
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The word embedding model word2vec tends to ignore the importance of a single word to the entire document, which affects the accuracy of the news text classification method. To address this problem, a method that combines word2vec, a topic-based TF-IDF algorithm, and an improved convolutional neural network is proposed in this paper, which is named WTL-CNN. Firstly, word2vec is used to convert text data into word vectors. Secondly, an improved TF-IDF algorithm is proposed to weight word vectors. The improved TF-IDF algorithm introduces LDA topic generation model to enhance the topic semantic information of TF-IDF values. Thirdly, according to the location distribution law of important features of news texts, the location information is converted into weights and integrated into the pooling process convolutional neural network to further improve the accuracy of classification. At last, WTL-CNN has been evaluated and compared with seven contrast models on datasets THUCNews and SogouCS under the environment of TensorFlow. The experimental results show that the precision rate, recall rate and F1 value of WTL-CNN model reach 95.76%, 93.43%, 94.98% respectively on the THUCNews, and reach 94.61%, 93.43%, 94.01 respectively on the SogouCS.
1. Introduction
Text classification is the process of a computer automatically categorizing text into one or more categories depending on its contents. The text classification technique has become one of the most important study paths in the field of natural language processing, thanks to the significant expansion of text data on the Internet. Text classification technology is often used in sentiment analysis, automatic question answering systems, and spam filtering. According to the text characteristics of the application field, it is an important idea to extract text semantic features for classification. A Chinese movie rating classification method based on an extended sentiment dictionary (Wang et al., Citation2021) was proposed to improve the accuracy of Chinese movie ratings. First, the improved K-means++ algorithm was used to cluster and select the seed words with obvious emotional tendencies, and then the DW-PMI algorithm was used to determine the sentiment polarity of sentiment words in the domain of movie reviews. For the characteristics of sparse, interlaced, and irregular Chinese short comment texts, a method based on ELECTRA and a hybrid neural network (Zhang et al., Citation2021) is proposed to classify the subjective sentiment tendency of comments. This method can better capture the emotional features of texts and enhance text classification accuracy. Dai and Wang (Citation2021) conceptualized and characterized marketing posts and used machine learning methods to predict and classify customer engagement behaviours.
News text classification has important industrial significance. On the one hand, it is possible to analyse the prognosis of changes in market conditions by classifying different internet news, acquiring economic and current political news, and further analysing these news ( Dai & Wang, Citation2021). On the other hand, it can help readers by categorizing and analyzing the news they have previously read to recommend news they might find interesting (Reddy et al., Citation2019; Wu & Yang, Citation2021). In addition, classifying news texts plays an important role in rumour detection (Verma et al., Citation2021; Zhang et al., Citation2020), public sentiment analysis (Amit et al., Citation2020; Chang, Citation2020; Liu et al., Citation2020; Zhang et al., Citation2020), spam news filtering, etc.
At present, text classification methods are broadly classified into two categories, one is a classification method based on traditional machine learning, and the other is a deep learning-based classification method.
The core parts of the classification method based on traditional machine learning are artificial feature extraction and classification algorithm. Commonly used feature extraction methods are chi-square test (CHI), Information Gain (IG), Support Vector Machine (SVM) (Chen & Hsieh, Citation2006), Naive Bayesian (NB) (Frank & Bouckaert, Citation2004), and K-NearestNeighbor (KNN) (Guo et al., Citation2004). The majority of local and international academics’ work on machine learning classification methods focuses on enhancing and combining the above feature extraction techniques and classification algorithms. For example, word frequency factors and intra-class distribution factors were added in some works to improve the performance of CHI and IG feature selection methods (Sun et al., Citation2017; Wu et al., Citation2015; Xu & Jiang, Citation2015), and SVM combined with LDA, KNN, and logistic regression respectively (Bian et al., Citation2019; Wang et al., Citation2019). The majority of the classification techniques mentioned above rely on statistical feature extraction methods. These methods evaluate the importance of feature words by counting the frequency of feature words or the relationship between feature words and categories, and input the extracted features into each classification algorithm to perform text classification. Although it can increase text categorization accuracy to some extent, there are still problems such as missing semantics, weak text representation, lost word order, and high-dimensional sparse matrix.
Since the emergence of deep learning and neural networks, several researchers have successfully used neural networks in the field of text classification. CNN was utilized for the first time in the field of text classification by the traditional TextCNN model (Yoon, Citation2014). The method eliminated the artificial feature selection project based on statistical information and learned the best text feature representation automatically. TextCNN model significantly improves the classification performance, which makes the neural network quickly become a hot spot in text classification research. RNN (Cheng et al., Citation2017) and LSTM (Huan et al., Citation2022; Lin et al., Citation2020; Xie et al., Citation2019) were also successfully used in text classification. For example, the study (Xie et al., Citation2019) proposes an attention mechanism-based Bi-LSTM text classification method, which captures contextual information from the contextual information and combines the attention mechanism to improve the efficiency of text classification. The important premise of a neural network for text classification is word embedding. Tan et al. (Citation2022) introduced a dynamic embedding projection gate (DEPG) into the word embedding matrix, by using gating units to control how much context information is incorporated into each specific position of the word embedding matrix in the text. The classic word embedding model word2vec (Zhou et al., Citation2018) used the relationship between words and their context to train word vectors and reasonably solved the problem that the feature selection method based on statistics does not consider semantics. As a special kind of text, news text has strong generalization, clear theme, strong hierarchy and relatively unified structure. Existing text classification methods ignore the features of news texts. It is a method to improve the accuracy of news text classification by analyzing the structural characteristics of news texts and combining the obtained text subject information.
In this paper, first of all, in view of the problem that the Word2vec model has low classification accuracy due to ignoring the local and global relationships, the LDA model is introduced. LDA model is used to define and calculate the topic information of the words in the document, thus obtaining a topic information matrix to represent the importance of the word to the document. Secondly, an improved TF-IDF algorithm based on topic information is proposed, which combines the word frequency and the semantic information of the word to obtain the weight matrix containing the document information. The original Word2vec word vectors are weighted by the matrix to generate document vectors that contain more document semantic information. Thirdly, according to the hierarchical characteristics of the analyzed news text, a feature position weight factor is introduced in the pooling layer of the CNN to enhance the important information in the news document and weaken the unimportant information.
The main work of this paper is as follows:
On the basis of the classic TextCNN model, in view of the problem that the word vector model word2vec ignores the importance of a single word to the entire document and affects the classification accuracy, the LDA topic model is introduced, and an improved TF- IDF algorithm. By weighting the word vector, a more accurate document vector is generated.
In order to further improve the classification accuracy of news texts, according to the distribution law of important features of news texts, the pooling layer of the CNN is improved, and the location information of features is converted into weights and integrated into the pooling process.
The following is how the rest of the paper is organized: Section 2 describes related work on news text classification. Section 3 introduces the main algorithms and principles used in this paper in detail. Section 4 presents a convolutional neural network text classification model based on weighted word embeddings. Section 5 explains how the experiment was set up and how the findings were analyzed. Section 6 draws conclusions.
2. Related work
2.1. News text classification
Text classification has attracted the attention of numerous scholars as an essential aspect of natural language processing research. Now new internet media have become a significant means of disseminating information, and news, as a carrier of information, has also shown explosive growth in data. Using deep learning algorithms to classify news texts can help different reading groups efficiently retrieve news they are interested in from a large number of news materials according to their needs.
For news text classification, LSTM is used to extract document context and sequence features (Xie et al., Citation2019). Liu et al. (Citation2019) presented a hierarchical model structure to sequentially extract context and information from Chinese text, which is a combination of LSTM and temporal convolutional network. Zhang et al. took advantage of BERT's self-attention and incorporated BERT into the TextCNN model to classify news texts (Zhang & Shao, Citation2021). Chen et al. (Chen et al., Citation2022) introduced a local feature convolution network based on BERT that created a feature vector by capturing local features in the text for classification, to address the characteristics of Chinese news with long text and significant amounts of information. Zhu (Citation2021) uses the VSM vector space model to determine the text weight, calculate the information gain, and obtain the text features.
2.2. Improved TextCNN
CNN was first proposed for image processing, and then the CNN proposed by Yoon (Citation2004) made it more effective for sentence classification.
The classic TextCNN mode (Yoon, Citation2014) designs a layer of convolution on top of the word vector obtained by an unsupervised neural language model, keeping the initially obtained word vector static, and learning just the model's other parameters. However, the Word2vec model only considers the semantic connection between the feature word and its fixed-length context but does not consider the connection between the feature word and its overall document. The study (Song et al., Citation2019) used the TF-IDF algorithm to calculate the weight of each word in the document and combined the word2vec word vector to generate the document vector. Based on the word frequency, the important relationship between the feature word and the document is established. But only considering the use of word frequency as the weight, the generated document vector is not accurate enough. The study (Tian & Wu, Citation2018) considered the semantic meaning of the distance between words when using word2vec to train word vectors. However, the resulting word vector is still not precise enough because other criteria, such as word frequency and placement within the entire article, are not taken into account.
The efficiency of text classification can be improved by the more reasonable weighting of word vectors generated by word2vec. Since the titles and first paragraphs of most news texts often contain important features, which can more accurately express the topic of the text, improving the pooling layer by converting location information into weights could improve the accuracy of text classification.
2.3. Topic information
The topic model is a statistical model of unsupervised learning (Liu et al. Citation2019). Probabilistic latent semantic analysis (pLSA) (Hofmann, Citation1999), latent Dirichlet allocation (LDA) (David et al., Citation2003), and their varieties are common statistical models. The LDA model is often used to identify topics in a group of documents, which may better handle the problems of relying on word frequency to find topics. According to the LDA model, topics can be represented by a lexical distribution, and articles can be represented by a topic distribution. The main task of LDA is to train and estimate the multinomial distribution satisfied between documents and topics, and the multinomial distribution
satisfied between topics and words. From the two distributions obtained by training, it can be inferred that the greater the probability of a topic word under a certain topic, the more important the word is to the topic. Meanwhile, the greater the probability of a topic appearing in the document, the greater the probability of this topic for the document more important. Therefore, the greater the sum of the distribution probability of all topics in a document and the probability of a word in the corresponding topic, the more important the word is in the text. Shao et al. (Citation2022) fused the improved LDA model with the LSTM network to classify news texts, which effectively improved the classification effect. The LDA model is proven to be useful in text classification.
3. Proposed method
3.1. word2vec
Word2vec, A shallow neural network, is a commonly used word vector conversion model. Every word is mapped to a low-dimensional, computable, fixed-length word vector through training on a large corpus. The idea of Word2vec is that a word is only related to the words around it, and has nothing to do with other words in the text. CBOW and skip-gram are the two major models in Word2vec. The CBOW model predicts the target word
by the context of
. The objective function to be optimized for training is as Formula (1). The Skip-Gram model uses the target word
to anticipate its context. The objective function is as Formula (2). In the formula,
is the whole words in the training set. Combine the negative sampling or hierarchical softmax method to optimize the conditional probability function in Formula (1) or (2):
(1)
(1)
(2)
(2) After word2vec training is completed, a similar pattern can be found: “king"-"man” “queen"-"woman”. It can be seen that word2vec retains the semantic characteristics of words well. However, the word2vec model only uses the fixed-length context of the target word to train the word vector, so feature words with the same context have highly comparable word vectors. Such as “I like natural language processing” and “I hate natural language processing.” “Like” and “hate”, the context is the same, and the word vectors trained with word2vec are very similar, but they are antonyms.
3.2. LDA
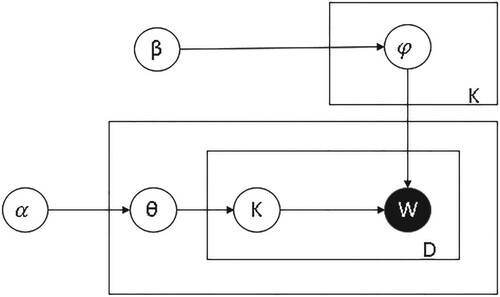
LDA Is a topic generation model (David et al., Citation2003; Liu et al., Citation2019; Zhang et al., Citation2019), and the model probability diagram is shown in Figure . In the figure, document is made up of several implicit topics
, each of which is made up of a series of words
. The document and topic satisfy the polynomial distribution
,
represents the hyperparameter of the Dirichlet prior distribution distributed by
. The topic and the word satisfy the polynomial distribution
, and
is the hyperparameter of Dirichlet prior distribution distributed by
.
(3)
(3)
(4)
(4) In Formula (4),
indicates the amount of topic
appears in document
,
is the number of topics.
indicates the number of times word
is allocated to topic
and
is the total number of words in a document.
Figure 1. LDA probability model diagram.
3.3. Improved TF-IDF word vector weighting algorithm based on topic information
TF-IDF is a feature weight calculation method based on statistics. It evaluates the importance of feature words by calculating their word frequency and inverse document frequency. Word frequency refers to the proportion of the occurrences of a word in the sum of the occurrences of all words in the entire document
, indicating the frequency of a word or phrase in the document. Word frequency calculation is shown in Formula (5):
(5)
(5) In Formula (5),
represents the word frequency of feature word
in document
. The numerator represents the number of times
emerges in document
. The denominator is the total number of times each word appears in the document. The inverse document frequency is shown in Formula (6):
(6)
(6) In Formula (6),
indicates the inverse document frequency of the feature word
.
indicates the total number of texts in the set of documents, and
indicates the number of documents in the document set that include the
. The normalized TF-IDF value of the final feature word is shown in Formula (7):
(7)
(7) As shown in Formula (7), the importance of the feature word
to the text
is proportional to the number of times it exists in document
, and the number of documents contained
in the data set is inversely proportional. However, the weight of the TF-IDF algorithm is only based on the statistical word and document frequency, and lacks the semantic information of the feature words, which is not accurate.
In order to obtain more semantic information about words in documents, the LDA model is introduced to improve the TF-IDF algorithm. the text-topic probability distribution and the topic-word probability distribution
in the LDA model are used to obtain the generation probability of feature words in the text. The higher the generation probability, the more important the feature word is to the text. The topic information of the word, as shown in Formula (8):
(8)
(8) In Formula (8),
represents the topic information of the feature word
in the text
.
represents the number of topics,
represents the probability that the topic
occupies in document
, and
represents the probability of
in topic
. The greater the probability that the feature word
is under the topic
, indicating that
is more important to the topic
. The greater the probability that the topic
exists in document
, it means that the topic
is more important to the document. Therefore, the word's topic information is more extensive, which indicates how significant the word
is to the text
. The topic semantic information of the TF-IDF value can be enhanced by the topic information of the word. Formula (9) shows the improved TF-IDF algorithm based on topic information:
(9)
(9) The TF-IDF algorithm, based on topic information, associates feature words with documents through underlying topics, establishing important links between individual words and the whole document at the level of word frequency and topic semantics. Therefore, the calculated word vector weights are more reasonable and accurate.
4. Convolutional neural network text classification model based on weighted word embedding
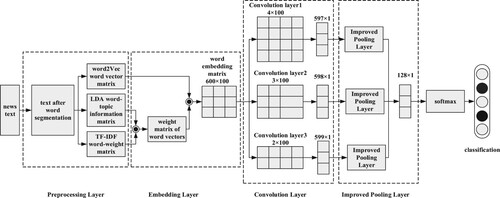
Figure depicts the suggested news text classification model of a CNN based on weighted word embedding in this paper. The model was mainly made up of five components: preprocessing layer, embedding layer, convolution layer, improved pooling layer and classification layer.
Figure 2. WTL-CNN model.
4.1. Preprocessing Layer
First, the dataset is preprocessed, including word segmentation, punctuation removal, stop word removal, and part-of-speech tagging. Aiming at the problem that Chinese adverbs and punctuation marks appear frequently, but the meaning of words is weak, the accuracy is improved by deleting such words and retaining only nouns, adjectives and verbs. The preprocessed text represents .
The word vector library can be obtained in two ways. One is to use our own data set to train the word vector, while the other option is to use the trained open-source large-scale global word vector library. This paper adopts the first method, training the word vector with the CBOW model, which can integrate some previous information in the text into the word vector. Meanwhile, the word vector contains richer semantic information, which is helpful for our subsequent classification tasks. We use a subset of the Chinese text classification dataset THUCNews to train word vectors to obtain a local word vector library. In this paper, the training parameters of word2vec are shown in Table . There are 114576435 effective vocabularies in the training set. After training, a total of 260976 100-dimensional word vectors are obtained. The top 10 word vectors that are most similar to the meaning of “China” are extracted as shown in Table . (The word vectors are in Chinese. Due to the requirements of the journal, the Chinese texts are translated into English.) It is clear to observe that the word vectors trained by word2vec can well preserve the semantic features of words.
Table 1. Word2vec training parameters.
Table 2. Words with similar meaning to “China”.
4.2. Embedding layer
By comparing words in the document with the word2vec word vector library trained in Section 4.1, the words in the text were transformed into low-dimensional, computable, fixed-length word vectors. An
word vector matrix
was formed. In the Formula (10),
represents the word vector dimension:
(10)
(10) Since the word vector fails to express the connection between a single word and the complete document, the weight of each word vector in the document
was calculated using the Formula (9). An
weight matrix
was formed:
(11)
(11) Then, the final vector-matrix
of document
was expressed as the dot product of the two matrices in Formula (10) and Formula (11).
(12)
(12)
4.3. Convolution Layer
In the realm of natural language processing, two-dimensional convolution of text data has no value. Therefore, the convolution kernel only performs one-dimensional sliding, that is, the width of the convolution kernel is equal to the dimension of the word vector. Each time a convolution operation is performed in a window of height , a new local feature
is extracted, as shown in Formula (13). In this paper, convolution kernels with heights of 2, 3, and 4 are used for convolution operations. That is, each convolution operation covers two words, three words, and four words. The total number of convolution kernels is 128.
(13)
(13)
(14)
(14) In Formula (13),
represents the feature extracted by one convolution kernel in one convolution,
represents the word vector with window
,
represents the convolution kernel,
represents the offset, and
represents the ReLU activation function, as shown in Formula (14). After a text is convolved, the feature vector
can be obtained:
(15)
(15)
4.4. Improved pooling Layer
The pooling operation is to perform a second screening on the feature vectors extracted by the convolution layer to draw out the most important features. Common pooling methods include max-pooling and average pooling. Max-pooling and average-pooling are two common pooling approaches. Max-pooling is to take the maximum value of all the feature values and input it into the fully connected layer, as shown in Formula (16):
(16)
(16) Average pooling refers to averaging all feature values and feeding them into the fully connected layer, as in formula (17):
(17)
(17)
Neither pooling method takes into account the impact of feature location information on classification accuracy. In news texts, headlines and first paragraphs often contain important features, which are more accurate than features in other locations that express the text locally. Therefore, an average weighted pooling method based on location information was proposed, such as Formula (18):
(18)
(18) In Formula (18),
, and
is the feature vector extracted after a convolution operation. In general, the total number of effective feature words intercepted by the data of each news text is between 600 and 700. Therefore, the first one-sixth of each text is set to the title and the first paragraph, and the weight is set to
. The remaining part is the content of the text body, set the weight to
. The experimental value starts from
(that is, regardless of location information, degenerates to average pooling), with 0.1 as a change interval, it can measure the accuracy of different location weight on classification accuracy influences.
For the convolutional feature vector obtained by Formula (15), the average weighted pooling method based on position information was used, as in the above Formula (18). The important features are extracted twice to form a feature vector C. Enter the fully connected layer for softmax classification, and then optimize the model parameters through back propagation.
(19)
(19)
5. Experimental verification and result analysis
5.1. Experimental environment
The experimental software environment in this paper adopts Google's open-source TensorFlow framework, and the programming language adopts python3.6; the open-source toolkit jieba is used to segment the dataset; the toolkit Gensim is used to train the word2vec word vector and LDA topic vector of the dataset, and scipy and sklearn tools are used to perform other calculations. Pycharm is selected as the code editor. The specific operating environment version is shown in Table . The hardware environment is: the operating system is Windows 10, and the running memory needs to be greater than 16GB.
Table 3. Experimental operating environment and version.
5.2 Datasets and comparison methods
5.2.1 Datasets
In order to evaluate the effectiveness of this model method on the task of news topic text classification, this paper adopts the THUCNews dataset (http://thuctc.thunlp.org/), the Sohu News dataset (SogouCS) and Fudan University Chinese text corpus dataset for model experiments, as shown in Table .
Table 4. Dataset information.
THUCNews is a Chinese text classification data set from the Natural Language Processing Laboratory of Tsinghua University. Twelve categories of news data including finance, entertainment, sports, technology, games, furniture, fashion, real estate, education, current affairs, stocks, and society were selected, and 20,000 articles were randomly selected from each category of text data, of which 16,000 articles were as the training set, 3000 as the test set, and 1000 as the validation set.
The data of SogouCS comes from Sohu News. We selected news data from 12 categories, including entertainment, finance, real estate, tourism, technology, sports, health, education, automobiles, current affairs, culture, and women, and cleaned the data set to remove some missing labels to preserve news topics and content. 2800 news articles were randomly selected from each type of text data, of which 2200 were used as a training set, 400 were used as a test set, and 200 were used as a validation set.
The Chinese text classification dataset of Fudan University was constructed by the Natural Language Processing Group of the Department of Computer and Technology, Fudan University. The dataset contains 9833 Chinese texts in 20 categories, of which 70% of the texts are used as the training set, 20% are used as the test set, and the remaining 10% are used as the validation set.
5.2.2 Comparison methods
The following seven text classification methods were chosen for comparative studies in order to further validate the performance of the WTL-CNN:
Experiment 1: Zhai et al. (Citation2018) proposed a feature word extraction method based on chi-square statistics for text classification tasks. This method classifies the text by analyzing the text feature words and using both words and double words as features.
Experiment 2: The classic TextCNN model proposed by Yoon (Citation2004).
Experiment 3: Song Peng et al. (Song et al., Citation2019) proposed a text classification method that used the TF-IDF algorithm to calculate the weight of each word in the document and combined the word2vec word vector to generate the document vector. It is combined with a CNN based on the word frequency for text classification.
Experiment 4: A classification method combining the LDA topic model and CNN proposed by Luo (Citation2019). First, the topic distribution of the text is obtained by training the LDA topic model, and the text feature vector is constructed. Then, the CNN with GRU is used as the classifier to classify according to the input feature matrix.
Experiment 5: Zheng Jin et al. proposed a text classification method that used word2vec to automatically construct word vectors and a bidirectional recurrent structure to capture contextual information. Then it Combined CNN and attention mechanism to capture key components of documents for text classification (Zheng & Zheng, Citation2019).
Experiment 6: WT-CNN: To demonstrate the effectiveness of the improved enhanced TF-IDF algorithm in the model, we design an ablation experiment. WT-CNN is a WTL-CNN model that uses the improved TF-IDF algorithm based on the topic information proposed in this paper. The position weight factors α and β are also added to the pooling layer, which are set to 1.3 and 0.7, respectively.
Experiment 7: GTL-CNN: In order to compare the effects of different word vector training models, GTL-CNN is designed. GTL-CNN uses Glove to train word vectors and uses an improved TFIDF algorithm based on topic information to weight the word vectors. In the pooling layer of CNN, the position weighting factors α and β are also added, which are set to 1.3 and 0.7 respectively.
5.3. Experimental evaluation criteria
The test set was utilized to assess the performance of the classification model in this paper. The classification algorithm is mainly evaluated from three indicators: Precision(p), recall(r), and F1 value.
The accuracy rate is the percentage of the number of documents identified as subject A in the subject A document under test to the total number of documents in subject A, reflecting the degree to which the model can accurately identify the document category, as shown in Formula (20):
(20)
(20) Where
denotes the number of true samples that were classified as true,
is the number of true samples that were classed as false. The recall rate is the proportion of the number of correct documents identified by the model among all results actually belonging to topic A, as shown in Formula (21):
(21)
(21) Where
is the number of false samples that were classified as true. The F1 value is a performance metric that takes both accuracy and recall into account, as shown in Formula (22):
(22)
(22)
5.4. Experimental parameter settings
5.4.1 LDA parameter settings
When modelling LDA for text, Table lists the parameters that must be manually set:
Table 5. LDA model parameter setting.
and
are empirical values. LDA parameter optimization is not the focus of this paper, so using empirical values can accelerate the speed of convergence. The sample interpretation is best when
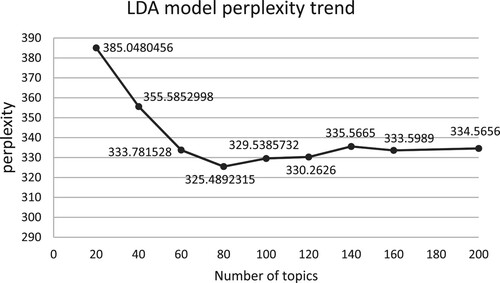
takes the optimal number of topics, so the LDA standard evaluation function perplexity is used to find out the optimal number of topics. The smaller the perplexity, the better the generalization ability of the LDA model. The number of topics was set to 2, 4, 6, 8–200 to calculate the model perplexity. Figure depicts the end outcome. The perplexity progressively converges to a somewhat constant value as the number of topics rises; at this point, the LDA model has the best generalization ability, so the optimal number of topics is set to k = 80:
Figure 3. Change trend of perplexity of LDA model.
5.4.2 Convolutional Neural Network Parameter Settings
In the model of this paper, CNN uses three sizes of convolution kernels to perform convolution operations on the text, namely 3, 4, and 5, and the number of convolution kernels of each size is set to 128. In order to prevent overfitting, the Dropout strategy is adopted in the fully connected layer, and the dropout rate is set to 0.5, that is, half of the parameters are randomly selected and dropped. The parameter settings for CNN model training are shown in Table :
Table 6. The convolutional neural network parameter.
5.4.3 Pooling layer feature location weight factor settings
The feature position weight factors and
of the pooling layer are used as the predetermined parameters of the pooling layer, which affect the effectiveness of the pooling layer. When
and
, it degenerates to the average pooling algorithm, ignoring the location information. The larger the
, the greater the emphasis on the title and the first paragraph. Meanwhile, the smaller the
, the more obvious the weakening effect on the rest. The text classification algorithm proposed in this paper conduct experiments by the control variable method. Starting from
and
, with 0.1 as the change interval, the average F1 value changes on the two data sets are obtained respectively, as shown in Figure :
Figure 4. Variation of average F1 value of ten categories with a position weight coefficient.
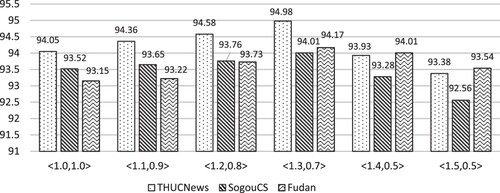
It can be seen from Figure that when the (,
) value of the featured item is (1.3, 0.7), the F1 value of the text category is higher. That is, the weight
of the featured item in the title and first paragraph area is set to 1.3, and the weight
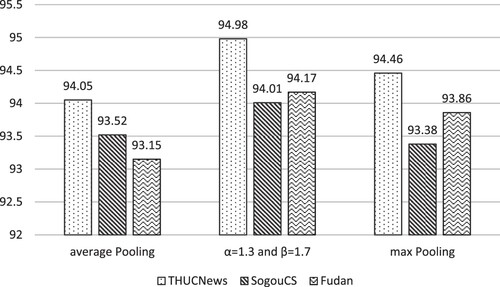
in the body area is set to 0.7, a better classification effect can be obtained. It can be seen from Figure that compared with the average pooling without considering the positional importance of the featured item in the text (α = 1, β = 1), the F1 value of text classification on the three datasets increased by 0.93%, 0.49% and 1.02% respectively. Compared with max pooling, the average F1 value of classification is improved by 0.52%, 0.63% and 0.31% respectively. It shows that the improved pooling layer in this experiment can heighten the performance of text classification.
Figure 5. Changes in average F1 value under different pooling methods.
5.5. Analysis of results
In this section, the experimental results are introduced in detail, and the experimental results are compared and analyzed. When the weights (,
) of the feature items are (1.3, 0.7), the classification experimental results of the WTL-CNN model on the THUCNews, SogouCS and Fudan datasets are shown in Table respectively:
Table 7. Model test results in THUCNews.
Table 8. Model test results in SogouCS.
Table 9. Model test results in SogouCS.
The experimental results show that the accuracy, recall, and F1 value of the model on the THUCNews dataset reached 95.76%, 94.26%, and 94.98% respectively. On the SogouCS dataset, the precision rate, recall rate, and F1 value reached 94.61%, 93.43%, and 94.01% respectively. On the Fudan University Chinese yext classification dataset, the precision rate, recall rate, and F1 value reached 94.67%, 93.68%, and 94.17% respectively. It can be seen from the experimental results that the effect of the model on the two data sets is relatively small, and the effect on the SogouCS and Fudan data set is slightly worse than that on THUCNews. The reasons for the analysis are as follows: First, due to the lack of data in the SogouCS and Fudan data set, The training is not as adequate as in THUCNews. Second, compared with the news data in THUCNews, the length of news in the SogouCS data set is shorter, which increases the difficulty of extracting effective information.
The experimental data still uses the text data introduced in Section 5.2.1, and the same data preprocessing method is carried out. The average precision rate, recall rate, F1 value of all categories is used as the evaluation index, and the results are compared with the models listed in Section 5.2.2. The experimental results are shown in Figures :
Figure 6. Changes in average accuracy under different text classification methods.
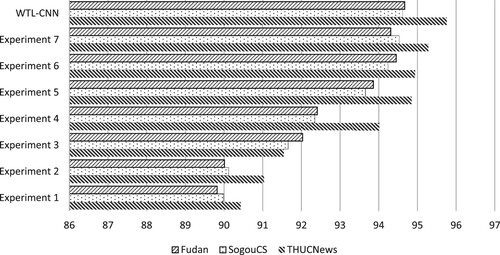
Figure 7. Changes in average recall rate under different text classification methods.
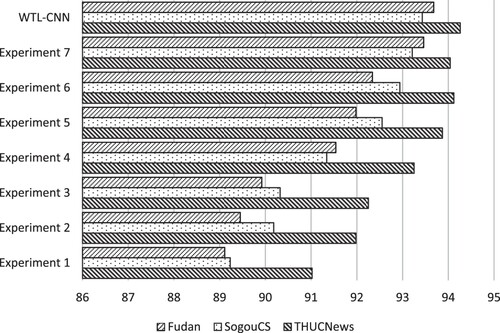
Figure 8. Changes in average F1 value under different text classification methods.
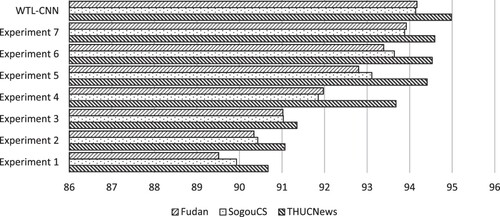
The effect of the Experiment 1 model is much lower than that of the other models. It can be seen that the performance of text classification methods based on traditional machine learning is far lower than that of other deep learning methods, which proves that the classification algorithm based on deep learning can perform better than the method based on traditional machine learning.
On the THUCNews dataset, the average F1 value of the Experiment 2 model is 0.28% lower than that of the Experiment 3 model, and 3.91% lower than that of WTL-CNN. It is shown that the performance is improved after the weight of word vectors calculated according to word frequency is introduced. And the improved TF-IDF weight algorithm based on topic information is better than the classic TF-IDF weight algorithm.
On the THUCNews dataset, the average F1 value of the Experiment 4 model is 2.33% higher than that of the Experiment 3 model, and 1.3% lower than that of WTL-CNN. It can be shown that training the topic distribution of text through the LDA topic model and applying it to text classification can improve classification accuracy. But only considering the topic distribution is not enough. Considering and obtaining text features, combining each feature can achieve better classification results. It also shows that combining traditional machine learning with deep learning can achieve better performance.
In addition, through the comparison of Experiment 5 and other experiments, it can be seen that LSTM bidirectional cyclic structure can better obtain context information. But weighting the word vectors according to the topic information obtained from the news text features is more conducive to the classification of news texts.
Comparing Experiment 6 with WTL-CNN, on the THUCNews dataset, the average accuracy, recall and F1 value of WTL-CNN are 0.82%, 0.14% and 0.45% higher than that of Experiment 6 respectively. On the SogouCS dataset, the average precision, recall and F1 value of our model are 0.38%, 0.69%, and 0.5% higher than those of Experiment 6 respectively. It can be seen from the experimental results that our improved TF-IDF algorithm based on topic information is effective and can improve the accuracy of text classification.
On the THUCNews, the average accuracy, recall and F1 values of WTL-CNN were 0.48,0.22,0.39% higher than those of Experiment 7, respectively. It can be seen that the effect of WTL-CNN is slightly better than that of GTL-CNN. It shows that the word vector model selected in this paper is more suitable for the model in this paper. The reason for the analysis is that Word2Vec can infer word meaning according to the context, and the word vector obtained by training contains more word meaning information.
It can be seen from the above comparison that word vectors and CNN can have high accuracy in text classification, but there is still room for improvement; analyzing the characteristics of different texts is conducive to extracting more accurate information, thereby improving the accuracy of classification. How to analyze the characteristics of text and obtain more information contained in the text through different algorithms should become an important research point in the field of text classification in the future.
6. Summary
How to classify text data has always been a research hotspot in numerous domains. Categorizing news texts is helpful for news information management and news data mining, and also provides methods for news reading recommendations and spam news filtering. This paper proposes the WTL-CNN model to address the importance of missing feature words to documents in existing classification methods. The model uses LDA model to compute topic information of words which is integrated into the TF-IDF values as weights for word vectors trained by word2vec. In addition, WTL-CNN improves the pooling layer of CNN according to the distribution rules of important features of news texts. During the pooling process, the location information of features is converted into weights to improve the accuracy of news text classification. The effectiveness of the method is proved by experiments. Meanwhile, it is found through comparative experiments that the text classification model based on deep neural networks has a higher classification accuracy than model based on traditional machine learning. However, it was also found that the time efficiency of using deep neural networks to train classification models is much lower than that of using traditional machine learning. Regarding the improvement of the pooling layer, we only roughly divided the text according to the characteristics of the text. Obtaining the key topic parts of the text through algorithm analysis, and applying relevant information to the pooling layer is the next problem we want to solve.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Amit, K. S., Sandeep, C., & Devesh, K. S. (2020). Sentimental short sentences classification by using CNN deep learning model with fine tuned Word2Vec, Procedia Computer Science 1139–1147. https://doi.org/10.1016/j.procs.2020.03.416
- Bian, W. S., Wang, C. Z., Ye, Z., & Yan, L. (2019). Emotional text analysis based on ensemble learning of three different classification algorithms. 2019 10th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), 938–941. https://doi.org/10.1109/IDAACS.2019.8924413
- Chang, Q. Q. (2020). The sentiments of open financial information, public mood and stock returns: An empirical study on Chinese growth enterprise market. International Journal of Computational Science and Engineering, 23(2), 103–114. https://doi.org/10.1504/IJCSE.2020.110550
- Chen, R. C., & Hsieh, C. H. (2006). Web page classification based on a support vector machine using a weighted vote schema. Expert Systems with Applications, 31(2), 427–435. https://doi.org/10.1016/j.eswa.2005.09.079
- Chen, X. Y., Cong, P. M., & Lv, S. (2022). A long-text classification method of Chinese news based on BERT and CNN, IEEE Access, 10, 34046–34057. https://doi.org/10.1109/ACCESS.2022.3162614
- Cheng, J. J., Zhang, S., Li, P., Zhang, X., & Wang, H. (2017). Deep convRNN for sentiment parsing of Chinese microblogging texts. 2017 2nd IEEE International Conference on Computational Intelligence and Applications (ICCIA), Beijing, 265–269. https://doi.org/10.1109/CIAPP.2017.8167220
- Dai, Y., & Wang, T. (2021). Prediction of customer engagement behaviour response to marketing posts based on machine learning. Connection Science, 33(4), 891–910. https://doi.org/10.1080/09540091.2021.1912710
- David, M. B., Ng Andrew, Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of Machine Learning Research, 3, 993–1022. https://dl.acm.org/doi/10.5555944919.944937
- Deng, J., Cheng, L., & Wang, Z. (2021). Attention-based BiLSTM fused CNN with gating mechanism model for Chinese long text classification. Computer Speech & Language, 68(6), 101182. https://doi.org/10.1016/j.csl.2020.101182
- Frank, E., & Bouckaert, R. R. (2004). Naive Bayes for text classification with unbalanced classes. Knowledge Discovery in Databases, 503–510. https://doi.org/10.1007/978-3-540-24630-5_69
- Guo, G., Wang, H., & David, B. (2004). An kNN model-based approach and its application in text categorization. Computational Linguistics and Intelligent Text Processing, 559–570. https://doi.org/10.1007/978-3-540-24630-5_69
- Hofmann, T. (1999). Probabilistic latent semantic indexing. In: Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, 50–57. https://doi.org/10.1145/312624.312649
- Huan, H., Guo, Z. L., Cai, T. T., & He &, Z. C. (2022). A text classification method based on a convolutional and bidirectional long short-term memory model. Connection Science, 34(1), 2108–2124. https://doi.org/10.1080/09540091.2022.2098926
- Johnson, R., & Zhang, T. (2017). Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 562–570. https://doi.org/10.18653/v1/P17-1052
- Li, X., & Ning, H. (2020). Chinese text classification based on hybrid model of CNN and LSTM. Proceedings of the 3rd International Conference on Data Science and Information Technology, 129–134. https://doi.org/10.1145/3414274.3414493
- Lin, Y., Li, J. P., Yang, L., Xu, K., & Lin, H. F. (2020). Sentiment analysis with comparison enhanced deep neural network. IEEE Access, 8, 78378–78384. https://doi.org/10.1109/ACCESS.2020.2989424
- Liu, H., Chatterjee, I., Zhou, M., Lu, X. S., & Abusorrah, A. (2020). Aspect-based sentiment analysis: A survey of deep learning methods. IEEE Transactions on Computational Social Systems, 7(6), 1358–1375. https://doi.org/10.1109/TCSS.2020.3033302
- Liu, J. G., Xia, C. H., Yan, H. H., Xie, Z. P., & Sun, J. (2019). Hierarchical comprehensive context modeling for Chinese text classification. IEEE Access, 7, 154546–154559. https://doi.org/10.1109/ACCESS.2019.2949175
- Liu, X. B., Zhang, Z., & Li, B. X. (2019). Keywords extraction method for technological demands of small and medium-sized enterprises based on LDA. 2019 Chinese Automation Congress (CAC), Hangzhou, 2855–2860. https://doi.org/10.1109/CAC48633.2019.8996936
- Luo, L. X. (2019). Network text sentiment analysis method combining LDA text representation and GRU-CNN. Personal and Ubiquitous Computing, 405–412. https://doi.org/10.1007/s00779-018-1183-9
- Papadimitriou, C. H., Raghavan, P., Tamaki, H., & Vempala, S. (2000). Latent semantic indexing: A probabilistic analysis. Journal of Computer and System Sciences, 61(2), 217–235. https://doi.org/10.1006/jcss.2000.1711
- Reddy, S., Nalluri, S., Kunisetti, S., Ashok, S., & Venkatesh, B. (2019). Smart innovation, systems and technologies. Smart Intelligent Computing and Applications, 391–397. https://doi.org/10.1007/978-981-13-1927-3_42
- Shao, D. G., Li, C. Y., Huang, C. S., Xiang, Y., & Yu, Z. T. (2022). A news classification applied with new text representation based on the improved LDA, Multimedia Tools and Applications, 81(15), 21521–21545. https://doi.org/10.1007/s11042-022-12713-6
- Song, P., Geng, C. Y., & Li, Z. J. (2019). Research on text classification based on convolutional neural network. 2019 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi'an, 229–232. https://doi.org/10.1109/ICCNEA.2019.00052
- Sun, J., Zhang, X., & Liao, D. (2017). Efficient method for feature selection in text classification. International Conference on Engineering and Technology (ICET), 1–6. https://doi.org/10.1109/ICEngTechnol.2017.8308201
- Tan, Z. P., Chen, J., Kang, Q., Zhou, M., Abusorrah, A., & Sedraoui, K. (2022). Dynamic embedding projection-gated convolutional neural networks for text classification. IEEE Transactions on Neural Networks and Learning Systems, 33(3), 973–982. https://doi.org/10.1109/TNNLS.2020.3036192
- Tian, H., & Wu, L. A. (2018). Microblog emotional analysis based on TF-IWF weighted Word2vec model. 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, 893–896. https://doi.org/10.1109/ICSESS.2018.8663837
- Verma, P. K., Agrawall, P., Amorim, I., & Prodan, R. (2021). WELFake: Word embedding over linguistic features for fake news detection. IEEE Transactions on Computational Social Systems, 8(4), 881–893. https://doi.org/10.1109/TCSS.2021.3068519
- Wang, Q., Peng, R. Q., Wang, J. Q., Xie, Y. S., & Zhou, Y. F. (2019). Research on text classification method of LDA-SVM based on PSO optimization. 2019 Chinese Automation Congress (CAC), Hangzhou,1974-1978, https://doi.org/10.1109/CAC48633.2019.8996. 952.
- Wang, Q. Y., Zhu, G. L., Zhang, S. X., Li, K. C., & Chen, X. (2021). Extending emotional lexicon for improving the classification accuracy of Chinese film reviews. Connection Science, 33(2), 153–172. https://doi.org/10.1080/09540091.2020.1782839
- Wei, Z., Liu, W., Zhu, G., Zhang, S., & Hsieh, M. Y. (2022). Sentiment classification of Chinese weibo based on extended sentiment dictionary and organisational structure of comments. Connection Science, 34(1), 409–428. doi:https://doi.org/10.1080/09540091.2021.2006146
- Wu, G. H., Wang, L. Y., Zhao, N. L., & Lin, H. R. (2015). Improved expected cross entropy method for text feature selection. 2015 International Conference on Computer Science and Mechanical Automation (CSMA), Hangzhou, 49–54. https://doi.org/10.1109/CSMA.2015.17
- Wu, J., & Yang, B. L. (2021). News text classification and recommendation technology based on wide & deep-bert model. 2021 IEEE International Conference on Information Communication and Software Engineering, 209–216. https://doi.org/10.1109/ICICSE52190.2021.9404101
- Xie, J., Chen, B., Gu, X. L., Liang, F. M., & Xu, X. Y. (2019). Self-attention-based BiLSTM model for short text fine-grained sentiment classification. IEEE Access, 7, 180558–180570. https://doi.org/10.1109/ACCESS.2019.2957510
- Xu, J. M., & Jiang, H. (2015). An improved information gain feature selection algorithm for SVM text classifier. 2015 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Xi'an, 273–276. https://doi.org/10.1109/CyberC.2015.53
- Yoon, K. (2014). Convolutional neural networks for sentence classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1746–1751. https://doi.org/10.48550/arXiv.1408.5882
- Yu, L., Duan, Y., & Li, K. (2021). A real-world service mashup platform based on data integration, information synthesis, and knowledge fusion. Connection Science, 33(3), 463–481. https://doi.org/10.1080/09540091.2020.1841110
- Yu, Y. J., Yoon, S. J., Jun, S. Y., & Kim, J. W. (2021). TABAS: Text augmentation based on attention score for text classification model. ICT Express, 2405–9595. https://doi.org/10.1016/j.icte.2021.11.002
- Zhai, Y. J., Song, W., Liu, X. J., & Zhao, X. L. (2018). A Chi-square statistics based feature selection method in text classification. 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), 160–163. https://doi.org/10.1109/ICSESS.2018.8663882
- Zhang, F., Gao, W., & Fang, Y. (2019). News title classification based on sentence-LDA model and word embedding. 2019 International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, 237–240. https://doi.org/10.1109/MLBDBI48998.2019.00053
- Zhang, S. X., Yu, H. B., & Zhu, G. L. (2022). An emotional classification method of Chinese short comment text based on ELECTRA. Connection Science, 34(1), 254–273. https://doi.org/10.1080/09540091.2021.1985968
- Zhang, X. W., & Shao, J. F. (2021). Research on News Text Classification Based on Improved BERT-CNN Model, 45((07|7)), 146–150. https://doi.org/10.16280/j.videoe.2021.07.040
- Zhang, Y., Xu, B., & Zhao, T. (2020). Convolutional multi-head self-attention on memory for aspect sentiment classification. IEEE/CAA Journal of Automatica Sinica, 7(4), 1038–1044. https://doi.org/10.1109/JAS.2020.1003243
- Zhang, Y. M., Liu, F., Koura, Y. H., & Wang, H. (2021). Analysing rumours spreading considering self-purification mechanism. Connection Science, 81–94. https://doi.org/10.1080/09540091.2020.1783640
- Zheng, J., & Zheng, L. M. (2019). A hybrid bidirectional recurrent convolutional neural network attention-based model for text classification. IEEE Access, 7, 106673–106685. https://doi.org/10.1109/ACCESS.2019.2932619
- Zhou, X. S., Jiang, L., & Lin, S. Q. (2018). The Text Feature Representation Method Based on Word2vector, 30(2), 272–279.
- Zhu, Y. L. (2021). Research on news text classification based on deep learning convolutional neural network, Wireless Communications and Mobile Computing, https://doi.org/10.1155/2021/1508150