
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In recent years, image aesthetic quality assessment has attracted considerable attention due to the massive growth of digital images in social platforms and the Internet. However, automatically assessing aesthetic quality of an image is a challenging task, because image aesthetic is affected by various factors, and the criteria for judging the aesthetic of images with diverse semantic information are different. To this end, a Semantic-Aware Multi-task convolution neural network (SAM-CNN) for evaluating image aesthetic quality is proposed in this paper. The network can fuse intermediate features of different layers at different scales in CNN to obtain a more comprehensive and accurate aesthetic expression, under the joint supervision of image aesthetic quality assessment task and semantic classification task in a multi-task learning manner. Besides, by applying the attention mechanism, semantic information with a large receptive field extracted from deep layers is utilised to guide the network to focus on the key parts of features to be fused, to improve the effectiveness of feature fusion. Experimental results on the AVA dataset and Photo.net dataset demonstrate the effectiveness and superiority of the proposed SAM-CNN.
Introduction
In computer vision, Aesthetic Visual Analysis (AVA) tries to enable the computer to understand and effectively measure “image beauty”, to conveniently perform image management, image beautification and other tasks, and then be applied to various image processing scenarios (Zhang, Miao, and Yu, Citation2021). Because the quality of image visual aesthetic is a subjective attribute, human evaluation of aesthetic quality usually involves personal taste and emotion. However, people's judgments usually have a certain degree of consistency for the aesthetic of an image. Therefore, currently, for research on image aesthetic quality assessment, most of them aim to design an algorithm to simulate universal aesthetic perception of most people, and then the prediction of image aesthetic is made accordingly, which is consistent with the subjective judgment of human on image aesthetic. In addition, due to different ways of image acquisition, images include different content types such as artistic paintings and photographic photos. Existing studies on aesthetic quality assessment focus on photographic photos, i.e. natural images. The images in this paper refer to natural images. Automatically assessing aesthetic quality of natural images is a fundamental and essential pre-processing step for many image-processing tasks, such as image enhancement (Deng et al., Citation2018; Hong et al., Citation2016; Li et al., Citation2018; Ni et al., Citation2020), image retrieval (Lu et al., Citation2014; Samii et al., Citation2015; Xu et al., Citation2010; Zhang, Gao, He, et al., Citation2021) and image beautification (Yan et al., Citation2016; Zhao et al., Citation2020), with many different application scenarios, such as automatically editing and beautifying the photos taken by users to enhance their aesthetics (Ni et al., Citation2020; Sun et al., Citation2017); screening beautiful photos in user albums and recommending them to users, managing albums, so as to reduce storage overhead and save storage space (Tang et al., Citation2013; J. Zhang, Miao, & Yu, Citation2021); assisting search engines to retrieve high aesthetic quality images, and ranking images aesthetically to provide users with more attractive search results (Cui et al., Citation2019).
Generally speaking, the aesthetic of an image is a kind of image quality. Specifically, image quality assessment refers to evaluating the degree of visual distortion of images, and many image quality assessment methods have been proposed in recent years (Fang et al., Citation2020; Madhusudana et al., Citation2022; You & Korhonen, Citation2021; Zhou et al., Citation2021). However, image aesthetic quality assessment tasks aim to design an algorithm to simulate the universal aesthetic perception of most people, which is consistent with the subjective judgment of humans on image aesthetic. Different from image quality assessment approaches, early research on image aesthetic quality assessment characterised the aesthetics of images through artificially designed aesthetic features. These features are based on various photography rules such as colour harmony, rule of thirds, diagonal rule and symmetry and so on (Datta et al., Citation2006; Dhar et al., Citation2011; Ke et al., Citation2006; Tang et al., Citation2013). However, most photographic rules are abstract, so that it is difficult to accurately model them mathematically. In addition, there are also evaluation methods that propose to utilise more general features, such as Fisher vector (Marchesotti et al., Citation2011) and Bag-of-Visual Words (Nishiyama et al., Citation2011), to characterise image aesthetic. However, since these features are originally designed to represent general characters of natural images, they are not fully suitable for describing the aesthetic of images.
Recently, with the successful application of deep learning method in the field of computer vision due to its powerful fitting ability (Han et al., Citation2022; He et al., Citation2016; Jiao et al., Citation2018), many approaches to image aesthetic quality assessment based on deep convolutional neural networks (CNN) have emerged (Lu et al., Citation2014; Zeng et al., Citation2020; Zhang, Gao, Lu, et al., Citation2021). This kind of method can automatically extract the aesthetic features of an image and evaluate the image aesthetic quality. And the performance of them far exceeds that of methods based on artificially designed aesthetic features. However, these methods only utilise highly abstract features output by deep convolutional layers for further processing, to finally evaluate the image aesthetic. The diversity of information contained in the intermediate features of CNN is ignored, and the features represent aesthetic characteristics at different scales. Furthermore, these methods do not take into account differences in image content and attempt to design a general aesthetic quality assessment model to make aesthetic predictions for all types of images. However, semantic category and aesthetics of images are two closely related attributes, and high aesthetic quality images that contain different semantic information generally require different photographic rules. To evaluate the aesthetic quality of images more efficiently and accurately, explicit assistance of semantic information is significant.
For the above issues, we propose a deep neural network framework for image aesthetic prediction, named Semantic-Aware Multi-task convolution neural network (SAM-CNN). The proposed framework fully utilises the diversity of features at different levels in CNN, combining local details contained in the shallower features and global information contained in the deeper features. Besides, SAM-CNN utilises the characteristics of larger receptive field and higher abstraction level of deeper features and applies visual attention mechanism to feature fusion. Specifically, the framework generates attention weights according to deeper features, to guide the model to focus on key parts of features that contribute more to aesthetic quality, and suppress those parts that are not important to image aesthetic, which improves the effect of feature fusion. Furthermore, considering the correlation between image semantic information and aesthetic quality, a multi-task approach is adopted to integrate image semantic information into the aesthetic quality assessment model. The proposed framework predicts the semantic category and aesthetic quality of input images respectively and improves its performance in aesthetic prediction through the perception of the semantic category.
Overall, our main contributions are summarised as follows:
We propose to apply a novel visual attention mechanism to enable critical parts of aesthetic features at different scales to be sufficiently focused on, according to the weights generated in deeper layers, to improve the representation of aesthetic features and prediction performance of the model.
In the feature fusion module, the attentional feature fusion (AFF) mechanism with the Multi-Scale Channel Attention Module (MS-CAM) is implemented to fuse features at different levels for image aesthetic prediction, which can effectively address the issue of scale and semantic inconsistency among features to be fused, to achieve better fusion effect.
A deep neural network framework based on multi-task learning is proposed, which can learn the aesthetic pattern of images according to the perceived semantic meanings. The Earth Mover's Distance (EMD) and binary cross-entropy loss function are adopted to balance these two tasks. Experimental results have demonstrated the effectiveness of the proposed SAM-CNN.
Related works
Image aesthetics assessment
Early research on image aesthetic quality assessment is to design effective aesthetic characteristics to evaluate image aesthetic. These characteristics are based on human perceptions of aesthetics and photography rules. Datta et al. (Citation2006) design and extract 56 features in total from images, including low-level features such as brightness, colour, saturation and aspect ratio, and high-level features such as the rule of thirds, region composition and so on. An SVM classifier is trained on 15 most effective features to make binary predictions on the aesthetic quality of images. Ke et al. (Citation2006) extract features such as brightness, blur, hue count, and spatial distribution of colours and edges to quantitatively model the global aesthetic properties of images to distinguish snapshots from professional photography. However, the artificial designed aesthetic features are heuristic, the aesthetic expression ability of which is limited, and photography rules as the basis of design are abstract, therefore, it is arduous to produce a comprehensive and accurate mathematical modelling of image aesthetic artificially.
In recent years, methods based on deep CNN have gradually been proposed to complete image aesthetic evaluation tasks and achieved excellent results. This kind of method can automatically extract features to predict the aesthetic quality of images, and their aesthetic evaluation performance represents a great improvement over conventional methods. The most typical class of methods is assessing aesthetic quality by fusing global and local features of images. Lu et al. (Citation2014) propose a network model with a two-column CNN architecture, RAPID model, in which one column of CNN takes the deformed original image as input to extract global features, and the other column uses a randomly cropped patch from the original image. The purpose of patch cropping is to extract local fine-grained features from the original image, and then the local and global features are fused to output the final aesthetic prediction result. Considering that the fine-grained local details of a single patch cannot comprehensively characterise the local features of an image, Lu et al. (Citation2015) propose a multi-patch aggregation network (DMA-Net), which uses multiple randomly cropped image patches as the input of the network, and fuses the features extracted from multiple image patches by two different methods of “statistics” and “sorting”. However, random cropping means that there may be a large overlap area between image patches, or it may not be able to cover the key areas for image aesthetic. Moreover, the method in Lu et al. (Citation2015) does not encode global information of images. To address this limitation, Ma et al. (Citation2017) propose A-lamp CNN model. Based on DMA-Net, A-lamp utilises the method of object detection to build an attribute diagram to encode global composition and then integrates the local features from multiple image patches and global composition information extracted. The accuracy of A-lamp model's binary classification prediction has reached 82.50%, however, when this method is applied, the number of attribute map nodes needs to be given in advance, which is not suitable for most of the cases. Zeng et al. (Citation2020) propose a unified probabilistic formulation to deal with different tasks (i.e. binary classification aesthetic prediction, aesthetic score regression and aesthetic score distribution prediction), to further improve the performance on both binary classification and quality score regression problems. Besides, She et al. (Citation2021) propose Hierarchical Layout-Aware Graph Convolutional Network (HLA-GCN) to capture global layout information in coordinate space and latent space, and based on the global information which represents dependencies between visual elements in images, the aesthetic prediction of images is completed. Similar to the ideas of these methods, our method integrates multi-scale local features and global features of images to enhance the aesthetic perception of our model. Different from the above methods, our method fuses multiple levels of middle features with different receptive fields, so as to combine local and global characteristics.
Attention mechanism based AVA methods
Attention mechanisms can be understood as a way of skewing the allocation of available computing resources toward the component with the largest amount of information in the signal (Montoya Obeso et al., Citation2019; Vaswani et al., Citation2017). In computer vision, visual attention mechanisms adjust features by focusing on relevant key information and filtering extraneous information. Many methods have also applied the mechanism of visual attention to aesthetic quality assessment models and achieved good results. Zhang, Gao, et al. (Citation2019) propose a neural network model with two subnets. They use a top-down visual attention mechanism as a guide to select the key area in images. In this way, the network can extract fine-grained local detail features that are critical to image aesthetic. Subsequently, the local and global features extracted by the two subnets are fused by a gated information fusion module. Different from the method in Zhang, Gao, et al. (Citation2019), Sheng et al. (Citation2018) propose to use randomly cropping image patches as input, which are adaptively weighted based on prediction errors by an attention mechanism, and the weights of each image patch are dynamically adjusted during training to improve learning effect. In contrast to the method in Zhang, Gao, et al. (Citation2019), which applies the attention mechanism to patch cropping, and the method in Sheng et al. (Citation2018), which applies the attention mechanism to patch aggregation, Xu et al. (Citation2020) construct context-aware attention modules from two different dimensions, hierarchical and spatial. They enhance multi-scale fused features by learning context-aware attention, to preserve contextual relationship between local and global views. Besides, Zhang, Gao, et al. (Citation2021) utilise self-attention mechanism to capture the long-range dependence of aesthetic features. As the spatial response between visual elements, this dependence is important for the prediction of image aesthetic quality. Moreover, they model the relationship between an image's visual aesthetic features and the user's comments on that image by using a joint attention mechanism. Unlike these methods, our method applies visual attention mechanism to feature fusion. Based on the global characteristics and highly abstract semantic information contained in deep features, which has large receptive fields, visual attention is generated to guide the model to focus on the key information in aesthetic features of different scales, to improve the performance of subsequent feature fusion.
Semantic information assisted AVA
For images with different semantics, it is usually essential to use different photography skills to screen and adopt different aesthetic standards to judge their aesthetics. Therefore, a generic semantic independent aesthetic evaluation method is generally unable to comprehensively perceive the diversity of image semantics, and thus cannot fully learn the internal relationship between image aesthetic and semantic information. In general, semantic information closely related to image aesthetic can be used as auxiliary information for image aesthetic evaluation tasks. Dhar et al. (Citation2011) propose to utilise low-level features to estimate descriptive attributes such as patterning, image content, sky lighting and so on, which in turn can assist in aesthetic quality evaluation tasks. Tang et al. (Citation2013) propose to divide images into seven categories of animal, plant, human, static, building, landscape, night view based on the difference of semantic information contained by images, and to model photographic rules such as patterning, brightness and colour arrangement for different categories of images. In addition to these traditional aesthetic evaluation methods, some deep learning methods also introduce semantic information into image aesthetic prediction tasks. Wang et al. (Citation2016) propose a multi-scene deep learning model, which replaces one convolution layer in Alexnet with seven convolution groups in parallel, each group being pre-trained independently in a dataset of one semantic category, and finally fine-tune parameters of the entire model end-to-end. Their experimental results show the importance of semantic information in image aesthetic evaluation. Similarly, Zhang, Zhai, et al. (Citation2019) propose a two-stream network based on feature fusion, which designs two subnets that are pre-trained in different datasets. The two subnets extract the features that characterise image scene and contained objects respectively. Then, these features are fused to optimise the model's perception of image aesthetic. These methods extract general features related to semantic information through pre-training and then train the models in an end-to-end manner to learn aesthetic representation. Unlike such methods, the proposed method utilises multi-task learning to apply image semantics as auxiliary information to aesthetic quality assessment tasks. Li et al. (Citation2020) propose a personality-assisted multi-task learning framework, which is jointly trained using personalisation data and aesthetic data. They capture common features through multi-task learning and utilise personalisation data as auxiliary information to improve aesthetic prediction capabilities. As closely related tasks, image semantic category classification and aesthetic quality evaluation share visual features with rich information. In the process of multi-task learning, the aesthetic quality evaluation task uses the domain-specific information as inductive bias, which is possessed by the training signal of semantic category classification task, to improve its generalisation ability.
Proposed method
To some extent, the image aesthetic quality assessment task implicitly includes the semantic category classification task. Imperceptibly, humans unconsciously associate image aesthetic and their semantic information. While humans judge the aesthetic of an image, the process of perceiving semantic information of the image is in progress or has been completed. In this paper, an image aesthetic quality evaluation model based on semantic perception, SAM-CNN, is proposed. The overall structure of SAM-CNN model is shown in Figure . It roughly includes four parts: Feature Extraction Module (FEM), Attention Guidance Module (AGM), Feature Fusion Module (FFM) and Multitask Monitoring.
Figure 1. The overall structure of proposed SAM-CNN.
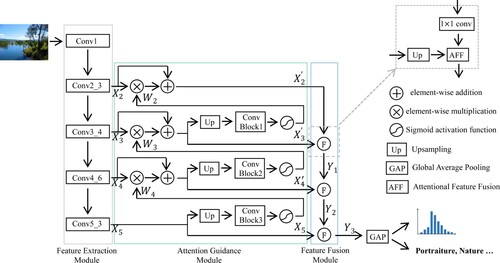
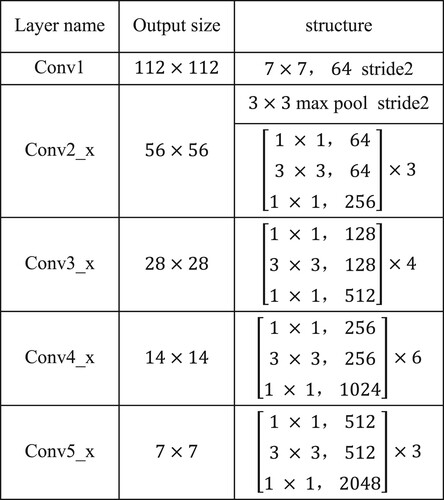
Resnet model is embedded in various network models for its excellent performance to complete computer vision tasks such as classification, recognition, object detection, semantic segmentation and so on. The SAM-CNN utilises Resnet-50 (He et al., Citation2016) as the backbone network and removes the average pooling layer and full connection layer to construct the FEM to implement initial feature extraction. The structure of convolution part of modified Resnet-50 model is shown in Figure . Specifically, we choose the last convolution structures (bottleneck convolution structure) in the second to the fifth phases, i.e. Conv2_3, Conv3_4, Conv4_6 & Conv5_3, and take the output features ,
,
and
as features to be fused. The receptive fields of these features are different in size, representing information of different scales, and the meanings of this information to the aesthetic of input images are different. The first stage Conv1 contains a small number of convolutional layers, and the output feature
contains limited effective information, which is not selected as the feature to be fused. Then features
,
,
and
extracted by FEM are input into AGM. The function of this module is to generate attention weights, according to more abstract high-level semantic information on larger receptive fields contained in deeper features, and then perform attention weights on shallow features, to guide the model to pay sufficient attention to key parts of shallow features that are more important to image aesthetic. Finally, FFM fuses the attention-enhanced features
,
,
and
to combine local features at different scales and global features, and the features obtained after fusion are operated by global average pooling (GAP) and two parallel output layers to complete the aesthetic quality assessment task and the semantic category classification task, respectively. While perceiving the semantic of input images, SAM-CNN performs aesthetic feature extraction, attention weighting and feature fusion according to the different semantic categories, and finally evaluates aesthetic quality.
Figure 2. The architecture of the convolutional part of Resnet-50.
Attention guidance module in SAM-CNN
The method aims to make full use of the intermediate features extracted at each level in convolution process, and fuse these features to combine information of different scales to enhance the model's perception of image aesthetics. Because the convolution operation of convolution kernel has the characteristics of locality, it is difficult to extract long-range dependencies due to the inherent limitation of the receptive field, therefore, global information of images cannot be perceived at a shallow layer. For each feature to be fused, the importance of feature elements of different channels and different spatial positions to image aesthetic is generally different. To enable the model to better focus on the key parts of them, an attention guidance module is constructed. According to the abstract semantics and global information contained in deep-level features, AGM guides the model to focus on key parts of shallow features, which are more important to image aesthetic, enhances aesthetic expression ability of the features to be fused, and outputs new features ,
and
. Specifically, AGM generates attention weights based on deeper features and performs attention weights on elements at each position of upper-level features. As shown in Figure , at first, an attention weight matrix
is generated from the feature
and
is weighted to obtain a new feature
. The attention weight matrix is computed as follows:
(1)
(1) where
is the sigmoid activation function,
represents the convolution operation of Conv Block
in Figure ,
.
represents a double upsampling operation, and the specific method of upsampling is linear interpolation. In this paper, residual structure is employed to generate new features when performing attention weights on the features. The calculation process can be expressed as follows:
(2)
(2) where
. Subsequently,
and
are calculated according to the new features
and
obtained after weighting through Equations (3) and (4) respectively:
(3)
(3)
(4)
(4)
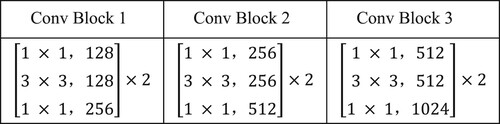
The Conv Block 1, Conv Block 2 and Conv Block 3 in AGM all use the bottleneck convolution structure in Resnet-50. Taking Conv Block 1 as an example, the structure of bottleneck convolution structure is shown in Figure . Each convolution block does not change the size of input features. The stride of each convolution layer in the block is 1, and convolution operation with a kernel size of 3 × 3 ensures that the size of feature map remains unchanged by padding. The function of convolution operation with kernel size of 1 × 1 is to reduce and increase dimension to reduce the amount of calculation. The details of parameters in each convolution block are shown in Figure .
Figure 3. The complete structure of Conv Block 1.
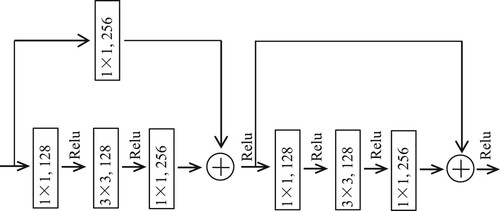
Figure 4. The parameter details of each convolutional block in AGM.
Feature fusion module in SAM-CNN
In computer vision, the importance of multi-scale features has been demonstrated in various deep learning tasks (Kirillov et al., Citation2019; Lin et al., Citation2017; Zhao et al., Citation2020). Many image aesthetic quality assessment methods improve evaluation performance by extracting multi-scale information (Dai et al., Citation2021; Liu et al., Citation2020; Ni et al., Citation2020; Xu et al., Citation2020). Generally, the deep intermediate features in CNN represent global information and abstract high-level semantics with a large receptive field. The shallow intermediate features contain local details with a small receptive field and the positional relationship between pixels. Features at different levels contain information of different scales, and they have different meanings for the aesthetic quality of input images. Fusion of these features at different scales can generally enhance the performance of aesthetic evaluation models. The proposed SAM-CNN applies Attentional Feature Fusion (AFF) to layer-by-layer fusion of intermediate features at different levels. As is illustrated in Figure , for features of each level ,
,
and
,
and
are first fused, and the fusion process can be expressed as
(5)
(5) then the fused features are fused with the features of the next level in the same way. Similarly, the calculation process of fusion can be expressed as follows:
(6)
(6)
(7)
(7) where
denotes an
convolution, whose function is to change the dimension of input features for subsequent fusion operations, and
denotes Attentional Feature Fusion,
.
AFF is a general feature fusion formula with plug-and-play characteristic, suitable for most common scenarios, including short skip connections (such as Resnet), long skip connections (such as U-Net) and feature fusion within the same layer (such as InceptionNet), and usually has better performance than conventional linear operations such as summation and concatenation. The core functional module of AFF is Multi-Scale Channel Attention Module (MS-CAM), which applies attention mechanism in space to fuse multi-scale information and adds local channel context to global channel-wise statistics. Based on its well-designed structure, AFF enables the model to do a soft selection or weighted average for the features to be fused, which solves the problem of scale and semantic inconsistency among them. The structure of AFF is illustrated in Figure . Given two feature maps and
of the same shape, assuming that the receptive field of feature B is larger, the fusion process of AFF is as follows:
(8)
(8) where
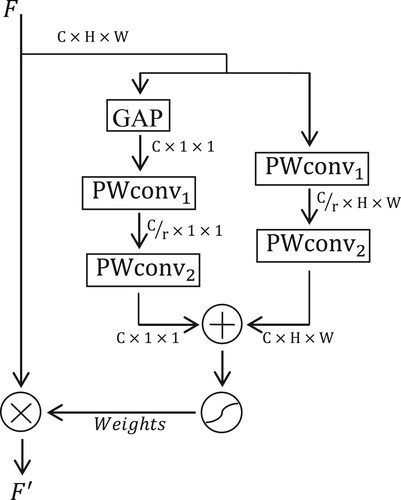
represents the calculation process of generating attention weights in MS-CAM, and the specific process is shown in Figure . As illustrated in Figure , the structure of MS-CAM is simple. The attention weights of channels are generated by two branches of different scales. One branch implements global contextual feature extraction through a global average pooling operation. To make the module lightweight, the other branch uses point-wise convolution to leverage point-wise channel interactions at each spatial location to aggregate local contextual features of channels. To reduce parameters and computation, MS-CAM adopts a bottleneck structure. Given the input feature
, the calculating process of refined
from the module can be expressed as follows:
(9)
(9)
(10)
(10)
(11)
(11) where
represents point-wise convolution, the kernel sizes of
and
are and
, respectively. It is worth noting that “+” in Equation (11) denotes element-wise addition with broadcast. The channel reduction ratio
is set to 2.
Figure 5. Illustration of Attentional Feature Fusion.
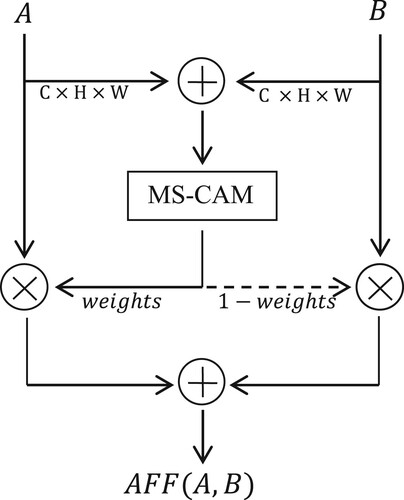
Figure 6. Illustration of Multi-Scale Channel Attention Module.
Semantic-aware multi-task learning
Multi-task learning can be viewed as an inductive transfer, which improves models by introducing an inductive bias that makes them more inclined to certain assumptions. In the multi-task learning scenario of this paper, the inductive bias is provided by the semantic classification task as an auxiliary task, which causes our model to prefer solutions that can explain multiple tasks at the same time. This makes the model generalised better for aesthetic quality assessment tasks. Usually, semantic category information of an image is significantly relevant for evaluating its aesthetic quality, and for humans, images of different semantic categories generally have different aesthetic patterns. In this paper, the method of parameter hard sharing mechanism is adopted. By simultaneously learning these two objectives from the shared representation at the bottom of network, the domain-specific information that has learned can be shared and complemented with each other, to improve the learning efficiency and generalisation effect of the model. This approach, which enables models to capture the same representation for both tasks, has been demonstrated to have a regularising effect that mitigates the risk of overfitting(Liu et al., Citation2019).
As illustrated in Figure , input image is mapped by AGM and FFM, then feature is output, and the dimension of it is 14 × 14 × 2048. Global average pooling operation is performed on it to obtain a 2048-dimensional feature vector. The feature vector predicts the semantic category of input image and probability distribution of its aesthetic quality score through two output layers, which are activated by Sigmoid function and Softmax function, respectively. The dimensions of them are the number of semantic categories and aesthetic ratings in the experimental dataset, respectively. In output layers, to enable the model to perceive the magnitude relationship between image aesthetic quality scores, rather than just treat aesthetic prediction as a simple classification problem, we adopt EMD (Earth Mover's Distance) loss function (Talebi & Milanfar, Citation2018) to supervise the probability distribution prediction of image aesthetic quality score, which is defined as follows:
(12)
(12) where
and
are true aesthetic score probability distribution and predicted probability distribution of images, respectively.
,
, where
is ordered aesthetic rating.
is the Cumulative Distribution Function, which is defined as follows:
(13)
(13)
As in Talebi and Milanfar (Citation2018), is set to 2 to penalise the Euclidean distance between
. The image aesthetic quality assessment problem can be regarded as an ordered class classification problem, that is
, in which cross-entropy loss lacks the size relationship between classes (i.e. between individual aesthetic rating). However, EMD can measure the similarity between two probability distribution histograms and include ordering between classes, so training a model with
allows the model to make predictions on the probability distribution of image aesthetic scores, rather than treating the aesthetic evaluation problem as a classification problem, which conforms formally to the probability distribution histogram produced by human scoring system. The binary cross-entropy loss function is used for semantic category prediction which is defined as follows:
(14)
(14) where
is the number of semantic categories, and the labels of image semantic categories are in the form of One-hot vector.
are ground truth of the image semantic category, and
are predicted values. The update of network parameters and supervision of model training are completed by the combination of the two loss functions. The role of the semantic classification task is to serve as an auxiliary task for better aesthetic evaluation. These two tasks are not equally important, and the scales of different loss functions are quite different. If the total loss function is constructed by directly adding loss functions of these two tasks, due to the difference in scale between them, a certain task may dominate the supervision of model training, causing parameter-sharing parts of the model to tend to fit this task, and the prediction accuracy of the other will be greatly reduced. Therefore, we unify the scale of losses by weighting the loss of auxiliary tasks. The total loss function is as follows:
(15)
(15) where
is used to adjust the scale of semantic classification loss and control the contribution of semantic information.
Experiments
Dataset and evaluation metrics
The experiments are conducted on AVA and Photo.net.
As the largest publicly available image aesthetic evaluation dataset, AVA (Aesthetic Visual Analysis) dataset (Murray et al., Citation2012) includes more than 250,000 images collected from www.dpchallenge.com. Each image is rated by approximately 200 raters, with an aesthetic score ranging from 1 to 10, where 10 represents the highest aesthetic quality. The aesthetic label corresponding to images is the distribution of raters’ number for each aesthetic score, which can be transformed into aesthetic score distribution by -normalisation. When the training data is images in AVA dataset,
in Equation (12). The AVA dataset contains 66 semantic labels, and there are most 2 semantic labels associated for each image. Figure shows some images in AVA dataset with different semantic information and their mean aesthetic scores. A total of 190,599 images are selected as experimental objects, and the total number of semantic categories to which they belong is 30, therefore,
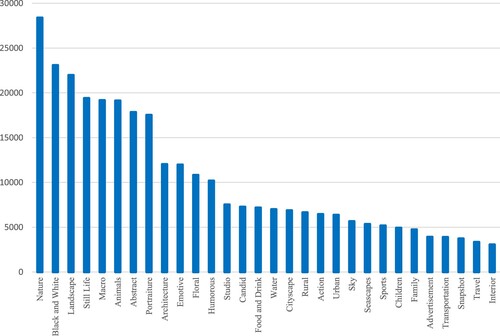
in Equation (14), and the selection basis is that the number of images contained in each semantic category is at least 3000. The number of images contained in each semantic label selected is shown in Figure . Following the work in Lu et al. (Citation2015) and Zhang, Gao, et al. (Citation2019), among all the selected images, 172,000 images are selected as the training set, and the rest are used as the test set.
Figure 7. Randomly selected sample images in the AVA dataset and their aesthetic mean scores and semantic categories.

Figure 8. The number of images for each semantic label.
The Photo.net dataset is one of the earliest large-scale databases for image aesthetic evaluation. Different with AVA dataset, semantic labels are not available on Photo.net dataset and images in it only have corresponding aesthetic labels. Photo.net dataset contains 20,278 images collected from www.photo.net, and each image is rated by at least 10 raters, with an aesthetic score ranging from 1 to 7, with 7 representing the highest aesthetic. The form of corresponding aesthetic labels for each image is the same as AVA dataset. When using images in Photo.net dataset as training data, in Equation (12). Due to the loss of some image labels, the resulting total number of images is 17,183. Following the work in Zhang, Gao, et al. (Citation2019), 15,000 images are selected as training set and the rest as test set.
The network proposed utilises EMD loss function for probability distribution prediction of image aesthetic scores. However, many other aesthetic quality assessment methods regress the mean of image aesthetic scores or perform binary classification of image aesthetic quality. To compare fairly with other methods and evaluate the performance of network models more comprehensively, several evaluation metrics such as Accuracy, SRCC, PLCC, RMSE, EMD are adopted.
For the binary classification problem of image aesthetic quality, Accuracy is selected to evaluate the classification performance of models. The calculation formula of Accuracy is as follows:
(16)
(16) where
and
represent the number of correctly classified image samples of high and low aesthetic quality, respectively.
and
represent the number of image samples predicted to be high aesthetic quality and low aesthetic quality, respectively. Following the work in Lu et al. (Citation2015), Talebi and Milanfar (Citation2018), Zhang, Gao, et al. (Citation2019), we choose 5 as the threshold for judging the category of image aesthetic quality. Specifically, those images with an average aesthetic score of 5 or less are classified as low aesthetic quality, and those images with an average aesthetic score greater than 5 are classified as high aesthetic quality. The average aesthetic score of an image can be calculated by the weighted summation of its aesthetic scores probability distribution. A larger Accuracy value indicates a higher classification accuracy. Accuracy is abbreviated as ACC in the experimental part.
For the image aesthetic score regression problem, SRCC, PLCC, RMSE are selected to evaluate the regression performance of models. In regression problem, the true and predicted value of image aesthetic scores can be calculated using the corresponding probability distribution. Among them, SRCC (Spearman Rank-order Correlation Coefficient) is used to evaluate the ranking correlation between the true values and predicted values of aesthetic scores. Suppose there are images in test set,
are the true values of image aesthetic scores,
are the predicted values of image aesthetic scores,
are the ranks of images in the test set with respect to true values of aesthetic scores, and
are the ranks of images in test set with respect to predicted values of aesthetic scores,
. SRCC is defined as follows:
(17)
(17)
PLCC (Pearson's Linear Correlation Coefficient) provides an evaluation of prediction accuracy, which is a measure of the linear correlation, and the definition is as follows:
(18)
(18) where
and
are the mean of
and
, respectively. RMSE (Root-Mean-Squared Error) is used to measure mean error, which is defined as follows:
(19)
(19)
As mentioned earlier, EMD measures the error between the true probability distributions and predicted distributions of image aesthetic scores.
Implementation details
The proposed SAM-CNN model is implemented based on Tensorflow framework. Resnet-50 with the last average pooling layer and fully connected layer removed is used as the backbone network for preliminary feature extraction. The parameters of the backbone network are initialised by pre-training on ImageNet (Deng et al., Citation2009). The model was trained using SGD optimiser, the parameter value of momentum was set to 0.9, the parameter value of weight decay was set to , and batch size was set to 32. First, the parameters of the backbone network are fixed, and the rest of the parameters are trained. The initial value of the learning rate is set to
. The entire network is then fine-tuned in an end-to-end manner with the initial learning rate set to
. For all learning rates, if the loss on the validation set does not drop after 10 epochs of training, learning rate decays to one-tenth of the original. Following the work in Talebi and Milanfar (Citation2018), during training, the resolution of images is first adjusted to 256 × 256, and then randomly cropped to obtain an image with a resolution of 224 × 224, which is then input into the network, such pre-processing can mitigate potential overfitting.
Hyperparameter validation
The role of in loss function is to control the degree of participation of semantic information in supervising model training and unify the scales of aesthetic quality prediction loss and semantic classification loss in the overall loss function. To determine the best value of
, we conduct experiments to compare the prediction effect of the model on image aesthetic quality under different
, and the experimental results are shown in Figure .
Figure 9. Aesthetic quality prediction accuracy of SAM-CNN model with different values of on AVA dataset.
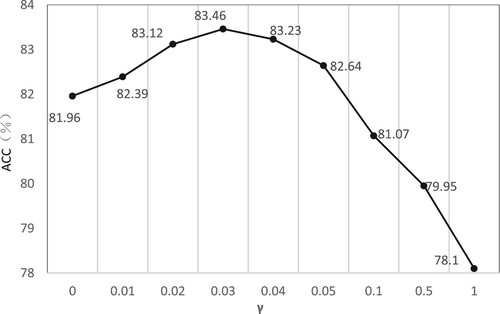
By comparing prediction results of the model in different situations, it can be observed that the participation of semantic information in supervision of model training is effective for image aesthetic quality assessment tasks, and the prediction accuracy of model is at most 1.50% higher than when there is no semantic information. Moreover, the model performance is notably affected by the change in the value of . When
is large, the parameter training of the model is greatly affected by semantic information, and multi-task learning is dominated by semantic classification task, and the model tends to fit the task. The performance of the image aesthetic quality assessment task is negatively affected, and the prediction performance of the model deteriorates. When
, the accuracy of model prediction drops by 3.86% compared to the case without semantic classification loss supervision. At this time, the supervision of semantic classification loss makes the model's aesthetic quality prediction performance worse. In addition, when
, the model has the highest accuracy for image aesthetic quality prediction, reaching 83.46%. At this time, the two tasks are balanced, and the scales of their losses are roughly the same. In subsequent experiments, the value of
in total loss function is set to 0.03.
Ablation study
This section will evaluate the effectiveness of each module in the SAM-CNN model, which is both trained and evaluated on the AVA dataset.
To evaluate the effectiveness of multi-level feature fusion, two models are constructed and trained: Resnet and Resnet + FFM. To fairly compare the performance of the models, Resnet model adds an output layer of dimension 10 with the same structure as in Figure based on removing the last fully connected layer in the original Resnet-50. Resnet + FFM model adds FFM based on the Resnet model and performs subsequent average pooling layer and output layer operations on the output features of FFM. The experimental results of ablation experiments are shown in Table . Params in Table represents the parameter quantity of network models, and FLOPs is floating point operations, which is utilised to measure the computational complexity of models. From the experimental data of the first two lines, it can be observed that the performance of Resnet + FFM is significantly improved compared to Resnet, the accuracy of aesthetic quality binary classification is increased by 1.41%, SRCC is increased from 0.6902 to 0.6983, and PLCC is increased from 0.6937 to 0.7032. This proves the effectiveness of multi-level feature fusion for image aesthetic quality prediction. In addition, we construct the Resnet + FFM’ model, which replaces the AFF contained in FFM with the operation of element-wise addition, based on Resnet + FFM. Compared with Resnet, the performance of Resnet + FFM’ has a certain improvement, however, the degree of improvement is significantly less than that of Resnet + FFM, which proves that AFF has a better effect on the fusion of different scale aesthetic features than element-wise addition. The FFM applies AFF to combine aesthetic features of different scales, which enhances the model's aesthetic perception of the input image and improves the model's prediction performance.
Table 1. Ablation study on the AVA dataset.
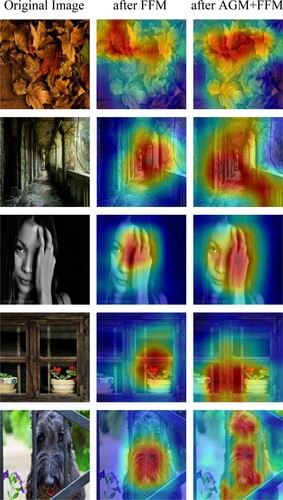
To demonstrate the effectiveness of the attention mechanism proposed for feature fusion, AGM is added based on the Resnet + FFM model. Before feature fusion, attention weights are generated according to the information contained in deeper features, and based on this, the model is guided to focus on key parts of the shallower features, where the attentional weight is performed on. The other parts of the model are not changed, which is recorded as Resnet + AGM + FFM. The relevant data in Table suggests that the aesthetic quality prediction performance of Resnet + AGM + FFM is improved to a certain extent compared with Resnet + FFM, the prediction accuracy is increased by 1.23%, SRCC is increased from 0.6983 to 0.7086, and PLCC is improved from 0.7032 to 0.7135, which demonstrates the effectiveness of AGM. Similarly, we construct Resnet + AGM + FFM’, and its aesthetic prediction performance has also been correspondingly improved compared with Resnet + FFM’. Besides, following the works in Liu et al. (Citation2020), She et al. (Citation2021), we visualise aesthetics-specific activation within models by directly extracting Class Activation Maps (CAM) from our fine-tuned Resnet + FFM and Resnet + AGM + FFM. The CAM of feature maps after FFM and the CAM of feature maps after AGM + FFM are shown respectively in Figure . It can be observed that, areas that are more significant to image aesthetic get a higher response (highlighted in red) with the guidance of AGM, which further verifies the effectiveness of the AGM. The AGM improves the limitation of shallower features’ receptive field to a certain extent. By feeding back the information contained in deep features to shallower layers, the model is more sensitive to key information in the features of each scale at different levels. Under the guidance of deeper features, focusing on the parts that are more important to image aesthetic can strengthen the model's perception of image aesthetics and improve the effect of feature fusion.
Figure 10. Qualitative results of Class Activation Maps. Best viewed in colour.
To evaluate the auxiliary role of semantic information for aesthetic quality prediction, a branch is added to the Resnet + AGM + FFM and Resnet respectively, to complete the classification task of image semantic categories, which are recorded as SAM-CNN and Resnet (w/ semantic-aware) respectively. The relevant data in Table show that the performance of the complete network model SAM-CNN with the addition of semantic classification sub-task has been significantly improved, compared with the Resnet + AGM + FFM model. Specifically, the accuracy of aesthetic quality binary classification increased from 81.96% to 83.46%, SRCC increased from 0.7086 to 0.7129, and PLCC increased from 0.7135 to 0.7203. Besides, compared with Resnet, the aesthetic prediction performance of Resnet (w/ semantic-aware) has also been well improved. These fully prove the importance of semantic information for image aesthetics, and rationally integrating the semantic information of images into network model can improve the model's evaluation performance on aesthetic quality.
Comparison with state-of-the-art networks
To verify the superiority of the model, SAM-CNN is quantitatively compared with several advanced methods and the experiments is completed on the AVA dataset. The experimental results are shown in Table . The same criterion is utilised for the calculation of ACC of various methods in Table , which is that the mean aesthetic score 5 was chosen as the threshold value to judge the high or low aesthetic quality. The results of other methods in Table were quoted from their original papers. It can be observed that the SAM-CNN model proposed outperforms almost all other advanced methods in the table under each evaluation index.
Table 2. Comparison with State-Of-The-Art methods on AVA dataset.
The idea of methods proposed in Lu et al. (Citation2014, Citation2015), Zhang, Gao, et al. (Citation2019) is to crop one or more image patches from the original images as the input of the model to extract local features, and fuse them with different forms of global features, to finally predict image aesthetic quality. The method proposed does not crop image patches from original images, but adjusts the whole image and inputs it into the model. Under the guidance of the attention mechanism, it combines local details and global information by fusing the features of different scales to predict the aesthetic quality of input images. As shown in Tables and , the performance of the Resnet + AGM + FFM model is better than other methods mentioned above and compared with the method in Zhang, Gao, et al. (Citation2019), which performs the best image aesthetic quality evaluation, the accuracy is improved by 1.26%, and SRCC and PLCC are improved by 0.0324 and 0.0267, which demonstrates the effectiveness and superiority of the proposed FFM and AGM.
Compared with the method in W. Kao et al. (Citation2017), Mai et al. (Citation2016), Zhang, Zhai, et al. (Citation2019), which also utilises semantic information to assist aesthetic learning tasks, the aesthetic prediction accuracy of the SAM-CNN model proposed is improved by 4.38%, 6.06% and 3.45%, respectively. In addition, compared with the method based on comparison in Kong et al. (Citation2016), the method of adaptively weighting the loss of multiple image patches in Sheng et al. (Citation2018), the method of using adaptive fractional dilated convolution to preserve the original aspect ratio of input images in Chen et al. (Citation2020), the method of personality-assisted multi-task learning in Li, Zhu, et al. (Citation2020), the method of enhancing multi-scale fused features by learning context-aware attention, the method of using attribute graph to capture the overall layout of images in Ma et al. (Citation2017), and the method of combining CNN features with traditional aesthetic features in Li, Li, et al. (Citation2020), the prediction accuracy of SAM-CNN model is also increased by 6.13%, 0.43%, 0.22%, 0.56%, 2.56%, 0.96% and 0.63% respectively, which proves the effectiveness and superiority of SAM-CNN model.
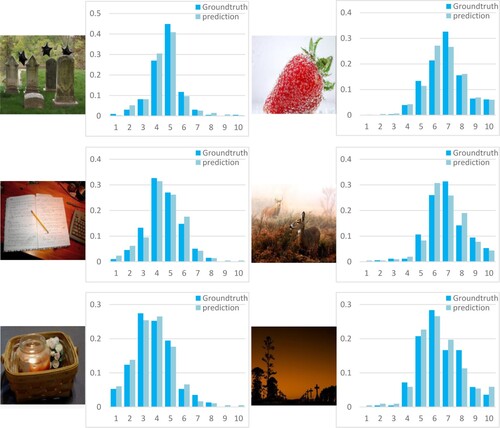
Besides, compared with the method based on Graph Convolution Network in She et al. (Citation2021), although the aesthetic prediction accuracy of the SAM-CNN model does not achieve better performance, SRCC and PLCC values of our method are improved by 0.0574 and 0.0427, respectively. And compared to the unified probabilistic formulation method proposed in Zeng et al. (Citation2020), SRCC and PLCC values of our method are not significantly improved, however, the accuracy of the binary classification aesthetic prediction is increased by 2.65%. It can be observed that the method proposed achieves competitive evaluation results for both the image aesthetics binary classification problem and aesthetic score regression problem. Under the auxiliary supervision of semantic classification task, adopting attention mechanism to guide multi-level feature fusion enables our model to more accurately evaluate the aesthetic quality of images. Figure shows some prediction results of the model proposed on some randomly selected images in the test set. It can be observed from Figure that SAM-CNN can achieve a relatively high accuracy in predicting the aesthetic score probability distribution of images.
Figure 11. Prediction results of SAM-CNN on some randomly selected images in the AVA dataset. The column on the left is low aesthetic quality images, the column on the right is high aesthetic quality images.
Model performance on Photo.net dataset
To further evaluate the performance of the proposed model, we performed transfer learning on the SAM-CNN model in the Photo.net dataset. The images in the Photo.net dataset only have corresponding aesthetic labels. Therefore, for SAM-CNN that has fully learned aesthetic and semantic representations on the AVA dataset, the semantic category prediction branch is removed and the aesthetic quality prediction branch is replaced. Then the parameters of model are fine-tuned in an end-to-end manner, and the prediction performance of the SAM-CNN model and methods such as GIST (Marchesotti et al., Citation2011), FisherVector (Marchesotti et al., Citation2011), MTCNN (Kao et al., Citation2017) and GPF-CNN (Zhang, Gao, et al., Citation2019) are compared. The results of these other methods are quoted from their original papers and comparison results are shown in Table . The Photo.net dataset is more challenging, and the prediction accuracy of the SAM-CNN model on the Photo.net dataset is significantly lower than that of the AVA dataset.
Table 3. Comparison with State-Of-The-Art methods on Photo.net dataset.
It can be observed from Table that the prediction accuracy of the SAM-CNN model is ahead of several other methods. Compared with the two traditional methods GIST_SVM and FV_SIFT_SVM, the prediction accuracy of the SAM-CNN model is increased by 18.13% and 17.23%, respectively. Compared with two deep learning methods, MTCNN and GPF-CNN, the prediction accuracy of SAM-CNN is improved by 12.83% and 2.43%, respectively.
Conclusion
In this paper, a novel image aesthetic quality assessment network is proposed, which takes into account the characteristics of deep features, large receptive field and high-level abstract semantics. Attention weights are generated according to deep features and then fed back to intermediate features at different levels in the network. They can guide the model to focus on key parts of features at different scales that are significant to image aesthetic. This alleviates the inherent limitation of the convolution kernel's receptive field to a certain extent, and as a pre-processing operation of feature fusion, the guidance of attention enhances the aesthetic perception of features to be fused. In addition, AFF is utilised to fuse features at different levels, which alleviates the problem of scale and semantic inconsistency between the features to be fused. Moreover, semantic information of images is utilised to assist the learning of image aesthetic in a multi-task learning manner, and the model's perception of semantic information effectively improves the performance of its aesthetic quality assessment task. The effectiveness of each part of the proposed SAM-CNN model has been verified by experiments. The experimental results show that, while perceiving semantic information of images, focused features fusion can enhance the aesthetic expression of model, and the accuracy of image aesthetic quality prediction.
Acknowledgements
The authors would like to thank the editor and anonymous reviewers for their helpful comments and suggestions.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Chen, Q., Zhang, W., Zhou, N., Lei, P., Xu, Y., Zheng, Y., & Fan, J. (2020). Adaptive fractional dilated convolution network for image aesthetics assessment. 2020 IEEE/CVF conference on computer vision and pattern recognition (CVPR), 14102–14111. https://doi.org/10.1109/CVPR42600.2020.01412
- Cui, C., Liu, H., Lian, T., Nie, L., Zhu, L., & Yin, Y. (2019). Distribution-oriented aesthetics assessment with semantic-aware hybrid network. IEEE Transactions on Multimedia, 21(5), 1209–1220. https://doi.org/10.1109/TMM.2018.2875357
- Dai, Y., Gieseke, F., Oehmcke, S., Wu, Y., & Barnard, K. (2021). Attentional feature fusion. 2021 IEEE winter conference on applications of computer vision (WACV), 3559–3568. https://doi.org/10.1109/WACV48630.2021.00360
- Datta, R., Joshi, D., Li, J., & Wang, J. Z. (2006). Studying aesthetics in photographic images using a computational approach. In A. Leonardis, H. Bischof, & A. Pinz (Eds.), Computer vision – ECCV 2006. Springer Berlin Heidelberg (Vol. 3953, pp. 288–301). https://doi.org/10.1007/11744078_23
- Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. 2009 IEEE conference on computer vision and pattern recognitio, 248–255. https://doi.org/10.1109/CVPR.2009.5206848
- Deng, Y., Loy, C. C., & Tang, X. (2018). Aesthetic-driven image enhancement by adversarial learning. Proceedings of the 26th ACM international conference on multimedia, 870–878. https://doi.org/10.1145/3240508.3240531
- Dhar, S., Ordonez, V., & Berg, T. L. (2011). High level describable attributes for predicting aesthetics and interestingness. CVPR, 2011, 1657–1664. https://doi.org/10.1109/CVPR.2011.5995467
- Fang, Y., Zhu, H., Zeng, Y., Ma, K., & Wang, Z. (2020). Perceptual quality assessment of smartphone photography. 2020 IEEE/CVF conference on computer vision and pattern recognition (CVPR), 3674–3683. https://doi.org/10.1109/CVPR42600.2020.00373
- Han, J., Yao, X., Cheng, G., Feng, X., & Xu, D. (2022). P-CNN: Part-based convolutional neural networks for fine-grained visual categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(2), 579–590. https://doi.org/10.1109/TPAMI.2019.2933510
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. 2016 IEEE conference on computer vision and pattern recognition (CVPR), 770–778. https://doi.org/10.1109/CVPR.2016.90
- Hong, R., Zhang, L., & Tao, D. (2016). Unified photo enhancement by discovering aesthetic communities from Flickr. IEEE Transactions on Image Processing, 25(3), 1124–1135. https://doi.org/10.1109/TIP.2016.2514499
- Jiao, Z., Gao, X., Wang, Y., Li, J., & Xu, H. (2018). Deep convolutional neural networks for mental load classification based on EEG data. Pattern Recognition, 76, 582–595. https://doi.org/10.1016/j.patcog.2017.12.002
- Jin, X., Wu, L., Li, X., Zhang, X., Chi, J., Peng, S., Ge, S., Zhao, G., & Li, S. (2019). ILGNet: Inception modules with connected local and global features for efficient image aesthetic quality classification using domain adaptation. IET Computer Vision, 13(2), 206–212. https://doi.org/10.1049/iet-cvi.2018.5249
- Kao, Y., He, R., & Huang, K. (2017). Deep aesthetic quality assessment with semantic information. IEEE Transactions on Image Processing, 26(3), 1482–1495. https://doi.org/10.1109/TIP.2017.2651399
- Ke, Y., Tang, X., & Jing, F. (2006). The design of high-level features for photo quality assessment. 2006 IEEE computer society conference on computer vision and pattern recognition – volume 1 (CVPR’06), 1, 419–426. https://doi.org/10.1109/CVPR.2006.303
- Kirillov, A., Girshick, R., He, K., & Dollar, P. (2019). Panoptic feature pyramid networks. 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), 6392–6401. https://doi.org/10.1109/CVPR.2019.00656
- Kong, S., Shen, X., Lin, Z., Mech, R., & Fowlkes, C. (2016). Photo aesthetics ranking network with attributes and content adaptation. In B. Leibe, J. Matas, N. Sebe, & M. Welling (Eds.), Computer vision – ECCV 2016. Springer International Publishing (Vol. 9905, pp. 662–679). https://doi.org/10.1007/978-3-319-46448-0_40
- Li, D., Wu, H., Zhang, J., & Huang, K. (2018). A2-RL: Aesthetics aware reinforcement learning for image cropping. 2018 IEEE/CVF conference on computer vision and pattern recognition, 8193–8201. https://doi.org/10.1109/CVPR.2018.00855
- Li, L., Zhu, H., Zhao, S., Ding, G., & Lin, W. (2020). Personality-assisted multi-task learning for generic and personalized image aesthetics assessment. IEEE Transactions on Image Processing, 29, 3898–3910. https://doi.org/10.1109/TIP.2020.2968285
- Li, X., Li, X., Zhang, G., & Zhang, X. (2020). A novel feature fusion method for computing image aesthetic quality. IEEE Access, 8, 63043–63054. https://doi.org/10.1109/ACCESS.2020.2983725
- Lin, T.-Y., Dollar, P., Girshick, R., He, K., Hariharan, B., & Belongie, S. (2017). Feature pyramid networks for object detection. 2017 IEEE conference on computer vision and pattern recognition (CVPR), 936–944. https://doi.org/10.1109/CVPR.2017.106
- Liu, D., Puri, R., Kamath, N., & Bhattacharya, S. (2020). Composition-aware image aesthetics assessment. 2020 IEEE winter conference on applications of computer vision (WACV), 3558–3567. https://doi.org/10.1109/WACV45572.2020.9093412
- Liu, S., Johns, E., & Davison, A. J. (2019). End-To-end multi-task learning with attention. 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), 1871–1880. https://doi.org/10.1109/CVPR.2019.00197
- Lu, X., Lin, Z., Jin, H., Yang, J., & Wang, J. Z. (2014). RAPID: Rating pictorial aesthetics using deep learning. Proceedings of the 22nd ACM international conference on multimedi, 457–466. https://doi.org/10.1145/2647868.2654927
- Lu, X., Lin, Z., Shen, X., Mech, R., & Wang, J. Z. (2015). Deep multi-patch aggregation network for image style, aesthetics, and quality estimation. 2015 IEEE international conference on computer vision (ICCV), 990–998. https://doi.org/10.1109/ICCV.2015.119
- Ma, S., Liu, J., & Chen, C. W. (2017). A-Lamp: Adaptive layout-aware multi-patch deep convolutional neural network for photo aesthetic assessment. 2017 IEEE conference on computer vision and pattern recognition (CVPR), 722–731. https://doi.org/10.1109/CVPR.2017.84
- Madhusudana, P. C., Birkbeck, N., Wang, Y., Adsumilli, B., & Bovik, A. C. (2022). Image quality assessment using contrastive learning. IEEE Transactions on Image Processing, 31, 4149–4161. https://doi.org/10.1109/TIP.2022.3181496
- Mai, L., Jin, H., & Liu, F. (2016). Composition-preserving deep photo aesthetics assessment. 2016 IEEE conference on computer vision and pattern recognition (CVPR), 497–506. https://doi.org/10.1109/CVPR.2016.60
- Marchesotti, L., Perronnin, F., Larlus, D., & Csurka, G. (2011). Assessing the aesthetic quality of photographs using generic image descriptors. 2011 International conference on computer vision, 1784–1791. https://doi.org/10.1109/ICCV.2011.6126444
- Montoya Obeso, A., Benois-Pineau, J., Garcia Vazquez, M. S., & Ramirez Acosta, A. A. (2019). Forward–backward visual saliency propagation in deep NNs vs internal attentional mechanisms. 2019 Ninth international conference on image processing theory, tools and applications (IPTA), 1–6. https://doi.org/10.1109/IPTA.2019.8936125
- Murray, N., Marchesotti, L., & Perronnin, F. (2012). AVA: A large-scale database for aesthetic visual analysis. 2012 IEEE conference on computer vision and pattern recognition, 2408–2415. https://doi.org/10.1109/CVPR.2012.6247954
- Ni, Z., Yang, W., Wang, S., Ma, L., & Kwong, S. (2020). Towards unsupervised deep image enhancement with generative adversarial network. IEEE Transactions on Image Processing, 29, 9140–9151. https://doi.org/10.1109/TIP.2020.3023615
- Nishiyama, M., Okabe, T., Sato, I., & Sato, Y. (2011). Aesthetic quality classification of photographs based on color harmony. CVPR, 2011, 33–40. https://doi.org/10.1109/CVPR.2011.5995539
- Samii, A., Měch, R., & Lin, Z. (2015). Data-driven automatic cropping using semantic composition search: Data-driven automatic cropping. Computer Graphics Forum, 34(1), 141–151. https://doi.org/10.1111/cgf.12465
- She, D., Lai, Y.-K., Yi, G., & Xu, K. (2021). Hierarchical layout-aware graph convolutional network for unified aesthetics assessment. 2021 IEEE/CVF conference on computer vision and pattern recognition (CVPR), 8471–8480. https://doi.org/10.1109/CVPR46437.2021.00837
- Sheng, K., Dong, W., Ma, C., Mei, X., Huang, F., & Hu, B.-G. (2018). Attention-based multi-patch aggregation for image aesthetic assessment. Proceedings of the 26th ACM international conference on multimedia, 879–886. https://doi.org/10.1145/3240508.3240554
- Sun, W.-T., Chao, T.-H., Kuo, Y.-H., & Hsu, W. H. (2017). Photo filter recommendation by category-aware aesthetic learning. IEEE Transactions on Multimedia, 19(8), 1870–1880. https://doi.org/10.1109/TMM.2017.2688929
- Talebi, H., & Milanfar, P. (2018). NIMA: Neural image assessment. IEEE Transactions on Image Processing, 27(8), 3998–4011. https://doi.org/10.1109/TIP.2018.2831899
- Tang, X., Luo, W., & Wang, X. (2013). Content-based photo quality assessment. IEEE Transactions on Multimedia, 15(8), 1930–1943. https://doi.org/10.1109/TMM.2013.2269899
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need (arXiv:1706.03762). arXiv. http://arxiv.org/abs/1706.03762
- Wang, W., Zhao, M., Wang, L., Huang, J., Cai, C., & Xu, X. (2016). A multi-scene deep learning model for image aesthetic evaluation. Signal Processing: Image Communication, 47, 511–518. https://doi.org/10.1016/j.image.2016.05.009
- Wang, Z., Liu, D., Chang, S., Dolcos, F., Beck, D., & Huang, T. (2017). Image aesthetics assessment using deep Chatterjee’s machine. 2017 International joint conference on neural networks (IJCNN), 941–948. https://doi.org/10.1109/IJCNN.2017.7965953
- Xu, H., Wang, J., Hua, X.-S., & Li, S. (2010). Image search by concept map. Proceeding of the 33rd international ACM SIGIR conference on research and development in information retrieval – SIGIR ‘10, 275. https://doi.org/10.1145/1835449.1835497
- Xu, M., Zhong, J.-X., Ren, Y., Liu, S., & Li, G. (2020). Context-aware attention network for predicting image aesthetic subjectivity. Proceedings of the 28th ACM international conference on multimedia, 798–806. https://doi.org/10.1145/3394171.3413834
- Yan, Z., Zhang, H., Wang, B., Paris, S., & Yu, Y. (2016). Automatic photo adjustment using deep neural networks. ACM Transactions on Graphics, 35(2), 1–15. https://doi.org/10.1145/2790296
- You, J., & Korhonen, J. (2021). Transformer For image quality assessment. 2021 IEEE international conference on image processing (ICIP), 1389–1393. https://doi.org/10.1109/ICIP42928.2021.9506075
- Zeng, H., Cao, Z., Zhang, L., & Bovik, A. C. (2020). A unified probabilistic formulation of image aesthetic assessment. IEEE Transactions on Image Processing, 29, 1548–1561. https://doi.org/10.1109/TIP.2019.2941778
- Zhang, J., Miao, Y., & Yu, J. (2021). A comprehensive survey on computational aesthetic evaluation of visual Art images: Metrics and challenges. IEEE Access, 9, 77164–77187. https://doi.org/10.1109/ACCESS.2021.308307
- Zhang, W., Zhai, G., Yang, X., & Yan, J. (2019). Hierarchical features fusion for image aesthetics assessment. 2019 IEEE international conference on image processing (ICIP), 3771–3775. https://doi.org/10.1109/ICIP.2019.8803599
- Zhang, X., Gao, X., He, L., & Lu, W. (2021). MSCAN: Multimodal self-and-collaborative attention network for image aesthetic prediction tasks. Neurocomputing, 430, 14–23. https://doi.org/10.1016/j.neucom.2020.10.046
- Zhang, X., Gao, X., Lu, W., & He, L. (2019). A gated peripheral-foveal convolutional neural network for unified image aesthetic prediction. IEEE Transactions on Multimedia, 21(11), 2815–2826. https://doi.org/10.1109/TMM.2019.2911428
- Zhang, X., Gao, X., Lu, W., He, L., & Li, J. (2021). Beyond vision: A multimodal recurrent attention convolutional neur A multi-scene deep learning model for image aesthetic evaluational network for unified image aesthetic prediction tasks. IEEE Transactions on Multimedia, 23, 611–623. https://doi.org/10.1109/TMM.2020.2985526
- Zhao, X., Pang, Y., Zhang, L., Lu, H., & Zhang, L. (2020). Suppress and balance: A simple gated network for salient object detection. In A. Vedaldi, H. Bischof, T. Brox, & J.-M. Frahm (Eds.), Computer vision – ECCV 2020. Springer International Publishing (Vol. 12347, pp. 35–51). https://doi.org/10.1007/978-3-030-58536-5_3
- Zhou, W., Wang, Z., & Chen, Z. (2021). Image super-resolution quality assessment: Structural fidelity versus statistical naturalness. 2021 13th international conference on quality of multimedia experience (QoMEX), 61–64. https://doi.org/10.1109/QoMEX51781.2021.9465479.