Abstract
Dominance effect refers to the allele interaction in a locus. In this study, different portions of dominance standard deviations underlying quantitative trait loci (QTL) effect were considered. The F2 design is frequently employed in QTL mapping experiments using Haley and Knott regression method for QTL mapping analysis. This simulation study is carried out to consider the effect of the total standard deviation of QTL (SDQ) with different portions of additive/dominance effects in the context of different levels of population size, marker spacing and relative position of QTL from marker bracket on power of detecting QTL, precision of estimated QTL position and additive and dominance effects. The other aims of the study were to design an optimal artificial neural network (ANN) model to predict Haley–Knott (HK) results for more combinations of simulated parameters. SDQ of QTL strongly affected the power of QTL detection, therefore, in every combination of other parameters when SDQ is either 0.5 or 0.8, power was 100%. In all scenarios, the power increased when the ratio of additive and dominant SD of QTL effects was low or high (0.25 or 0.75). Increase of additive effect compared with the dominance effect decreased the precision of QTL location. Precision of estimated additive effect and dominance effect was good but precision of dominance effect was more affected by the considered parameter combinations than the additive effect. This study developed an ANN model with minimum dimensions and minimum errors for prediction of efficiency parameters of HK method given the simulated parameters. Moreover, for the first time, this study shows the use of trained ANN model for prediction of large-scale combinations of simulated parameters.
Introduction
A large number of traits in agricultural species are quantitative, mapping quantitative trait loci (QTL) is a basic operation for positional cloning and for application of marker-assisted selection or marker-assisted introgression in genetic improvement (Soller Citation1994). In selfing species, and outcrossers for which inbred lines are available, QTL mapping through linkage analysis with genetic markers is efficiently carried out in F2 or backcross populations (Soller et al. Citation1976). In line-crossing experiments, a segregating population derived from the crosses of some carefully chosen inbred lines, that is, F2 or backcross populations, is widely used to map QTL (Zhu et al. Citation2007). QTL mapping in experimental crosses provides an excellent alternative. By choosing a suitable model organism we can home a particular aspect of the phenotype of interest (Broman and Sen Citation2009). If a QTL segregates between two strains, backcross and F2 designs reliably detect it (Valdar et al. Citation2006). A powerful approach to the detection of QTL is based on crosses between inbred lines differing significantly for the trait of interest (Baret et al. Citation1998).
The development of genetic maps of markers based on DNA polymorphisms is beginning to provide the experimental geneticists and the plant and animal breeders with powerful tools for the study of quantitative genetic variation. The use of markers to detect individual locus responsible for quantitative genetic variation (QTL) provides much greater power than segregation analysis without marker information (Haley and Knott Citation1992). The use of flanking marker methods has proved to be a powerful tool for the mapping of QTL in the segregating generations derived from crosses between inbred lines (Haley and Knott Citation1992).
The mapping of QTL is the first step towards the identification of genes and causal polymorphisms for traits of importance in agriculture and human medicine (Haley and Knott Citation1992). Identification of QTLs in experimental animals is critical for understanding the biochemical bases of complex traits, and thus for identification of the drug targets (Broman Citation2001).
Haley–Knott (HK) regression method is based on multiple regression which can be applied using any general statistical package, as developed by Haley and Knott (Citation1992). They used the example of mapping in an F2 population and showed that these regression methods produce very similar results to those obtained using maximum likelihood (Haley and Knott Citation1992). The HK regression method continues to be a popular approximation to standard interval mapping (IM) of QTL in experimental crosses (Feenstra et al. 2006). Currently, the HK method is preferred as a fast approximation to the IM method for estimating model parameters (Feenstra et al. 2006) and because of fastness implementation of permutation tests to set chromosome or genome-wide significance thresholds (Churchill and Doerge Citation1994) and a bootstrap procedure to estimate the confidence interval of a QTL location (Visscher et al. 1996).
Empirical power is a critical part of results up from any QTL mapping experiments. The other key factor contributing to the success of a quantitative trait locus mapping experiment is the precision, which sometimes referred to as map resolution. The factors affecting map resolution that can be controlled during experimental design are the number of individuals in the sample and the nature of the genetic cross (Mackay Citation2001).
The artificial neural network (ANN) technique is used to solve a wide variety of problems in science and engineering, particularly for some areas where the mathematical modelling methods fail (Khazaei et al. Citation2008). The most popular ANNs are the multi-layer feed-forward neural networks, where the neurons are arranged into layers of input, hidden and output (Khazaei et al. Citation2008). ANN models are able to learn relationships between dependent and independent variables through the data itself rather than assuming the functional form of the relationships (Mittal and Zhang Citation2000). Several authors have shown greater performances of ANN compared to regression models (Lek et al. Citation1996; Park et al. Citation2005). The most powerful ability of ANN to solve large-scale complex problems is training or education. The best-known and most commonly used training algorithm is back-propagation (Drummond et al. Citation2004; Zhang et al. Citation2002).
In this study, a comprehensive simulation study is carried out in order to determine the effect of marker spacing, population size, standard deviation of QTL (SDQ) effect, ratio of additive vs. dominance effect of QTL and QTL location relative to flanking markers on the efficiency of HK regression method. The other objectives of this research were (1) to build up an ANN model to approximate a non-linear function relating simulated parameters to power of QTL detection, precision of estimated QTL location and its effects, (2) to evaluate the predictive performance of the ANN model and (3) to predict power and precisions of HK for large-scale combination of simulated parameters using designed adequate ANN. The review of literature found no studies of ANN modelling on the effect of different parameters on the precision of estimated QTL position, and effects and power of QTL detection.
Material and methods
Haley and Knott regression method
We assume that y i ∣g i ~N(µgi ,σ2), where y i is the phenotype of individual i and g i is its (unobserved) QTL genotype. The conditional QTL genotype given marker genotype was calculated using p ij =pr(g i ∣M i ), where M i is marker genotype data of individual I. Phenotype of individual i given marker data follows a mixture of normal distribution. E(y i ∣M i ) = S j p ij µ j , where y i is the phenotype of individual i, M i is marker genotype data for individual i, p ij is probability of jth QTL genotype for individual i given its marker data and µ j is the mean of individual's phenotype with jth QTL genotype. Hence, the conditional phenotype average given marker data is linear in the µ j and might be estimated by the linear regression of y i on p ij . Therefore, at each position across genome, the p ij was calculated and then the phenotype was regressed on this matrix.
Data simulation
The F2 population derived from crossing between two inbred lines each with alternate homozygote genotype in marker loci and QTL, with different population size was simulated. A total of 11 markers were used with different equal spaces of 5 and 10 centimorgan (CM). The mapped chromosome length was different corresponding to the marker spaces from 50 and 100, respectively, in the presence of one QTL at the chromosome. The F2 Populations were simulated with parameter combination of population sizes (PS) of 300, 600 and 900; and the SDQ effects of 0.2, 0.5, 0.8, and with different portions of additive to dominance effects (Rad) of 0.25, 0.5 and 0.75. In each parameter combination, QTL located between sixth and seventh markers relatively with 0, 0.25 and 0.5 of the interval separated from the sixth marker. Therefore, 162 scenarios were considered. Each scenario was replicated 100 times. The trait had a normal distribution in all scenarios.
The genotypes of markers and QTL was sampled from binomial distribution using haldane mapping function. Therefore, crossing over between markers and between markers and QTL was simulated using haldan mapping function. Trait value was sampled from normal distribution with corresponding mean according to genotype of QTL and with standard deviation of unexplained variation by QTL equal 1 standard deviation (σ = 1).
QTL mapping analysis
Interval mapping (IM) of QTL was carried out by employing Haley–Knott regression method using R/qtl package. First, a genome scan with a single QTL model for estimating probable QTL position with higher log10 likelihood ratio (LOD) score on the chromosome was carried out. The LOD scores were calculated as LOD = (n/2)log10(RSS0/RSS1), where n is the sample size, RSS0 is the null residual sum of squares and RSS1 is the model residual sum of squares (the model is defined as regression of phenotypes on the conditional QTL genotypes depending on markers’ genotypes). For estimating intercept (mean), additive effect and dominance effect and their corresponding standard errors, a single QTL model using HK method was fitted in the model. The permutation with 1000 replications for finding threshold LOD scores for α = 0.05 was done by using the defined model.
Efficiency of parameters
To evaluate the efficiency of parameters power of QTL detection and Bias, mean square error (MSE) and Precision of estimated QTL location, additive and dominance effects were considered. The power was calculated as the percent of significant QTLs with 5% type I error. For estimated QTL position, additive and dominance effects of QTL, the bias, MSE and precision (P) were calculated as follows:
where, EP is estimated parameter, SP is the simulated parameter in each scenario and n is the number of replicates that are significant for QTL.
Modelling using ANN
The results obtained from 162 scenarios, each with nine components (five independent input or simulated parameters and four dependent output or power of QTL detection and the precision results for QTL position and effects), were used for training and testing the neural networks. To fit a multi-input, multi-output model using ANN a total of 112 and 50 scenarios were randomly chosen and used for the training and the testing, respectively. A multi-layer perceptron ANN model trained by backpropagation algorithms was developed to predict powers and precisions of resulted parameters using HK method based on the five simulated parameters. The best of learning rate, momentum coefficient, the number of hidden layers, the number of hidden neurons and the number of training cycles or epochs were chosen to obtain the optimal ANN. A wide range of network parameters (containing learning rate, the momentum coefficient, the number of hidden layers, the number of hidden neurons and the number of training cycles or epochs) tried to obtain the adequate ANN model. The ANN modelling was carried out using the Neural Works Professional II/plus software Version 5.23 (Neural Ware Inc.).
To determine the adequacy of the neural networks’ model, and to predict outputs for a given data-set, three statistical parameters of root MSE (RMSE), T value and R 2 (EquationEquation 1) were used. The T statistics measures the scattering around fitted line using the ANN. When T is close to 1.0, the fitting is desirable (Khazaei et al. Citation2005). Ideally, the RMSE values should be close to zero, indicating that, on average, there were no significant differences between predicted and measured values.
where, n is the number of data-set, is the average of X over the n samples and X
m and X
p are the actual and by ANN model predicted HK efficiency parameters, respectively. The final network was selected on the basis of the lowest error on the train data and test data. The ANN configuration that minimised the RMSE and optimised the T and R
2 values was selected as the optimum.
After finding the adequate parameters for the best ANN, we repeated the step of randomly chosen test data-set and train data-set, and the best ANN on them was run for 10 times to predict variation of different adequacy parameters of ANN with different shuffled data-set.
By designing optimal ANN model, many scenarios with different simulated parameters were solved by using the ANN model. The different combinations of simulated parameters are presented in . In total, a number of 36,036 different scenarios were obtained by using different combinations of the simulated parameters.
Table 1. The different combinations of simulated parameters which were analysed using optimal ANN model.
Results and discussion
In this study, the effects of PS, MS, SDQ, Rad and rpQ on the efficiency parameters of HK method were considered. Moreover, large-scale simulation study was carried out using the ANN model. This study showed that F2 design with HK method analysis is preferable to detect QTLs with large and medium (SD of QTL equal to 0.8 and 0.5) effects in every combinations of demanding factors such as PS and MS or other considered parameters. The results show that in presence of both additive and dominance effects, result of HK method was affected by the simulated parameters, especially for precision of additive effect; thus, when ratio of additive effect increase it fairly decreases the precision.
Power
In any combination of parameters when SDQ is 0.5 or 0.8 the power was 100%. When SDQ was 0.2 with increase of PS the power was increased and it was decreased with increase in MS. However, the increase was not constant with different PS and MS combinations. shows powers of different combinations of parameters with SDQ of 0.2. QTLs with a low standard deviation of effect can be detected properly by population size of 900; the result is the same as the results of Darvasi et al. (Citation1993). The SDQ of QTL strongly affects the power of QTL detection, because in all combinations of other parameters when SDQ is 0.5 or 0.8 the power was 100%. Power increased when Ratio of additive and dominant SDs of QTL effects was low or high (0.25 or 0.75) in all scenarios.
Table 2. Powers of different combinations of parameters with SDQ of 0.2.
Bias, MSE and precision of estimated QTL position
Generally, by increasing PS and SDQ, precision was improved. However, it was decreased by increase in MS. Bias and MSE had the same trend as precision was affected by mentioned parameters. Precision was affected interactively by different combinations of the parameters. shows the average precision of QTL position in different combinations of PS, SDQ and MS, without respecting Rad and rpQ. As shown in , increase of SDQ in every combination of PS and MS remarkably increased the efficiency of precision. The average precision of QTL position at different levels of SDQ, Rad and rpQ without attention to PS and MS is presented in . PS, SDQ and MS are important in the precision of estimated QTL position. The narrow marker spaces positively affect the precision of QTL mapping even with reduced size of population and effect. This study showed that in medium or high SDQ increasing proportion of dominance effect increased the precision of QTL map location. Increase of additive effect relative to dominance effect decreased the precision of QTL location. Presence of QTL on the marker positively affects the precision.
Table 3. Average precision of QTL position (in CM) in combination of PS, SDQ and MS.
Table 4. Average precision of estimated QTL position (in CM) in the context of SDQ, Rad and rpQ.
Bias, MSE and precision of estimated QTL additive effect
The bias of an effect was negative in all scenarios, and except for one scenario the biases were smaller than 1. Therefore, MSE was very low for estimates of additive effects. In all scenarios precision of additive effect had better precise. The effects of PS, MS and SDQ on the precision of estimated additive effect are presented in . In all scenarios, except for one, additive effect was underestimated compared with the actual amount, but the difference was small. The additive effect estimates were very precise in all combinations of parameters.
Table 5. Effects of PS, MS and SDQ on precision of estimated additive effect.
Bias, MSE and precision of estimated QTL dominance effect
The bias of estimated dominance effect in most scenarios was positive and in all cases was less than 1. Therefore, MSE of the estimates was very small. Precision of the estimates was not improved compared with the precision of estimated additive effect. There were some interactions between different levels of parameters for the precision. and show the effect of PS, SDQ and MS combinations and SDQ, Rad and rpQ combinations on precision of estimated dominance effects. The best precision was obtained for the combination of PS = 900, MS = 5 and SDQ = 0.5. Precision of dominance QTL effect improved with increase of PS, SDQ and decrease of MS, but precision of additive effect compared with the dominance was better in all scenarios. In precision of dominance effect, PS had a stronger effect than the other parameters. Increase of portion of additive effect decreased the precision of estimated dominance effect.
Table 6. Average precision of combined different levels of PS, SDQ and MS on estimated dominance effect.
Table 7. Average precision of estimated dominance effect of different SDQ, Rad and rpQ levels combination.
Efficiency prediction using ANN
The other aim of this study was to design an ANN model with minimum dimensions and minimum errors in training and testing. The best combination of the network parameters was used to predict the power of QTL detection and precision of QTL position and effects for large-scale combinations of simulated parameters. Adequacy parameters of the ANN and their standard deviation of the obtained best ANN model for every HK efficiency parameters are presented in . The ANN model structure had the following layers: the input, first hidden layer, second hidden layer and the output. Based on the RMSE of the training examples, it was clear that the 5-10-6-4 structure had the lowest RMSEs among all the ANN model structures for power of QTL detection and precision of QTL position and effects.
Table 8. Adequacy parameters of the best ANN model and their standard deviations for every HK efficiency parameters.
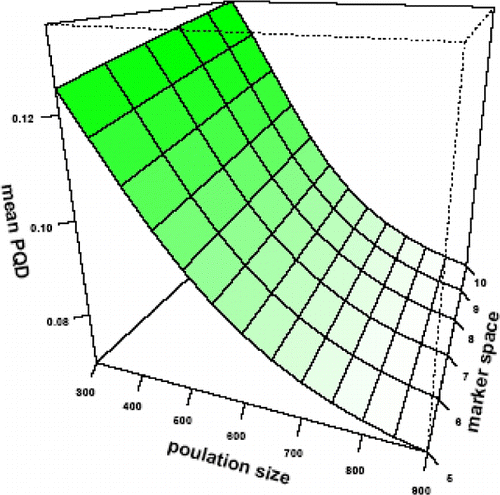
Haley–Knott (HK) results obtained from ANN model for power of detection and precision of QTL parameters were the same as the ones resulted from actual analysis. The effects of population size and marker space on the mean of considered results of HK method are presented in Plots 1–4. At the
Plot 1. Effect of population size and marker space on mean of precision of QTL position (PQP).
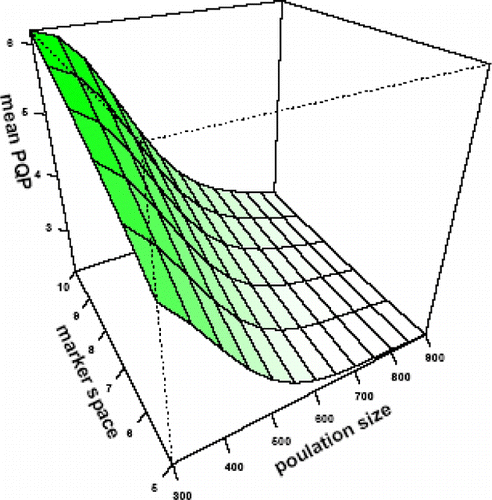
Plot 2. Effect of population size and marker space on power of QTL detection mean.
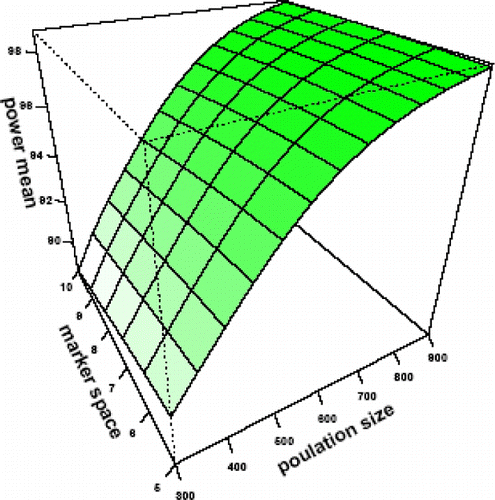
Plot 3. Effect of population size and marker space on mean of precision of QTL additive effect (PQA).
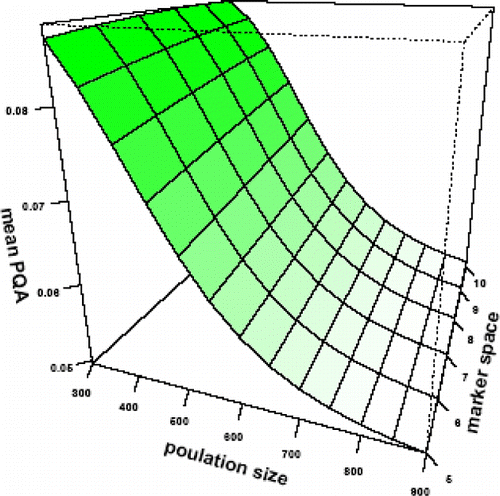
Plot 4. Effect of population size and marker space on mean of precision of QTL dominance effect (PQD).
Plot 5. Effect of SDQ and Rad on mean of power of QTL detection given PS300 MS10.
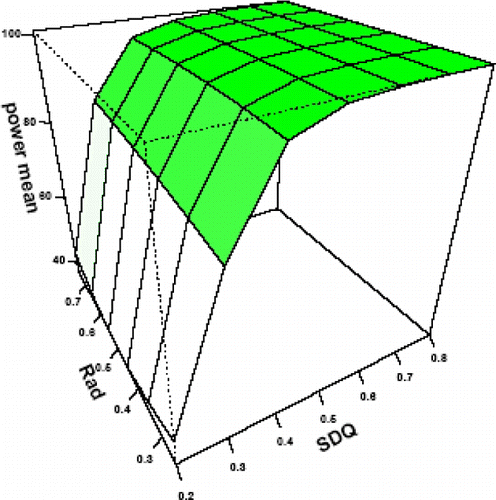
Plot 6. Effect of SDQ and Rad on mean of precision of dominance effect given PS300 MS10.
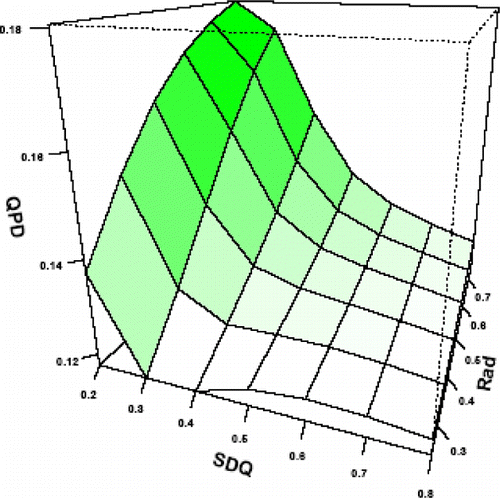
Table 9. Combinations of simulated parameters that obtained higher and lower precisions and power of detection at demanding level of PS (300) and MS (10 cm).
Conclusion
The results of this study show that the ANN modelling could be employed for the simulation study of considered parameters to predict results for more combinations of the parameters.
Acknowledgements
The authors are grateful to Ferdowsi University of Mashhad for supporting the research.
References
- Baret , PV , Knott , SA and Visscher , PM . 1998 . On the use of linear regression and maximum likelihood for QTL mapping in half-sib designs . Genetical Research , 72 : 149 – 158 .
- Broman , KW . 2001 . Review of statistical methods for QTL mapping in experimental cross . Lab Animal , 30 ( 7 ) : 44 – 52 .
- Broman , KW and Sen , S . 2009 . A guide to QTL mapping with R/qtl 2 – 132 . Springer , NY
- Churchill , GA and Doerge , RW . 1994 . Empirical threshold values for quantitative trait mapping . Genetics , 138 : 963 – 971 .
- Darvasi , A , Weinreb , A , Minke , V , Weller , JI and Soller , M . 1993 . Detecting marker-QTL linkage and estimating QTL gene effect and map location using a saturated genetic map . Genetics , 134 : 943 – 951 .
- Drummond , ST , Sudduth , KA , Joshi , A , Birrell , SJ and Kitchen , NR . 2004 . Statistical and neural methods for site-specific yield prediction . Transactions of the ASAE , 46 : 5 – 14 .
- Feenstra , B , Skovgaard , IM and Broman , KW . 2006 . Mapping quantitative trait loci by an extension of the Haley–Knott regression method using estimating equations . Genetics , 173 : 2269 – 2282 .
- Haley , CS and Knott , SA . 1992 . A simple regression method for mapping quantitative trait loci in line crosses using flanking markers . Heredity , 69 : 315 – 324 .
- Khazaei , J , Chegini , GR and Kianmehr , MH . 2005 . Modeling physical damage and percentage of threshed pods of chickpea in a finger type thresher using artificial neural networks. Journal of Lucrari Stiintifice . Seria Agronomie , 48 : 594 – 607 .
- Khazaei , J , Shahbazi , F , Massah , J , Nikravesh , M and Kianmehr , MH . 2008 . Evaluation and modeling of physical and physiological damage to wheat seeds under successive impact loadings: mathematical and neural networks modeling . Crop Science , 48 : 1532 – 1544 .
- Lek , S , Delacoste , M , Baran , P , Dimopoulos , I , Lauga , J and Aulagnier , S . 1996 . Application of neural networks to modeling nonlinear relationships in ecology . Ecological Modelling , 90 : 39 – 52 .
- Mackay , TF . 2001 . The genetic architecture of quantitative traits . Annual Review of Genetics , 35 : 303 – 339 .
- Mittal , GS and Zhang , J . 2000 . Prediction of temperature and moisture content of frankfurters during thermal processing using neural network . Meat Science , 55 : 13 – 24 .
- Park , SJ , Hwang , CS and Vlek , PLG . 2005 . Comparison of adaptive techniques to predict crop yield response under varying soil and land management conditions . Agricultural Systems , 85 : 59 – 81 .
- Soller , M . 1994 . Marker-assisted selection, an overview . Animal Biotechnology , 5 : 193 – 208 .
- Soller , M , Brody , T and Genizi , A . 1976 . On the power of experimental designs for the detection of linkage between marker loci and quantitative loci in crosses between inbred lines . Theoretical and Applied Genetics , 47 : 35 – 39 .
- Valdar , W , Flint , J and Mott , R . 2006 . Simulating the collaborative cross: power of quantitative trait loci detection and mapping resolution in large sets of recombinant inbred strains of mice . Genetics , 172 : 1783 – 1797 .
- Visscher , PM , Thompson , R and Haley , CS . 1996 . Confidence intervals for QTL locations using bootstrapping . Genetics , 143 : 1013 – 1020 .
- Zhang , Q , Yang , SX , Mittal , GS and Yi , S . 2002 . Prediction of performance indices and optimal parameters of rough rice drying using neural networks . Biosystems Engineering , 83 : 281 – 290 .
- Zhu , CS , Huang , J and Zhang , YM . 2007 . Mapping binary trait loci in the F2:3 design . Heredity , 98 : 337 – 344 .