

Abstract
The world has experienced impressive improvements in wealth and health, with, for instance, the world's real GDP per capita having increased by 180% from 1970 to 2007 accompanied by a 50% decline in infant mortality rate. Healthier and wealthier. Pl Are health gains arising from wealth growth? Or, has a healthier population enabled substantial growth in wealth? We contribute to understanding the dynamic links between wealth and health by examining for causal, rather than associative, links between health (as measured by infant mortality rate) and wealth (as measured by GDP per capita) for a panel of 58 developing countries using quinquennial data covering the period 1960–2005. Estimating as a panel allows us to account for unobserved heterogeneity, as well as permitting heterogeneous causal effects. We test for panel and country-specific noncausality, and we explore robustness of outcomes to level of economic development (as measured by national income), whether we account for bias in least squares estimators, and to our heterogeneity assumption on the causal coefficients. Overall, our panel tests detect bidirectional links between wealth and health, compatible with other research. However, our country-specific work suggests that the panel results arise from the dominance of a few countries, as there is evidence of noncausality between health and wealth for a majority of countries. These findings contrast with earlier research, and likely arise from different metrics being used to measure the health of a nation. Our work highlights the usefulness of panel causality tests accompanied by unit specific analysis and the importance of examining different metrics for health.
JEL Classifications:
Acknowledgements
We thank Merwan Engineer and Thanasis Stengos for comments and suggestions on an earlier draft of this paper, Diana Weinhold for helpful correspondence, and participants at meetings of the Western Economic Association and the Canadian Economic Association for useful feedback. The reviewers provided most helpful comments that substantially improved our paper.
Notes
Notes: The averages (standard deviations in parentheses) are based on the countries listed in Table . AC = all countries; MIC = middle-income countries; LIC = low-income countries; IMR = infant mortality rate; GDP = real per capita GDP.
Note: The ‘L' at the beginning of a variable name indicates that the natural logarithmic transformation has been used.
Notes: * The null is for testing whether wealth is panel G-noncausal for health. ** The null is for testing whether health is panel G-noncausal for wealth. The statistic W
N,T
is the average of the individual country Wald statistics for testing homogenous G-noncausality, with 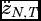 , adjusted for finite-sample moments, and used to test the null with a limiting standard normal null distribution. The Wald statistic, for the random causal coefficients case, tests whether the mean causal parameter is zero with the p-value obtained from a χ2(1) distribution. The p-values are calculated using panel corrected standard errors (PCSEs). The variance estimator of the distribution of causal coefficients is
, adjusted for finite-sample moments, and used to test the null with a limiting standard normal null distribution. The Wald statistic, for the random causal coefficients case, tests whether the mean causal parameter is zero with the p-value obtained from a χ2(1) distribution. The p-values are calculated using panel corrected standard errors (PCSEs). The variance estimator of the distribution of causal coefficients is  .
.
Notes: Figures are coefficient estimates (PCSEs in parentheses) for the model under fixed, different, causal coefficients when estimated by LS. In the ‘Range' column, the figures presented are the ‘smallest, largest; mean' estimates with their corresponding PCSEs in parentheses. For country i, the parameter γ12,i1 is the impact of wealth on health, while the parameter γ21,i1 is the impact of health on wealth.
Notes: G-noncausality outcomes are based on a nominal 5% significance level using a χ2(1) critical value. Low-income countries are italicized.
Notes: * The null is for testing whether wealth is panel G-noncausal for health. ** The null is for testing whether health is panel G-noncausal for wealth. The statistic W
N,T
is the average of the individual country Wald statistics for testing homogenous G-noncausality, with 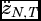 , adjusted for finite-sample moments, and used to test the null with a limiting standard normal null distribution. The Wald statistic, for the random causal coefficients case, tests whether the mean causal parameter is zero with the p-value obtained from a χ2(1) distribution. The variance estimator of the distribution of causal coefficients is
, adjusted for finite-sample moments, and used to test the null with a limiting standard normal null distribution. The Wald statistic, for the random causal coefficients case, tests whether the mean causal parameter is zero with the p-value obtained from a χ2(1) distribution. The variance estimator of the distribution of causal coefficients is  .
.
Notes: * The null is for testing whether wealth is panel G-noncausal for health. ** The null is for testing whether health is panel G-noncausal for wealth. The statistic W
N,T
is the average of the individual country Wald statistics for testing homogenous G-noncausality, with 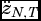 adjusted for finite-sample moments, and used to test the null with a limiting standard normal null distribution.
adjusted for finite-sample moments, and used to test the null with a limiting standard normal null distribution.
Table 8 Time stationarity and G-noncausality tests under cross-country homogeneity.
Notes: Figures are the Wald statistics (associated χ2 p-value in parentheses) for time stationarity (TS) and G-noncausality tests. * The null is for testing whether wealth is G-noncausal for health (associated χ2 p-value in parentheses). ** The null corresponds to whether health is G-noncausal for wealth (associated χ2 p-value in parentheses).
1. World Bank's online World Development Indicators with GDP per capita measured in constant 2005 US$ and the infant mortality rate expressed as infant deaths per 1000 live births.
2. A cut-off income of US$5000 per capita is adopted in this work.
3. Based on the World Bank's classifications.
4. Preliminary work for this paper was undertaken for the fourth chapter of the first author's PhD dissertation, published as Chen (Citation2010). This work differs in a number ways. First, we have included a detailed literature review and data summary. Second, we extended the data to include 2005. Third, given the long period of time considered (1960–2005), we control for period effects. Finally, we use a number of different estimators not considered in Chen (Citation2010) including the mean group estimator and bootstrapped bias corrected estimators.
5. We define a developing country as one that falls into the World Bank's categories of low-income and middle-income. Also, as a number of countries (e.g., Greece, Malta, Portugal, and Trinidad and Tobago) moved, over the last two decades, from being classified as middle-income to high-income, we adopted the World Bank's 1987 groupings, the year that the Bank began classifying in this way and a point roughly half way through our sample of years.
6. Life expectancy is calculated by applying age and sex-specific mortality rates from the population under study to a hypothetical birth cohort of 100,000 individuals.
7. See, e.g. Murray, Salomon, and Mathers (Citation2000).
8. See http://www.unicef.org/mdg/childmortality.html (accessed January 21, 2013).
9. See http://www.who.int/topics/millennium_development_goals/en/ (accessed January 21, 2013).
10. Eight Millennium Development Goals, adopted by member countries of the United Nations, arose from the 2000 Millennium Summit. A complete list of the goals is available at http://www.undp.org/content/undp/en/home/mdgoverview.html (accessed January 21, 2013).
11. Indeed, the 2011 IMGE report on child mortality (You, Jones, and Wardlaw Citation2011, 1) states that ‘Over 70 percent of under-five deaths occur within the first year of life.' In addition, several empirical studies report close qualitative agreement for income effects on CMR and IMR; e.g. Easterly (Citation1999), Filmer and Pritchett (Citation1999), and Hanmer, Lensink, and White (Citation2003).
12. See, e.g. Bloom, Canning, and Jamison (Citation2004).
13. See, e.g. Mushkin (Citation1962).
14. World Fertility Surveys in the early part of the sample and Demographic and Health Surveys (Macro International) and Multiple Cluster Surveys (UNICEF) for the later observations.
15. See, for instance World Bank (Citation2012, 296) and You, Jones, and Wardlaw (Citation2011).
16. Specifically, we use RGDPCH; see http://pwt.econ.upenn.edu/php_site/pwt70/pwt70_form.php (accessed January 21, 2013).
17. Details of this preliminary investigation are available on request.
18. Specifically, under sequential convergence (T → ∞ followed by N → ∞), HV show that W
N, T
converges in distribution as ![]()
![]() . Considering the semi-asymptotic distribution of W
N, T
for fixed T as N → ∞, Hurlin shows that for a balanced panel without period effects, Wi
has a finite first moment when T > q + 2 and second moment when T > q + 4, with q = Kp + 1 parameters, leading to the result that
. Considering the semi-asymptotic distribution of W
N, T
for fixed T as N → ∞, Hurlin shows that for a balanced panel without period effects, Wi
has a finite first moment when T > q + 2 and second moment when T > q + 4, with q = Kp + 1 parameters, leading to the result that ![]() . Then, for realizations of the explanatory variables, E(Wi
)=p(T − q)/(T − q − 2)(Wi)=2p(T − q)2(T − q − 2+p)/((T − q − 2)2(T − q − 4), which are used in the expression for
. Then, for realizations of the explanatory variables, E(Wi
)=p(T − q)/(T − q − 2)(Wi)=2p(T − q)2(T − q − 2+p)/((T − q − 2)2(T − q − 4), which are used in the expression for ![]() .
.
19. The estimator ![]() is consistent and asymptotically normal when
is consistent and asymptotically normal when ![]() as both N and T → ∞ (Hsiao, Pesaran, and Tahmiscioglu Citation1999).
as both N and T → ∞ (Hsiao, Pesaran, and Tahmiscioglu Citation1999).
20. Asymptotically, the GLS estimator is equivalent to the MG estimator (Hsiao, Pesaran, and Tahmiscioglu Citation1999).
21. It would be interesting to explore the sensitivity of our findings to the lag order assumption when additional quinquennial data are available. Given our choice of a one period lag and that we likely have omitted variables, we examined residual correlograms (available on request) for our estimated models, which showed some mild autocorrelation in the residuals for four of the 58 countries for the LGDP equation, and for six of the 58 countries for the LIMR equation. Overall, these findings suggest that the one period lag models are adequate and that the lagged variables are likely reasonably capturing the effect of the omitted variables.
22. The full set of coefficient estimates show that least squares leads to explosive roots for 13 of the 58 countries (Bolivia, Brazil, Comoros, Ecuador, El Salvador, Guatemala, India, Indonesia, Morocco, Nepal, Niger, Pakistan, Peru, Philippines, Tanzania, Thailand, Turkey, and Uruguay), contrary to expectations that roots of the vector autoregression are at most unity. For 10 of these cases, the explosive root is in IMR, whereas it is in GDP for the remaining three (India, Indonesia, and Paraguay). This may be from the bias associated with least squares in small samples (e.g. Andrews and Chen Citation1994, Qureshi Citation2008); e.g. the simulations of Qureshi (Citation2008) show that least squares can have a high frequency of estimated explosive roots even when the variables are indeed stationary. That we observe estimated roots greater than 1 in magnitude may also be implying data exhibiting exponential growth, past shocks have an increasingly large effect on the present so that the variance increases exponentially in t; see, e.g. Sims (Citation1989) for discussion and Juselius and Mladenovic (Citation2002) for an illustration. An examination of the data for these 13 series shows (typically) increasingly higher growth rates (in magnitude), consistent with an explosive root for six cases (Brazil, El Salvador, India, Malaysia, Peru, and Turkey). For another five series (Congo Republic, Indonesia, Madagascar, Niger, and Philippines), there are possible structural breaks that are perhaps leading to the observed explosive root. There seems to be a combination of increasing growth rates and a structural break for the series of issue for the Dominican Republic and Paraguay. To ensure that the cases with structural breaks were not distorting outcomes, we repeated the analysis deleting them from the dataset. Similar qualitative outcomes (available on request) resulted, leading us to continue including these cases.
23. It would be interesting to bootstrap p-values in future work.
24. Three countries (Argentina, Gambia, and Turkey) that showed wealth to health causality now exhibit noncausality; six countries (Chile, Comoros, Costa Rica, Dominican Rep., Morocco, Nicaragua, and Togo) have no causal links that displayed health to wealth causality under LS; two countries (Algeria and Madagascar) have no causality that previously showed causal links; two countries (Colombia and Mali) now only exhibit unidirectional causality from wealth to health; and bidirectional causality is now evident for Sri Lanka.
25. A necessary condition for identification is that there are at least as many instruments as right-hand side variables. As there are [K(p + 1) + 1] variables on the right-hand side of equation (2) and the number of distinct elements in Qit is [K(t−2) + 1], we require t ≥ (p + 3).
26. We recognize the pretesting complications introduced by such a testing strategy. Exploration of this is left for future work.
27. Coefficient estimates and standard errors are available on request.
28. See http://data.worldbank.org/about/country-classifications/a-short-historyandtheexcelfiletherein (Accessed January 21, 2013).
29. We also generated causal links under the random coefficients assumption, which are available on request.