
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Computer vision is now playing a vital role in modern UAV (Unmanned Aerial Vehicle) systems. However, the on-board real-time small object detection for UAVs remains challenging. This paper presents an end-to-end ViT (Vision Transformer) detector, named Sparse ROI-based Deformable DETR (SRDD), to make ViT model available to UAV on-board systems. We embed a scoring network in the transformer T-encoder to selectively prune the redundant tokens, at the same time, introduce ROI-based detection refinement module in the decoder to optimise detection performance while maintaining end-to-end detection pipeline. By using scoring networks, we compress the Transformer encoder/decoder to 1/3-layer structure, which is far slim compared with DETR. With the help of lightweight backbone ResT and dynamic anchor box, we relieve the memory insufficient of on-board SoC. Experiment on UAVDT dataset shows the proposed SRDD method achieved 50.2% mAP (outperforms Deformable DETR at least 7%). In addition, the lightweight version of SRDD achieved 51.08% mAP with 44% Params reduction.
1. Introduction
Convolutional Neural Network (CNN) (Krizhevsky et al., Citation2012) has become the dominant model for vision tasks since 2012, and more efficient structures have been developed in recent years. Transformer (Vaswani et al., Citation2017), which achieved great success in Natural Language Processing study, has gradually become a new research area for vision problems (Bai et al., Citation2021; C. Wang et al., Citation2020; Yan et al., Citation2021), called ViT (Vision Transformer). Unlike the complex detection structure in mainstream detectors, ViT turns object detection problem into a direct set-prediction problem (Carion et al., Citation2020). This method can simplify the detection process and eliminate many hand-designed components of previous detection algorithms, such as non-maximum suppression (NMS) or anchor boxes, thus eliminate a lot of computation consumption that were considered hard to parallelise. However, ViT models usually take more time to converge while training and has relatively low performance in detecting small objects since it is not a multi-scale structured network. To solve this problem, X. Zhu et al. (Citation2021) proposed deformable attention inspired by the deformable convolution (Dai et al., Citation2017). By using deformable attention, Deformable DETR (Detection Transformer) addresses the slow convergence and high complexity issue of DETR, which enables the transformer encoder to use multi-scale features as input and significantly improves performance in small objects detection. At the same time, Zheng et al. (Citation2021) proposed the ACT (Adaptive Clustering Transformer) to reduce the computational complexity of the attention module. Y. Wang et al. (Citation2022) proposed an variation called Row-Column Decoupled Attention (RCDA) to solve the one region but multiple objects problem. And Conditional DETR (Meng et al., Citation2021) speeds up the convergence of DETR by explicitly finding the extremity region of the object.
Deformable DETR successfully combines Transformer and deformable convolution with sparse spatial sampling locations to tackle the slow convergence and high complexity problem of DETR. Deformable DETR uses multi-scale features as encoder inputs, which significantly increases the number of tokens to be processed, and eventually the complexity of the network increases. EViT (Liang et al., Citation2022) identify the attentive image tokens between MHSA and FFN (i.e. feed-forward network) modules, which is guided by the corresponding class token attention, then, reorganise image tokens by preserving attentive image tokens and fusing inattentive ones to expedite subsequent MHSA and FFN computations. Pan et al. (Citation2021) propose a Hierarchical Visual Transformer (HVT) which progressively pools visual tokens to shrink the sequence length and hence reduces the computational cost, analogous to the feature maps downsampling in CNNs. Similar to EViT, Roh et al. (Citation2022) found that the number of encoder tokens referenced by decoders during the Deformable DETR model with convergence inferred on the COCO dataset was only about 45%, reducing the number of tokens is the key to speed up Deformable DETR operations. However, token sparsification can reduce the computational cost, the detection result on UAVDT (Du et al., Citation2018) test set is unsatisfying. Through experiments, we believe the reason is Transformer does not initially focus on the foreground but distributes the attention weights evenly to all regions, leading to considerable redundancy and requiring extra time to induce the detector to concentrate on the area of interest.
In this paper, to address the above problems, we propose a pure Transformer-based object detector named Sparse RoI-based Deformable DETR (SRDD). We selectively reduce the number of encoder tokens by using a scoring network and further induces the network to focus on the region where the target is located by RoI-based attention modelling. Efficient DETR brings of 1-decoder structure and 6-decoder structure by using dense detection and sparse set detection. In SRDD, Unlike Efficient DETR, we use only 1-layer transformer encoder and 3-layer transformer decoder. The experimental results of layer comparison between encoder and decoder are shown in Section 4.3.1. The experiments show that SRDD can obtain 50.15% AP under UAVDT dataset with the backbone of Swin-T, 50 training epochs.
Currently, Transformer is too large to fit in mobile devices. Scientists in Apple Inc. proposed a lightweight vision network model mobileViT (Mehta & Rastegari, Citation2021) combined the advantages of CNN and VIT, in which they use mobilevit block to create lightweight ViT model. M. Zhu et al. (Citation2021) presents a ViT pruning approach, which identifies the impacts of dimensions in each layer of transformer and then executes pruning accordingly. Quantisation is another effective way to compress neural networks. PTQ4ViT (Yuan et al., Citation2021) proposes the twin uniform quantisation method to reduce the quantisation error on activation values. Chen et al. (Citation2021) propose a new one-shot architecture search framework, called AutoFormer, dedicated to ViT architecture search. To allow the ViT run as fast as MobileNet while achieving high performance, Li et al. (Citation2022)introduced a dimensionally consistent pure converter (no MobileNet blocks) as a design paradigm.
Our goal is to find a way to make ViT model running on embedded platform in UAVs. To achieve this goal, we utilise the lightweight backbone ResT (Zhang & Yang, Citation2021), which constructs a memory-efficient multi-headed self-attention module and handle input images of arbitrary size. Meanwhile, Dynamic Anchor box (S. Liu et al., Citation2021), which performs soft ROI pooling layer-by-layer in a cascade manner, has been introduced to reduce the computational cost. Through the above efforts, the FPS of the lightweight version of SRDD improved from 14.87 to 16.56, with a 39% reduction in the number of parameters. The main contributions of this paper are summarised as below:
We embed a scoring network in the transformer encoder to selectively prune the redundant tokens, by which we lighten the attention complexity in the transformer encoder.
We introduce ROI-based detection refinement module in the decoder to optimise detection performance while maintaining end-to-end detection pipeline.
We use a lightweight transformer as the backbone network and a dynamic anchor box to refine the bounding box information without adding extra memory. The lightweight model can shrink the model and maintain good accuracy.
2. Related works
2.1. Object detectors
The object detection benchmarks have been systematically dominated by deep learning-based methods (C. Wang et al., Citation2022; Zhou et al., Citation2020) in the last few years. They can be broadly divided into three categories: two-stage, one-stage and end-to-end. Two-stage detectors are Mask-CNN (He et al., Citation2017), Fast R-CNN (Girshick, Citation2015), Faster R-CNN (Ren et al., Citation2015) and etc. This detection approaches divide the object detection task into two stages: extract ROIs, and classify and regress the ROIs. One-stage detectors are YOLO (Redmon & Farhadi, Citation2018), SSD (W. Liu et al., Citation2016), CornerNet (Law & Deng, Citation2018) and etc. It removes the RoI extraction process and directly classifies and regresses the candidate anchor boxes. Generally, two-stage detectors and one stage have an advantage in accuracy and speed, respectively. Moreover, two-stage and one-stage methods need complicated post-processing to generate the final bounding box predictions.
End-to-end detectors, such as DETR, Deformable DETR and Sparse RCNN (Sun et al., Citation2021), do not require extra post-processing stages and perform object detection in an end-to-end framework. DETR is an encoder–decoder architecture that originates from the original Transformer. Combined with a set-based Hungarian loss (Kuhn, Citation1955) that forces unique predictions for each ground-truth bounding box via bipartite matching, its output layer is an MLP (Multi-Layer Perception ). Since DETR directly returns to the absolute coordinates of the bounding box and does not rely on any prior, it takes a long time to train the model to achieve convergence. Furthermore, the experimental results show that DETR has relatively low performance detecting small objects. To solve this problem, Deformable DETR follows the framework of the DETR and proposes two modules: the Deformable Attention Module and the Multi-scale Deformable Attention Module. The former only attend to a small set of crucial sampling points around a reference point, regardless of the spatial size of the feature maps, which alleviates the problem of extensive computation. This modification turns the global connections in the Transformer into local connections and significantly raises the converging speed from 500 epochs of DETR to 50 epochs. The latter expands the feature map into a multi-scale feature map to solve the problem of small targets, which increases the number of tokens to be processed by about 20 times than DETR. DETR-like models, such as Conditional DETR (Meng et al., Citation2021) and Anchor DETR (Y. Wang et al., Citation2022), tend to improve the spatial embedding in the Transformer, focusing attention mechanism on potentially valuable regions in the images learned through the positional embedding, enhancing the local modelling of the Transformer, thereby helping Speed up training. In contrast, improvements based on deformable DETR, such as Efficient DETR (Yao et al., Citation2021) and PnP DETR (T. Wang et al., Citation2021), tend to reduce the computational load of the algorithm and improve sure accuracy. PnP DETR shortens the token length of the transformer encoder by introducing the Polling and Pull (PnP) module to sample the foreground tokens and condense the background tokens into a smaller set. Efficient DETR takes advantage of both dense and sparse set detection, which can bridge the performance gap between the 1-decoder structure and the 6-decoder structure.
2.2. Effective vision transformers
Transformers are initially proposed to handle the learning of long sequences in NLP tasks. Dosovitskiy et al. (Citation2020) and Carion et al. (Citation2020) adapt the transformer architecture to classification and detection, respectively, and achieve competitive performance against CNN counterparts with stronger training technique and larger-scale datasets. The Transformer relies on the attention mechanism, and the model includes two parts: Transformer encoder and Transformer decoder (T-encoder and T-decoder). The T-encoder consists of six identical layers, and each layer consists of two sublayers: multi-head attention and feed-forward network (FFN). Around each of the two sub-layers performs residual connection followed by layer normalisation. The multi-head attention module is applied as
(1)
(1)
the
denotes the query token, key token and the value token, respectively.
is parameter matrices.
is the ith self-attention head of Transformer, usually compute as follows:
(2)
(2)
where
,
,
are parameter matrices, to project Q, K, V, respectively.
The T-decoder is also composed of a stack of six identical layers. In the decoder, there are cross-attention, FFN and self-attention modules. In the cross-attention, it performs multi-head attention over the output of the T-encoder stack. The other two parts are the same as the decoder. Significantly, the first self-attention layers are modified to prevent positions from attending to subsequent positions, improving the model's generalisation.
It is a well-known problem that the attention computation in Transformer incurs the high time and memory complexity. The visual Transformers need to consume more tokens as input, which requires the detector to take on more computation. One way to reduce transformer attention is to input correlation token sparse. Dynamic VIT (Rao et al., Citation2021) proposes a dynamic Token sparsification framework that progressively and dynamically cuts out redundant tokens based on the input information. PnP DETR (T. Wang et al., Citation2021) believes that the main reason why DETR's Transformer network is too computationally intensive in computing attention is that the spatial features of the image feature map are redundant, so it only computes attention between the fine-grained foreground feature and the coarse-grained background feature, which greatly reduces the computational effort. In this paper, we mainly use a similar idea to Dynamic VIT, using a scoring network to obtain a sparse, useful set of tokens from a dense set of tokens.
Vision transformers (ViTs) are usually considered to be less light-weight than convolutional neural networks (CNNs). To obtain a lightweight ViT, present LightViT that introduce a global yet efficient aggregation scheme into both self-attention and feed-forward network (FFN) of ViTs, and additional learnable tokens to capture global dependencies. Different from EViT's transformer structure, MObile-Former present a parallel design of MobileNet and transformer with a two-way bridge in between, which converters contain very few tokens (e.g. 6 or fewer tokens) that are randomly initialised to learn global priors, resulting in low computational cost. In this paper, we utilise lightweight backbone ResT, a efficient multiple self-attention backbone network, to reduce the computational cost, and Dynamic Anchor BoX for soft ROI pooling to obtain high detection performance.
3. Our method: sparse RoI-based deformable DETR
In this paper, we propose a simple but efficient target detection method called SRDD. We use Swin Transformer as a backbone and add a scoring network to decrease object queries and the RoI-based refinement module to tackle the complicated training problem for attention modelling. Meanwhile, we reduce the T-encoder to 1 layer and the T-decoder to 3 layers, which reduces the algorithm's computational complexity. Furthermore, we use the lightweight backbone network ResT and Dynamic Anchor Box (DAB) method to build the algorithm on the UAV platform. Our network structure is shown in Figure .
Figure 1. (a) Framework of our proposed SRDD method. SRDD introduces two additional components on top of Deformable DETR: the token sparsification module and the RoI-based refinement module. (b) Token Sparsification Module. With LayerNorm, Linear and GELU, we can get top-ρ% tokens. (c) RoI-based Refinement module. It has three stages, and each stage uses previously detected bounding boxes to extract glimpse features. (a) Framework of proposed SRDD method. The blue block is token sparsification module and the green block is RoI-based refinement module. (b) Token Sparsification Module and (c) RoI-based Refinement Module.
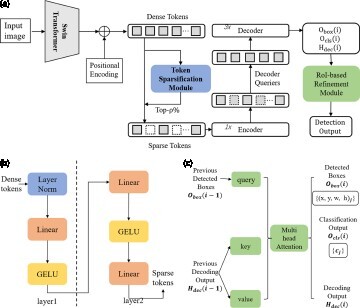
As shown in the left half of Figure (a), we use a scoring network to measure the saliency of each token in the dense tokens. Then, we define the ρ-salient region as the top-ρ% tokens with the highest scores. Based on this region, we can obtain sparse tokens, which is served as the decoder object queries. In the last column of the graph, SRDD performs a multi-stage Region-of-Interest (RoI) based attention modelling refinement procedure by gradually focusing on more accurate areas. In Figure (c), and
represent the classification and bounding box regression output of the ith recurrent processing stage, respectively,
represents the refined attention of this stage after decoding. For the first stage, where i = 0, we use the outputs of the original. During the ith processing stage, the glimpsed-based decoder collects visual features from areas around the detected bounding boxes
. It then performs cross-attention to investigate the relations between the collected visual features and previous attention outputs. Finally, we can get the detection output.
3.1. Backbone
Swin Transformer is a general backbone for computer vision, achieving state-of-the-art performance on various vision tasks (e.g. COCO Object Detection). Swin Transformer uses shifted windows while generating representations. At the input stage, it splits an input RGB image into many non-overlapping patches via patch splitting module. Each splitted patch will be flattened and embedded to generate tokens for the following self-attention module. In our implementation, we set the patch size as , thus, feature dimension for each patch is
. In this work, we adopt a tiny variation of Swin-T as the default backbone instead of original one, which is similar to the design of Deformable DETR. We extract a multi-scale feature map from the output feature maps of stages C2 through C4 in Swin Transformer (transformed by a 1×1 convolution). The last feature map is obtained via a 3×3 stride 2 convolutions on the final C4 stage. Therefore, the multi-scale slender object feature maps are captured from the backbone. Lastly, the multi-scale slender object feature maps are input to the Transformer to enhance the ability of semantic and geometric information representation.
3.2. Token sparsification
The core issue of applying Transformer attention on an image feature map is that it will look over all possible spatial positions to generate much redundant information and increase the computational complexity. To address this, Deformable DETR proposed a deformable attention module, which allows it only to attend to a small set of key sampling points around the reference point. It can be viewed as a key sparsification method but with dense queries. We further reduce the attention complexity through query sparsification. Since measuring objectness per each input token of the T-encoder is very natural to determine which ones from the backbone feature should be further updated in the T-encoder, we introduce the scoring network to sparsify encoder tokens. Figure is the reference point processed by different T-encoders. Then the ith T-encoder layer updates the features by
(3)
(3)
in which
(4)
(4)
where
denotes ρ-salient regions for a given keeping ratio ρ,
denotes the token feature being scored of the ith layer. DefAttn refers to deformable attention, LN to layer normalisation (Ba et al., Citation2016), and FFN to a feed-forward network.
Figure 2. (a) In the DETR, object queries are randomly initialised. (b) In the SRDD, Initialising reference point with top-ρ% tokens.
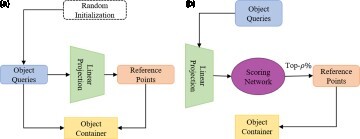
We can select the top-ρ% T-encoder tokens with the highest-class scores as a salient token. Different from DETR variants, SRDD adds auxiliary heads only for sparsified encoder tokens. We empirically observe that applying an auxiliary detection head along with Hungarian loss on the selected tokens stabilises the convergence of deeper T-encoders by alleviating the vanishing gradient issue and even improves the detection performance.
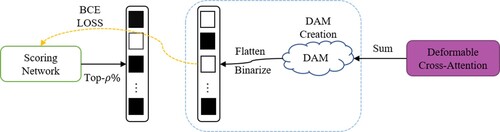
To train the scoring network, we have to aggregate the decoder cross-attentions between all objects queries and the T-encoder output, so we use Decoder cross-Attention Maps (DAM) (Roh et al., Citation2022), which sum up attention maps from every decoder layer to make the top-ρ% (by attention weights) of T-encoder tokens is only trained. Through implementation, we find that such selective input will not only reduce the accuracy of detection but also speed up the convergence time of the algorithm. Figure summarises how to train the scoring network.
3.3. RoI-based refinement
In DETR and Deformable DETR, decoder queries are given by only learnable object queries or with predicted reference points via another head after the T-encoder. In Efficient DETR, the decoder takes a part of the T-encoder output as input, similar to RoI Pooling (Ren et al., Citation2015). Sparse DETR attaches an auxiliary detection head to the T-encoder output, and the head calculates each T-encoder output's objectness (class) score. Based on the score, the top-k T-encoder outputs are passed as decoder queries, similar to objectness score-based T-encoder token sparsification. Since this outperforms the methods based on learnable object queries or the two-stage scheme, we include this top-k decoder query selection in our final architecture. However, we found that although the scoring network can reduce the tokens of the T-encoder, it still takes a long time to obtain the area that needs to be concentrated in the early stage of the training, so we add RoI-based refinement module to improve detection results, which consists of two major components. The first is a multi-stage recurrent processing structure that progressively augments attention modelling outputs and improves the detection. In each stage, previously detected bounding boxes are used to obtain ROIs for extracting glimpse features. Then, glimpse features are translated into refined attention decoding outputs for describing detected objects according to previous attention decoding outputs. The refined attention decoding outputs can provide improved detection results. Thus, for the ith processing stage, we propose to detect objects according to:
(5)
(5)
where
and
represent the classification and bounding box regression outputs of the ith recurrent processing stage, respectively, and
represents the refined attention of this stage after decoding.
Figure 3. The learning process of the scoring network. Illustration on how to learn a scoring network by predicting binarised Decoder Cross-Attention Map (DAM), where a dash orange arrow means a backpropagation path.
The second is the glimpse-based decoder used in each stage to perform the refinement explicitly. During the ith processing stage, the glimpse-based decoder collects visual features from areas around the detected bounding boxes from the previous stage. It then performs cross-attention to investigate the relations between the collected visual features and previous attention outputs and compute translated glimpse features of the current stage.
3.4. Loss function
We use a bipartite graph matching loss, which is used to measure the similarity between two sets, to score predicted objects (class, position, size) with respect to the ground truth. We denote that y is the ground truth set of objects, and the set N of N predictions. To find a bipartite matching between these two sets we search for a permutation of N elements with the lowest cost:
(6)
(6)
which is a pairwise matching cost between ground truth
and a prediction with index
. This optimal assignment is computed efficiently with the Hungarian algorithm:
(7)
(7)
where
is the target class label and
is the vector that defines ground truth box centre coordinates and its height and width relative to the image size. For the prediction with index
, the probability of class
is
and the predicted box is
.
is an indicator function, which the input is True, the output is 1, and the input is False, the output is 0. To train the scoring network, we need minimise the binary cross entropy (BCE) loss between the binarised DAM and prediction, to find a small subset of T-encoder tokens that the decoder references the most.
(8)
(8)
In Equation (Equation8
(8)
(8) ),
means the binarised DAM value of the ith encoder token, and
is to predict how likely a given T-encoder token is included in the top-ρ% most referenced tokens, and g means a 4-layer scoring network. In addition, we introduce additional loss: T-encoder auxiliary loss. Auxiliary loss (Szegedy et al., Citation2015) is widely adopted to deliver gradients to the early layers of deep networks. In DETR variants, auxiliary detection heads are attached to decoder layers but not to T-encoder layers. Extending the layerwise auxiliary loss to the multi-scale T-encoder increases the training time cost. In SRDD, however, only part of T-encoder tokens is defined by the T-encoder, so we can add auxiliary heads for sparsified T-encoder tokens without increasing the computational cost. The result shows that applying Hungarian loss at the intermediate layers helps distinguish the confusing features in the T-encoder, which contributes to the detection performance in the final head. The total loss function is as follows:
(9)
(9)
in which
(10)
(10)
and
(11)
(11)
3.5. Lightweight design
To make our network easier to deploy on mobile devices, as far as accuracy is concerned, we reduce the number of computational parameters as much as possible and improve the network training speed. We replace the backbone network from Swin Transformer to ResT (Zhang & Yang, Citation2021), which adopts a design idea similar to ResNet. Stem extracts the underlying feature information, and stages capture multi-scale feature information. The standard transformer module consists of two sub-layers: the Multi-Head Self-Attention (MSA) and the Feed Forward Network (FFN). The output of each transformer block is:
(12)
(12)
in which
(13)
(13)
and
(14)
(14)
We found that MSA has two shortcomings: (1) The computation scales quadratically with
or n according to the input token, causing vast overheads for training and inference; (2) Each head in MSA is only responsible for a subset of embedding dimensions, which may impair the performance of the network, mainly when the tokens embedding dimension (for each head) is short. So, we replace MSA with Efficient Multi-head Self-Attention (EMSA), as shown in Figure . To compress the model, the token
is reshaped from 2D to a 3D input token, and the height and width are reduced by a factor s through a depthwise convolution operation, which s is an adaptive set by the feature map size or the stage number.
Figure 4. Efficient Multi-Head Self-Attention. The 2D input token is reshaped to 3D one long the spatial dimension. Then, Q is obtained through a linear layer. K and V are obtained through a depth-wise convolution operation and a linear layer.
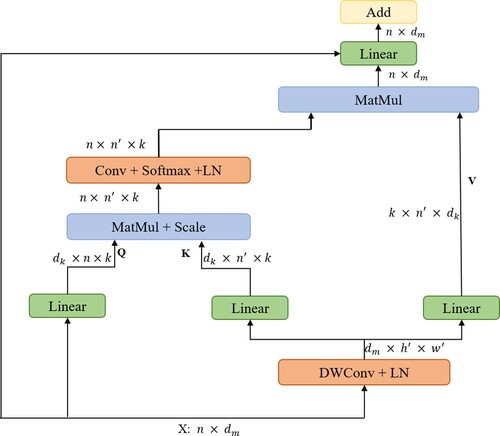
The attention function on query Q, key K and value V is
(15)
(15)
the input of Equation (Equation15
(15)
(15) ) consists of queries, keys of dimension
and values of dimension
. First, we compute the dot products of the query with all keys, divide each by
, and apply a softmax function to obtain the weights on the values. Then, after Softmax. We add an Instance Normalisation to restore the ability of MSA to attend to information.
Meanwhile, we find that RoI-based refinement module have three layers, which increases the number of parameters. To alleviate the model's size, we adopt the dynamic anchor box proposed by S. Liu et al. (Citation2022) instead of the RoI-based refinement module. We found that to improve the convergence speed of the algorithm, it is necessary to increase the learning speed of the decoder. We find that a Dynamic Anchor Box (DAB) not only encodes the location information of the anchor point but also applies the level-by-level idea, and each layer continuously refines the anchor box. There are two attention modules in each decoder layer, including a self-attention module and a cross-attention module, which are used for query updating and feature probing, respectively. Each module needs queries, keys and values to perform attention-based value aggregation, yet the inputs of these triplets differ. We denote as the qth anchor,
,
,
,
, and
and
as its corresponding content query and positional query, where D is the dimension of decoder embeddings and positional queries. Given an anchor
, its positional query
is generated by
(16)
(16)
PE means positional encoding to generate sinusoidal embeddings from float numbers, and then parameters of MLP are shared across all layers. As
is a quaternion, we overload the PE operator here:
(17)
(17)
The notion Cat means concatenation function. In our implementations, the positional encoding function PE maps a float to a vector with D/2 dimensions as PE:
. Hence the function MLP projects a 2D dimensional vector into D dimensions: MLP:
. The MLP module has two submodules, each composed of a linear layer and an ReLU activation (Glorot et al., Citation2011), and the feature reduction is conducted at the first linear layer. The experimental results show that this method has no additional parameters and can improve the algorithm's accuracy.
4. Experiments
We compare SRDD with the conventional object detectors, including the recently proposed ones in the DETR family. In addition, we conduct an ablation study, presenting the performance comparison between T-encoder and T-decoder layers, the effectiveness of the token sparsification and the RoI-based refinement module during inference, and the effectiveness of the T-encoder auxiliary loss.
4.1. Implementation details
To validate the effectiveness of our method, we trained and evaluated it on the UAVDT dataset (Du et al., Citation2018). The proposed UAVDT benchmark consists of 10 h of raw videos, from which 100 video sequences of about 80,000 representative frames are selected. The sequences contain between 83 and 2970 frames. The videos are captured by a UAV platform at various urban locations such as squares, arterial streets, toll stations, highways, crossings and T-junctions. The video sequences are recorded at 30 fps with a resolution of 1080*540 pixels. Figure 8 shows example frames of UAVDT with their ground truth. The dataset contains 21,728 training images and 16,592 testing images. We used a subset of the training data for validation. Evaluation is done using the MATLAB code provided by the authors of both datasets. The performance measure used for evaluation is the mAP, the Average mean accuracy, with a minimum IOU of 0.7 in the inferred and ground-truth bounding boxes.
We use ResNet-50 and Swin Transformer as pre-trained backbone networks. We train the model with a total batch size of 4 for 50 epochs, where the initial learning rate is 0.0002 and decayed by 1/10 at the 40 epochs. The weight optimisation algorithm is AdamW, and the weight attention is 0.0001. Other hyperparameter settings and training strategies are mainly followed by Deformable DETR.
4.2. Experimental results
We compared SRDD with Faster RCNN, Yolov5, DETR, Deformable DETR, Sparse DETR and REGO Deformable DETR. We also compare SRDD on different backbones, including Resnet50 (He et al., Citation2016) and Swin Transformer. Table shows the evaluation results of SRDD and other detectors on the UAVDT test set. We can also see that Swin Transformer performs much better than the Resnet50 under the detection framework. We think this is because Transformer can pay more attention to global features than CNN when extracting features. Figure shows the detection results of the algorithm under different lighting and weather conditions.
Table 1. Comparison with modern object detectors on UAVDT test set. Boldface indicates the best result overall, DETR is 500 epochs, other algorithms are 50 epochs, notation * denotes that the backbone network is swin Transformer.
We compare the effects of lightweight backbone and Dynamic Anchor Box (DAB) on the model, as shown in the following table. Using the two methods simultaneously can minimise the model and have the highest frame rate, and the mAP will be higher than when the two methods are not applicable. Table shows that using lightweight backbone ResT can reduce the number of model parameters by nearly 1.5 times, and using DAB can speed up the inference speed of the model. All experiments are performed on rho = 0.1, the number of T-encoder layers is 1, and the number of T-decoder layers is 3.
Figure 5. Different methods' test results under different weather and light conditions: (a) the result of SRDD, (b) the result of Sparse DETR and (c) the result on REGO Deformable DETR.

Table 2. Comparisons of results of lightweight methods using SRDD.
4.3. Ablation study
Ablation studies are performed to analyse the components of SRDD. Models in this part are based on Deformable DETR with iterative bounding box refinement and two-stage, an optimised version that iteratively updates reference points after each T-decoder layer. If there are no special instructions, we use Swin Transformer, a 1-layer T-encoder, 3-layer T-decoder, 300 proposals, rho = 0.1 and 50 epochs training schedule.
4.3.1. Encoder and decoder layers
The DETR series are in an encoder–decoder architecture. Both T-encoder and T-decoder cascade six identical layers. Although this can improve the detector's accuracy, it also brings tremendous pressure on the calculation of the model. Table illustrates that SRDD is more sensitive to the number of T-encoder layers, which implies that the T-encoder is more critical than the decoder for SRDD. Significantly, an SRDD with 3-encoders and 3-decoders is adopted as our baseline. AP could be increased by about 1.19 if removing two layers in the T-encoder. In contrast, removing two layers in the T-decoder only caused a 0.58 AP drop. Through experiments, we found that the change in the number of T-encoder layers has a large impact on the result of the operation. Yao et al. (Citation2021) proposed that the T-encoder layers play a similar role as convolutions and extract context features from a CNN backbone. The auxiliary decoding loss is the main reason why DETR is more sensitive to the number of decoder layers. In the paper, we use auxiliary losses in the T-encoder as well, which indicates that SRDD is also sensitive to the number of layers in the T-encoder. By comparing the experimental results, we find that the detection effect is best when the T-decoder layers are 1 and the T-encoder layers are 3.
Table 3. Encoder vs. Decoder. Experiments are conducted on SRDD.
4.3.2. Token sparsification and RoI-based refinement
SRDD mainly uses two methods, token sparsification and RoI-based refinement. Through experiments, we find that using two methods can lead to the best results while keeping other parameters consistent. Table shows the experimental results and experimental data using different methods in the case of 1-layer T-encoder, 3-layer T-decoder, and the backbone network is swin Transformer. We also compare the effect of different proportional sparsification.
Table 4. Comparison between the effectiveness of token sparsification and RoI-based refinement. The baseline indicates Deformable DETR.
4.3.3. Effectiveness of the encoder auxiliary loss
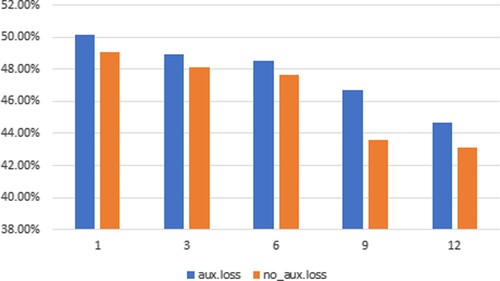
It is proposed that in deformable DETR, only the decoder has an auxiliary loss. Because the T-encoder contains a large number of tokens, the T-encoder does not add auxiliary loss. However, because the scoring network in our algorithm makes the token sparse, we can apply the auxiliary loss to the T-encoder without sacrificing too much computing cost. Through experiments, it is found that using the auxiliary loss of the T-encoder can improve the efficiency and performance and enable us to stack more T-encoders without convergence. Figure shows that the effect of using the auxiliary loss of the T-encoder is better.
Figure 6. Effectiveness of the T-encoder auxiliary loss using SRDD. The horizontal coordinate is the number of layers in the T-encoder, the vertical coordinate is mAP, and the number of layers in the T-decoder are both 3.
5. Conclusion
In this paper, we propose a combination of T-encoder token sparse algorithm and the RoI-based refinement module, which accelerates the convergence of Deformable DETR and reduces the computational cost by reducing the number of layers of T-encoder and T-decoder. Experiments show that when we use the swin Transformer as the backbone network, rho=0.1, the number of T-encoder layers is 1, and the number of decoder layers is 3, the algorithm can achieve the best results. At the same time, to enable the model to be transplanted to the UAV platform, we replaced the backbone network swin transformer with a lightweight ResT. We used a dynamic anchor box instead of the RoI-based refinement module to refine the bounding box information. The results show that the proposed algorithm achieves state-of-the-art performance on the UAVDT dataset, with an accuracy improvement of 7.09% compared to Deformable DETR.
Although our algorithm improves the mAP of deformable DETR and speeds up the FPS, the structure of the T-encoder and T-decoder of deformable DETR makes its FPS lower than that of the existing yolo series detectors. So for the next task, we need to further improve the FPS of the algorithm while maintaining the accuracy, so that it can be better applied to real-time detection tasks.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer normalization. arXiv preprint arXiv:1607.06450.
- Bai, X., Wang, X., Liu, X., Liu, Q., Song, J., Sebe, N., & Kim, B. (2021). Explainable deep learning for efficient and robust pattern recognition: A survey of recent developments. Pattern Recognition, 120, Article 108102. https://doi.org/10.1016/j.patcog.2021.108102
- Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). End-to-end object detection with transformers. In European conference on computer vision (ECCV) (pp. 213–229). ISBN: 978-3-030-58451-1.
- Chen, M., Peng, H., Fu, J., & Ling, H. (2021). Autoformer: Searching transformers for visual recognition. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 12270–12280). IEEE.
- Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., & Wei, Y. (2017). Deformable convolutional networks. In Proceedings of the IEEE international conference on computer vision (CVPR) (pp. 764–773). ICCV.
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., & Uszkoreit, J. (2020). An image is worth 16×16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
- Du, D., Qi, Y., Yu, H., Yang, Y., Duan, K., Li, G., Zhang, W., Huang, Q., & Tian, Q. (2018). The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European conference on computer vision (ECCV) (pp. 370–386). ECCV.
- Girshick, R. (2015). Fast r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 1440–1448). ICCV.
- Glorot, X., Bordes, A., & Bengio, Y. (2011). Deep sparse rectifier neural networks. In Proceedings of the fourteenth international conference on artificial intelligence and statistics (pp. 315–323). PMLR.
- He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 2961–2969). ICCV.
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778). CVPR.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 60, 84–90. https://doi.org/10.1145/3065386
- Kuhn, H. W. (1955). The hungarian method for the assignment problem. Naval Research Logistics Quarterly, 2(1–2), 83–97. https://doi.org/10.1002/(ISSN)1931-9193
- Law, H., & Deng, J. (2018). Cornernet: Detecting objects as paired keypoints. In Proceedings of the European conference on computer vision (ECCV) (pp. 734–750). ECCV.
- Li, Y., Yuan, G., Wen, Y., Hu, E., Evangelidis, G., Tulyakov, S., Wang, Y., & Ren, J. (2022). Efficientformer: Vision transformers at mobilenet speed. arXiv preprint arXiv:2206.01191.
- Liang, Y., Ge, C., Tong, Z., Song, Y., Wang, J., & Xie, P. (2022). Not all patches are what you need: Expediting vision transformers via token reorganizations. arXiv preprint arXiv:2202.07800.
- Liu, S., Li, F., Zhang, H., Yang, X., Qi, X., Su, H., Zhu, J., & Zhang, L. (2021). Dab-detr: Dynamic anchor boxes are better queries for detr. In International conference on learning representations. ICLR.
- Liu, S., Li, F., Zhang, H., Yang, X., Qi, X., Su, H., Zhu, J., & Zhang, L. (2022). Dab-detr: Dynamic anchor boxes are better queries for detr. arXiv preprint arXiv:2201.12329.
- Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A. C. (2016). SSD: Single shot multibox detector. In European conference on computer vision (pp. 21–37). LNIP.
- Mehta, S., & Rastegari, M. (2021). Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer. arXiv preprint arXiv:2110.02178.
- Meng, D., Chen, X., Fan, Z., Zeng, G., Li, H., Yuan, Y., Sun, L., & Wang, J. (2021). Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 3651–3660). ICCV.
- Pan, Z., Zhuang, B., Liu, J., He, H., & Cai, J. (2021). Scalable vision transformers with hierarchical pooling. In 2021 IEEE/CVF international conference on computer vision (ICCV) (pp. 367–376). ICCV.
- Rao, Y., Zhao, W., Liu, B., Lu, J., Zhou, J., & Hsieh, C.-J. (2021). DynamicViT: Efficient vision transformers with dynamic token sparsification. In A. Beygelzimer, Y. Dauphin, P. Liang, & J. Wortman Vaughan (Eds.), Advances in Neural Information Processing Systems. https://openreview.net/forum?id=kR95DuwwXHZ
- Redmon, J., & Farhadi, A. (2018). Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767.
- Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 28. ISBN: 9781510825024.
- Roh, B., Shin, J., Shin, W., & Kim, S. (2022). Sparse DETR: Efficient end-to-end object detection with learnable sparsity. In International conference on learning representations. ICLR.
- Sun, P., Zhang, R., Jiang, Y., Kong, T., Xu, C., Zhan, W., Tomizuka, M., Li, L., Yuan, Z., Wang, C., & Luo, P.. (2021). Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 14454–14463). CVPR.
- Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1–9). CVPR.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30. ISSN: 9781510860964.
- Wang, C., Bai, X., Wang, X., Liu, X., Zhou, J., Wu, X., Li, H., & Tao, D. (2020). Self-supervised multiscale adversarial regression network for stereo disparity estimation. IEEE Transactions on Cybernetics, 51(10), 4770–4783. https://doi.org/10.1109/TCYB.2020.2999492
- Wang, C., Wang, X., Zhang, J., Zhang, L., Bai, X., Ning, X., Zhou, J., & Hancock, E. (2022). Uncertainty estimation for stereo matching based on evidential deep learning. Pattern Recognition, 124, Article 108498. https://doi.org/10.1016/j.patcog.2021.108498
- Wang, T., Yuan, L., Chen, Y., Feng, J., & Yan, S. (2021). Pnp-detr: Towards efficient visual analysis with transformers. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 4661–4670). ICCV.
- Wang, Y., Zhang, X., Yang, T., & Sun, J. (2022). Anchor detr: Query design for transformer-based detector. In Proceedings of the AAAI conference on artificial intelligence (Vol. 36, pp. 2567–2575). AAAI.
- Yan, C., Pang, G., Bai, X., Liu, C., Ning, X., Gu, L., & Zhou, J. (2021). Beyond triplet loss: person re-identification with fine-grained difference-aware pairwise loss. IEEE Transactions on Multimedia, 24, 1665–1677. https://doi.org/10.1109/TMM.2021.3069562
- Yao, Z., Ai, J., Li, B., & Zhang, C. (2021). Efficient detr: improving end-to-end object detector with dense prior. arXiv preprint arXiv:2104.01318.
- Yuan, Z., Xue, C., Chen, Y., Wu, Q., & Sun, G. (2021). Ptq4vit: post-training quantization framework for vision transformers. arXiv preprint arXiv:2111.12293.
- Zhang, Q., & Yang, Y.-B. (2021). Rest: An efficient transformer for visual recognition. Advances in Neural Information Processing Systems, 34, 15475–15485. ISBN: 9781713845393.
- Zheng, M., Gao, P., Zhang, R., Li, K., Wang, X., Li, H., & Dong, H. (2021). End-to-end object detection with adaptive clustering transformer. In 32nd British machine vision conference 2021, BMVC 2021, online. BMVC.
- Zhou, L., Bai, X., Liu, X., Zhou, J., & Hancock, E. R. (2020). Learning binary code for fast nearest subspace search. Pattern Recognition, 98, Article 107040. https://doi.org/10.1016/j.patcog.2019.107040
- Zhu, M., Tang, Y., & Han, K. (2021). Vision transformer pruning. arXiv preprint arXiv:2104.08500.
- Zhu, X., Su, W., Lu, L., Li, B., Wang, X., & Dai, J. (2021). Deformable detr: Deformable transformers for end-to-end object detection. In International conference on learning representations. ICLR.