
Abstract
The chloroplast genome contains information that is applicable in many scientific fields, such as plant systematics, phylogenetic reconstruction and biotechnology, because its features are highly conserved among species. To date, several complete green algal chloroplast genomes have been sequenced and assembled. In this study, the nucleotide sequence of the chloroplast genome (cpDNA) of Chlorella sorokiniana SAG 211-8k is reported and compared for the first time to the chloroplast genomes of 10 Chlorellaceae. The recently updated Chlorella sorokiniana cpDNA sequence, assembled as a circular map of 109 811 bp, encodes 113 genes. Similar to other Chlorella strains, this chloroplast genome does not show a quadripartite structure and lacks the large rRNA operon-encoding Inverted Repeat (IR). The Chlorella sorokiniana plastid encodes the tRNA(Ile)-lysidine synthetase (tilS), which is responsible for modifying the CAU anticodon of a unique tRNA. Gene ordering and clustering highlight the close relationships among Chlorella clade members and the preservation of crucial gene clusters in photosynthetic strains. The features of Chlorella sorokiniana presented here reinforce the monophyletic character of Chlorellaceae and provide important information that sheds light on chloroplast genome evolution among species of Chlorella.
Introduction
Chloroplast sequence data are widely used to infer phylogenies of plants and algae (Fučíková et al., Citation2016). The chloroplast genome is particularly useful for phylogenetic reconstruction because of its relatively high and condensed gene content, in comparison to nuclear genomes (Leliaert et al., Citation2012). To date, several complete chloroplast genomes of chlorophyte algae have been sequenced and assembled (Hamaji et al., Citation2013, Lemieux et al., Citation2014) including 13 for the Chlorellaceae (Wakasugi et al., Citation1997; de Koning & Keeling, Citation2006; Turmel et al., Citation2009; Jeong et al., Citation2014; Orsini et al., Citation2016a, b).
The Chlorellaceae is a family in the order Chlorellales that mostly includes unicellular coccoids of minute size which thrive in an extremely broad range of habitats (Friedl & Rybalka, Citation2012). They are assigned to the Trebouxiophyceae, one of the four classes of chlorophyte algae or Chlorophyta sensu stricto. The chlorophyte algae or Chlorophyta sensu stricto comprise most of what are commonly called green algae. Four classes have traditionally been defined using ultrastructural characters, namely flagellar apparatus configuration and features of the cell division process: Ulvophyceae, Trebouxiophyceae, Chlorophyceae and Prasinophyceae (e.g. Mattox & Stewart, Citation1984; Fučíková et al., Citation2014). The class Trebouxiophyceae is largely composed of unicellular and colonial green algae, which are mostly found in sub-aerial habitats and as phycobionts in lichens. Moreover, there are some genera which include unicellular non-flagellate parasites/pathogens that still retain vestigial plastids (Figueroa-Martinez et al., Citation2014). Some recent studies have revealed that the class Trebouxiophyceae sensu stricto is not a monophyletic group (Lemieux et al., Citation2014; Fučíková et al., Citation2014). It comprises several orders among which two major ones can be identified: the Trebouxiales and Chlorellales (Krienitz & Bock, Citation2012).
Chlorellaceae lineage
Four clades were delineated in the family: the Chlorella and Parachlorella clades (Krienitz et al., Citation2004), the Auxenochlorella clade (Proschold & Leliaert, Citation2007) and the Marvania clade (Lemieux et al., Citation2014). Among them, Chlorella represents the archetype of unicellular green algae. Many taxa formerly included in Chlorella have been reassigned into independent lineages on the basis of molecular markers from different cell compartments or entire organelle genomes (Krienitz et al., Citation2015). On the basis of biochemical and molecular data it was proposed that the genus should be reduced to a set of the five currently accepted Chlorella species: C. vulgaris Beyerinck, the type species (lectotype) of the genus (Krienitz et al., Citation2015), C. lobophora Andreyeva, C. sorokiniana Shihira & Krauss, C. heliozoae Pröschold & Darienko and C. variabilis Shihira & Krauss (Huss et al., 2011; Krienitz et al., Citation2004; Pröschold et al., Citation2011).
In this study, we updated the complete nucleotide sequence of the chloroplast genome DNA (cpDNA) of Chlorella sorokiniana SAG 211-8k, and performed multi-gene phylogenetic and comparative genomic analyses. Chlorella sorokiniana is a non-motile and spherical unicellular freshwater green microalga. We selected this green alga because it is able to accumulate significant quantities of lipids which can be exploited for the production of biofuels. This characteristic makes this strain, as well as most of the species belonging to the Chlorella genus, particularly promising in the biotechnological, environmental and energy sectors (Concas et al., Citation2010, Citation2012, 2104, Citation2016). To reinforce the monophyletic character of Chlorellaceae and better understand its relationship to other species of environmental and industrial importance, we compared the C. sorokiniana chloroplast sequence to other Chlorellaceae plastid genomes, chosen at different levels (strain, species, genus and family).
Materials and methods
Strain and culture conditions, cpDNA extraction and sequencing
A unialgal culture of Chlorella sorokiniana (SAG 211-8k; authentic strain) was obtained from Sammlung von Algenkulturen, University of Göttingen (SAG), Germany. The culture was maintained under axenic conditions in shaken flasks illuminated by a photon flux of 90–100 µmol photons m–2 s–1 and containing modified WARIS-H culture medium (McFadden & Melkonian, Citation1986) without soil extract (Orsini et al., Citation2016a). The microalga was grown with a light/dark photoperiod of 12 h until growth reached log phase. Cells were harvested by centrifugation for 10 min at 4000 × g at 4°C, and the cell pellet was ground to powder under liquid nitrogen using a mortar and pestle. DNA was extracted and purified from fresh algal pellets with a DNeasy plant mini kit (Qiagen, Valencia, California, USA) following the manufacturer’s instructions. DNA concentration was measured with a NanoDrop ND-1000 Spectrophotometer (Thermo Fisher Scientific, Wilmington, Delaware, USA) and the quality of extracted DNA was assessed by electrophoresis on a 1% 1× TAE agarose gel. Whole-genome sequencing of the C. sorokiniana strain was performed using an Illumina HiSeq2000 platform. Genomic DNA was fragmented by sonication, and whole genome sequencing libraries were prepared using the TruSeq DNA Library Preparation Kit (Illumina) and loaded into TruSeq PE v3 flowcells on an Illumina cBot followed by indexed paired-end sequencing (101+7+101 bp) using TruSeq SBS Kit v3 chemistry (Illumina). Quantification and size distribution of the libraries were determined using the Agilent DNA 1000 kit. Each barcoded sample was sequenced from both ends for 100 cycles and achieved 35 Gb of raw DNA sequence data each that enabled an average of 1000-fold estimated coverage.
Assembly of Chlorella sorokiniana chloroplast genome sequence
Reads were assembled using Velvet (Zerbino & Birney, Citation2008) and obtained contigs were assembled into scaffolds by SSPACE (Boetzer et al., Citation2011). Sequence gaps were then filled in using a python script that implements a rough greedy algorithm surrounding contig edges (unpublished script). Finally, reads were pileupped against genome sequence using BWA (Li & Durbin, Citation2010) and SamTools (Li et al., Citation2009), and alignment visually inspected to exclude artifacts. Genome annotation was based on GeneMarkS (Besemer et al., Citation2001), Dogma (Wyman et al., Citation2004), RNAmmer (Lagesen et al., Citation2007) and trna scan (Schattner et al., Citation2005), followed by manual inspection. The availability of the cp genome sequence of the Chlorella sorokiniana 1230 strain and its high similarity with the genome of the Chlorella sorokiniana SAG 211-8k strain (Orsini et al., Citation2016a), led us to reannotate the latter. In our first release, automatic annotation missed four genes (ycf47, ycf12, psbK, rpoA) probably because of their short length or annotation software mis-settings. Conversely, these four genes have been reported in the C. sorokiniana 1230 strain annotation; therefore, on the basis of the sequence identity between the two genomes and the conservation of the corresponding protein products within green algae (on the basis of a blastx search over nr database, data not shown), we included them in the genome annotation updates.
Phylogenetic analysis and comparative analysis of cp genomes
The DNA sequences of chloroplast rRNA operon datasets (16S-tRNA Ile-Ala-23S) were derived from complete genome sequences of strains included in this study (C. sorokiniana SAG 211-8k; C. sorokiniana 1230; C. vulgaris C-27; C. variabilis NC64A; Chlorella sp. ArM0029B; Parachlorella kessleri SAG 211-11g, Auxenochlorella protothecoides 0710; Helicosporidium sp. ATCC 50920; Prototheca wickerhamii SAG 263-11; Marvania geminata SAG:12.88; Pseudochloris wilhelmii SAG:1.80; and Dicloster acuatus SAG:41.98), while the 18S-tRNA nuclear rDNA sequences were downloaded from NCBI, when available. Sequences from these two datasets were aligned by MAFFT, with Q-INS-i parameters optimized for RNA secondary structure (Katoh et al., Citation2013), and MAUVE (Darling et al., Citation2004). Maximum likelihood trees were inferred by MEGA package using GRT + Gamma 4 model of sequence evolution. Confidence of branch points was evaluated for each tree by fast-bootstrap analyses with 500 replicates. Amino acid sequences set for 71 chloroplast protein coding genes (accD, atpA, B, E, F, H, I, ccsA, cemA, chlB, I, L, N, clpP, ftsH, infA, petA, B, D, G, L, psaA, B, C, I, J, M, psbA, B, C, D, E, F, H, I, J, K, L, M, N, T, Z, rbcL, rpl2, 5, 14, 16, 20, 23, 32, 36, rpoA, B, C1, C2, rps2, 3, 4, 7, 8, 9, 11, 12, 14, 18, 19, tufA, ycf1, 3, 4, 12) were derived from annotated genomes as made by Lemieux et al. (Citation2014). The amino acid sequences were aligned by MAFFT with G-INS-1 parameters (progressive accurate method), while the ambiguously aligned regions were removed using TRIMAL (Capella-Gutierrez et al., Citation2009) with parameters as indicated in Lemieux et al. (Citation2007). Trimmed alignments were concatenated using Phyutility (Smith & Dunn, Citation2008). Phylogenetic relationships were inferred by Maximum likelihood method implemented in MEGA6 (Tamura et al., Citation2013) using cpREV + Gamma 4 model of sequence evolution. Confidence of branch points was evaluated by fast-bootstrap analysis with 500 replicates.
We decided to use pedinophycean members as outgroups since they were used to construct the phylogenies recently reported by Lemieux et al. (Citation2014) and Turmel et al. (Citation2015). Specifically, Coccomyxa subellipsoidea and Pedinomonas minor were selected as outgroups because full chloroplast sequences were available for both.
Conserved cluster genes among Chlorella clade organisms were identified by BLASTN searches (Altschul et al., Citation1997), while genoPlotR (Guy et al., Citation2010) was used to prepare figures.
Results and discussion
Gene structure
The Chlorella sorokiniana cpDNA sequence, assembled as a circular map of 109 811 bp, encodes 113 genes (Supplementary Fig. 1). Compared with C. sorokiniana 1230, the only difference between the two genomes is the insertion of eight nucleotides in Chlorella sorokiniana SAG 211-8k, located between the trnI(gau) and the rrnL genes in the rRNA operon. This region is often used for phylogenetic studies. Global features of all cpDNAs included in this study are summarized in Supplementary Table 1.
The Chlorella sorokiniana cpDNA is the smallest plastid genome of the Chlorella species with an AT content of 66.0%, similar to the other Chlorella species (see details in ). It does not show any evidence of introns (Orsini et al., Citation2016a). Coding strand distribution of genes is strongly skewed, with 87 genes (77%) occupying the forward strand and 26 genes occupying the reverse. The other Chlorellaceae showed values of 68.4% and 65.2% of genes occupying the forward strand for C. variabilis and Chlorella sp. ArM0029B, respectively. On the other hand, C. vulgaris shows a value of 49.2%. The chloroplast genome of C. sorokiniana includes 79 protein coding genes, three rRNAs and 31 tRNAs.
Table 1 General features of cp DNAs from Chlorella sorokiniana 211-8k (C. sor 211-8k) and the other Chlorellaceae: Chlorella sorokiniana 1230 (C. sor 1230), C. vulgaris C-27 (C. vul), C. variabilis NC64A (C. var), Chlorella sp. ArM0029B (C. sp), Parachlorella kessleri SAG 211-11g (P. kess), Auxenochlorella protothecoides 0710 (A. prot), Pseudochloris wilhelmii SAG:1.80 (P. wil), Marvania geminata SAG:12.88 (M. gem), Dicloster acuatus SAG:41.98 (D. acu), Prototheca wickerhamii SAG 263-11 (P. wic) and Helicosporidium sp. ATCC 50920 (H. sp).
The Chlorellaceae family chloroplast genomes encode a similar number of genes, while genome size is not uniform among them.
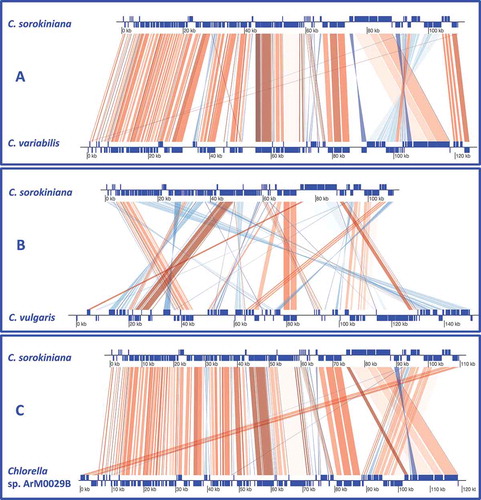
Chlorella sorokiniana cpDNA has one of the more compact genomes among Chlorellaceae. Like other Chlorella strains, the genome does not show a genome architecture composed of a large single-copy region (LSC) and a small single-copy separated by a pair of inverted repeats (IRs). Its genome architecture exhibited a substantial collinearity with those of Chlorella sp. ArM0029B and C. variabilis, with very few rearrangements. In particular, the comparison between the C. sorokiniana and Chlorella sp. ArM0029B chloroplast genomes highlighted four inverted blocks containing the genes tRNA-His, Ycf3, mindD and rbcL, plus an additional three consecutive blocks comprising genes from trn-His to psbZ, which are inverted and reciprocally translocated (Supplementary Fig. 2). The comparison of C. sorokiniana with C. variabilis reported similar results, with a few exceptions: the block containing the tRNA-His gene is deleted, the block containing the minD gene is in the same orientation as in C. sorokiniana. Five non-consecutive additional blocks (containing the following genes: psbA, ycf1, cysT, rpl32, ccsA, chlL, chlN, tRNA-Arg, tRNA-Asn, psaC, tRNA-Met, ycf20, rps14) are inverted and translocated in C. variabilis (Supplementary Fig. 2) to form a single cluster, interrupted by the block containing the minD gene only. Conversely, the alignment of C. sorokiniana against C. vulgaris shows substantial rearrangements, despite block conservation collinearity between the two genomes being difficult to recognize. Moreover, C. vulgaris differs from the other Chlorella species in the controversial presence of the minE gene (Wakasugi et al., Citation1997).
Gene content
The chloroplast protein coding genes can be functionally categorized in the following classes: genes directly involved in photosynthesis and those which take care of transcription, translation and division. Chlorella sorokiniana cpDNA investigation supports the common origin of the Chlorella clade. Among the genes involved in chlorophyll biosynthesis, the C. sorokiniana cp genome lacks psbX and psbY, which is similar to other Chlorellaceae and many other green algae (Chlorophyceae). Genomic inspections and alignments of the psbY amino acid sequence revealed that the protein is present in all photosynthetic plants, in some algal chloroplasts (formerly ycf32) and also in various cyanobacteria (formerly identified as psbY, ycf32 or Sml0007) (Gau et al., Citation1998). In higher plants, psbY is nuclear-encoded and targeted to the thylakoids (Plöchinger et al., Citation2016). Four genes, chlB, I, L, N, are conserved as well as 11 small hydrophobic proteins (psbH, I, J, K, L, M, T, X, Y, Z and ycf12) involved in photosynthesis that are well conserved from Cyanobacteria (Inoue-Kashino et al., Citation2011) to higher plants (Shi & Schroder, Citation2004; Kashino et al., Citation2007; Iwai et al., Citation2010). In addition, the C. sorokiniana cp genome lacks the full set of ndh genes as do most algal chloroplasts (Stoebe et al., Citation1998). It has been suggested that all the ndh genes have been transferred to the nuclear genome in algae (Wakasugi et al., Citation1997). The Chlorella sorokiniana plastid encodes for tRNA(Ile)-lysidine synthetase (tilS), which is responsible for modifying the CAU anticodon of a unique tRNA, an adaptor molecule that is generally encoded by the nuclear genome and targeted to the organelle (de Koning et al., Citation2006).
rRNAs and tRNAs
The rRNA operon in C. sorokiniana exhibits the standard architecture of Chlorophyta (16S rDNA –tRNA Ile – tRNA Ala – 23S rDNA) (Orsini et al., Citation2016a). The C. sorokiniana chloroplast genome contains 31 tRNAs: 24 genes occupying one strand and seven on the other. Twenty-two of them were also found in the cpDNAs of the other Chlorellaceae analysed in this study. The trnG (gcc) and trnM (cau) were found in double copy while trnL (uaa) was not present. In addition, C. sorokiniana, C. variabilis and P. wickerhamii have lost the trnI (cau). We have clearly established that the presence of trnS (gga) is a characteristic of all the photosynthetic species we analysed. This gene is present in the ancestral-type genome of the Prasinophycean Nephroselmis and it has been lost from several UTC (Ulvophyceae, Trebouxiophceae, Chlorophyceae) algal cpDNAs (Turmel et al., Citation2009). Finally, the C. sorokiniana chloroplast genome includes the trnP (ggg) tRNA that has thus far only been found in P. wickerhamii.
Gene order
Gene order of cp genomes among C. sorokiniana, Chlorella sp. ArM0029B, C. vulgaris and C. variabilis is compared in . The gene order between C. sorokiniana and Chlorella sp. ArM0029B is generally conserved; major rearrangements between the two species were found in three regions. The clusters psbI-ycf3-trnR and trnQ-psaM-ycf12-psbK were observed in the inverse orientation in the C. sorokiniana cp genome in comparison with both other strains. The Chlorella sorokiniana region comprising the trnG-trnH-ycf47-trnF-trnC-psbZ gene cluster was in inverse orientation in the Chlorella sp. ArM0029B and C. variabilis genomes. Moreover, in the latter strain, this region displays an inversion (psbZ-trnK-tilS-trnF-ycf47 instead of ycf47-trnF- tilS-trnK-psbZ). A more complex rearrangement was observed in the C. sorokiniana psaB-rpl32 region: the cluster rpoC2-rpoC1-rpoB-trnC, which leads this region, shares conserved orientation among the three considered strains. The Chlorella sorokiniana rbcL-rpl32 region can be considered as composed of several subclusters. The trnR-rpl32 one is conserved in orientation between C. sorokiniana and Chlorella sp. ArM0029B while it shows an inversion between C. sorokiniana and C. variabilis. The minD gene is present in the same orientation in C. sorokiniana and C. variabilis, and in the opposite direction in Chlorella sp. ArM0029B. The trnM-psaC-trnN cluster shows the same orientation between C. sorokiniana and Chlorella sp. ArM0029B. Even though in the latter strain the ycf20 gene is inserted between the trnN and psaC genes, it is in inverse orientation for the C. sorokiniana and C. variabilis genomes. The rbcL-rps14 cluster is inverted in C. sorokiniana and the other two organisms. This region can therefore be considered as a large cluster, comprising the genes rbcL-rps14-trnN-psaC-trnN, which is inverted for C. sorokiniana and C. variabilis. Moreover, the cluster itself, if compared between C. sorokiniana and Chlorella sp. ArM0029B, can be divided in two subclusters: rbcL-rps14 which is inverted in Chlorella sp. ArM0029B and in the C. variabilis genome, and the subcluster trnN-psaC-trnM, which is conserved between C. sorokiniana and Chlorella sp. ArM0029B. The comparison between C. sorokiniana and C. vulgaris () presents a greater number of rearrangements, each of them involving a larger number of genes, with respect to C. vulgaris. Six clusters were found in the same orientation, even if in different order, between the two strains: trnE-rpl20-rps18-trnW-trnP-psaJ-rps12-rps7-tnfA-rpl19-ycf4-psbI-ycf3-trnR, rrns-trnI-trnA-rrnL-rrn5 (in C. vulgaris the rrnL gene is interrupted and contains an intron plus the I-cvuI gene); trnG-trnH; trnK-psbZ-chlB-psaA-psaB (this cluster in C. vulgaris is interrupted by the insertion of multiple genes); rbcL-rps14; chlN-chlL_1-chlL_2-ycf5-rpl32-cysT; petD-petB-clpP. Other clusters, on the contrary, are present in inverse orientation and different order between the two strains: psbN-psbH; rpl12-trnR-chlI-petA-petL-petG; trnT-rps2-atpI-atpH-atpF-atpA; atpB-atpE-rps4; psaI-accD-cysA; psbE-psbF-psbI-psbJ; trnN-minD-trnR. In addition, regarding the psb cluster, the psbA gene is inverted in C. variabilis while it does not occur in the cluster in the C. vulgaris cp genome. It should be noted that in the C. vulgaris the minE gene interrupts the trnN-minD-trnR cluster.
Fig. 1. Overview of comparison of the cp genomes of C. sorokiniana vs C. variabilis (A), C. sorokiniana vs C. vulgaris (B), C. sorokiniana vs Chlorella sp. ArM0029B (C). Thick bars represent protein-coding genes, rRNA genes and tRNA genes. Genes in the inverted region are connected by blue lines. The entire list of genes is available in Supplementary Table 3.
Ancestral clusters
The multiple genes encoded in the chloroplast genome (cpDNA) represent an invaluable source of data for resolving difficult phylogenetic questions, including deep relationships in green plants (Leliaert et al., Citation2016). More insight may be obtained by considering the organization of genes in genomes by gene-cluster analysis. Green plants are divided into two sister lineages: the Chlorophyta which comprise the green algal classes, and the Streptophyta which comprise the Charophyceae and land plants. Nephroselmis olivacea is a member of the Prasinophyceae. Nephroselmis represents an early branch of the Chlorophyta, and any similarity between its cpDNA and those of its land plant counterparts can be interpreted as reflecting a feature of the cpDNA architecture from the common ancestor of chlorophytes and streptophytes (Turmel et al., Citation1999). Mesostigma has a similar position in plastid phylogenomic analyses. Lemieux et al. (Citation2000) reported that the flagellate Mesostigma viride belongs to the earliest diverging green plant lineage discovered to date. Many genes in Mesostigma cpDNA form clusters that are shared exclusively with chlorophytes and/or streptophytes (Lemieux et al., Citation2000). In order to include descendants of the earliest-diverging green algae, de Cambiaire et al. (Citation2007) compared Mesostigma and Nephroselmis with several green algae belonging to the Chlorophyta and Streptophyta, to better understand the mechanism of the evolution in these chloroplast genomes. We used the same approach to clarify the evolution of the single organism investigated in our study of the Chlorellaceae family. To date, only C. vulgaris has been used as representative of the genus Chlorella.
Comparison of gene clusters
The 11 cpDNA genomes were compared with respect to the 24 gene clusters proposed by de Cambiaire et al. (Citation2007). Our analysis focused on the 14 out of 24 gene clusters found in the Chlorellaceae family. All the photosyntethic strains completely retained seven of them. Here, we emphasized only the main features of the analysis. All differences are depicted in . The first cluster is pretty much conserved across almost all plastids (Provan et al., Citation2004). The largest of these clusters (rpl23 to rps9) is present in Mesostigma/Nephroselmis and corresponds to the str-S10-spc-α operons of Escherichia coli (Turmel et al., Citation1999). In cluster 2, nine out of the 11 strains present a fragmentation of the ancestral cluster in two clusters. We observed that the CemA gene has only been relocated in C. vulgaris, while Helicosporidium sp. and P. wickerhamii have lost, respectively, six and five genes of the ancestral cluster. In cluster 3, the trnR(acg) gene is separated and creates another cluster together with minD, as previously described in Turmel et al. (Citation2009). Notably, this cluster is distinctive of the Chlorellaceae family. We underlined that the rps2 gene moved from cluster 4 in Mesostigma/Nephroselmis to cluster 5 considering all the 11 cpDNA genomes. The majority of the Chlorellaceae include the clpP gene in cluster 7, while in C. vulgaris, A. protothecoides and M. geminata this gene is relocated on the chloroplast genome. In our analysis, we confirmed the data previously reported (de Cambiaire et al., Citation2007) regarding the loss of all photosynthetic genes in Helicosporidium and Prototheca wickerhamii. Even if gene ordering and clustering underline the close relationships among Chlorella clade members, ancestral cluster retention denotes the common origin of the Trebouxiophyceae. This latter is also true in C. vulgaris when events such as the loss of clpP from the psbH-psbN, psbT, psbB cluster are taken into account. Cluster eight, which comprises the four PSII genes psbE, psbF, psbL and psbJ, is conserved in the Chlorellaceae. This gene cluster is conserved in all photosynthetically active multicellular plant species investigated to date but is not found in the unicellular green alga Chlamydomonas reinhardtii (Hager et al., Citation2002).
Fig. 2. Chlorellaceae cpDNAs gene cluster comparison to Mesostigma sp. and Nephroselmis sp. algae. For each genome, the set of genes making up each of the identified clusters is shown as black boxes connected by a horizontal line. Black boxes that are contiguous but not linked together indicate that the corresponding genes are not adjacent on the genome and empty boxes represent missing genes. Grey boxes denote cluster numbers in the lower part of the figure. The relative polarities of the genes are not shown.

Phylogenetic analysis
The Maximum Likelihood phylogenetic trees (Supplementary Fig. 3) were inferred using nuclear 18S rDNA (panels a1 and a2), chloroplast rRNA operon (16S-tRNA Ile-Ala-23S) (panel b) and 71 chloroplast protein coding genes (panel c). Trees were focused on the Chlorellaceae with an emphasis on the Chlorella clade, while the dataset included photosynthetic and colourless Chlorellales. When possible, we considered strains from the same culture collection for the 18S-based analysis. Coccomyxa subellipsoidea and Pedinomonas minor were included as outgroups. In the 18S rDNA based tree, the four Chlorella strains are all included in one clade, as supported by high bootstrap values (91%). The closest genera to Chlorella groups are Parachlorella-Dicloster and Marvania. In the 16S operon tree, the clustering of C. sorokiniana with other members of the ‘true Chlorella’ clade is supported by a high bootstrap value (98%), with the exclusion of C. vulgaris which branched early in the radiation of the genus Chlorella (Germond et al., Citation2013). The long branch for C. vulgaris can be explained by the presence of an intron in the rrn23 gene of 815 bp (AB001684 position: 27395-28209) as previously described by Wakasugi et al. (Citation1997). This intron contains a protein coding gene (I-CvuI) which has not been found in land plants. The Chlorella clade is then separated by the Auxenochlorella/Marvania clade which cluster as sister groups with very low (40%) bootstrap support, while Parachlorella/Dicloster cluster as an early diverged subclade with 100% bootstrap support. Phylogenetic inference based on the 71 ptDNA supports a close relationship of C. sorokiniana to C. variabilis and Chlorella sp. ArM0029B. The addition of the paraphyletic C. vulgaris forms the so-called Chlorella clade. Global results showed two large sister groups composed of the Chlorella/Parachlorella/Marvania clade and the Auxenoclorella/Prothoteca, Pseudochloris/Helicosporidium clades.
Phylogenetic analysis performed using nuclear 18S rRNA sequences and the 16S rRNA chloroplast operon supports five distinct clades of Chlorellaceae: the Chlorella, Parachlorella, Auxenochlorella, Marvania and Helicosporidium clades. Our results, which have considered chloroplast protein coding genes independently, and included Coccomyxa and Pedinomonas as outgroups, confirm the monophyletic origin of Chlorellaceae (Krienitz et al., Citation2003; Turmel et al., Citation2009; Heeg & Wolf Citation2015). However, precise designations within the family have remained provisional due to a lack of bootstrap support in any molecular analysis (Heeg & Wolf, Citation2015).
The identification of the relationship among the main microalgal lineages, and for Chlorella in particular, is crucial to understand their evolution history and their adaptations to changing environments. Our analysis has highlighted shared traits between the chloroplast genomes of C. sorokiniana and the other Chlorellaceae members, thus supporting the hypothesis of a common evolution. The chloroplast genome structure and phylogenetic analyses confirmed the position of C. sorokiniana inside the Chlorella clade. Our phylogenetic analysis supported a monophyletic Parachlorella, in accordance with Heeg & Wolf (Citation2015) who used ITS2 secondary structure. Moreover, we show how the genera are related to each other.
Supplementary information
The following supplementary material is accessible via the Supplementary Content tab on the article’s online page at http://dx.doi.org/10.1080/09670262.2017.1287959
Supplementary figure 1. Updated gene map of the chloroplast genome of Chlorella sorokiniana SAG 211-8k (KJ397925.1).
Supplementary figure 2. Sequence comparison of chloroplast genomes from the four Chlorella strains.
Supplementary figure 3. Molecular phylogenetic analysis.
Supplementary table 1. Gene list for the Chlorella sorokiniana chloroplast chromosome.
Supplementary table 2. GenBank accession numbers of green algal genomes compared in the study.
Supplementary table 3. Gene list details used for comparison of the cp genomes of C. sorokiniana vs C. variabilis; C. sorokiniana vs C. vulgaris; and C. sorokiniana vs Chlorella sp. ArM0029B.
Supplemental_Material.zip
Download Zip (4.6 MB)Acknowledgements
The authors report no conflicts of interest. The authors wish to thank Dr MB Whalen who assisted in the editing, checking and correction of the manuscript.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Veronica Malavasi
V. Malavasi: culturing, phylo-genomic analysis and drafting manuscript; C. Costelli: nucleic acid extractions and sequencing; R. Cusano: nucleic acid extractions and sequencing; M. Orsini: genome assemblies and annotations, phylo-genomic analysis and drafting manuscript; A. Angius: original concept, genome assemblies, analysis, drafting and editing manuscript; G. Cao: original concept, funded research, drafting and editing manuscript
Cristina Costelli
V. Malavasi: culturing, phylo-genomic analysis and drafting manuscript; C. Costelli: nucleic acid extractions and sequencing; R. Cusano: nucleic acid extractions and sequencing; M. Orsini: genome assemblies and annotations, phylo-genomic analysis and drafting manuscript; A. Angius: original concept, genome assemblies, analysis, drafting and editing manuscript; G. Cao: original concept, funded research, drafting and editing manuscript
Massimiliano Orsini
V. Malavasi: culturing, phylo-genomic analysis and drafting manuscript; C. Costelli: nucleic acid extractions and sequencing; R. Cusano: nucleic acid extractions and sequencing; M. Orsini: genome assemblies and annotations, phylo-genomic analysis and drafting manuscript; A. Angius: original concept, genome assemblies, analysis, drafting and editing manuscript; G. Cao: original concept, funded research, drafting and editing manuscript
Roberto Cusano
V. Malavasi: culturing, phylo-genomic analysis and drafting manuscript; C. Costelli: nucleic acid extractions and sequencing; R. Cusano: nucleic acid extractions and sequencing; M. Orsini: genome assemblies and annotations, phylo-genomic analysis and drafting manuscript; A. Angius: original concept, genome assemblies, analysis, drafting and editing manuscript; G. Cao: original concept, funded research, drafting and editing manuscript
Andrea Angius
V. Malavasi: culturing, phylo-genomic analysis and drafting manuscript; C. Costelli: nucleic acid extractions and sequencing; R. Cusano: nucleic acid extractions and sequencing; M. Orsini: genome assemblies and annotations, phylo-genomic analysis and drafting manuscript; A. Angius: original concept, genome assemblies, analysis, drafting and editing manuscript; G. Cao: original concept, funded research, drafting and editing manuscript
Giacomo Cao
V. Malavasi: culturing, phylo-genomic analysis and drafting manuscript; C. Costelli: nucleic acid extractions and sequencing; R. Cusano: nucleic acid extractions and sequencing; M. Orsini: genome assemblies and annotations, phylo-genomic analysis and drafting manuscript; A. Angius: original concept, genome assemblies, analysis, drafting and editing manuscript; G. Cao: original concept, funded research, drafting and editing manuscript
Related Research Data
References
- Altschul, S.F., Madden, T.L., Schäffer, A.A., Zhang, J., Zhang, Z., Miller, W. & Lipman, D.J. (1997). Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Research, 25: 3389–3402.
- Besemer, J., Lomsadze, A. & Borodovsky, M. (2001). GeneMarkS: a self-training method for prediction of gene starts in microbial genomes. Implications for finding sequence motifs in regulatory regions. Nucleic Acids Research, 29: 2607–2618.
- Boetzer, M., Henkel, C.V., Jansen, H.J., Butler, D. & Pirovano, W. (2011). SSPACE: Scaffolding pre-assembled contigs using SSPACE. Bioinformatics, 27: 578–579.
- Capella-Gutierrez, S., Silla-Martinez, J.M. & Gabaldon, T. (2009). trimAl: a tool for automated alignment trimming in large-scale phylogenetic analyses. Bioinformatics, 25: 1972–1973.
- Concas, A., Pisu, M. & Cao, G. (2010). Novel simulation model of the solar collector of BIOCOIL photobioreactors for CO2 sequestration with microalgae. Chemical Engineering Journal, 157: 297–303.
- Concas, A., Lutzu, G.A., Pisu, M. & Cao, G. (2012). Experimental analysis and novel modeling of semi-batch photobioreactors operated with Chlorella vulgaris and fed with 100% (v/v) CO2. Chemical Engineering Journal, 213: 203–213.
- Concas, A., Steriti, A., Pisu, M. & Cao, G. (2014). Comprehensive modeling and investigation of the effect of iron on the growth rate and lipid accumulation of Chlorella vulgaris photobioreactors. Bioresource Technology, 153: 340–350.
- Concas, A., Malavasi, V., Costelli, C., Fadda, P., Pisu, M. & Cao, G. (2016). Autotrophic growth and lipid production of C. sorokiniana in lab batch and BIOCOIL photobioreactors: experiments and modeling. Bioresource Technology, 211: 327–338.
- Darling, A.C., Mau, B., Blattner, F.R. & Perna, N.T. (2004). Mauve: multiple alignment of conserved genomic sequence with rearrangements. Genome Research, 14: 1394–1403.
- de Cambiaire, J.C., Otis, C., Lemieux, C. & Turmel, M. (2007). The chloroplast genome sequence of the green alga Leptosira terrestris: multiple losses of the inverted repeat and extensive genome rearrangements within the Trebouxiophyceae. BMC Genomics, 8: 213.
- de Koning, A.P. & Keeling, P.J. (2006). The complete plastid genome sequence of the parasitic green alga Helicosporidium is highly reduced and structured. BMC Biology, 4: 12.
- Figueroa-Martinez, F., Nedelcu, M.A., Smith, D.R. & Reyes-Prieto, A. (2014). When the lights go out: the evolutionary fate of free-living colorless green algae. New Phytologist, 206: 972–982.
- Friedl, T. & Rybalka, N. (2012). Systematics of the green algae: a brief introduction to the current status. Progress in Botany, 73: 259–280.
- Fučíková, K., Leliaert, F., Cooper, E.D., Škaloud, P., D’Hondt, S., De Clerck, O., Gurgel, C.F.D., Lewis, L.A., Lewis, P.O., Lopez-Bautista, J.M., Delwiche, C.F. & Verbruggen, H. (2014). New phylogenetic hypotheses for the core Chlorophyta based on chloroplast sequence data. Frontiers in Ecology and Evolution, 2: 63.
- Fučíková, K., Lewis, L.A. & Lewis, P.O. (2016). Comparative analyses of chloroplast genome data representing nine green algae in Sphaeropleales (Chlorophyceae, Chlorophyta). Data in Brief, 7: 558–570.
- Gau, A.E., Thole, H.H., Sokolenko, A., Altschmied, L., Hermann, R.G. & Pistorius, E.K. (1998). PsbY, a novel manganese-binding, low-molecular-mass protein associated with photosystem II. Molecular and General Genetics, 260: 56–68.
- Germond, A., Hata, H., Fujikawa, Y. & Nakajima, T. (2013). The phylogenetic position and phenotypic changes of a Chlorella-like alga during 5-year microcosm culture. European Journal of Phycology, 48: 485–496.
- Guy, L., Kultima, J.R. & Andersson. S.G. (2010). genoPlotR: comparative gene and genome visualization in R. Bioinformatics, 26: 2334–2335.
- Hager, M., Hermann, M., Biehler, K., Krieger-Liszkay, A. & Bock, R. (2002). Lack of the small plastid-encoded PsbJ polypeptide results in a defective water-splitting apparatus of photosystem II, reduced photosystem I levels, and hypersensitivity to light. Journal of Biological Chemistry, 277: 14031–14039.
- Hamaji, T., Smith, D.R., Noguchi, H., Toyoda, A., Suzuki, M., Kawai-Toyooka, H., Fujiyama, A., Nishii, I., Marriage, T., Olson, B.J. & Nozaki, H. (2013). Mitochondrial and plastid genomes of the colonial green alga Gonium pectorale give insights into the origins of organelle DNA architecture within the Volvocales. PLoS ONE, 8: e57177.
- Heeg, J.S. & Wolf, M. (2015). ITS2 and 18S rDNA sequence-structure phylogeny of Chlorella and allies (Chlorophyta, Trebouxiophyceae, Chlorellaceae). Plant Gene, 4: 20–28.
- Huss, V.A.R., Frank, C., Hartmann, E.C., Hirmer, M., Kloboucek, A., Seidel, B.M., Wenzeler, P., Inoue-Kashino, N., Kashinob, Y. & Takahashia, Y. (2011). Psb30 is a photosystem II reaction center subunit and is required for optimal growth in high light in Chlamydomonas reinhardtii. Journal of Photochemistry and Photobiology B: Biology, 104: 220–228.
- Inoue-Kashino, N., Kashino, Y., Takahashi, Y. (2011). Psb30 is a photosystem II reaction center subunit and is required for optimal growth in high light in Chlamydomonas reinhardtii. Journal of Photochemistry and Photobiology B: Biology, 104: 220–8.
- Iwai, M., Suzuki, T., Kamiyama, A., Sakurai, I., Dohmae, N., Inoue, Y. & Ikeuchi, M. (2010). The PsbK subunit is required for the stable assembly and stability of other small subunits in the PSII complex in the thermophilic cyanobacterium Thermosynechococcus elongatus BP-1. Plant and Cell Physiology, 51: 554–560.
- Jeong, H., Lim, J.M., Park, J., Sim, Y.M., Choi, H.G., Lee, J. & Jeong, W.J. (2014). Plastid and mitochondrion genomic sequences from Arctic Chlorella sp. ArM0029B. BMC Genomics, 15: 286.
- Kashino, Y., Takahashi, T., Inoue-Kashino, N., Ban, A., Ikeda, Y., Satoh, K. & Sugiura, M. (2007). Ycf12 is a core subunit in the photosystem II complex. Biochimica et Biophysica Acta, 1767: 1269–1275.
- Katoh, K. & Standley, D.M. (2013). MAFFT multiple sequence alignment software version 7: improvements in performance and usability. Molecular Biology and Evolution, 30: 772–780.
- Krienitz, L. & Bock, C. (2012). Present state of the systematics of planktonic coccoid green algae of inland waters. Hydrobiologia, 698: 295–326.
- Krienitz, L., Hegewald, E., Hepperle, D. & Wolf, A. (2003). The systematics of coccoid green algae: 18S rRNA gene sequence data versus morphology. Biologia, 58: 437–446.
- Krienitz, L., Hegewald, E., Hepperle, D., Huss, V., Rohr, T. & Wolf, M. (2004). Phylogenetic relationship of Chlorella and Parachlorella gen. nov. (Chlorophyta, Trebouxiophyceae). Phycologia, 43: 529–542.
- Krienitz, L., Huss, V.A.R. & Bock, C. (2015). Chlorella: 125 years of the green survivalist. Trends in Plant Science, 20: 67–69.
- Lagesen, K., Hallin, P.F., Rødland, E., Stærfeldt, H.H., Rognes, T. & Ussery, D.W. (2007). RNAmmer: consistent annotation of rRNA genes in genomic sequences. Nucleic Acids Research, 35: 3100–3108.
- Leliaert, F., Smith, D.R., Moreau, H., Herron, M.D., Verbruggen, H., Delwiche, C.F. & De Clerck, O. (2012). Phylogeny and molecular evolution of the green algae. Critical Reviews in Plant Sciences, 31: 1–46.
- Leliaert, F., Tronholm, A., Lemieux, C., Turmel, M., DePriest, M.S., Bhattacharya, D., Karol, K.G., Fredericq, S., Zechman, F.S. & Lopez-Bautista, J.M. (2016). Chloroplast phylogenomic analyses reveal the deepest-branching lineage of the Chlorophyta, Palmophyllophyceae class. nov. Scientific Reports, 6: 25367.
- Lemieux, C., Otis, C. & Turmel, M. (2000). Ancestral chloroplast genome in Mesostigma viride reveals an early branch of green plant evolution. Nature, 403: 649–652.
- Lemieux, C., Otis, C. & Turmel, M. (2007). A clade uniting the green algae Mesostigma viride and Chlorokybus atmophyticus represents the deepest branch of the Streptophyta in chloroplast genome-based phylogenies. BMC Biology, 5: 2.
- Lemieux, C., Otis, C. & Turmel, M. (2014). Six newly sequenced chloroplast genomes from prasinophyte green algae provide insights into the relationships among prasinophyte lineages and the diversity of streamlined genome architecture in picoplanktonic species. BMC Genomics, 15: 857.
- Li, H. & Durbin, R. (2010). BWA: Fast and accurate long-read alignment with Burrows-Wheeler transform. Bioinformatics, 26: 589–95.
- Li, H., Handsaker, B., Wysoker, A., Fennell, T., Ruan, J., Homer, N., Marth, G., Abecasis, G., Durbin, R. & 1000 Genome Project Data Processing Subgroup. (2009). SAMtools: The Sequence Alignment/Map format and SAMtools. Bioinformatics, 25: 2078–9.
- Mattox, K.R. & Stewart, K.D. (1984). Classification of the green algae: a concept based on comparative cytology. In Systematics of the Green Algae (Irvine, D.E.G & John, D.M., editors), 29–72. Academic Press, London.
- McFadden, G.I. & Melkonian, M. (1986). Culture Medium Waris-H. Phycologia, 25: 551–557.
- Orsini, M., Cusano, R., Costelli, C., Malavasi, V., Concas, A., Angius, A. & Cao, G. (2016a). Complete genome sequence of chloroplast DNA (cpDNA) of Chlorella sorokiniana. Mitochondrial DNA, 27: 838–839.
- Orsini, M., Costelli, C., Malavasi, V., Cusano, R., Concas, A., Angius, A. & Cao, G. (2016b). Complete sequence and characterization of mitochondrial and chloroplast genome of Chlorella variabilis NC64A. Mitochondrial DNA, 27: 3128–3130.
- Plöchinger, M., Schwenkert, S., von Sydow L., Schröder, W.P. & Meurer, J. (2016). Functional update of the auxiliary proteins PsbW, PsbY, HCF136, PsbN, TerC and ALB3 in maintenance and assembly of PSII. Frontiers in Plant Science, 7: 423.
- Proschold, T. & Leliaert, F. (2007). Systematics of the green algae: conflict of classic and modern approaches. In Unravelling the Algae: The Past, Present, and Future of Algal Systematics (Brodie, J. & Lewis, J., editors), 123–153. CRC Press, Boca Raton, FL.
- Pröschold, T., Darienko, T., Silva, P.C., Reisser, W. & Krienitz, L. (2011). The systematics of Zoochlorella revisited employing an integrative approach. Environmental Microbiology, 13: 350–364.
- Provan, J., Murphy, S. & Maggs, C.A. (2004). Universal plastid primers for Chlorophyta and Rhodophyta. European Journal of Phycology, 39: 43–50.
- Schattner, P., Brooks, A.N. & Lowe, T.M. (2005). The tRNAscan-SE, snoscan and snoGPS web servers for the detection of tRNAs and snoRNAs. Nucleic Acids Research, 33: W686–W689.
- Shi, L.X. & Schroder, W.P. (2004). The low molecular mass subunits of the photosynthetic supracomplex, photosystem II. Biochimica et Biophysica Acta, 1608: 75–96.
- Smith, S.A. & Dunn, C.W. (2008). Phyutility: a phyloinformatics tool for trees, alignments, and molecular data. Bioinformatics, 24: 715–716.
- Stoebe, B., Martin, W. & Kowallik, K.V. (1998). Distribution and nomenclature of protein-coding genes in 12 sequenced chloroplast genomes. Plant Molecular Biology Reporter, 16: 243–255.
- Tamura, K., Stecher, G., Peterson, D., Filipski, A. & Kumar, S. (2013). MEGA6: Molecular Evolutionary Genetics Analysis version 6.0. Molecular Biology and Evolution, 30: 2725–2729.
- Turmel, M., Otis, C. & Lemieux, C. (1999). The complete chloroplast DNA sequence of the green alga Nephroselmis olivacea: insights into the architecture of ancestral chloroplast genomes. Proceedings of the National Academy of Sciences USA, 96: 10248–10253.
- Turmel, M., Otis, C. & Lemieux, C. (2009). The chloroplast genomes of the green algae Pedinomonas minor, Parachlorella kessleri, and Oocystis solitaria reveal a shared ancestry between the Pedinomonadales and Chlorellales. Molecular Biology and Evolution, 26: 2317–2331.
- Turmel, M., Otis, C., Lemieux, C. (2015). Dynamic evolution of the chloroplast genome in the green algal classes Pedinophyceae and Trebouxiophyceae. Genome Biology and Evolution, 7: 2062–2082.
- Wakasugi, T., Nagai, T., Kapoor, M., Sugita, M., Ito, M., Ito, S., Tsudzuki, J., Nakashima, K., Tsudzuki, T., Suzuki, Y., Hamada, A., Ohta, T., Inamura, A., Yoshinaga, K. & Sugiura, M. (1997). Complete nucleotide sequence of the chloroplast genome from the green alga Chlorella vulgaris: the existence of genes possibly involved in chloroplast division. Proceedings of the National Academy of Sciences USA, 94: 5967–5972.
- Wyman, S.K., Jansen, R.K. & Boore, J.L. (2004). Automatic annotation of organellar genomes with DOGMA. Bioinformatics, 20: 3252–3255.
- Zerbino, D.R. & Birney, E. (2008). Velvet: algorithms for de novo short read assembly using de Bruijn graphs. Genome Research, 18: 821–829.