
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Livestock behavior is related to the healthy breeding and welfare level. Therefore, monitoring the behavior of sheep is helpful to predict the health status of sheep and thus safeguard the production performance of sheep. Taking semi-housed sheep as the research object, a behavior identification method for housed sheep based on spatio-temporal information is proposed. Firstly, video acquisition of housed sheep is carried out, and sheep detection and tracking is implemented based on the YOLOv5 coupled with a Deep-SORT algorithm, which detects sheep from the flock and labels their identity information; then, sheep posture estimation is done based on the Alphapose algorithm, which estimates the keypoints in the skeleton; finally, the detected keypoints are inputted into the trained spatio-temporal graph convolutional network model, and the spatio-temporal graph constructed from the keypoints and edge information is used for sheep behavior recognition. In the study, two keypoints selection proposals were made to implement sheep behavior recognition for non-contacted detection of ruminating, lying down and other behaviors. The results show the feasibility of sheep behavior recognition based on spatio-temporal information in semi-housed farming. The method provides a new solution idea for intelligent monitoring of sheep behavior and health assessment.
1. Introduction
In recent years, intensive farming has become the primary form of the animal husbandry industry, and the health and welfare of animals under intensive farming conditions have become a major concern (Man et al. Citation2022). Sheep's economic value is limited, and its farming income is seriously dependent on its farming scale. Therefore, sheep's health is related to production efficiency, and it is the key to determining farming efficiency. Sheep have the external presentation of their physiological and psychological conditions, such as healthy sheep have a strong appetite, compete for food first, have a good physical condition, exercise from time to time, ruminate powerfully and for a long time, etc. whereas sick sheep have a poor appetite, or even abolished, away from the flock, stay in the fence or wall, ruminating powerless or even stopped ruminating. Therefore, sheep's walking, eating and ruminating behaviours can reflect the physical condition of sheep to a certain extent, and the study of sheep behavioural movement is conducive to the prediction of the health status of sheep, which in turn protects the benefits of sheep rearing (Birthe et al. Citation2024; Barbara et al. Citation2023).
The traditional method of manually observing the behaviours of sheep is time-consuming and laborious. With the introduction of intelligent technology in livestock farming, the method of behaviour recognition through acceleration sensors began to be applied to livestock behaviour recognition (Giovanetti et al. Citation2017; Decandia et al., Citation2018; Mansbridge et al. Citation2018; Zhang et al. Citation2020; Ying et al. Citation2020). However, the sensor method requires arranging the equipment or device to the sheep's body, which is easy to cause livestock stress. The livestock's stress response will affect the accuracy of the returned data. It will also lead to a decrease in the level of animal welfare. Meanwhile, the sensors will only record the data to the individual, which will pose a challenge to the practice of large-scale livestock farming.
With the development of computer vision technology, scholars have begun to focus on the use of video cameras to capture animal movement video and then based on digital image processing technology and machine learning technology for animal behaviour recognition. Compared with the ‘wearable’ sensor method, the method based on vision technology can realize contactless behaviour detection, which is easier and more stable. Zhu et al. (Citation2017) proposed using machine vision to recognize the presence of an individual pig. Meunier et al. (Citation2018) propose a generalizable methodology based on a static image analysis technique to quickly gauge the potential extractability of behavioural patterns from positioning data. Nasirahmadi et al. (Citation2019) applied an image processing algorithm with a Support Vector Machine (SVM) classifier for lateral and sternal lying posture detection in grouped pigs. These methods are effective, but there are some challenges because they need manual extraction of features during the recognition process.
Deep learning methods have been developing rapidly in recent years. Deep learning technology can learn the potential laws of sample data, which can be used for ‘feature learning’ or ‘representation learning’ of samples, solving many complex pattern recognition problems. Scholars have also carried out a lot of research based on the deep learning method of livestock behaviour recognition. Zheng et al. (Citation2018) traduced a detector, Faster R-CNN, on a deep learning framework to identify five postures (standing, sitting, sternal recumbency, ventral recumbency and lateral recumbency) and obtain sows accurate locations in loose pens. Nasirahmadi et al. (Citation2019) applied Faster R-CNN, SSD and R-FCN to detect the lying and standing postures of pigs. YOLO (You Only Look One) network is a convolutional neural network (CNN)-based object detection model. Compared to other region-based CNN detection models, YOLO framed object detection as a model regression problem to spatially separated bounding boxes and associated class probabilities. The YOLO algorithm has better real-time performance, so it has many applications in real-time behaviour detection. Recently, tracking-by-detection has become the leading paradigm in multiple-object tracking. Deep-SORT, a deep simple online real-time tracking algorithm, builds upon the SORT framework by incorporating a pre-trained association metric (Wojke et al. Citation2017). This algorithm combines visual and distance-based tracking techniques to accurately track objects. By integrating Yolo with Deep-SORT, a powerful tracking-by-detection system is created, capable of effectively tracking multiple objects in real time. Bhujel et al. (Citation2021), based on the Yolov4 coupled with a Deep-SORT tracing algorithm, detect and track the pig activities. After that, Tu et al. (2022) proposed an improved DeepSORT algorithm for behaviour tracking based on YoloV5s. In summary, deep learning not only facilitates animal behaviour recognition but also reduces the influence of subjective factors on the detection results and improves the accuracy and robustness.
The introduction of deep learning into animal behaviour recognition eliminates the shortcomings of manual selection of features, promotes the improvement of animal behaviour recognition accuracy reduces the influence of subjective factors on the detection results, and the method is robust. Deep learning methods have achieved significant results in the field of animal behaviour recognition, but the relevant research is mainly focused on pigs, cows and other livestock whose bodies are similar to the ‘rigid body’. Although sheep belong to the large livestock with pigs and cows, their bodies are flexible; in addition, sheep belong to the herd animals, and often appear in small groups crowded together, the above characteristics pose a challenge for sheep behaviour recognition. Cheng et al. (Citation2022) proposed a deep learning model based on the YoloV5 network for sheep behaviour (standing, lying, drinking and feeding) recognition. But each target experiment pen only has one sheep who was late pregnant ewes. Separate space is an effective method to solve the problem of behavioural identification of group-living animals, but it is not widely applicable to the practical application in commercial breeding environments. From the related research, existing studies judge the behaviour of the livestock only based on the posture of the pig in a still image frame, without considering the motion information of the behaviour.
To dissolve the problem of dynamic behaviour analysis of animal targets, scholars have proposed relevant methods to identify animal behaviour based on spatial and temporal features. Kashiha et al. (Citation2014) automatically quantified locomotion involved localizing pigs through background subtraction and tracking them over a set period. Zhang et al. (Citation2020) achieved pig behaviour recognition by extracting the temporal and spatial behavioural characteristics from videos. The experimental results showed the method was able to recognize pig feeding, lying, walking, scratching and mounting behaviours with a higher average accuracy. Yang et al. (Citation2021) proposed a pig mounting behaviour recognition algorithm by exploiting video spatial–temporal features. The above studies combined the information of temporal and spatial features to make livestock behaviour recognition and proved the effectiveness of the methods.
According to the above information, monitoring the behaviour of semi-housed sheep is valuable. Deep learning has the ability of ‘feature learning’. Spatio-temporal information can better express the process of behaviour. Therefore, this study made a performance using deep learning algrithms to recognize the behaviours, including ruminating, lying and others, of semi-housed sheep based on spatio-temporal information.
2. Material and methods
2.1. Experiments and data acquistion
The experiments were conducted on a single sheepfold at Smart Breeding Base, Hohhot, Inner Mongolia, China. The pen had a length of 4.5 m and a width of 5 m. The sheep graze during the day and rest in the sheepfold at night. Considering grazing behaviours are difficult to detect, rumination is an important behaviour which can reflect sheep’s health status and physiological stages. So, the experiment was done on the night at which time the sheep was resting in the pen.
In the experiment, the pen, which have 15 sheep, was chosen and it was equipped with a camera (HIKVISION) installed on the walls and having a focal length of 8 mm. The camera is set at the height and angle of 1.2 m and 50°, respectively, as shown in .
Figure 1. Video data collection.

2.2 Behaviour recognition content
In the semi-housed farming model, the main behaviours of sheep after returning to the pen at the end of the grazing period are ruminating and lying, with occasional small-scale movements such as changing posture, walking or defecation. Considering that rumination and lying are the main behaviours of sheep during the housing period and they also are the important external presentations of the health status of sheep, the behaviour of sheep in this study was classified into three types: rumination, lying and others (other behaviours contain changing posture, walking, rubbing against walls, defecating, etc.). The basic behaviours of sheep in a house are outlined in .
Table 1. The basic behaviours of sheep in a house.
2.3. Data processing environment
The software is developed on Visual Studio 2015 Community, the development language is Python. The model training environment and parameter configuration are shown in .
Table 2. The model training environment and parameter configuration.
3. Development of behavioural recognition of housed sheep based on spatio-temporal information
Skeleton keypoints can express the posture of the sheep, and the keypoint coordinates of consecutive frames can describe the behaviour from the temporal and spatial dimensions. Therefore, this study designed the behaviour recognition process, as shown in .
Figure 2. Flow chart of sheep behaviour identification.
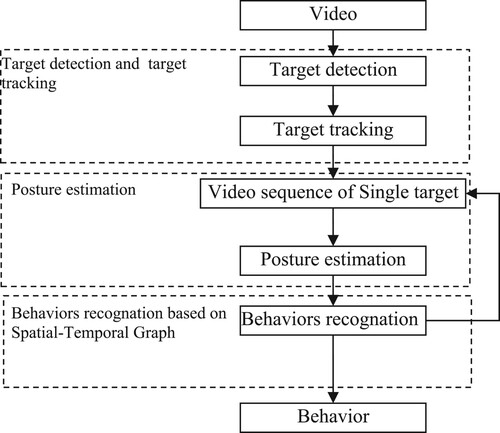
Individual sheep were first detected from the flock of video and labelled with their identitying information. The individual information of continuous frames has formed a track of one individual sheep. Then, the skeleton keypoints were extracted for each frame to express the posture of a sheep. Finally, the spatial–temporal information of the skeleton keypoints in fixed duration was inputted in the spatial–temporal graph convolutional network to recognize the behaviours.
3.1. Multi-target detection and tracking
In multi-target tracking, detection and tracking are two complementary problems. The Yolo series of models have achieved remarkable results in the field of object detection. Compared with the other versions, YoloV5s is a lightweight model, with the advantages of fast speed and high precision (Hu et al. Citation2022), which was selected as the basic model for sheep detection.
Based on YoloV5s detection and recognition of sheep, the multi-target tracking method is further studied. DeepSort is an online target-tracking algorithm, which mainly includes track state estimation, association and cascade matching (Wojke et al. Citation2017). It adds the cascade matching strategy based on the Sort algorithm to avoid misprediction caused by identity transformation. In this paper, the lightweight YoloV5 detector is combined with the multi-target tracking algorithm DeepSort to ensure the speed and accuracy of sheep while reducing the calculation cost.
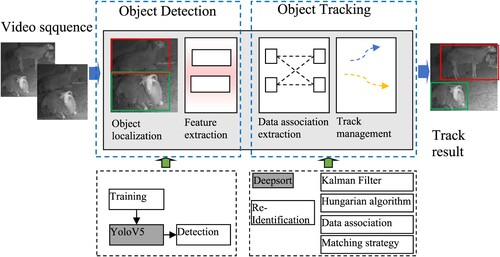
The flowchart of multi-target detection and tracking is shown in . After the input video image, the YoloV5 model obtains the target location detection box, and then through the re-identification extracts the test box in the depth of the target appearance characteristics, and then through the distance measurement between two frames before and after the target similarity calculation, the Kalman algorithm for trajectory prediction, the Hungarian algorithm matches the tracks between two frames of the target and finally assigns different tracking ids to each target through data association.
Figure 3. Flowchart of multi-target detection and tracking algorithm.
3.2. Pose estimation
Sheep visual behaviour recognition relies on the distinct information conveyed by sheep in each frame of an image. By considering both the spatial characteristics of the behaviour and the temporal characteristics observed over time, accurate behaviour judgments can be made. Consequently, the initial step involves performing pose estimation for sheep behaviour in individual frame images.
Pose estimation involves localizing sparse keypoints within the target skeleton in a single-frame image (Zhang et al. Citation2022). The AlphaPose algorithm, developed by Cewu Lu from Shanghai Jiaotong University, is a well-established top-down human pose estimation algorithm. It detects individual targets in the image using a target detector and subsequently estimating keypoints for each target (Fang et al. Citation2016). In this study, the AlphaPose pose estimation method is utilized for sheep behavioural pose estimation.
3.2.1. Sheep keypoint selection
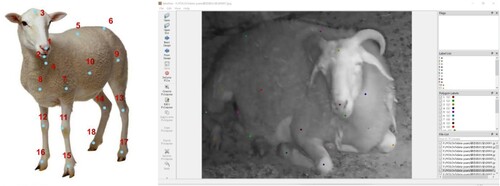
Following the keypoint selection strategy for the human body keypoints and considering the spatial characteristics of sheep behaviour features, 18 key points on the sheep are selected for sheep pose estimation, including the nose, lower lip, head, neck, back, hip joint, elbow joints (4 locations), knee joints (4 locations) and toe joints (4 locations). The schematic diagram and actual labelling of sheep keypoints are shown in .
Figure 4. Selection of the sheep’s keypoints. (a) Schematic of the sheep’s keypoints Selection (b) Example of the sheep’s keypoints labelling 1. Nose; 2. Lower lip; 3. Head; 4. Neck; 5. Back; 6. Rump; 7. The elbow of the left front leg; 8. The elbow of the right front leg; 9. The elbow of the left back leg; 10. The elbow of the right back leg; 11. The knee joint of the left front leg; 12. The knee joint of the right front leg; 13. The knee joint of the left back leg; 14. The knee joint of the right back leg; 15. The toe of the left front leg; 16. The toe of the right front leg; 17. The toe of the left back leg; 18. The toe of the right back leg.
3.2.2. Dataset for sheep’s keypoints
In this study, the individual sheep in single-frame images were first cropped. Images with complete body views, diverse angles, different sheep and fewer sheltered parts were selected as the calibration dataset. The Labelme software was used to annotate the keypoints. Finally, a total of 477 images were selected from the original dataset, which included different sheep with various postures and exhibiting various types of behaviours. The details of the data are shown in .
Table 3. The basic behaviours of sheep in a house.
The training and testing sets were randomly selected from various types of data in a ratio of 9:1. They were used for training and testing the pose estimation model.
3.2.3. Sheep’s keypoint extraction based on AlphaPose
AlphaPose, an open-source keypoint detection algorithm, utilizes a top-down approach for pose estimation. It is an easy application in real-life situations. AlphaPose framework consists of three modules – (i) Spatial Symmetric Transformer Network (SSTN) (ii) Parametric Pose Non-Max Suppression (NMP) and (iii) Pose Guided Proposals Generator (PGPG). The SSTN is used to extract high-quality single-person area in the image from an inaccurate bounding box which can come from a sub-optimal object detector. The Parametric Pose NMS eliminates redundant poses using a novel pose distance metric. The PGPG is used to augment the training data to generate (sub-optimal) bounding boxes based on the given pose which are used to train the SSTN. The flow of the Alphapose algorithm is shown in .
Figure 5. The flow of the Alphapose algorithm.
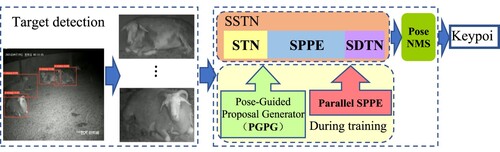
SSTN consists of a spatial transformer network (STN) and a spatial detransformer network (SDTN) which are attached before and after the single-person pose estimator (SPPE). The STN receives sheep proposals and the SDTN generates pose proposals. The Parallel SPPE acts as an extra regularizer during the training phase. Finally, the parametric Pose NMS is carried out to eliminate redundant pose estimations. The SSTN + SPPE module is trained by images generated by pose-guided proposal generator (PGPG).
To further help STN extract good sheep-dominant regions, a parallel SPPE branch is added in the training phase. This branch shares the same STN with the original SPPE, but the SDTN is omitted. The output of this SPPE branch is directly compared to labels of centre-located ground truth poses. If the extracted pose of the STN is not centre-located, the parallel branch will back-propagate large errors. The way helps the STN to focus on the correct area and extract high-quality sheep-dominant regions. The illustration of SSTN and parallel SEEP model training strategy is shown in .
Figure 6. The illustration of SSTN and parallel SEEP model training strategy.
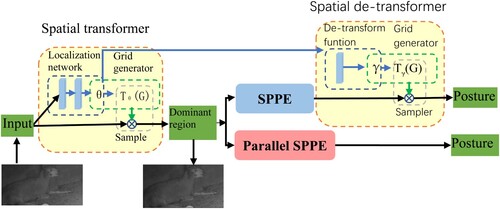
The SDTN takes a parameter θ, generated by the localization net and computes the γfor de-transformation. It follows the grid generator and sampler to extract a sheep-dominant region. For the parallel SPPE branch, a centre-located pose label is specified. It freezes the weights of all layers of the parallel SPPE to encourage the STN to extract a dominant single sheep proposal.
3.3. Behaviour recognition
The dynamics of sheep body skeletons convey significant information for sheep action recognition. The Spatial–Temporal Graph Convolutional Networks (ST-GCN) model has been exposed to study spatial and temporal dependencies effectively from skeleton data. So, the ST-GCN was applied to create a standard depiction of skeleton sequences for sheep’s behaviour recognition.
3.3.1. Dataset creation
The YoloV5 + DeepSORT algorithm had been used to detect and track multi-sheep. First, we located the target information of each sheep by the ID number, as well as the corresponding video frame. Next, the video segment that captures the sheep behaviour is cropped, focusing only on the region within the target frame of each sheep. The regions outside the target anchor box are processed by setting their pixel values to zero. The result is illustrated in .
Figure 7. The result of zeroing of pixel values of non-object area.

The initial flock video was edited in 6s duration to produce a dataset of individual sheep behavioural video segments, and behavioural labels were prepared for each segment: rumination, lying and other.
After preprocessing the sheep behaviour video data, the pose estimation algorithm, in conjunction with the trained pose estimation model, was utilized to extract the keypoints information of the sheep in each frame of the behaviour video segment. The keypoints data of each frame were merged and saved in the format of the kinetics-skeleton dataset. In total, 1703 samples of sheep behaviour data were obtained, comprising 788 samples of rumination, 650 samples of lying and 265 samples of other behaviours. To train and evaluate the model, the dataset was divided into a training set and a test set, following the ratio 8:2.
3.3.2. Creation model of the sheep’s ST-GCN
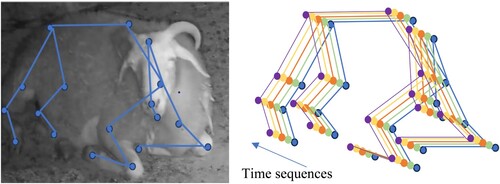
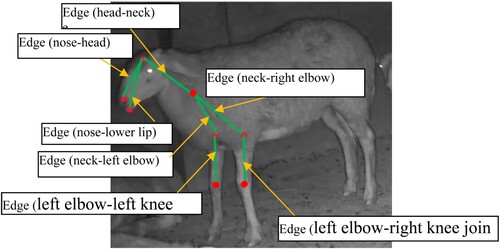
ST-GCN is the first to apply graph convolution network (GCN) to skeleton-based motion recognition tasks. ST-GCN constructs a skeleton spatial-temporal graph of the skeleton keypoints sequence obtained by Alphapose and a skeleton spatiotemporal graph G = (V, E) is obtained, as shown in .
Figure 8. Alphapose model and sequence of skeleton keypoints.
where where
represents the total number of frames of the video and
represents the number of keypoints of bones in the sheep body.
is composed of skeleton edges in a skeleton space–time diagram, which includes two parts. The first part is the skeleton edges formed by two adjacent skeleton points in space, which is
, where
is a group of naturally connected sheep joints. The second part is that the skeleton edge formed by two identical skeleton points in time is composed of two subsets, which are
.
As shown in , ST-GCN processes spatial-temporal skeleton graph data through multiple spatial temporal convolution modules. The basic module of spatial-temporal convolution mainly consists of a temporal convolution layer and a spatial convolution layer. The network structure is composed of nine layers of basic modules with a spatial-temporal convolution kernel size of . Each ST-GCN unit uses feature residual fusion mode to achieve cross-region feature fusion to increase the learning ability of the model. Each ST-GCN unit adopts a dropout probability of 0.5 to reduce the risk of model overfitting. Finally, the generated feature vector is fed to the SoftMax classifier to output motion classification.
Figure 9. ST-GCN network structure.
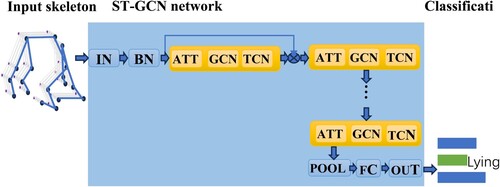
The ST-GCN-based sheep behaviour recognition method can be divided into two main parts: the spatial convolution layer and the temporal convolution layer. In the spatial convolution layer, the input is the spatio-temporal information of the sheep skeleton. This input (IN) is first normalized using batch normalization (BN) and then fed into the ST-GCN. ST-GCN consists of three modules. The first module is the attention (ATT) model, which is used to extract the feature information of the keypoints on time sequences. The second module is the 3D Graph Convolutional Neural Network (GCN), which is responsible for extracting feature information from the spatial graph convolution. In the time sequences analysis part, the keypoints time sequences obtained from the spatial graph convolution are used to train the Temporal Convolutional Network (TCN) classification model. This model analyzes the temporal patterns in the data to classify sheep behaviour. To extract high-level semantic features from the graph structure inputs, multiple ST-GCNs are stacked together. This allows for the continuous extraction of features. Finally, the prediction results are obtained by passing the processed features through the Full Convolutional Layer (FC) classification process. The Pooling of the Overall Level (POOL) is used to further refine the features before the final classification.
4. Model training and validation
4.1. Training and validation of the detection and tracking model
The Labelling is utilized to annotate objects in video frames by creating bounding boxes covered by the head, body and limbs. A total of 5215 images were annotated. Additionally, to enhance the diversity of the training dataset and improve the robustness of the final detection model, an offline data enhancement method was employed. This method involves applying operations such as adding Gaussian noise and greyscale noise to the data, effectively expanding the dataset. As a result, a dataset containing 20,860 images was obtained after data enhancement. To ensure unbiased evaluation, the dataset was randomly divided into a training set and a validation set, with a ratio of 9:1.
A total of 6645 images of sheep were used to train the DeepSORT network. Detections have been thresholded at a confidence score of 0.45, the intersection over union (IoU) of 0.35 and the iterations of 300.
The hyperparameters of YoloV5 models were set as shown: The learning rate was set to 0.01. The batch size of each training was set as eight times to improve the training speed. The resolution size of the input picture was set at 320 × 320 pixels according to the common size, and the number of iterations was set to 2000.
The model was evaluated by location loss (box_loss), confidence loss (obj_loss), precision, recall and mean average precision (mAP). Box_loss refers to the error between predicted and real bounding boxes. Obj_loss refers to the confidence of the detection network. Precision refers to the number of real positive samples in positive sample results detected based on the predicted results. Recall refers to the number of real positive samples in the test set based on real results. mAP is the average identification accuracy of all classes. [email protected] indicates the mAP of positive samples detected when the threshold of IOU is 0.5. The expressions for precision and recall are shown below.
where
is the number of positive samples detected as positive samples,
is the number of negative samples detected as positive samples, and
is the number of positive samples detected as negative samples.
The training results of the model are shown in and .
Figure 10. Graph of the change in the curve of the training indicators.
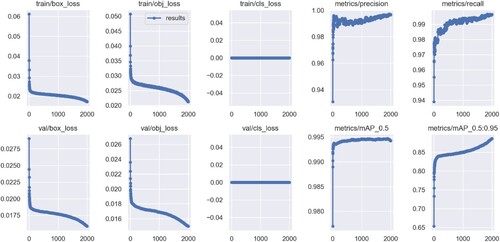
Table 4. The test results of Yolo V5 for multi-target tracking.
The results indicate that the detection and tracking model performs well on both the training and test sets. It exhibits low localization loss and confidence loss, ensuring accurate identification and tracking of sheep. The accuracy and recall, measured by mAP_0.5, surpass 99% on the test set, further highlighting the model's effectiveness. Additionally, the mAP_0.5:0.95 exceeds 88%. These findings demonstrate that the YOLOv5 model is highly proficient in detecting and tracking sheep.
4.2. Training and validation of the posture estimation model
The detection results of YoloV5 + deepsort were used as input to Alphapose. The training input image size is 256 × 192, the batch size is 32, the learning rate is set to 0.1 and the number of training iteration epoches is 500. During the training process, online data augmentation techniques, such as flipping, provided by Alphapose, were applied to enhance the training data.
After the completion of the 500 iterations, the pose estimation network model was evaluated on both the training and test sets. The final accuracy of the keypoint detection was obtained, and the results are 90.2% and 89.5% on training and test sets respectively. The average accuracy of each keypoint is shown in .
Table 5. The average accuracy of Alphapose for different key points.
The results show that the posture estimation algorithm has a high performance of key points for the lower lip, nose and head, which proves that the recognition of rumination behaviour can be done by chewing. The algorithm's accuracy of keypoints for the neck, back and limb parts is relatively low.
The results indicate that the posture estimation algorithm exhibits a high level of accuracy in detecting keypoints such as the lower lip, nose and head. This finding suggests that the algorithm is capable of recognizing rumination behaviour by detecting the chewing motion of the mouth. However, the accuracy of keypoints for other body parts such as the neck, back and limbs is relatively lower.
4.3. Training and validation of the behaviour recognition model
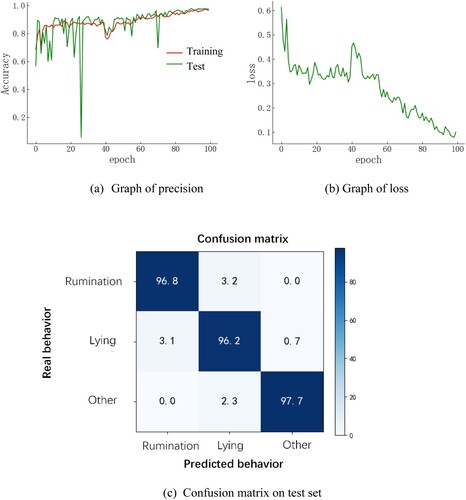
A spatio-temporal graph convolutional network model was trained using the behaviour dataset, as described in section 3.3.1. The model was trained with a learning rate of 0.1, three classifications and 100 iterations (epochs). After 100 iterations, the model showed gradual convergence, with a significant decrease in the loss value. The average accuracy on the test set reached an impressive 99.9%. The training graphs and confusion matrix of the spatio-temporal graph convolutional network on the test set is depicted in .
Figure 11. The result of the test. (a) Graph of precision; (b) Graph of loss; (c) Confusion matrix on test set.
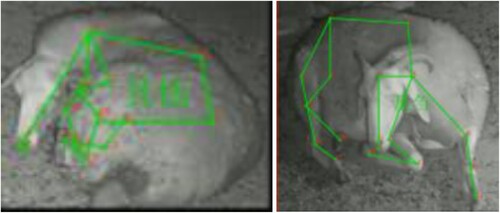
The results of the recognition are shown in .
Figure 12. Sheep’s behaviour recognition results. (a) Rumination; (b) Lying; (c) Other.

From the classification results, it can be seen that the model can better classify the behaviour of the sheep. It reflects the effectiveness and feasibility of the spatio-temporal graph convolutional network-based behaviour recognition model for lying and rumination of housed sheep.
5. Improvement method
To enhance the system's recognition method, an analysis was conducted on the unsuccessful behavioural data (refer to ). It was observed that sheep tend to engage in ruminating and lying behaviours during the night. These behaviours are characterized by specific postures, such as limbs curling up and the hind limbs are often covered by the body. Additionally, the sheep's body is soft and can assume various postures, often curling up, which presents a challenge in effectively detecting keypoints, such as neck and hind limbs.
Figure 13. Examples of recognition errors.
5.1. Improved selection of keypoints
Analyzing the recognition results, it was found that the body size and community activity rules of the sheep determined that the forebody of the sheep had a small chance of being covered. And from the perspective of behaviour recognition, the forebody can express information about sheep's behavioural characteristics. Therefore, an optimization method was proposed, i.e. the rumination is expressed by the nose and the lower lip keypoints is the elbow and knee joints of the forelimbs were chosen to express the limb features and the neck feature point was used to link the head behaviour and the limb behaviour. The optimized keypoints include the nose, lower lip, head, neck, left and right elbow joints and knee joints of the forelimbs. The schematic diagram of the improved keypoints is shown in .
Figure 14. Improved selection of the sheep’s keypoints. 1. Nose; 2. Lower lip; 3. head; 4. neck; 5. The elbow of the left front leg; 6. The elbow of the right front leg; 7. The knee joint of the left front leg; 8. The knee joint of the right front leg.

The spatio-temporal map of the sheep skeleton constructed under the improved keypoint selection strategy is shown in .
Figure 15. Improved spatial temporal graph of sheep skeldom.
5.2. Training and validation of the improved model
With the same system configuration, the posture estimation network model is finally obtained after 500 iterations. The result is shown in .
Table 6. The test results of Alphapose for posture estimation.
The average accuracy of the keypoints is shown in .
Table 7. The average accuracy of Alphapose for different key points.
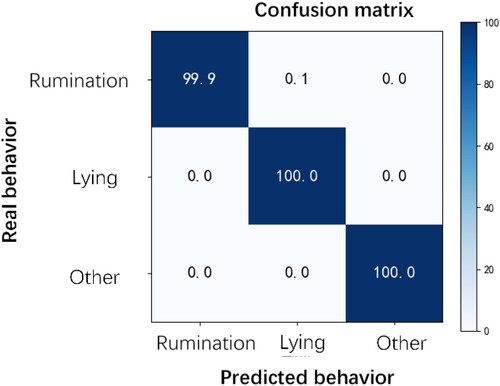
The confusion matrix of the spatio-temporal graph convolutional network on the test set is shown in .
Figure 16. Confusion matrix on the test set.
The results of behaviour recognition based on the spatio-temporal graph convolutional network model are shown in .
Figure 17. Behaviour recognition results of the improved model. (a) Rumination; (b) Lying; (c) Other.

It can be seen that the improved model of sheep behaviour recognition is perfect.
4. Conclusions
In this paper, the behaviour recognition method of housed sheep based on spatio-temporal information is studied by constructing a behavioural keypoint detection model. YOLOv5 + Deepsort was chosen to implement sheep detection and tracking, Alphapose was used for sheep posture estimation and ST-GCN was used to extract the spatial characteristics and time sequences features of behaviour to realize the recognition of lying, ruminating and other behaviours. The results show that after the improved the keypoints selection strategy, the average accuracy of the sheep posture estimation model on the test set reaches 95.6%; the average accuracy of the behaviour recognition model on the test set reaches 99.9%, which proves the method is feasibility and validity for the behaviour recognition of housed sheep. This study suggests that the behaviour of livestock should be comprehensively considered in identification strategies.
Recently, YOLOv8 series models also take into account both model accuracy and detection speed (Zheng et al. Citation2018; Wei et al. Citation2023). So, we added comparative experiments. The results in . show that the YOLOv5 and YOLOv8n series can do a great job in object detection.
Table 8. The test results of Yolo V8n for multi-target tracking.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Barbara RR, Nguyen T, Sujani S, White RR. 2023. Open-source wearable sensors for behavioral analysis of sheep undergoing heat stress. Journal title. 13:9281.
- Bhujel A, Arulmozhi E, Moon B, Kim, HT. 2021. Deep-learning-based automatic monitoring of pigs’ physico-temporal activities at different greenhouse gas concentrations. Animals (Basel). 11(11):3089.
- Birthe K, Jürgen H, Alexander R, Marcus C, Martin H. 2024. Comparative study of feeding and rumination behaviour of goats and sheep fed mixed grass hay of different chop length. Journal of Animal Physiology and Animal Nutrition. 1–11.
- Cheng M, Yuan H, Wang Q, Cai Z, Liu Y, Zhang Y. 2022. Application of deep learning in sheep behaviors recognition and influence analysis of training data characteristics on the recognition effect. Comput Electron Agric. 198:107010. doi:10.1016/j.compag.2022.107010.
- Decandia M, Giovanetti V, Molle G, Acciaro M, Mameli M, Cabiddu A, Cossu R, Serra MG, Manca C, Rassu SPG, et al. 2018. The effect of different time epoch settings on the classification of sheep behaviour using tri-axial accelerometry. Comput Electron Agric. 154:112–119. doi:10.1016/j.compag.2018.09.002.
- Fang H, Xie S, Tai Y, Cewu L. 2016. Rmpe: regional multi-person pose estimation. IEEE. doi:10.48550/arXiv:1612.00137v1.
- Giovanetti V, Decandia M, Molle G, Acciaro M, Mameli M, Cabiddu A, Cossu R, Serra MG, Manca C, Rassu SPG, et al. 2017. Automatic classification system for grazing, ruminating and resting behaviour of dairy sheep using a tri-axial accelerometer. Livest Sci. 196:42–48. doi:10.1016/j.livsci.2016.12.011.
- Hu Y, Zhan J, Zhou G, Chen A, Cai W, Guo K, Hu Y, Li L. 2022. Fast forest fire smoke detection using MVMNet. Knowl Based Syst. 241:108219. doi:10.1016/j.knosys.2022.108219.
- Kashiha MA, Bahr C, Ott S, Moons CPH, Niewold TA, Tuyttens F, Berckmans D. 2014. Automatic monitoring of pig locomotion using image analysis. Livest Sci. 159:141–148. doi:10.1016/j.livsci.2013.11.007.
- Man C, Hongbo Y, Qifan W, Zhenjiang C, Yueqin L, Yingjie Z. 2022. Application of deep learning in sheep behaviours recognition and influence analysis of training data characteristics on the recognition effect. Computers and Electronics in Agriculture. 198:107010.
- Mansbridge N, Mitsch J, Bollard N, Ellis K, Miguel-Pacheco G, Dottorini T, Kaler J. 2018. Feature selection and comparison of machine learning algorithms in classification of grazing and rumination behaviour in sheep. Sensors. 18:3532. doi:10.3390/s18103532.
- Meunier B, Pradel P, Sloth KH, Cirié C, Delval E, Mialon MM, Veissier I. 2018. Image analysis to refine measurements of dairy cow behaviour from a real-time location system. Biosystems Eng. 173:32–44. doi:10.1016/j.biosystemseng.2017.08.019.
- Nasirahmadi A, Sturm B, Edwards S, Jeppsson K-H, Olsson A-C, Müller S, Hensel O. 2019. Deep learning and machine vision approaches for posture detection of individual pigs. Sensors. 19:3738. doi:10.3390/s19173738.
- Wei JC, Tang X, Liu JX, Zhang Z. 2023. Detection of pig movement and aggression using deep learning approaches. Animals (Basel). 13(19):3074.
- Wojke N, Bewley A, Paulus D. 2017. Simple online and real-time tracking with a deep association metric. Proceedings of the IEEE International Conference on Image Processing (ICIP). p. 3645–3649.
- Yang Q, Xiao D, Cai J. 2021. Pig mounting behaviour recognition based on video spatial–temporal features. Biosystems Eng. 206:55–66. doi:10.1016/j.biosystemseng.2021.03.011.
- Ying Y., Zeng S., Zhao A., Yan. 2020. Recognition method for prenatal behavior of ewes based on the acquisition nodes of the collar. Transactions of the Chinese Society of Agricultural Engineering. 36(21):210–219.
- Zhang K, Li D, Huang J, Chen Y. 2020. Automated video behavior recognition of pigs using two-stream convolutional networks. Sensors. 20(4):1085. doi:10.3390/s20041085.
- Zhang Y, Wen GZ, Mi S, Zhang M, Geng X. 2022. Overview on 2D human pose estimation based on deep learning. J Softw. 33(11):4173–4191.
- Zheng C, Zhu X, Yang X, Wang L, Tu S, Xue Y. 2018. Automatic recognition of lactating sow postures from depth images by deep learning detector. Comput Electron Agric. 147:51–63. doi:10.1016/j.compag.2018.01.023.
- Zhu W, Guo Y, Jiao P, Ma C-h, Chen C. 2017. Recognition and drinking behaviour analysis of individual pigs based on machine vision. Livest Sci. 205:129–136. doi:10.1016/j.livsci.2017.09.003.