
Abstract
Hyperspectral image provides abundant spectral information for remote discrimination of subtle differences in ground covers. However, the increasing spectral dimensions, as well as the information redundancy, make the analysis and interpretation of hyperspectral images a challenge. Feature extraction is a very important step for hyperspectral image processing. Feature extraction methods aim at reducing the dimension of data, while preserving as much information as possible. Particularly, nonlinear feature extraction methods (e.g. kernel minimum noise fraction (KMNF) transformation) have been reported to benefit many applications of hyperspectral remote sensing, due to their good preservation of high-order structures of the original data. However, conventional KMNF or its extensions have some limitations on noise fraction estimation during the feature extraction, and this leads to poor performances for post-applications. This paper proposes a novel nonlinear feature extraction method for hyperspectral images. Instead of estimating noise fraction by the nearest neighborhood information (within a sliding window), the proposed method explores the use of image segmentation. The approach benefits both noise fraction estimation and information preservation, and enables a significant improvement for classification. Experimental results on two real hyperspectral images demonstrate the efficiency of the proposed method. Compared to conventional KMNF, the improvements of the method on two hyperspectral image classification are 8 and 11%. This nonlinear feature extraction method can be also applied to other disciplines where high-dimensional data analysis is required.
1. Introduction
Hyperspectral images can synchronously obtain spatial and spectral information of earth targets and have extremely high spectral resolution which makes it possible to precisely identify the target classes (Plaza et al. Citation2009; Li et al. Citation2012). However, hyperspectral data have relatively more bands. The number of bands can reach up to hundreds, which produce challenges for analysis and application of hyperspectral data. On the one hand, the large data size and high calculation complexity of hyperspectral images generate high requirements for hardware equipment. On the other hand, the high-dimensional features of hyperspectral data are unconducive to the precise classification of hyperspectral images. The higher the number of hyperspectral data bands is, the more the samples are required to achieve the desired classification accuracy. Yet, it is difficult to obtain labeled samples, which usually demands significant human and material resources (Hughes Citation1968).
In this study, dimensionality reduction is considered to be an effective method to solve these problems (Jia, Kuo and Crawford Citation2013; Benediktsson, Palmason and Sveinsson Citation2005). Hyperspectral dimensionality reduction aims to simplify and optimize image features. It could effectively express high-dimensional data information, greatly reduce data size, and enable rapid and precise extraction of target information. Therefore, dimensionality reduction is important to the effective use of hyperspectral images. The common methods of dimensionality reduction are divided into two major categories: band selection and feature extraction. According to relevant evaluation indicators, band selection chooses band subsets from original data. The criteria of band selection are mainly based on information theory and spectral variance, such as methods based on information entropy proposed by Bajcsy and Groves (Citation2004), mutual information to evaluate the information content of different bands proposed by Guo et al. (Citation2006), and information covariance proposed by Ball et al. (Citation2007). Feature extraction refers to the transformation of original data to the optimized subspace using mathematical transformation and thereby generating novel spectral data features. Traditional feature extractions include the linear and nonlinear feature extraction methods. Principal component analysis (PCA) (Roger Citation1996) and minimum noise fraction (MNF) (Green et al. Citation1988) are the two commonly used linear dimensionality reduction methods. PCA uses information content as evaluation index of feature extraction and sorts the components by descending order of image information content after transformation. However, some studies found that, when noise distribution is uneven in each band, PCA transformation could not guarantee that the image components were sorted in accordance with quality (Green et al. Citation1988). Noise fraction (NF) is used as evaluation index of MNF. After MNF transformation, the components are sorted in accordance with image quality and are not affected by the noise distribution (Lee, Woodyatt and Berman Citation1990). However, MNF is unable to achieve reliable performances in real applications (Gao et al. Citation2013b). Some work has reported that the fundamental reason constraining the transformation of MNF was inaccuracy in the calculation of NF (Greco Citation2006; Liu et al. Citation2009; Gao et al. Citation2011; Zhao, Gao and Zhang, Citation2016; Gao et al. Citation2017). The information content for a particular hyperspectral image remains unchanged; the calculation accuracy of NF mainly depends on the noise estimation results. The original MNF transformation uses spatial neighborhood information to estimate noise. However, hyperspectral images usually have low spatial resolution with severely mixed pixels. There are relatively large errors related to the sole use of spatial information to calculate NF. Furthermore, the estimation results are unstable. Therefore, Gao et al. (Citation2011; Gao, Du, et al., Citation2013; Gao, Zhang, et al., Citation2013; Citation2012) introduced the optimized minimum noise fraction (OMNF) method. This method adopts spectral and spatial decorrelation (SSDC) method to estimate noise by considering the high correlation between bands. This measure improves the results of the noise estimation and increases the accuracies of NF. Ultimately, the performance of original MNF transformation is improved. However, the above-mentioned methods can only extract linear features of hyperspectral data and are unable to find the nonlinear features.
Currently, the widely used nonlinear feature extraction methods are primarily kernel-based. The advantages of these methods mainly are that nonlinear features can be extracted effectively. Based on kernel function, these algorithms can transform the original data into a higher dimensional feature space. Thus, linear inseparable data in the original space can be separated in high-dimensional feature space. Nielsen (Citation2011), Gómez-Chova and Nielsen (Citation2011), Nielsen and Vestergaard (Citation2012) proposed the kernel-based minimum noise fraction (KMNF) method based on this principle. This method has achieved great results in variation detection of remote sensing images with high spatial resolution, while failing to obtain the desired effect for hyperspectral images in practical application. From the theoretical analyses of KMNF, similar to MNF, KMNF also adopts spatial neighborhood information to estimate noise; thus, NF is also inaccurate. To overcome this problem, the optimized kernel minimum noise fraction (OKMNF) method was proposed (Zhao, Gao and Zhang Citation2016). This method also uses SSDC to estimate noise; thus, the performance of KMNF was improved greatly by introducing SSDC to estimate noise. However, in practical applications, it was found that the performance of OKMNF is still unstable for hyperspectral images with complex surface features. The main reason is: there is certain inadequacy in using SSDC to evaluate noise in hyperspectral images. In SSDC, the minimum region of multiple linear regression (MLR) is determined by empirical value, such as 6 × 6 pixels and 8 × 8 pixels (Gao et al. Citation2013a). This would involve other surface features inevitably to minimum regions, such as borders, when hyperspectral images have complex earth objects. Hence, the consistency of classes cannot be ensured within all divided areas, and this would produce errors while estimating noise and decrease the performance of feature extraction.
To overcome the above limitations, we introduce image segmentation to feature extraction algorithm. Image segmentation divides image into several subregions which do not intersect each other. The features are homogeneous within each subregion, while there are significant differences from different subregions. Traditional image segmentation methods can be divided into four categories: threshold-based image segmentation, region-based image segmentation, edge-based image segmentation, and theory-based image segmentation (Huang Citation1998; Kanungo et al. Citation2002). The key to threshold-based image segmentation is to determine a suitable threshold to divide images. Common threshold processing techniques include the adaptive threshold method, global threshold method, and optimal threshold method. The region-based image segmentation searches region directly. This method has two different search modes, including region growing and region splitting with merging. The edge-based image segmentation attempts to divide images through detecting marginal information of different regions. However, this method is extremely sensitive to noise and thus only suitable for low-noise images. Theory-based image segmentation combines theories and methods based on the development of various disciplines in new theories. In recent years, common theory-based image segmentation methods are primarily based on the mathematical morphology, fuzzy theory, gene coding, wavelet transform, machine learning, and clustering analysis. These image segmentation methods based on different specific theories have their own applications. In particular, image segmentation based on clustering analysis, by considering not only spatial information but also spectral information, is more suitable for the processing of hyperspectral images.
This paper proposes a new kernel method (KM-KMNF) for hyperspectral image feature extraction. Figure shows the flowchart of the proposed KM-KMNF method.
Figure 1. Flowchart of the KM-KMNF algorithm.
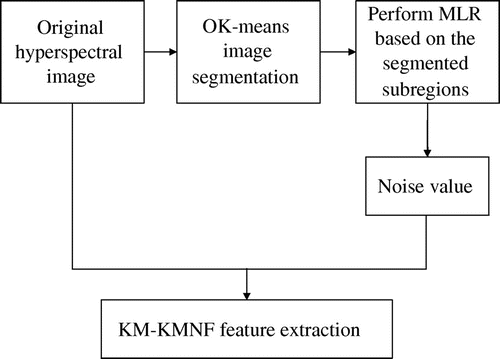
The method exploits the homogeneous region generated by image segmentation as the minimum region for multiple linear regression. By integrating the spatial information of the homogeneous region with spectral decorrelation, KM-KMNF improves noise estimation for feature extraction, enabling better performances on feature extraction and the post-applications (e.g. classification).
The remainder of this paper is organized as follows: Section 2 introduces the KM-KMNF algorithm. Section 3 evaluates the classification performance of KM-KMNF in comparison with another established dimensionality reduction methods by using two real hyperspectral data sets. Finally, Section 4 concludes the paper.
2. KM-KMNF algorithm
2.1. Optimized K-means clustering method
Conventional K-means clustering is a rather effective unsupervised clustering method. With a certain similarity as a measure criterion, this method divides hyperspectral images into different subregions. The characteristics are homogeneous within the same subregion, while there are significant differences for different subregions. For a given hyperspectral image X containing n pixels and b bands, the algorithmic flow of K-means clustering is as follows: at the beginning, k pixels are randomly chosen as initial cluster centers from hyperspectral image. In addition, other pixels are assigned to the most similar clusters by computing their similarity with all cluster centers. The next step is to calculate the cluster centers of new clusters and to repeat the process until the standard measure function begins to converge. After K-means clustering, each cluster is a subregion of image segmentation. However, as showed in Figure (c) and Figure (c), pixels within the same subregions are distributed discretely. Thus, not all pixels within the same subregion can form a connected region. Moreover, homogeneity of the internal features cannot be guaranteed in the same subregion. Therefore, the segmentation results of the conventional K-means clustering cannot meet the algorithm requirements. To solve these problems, we optimize the K-means (OK-means) clustering algorithm. Firstly, in the segment of hyperspectral images, to ensure the homogeneous features within the subregions, the number of subregions k should be far higher than that of normal segmentation. Then, to ensure the connection within each subregion, the search area of pixels, in which the similarity of pixel with its adjacent cluster center be measured, should be limited. Finally, pixels are assigned to the most similar clusters. By conducting OK-means image segmentation, all pixels within the same subregion can form a connected region, and homogeneity of the internal features can be guaranteed in each subregion. Therefore, OK-means image segmentation algorithm is more suitable for the processing of hyperspectral images. The segmentation results of the OK-means algorithm are shown in Figure (d) and Figure (d).
Figure 2. Experiment results on Pavia University data (a) Original Pavia University image. (b) Ground reference map containing nine land-cover classes. (c) Original K-means clustering result (same-colored region belongs to the same subregion). (d) The result of the image segmentation using the OK-means clustering method (each closed region is a subregion). The results of the ML classification after using different dimensionality reduction methods (number of features = 8), (e) OMNF method, (f) KMNF method, (g) OKMNF method, and (h) KM-KMNF method.

The flow of algorithm is as follows:
Step 1: Initialize K cluster centers. For a hyperspectral image X with n pixels and b bands, the ideal subregion size is. With
as step length, K pixels are selected as initial cluster centers (c1, c2, ..., ck).
Step 2: Assign pixel xi to the most similar cluster. According to the formula , the similarity between pixel xi and cluster center cv located in the spatial neighborhood is calculated, and this pixel is assigned to the cluster with the greatest similarity. In other words, this pixel is labeled with the cluster that is most similar to it. Where the cluster center located in the spatial neighborhood of xi is where the cluster center is covered in the area of
with xi as the center.
Step 3: Correct cluster center. The centers of pixels belonging to the same cluster labels are regarded as the new cluster centers.
Step 4: Calculate distance D. This distance is the difference between pixels and their cluster centers. The algorithm will be terminated if D converges. Otherwise, it is required to return to Step 2.
2.2. KM-KMNF algorithm
Remote sensing images are inevitably degraded by certain types of noise due to the influence of sensor instrument errors and other environmental factors. The hyperspectral image X, which contains n pixels and b bands, is composed of two parts signal and noise (Green et al. Citation1988; Landgrebe and Malaret Citation1986),(1)
where x(p) is the pixel vector at position p, xs(p) and xN(p) are the signal and noise contained in x(p), respectively. For optical images, the signal and noise are commonly considered independent of each other (Landgrebe and Malaret Citation1986; Green et al. Citation1988). Thus, the covariance matrix S of image X can be expressed as the sum of the noise covariance matrix SN and the signal covariance matrix SS:(2)
Using to represent the mean value of all pixels in the k-th band of the image, the mean matrix Xmean with n rows b columns can be obtained.
(3)
Then, the centralization matrix Z of X can be expressed as follows:(4)
The covariance matrix of image X can be expressed as(5)
Similarly, Let us consider as the average of the noise in k-th band, the mean noise matrix Xmean with n rows b columns can be obtained.
(6)
The centralization matrix ZN of the noise matrix XN can be expressed as:(7)
The covariance matrix SN of the noise matrix XN can be expressed as:(8)
The NF is defined as the ratio of the noise covariance matrix to the total covariance matrix of image X. Therefore, for the linear combination aTZ(p),(9)
where a is the eigenvector of NF. In NF, it is significant that the noise is estimated reliably. The original KMNF method primarily uses the spatial neighborhood 3 × 3 information of a hyperspectral image to estimate noise ZN, as shown below: (10)
where zi,j,k is the pixel value in the i-th row, j-th column, and k-th band of hyperspectral image Z, is the estimated value of this pixel, and ni,j,k represents the estimated noise value ofzi,j,k. Many works have reported that the estimated results have a relatively large error and are unstable when the noise is estimated by only using the spatial neighborhood information alone (Gao et al. Citation2013a; Citation2013b). In comparison, the results are more accurate using the SSDC method in OKMNF, as shown in Equation (Equation11
(11) ):
(11)
where the parameters a, b, c, and d are the coefficients of the MLR, and zp,k represents the pixel value of the adjacent spatial positions at the same band. To estimate noise, we calculate the inversion parameters of the MLR, which is equivalent to identify minimum region of the MLR. In OKMNF, a region covering 6 × 6 pixels is set as the minimum region to obtain MLR parameters by virtue of the empirical value. However, this segmentation method would inevitably separate other classes to the same minimum region, such as boundary, this makes it difficult to guarantee homogeneous category within the region. In comparison, in the KM-KMNF algorithm, subregion Xsub generated by OK-means clustering is used as the minimum region to estimate noise, ensuring the homogeneity of the pixel features in the minimum region. Meanwhile, within each minimum region, the noise estimated by spectral decorrelation (which only considers the spectral information of hyperspectral image and the correction made by spatial neighborhood pixel zp,k to zi,j,k in Equation (Equation11(11) )) is eliminated. Thus, the impact of heterogeneous information of the image spatial neighborhood on the noise estimation results can be avoided. The equation for the spectral decorrelation excluding the spatial neighborhood information is as follows:
(12)
The adopted MLR model can be expressed as:(13)
(14)
where B represents the spectral neighborhood matrix, μ is the coefficient matrix, and is the residual value. Then, μ could be estimated by:
(15)
The signal value could be estimated through:(16)
The noise value can be obtained from the difference between the true and estimated values:(17)
Then, estimating noise in all subregions was performed by image segmentation. The noise estimation result N of the whole hyperspectral image can be obtained accurately. To acquire the kernel minimum noise fraction (KNF), the noise estimation result is inserted into the NF calculation Equation (Equation9(9) ), and NF is performed with dual transformation a
ZTb and kernel transformation (Nielsen and Vestergaard Citation2012).
(18)
where κ is the Gaussian radial basis function (RBF).(19)
where σ is the proportional parameter, which can be obtained by calculating the mean distance between the observed value xi and xj (Nielsen Citation2011). To sort the image components according to the quality order after dimensionality reduction, KNF needs to be minimized, thus by solving the transformation matrix for feature extraction. Solving the minimized KNF equals to solve the symmetric generalized eigenvalues that can be solved using the maximized Rayleigh entropy (Nielsen Citation2011) which does not elaborate the detailed solution process. It should be noted that as far as KNF is concerned, the kernel noise value is calculated in the kernel space. In other words, the real X of hyperspectral image and the estimated of the MLR are converted to the kernel space at the same time. Subsequently, the noise value is obtained in the kernel space instead of the original space (Nielsen and Vestergaard Citation2012). Finally, the feature extraction results can be expressed as:
(20)
3. Experiment and analysis
We compare the KM-KMNF with OMNF, KMNF, and OKMNF on two real hyperspectral remote sensing images. The features extracted by each method are used as input of the maximum likelihood (ML) classification and support vector machine (SVM) to validate the performances. The SVM classifier with RBF kernels in MATLAB SVM Toolbox, LIBSVM (Chang and Lin Citation2011; Liao et al. Citation2012), is applied in our experiments. The fivefold cross-validation is used to find the best parameters in SVM (Liao et al. Citation2012). Each experiment runs ten times, and the average value of these ten experiments is reported for comparison.
3.1. Experiment on Pavia University data
The Italian hyperspectral data of Pavia University were collected using the reflective optical system imaging spectrometer in 2001. The data contain 610 × 340 pixels and 103 spectral bands. In addition, the spectrum ranges from 0.43 μm to 0.86 μm, and the data have a spatial resolution of 1.3 m. The image contains nine different types of surface classes (Figure (a) and (b)). About 50% of the samples are randomly selected as the training samples. The remaining 50% of the samples are used as testing samples. The sample categories and quantities are shown in Table . The classification accuracy of the different feature extraction methods is shown in Table and Figure . The results of classification are shown in Figure (e−h).
Table 1. Pavia University samples used for training and testing.
Table 2. Overall accuracy of the ML classification on Pavia University image using different dimensionality reduction methods.
Figure 3. Comparison of the accuracies of the ML classification on Pavia University image using different number of features.
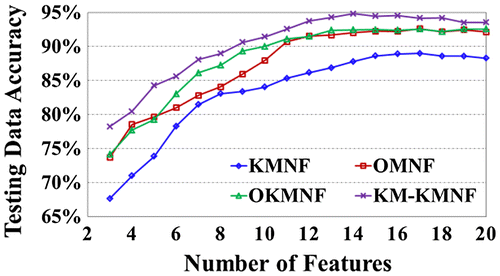
In Table , the classification accuracy of the four different feature extraction methods increases with the growing number of features. In particular, KM-KMNF produces a higher accuracy than the other three methods. Compared with KMNF and OKMNF, the accuracy of KM-KMNF could be improved by 10.95 and 4.69%, respectively, which indicates that incorporating the spatial information through image segmentation to the KM-KMNF algorithm as the minimum region of the MLR benefits post-applications. The accuracies of KM-KMNF and OKMNF are much higher than that of KMNF. In the meantime, the KM-KMNF performs better than OKMNF. The results show that for the noise estimation in KMNF algorithm, the spectral information is more important than the spatial dimension information of hyperspectral image. Moreover, Figure (e–h) shows that the classification results after KM-KMNF transformation are more consistent with the actual distribution of the surface features than those of other methods.
3.2. Experiment on Indian Pines data
Indian Pines hyperspectral data are acquired by the Airborne Visible/Infrared Imaging Spectrometer in 1992, which contains 145 × 145 pixels and 220 bands. The spectrum ranges from 0.4 μm to 2.5 μm, and the spatial resolution is 20 m. Only 200 bands of the image are taken into account in this experiment, whereas the noise bands and the atmospheric vapor absorption bands are excluded. Nine large classes are considered in this experiment (Figure (a) and (b)). About 25% percent of the samples are randomly selected as the training samples. The remaining 75% of the samples are used as testing samples. The sample categories and quantities are shown in Table . The classification accuracy of the different classifiers (ML and SVM) using different feature extraction methods is shown in Table , Table , and Figure . The classification results are shown in Figure (e−h).
Figure 4. Experiment results on Indian Pines data (a) Original Indian Pines image. (b) Ground reference map containing nine land-cover classes. (c) Original K-means clustering result (same-colored region belongs to the same subregion). (d) The result of image segmentation using the optimal K-means clustering method (each closed region is a subregion). The results of the ML classification after using different dimensionality reduction methods (number of features = 8), (e) OMNF method, (f) KMNF method, (g) OKMNF method, and (h) KM-KMNF method.

Table 3. Samples from Indian Pines used for training and testing.
Table 4. Overall accuracies of the ML classification on Indian Pines image using different dimensionality reduction methods.
Table 5. Overall accuracies of the SVM classification on Indian Pines image using different dimensionality reduction methods.
Figure 5. Comparison of the accuracies of the SVM classification on Indian Pines image after using different dimensionality reduction methods.
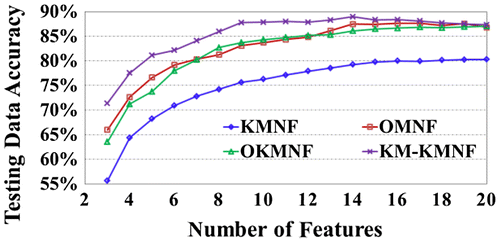
Tables and show that KM-KMNF contributes a higher accuracy than the other algorithms as the number of features increases, similar to that of the Pavia University data. This further demonstrates that the efficiency of KM-KMNF on feature extraction. Figure also reveals that the accuracies of the three methods. By taking the spatial and spectral information of image into consideration, our KM-KMNF produces higher accuracy than that of the KMNF method which solely considers the spatial information for noise estimation. This confirms that the accurate calculation of the noise is crucial to the performance of the feature extraction for KMNF and MNF-based methods. In Table , we also can find that most standard deviations of KM-KMNF are relatively smaller than the others, indicating the stable performance of KM-KMNF. From Figure and Figure , as the number of extracted features increases, the performance of each feature extraction method first increases and then decreases. It confirms that feature extraction can improve the classification performance on hyperspectral images, and most information can be preserved even with a few extracted features. With SVM classifier, we have similar findings as that of the ML classifiers. The KM-KMNF produces better results than the others. In particular, KM-KMNF with ML classifier outperforms those of SVM classifier.
We also conduct experiments by increasing the number of training samples, as shown in Table . We find that as the number of training samples increases, the classification accuracy first increases and then keeps a relative stable status. To compare the efficiency of feature extraction methods, we take Indian Pines data as an example (by extracting 20 features), and the consumed time of KM-KMNF, OKMNF, OMNF, and KMNF is 21.57 s, 19.99 s, 20.71 s, and 1.50 s, respectively. We find that KM-KMNF consumes relative more time but with better performances. When extracting less features, KM-KMNF can reduce the consumed time, and get the best performance when using around 14 features.
Table 6. Overall classification accuracies by using different number of training samples.
4. Conclusions
This paper is to propose a new kernel minimum noise fractional transformation for the feature extraction of hyperspectral data. Our method uses spectral-dimension decorrelation for calculation of the NF, and further improves the accuracy of the NF by introducing the spatial information through image segmentation to determine the minimum region of the MLR. Moreover, the conventional K-means clustering method has been improved to make OK-means algorithm more suitable for hyperspectral image segmentation. Two real hyperspectral image data sets are used for the experiments, and the classification accuracy is used as the index to evaluate the performances of feature extraction algorithms. The results show that the accuracy of the MNF based on image segmentation is much higher than that of the original KMNF algorithm. Meanwhile, it is also much higher than that of the OMNF and OKMNF algorithms. Better noise estimation brings better performances on both feature extraction and its post-application to hyperspectral image classification for MNF- and KMNF-based methods.
Notes on contributors
Bin Zhao is a Postgraduate of Electronics and Communication Engineering at the Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences. His research interests include hyperspectral image feature extraction and classification.
Lianru Gao is currently a Professor with the Key Laboratory of Digital Earth Science, Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences. He received the BS degree in civil engineering from Tsinghua University, Beijing, China, in 2002, and the PhD degree in cartography and geographic information system from the Institute of Remote Sensing Applications, Chinese Academy of Sciences, Beijing, China, in 2007. His research interests include hyperspectral image processing and information extraction. He has published more than 100 papers in China and abroad.
Wenzhi Liao, since 2012, has been working as a Postdoc at Ghent University and as a Postdoctoral Fellow with the Fund for Scientific Research, Flanders-FWO. He received the BS degree in mathematics from Hainan Normal University, Haikou, China, in 2006, the PhD degree in engineering from South China University of Technology, Guangzhou, China, in 2012, and the PhD degree in computer science engineering from Ghent University, Ghent, Belgium, in 2012. His current research interests include pattern recognition, remote sensing, and image processing. In particular, his interests include mathematical morphology, multitask feature learning, multisensor data fusion, and hyperspectral image restoration.
Bing Zhang is a Professor and the Deputy Director of the Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences. He received the BS degree in geography from Peking University, Beijing, China, and the MS and PhD degrees in remote sensing from the Institute of Remote Sensing Applications, Chinese Academy of Sciences, Beijing, China. His research interests include the development of Mathematical and Physical models and image processing software for the analysis of hyperspectral remote sensing data in many different areas, such as geology, hydrology, ecology, and botany. He has developed five software systems in the image processing and applications. He has authored more than 300 publications, including 171 journal papers.
Funding
This work was supported by the National Natural Science Foundation of China [Grant Number 41722108], [Grant Number 91638201]; and FWO project: data fusion for image analysis in remote sensing [Grant Number G037115N].
Acknowledgments
The authors would like to thank the Jet Propulsion Laboratory for providing the AVIRIS data sets.
References
- Bajcsy, P., and P. Groves. 2004. “Methodology for Hyperspectral Band Selection.” Photogrammetric Engineering & Remote Sensing 70 (7): 793–802.10.14358/PERS.70.7.793
- Ball, J. E., L. M. Bruce, T. West, and S. Prasad. 2007. “Level Set Hyperspectral Image Segmentation Using Spectral Information Divergence-based Best Band Selection.” IEEE International Conference: the Geoscience & Remote Sensing Symposium, Barcelona, Spain, July 23−28. doi: 10.1109/igarss.2007.4423739.
- Benediktsson, J. A., J. A. Palmason, and J. R. Sveinsson. 2005. “Classification of Hyperspectral Data from Urban Areas based on Extended Morphological Profiles.” IEEE Transactions on Geoscience & Remote Sensing 43 (3): 480–491. doi:10.1109/tgrs.2004.842478.
- Chang, C. C., and C. J. Lin. 2011. “LIBSVM: A Library for Support Vector Machines.” ACM Transactions on Intelligent Systems and Technology 2 (3): 1–27.10.1145/1961189
- Gao, L., B. Zhang, Z. Chen, and L. Lei. 2011. “Study on the Issue of Noise Estimation in Dimension Reduction of Hyperspectral Images.” The 3rd Workshop Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Lisbon, Portugal, June 6−9. doi: 10.1109/whispers.2011.6080944.
- Gao, L., Q. Du, W. Yang, and B. Zhang. 2012. “A Comparative Study on Noise Estimation for Hyperspectral Imagery.” The Workshop on Hyperspectral Image & Signal Processing: Evolution in Remote Sensing. Shanghai, China, June 4−7. doi: 10.1109/whispers.2012.6874262.
- Gao, L., Q. Du, B. Zhang, W. Yang, and Y. Wu. 2013. “A Comparative Study on Linear Regression-Based Noise Estimation for Hyperspectral Imagery.” IEEE Journal of Selected Topics in Applied Earth Observations & Remote Sensing 6 (2): 488–498. doi:10.1109/jstars.2012.2227245.
- Gao, L., B. Zhang, X. Sun, S. Li, Q. Du, and C. Wu. 2013. “Optimized Maximum Noise Fraction for Dimensionality Reduction of Chinese HJ-1A Hyperspectral Data.” EURASIP Journal on Advances in Signal Processing 2013 (1): 1–12. doi:10.1186/1687-6180-2013-65.
- Gao, L. R., B. Zhao, X. P. Jia, W. Z. Liao, and B. Zhang. 2017. “Optimized Kernel Minimum Noise Fraction Transformation for Hyperspectral Image Classification.” Remote Sensing 9 (6): doi:10.3390/rs9060548.
- Gómez-Chova, L., and A. A. Nielsen. 2011. “Explicit Signal to Noise Ratio in Reproducing Kernel Hilbert Spaces.” The IEEE International Conference: the Geoscience & Remote Sensing Symposium, Vancouver, BC, Canada, July 24−29. doi: 10.1109/igarss.2011.6049993.
- Greco, M. 2006. “Analysis of the Classification Accuracy of A New MNF-based Feature Extraction Algorithm.” Proceedings of SPIE 6365 63650V-1. doi:10.1117/12.689961.
- Green, A. A., M. Berman, P. Switzer, and M. D. Craig. 1988. “A Transformation for Ordering Multispectral Data in Terms of Image Quality with Implications for Noise Removal.” IEEE Transactions on Geoscience & Remote Sensing 26 (1): 65–74. doi:10.1109/36.3001.
- Guo, B., S. R. Gunn, R. I. Damper, and J. D. B. Nelson. 2006. “Band Selection for Hyperspectral Image Classification Using Mutual Information.” IEEE Geoscience & Remote Sensing Letters 3 (4): 522–526. doi:10.1109/lgrs.2006.878240.
- Huang, Z. 1998. “Extensions to the k-Means Algorithm for Clustering Large Data Sets with Categorical Values.” Data Mining & Knowledge Discovery 2 (3): 283–304. doi:10.1023/a:1009769707641.
- Hughes, G. 1968. “On the Mean Accuracy of Statistical Pattern Recognizers.” IEEE Transactions on Information Theory 14 (1): 55–63. doi:10.1109/tit.1968.1054102.
- Jia, X., B. C. Kuo, and M. M. Crawford. 2013. “Feature Mining for Hyperspectral Image Classification.” Proceedings of the IEEE 101 (3): 676–697. doi:10.1109/jproc.2012.2229082.
- Kanungo, T., D. M. Mount, N. S. Netanyahu, C. D. Piatko, R. Silverman, and A. Y. Wu. 2002. “An Efficient k-Means Clustering Algorithm: Analysis and Implementation.” IEEE Transactions on Pattern Analysis & Machine Intelligence 24 (7): 881–892. doi:10.1109/tpami.2002.1017616.
- Landgrebe, D. A. and E. Malaret. 1986. “Noise in Remote-Sensing Systems: The Effect on Classification Error.” IEEE Transactions on Geoscience & Remote Sensing GE-24(2): 294−300. doi:10.1109/tgrs.1986.289648.
- Lee, J. B., A. S. Woodyatt, and M. Berman. 1990. “Enhancement of High Spectral Resolution Remote-Sensing Data by A Noise-adjusted Principal Components Transform.” IEEE Transactions on Geoscience & Remote Sensing 28 (3): 295–304. doi:10.1109/36.54356.
- Li, W., S. Prasad, J. E. Fowler, and L. M. Bruce. 2012. “Locality-Preserving Dimensionality Reduction and Classification for Hyperspectral Image Analysis.” IEEE Transactions on Geoscience & Remote Sensing 50 (4): 1185–1198. doi:10.1109/TGRS.2011.2165957.
- Liao, W., A. Pizurica, P. Scheunders, W. Philips, and Y. Pi. 2012. “Semisupervised Local Discriminant Analysis for Feature Extraction in Hyperspectral Images.” IEEE Transactions on Geoscience & Remote Sensing 51 (1): 184–198. doi:10.1109/tgrs.2012.2200106.
- Liu, X., B. Zhang, L. R. Gao, and D. M. Chen. 2009. “A Maximum Noise Fraction Transform with Improved Noise Estimation for Hyperspectral Images.” Science in China 52 (9): 1578–1587. doi:10.1007/s11432-009-0156-z.
- Nielsen, A. A. 2011. “Kernel Maximum Autocorrelation Factor and Minimum Noise Fraction Transformations.” IEEE Transactions on Image Processing 20 (3): 612–624. doi:10.1109/tip.2010.2076296.
- Nielsen, A. A., and J. S. Vestergaard. 2012. “Parameter Optimization in the Regularized Kernel Minimum Noise Fraction Transformation.” IEEE International Conference: Geoscience and Remote Sensing Symposium (IGARSS), Munich, Germany, July 22−27. doi: 10.1109/igarss.2012.6351561.
- Plaza, A., J. A. Benediktsson, J. W. Boardman, J. Brazile, L. Bruzzone, G. Camps-Valls, and J. Chanussot. 2009. “Recent Advances in Techniques for Hyperspectral Image Processing.” Remote Sensing of Environment 113 (1): S110–S122. doi:10.1016/j.rse.2007.07.028.
- Roger, R. E. 1996. “Principal Components transform with simple, automatic noise adjustment.” International Journal of Remote Sensing 17 (14): 2719–2727.10.1080/01431169608949102
- Zhao, B., L. Gao, and B. Zhang. 2016. “An Optimized Method of Kernel Minimum Noise Fraction for Dimensionality Reduction of Hyperspectral Imagery.” IEEE International Conference: the Geoscience & Remote Sensing Symposium, Beijing, China, July 10−15. doi: 10.1109/igarss.2016.7729003.