
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Morphological segmentation is a basic task in agglutinative language information processing, dividing words into the smallest semantic unit morphemes. There are two types of morphological segmentation: canonical segmentation and surface segmentation. As a typical agglutinative language, Uyghur usually uses statistical-based methods in canonical segmentation, which relies on the artificial extraction of features. In surface segmentation, the artificial feature extraction process is avoided by using the neural network. However, to date, no model can provide both segmentation results in Uyghur without adding features. In addition, morphological segmentation is usually regarded as a sequence annotation task, so label imbalance easily occurs in datasets. Given the above situation, this paper proposes an improved labelling scheme that joins morphological boundary labels and voice harmony labels for the two kinds of segmentation simultaneously. Then, a convolution network and attention mechanism are added to capture local and global features, respectively. Finally, morphological segmentation is regarded as a sequence labeling task of character sequences. Due to the problem of label proportion imbalance and noise in the dataset, a focal loss function with label smoothing is used. The experimental results show that the F1 values of canonical segmentation and surface segmentation achieve the best results.
1. Introduction
Morphological segmentation, also known as morpheme segmentation (Sorokin, Citation2019), refers to the segmentation of a given word into meaningful independent units called morphemes. These independent units are the manifestations of the underlying abstract morphemes, and different contexts have different forms. For languages with complex morphology, morphological segmentation is an indispensable step in natural language processing (NLP) (Wang et al., Citation2019), which can reduce the word space of models and effectively reduce problems such as data sparseness. Therefore, morphological segmentation has been widely used in NLP downstream tasks such as named entity recognition, speech recognition, and machine translation (Abudubiyaz et al., Citation2020; Bareket & Tsarfaty, Citation2021; Ortega et al., Citation2020).
In the literature, most researchers divide segmentation methods into two types (Moeng et al., Citation2021), namely, canonical segmentation and surface segmentation. This is because when morphemes are connected, due to the phenomenon of voice harmony, characters weaken, lose or insert the connection between morphemes, resulting in changes in the form of morphemes. The process of restoring these phenomena are called voice harmony restoration (Haibo et al., Citation2014). Table below shows some examples:
Table 1. The difference in surface and canonical segmentation in Uyghur.
In the above examples, it is easy to see the difference between the two segmentation methods. Surface segmentation refers to the segmentation of a word into its connected morpheme sequence, while canonical segmentation refers to the segmentation of a word into standard forms of morphemes it connects to. Therefore, voice harmony restoration can be regarded as a process that changes from surface segmentation to canonical segmentation. From Table , we find that compared with surface segmentation, canonical segmentation has more challenges and opportunities, and thus, it has received increasing attention from researchers in the last few years. The original morphological segmentation, for the identification of English morpheme boundaries, can be traced back to 1955 (Harris, Citation1955). At present, mature and open morphological segmentation tools can be found in languages, including English, Finnish and Chinese, which not only promotes these languages’ information processing technology but also influences the development of morphological segmentation technology in other languages.
In natural language processing, the most important parts are the data and algorithms. Although related datasets have been constructed in Uyghur morphological segmentation, there are few data resources available. Abudukelimu et al. (Citation2018) constructed the Uyghur morphological segmentation dataset (THUUyMorph), which included the surface segmentation dataset and the canonical segmentation dataset to ensure that THUUyMorph solved the lack of resources problem. The morphological segmentation models of Uyghur have rule-, dictionary – or feature-based methods and neural network-based methods. With the development of technology, Uyghur morphological canonical segmentation mainly focuses on dictionary-based methods and statistical methods (Haibo et al., Citation2014; Parhat et al., Citation2019; Sardar et al., Citation2020). Generally, this segmentation uses a lexicon, grammatical rules, finite state automata or grammatical features to construct models. Usually, language rules and manually extracted features are only applicable to one language. With poor transferability and small coverage, this model has room for performance improvement. Neural networks are mainly used for surface segmentation. Based on the THUUyMorph dataset, Abudukelimu et al. (Citation2017) regard morphology segmentation as sequence labeling tasks, and they first proposed a deep learning Uyghur morphological segmentation model. The segmentation results are compared with the conditional random field model (CRF) and Morfessor. Experimental results show that the deep learning model effectively reduces the problem of data sparsity, and the model performance is relatively high. Yang et al. (Citation2019) found that (B, M, E, S) labels only use the B label and the S label to correct the segmentation, and thus, fewer independent labels are used, while the pointer network is used to analyze the morphology. Segmentation task modelling resolves the label dependence problem and improves the robustness of the model (Liu et al., Citation2021).
Although the existing research has achieved good results, the canonical segmentation of Uyghur also relies on rules or statistical methods. The rules method requires linguistic rules. Then, statistical methods need to manually extract features. Surface segmentation has used neural network methods based on sequence labeling. In sequence labeling, position labels are usually used, and thus, there is a label dependence problem (Yang et al., Citation2019). In addition, there is also some noise caused by labelling in the dataset, inconsistent labels, and mislabelling. Therefore, in these two segmentation methods, there is a certain research space and room for improvement in the model’s performance.
Unlike previous studies, this paper proposes an improved tagging scheme and Uyghur morphological segmentation model with an attention mechanism. The tagging scheme joins morphological position and voice harmony. Joint labels act on both surface segmentation and canonical segmentation, which avoids error propagation. The convolutional networks and attention mechanism are used to extract features in the model, which reduces the manual feature extraction process. To improve the cross-entropy loss function, the label imbalance problem is alleviated. The experimental results show that in the method proposed in this paper, the surface segmentation and canonical segmentation F1 value achieves 97.70% and 89.48% on THUUyMorph, respectively. The main contributions of this paper are as follows:
An improved tagging scheme is proposed to jointly label morphological position and voice harmony, which can easily transform the two segmentation tasks into character sequence labeling.
Combined with the attribution of morphological segmentation, a convolutional neural network and an attention mechanism are used to extract features to ensure that the feature extraction layer automatically learns character features and captures the characteristics of the internal structure of words. The cross-entropy loss function is changed into the focus loss function, and label smoothing technology is introduced to improve the robustness of the model.
The method proposed in this paper achieves a state-of-the-art F1 value on the THUUyMorph dataset.
2. Related work
Morphological segmentation has progressed from initial morpheme boundary recognition to morpheme segmentation to morpheme restoration. The research methods of morphological segmentation can be roughly divided into rule-based, statistical learning-based and neural network-based methods. The initial research used dictionaries or finite-state automata for morpheme segmentation. This method relies on grammatical rules and requires building a rule base. Neither can it combine context information, nor can it work when rule conflict or ambiguity occurs. Compared with the rule method, the performance of statistical learning is better, and there is no need to build a large dictionary and complicated grammar rules. Improving the performance of the model still relies on key artificial feature engineering. With the rise of deep learning models, researchers have found that the performance of neural network models is higher than that of traditional machine learning fusion feature engineering models without manual intervention. Therefore, deep learning models are widely used in various fields (Lin et al., Citation2022; Wu et al., Citation2022; Xu et al., Citation2022; Yan et al., Citation2021). In addition, the proposal of pretrained models also accelerate the development of natural language processing techniques (Cao et al., Citation2021; Wu et al., Citation2022; Yan et al., Citation2021; Zhang et al., Citation2022; Zhao et al., Citation2020; Zhao et al., Citation2022). Similarly, these novel models have also become mainstream models in the recent morphological segmentation task.
In surface segmentation, researchers tend to use sequence labeling methods to label morphemes through BMES labelling. Sorokin and Kravtsova (Citation2018) annotated morphemes using BMES on a deep convolutional neural network model. Based on the study of (Sorokin & Kravtsova, Citation2018), Sorokin (Citation2019) also used the BMES labelling method to propose a multitask training model for low-resource morphological segmentation, which not only predicts the segmentation result of the current word but also predicts the next word. Moeng et al. (Citation2021) trained supervised and unsupervised morphological surface segmentation models, feature-based CRFs and entropy morphological surface segmentation models. The results showed that the feature-based CRFs were more suitable for surface segmentation than BiLSTM. In the unsupervised entropy approach to morphological surface segmentation, the character-based BiLSTM language model was used, but this model performed more poorly than Morfessor (Grönroos et al., Citation2020) in some languages. Tang et al. (Citation2022) proposed a Chinese word segmentation model based on a heterogeneous graph neural network, which encodes multilevel external information by combining a pretraining language model and a heterogeneous graph neural network. In a study of Uyghur morphological segmentation in recent years, Haibo et al. (Citation2014) argued that the error rate of voice harmony restoration would directly affect the correct rate of morphological segmentation. Thus, they proposed a joint voice harmony restoration and morphological segmentation model for morphological analysis. Abudukelimu et al. (Citation2017) regarded morphological segmentation as a sequence annotation task introduced (B, M, E, S) labels and proposed a morphological surface segmentation model based on GRU. If labels are used, there will be a label dependence problem. Therefore, Yang et al. (Citation2019) proposed a morphological surface segmentation method for pointer networks with attention, and the model achieves state-of-the-art segmentation results. As a morphological segmentation-derived task, stemming refers to extracting stem morphemes after morphological segmentation, which is also regarded as a sequence annotation task. Abudouwaili et al. (Citation2019) proposed a stemming model based on the Bi-LSTM-CRF model, used (B, I, O) labels, and combined phonological features with phonetic features. Based on the BiLSTM-CRF model, Imin et al. (Citation2022) added the stem and suffix labels to the tags and proposed a multilingual stemming model (supporting Uyghur, Kazakh and Kirgiz) with an attention mechanism.
By analyzing the above literature, we reached some conclusions. First, the research method of surface segmentation is relatively simple and is usually regarded as the task of sequence annotation. Second, the morpheme boundaries are learned by introducing (BIO or BMES) labels to annotate the character position. However, the label distribution will be affected by the word length; that is, the longer the word is, the number of labels representing the middle position will be much greater than that of other labels, which easily causes model overfitting by label independence and unbalanced distribution.
Because the voice harmony needs to be restored in the canonical segmentation, the task difficulty degree is higher than the surface segmentation, and the sequence labeling cannot be simply used. In earlier studies, researchers preferred to use the minimum editing distance. Although this method is relatively simple, the performance of the model is poor. With the rise of deep learning technology, many canonical segmentation research methods have been proposed. Moeng et al. (Citation2021) proposed the seq2seq model for the canonical segmentation task. Brusilovsky and Tsarfaty (Citation2022) proposed a morphological segmentation model based on the character encoding-decoding model, which improved the performance of the model by adding a contextualized vector. Mager et al. (Citation2020) proposed two new models for the task of canonical segmentation in the low-resource setting: an LSTM pointer-generator model and a neural transducer trained with imitation learning. Due to the strong connection between morphological segmentation and morphological analysis, researchers also used a pipeline model for both tasks (Li & Girrbach, Citation2022; Seker & Tsarfaty, Citation2020), which predicts the results of morphological analysis through the results of segmentation. Compared with surface segmentation, Uyghur canonical segmentation has fewer relevant studies, and the method is relatively old. Munire et al. (Citation2019) combined linguistic rules and statistical methods and proposed a Uyghur noun reinflection model to achieve harmony. Osman et al. (Citation2019) combined morpheme boundaries, annotations and phonetic changes into a composite label and proposed a character-level morphological collaborative analysis by using CRF. Chun et al. (Citation2018) regarded morphological segmentation and voice harmony restoration as sequence labeling problems based on character classification. They proposed a discriminant model of a graphic structure by describing the correlation between the morphological components of the words inside and adjacent words.
From these related works, there are many research methods of canonical segmentation, but surface segmentation or other additional features are usually added to improve the performance of the model, which is prone to propagation errors and cannot provide two segmentation methods simultaneously. The Uyghur surface segmentation method is old and usually relies on manual feature extraction.
Therefore, based on previous studies, this paper proposes an improved joint label that regards morphological segmentation as a sequence labeling task, replaces the manual feature extraction process through a convolution network and an attention mechanism, and predicts the two segmentation results at the same time. To address the problem of unbalanced label distribution, label smoothing technology is introduced into the loss function, which improves the robustness of the model.
3. The Uyghur morphological segmentation model with attention
We propose a Uyghur morphological segmentation model with an attention mechanism using a joint label. In this section, we focus on defining the morphological segmentation task, the improved tagging scheme and the model proposed in this paper.
3.1. Task definition
Given any word that consists of
characters or
morphemes, i.e.
or
, where
. The canonical segmentation of morphology refers to the restoration of morphemes on the basis of surface segmentation to obtain the standard forms of morphemes. There is a word,
(W consists of l morphemes), and W is divided to obtain l morphemes. Each morpheme is composed of several characters. When the morphemes are connected, the following phenomena occur in the characters inside the morpheme: character insertion
, character deletion
, character replacement
or no change
. We suppose the j-th morpheme in word W is composed of n characters, or
. Since any one of the first three phenomena occurs in the morpheme, the morpheme obtained after surface segmentation is a nonstandard morpheme and, as a result, needs to be restored to obtain standard morphemes.
3.2. The tagging scheme
To avoid the influence of voice harmony restoration and error propagation on morphological segmentation, this paper uses an improved morphological tagging scheme. We tag the morphological position and voice harmony of each character. The morphological position is tagged with the BMES label. B represents the first character of the morphology, M represents the middle character of the morphology, E represents the last character of the morphology, and S represents the single character. The voice harmony label is inspired by previous studies (Haibo et al., Citation2014; Osman et al., Citation2019). First, we use NSIR (N represents the current character no voice harmony occurs, S for the current character weakening, I for the current character insertion, R for the current character falls off between the next character) to annotate the voice harmony phenomenon that occurs in each character. Second, based on the NSIR tag, the characters are added before the change to form a voice harmony label. The two labels are merged to obtain the final joint label, and Figure shows an example.
Figure 1 Example of Label definition.

In Figure , the position label represents the position of the current character in the morphology, and the voice harmony label represents the type of voice harmony of the current character and the character before the change. For example, the joint label of the first character “i” is “M-S_a”. This means that “i” is in the middle of the current morphology, and it has weakened, weakening “i” into “a”.
3.3. The model framework
By analyzing the definition of the morphological segmentation task, the improved tagging scheme and the problems of existing methods, and referring to the character sequence labeling model, this paper proposes a Uyghur morphological segmentation model with an attention mechanism. This model includes the character feature layer, the bidirectional LSTM layer with attention mechanism, and the last layer (CRF layer/loss function). The model structure is shown in Figure . First, the character features are extracted from the word through the convolution layer, and then the character vectors and features are input into the BiLSTM layer with the attention mechanism. In this layer, the model learns the characteristics of the word vectors and the voice harmony phenomenon of each character and inputs it to the last layer. To avoid the model overfitting caused by label distribution, this paper improves the loss function to make the model more suitable for the label imbalance situation.
Figure 2. The structure of the morphological segmentation model.
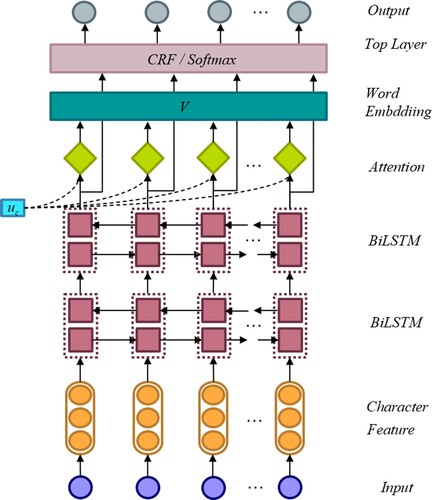
3.3.1. Character feature layer
In morphological restoration, character-level feature extraction is particularly important. In the related literature, feature engineering mainly relies on artificial feature extraction. Therefore, to reduce the manual workload, this paper uses a character-level CNN network to learn character features. The initial vector of the input character is a d-dimensional vector, or . Assuming that there is an existing convolution kernel
, the input is convolved to obtain the result O, and the formula is shown in (1). To obtain more features, n (n> = 2) convolution kernels are usually set, and they are finally spliced together to represent the output of the convolution layer, which is shown in Formula (2) as follows:
(1)
(1)
(2)
(2)
3.3.2. The BiLSTM layer with an attention mechanism
For sequence labeling tasks, the RNN model can effectively learn time-series information, and the bidirectional RNN can learn not only past but also future information. However, there is a problem of gradient disappearance or explosion for long sequences. To solve long-distance dependencies, (Hochreiter & Schmidhuber, Citation1997) proposed a variant of the RNN model LSTM, which controlled the transmission and forgetting of information through a gate mechanism. In this paper, the input of the BiLSTM model is obtained by concatenating the character feature layer and the character vector, which is shown in Formula (3). The output of the BiLSTM layer can be represented as , where
represents the forward hidden state and
represents the backward hidden state as follows:
(3)
(3) The BiLSTM output is input to the attention mechanism layer, and the characters that affect the morphological segmentation are learned through the attention mechanism. In the deep learning model, the important parts or features are calculated by the attention matrix, and the model also focuses on this important information during training. This paper refers to the soft attention mechanism in (Pappas & Popescu-Belis, Citation2017) and applies it to the morphological segmentation model. The output of BiLSTM input
into a single-layer perceptron to obtain its representation
, which is shown in Formula (4), where
;
and
represent parameters learned by the model. To measure the importance of characters, the similarity is calculated as
with the context character vector obtained by random initialisation
, and then a softmax is used to obtain its normalised attention matrix
, which represents the weight of the i-th character, which is shown in Formula (5). The word vector
is regarded as the weighted sum of the character vectors that make up these words, as shown in Formula (6). Finally, the word vector is multiplied by the output of BiLSTM to calculate the importance or the similarity as the input of the last layer as follows:
(4)
(4)
(5)
(5)
(6)
(6)
3.3.3. CRF layer
The last layer of the sequence labeling model is generally set to CRF, and thus, this paper also refers to this structure. Given a sequence of length n, , the label sequence predicted by CRF is
, and the score of the sequence is defined by Formula (7) as follows:
(7)
(7) In this paper, P is the score BiLSTM output, and
represents the score of the
-th label in the sequence in the i-th character; A is the transition matrix generated by the CRF layer, which is independent of the position, and
represents the transfer from label i to label j score.
3.3.4. Loss function
When the last layer of the model does not use CRF decoding, to reduce the impact of incorrect labels and label imbalance in the dataset on the prediction results, referring to (Müller et al., Citation2019) and (Lin et al., Citation2017), data smoothing and the focal loss function are used instead of the cross-entropy loss function (Equation Equation(8)(9)
(9) is the cross-entropy loss function), and a focal loss function with label smoothing is proposed. In Formula (8), k is the index of the label category, K is the number of labels,
is the probability that the model predicts label k, and
is the target probability of label k. When k is equal to the target label, the probability is 1; otherwise, it is 0. Formula (8) shows that only the correct labels participate in training, while the wrong labels do not. Therefore, to constrain the model confidence on the correct label, the distribution of target labels introduces
to prevent overfitting. This operation calls label smoothing, as shown in Formula (9), where
is a parameter set manually, usually set to 0.1, and K is the number of labels. The definition of focal loss is shown in Formula (10), where
and
are manually set parameters that do not participate in model parameter learning, and both are set to 0.25 and 2.0 in the paper, respectively. Then, it is not difficult to deduce the definition of the focal loss function with label smoothing through the above formulas, which is shown in Formula (11), and the parameters contained in it are explained as follows:
(8)
(8)
(9)
(9)
(10)
(10)
(11)
(11)
4. Experiment
In the experiment, we introduce the data, model hyperparameters, evaluation metrics, experimental settings, experimental results and analysis in detail.
4.1. Dataset
This paper experiments on the THUUyMorph dataset (Abudukelimu et al., Citation2018), where the surface segmentation and reduction forms of words that occur in voice harmony phenomena are annotated. With two forms, we firstly restore the words and list the canonical segmentation. Secondly, the joint label proposed in this paper is used to tag each character. In this paper, we used the 10-fold cross-validation method (train: test: dev = 8:1:1), its data size and related information are shown in Table (all averages). It is found from Table that the weakening phenomenon accounts for a large part of the dataset compared with the insertion and loss phenomenon. Due to the large difference between the ratio of each type of label, it is prone to occur label imbalance, resulting in poor model learning ability.
Table 2. Data size.
4.2. Hyperparameters
The experimental environment is based on Python 3.8Footnote1, and the deep learning framework is based on PyTorch 1.9.0.Footnote2 The hyperparameters of the model are shown in Table . In the experiment, 30 filters with a window size of [1,2,3] are used to extract character features; the bidirectional LSTM has a hidden layer and a dimension of 200, and the attention mechanism layer is also 200. To prevent overfitting, the dropout used in the model is 0.5, the batch size is 32, and the stochastic gradient descent method is used. The initial learning rate is 0.015, and the decay rate is 0.05.
Table 3. Hyperparameter settings.
4.3. Evaluation
To evaluate the morphological segmentation and restoration performance of the model and compare segmentation results generated by the model with the gold standards, we use word error rate, morpheme error rate, average edit distance, surface segmentation precision, recall, F-score, canonical segmentation precision, recall, and F-score.
4.4. Experimental setup
According to related research, this paper takes the five morphological segmentation models proposed in the last few years as baseline models (Abudukelimu et al., Citation2017; Imin et al., Citation2022; Moeng et al., Citation2021; Osman et al., Citation2019; Yang et al., Citation2019). The first baseline model (Moeng et al., Citation2021) is the canonical segmentation model based on the transformer. Therefore, only the canonical segmentation results are compared in the experiment. The second baseline model (Osman et al., Citation2019) is a CRF-based morphological collaborative analysis model, which combines morpheme segmentation, morphological annotation, and a reduction in phonetic changes to analyze words. Since the focus of this paper is not on morphological analysis, the morphological labels are ignored in the model, and only segmentation labels and voice harmony labels are referred to. The third baseline model (Abudukelimu et al., Citation2017) is a morphological segmentation model based on BiGRU, where only morphological surface segmentation is studied. The fourth model (Yang et al., Citation2019) is based on the pointer network, which is the best model of surface segmentation in Uyghur. The fifth model (Imin et al., Citation2022) is a multilingual stemming model of characters based on BiLSTM-ATT-CRF. The last three models only study surface segmentation. Likewise, the surface segmentation results are compared in the experiment.
This paper regards the morphological segmentation task as a sequence labelling task. BiLSTM and CRF are the classical models of sequence labelling task, so we selected this model as the benchmark and carried out related experiments. To further verify the effectiveness of the proposed model, we compare the experimental results of the following models on the same dataset and parameters. Please refer to Section 4.2 for the hyperparameters.
BiLSTM: The bidirectional long short-term memory model is the first choice for sequence labeling tasks and can better capture information through learning both forward and backward.
CNN-BiLSTM: A convolutional neural network is a strong feature extractor that can reduce the process of manual feature extraction.
BiLSTM-ATT: Combined with the BiLSTM model of the soft attention mechanism, more important lexical information can be learned based on the BiLSTM.
BiLSTM-MHSA (Vaswani et al., Citation2017): A model combining the multihead attention mechanism used in the transformer and the BiLSTM, the number of heads in this paper is 4.
BiLSTM-CRF: The BiLSTM prediction results are constrained by the CRF layer, which is suitable for sequence labeling tasks.
CNN-BiLSTM-ATT: The BiLSTM model combines a CNN and the attention mechanism proposed in this paper.
CNN-BiLSTM-CRF: This is the fusion of a CNN and the BiLSTM-CRF model proposed in this paper.
CNN-BiLSTM-ATT-CRF: This is the BiLSTM-CRF model that combines a CNN and the attention mechanism proposed in this paper.
CNN-BiLSTM-ATT_FL: This improves the loss function of the CNN-BiLSTM-ATT model and introduces label smoothing.
CNN-BiLSTM-ATT_FLLS: The CNN-BiLSTM-ATT model with a label smoothing focal loss function proposed in this paper can resolve the problem of low model performance caused by noise (label error) or label imbalance in the data.
4.5. Experimental results and analysis
The comparison of related works and the ablation study results are shown in Tables and . The data used in the experiments are all the same.
A comparison with related work
Table 4. Comparative experiments with related work.
Table 5. Results of the ablation study experiments.
Ablation Study
In Table , the model proposed in this paper is compared with the other nine models, and the following points are found through experiments. (1) Compared with the BiLSTM model, the word error rate, morpheme error rate and average edit distance of CNN-BiLSTM decreases by 0.716%, 0.750%, and 1.561%, respectively, and the experimental results of the surface segmentation and the canonical segmentation are also improved. A character feature extraction layer CNN can indeed effectively extract key features. (2) In the BiLSTM, BiLSTM-ATT and BiLSTM-MHSA models, the soft attention mechanism used in this paper is more suitable for the Uyghur morphological segmentation task than the multihead self-attention mechanism. The word error rate, morpheme error rate and average edit distance drops to 7.780%, 8.646% and 8.837%, respectively. Canonical segmentation has been substantially improved. (3) Usually, after the BiLSTM model is added to the CRF layer, the model performance improves. However, the experimental results of the BiLSTM and BiLSTM-CRF models are similar, and some results are even lower. (4) Between the four models, such as the CNN-BiLSTM, the CNN-BiLSTM-ATT, the CNN-BiLSTM-CRF and the CNN-BiLSTM-ATT-CRF, the result of the CNN-BiLSTM-ATT-CRF has been considerably improved compared with the previous models, and the word error rate, morpheme error rate and average edit distance drop to 6.778%, 7.660% and 6.849%, and the surface segmentation and canonical segmentation F1 values reach 96.748% and 85.495%. The attention mechanism and the CRF layer also work, the attention mechanism captures important morphological information, and the CRF constraints the labels. (5) Due to the label imbalance and noise in the dataset, this paper improves the robustness of the model by modifying the loss function and reducing the impact of label imbalance and noise on the model. Compared with the CNN-BiLSTM-ATT_FLLS, the word error rate, morpheme error rate, and average edit distance are reduced by 0.857%, 1.187%, and 2.472%, respectively. The F1 value of the surface segmentation and the canonical segmentation increase by 0.92% and 3.696%, respectively.
Learning Hyperparemeters
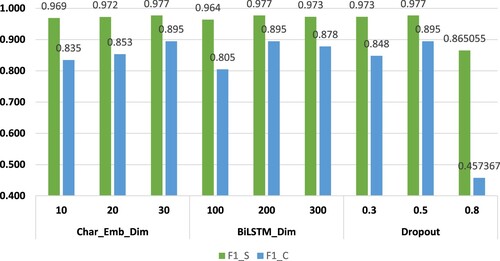
To study the influence of hyperparameters on the CNN-BiLSTM-ATT_FLLS model, this paper conducts a set of verification experiments for the character vector dimension, BiLSTM dimension, and drop rate. The experimental results are shown in Figure . When the character vector dimension is 30, the BiLSTM dimension is 200, and the dropout is 0.5, the model achieves a better performance. When the hyperparameter takes other values, such as when the character vector dimension is 10 and the BiLSTM dimension is 100 or 300, the model fails to learn features carefully or learns noisy information, leading to overfitting.
Figure 3. Effects of different hyperparameters on model performance.
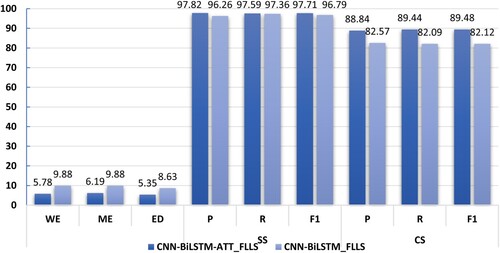
To further explore the impact of the attention mechanism used on the two segmentation methods, in this paper, the models with attention mechanism and without attention mechanism are verified, and the experimental results are shown in Figure . The CNN-BiLSTM-ATT_FLLS model has better performance than CNN-BiLSTM_FLLS on both segmentations. Comparing the two segmentations, surface segmentation is relatively simple and does not require voice harmony restoration, while canonical segmentation does, so the model needs to be sensitive to characters that have voice harmony. During training, the model makes the attention vector more similar to the character embedding that will appear in voice harmony, so that the distance between the two vectors is closer. Although different words have the same character or morphology, they express different information. Therefore, it is necessary to use the attention mechanism to capture information rather than simple unified processing. Since this paper predicts both surface segmentation and canonical segmentation, the two segmentation results do not affect each other, so there is no error propagation problem cause by surface segmentation.
Error analysis and case study
Figure 4. Effect of attention mechanism on two segmentations.
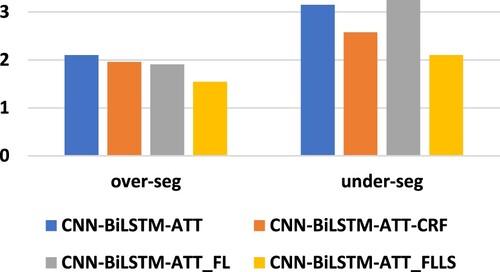
There are two types of errors in morphological segmentation (Grönroos et al., Citation2020). Over-segmentation occurs when a boundary is incorrectly assigned within a morph segment. In under-segmentation, the correct morph boundary is omitted from the generated segmentation. In this paper, these two error types are used to further analyze the model. Figure lists the four models, the CNN-BiLSTM-ATT, the CNN-BiLSTM-ATT-CRF, the CNN-BiLSTM-ATT_FL and the CNN-BiLSTM-ATT_FLLS, over-segmentation and under-segmentation. Among the prediction results of the four models, under-segmentation occurs more frequently than over-segmentation. The method proposed in this paper achieves lower results in both error analyses. In addition, Table and Figure show that the CNN-BiLSTM-ATT-CRF model also achieves better experimental results. The followings provide examples for analyzing the experimental results of the CNN-BiLSTM-ATT_FLLS model. P represents the segmentation result predicted by the model, and G represents the gold segmentation.
Figure 5. Model error analysis.
In data, there are many weakening phenomena, so the model has a high ability to identify the weakening phenomenon and can correctly capture the location of the phenomenon, such as (G:ahirlixip→ahirlax + ip, P:ahirlax + ip) (translation:finish) and (G:dErijidin→dErijE + din, P:dErijE + din) (translation: from the level). From the above two examples, it is found that the model can effectively capture the rule of weakening. Compared with the weakening, the times of insertion and loss in the dataset are less, so the recognition ability of the model for these two phenomena is not stable, and there are some problems in restoration, such as (G:burnidin→burun + i + din, P:burn + i + din) (translation:from the nose) and (G:kONlvmdin→kONvl + vm + din, P:kONl + vm + din) (translation: from the heart). Although the loss character “u” is not predicted in the example “burnidin”, the character “v” is correctly predicted in the example, “kONlvmdin”.
In addition, through experimental results, it was found that the prediction results of the model proposed in this paper are more accurate than the gold standard (true label), such as (G:kEqvrgEndE→kEqvrgEn + dE) (translation: when forgiving you) and (G:OtkvzgEndin→Otkvz + gEn + din) (translation: missed). There is a “gEn” morpheme in both examples, it does not segment in “kEqvrgEndE”, but segments in “OtkvzgEndin”. Similar to (G:selixKa→selix + Ka) (translation: built) and (G:tarKilixni→tarKalix + ni) (translation: spreading), the “ix” morpheme is not annotated in “selixKa”, but the morpheme is annotated in “tarKilixni”. The model segmentation results of the above four instances are (P:kEqvr + gEn + dE), (P:Ot + kvz + gEn + din), (P: sal + ix + Ka), (P: tarKal + ix + ni). The model not only recognises the “gEn”, “ix” and “kvz” morphemes but also restores the “sal” morpheme, which cannot be reflected on the gold standard. There are also some ambiguous morphemes in the dataset. In this case, the model needs analysis of every word, such as “dEk”. In most cases, “dEk” needs to be segmented, such as (G:bvgvnkidEk→bvgvn + ki + dEk, P: bvgvn + ki + dEk) (translation: like today), but there are also a few cases that do not require segmentations, such as (G:HEydEkqilik→HEydEkqilik, P: HEydEkqilik) (translation: to supervise), which are relatively rare. Through analyzing the above examples, it is found that this paper reduces the difference between the error label and the true label by using label smoothing. It improves the robustness of the model by joining the error label to the model training.
The labels generated by the above examples are shown in Table . The morpheme or characters that need attention are bold, the key points that are consistent with the true label are in italics, and the key points that are inconsistent with the true label are underlined. From Table , it is found that there is a serious label imbalance problem in the real labels, such as B-N: 19, M-N: 30, E-N: 18, M-S_a:2, E-S_E: 1, M-R_v: 1, M–R_u: 1, S-N: 1. The labels without voice harmony phenomena account for a large proportion, compared to other labels with voice harmony in the dataset, so the model easily tends to many negative classes when recognising this voice harmony. By using the focal loss function, this phenomenon can be effectively alleviated. For example, in the words “ahirlixip”, “kONlvmdin”, “tarKilixni” and other words in Table , voice harmony is recognised. However, if the number of labels of one type is very small, there will be unstable model performance, such as “burnidin” in Table .
Table 6. Label analysis of results.
Table 7. performance comparison of different models.
From the experimental results, it is found that the accuracy of the CNN-BiLSTM-ATT_FLLS model is higher than that of other models. However, models with high accuracy tend to take a longer time to train and use more computing resources. To be more applicable to the actual situation, this paper compares several models in terms of computing time and resource utilisation, and the results are shown in Table . Table compares the model training time, execution speed per batch, model loading time, testing time, model training stop iteration, and GPU occupancy. The early stop method is used during model training, so the number of stopping iterations of the model is also different, and the model loading time and test time are the same. In Table , we find that the F1 value of the CNN-BiLSTM-ATT-CRF model achieves a high score in the two segmentations, and the GPU utilisation rate is relatively low, but it requires considerable time. The above situation is not suitable for practical use. Among the other three models, the time and GPU utilisation of CNN-BiLSTM-ATT_FLLS model and CNN-BiLSTM-ATT are similar. Compared with CNN-BiLSTM-ATT_FL, CNN-BiLSTM-ATT_FLLS takes less time and has less GPU utilisation. Considering the F1 value of the two segmentations, the CNN-BiLSTM-ATT_FLLS model is still the best choice. If pursuing a model with high accuracy in a short time, the CNN-BiLSTM-ATT_FL model is also a good choice.
5. Conclusions and future work
This paper proposes an improved morphological tagging scheme and applies it to the Uyghur morphological segmentation model. The model can predict morphological canonical segmentation and surface segmentation tasks simultaneously by labeling morphological position and voice harmony. This method does not rely on external features and artificial feature engineering. Feature extraction is performed independently by the convolutional neural network in the model, which automatically learns character features. Feeding its features into the bidirectional two-layer LSTM network, the lexical information of each word is captured, and the attention mechanism is used to focus on the important characters features. Then, they are input into the label classification layer. The F1 values of the model achieve state-of-the-art in two segmentations. To further improve the model performance and make the model more suitable for the actual dataset and alleviate the imbalance of label distribution caused by labels, this paper uses the focal loss function with label smoothing, and its surface segmentation and canonical segmentation results are improved by 0.923% and 4.498%, respectively. The experimental results show that our model in the surface segmentation task is 2.62% higher than the CRF model, 1% higher than the BiGRU model, 0.18% higher than the Pointer Network and 4.96% higher than the BiLSTM-Attention-CRF; in the canonical segmentation task, it is 11.01% higher than the CRF model and 16.22% higher than the transformer model. There is an improvement in both segmentation tasks.
In a deep learning model, the size and distribution of the dataset directly affect the model performance. The larger data scale is, the more types of lexical or grammatical phenomena it contains. However, for low-resource languages, it is difficult to construct a large-scale annotated dataset. The distribution of the dataset is very important. Although the model is well trained, if the distribution of the training set and test set are different, the performance of the model will be very low. This paper uses a word-level dataset, so there are no ambiguous words. Whether it is canonical segmentation or surface segmentation, each word has only one segmentation form. However, the actual situation is often more complex, and there will be polysemy, ambiguity in context, and other situations, which need to be analyzed in each situation. Due to the lack of data resources and complex test data, in the future, we will combine domain adaptation technology with analyzing the data distribution and use the context information and the cross-language pretraining model to train a cross-language morphological segmenter. Then, we will fine-tune the cross-language morphological segmenter for Uyghur and focus on the difficulty in morphology – ambiguity issue.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
References
- Abudouwaili, G., Tuergen, Y., Kahaerjiang, A., & Wang, L. (2019). Research on Uyghur stemming based on Bi-LSTM-CRF model. Journal of Chinese Information Processing, 33(8), 60–66. https://doi.org/10.3969/j.issn.1003-0077.2019.08.008
- Abudubiyaz, A., Ablimit, M., & Hamdulla, A. (2020). The acoustical and language modeling issues on Uyghur speech recognition. 2020 13th international conference on intelligent computation technology and automation (ICICTA) (pp. 366-369). IEEE.
- Abudukelimu, H., Sun, M., Liu, Y., & Abulizi, A. (2017). Uyghur morphological segmentation with bidirectional GRU neural networks. Journal of Tsinghua University(Science and Technology), 57(1), 1–6. https://doi.org/10.16511/j.cnki.qhdxxb.2017.21.001
- Abudukelimu, H., Sun, M., Liu, Y., & Abulizi, A. (2018). THUUyMorph: An Uyghur morpheme segmentation corpus. Journal of Chinese Information Processing, 32(2), 81–86. https://doi.org/10.3969/j.issn.1003-0077.2018.02.011
- Bareket, D., & Tsarfaty, R. (2021). Neural modeling for named entities and morphology (NEMO2). Transactions of the Association for Computational Linguistics, 9, 909–928. https://doi.org/10.1162/tacl_a_00404
- Brusilovsky, I., & Tsarfaty, R. (2022). Neural Token Segmentation for High Token-Internal Complexity. arXiv:2203.10845.
- Cao, Z., Zhou, Y., Yang, A., & Peng, S. (2021). Deep transfer learning mechanism for fine-grained cross-domain sentiment classification. Connection Science, 33(4), 911–928. https://doi.org/10.1080/09540091.2021.1912711
- Chun, X. U., Tong-Hai, J. I., Kai, Y. U., & Wen-Bin, J. I. (2018). Model construction of Uygur and Korean morphological analysis. Journal of Beijing University of Posts and Telecom, 41(1), 88–94. https://doi.org/10.13190/j.jbupt.2017-117
- Grönroos, S.-A., Virpioja, S., & Kurimo, M.. (2020). Morfessor EM + prune: Improved subword segmentation with expectation maximization and pruning. In Proceedings of the Twelfth Language Resources and Evaluation Conference (pp. 3944–3953).
- Haibo, Z., Qiawu, C., Wenbin, J., Yajuan, L., & Qun, L. (2014). A joint voice harmony restoration and morphological segmentation model for morphological analysis. Journal of Chinese Information Processing, 28(6), 9–17. https://doi.org/10.3969/j.issn.1003-0077.2014.06.002
- Harris, Z. S. (1955). From phoneme to morpheme. Linguistic Society of America. 190-222.
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
- Imin, G., Ablimit, M., Yilahun, H., & Hamdulla, A. (2022). A character string-based stemming for morphologically derivative languages. Information, 13(4), 170. https://doi.org/10.3390/info13040170
- Li, J., & Girrbach, L. (2022). Word Segmentation and Morphological Parsing for Sanskrit. arXiv e-prints: p. arXiv:2201.12833.
- Lin, N., Li, J., & Jiang, S. (2022). A simple but effective method for Indonesian automatic text summarisation. Connection Science, 34(1), 29–43. https://doi.org/10.1080/09540091.2021.1937942
- Lin, T. Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. IEEE transactions on pattern analysis & machine intelligence. 99: p. 2999-3007.
- Liu, C., Abulizi, A., YAO, D., &Abudukelimu, H. (2021). Survey for Uyghur morphological analysis. Computer Engineering and Applications, 57(15), 42–61. https://doi.org/10.3778/j.issn.1002-8331.2103-0278
- Mager, M., Çetinoğlu, Ö, & Kann, K. (2020). Tackling the Low-resource Challenge for Canonical Segmentation. arXiv:2010.02804.
- Moeng, T., Reay, S., Daniels, A., & Buys, J. (2021). Canonical and surface morphological segmentation for nguni languages. Southern African conference for artificial intelligence research (pp. 125-139), Springer, Cham.
- Müller, R., Kornblith, S., & Hinton, G. (2019). When Does Label Smoothing Help? arXiv:1906.02629.
- Munire, M., Li, X., & Yang, Y. (2019). Construction of the Uyghur noun morphological Re-inflection model based on hybrid strategy. Applied Sciences, 9(4), 722. https://doi.org/10.3390/app9040722
- Ortega, J. E., Castro Mamani, R., & Cho, K. (2020). Neural machine translation with a polysynthetic low resource language. Machine Translation, 34(4), 325–346. https://doi.org/10.1007/s10590-020-09255-9
- Osman, T., Yang, Y., Tursun, E., & Cheng, L. (2019). Collaborative analysis of Uyghur morphology based on character level. Acta Scientiarum Naturalium Universitatis Pekinensis, 55(1), 47–54. https://doi.org/10.13209/j.0479-8023.2018.067
- Pappas, N., & Popescu-Belis, A. (2017). Multilingual hierarchical attention networks for document classification. International joint conference on natural language processing (pp. 1015–1025).
- Parhat, S., Ablimit, M., & Hamdulla, A. (2019). A robust morpheme sequence and convolutional neural network-based Uyghur and Kazakh short text classification. Information, 10(12), 387. https://doi.org/10.3390/info10120387
- Sardar, P., Mijit, A., & Askar, H. (2020). Uyghur short text classification based on robust morpheme sequence and LSTM. Journal of Chinese Information Processing, 34(1), 63–70. https://doi.org/10.3969/j.issn.1003-0077.2020.01.009
- Seker, A., & Tsarfaty, R. (2020). A Pointer Network Architecture for Joint Morphological Segmentation and Tagging. Online: Association for Computational Linguistics.
- Sorokin, A. (2019). Convolutional neural networks for low-resource morpheme segmentation: Baseline or state-of-the-art? Association for Computational Linguistics.
- Sorokin, A., & Kravtsova, A. (2018). Deep convolutional networks for supervised morpheme segmentation of Russian language. Springer International Publishing.
- Tang, X., Wang, J., & Su, Q. (2022). Chinese Word Segmentation with Heterogeneous Graph Neural Network. arXiv e-prints: p. arXiv:2201.08975.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł, & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998–6008. https://doi.org/10.48550/arXiv.1706.03762
- Wang, W., Fam, R., Bao, F., Lepage, Y., & Gao, G. (2019). Neural morphological segmentation model for Mongolian. International joint conference on neural network. p. 1-7.
- Wu, S., Liu, Y., Zou, Z., & Weng, T. H. (2022). S_I_LSTM: Stock price prediction based on multiple data sources and sentiment analysis. Connection Science, 34(1), 44–62. https://doi.org/10.1080/09540091.2021.1940101
- Xu, H., Zhang, S., Zhu, G., & Zhu, H. (2022). ALSEE: A framework for attribute-level sentiment element extraction towards product reviews. Connection Science, 34(1), 205–223. https://doi.org/10.1080/09540091.2021.1981825
- Yan, Y., Xiao, Z., Xuan, Z., & Ou, Y. (2021). Implicit emotional tendency recognition based on disconnected recurrent neural networks. International Journal of Computational Science and Engineering, 24(1), 1–8. https://doi.org/10.1504/IJCSE.2021.113616
- Yang, Y., Li, S., Zhang, Y., & Zhang, H. P. (2019). Point the point: Uyghur morphological segmentation using pointernetwork with GRU. China national conference on Chinese computational linguistics (pp. 371-381), Springer, Cham.
- Zhang, S., Yu, H., & Zhu, G. (2022). An emotional classification method of Chinese short comment text based on ELECTRA. Connection Science, 34(1), 254–273. https://doi.org/10.1080/09540091.2021.1985968
- Zhao, H., Lu, J., & Cao, J. (2020). A short text conversation generation model combining BERT and context attention mechanism. International Journal of Computational Science and Engineering, 23(2), 136–144. https://doi.org/10.1504/IJCSE.2020.110536
- Zhao, W., Zhao, S., Chen, S., Weng, T. H., & Kang, W. (2022). Entity and relation collaborative extraction approach based on multi-head attention and gated mechanism. Connection Science, 34(1), 670–686. https://doi.org/10.1080/09540091.2022.2026295