
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Business process recommendation can be used to simplify the working procedures of enterprises, avoid unnecessary expenses, and promote the development of enterprises. In the process of process recommendation, there are a lot of activities that are similar in structure and difficult to choose. Here, a process recommendation method based on cost constraints is proposed to solve the problem of difficult to distinguish similar processes. First, the business process is transformed into a labelled Petri net, and the execution probability of each transition is calculated according to the business process log. Then, the matrix used to represent Petri nets is constructed according to the adjacent relationship between transitions, and the matrix is made into the same dimension, and the similarity between matrices is calculated by biggest–smallest approach degree, and the set of Petri nets with similar structure is established. Finally, a cost constraint-based process recommendation method is proposed to find lower service cost items in similar process sets. In the experimental part, the feasibility of the method is compared and verified.
1. Introduction
In the past decades, the application fields of business processes have been expanding, such as intelligent financial management (Shao et al., Citation2021), underwater sensor networks (Wu et al., Citation2021), intelligent manufacturing systems (Fu et al., Citation2021), and robotic mission planning. Enterprises are also constantly innovating, and the scale of business processes of enterprises is constantly expanding, especially large enterprises may generate hundreds of business processes. This makes enterprises face a series of new challenges in process analysis, process management, process retrieval, and process recommendation. For example, in the aspect of process management, a series of process model libraries are established to better manage the process. In terms of process retrieval and process recommendation, in order to retrieve effective process models from the process model library for process recommendation, a corresponding model retrieval mechanism is established. The implementation of these aspects requires the similarity calculation of the process model. Therefore, similarity calculation is an important solution to efficiently solve business process problems.
At present, due to the different needs of users, the calculation basis of similarity is also different, which can be roughly divided into three categories (Dijkman et al., Citation2011): node matching similarity, structural similarity, and behavioural similarity.
Node matching is usually to map the node labels in two process models to calculate similarity. Dijkman et al. (Citation2011) analysed process model similarity from five perspectives, namely, syntax, semantics, attributes of node labels, and node types and node contexts. Ehrig et al. (Citation2007) measured similarity by transforming Petri nets into Semantic Business Process Models (SBPMs). This method does not consider the structure and behaviour of the process, resulting in inaccurate similarity results. Bergmann and Gil (Citation2014) proposed a graph-based semantic workflow similarity measure and combined with cases to improve the traditional graph similarity algorithm, but the retrieval performance is not very high as the number of cases increases.
Most of the structural similarity measurement methods convert business processes into graphs or trees to calculate edit distance and measure the similarity between processes. Dijkman et al. (Citation2009) used graph edit distance to measure the similarity between two processes, i.e. the minimum cost required to transform one graph into another, but cannot distinguish parallel relationships. Zhou et al. (Citation2019) first constructed weighted business process graph, and then used the weighted graph edit distance to measure business process similarity, which can distinguish parallel relationships. Jia et al. (Citation2012) measured the similarity by the tree edit distance between the two trees. Automata can be represented as directed graphs, and Wombacher and Rozie (Citation2006) analysed the structural similarity of workflows from the perspective of automata. Bae et al. (Citation2007) gave the concept of a process dependency graph and transformed this graph into a process matrix to measure the distance between processes.
For behavioural similarity, many methods are currently proposed to calculatebehavioural similarity. Wang et al. (Citation2010) studied the process similarity problem based on PTS, but divided the sequence into cyclic and acyclic structures to calculate the similarity, which destroyed the semantics of the complete sequence. Dong et al. (Citation2014) proposed to use the complete firing sequences to calculate the process similarity for the loop structure problem in Wang et al. (Citation2010), which can effectively deal with the loop structure, but the concurrent structure needs to be listed one by one. Wang et al. (Citation2013) constructed an SSDT matrix according to the shortest succession distance between task in the process, and calculated the similarity by dividing the number of the same elements in the matrix by the total number, which can deal with various structures, but cannot be used for processes index. Zha et al. (Citation2010) measure process similarity according to adjacent relations between activities and can deal with loop structures, but are insensitive to non-free choice structures and ignore the importance of adjacent relations. Yin et al. (Citation2015) added important coefficients to measure similarity based on Zha et al. (Citation2010). Weidlich et al. (Citation2010) extended the adjacent relations of activities, proposed the concept of behaviour profile, and calculated the process similarity according to the behaviour relationship, but it has limitations in the processing of hidden transition, and it is difficult to distinguish between similar structures, that is, it is not easy to retrieve. Facing the problem of process retrieval with similar structures, people hope to find a business process that meets the requirements and conditions, rather than re-develop the process by themselves. At present, most of the process retrieval is to retrieve multiple processes with similar structure, and does not consider variable constraints, such as service cost, and different service quality corresponds to different service cost. For processes that are structurally similar and indistinguishable, people prefer to choose business processes with lower costs. Therefore, this paper analyses and recommends business processes from the perspective of cost constraints.
As the premise of process recommendation, process similarity calculation either only considers process behaviour, or only considers the control flow structure of the process, and does not consider the data flow of the process, that is, the occurrence of actual activities. Based on this, this paper proposes a process similarity calculation method by synthesising the structure, behaviour and activities of the process, and adds cost constraints to recommend the process.
The main contributions of this paper are as follows:
Establish a process matrix with execution probability based on Petri net, and co-dimensionalise the matrix, describe the similarity between two processes through the maximum and minimum closeness, and establish a process set with similar structure;
Propose a process recommendation method based on cost constraints, and find out the business process with lower service cost in the process set for recommendation.
The structure of the paper is as follows: Section 2 introduces a motivation example, Section 3 gives the basic concepts, and Section 4 introduces the method of calculating similarity between processes. Section 5 describes the cost-based process recommendation algorithm, Section 6 experimental analysis, Section 7 conclusions and future directions.
2. Motivation
Taking the three bank loan processes ,
and
in as an example, analyse the similarity of
,
and
from the perspective of process behaviour.
Figure 1. Bank loan process.
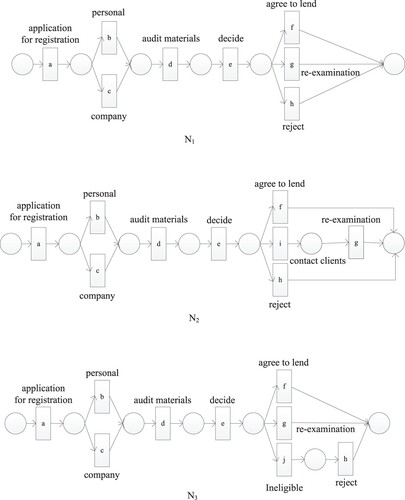
The similarity between two processes is calculated according to the transition adjacency relation proposed by Zha et al. (Citation2010). The transition adjacency sets of ,
and
are respectively
According to the similarity formula , we can get
At this time, the structure of the process is similar, and the similarity between
and
and the similarity between
and
cannot be distinguished according to the transition adjacency relationship, that is, further process recommendation cannot be performed. We improve the calculation method of process similarity, first analyse the activity execution probability, and establish a process matrix, use the concept of closeness in fuzzy mathematics to measure the similarity of two processes, and construct a process set with similar structure, and then a cost constraint-based process recommendation method is proposed to find out the business process with lower service cost in the process set, that is, the business process we want to recommend.
3. Basic concept
The establishment of business process model is crucial to the realisation of process recommendation. There are many modelling notations such as Event-Driven Process Chaining (EPC) (Van der Aalst, Citation1999), UML Activity Diagram (Eshuis & Wieringa, Citation2004), Business Process Modeling Notations (BPMN) (Weske, Citation2019) and Petri Nets (Cheng et al., Citation2014), by comparing, this paper uses Petri net to represent the business process model. At present, Petri nets have been widely used in intelligent manufacturing systems, communication and artificial intelligence, etc. Different forms of model expansion are carried out on the basis of retaining the basic Petri net model structure and representation method. The process modelling results are easier to understand, such as the extension of the transition connotation in the Petri net to obtain a Petri net with labels, which is defined as follows:
Definition 3.1
((Labelled Petri Net) (Wang et al., Citation2021)): A 5-tuple that satisfies the following conditions is called a labelled Petri net:
;
Definition 3.2
((Trace, Event Log) (Fang et al., Citation2020)): Let be the active transition set of transitions, then the active label sequence is called trace
;
is the multi-set of traces, called the event log, in short, the active labels in the trace only the name, while the active label in the log contain timestamps, resources, etc.
During the actual execution of the business process, some activities may be easy to perform, and others may not occur. The actual implementation of the net of is shown in .
Table 1. Activity performance.
Definition 3.3
(Activity execution probability): Let N be a labelled Petri net, L is the trace set of the event log, which contains traces in total, and the execution probability
of each activity t in N is the participation rate of each activity in the event log, that is
, where
is the number of occurrences of t in the trace.
Definition 3.4
(Low Frequency Sequence): Let L be the event log, which contains K traces in total. For any trace, the frequency of occurrence in the event log is
, then the occurrence frequency of this trace is
, If the frequency of occurrence is lower than a given threshold
, the trace is a low frequency sequence.
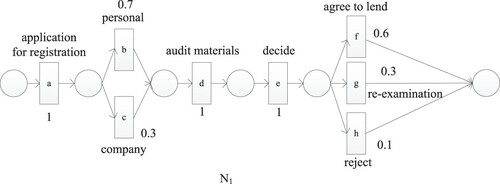
Let , and the occurrence frequency of trace acdgf is
, which is a low-frequency sequence. At this time, preprocessing is performed to delete it. Then combine and to get the execution probability of each activity in the net
, such as
. The execution probability graph of net
is shown in .
Figure 2. Petri net with execution probability.
Definition 3.5
(Adjacent Activity): In the process model, ,
is the adjacent activity if and only if there is an occurrence sequence
, such that
,
, where
.
For example, the adjacent activities in are ab, ac, bd, cd, etc.
Definition 3.6 (Process Matrix): Let N be a labelled Petri net, and the process matrix NM of N is as follows:
(1)
(1)
For example,
,
in
, the process matrix of
is shown in . According to the actual situation, the process matrix of
and
can be obtained in the same way, as shown in Tables and .
Table 2. Process matrix for N1.
Table 3. Process matrix for N2.
Table 4. Process matrix for N3.
Observing the three process matrices, it is found that the dimensions of the matrices are different, so to compare the similarity of the two processes through the process matrix, the process matrix needs to be co-dimensionalised.
Definition 3.7 (Homodimensionalisation of Process Matrix): Let and
be two labelled Petri net processes,
and
are corresponding process matrices,
and
are homodimensional process matrices, defined as follows:
The matrix
For example, the process matrices of ,
and
are co-dimensionalised to obtain Tables .
Table 5. Homogeneous matrix of N1.
Table 6. Homogeneous matrix of N2.
Table 7. Homogeneous matrix of N3.
4. Similarity between business processes
Nearness degree is the degree of similarity between fuzzy sets described in fuzzy mathematics (Xie & Liu, Citation2013). This paper adopts the concept of nearness degree to measure the degree of similarity between business processes.
Definition 4.1
(Nearness Degree): is the nearness degree of A and B, iff
if
Definition 4.2
(Proximity Principle): It is assumed that there are m fuzzy subsets on the universe X to form a standard model library, B is the model to be identified, if there is
such that
, then B is said to be the closest to
, or B into the AK category, this is the proximity principle.
Definition 4.3
(Biggest–Smallest Approach Degree): Let and
be two labelled Petri net, the biggest–smallest approach degree of
and
is defined as
(4)
(4)
where
.
For example, calculate the biggest–smallest approach degree between and
and between
and
.
In addition to the biggest–smallest approach degree, the approach degree includes lattice approach degree, distance approach degree, and minimum approach degree, etc. The calculation methods are as follows ():
Table 8. Comparison of calculation methods for approach degree.
Lattice approach degree:
(5)
(5)
Distance approach degree:
(6)
(6)
Minimum approach degree:
(7)
(7)
Comparing the four approach degree,
. In order to select the appropriate approach degree to calculate the similarity, we calculate the average value of the four methods to be 0.775. At this time, the biggest–smallest approach degrees are the closest to the average value, so the biggest–smallest approach degrees are selected as the method to calculate the similarity, namely
Table
For ,
, the optimal process cannot be selected. In order to select the business process with the lowest cost service, this paper proposes a process recommendation method based on cost constraints.
5. Process recommendation method based on cost constraints
In the actual execution process of the process, there may be certain preferences, which make some activities have a high probability of execution, and some activities have a low probability of execution, correspondingly, some paths are frequent sequences, and some paths are infrequent sequences. Since is similar in structure to
and
, and the similarity is the same, in order to distinguish, add a double constraint, that is, the cost constraint, and choose the process with less cost of the two, which is the process we finally choose. Therefore, a process recommendation method based on cost constraints is proposed.
Definition 5.1
(Cost Constraint): The cost constraint is denoted by the interval , where
and
are non-negative real numbers, and
, the length of the cost constraint
is denoted by
.
Definition 5.2
(Occurring Sequence Set): Let N be a labelled Petri net, the set of all possible occurring sequences from the start node to the target node, denoted as SN.
Definition 5.3
(Frequent Sequence, Sequence Cost): Any occurrence sequence ,
represents the length of the occurrence sequence, then the occurrence probability of
is
, if
(threshold), then
is called a frequent sequence. Call
the cost of the sequence occurrence, where the cost of
is determined by the length of the cost constraint.
Table
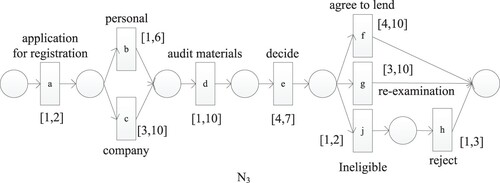
Example: calculate the probabilistic cost of and
, and the probabilistic cost of
and
(Figures and ).
Figure 3. Cost constraint of N2.
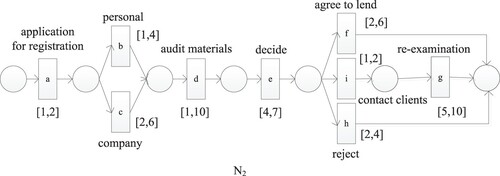
Figure 4. Cost constraint of N3.
Let , the frequent sequence of process
is
, and the occurrence sequence of process
is most similar to the frequent sequence of process
, which are
,
, and
. The consumption costs of these three sequences are 24, 23, and 26, respectively, and the probabilistic cost is
; The occurrence sequence of process
is most similar to the frequent sequence of process N1, which are
,
, and
. The consumption costs of these three sequences are 29, 30 and 31, respectively, and the probabilistic cost is
. Therefore, process
is selected as the optimal process of process
(Tables and ).
Table 9. Occurrence sequence and occurrence probability of N1.
Table 10. Occurrence sequence and consumption cost of N3.
Table 11. Occurrence sequence and consumption cost of N3.
6. Experiment and evaluation
6.1. Feasibility analysis of similarity calculation method
The similarity between the processes is calculated by using the current mainstream similarity algorithm, and compared with the calculation method in this paper. The results are shown in . The result of algorithm 1 is 0.78, and the result of the mainstream algorithm is in the range of 0.7∼0.94, so it is feasible.
Table 12. Algorithm comparison.
6.2 .Time complexity analysis
Algorithm 1 mainly consists of two parts: calculating the homodimension matrix and calculating the similarity. For the homodimension matrix, if the order is n, the complexity of the homodimension matrix is . Similarity calculation involves the calculation of
. At this time, the time complexity is
, so the total time complexity is
.
Algorithm 2: The number of occurrence sequences of and
is
and
respectively, and the time required to traverse each occurrence sequence of
and
, and calculate the similarity, and the required time is
.
6.3. Performance evaluation
To evaluate the performance of the algorithm, this paper manually created 200 process models and randomly assigned them into 3 datasets, where dataset 1, dataset 2 and dataset 3 contained 38, 62 and 100 process models, respectively.
We know that the greater the distance between the two processes, the smaller the similarity, and conversely, the smaller the distance, the greater the similarity. The similarity can be converted into distance to check the related properties. The distance between the two processes is .
Non-negativity: the distance between two processes
, So it is non-negative.
Symmetry: The distance between any two processes is unique,
Identity: If the two processes are the same, the distance between them is 0, that is,
Triangular inequality: Given any three processes N1, N2 and N3 and the distances
For the verification of the triangle inequality, it is converted into the triangle inequality satisfaction rate for verification. Assuming that there are a total of n process models, three are randomly selected from them, and there are ways of taking them. If m of them satisfy the triangle inequality, the satisfaction rate of the triangle inequality is
.
Comparing the triangular inequality satisfaction rate of mainstream algorithms (), it is found that SSDT algorithm and CF algorithm are poor in triangular inequality satisfaction rate, PTS only has some data satisfying triangular inequality, TAR, GED, BP, Algorithm 1 has a better satisfaction rate than PTS, SSDT and CF algorithms.
Figure 5. Comparison of Triangular Inequality Satisfaction Rates.
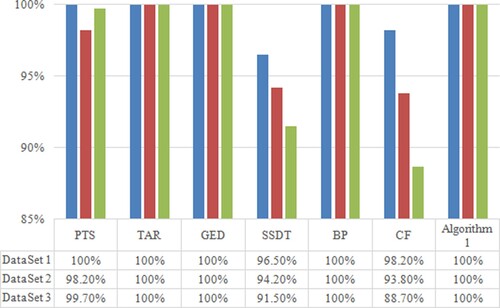
In addition to satisfying the above four properties, the similarity algorithm in this paper is also related to data and cost ().
Table 13. Performance comparison of different algorithms.
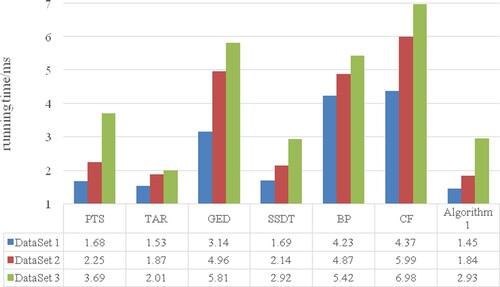
In terms of running time, the running times of different algorithms under several sets of data sets are compared, as shown in . It is found that the CF algorithm is time-consuming and has poor running efficiency. The time consumption of algorithm 1 is lower than that of the other algorithms except that of the TAR algorithm.
Figure 6. Comparison of running time.
7. Conclusion and future
In order to simplify the working procedure of enterprises and avoid unnecessary expenses, a process recommendation method based on cost constraint is proposed to solve the existing problems in process retrieval. First, the concept of activity execution probability is given, the execution probability of each activity is calculated, and a process matrix is constructed based on this, and then the similarity between processes is calculated by the biggest–smallest approach degree, and the process set with similar structure is found. Finally, in order to distinguish processes with similar structures, a cost constraint-based process recommendation method is proposed to find out the business processes with lower service cost in the process set. The experimental results show that the similarity calculation is feasible, and the business process with lower cost is recommended. Although the data and cost are considered, the operation efficiency is not worse than other algorithms.
However, the method proposed in this paper requires a process model and a specific process execution log. Compared with other methods, the input conditions are more, and the infrequent behaviour is directly ignored when calculating the execution probability. In the future, in addition to considering infrequent behaviours, further research will be done on the application of process recommendation methods to industrial scenarios to make the methods more adaptable.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Bae, J., Liu, L., Caverlee, J., Zhang, L. J., & Bae, H. (2007). Development of distance measures for process mining, discovery and integration. International Journal of Web Services Research, 4(4), 1–17. https://doi.org/10.4018/jwsr.2007100101
- Bergmann, R., & Gil, Y. (2014). Similarity assessment and efficient retrieval of semantic workflows. Information Systems, 40(MARa), 115–127. https://doi.org/10.1016/j.is.2012.07.005
- Chen, X., Lu, R., Ma, X., & Pang, J. (2014). Measuring user similarity with trajectory patterns: Principles and new metrics. In L. Chen, Y. Jia, T. Sellis, and G. Liu (Eds.), Web technologies and applications (pp. 437–448). Springer International Publishing. https://doi.org/10.1007/978-3-319-11116-2_38
- Cheng, J., Liu, C., Zhou, M., Zeng, Q., & Ylä-Jääski, A. (2014). Automatic composition of semantic web services based on fuzzy predicate petri nets. IEEE Transactions on Automation Science and Engineering, 12(2), 680–689. https://doi.org/10.1109/TASE.2013.2293879
- Dijkman, R., Dumas, M., & García-Bañuelos, L. (2009). Graph matching algorithms for business process model similarity search. In U. Dayal, J. Eder, J. Koehler, and H. A. Reijers (Eds.), Business process management (pp. 48–63). Springer. https://doi.org/10.1007/978-3-642-03848-8_5
- Dijkman, R., Dumas, M., Van Dongen, B., Käärik, R., & Mendling, J. (2011). Similarity of business process models: Metrics and evaluation. Information Systems, 36(2), 498–516. https://doi.org/10.1109/TASE.2010.09.006
- Dong, Z., Wen, L., Huang, H., & Wang, J. (2014). CFS: A behavioral similarity algorithm for process models based on complete firing sequences. In R. Meersman, H. Panetto, T. Dillon, M. Missikoff, L. Liu, O. Pastor, A. Cuzzocrea, and T. Sellis (Eds.), On the move to meaningful Internet systems: OTM 2014 conferences (pp. 202–219). Springer. https://doi.org/10.1007/978-3-662-45563-0_12
- Dongen, B. V., Dijkman, R., & Mendling, J. (2013). Measuring similarity between business process models. In J. Bubenko, J. Krogstie, O. Pastor, B. Pernici, C. Rolland, and A. Sølvberg (Eds.), Seminal contributions to information systems engineering: 25 years of CAiSE (pp. 405–419). Springer. https://doi.org/10.1007/978-3-642-36926-1_33
- Ehrig, M., Koschmider, A., & Oberweis, A. (2007). Measuring similarity between semantic business process models. In APCCM (Vol. 7, pp. 71–80). https://dl.acm.org/doi/10.55551274453.1274465
- Eshuis, R., & Wieringa, R. (2004). Tool support for verifying UML activity diagrams. IEEE Transactions on Software Engineering, 30(7), 437–447. https://doi.org/10.1109/TSE.2004.33
- Fang, H., Li, D., Sun, S., & Fang, X. (2020). Process conformance checking method based on alignment of direct succession relations. Computer Integrated Manufacturing Systems, 26(6), 1473–1482. https://doi.org/10.13196/j.cims.2020.06.004
- Fu, Y., Hou, Y., Wang, Z., Wu, X., Gao, K., & Wang, L. (2021). Distributed scheduling problems in intelligent manufacturing systems. Tsinghua Science and Technology, 26(5), 625–645. https://doi.org/10.26599/TST.2021.9010009
- Jia, N., Fu, X., Huang, Y., Liu, X., & Dai, Z. (2012). Workflow distance metric based on tree edit distance. Journal of Computer Applications, 32(12), 3529–3533. http://www.joca.cn/EN/10.3724SP.J.1087.2012.03529 https://doi.org/10.3724/SP.J.1087.2012.03529
- Levenshtein, V. I. (1966). Binary codes capable of correcting deletions, insertions, and reversals. In Soviet Physics Doklady, 10(8), 707–710. http://mi.mathnet.ru/eng/dan/v163/i4/p845
- Liu, C., Zeng, Q., Duan, H., Gao, S., & Zhou, C. (2019). Towards comprehensive support for business process behavior similarity measure. IEICE TRANSACTIONS on Information and Systems, 102(3), 588–597. https://doi.org/10.1587/transinf.2018EDP7127
- Ma, Y., Zhang, X., & Lu, K. (2014). A graph distance based metric for data oriented workflow retrieval with variable time constraints. Expert Systems with Applications, 41(4), 1377–1388. https://doi.org/10.1016/j.eswa.2013.08.035
- Shao, Q., Yu, R., Zhao, H., Liu, C., Zhang, M., Song, H., & Liu, Q. (2021). Toward intelligent financial advisors for identifying potential clients: A multitask perspective. Big Data Mining and Analytics, 5(1), 64–78. https://doi.org/10.26599/BDMA.2021.9020021
- Van der Aalst, W. M. (1999). Formalization and verification of event-driven process chains. Information and Software Technology, 41(10), 639–650. https://doi.org/10.1016/S0950-5849(99)00016-6
- Van der Aalst, W. M. P., de Medeiros, A. K. A., & Weijters, A. J. M. M. (2006). Process equivalence: Comparing two process models based on observed behavior. In S. Dustdar, J. L. Fiadeiro, & A. P. Sheth (Eds.), Business process management (pp. 129–144). Springer. https://doi.org/10.1007/11841760_10
- Wang, J., He, T., Wen, L., Wu, N., Ter Hofstede, A. H., & Su, J. (2010). A behavioral similarity measure between labeled Petri nets based on principal transition sequences. In OTM Confederated International Conferences “On the Move to Meaningful Internet Systems” (pp. 394–401). Springer. https://doi.org/10.1007/978-3-642-16934-2_27
- Wang, L. L., Fang, X. W., Shao, C. F., & Asare, E. (2021). An approach for mining multiple types of silent transitions in business process. IEEE Access, 9, 160317–160331. https://doi.org/10.1109/ACCESS.2021.312857
- Wang, S., Wen, L., Wei, D. S., Wang, J., & Yan, Z. Q. (2013). SSDT matrix-based behavioral similarity algorithm for process models. Computer Integrated Manufacturing Systems, 19(8), 1822–1831. https://doi.org/10.13196/j.cims.2013.08.023
- Weidlich, M., Mendling, J., & Weske, M. (2010). Efficient consistency measurement based on behavioral profiles of process models. IEEE Transactions on Software Engineering, 37(3), 410–429. https://doi.org/10.1109/TSE.2010.96
- Weske, M. (2019). Business process management architectures. In M. Weske (Ed.), Business process management: Concepts, languages, architectures (pp. 351–384). Springer. https://doi.org/10.1007/978-3-662-59432-2_8
- Wombacher, A., & Rozie, M. (2006). Evaluation of workflow similarity measures in service discovery. In Service-Oriented Electronic Commerce, Proceedings zur Konferenz im Rahmen der Multikonferenz Wirtschaftsinformatik (pp. 20–22). https://dl.gi.de/handle/20.500.12116/24294
- Wu, J., Sun, X., Wu, J., & Han, G. (2021). Routing strategy of reducing energy consumption for underwater data collection. Intelligent and Converged Networks, 2(3), 163–176. https://doi.org/10.23919/ICN.2021.0012
- Xie, J., & Liu, C. (2013). Fuzzy mathematics method and its application. Huazhong University of Sclence & Technology Press.
- Yan, Z., Dijkman, R., & Grefen, P. (2010). Fast business process similarity search with feature-based similarity estimation. In OTM Confederated International Conferences “On the Move to Meaningful Internet Systems” (pp. 60–77). Springer. https://doi.org/10.1007/978-3-642-16934-2_8
- Yin, M., Wen, L. J., Wang, J. M., Xiao, H., Ding, Z., & Gao, X. (2015). Process similarity algorithm based on importance of transition adjacent relations. Computer Integrated Manufacturing Systems, 21(2), 344–358. https://doi.org/10.13196/j.cims.2015.02.007
- Zha, H., Wang, J., Wen, L., Wang, C., & Sun, J. (2010). A workflow net similarity measure based on transition adjacency relations. Computers in Industry, 61(5), 463–471. https://doi.org/10.1016/j.compind.2010.01.001
- Zhou, C., Liu, C., Zeng, Q., Lin, Z., & Duan, H. (2019). A comprehensive process similarity measure based on models and logs. IEEE Access, 7, 69257–69273. https://doi.org/10.1109/ACCESS.2018.2885819