
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The cross-domain sequential recommendation aims to predict the next item based on a sequence of recorded user behaviours in multiple domains. We propose a novel Cross-domain Sequential Recommendation approach with Graph-Collaborative Filtering (CsrGCF) to alleviate the sparsity issue of user-interaction data. Specifically, we design time-aware and relation-aware graph attention mechanisms with collaborative filtering to exploit high-order behaviour patterns of users for promising results in both domains. Time-aware Graph Attention mechanism (TGAT) is designed to learn the inter-domain sequence-level representation of items. Relationship-aware Graph Attention mechanism (RGAT) is proposed to learn collaborative items' and users' feature representations. Moreover, to simultaneously improve the recommendation performance in the two domains, a Cross-domain Feature Bidirectional Transfer module (CFBT) is proposed, transferring user's common sharing features in both domains and retaining user's domain-specific features in a specific domain. Finally, cross-domain and sequential information jointly recommend the next items that users like. We conduct extensive experiments on two real-world datasets that show that CsrGCF outperforms several state-of-the-art baselines in terms of Recall and MRR. These demonstrate the necessity of exploiting high-order behaviour patterns of users for a cross-domain sequential recommendation. Meanwhile, retaining domain-specific features is an important step in the process of cross-domain feature bidirectional transferring.
1. Introduction
Sequential recommendation (RS) (Fang et al., Citation2019; S. Wang et al., Citation2019) predicts the next items by leveraging the user's historical interactions. Many existing methods have followed the same propagation rules in GNN to model users' behaviour sequences and achieve promising results. However, these RNN-based methods have limited capability to accurately capture the intention of users who lack rich historical behaviours. Data sparsity has become a significant challenge problem that most sequential recommendation methods are confronted with. Cross-domain sequential recommendation (CSR) (D. Liu & Zhu, Citation2021) considers cross-domain historical behaviours of users to alleviate data sparsity for improving the performance of personalised recommendations (C. Li et al., Citation2022). Data from multiple domains might effectively discover the users' current preferences, which has been extensively applied in advertising, e-commerce and web search (P. Li et al., Citation2021; Z. Wang et al., Citation2019). For example, after a person watches a movie in the movie domain, that person is more inclined to listen to the theme of the movie in the music domain, or read a novel with the same name in the book domain, and then watch another similar movie in the movie domain.
Transfer learning (TL) (Pan & Yang, Citation2009) is an effective solution to the data sparsity problem, recognising and applying knowledge learned in related domains to a new domain. In real life, a client unavoidably interacts with multiple domains to fulfil the need of his life (Z. Cao et al., Citation2021). When the interaction history is less in domain S, it is natural to consider getting some common knowledge from related domain T that includes more data. Earlier, transfer learning was introduced to recommendation systems to address the challenge of data sparsity (B. Cao et al., Citation2010; Hu et al., Citation2018, Citation2019; B. Li et al., Citation2009), which leverage explicit feedbacks from multiple domains to promote recommendation performance with collaborative filtering. Many research proved that the recommendation performance could be improved by transfer learning from multiple domains. Later, several methods take deep learning as a basic model to enhance the effect of transfer learning (Guo et al., Citation2021; Hong et al., Citation2020; Z. Liu et al., Citation2019; Zhao et al., Citation2019). This is an effective method to not only leverage sharing information between domains, but also differences from different domains. On this basis, more effective methods are proposed. BITGCF (M. Liu et al., Citation2020) proposed bi-directional transfer learning for data sparsity in cross-recommendation. DSLN (H. Liu et al., Citation2022) consists of two deep learning networks to extract the features of users and items from users' reviews and select useful knowledge from the auxiliary domains.
Despite their effectiveness, it is a significant challenge to alleviate the data sparsity problem because of the following two main issues. Firstly, existing methods gain user representation from the common features in different domains, but without considering domain-specific features. Such simple knowledge transferring leads to modelling users' preferences and interests exactly the same in both domains, which might reduce the impact of transfer especially when both domains have low similarity. This means that it should model the features of users in a single domain by learning users' features from multiple domains. Secondly, current approaches model sequential dependencies between items ignoring interaction intervals, which only consider items transformation relationships in relative temporal. In fact, the interaction time interval is closely related to the sequential dependencies between items.
Given the above limitations and inspired by the idea of graph-collaborative filtering (X. Wang et al., Citation2019), we propose a Cross-domain Sequential recommendation with Graph-Collaborative Filtering (CsrGCF) to solve the data sparsity issue by mining the users' high-order behaviour pattern and transferring knowledge among different domains. Specifically, we first propose TGAT to obtain complex sequential dependencies between items from the user history behaviour sequence. Then a novel module RGAT is proposed to learn item and user collaborative feature representations based on the user-item interaction graph. Finally, we note that common sharing features and domain-specific features motivate the module. Thus, we propose CFBT can better fit the real-life data and achieve better performance. Furthermore, we empirically demonstrate that our proposed model outperforms all state-of-the-art models on two real datasets. Compared to previous methods, the proposed model has the following contributions:
We propose a new cross-domain sequential recommendation algorithm by applying the Neural Graph-Collaborative Filtering for recommendations. In CrsGCF, we design time-aware and relation-aware graph attention mechanisms to exploit high-order behaviour patterns of users for promising results in both domains.
A novelty Cross-domain Feature Bi-directional Transfer module (CFBT) is proposed to capture common sharing features and domain-specific features representations. Moreover, we conduct simulation experiments to validate the importance of users' domain-specific features.
We conduct extensive experiments on real-world datasets, validating that CsrGCF can improve the recommendation performance. Furthermore, our proposed model effectively alleviates the data sparsity issue.
This paper is organised as follows. In Section 2, we briefly review recent literature related to the cross-domain sequential recommendation. Then, We give a detailed explain the CsrGCF method in Section 3. In Section 4, the experiments and analysis are presented in detail. Finally, we summarised the main content of the paper and concluded with future works in Section 5.
2. Related work
2.1. GNN-based sequential recommendation
The rich data can be represented as a graph structure in the recommender system. In recent years, with the improvement of graph data learning capability, graph neural network (GNN) (G. Li et al., Citation2019; Z. Wu et al., Citation2020) has become one of the most successful methods for recommender systems. It has been widely applied in various recommendation tasks. Recent advances in graph neural networks further boost the performance of sequential-based behaviour prediction by modelling behaviour sequences as a graph to achieve advanced performance (K. Xu et al., Citation2018). Wu et al. proposed SR-GNN (S. Wu et al., Citation2019) for the first time by constructing a directed graph of session data, which applies a gated graph neural network (GGNN) (Weinzierl, Citation2021) to learn feature presentations of users and items. However, its design is too complex. After that, the idea of stacking multiple embedding propagation layers by exploiting user-item interaction graph promoted inferring users' preferences. Specifically, some research (Cui et al., Citation2020; Qiu et al., Citation2019; Y. Wu et al., Citation2018; C. Xu et al., Citation2019) is designed to model the sequential order of items and generate predictions based on historical sequential behaviours. GCE-GNN (Z. Wang et al., Citation2020) employs a session-aware attention mechanism to recursively incorporate the neighbours' embeddings of each node on the graph. C. Ma et al. (Citation2020) propose a memory-augmented graph neural network to capture items' short-term contextual information and long-range dependencies. In summary, the above works take into account simple relationships for sequential item pairs. However, complex relationships between non-sequential pairs of items can promote recommendation effectiveness.
In this paper, we propose time-aware and relation-aware graph neural networks to exploit the user's high-order behaviour patterns for overcoming data sparsity issues and improving recommendation performance.
2.2. Cross-domain recommendation
Cross-domain recommendation leveraging data from multiple domains has been proven effective in dealing with data sparsity and cold-start issues (Zhu et al., Citation2021). Traditionally, existing methods had two main ways. One is to aggregate knowledge between multiple domains. Another is to transfer knowledge from the source domain to the target domain. The method to transfer knowledge is abundant. For example, Collective Matrix Factorisation(CMF) (Singh & Gordon, Citation2008) and Codebook Transfer (B. Li et al., Citation2009) are based on Matrix Factorisation(MF) applied in all domains (M. Liu et al., Citation2020). Ma et al. proposed π-Net (M. Ma et al., Citation2019) to generate recommendations for two domains simultaneously: the shared account filter unit (SFU) addresses the challenge raised by shared accounts, and the cross-domain transfer unit (CTU) addresses the challenge raised by the cross-domain setting. Then, Guo et al. further improved the SCRM (Lei et al., Citation2021) model by replacing RNN with a self-attentive network for π-Net to address that RNNs cannot model long-term dependencies among items. This proves that it is effective to adopt transfer learning for improving cross-domain recommendation performance and alleviating data sparsity. We design the process of transferring knowledge to combine common sharing features and domain-specific features.
2.3. Neural graph-collaborative filtering
The recommender system typically mines users' preferences by exploring the history interactions to provide personalised services. Collaborative filtering (CF) is the earliest and most widely used recommender system by modelling users' preferences based on the interactive history (He et al., Citation2017). Neural Graph-Collaborative filtering (NGCF) learns users and item preferences to predict items by exploiting user-item interaction graph. For example, He et al. devised a general framework NCF (He et al., Citation2017) that model user-item interactions differently. NGCF exploits the user-item graph structure by propagating embeddings on it. It leads to the expressive modelling of high-order connectivity in a user-item graph, effectively injecting the collaborative signal into the embedding process in an explicit manner (Lian & Tang, Citation2022). LR-GCCF (Chen et al., Citation2020), LightGCN (He et al., Citation2020) and Multi-GCCF (Sun et al., Citation2019) improve on NGCF, respectively. However, the above works learning user features require sufficient user-item interaction data, which performance is significantly affected by data sparsity and cold-start problems. In this paper, we introduce transfer learning to transfer interaction data between two domains to improve the recommendation performance in two domains.
3. Methodologies
3.1. Problem definition
Cross-domain Sequential Recommender recommends the next item via leveraging a user's historical interactions in different domains. This paper focuses on solving the data sparsity problem in cross-domain sequence recommendation. We consider two different domains T and S. We represent a set of cross-domain overlapping users in both domains T and S, where l is the number of overlapping users. Let the set of all items in both domains T and S be
and
, respectively. To obtain the sequential dependencies between items, we apply the interaction sequences of a specific user in two domains. Take the user u as an example, let
,
be the interaction sequences from domain T and S, respectively, where
donates the kth session for user u in domain d
. Given
and
, the task of CsrGCF is to recommend the next item based on the past behaviour sequences in the two domains. The recommendation probabilities for all candidate items in domains T and S are:
(1)
(1)
(2)
(2)
3.2. An overview of CsrGCF
In this paper, the proposed CsrGCF tempts to alleviate the data sparsity issue and to improve the accuracy of recommendation results in cross-domain sequential recommendation scenarios. Figure presents an overview of CsrGCF, we will describe each component of the methods in detail.
Figure 1. The Frame of CsrGCF. The left and right sides of this picture represent the recommendation model for domains S and T, respectively. We obtain the final estimated ratings by aggregating items and user features and transferring users' feature representations cross-domain bi-directional across two domains.
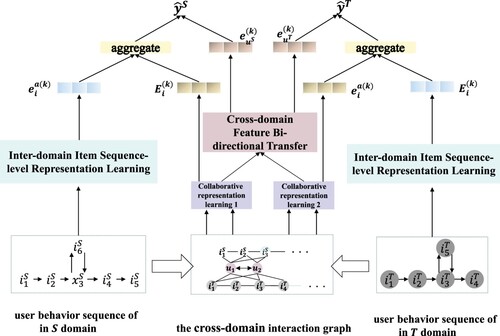
3.2.1. User and item initialisation embedding layer
To effectively model features of users and items, this module maps the information of users and items into embedding vectors,
(3)
(3)
(4)
(4) where
and
are the initialisation embeddings of user u (
) and item i (
) in d (
) domain. P and Q are the learnable parameters matrix of user and item. Note that
and
are one-hot encodings of user u and item i.
3.2.2. Inter-domain item sequence-level representation learning module
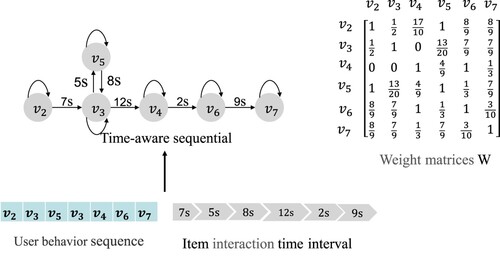
In this module, we mine high-order complex transformation relationships and temporal dependencies between items from a given historical behaviours sequence of a user in a specific domain. Given the historical behaviour sequence of a user, the information of inter-item interaction time can reflect the association relationship between items. Besides, the closeness of the relationship between items is inversely proportional to the length of the interaction time interval. In other words, the shorter the time interval between two items interaction, the more intimate between the two items. Then, a time-aware graph attention mechanism (TGAT) is designed to learn the inter-domain sequence-level representation of items. We construct directed session graphs , which based on the method mentioned SR-GNN. V and E denote the nodes and edges, V can be the set of items that have been interacted with and E representing relations between users and items. The time-aware sequential schematic as shown in Figure . When there is a bidirectional edge between two nodes in a directed graph, the degree of association between the nodes is greater than that of only one edge. To clearly show this difference, we designed four types of edges
.
denotes that there is only one directed edge from item i to item j, and
denotes that there is only one directed edge from item j to item i, and
denotes there is a bidirectional edge connected two nodes i and j, and
denotes that it's a self-connecting edge of a node i. The weight matrix
is a matrix of time-aware weights calculated from the interaction time between items in the sequence, and the
are calculated as follows:
(5)
(5) where
is the interaction time interval between items i and j.
and
denote the maximum and minimum interaction time interval between two items in a given sequence, respectively. Items with greater
(
) are more likely to be recommended to users. We have learned the presentations of items from the above-directed session graphs. The information of each relationship is aggregated, and the presentations of nodes are updated. Improved edge-type-aware attention is designed to model the association between items by considering the weight
:
(6)
(6) where
denotes the relevance between items i and j.
and
are the edge-type-aware attention weight and time-aware weight, respectively. Further, to increase the comparability between nodes, the above attention weights are performed normalised as flow:
(7)
(7) where
denotes the contributions of different neighbour nodes to the target node. The previous node sequence representation has an impact on the current node, aggregating the previous sequence representation:
(8)
(8) TGAT aggregates the information of one-hop neighbour nodes from the target node. And multi-layers Ta-GAT obtains a k-order representation of items, which aggregates more available auxiliary information for modelling higher-order complex relationships between items:
(9)
(9) where
is aggregation functions.
Figure 2. The time-aware sequential schematic. The blue circles indicate the sequence of items that the user interacted with, and the arrows indicate the sequence and time interval of the interaction. The matrix on the right is the matrix of time-aware weights learned by the model.
3.2.3. Item and user-collaborative representation learning module
In this section, we mine more information from the interaction behaviours of users in a domain for sequential recommendations. We model user-item bipartite graph . U denotes the set of users, V denotes the set of items, and E denotes the interaction behaviours between users and items. Intuitively, the interacted items provide direct evidence of a user's preferences. A user's preferences are influenced by the items he has interacted with and by users with similar interests and tastes. A relationship-aware graph attention mechanism (RGAT) is proposed to learn the collaborative representations of users and items. Inspired by R-GCN (Schlichtkrull et al., Citation2018), we treat edge “
” and edge “
” as two different types of edges, which denote “user u like item v” and “item v is liked by user u”, respectively. Different types of edges have different effects on the final recommendation results. Take the representation learning process of domain T as an example, and domain S is the same as T method:
(10)
(10) where
, R denotes the edge four types,
is the set of neighbour nodes of node i,
is the relation attention of items i and j:
(11)
(11) where q is the transfer matrix, ⊕ is the embedding concatenate operation. In this way, it can effectively model the complex transformation relationships between nodes in interaction graph and enrich the collaborative representations of items and nodes.
3.2.4. Cross-domain features bi-directional transfer modules
The item feature aggregates the item collaborative representation and the item sequence embeddings. Besides, we refine the user feature representations by leveraging feature aggregation and feature transfer. We use the same approach to aggregate users and items features. Since the characteristics of the items are stable, in this paper, we only consider the transfer of the user's preference representation across two domains. Then we propose a novel Cross-domain Feature Bi-directional Transfer Module (CFBT) to learn the bi-directional transfers of feature across two domains.
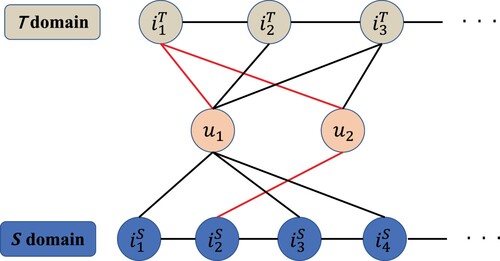
Taking the red path in Figure as an example, for item node , it updates its representation by aggregating the information from its one-hop neighbour user node
, while user node
also aggregates the information from its one-hop neighbour item node
, then the user
and item
establish the following cross-domain association path across two domains:
. From the path, the connectivity between
and
can be learned. Most previous works only consider the common features across two domains. The difference between our method and previous methods is that we also consider domain-specific features. The bi-directional feature transfer process is as follows:
(12)
(12)
(13)
(13)
(14)
(14)
(15)
(15)
(16)
(16) where
and
are calculated from Equation (Equation8
(8)
(8) ),
and
denote user-related weight factors across domain two domains.
and
are hyperparameters used to control the proportion of user features retained in the corresponding domain.
Besides,
(17)
(17)
(18)
(18) where
and
denote the number of one-hop neighbours for user node u, specially, number of items that user u has interacted with in the S and T domains. This is because the more interaction records a user has in a domain means the more distinctive the feature is in that domain. As a result, there is a greater proportion of features in this domain and a smaller proportion of transfer features from other domains. The user feature representation in S domain based on transfer features is
(19)
(19) Note that domain T can be processed similarly to calculate
.
Figure 3. The cross-domain interaction. Users and
gain information from their one-hop neighbours (eg.
,
) to refine its feature, respectively. Then the connectivity between items
and
can be learned by Cross-domain Feature Bi-directional Transfer Module.
3.2.5. Prediction and optimisation layer
After the above steps, we obtain the feature representations of users and items learned from behaviour sequences. After the embedding of the sequence-level item and item-collaborative representation are obtained, we calculate the possibility to recommend item i to user u in domain d:
(20)
(20) where ⊕ is the embedding concatenate operation. And
denotes the transposition of the matrix. We use the binary cross-entropy function as the objective function for model training and optimisation:
(21)
(21) where
and
denote the given set of interaction history records and the set of user history interaction records constructed by random sampling, respectively.
4. Experiments
4.1. Experimental setup
We intend to answer the following research questions:
| RQ1 | How does our proposed CsrGCF method perform compared with other state-of-the-art methods in cross-domain recommendation scenarios? | ||||
| RQ2 | What is the effect of different modules in the methods for the recommended performance? | ||||
4.1.1. Datasets
We evaluate the effectiveness of CsrGCF on real-world datasets that AmazonFootnote1 released. The Amazon datasets contain user interactions in multiple domains, satisfying the cross-domain sequential recommendation scenarios. We chose Movie-Book and Food-Kitchen cross-domain datasets. We process the data by the method in article (M. Ma et al., Citation2019). We aim to improve the cross-domain recommendation performance and alleviate the data sparsity issue in both domains. We retain those overlapping users who interacted with more than 10 items and items with more than 10 recorded interactions. Besides, we need to preprocess the behaviour sequences for a sequential recommendation. We first sort the user interaction records chronologically and split them into subsequences. These subsequences are treated as sessions containing successive interactions and at least three items. The statistics of the two processed datasets are shown in Table .
Table 1. Statistics of the processed two datasets applied in our experiments.
4.1.2. Evaluation protocols
For evaluation, in our experiments, the widely used evaluation metrics of Recall and MRR are adopted to evaluate the performance of all algorithms. Recall measures the proportion of cases of all test cases in which the correct result is amongst the Top-K with . MRR is the average reciprocal rank of the correct items, which is the mean value of the ranking of the first select item.
4.1.3. Baselines
To demonstrate the effectiveness of CsrGCF, we use the single-domain recommendation models, single domain sequential recommendation models, cross-domain recommendation models, and cross-domain sequential recommendation models. We set the number of GNN layers to 3. We compare our proposed TRaGCF with competitive recommendation methods:
| Single-domain Recommendation Model: |
| ||||
| Single-domain Sequential Recommendation Model: |
| ||||
| Cross-domain Recommendation Model: |
| ||||
| Cross-domain Sequential Recommendation Model: |
| ||||
4.2. Results and discussion
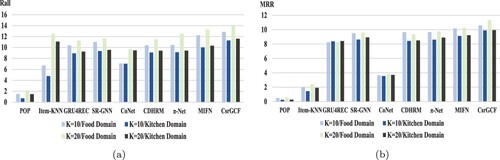
Figures and show the comparison results of CsrGCF over other baselines on Movie-Book dataset and Food-kitchen dataset,respectively. According to the evaluation criteria MRR and Rall, CsrGCF achieves better performance compared to other baselines for Top-K recommendations. For single-domain and cross-domain recommendation scenarios, the sequential recommendation models outperform all non-sequential recommendations models, illustrating the effectiveness of sequential recommendations in modelling user behaviour sequences. For sequential recommendation scenarios, cross-domain methods outperform single-domain methods recommendations, validating the effectiveness of feature transfer module for improving the recommendation performance and alleviating the data sparsity issue in the cross-domain recommendation. For single-domain recommendation scenarios, sequential recommendation performs better than traditional methods on two datasets. It indicates that sequential dependencies between items help achieve promising results. Then we analyse the performance of SR-GNN and GRU4Rec, supporting the effective of mining high-order complex relations based on GNN for better recommendation performance. For Cross-domain recommendation scenarios, we observe that π-Net performs better than CoNet. It demonstrates that the bi-directional features transfer module can improve the recommendation performance. When modelling user behaviour sequences from across domains to mine user preferences using item intrinsic association information can increase inter-domain connections to improve performance. For Cross-domain sequential recommendation scenarios, CsrGCF outperforms all recommendation baselines on two datasets. It effectively demonstrates that the method mines high-order complex relationships based on GNN and fuses common sharing features and domain-specific features through a bi-directional feature transfer module. Meanwhile, We also observe that the performance is rising rapidly on the Movie-Book dataset, which is maybe because the closer relationship between the film and the book has a greater effect for the recommendation.
Figure 4. Overall performance of various methods on the Amazon Movie-Book. As can be seen, four colours denote four different conditions. The two lighter colours denote the movie domain, and the other two denote the book domain. In each domain, lighter one's K = 10, and another K = 20. In (a), we use Recall to evaluate the performance of models, and in (b), the index is MRR.
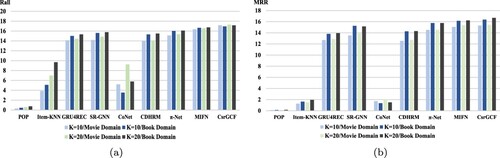
Figure 5. Overall performance of various methods on the Amazon Food-Kitchen. As one can easily see, the two lighter and deeper colours denote food and kitchen domain, respectively. In each domain, the lighter one's K = 10, and the deeper one's K = 20. In (a), we use Recall to evaluate the performance of all models, and in (b), the index is MRR.
4.3. Ablation study of CsrGCF
We conduct an ablation study on CsrGCF to validate the function of its main components on the Food-Kitchen dataset. We use Recall@20 and MRR@20 to measure the results. The comparison results of the contributions of CsrGCF as shown in Table , with the best results heightened in boldface.
CsrGCF
SBM: We remove Inter-domain Item Sequence-level Representation Learning Module from CsrGCF. Then we perform the dot product operation in the recommendation prediction module by directly integrating the user's collaborative preference representation with the item's collaborative representation.
CsrGCF-GCF
Table 2. The comparison results of ablations studies on Amazon Food-Kitchen dataset.
From Table , we obverse that the performance of CsrGCF_SBM is the worst on both datasets. It indicates that sequential mining dependencies between items in the historical behaviours significantly improve the cross-domain recommendation results. Meanwhile, the variation of recommendation performance on the Food domain is larger than that on the Kitchen domain. It is maybe because the food in the Food domain is more closely related. The close relation helps to fully exploit the complex relationship among items to improve the recommendation effect. In contrast, the relations between different items in the Kitchen domain have a weaker impact on the recommendation results. The possible reason for this result is the immensely complex relationship of the item and user features in the Food domain. In the Kitchen domain, users buy items on demand and are less influenced by the behaviour of other users. It is worth noting the modest change in performance of CsrGCF_CBM. Again, the variation of recommendation performance on the Food domain is larger than that on the Kitchen domain. It is necessary to distinguish the effect of different relationships on the recommendation results in the scenario with complex relationships.
4.4. Parameter sensitive analysis and model training efficiency
4.4.1. Parameter sensitive analysis
and
, which are used to control the proportion of user features retained in the corresponding domains, and play a vital role in expressiveness. In this section, we conduct experiments to investigate the sensitivity of hyperparameters
and
on the model performance. For convenience, we design a single parameter
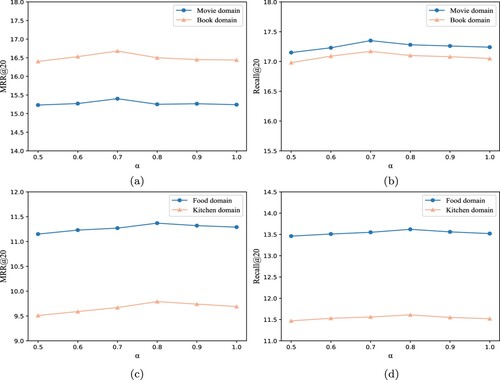
ranging in [0.5, 1] with a step size of 0.1. Figure (a) shows the results on the Movie-Book dataset, the optimal α is 0.7 for the recommendation. Figure (b) shows the results on the Food-Kitchen dataset, the optimal α is 0.8 for the recommendation. It is obvious that the parameter α has a significant impact on the recommendation. In particular, the Movie-Book dataset having lower similarity between the two domains is more sensitive to parameter α. This demonstrates that it is necessary to retain domain-specific features, especially when the two domains have little similarity.
Figure 6. The performance of different α on Movie-Book dataset and Food-Kitchen dataset with. One can easily see that with the α increase, the recommendation performance is changed. Moreover, the variation is more obvious on Movie-Book dataset. (a) MRR@20 on Movie-Book. (b) Recall@20 Movie-Book. (c) MRR@20 Food-Kitchen and (d) Recall@20 Food-Kitchen.
4.4.2. Model training efficiency
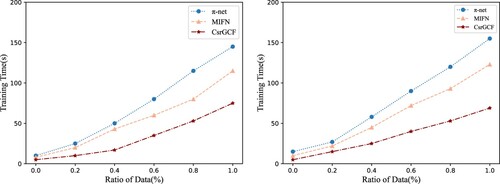
To explore the training efficiency and scalability of our model, we further conduct experiments via measuring the time cost for the model training with different dataset proportions in [0.1, 1.0]. The comparison results with other cross-domain sequential baselines are shown in Figure . From the result we can find that our proposal requires less training time than other baselines. Moreover, we observe that the training time slowly increases as the proportion of the dataset gradually increases, which indicates the validity of our model for large-scale datasets.
Figure 7. Model Training Efficiency on Movie-Book and Food-Kitchen datasets. (a) Training efficiency on Movie-Book dataset and (b) Training efficiency on Food-Kitchen dataset.
5. Conclusions
Cross-domain sequential recommendation can predict next items via modelling the sequence of historical interactions data. However, there is the challenge of data sparsity in exiting method. This paper presents a novel method for the cross-domain sequential recommendation with graph-collaborative filtering to mine user's high-order behaviour for alleviating the data sparsity problem. The method introduces graph-collaborative filtering to build the bridge for user cross-domain preferences in sequence recommendations. First, to mine user high-order behaviour and predict user's current intentions, we propose time-aware and relation-aware graph attention mechanisms to model the complex correlations between items and users. The time-aware graph attention mechanism learns the inter-domain sequence-level representation of items, and the relation-aware graph attention mechanism learns item-collaborative representations and collaborative user representations. Then we devised a Cross-domain Feature Bidirectional Transfer module transferring common sharing features in both domains and retaining domain-specific features in a specific domain to achieve excellent recommendation performance in both domains. The novel method considers both common sharing features and retains domain-specific features to refine user features. The experimental results on real-world datasets demonstrate the validity of the proposed method. However, it assumes that the users of the two domains overlap entirely, and we will consider a subsequent extension of the model to scenarios with partially overlapping users. Moreover, we will extend the method to more than two domains.
Acknowledgments
The authors would like to thank the editors and the reviewers of Connection Science for providing such an opportunity.
Data availability statement
The datasets generated and/or analysed during the current study are available from the corresponding author on reasonable request.
Disclosure statement
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Funding
Notes
References
- Cao, B., Liu, N. N., & Yang, Q. (2010). Transfer learning for collective link prediction in multiple heterogenous domains. In ICML. Omnipress
- Cao, Z., Zhou, Y., Yang, A., & Peng, S. (2021). Deep transfer learning mechanism for fine-grained cross-domain sentiment classification. Connection Science, 33(4), 911–928. https://doi.org/10.1080/09540091.2021.1912711
- Chen, L., Wu, L., Hong, R., Zhang, K., & Wang, M. (2020). Revisiting graph based collaborative filtering: A linear residual graph convolutional network approach. In Proceedings of the AAAI conference on artificial intelligence (Vol. 34, pp. 27–34). AAAI Press.
- Cui, Z., Xu, X., Fei, X., Cai, X., Cao, Y., Zhang, W., & Chen, J. (2020). Personalized recommendation system based on collaborative filtering for IoT scenarios. IEEE Transactions on Services Computing, 13(4), 685–695. https://doi.org/10.1109/TSC.4629386
- Fang, H., Guo, G., Zhang, D., & Shu, Y. (2019). Deep learning-based sequential recommender systems: Concepts, algorithms, and evaluations. In International conference on web engineering (pp. 574–577). Springer.
- Guo, L., Tang, L., Chen, T., Zhu, L., Nguyen, Q. V. H., & Yin, H. (2021). DA-GCN: A domain-aware attentive graph convolution network for shared-account cross-domain sequential recommendation. arXiv preprint arXiv:2105.03300.
- He, X., Deng, K., Wang, X., Li, Y., Zhang, Y., & Wang, M. (2020). Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval (pp. 639–648). ACM.
- He, X., Liao, L., Zhang, H., Nie, L., Hu, X., & Chua, T. S. (2017). Neural collaborative filtering. In Proceedings of the 26th international conference on world wide web (pp. 173–182). ACM.
- Hidasi, B., Karatzoglou, A., Baltrunas, L., & Tikk, D. (2021). Session-based recommendations with recurrent neural networks. arXiv preprint arXiv:1511.06939.
- Hong, W., Zheng, N., Xiong, Z., & Hu, Z. (2020). A parallel deep neural network using reviews and item metadata for cross-domain recommendation. IEEE Access, 8(1), 41774–41783. https://doi.org/10.1109/Access.6287639
- Hu, G., Zhang, Y., & Yang, Q. (2018). Conet: Collaborative cross networks for cross-domain recommendation. In Proceedings of the 27th ACM international conference on information and knowledge management (pp. 667–676). ACM.
- Hu, G., Zhang, Y., & Yang, Q. (2019). Transfer meets hybrid: A synthetic approach for cross-domain collaborative filtering with text. In The world wide web conference (pp. 2822–2829). ACM.
- Lei, G., Qiuju, L., Fang'ai, L., & Xinhua, W. (2021). Shared-account cross-domain sequential recommendation with self-attention network. Journal of Computer Research and Development, 58(11), 2524–2537. https://doi.org/10.7544/issn1000-1239.2021.20200564
- Li, B., Yang, Q., & Xue, X. (2009). Can movies and books collaborate? Cross-domain collaborative filtering for sparsity reduction. In Twenty-first international joint conference on artificial intelligence. Morgan Kaufmann.
- Li, C., Zhao, M., Zhang, H., Yu, C., Cheng, L., Shu, G., Kong, B., & Niu, D. (2022). RecGURU: Adversarial learning of generalized user representations for cross-domain recommendation. In Proceedings of the fifteenth ACM international conference on web search and data mining (pp. 571–581). ACM.
- Li, G., Muller, M., Thabet, A., & Ghanem, B. (2019). Deepgcns: Can GCNs go as deep as CNNs? In Proceedings of the IEEE/CVF international conference on computer vision (pp. 9267–9276). IEEE.
- Li, P., Jiang, Z., Que, M., Hu, Y., & Tuzhilin, A. (2021). Dual attentive sequential learning for cross-domain click-through rate prediction. In Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining (pp. 3172–3180). ACM.
- Lian, S., & Tang, M. (2022). API recommendation for Mashup creation based on neural graph collaborative filtering. Connection Science, 34(1), 124–138. https://doi.org/10.1080/09540091.2021.1974819
- Liu, D., & Zhu, C. (2021). Cross-domain sequential recommendation based on self-attention and transfer learning. Journal of Physics: Conference Series, 2010(2021). https://doi.org/10.1088/1742-6596/2010/1/012036
- Liu, H., Liu, Q., Li, P., Zhao, P., & Wu, X. (2022). A deep selective learning network for cross-domain recommendation. Applied Soft Computing, 125(1), Article 109160. https://doi.org/10.1016/j.asoc.2022.109160
- Liu, M., Li, J., Li, G., & Pan, P. (2020). Cross domain recommendation via bi-directional transfer graph collaborative filtering networks. In Proceedings of the 29th ACM international conference on information & knowledge management (pp. 885–894). ACM.
- Liu, Z., Zheng, L., Zhang, J., Han, J., & Philip, S. Y. (2019). JSCN: Joint spectral convolutional network for cross domain recommendation. In 2019 IEEE international conference on big data (big data) (pp. 850–859). IEEE.
- Ma, C., Ma, L., Zhang, Y., Sun, J., Liu, X., & Coates, M. (2020). Memory augmented graph neural networks for sequential recommendation. In Proceedings of the AAAI conference on artificial intelligence (Vol. 34, pp. 5045–5052). IEEE.
- Ma, M., Ren, P., Chen, Z., Ren, Z., Zhao, L., Liu, P., Ma, J., & de Rijke, M. (2022). Mixed information flow for cross-domain sequential recommendations. ACM Transactions on Knowledge Discovery from Data (TKDD), 16(4), 1–32. https://doi.org/10.1145/3487331
- Ma, M., Ren, P., Lin, Y., Chen, Z., Ma, J., & Rijke, M.d. (2019). π-net: A parallel information-sharing network for shared-account cross-domain sequential recommendations. In Proceedings of the 42nd international ACM SIGIR conference on research and development in information retrieval (pp. 685–694). ICM.
- Pan, S. J., & Yang, Q. (2009). A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 22(10), 1345–1359. https://doi.org/10.1109/TKDE.2009.191
- Qiu, R., Li, J., Huang, Z., & Yin, H. (2019). Rethinking the item order in session-based recommendation with graph neural networks. In Proceedings of the 28th ACM international conference on information and knowledge management (pp. 579–588). ACM.
- Reddy, S., Nalluri, S., Kunisetti, S., Ashok, S., & Venkatesh, B. (2019). Content-based movie recommendation system using genre correlation. In Smart intelligent computing and applications (pp. 391–397). Springer.
- Schlichtkrull, M., Kipf, T. N., Bloem, P., Berg, R.v.d., Titov, I., & Welling, M. (2018). Modeling relational data with graph convolutional networks. In European semantic web conference (pp. 593–607). Springer.
- Singh, A. P., & Gordon, G. J. (2008). Relational learning via collective matrix factorization. In Proceedings of the 14th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 650–658). ACM.
- Sun, J., Zhang, Y., Ma, C., Coates, M., Guo, H., Tang, R., & He, X. (2019). Multi-graph convolution collaborative filtering. In 2019 IEEE international conference on data mining (ICDM) (pp. 1306–1311). IEEE.
- Wang, S., Hu, L., Wang, Y., Cao, L., Sheng, Q., & Orgun, M. (2019). Sequential recommender systems: Challenges, progress and prospects. In Twenty-eighth international joint conference on artificial intelligence. Mprgan Kaufmann. {IJCAI-19 }.
- Wang, X., He, X., Wang, M., Feng, F., & Chua, T. S. (2019). Neural graph collaborative filtering. In Proceedings of the 42nd international ACM SIGIR conference on research and development in information retrieval (pp. 165–174). ACM.
- Wang, Y., Guo, C., Chu, Y., Hwang, J. N., & Feng, C. (2020). A cross-domain hierarchical recurrent model for personalized session-based recommendations. Neurocomputing, 380(1), 271–284. https://doi.org/10.1016/j.neucom.2019.11.013
- Wang, Z., Du, B., & Guo, Y. (2019). Domain adaptation with neural embedding matching. IEEE Transactions on Neural Networks and Learning Systems, 31(7), 2387–2397. https://doi.org/10.1109/TNNLS.5962385
- Wang, Z., Wei, W., Cong, G., Li, X. L., Mao, X. L., & Qiu, M. (2020). Global context enhanced graph neural networks for session-based recommendation. In Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval (pp. 169–178). ACM.
- Weinzierl, S. (2021). Exploring gated graph sequence neural networks for predicting next process activities. In International conference on business process management (pp. 30–42). Springer.
- Wu, S., Tang, Y., Zhu, Y., Wang, L., Xie, X., & Tan, T. (2019). Session-based recommendation with graph neural networks. In Proceedings of the AAAI conference on artificial intelligence (Vol. 33, pp. 346–353). AAAI Press.
- Wu, Y., Liu, H., & Yang, Y. (2018). Graph convolutional matrix completion for bipartite edge prediction. In KDIR (pp. 49–58). SciTePress.
- Wu, Z., Pan, S., Chen, F., Long, G., Zhang, C., & Philip, S. Y. (2020). A comprehensive survey on graph neural networks. IEEE Transactions on Neural Networks and Learning Systems, 32(1), 4–24. https://doi.org/10.1109/TNNLS.5962385
- Xu, C., Zhao, P., Liu, Y., Sheng, V. S., Xu, J., Zhuang, F., Fang, J., & Zhou, X. (2019). Graph contextualized self-attention network for session-based recommendation. In IJCAI (Vol. 19, pp. 3940–3946). Morgan Kaufmann.
- Xu, K., Hu, W., Leskovec, J., & Jegelka, S. (2018). How powerful are graph neural networks? arXiv preprint arXiv:1810.00826.
- Zhao, C., Li, C., & Fu, C. (2019). Cross-domain recommendation via preference propagation graphnet. In Proceedings of the 28th ACM international conference on information and knowledge management (pp. 2165–2168). ACM.
- Zhu, F., Wang, Y., Chen, C., Zhou, J., Li, L., & Liu, G. (2021). Cross-domain recommendation: Challenges, progress, and prospects. In 30th international joint conference on artificial intelligence, IJCAI 2021 (pp. 4721–4728). Morgan Kaufmann.