
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Differential privacy mechanisms vary in modalities, and there have been many methods implementing differential privacy on unimodal data. Few studies focus on unifying them to protect multimodal data, though privacy protection of multimodal data is of great significance. In our work, we propose a multimodal differential privacy protection framework. Firstly, we use multimodal representation learning to fuse different modalities and map them to the same subspace. Then based on this representation, we use the Local Differential Privacy (LDP) mechanism to protect data. We propose two protection methods for low-dimensional and high-dimensional fusion tensors respectively. The former is based on Binary Encoding, and the latter is based on multi-dimensional Fourier Transform. To the best of our knowledge, we are the first to propose LDP-based methods for the representation learning of multimodal fusion. Experimental results demonstrate the flexibility of our framework where both approaches show efficient performance as well as high data utility.
1. Introduction
The ways humans perceive the world vary with a direct display of different modalities, such as images, text, voice and other sensory data and structured data like demographic data. These multimodal data can give humans comprehensive information to make better judgments (Baltrušaitis et al., Citation2018). During the past decade, the ways and the amount of data collected greatly increase to bring us an unprecedented opportunity to perceive some phenomena behind them. Naturally enough, there is commonly used information in tabular data, symptom description in text data, CT image data for one patient, comments in text data, posted pictures in image data and demographic data for one netizen. It is natural for any individual to have multimodal information.
Every unimodal information has its advantages. For instance, when identifying humans crying, audio information contributes more than video information (Atrey et al., Citation2010). It has been found that multimodal data classifiers perform better than unimodal data classifiers (Ngiam et al., Citation2011). This indicates that the integration of multimodal data can often make better judgements, which is consistent with the way of human understanding the world.
Though methods vary in learning information of inter- and intra-modality, multimodal fusion has gained popularity in recent years due to its flexibility in fusing at different levels as well as capturing cross information among modalities (Atrey et al., Citation2010). Traditional multimodal fusion methods are difficult to capture nonlinear relationships. The development of deep learning has brought new ideas to multimodal fusion, in which multimodal fusion representation learning has gradually become the mainstream.
Based on information theory, differential privacy can resist the arbitrary computational power of adversary (Dwork, Citation2008). It balances the problem of protecting personal privacy while preserving the distribution, which coincides with the urgent need for data analysis nowadays. Further, it provides rigorous privacy protection rules. When the input of DP is a database, it's named Centralized Differential Privacy (CDP) which requires a trusted third party to collect raw data. Unlike CDP, Local Differential Privacy (LDP) takes each individual as input which offers a stronger privacy protection level. Since LDP does not need to be constrained by trusted third parties, it is widely used by Apple, Google, Microsoft and other organisations (Cormode et al., Citation2018). However, differential privacy is a mechanism and needs to be elaborated for specific scenes to gain specific algorithms. The diversity of modality generates different definitions of differential privacy algorithms, which leads to difficulties in unifying them into one algorithm.
Further, academia and industry are exploring the multimodal field after the progress of unimodal techniques. For example, multimodal data were used in recommendation systems to obtain representations of items and users (Deldjoo et al., Citation2022). The traditional differential privacy methods for unimodal data have been difficult to meet the demands of data utility and privacy protection because of the correlation between different modalities.
This brings us to the purpose of our work. We propose a multimodal Local Differential Privacy (LDP) framework for deep learning. We also propose two LDP approaches for different representation dimensions. The first is based on low-rank decomposition which obtains the low-dimensional vector representation, and the second approach can handle high-dimensional fusion representation situations. Specifically, our contributions are as follows:
To the best of our knowledge, we are the first to propose a general multimodal differential privacy framework in deep representation learning to deal with various kinds of modalities. The framework is composed of three modules including Encoding, Perturbation and Aggregation. The models inside Encoding and Aggregation modules can be replaced according to specific tasks.
The first approach we propose is suitable for low-dimensional representation. The coding module adopts the low-rank decomposition based on Canonical Polyadic (CP) decomposition, which does not need to directly obtain the high-dimensional fusion tensor but to explicitly obtain the low-dimensional fusion representation. The Binary Encoding-based LDP mechanism is then conducted to output protected representations, which can be aggregated by an untrusted third party.
Since the low-rank decomposition is only approximate and will lose some information inevitably, we propose the second approach which firstly adopts Tensor Fusion Network (TFN) to obtain a high-dimensional tensor, then based on the multi-dimensional Discrete Fourier Transform, we perturb the data in the form of complex tensor according to
, a version of approximate differential privacy.
Experimental results on several commonly used multimodal datasets show that data processed by our privacy protection method remain high utility even in a low privacy budget.
The remainder of this paper is structured as follows: Section 2 and Section 3 introduce related works and preliminary concepts respectively. Section 4 presents our proposed framework in detail, including Encoding, Perturbation and Aggregation modules. Section 5 introduces our Binary Encoding-based LDP approach and Fourier transform based LDP approach for different representation dimensions. Section 6 describes datasets carried on in our work and experimental settings. In Section 7, experimental results are illustrated as well as further discussion. Section 8 concludes the paper.
2. Related work
Differential Privacy was proposed by Dwork (Citation2008). It has become a de facto standard in the data privacy protection field. Many works have been done for unimodal data with differential privacy but few works on multimodal fusion data. A differential privacy mechanism named -privacy was proposed in Fernandes et al. (Citation2019), to hide the clues about the author's writing style while keeping the text content remains unchanged. The privacy protection level is defined at the bag of words. Yue et al. (Citation2021), first divided different tokens of documents into high and low sensitivity ones, according to token frequency, then used token similarity to define the sensitivity and selection method of differential privacy. Lyu et al. (Citation2020) proposed Optimized Multiple Encoding (OME) algorithm, an LDP protocol, to perturb text embeddings output by a pretrained model.
When it comes to the image data, Fan (Citation2019) employed Single Value Decomposition (SVD) technique to extract a feature vector from an image, and then employ sampling methods on the vector to achieve privacy guarantees under -privacy. Fan (Citation2018) defined the “m-neighborhood” notion to employ a differential privacy mechanism which allows protecting sensitive information under at most m pixels. For audio data, Han et al. (Citation2020) extracted x-vector that represents voiceprint and then computed the similarity between x-vector pairs. Finally, voiceprint was replaced and merged with speech content to get synthesised audio.
In addition to the above works, Rastogi and Nath (Citation2010) proposed algorithm PASTE based on differential privacy to protect distributed time-series data. PASTE uses algorithm to perturb k discrete Fourier transform (DFT) coefficients that can be used to reconstruct n query answers. To improve
, Acs et al. (Citation2012) proposed Enhanced Fourier Perturbation (EFPA) under the histogram scenario to select k with a certain probability. Bao et al. (Citation2021) observed the strong autocorrelations of streaming data consisting of regular updates and proposed Correlated Gaussian Mechanism (CGM) to realise local differential privacy. Yang et al. (Citation2021) provided a privacy guarantee for tensor-valued queries by Tensor Variate Gaussian (TVG). The added noise gained from a tensor-valued random variable in a standard normal distribution is conducted with an n-mode matrix product with n different matrices.
The part of our work on tensor LDP perturbation is different from all these works. The data we should perturb is tensor, but not time-series. It is generated by multi-dimensional DFT, but not one-dimensional. The tensor entries are complex, but not just real. These existing techniques can not be directly applied to such kinds of data. In order to compare these works with our work clearly, we also summarise them in Table .
Table 1. Summary of related differential privacy work.
3. Preliminaries
3.1. Multimodal representation fusion
Different representations of information will affect the ways of processing the data. A good representation will make the subsequent processing of information more convenient. However, how to remove redundant information and represent the input data without losing much accuracy is the main problem. Deep learning provides us with a new idea, which allows us to map the input data to a low-dimensional representation. Because the low-dimensional representation will be restored to the original data label through the subsequent network of neural networks, as long as the recovery is accurate enough, the low-dimensional vector can be used as the representation of the input data. Furthermore, the connection ways of neural network can combine input features to extract high-order abstract features. The convergence of network parameters ensures that the representation is sufficiently representative.
Zadeh et al. (Citation2016) were the first to use a deep learning network to get fusion representations by fully connecting sub-representations from sub-networks. The disadvantage of this model is that the complementary information among different modalities is difficult to be learned by the model. In response to this problem, Zadeh et al. (Citation2017) modelled sub-representations as different dimensions of n-fold Cartesian space. Therefore, the fusion process between different modalities can be carried out by tensor outer product. However, this also brings the curse of dimensionality. Liu et al. (Citation2018) extended previous work by applying the low-rank decomposition to gradient weight. By simplifying the mathematical formula, the representation vector can be gained directly instead of calculating the outer product and thereby reducing the complexity.
3.2. Differential privacy
If two databases differ in only one record, we call them adjacent databases and record them as D and respectively. Given a protection mechanism M which takes database D as input and output
, we say M satisfies ϵ-differential privacy (Dwork & Roth, Citation2014), if for any pair of
, and all possible subsets
,
(1)
(1) We call ϵ the privacy budget which means the protection level of data. A lower budget implies better protection of privacy, but usually lower data utility. Based on the definition of DP, there are two common ways to employ the DP mechanism for data analysis. One is Centralized Differential Privacy (CDP) where the input data is a database. It implies a third party collects the raw data from each individual and is responsible for answering any query without disclosing the existence of any individual's data. According to Dwork and Roth (Citation2014), it perplexes the views of attacker on whether individuals data is or not part of the database, thus protecting them from any harm that they may face due to their data being in the database.
Obviously, CDP needs a trusted third party, otherwise, privacy will be leaked. However, in most real settings, it is difficult to meet the demand. Therefore, the other approach, Local Differential Privacy (LDP), taking a record as input has also been widely adopted.
3.2.1. Local differential privacy
In the local setting, each user corresponds to one record. Algorithm M inputs a record and outputs a privacy-protected record. Intuitively, according to an output result of privacy algorithm M, it is almost impossible to infer which record its input data is. As in Equation (Equation2(2)
(2) ), suppose
is the true data,
is fake data from some domain, it will be difficult for an attacker to infer the output of M is generated from
or
. Since the algorithm M can be implemented by the local user himself, the constraint of a trusted third party as in CDP no longer exists.
(2)
(2) According to Xiong et al. (Citation2020), LDP possesses sequential composition, parallel composition, post-processing properties.
3.2.2.
mechanism (Hall et al., Citation2013) is an approximation of differential privacy when the randomised algorithm in dataset D outputs a vector
. The output is:
(3)
(3)
(3a)
(3a)
(3b)
(3b) in which
is the adjacent database and positive definite symmetric matrix
. The case when
is equivalent to Euclidean distance (Dwork et al., Citation2006) where
is the identity matrix.
is actually an alias of
, which was originally proposed for CDP. However, according to Dwork and Roth (Citation2014), an ϵ-CDP algorithm that takes as input a database of size n = 1 can be an ϵ-local algorithm for the local DP. If the local user has a database with a size larger than 1, the parallel composition can be utilised. It was pointed out that
satisfies parallel and sequential compositions, as well as the post-processing property (Near & Abuah, Citation2021). In this paper, we will implement
of Hall et al. (Citation2013), in the LDP model.
Parallel Composition: Specifically, when mechanism satisfying
and
satisfying
are applied respectively on two disjoint databases
and
, then
satisfies
in which
,
.
Sequential Composition: When mechanism satisfying
and
satisfying
are applied sequentially on the same database D, then D satisfies
.
Post-processing: When M satisfying is applied to database D, the input of function G is output of M, then G also satisfies
.
3.3. Binary encoding methods
Based on randomised response algorithms, we can protect privacy by flipping bits in binary vectors. How to choose the flip probability under the guarantee of LDP is the main problem. When it comes to a real vector instead of a binary vector, we can transmit the vector to a binary matrix. The following sections describe different LDP methods based on binary encoding.
3.3.1. Unary encoding (UE)
For a binary vector , UE encodes
to
by the rules:
(4)
(4) The unary encoding satisfies ϵ-LDP for
(5)
(5) Among different choices for p and q, there are Symmetric Unary Encoding, Optimized Unary Encoding (Wang et al., Citation2017) and Optimized Multiple Encoding algorithms (Lyu et al., Citation2020).
3.3.2. Symmetric unary encoding (SUE)
RAPPOR's implementation (Erlingsson et al., Citation2014) chooses p = 0.75 and q = 0.25 such that p + q = 1, making the treatment of 1 and 0 symmetric.
(6)
(6) Changing one bit of the vector has the greatest impact on 2 bits difference between the two vectors, so the sensitivity is 2 here. In Equation (Equation6
(6)
(6) ),
can be replaced by
.
3.3.3. Optimized unary encoding (OUE)
When the relative number of either 0 or 1 in the binary vector is obviously large, we can use the ratio of unchanged bits to flipped bits to allocate different privacy budgets respectively. For example, when there are more 1s than 0s, we can allocate more privacy budgets to 1 to maintain utility:
(7)
(7)
3.3.4. Optimized multiple encoding (OME)
Suppose the length of fusion representation is r, then for OUE and SUE, the sensitivity are both
because they are binary vectors. When the representation value is real, we can extract the vector into a binary matrix (Lyu et al., Citation2020), that is, for
, each
can be transformed into a length-l binary vector
to obtain a binary matrix
. In this case, the sensitivity
is rl. The choices of p and q are in Equations (Equation8
(8)
(8) ) and (Equation9
(9)
(9) ).
(8)
(8)
(9)
(9) According to Lyu et al. (Citation2020), λ here is a randomisation factor, which is used to balance the utility and privacy. When there are more 0s than 1s in the data, increasing λ will make q smaller, then one bit “0” will not be flipped to “1” with higher probability. If there are more 1s than 0s, p can also be calibrated to an increase by adjusting λ, so that “1” will not also be flipped with higher probability.
3.4. Fourier transform
A signal can be represented in terms of the linear combination of orthogonal functions. It is known as the trigonometric Fourier series when these orthogonal functions are trigonometric functions. As the limit form of Fourier series, the Fourier transform (or FT) decomposes functions from time domain to frequency domain in the form of linear transformation. The Fourier transform of a function in n-dimensional space is
, defined as follows (Equation (Equation10
(10)
(10) )):
(10)
(10)
(11)
(11) where
. Equation (Equation11
(11)
(11) ) is the inverse Fourier transform (or IFT) of a function
. Note that the n-fold multiple integral goes from
to ∞ and the output shape of FT and IFT is the same as input.
3.4.1. Multi-dimensional discrete Fourier transform
Since computers can only process discrete signals, Discrete Fourier transform (DFT) can be employed to decompose discrete signals obtained by interval sampling. For multi-dimensional discrete signals which can be represented by tensors, multi-dimensional DFT can be conducted (Diaz & Lutoborski, Citation2017). As in Equation (Equation12(12)
(12) ), f is a tensor of order n, and its i-th index has
dimensions. Note that
,
.
(12)
(12) Let
, then
is:
(13)
(13) The time consumption of directly calculating DFT of N-point signals is
, while the Fast Fourier transform (or FFT) proposed by Cooley and Tukey (Citation1965) utilises the symmetry of root of unity to break the DFT into smaller DFTs, reducing the computation time to
. In our work, we use FFT to calculate DFT on discrete signals.
4. Multimodal fusion representation learning framework
Our framework consists of three modules including Encoding, Perturbation and Aggregation, which are explained in detail in the following.
4.1. Encoding module
Encoding module takes the raw multimodal data as input and outputs fusion representations. Firstly, sub-encoders encode raw multimodal data into sub-representations. There are many effective pretrained models that can output high-quality representations, and we can choose the one that well suits the data type. Models can also be compressed by techniques like knowledge distillation, to speed up the processing of data. Therefore the computation cost of sub-encoders will not be a great burden for local users.
Secondly, sub-representations are fused to achieve a fusion representation. What should be considered here is how to reserve the intra-modality information in the fusion for purpose of further learning. In addition to directly concatenating sub-representations, the fusion representation can be gained by outer product (Zadeh et al., Citation2017), as Equation (Equation14(14)
(14) ) shows. Here
is a sub-representation of the m-th modality,
is the representation size of each modality, and
is the outer product for tensors.
(14)
(14)
4.2. Perturbation module
The Perturbation module will apply privacy-preserving methods like the LDP mechanism given some privacy budget to convert fusion representations to protected representations. The shape of converted representation may be different from the original, depending on how the third party specifies the data usage. An example here is our proposed Binary Encoding-based approach (Figure ), where the representation is a 1-D tensor and the output is a binary matrix. The other case when representations share the same shape will also bring some convenience. For example, some methods can be defined to mix the original data with the protected data after perturbation to make a better utility-protection balance. We use the same shape for these representations in our Fourier transform based LDP approach.
Figure 1. The encoding module based on low-rank multimodal fusion.
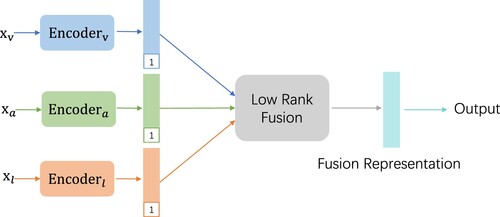
Figure 2. The perturbation and aggregation modules based on binary encoding.

4.3. Aggregation module
In the Aggregation module, the untrusted third party can use its well-designed network to analyse the representation data obtained by original data and train the model. The fusion representations are abstract, which do not necessarily have specific semantics. However, supervised learning or unsupervised learning can still be carried out from these fusion representations. This is as similar as we can judge whether an object is an aircraft because we have abstract impressions of aircraft, even if we cannot draw the appearance and structure of the aircraft concretely. This also provides an advantage to resist the third party to infer the privacy information of a specific sample. Besides, the network structure can be flexible to adapt to different privacy budgets for specific problem requirements.
5. LDP approaches for fusion representation
5.1. Binary encoding-based LDP for fusion vector
As shown in Figure , we take multimodal datasets as input of the Encoding module to get one-dimensional fusion representation by low-rank decomposition. In this figure, a typical dataset consisting of video (), audio (
) and textual (
) data is input into encoders, and different encoders can be used for the corresponding modalities to gain sub-representations. Then they are fused implicitly to a cube tensor by decomposing the fusion tensor weights into CP decomposition forms. This avoids the exponential increase of computation cost in direct calculations with sub-representations (Liu et al., Citation2018).
We utilise a network architecture with weight to transform a tensor
into a vector
, i.e.
.
The CP decomposition (Hitchcock, Citation1928) decomposes an Nth-order tensor into a linear combination of rank-1 tensors, as illustrated in Equation (Equation15(15)
(15) ).
is the N-th order tensor of size
.
is outer product among vectors
from dimension i until rank R. We apply CP decomposition to the network weight
, and adopt the method proposed by Liu et al. (Citation2018), to decompose
into matrix
made up of rank-1 vectors, i.e.
.
(15)
(15)
(16)
(16) According to Zadeh et al. (Citation2017), the fusion tensor
created by outer product can be decomposed together with the weight in the network. As Equation (Equation16
(16)
(16) ) shows,
is outer product between matrices,
means the element-wise product, · is the dot product with the effect of tensor contractions, and
is a vector obtained. Thus we can gain the fusion representation
without explicit calculation of the tensors. This low-rank trick remains high efficiency and performance. Concretely, this derivation reduces the computation complexity from
to
, where
is the size of vector
.
After gaining the fusion representation in the form of vector, we apply OME on
since it scales well even if the domain size is large. We firstly extract an l-length binary vector on each element in
, and transform
into a binary matrix. Then each bit in the matrix is perturbed according to Equations (Equation8
(8)
(8) ) and (Equation9
(9)
(9) ). We follow the intuition that 0s and 1s happen at different ratios and each ratio owns its privacy budget, as Equation (Equation7
(7)
(7) ) shows. Further, the odds of 0 and 1 bits flipping should satisfy Equations (Equation8
(8)
(8) ) and (Equation9
(9)
(9) ). When given fixed representation size and vector extracting size, if randomisation factor λ is constant, lower ϵ values and higher rl will result in higher q value.
If the local user has more than one , the above perturbation can be implemented on each of them. Suppose the same privacy budget is used for each perturbation, by parallel composition, the union of their outputs satisfies ϵ-LDP.

Finally, the Aggregation module trains the perturbed binary matrices. By the post-processing property, the output of aggregation also satisfies ϵ-LDP. The diagram of perturbation and aggregation is shown in Figure . The whole process is shown as Algorithm 1.
5.2. Fourier transform based LDP for fusion tensor
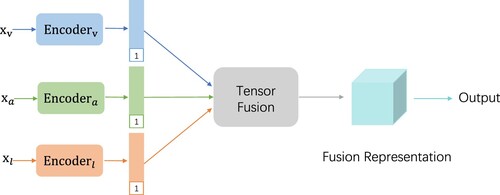
Since the low-rank decomposition will inevitably lead to the loss of accuracy, as an upstream task, sometimes we may want to trade a slight increase in the time cost for more accurate and more informative high-dimensional representations. Although the rise in accuracy will lead to the growth of exponential complexity, considering the real situations where a limited number of modalities are encountered, we can still use the high dimensional but accurate representations. The outer product fusion schemes, such as TFN (as Figure shows), were proposed for these scenarios. Therefore, we further explore how to carry out the differential privacy method when the Encoding module outputs tensor representation.
Figure 3. The encoding module based on tensor fusion.
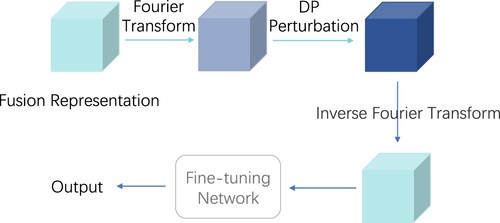
For a reason that representation may have abstract semantics in higher dimensional semantic space, it can be regarded as a signal. Based on this signal, we exploit the semantic information about time in different dimensions.
Instead of directly adding DP noise to data, we will add noise to the DFT tensor of the data. The multi-dimensional DFT is employed on fusion tensor to get the DFT tensor. Both the DFT tensor and
are in the order of M. In the m-th dimension of the DFT tensor,
points are kept, and we choose
to alleviate the problem of exponential growth. Let
, we denote the DFT tensor of
by
. The whole process of Perturbation module is illustrated in Figure .
Figure 4. Fourier transform based LDP perturbation module.
It is worth mentioning that in each element is a complex number. To perturb the Fourier transform coefficients means to perturb each complex number. Instead of perturbing only the real part of a complex number as used in the exiting works, we treat each complex number as a two-dimensional vector composed of its real and imaginary parts. We use the approximate differential privacy for vector-valued output, i.e.
introduced in Section 3.2.2, to perturb each complex number.
We define two fusion tensors which differ in only one entry as adjacent tensors, and denote them by and
. Let
and
be entry at position
of the DFT tensor
and
, respectively, in which
, and each
for
. We treat both
and
as two-dimensional vectors. In Equation (Equation17
(17)
(17) ), we choose
, the identity matrix of
. Among all pairs of vectors
and
, we calculate the supremum of
as Δ. However, a brute-force searching could be too time-consuming. Below we give a method to efficiently compute Δ.
(17)
(17) An efficient method to compute Δ: Since we are using LDP for perturbation, we can only assume the local range of tensor
is known. Let
be the local sensitivity of
,
, i.e. the entry at position
of tensor
(each
for
). That is,
, a and b belong to the local range of
. By the following theorem, Δ in Equation (Equation17
(17)
(17) ) is actually the maximum of all local sensitivities at all entries of
.
Theorem 5.1
Let be the local sensitivity of
, the entry at position
of tensor
,
, each
for
. Then
.
Proof.
Let , in which each
for
. Let
. By Equation (Equation12
(12)
(12) ), the corresponding multiple DFT of
is given by
in which
when any
.
Suppose and
differ in only one entry at position
. Let
be the entry at position
of tensor
. Then
By Equation (Equation17
(17)
(17) ),
and this concludes the proof.
After Δ is computed, by -DP,
is perturbed as follows,
Let
be the perturbed DFT tensor. Then by the sequential composition of
-DP, this perturbed tensor satisfies
-DP.
If the user has more than one fusion tensor, the above mechanism can be applied independently to each fusion tensor. For simplification, we just assume on each tensor entry, mechanism of -DP is applied. Since these tensors are disjoint, by parallel composition, the union of these tensors can have a mechanism satisfying
-DP.
Let represents the Inverse Discrete Fourier Transform (or IDFT) of
. By the post-processing property of
-DP, the result of IDFT also satisfies
-DP. The whole process is shown as Algorithm 2.

6. Experiments
6.1. Datasets
We evaluate our framework on three commonly used multimodal datasets (Table ) including the Multimodal Corpus of Sentiment Intensity (CMU-MOSI) (Zadeh et al., Citation2016), the Persuasive Opinion Multimedia (POM) (Park et al., Citation2014) and Interactive Emotional Dyadic Motion Capture Database (IEMOCAP) (Busso et al., Citation2008).
Table 2. Overview of experimental datasets.
The datasets are split into training, validation, and test sets following the proportion and settings by Liu et al. (Citation2018). Considering the generalisation performance of the model, we train the data in the training set, find the parameters that make the validation set perform best during the training process, and finally evaluate the performance on the test set. The maximum epoch and patience are set to 1000 and 50 respectively. For the regression task of CMU-MOSI and POM dataset, we use L1 Loss. For the classification task of IEMOCAP, we use CrossEntropy Loss. For audio and video data, we use fully connected network as the encoder. For text data, we apply Long Short-Term Memory (LSTM) network as the encoder. The composition structure of these sub-networks is shown in Figure . It is worth mentioning that for training multimodal data, we need to align the data of different modalities firstly, and we use the word-level alignment here.
We first train model on specific network structures of Figures and , and then export representation. DP approaches are conducted on these representations. Finally, we train a three-layer fully connected network as our Aggregation module which takes privacy-protected representations as input and evaluates different metrics on test set.
6.2. Binary encoding-based LDP
We evaluate Mean Absolute Error (MAE) and Multi-Acc (average accuracy of output classes) on POM, F1 score and accuracy on IEMOCAP, and MAE on CMU-MOSI.
We compare SUE, OUE and OME methods which have different combinations of p and q (Equations (Equation6(6)
(6) ), (Equation7
(7)
(7) ), (Equation8
(8)
(8) ) and (Equation9
(9)
(9) )). As illustrated in Figure , different choices of privacy budgets ϵ ranging from 0.5 to 10 show the influence on
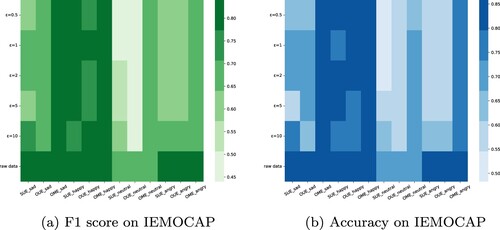
score and accuracy. The last row of heat map shows the results of raw data without privacy protection.
Figure 5. Experimental results shown in heat map on IEMOCAP dataset. Figure (a) shows the F1 score result. The bottom row shows the results of raw data with no perturbation. Figure (b) shows the accuracy.
In our implementation, the Aggregation module is composed of three fully connected layers, which is simple but effective enough to evaluate the effectiveness of our framework and approaches. In real applications, a better fine-tuning network may be needed to solve problems such as overfitting.
In addition, we also employ the Laplace mechanism directly to raw multimodal data. The results of this experiment can reflect the difference between the method of employing DP on representation and employing DP on raw multimodal data directly.
6.3. Fourier transform based
We evaluate our approach by three metrics consisting of Binary Accuracy, MAE and F1 score to provide diverse perspectives of the effect on data utility under the compositions of different α and β. The preprocessing and alignment of different modalities data, as well as the sub-networks, are the same as those experiments for Binary Encoding-based LDP. The main difference is the fusion method in the Encoding module. Here we use Tensor Fusion Network (Zadeh et al., Citation2017). We compare the results by setting different combinations of α and β. For each pair of α and β, we conduct experiments for 10 runs and take the arithmetic mean value. Note that as per the requirement of Hall et al. (Citation2013). In our experiments α ranges from 0.15 to 0.9, and β ranges from 0.001 to 2.
7. Results and discussion
As heat maps shown in Figure , both score and accuracy increase when more privacy budgets ϵ are given. The last row is the result of raw data without privacy protection method. From the darkness of the map, we can see that the OME mechanism remains stable under different ϵ, the reason for which is mainly attributed to the large sensitivity of representation defined in OME. We can also see that the OME mechanism performs well even on a tight privacy budget. This shows the high utility of data under OME because the randomisation factor λ in OME dynamically adjusts the flip probability of 0 and 1.
Interestingly, we can see that on the happiness emotion, when a relatively small privacy budget is given, there are still fairly accurate results in all algorithms. In contrast, all algorithms perform with lower accuracy on the anger emotion. Further analysis of the cause will be explored in the future work.
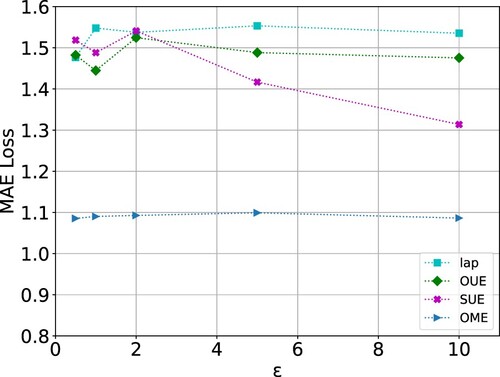
Figure shows the MAE loss of our Binary Encoding-based LDP approaches on the CMU-MOSI dataset. When given more privacy budgets ϵ, the MAE loss decreases on all three binary encoding methods. Among them, OME remains stable and highest utility. When given a small privacy budget, the score will shake because of the low utility of data. We can also find that all these methods perform better than the direct employment of Laplace DP mechanism on the raw multimodal data. Thus for multimodal data with high-dimensional features, processing the original data directly may not be the best choice for the reason that noises may also grow exponentially.
Figure 6. Experimental results on POM dataset given different privacy budgets ϵ ranging from 0.5 to 10. Figure (a) shows the results of average accuracy of output classes (Multi-Acc). Figure (b) shows the MAE Loss results.
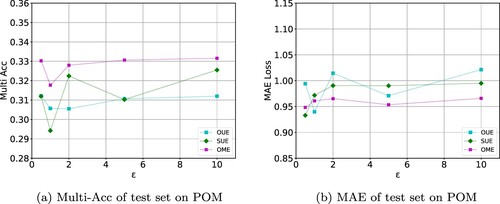
Figure 7. MAE loss on dataset CMU-MOSI, where the horizontal axis denotes privacy budget ϵ. The line “lap” demonstrates the results of applying the Laplace DP mechanism to raw data.
In experiments of employing Binary Encoding-based LDP on POM dataset, we can find accuracy gets higher when more ϵ are given, as Figure (a) shows. Compared with the other two mechanisms, OME remains the highest accuracy as well as the lowest MAE loss. When the privacy budget approaches 0, there will be of great shake because the noise is large relatively and the data utility is extremely poor.
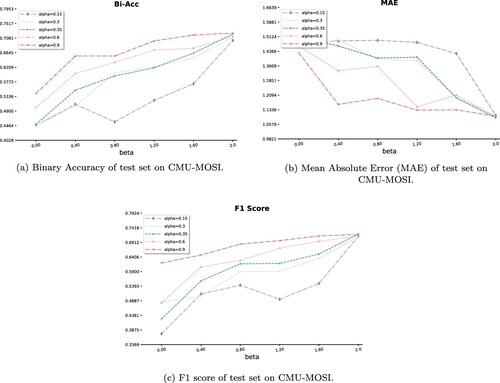
The result of experiments on implementing Fourier transform based LDP accord with the theoretical results. As Figure (b) shows, when α is fixed, the MAE will decrease with the increase of β. When given more privacy budgets, the data will gain better utility. When β remains unchanged, we can see that the MAE decreases with the increase of α. In the real scenarios, the user just needs to select acceptable α and β.
Figure 8. Experimental results on MOSI dataset carried out Fourier transform based LDP mechanism. (a) Binary Accuracy of test set on CMU-MOSI. (b) Mean Absolute Error (MAE) of test set on CMU-MOSI. (c) F1 score of test set on CMU-MOSI.
Complexity Analysis. Since the user does not need to train data locally, the complexity (user's perspective) consists of two parts, the first part is the Encoding module, and the second part is the Perturbation module. The Encoding module is determined by different encoding structures, which depend on the specific task. If it is the neural network like our experiments, the complexity is , where
means the number of nodes in the ith layer of neural network. The complexity of Perturbation module depends on the specific approach. For Binary Encoding-based approach, the fusion complexity is
where r denoted the rank,
denotes the output size and
denotes the size of sub-representations of each modality. Perturbation complexity is
where r and l are the dimension of representation and the expansion length of real numbers respectively. The complexity of Fourier transform based LDP approach is
where m is the number of modalities. Therefore, the total complexity is
for Binary Encoding-based LDP approach, and
for Fourier transform based LDP approach.
Discussions. Under the definition of local differential privacy, our approaches can provide local users with plausible deniability, which means from the outputs of perturbation mechanisms, it is impossible to infer which value the input is (Xiong et al., Citation2020). The approaches can resist attackers with arbitrary background knowledge (Dwork & Roth, Citation2014). They can also prevent possible privacy attacks by untrusted data collectors because the data is processed locally. Furthermore, it is difficult to reconstruct high-dimensional multimodal data by attackers given the low-dimensional representation, which provides an additional protection on privacy.
One limitation of our framework is that when high-dimensional raw multimodal data is encoded into representations, some original information may be lost inevitably. Since multimodal data is inherently high-dimensional and extremely sparse, utilising an appropriate representation can well balance data storage and accuracy. In addition, the accuracy (or data utility) of specific task is also affected by the models in Encoding and Aggregation modules, not just the data itself. Thus utilising suitable models is also important for performance advancement.
8. Conclusions
We propose a framework for multimodal differential privacy based on fusion representation learning. The framework is designed for general purposes of multimodal fusion representation learning, and consists of Encoding, Perturbation and Aggregation modules. Based on the framework, we propose two approaches for vector-valued and tensor-valued representation respectively. Both our approaches reach great data utility while maintaining a privacy guarantee. We validate our framework and approaches on three representative multimodal datasets. Experimental results show the high performance on data utility and privacy protection, and also demonstrate the flexibility and practicability of the framework. In the future, we will improve the general framework by making full use of the advantages of deep learning models and reducing information loss. We will also improve the differential privacy mechanisms on representations, such as assigning different privacy budgets to different modalities.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Acs, G., Castelluccia, C., & Chen, R.2012). Differentially private histogram publishing through lossy compression. In 2012 IEEE 12th International Conference on Data Mining (pp. 1–10). IEEE.
- Atrey, P. K., Hossain, M. A., El Saddik, A., & Kankanhalli, M. S. (2010). Multimodal fusion for multimedia analysis: A survey. Multimedia Systems, 16(6), 345–379. https://doi.org/10.1007/s00530-010-0182-0
- Baltrušaitis, T., Ahuja, C., & Morency, L. P. (2018). Multimodal machine learning: A survey and taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(2), 423–443. https://doi.org/10.1109/TPAMI.2018.2798607
- Bao, E., Yang, Y., Xiao, X., & Ding, B. (2021). CGM: An enhanced mechanism for streaming data collection with local differential privacy. Proceedings of the VLDB Endowment, 14(11), 2258–2270. https://doi.org/10.14778/3476249.3476277
- Busso, C., Bulut, M., Lee, C. C., Kazemzadeh, A., Mower, E., Kim, S., Chang, J. N., Lee, S., & Narayanan, S. S. (2008). IEMOCAP: Interactive emotional dyadic motion capture database. Language Resources and Evaluation, 42(4), 335–359. https://doi.org/10.1007/s10579-008-9076-6
- Cooley, J. W., & Tukey, J. W. (1965). An algorithm for the machine calculation of complex Fourier series. Mathematics of Computation, 19(90), 297–301. https://doi.org/10.1090/mcom/1965-19-090
- Cormode, G., Jha, S., Kulkarni, T., Li, N., Srivastava, D., & Wang, T. (2018). Privacy at scale: Local differential privacy in practice. In Proceedings of the 2018 International Conference on Management of Data (pp. 1655–1658). Association for Computing Machinery (ACM).
- Deldjoo, Y., Schedl, M., Hidasi, B., Wei, Y., & He, X. (2022). Multimedia recommender systems: Algorithms and challenges. In Recommender systems handbook (pp. 973–1014). Springer.
- Diaz, S. P., & Lutoborski, A. (2017). Discrete fourier transform tensors and their ranks. SIAM Journal on Matrix Analysis and Applications, 38(3), 1010–1027. https://doi.org/10.1137/16M1084717
- Dwork, C. (2008). Differential privacy: A survey of results. In International Conference on Theory and Applications of Models of Computation (pp. 1–19). Springer.
- Dwork, C., Kenthapadi, K., McSherry, F., Mironov, I., & Naor, M. (2006). Our data, ourselves: Privacy via distributed noise generation. In Annual International Conference on the Theory and Applications of Cryptographic Techniques (pp. 486–503). Springer.
- Dwork, C., & Roth, A. (2014). The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science, 9(3–4), 211–407.https://doi.org/10.1561/0400000042
- Erlingsson, Ú., Pihur, V., & Korolova, A. (2014). Rappor: Randomized aggregatable privacy-preserving ordinal response. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security (pp. 1054–1067). ACM.
- Fan, L. (2018). Image pixelization with differential privacy. In IFIP Annual Conference on Data and Applications Security and Privacy (pp. 148–162). Springer.
- Fan, L. (2019). Practical image obfuscation with provable privacy. In 2019 IEEE International Conference on Multimedia and Expo (ICME) (pp. 784–789). IEEE.
- Fan, L. (n.d.). Image pixelization with differential privacy, 14.
- Fernandes, N., Dras, M., & McIver, A. (2019). Generalised differential privacy for text document processing. In International Conference on Principles of Security and Trust (pp. 123–148). Springer.
- Hall, R., Rinaldo, A., & Wasserman, L. (2013). Differential privacy for functions and functional data. The Journal of Machine Learning Research, 14(1), 703–727.https://doi.org/10.5555/2567709.2502603
- Han, Y., Li, S., Cao, Y., Ma, Q., & Yoshikawa, M. (2020). Voice-indistinguishability: Protecting voiceprint in privacy-preserving speech data release. In 2020 IEEE International Conference on Multimedia and Expo (ICME) (pp. 1–6). IEEE.
- Hitchcock, F. L. (1928). Multiple invariants and generalized rank of a p-way matrix or tensor. Journal of Mathematics and Physics, 7(1-4), 39–79. https://doi.org/10.1002/sapm19287139
- Liu, Z., Shen, Y., Lakshminarasimhan, V. B., Liang, P. P., Zadeh, A., & Morency, L. P. (2018). Efficient low-rank multimodal fusion with modality-specific factors. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers). Association for Computational Linguistics.
- Lyu, L., Li, Y., He, X., & Xiao, T. (2020). Towards differentially private text representations. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 1813–1816). ACM.
- Near, J. P., & Abuah, C. (2021). Programming differential privacy (Chapter 6). Jupyter Book.
- Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., & Ng, A. Y. (2011). Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML'11) (pp. 689–696). Omnipress.
- Park, S., Shim, H. S., Chatterjee, M., Sagae, K., & Morency, L. P. (2014). Computational analysis of persuasiveness in social multimedia: A novel dataset and multimodal prediction approach. In Proceedings of the 16th International Conference on Multimodal Interaction (pp. 50–57). ACM.
- Rastogi, V., & Nath, S. (2010). Differentially private aggregation of distributed time-series with transformation and encryption. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (pp. 735–746). ACM.
- Wang, T., Blocki, J., Li, N., & Jha, S. (2017). Locally differentially private protocols for frequency estimation. In 26th USENIX Security Symposium (USENIX security 17) (pp. 729–745). USENIX Association.
- Xiong, X., Liu, S., Li, D., Cai, Z., & Niu, X. (2020). A comprehensive survey on local differential privacy. Security and Communication Networks 2020.
- Yang, J., Xiang, L., Chen, R., Li, W., & Li, B. (2021). Differential privacy for tensor-valued queries. IEEE Transactions on Information Forensics and Security, 17, 152–164. https://doi.org/10.1109/TIFS.2021.3089884
- Yue, X., Du, M., Wang, T., Li, Y., Sun, H., & Chow, S. S. (2021). Differential privacy for text analytics via natural text sanitization. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 (pp. 3853–3866). Association for Computational Linguistics.
- Zadeh, A., Chen, M., Poria, S., Cambria, E., & Morency, L. P. (2017). Tensor fusion network for multimodal sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (pp. 1103–1114). Association for Computational Linguistics.
- Zadeh, A., Zellers, R., Pincus, E., & Morency, L. P. (2016). Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages. IEEE Intelligent Systems, 31(6), 82–88. https://doi.org/10.1109/MIS.2016.94