
ABSTRACT
Geographical studies of outdoor activities have increased in recent years with the rise in popularity of these activities worldwide, including in Japan. Volunteered geographic information (VGI) is a key tool for organizing outdoor activities as it offers a means to determine the locational information and names of places. To evaluate the quality of VGI, geospatial data generated by land survey agencies and other VGI are often utilized as reference data. However, since these reference data may not be available, other methods are necessary to assure the quality of VGI. In this study, we examined five trust indicators based on the inherent characteristics of VGI through an empirical case study. We used mountain names extracted from OpenStreetMap in Japan as data because there were almost no other VGI in the vicinity. As a result, we isolated three trust indicators, namely versions, users, and tag corrections, to examine the thematic accuracy of VGI because these were the only statistically significant indicators. However, we found that the prediction rate of thematic accuracy was very low. To improve thematic accuracy, this study recommends using the most accurate versions, applying correctly given tags, and considering the motivations and characteristics of the VGI contributors.
1. Introduction
Geographical studies of outdoor activities have increased in recent years with the growing popularity of these activities worldwide, including in Japan (Brown Citation2014; Kil, Stein, and Holland Citation2014; Ballantyne and Pickering Citation2015). In most of the EU member states, more time was spent on outdoor activities between 2000 and 2010 than in previous decadesFootnote1. A similar upward trend was observed in both the United StatesFootnote2 and CanadaFootnote3. In Japan, between 2011 and 2016, the Statistics Bureau of Japan indicated an increase in weekly hours for sports and outdoor activities (Statistics Bureau of Japan Citation2012, Citation2017). Yet more recently, COVID-19 has increased the popularity of outdoor activities because of the need for physical distancing. Such outdoor activities often take place outside the cities.
Geospatial information, including locational information and names of places, is essential for outdoor activities particularly outside of cities. In hiking, for instance, it is useful to know the names of the places on a trail so that hikers can check whether they are staying on the planned trail and so avoid the risk of getting lost. It is also important for identifying the locations of non-urban areas. While the importance of geospatial information for non-urban areas has been recognized, the maps produced by cartographic organizations are not sufficiently developed because demand for geospatial information is lower in non-urban areas than in urban areas with lower concentrations of population and industries. In fact, the creation of geospatial information in non-urban areas chiefly relies on the volunteered geographic information (VGI) contributors. For example, the Geospatial Information Authority of Japan (GSI), which is the national organization for surveying and mapping, has been receiving big data, such as information on the travel routes of climbers through its partner companies since 2018, and has been using these big data to update mountain trails on topographic mapsFootnote4. Regarding the use of VGI by national mapping agencies (NMAs), the situation in Japan differs from those in North America and Europe. In line with the use of VGI for improving or updating geospatial data authorized by NMAs (Foody et al. Citation2017), the use of VGI by NMAs has already been studied in North America and Europe since the early 2010s with Bégin (Citation2012)’s pioneer work. In recent years, research on the use of VGI by NMAs pointed out challenges against the enhancement of such use (Mooney, Crompvoets, and Lemmens Citation2018; Rönneberg, Laakso, and Sarjakoski Citation2019) and presented tools to overcome these challenges (Ivanovic et al. Citation2020).
Even though a large volume of VGI has been created for outdoor activities in non-urban areas, the quality of VGI for outdoor activities cannot be guaranteed (Parker, May, and Mitchell Citation2013; Zhang, Zhang, and Fan Citation2018; Norman, Pickering, and Castley Citation2019). Research on the VGI quality assessment in natural and mountainous areas has been conducted mainly in Europe (Acheson, De Sabbata, and Purves Citation2017; Van Damme, Olteanu-Raimond, and Méneroux Citation2019). Artificial intelligence, machine learning, and other tools were also employed recently to ensure the quality of VGI (Mohammadi and Malek Citation2015; Xu et al. Citation2017; Maidaneh, Le Guilcher, and Olteanu-Raimond Citation2020). To evaluate VGI, including OpenStreetMap (OSM) data, the categories of data quality in the ISO (International Organization for Standardization) 19157:2013 have long been used. These categories are: completeness, logical consistency, positional accuracy, temporal accuracy, and thematic accuracy. Positional accuracy of OSM data has been considered frequently after Haklay’s pioneering work (Haklay Citation2010). Using these categories, the data quality of VGI can be ensured by comparing VGI data to geospatial data authorized by the NMAs. For non-urban areas, however, these geospatial data are often less available because the GSI or private surveying companies have not produced data with high quality standards as they do for urban areas. Especially in less populated mountainous areas, only one source of VGI may be available due to the lack of VGI contributors. Since VGI data quality cannot be determined by comparison with other VGIs, it is necessary to consider how to evaluate VGI quality using inherent characteristics.
Some recent studies of VGI have investigated such data quality indicators, including credibility, reputation, and trust/trustworthiness (Senaratne et al. Citation2017)Footnote5. Following Sztompka (Citation1999), Keßler and de Groot (Citation2013) defined “trust” as a person’s bet on contingent behavior of others in future (p. 25). Many studies have dealt with trust as a VGI data quality indicator (Wang, Wang, and Li Citation2015; Gao et al. Citation2017; Brown and Kyttä Citation2018; Haworth Citation2018); while these studies frequently cite the trust indicators presented by Keßler and de Groot (Citation2013), there are not yet enough studies to validate these trust indicators because most studies of VGI have evaluated trust in comparison with geospatial data produced by the ISO 19157:2013 rather than by inherent characteristics. Additionally, few studies have shown that trust is a good predictor of VGI quality (Yan, Feng, and Wang Citation2017). This study seeks to validate trust as a predictor of VGI data quality through three steps: 1) comparing VGI data with public data that meet ISO geospatial standards to determine data quality, 2) investigating whether Keßler and de Groot (Citation2013)’s trust indicators can assure data quality, and 3) considering whether these trust indicators can accurately predict data quality. We extracted the names of mountains from OSM data in Japan as a test case for evaluating this validity of trust indicators. The results showed that trust indicators were little likely to be valid for VGI data quality assessment. This finding could contribute to an improvement in the trust studies for VGI.
2. Related work
Research on trust has been flourishing since Bishr and Kuhn (Citation2007) proposed trust as a proxy data quality measure for VGI (Golbeck Citation2008; Vahidi, Klinkenberg, and Yan Citation2017). For instance, Bishr and Janowicz (Citation2010) have pointed out that VGI is trustworthy when its data quality is secured by various indicators based on its features and that such trust indicators can be considered as proxy measures for VGI data quality. Various trust indicators have since been developed. Some studies have assessed VGI data quality with a single indicator (Foody et al. Citation2013; Jackson et al. Citation2013), while others have used several indicators (D’Antonio, Fogliaroni, and Kauppinen Citation2014) as well as the entire dataset (Du et al. Citation2012). Scholars have proposed models for trust indicators based on VGI-specific features; Fogliaroni, D’Antonio, and Clementini (Citation2018) used VGI geometric and semantic features, and Severinsen et al. (Citation2019) proposed three trust components: trust of VGI contributors, spatial trust of VGI, and temporal trust of VGI. Scholars have also attempted to ensure trust of VGI by comparing it with other reference data. Kashian et al. (Citation2019) proposed a tool that automatically validates the trust of a particular point of interest (POI) datum from the OSM by using the geospatial relationship between it and the surrounding landforms. Similarly, Brovelli and Zamboni (Citation2018) proposed verifying the positional accuracy of VGI for buildings through comparison with the public geospatial data produced by land survey procedures.
A few scholars have considered the trustworthiness of contributors. Haklay et al. (Citation2010) and Goodchild and Li (Citation2012) suggested crowdsourcing to correct errors by individual contributors. The crowdsourcing approach is chiefly based on Linus’s Law formulated by Raymond (Citation1999). This approach, however, has been disproved by Yamashita et al. (Citation2019) who found that Japanese OSM contributors were not aware of the ISO19157:2013 data quality categories and so concluded that crowdsourcing did not secure VGI data quality. Goodchild and Li (Citation2012) also proposed a social approach: highly qualified VGI contributors act as gatekeepers for data from other contributors. Using this approach, Moreri, Fairbairn, and James (Citation2018b) proposed the TR (Trust and Reputation) model, incorporating trust and computation and determined its validity for land use classification. As another social approach, Seto, Kanasugi, and Nishimura (Citation2020) focused on quality control through interactive communication among OSM contributors, based on the worldwide trend of posting annotation functions called OSM-Notes.
With the public reference data and the social approach, it is difficult to ensure the trust of VGI consistently; such reference data or outsiders may not always be available. In contrast, trust indicators based on VGI-specific features can always be available to guarantee data quality (Muttaqien, Ostermann, and Lemmens Citation2018). Consequently, this study turns to these VGI-specific features to evaluate trust indicators, especially the model presented by Keßler and de Groot (Citation2013).
Keßler and de Groot (Citation2013) proposed trust indicator model includes five VGI-specific indicators: versions, users, confirmations, tag corrections, and rollbacks. Versions indicate the number of times a piece of land has been revised, and the number of versions suggests the degree of VGI data quality. Users are VGI contributors, and a large number of users makes VGI more trustworthy. Confirmations are the number of times a geospatial feature has been edited, specifically the number of times VGI features have been edited within a 50 m radius of the main VGI feature since the last edit of that feature. The more times confirmations are made, the more VGI is trustworthy. Tag corrections are defined as the number of times the tag of a VGI feature was changed. A large number of tag corrections indicates ambiguity in the thematic accuracy of a VGI feature and so reduces its degree of trustworthiness. Finally, rollback is a different type of tagging corrections; it occurs when the tag of a VGI feature is altered to a previous one. Again, a large number suggests uncertainty and a lower level of trustworthiness.
3. Study methodology
In our study, we used OSM data of names for mountain peaks in Japan to evaluate these five indicators. The name of a peak becomes the name of the node data (NAME = xxx) in the OSM data with the tag of natural = peak (OSM-NM data for short). To evaluate the five trust indicators, we used the OSM history dump dataFootnote6. The OSM-NM data were extracted from the OSM historical dump data using the PostgreSQL with the tag “natural = peak”. We chose to focus on mountain peaks primarily because these data are isolated from other VGI and so are suitable for verifying the trustworthiness of OSM data using only these data. Names of mountain peaks are also particularly important because of the popularity of mountain climbing in Japan. Consequently, a substantial amount of data related to mountain peaks has been collected, and this information will be much used in mobile apps for mountain climbing and other outdoor activities. For instance, the GSI has been receiving large amounts of data (such as geospatial information on mountain trails) from ordinary climbers through private companies and has been using this information to update mountain trails on topographic maps since 2018. Finally, there are recognized issues of trustworthiness with this mountain peak data, as problems of accuracy have been observed in the descriptions of names of Japanese mountains, especially for low mountains, which are often not maintained by official cartographic institutions. Descriptions of these lower mountains can thus differ from one map to another.
First, we secured the positional and thematic accuracy of the OSM-NM data for these mountain peaks because inaccurate OSM-NM data would distort evaluation of these trust indicators. To secure positional and thematic accuracy, we used the mountain node data from the Place Name Information (Natural Place Names) (the public NM data for short) provided by GSI’s experimental project of vector-tile geospatial data provisionFootnote7. GSI data was used because these data are the most reliable ones for land surveys and are provided for free. For both thematic and positional accuracy, we extracted the single public NM datum with the most similar name to a specific OSM-NM one in a 200 m radius. We did not explore the OSM data beyond the 200 m radius. In this extraction process, unnamed peaks were excluded from the OSM data. The number of unnamed peaks was 2611. To determine thematic accuracy, we compared the name of a specific OSM-NM datum for a peak, i.e. NAME = *, with that of the corresponding public NM one. If the names of OSM-NM and public data were the same, we concluded that the former was accurate. While distances were only used to measure the positional accuracy, no distance, such as Levenshtein distance, was employed to evaluate the thematic accuracy. To determine positional accuracy, the Euclidean distance between each OSM-NM datum and its corresponding public NM one was measured using latitudes and longitudes of both data transformed in the Japan plane rectangular coordinate system zone I (EPSG: 6669) to XIX (EPSG: 6687). The Euclidean distance was measured in meters. A shorter distance indicates higher positional accuracy of the OSM-NM data. For both thematic and positional accuracy, all OSM-NM data were then divided into two groups, consistent cases and inconsistent cases, depending on whether the OSM names did or did not match those of the public NM data (thematic accuracy) and whether a datum was or was not a certain distance from the public NM data (positional accuracy).
Second, we investigated the relationship between Keßler and de Groot’s five trust indicators and the public NM data. Effects of the five indicators on positional and thematic accuracy were examined using multiple regression analysis for three groups of data, namely, the entire OSM-NM dataset and the consistent and inconsistent cases (relative to the public NM data) within the entire dataset. Multiple regression analyses were performed using the five trust indicators as independent variables. Although multicollinearity or spatial autocorrelation might be expected among the five trust indicators and positional and thematic accuracies, we deliberately employed multiple regression analyses because this analysis has the advantage of explicitly examining the direct effects of these indicators on positional and thematic accuracies. For positional accuracy, distances between the OSM-NM and public NM data were the dependent variables. For thematic accuracy, a dummy variable was employed as the dependent variable. The dummy variable was set to 1 when the name of the OSM-NM datum was consistent with that of the public NM one; otherwise, it was set to 0. When the partial regression coefficient of a trust indicator was statistically significant for both positional and thematic accuracy, we concluded that this indicator suggested trustworthiness.
Third, we considered whether positional and thematic accuracy could be predicted by these statistically significant trust indicators on the basis of results derived from the multiple regression analyses. If these trust indicators could predict positional and thematic accuracy, they were regarded as robust indicators for VGI data quality assessment. To assess the accuracy of predictions by these indicators, we first extracted the OSM-NM data that did not correspond to public NM data. Among the extracted data, we only selected the OSM-NM data with Japanese names of mountains (OSM-NMJ data for short). Only data in the first nine regional meshes were chosen. Regional meshes have been a basic unit of geospatial data in Japan (for economic, agricultural, and forestry studies as well as population censuses) since the 1965 population census; the former Administrative Management Agency codified these meshes into national legal units first in 1968 and then again in 1976, making meshes the Japan Industry Standard (JIS), a national standard in accordance with the ISO rules. A regional mesh is an area defined on the basis of latitude and longitude. The first mesh, which has the largest area of the regional meshes, is divided by 40 minutes in latitude and one degree in longitude. Since one side of the first mesh is approximately 80 km, one side of the study area for the OSM-NMJ data was roughly 240 km. Each first mesh is given a regional mesh code with 4-digit numbers in the following way. The first mesh code = (latitude × 1.5 × 100) + (longitude −100).
Because the OSM-NMJ data did not have corresponding public data, new reference data were required for verification of the predictions. As new reference data, we employed the control points chosen from the fundamental geospatial data created by the GSIFootnote8. The control points are GPS-based control points, triangulation points, bench marks, and others. Because locations and elevations of all the control points were accurately measured, they are utilized as the basis for a range of land surveys, such as public and cadastral surveying and crustal movement observation. Using the control points, we tested the robustness of the five trust indicators for positional and thematic accuracy of VGI. First, we extracted the reference points corresponding to the individual OSM-NMJ data. In the extraction process, we focused on the control point that corresponded to an individual OSM-NMJ datum, when the former was included in the buffer zones of the latter. Two buffer sizes were employed: the mean distance between the OSM-NM and public NM data obtained in the first analysis of this study and distance with mean plus a half of standard deviation. Values of partial correlation coefficients pertaining to statistically significant variables only were used to predict positional and thematic accuracy. Regarding positional accuracy, the observed values of individual OSM-NMJ data were used as the statistically significant dependent variables of the multiple regression analysis to generate the predicted distances of this OSM-NMJ data from the corresponding control points. Next, we calculated the observed distances between individual OSM-NMJ data and the corresponding control points. Finally, the differences between the predicted and observed distances were measured. If differences were less than half of the mean distance between OSM-NM data and public NM data, the prediction was considered to be correct. Otherwise, the prediction was considered incorrect. The hit ratio is defined as the number of correct predictions among all predictions. A high hit ratio indicates that the trust indicators are robust. Like positional accuracy, the results derived from regression analysis were applied to thematic accuracy. For thematic accuracy, the percent of consistencies between the names of individual OSM-NMJ data and those of the corresponding control points were generated in the multiple regression analysis as the predicted values. The predicted values were rounded to 0 or 1. Predicted values of 1 indicate that the names of the OSM-NMJ data match those of the corresponding control points. Otherwise, this data did not match the control points. Consequently, we compared the names of the individual OSM-NMJ data with the names of the corresponding control points to obtain the observed values. If the names of the two data coincided with each other, the measured values were set to 1, and if not, the values were set to 0. Finally, the predicted and observed values were compared, and if the predicted and measured values were the same, the prediction was considered to be correct. Conversely, if the predicted and measured values were different, the prediction was considered to be incorrect. Again, the robustness of trust indicators was inferred from a high hit ratio of predictions.
4. Results
4.1. Positional and thematic accuracy of the OSM-NM data
The OSM-NM data () showed significant positional and thematic accuracy. This finding indicates that the quality of the OSM-NM data was secured by the ISO standards. Regarding the positional accuracy, the mean distance between OSM-NM data and public NM data was 19.13 m and the standard deviation was 54.34 m. The distances standardized according to the mean and standard deviation are summarized in the frequency table with 0.5 intervals (). Most (93.6%) of the standardized distances were distributed within 0 ± 0.5. The OSM-NM data were classified as consistent (N = 6460) or inconsistent (N = 443) depending on whether they fell within ±0.5 categories or not. Among the OSM-NM data classified as consistent, 85.9% were located very close to the public NM data, as the distances between them were shorter than the mean. This indicates that the positional accuracy of the OSM-NM data was very high. The thematic accuracy of the OSM-NM data was also very high because 95.3% of the names matched names in the public NM data (). These OSM-NM data (N = 6576) were categorized as consistent, while the rest (N = 327) were considered inconsistent.
Figure 1. Distribution of matched OSM-NM data (N = 6903).
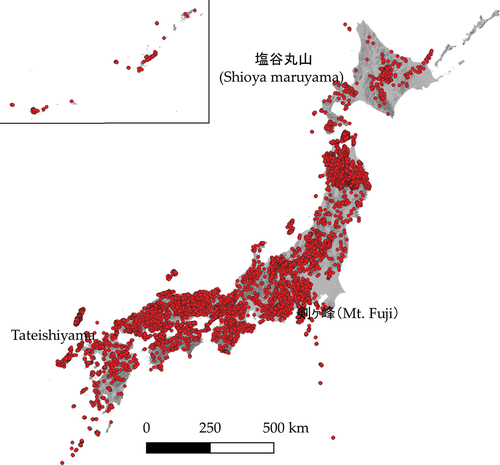
Table 1. Evaluation of positional accuracy.
Table 2. Evaluation of thematic accuracy.
When we focus on examples of discrepancies in thematic accuracy in the inconsistent cases, several trends can be observed. The first trend resulted from the use of Japanese kanji characters. Examples are “嶺” vs. “巓,” “ケ” vs. “ヶ” and “川” vs. “河.” These examples are the same in terms of reading and meaning, but are written differently in unique Japanese kanji characters. The second trend was caused by differences in written characters–for instance, “火山” vs. “Hiyama” and “立石山” vs. “Tateishiyama.” In each case, the pronunciations of the names are same. The names of public NM data are written in kanji characters by the GSI, and never in alphabet, while those of the OSM-NM data were sometimes expressed in alphabet. The third trend is the addition of regional names to the names of peaks because such names are common throughout Japan, and OSM contributors tried to distinguish these names from others. Examples are “丸山” vs. “塩谷丸山” and “城山” vs. “小仏城山.” The fourth trend is when the notations of the OSM-NM data were completely different from those of the public NM data. Since most discrepancies in the names of OSM-MN data occurred in the first to third trends that reflected differences in name notation, we concluded that the thematic accuracy of the OSM-MN data was extremely high.
4.2. Validity of the trust indicators
The relationship between the five trust indicators and positional and thematic accuracy was examined using multiple regression analyses for all 6903 OSM-NM data in six instances: whole, consistent and inconsistent categories for both positional and thematic accuracy (). The results in these categories reveal that the five trust indicators seemed to hardly be proxy measures for ensuring VGI data quality.
Table 3. Examinations of trust indicators for securing VGI data quality
The five trust indicators effectively explained both the positional and thematic accuracy as a whole. The coefficient of determination in the multiple regression model is statistically significant at the 1% level in all six categories. For thematic accuracy, the explanation rates of the five indicators are very high. This might partly result from the fact that the dependent variables were dummy ones. Positional accuracies were chiefly determined by two trust indicators, versions and tag corrections, whereas the thematic accuracies were explained by all indicators except for confirmations. Users and rollbacks in the consistent category for positional accuracy and confirmations in the whole category of thematic accuracy were statistically significant at least at the 10% level. However, effects of the five trust indicators on positional and thematic accuracy were different from those in the hypotheses stated by Keßler and de Groot (Citation2013). According to their hypotheses, versions, users, and confirmations should be negatively related to the dependent variable for positional accuracy, and tag corrections and rollbacks should be positively related because the larger distance between locations of the OSM-NM and public NM data indicates a mismatch between them. Although versions and tag corrections were both statistically significant, versions were positively and tag corrections were negatively related to the dependent variables. Only rollbacks in the consistent case support their hypothesis since rollbacks is positively related to the dependent variable and statistically significant at the 1% level. From these findings, it was inferred that the five trust indicators could hardly represent proxy measures of VGI data quality for positional accuracy. On the other hand, the four indicators of versions, users, tag revisions, and rollbacks were statistically significant at 1% level in all three categories for thematic accuracy. According to the hypotheses of Keßler and de Groot (Citation2013), versions and users should be positively related to the independent variable for thematic accuracy and tag corrections and rollbacks negatively related. However, multiple regression analysis shows that rollbacks were positively related to the independent variable. Conversely, the other statistically significant indicators, versions, users, and tag corrections, were consistent with Keßler and de Groot (Citation2013)’s hypotheses because versions and users were positively related to the independent variable and tag corrections were negatively related. From these findings, we inferred that versions, users and tag corrections were effective trust indicators for thematic accuracy. Consequently, we could not make predictions for positional accuracy using the five trust indicators, but we could make predictions for thematic accuracy.
4.3. Robustness of the trust indicators
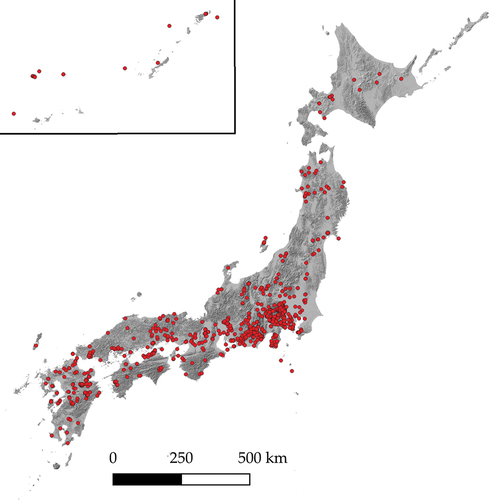
Since versions, users, and tag corrections were the only trust indicators with effects identical to Keßler and de Groot (Citation2013)’s hypotheses, we examined the robustness of these three indicators by comparing their predicted values with observed ones. Using the partial regression coefficients shown in we predicted whether the names of OSM-NM data did or did not match those of the control points. From the OSM-NM data, we extracted 810 OSM-NMJ data that did not have corresponding public NM data but had Japanese names of mountains ().
Figure 2. Distribution of OSM-NMJ data (N = 810).
Of the 810 OSM-NMJ data, 340 in the first nine meshes, i.e. 5238, 5239, 5240, 5338, 5339, 5340, 5438, 5439, 5439, and 5440, were selected for the predictions (). Among the 340 OSM-NMJ data, 86 and 94 control points were included in the mean distance (19.13 m) and the mean distance plus a half of the standard deviation (46.30 m) from the OSM-NMJ data, respectively. The results of the comparison of the observed and predicted values obtained from this data are summarized in . Regarding the observed values, the consistent cases, in which the names of the OSM-NMJ data matched those of control points, are set to 1 and shown in the third row of this table, whereas the inconsistent cases are expressed as 0 and presented in the fourth row. Concerning the predicted values, the consistent cases, in which the results derived from multiple regression analysis were 1, are shown in the third and sixth columns of , whereas the inconsistent cases, in which the predicted values are 0, are placed in the fourth and seventh columns. The predictions were considered correct when both the observed and predicted values have the same number, namely 1 in the upper left cells of both and 0 in the bottom right cells of both tables. Contrarily, the predictions were regarded as incorrect when the observed values differed from the predicted ones; this is shown in the upper right cells and the bottom left cells of . The hit ratios, calculated by dividing correctly predicted cases with the total number of cases (86 for the 19.13 m buffer and 94 for the 46.30 m buffer), were 10.5% and 12.8%. These low ratios indicate that the three trust indicators of versions, users, and tag corrections are less likely to be robust as proxy measures for VGI data quality assessment and so have a lower degree of robustness. Even in the predictions of the names of control points, there were wide discrepancies between these names and those of the OSM-NMJ data, but we should perhaps simply take such discrepancies as data inconsistency.
Figure 3. Distribution of OSM-NMJ data and control points.
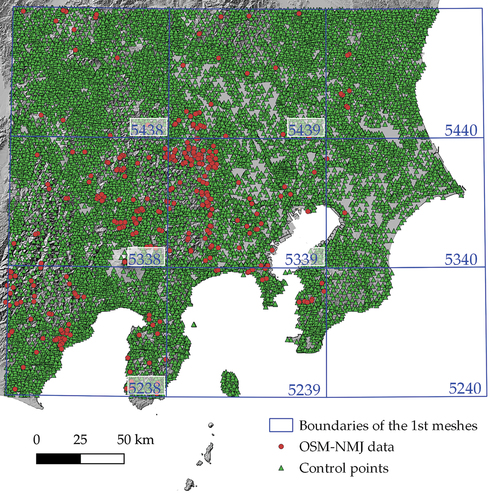
Table 4. Comparison of observations and predictions calculated by the trust indicators for the thematic accuracy.
The lower degree of robustness of versions, users, and tag corrections can be demonstrated by Cohen’s coefficients of agreement, also known as the Kappa coefficients (Cohen Citation1960). These coefficients have been used in previous studies as indicators of VGI data quality (Foody et al. Citation2013; Moreri, Fairbairn, and James Citation2018a) and express the degree of agreement between the observations by two observers of a phenomenon; 0 indicates no agreement, while 1 indicates perfect agreement. The Kappa coefficients for the two cases of the buffer distance of 19.13 m and 46.30 m, shown in , were close to 0 at 0.0024 and 0.0052. Consequently, it is clear that versions, users, and tag corrections could hardly predict reference point data.
5. Discussion
The findings in this study have been discussed from three aspects, namely, the positional and thematic accuracy of VGI, trust indicators as proxy measures of VGI data quality assessment, and the robustness of the trust indicators.
For both positional and thematic accuracy, our results differed from previous VGI studies by highlighting factors related to the data points themselves rather than crowdsourcing. Among previous studies focusing on crowdsourcing, for instance, Haklay et al. (Citation2010) suggested that a small number of VGI contributors may enhance the positional accuracy of VGI, while a large number may adversely affect it. Spielman (Citation2014) also observed that geospatial information generated by some groups of VGI contributors had a higher degree of positional accuracy than the geospatial information generated by other groups. Contrary to these assertions, the reason for the high degree of location accuracy of our OSM-NM data may be due to the uniqueness of the mountain names. For example, the POI data of shops and facilities, such as restaurants and cafes, can be evenly distributed over a geographic space. In contrast to these general POI data, the name data of mountains used in this study refer to only one mountain top. For this reason, it is presumed that the positional accuracy of the OSM-NM data was high.
Our data for thematic accuracy likewise called into question previous emphasis on the roles of contributors of data. Foody et al. (Citation2013), for instance, noted that while a small number of contributors yielded highly accurate VGI, the majority of contributors produced less accurate VGI. Contrary to this assertion, the reason for the high thematic accuracy of OSM-NM data in this study is that mountain names are used for common, single landmarks where there would be little fluctuation in notation, in contrast to the naming of restaurants, cafes and other POIs. For this reason, it is inferred that the names of the mountains in the OSM-NM data were not significantly different from those in the official NM data. As mentioned above, although there was a blurring of Kanji and Romanization, the names of the mountains did not differ greatly between the OSM-NM and official NM data.
The results of this study on the three trust indicators, namely versions, users, and tag corrections, support previous studies. First, the validity of users as a trust indicator is in line with the aforementioned sources examining crowdsourcing. The reason for this is that crowdsourcing assumes that a larger number of users leads to greater thematic accuracy, and this hypothesis was tested in this study by comparing the public NM data with the OSM-NM data. Although not validated by the comparison of public NM and OSM-NM data, one can also imagine that in the context of crowdsourcing approach, an increase in the number of versions as well as users could lead to an increase in the thematic accuracy. With regard to tag corrections, Mooney and Corcoran (Citation2012) pointed out that overly edited objects contain problems with respect to geospatial data accuracy. This means that the fewer times the tag is edited, the more accurate the geospatial information is. This is consistent with the findings of this study.
However, our findings on the robustness of versions, users, and tag corrections contradict some previous studies and confirm others. For versions, while several previous studies had found a positive relationship between the number of versions and VGI accuracy (Keßler and de Groot Citation2013; D’Antonio, Fogliaroni, and Kauppinen Citation2014; Zhao et al. Citation2016; Touya et al. Citation2017), we found low robustness with Kappa coefficients close to 0. Our results may differ from these previous studies because the most recently created version does not always offer the most accurate geospatial information. Consequently, our study reinforces the proposal by Nasiri et al. (Citation2018) of a data-cleaning program identifying outliers among OSM data and removing them. To improve the robustness of trust indicators, it is necessary to use the most accurate versions rather than simply the most recent ones.
Likewise, for users, our results challenged as well as reinforced previous studies. Although some studies have found a positive correlation between the number of contributors and VGI accuracy (Girres and Touya Citation2010; Haklay et al. Citation2010; Keßler and de Groot Citation2013; Foody et al. Citation2015; Delmelle et al. Citation2019), we determined a low degree of robustness for users as a trust indicator. This low degree of robustness may have occurred because we focused on the number of contributors and did not consider contributor motivations and characteristics (Coleman, Georgiadou, and Labonte Citation2009; Olteanu-Raimond et al. Citation2017) in order to isolate the question of the robustness of the trust indicators presented by Keßler and de Groot (Citation2013). For instance, Sehra, Singh, and Rai (Citation2017) found that higher contributor motivation resulted in higher VGI accuracy, and Kashian et al. (Citation2019) as well as Truong, de Runz, and Touya (Citation2019) have shown how contributor characteristics, such as skill level, can affect VGI accuracy. Therefore, to increase the robustness of users as a trust indicator, it is necessary to take into account the motivations and characteristics of contributors.
Third, our findings on tag corrections contradicted those of Keßler and de Groot (Citation2013) but reinforced more recent studies. As a result, we did not find the negative correlation between the number of times a tag was corrected and the accuracy of VGI that Keßler and de Groot (Citation2013) had assumed. This may have occurred because of the low accuracy of the tags themselves. From the low accuracy of the tags, it could be inferred that a small number of tag corrections does not always represent VGI thematic accuracy, and in turn, that a negative correlation between them could not be statistically detected. Like our study, that of Davidovic et al. (Citation2016) found that tagging was not perfect for OSM data. Similarly, Vandecasteele and Devillers (Citation2015) showed that with OSM Semantic, a JOSM plugin, wrong tagging by contributors can be avoided, thus increasing the thematic accuracy of VGI. Therefore, as our study also suggests, in order to improve the robustness of the trust indicator, it is necessary to use correctly given tags rather than simply the number of tag corrections.
Compared with the existing tools for the quality assessment of VGI, the indicators in this study have several advantages. First, one such existing tool is the iOSMAnalyser, which evaluates data quality of OSM using its intrinsic characteristics (Barron, Neis, and Zipf Citation2014). The iOSMAnalyser, which consists of six components, has the advantage over a comprehensive evaluation of OSM data quality. However, the analysis is limited to small regions. Contrarily, the indicators presented in this study can handle large regions, as in the case study of all of Japan. Another tool is the OSMantic, a plugin of JOSM (Vandecasteele and Devillers Citation2015), which automatically suggests “relevant” tags to OSM contributors during the editing process of OSM. However, it suggests only “relevant” and not accurate tags. Contrarily, the thematic accuracy of OSM can be verified using the indicators in this study. Finally, Sehra, Singh, and Rai (Citation2017) developed an extension of the QGIS processing toolbox to assess the OSM data quality. Nevertheless, usage of this extension is restricted to compare two time points for line features only. Contrarily, the indicators in this study can be used to analyze multiple time points. Moreover, as mentioned in the third chapter, the discrepancy between the results of the present study and those of the previous studies may partly be due to the multiple regression analysis used in this study.
6. Conclusions
The purposes of this article were threefold: to confirm the data quality of target VGI, namely of mountain peaks in Japan; to examine the validity of the five trust indicators presented by Keßler and de Groot (Citation2013) as proxy measures for securing VGI data quality; and to evaluate the robustness of these trust indicators. While both positional and thematic accuracy of the OSM data were high, multiple regression analysis showed that all five trust indicators could not be considered as proxy measures guaranteeing VGI data quality; only versions, users, and tag corrections for thematic accuracy could potentially be effective guarantees of trustworthiness. However, the weak prediction of the control point data by these three trust indicators indicates less robustness as proxy measures for trustworthiness of VGI data. The results of this study may be limited by the use of OSM peak data with a specific Japanese notation, therefore, it was concluded that these three indicators are less likely to be robust as trust measures for VGI data quality. As mentioned in the Section 4.1.1, the Japanese notation was considered to have a particularly strong influence on the thematic accuracy of the OSM-NM data. More specifically, such influence was derived from Japanese kanji characters, such as the differences in written Japanese characters, and also from the regional Japanese names to the names of peaks.
Since only three trust indicators were effective at predicting accuracy, the results of our study suggest that there is room to develop new indicators of trust based on other features rather than VGI-specific ones. There are two directions for developing new indicators. The first is to investigate the usefulness of the social approach based on external evaluators of the VGI (Goodchild and Li Citation2012; Moreri, Fairbairn, and James Citation2018b) because results of the present study showed that it was hard to guarantee VGI data quality from only VGI-specific features. The second is to empirically evaluate VGI data quality using other data quality indicators, such as reputations, which are also independent from VGI-specific characteristics (Bordogna et al. Citation2014).
In addition, this study raises the possibility of rethinking the relationship between VGI and geospatial data authorized by the NMAs. We treated the names of control points (from public data) as “true values”; if the name of an OSM-NMJ datum did not agree with a control point, we judged it to be incorrect. In coexisting situations of a “true” tag, such as a name of a peak given by an NMA, with other “false” tags for the same feature by VGI contributors, it is suggested that quality assessment research for geospatial information should be conducted from an ontological perspective (Mocnik et al. Citation2018). However, instead of treating such names as incorrect, VGI data may offer new information and so could coexist with public data. In the same vein, Brovelli and Zamboni (Citation2018) have noted that approximately 9% of all building data exists only in OSM data, and so, OSM data can be integrated with geospatial data authorized by the NMAs, rather than assuming that the public data are complete. Ghaffarian et al. (Citation2019) have also stressed such integrated usage of public data with VGI represented by OSM. In other words, geographic information with multiple tags rather than a single one suggests the need for a VGI study from a viewpoint of folksonomy (Mocnik, Zipf, and Raifer Citation2017). In line with folksonomy, VGI contributors could add new tags to a tag, such as the name of a mountain given by an NMA. Therefore, further studies on integrated usage of geospatial data authorized by the NMAs with VGI, mainly OSM, should be conducted in future studies.
Data availability statement
The data that support the findings of the study are openly available in the following repositories at the given URLs:
1. Planet OSM: Available online: https://planet.openstreetmap.org/planet/full-history/
2. The Geospatial Information Authority of Japan (GSI)‘s experimental project of vector-tile geospatial data provision: https://github.com/gsi-cyberjapan/experimental_pni
3. The Fundamental Geospatial Data Download Service (in Japanese): https://fgd.gsi.go.jp/download/menu.php
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Jun Yamashita
Jun Yamashita is a professor at the Faculty of Social and Cultural Studies, Kyushu University, Fukuoka, Japan. His research interests lie in the volunteered geographical information, sustainable urban development and sustainability transitions.
Toshikazu Seto
Toshikazu Seto is an associate professor at the Faculty of Letters, Komazawa University, Tokyo, Japan. He has research interests in the volunteered geographic information, participatory GIS, civic tech and open data.
Nobusuke Iwasaki
Nobusuke Iwasaki is a principal researcher at the Institute for Agro-Environmental Sciences, NARO, Tsukuba, Japan. His research interests are rural planning, open data, and free and open source software for geospatial (FOSS4G).
Yuichiro Nishimura
Yuichiro Nishimura is a professor at the Faculty of Letters, Nara Women’s University, Nara, Japan. He has research interests in the participatory mapping, participatory GIS, critical GIS and counter-mapping.
Notes
1. Overview – Harmonized European Time Use Surveys (HETUS): https://ec.europa.eu/eurostat/web/time-use-surveys/overview (accessed on 31 May 2021).
2. 2020 Outdoor Participation Report: https://oia.outdoorindustry.org/l/51282/2021-02-10/df3jyq/51282/16129789342ob5nHjC/20_OIA_007_Participation_Report_FINAL.pdf (accessed 31 May 2021).
3. Participation in outdoor activities: https://www150.statcan.gc.ca/t1/tbl1/en/tv.action?pid=3810012101 (accessed on 31 May 2021).
4. Big Data Contributes to Safer Mountain Climbing. Available online: https://www.gsi.go.jp/kokusaikoryu/kokusaikoryu-e31022.html (accessed on 31 May 2021).
5. Along with the credibility, reputation, and trust (or trustworthiness), Ballatore and Zipf (Citation2015) identified six other data quality indicators for VGI: accuracy, completeness, compliance, consistency, granularity, and richness. Among them, accuracy, completeness, and consistency are included in the categories of data quality in the ISO 19,157:2013. To assure the data quality of VGI, Almendros-Jiménez and Becerra-Terón (Citation2018) pointed out further consideration of the rest of indicators, namely, compliance, granularity, and richness.
6. Planet OSM. Available online: https://planet.openstreetmap.org/planet/full-history/(accessed on 31 May 2021).
7. gsi-cyberjapan/experimental_pni. Available online: https://github.com/gsi-cyberjapan/experimental_pni (accessed on 31 May 2021).
8. Fundamental Geospatial Data Download Service (in Japanese). Available online: https://fgd.gsi.go.jp/download/menu.php (accessed on 31 May 2021).
References
- Acheson, E., S. De Sabbata, and R. S. Purves. 2017. “A Quantitative Analysis of Global Gazetteers: Patterns of Coverage for Common Feature Types.” Computers, Environment and Urban Systems 64: 309–320. doi:10.1016/j.compenvurbsys.2017.03.007.
- Almendros-Jiménez, J. M., and A. Becerra-Terón. 2018. “Analyzing the Tagging Quality of the Spanish OpenStreetmap.” ISPRS International Journal of Geo-Information 7 (8): 323. doi:10.3390/ijgi7080323.
- Ballantyne, M., and C. M. Pickering. 2015. “The Impacts of Trail Infrastructure on Vegetation and Soils: Current Literature and Future Directions.” Journal of Environmental Management 164: 53–64. doi:10.1016/j.jenvman.2015.08.032.
- Ballatore, A., and A. Zipf. 2015. “A Conceptual Quality Framework for Volunteered Geographic Information.” In Spatial Information Theory, edited by S. I. Fabrikant, M. Raubal, M. Bertolotto, C. Davies, S. Freundschuh, and S. Bell, 89–107. Cham: Springer. doi:10.1007/978-3-319-23374-1_5.
- Barron, C., P. Neis, and A. Zipf. 2014. “A Comprehensive Framework for Intrinsic OpenStreetmap Quality Analysis: A Comprehensive Framework for Intrinsic OpenStreetmap Quality Analysis.” Transactions in GIS 18 (6): 877–895. doi:10.1111/tgis.12073.
- Bégin, D. 2012. “Towards Integrating VGI and National Mapping Agency Operations – a Canadian Case Study.” In Paper presented at the Role of Volunteer Geographic Information in Advancing Science: Quality and Credibility Workshop, GIScience Conference, Columbus, Ohio, USA, September 18.
- Bishr, M., and W. Kuhn. 2007. “Geospatial Information Bottom-Up: A Matter of Trust and Semantics.” In The European Information Society, edited by S. I. Fabrikant and M. Wachowicz, 365–387. Berlin: Springer. doi:10.1007/978-3-540-72385-1_22.
- Bishr, M., and K. Janowicz. 2010. “Can We Trust Information? – the Case of Volunteered Geographic Information.” Accessed June 30, 2021. http://ceur-ws.org/Vol-640/paper3.pdf.
- Bordogna, G., P. Carrara, L. Criscuolo, M. Pepe, and A. Rampini. 2014. “A Linguistic Decision Making Approach to Assess the Quality of Volunteer Geographic Information for Citizen Science.” Information Sciences 258: 312–327. doi:10.1016/j.ins.2013.07.013.
- Brovelli, M., and G. Zamboni. 2018. “A New Method for the Assessment of Spatial Accuracy and Completeness of OpenStreetmap Building Footprints.” ISPRS International Journal of Geo-Information 7 (8): 289. doi:10.3390/ijgi7080289.
- Brown, K. M. 2014. “Spaces of Play, Spaces of Responsibility: Creating Dichotomous Geographies of Outdoor Citizenship.” Geoforum 55: 22–32. doi:10.1016/j.geoforum.2014.05.002.
- Brown, G., and M. Kyttä. 2018. “Key Issues and Priorities in Participatory Mapping: Toward Integration or Increased Specialization?” Applied Geography 95: 1–8. doi:10.1016/j.apgeog.2018.04.002.
- Cohen, J. 1960. “A Coefficient of Agreement for Nominal Scales.” Educational and Psychological Measurement 20 (1): 37–46. doi:10.1177/001316446002000104.
- Coleman, D., Y. Georgiadou, and J. Labonte. 2009. “Volunteered Geographic Information: The Nature and Motivation of Producers.” International Journal of Spatial Data Infrastructures Research 4 (4): 332–358.
- D’-Antonio, F., P. Fogliaroni, and T. Kauppinen. 2014. “VGI Edit History Reveals Data Trustworthiness and User Reputation.” In Paper presented at the Proceedings of the AGILE’2014 International Conference on Geographic Information Science, Castellón, Spain, June 3-6, 1–4. AGILE Digital Editions. http://repositori.uji.es/xmlui/handle/10234/98921.
- Davidovic, N., P. Mooney, L. Stoimenov, and M. Minghini. 2016. “Tagging in Volunteered Geographic Information: An Analysis of Tagging Practices for Cities and Urban Regions in OpenStreetmap.” ISPRS International Journal of Geo-Information 5 (12): 232. doi:10.3390/ijgi5120232.
- Delmelle, E. M., D. M. Marsh, C. Dony, and P. L. Delamater. 2019. “Travel Impedance Agreement Among Online Road Network Data Providers.” International Journal of Geographical Information Science 33 (6): 1251–1269. doi:10.1080/13658816.2018.1557662.
- Du, H., S. Anand, N. Alechina, J. Morley, G. Hart, D. Leibovici, M. Jackson, and M. Ware. 2012. “Geospatial Information Integration for Authoritative and Crowd Sourced Road Vector Data.” Transactions in GIS 16 (4): 455–476. doi:10.1111/j.1467-9671.2012.01303.x.
- Fogliaroni, P., F. D’-Antonio, and E. Clementini. 2018. “Data Trustworthiness and User Reputation as Indicators of VGI Quality.” Geo-Spatial Information Science 21 (3): 213–233. doi:10.1080/10095020.2018.1496556.
- Foody, G. M., L. See, S. Fritz, M. Van der Velde, C. Perger, C. Schill, and D. S. Boyd. 2013. “Assessing the Accuracy of Volunteered Geographic Information Arising from Multiple Contributors to an Internet Based Collaborative Project: Accuracy of VGI.” Transactions in GIS 17 (6): 847–860. doi:10.1111/tgis.12033.
- Foody, G. M., L. See, S. Fritz, M. van der Velde, C. Perger, C. Schill, D. S. Boyd, and A. Comber. 2015. “Accurate Attribute Mapping from Volunteered Geographic Information: Issues of Volunteer Quantity and Quality.” The Cartographic Journal 52 (4): 336–344. doi:10.1080/00087041.2015.1108658.
- Foody, G., L. See, S. Fritz, P. Mooney, A.-M. Olteanu-Raimond, C. Costa Fonte, and V. Antoniou. 2017. Mapping and the Citizen Sensor. London: Ubiquity Press. doi:10.5334/bbf.
- Gao, S., L. Li, W. Li, K. Janowicz, and Y. Zhang. 2017. “Constructing Gazetteers from Volunteered Big Geo-Data Based on Hadoop.” Computers, Environment and Urban Systems 61: 172–186. doi:10.1016/j.compenvurbsys.2014.02.004.
- Ghaffarian, S., N. Kerle, E. Pasolli, and J. J. Arsanjani. 2019. “Post-Disaster Building Database Updating Using Automated Deep Learning: An Integration of Pre-Disaster OpenStreetmap and Multi-Temporal Satellite Data.” Remote Sensing 11 (20): 2427. doi:10.3390/rs11202427.
- Girres, J.-F., and G. Touya. 2010. “Quality Assessment of the French OpenStreetmap Dataset.” Transactions in GIS 14 (4): 435–459. doi:10.1111/j.1467-9671.2010.01203.x.
- Golbeck, J. 2008. “Computer Science: Weaving a Web of Trust.” Science 321 (5896): 1640–1641. doi:10.1126/science.1163357.
- Goodchild, M. F., and L. Li. 2012. “Assuring the Quality of Volunteered Geographic Information.” Spatial Statistics 1: 110–120. doi:10.1016/j.spasta.2012.03.002.
- Haklay, M. 2010. “How Good is Volunteered Geographical Information? a Comparative Study of OpenStreetmap and Ordnance Survey Datasets.” Environment and Planning B, Planning & Design 37 (4): 682–703. doi:10.1068/b35097.
- Haklay, M., S. Basiouka, V. Antoniou, and A. Ather. 2010. “How Many Volunteers Does It Take to Map an Area Well? the Validity of Linus’ Law to Volunteered Geographic Information.” The Cartographic Journal 47 (4): 315–322. doi:10.1179/000870410X12911304958827.
- Haworth, B. T. 2018. “Implications of Volunteered Geographic Information for Disaster Management and Giscience: A More Complex World of Volunteered Geography.” Annals of the American Association of Geographers 108 (1): 226–240. doi:10.1080/24694452.2017.1321979.
- Ivanovic, S. S., A.-M. Olteanu-Raimond, S. Mustière, and T. Devogele. 2020. “Potential of Crowdsourced Traces for Detecting Updates in Authoritative Geographic Data.” In Geospatial Technologies for Local and Regional Development, edited by P. Kyriakidis, D. Hadjimitsis, D. Skarlatos, and A. Mansourian, 205–221. Cham: Springer. doi:10.1007/978-3-030-14745-7_12.
- Jackson, S., W. Mullen, P. Agouris, A. Crooks, A. Croitoru, and A. Stefanidis. 2013. “Assessing Completeness and Spatial Error of Features in Volunteered Geographic Information.” ISPRS International Journal of Geo-Information 2 (2): 507–530. doi:10.3390/ijgi2020507.
- Kashian, A., A. Rajabifard, K.-F. Richter, and Y. Chen. 2019. “Automatic Analysis of Positional Plausibility for Points of Interest in OpenStreetmap Using Coexistence Patterns.” International Journal of Geographical Information Science 33 (7): 1420–1443. doi:10.1080/13658816.2019.1584803.
- Keßler, C., and R. T. A. de Groot. 2013. “Trust as a Proxy Measure for the Quality of Volunteered Geographic Information in the Case of OpenStreetmap.” In Geographic Information Science at the Heart of Europe, edited by D. Vandenbroucke, B. Bucher, and J. Crompvoets, 21–37. Cham: Springer. doi:10.1007/978-3-319-00615-4_2.
- Kil, N., T. V. Stein, and S. M. Holland. 2014. “Influences of Wildland–urban Interface and Wildland Hiking Areas on Experiential Recreation Outcomes and Environmental Setting Preferences.” Landscape and Urban Planning 127: 1–12. doi:10.1016/j.landurbplan.2014.04.004.
- Maidaneh, A., I. A. Le Guilcher, and A.-M. Olteanu-Raimond. 2020. “A Regression Model for Spatial Accuracy Prediction for OpenStreetmap Buildings.” ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences 4: 39–47. doi:10.5194/isprs-annals-V-4-2020-39-2020.
- Mocnik, F.-B., A. Zipf, and M. Raifer. 2017. “The OpenStreetmap Folksonomy and Its Evolution.” Geo-Spatial Information Science 20 (3): 219–230. doi:10.1080/10095020.2017.1368193.
- Mocnik, F.-B., A. Mobasheri, L. Griesbaum, M. Eckle, C. Jacobs, and C. Klonner. 2018. “A Grounding-Based Ontology of Data Quality Measures.” Journal of Spatial Information Science 16: 1–25. doi:10.5311/JOSIS.2018.16.360.
- Mohammadi, N., and M. Malek. 2015. “Artificial Intelligence-Based Solution to Estimate the Spatial Accuracy of Volunteered Geographic Data.” Journal of Spatial Science 60 (1): 119–135. doi:10.1080/14498596.2014.927337.
- Mooney, P., and P. Corcoran. 2012. “The Annotation Process in OpenStreetmap.” Transactions in GIS 16 (4): 561–579. doi:10.1111/j.1467-9671.2012.01306.x.
- Mooney, P., J. Crompvoets, and R. Lemmens. 2018. “Crowdsourcing in National Mapping – a Workshop Report.” Accessed June 30, 2021. http://www.eurosdr.net/publications/workshop-report-crowdsourcing-national-mapping-2020.
- Moreri, K., D. Fairbairn, and P. James. 2018a. “Issues in Developing a Fit for Purpose System for Incorporating VGI in Land Administration in Botswana.” Land Use Policy 77: 402–411. doi:10.1016/j.landusepol.2018.05.063.
- Moreri, K. K., D. Fairbairn, and P. James. 2018b. “Volunteered Geographic Information Quality Assessment Using Trust and Reputation Modelling in Land Administration Systems in Developing Countries.” International Journal of Geographical Information Science 32 (5): 931–959. doi:10.1080/13658816.2017.1409353.
- Muttaqien, B. I., F. O. Ostermann, and R. L. G. Lemmens. 2018. “Modeling Aggregated Expertise of User Contributions to Assess the Credibility of OpenStreetmap Features.” Transactions in GIS 22 (3): 823–841. doi:10.1111/tgis.12454.
- Nasiri, A., R. A. Abbaspour, A. Chehreghan, and J. J. Arsanjani. 2018. “Improving the Quality of Citizen Contributed Geodata Through Their Historical Contributions: The Case of the Road Network in OpenStreetmap.” ISPRS International Journal of Geo-Information 7 (7): 253. doi:10.3390/ijgi7070253.
- Norman, P., C. M. Pickering, and G. Castley. 2019. “What Can Volunteered Geographic Information Tell Us About the Different Ways Mountain Bikers, Runners and Walkers Use Urban Reserves?” Landscape and Urban Planning 185: 180–190. doi:10.1016/j.landurbplan.2019.02.015.
- Olteanu-Raimond, A.-M., G. Hart, G. M. Foody, G. Touya, T. Kellenberger, and D. Demetriou. 2017. “The Scale of VGI in Map Production: A Perspective on European National Mapping Agencies.” Transactions in GIS 21 (1): 74–90. doi:10.1111/tgis.12189.
- Parker, C. J., A. May, and V. Mitchell. 2013. “The Role of VGI and PGI in Supporting Outdoor Activities.” Applied Ergonomics 44 (6): 886–894. doi:10.1016/j.apergo.2012.04.013.
- Raymond, E. S. 1999. The Cathedral and the Bazaar: Musings on Linux and Open Source by an Accidental Revolutionary. Cambridge, Mass: Oreilly & Associates Inc.
- Rönneberg, M., M. Laakso, and T. Sarjakoski. 2019. “Map Gretel: Social Map Service Supporting a National Mapping Agency in Data Collection.” Journal of Geographical Systems 21 (1): 43–59. doi:10.1007/s10109-018-0288-z.
- Sehra, S., J. Singh, and H. S. Rai. 2017. “Assessing OpenStreetmap Data Using Intrinsic Quality Indicators: An Extension to the QGIS Processing Toolbox.” Future Internet 9 (2): 15. doi:10.3390/fi9020015.
- Senaratne, H., A. Mobasheri, A. L. Ali, C. Capineri, and M. Haklay. 2017. “A Review of Volunteered Geographic Information Quality Assessment Methods.” International Journal of Geographical Information Science 31 (1): 139–167. doi:10.1080/13658816.2016.1189556.
- Seto, T., H. Kanasugi, and Y. Nishimura. 2020. “Quality Verification of Volunteered Geographic Information Using OSM Notes Data in a Global Context.” ISPRS International Journal of Geo-Information 9 (6): 372. doi:10.3390/ijgi9060372.
- Severinsen, J., M. de Roiste, F. Reitsma, and E. Hartato. 2019. “Vgtrust: Measuring Trust for Volunteered Geographic Information.” International Journal of Geographical Information Science 33 (8): 1683–1701. doi:10.1080/13658816.2019.1572893.
- Spielman, S.E. 2014. “Spatial Collective Intelligence? Credibility, Accuracy, and Volunteered Geographic Information.” Cartography and Geographic Information Science 41 (2): 115–124. doi:10.1080/15230406.2013.874200.
- Statistics Bureau of Japan. 2012. “2011 Survey on Time Use and Leisure Activities.” Accessed June 30, 2021. https://www.stat.go.jp/english/data/shakai/2011/h23kekka.html.
- Statistics Bureau of Japan. 2017. “2016 Survey on Time Use and Leisure Activities.” Accessed June 30, 2021. https://www.stat.go.jp/english/data/shakai/2016/h28kekka.html.
- Sztompka, P. 1999. Trust: A Sociological Theory. Cambridge: Cambridge University Press.
- Touya, G., V. Antoniou, A.-M. Olteanu-Raimond, and M.-D. Van Damme. 2017. “Assessing Crowdsourced POI Quality: Combining Methods Based on Reference Data, History, and Spatial Relations.” ISPRS International Journal of Geo-Information 6 (3): 80. doi:10.3390/ijgi6030080.
- Truong, Q. T., C. de Runz, and G. Touya. 2019. “Analysis of Collaboration Networks in OpenStreetmap Through Weighted Social Multigraph Mining.” International Journal of Geographical Information Science 33 (8): 1651–1682. doi:10.1080/13658816.2018.1556395.
- Vahidi, H., B. Klinkenberg, and W. Yan. 2017. “A Fuzzy System for Quality Assurance of Crowdsourced Wildlife Observation Geodata.” In Paper presented at the Proceedings of the 2017 International Electronics Symposium on Knowledge Creation and Intelligent Computing (IES-KCIC), Surabaya, Indonesia, September 26-27, 55–58. doi:10.1109/KCIC.2017.8228563.
- Van Damme, M.-D., A.-M. Olteanu-Raimond, and Y. Méneroux. 2019. “Potential of Crowdsourced Data for Integrating Landmarks and Routes for Rescue in Mountain Areas.” International Journal of Cartography 5 (2–3): 195–213. doi:10.1080/23729333.2019.1615730.
- Vandecasteele, A., and R. Devillers. 2015. “Improving Volunteered Geographic Information Quality Using a Tag Recommender System: The Case of OpenStreetmap.” In OpenStreetmap in Giscience: Experiences, Research, and Applications, edited by J. J. Arsanjani, A. Zipf, P. Mooney, and M. Helbich, 59–80. Cham: Springer. doi:10.1007/978-3-319-14280-7_4.
- Wang, S., Y. Wang, and Y. Li. 2015. “Efficient Map Reconstruction and Augmentation via Topological Methods.” In Paper presented at the Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems - GIS ’15, Seattle, USA, November 3-6, 1–10. doi:10.1145/2820783.2820833.
- Xu, Y., Z. Chen, Z. Xie, and L. Wu. 2017. “Quality Assessment of Building Footprint Data Using a Deep Autoencoder Network.” International Journal of Geographical Information Science 31 (10): 1929–1951. doi:10.1080/13658816.2017.1341632.
- Yamashita, J., T. Seto, Y. Nishimura, and N. Iwasaki. 2019. “VGI Contributors’ Awareness of Geographic Information Quality and Its Effect on Data Quality: A Case Study from Japan.” International Journal of Cartography 5 (2–3): 214–224. doi:10.1080/23729333.2019.1613086.
- Yan, Y., C.-C. Feng, and Y.-C. Wang. 2017. “Utilizing Fuzzy Set Theory to Assure the Quality of Volunteered Geographic Information.” GeoJournal 82 (3): 517–532. doi:10.1007/s10708-016-9699-x.
- Zhang, M., B. Zhang, and H. Fan. 2018. “An Automatic Data Integration Approach to Enrich ATKIS with the VGI of Outdoor-Sports Data.” Arabian Journal of Geosciences 11 (17): 486. doi:10.1007/s12517-018-3849-z.
- Zhao, Y., X. Zhou, G. Li, and H. Xing. 2016. “A Spatio-Temporal VGI Model Considering Trust-Related Information.” ISPRS International Journal of Geo-Information 5 (2): 10. doi:10.3390/ijgi5020010.