
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Network pruning facilitates the deployment of convolutional neural networks in resource-limited environments by reducing redundant parameters. However, most of the existing methods ignore the differences in the contributions of the output feature maps. In response to the above, we propose a novel neural network pruning method based on the channel attention mechanism. In this paper, we firstly utilise the principal component analysis algorithm to reduce the influence of noisy data on feature maps. Then, we propose an improved Leaky-Squeeze-and-Excitation block to evaluate the contribution of each output feature map using the channel attention mechanism. Finally, we effectively remove lower contribution channels without reducing the model performance as much as possible. Extensive experimental results show that our proposed method achieves significant improvements over the state-of-the-art in terms of FLOPs and parameters reduction with similar accuracies. For example, with VGG-16-baseline, our proposed method reduces parameters by 83.3% and FLOPs by 66.3%, with only a loss of 0.13% in top-5 accuracy. Furthermore, it effectively balances pruning efficiency and prediction accuracy.
1. Introduction
Convolutional neural networks (CNNs) have been in applied in many applications and demonstrated extraordinary abilities in the fields of computer vision, speech recognition and natural language processing. However, complex network architectures challenge efficient real-time deployment and require significant computation resources and energy costs (Liang et al., Citation2021). For example, VGG-16 has 1.5 million nodes, occupies 528M runtime memory, and the classification of each image requires up to 15B FLOPs (floating-point operations). In general, the training of large-scale CNNs relies heavily on parallel processing technologies and high-performance GPUs (Graphics Processing Units). It is difficult to achieve the desired effect by directly adopting the original network model, especially in mobile or embedded devices. Network pruning is a model compression method for cutting off the redundant branches in pursuit of more lightweight subnetworks (Wang, Li, et al., Citation2020). By reducing redundant parameters of CNNs, network pruning can improve the inference speed of the networks under the same hardware environment without affecting the accuracy, and finally can be used in resource-limited environments such as mobile or embedded devices. Generally, the process of network pruning includes three steps: (i) Calculating the importance of filters according to the evaluation criteria; (ii) Sorting the important values and determining the minimum value under the constraint of specifying pruning rate; (iii) Fine-tuning the pruned model using the original data. Pruning approaches can be further divided into non-structured pruning and structured pruning.
For non-structured pruning, elements of the weight matrix can be removed according to certain criteria (Aghasi et al., Citation2017; Guo et al., Citation2016; Han et al., Citation2015; Hassibi & Stork, Citation1992). It performs in-kernel pruning at the filter granularity and removes invalid weights in the filter. Its disadvantage is that obtaining a sparse weight matrix not only increases the computational costs, but also requires specialised hardware due to irregular memory access.
For structured pruning, it removes the entire filters or channels based on certain metrics. It not only greatly reduces computational costs but also significantly decreases storage usage. Compared with unstructured pruning, structured pruning wins in hardware compatibility at the expense of compression ratio. For example, a method of estimating filter contributions using a Taylor expansion was proposed, which iterated over the squared change in the final loss and removed those with smaller scores (Molchanov et al., Citation2019). Instead of pruning the entire filter, SWP (Stripe-Wise Pruning) treated each filter as a combination of multiple stripes and performed pruning on the stripes (Meng et al., Citation2020). It also introduced Filter Skeleton (FS) to efficiently learn the optimal shape of the filters for pruning. However, the filter weights and FS are jointly optimised in the training process, and it is difficult to avoid the influence of noisy data and lead to wrong pruning. In addition, a filter pruning based on a high rank (HRank) of feature maps simplified pruning complexity without retraining the model or introducing additional auxiliary constraints (Lin et al., Citation2020). Notably, existing single-shot pruning algorithms at initialisation suffer from layer collapse (Tanaka et al., Citation2020). The relevant enlightenments are drawn from the above-mentioned solutions as follows: (i) Due to the influence of noisy data, the rank of the feature map is difficult to accurately estimate the contribution of the filter. (ii) In practice, each filter in the same layer has different states and contributions, so the feature maps they generate also have different contributions. (iii) It is difficult to guarantee the stability of pruning efficiency and prediction accuracy. In particular, there are cases where layer-collapse results in a sudden drop in accuracy.
To address this limitation, this paper proposes a novel neural network pruning method based on a channel attention mechanism to achieve the following goals: denoising original data to ensure the amount of information carried by the output feature maps; accurately evaluating the contribution of output feature map; removing lower contribution channels without reducing the model performance. The method firstly exploits the principal component analysis (PCA) algorithm to denoise of original data. Then it introduces an improved Leaky-Squeeze-and-Excitation (Leaky-SE) block to evaluate the contribution of each output feature map using channel attention mechanism. Finally, it effectively removes lower contribution channels without reducing the model performance.
The key contributions of our work are:
In order to more accurately evaluate the amount of information carried by the output feature maps, PCA is used to reduce the influence of noisy data on the feature maps.
Unlike existing methods that only consider intrinsic parameters, an improved Leaky-SE block is exploited to evaluate the contribution of the output feature map using a channel attention mechanism.
A channel attention-based neural network pruning algorithm removes lower contribution without degrading the model performance as much as possible. On the one hand, it has good initial pruning performance to avoid suffering from layer collapse. On the other hand, it has good pruning stability, that is, it effectively balances pruning efficiency and prediction accuracy, which is beneficial for users to achieve the compression goal.
Extensive experimental results and real cases show that our proposed method exhibits good parameters and FLOPs reduction. For example, with VGG-16-baseline, our proposed method reduces parameters by 83.3% and FLOPs by 66.3%, with only a loss of 0.13% in top-5 accuracy. In a real case, the mask-wearing detection model based on YOLOv5s is deployed on Android mobile devices to detect mask wearing. Compared with the YOLOv5s-baseline, our proposed method reduces GFLOPs by 19.3% and parameters by 40.2%, with a loss of accuracy by 5.3%.
In the following, some related works are introduced in Section 2. Section 3 describes the proposed method. Section 4 explains the experimental results. Section 5 is the conclusions and recommendations for future work.
2. Related work
2.1. Non-structured pruning
Unstructured pruning is mainly to delete individual weights, i.e. elements of the weight matrix can be removed according to certain criteria. Such as OBD (Optimal Brain Damage) reduced the size of the learning network by selectively removing weights (LeCun et al., Citation1989). Second-derivatives information was used to make trade-off between network complexity and training set error. In order to increase the speed of further training, reduce hardware or storage requirements, simplify networks, OBS (Optimal Brain Surgeon) recalculated the weights to compensate for activation values and set less important weights to zero for better compression (Hassibi & Stork, Citation1992).
In order to reduce storage requirements without affecting accuracy, a deep compression included pruning, trained quantisation and Huffman coding (Han et al., Citation2015). Cynamic network surgery significantly reduced the network complexity by using on-the-fly connection pruning (Guo et al., Citation2016). To remove connections at each layer with maintaining performance, a Net-Trim algorithm pruned the trained network layer-wise (Aghasi et al., Citation2017). In addition, to avoid spatial redundancy within most filters in a CNN, Liu et al. (Citation2018) proposed a frequency-domain dynamic pruning scheme to exploit the spatial correlations. Besides, an approach compressed super-resolution networks through weight pruning, which first cleared the redundant parameters to zero, and then, built a sparse-aware attention and an informative multi-slicing network for a more lightweight network (Jiang et al., Citation2021). Reiners et al. (Citation2022) proposed an efficient and sparse neural network by pruning weights in a multi-objective learning approach. Prediction accuracy and the network complexity were treated as two individual objective functions in a bi-objective optimisation problem (Wu et al., Citation2022).
However, a key disadvantage of the above non-structured pruning methods is that the generated weight matrices are sparse, which cannot achieve compression and acceleration without specialised hardware.
2.2. Structured pruning
Structured Pruning performs pruning at the filter, channel, or even layer level and does not require specialised hardware/libraries for compression or acceleration.
Compared to unstructured pruning, structured pruning is a more popular method. A filter-level pruning method called ThiNet achieved compression of deep neural network, where the filter was pruned based on statistics of the next layer rather than the current layer (Li, Cao, et al., Citation2021; Luo et al., Citation2017). You et al. (Citation2019) proposed a global filter pruning algorithm called Gate Decorator, which took the output of the original CNN module multiplied by a channel-wise scaling factor as its transform. Furthermore, Gate Decorator could be regarded as a task-driven network architecture search algorithm. To reduce the effect of error propagation in deep networks, Yu et al. (Citation2018) proposed a pruning method called Neuron Importance Score Propagation (NISP) to propagate the importance scores of final responses to every neuron in the network. A structured pruning method removed the independent neuron of recurrent neural networks through neuron selection without affecting performance (Wen et al., Citation2020). Bao et al. (Citation2018) proposed cross-entropy pruning method for compressing CNNs and prune the weights in a group-wise way. A framework based on layer-wise relevance propagation was proposed to compress and accelerate the networks without affecting predictive performance (Yeom et al., Citation2021). Chang et al. (Citation2021) proposed a mixed-pruning-based framework containing compression and acceleration, with almost no loss of accuracy, which is deployed on embedded systems. An accelerator-aware pruning method for CNNs was proposed, which focused on the internal activation buffer and multipliers (Kang, Citation2019; Wang, Xing, et al., Citation2020). An effective structured pruning jointly pruned filters together with other structures in an end-to-end manner (Lin et al., Citation2019). A two-stage retraining-free pruning called RFPruning was used to achieve both good performance and fast deployment (Wang et al., Citation2021). Li, Wang, et al. (Citation2021) considered the importance of convolutional filters through both instability and sensitivity, and developed a visual analytics approach, named CNNPruner, which allowed users to interactively create pruning plans according to a desired goal on model size or accuracy. Fernandes Jr. and Yen (Citation2021) proposed a novel algorithm to perform filter pruning by using a Multi-Objective Evolution Strategy (MOES) algorithm. Notably, pruning algorithm called SynFlow preserved the total flow of synaptic strengths through the network at initialisation and its constrained by sparsity (Tanaka et al., Citation2020).
Many methods pruned the neural network based on the input importance. Such as, Li et al. (Citation2016) proposed to evaluate the importance of channels based on the L1-norm criterion. Hewahi (Citation2019) designed an algorithm called Neural Network Pruning Based on Input Importance (NNPII). Collaborative channel pruning was used to evaluate channel importance, combining the convolution layer weights and the BN layer scaling factors. Furthermore, it could remove unimportant channels without affecting the model performance (Chen et al., Citation2021). The feature map information entropy was considered as the evaluation criterion of filter importance in the current layer (Shao et al., Citation2021). Similarly, the contribution of output feature map was exploited to filter pruning, which effectively removes low-contribution parts without degrading the model performance as much as possible (Chen et al., Citation2022). Chen et al. (Citation2020) designed a Low-rank Approximated channel Pruning (LAP) framework was utilised to eliminate redundancy within the filter, pursuing a higher acceleration ratio and compression ratio on CNNs with the constraint of negligible performance decay. According to relative cosine distances in the feature space, some redundant features and their associated feature maps were pruned (Ayinde et al., Citation2019).
Many inspirations can be drawn from the above literature, which is summarised as follows: (i) Most of the works ignore the differences in the contributions of the output feature maps. (ii) Structured pruning methods may often mistakenly remove important channels because they use statistics based on sparse network convolutional layers to evaluate the importance of channels. There is an urgent need for a reasonable evaluation method to estimate the importance of channels. (iii) Structured pruning is inflexible, as it usually lies on the hard threshold of the pruning criterion, making it difficult to trade off pruning efficiency and prediction accuracy. (iv) It is crucial to avoid lay-collapse at the initialisation of the pruning algorithm.
3. The proposed method
To remove the redundant filters of neural networks, we propose a novel neural network pruning based on the channel attention mechanism. First, PCA is utilised to reduce the influence of noisy data. Then, an improved Leaky-SE block is introduced to evaluate the contribution of each output feature map using the channel attention mechanism. Finally, a channel attention-based neural network pruning algorithm is exploited to remove lower contribution channels without reducing the model performance.
3.1. Denoising algorithm based on PCA
In order to more accurately evaluate the amount of information carried by the output feature maps, it is necessary to reduce the influence of noisy data on the feature maps and retain effective target information as much as possible. In view of the above problem, we propose a denoising algorithm based on PCA to reduce data noise information as the pre-work of network pruning.
PCA can find a set of projection vectors so that the projected data can provide an efficient representation for data (Wang et al., Citation2022; Warmenhoven et al., Citation2021). On the basis of the above analyses, a denosing algorithm-based PCA is as shown in Algorithm 1.
Table
3.2. An improved Leaky-SE block with channel attention
In practice, features learning of CNN can be enhanced by explicitly modelling channel interdependencies and improving their sensitivity to informative features. Since each learned filter overemphasises a local receptive field, the transformed output cannot utilise contextual information outside of this region. To this end, we introduce an improved Leaky-SE (Squeeze-and-excitation) block into CNN, where SE block adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels (Hu et al., Citation2018). Leaky-SE block generates weights of different sizes for different channel feature maps through channel attention. Besides, Leaky-SE block was designed to access global information and recalibrate filter responses before feeding them into the next transformation. It is worth noting that the importance of channels is calculated through the attention mechanism.
For any given transformation, maps form the input X to feature maps Z, where X refers to the original feature map
. The composite feature map
can be obtained by aggregating the weighted feature map and the original feature map using the attention mechanism (Hu et al., Citation2018). Therefore, we perform the global average pooling (GAP) operation on feature maps X and reduce X from dimensions
to
.
In order to obtain the joint feature map
through squeeze operation, we have a channel descriptor by applying GAP to X, and the joint feature map
The two-layer full connection is exploited to fully capture channel-wise relationships. The first layer and the second can learn non-linear interactions between channels and non-mutually exclusive dependencies, respectively (Hu et al., Citation2018). Due to the existence of redundant filters, the partial channel weights of the joint feature map
In general, the ReLU activation function used in the Squeeze-and-Excitation Network has dead neuron problems (Lu et al., Citation2019), where ReLU neurons become inactive and only output 0 for any input. In particular, gradient updates are difficult when the joint value of most channels is less than zero. Therefore, the Leaky-Relu function is used as the activation function of the first fully connected layer. The Leaky-Relu is shown in formula
(3)
(3) where
was introduced to ReLUs such that the gradients will not be zero at any time during training.
In essence, the result
The neural network does not change the structure after introducing the Leaky-SE block module, and compress invalid channels at the channel-level through channel attention mechanism. The GAP operation on the feature map in the Leaky-SE block module can fuse the spatial features, eliminating the influence of the spatial dimension information on the channel dimension. The attention mechanism is introduced into the network training process to improve the accuracy of the network. Moreover, the weight value generated by the attention mechanism to each channel is used as the criterion to evaluate contribution of the channel.
3.3. Channel pruning
To reduce the influence of noisy data on the evaluation of feature map, we first use the PCA algorithm to reduce noise. Then, for an initialised model with a filter set , an improved Leaky-SE block is introduced into CNN to evaluate the contribution of each output feature map. According to the preset pruning rate, we remove the feature map with low contribution and the filter that generates the output feature map accordingly. Finally, we will fine-tune the new model to restore its performance of the model and obtain a high-performance and compact model.
Let {,
} be N-layer CNNs, where
is the
filter,
is the index of layer and
is kernel size,
,
is the input and output of the
channel, respectively. Let
be the pruning indicator, if
is zero, the corresponding filter
is less important and should be pruned safely. Set the filter pruning rate of the
layer to
, then the filters corresponding to the
channels with the smallest weight should be removed from the
channels, where
is the total number of channels. Pruning process is regarded as a multi-objective optimisation problem, i.e.
(4)
(4) where
measures the importance of a filter
to the feature map. After obtaining feature map
generated by the Leaky-SE block module, the importance is re-ranked according to the weights of each channel of the
feature map, where
represents the cth channel of feature map
. Equation Equation(4)
(4)
(4) is equal to removing the
least important channels.
A channel attention-based neural network pruning algorithm is as shown in Algorithm 2. The algorithm has the following characteristics: (i) Introducing Leaky-SE blocks into the network for training. (ii) Obtaining the importance of each channel according to the feature map
on
sub-dataset. (iii) Accumulating
as the final importance of the filter on the complete dataset. (iv) Determining the number of pruned filters and removing feature maps corresponding to channels with zero weights. (v) Fine-tuning the new model to restore its accuracy.
Table
Weight-based pruning methods, such as L1 (Zhuang et al., Citation2020) and FPGM (He et al., Citation2019), only consider one of the statistical information of the weight or the scaling factor to determine the channel to be deleted. Our proposed pruning method exploits an improved Leaky-SE block for evaluating the contribution of each output feature map using a channel attention mechanism, and channel removal is more comprehensive and effective.
Our proposed pruning method effectively integrates the prior knowledge of the network model and uses the channel self-attention information to prune the feature map, which can effectively avoid false pruning.
Our proposed pruning method uses PCA to reduce the influence of noise data on feature maps, thereby more effectively preserving feature maps containing target information. On the contrary, existing methods such as HRank (Lin et al., Citation2020) determine the relative importance of filters by observing the rank of feature maps, and it is easy to retain a large number of invalid feature maps if affected by noise.
4. Experiment
4.1. Experimental setting and dataset
In order to prove the effectiveness of our method, in this section, we evaluate our method on the CIFAR-10, CCTSDB (CSUST Chinese Traffic Sign Detection Benchmark) datasets, using two popular networks, VGG-16 (Simonyan & Zisserman, Citation2014) (single-branch network) and ResNet-56 (He et al., Citation2016) (multiple-branch network) for the experiment. CIFAR-10 has 10 classes, including 60,000 images, i. e., 50,000 training images and 10,000 test images respectively. Similarly, the traffic signs are classified into mandatory signs, danger signs, and prohibitory signs in CCTSDB, containing 15,734 images. Because VGG and ResNet are designed for the ImageNet dataset, in this paper, we choose their variants for the experiment.
The experiment is based on the Pytorch framework and python v3.7, using the 12G NVDIA GeForce RTX2080Ti for training. On the CCTSDB dataset and CIFAR-10 dataset, we train 300 epochs for mini-batch 128 and 150 epochs for mini-batch 256, respectively. The initial learning rate on both datasets is set to 0.1, and reduces to the previous 10% at 100 and 50 epochs, respectively.
4.2. Experimental results
4.2.1. Results on CIFAR-10 dataset
Table shows the VGG-16 performance of different methods, including L1, FPGM, and HRank. Compared with L1, our proposed method provides better top-5 accuracy, parameters and FLOPs reductions (93.71% vs. 93.40%, 83.3% vs. 63.7% and 66.3% vs. 34.3%), which demonstrates the superiority of exploiting the contribution of output feature map using a channel attention mechanism. Compared with FPGM, where 93.54% top-5 accuracy and 34.2% FLOPs reduction are obtained, our proposed method gains a better top-5 accuracy and FLOPs reduction. The main reason for the above results is that L1 and FPGM only consider the statistical information of one of the weights and the scaling factors to determine the channel to be deleted. Compared with HRank, our proposed method is advantageous in all aspects (93.71% vs. 93.43% in top-5 accuracy, 83.3% vs. 83.2% in parameters reduction, and 66.3% vs. 53.6% in FLOPs reduction). Our proposed method demonstrates its ability to compress VGG-16 on CIFAR-10 Dataset.
Table 1. Experimental results on CIFAR-10.
Next, we analyse the performance on ResNet-56. Compared with L1, our proposed method is also advantageous in all aspects (93.78% vs. 93.01% in top-5 accuracy, 0.20% vs. 14.1% in parameters reduction, and 28.7% vs. 27.6% in FLOPs reduction). This is significantly better than L1, which indicates our proposed method is more efficient. Our proposed method obtains 93.78% top-5 accuracy and 28.7% FLOPs reduction. Correspondingly, HRank gains 93.52% in top-5 accuracy and 29.3% in FLOPs reduction. HRank determines the relative importance of filters by observing the rank of feature maps. When it is affected by noise, a large number of invalid feature maps will be generated, which will affect the accuracy of the network. Besides, it demonstrates that in the multi-branch network structure, our method not only does not change the network structure, but also does not increase the additional computational cost. More importantly, the neural network maintains high accuracy after pruning and compression.
4.2.2. Results on CCTSDB dataset
The comparison on VGG-16 and ResNet-56 is shown in Table . Compared with the VGG-16-baseline, our proposed method gains an improvement in parameters (82.8%) and FLOPs reduction (48.2%), with only a small loss in top-5 accuracy of 0.92%. In addition, compared with L1, our proposed method is also advantageous in all aspects (92.59% vs. 92.02% in top-5 accuracy, 82.8% vs. 57.1% in parameters reduction, and 48.2% vs. 34.1% in FLOPs reduction). Compared with FPGM, with a great FLOPs reduction (48.2% vs. 32.3%), our proposed method gains better top-5 accuracy (92.59% vs. 92.10%). Finally, in comparison with HRank, our proposed method reduces the parameters by 0.5% (82.8% vs. 82.3%) and FLOPs by 4% (48.2% vs. 44.2%), with only a small loss in top-5 accuracy of 0.09%. HRank can effectively reflect the relative importance of a filter, but our proposed method also maintains a similar accuracy (Figure ).
Figure 1. Examples of (a) CIFAR-10 dataset and (b) CCTSDB dataset.

Table 2. Experimental results on CCTSDB dataset.
Next, we analyse the performance on ResNet-56. Compared with the ResNet-56-baseline, ours proposed method obtains excellent FLOPs reduction but suffers a 0.08% accuracy drop. Besides, compared with L1, our proposed method provides better parameters (19.0% vs. 18.1%) and FLOPs reduction (45.5% vs. 25.9%), with a loss of top-5 accuracy 0.07%. In addition, compared with HRank, our proposed method achieves a similar parameter reduction and FLOPs reduction advantage of 5.2% (45.5% vs. 40.3%), but loses 0.4% in top-5 accuracy. HRank is more suitable for pruning neural networks with residual blocks than our proposed method. Since some convolutional layers of the residual module are not pruned, the performance of our proposed method is slightly lower than that of single-branch CNNs such as VGG-16.
4.2.3. The relationship between top-5 accuracy and pruning rate
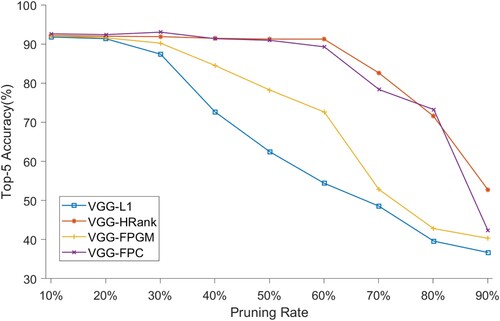
To highlight pruning stability, we compare our proposed method with another three pruning strategies, VGG-L1, VGG-HRank and VGG-FPGM, as shown in Figure . VGG-L1 and VGG-FPGM have small decreases in accuracy when the pruning rate is below 30%, and when the pruning rate is greater than 30%, the top-5 accuracy fluctuates more and more dramatically. With the pruning process going forward (i.e. pruning rate changes from 10% to 60%), the top-5 accuracy of VGG-HRank gradually decreases. When the pruning rate increases to 90%, the top-5 accuracy rate of about 51.3%. For our proposed method on the VGG model (VGG-FPC), when the pruning rate is above 60%, the top-5 accuracy rate of more than 89.23% can be stably maintained, and when the pruning rate increases to 80%, the accuracy rate of about 73% can still be maintained. Our proposed method can greatly compress the network while ensuring that the accuracy of the model decreases less. At the same time, it can also be observed from Figure that VGG-FPC has good initial pruning performance to avoid suffering from layer collapse. In practice, users mainly focus on the accuracy of the final model and tend to ignore the intermediate pruning process. Our proposed method balances pruning efficiency and prediction accuracy relatively effectively, which is beneficial for users to achieve compression goals. In the pruning process, a small amount of removal makes it easy for the model to recover from pruning and usually leads to the best pruning results.
Figure 2. Top-5 accuracy of VGG models with different pruning rates on the CCTSDB dataset.
4.3. A case: face mask-wearing detection model based on YOLOv5s neural network
The widespread reported use of face masks combined with physical distancing increases the probability of CoV-19 transmission control (Hu et al., Citation2019, Citation2022). In train stations, shopping malls, airports, buses and other places with dense population, it is very inefficient to rely on the staff to check whether masks are properly worn. Embedded devices, such as cameras and face recognition gates in public places, can realise automatic detection, which can reduce the risk of epidemic transmission more quickly and efficiently. Network pruning can improve the inference speed of the networks under resource-limited environments without affecting the accuracy.
To solve this problem, YOLOv5s were used to detect face mask wearing. YOLOv5, occupies 28.28M runtime memory and 7.07M parameters and requires about 8.39 GFLOPs to each image. Take YOLOv5s as a baseline, our proposed method (YOLOv5s-channel pruning) avoids network sparseness and reduces GFLOPs by 19.3% and parameters by 40.2%, and the accuracy of the model by 5.3% (89.3% vs. 94.6%). Besides, YOLOv5s-depth-wise separable convolution + pruning reduces GFLOPs by 0.04% and parameters 21.4% (5.56M vs. 7.07M), and the accuracy is lost by 3.5% (91.1% vs. 94.6%). Similarly, YOLOv5s-quantisation (Lu, Citation2021) reduces Memory by 75%, and the accuracy is only lost by 0.8% (93.8% vs. 94.6%). To sum up, our method has great advantages in parameters, memory, GLOPS and forward inference time, but it is weaker than other methods in the accuracy of the model. The comparison of channel pruning, depth-wise separable convolution + pruning and quantisation is shown in Table .
Table 3. Experimental results of network compression.
The pruning process of the face mask wearing detection model based on YOLOv5 neural network is as follows:
Using the trained YOLOv5s mask wearing detection model as the benchmark, and load the trained model as the initial model to be compressed.
Adding Leaky-SE block module to each residual module, and evaluate the importance of feature map according to neural network pruning based on channel attention mechanism.
Pruning convolution kernel according to the obtained network feature map importance and evaluating the pruning sensitivity and determine the pruning ratio.
Taking the pruned network model as student model, and the network model before pruning as the teacher model, and then use the original training dataset for knowledge distillation and retraining. Reduce the memory occupation of network parameters of YOLOv5s mask-wearing detection model.
Furthermore, we deploy CNNs on resource-constrained devices with CUP (Qualcomm Snapdragon 865), GUP (Adreno 650), Memory (12GB) and 256GB storage capacity. Specifically, it includes the following steps:
Converting the compressed YOLOv5s Pytorch model into an ONNX model.
Converting the ONNX model into an NCNN model.
Building an Android application with the NCNN model.
The Android project contained NCNN model is packaged into an APK and transplanted to the mobile device for installation and operation.
The YOLOv5 mask-wearing detection model is responsible for localised forward inference. In mobile Android device, the CPU and GPU are used for forward inference, respectively. Compared with CPU, GPU has faster inference speed with 15FPS vs. 5FPS due to the fit matrix, which is enough to meet the usage scenarios. The results of face mask-wearing detection model are shown in Figure .
Figure 3. The results of face mask wearing detection in a mobile Android device. (a) The deployment of the model; (b) the actual application effect of the model.
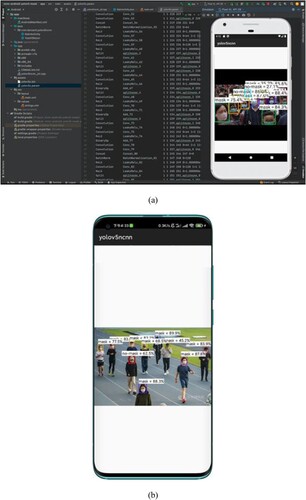
The YOLOv5 mask wearing detection model is used for localised forward inference. In mobile Android devices, both CPU and GPU can be used for forward inference. However, compared with CPU, inference speed of GPU is faster (15FPS vs. 5FPS), the main reason is that GPU is more suitable for matrix operations, which is enough to meet the use of application scenarios, including train stations, shopping malls, airports, buses and other places. The results of the mask wearing detection model are shown in Figure , where 3(a) shows the deployment of the model, and 3(b) shows the actual application effect of the model.
5. Conclusions
In this paper, we present a novel neural network pruning method based on channel attention. We firstly exploit the PCA algorithm to denoise of original data. Then, we introduce an improved Leaky-SE block to a CNN to evaluate the contribution of each output feature map. Finally, we remove the feature map with low contribution and the filter that generates the output feature map accordingly. Compared with VGG-16-L1 and VGG-16-HRank, our proposed method achieves significant improvements in terms of FLOPs and parameters reduction with similar accuracies. Furthermore, the method can ensure the stability of accuracy during the pruning process. In future work, we will exploit spatial self-attention to make the filter focus on the spatial position of valid features and prune the filter that extracts the spatial position of invalid features. In addition, we will combine other compression methods to achieve further compression.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Aghasi, A., Abdi, A., Nguyen, N., & Romberg, J. (2017). Net-trim: Convex pruning of deep neural networks with performance guarantee. Advances in Neural Information Processing Systems, 30, 3180–3189. https://dl.acm.org/doi/10.5555/3294996.3295077
- Ayinde, B. O., Inanc, T., & Zurada, J. M. (2019). Redundant feature pruning for accelerated inference in deep neural networks. Neural Networks, 118, 148–158. https://doi.org/10.1016/j.neunet.2019.04.021
- Bao, R., Yuan, X., Chen, Z., & Ma, R. (2018). Cross-entropy pruning for compressing convolutional neural networks. Neural Computation, 30(11), 3128–3149. https://doi.org/10.1162/neco_a_01131
- Chang, X., Pan, H., Lin, W., & Gao, H. (2021). A mixed-pruning based framework for embedded convolutional neural network acceleration. IEEE Transactions on Circuits and Systems I: Regular Papers, 68(4), 1706–1715. https://doi.org/10.1109/TCSI.2020.3048260
- Chen, Y., Wen, X., Zhang, Y., & He, Q. (2022). FPC: Filter pruning via the contribution of output feature map for deep convolutional neural networks acceleration. Knowledge-Based Systems, 238, 107876. https://doi.org/10.1016/j.knosys.2021.107876
- Chen, Y., Wen, X., Zhang, Y., & Shi, W. (2021). CCPrune: Collaborative channel pruning for learning compact convolutional networks. Neurocomputing, 451, 35–45. https://doi.org/10.1016/j.neucom.2021.04.063
- Chen, Z., Chen, Z., Lin, J., Liu, S., & Li, W. (2020). Deep neural network acceleration based on low-rank approximated channel pruning. IEEE Transactions on Circuits and Systems I: Regular Papers, 67(4), 1232–1244. https://doi.org/10.1109/TCSI.2019.2958937
- Fernandes Jr., F. E., & Yen, G. G. (2021). Pruning deep convolutional neural networks architectures with evolution strategy. Information Sciences, 552, 29–47. https://doi.org/10.1016/j.ins.2020.11.009
- Guo, Y., Yao, A., & Chen, Y. (2016). Dynamic network surgery for efficient dnns. Advances in Neural Information Processing Systems, 29, 1387–1395. https://dl.acm.org/doi/10.5555/3157096.3157251
- Han, S., Mao, H., & Dally, W. J. (2015). Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149.
- Hassibi, B., & Stork, D. (1992). Second order derivatives for network pruning: Optimal brain surgeon. Advances in Neural Information Processing Systems, 5, 164–171. https://dl.acm.org/doi/10.5555/645753.668069
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778). IEEE. https://doi.org/10.1109/CVPR.2016.90
- He, Y., Liu, P., Wang, Z., Hu, Z., & Yang, Y. (2019). Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 4340–4349). IEEE. https://doi.org/10.1109/CVPR.2019.00447
- Hewahi, N. M. (2019). Neural network pruning based on input importance. Journal of Intelligent & Fuzzy Systems, 37(2), 2243–2252. https://doi.org/10.3233/JIFS-182544
- Hu, J., Liang, W., Hosam, O., Hsieh, M. Y., & Su, X. (2022). 5GSS: A framework for 5G-secure-smart healthcare monitoring. Connection Science, 34(1), 139–161. https://doi.org/10.1080/09540091.2021.1977243
- Hu, J., Shen, L., & Sun, G. (2018). Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7132–7141). IEEE. https://doi.org/10.1109/CVPR.2018.00745
- Hu, J., Wu, K., & Liang, W. (2019). An IPv6-based framework for fog-assisted healthcare monitoring. Advances in Mechanical Engineering, 11(1), 168781401881951. https://doi.org/10.1177/1687814018819515
- Jiang, X., Wang, N., Xin, J., Xia, X., Yang, X., & Gao, X. (2021). Learning lightweight super-resolution networks with weight pruning. Neural Networks, 144, 21–32. https://doi.org/10.1016/j.neunet.2021.08.002
- Kang, H. J. (2019). Accelerator-aware pruning for convolutional neural networks. IEEE Transactions on Circuits and Systems for Video Technology, 30(7), 2093–2103. https://doi.org/10.1109/TCSVT.2019.2911674
- LeCun, Y., Denker, J., & Solla, S. (1989). Optimal brain damage. Advances in Neural Information Processing Systems, 2, 598–605. https://dl.acm.org/doi/10.5555/2969830.2969903
- Li, G., Wang, J., Shen, H. W., Chen, K., Shan, G., & Lu, Z. (2021). CNNpruner: Pruning convolutional neural networks with visual analytics. IEEE Transactions on Visualization and Computer Graphics, 27(2), 1364–1373. https://doi.org/10.1109/TVCG.2020.3030461
- Li, H., Kadav, A., Durdanovic, I., Samet, H., & Graf, H. P. (2016). Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710.
- Li, J., Cao, F., Cheng, H., & Qian, Y. (2021). Learning the number of filters in convolutional neural networks. International Journal of Bio-Inspired Computation, 17(2), 75–84. https://doi.org/10.1504/IJBIC.2021.114101
- Liang, T., Glossner, J., Wang, L., Shi, S., & Zhang, X. (2021). Pruning and quantization for deep neural network acceleration: A survey. Neurocomputing, 461, 370–403. https://doi.org/10.1016/j.neucom.2021.07.045
- Lin, M., Ji, R., Wang, Y., Zhang, Y., Zhang, B., Tian, Y., & Shao, L. (2020). Hrank: Filter pruning using high-rank feature map. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 1529–1538). IEEE. https://doi.org/10.1109/CVPR42600.2020.00160
- Lin, S., Ji, R., Yan, C., Zhang, B., Cao, L., Ye, Q., Huang, F., & Doermann, D. (2019). Towards optimal structured cnn pruning via generative adversarial learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 2790–2799). IEEE. https://doi.org/10.1109/CVPR.2019.00290
- Liu, Z., Xu, J., Peng, X., & Xiong, R. (2018). Frequency-domain dynamic pruning for convolutional neural networks. Advances in Neural Information Processing Systems, 31, 1051–1061. https://dl.acm.org/doi/10.5555/3326943.3327040
- Lu, L., Shin, Y., Su, Y., & Karniadakis, G. E. (2019). Dying relu and initialization: Theory and numerical examples. arXiv preprint arXiv:1903.06733.
- Lu, T. C. (2021). CNN convolutional layer optimisation based on quantum evolutionary algorithm. Connection Science, 33(3), 482–494. https://doi.org/10.1080/09540091.2020.1841111
- Luo, J. H., Wu, J., & Lin, W. (2017). Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE international conference on computer vision (pp. 5058–5066). IEEE. https://doi.org/10.1109/ICCV.2017.541
- Meng, F., Cheng, H., Li, K., Luo, H., Guo, X., Lu, G., & Sun, X. (2020). Pruning filter in filter. Advances in Neural Information Processing Systems, 33, 17629–17640. https://arxiv.org/abs/2009.14410
- Molchanov, P., Mallya, A., Tyree, S., Frosio, I., & Kautz, J. (2019). Importance estimation for neural network pruning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 11264–11272). IEEE. https://doi.org/10.1109/CVPR.2019.01152
- Reiners, M., Klamroth, K., Heldmann, F., & Stiglmayr, M. (2022). Efficient and sparse neural networks by pruning weights in a multiobjective learning approach. Computers & Operations Research, 141, 105676. https://doi.org/10.1016/j.cor.2021.105676
- Shao, L., Zuo, H., Zhang, J., Xu, Z., Yao, J., Wang, Z., & Li, H. (2021). Filter pruning via measuring feature map information. Sensors, 21(19), 6601. https://doi.org/10.3390/s21196601
- Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Tanaka, H., Kunin, D., Yamins, D. L., & Ganguli, S. (2020). Pruning neural networks without any data by iteratively conserving synaptic flow. Advances in Neural Information Processing Systems, 33, 6377–6389. https://doi.org/10.48550/arXiv.2009.14410
- Wang, S., Xing, C., & Liu, D. (2020). Efficient deep convolutional model compression with an active stepwise pruning approach. International Journal of Computational Science and Engineering, 22(4), 420–430. https://doi.org/10.1504/IJCSE.2020.109401
- Wang, Z., Han, D., Li, M., Liu, H., & Cui, M. (2022). The abnormal traffic detection scheme based on PCA and SSH. Connection Science, 34(1), 1201–1220. https://doi.org/10.1080/09540091.2022.2051434
- Wang, Z., Li, F., Shi, G., Xie, X., & Wang, F. (2020). Network pruning using sparse learning and genetic algorithm. Neurocomputing, 404, 247–256. https://doi.org/10.1016/j.neucom.2020.03.082
- Wang, Z., Xie, X., & Shi, G. (2021). RFPruning: A retraining-free pruning method for accelerating convolutional neural networks. Applied Soft Computing, 113, 107860. https://doi.org/10.1016/j.asoc.2021.107860
- Warmenhoven, J., Bargary, N., Liebl, D., Harrison, A., Robinson, M. A., Gunning, E., & Hooker, G. (2021). PCA of waveforms and functional PCA: A primer for biomechanics. Journal of Biomechanics, 116, 110106. https://doi.org/10.1016/j.jbiomech.2020.110106
- Wen, L., Zhang, X., Bai, H., & Xu, Z. (2020). Structured pruning of recurrent neural networks through neuron selection. Neural Networks, 123, 134–141. https://doi.org/10.1016/j.neunet.2019.11.018
- Wu, X., Wang, Y., & Wang, Z. (2022). A centerline symmetry and double-line transformation based algorithm for large-scale multi-objective optimization. Connection Science, 34(1), 1454–1481. https://doi.org/10.1080/09540091.2022.2075828
- Yeom, S. K., Seegerer, P., Lapuschkin, S., Binder, A., Wiedemann, S., Müller, K. R., & Samek, W. (2021). Pruning by explaining: A novel criterion for deep neural network pruning. Pattern Recognition, 115, 107899. https://doi.org/10.1016/j.patcog.2021.107899
- You, Z., Yan, K., Ye, J., Ma, M., & Wang, P. (2019). Gate decorator: Global filter pruning method for accelerating deep convolutional neural networks. Advances in Neural Information Processing Systems, 32, 1–12. https://doi.org/10.48550/arXiv.1909.08174
- Yu, R., Li, A., Chen, C. F., Lai, J. H., Morariu, V. I., Han, X., Gao, M., Lin, C.-Y., & Davis, L. S. (2018). NISP: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 9194–9203). IEEE. https://doi.org/10.1109/CVPR.2018.00958
- Zhuang, T., Zhang, Z., Huang, Y., Zeng, X., Shuang, K., & Li, X.. (2020). Neuron-level structured pruning using polarization regularizer. In H. Larochelle, M. Ranzato, R. Hadsell , M. F. Balcan, & H. Lin (Eds.), Proceedings of the conference on neural information processing systems (NeurlPS 2020) (pp. 9865–9877). Curran Associates, Inc.