
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Text classification is a popular research topic in the natural language processing. Recently solving text classification problems with graph neural network (GNN) has received increasing attention. However, current graph-based studies ignore the hidden information in text syntax and sequence structure, and it is difficult to use the model directly for processing new documents because the text graph is built based on the whole corpus including the test set. To address the above problems, we propose a text classification model based on long short-term memory network (LSTM) and graph attention network (GAT). The model builds a separate graph based on the syntactic structure of each document, generates word embeddings with contextual information using LSTM, then learns the inductive representation of words by GAT, and finally fuses all the nodes in the graph together into the document embedding. Experimental results on four datasets show that our model outperforms existing text classification methods with faster convergence and less memory consumption than other graph-based methods. In addition, our model shows a more notable improvement when using less training data. Our model proves the importance of text syntax and sequence information for classification results.
1. Introduction
Text classification is a fundamental task in the field of natural language processing (NLP) and has an extensive range of applications in practice, such as article organisation, sentiment analysis (Xu et al., Citation2020), opinion mining (Bai et al., Citation2018), spam filtering, and recommendation systems (Gemmis et al., Citation2015), etc. Text representation is an essential part of text classification. Text is composed of words arranged in a certain order, and different word orders can represent different meanings. According to human reading habits, distinguishing the attributes of words (e.g. subject, predicate, object) and analysing the syntactic structure of the text are the basis for understanding the semantics of text. Therefore, the information hidden in the word sequences and syntactic structure of the text will have a non-negligible impact on the text representation. Traditional machine learning based methods feature vectors are usually high-dimensional and sparse, which makes feature extraction difficult and ignores the semantic information of the text. Over the years, various neural network models have been successfully applied to text representation under their excellent feature learning capabilities. Among them, Recurrent Neural Network (RNN) (Mikolov et al., Citation2010), Convolutional Neural Network (CNN) (Jaderberg et al., Citation2016; Wang et al., Citation2016), Transformer (Vaswani et al., Citation2017), and their variants are the representative neural network models. However, these deep learning models ignore the non-contiguous and long-range text semantic information. Recently, Graph Neural Network (GNN) has attracted much academic attention and has been successfully applied to natural language processing, which treats a text sequence as a graph structure. Defferrard et al. (Citation2016) first used graph convolutional neural networks for text classification tasks and outperformed traditional CNN models. Yao et al. (Citation2019) constructed a corpus-level text graph and used graph convolutional neural networks to transform the text classification task into a node classification task. Huang et al. (Citation2019) introduced a message passing mechanism in the graph neural network to reduce memory consumption.
However, the current GNN-based classification methods have three main drawbacks. First, the contextual relationship of words in each document is ignored, and the original word order information of the text is lost after transforming the text into a graph structure representation. Second, it does not consider that words will have different importance in different documents. Third, constructing a graph for the whole corpus can cause high memory consumption because multiple edges are needed. Moreover, because the structure and parameters of the graph of such models depend on the entire corpus, the test set must be included when constructing the graph, which is difficult to modify after training, so it cannot be directly used in new documents.
Therefore, we propose a text classification model based on LSTM and graph attention network (GAT) based on the above problems. The model first builds a separate graph for each document in the corpus by dependent syntactic analysis, then captures the contextual information of words by LSTM, and uses GAT to learn the importance of different neighbouring nodes. Finally, the feature representation of all nodes in the graph is summarised to generate semantic embeddings of the text graph for label prediction. The text classification is turned into a graph classification problem.
The research contribution of this paper has three main aspects.
Instead of building one text graph for all documents (including test set), our model generates a separate graph for each input document. In this way, our model does not need to retrain parameters when processing new documents, which is convenient for online testing.
We use the dependency syntax analysis tool in the construction of the text graph to obtain the syntactic structure information of the text. We obtain the context information of the text through LSTM, which solves the problem that the nodes in the graph lose the order information of the original text.
We use a graph attention network to update the representation of a node by assigning different weights to its neighbours. This increases the influence of important words while reducing the influence of irrelevant data.
The rest of this paper is organised as follows. Section 2 reviews some related work on text classification. Section 3 describes the structure of our model in detail. Section 4 presents the results of our experiments. Section 5 concludes the paper and points out some of our future work.
2. Related work
Traditional machine learning-based text classification models are less time-consuming to train, such as Support Vector Machine (SVM), Naive Bayesian (NB) (Liang et al., Citation2020), decision trees, k-means, etc. This text classification method trains in pre-classified texts, then builds a specified classifier, and finally classifies texts with unknown class labels. Compared with knowledge engineering-based text classification methods, this approach can be applied to text collections in various domains, and the classification accuracy is improved to some extent. However, such models require feature engineering, consume a lot of human and material resources, and have disadvantages such as sparse feature vectors, dimensional explosion, and difficult feature extraction. Words are the smallest unit of language, and the vector representation of words determines how machine learning models are built. The task of NLP first deals with the word, which is the smallest semantic unit of the text. Usually, each word in the thesaurus is typically represented as a high-dimensional vector (the dimension is the size of thesaurus). Only one dimension of the vector has a value of 1, which represents the position of the current word in the vocabulary, and other dimensions have a value of 0. Although this one-hot word representation method is simple and effective, it is prone to the problem of dimension disaster (Aggarwal & Zhai, Citation2012). And it only symbolises words, which is independent between words. It can’t reflect the semantic similarity between words, and can’t consider the text word order information. Traditional text representation models include Boolean models, vector space models, probability models, and graph space models. However, these traditional methods of text representation lack the ability of semantic representation.
Deep learning can automatically extract the essential feature representation of the data by learning multiple times, avoiding a lot of manual extraction of features, and achieving high accuracy in classification tasks. CNN has the ability to exploit the translational invariance of data, local connectivity, etc., which makes them popular in computer vision and natural language processing (Khan et al., Citation2020). Kim (Citation2014) used CNN for text classification for the first time and proposed a CNN that inputs static and dynamic word vectors into two channels of CNN respectively and uses multiple convolution cores. The CNN model is characterised by the ability of convolutional operations to capture text features at different levels in parallel, pooling operations to capture local features of text effectively, and high computational efficiency. RNN is more suitable for NLP than CNN because of its timing and the ability to process variable-length input and explore long-term dependence (Yin et al., Citation2017). However, RNNs suffer from the semantic bias problem, in which words at the back of the sentence occupy a more critical position relative to words at the front, which affects the semantic accuracy of the whole sentence. Therefore, LSTM (Hochreiter & Schmidhuber, Citation1997) proposed by scholars selectively forgets the previous information and solves RNN gradient explosion and gradient disappearance problems. In recent years, the attention mechanism has attracted extensive attention in the academic community. The attention mechanism imitates the human perception (Vaswani et al., Citation2017), which can focus attention on more important parts and be applied to various tasks of NLP. However, such models based on RNN and CNN focus on the localisation of words and lack information between distant, non-contiguous words.
As more and more data are represented in the form of graphs, previous neural networks cannot be directly applied to graphs. Driven by the strong demand for practical applications and potential research value, GNN has attracted extensive academic attention and has been successfully applied to natural language processing (Pal et al., Citation2020), including text classification (Defferrard et al., Citation2016), sequence tagging (Zhang et al., Citation2018), machine translation (Bastings et al., Citation2017), etc. Graph neural network is a neural model, which captures graph dependencies through message passing between graph nodes (Zhou et al., Citation2020). Yao et al. (Citation2019) introduced graph convolutional neural networks (GCN) to multi-class text classification tasks and proposed TextGCN. TextGCN builds a heterogeneous graph for the whole corpus and treats documents and words as two classes of nodes. It transforms text classification into a node classification problem (Wang et al., Citation2021). Global word co-occurrence information can be captured by using a fixed-size sliding window for all documents to collect lexical co-occurrence statistics. Zhang et al. (Citation2020) proposed to create edges by considering lexical co-occurrence relations within a certain window when constructing a graph for each document and used gated graph neural networks to learn word representations based on local structure. Finally, word nodes are incorporated into document embeddings. Huang et al. (Citation2019) proposed a new GNN-based message-passing model that uses smaller sliding windows to obtain local co-occurrence relations of words to generate text graphs, which reduces the number of edges and memory consumption. Veličković et al. (Citation2018) proposed a Graph Attention Networks (GAT) incorporating an attention mechanism, a new type of GCN. It uses a vector embedding representation of each node and a self-attentive mechanism to learn the weight relationship between nodes and then update the representation of nodes by passing information through this relationship, which has achieved good performance on node classification datasets. Hu et al. (Citation2019) constructed a heterogeneous graph attention network model (HGAT) based on a dual attention mechanism, which uses a dual-level attention mechanism, including node-level and type-level attention, to achieve semi-supervised text classification considering the heterogeneity of various types of information. Liu et al. (Citation2021) introduced the attention diffusion mechanism in GNN to capture the context information of indirect neighbours in a single layer. In addition, node level attention technology is introduced to obtain more accurate document level representation. Jia and Wang (Citation2022) proposed an enhanced capsule network text classification model (Syntax-ATCapsNet), which uses graph convolution neural network to encode syntactic dependency trees, constructs multiple heads of attention to encode dependencies in text sequences, and finally improves the effect of text classification through the fusion of capsule network and semantic information. Wang et al. (Citation2022) proposed an inductive text classification model, which uses one-way GCN for message transmission without pre trained word embedding under the condition of limited training set.
3. The proposed method
Our model consists of three modules: syntax module, LSTM module, and GAT module. The syntax module uses the Stanford CoreNLP tool to analyse the syntactic dependency tree of the text and represents it with an adjacency matrix, so that the syntactic information of the text is extracted. At the same time, the LSTM module encodes the word order information of the text to form the feature representation of words. Finally, based on the syntax and word order information extracted by the syntactic module and the LSTM module, the GAT module outputs the word embeddings with attention through the two-layer GAT. We use max-pooling on all word embedding vectors in a single text to obtain the maximum value in each dimension, generate the embedded representation of the text, and classify the text. The overall network structure is shown in Figure .
Figure 1. The architecture of our model. The figure shows the processing of a single text.
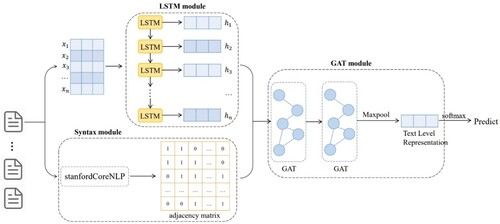
3.1. Syntax module
We regard each text as a graphic structure, which helps us learn the information between long-distance, discontinuous words. The purpose of this module is to convert each input text into a text graph. First, we use the natural language processing tool Stanford CoreNLP to analyse the dependency syntax of the input sentence (Jia & Wang, Citation2022), generate the syntactic dependency tree of the sentence, and construct the text graph according to the syntactic dependency tree obtained from the analysis. In order to enrich text features, text graph is regarded as undirected graph G = (V, E), which is represented by adjacency matrix A. V(|V| = n) and E are the sets of nodes and edges, respectively. Nodes represent words, and edges represent the existence of syntactic dependency between two words. The syntax dependency tree of the example sentence “The woman wrote a book” is shown in Figure . “Woman” is the subject of the predicate “wrote”, and “book” is the direct object of “wrote”. The adjacency matrix corresponding to this example is shown in Figure .
Figure 2. The example of syntactic dependency tree.
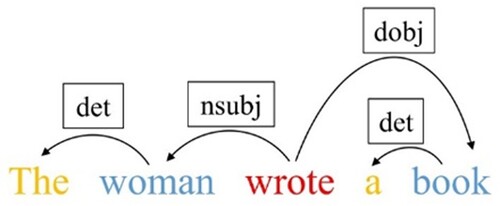
Figure 3. The adjacency matrix of the example sentence.
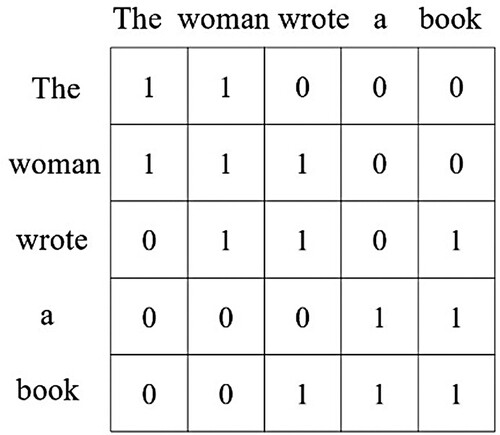
Compared with previous graph construction methods, our textual graph construction method can significantly reduce the number of nodes and edges and reduce memory consumption.
3.2. LSTM module
The LSTM is a variation of RNN, which can better contact the context and process data serially. LSTM has an internal mechanism called “gate”. It can retain and delete information through input gate, forgetting gate, and output gate. LSTM is composed of several neural units, and its structure (https://colah.github.io/posts/2015-08-Understanding-LSTMs) is shown in Figure .
Figure 4. The architecture of LSTM.
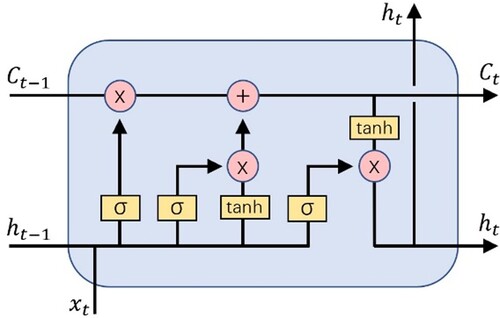
In the figure is the state of the previous neuron, and
is the output of the previous neuron,
is the current input, and σ is the Sigmoid function, which together determine the output
of the current neuron. The gate is adjusted using the Sigmoid function so that the output value of the gate is a value between 0 and 1 (Liu et al., Citation2016). The forgetting gate ignores all previous memories when it is 0, and the output gate ignores the newly calculated states when it is 0.
The feature representation of a node is initialised by word embedding, and the feature matrix containing all node embeddings is represented by matrix , where m is the dimension of the feature vector. We take the matrix
as the input to the LSTM, and then through LSTM, we can get the feature matrix
containing text sequence information.
3.3. GAT module
After generating a text graph for each text, we pass and update the information between nodes through GAT to obtain the node representation containing text syntax and sequence information. The graph attention mechanism is different from the self-attention mechanism (Veličković et al., Citation2018). The self-attention mechanism assigns attention weights to all nodes in the document. The graph attention mechanism does not need to know the whole graph structure in advance. It can flexibly assign different weights to different numbers of neighbour nodes, and can be processed in parallel on all nodes in the graph, with high computational efficiency.
There are two inputs to GAT. One is the feature matrix output by the LSTM module,
,
. The other input is the adjacency matrix A obtained through the syntax module, from which GAT can obtain the neighbour relationship of nodes. The output of GAT is the updated new node feature matrix
,
. The single-layer graph neural network updates the node representation as follows.
(1)
(1)
(2)
(2)
(3)
(3)
Where is a single-layer feedforward neural network,
is a shared parameter vector, and
is a shared weight matrix of linear transformations that transform the input features into higher-level features to obtain sufficient expressiveness. Both
and
are parameters that can be learned by neural networks.
denotes the splicing operation of the vectors.
is the first-order neighbour of node i in the graph. To make the coefficients easy to compare among different nodes, we normalise
using softmax to obtain the attention coefficient
between
and
. The node feature representation after the update is obtained by Equation (3).
To stabilise the learning process of the model, we use a multi-headed attention mechanism. The hidden states of the nodes are calculated by using K independent attention mechanisms through Equation (3), and then the K outputs are stitched together as the input of the next layer. The overall calculation process is shown in Equation (4). After one graph attention layer calculation, only the information of the first-order neighbours of the node can be aggregated. We capture the information of the higher-order neighbours of the node by overlaying two-layer GAT to enrich the feature representation of the node. The second layer of GAT is computed as shown in Equation (5), and is the attention coefficient between the spliced node vectors to obtain the final representation of the word nodes
,
.
(4)
(4)
(5)
(5) Finally, the information of all nodes in the text graph after updating is fused to generate graph-level features for subsequent label prediction. We turn text classification into a graph classification task. We use maximum pooling to obtain the most important node data as the feature representation of the text graph, and then obtain the predicted labels by softmax:
(6)
(6) The purpose of training is to minimise the cross-entropy loss between the true and predicted labels, and the loss function is defined as
(7)
(7) where N is the number of documents, and
is the actual label of the document, and
is the predicted label of the document.
4. Experiments
4.1. Experimental setup
This paper selects Python 3.7 development environment, and downloads pytorch, numpy and other toolkits through Anaconda. The experiment is carried out on the development platform with 2-core CPU and 16GB memory. To validate the effectiveness of our proposed model, we conducted experiments on the following five datasets: two subsets R52 and R8 of the Reuters 21578 dataset, a movie review dataset MR of with binary sentiment classification, the 23-class single-label medical literature Ohsumed from the MEDLINE database, and the large movie review dataset IMDb. Table lists the statistical information of the datasets, and Prop.NW denotes the proportion of new words in the test set.
Table 1. Summary statistics of datasets.
We compare our model with the following 10 baseline models.
CNN (Kim, Citation2014): The first use of convolutional neural networks for text classification tasks, using pre-trained word vectors and maximum pooling operations to obtain text representations.
LSTM (Liu et al., Citation2016): The model uses the last hidden state as a representation of the whole text. Pre-trained word vectors are used in our experiments.
Bi-LSTM: is a bi-directional LSTM that uses pre-trained word embeddings.
fastText (Joulin et al., Citation2016): A simple and efficient text classification method that does not require initialisation with pre-trained word vectors and is faster to train than a typical neural network.
Bert (Devlin et al., Citation2018): Bidirectional Encoder Representations from Transformer. It is a very advanced natural language processing framework.
Graph-CNN (Defferrard et al., Citation2016): a graph CNN model that operates convolutions over word embedding similarity graphs, in which Chebyshev filter is used.
TextGCN (Yao et al., Citation2019): A model for text classification using GCN, which constructs a big picture for the entire corpus.
InducT-GCN (Wang et al., Citation2022): An inductive text classification model based on GCN, which uses less parameters and space than TextGCN.
Syntax-AT-Capsule (Jia & Wang, Citation2022): An enhanced capsule network text classification model, which uses GCN as a submodule to encode the syntactic dependency tree and extract the syntactic information in the text.
Text-level-GNN (Huang et al., Citation2019): uses GNN for message passing between nodes, which builds text graphs for a text individually.
For all datasets, we randomly divide the training set in the ratio of 9:1 as the training and validation sets in our experiments. We use 300-dimensional Glove pre-trained word embeddings as the input features. We use Adam as the optimisation algorithm with L2 weight decay rate of 10−4, learning rate set to 0.0005, batch size set to 32, and add a dropout layer to prevent model overfitting and set the dropout ratio to 0.5. In the graph attention module, we use the graph attention mechanism with K = 8 for the first layer and single-headed attention for classification in the second layer. We stop training if the validation loss does not decrease for 10 consecutive epochs. For comparison purposes, the baseline model uses the same 300-dimensional Glove word embedding and uses the default parameter configuration.
4.2. Experimental results
Table shows the comparison of the accuracy of our model and the other ten baseline text classification models on the test set. We take the mean ± standard deviation of the results of running the model 10 times as the test results. Table records the F1-score of each classification model.
Table 2. Test accuracy (%) of various models on five datasets. OOM: out of memory (>16GB).
Table 3. F1-score (%) of various models on five datasets. OOM: out of memory (>16GB).
It can be observed that our model outperforms other baseline models and the graph-based approach generally outperforms general neural network approaches such as CNN and LSTM. This shows that by converting the text to a graph-structured data representation, the model can be more flexible in accessing the hidden information in the text since each node can have a different number of neighbours. LSTM performs better than CNN. CNN pays more attention to the local information in the text, and LSTM can capture the context semantic information of the text. FastText uses N-gram and bag of words model as text features and performs well in experiments on various data sets. Although Bert performs well on all five datasets, it requires a lot of memory and longer training time. On MR, Bert outperforms GNN-based models thanks to large-scale pre-training. Furthermore, the text in MR is shorter, which limits the message passing ability of the graph structure. The reason why our model performs better than TextGCN and Text-level-GNN on MR dataset is that sentiment analysis requires a higher word order, and the different order of words will directly affect the category of text. TextGCN, Text-level-GNN and other models based on GNN don’t utilise the word order information of the text, while the LSTM module in our model can capture the word order information of the text. TextGCN builds a graph for the whole corpus, and the short text of MR dataset limits the ability of message-passing between document nodes and word nodes. The result of Text-level-GNN on Ohsumed is poor because Ohsumed is a long text dataset, and the number of training set is less than the test set. This indicates that the Text-level-GNN model ignores the important global and long-distant semantic information in a long text, and has poor inductive learning ability of text.
Table compares the number of edges in the text graph between the two representative GNN-based models and our model. As can be seen from the table, the number of edges in the graph in our model is significantly less than that in TextGCN and Text-level-GNN, which indicates that our model can significantly reduce memory consumption. TextGCN builds edges based on the co-occurrence of words within a fixed-size sliding window for the whole corpus, and the graph also includes edges between document nodes and word nodes. Text-level-GNN similarly connects words that occur simultaneously within a reasonably sized sliding window. In contrast, the edges in our model are generated based on the syntactic dependencies of the text, which can efficiently obtain important information about the text and reduce unnecessary edges. At the same time, we can also obtain the information between long-distance words according to the syntactic information, which is not limited by the size of the sliding window.
Table 4. Comparison of the number of edges in the model. OOM: out of memory(>16GB).
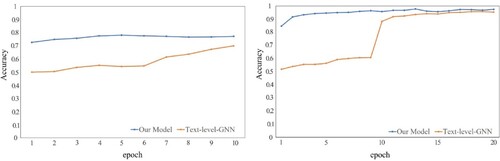
Figure shows the comparison of the training speed of our model and Text-level-GNN on MR and R8. It can be seen that our model has high accuracy after the first epoch on both MR and R8, and even our model can get the optimal model in the 5th epoch on MR, and the optimal model on R8 can be obtained within 20 epochs. This indicates that the GAT module in our model can quickly capture the words with high impact on the text classification results, give it a correspondingly large attention weight, and continuously adjust it to reach the optimum in subsequent training.
Figure 5. Comparison of model training speed. The left panel is the result on MR and the right panel is the result on R8.
4.3. Parameter sensitivity
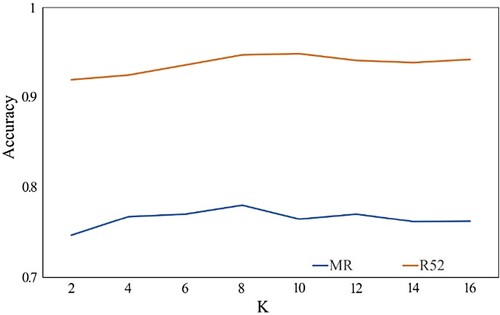
As shown in Figure , we compared different head-count attention mechanisms on the MR and R52 datasets. As the number of heads K increases, the test accuracy gradually improves. However, when K > 8, the average accuracy no longer improves. This indicates that too few attention heads cannot obtain enough information to calculate the attention weights among words and cannot capture the keywords that affect the text classification results more accurately, while too many attention heads may capture some information with interference and slow down the model training and spend more time.
Figure 6. Test accuracy by using GAT with different numbers of heads.
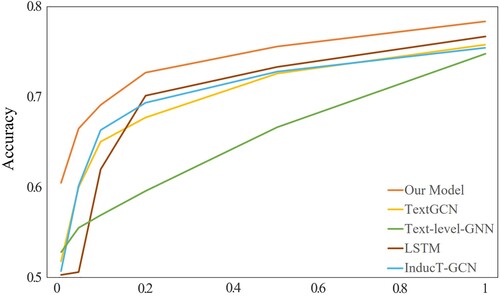
To test the inductive performance of our model for word feature representation, we randomly selected training sets with different percentages from 0.5% to 1 on the MR dataset and tested the accuracy of these models separately using the original test sets. We did experiments with 0.5%, 5%, 10%, 20%, 50%, and 100% training sets, respectively, and the results are shown in Figure . Using fewer training sets means more new words in the test set. As can be seen from the figure, the accuracy of our model can outperform the baseline model by about 10% when using only 0.5% of the training set (20 labelled documents per class), which indicates that our model has inductive learning ability and the more new words that are not seen in the test set, the more obvious the gain of our model.
Figure 7. Test accuracy by using different percent of training data ranging from 0.005 to 1 on MR.
To further analyse our model, we performed an ablation study, and Table shows the experimental results.
Table 5. Results of the ablation study. We run all models 5 times and averaged the results.
In (1), we remove the LSTM module. As can be seen from Table , the performance drop on MR is more obvious. The accuracy decreases slightly on the other three datasets. This is because the word order information has a greater impact on the text of the MR dataset. Therefore, the importance of the LSTM module in our model is more evident on MR.
In (2), we change max-pooling to mean-pooling and use mean-pooling for word embeddings in the text to generate an embedding representation of the text. This is similar to the pooling operation on CNNs. In the original model, the nodes obtain new representations from the received messages by obtaining the maximum value of each dimension individually. From the experimental results, it can be seen that max-pooling can achieve better results. max-pooling highlights the most important node data and provides non-linear features, which helps to obtain better results.
In (3), we reduce 1 layer of the GAT network. And the results indicate a decrease in the performance of the model. The relatively large drop on Ohsumed indicates that the second-order neighbours of long texts still contain important information and can have a non-negligible impact on the classification results. Also, this proves the necessity of our setting up two layers of GAT to take the information of the second-order neighbours.
5. Conclusion and future work
In this paper, we proposed a new inductive text classification model based on LSTM and GAT. Each text has a separate structural graph and turns the text classification problem into a graph classification problem. Our model captures word order information and syntactic information of the text and can build edges without the limitation of inter-word distance, while the graph attention network attenuates the influence of noisy data and increases the weight of important words. Experiments on multiple datasets demonstrate the effectiveness of our model, being able to learn inductive representations of words on a limited number of labelled documents, and significantly reducing memory consumption. However, because our model uses syntactic analysis tools, it suffers from the problem of long training time when processing texts with an average length of 200 words or more. Future work will investigate unsupervised graph-attentive text classification models, or make full use of little label data to improve classification performance. Apart from that, we can study how to extend node features to improve classification performance.
Acknowledgements
The authors would like to thank the editors and reviewers for handling and reviewing our paper.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Aggarwal, C. C., & Zhai, C. (2012). A survey of text classification algorithms. In C. C. Aggarwal & C. Zhai (Eds.), Mining text data (pp. 163–222). Springer. https://doi.org/10.1007/978-1-4614-3223-4_6.
- Bai, H., Chen, Z., Lyu, M. R., King, I., & Xu, Z. (2018). Neural relational topic models for scientific article analysis. Proceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM) (pp. 27–36). Association for Computing Machinery, New York, NY, USA, 22–26 October 2018. https://doi.org/10.1145/3269206.3271696.
- Bastings, J., Titov, I., Aziz, W., Marcheggiani, D., & Sima'an, K. (2017). Graph convolutional encoders for syntax-aware neural machine translation. arXiv preprint arXiv:1704.04675.
- Defferrard, M., Bresson, X., & Vandergheynst, P. (2016). Convolutional neural networks on graphs with fast localized spectral filtering. Proceedings of the 30th International Conference on Neural Information Processing Systems(NIPS) (pp. 3844–3852). Curran Associates Inc., Red Hook, NY, United States, 5 December 2016.
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805
- Gemmis, M. D., Lops, P., Musto, C., Narducci, F., & Semeraro, G. (2015). Semantics-aware content-based recommender systems. In F. Ricci, L. Rokach, & B. Shapira (Eds.), Recommender systems handbook (pp. 119–159). Springer. https://doi.org/10.1007/978-1-4899-7637-6_4.
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
- Hu, L., Yang, T., Shi, C., Ji, H., & Li, X. (2019). Heterogeneous graph attention networks for semi-supervised short text classification. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (pp. 4821–4830), Association for Computational Linguistics, Hong Kong, China, 3-7 November 2019. https://doi.org/10.18653/v1/D19-1488.
- Huang, L., Ma, D., Li, S., Zhang, X., & Wang, H. (2019). Text level graph neural network for text classification. arXiv preprint arXiv:1910.02356.
- Jaderberg, M., Simonyan, K., Vedaldi, A., & Zisserman, A. (2016). Reading text in the wild with convolutional neural networks. International Journal of Computer Vision, 116(1), 1–20. https://doi.org/10.1007/s11263-015-0823-z
- Jia, X., & Wang, L. (2022). Attention enhanced capsule network for text classification by encoding syntactic dependency trees with graph convolutional neural network. PeerJ Computer Science, 7, e831. https://doi.org/10.7717/peerj-cs.831
- Joulin, A., Grave, E., Bojanowski, P., & Mikolov, T. (2016). Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759.
- Khan, A., Sohail, A., Zahoora, U., & Qureshi, A. S. (2020). A survey of the recent architectures of deep convolutional neural networks. Artificial Intelligence Review, 53(8), 5455–5516. https://doi.org/10.1007/s10462-020-09825-6
- Kim, Y. (2014). Convolutional neural networks for sentence classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing(EMNLP) (pp. 1746–1751), Doha, Qatar, 25-29 October 2014.
- Liang, Z., Xie, H., & An, W. (2020). Text classification based on BiGRU and Bayesian classifier. Computer Engineering and Design, 41(2), 381–385. https://doi.org/10.16208/j.issn1000-7024.2020.02.013.
- Liu, P., Qiu, X., & Huang, X. (2016). Recurrent neural network for text classification with multi-task learning. arXiv preprint arXiv:1605.05101.
- Liu, Y., Guan, R., Giunchiglia, F., Liang, Y., & Feng, X. (2021). Deep attention diffusion graph neural networks for text classification. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing(EMNLP) (pp. 8142–8152), Association for Computational Linguistics, Punta Cana, Dominican Republic, November 2021. https://doi.org/10.18653/v1/2021.emnlp-main.642.
- Mikolov, T., Karafiát, M., Burget, L., Cernocký, J., & Khudanpur, S. (2010). Recurrent neural network based language model. Interspeech, 2(3), 1045–1048. https://doi.org/10.21437/Interspeech.2010-343
- Pal, A., Selvakumar, M., & Sankarasubbu, M. (2020). Multi-label text classification using attention-based graph neural network. arXiv preprint arXiv:2003.11644.
- Vaswani, A., Shazeer, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need. 31st Conference on Neural Information Processing Systems (NIPS) (pp. 6000–6010). Long Beach, CA, USA, 4 December 2017https://doi.org/10.48550/arXiv.1706.03762.
- Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., & Bengio, Y. (2018). Graph attention networks. arXiv preprint arXiv:1710.10903.
- Wang, K., Han, S. C., & Poon, J. (2022). InducT-GCN: Inductive graph convolutional networks for text classification. arXiv preprint arXiv:2206.00265.
- Wang, P., Xu, B., Xu, J., Tian, G., Liu, C.-L., & Hao, H. (2016). Semantic expansion using word embedding clustering and convolutional neural network for improving short text classification. Neurocomputing, 174, 806–814. https://doi.org/10.1016/j.neucom.2015.09.096
- Wang, Y., Jin, J., Zhang, W., Yu, Y., Zhang, Z., & Wipf, D. (2021). Bag of tricks for node classification with graph neural networks. arXiv preprint arXiv:2103.13355.
- Xu, G., Li, W., & Liu, J. (2020). A social emotion classification approach using multi-model fusion. Future Generation Computer Systems, 102, 347–356. https://doi.org/10.1016/j.future.2019.07.007
- Yao, L., Mao, C., & Luo, Y. (2019). Graph convolutional networks for text classification. Proceedings of the AAAI Conference on Artificial Intelligence, 33(1), 7370–7377. https://doi.org/10.1609/aaai.v33i01.33017370.
- Yin, C., Zhu, Y., Fei, J., & He, X. (2017). A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access, 5, 21954–21961. https://doi.org/10.1109/ACCESS.2017.2762418
- Zhang, Y., Liu, Q., & Song, L. (2018). Sentence-state lstm for text representation. arXiv preprint arXiv:1805.02474.
- Zhang, Y., Yu, X., Cui, Z., Wu, S., Wen, Z., & Wang, L. (2020). Every document owns its structure: Inductive text classification via graph neural networks. arXiv preprint arXiv:2004.13826.
- Zhou, J., Cui, G., Hu, S., Zhang, Z., Yang, C., Liu, Z., Wang, L., Li, C., & Sun, M. (2020). Graph neural networks: A review of methods and applications. AI Open, 1, 57–81. https://doi.org/10.1016/j.aiopen.2021.01.001