
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This paper critically discusses a recent EJIS paper entitled “Will PLS have to become factor-based to survive and thrive?”, which laments that covariance-based structural equation modelling cannot handle composite models, postulates that PLS should become factor-based, and advocates the use of the PLSF-SEM method. We clarify that covariance-based structural equation modelling can handle composite models, e.g. using the so-called Henseler – Ogasawara specification, agree that PLS in its original form cannot consistently estimate the parameters of reflective measurement models, and reiterate that consistent PLS is a viable means to overcome this limitation. Finally, we study the performance of PLSF-SEM through scenario analyses. Based on our results, we conclude that PLSF-SEM is inferior to covariance-based structural equation modelling and consistent PLS in almost all respects. Therefore, we cannot currently recommend the use of PLSF-SEM, and it is up to future research to demonstrate potential advantages over existing structural equation modelling techniques.
1. Introduction
Structural equation modelling (SEM) is a versatile analytical tool for theory testing, which is widely applied in information systems (IS) and many other disciplines of business and social science. It relies on a representation of a theory in the form of a statistical model and compares the model-implied variance-covariance matrix with the variance-covariance matrix of the data at hand to judge the quality of the model. While there are many different SEM techniques, two types of SEM techniques prevail: covariance-based SEM (CB-SEM) and variance-based SEM. The most prominent variance- and covariance-based SEM technique are partial least squares (PLS) and maximum likelihood, respectively.
A recent issues and opinion piece published in this journal (Kock, Citation2024, further abbreviated as K24) opens a debate about the future of SEM in IS research. In essence, K24 identifies two major problems in the SEM context and proposes a solution. The first problem is that although composites play a pivotal role in research and society, CB-SEM cannot deal with composites, which renders composite models paradoxical. The second problem is that PLS, which actually deals with composite models, cannot consistently estimate reflective measurement models. The latter is also known as common factor model. Therefore, K24 argues that “PLS-based methods will have to become factor-based to survive and thrive in the context of SEM”. As a solution, K24 proposes factor-based PLS (PLSF-SEM; Kock, Citation2017, Citation2019a, Citation2019b). K24 regards PLSF-SEM as a suitable means to address most of the criticisms of PLS as expressed in a recent debate in the journal Communications of the Association of Information Systems (cf. Evermann & Rönkkö, Citation2023a, Citation2023b; Kock, Citation2023). K24 is not only an opinion piece, but also an advocacy paper for PLSF-SEM.
In our commentary, we would like to draw attention to the issues that are relevant for IS researchers: To what extent do the capabilities of SEM techniques such as CB-SEM and PLS satisfy the methodological needs of IS researchers? What are the actual benefits of using PLSF-SEM? Which SEM technique should be preferred in typical IS research situations? We show that the two problems that K24 raises have already been solved: CB-SEM can be used for structural equation models containing composites (cf. Grace & Bollen, Citation2008; Schuberth, Citation2023), and if a correction for attenuation is applied to PLS as is done in consistent PLS (PLSc; Dijkstra & Henseler, Citation2015a, Citation2015b), analysts can obtain consistent estimates for common factor models. Finally, we show through scenario analysis that PLSF-SEM is inferior to existing solutions in several respects. Since the adoption of premature techniques can harm the progress of science (Evermann & Rönkkö, Citation2023a), we recommend to stick to more established techniques, particularly CB-SEM or PLSc. Both of them can deal with models that contain composites and common factors.
2. SEM in IS research from a helicopter view
Theories of IS research are often expressed as relationships between theoretical constructs. To empirically test such theories, IS researchers strongly rely on SEM. An additional complexity arises from the fact that some constructs of IS research are best modelled as common factors, whereas other constructs are better modelled as composites (Yu et al., Citation2021). Therefore, as K24 implicitly notes – and we fully agree with this notion – SEM techniques only have a future for IS research if they can cope with both, common factors and composites.
Traditionally, CB-SEM and PLS were only capable of modelling theoretical constructs in a single way: CB-SEM modelled constructs as common factors (see e.g., Bollen, Citation1989), whereas PLS modelled constructs as composites (see e.g., Dijkstra, Citation2017; Sarstedt et al., Citation2016). Consequently, the way of how the theoretical constructs should be modelled dictated the choice of the SEM technique. The decision for or against a method was not to be made light-heartedly, because using the wrong model for one’s theoretical constructs can easily result in biased estimates and lead to erroneous conclusions (c.f. Jarvis et al., Citation2003; Sarstedt et al., Citation2016; Schuberth, Rosseel, et al., Citation2023).
In recent years, methodological research on SEM has made significant progress, so that the formerly strict relation between the SEM techniques and the way of modelling theoretical constructs has been relaxed (Henseler, Citation2021; Schuberth et al., Citationin press; Schuberth, Zaza, et al., Citation2023). More specifically, the advent of the Henseler–Ogasawara specification (H–O specification, see Schuberth, Citation2023) allows to specify composites in CB-SEM with the same ease as common factors, and consistent PLS (PLSc, see Dijkstra & Henseler, Citation2015a, Citation2015b) makes it possible to obtain consistent estimates for common factor models using the iterative PLS algorithm. In the following subsection, we will discuss both developments in more detail.
2.1. Modeling composites with CB-SEM using the H–O specification
Specifying composites in CB-SEM is neither impossible nor paradoxical.Footnote1 Although traditionally, CB-SEM has mainly been used for modelling common factors, researchers have also occasionally investigated its use for modelling composites (e.g., Dolan et al., Citation1999; Fan, Citation1997; Grace & Bollen, Citation2008; Hancock et al., Citation2013; Rose et al., Citation2019). Admittedly, all of these approaches have their limitations; they either require multiple estimation steps, are limited to exogenous constructs, require complex constraints, or work only with pre-specified weights. This means that none of these approaches can model composites as easily as PLS.
This situation changed with the development of the H–O specification, which allows researchers using CB-SEM to model composites with the same flexibility that they are accustomed from modelling common factors (Schuberth, Citation2023; Yu et al., Citation2023). It expresses the relationships between a composite and its components by means of composite loadings, not weights. The variances and covariances of a block of components are explained by a focal composite, i.e., the emergent variable, and a set of potentially correlated, but not fully linearly dependent composites that capture the remaining variances and covariances, i.e., the excrescent variables (Henseler, Citation2021; Yu et al., Citation2023). Note that the H–O specification models a composite in such a way that it accounts for the covariances between its components and other variables of the model (for an alternative that specifies composites without that characteristic, see the pseudo-indicator model proposed by Rose et al., Citation2019).
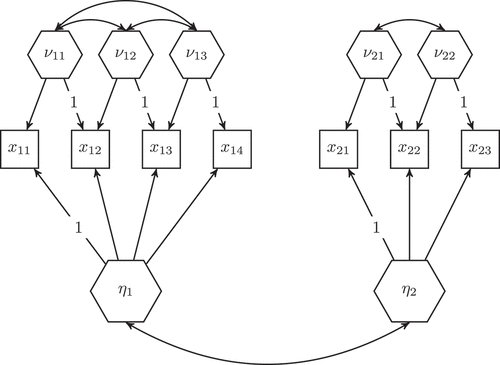
depicts a model consisting of two emergent variables, and
, and seven observed variables (
–
and
–
). It also contains five excrescent variables,
,
,
,
, and
. The model is identified and has 6 degrees of freedom. In analogy to the kind of model studied in confirmatory factor analysis, which typically consists of correlated common factors, this model consists of correlated composites and is the underlying type of model studied in a confirmatory composite analysis (CCA, see Hubona et al., Citation2021; Schamberger et al., Citation2023; Schuberth et al., Citation2018a). Various estimators have been proposed for CCA: Next to maximum likelihood and other estimators of CB-SEM (Liu et al., Citation2022; Schamberger et al., Citation2023), also PLS (Henseler & Schuberth, Citation2020; Schuberth, Citation2021) or MAXVAR (Schuberth et al., Citation2018a) can be employed.
Figure 1. Specifying composites in CB-SEM.
2.2. Estimating models containing common factors with PLSc
It is well established in the literature that PLS can consistently estimate structural models that contain composites (Dijkstra, Citation2017). In contrast, when a structural equation model contains common factors, PLS estimates are known to be only consistent at large, i.e., only when both the number of indicators and the number of observations tend to infinity will consistent estimates be obtained (Hui & Wold, Citation1982). Therefore, drawing conclusions from structural equation models containing common factors that have been estimated by PLS can severely compromise a researcher’s conclusions (Evermann & Rönkkö, Citation2023a; Rönkkö & Evermann, Citation2013; Schuberth, Citation2021; Schuberth, Rosseel, et al., Citation2023; Schuberth, Schamberger, et al., Citation2023).
As a remedy, a consistent version of PLS, namely consistent PLS (PLSc) was introduced (Dijkstra, Citation1985; Dijkstra & Henseler, Citation2015b). In a first step, PLSc conducts the traditional PLS algorithm using Mode A to obtain weight estimates. Subsequently, PLSc applies a correction for attenuation to consistently estimate factor loadings and path coefficients. Consistent factor loading estimates of the indicators associated with a common factor are obtained as follows:
where is the vector containing the PLS Mode A weight estimates. The correction factor
is obtained in such a way that the off-diagonal elements of the indicators’ empirical correlation matrix
are “reproduced as best as possible in a least squares sense” (Dijkstra & Henseler, Citation2015a):
Moreover, the reliability of the factor scores obtained by PLS Mode A weights can be estimated as . In the literature, this reliability coefficient is also known as Dijkstra-Henseler’s
(Dijkstra & Henseler, Citation2015a). Consequently, the correlation between PLS Mode A factor scores can be corrected for attenuation to obtain consistent common factor correlation estimates:
In the final step, these common factor correlations are used to consistently estimate the path coefficient by ordinary least squares or two-stage least squares in case of recursive or non-recursive structural models, respectively. Since PLSc applies the correction for attenuation for each construct separately, it can be applied to models containing both common factors and composites. In case of a composite, the respective reliability estimate is set to one and thus no correction for attenuation is applied. shows schematically the steps of PLSc.
Figure 2. Schematic illustration of PLSc (adapted from Schuberth et al., Citation2018b).

Nowadays, PLSc is well explored. For instance, its asymptotical properties have been derived (e.g., Dijkstra, Citation1985; Schuberth, Rosseel, et al., Citation2023), and its finite sample performance has been studied and compared to existing approaches (e.g., Aguirre-Urreta & Rönkkö, Citation2018; Dijkstra & Henseler, Citation2015a; Dijkstra & Schermelleh-Engel, Citation2014; Schuberth, Hubona, et al., Citation2023; Takane & Hwang, Citation2018; Yuan et al., Citation2020). Moreover, PLSc has been extended to deal with ordinal indicators (Schuberth et al., Citation2018b), to allow for correlated measurement errors within blocks of indicators (Rademaker et al., Citation2019), to overcome multicollinearity issues in the structural model (Jung & Park, Citation2018), and to handle outliers (Schamberger et al., Citation2020). Finally, various guidelines for applied IS researchers who want to use PLSc have been proposed (e.g., Benitez et al., Citation2020; Evermann & Rönkkö, Citation2023a; Henseler et al., Citation2016).
3. What about PLSF-SEM?
K24 strongly advocates another technique: PLSF-SEM. Arguably, PLSF-SEM addresses many criticisms brought forward against PLS (cf. Evermann & Rönkkö, Citation2023a). But is PLSF-SEM a viable methodological option for IS researchers? In this section we try to answer some basic questions about PLSF-SEM: What is PLSF-SEM? What are its capabilities? What benefits can it offer to IS researchers?
3.1. What is PLSF-SEM?
The working principle of PLSF-SEM can be summarised in a single sentence: PLSF-SEM takes the results of PLSc and tries to reproduce them. In other words, “as far as parameter estimation is concerned, [PLSF-SEM] is simply PLSc but slower and more difficult to understand” (Evermann & Rönkkö, Citation2023b, p. 763). Taking a more granular look at PLSF-SEM as is done in , one could say that it consists of three steps that are performed in a sequence: PLS Mode A, PLSc, and the actual PLSF-SEM algorithm. In the third step, an iterative algorithm called CFM1 (Kock, Citation2022) mixes indicator data and random data in order to create factor scores. These factor scores are constructed in such a way that they reproduce the common factor correlations obtained from PLSc as close as possible (Kock, Citation2017).
Figure 3. The three steps toward PLSF-SEM.
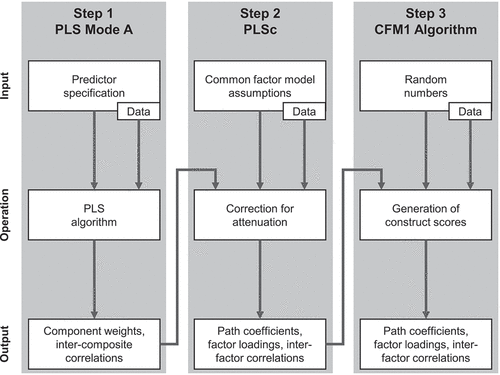
All three steps take the data, the output of the previous step (if available), and some external input; perform an operation; and produce some output. However, the third step differs from the other two in two important ways: the (lack of) quality of the external input and the (lack of) novelty of the output. Whereas in the first two steps, the external input provides new information, the external input of the third step is either uninformative or bears the danger of incorporating inappropriate information. And while the first two steps produce output that represents new information, the third step produces output that has already been produced in Step 2. The equivalence of the output of Steps 2 and 3 is a logical consequence of the requirement that the inter-factor correlations produced by PLSF-SEM be equal to those produced by PLSc. This requirement “drives the iterative convergence process” (Kock, Citation2019b, p. 681).
Since PLSF-SEM merely reproduces the output of PLSc, the only added value of PLSF-SEM could be the factor scores it generates. But even this remaining possibility of added value is questionable. Factor scores serve as carriers of information. However, the information carried by PLSF-SEM factor scores is either known by design, known from a previous step, or untrustworthy. Information like the mean and variance of PLSF-SEM factor scores are known by design: Since they are standardised, they have a mean of 0 and a variance of 1. Information like path coefficients, inter-factor correlations, R2 values, variance inflation factors, factor loadings, construct reliabilities, item reliabilities, average variance extracted are all known or can be calculated from the output of Step 2, i.e., PLSc. Since these values are already available, there is no need to have the factor scores for their determination. K24 sees merits in the PLSF-SEM factor scores for the study and visualisation of interactions and other nonlinear effects. However, Dijkstra and Schermelleh-Engel (Citation2014) could not find any obvious advantage of scores-based analyses of interactions and other nonlinear effects over CB-SEM (concretely, latent moderated structural equations, LMS, Klein & Moosbrugger, Citation2000), and surface plots of models with interaction effects require only a regression equation with estimated coefficients, not factor scores. Moreover, it remains unclear how researchers should deal with the fact that PLSF-SEM creates different factor scores with different random data, so that any analysis based on PLSF-SEM factor scores might not be reproducible. The approach taken by PLSF-SEM – holding the random number seed constant – is not a satisfactory solution, because the factor scores will still differ from one analysis to another if the model is built in a different order. In general, it cannot be ruled out that the random data contained in PLSF-SEM’s factor scores has undesired effects on the results of any more advanced analysis. Moreover, based on a comparison of PLSF-SEM, Thurstone and Bartlett factor scores conducted in Kock (Citation2019a), K24 notes that “PLSF produced the highest quality estimates of correlation-preserving factors”. However, literature has been established that neither Bartlett factor scores nor Thurstone factor scores are correlation preserving, i.e., the correlations among the factor scores is different to the correlations among the factors (e.g., DiStefano et al., Citation2009; Skrondal & Laake, Citation2001). Against this background, we do not share the optimistic view on PLSF-SEM factor scores.
3.2. Can PLSF-SEM deal with common factors?
As the letter “F” in its name suggests, PLSF-SEM is devoted to structural equation models with common factors. K24 regards PLSF-SEM as the obvious solution for making PLS factor-based; it has “some advantages not only over classic PLS implementations, but also over covariance-based SEM approaches”. According to Kock (Citation2019b, p. 682), one of PLSF-SEM’s main advantages is the “ability to generate estimates of the true factors”.
To assess PLSF-SEM’s ability to deal with common factors, we subject it to a scenario analysis. A scenario analysis has the advantage that the true parameter values are known (for the researcher, not for the method). In this way, we aim to answer the question of how PLSF-SEM performs in a certain research situation. For this purpose, we rely on the same population model as used in K24 () to illustrate the performance of PLSF-SEM relative to that of CB-SEM and PLS. This population model is depicted in . However, while K24 drew a sample of from this population model, we make use of a dataset of the same size that functions exactly according to the population model. We use CB-SEM as implemented in the R package lavaan (version 0.6–14; Rosseel, Citation2012), PLS and PLSc as implemented in the R package cSEM (version 0.5.0; Rademaker & Schuberth, Citation2022), and PLSF-SEM with the Type CFM1 algorithm as implemented in WarpPLS (version 8.0; Kock, Citation2022). Among the available PLSF-SEM algorithms, the Type CFM1 algorithm is the only one documented in the user manual.
Figure 4. Population model with three common factors.
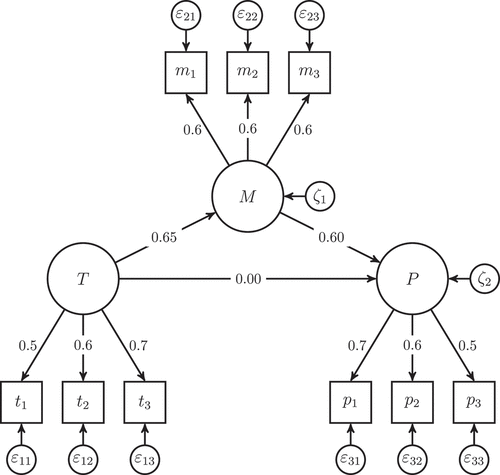
Table 1. Comparison of results for a structural equation model with common factors only.
reports the coefficients and the parameters retrieved from the four methods. Based on these values, at least three observations can be made regarding the performance of PLSF-SEM: First, the obtained values suggest that PLSF-SEM certainly deserves the qualifier “factor-based”. In contrast to traditional PLS, PLSF-SEM produces results that are much closer to the true values. Second, in contrast to CB-SEM and PLSc, PLSF-SEM cannot retrieve the true parameter values. Although the deviations are small, they are noticeable and non-negligible. The occurrence of these deviations indicates that PLSF-SEM is not Fisher consistent. Finally, the model estimated by PLSF-SEM shows some misfit (in terms of SRMR). This is surprising, because the population model works according to a common factor model. Although the degree of misfit is still much smaller than that of traditional PLS, it still means that PLSF-SEM is not able to identify a perfectly fitting model as such.
In order to assess PLSF-SEM’s ability to generate estimates of the true factors, we inspect the produced factor scores and compare them to their true values. shows the scores of all three factors for the first five cases as well as the last case in our dataset. This table lists the factor scores from two different PLSF-SEM runs. The runs differ only with regard to the order in which the model was built by the modeller. allows two important insights: First, the PLSF-SEM factor scores differ from one run to another, which means that the factor scores are determined differently without that the data or the model would have changed. The metrological uncertainty that we can witness here originates from factor indeterminacy (Rigdon et al., Citation2019). Factor indeterminacy can be defined as “the inability to determine uniquely the common and unique factor variables of the common factor model from the uniquely defined ‘observed variables’ because the number of observed variables is smaller than the number of common and unique factors” (Mulaik & McDonald, Citation1978, p. 177). Since the “estimates of the true factors” of PLSF-SEM are to a certain extent arbitrary, they should not be understood as estimates in the statistical sense. Second, the factor scores produced by PLSF-SEM can be quite far off from the true values. In the current case, the correlation between the PLSF-SEM factor scores and the true factor scores is approximately 0.7 (see the last row of ), which means that the PLSF-SEM factor scores have about one half of their variance in common with the true factor scores. Notably, the PLSF-SEM factor scores deviate even more from the true scores than the composite scores generated by PLS. The correlation between PLS composite scores and the true factor scores is 0.803 for T and P, and 0.792 for M. Thus, at least for the illustrative model in K24 (), PLSF-SEM factor scores cannot be regarded as an improvement over PLS composite scores.
Table 2. True factor scores and factor scores from two PLSF-SEM runs for three common factors.
3.3. Can PLSF-SEM deal with composites?
According to K24, composites can play an important role not only in IS research, but also in many other fields of business and social science. A substantial body of methodological literature agrees with this assessment (cf. Diamantopoulos & Winklhofer, Citation2001; Petter et al., Citation2007; Rose et al., Citation2019; Yu et al., Citation2021) and regards composites as important way to model phenomena of interest. Thus, there is a need for statistical methods that can deal with composite models. Originally, PLS is a composite-based technique, and it can consistently estimate composite models (Dijkstra, Citation2017). PLSF-SEM should have inherited this characteristic.Footnote2 But is PLSF-SEM a consistent estimator when structural equation models contain composites? And can PLSF-SEM retrieve the true composite scores?
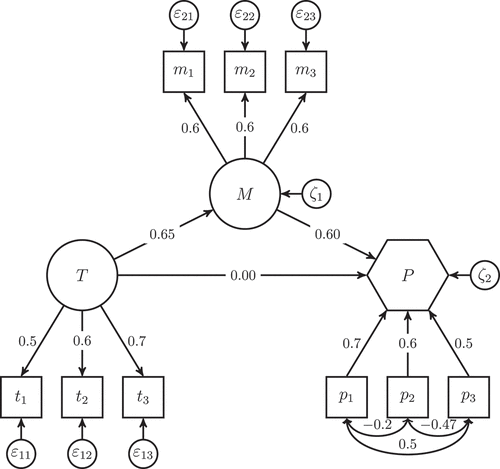
To assess PLSF-SEM’s ability to deal with composites, we subject it to another scenario analysis. In this case, we rely on a slightly modified population model as depicted in . It differs from the previous population model with regard to the endogenous construct :
is now modelled as a composite, and instead of factor loadings, we now have weights with values of 0.7, 0.6., and 0.5. Again, we make use of a dataset comprising 10,000 observations that functions exactly according to the population model.
Figure 5. Population model with two common factors and one composite.
To estimate the model parameters, we use CB-SEM as implemented in the R package lavaan (version 0.6–14; Rosseel, Citation2012) in combination with the H–O specification (Yu et al., Citation2023), PLS (Mode A for the common factors, Mode B for the composite) and PLSc (Mode A with correction for attenuation for the common factors and Mode B for the composite) as implemented in the R package cSEM (version 0.5.0; Rademaker & Schuberth, Citation2022), and PLSF-SEM with the Type CFM1 algorithm as implemented in WarpPLS (version 8.0; Kock, Citation2022). Again, we report the results of two PLSF-SEM runs that differ with regard to the order in which the model was built. While lavaan and cSEM work without any problems, WarpPLS displays a warning message for the model. Since the warning message is uncriticalFootnote3 and we do not see any obvious reason why PLSF-SEM should fail when the other methods work reliably, we continue with the PLSF-SEM analysis.
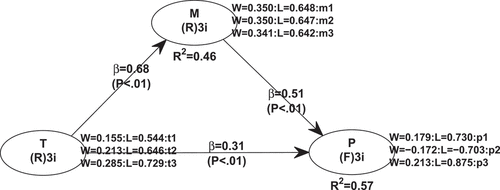
shows the model specification for PLSF-SEM as well as a selection of the results such as weights, loadings, path coefficients and R2 values. These values differ from the population values depicted in . In particular, all values related to the composite are far off from their true values; this holds for the weights, the path coefficients, and the R2 value. provides a detailed comparison of the results obtained for the four methods. It clearly shows that CB-SEM and PLSc are able to retrieve the correct values, whereas PLSF-SEM fails to do so. PLS is only able to reproduce the weights correctly. The clearest signal is emitted by the overall model fit as quantified by the SRMR: While the models estimated with CB-SEM and PLSc yield a perfect fit (SRMR = 0), the models estimated by PLS and PLSF-SEM show a substantial amount of misfit. In particular, the SRMR of 0.193 obtained from PLSF-SEM is far above any common threshold (see e.g., Hu & Bentler, Citation1999; Schermelleh-Engel et al., Citation2003).
Table 3. Comparison of results for a structural equation model with two common factors and a composite.
Figure 6. Model with two common factors and a composite estimated with PLSF-SEM (WarpPLS 8.0 screenshot).
In order to assess PLSF-SEM’s ability to produce composite scores, we inspect the produced composite scores and compare them to the true values. shows the scores of the composite for the first five cases as well as the last case in our dataset. Again, this table lists the composite scores from two different PLSF-SEM runs. The two runs differ only with regard to the order in which the model was built by the modeller. allows two important insights: First, the composite scores produced by PLSF-SEM can be quite far off from the true values. In the current case, the correlation between the PLSF-SEM composite scores and the true composite scores is approximately 0.527, which means that the PLSF-SEM composite scores have less than one third of their variance in common with the true composite scores. This means that the composite scores generated by PLSF-SEM are even less valid than the factor scores generated by PLSF-SEM, although the components of the composite are not contaminated by random measurement error. PLSF-SEM’s inability to generate valid composite scores weighs even harder taking into account that CB-SEM and and PLSc are able to perfectly reproduce the true composite scores. Also for structural equation models containing composites, there appear to be substantial differences between the results obtained from two different PLSF-SEM runs. Consequently, PLSF-SEM cannot be regarded as a valid method for structural equation models containing composites (formative constructs), which poses a validity threat for extant and future studies that used or will use PLSF-SEM under such circumstances.
Table 4. Scores for the composite P obtained through different approaches.
3.4. A summative evaluation of PLSF-SEM
The starting point for our evaluation is the claims that have been made about PLSF-SEM. Kock (Citation2017, p. 48) claims that PLSF-SEM is “a new method that generates estimates of both true composites and factors”. As our conceptual and scenario analyses have shown, this notion is erroneous in at least two ways. First, PLSF-SEM does not generate estimates of true factors. Since the obtained factor scores contain a substantial portion of random data, their values depend on the concrete random data used for this purpose. We found that the creation of factor scores is influenced by the order in which the structural equation model is built by the analyst. This makes the factor scores unreproducible. For estimates, this is undesirable. Second, PLSF-SEM does not generate estimates of true composites, leading to distorted results if a model contains a composite. This makes PLSF-SEM a clearly inferior method, since CB-SEM and PLSc are able to generate true composite scores without any problems. Finally, in contrast to what the term “new method” might suggest, PLSF-SEM does not provide any new insights; it simply tries to reproduce the results of an existing method, namely PLSc. Against this background, we cannot currently identify any advantages of PLSF-SEM that outweigh its weaknesses.
4. Implications
There is a good message for IS researchers who need a versatile technique to estimate structural equation models: There is still something to choose! compiles what is known and what is not known about the four techniques mentioned by K24 with regard to possible model specifications, properties of the estimator, and available model assessment tools.
If researchers deal with a structural equation model that only consists of composites, they may use CB-SEM with the H–O specification or PLS using Mode B. Both techniques provide consistent estimates. First simulation results indicate that for correctly specified composite models, the two techniques have a very similar performance in terms of parameter recovery (Schuberth, Hubona, et al., Citation2023). However, CB-SEM is asymptotically efficient, offers more flexibility in modelling, and facilitates model comparisons. Thus, until the PLS literature demonstrates a use case where PLS outperforms CB-SEM with the H–O specification, there seems to be little reason to use PLS over CB-SEM.
If a structural equation model contains one or more common factors, it is indispensable to rely on a technique that has been designed for this purpose, e.g., CB-SEM or PLSc. Particularly for CB-SEM and PLSc, there is ample evidence that they consistently estimate structural equation models containing both composites and common factors. Unfortunately, the same does not hold true for PLSF-SEM. PLSF-SEM is characterised by the fact that it almost reproduces the parameter estimates of PLSc for common factor models, but cannot cope with composites. Because of this weakness, its lack of added value over PLSc, and its unclear characteristics, we can currently not identify any situation in which we would recommend the use of PLSF-SEM. Until the ambiguities surrounding PLSF-SEM are resolved and clear advantages of PLSF-SEM over existing techniques are demonstrated, IS researchers should not prematurely adopt PLSF-SEM. Instead, they rather should use CB-SEM or PLSc. First simulation results indicate that for correctly specified common factor models, the two techniques have a very similar performance in terms of parameter recovery (Schuberth, Hubona, et al., Citation2023). PLSc has the advantage of being a limited information estimator, meaning that misspecification in one part of the model has little effect on the rest of the model. However, CB-SEM is more efficient (Takane & Hwang, Citation2018), offers more flexibility in modelling (cf. Schuberth, Zaza, et al., Citation2023), facilitates model comparisons, and is less prone to chance correlations (see Rönkkö, Citation2014), making it the preferred technique in most research settings.
As illustrates, among the SEM techniques discussed in K24, CB-SEM offers the largest amount of features and it is most well-understood. We therefore conclude that in most research settings, using CB-SEM is the most promising avenue. However, if CB-SEM does not produce results, PLSc could be a good alternative (Evermann & Rönkkö, Citation2023a; Schuberth, Zaza, et al., Citation2023).
Table 5. Comparing the suitability of CB-SEM, PLSc, PLSF-SEM, and PLS for IS research.
5. Conclusion
IS research requires SEM techniques that can deal with both common factors and composites. To this end, it is desirable that PLS could also be used to estimate models containing common factors and CB-SEM could also be used to estimate models containing composites. Fortunately, methodological research has provided various developments of these two techniques. On the one hand, the PLS estimates can be corrected for attenuation bias in case of common factors using Cronbach’s alpha or Dijkstra-Henseler’s (Dijkstra & Henseler, Citation2015b; Yuan et al., Citation2020). On the other hand, specifications have been proposed for CB-SEM that allow for dealing with composites (Grace & Bollen, Citation2008; Rose et al., Citation2019; Schuberth, Citation2023; Yu et al., Citation2023).
Acknowledgements
The authors thank Iris Junglas, Senior Editor of the European Journal of Information Systems, for the invitation to write this commentary. They also thank Alexandra Elbakyan for her efforts in making science accessible. During the preparation of this work, the authors used DeepL in order to improve the readability and language of the manuscript. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1. K24 () presents two unidentified composite models and uses them to illustrate an alleged “paradox of composite-based models”. However, unidentified models should not be used as a basis for interpretation. In particular, they do not allow for general statements about composite models or CB-SEM.
2. According to Kock (Citation2017, p. 48), PLSF-SEM can deal with structural equation models that contain composites, because “factors and measurement errors are only adjusted in those cases where measurement error is assumed to exist”.
3. The displayed warning message is “At least one measurement error weight is greater than the related composite weight”. None of the leading textbooks on SEM regards this issue as problematic (cf. Bollen, Citation1989; Byrne, Citation2011; Kline, Citation2023; Schumacker & Lomax, Citation2004).
References
- Aguirre-Urreta, M. I., & Rönkkö, M. (2018). Statistical inference with PLSc using bootstrap confidence intervals. MIS Quarterly, 42(3), 1001–1020. https://doi.org/10.25300/MISQ/2018/13587
- Benitez, J., Henseler, J., Castillo, A., & Schuberth, F. (2020). How to perform and report an impactful analysis using partial least squares: Guidelines for confirmatory and explanatory IS research. Information & Management, 57(2), 1–16. https://doi.org/10.1016/j.im.2019.05.003
- Bollen, K. A. (1989). Structural equations with latent variables. Wiley.
- Bollen, K. A., Harden, J. J., Ray, S., & Zavisca, J. (2014). BIC and alternative Bayesian information criteria in the selection of structural equation models. Structural Equation Modeling: A Multidisciplinary Journal, 21(1), 1–19. https://doi.org/10.1080/10705511.2014.856691
- Bollen, K. A., & Stine, R. A. (1992). Bootstrapping goodness-of-fit measures in structural equation models. Sociological Methods & Research, 21(2), 205–229. https://doi.org/10.1177/0049124192021002004
- Byrne, B. M. (2011). Structural equation modeling with Mplus: Basic concepts, applications, and programming. Routledge.
- Callaghan, W., Wilson, B., Ringle, C. M., & Henseler, J. (2007, September 5–7). Exploring causal path directionality for a marketing model using Cohen’s path method. In 5th International Symposium on PLS and Related Methods., Ås, Norway.
- Chin, W. W. (1998). The partial least squares approach to structural equation modeling. In G. A. Marcoulides (Ed.), Modern methods for business research (pp. 295–336). Lawrence Erlbaum.
- Diamantopoulos, A., & Winklhofer, H. M. (2001). Index construction with formative indicators: An alternative to scale development. Journal of Marketing Research, 38(2), 269–277. https://doi.org/10.1509/jmkr.38.2.269.18845
- Dijkstra, T. K. (1985). Latent variables in linear stochastic models: Reflections on “maximum likelihood” and “partial least squares” methods (Vol. 1). Sociometric Research Foundation.
- Dijkstra, T. K. (2017). A perfect match between a model and a mode. In H. Latan & R. Noonan (Eds.), Partial least squares path modeling (pp. 55–80). Springer.
- Dijkstra, T. K., & Henseler, J. (2015a). Consistent and asymptotically normal PLS estimators for linear structural equations. Computational Statistics & Data Analysis, 81, 10–23. https://doi.org/10.1016/j.csda.2014.07.008
- Dijkstra, T. K., & Henseler, J. (2015b). Consistent partial least squares path modeling. MIS Quarterly, 39(2), 297–316. https://doi.org/10.25300/MISQ/2015/39.2.02
- Dijkstra, T. K., & Schermelleh-Engel, K. (2014). Consistent partial least squares for nonlinear structural equation models. Psychometrika, 79(4), 585–604. https://doi.org/10.1007/s11336-013-9370-0
- DiStefano, C., Zhu, M., & Mindrila, D. (2009). Understanding and using factor scores: Considerations for the applied researcher. Practical Assessment, Research & Evaluation, 14(20), 1–11. https://doi.org/10.7275/da8t-4g52
- Dolan, C., Bechger, T., & Molenaar, P. (1999, January). Using structural equation modeling to fit models incorporating principal components. Structural Equation Modeling: A Multidisciplinary Journal, 6(3), 233–261. https://doi.org/10.1080/10705519909540132
- Evermann, J., & Rönkkö, M. (2023a). Recent developments in PLS. Communications of the Association for Information Systems, 52(1), 663–667. https://doi.org/10.17705/1CAIS.05229
- Evermann, J., & Rönkkö, M. (2023b). Rejoinder to comments on recent developments in PLS. Communications of the Association for Information Systems, 52(1), 760–764. https://doi.org/10.17705/1CAIS.05236
- Fan, X. (1997). Canonical correlation analysis and structural equation modeling: What do they have in common? Structural Equation Modeling: A Multidisciplinary Journal, 4(1), 65–79. https://doi.org/10.1080/10705519709540060
- Grace, J. B., & Bollen, K. A. (2008). Representing general theoretical concepts in structural equation models: The role of composite variables. Environmental and Ecological Statistics, 15(2), 191–213. https://doi.org/10.1007/s10651-007-0047-7
- Hancock, G. R., Mao, X., & Kher, H. (2013). On latent growth models for composites and their constituents. Multivariate Behavioral Research, 48(5), 619–638. https://doi.org/10.1080/00273171.2013.815579
- Henseler, J. (2010). On the convergence of the partial least squares path modeling algorithm. Computational Statistics, 25(1), 107–120. https://doi.org/10.1007/s00180-009-0164-x
- Henseler, J. (2017). Bridging design and behavioral research with variance-based structural equation modeling. Journal of Advertising, 46(1), 178–192. https://doi.org/10.1080/00913367.2017.1281780
- Henseler, J. (2021). Composite-based structural equation modeling: Analyzing latent and emergent variables. Guilford Press.
- Henseler, J., Dijkstra, T. K., Sarstedt, M., Ringle, C. M., Diamantopoulos, A., Straub, D. W., Ketchen, DJ, Hair, JF, Hult, GT, Calantone, R. J. (2014). Common beliefs and reality about PLS: Comments on Rönkkö and Evermann (2013). Organizational Research Methods, 17(2), 182–209. https://doi.org/10.1177/1094428114526928
- Henseler, J., Hubona, G., & Ray, P. A. (2016). Using PLS path modeling in new technology research: Updated guidelines. Industrial Management & Data Systems, 116(1), 2–20. https://doi.org/10.1108/IMDS-09-2015-0382
- Henseler, J., Lee, N., Roemer, E., Kemény, I., Dirsehan, T., & Cadogan, J. W. (2024). Beware of the Woozle effect and belief perseverance in the PLS-SEM literature!. Electronic Commerce Research. https://doi.org/10.1007/s10660-024-09849-y
- Henseler, J., & Schuberth, F. (2020). Using confirmatory composite analysis to assess emergent variables in business research. Journal of Business Research, 120, 147–156. https://doi.org/10.1016/j.jbusres.2020.07.026
- Hu, L.-T., & Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling: A Multidisciplinary Journal, 6(1), 1–55. https://doi.org/10.1080/10705519909540118
- Hubona, G. S., Schuberth, F., & Henseler, J. (2021). A clarification of confirmatory composite analysis (CCA). International Journal of Information Management, 61, 102399. https://doi.org/10.1016/j.ijinfomgt.2021.102399
- Hui, B. S., & Wold, H. (1982). Consistency and consistency at large of partial least squares estimates. In K. G. Jöreskog & H. Wold (Eds.), Systems under indirect observation: Causality, structure, prediction part ii (pp. 119–130). North-Holland.
- Jarvis, C. B., MacKenzie, S. B., & Podsakoff, P. M. (2003). A critical review of construct indicators and measurement model misspecification in marketing and consumer research. Journal of Consumer Research, 30(2), 199–218. https://doi.org/10.1086/376806
- Jöreskog, K. G. (1970). A general method for estimating a linear structural equation system. ETS Research Bulletin Series, 1969(2), i–41. https://doi.org/10.1002/j.2333-8504.1970.tb00783.x
- Jöreskog, K. G., & Goldberger, A. S. (1975). Estimation of a model with multiple indicators and multiple causes of a single latent variable. Journal of the American Statistical Association, 70(351a), 631–639. https://doi.org/10.1080/01621459.1975.10482485
- Jung, S., & Park, J. (2018). Consistent partial least squares path modeling via regularization. Frontiers in Psychology, 9. https://doi.org/10.3389/fpsyg.2018.00174
- Klein, A., & Moosbrugger, H. (2000). Maximum likelihood estimation of latent interaction effects with the LMS method. Psychometrika, 65(4), 457–474. https://doi.org/10.1007/BF02296338
- Kline, R. B. (2023). Principles and practice of structural equation modeling. Guilford Press.
- Kock, N. (2017). Going beyond composites: Conducting a factor-based PLS-SEM analysis. In H. Latan & R. Noonan (Eds.), Partial least squares path modeling: Basic concepts, methodological issues and applications (pp. 41–53). Springer.
- Kock, N. (2019a). Factor-based structural equation modeling with WarpPLS. Australasian Marketing Journal, 27(1), 57–63. https://doi.org/10.1016/j.ausmj.2019.02.002
- Kock, N. (2019b). From composites to factors: Bridging the gap between PLS and covariance-based structural equation modelling. Information Systems Journal, 29(3), 674–706. https://doi.org/10.1111/isj.12228
- Kock, N. (2022). WarpPLS user manual: Version 8.0 [Computer software manual]. ScriptWarp Systems.
- Kock, N. (2023). Contributing to the success of PLS in SEM: An action research perspective. Communications of the Association for Information Systems, 52(1), 730–734. https://doi.org/10.17705/1CAIS.05233
- Kock, N. (2024). Will PLS have to become factor-based to survive and thrive? An information systems action research outlook. European Journal of Information Systems, in print.
- Liu, Y., Schuberth, F., Liu, Y., & Henseler, J. (2022). Modeling and assessing forged concepts in tourism and hospitality using confirmatory composite analysis. Journal of Business Research, 152, 221–230. https://doi.org/10.1016/j.jbusres.2022.07.040
- Lohmöller, J.-B. (1988). The PLS program system: Latent variables path analysis with partial least squares estimation. Multivariate Behavioral Research, 23(1), 125–127. https://doi.org/10.1207/s15327906mbr2301_7
- Mulaik, S. A., & McDonald, R. P. (1978). The effect of additional variables on factor indeterminacy in models with a single common factor. Psychometrika, 43(2), 177–192. https://doi.org/10.1007/BF02293861
- Nevitt, J., & Hancock, G. (2001). Performance of bootstrapping approaches to model test statistics and parameter standard error estimation in structural equation modeling. Structural Equation Modeling: A Multidisciplinary Journal, 8(3), 353–377. https://doi.org/10.1207/S15328007SEM0803_2
- Petter, S., Straub, D., & Rai, A. (2007). Specifying formative constructs in information systems research. MIS Quarterly, 31(4), 623–656. https://doi.org/10.2307/25148814
- Rademaker, M. E., & Schuberth, F. (2022). cSEM: Composite-based structural equation modeling. [Computer Software Manual]. R package version: 0.5.0. https://m-e-rademaker.github.io/cSEM/
- Rademaker, M. E., Schuberth, F., & Dijkstra, T. K. (2019). Measurement error correlation within blocks of indicators in consistent partial least squares: Issues and remedies. Internet Research, 29(3), 448–463. https://doi.org/10.1108/IntR-12-2017-0525
- Reinartz, W., Haenlein, M., & Henseler, J. (2009). An empirical comparison of the efficacy of covariance-based and variance-based SEM. International Journal of Research in Marketing, 26(4), 332–344. https://doi.org/10.1016/j.ijresmar.2009.08.001
- Rigdon, E. E., Becker, J.-M., & Sarstedt, M. (2019). Factor indeterminacy as metrological uncertainty: Implications for advancing psychological measurement. Multivariate Behavioral Research, 54(3), 429–443. https://doi.org/10.1080/00273171.2018.1535420
- Rönkkö, M. (2014). The effects of chance correlations on partial least squares path modeling. Organizational Research Methods, 17(2), 164–181. https://doi.org/10.1177/1094428114525667
- Rönkkö, M., & Evermann, J. (2013). A critical examination of common beliefs about partial least squares path modeling. Organizational Research Methods, 16(3), 425–448. https://doi.org/10.1177/1094428112474693
- Rose, N., Wagner, W., Mayer, A., Nagengast, B., Savalei, V., & Savalei, V. (2019). Model-based manifest and latent composite scores in structural equation models. Collabra: Psychology, 5(1). https://doi.org/10.1525/collabra.143
- Rosseel, Y. (2012). Lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48(2), 1–36. https://doi.org/10.18637/jss.v048.i02
- Sarstedt, M., Hair, J. F., Ringle, C. M., Thiele, K. O., & Gudergan, S. P. (2016). Estimation issues with PLS and CBSEM: Where the bias lies! Journal of Business Research, 69(10), 3998–4010. https://doi.org/10.1016/j.jbusres.2016.06.007
- Schamberger, T., Schuberth, F., & Henseler, J. (2023). Confirmatory composite analysis in human development research. International Journal of Behavioral Development, 47(1), 89–100. https://doi.org/10.1177/01650254221117506
- Schamberger, T., Schuberth, F., Henseler, J., & Dijkstra, T. K. (2020). Robust partial least squares path modeling. Behaviormetrika, 47(1), 307–334. https://doi.org/10.1007/s41237-019-00088-2
- Schermelleh-Engel, K., Moosbrugger, H., & Müller, H. (2003). Evaluating the fit of structural equation models: Tests of significance and descriptive goodness-of-fit measures. Methods of Psychological Research Online, 8(2), 23–74.
- Schuberth, F. (2021). Confirmatory composite analysis using partial least squares: Setting the record straight. Review of Managerial Science, 15(5), 1311–1345. https://doi.org/10.1007/s11846-020-00405-0
- Schuberth, F. (2023). The Henseler-Ogasawara specification of composites in structural equation modeling: A tutorial. Psychological Methods, 28(4), 843–859. https://doi.org/10.1037/met0000432
- Schuberth, F., Henseler, J., & Dijkstra, T. K. (2018a). Confirmatory composite analysis. Frontiers in Psychology, 9, 2541. https://doi.org/10.3389/fpsyg.2018.02541
- Schuberth, F., Henseler, J., & Dijkstra, T. K. (2018b). Partial least squares path modeling using ordinal categorical indicators. Quality & Quantity, 52(1), 9–35. https://doi.org/10.1007/s11135-016-0401-7
- Schuberth, F., Hubona, G., Roemer, E., Zaza, S., Schamberger, T., Chuah, F., Cepeda-Carrión G, Henseler, J. (2023). The choice of structural equation modeling technique matters: A commentary on Dash and Paul (2021). Technological Forecasting & Social Change, 194(September), 122665. https://doi.org/10.1016/j.techfore.2023.122665
- Schuberth, F., Rademaker, M., & Henseler, J. (2023). Assessing the overall fit of composite models estimated by partial least squares path modeling. European Journal of Marketing, 57(6), 1678–1702. https://doi.org/10.1108/EJM-08-2020-0586
- Schuberth, F., Rosseel, Y., Rönkkö, M., Trinchera, L., Kline, R. B., & Henseler, J. (2023). Structural parameters under partial least squares and covariance-based structural equation modeling: A comment on Yuan and Deng (2021). Structural Equation Modeling: A Multidisciplinary Journal, 30(3), 339–345. https://doi.org/10.1080/10705511.2022.2134140
- Schuberth, F., Schamberger, T., & Henseler, J. (2023). More powerful parameter tests? No, rather biased parameter estimates. Some reflections on path analysis with weighted composites. Behavior Research Methods. https://doi.org/10.3758/s13428-023-02256-5
- Schuberth, F., Schamberger, T., Rönkkö, M., Liu, Y., & Henseler, J. (in press). Premature conclusions about the signal-to-noise ratio in structural equation modeling research: A commentary on Yuan and Fang (2023). British Journal of Mathematical and Statistical Psychology, in print. 76(3), 682–694. https://doi.org/10.1111/bmsp.12304
- Schuberth, F., Zaza, I., & Henseler, J. (2023). Partial least squares is an estimator for structural equation models: A comment on Evermann and Rönkkö (2021). Communications of the Association for Information Systems, 52(32), 711–729. https://doi.org/10.17705/1CAIS.05232
- Schumacker, R. E., & Lomax, R. G. (2004). A beginner’s guide to structural equation modeling. Lawrence Erlbaum Associates.
- Sharma, P. N., Liengaard, B. D., Sarstedt, M., Hair, J. F., & Ringle, C. M. (2023). Extraordinary claims require extraordinary evidence: A comment on “Recent Developments in PLS”. Communications of the Association for Information Systems, 52(1), 739–742. https://doi.org/10.17705/1CAIS.05234
- Sharma, P., Sarstedt, M., Shmueli, G., Kim, K. H., & Thiele, K. O. (2019). PLS-based model selection: The role of alternative explanations in information systems research. Journal of the Association for Information Systems, 20(4), 4. https://doi.org/10.17705/1jais.00538
- Skrondal, A., & Laake, P. (2001). Regression among factor scores. Psychometrika, 66(4), 563–575. https://doi.org/10.1007/BF02296196
- Takane, Y., & Hwang, H. (2018). Comparisons among several consistent estimators of structural equation models. Behaviormetrika, 45, 157–188. https://doi.org/10.1007/s41237-017-0045-5
- Wold, H. (1974). Causal flows with latent variables: Partings of the ways in the light of NIPALS modelling. European Economic Review, 5(1), 67–86. https://doi.org/10.1016/0014-2921(74)90008-7
- Wong, C.-S., & Law, K. S. (1999). Testing reciprocal relations by nonrecursive structural equation models using cross-sectional data. Organizational Research Methods, 2(1), 69–87. https://doi.org/10.1177/109442819921005
- Yuan, K.-H., Wen, Y., & Tang, J. (2020). Regression analysis with latent variables by partial least squares and four other composite scores: Consistency, bias and correction. Structural Equation Modeling: A Multidisciplinary Journal, 27(3), 333–350. https://doi.org/10.1080/10705511.2019.1647107
- Yu, X., Schuberth, F., & Henseler, J. (2023). Specifying composites in structural equation modeling: A refinement of the Henseler–Ogasawara specification. Statistical Analysis and Data Mining, 16(4), 348–357. https://doi.org/10.1002/sam.11608
- Yu, X., Zaza, S., Schuberth, F., & Henseler, J. (2021). Counterpoint: Representing forged concepts as emergent variables using composite-based structural equation modeling. ACM SIGMIS Database: The DATABASE for Advances in Information Systems, 52(SI), 114–130. https://doi.org/10.1145/3505639.3505647