
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
LiDAR devices are capable of acquiring clouds of 3D points reflecting any object around them, and adding additional attributes to each point such as color, position, time, etc. LiDAR datasets are usually large, and compressed data formats (e.g. LAZ) have been proposed over the years. These formats are capable of transparently decompressing portions of the data, but they are not focused on solving general queries over the data. In contrast to that traditional approach, a new recent research line focuses on designing data structures that combine compression and indexation, allowing directly querying the compressed data. Compression is used to fit the data structure in main memory all the time, thus getting rid of disk accesses, and indexation is used to query the compressed data as fast as querying the uncompressed data. In this paper, we present the first data structure capable of losslessly compressing point clouds that have attributes and jointly indexing all three dimensions of space and attribute values. Our method is able to run range queries and attribute queries up to 100 times faster than previous methods.
1. Introduction
By scanning the entire field of view with a laser beam at a high speed, a LiDAR sensor produces a dense cloud of points that can be used to determine the 3D geometry of the objects around the sensor. The cost of LiDAR sensors has dropped dramatically in recent years. Hence, they have been included in autonomous cars (Royo and Ballesta-Garcia Citation2019) to map the environment and identify obstacles or in consumer devices such as the 2020 iPad Pro to more accurately focus images and videos in low-light conditions and reduce capture time.Footnote1 As a result, the applications that use LiDAR-acquired point clouds are increasing, and thus, large data sets are being produced that require large computational resources to be processed.
In this work, we focus on LiDAR data, but it can be generalized to any scenario where i) we need to store point clouds in the 3D space, ii) those points have attribute values, such as color, intensity, scan angle, etc., and iii) it is relevant to query those data combining the 3D space and the attribute values associated with the points. Traditionally, compression of point clouds is tied to image compression, but in this field, the aforementioned query capacity is not supported.
In the traditional setup, data reside on disk. Every time a given datum is desired, an I/O transfer between disk and main memory is required, which is extremely slow when compared to CPU speeds. Although important improvements in processors and parallel computing are appearing, disk accesses still represent a bottleneck. Moreover, the increase in the size of the datasets requires the development of new strategies to obtain also improvements in processing time or scalability. Hence, many approaches that compress the data have appeared not only to save disk space but also to reduce transmission time in networks.
Dewitt et al. (Citation1984) proposed to get rid of disk accesses in database management systems and keep all data in main memory all the time. This gave rise to a new line of research called “in-memory data management” (Plattner Citation2009; Plattner and Zeier Citation2012). Although main memory is getting cheaper, thus, allowing more data to be represented and processed in main memory, the size of current datasets is growing at a faster pace. This has promoted the use of compression with the goal of fitting larger datasets in main memory. From a compression point of view, the compression methods for this scenario must have different characteristics with respect to classic archival methods. In particular, access to the data must be very fast so as not to impair processing times. That is, compression and decompression times are now more important than a high compression capability.
With this goal in mind, a new research field called compact data structures (Navarro Citation2016) has emerged. These are compression methods that go one step further. The traditional methods require decompressing large parts of the dataset when a given datum is needed (e.g. compressing a column of a table using traditional algorithms such as deflate requires decompressing the whole column when a value is required). In compact data structures, the desired data can be accessed without any previous decompression. This speeds up access times. Moreover, to match the access times of uncompressed data structures, compact data structures are usually equipped with indexes within the compressed data, and the index itself is also compressed.
In this paper, we present two compact data structures to store point clouds having additional attributes: and
. They reside in main memory all the time and thus they do not access the disk. In addition, they index all dimensions, the space, and the attributes, so that they obtain remarkable query times. The trade-off is a lower performance in information compression.
The rest of the paper is structured as follows. Section 2 describes the LAS and LAZ file formats and the background knowledge required to understand our data structures. Section 3 describes the to represent point clouds including a 3D spatial index. Section 4 describes the
that includes and additional index over the attributes. Section 5 presents an evaluation of the data structures comparing their time and space requirements against the LAZ file format. Finally, Section 6 presents the conclusions and future work.
2. Related work
2.1. LiDAR
LiDAR (Light Detection and Ranging) technology has been used to classify and recognize objects in many different application fields during the last four decades (Dong and Chen Citation2017). LiDAR sensors work by shooting a laser beam that is reflected by nearby objects and the time it takes for the reflection of the beam to return is used to compute the location of a point in the 3D space. Furthermore, additional information can be attached to the point, such as the intensity of the reflection, the georeferenced position of the point if the sensor includes a GPS sensor or an inertial navigation system, or the color of the point if the sensor includes a visible-light sensor.
LiDAR point clouds are used, for example, to classify and recognize objects in the natural environment (e.g. forests (Hyyppa et al. Citation2018), landslides (Jaboyedoff et al. Citation2012)), in urban environments (Wang, Peethambaran, and Chen Citation2018), or even underwater (Palomer et al. Citation2018). The following sections describe the LAS and LAZ formats that are commonly used to store and process LiDAR point clouds.
2.1.1. LAS and LAZ formats
The American Society for Photogrammetry and Remote Sensing (Citation2019) defined the LASer (LAS) file format to store clouds of LiDAR points. It is an open binary format composed of a header block that describes general information about the point cloud (e.g. number of points, bounding box, etc.), optional variable-length records to describe additional information such as georeferencing information or other metadata, and fixed-length point records. There are eleven types of these point records. Each type includes coordinates (i.e. ,
, and
), and several other attributes, such as the intensity, color, time, etc. The exact additional values depend on the record type.
Even though the coordinates are stored as scaled and offset integers, LAS files are usually large. Therefore, a lossless compressed version of the LAS file format, called LAZ or LASzip (Isenburg Citation2013), was defined.
Using common point compression terminology, LAZ is a lossless, non-progressive, streaming, and order-preserving compressor. Non-progressive means that it is not capable of providing a faster lower resolution image; streaming means that it is capable of compressing the data as they arrive, that is, it does not need to have all the points before starting the compression; order-preserving means that it keeps the original order of the points. Additionally, LAZ provides, to some extent, random access, that is, LAZ is capable of decompressing parts of the data without having to start the decompression from the beginning.
The LAZ file format independently compresses points in chunks of 50,000 points, by default. This can be configured, yielding different compression levels, but (Isenburg Citation2013) advises values between 5,000 and 50,000. A chunk table at the end of the compressed file gives the position of the initial byte of the chunk in the original uncompressed array.
LAZ neither compresses the header nor the variable-length records. These parts are small and barely compressible. For compressing the ,
, and
coordinates, each chunk stores the first point uncompressed, and the rest are compressed with a context-based arithmetic compressor (Ida Mengyi Citation2006). Instead of compressing the absolute coordinates, for a given point, it compresses the difference between the actual value and a prediction based on the previous points. This is the key factor causing LAZ to not have real random access. To decompress a given point, LAZ needs to have the previous points uncompressed up to the first uncompressed point of the chunk. However, each chunk can be decompressed independently, and thus, unlike traditional compression methods, it allows, to some extent, random access decompression. To obtain a given point or set of points, we can only decompress the chunks where they are located. Moreover, range (cube) queries can be solved by storing the bounding box of each chunk, in the chunk table. Regarding the attributes, each one has its own compression method, but some of them also need to have the uncompressed versions of the previous points.
The LAZ file format obtains notable results in compression, achieving compression ratios similar to or better than general-purpose compressors such as ZIP or RAR. In addition, since LAZ does not alter the original order and it does not use an octree, it can start the compression as the points arrive. This type of compression yields a low memory footprint because once the points are compressed they can be output to disk, freeing up the main memory.
2.1.2. LAS index
One advantage of the LAZ file format is that the response times can be improved thanks to the possibility of adding an adaptive quadtree that indexes the points, which is called LASindex or LAX (Isenburg Citation2012). The setup of this index is the traditional. Data are arranged in a sequence of fixed-length records, that is, an array of records. Even if we compress the LAS records into a LAZ format, conceptually, it is an array of records. The LAX index is an auxiliary structure, an ordinary quadtree, that is, it only indexes the and
coordinates. The leaves of the quadtree contain i) the number of points within the region corresponding to that leaf, ii) the number of intervals, and iii) the list of intervals. The number of intervals in each leaf cannot be determined, due to the order preserving approach used by LAZ, that is, points are not arranged in the array according to the spatial position, but according to how they arrived in the compression process.
Figure 1. The setup of LAZ and LAX.
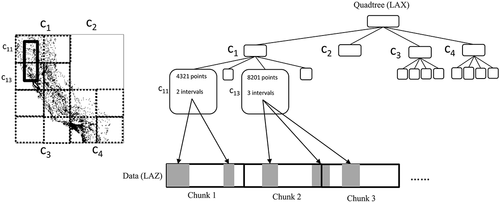
shows the typical setup of LAZ plus LAX. To solve a range query, the quadtree is traversed to determine the leaves that may have points in the queried region. Then, the relevant chunks are decompressed, and, finally, the resulting points are sequentially scanned to determine the points in the result. For example, in we want to retrieve the points within the region delimited by the rectangle with a thick solid line overlapping the quadrants and
. Observe that
and
are the quadrants on the left part of the bigger
, which contains four smaller quadrants that are surrounded by thick dotted lines. The search starts at the root of the quadtree following the quadrants overlapping the queried region. In this case, the search reaches the leaves corresponding to
and
. As seen,
contains 4321 points and 2 intervals. Each interval has an initial and a final position within the array storing the positions. In our example, since the two intervals are in the same chunk, only that chunk must be decompressed. In the case of
, it contains three intervals that are in chunks 2 and 3, thus both chunks must be completely decompressed to extract the points in the desired intervals.
The quadtree is limited to 2D space. Therefore, queries involving the third dimension are inefficient. In addition, there are no indexes for the attributes; thus, a sequential scan must be performed on the candidate points, making these queries inefficient as well. However, these queries are increasingly relevant because classification algorithms on point clouds may require the location of close points in the 3D space or nearby points in a 2D space with a given attribute value or range of values.
2.1.3. Scale factor and offset
LAS and LAZ store integer values. Therefore, the float numbers of real positions must be converted into positive integer values. For this purpose, LAS and LAZ use a scale factor and an offset for each dimension. The scale factor transforms a float value into an integer value. The offset is a value that moves the point cloud in the coordinate system to start at coordinate . Both values, the scale factor and the offset, are represented as double floating values. Given a scale factor
and an offset
, the formula to calculate the corresponding position
is:
, where
is the real coordinate in dimension
. For example, with
and
, the float value
is converted to
. Likewise, the original values can be recovered as
. Isenburg (Citation2013) shows that this strategy does not lose precision and thus it is a lossless representation. Moreover, this offers much more uniform precision than the corresponding floating-point value for the same number of bits. We will also use this strategy for representing the points in our proposal, using up to 64 bits for representing the integer coordinates.
2.2. Compact data structures
Compact data structures keep the data and the data structures around them in compressed form and provide the user with the capability of querying the data in compact form, that is, without decompressing them (Navarro Citation2016).
Most compact data structures are based on bitmaps or bitvectors. A bitmap is a bit array that supports the following operations: i)
, which returns the bit
, for any
, ii)
, which counts the number of occurrences of bit
in bitmap
until position
, and iii)
, which returns the position of the
-th occurrence of bit
in
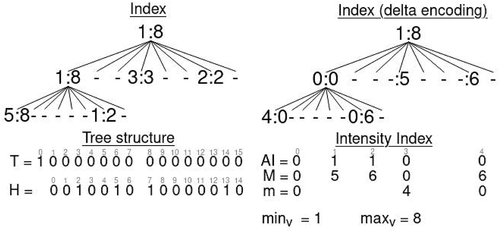
. With bitmaps, we can simulate trees, graphs, grids, which are then used to enhance all sorts of complex data structures such as text indexes, spatial indexes, etc. (Navarro Citation2016). The target is not only to save space but provide several nice features. For instance, a tree represented with a bitmap does not use pointers, using less space for its representation, and, at the same time, can be as efficiently navigated as a pointer-based tree.
shows an example. The tree in the upper part is only represented with the bitmap . By building rank and select structures on
, many operations can be done in constant time using only
. For example, it is possible to obtain the second child of the root node in constant time. Observe that the root node is represented by the bits at positions 3, 4, 5, and 6, and its first position is 3. The
child of the node whose description starts at position
can be computed as
, in our case
, that is, the description of the second child of the root node starts at position 10.
Figure 2. A tree represented with a bitmap.
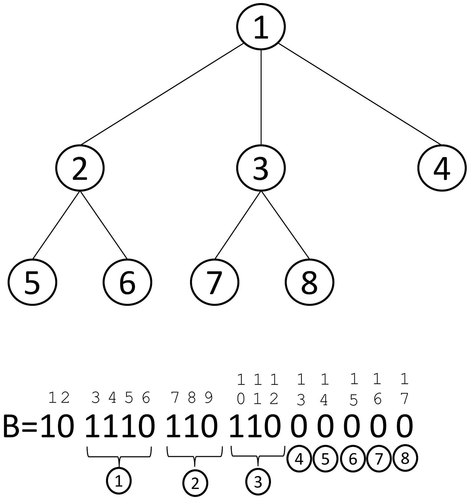
The key factor to improve efficiency is that rank and select operations can be solved in constant time (see Munro (Citation1996), for example), using bits of total space. In practice, usually, rank is solved in constant time, whereas select is solved in
time (Vigna Citation2008) with approximately 5% extra space over the original bitmap.
Several compact data structures have been developed for spatial data (Susana, Paramá, and Silva-Coira Citation2016; Ladra, Paramá, and Silva-Coira Citation2017; Pinto, Seco, and Gutierrez Citation2017; Brisaboa et al. Citation2020), but, until now, only for raster data.
2.3. Level-order unary degree sequence
Level-order unary degree sequence (LOUDS) (Jacobson Citation1989) is a compact data structure consisting in a level-wise representation of trees without pointers. In traditional tree representations, nodes are identified by the pointers to their position in memory. In a LOUDS representation, nodes are identified by their position in a bitmap. Therefore, using LOUDS, a tree is not physically implemented as a tree.
Given a tree , the LOUDS representation is a bitmap
where we first add bits 10. Then, we traverse
, starting at the root, level by level. For each node
with
children,
1-bits and one 0-bit are appended to
. These
bits are the description of the node
. is a LOUDS representation of the tree in the upper part.
By building rank and select structures on , we can perform several operations in constant time, among them, obtaining the parent, the
child, the sibling, or the degree of a given node. For example, in Section 2.2, we show how to obtain the
child of a given node.
If a tree has
nodes, we need
pointers for representing its topology, which typically require
bits, where
is the machine word. Instead, using LOUDS, we only need
bits for the topology. To support rank and select operations in constant time, the total space rises to
bits, which can be decreased to
bits when using slower implementations of rank and select (Navarro Citation2016).
LOUDS trees can reduce the space considerably, but, for our case, it is even more important that a node is not identified by its position in memory (i.e. by a pointer) but by its position in the bitmap defining the tree. As we will explain later, this will be helpful for our proposal.
2.4. Quadtrees and octrees for representation or indexation
As we will see, our method uses an octree for binary matrices built applying the latest developments in the field of compact data structures, which we call a . An octree is a quadtree for the 3D space. There are many variants of the quadtree (Samet Citation1984, Citation2006). We can roughly classify them into two groups, those mainly focused on compressing images (or rasters) and those focused on indexing data. The compression of images was its original target (Klinger Citation1971; Klinger and Dyer Citation1976), but many other works in this research line were later presented (Woodwark Citation1984; Lin Citation1997; Chan Citation2004; Chung, Liu, and Yan Citation2006; Zhang, You, and Gruenwald Citation2015; Graziosi et al. Citation2020).
The best-known quadtree-based method to index data consists in storing the leaves of a linear quadtree (Gargantini Citation1982) in a B+-tree (Abel and Smith Citation1983; Samet et al. Citation1984). Later, other indexes were also created based on quadtrees (Zhang and You Citation2010, Citation2013). As indexes, quadtrees were initially used to index black and white rasters (Corral, Vassilakopoulos, and Manolopoulos Citation1999) or point clouds (Finkel and Bentley Citation1974). We can say that those indexes only index the spatial component of the data, as they are only capable of finding white cells or points. In the case of rasters where cells can have more than two values, Zhang and You (Citation2010) enrich the inner nodes of a quadtree with the min-max values of the region represented by such a node. This data structure, called Binned Min-Max Quadtree, is an index of the space and the values at cells.
The addition of the min-max values at the nodes improves the search performance. As in normal database management systems, if we want to search by two or more attributes at the same time, the ideal data structure is an index of those attributes combined. Having one index for each attribute may result in a slow response time, since the constraints on each attribute may be fulfilled by many records, and then to obtain the final solution, we have to run a costly intersection of all these records, whereas only a few records may fulfill all constraints on all attributes (Elmasri and Navathe Citation2016). Having the min-max values at nodes avoids the use of two different indexes, a spatial one and another indexing the values at cells. Instead, with this approach, we only have to run one search, and, at each step of the search process, we can prune the search both in space and values.
The quadtree-based indexes shown so far were auxiliary data structures to speed up searches over a different data structure where data are stored. The first data structure that combines raster (image) compression (and thus it can represent the data) and indexing capabilities was the compact data structure (De Bernardo et al. Citation2013; Brisaboa et al. Citation2020). It uses quadtrees represented with a similar strategy to that of LOUDS. Later, other works improved their results (Ladra, Paramá, and Silva-Coira Citation2017; Chow et al. Citation2020, Citation2022). Two are the main differences between this work and those previous methods. Those structures were designed for rasters, and each cell of the raster only has one value. The differences in this work are that, first, we aim at storing point clouds, and second, each point may have several attributes, instead of one value as in the case of rasters.
As a summary, the main difference with respect to the more traditional approaches is that while these works are either focused on representing the data using compression or on designing an auxiliary index of the data, our work combines these two worlds. Moreover, our data structure combines the index and the data, as most self-indexes of compact data structures, such as the case of the in the case of spatial data, and many other examples in other data types (Navarro Citation2016). Instead, the normal setup is to have an array-like data structure to store the data and an auxiliary tree to index the data. Moreover, our index is twofold as indexes the space and all the attributes of the points combined. Observe that the LAS/LAZ setup is the typical, that is, data are stored in an array structure, and an auxiliary index is built, which only indexes the space.
2.5. Compression of point clouds
As explained, much research effort was devoted to compressing images, which can be regarded as rasters or sometimes also called meshes (Peng, Kim, and Kuo Citation2005). However, we can also find works focused on compressing point clouds, but, as in the case of images, they are mainly focused on compressing the point cloud, but they do not care about querying the points either spatially or by any property of the points such as color (Ochotta and Saupe Citation2004).
Compression is achieved using kd-trees (Devillers and Gandoin Citation2000), octrees (Botsch, Wiratanaya, and Kobbelt Citation2002; Peng and Kuo Citation2003; Schnabel and Klein Citation2006), or different spatial transformations (Zhang, Florencio, and Loop Citation2014; De Queiroz and Chou Citation2016; Shuman et al. Citation2013; Fan, Huang, and Peng Citation2013). Some of these works were only focused on compressing the points, but later works also faced the compression of colors of the points (Yan, Jingliang Peng, and Gopi Citation2008; Zhang, Florencio, and Loop Citation2014; Chou, Koroteev, and Krivokuca Citation2020). Point cloud compressors use those transformations as a step that is combined with several other techniques, such as the RAHT coder (ISO/IEC JTC 1/SC 29/WG 7 Citation2021). These techniques generally rely on a compression step where, in order to compress a given point, multiple neighbors are used to make a prediction that is somehow exploited by an entropy encoder. Recently, deep learning techniques have been also applied to improve different aspects of point cloud compression (Huang et al. Citation2020; Quach, Valenzise, and Dufaux Citation2020).
MPEG issued in 2017 a call for proposals for developing standards for point cloud compression (Liu et al. Citation2020; Graziosi et al. Citation2020). This effort already produced two standards: the geometry-based point cloud compression or G-PCC (ISO/IEC JTC 1/SC 29/WG 7 Citation2021) and video-based point cloud compression or V-PCC (Schwarz et al. Citation2019).
However, all these techniques are strictly tied to image or video compression, where the main target is to render the image, and not to query certain regions of the space (Cao, Preda, and Zaharia Citation2019).
The main difference of our work with these proposals is that we are not focused on image compression capable of fast decompression (rendering), but on the ability to index and thus to search part of the point clouds, fulfilling constraints both in the spatial dimension and in the attribute value dimension.
2.6. 
The is a compact data structure initially designed to store and query web graphs (Brisaboa, Ladra, and Navarro Citation2014). However, it turns out to be a modern version of a region quadtree (Samet Citation2006). Indeed, since then, it has been used, among other purposes, as a spatial index (De Bernardo et al. Citation2013; Brisaboa et al. Citation2017; Silva-Coira et al. Citation2020; Brisaboa et al. Citation2019, Citation2021). In those works, the
is used instead of a quadtree because it is more efficient in space and time since it is a pointerless representation of the quadtree equipped with efficient navigation through the tree. It is not a LOUD representation of a quadtree, but it is inspired in that representation.
Given a binary matrix of size
, and a parameter
,
is divided into
submatrices of size
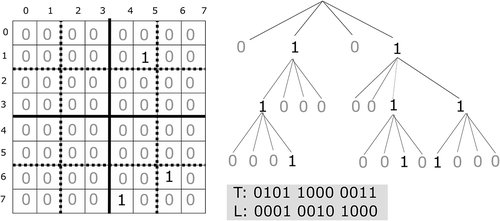
. For each of those submatrices, a child node is added to the root node. Each node only contains a bit: 0 indicates that the submatrix is full of 0-bits and 1 means that the submatrix contains at least one 1-bit. Now, for each of the submatrices with at least one 1-bit, the process continues recursively. The resulting tree is stored as a bitmap following a breadth-first traversal of the tree nodes. The
divides that bitmap in two:
, which is formed by the bits corresponding to the last level of the tree, and
, which contains the rest. The reason is that, in
, it is not necessary to build rank structures, since that level is never navigated, whereas in
it is necessary.
shows an example. The can efficiently answer several queries, like retrieving the value of a single cell, row/column queries, or spatial range queries. All of them require navigating the tree, which is a very fast process, since it is based on rank and select operations, which are constant-time operations. Given a 1-bit at position
in
, that is, a node with children, these children are sequentially located at positions
of
. The parent of a node at position
of
is computed as
. Of course, navigating a pointer-based tree requires also constant time operations. However the
has been shown 2–3 times faster than a traditional quadtree (Brisaboa et al. Citation2020).
Figure 3. A binary raster, the conceptual tree, and the corresponding , with
.
2.7.
The (De Bernardo et al. Citation2013) is the 3D version of the
. As the
, which is a modern region quadtree, the
is a modern octree (Meagher Citation1982) (a 3D quadtree). shows an example, including a three-dimensional binary matrix, its conceptual tree, and its representation, which is the
(bitmaps
and
). The
can be efficiently navigated using the same procedures as those for
, but extended to three dimensions.
Figure 4. A sequence of binary rasters and the corresponding .
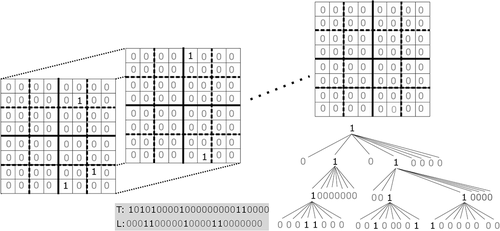
Given that if a node has children, then it has exactly children, we do not need to mark the end of the children of one node. Therefore, the
of a tree of
nodes uses exactly
bits to represent the topology. Thus, after adding the rank and select structures, it needs between
bits and
bits.
Therefore, the use of a LOUDS-based approach to represent an octree produces two benefits. First, a save in space, from the bits per node of a traditional octree to the
bits per node. Second, each node
is not identified by its pointer, but by its position in
or
. This property will allow us to index the different attributes of a point without having to place the information in the node of the octree. We will explain this later.
2.8. DACs
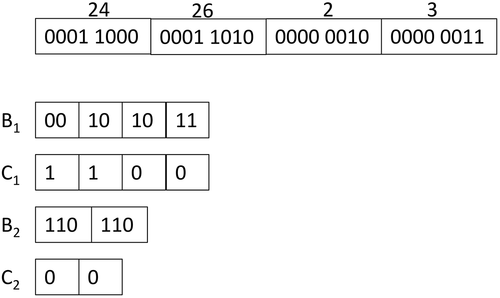
Directly Addressable Codes (DACs) (Brisaboa, Ladra, and Navarro Citation2013) consist in a compact data structure for sequences of integers, which not only compresses the sequence but, at the same time, supports the retrieval of any given integer of the sequence without the need to decompress the preceding integers. DACs obtain compression if the sequence of integers has a skewed frequency distribution toward smaller integer values.
Given a sequence of integers =
, DACs take the binary representation of each number and divide it into buckets that are stored as a level-shaped structure as follows. The first level is formed by a bitmap
that contains the first (least significant)
bits of the binary representation of each integer.
has an associated bitmap
to indicate whether the binary representation of each integer requires more than
bits (1) or not (0). In the second level, the bitmap
stores the next
bits of the integers with a value of 1 in
. The associated bitmap
signals the integers that need more than
bits, and so on. This process is repeated for as many levels as needed. The number of levels
and the number of bits of the buckets are calculated in order to maximize compression. Each value
is retrieved using
operations on the bitmaps
and extracting the corresponding chunks of the arrays
.
In , we can see a sequence of 8-bits integers and its corresponding representation using DACs. Integers 2 and 3 are represented with three bits, and numbers 24 and 26 are represented using seven bits. As seen, if numbers are small, compression is achieved. That is, instead of using bits per integer, DACs try to approach the optimal
bits per integer by using a clever algorithm to determine the bucket sizes.
Figure 5. An example of DACs. At the top part of the figure, we show the sequence of integers . At the bottom part of the figure, we show the DACs representation using a level-shaped data structure.
3. Our proposal:
In this section, we present a new compact data structure, called , which represents a cloud of LiDAR points in compressed space and also contains an index to perform efficient queries over the data. In this work, we assume that the set of points is represented in Point Data Record Format 0 of LAS Specification 1.4 (The American Society for Photogrammetry and Remote Sensing Citation2019). We are using the attributes defined by this standard, but our structure can be adapted to support other different formats. Section 2.1.3 gives some details on the conversion of coordinates from real values to positive integer values, which is also used by LAS.
In Section 3.1, we show the conceptual description of our structure. Section 3.2 lists the structures used to represent the . Then, in Section 3.3, the construction algorithm is explained. Finally, Section 3.4 describes the three queries implemented in this work.
3.1. Conceptual description
Let be an input three-dimensional matrix, or cube, of size
that stores a set of LiDAR points.Footnote2 A LiDAR point is composed of three coordinates (
,
, and
) and a set of attributes, like the intensity, scan direction, number of returns, etc.
Our structure follows a similar strategy to that used by the but adapted to store LiDAR points and not only to indicate in which cells there are points. Moreover, we need some additional structures to store the values of the attributes of the points.
The performs a recursive subdivision of the 3D cube
and builds the tree representation of that subdivision in a similar way as the
. However, unlike the original
, the division process stops in three different cases: when it reaches the tree depth; if the subcube is empty (i.e. it does not contain any points); and when the processed subcube contains fewer points than a defined threshold
, which is a common stop condition in octree segmentation (Elseberg, Borrmann, and Nuchter Citation2011) of the tree is empty or contains a set of LiDAR points. By navigating the tree, a specific point or set of points can be efficiently retrieved.
In order to store the attributes of each point, we use different compact data structures depending on the value type of each attribute. These structures must include direct access to any position of the array in an efficient way. Therefore, we can easily obtain the attributes of a specific point.
3.2. Data structures
We use different data structures to store the conceptual tree:
Tree structure (bitmap
Leaf nodes (bitmap
Number of points (bitmap
Coordinates: Let us consider a point with absolute coordinates
We use two different strategies to store the coordinates of the points.
Three arrays of coordinates (
Array of coordinates (P): The second option only uses one array to represent the three coordinates of a point. Each point of a node is encoded as a unique value computed as
In both cases, points that belong to the same node are sorted following a row-major order. That is, they are ordered first by the X coordinate, then by the Y coordinate, and finally by the Z coordinate. These arrays are aligned with bitmap . Once we know the range of positions of
we are interested in, the same positions in
,
,
(or
) contain the desired coordinates.
Attributes: We have one structure for each attribute. Depending on the type of attribute, we use integer arrays (for intensity, scan angle, return number, etc.) or bitmaps when we only need a single bit per value (as the scan direction and edge). The arrays of integers are encoded with DACs. Again, these arrays are aligned with bitmap
In order to return a point at position whose position in is
, we access
,
,
(or
if we are using the second strategy) and
,
, and so on.
3.3. Construction
The construction process starts by dividing the cube into
equal-sized subcubes. From the root of the tree, a child node is appended for each subcube. The algorithm then continues through each child node. If it does not contain any points, the process stops for that branch, adds a 0-bit to bitmap
, and continues with the next node. When the number of points is less than the threshold
, the process also stops for that branch, adding again a 0-bit to bitmap
, the number of points is encoded in bitmap
, and the list of points associated with that node is represented in the array(s) of coordinates (
or
). Otherwise, a 1-bit is added to bitmap
, the node is again divided into
subcubes and the previous process is repeated until reaching leaf nodes.
Let us explain the algorithm with an example. (upper-left) contains a cloud of LiDAR points in a space of size . The list of points is shown in the bottom left of the figure, where each one is represented as a circle with a unique identifier, a set of coordinates
, and the intensity value. To simplify the explanation, we have only taken into account the intensity attribute but the process is the same for the rest of the attributes. In this example, the scale factor is 1 and the offset is 0 for the three dimensions (transformation is not applied to the input data). Additionally, we are using a value of
and the threshold to stop dividing is
. The conceptual tree representation of the
is shown in the upper right part of the figure.
Figure 6. Example of LiDAR point cloud and its representation using . We only show here the data structures needed for representing the tree structure, using
and threshold
. A point (circle) is represented by a unique number and it has associated three coordinates and an intensity value. For example, point 5 is located at coordinates
and has an intensity value of 2.
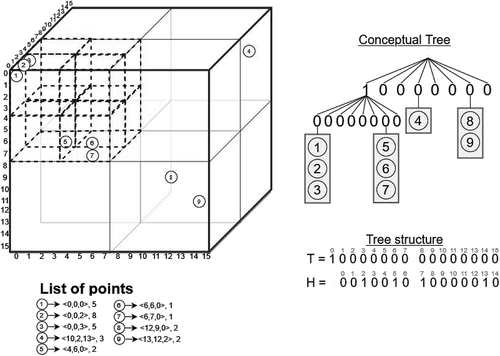
In this example, from the eight subcubes of size , only the one that contains points 1–7 is divided into subcubes of size
, since it contains more points than threshold
. This is reflected in the conceptual tree, where only the first child has a 1-bit to signal this. The four
subcubes are not further divided, and thus all their bits in the second level of the tree have a 0-bit.
is simply the levelwise traversal of the conceptual tree.
has a bit for each 0-bit in
. In the figure, we aligned the bits of
with the corresponding 0-bit of
, but observe that they are not really aligned, since
does not have bits for the 1-bits of
. This is done to save space. To recover the alignment between the 0-bits in
and their corresponding bits in
, we have to use rank operations, as previously explained.
shows how the LiDAR points are stored in our structure. Recall that points belonging to the same node are sorted following a row-major order. They are representing following a level-wise traversal of the tree; thus, we start with the fourth node at the first level of the tree. This node only contains point 4. First, we append the number of points in the bitmap in unary, in this case,
(1 in unary). Next, we calculate the local coordinates of the point, whose absolute coordinates are
. Notice that the subcube has size
, therefore,
,
, and
. Hence, the point
becomes
and it is stored as
,
, and
. We continue with the rest of the nodes, following a breadth-first order of the tree. In this example, with the seventh node of the first level and then with the first and seventh nodes of the next level.
Figure 7. Representation of the LiDAR points of the running example using the , including bitmap
and the coordinates and attribute arrays.

For a set of points that belong to the same node, we use some optimizations to make the values smaller. The coordinates of a point are stored using delta encoding with respect to the previous point
as
iff
for
. The target is to take advantage of the compression achieved by DACs. As seen in Section 2.8, DACs try to come closer to using
bits for an integer
, so by reducing the magnitude of the numbers, we obtain better compression.
We are going to explain this using the seventh node at the second level. This node contains points 5, 6, and 7. Observe in in the upper part the encoding of the points 5 and 6. Their absolute coordinates are and
that after applying modulo 4 became
and
. The first point of the leaf is stored with its local coordinates. For the second (point 6), the
coordinate is delta encoded, and it is highlighted with a box with dotted points. However, as soon as the box with dotted points has two different numbers, the next coordinates are not delta encoded. In this case, the
values of points 5 and 6 are different, and thus, the
and
coordinates are not delta encoded.
Figure 8. Example of delta encoding of points.
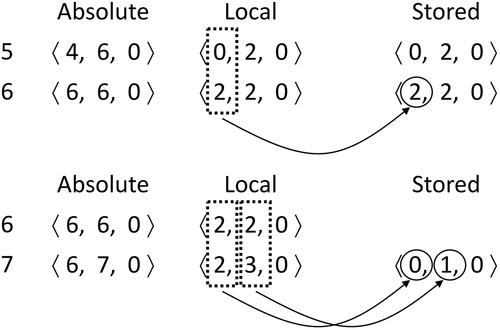
In the lower part, we can see how the point 7 is stored. The coordinate as always is delta encoded, and as it has the same value (2) in both points, the
coordinate is also delta encoded. However, the
coordinate has different values in point 6 (2) and point 7 (3), and thus the
coordinate is not delta encoded.
Finally, the intensity values are stored in the array following the same order as their points. In case of having more attributes, a sequence
is created for each one.
According to the classification of point compressors seen in Section 2.1.1, is a lossless, non-progressive, non-streaming, point-permuting compressor. The non-streaming property means that it needs to have all points before compression starts, thus its memory footprint is bigger. This is a common property of compact data structures. Since main memory is currently cheaper than in the time where the disk-based applications were mandatory, and as long as the data can fit in main memory, it is worthwhile to get rid of disk accesses. It is a point-permuting compressor, as all compressors based on a octree. However, unlike LAZ, which is not really a random-access compressor,
is a truly random-access compressor.
3.3.1. Storing coordinates in a unique array
We have implemented an alternative to store the coordinate in a unique array instead of three different structures. With this second option, the local coordinates are represented using a single value. For example, we store point 4, with local coordinate , as
, where
is the size of the current subcube. We repeat the process for the rest of the points. Moreover, we apply a delta encoding to points of the same node. For example, we represent the point
as
, the point
as
, and the point
as
. Then, we use delta encoding for these values, therefore we set
,
, and
3.4. Supported queries
In this section, we describe three queries implemented for the . These queries are common in multi-dimensional environments.
3.4.1. Obtaining all points in a region (getRegion)
This query obtains all points inside a region defined by
.Footnote3 The
performs a top-down traversal of the tree, following the nodes corresponding to subcubes that overlap with the region of interest. When the process reaches a leaf node, the coordinates of each point are obtained and checked. For those points that belong to the region of interest, their attributes are also retrieved and attached to the final result. In this step, our algorithm is able to reduce the number of points checked using some mechanisms. Recall that points follow a row-major order, for example, when the algorithm reaches a point
and
, the process stops because there are no more valid points in the current leaf node. In addition, the value of coordinate
is only retrieved when
and analogous for the value of coordinate
.
The pseudocode of this query is shown in Algorithm 1, which is a recursive procedure. Let be the size of the space and
,
,
,
, and
global parameters. The precalculated value
is the total number of 1s in bitmap T. In order to obtain all the points contained within a region
, the first call of the algorithm is invoked as
. Parameter
stores the list of points returned by this procedure.
Lines 1–3 determine which subcubes overlap the queried region, that is, which nodes have to be inspected to find the result. Line 4 obtains the position in of each subcube by using children_pos, which indicates the position of the first child of the node. The condition in line 5 determines if the node is at the maximum level
of the tree or at an intermediate level.
Next, line 6 indicates whether the current node is a leaf or an internal node. Lines 7–10, which are executed in the second case, compute first the local positions of the region, that is, determine the portion of the region that overlaps the current subcube, and then recursively invoke the function with those values (line 10). The position of its children in bitmap is calculated as
, and the size of the subcube is
.
Lines 12–22 are executed in the case of reaching a leaf node. In line 12, variable counts the number of leaves (0s in
) until position
. Next, line 13 checks if the current node is empty; otherwise, the algorithm calculates the initial and final position of the points in
. For that, line 14 counts the number of non-empty leaves (represented by a 1 in
) up to the current position (variable
). Lines 15–18 get the first and last positions in arrays
,
, and
using the operations
and
, respectively. All intermediate bits belong to the current node and are associated with a point. Finally, lines 18–22 return the coordinates of each point and check if it is within the queried region. Those that meet the condition are added to the result together with the values of their attributes.
Lines 24–32 are only executed when the algorithm reaches the tree depth, i.e. level . Observe that several points can have the same coordinates. This level is not represented in
; therefore, the position in
is calculated as
(line 24). Lines 25–32 are equal to lines 13–22 except that the algorithm does not need to calculate the local positions or check if they are within the region.
Algorithm 1: getRegion
returns all LIDAR points from region

shows an example of this operation. We want to retrieve the points in the cube , which is the shaded region in .
Figure 9. Example of getRegion.
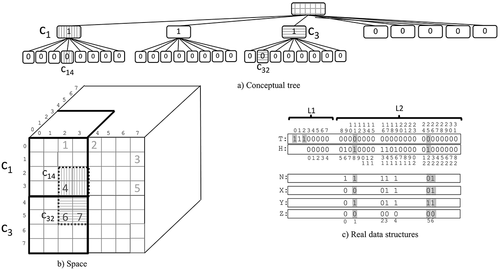
The operation is launched with getRegion(8,2,2,0,3,5,0,0). Lines 1–3 determine which subcubes of size overlap the queried region, which, in this case, are the subcubes
and
. These two subcubes are highlighted in the space of the figure with thick lines. The fors of lines 1–3 process those subcubes one by one. For
, line 4 computes its position in
, which is
(see that position highlighted in .
Since we are not at the last level of the tree (line 5), the flow reaches line 6. Since , lines 7–9 obtain the relative coordinates of the part of the queried region overlapping
. This is
, using relative coordinates within
, which is the region with vertical stripes in the space. Then, a new call getRegion(4,2,2,0,3,3,0,8) is issued, since
, that is, the position of the first child of
in
.
The call getRegion(4,2,2,0,3,3,0,8) processes . Lines 1–4 determine which subcubes of size
of
overlap the queried region, which, in this case, is only subcube
, which is highlighted with thick dotted lines in . Line 4 obtains the position in
corresponding to
, which is
. Observe that that bit corresponds to the node with vertical stripes in the last level of the conceptual tree. The check of line 5 takes the flow to line 6, and, since
, the flow jumps to line 12. This line obtains the bit in
corresponding to the current leaf. Observe that we are processing the subcube
whose bit in
is at position 11, but, as seen in the figure, its corresponding bit in
is at position
. We aligned them in the figure to facilitate the understanding, but observe that the positions are not the same for aligned bits.
As explained, in line 13, it is checked whether the subcube has points by accessing . Since it stores a 1-bit, the flow reaches line 14. Lines 14–17 compute the positions in bitmaps
,
, and
of the coordinates of the points within
. For this, the algorithm has to detect in
the positions corresponding to the position 8 of
. Line 14 counts the number of 1-bits in
until position
. Then, line 16 obtains the desired position as
, that is, the first bit in
corresponding to
is at that position. Then, the algorithm checks that position and the contiguous until reaching a 1-bit, each 0-bit means that a second, third, etc., point is present in the same cube, however since the position 1 of
already has a 1-bit, then
only contains one point, and its coordinates are at position 1 of
,
, and
.
Line 19 obtains the coordinates in the full space. Observe that from ,
, and
, we obtain the point
, but those are relative coordinates within
, the call to calculateCoord returns the absolute coordinates
. Line 19 checks if that point is within the queried region, and as in this case this is true, the point is reported as a result, and then this ends this recursive call.
Now, the flow returns to the first call getRegion(8,2,2,0,5,3,0,0) to process the second subcube of size overlapping with the queried region, that is
. Line 4 computes its position in
, which is
(see its position highlighted in
). Next, line 10 issues getRegion(4,4,4,0,5,5,0,24), since
, this is the position in
of the first child of
.
Lines 1–4 determine that the only subcube of size of
that overlaps the queried region is
. Line 4 obtains the position
in
corresponding to
. The bit in
corresponding to
is computed in line 12, which obtains
. Since
,
has points. Lines 14–17 determine that it has two points, since as it is highlighted in , the position in
corresponding to position 22 of
, that is position 5, has a 0-bit and position 6 a 1-bit. Then, in position 5 and 6 of
,
, and
, we can obtain the coordinates of those points.
3.4.2. Obtaining all points of a two-dimension region (getRegionxy)
For a region
, this query obtains the set of points that belong to the region of interest. This query is a straightforward extension of the query getRegion but without taking into account the coordinate of the
dimension.
3.4.3. Obtaining all points of a region filtered by attribute value (filterAttregion)
This query returns all points contained in a region
with the value of attribute A within a range
. The algorithm also performs a top-down traversal of the tree adding the points that meet the conditions. Unlike the query getRegion, when the process reaches a leaf node, the attribute value is obtained and compared to the given range
after checking the coordinates of the point. The rest of the attributes are only retrieved if the point belongs to the region of interest and the attribute value is within the range.
4. Adding attribute indexes:
This section introduces a new version of , denoted
, which includes an index to prune points using the values of attributes during a top-down traversal of the tree. This indexation is not provided by an additional index/tree, but it is included in the same tree used by the normal
. This allows the pruning of all dimensions (space and attribute values) at each step of the search.
The basic idea is to store at each node of the tree the minimum and maximum values of the indexed attribute of the points it contains. Although this section is explained for a single attribute, our structure can be expanded to include multiple indexes on different attributes following the same procedure.
In Section 4.1, we explain the new structures to represent the index in the version. Moreover, Section 4.2 gives details of the construction of this variant. Finally, Section 4.3 shows how the navigation varies concerning the original version presented in Section 3.4.3.
4.1. Data structures to represent the index
In addition to the structures explained in Section 3.2, the following are used to represent the index on an attribute:
Index tree (bitmap
Figure 10. Conceptual tree and structures of that represent the index of intensity attribute. Bitmaps
and
are not part of the attribute index, they correspond to the tree topology that are already part of
data structure, as shown in . In the conceptual tree of the attribute index, each node shows the minimum and maximum intensities of their points as
. The
adds arrays
,
and
for speeding up queries on that attribute.
Minimum and maximum values (arrays
As explained, our method combines in one data structure the data, an index of the space, and now, an index for each attribute. We describe the case of a single integer attribute. This setup is more efficient than that of a traditional configuration, where the index or indexes are separate data structures. To perform multikey searches (i.e. searches involving constraints on several attributes), it is better to have a single index for all indexed elements. In the literature, there are several methods to address this issue such as a grid file (Sevcik and Hinterberger Citation1984) or a partitioned hash (Burkhard Citation1976). However, in current database management systems, this issue is solved with an ordered index on multiple attributes (Elmasri and Navathe Citation2016, Sect 17.4.1) using as keys of the -tree the concatenation of the values of all indexed attributes. We can use the same idea for our case, extending the idea of the Binned Min-Max Quadtrees, to have a pair of min-max values in each node of the octree for each indexed attribute. For each node of the octree, this approach requires the
bits of the pointer to the node and another
bits per indexed attribute, that is,
bits, being
the number of attributes. Observe that we cannot compress these min-max values at the nodes of the octree, since they are concatenated, and to be able to access a given pair, they must be fixed in length. To this, we have to add the pointers to the data file storing the data themselves. As explained, LAS index stores for each leaf of the quadtree one or more intervals. Each of these intervals is encoded by using two positions of the data file where are placed the points corresponding to the leaf, that is
bits per interval. We cannot bound the number of intervals at each leaf but assuming a quadtree with
nodes of which
are leaves, we need at least
bits. Instead, our method gets rid of pointers, so this is
less bits. In addition, instead of using
bits per min-max pair at each node, since we are able to detach those values from the nodes of the tree, we can compress them with DACs, which use a variable-length code to obtain compression. This approaches to
bits per min-max value
, assuming a fixed chunk size
, by using DACS. That is, we require
bits, where
is the number of indexed points, as we require a 1 bit per point for the bitmap
.
To get rid of the pointers (and thus the factor), we rely on the capacity of the LOUDS-based approach of the
of identifying nodes by their position in the bitmaps
and
. Moreover, we also do not use pointers to indicate where the data are located, as the points corresponding to a leaf can be retrieved by using its position in
and the bitmap
.
Our setup is designed to obtain fast access times, by joining all indexes and data in one data structure, and this produces a loss of compression capability, since we cannot arrange the data in an array-like structure where a prediction approach coupled with an arithmetic compressor can be successful. That is, we present a new trade-off, where the compression is less powerful, but we are able to provide fast access to data by indexing all dimensions.
4.2. Construction of
The construction of the requires a new step that computes the maximum and minimum of the attribute values of each subcube and associates them with its corresponding node of the tree.
shows the intensity index of the example in . The index tree is represented in the top-left part of the figure, where each node contains the minimum and the maximum intensity values of its points. At the top-right part, we show the tree by applying delta encoding to the values. The new structures used in this version are shown on the bottom-right part of the figure.
Let us explain the building process with the example of . The root node stores the minimum and maximum values for the whole cube. The process divides the cube into subcubes and adds a child to the root for each node that contains points. The first child is not empty, and the minimum value is 1 and the maximum 8. Therefore, it contains points with different values and we set
. Then, both values are added to arrays
and
as the difference with its parent,
and
. The next two children are empty, and no data about them is stored in the index. The only point of the fourth child has a value of 3; therefore, the minimum and maximum are the same. In this case, we assign
and we only store the maximum value as
. The two points with identifiers 8 and 9, which are in the seventh child of the root, have the same value 2; therefore, again, only the maximum is stored as a difference with respect to the maximum value at the root
Finally, the first child of the root is split again. Its first child contains values between 5 and 8, which yield and
. The seventh child adds
and
.
4.3. Obtaining all points of a region filtered by attribute value (filterAttRegion) using the version
This query is similar to the one exposed in Section 3.4.3. The only difference is that the uses the minimum and maximum values at each node of the tree to prune the search.
Algorithm 2 shows the pseudocode of this query. Only the parts that differ from Section 3.4.3 are going to be explained below. Let be the region of interest and
the queried range of values for the attribute
.
The new parameters and
store the minimum and maximum values of the parent of the current node. The first call is invoked as
Line 6 checks if the node is empty or not. In the first case, the algorithm skips the current node and continues with the next one. Lines 7–16 calculate the values of the minimum and maximum of the current node. Line 7 compares the values of the parent node and, if they are equal, those values are assigned to the minimum and maximum of the current node (lines 15–16). Otherwise, lines 8–11 are executed to extract the values of the current node. Lines 8–9 calculate the maximum value. In line 9, it is checked whether all the points have the same value (if ) and, if so, the same value is assigned to the minimum. In another case, line 11 obtains the minimum value from the index. Finally, lines 12–13 compare if these values are within the range of interest. If the values are out of range, then the current node is discarded.
The rest of the algorithm continues as explained in Section 3.4.3.
Algorithm 2: filterAttRegion
returns all LIDAR points from region
with values for the attribute
between
and
. We mark with an asterisk the lines of the pseudocode that differ from those of Algorithm 1.

5. Experimental evaluation
5.1. Experimental framework
We ran a set of experiments to measure the space requirements and time performance of the two proposals, (see Section 3) and
(see Section 4). We compared our results with those obtained using LAS/LAZ format. More concretely, we show the space consumption in disk, peak main memory consumption when running a query, construction real times, and the user CPU time for executing a batch of queries of the three types defined in Section 3.4.
All our experiments were run on an isolated 11th Gen Intel® i7–11700 @ 2.50 GHz (16 cores) with 16 MB L3 cache, and 64 GB RAM. The server ran the Ubuntu 20.04 LTS operating system, with kernel 5.11.0 (64 bits). All techniques were executed using just one core.
The different datasets were converted to Point Data Record Format 0 (LAS Specification 1.4) and we use the LAZ format. Additionally, we created indexes for all files using the Lasindex tool of LAStools.Footnote4 These indexes are used to speed up the query time by indexing the and
dimensions (but not the
). Queries on LAS/LAZ files were implemented using the LASLib library in C++. In LAZ, we used the default chunk size of 50,000 points.
For the and
, we use a configuration with
and different threshold values
, from 50 to 1000. Sections 5.5, 5.4, and 5.6 show the result for
, and Section 5.7 discusses the performance of our approach when varying this parameter. The
version indexes the values of the intensity attribute. All our structures and algorithms were coded in C/C++ and compiled using gcc 9.4.0 with −03 option.
5.2. Datasets
We used ten different datasets of different nature, obtained from three different sources:
PNOA: We created a collection of three datasets of different sizes from the union of several tiles of the Spanish National Program for Aerial Orthophoto (PNOA).Footnote5 Each tile represents an area of
Figure 11. Visualization of the dataset labeled as PNOA-L using the software CloudCompare. The dataset is a point cloud acquired using an aircraft-mounted scanner with a density of at least 0.5 points/m2. the dataset is centered on the city of a Coruña (Spain) and it includes a high-density urban area, low-density intermediate areas, and sea areas.

ISPRS: We used two datasets extracted from the ISPRS benchmark on indoor modeling (Khoshelham et al. Citation2017).Footnote6 These datasets are labeled as TUB1 and FireBr. TUB1 is a point cloud captured in one of the buildings of the Technische Universitat Braunschweig, Germany, while FireBr represents an office of the fire brigade in Delft, the Netherlands. These datasets only contain the point coordinates, being the rest of the additional attributes empty.
LidarUSA: We used five datasets from LidarUSA sample data.Footnote7 The first three datasets (Velo1, Velo2, and Velo3) correspond to data collected from the back of a truck using a Velodyne HD32 scanner in a busy urban environment. The other two datasets (Ladyb1 and Ladyb2) correspond to data with a Scanlook Snoopy A-Series mounted on a truck and then colorized along with the corresponding Ladybug5 imagery. show a general and detailed visualization of dataset Ladyb2.
Figure 12. Visualization of the dataset labeled as Ladyb2 using the software CloudCompare. The dataset is a point cloud acquired using a truck-mounted scanner in a residential area and it includes a street, some trees and house facades.

Figure 13. Detail of the Ladyb2 described in .

and show the main properties of the datasets. For each one, we include the number of points, the maximum and minimum value for each coordinate, both the original value and also the converted one, which is used in the representation, and the range of values of the attributes it contains (intensity, return number, number of returns, edge of flight line, scan direction flag, classification, scan angle rank, and point source id). Datasets TUB1 and FireBr do not include any attribute, and datasets from LiDarUSA source only include intensity, scan angle rank, and point source id attributes.
Table 1. Dataset description. We show the number of points, the minimum and maximum values for the real coordinates , and the maximum
values, after the coordinates are converted (scaled and translated using an offset).
Table 2. Dataset description. We show the number of points, the minimum and maximum values for the real coordinates , and the maximum
values, after the coordinates are converted (scaled and translated using an offset).
We include in Appendix A the visualization of all the datasets. show the visualization of the largest and smallest datasets, i.e. PNOA-L and Ladyb2. We have used the open-source software CloudCompareFootnote8 to create the visualizations displaying the point intensity using a grayscale. For ISPRS datasets (i.e. TUB1 and FireBr), we have also included a visualization using an eye-dome lighting (EDL) shader. EDL is a non-photorealistic, image-based shading technique designed to improve depth perception in scientific visualization images (Ribes and Boucheny Citation2017).
5.3. Query sets and benchmarking setup
We report average CPU time needed by each method for running a set of random queries. The sets of queries are randomly created beforehand for each type of query, such that all techniques run the same sets of queries. The queries are executed in batch mode on the compressed point cloud, running the queries consecutively, starting the next query as soon as the previous one ends. In the case of LAZ, the LAX file is also created beforehand, and is not rebuilt when executing the queries, just loaded before the query set is launched. In the case of and
, the compact data structure is also created beforehand, and the complete data structure is loaded into the main memory before running the query set.
shows, for each type of query and for each dataset, the number of queries included in each query set and the number of points recovered after running those queries. In the case of the query getRegion, the queries consist of a 3D region defined by two 3D points. In the case of the query getRegionXY, the queries consist of a 2D region defined by two 2D points. In the case of the query filterAttRegion, the queries consist of a 3D region defined by two 3D points and a range of two values. For each query, the coordinate values of the points and the range values are chosen randomly between the minimum and maximum of the possible values, such that they are valid regions of the point cloud and valid ranges for the indexed attribute.
Table 3. Query set description. We show the number of random queries generated for each dataset and type of query, and the number of points recovered by each query set.
5.4. Space requirements
The comparison of space is shown in . We report the space required by each method when representing the datasets with all their attributes. We include two alternatives for and
depending on how the coordinates are being represented: using three arrays (column
) or just one array (column
). In the case of LAZ, the reported space also includes the size of LAX file. The size of this file is negligible in comparison to the size of the datasets (for these datasets, around 15–110 KB).
Table 4. Comparison of the space (MB) for the different approaches over all datasets. We include two alternatives for and
depending on how the coordinates are being represented: using three arrays (column
) or just one array (column
) The best value is in bold.
LAZ files obtain the best results in almost all cases, especially for the first five datasets extracted from PNOA and ISPRS data sources. However, our techniques achieve almost the same compact space as LAZ for the datasets extracted from LidarUSA. In particular, for Ladyb2, our version using just one array for representing the coordinate values outperforms LAZ in terms of space requirements. This good behavior of our approach for LidarUSA datasets is due to the fact that LidarUSA clouds are very dense, and they can be compactly captured by our proposal. However, both PNOA and ISPRS are much sparse 3D point clouds, which require a higher number of levels of the tree and higher numbers for representing the coordinates, which worsens the compression rate of their DACs representation.
Compared with the uncompressed format, LAZ shows a compression rate that ranges between 16.6% and 38.6% of the space required by LAS format. Our approaches obtain spaces lower than half the space required by LAS for all datasets (ranging 26.0%–48.7% of LAS format). We can also see that our approach requires around 1%–3% more space than
. This is due to the attribute indexes, which require a bit of extra space, but will allow more efficient filterAttRegion queries, as we will see in the next sections.
shows the comparison of space used in main memory running a query, specifically getRegion. LAZ obtains the best results in all cases and, furthermore, does not show variation for datasets of different nature. LAZ is stored on disk during the execution of the query. Thus, it is not necessary to load the whole file into the main memory.
Table 5. Comparison of the peak of space (MB) consumption running the query getRegion for the different approaches over all datasets. We include two alternatives for and
depending on how the coordinates are being represented: using three arrays (column
) or just one array (column
).
Comparing the results with the values in , we observe that the memory consumption is proportional to the space used to represent our structure. Recall that our solution is designed to reside in main memory all the time. Therefore, most of the consumption is due to the structure itself and our algorithm does not require much additional memory. In this case, the structure has a slightly higher consumption than the
because it also has to include the indexes on the attributes.
5.5. Construction time
shows the comparison among different approaches when measuring the construction time from a LAS file. In this case, we measured real-time, which also includes the disk-access times.
Table 6. Construction time (real time, in seconds) for the different approaches over all datasets. We breakdown the construction time for LAZ to show separately the process of creating the LAZ representation and the LAX file. For and
we include two alternatives depending on how the coordinates are being represented: using three arrays (column
) or just one array (column
) The best value is in bold.
For LAZ files, we break down the time reporting that required just to obtain the LAZ representation and also the building time of the LAX indexes. The construction of LAX indexes accounts for between 52% and 62% of the total construction time. As we can observe in the results, all methods have a comparable construction time. LAZ is faster for PNOA and ISPRS datasets, whereas using just one array
for the coordinates is the fastest method for LidarUSA datasets. The construction times obtained by
are consistent with the space results obtained by this technique. The final data structure is more compact, and it requires less time to be created.
5.6. Query times
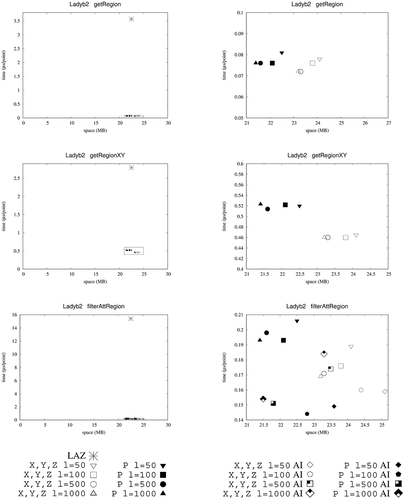
shows the results for queries getRegion and getRegionXY. We only show here the results obtained by , as these queries only require accessing the coordinates of the LiDAR points and not the values of the attributes; thus, the indexes over the attributes of
do not present any advantage. We can see that our approach
clearly outperforms LAZ, being around one order of magnitude faster for all datasets for getRegion query. More concretely,
is between 8 and 47 times faster than LAZ. In the case of getRegionXY query,
is between 4 and 7 times faster than LAZ. Among the two approaches for representing the coordinates in our
technique , the one that uses one array obtains the best performance for getRegion, but without filtering by the Z coordinate (getRegionXY) the version using three arrays achieves better times.
Table 7. Comparison of the time results for getRegion and getRegionxy queries (user CPU time, in microseconds per retrieved point) for the different approaches over all datasets. We include two alternatives for and
depending on how the coordinates are being represented: using three arrays (column
) or just one array (column
) The best value is in bold.
We can observe that, even than LAZ creates an index for and
coordinates, we obtain significantly better results when only those coordinates are used in the query, that is, for getRegionXY query. Moreover, as expected, for queries requiring the third dimension, that is, for getRegion queries,
shows a remarkable superior performance, as LAZ with LAX does not natively support this functionality. Thus, for those datasets requiring similar space, such as those extracted from LidarUSA,
is the perfect choice when considering the space/time trade-off.
Another interesting property of our approach is that it does not show a high variance in the time results (measured in microseconds per retrieved point); thus, it presents a more stable performance independently of the nature of the input dataset.
shows the results for query filterAttRegion when applying a filter over the attribute intensity. We can see here that the obtains the best results for all cases, in particular, the version using one array for representing the coordinates. It is on average 20% faster than
and between 11 and 107 times faster than LAZ. Again, our approach shows a more stable performance independently of the nature of the input dataset, which is a desirable property.
Table 8. Comparison of the time results for filterAttregion query (user CPU time, in microseconds per retrieved point) filtering by attribute intensity for the different approaches over all datasets containing that attribute. We include two alternatives for and
depending on how the coordinates are being represented: using three arrays (column
) or just one array (column
) The best value is in bold.
5.7. Varying the value of the threshold
In the previous sections, we have used a fixed value of for comparing the results of our method with those obtained by LAS and LAZ. However, this parameter, which determines the stop condition in the building process, may affect both the time performance and the space consumption. In general, when solving getRegion or getRegionXY queries, a higher number of points per leaf node, i.e. setting a high value for
, implies shorter trees, and thus better time performance. This is due to the fact that the top-down traversals on the tree needed to obtain the points at the leaves require a lower number of rank operations when the tree is shorter; thus, reducing the overall query time. However, they can require larger memory consumption in the case of
, as the representation is not exploiting the compressibility of those points. On the contrary, the
uses less memory for high values of
, as low values of
imply a higher number of levels of the tree, and also require a larger space of the attribute index. It is also interesting the behavior for filterAttRegion queries. In this case, having a high number of points in the leaves requires a longer process of filtering those points by attribute value. Thus, intermediate values for
is a good choice when considering time performance, as small values of
imply trees with a high number of levels, which are neither efficient in terms of time. Of course, this is highly dependent on the dataset and it should be configured for each dataset to obtain the best space/time trade-off.
show the space/time trade-off for different configurations of our approach for the three queries over datasets PNOA-L and Ladyb2. We have chosen those two datasets as they are the largest and smallest in terms of number of points, respectively. In the left part of each figure, we also show the space/time results for LAZ. As LAZ obtains significantly higher time results in all cases, we zoom the part of the figure that includes the results of the variations of our approach. These extracts of the plots are shown in the right part of the figure.
Figure 14. Space/time trade-off for different configurations over PNOA-L dataset when computing the three different types of queries. In the left part, we include the results for LAZ and for the four versions of our method varying threshold . In the right part of the figure, we zoom the figure to better illustrate the differences among the different configurations of our approach. We denote
the version using three different arrays for representing the coordinates and
the one using one unique array. We marked with the text ‘AI’ the configuration including an index over attribute intensity.
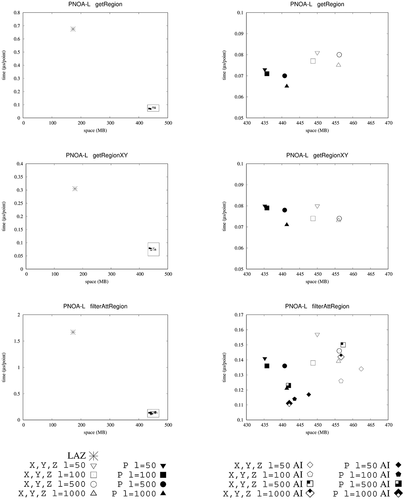
Figure 15. Space/time trade-off for different configurations over Ladyb2 dataset when computing the three different types of queries. In the left part, we include the results for LAZ and for the four versions of our method varying threshold . In the right part of the figure, we zoom the figure to better illustrate the differences among the different configurations of our approach. We denote
the version using three different arrays for representing the coordinates and
the one using one unique array. We marked with the text ‘AI’ the configuration including an index over attribute intensity.
In the case of PNOA-L, we can see the expected behavior. For , the best space results are obtained with small values of
, whereas the best time results are obtained with high values of
. On the other hand, for
, the best space results are obtained for high values of
, whereas the best time performance in the filterAttRegion query is obtained for
and using three arrays for representing the coordinates.
In the case of Ladyb2, the best time and space results of are obtained with high values of
. This differs from the results obtained for the PNOA-L dataset, where the best space results were obtained for a low value of
. This is caused by the fact that the points of the Ladyb2 LiDAR cloud are less clustered, more sparse, and thus, having a high number of levels in the tree does not exploit any compressibility of the dataset. For
, again, the best time performance in the filterAttRegion query is obtained for
and using three arrays for representing the coordinates. It is also worth noting that LAZ is clearly outperformed here both in space and time by several configurations of our approach, namely,
and
using just one array
for representing the coordinates and using high values for
.
5.8. Discussion
Next, we discuss the results of the experiments. The most important contribution of our proposal is that it efficiently supports searches involving the third spatial dimension or the additional attributes, due to the fact that has indexes on them, whereas LAZ/LAX does not. This has a direct implication in the time performance of these types of queries.
Moreover, our proposal also outperforms LAZ/LAX for searches that only include constraints on and
coordinates. This is because our
is a real random-access compressor, so it only has to recover/decompress the data the user requested, which are stored already at the leaves of our compact octree. Derived from this, two consequences arise. First, to obtain real random access, the compression techniques on which our method is based, basically DACs and delta encoding, are simple, but as a side effect, they are fast. However, the second consequence is that
compression power is lower, compared to the prediction methods coupled with an arithmetic coder of LAZ.
On the contrary, LAZ is not a real random-access method. To obtain some sort of random access, LAZ divides the data into chunks, with recommended size of 50,000 points, and even when only a small part of a chunk is needed, the complete chunk has to be decompressed. For example, in , chunks 1, 2, and 3 must be completely decompressed even when only the shaded regions may have points of interest. Finally, the compression of the coordinates of LAZ is based on a predictor that needs to check the five previous values to make a prediction, and then, the difference between the prediction and the actual value is encoded with an arithmetic encoder. During the decompression, that prediction must be also done and the arithmetic decompression is known to be very slow (Brisaboa et al. Citation2007).
Moreover, the traditional setup of LAZ/LAX implies two main drawbacks. First, the (spatial) index is an auxiliary structure separated from the data, so when a leaf of the index is reached, a pointer must be followed to access the data file. Second, the pointer points to a disk position, and the access could be slow. Another problem is that, as explained in Section 2.1.2, the pointers at leaves are indeed intervals; moreover, each leaf can have several intervals due to the fact that it is a streaming and order-preserving compressor. Thus, when searching a region, each affected leaf adds a list of intervals. In order to speed up the inspection of these intervals, LAX pays an extra time merging them, trying to get a lower number of less fragmented intervals.
On the other hand, as we already saw, consumes more main memory, as it is expected because it uses a compact data structure approach, and thus, it has to keep all the data in main memory all the time, whereas LAZ only loads the disk blocks it needs at each moment, and after using them, they can be deleted from main memory.
6. Conclusions
In this paper, we have presented a new representation for LiDAR point clouds that not only requires very compact spaces, similar to those obtained by state-of-the-art methods such as LAZ but, more importantly, it supports the efficient computation of queries over the compressed data. It solves typical queries, such as obtaining all the points in a 2D or 3D region between 4 and 47 times faster than the state-of-the-art methods. In addition, it offers the possibility to efficiently retrieve the points in a region filtered by an attribute value. Our approach computes these queries 11–88 faster than LAZ. Moreover, we also present a variant of our approach that adds an index over the attributes and, with around 1%–3% of extra space, improves these kinds of queries, being up to 107 faster than LAZ.
Our approach is configurable so it can be adapted to the different nature of the datasets. We include several options, such as different approaches to compact coordinate values or the number of points in the leaf nodes. This allows us to obtain different space/time trade-offs.
As future work, we will extend our technique to support additional queries over LiDAR point clouds and also explore the use of our approach for integrating it into visualization tools for LiDAR point clouds, as our tree-shaped representation can be of interest to efficiently manage the visualization of complex point clouds, in particular zoom-in and zoom-out functionalities.
Another research line would be to turn updatable, since it is a static data structure. This is not a big issue for LiDAR data, as acquiring LiDAR data is expensive, thus the updating rate of this type of data is low. Moreover, re-creating the compressed representation from scratch is not a costly process, as shown in our experiments of construction time, compared to the time required by detecting changes on the LiDAR data and updating its compressed representation. However, a dynamic version of our proposal could be of interest in other domains. This dynamic version will be based on practical implementations of dynamic bitmaps that have been presented in recent years (Cordova and Navarro Citation2016; Prezza Citation2017).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The source code of k3 – lidar and ki3 – lidar is publicly available in the following repository: https://gitlab.lbd.org.es/fsilva/k3-lidar/.
The datasets PNOA-S, PNOA-M, and PNOA-L are a derived work of LIDAR 1st Coverage (2008–2015) CC-BY Organismo Autónomo Centro Nacional de Información Geográfica (CNIG). CNIG grants permissions to use the datasets and to generate derived datasets for any purpose as long as the creator is attributed. Our derived datasets are openly available in figshare at https://figshare.com/collections/LiDAR/5720168, reference number 5,720,168.
The datasets TUB1 and FireBr are part of the ISPRS Benchmark on Indoor Modeling (Khoshelham et al. Citation2017) and can be downloaded from https://www2.isprs.org/commissions/comm4/wg5/benchmark-on-indoor-modelling. ISPRS grants permission to use the datasets for research purposes only, and it does not allow the datasets to be distributed. They have to be downloaded from the ISPRS website using the link above.
The datasets Velo1, Velo2, Velo3, Ladyb1, and Ladyb2 are available on request from the website of LidarUSA at https://www.lidarusa.com/sample-data.html. We have contacted a representative from the company that has granted us usage of the datasets for research purposes.
The query sets used in the experimental evaluation to measure time performance are openly available in figshare at https://figshare.com/collections/LiDAR_Queries/5915297, reference number 5,915,297.
Additional information
Funding
Notes on contributors
Susana Ladra
Susana Ladra is Associate Professor at the University of A Coruña, Spain. Her research interests include design and analysis of algorithms and data structures, and data compression and data mining in the fields of information retrieval and bioinformatics.
Miguel R. Luaces
Miguel Rodríguez Luaces received his Ph.D. in Computer Science from the University of A Coruña (Spain) in 2004. He undertook research in the area of spatial, temporal and spatio-temporal databases at the FernUniversität Hagen (Germany) under the ChoroChronos project funded by the European Union. Today, he is an Associate Professor at the University of A Coruña and his research interests include Geographic Information Systems, Spatial and Spatio-temporal Databases, Software Engineering, and Web-based Information Systems.
José R. Paramá
José R. Paramá is Associate Professor at the University of A Coruña, Spain. His research interests include compression and indexation of information, spatial databases, and bioinformatics.
Fernando Silva-Coira
Fernando Silva-Coira received the PhD degree in Computer Science from the University of A Coruña. He is an adjunct at the University of A Coruña. His research interests are compact data structures, algorithms, and spatial databases.
Notes
2. In the case of a cube with different sizes in each dimension, we conceptually fill the input data with empty space. This does not significantly affect the final result because our data structure is very efficient at representing the empty areas.
3. Notice that the cube can be defined from two 3D points by just taking a mixture of their elements to get the eight corner vertices in the 3D space.
References
- Abel, D. J., and J. L. Smith. 1983. “A Data Structure and Algorithm Based on a Linear Key for a Rectangle Retrieval Problem.” Computer Vision, Graphics, and Image Processing 24 (1): 1–13. doi:10.1016/0734-189X(83)90017-8.
- The American Society for Photogrammetry and Remote Sensing. 2019. LAS Specification 1.4 - R15. Format Specification. http://www.asprs.org/wp-content/up%20loads/2019/07/LAS_1_4_r15.pdf.
- Botsch, M., A. Wiratanaya, and L. Kobbelt. 2002. “Efficient High Quality Rendering of Point Sampled Geometry.” In Proceedings of the 13th Eurographics Workshop on Rendering, 53–64. EGRW ’02. Pisa, Italy: Eurographics Association.
- Brisaboa, N. R., A. Cerdeira-Pena, G. de Bernardo, G. Navarro, and Ó. Pedreira. 2020. “Extending General Compact Querieable Representations to GIS Applications.” Information Sciences 506: 196–216. doi:10.1016/j.ins.2019.08.007.
- Brisaboa, N. R., G. de Bernardo, G. Gutiérrez, M. R. Luaces, and J. R. Paramá. 2017. “Efficiently Querying Vector and Raster Data.” The Computer Journal 60 (9): 1395–1413. doi:10.1093/comjnl/bxx011.
- Brisaboa, N. R., A. Fariña, G. Navarro, and J. R. Paramá. 2007. “Lightweight Natural Language Text Compression.” Information Retrieval 10 (1): 1–33. doi:10.1007/s10791-006-9001-9.
- Brisaboa, N. R., T. Gagie, A. Gómez-Brandón, G. Navarro, and J. R. Paramá. 2021. “An Index for Moving Objects with Constant-Time Access to Their Compressed Trajectories.” International Journal of Geographical Information Science 35 (7): 1392–1424. doi:10.1080/13658816.2020.1833015.
- Brisaboa, N. R., A. Gómez-Brandón, G. Navarro, and J. R. Paramá. 2019. “GraCt: A Grammar-Based Compressed Index for Trajectory Data.” Information Sciences 483: 106–135. doi:10.1016/j.ins.2019.01.035.
- Brisaboa, N. R., S. Ladra, and G. Navarro. 2013. “DACs: Bringing Direct Access to Variable-Length Codes.” Information Processing & Management 49 (1): 392–404. doi:10.1016/j.ipm.2012.08.003.
- Brisaboa, N. R., S. Ladra, and G. Navarro. 2014. “Compact Representation of Web Graphs with Extended Functionality.” Information Systems 39: 152–174. doi:10.1016/j.is.2013.08.003.
- Burkhard, W. A. 1976. ”Hashing and Trie Algorithms for Partial Match Retrieval.” ACM Transactions on Database Systems. 1 (2): 175–187. (New York, NY, USA). doi:10.1145/320455.320469.
- Cao, C., M. Preda, and T. Zaharia. 2019. “3D Point Cloud Compression: A Survey.” In The 24th International Conference on 3D Web Technology, 1–9. Web3D ’19. LA, CA, USA: Association for Computing Machinery. doi:10.1145/3329714.3338130.
- Chan, Y.-K. 2004. “Block Image Retrieval Based on a Compressed Linear Quadtree.” Image and Vision Computing 22 (5): 391–397. doi:10.1016/j.imavis.2003.12.003.
- Chou, P. A., M. Koroteev, and M. Krivokuca. 2020. “A Volumetric Approach to Point Cloud Compression - Part I: Attribute Compression.” IEEE Transactions on Image Processing 29: 2203–2216. doi:10.1109/TIP.2019.2908095.
- Chow, K., D. Eustathios Olivier Tzamarias, M. Hernández-Cabronero, I. Blanes, and J. Serra-Sagristà. 2020. “Analysis of Variable-Length Codes for Integer Encoding in Hyperspectral Data Compression with the K2-Raster Compact Data Structure.” Remote Sensing 12 (12). doi:10.3390/rs12121983.
- Chow, K., D. Eustathios Olivier Tzarmarias, M. Hernandez-Cabronero, I. Blanes, and J. Serra-Sagrista. 2022. “Performance Improvement on K2-Raster Compact Data Structure for Hyperspectral Scenes.” IEEE Geoscience and Remote Sensing Letters 19:1–5. doi:10.1109/LGRS.2021.3084065
- Chung, K.-L., Y.-W. Liu, and W.-M. Yan. 2006. “A Hybrid Gray Image Representation Using Spatial- and DCT-Based Approach with Application to Moment Computation.” Journal of Visual Communication and Image Representation 17 (6): 1209–1226. doi:10.1016/j.jvcir.2006.01.002
- Cordova, J., and G. Navarro. 2016. ”Practical Dynamic Entropy- Compressed Bitvectors with Applications.” International Symposium on Experimental Algorithms, Vol. 9685, 105–117. Springer. doi:10.1007/978-3-319-38851-9_8.
- Corral, A., M. Vassilakopoulos, and Y. Manolopoulos. 1999. “Algorithms for Joining R-Trees and Linear Region Quadtrees.” In Advances in Spatial Databases, 251–269. Berlin, Heidelberg: Springer. doi:10.1007/3-540-48482-5_16.
- De Bernardo, G., S. Álvarez-García, N. R. Brisaboa, G. Navarro, and O. Pedreira. 2013. ”Compact Querieable Representations of Raster Data.” String Processing and Information Retrieval 8214: 96–108. LNCS. doi:10.1007/978-3-319-02432-5_14.
- De Queiroz, R. L., and P. A. Chou. 2016. “Compression of 3D Point Clouds Using a Region-Adaptive Hierarchical Transform.” IEEE Transactions on Image Processing 25 (8): 3947–3956. doi:10.1109/TIP.2016.2575005.
- Devillers, O., and P. M. Gandoin. 2000. “Geometric Compression for Interactive Transmission.” In Proceedings of the IEEE Visualization Conference, 319–326. IEEE. doi:10.1109/visual.2000.885711.
- Dewitt, D. J., R. H. Katz, F. Olkenr, L. D. Shapiro, M. R. Stonebraker, and D. Wood. 1984. “Implementation Techniques for Main Memory Database Systems.” In Proceedings of the ACM SIGMOD International Conference on Management of Data, 1–8. doi:10.1145/602259.602261.
- Dong, P., and Q. Chen. 2017. LiDar Remote Sensing and Applications. CRC Press. doi:10.4324/9781351233354.
- Elmasri, R., and S. B. Navathe. 2016. Fundamentals of Database Systems, 6th ed., (pp. 205–209). Boston, Massachusetts, United States: Pearson Harlow.
- Elseberg, J., D. Borrmann, and A. Nuchter. 2011. “Efficient Processing of Large 3D Point Clouds.” In 2011 XXIII International Symposium on Information, Communication and Automation Technologies, 1–7. doi:10.1109/ICAT.2011.61 02102.
- Fan, Y., Y. Huang, and J. Peng. 2013. “Point Cloud Compression Based on Hierarchical Point Clustering.” In 2013 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, 1–7. doi:10.1109/APSIPA.2013.6694334.
- Finkel, R. A., and J. L. Bentley. 1974. “Quad Trees a Data Structure for Retrieval on Composite Keys.” Acta Informatica 4 (1): 1–9. doi:10.1007/BF00288933.
- Gargantini, I. 1982. ”An Effective Way to Represent Quadtrees.” Communications of the ACM. 25 (12): 905–910. New York, NY, USA. doi:10.1145/358728.358741.
- Graziosi, D., O. Nak Agami, S. Kuma, A. Zaghetto, T. Suzuki, and A. Tabatabai. 2020. “An Overview of Ongoing Point Cloud Compression Standardization Activities: Video-Based (V-PCC) and Geometry-Based (G-PCC).” APSIPA Transactions on Signal and Information Processing 9 (1): e13. doi:10.1017/ATSIP.2020.12.
- Huang, L., S. Wang, K. Wong, J. Liu, and R. Urtasun. 2020. “OctSqueeze: Octree-Structured Entropy Model for Lidar Compression.” In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 1310–1320. doi:10.1109/CVPR42600.2020.00139.
- Hyyppa, J., Y. Xiaowei, K. Harri, K. Antero, J. Anttoni, X.-L. Liang, W. Yunsheng, H. Markus, V. Mikko, and H. Hyyppa. 2018. “Forest Inventory Using Laser Scanning.” In Topographic Laser Ranging and Scanning, 379–412. CRC Press. doi:10.1201/9781315154381-12.
- Ida Mengyi, P. 2006. ”Arithmetic Coding.” Fundamental Data Compression, Elsevier: 101–116. doi:10.1016/b978-075066310-6/50009-x.
- Isenburg, M. 2012. LASindex: simple spatial indexing of LiDAR data. https://rapidlasso.com/2012/12/03/lasindex-spatial-indexing-of-lidar-data/.
- Isenburg, M. 2013. “Laszip: Lossless Compression of LiDar Data.” Photogram- Metric Engineering and Remote Sensing 79 (2): 209–217. doi:10.14358/PERS.79.2.209.
- ISO/IEC JTC 1/SC 29/WG 7. 2021. G-PCC Codec Description. https://mpeg.chiariglione.org/standards/mpeg-i/geometry-based-point-cloud-compression/g-pcc-codec-description-v2.
- Jaboyedoff, M., T. Oppikofer, A. Abellán, M. Henri Derron, A. Loye, R. Metzger, and A. Pedrazzini. 2012. “Use of LIDAR in Landslide Investigations: A Review.” Natural Hazards 61 (1): 5–28. doi:10.1007/s11069-010-9634-2.
- Jacobson, G. 1989. “Space-Efficient Static Trees and Graphs.” In 30th Annual Symposium on Foundations of Computer Science, 549–554. doi:10.1109/SFCS.1989.63533.
- Khoshelham, K., L. Díaz Vilariño, M. Peter, Z. Kang, and D. Acharya. 2017. “The ISPRS Benchmark on Indoor Modelling.” The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences XLII-2/W7 (2): 367–372. doi:10.5194/isprs-archives-XLII-2-W7-367-2017.
- Klinger, A. 1971. Pattern and Search Statistics, 303–337. Academic Press. doi:10.1016/b978-0-12-604550-5.50019-5.
- Klinger, A., and C. R. Dyer. 1976. “Experiments on Picture Representation Using Regular Decomposition.” Computer Graphics and Image Processing 5 (1): 68–105. doi:10.1016/S0146-664X(76)80006-8.
- Ladra, S., M. R. Luaces, J. R. Paramá, and F. Silva-Coira. 2019. “Space- and Time-Efficient Storage of LiDar Point Clouds.” In String Processing and Information Retrieval, 513–527. Springer International Publishing. doi:10.1007/978-3-030-32686-9_36.
- Ladra, S., J. R. Paramá, and F. Silva-Coira. 2017. “Scalable and Queryable Compressed Storage Structure for Raster Data.” Information Systems 72: 179–204. doi:10.1016/j.is.2017.10.007.
- Lin, T.-W. 1997. “Compressed Quadtree Representations for Storing Similar Images.” Image and Vision Computing 15 (11): 833–843. doi:10.1016/S0262-8856(97)00031-0.
- Liu, H., H. Yuan, Q. Liu, J. Hou, and J. Liu. 2020. ”A Comprehensive Study and Comparison of Core Technologies for MPEG 3-D Point Cloud Compression.” IEEE Transactions on Broadcasting. 66 (3): 701–717. doi:10.1109/TBC.2019.2957652.
- Meagher, D. 1982. “Geometric Modeling Using Octree Encoding.” Computer Graphics and Image Processing 19 (2): 129–147. doi:10.1016/0146-664X(82)90104-6.
- Munro, J. I. 1996. “Tables.” In Proceedings 16th Conference Foundations of Software Technology and Theoretical Computer Science (FSTTCS), (pp. 37–42). Hyderabad, India.
- Navarro, G. 2016. Compact Data Structures: A Practical Approach, 553. Aire-la-Ville, Geneva, Switzerland: Cambridge University Press.
- Ochotta, T., and D. Saupe. 2004. “Compression of Point-Based 3D Models by Shape-Adaptive Wavelet Coding of Multi-Height Fields.” In SPBG’04 Symposium on Point - Based Graphics 2004. The Eurographics Association. doi:10.2312/SPBG/SPBG04/103–112.
- Palomer, A., P. Ridao, D. Youakim, D. Ribas, J. Forest, and Y. Petillot. 2018. “3D Laser Scanner for Underwater Manipulation.” Sensors 18 (4): 1086. doi:10.3390/s18041086.
- Peng, J., and C. C. J. Kuo. 2003. ”Octree-Based Progressive Geometry Encoder.” Internet Multimedia Management Systems IV, Vol. 5242, 301–311. SPIE. doi:10.1117/12.510857.
- Peng, J., C. Su Kim, and C. C. J. Kuo. 2005. “Technologies for 3D Mesh Compression: A Survey.” Journal of Visual Communication and Image Representation 16 (6): 688–733. doi:10.1016/j.jvcir.2005.03.001.
- Pinto, A., D. Seco, and G. Gutierrez. 2017. “Improved Queryable Representations of Rasters.” In Data Compression Conference Proceedings Part F127767, 320–329. doi:10.1109/DCC.2017.21.
- Plattner, H. 2009. “A Common Database Approach for OLTP and OLAP Using an In-Memory Column Database.” In SIGMOD-PODS’09 - Proceedings of the International Conference on Management of Data and 28th Symposium on Principles of Database Systems, 1–2. doi:10.1145/1559845.1559846.
- Plattner, H., and A. Zeier. 2012. In-Memory Data Management: Technology and Applications. Dagstuhl, Germany: Springer Science & Business Media.
- Prezza, N. 2017. “A Framework of DYNAMIC Data Structures for String Processing.” Leibniz International Proceedings in Informatics, LIPIcs 75 (11): 1–11:15. doi:10.4230/LIPIcs.SEA.2017.11.
- Quach, M., G. Valenzise, and F. Dufaux. 2020. “Improved Deep Point Cloud Geometry Compression.” In IEEE 22nd International Workshop on Multimedia Signal Processing, MMSP 2020, 1–6. doi:10.1109/MMSP48831.2020.9287077. arXiv: 2006.09043.
- Ribes, A., and C. Boucheny. 2017. “Eye-Dome Lighting : A Non- Photorealistic Shading Technique.” Kitware Source Quarterly Magazine 17 (April 2011, 3–4.
- Royo, S., and M. Ballesta-Garcia. 2019. “An Overview of Lidar Imaging Systems for Autonomous Vehicles.” Applied Sciences (Switzerland) 9 (19): 4093. doi:10.3390/app9194093.
- Samet, H. 1984. “The Quadtree and Related Hierarchical Data Structures.” ACM Computing Surveys (CSUR) 16 (2): 187–260. doi:10.1145/356924.356930.
- Samet, H. 2006. Foundations of Multidimensional And Metric Data Structures, 993. Morgan Kaufmann. http://books.google.com/books?id=vO-NRRKHG84C&pgis=1.
- Samet, H., A. Rosenfeld, C. A. Shaffer, and R. E. Webber. 1984. “A Geographic Information System Using Quadtrees.” Pattern Recognition 17 (6): 647–656. doi:10.1016/0031-3203(84)90018-9.
- Schnabel, R., and R. Klein. 2006. “Octree-Based Point-Cloud Compression.” Eurographics Symposium on Point-Based Graphics, 111–120. doi:10.2312/SPBG/SPBG06/111-120.
- Schwarz, S., M. Preda, V. Baroncini, M. Budagavi, P. Cesar, P. A. Chou, R. A. Cohen, et al. 2019. ”Emerging MPEG Standards for Point Cloud Compression.” IEEE Journal on Emerging and Selected Topics in Circuits and Systems 9 (1): 133–148. doi:10.1109/JETCAS.2018.2885981.
- Sevcik, K. C., and H. Hinterberger. 1984. “The Grid File: An Adaptable, Symmetric Multikey File Structure.” ACM Transactions on Database Systems (TODS) 9 (1): 38–71. doi:10.1145/348.318586.
- Shuman, D. I., S. K. Narang, P. Frossard, A. Ortega, and P. Vandergheynst. 2013. ”The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains.” IEEE Signal Processing Magazine. 30 (3): 83–98. arXiv: 1211.0053. doi:10.1109/MSP.2012.2235192.
- Silva-Coira, F., J. R. Parama, S. Ladra, J. R. Lopez, and G. Gutierrez. 2020. “Efficient Processing of Raster and Vector Data.” PLoS One 15 (1): 1–35. doi:10.1371/journal.pone.0226943.
- Susana, L., J. R. Paramá, and F. Silva-Coira. 2016. “Compact and Queryable Representation of Raster Datasets.” Proceedings of the 28th International Conference on Scientific and Statistical Database Management. SSDBM ’16. Budapest, Hungary, Association for Computing Machinery.doi:10.1145/2949689.2949710.
- Vigna, S. 2008. “Broadword Implementation of Rank/select Queries.” In Experimental Algorithms, edited by C. C. McGeoch, 154–168. Vol. 5038 LNCS. Berlin, Heidelberg: Springer. doi:10.1007/978-3-540-68552-4_12.
- Wang, R., J. Peethambaran, and D. Chen. 2018. “LiDar Point Clouds to 3-D Urban Models : A Review.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 11 (2): 606–627. doi:10.1109/JSTARS.2017.2781132.
- Woodwark, J. R. 1984. “Compressed Quad Trees.” The Computer Journal 27 (3): 225–229. doi:10.1093/comjnl/27.3.225.
- Yan, H., C. C. J. K. Jingliang Peng, and M. Gopi. 2008. “A Generic Scheme for Progressive Point Cloud Coding.” IEEE Transactions on Visualization and Computer Graphics 14 (2): 440–453. doi:10.1109/TVCG.2007.70441.
- Zhang, C., D. Florencio, and C. Loop. 2014. “Point Cloud Attribute Compression with Graph Transform.” 2014 IEEE International Conference on Image Processing, ICIP 2014, 2066–2070. doi:10.1109/ICIP.2014.7025414.
- Zhang, J., and S. You. 2010. “Supporting Web-Based Visual Exploration of Large-Scale Raster Geospatial Data Using Binned Min-Max Quadtree.” Scientific and Statistical Database Management 6187 LNCS: 379–396. doi:10.1007/978-3-642-13818-8_27.
- Zhang, J., and S. You. 2013. “High-Performance Quadtree Constructions on Large-Scale Geospatial Rasters Using GPGPU Parallel Primitives.” International Journal of Geographical Information Science 27 (11): 2207–2226. doi:10.1080/3658816.2013.8288401.
- Zhang, J., S. You, and L. Gruenwald. 2015. “Quadtree-Based Lightweight Data Compression for Large-Scale Geospatial Rasters on Multi-Core Cpus.” 2015 IEEE International Conference on Big Data (Big Data), 478–484. doi:10.1109/BigData.2015.7363789.
Appendix A:
Visualization of the Datasets
Figure A1. Visualization of the dataset labeled as PNOA-S.

Figure A2. Visualization of the dataset labeled as PNOA-M.

Figure A3. Visualization of the dataset labeled as PNOA-L.

Figure A4. Visualization of the dataset labeled as TUB1.
Figure A5. Visualization of a detail of the dataset labeled as TUB1.

Figure A6. Visualization of a detail of the dataset labeled as TUB1-Detail using an EDL shader.

Figure A7. Visualization of the dataset labeled as FireBr.

Figure A8. Visualization of a detail of the dataset labeled as FireBr.

Figure A9. Visualization of a detail of the dataset labeled as FireBr using an EDL shader.

Figure A10. Visualization of the dataset labeled as Velo1.

Figure A11. Visualization of a detail of the dataset labeled as Velo1.

Figure A12. Visualization of the dataset labeled as Velo2.

Figure A13. Visualization of a detail of the dataset labeled as Velo2.

Figure A14. Visualization of the dataset labeled as Velo3.

Figure A15. Visualization of a detail of the dataset labeled as Velo3.

Figure A16. Visualization of the dataset labeled as Ladyb1.

Figure A17. Visualization of a detail of the dataset labeled as Ladyb1.

Figure A18. Visualization of the dataset labeled as Ladyb2.

Figure A19. Visualization of a detail of the dataset labeled as Ladyb2.
