citation2017), it can solve the problem that Bi-LSTM cannot extract the key features in the article. This article further proposes a MIX attention scheme on this basis, and its internal structure is described as follows.
Figure shows MIX attention. MIX attention is composed of multiple dot-products. The text data are fed into the MIX attention module after passing through the Bi-LSTM model. In MIX attention, represents the value matrix with dimension
,
is the key matrix with dimension
,
denotes the query matrix with dimension
,
and
are all determined by multiplying the input by the matrix with dimensions
,
and
. The previous attention mechanism (Vaswani & Shazeer, Citation2017) uses the transposition of the query matrix and all the key matrices as a dot product and employs the softmax function to determine the weights:
(10)
(10)
Figure 5. MIX attention.
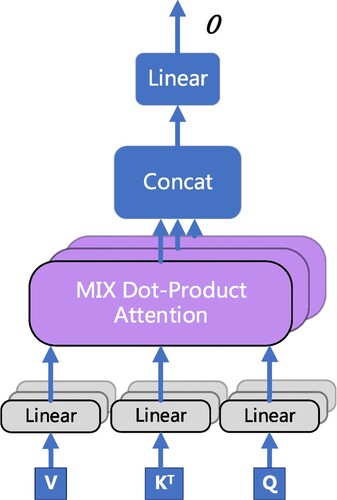
This kind of calculation method separates each head attention, so that each attention is isolated and has no connection with any other, which affects the extraction efficiency of key features. In order to further improve the feature extraction ability of the attention mechanism and improve the accuracy of text classification, the MIX module is designed in a dot-product form (Figure ).
Figure 6. MIX attention internal structure dot-product.
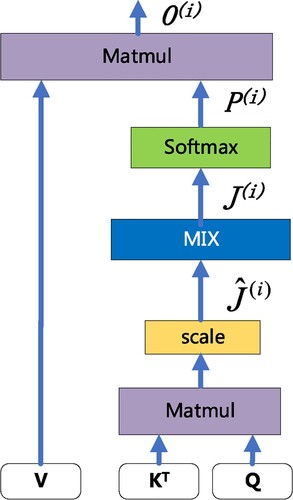
Figure shows the internal structure of the MIX attention module. First, the matrix and
matrix of each head are transposed before application of the dot product operation, and we then divide by
by way of scaling to get the information of each head
where
is the number of the attention head. The specific calculation formula is as follows:
(11)
(11)
Among them, is the number of attention heads. The original calculation method directly performs a softmax operation on the head information and then multiplies it by the
matrix, which leads to the inability of each head information to interact and reduces the feature extraction efficiency of the attention mechanism. As shown in Figure , these headers are multiplied by a randomly initialised fusion matrix, and the feature
fused with each header information is obtained, so that
captured by each head can be used in an interactive manner. Thereafter, the softmax function is used to normalise the weight of the feature
to obtain
, as follows:
(12)
(12)
(13)
(13)
is an intermediate variable fused with other attention head information, finally,
is multiplied by the respective
matrices, and each head attention is concatenated to obtain the final representation
of the deep global semantic features as follows:
(14)
(14)
(15)
(15)
The network obtains the global features of the text through Bi-LSTM, and then passes the output of Bi-LSTM to MIX attention, so that the network can extract the key features of the text again, thus forming a deep feature extraction module.
Finally, in this model, the two features extracted by the MCNN and Bi-LSTM are fused through the fusion module. The splicing function is used as the fusion method of the two, that is, aligning the tensor dimensions of and
above and using the addition operation for fusion.
4. Experiment
4.1. Data set introduction
Six text classification data sets are used (Table ). All six datasets can be downloaded from https://paperswithcode.com/datasets AGnews is a four-category news corpus, and DBPedia is a 14-category ontology data set from Wikipedia (Zhilin et al., Citation2019). Yelp.P is a review corpus that predicts sentiment categories and is a dual-classification data set. Yahoo! Answers is a question and answer data set, with a total of 10 categories (Zhang et al., Citation2015). text_class is a 20-category English data set. Amazon.F is an Amazon review data set with five categories (Zhilin et al., Citation2019).
Table 1. Data set information (SA stands for sentiment analysis, QA stands for question and answer).
4.2. Experimental details
The 300-dimensional Glove word vector (Pennington et al., Citation2014) is used for word embedding. When training the model, the word embeddings are updated along with other parameters. Stochastic gradient descent (SGD) is used as an optimiser for all trainable parameters. The experiment is run on a high-performance computer equipped with an NVIDIA T1 graphics card and 32-GB RAM using a pytorch 0.4.1 framework and Python 3.6.
To achieve better classification effect, some parameter tuning techniques are also adopted. First, a good experimental environment is configured, and the settings of all experimental variables for ease of adjustment can be centralised. Second, referring to the experimental parameters in the classic papers, the batch size, learning rate, etc are adjusted. Because an excessively batch size usually leads to insufficient video memory, in the experiment, the batch number is adjusted from large to small. When setting the learning rate, the situation of different data sets varies. Herein, we use an order of 10, and generally choose 0.01 or 0.001. In the MCNN module, the dimension of each output channel is set to 256; inside Bi-LSTM, the hidden layer unit is also set to 256. In MIX attention, the number of dot-products is set to 8, and the dimensions of , and
are all set to 64.
To prevent overfitting, the following measures are also taken: first of all, the dropout strategy is adopted in the training process, that is, a certain proportion of hidden layer units in the dropout layer (usually about 0.5) is randomly discarded. Since the hidden layer units discarded in each iteration are different, the network can return correct classification results through some neural units after multiple iterations, avoiding overfitting. Secondly, we also use an early stopping strategy, that is, stopping iterations before the model converges on the training dataset iterations to prevent overfitting. The specific approach is to calculate the accuracy of the validation set at the end of each epoch and stop training when the accuracy no longer improves over multiple consecutive epochs.
4.3. Experimental analysis
Glove is used as the text representation method and conducts improvement experiments on three English data sets. Model 1 is used as the baseline model with a single model CNN for classification. Model 2 uses the MCNN proposed herein for classification. Model 3 is a two-way long and short-term network plus attention mechanism. Model 4 integrates the proposed MCNN with Bi-LSTM. Model 5 is a hybrid model MCNN_Bi-LSTM_attention, which uses the MCNN and Bi-LSTM fusion attention mechanisms. Model 6 is the CBM model proposed herein: six groups of comparative experiments are conducted, and the experimental results are displayed in Table .
Table 2. Classification improvement experiments (%).
The experimental results indicate that the proposed model has achieved the best classification effect on all data sets. On the 20-category English data set, the accuracy reaches 82.24%, on the four-category data set AGnews, the accuracy reaches 92.50%, and on the 14-category DBPedia data set, the accuracy reaches 98.80%. Comparing Model 6 (proposed herein) with other single models and hybrid models shows that: compared with the baseline model CNN, the proposed model is improved by 2.74%, 0.62%, and 0.38%, respectively. The performance on the three data sets is better than the baseline model CNN; in particular, on the text_class data set, the improvement in classification accuracy is significant. Comparing Model 2 with Model 1, Model 5 with Model 3, and under the same control of other modules, the difference between these two groups of experiments is whether to use the MCNN module. From the data in Table , it can be found that in terms of classification accuracy, Model 2 and Model 5 using the MCNN module are better than Model 1 and Model 3. The improvement of the network performance of the MCNN module also verifies the effectiveness of the module. Models 4–6 are mixed models, and their accuracy on each data set has been improved compared to that achieved with a single model. The hybrid model can extract local features and global semantic features at the same time, making it more comprehensive than the single model, thus affecting the classification effect thereof. This result indicates that extracting shallow local features through the MCNN can significantly improve network performance, and the comparison with a single model also proves that the effect of the hybrid model is better than that of the single model.
Comparing Model 6 with Model 4, it can be seen from the table that there are 2.61%, 0.45%, and 0.15% improvements on the three data sets, respectively. Both are hybrid models using the MCNN and Bi-LSTM. Model 6 adopts the MIX attention module designed in the present research; the proposed model is then compared with Model 5. In the case of the same use of the MCNN and Bi-LSTM, the only difference is the attention mechanism and MIX attention. From the tabulated data, Model 6 (proposed herein) that is used on the text_class data set is 1.11% more accurate than Model 5; on AGnews, the accuracy is increased by 0.39%; on DBPedia, the accuracy is increased by 0.45%. Although the attention mechanism has achieved excellent classification results, the accuracy has reached more than 90% on both data sets, but the proposed MIX attention scheme is still improved on this basis, proving the effectiveness of the module. The MIX attention module mixes each head of information, and the extracted features are richer and more detailed than the pure attention mechanism, so the classification accuracy is also higher. The result also shows that the MIX attention scheme designed in the present research is better than the original attention mechanism.
To further prove the superiority of the proposed model, the outputs are compared with several other groups of models that also use CNN and Bi-LSTM in joint learning (Liu & Guo, Citation2019; Pradhan et al., Citation2021; Song, Citation2018; Trueman & Cambria, Citation2021), see Table for details.
Table 3. Accuracy of text classification: metric: classification accuracy rate (ACC, %).
It can be seen from Table that the proposed model is based on the same method on the three datasets. Models 1–4 are all series structures in terms of structure, that is, the Bi-LSTM network is followed by CNN. However, the proposed model is a parallel structure. It is believed that there is position information of the sequence in the text. If the method of the serial structure is used, the position information in the text sequence cannot be captured by the Bi-LSTM network, which will cause certain feature loss. The proposed method can avoid this problem. In addition, the MCNN module and MIX attention proposed herein can enhance the feature extraction ability of the network and are also better than similar methods in terms of classification accuracy.
To verify the reliability of the model, another experiment is conducted on the other five data sets and the result is compared with the classic model (Table ): the data pertain to neural network models using different methods, such as capsule network (Ren & Lu, Citation2018); CNN-based models include: Char-CNN (Zhang et al., Citation2015), very deep convolutional neural network (VDCNN) (Alexis & Holger, Citation2016), topic attention networks for neural topic modelling (TAN-NTM) (Panwar, Citation2020), Trans-CNN (Chia et al., Citation2019), and Char-CRNN (Xiao & Cho, Citation2016).
Table 4. Accuracy of text classification: metric: classification accuracy rate (ACC, %).
It can be seen from Table that the proposed feature-fusion method outperforms other methods on three of the data sets, being 1–2% higher than the model based on CNN or RNN. On the 4-category AGnews news data set, the accuracy is up to 92.50%; on the 14-category ontology data set DBPedia, the accuracy is up to 98.80%; on the 10 categories of Yahoo! on the Answers question and answer data set, an accuracy of 72.24% is achieved, which is higher than other models. Compared with a single model, such as Capsnets, Char-CNN, etc., the accuracy of the proposed model is increased by 0.26–2.01%. The experimental results imply that the model is better than the single model, and it also proves that the mixed model is better than the single model in text classification, which is in agreement with the conclusion drawn above. For the Yelp P and amazon datasets, optimisation is not achieved: these two data sets contain longer sequences and variable grammatical information; secondly, those model structures are more suitable for this type of data set, because this type of data set has certain advantages; in the end, those authors used some special training techniques during training, which can improve the classification performance of the model. Compared with the hybrid model Trans-CNN, the accuracy of the proposed model is 0.21–1.24% higher than on each data set, indicating that the hybrid method is better than Trans-CNN.
To verify the effectiveness of the model, the latest text classification methods are collected and compared (Table ); these methods include ULRIDTC (Unsupervised Label Refinement Improves Dataless Text Classification) (Chu et al., Citation2020) based on label enhancement, LCLETC (Label Confusion Learning to Enhance Text Classification) (Guo et al., Citation2020), AFTB (Adversarial Fine-Tuning BERT) (Javid et al., Citation2021) based on adversarial learning and SVSAE (Semi-Supervised VAE) based on semi-supervised learning (Ghazi et al., Citation2021). On the AGnews data set, the proposed model achieves a classification accuracy of 92.5%, which is higher than the other three methods; on the DBpedia data set, the proposed model achieves a classification accuracy of 98.8%, which is 1.40% higher than the classification accuracy of ULRIDTC. On the Yelp P data set, the proposed method achieves an accuracy of 93.56%, which is 0.71% higher than SVSAE and 4.66% higher than TAN-NTM. On the Yahoo Answers dataset, the proposed model achieves a classification accuracy of 72.24%, which is 5.54% higher than ULRIDTC.
Table 5. Accuracy of text classification: metric: classification accuracy rate (ACC, %).
In summary, the method proposed herein can improve the effect of text classification, and achieve the best results compared with other new method developed in the last two years. The text classification model fused with shallow features and deep features proposed herein can significantly improve the accuracy of text classification.
5. Conclusion
Text classification is an important task in the field of natural language processing, and it is widely used in tasks such as topic classification and public opinion analysis. Classification using CNN or RNN is a classic method in this field. However, they all show their own limitations: the performance of CNN is limited by the size of the convolution kernel window and cannot capture the context dependence between words; RNN cannot effectively extract the key features of the sentence. To solve these problems, based on the CBM model, an MCNN module is designed to extract the local features of the text, and the MIX attention is designed to extract the key features of the sentence. The effectiveness of the proposed module is verified through comparative experiments. On the three benchmark datasets, the methods proposed can achieve the best results. Compared with other methods, the limitation of our method is that the network scale is larger, and the training time is longer. In future research, the improvement space of this network will be further explored. In the future of e-commerce, text classification technology can more accurately analyze the emotional tendencies of users.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Alexis, C., & Holger, S. (2016). Very deep convolutional networks for natural language processing. Computer Science. arXiv:1606.01781. https://doi.org/10.48550/arXiv.1606.01781
- Cheng, X., Zhang, C., & Li, Q. (2021). Improved Chinese short text classification method based on ERNIE_BiGRU model. Journal of Physics: Conference Series, 1993(1), 012038. https://doi.org/10.1088/1742-6596/1993/1/012038
- Chia, Y. K., Witteveen, S., & Andrews, M. (2019). Transformer to CNN: Label scarce distillation for efficient text classification. Computation and Language, arXiv:1909.03508.
- Cho, K., Van, B., & Gulcehre, C. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. D14–1179). https://doi.org/10.3115/v1/D14-1179
- Chu, Z., Stratos, K., & Gimpel, K. (2020). Unsupervised label refinement improves dataless text classification. Computer Science. arXiv preprint arXiv:2012.04194.
- Deng, J., Cheng, L., & Wang, Z. (2021). Attention-based BiLSTM fused CNN with gating mechanism model for Chinese long text classification. Computer Speech & Language, 68(6), 101182. https://doi.org/10.1016/j.csl.2020.101182
- Deng, J., & Ren, F. (2021). Hierarchical network with label embedding for contextual emotion recognition. Research; A Journal of Science and Its Applications, 2021, 9. https://doi.org/10.34133/2021/3067943
- Ghazi, F., Joseph, L., & Djamé, S. (2021). Challenging the semi-supervised VAE framework for text classification. Computer Science. arXiv:2109.12969.
- Gu, J., & Peng, W. (2020). Sentiment classification method based on convolution attention mechanism. Computer Engineering and Design, 95–99.
- Guo, B., Han, S., & Han, X. (2020). Label confusion learning to enhance text classification models. Computer Science. arXiv:2012.04987.
- Hochreiter, S., & Jürgen, S. (1997). LSTM can solve hard long time lag problems. Annual Conference on Neural Information Processing Systems (pp. 473–479).
- Jair, C., Li, X., & Yu, W. (2014). Imbalanced data classification via support vector machines and genetic algorithms. Connection Science, 26(4), 335–348. https://doi.org/10.1080/09540091.2014.924902
- Javid, E., Hao, Y., & Zhang, W. (2021). How does Adversarial Fine-Tuning benefit BERT? Computer Science. arXiv:2108.13602v1.
- Jincheng, H., & Wang, T.. (2022). Two-stream attention network with local and non-local dependence for referring relationships. International Journal of Embedded Systems, 15(1), 53–60. https://doi.org/10.1504/IJES.2022.122059
- Johnson, R., & Zhang, T. (2017). Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 562–570). https://doi.org/10.18653/v1/P17-1052
- Joulin, A. (2017). Bag of tricks for efficient text classification. Computer Science. arXiv:1607.01759.
- Kim, Y. (2014). Convolutional neural networks for sentence classification. In Proc. EMNLP(pp. 1746–1751). https://doi.org/10.3115/v1/D14-1181
- Kontorovich, L. (2004). Uniquely decodable n-gram embeddings. Theoretical Computer Science, 329(1-3), 271–284. https://doi.org/10.1016/j.tcs.2004.10.010
- Li, X., & Ning, H. (2020). Chinese text classification based on hybrid model of CNN and LSTM. Proceedings of the 3rd International Conference on Data Science and Information Technology (pp.129–134). https://doi.org/10.1145/3414274.3414493
- Li, Z., Ren, A., & Li, J. (2016). Dscnn: Hardware-oriented optimization for stochastic computing based deep convolutional neural networks. 2016 IEEE 34th International Conference on Computer Design (ICCD) (pp. 678–681). IEEE. https://doi.org/10.1109/ICCD.2016.7753357
- Liu, G., & Guo, J. (2019). Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing, 337, 325–338. https://doi.org/10.1016/j.neucom.2019.01.078
- Mikolov, T. (2013). Distributed representations of words and phrases and their compositionality. Annual Conference on Neural Information Processing Systems (pp. 3136–3144). arXiv:1310.4546.
- Miyamoto, Y., & Cho, K. (2016). Gated word-character recurrent language model. In Proc. EMNLLP, Austin, Texas (pp. 1992–1997). https://doi.org/10.18653/v1/D16-1209
- Panwar, M. (2020). TAN-NTM: topic attention networks for neural topic modeling. Computer Science. arXiv:2012.01524.
- Pennington, J., Socher, R., & Manning, C. (2014). Glove: global vectors for word representation. In Proc. EMNLP, Doha, Qatar (pp. 1532–1543). https://doi.org/10.3115/v1/D14-1162
- Pradhan, T., Kumar, P., & Pal, S. (2021). CLAVER: An integrated framework of convolutional layer, bidirectional LSTM with attention mechanism based scholarly venue recommendation. Information Sciences, 559, 212–235. https://doi.org/10.1016/j.ins.2020.12.024
- Qiaoyun, W., Zhu, G., Zhang, S., Li, K.-C., Chen, X., & Xu, H. (2021). Extending emotional lexicon for improving the classification accuracy of Chinese film reviews. Connection Science, 33(2), 153–172. https://doi.org/10.1080/09540091.2020.1782839
- Ren, H., & Lu, H. (2018). Compositional coding capsule network with k-means routing for text classification. Computer Science. arXiv:1810.09177.
- Shunxiang, Z., Yu, H., & Zhu, G. (2022). An emotional classification method of Chinese short comment text based on ELECTRA. Connection Science, 34(1), 254–273. https://doi.org/10.1080/09540091.2021.1985968
- Song, M. (2018). Text sentiment analysis based on convolutional neural network and bidirectional LSTM model. International Conference of Pioneering Computer Scientists, Engineers and Educators. Springer.
- Sun, Y., Wang, S., & Li, Y. (2019). ERNIE: Enhanced representation through knowledge integration. Computation and Language. arXiv:1904.09223.
- Suruchi, C. (2021). Application of convolution neural network in web query session mining for personalised web search. International Journal of Computational Science and Engineering, 24(4), 417–428. https://doi.org/10.1504/IJCSE.2021.117029
- Tam, S., & Said, R. (2021). A ConvBiLSTM deep learning model based approach for twitter sentiment classification. IEEE Access, 9, 41283–41293. https://doi.org/10.1109/ACCESS.2021.3064830
- Trueman, T. E., & Cambria, E. (2021). A convolutional stacked bidirectional LSTM with a multiplicative attention mechanism for aspect category and sentiment detection. Cognitive Computation, 13(6), 1423–1432. https://doi.org/10.1007/s12559-021-09948-0
- Vaswani, A., & Shazeer, N. (2017). Attention is all you need. In Proc. NIPS, Long Beach, CA, USA(pp. 5998–6008). arXiv:1706.03762.
- Xiao, Y., & Cho, K. (2016). Efficient character-level document classification by combining convolution and recurrent layers. Computer Science. arXiv:1602.00367.
- Yang, Z., Yang, D., & Dyer, C. (2016). Hierarchical attention networks for document classification. In Proc. NAACL, San Diego, CA, USA (pp. 1480–1489). https://doi.org/10.18653/v1/N16-1174
- Zhang, D., & Lee, W. (2003). Question classification using support vector machines. Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 26–32). https://doi.org/10.1145/860435.860443
- Zhang, X., Zhao, J., & Yann, L. (2015). Character-level convolutional networks for text classification. Advances in Neural Information Processing Systems, 649–657. arXiv:1509.01626.
- Zhao, J. (2017). Comparison research on text pre-processing methods on twitter sentiment analysis. IEEE Access, 5, 2870–2879. https://doi.org/10.1109/ACCESS.2017.2672677
- Zhao, J., Zhan, Z., & Yang, Q. (2018). Adaptive learning of local semantic and global structure representations for text classification. Proceedings of the 27th International Conference on Computational Linguistics (pp. 2033–2043).
- Zhilin, Y., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R., & Le, Q. V. (2019). XLNet: Generalized autoregressive pretraining for language understanding. In Proceedings of the 33rd international conference on neural information processing systems (pp. 5753–5763). Curran Associates Inc.
- Zhongliang, W., Liu, W., Zhu, G., Zhang, S., & Hsieh, M.-Y. (2022). Sentiment classification of Chinese Weibo based on extended sentiment dictionary and organisational structure of comments. Connection Science, 34(1), 409–428. https://doi.org/10.1080/09540091.2021.2006146
- Zhou, C., Sun, C., & Liu, Z. (2015). A C-LSTM neural network for text classification. Computer Science, 1(4), 39–44. arXiv:1511.08630.
- Zhou, P., Qi, Z., & Zheng, S. (2016). Text classification improved by integrating bidirectional LSTM with two-dimensional max pooling. In Proc. COLING, Osaka, Japan (pp. 3485–3495). arXiv:1611.06639.