
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The deep learning-based building extraction methods produce different feature maps at different stages of the network, which contain different information features. The detailed information of the feature maps decreases along the depth of the network, and insufficiently detailed information results in limited accuracy. However, existing methods are incapable of making full use of low-level feature maps with rich details. To overcome these shortcomings, we proposed a Cross-stage Features Fusion Network (CFF-Net) for building extraction from remote sensing images. In the CFF-Net, we innovatively proposed a Cross-stage Features Fusion (CFF) module that fuses different features generated at different stages. And we used the attention mechanism to make the network more focused on important information at different scales. To further improve the accuracy of building extraction, we designed the Prediction Enhancement (PE) module, where the last convolutional layer and the feature map generated in the intermediate stage are used for prediction at the same time to enhance the final result. To evaluate the effectiveness of the proposed network, we conduct quantitative and qualitative experiments on the two publicly available datasets, i.e. the Inria dataset and the WHU datasets. CFF-Net outperformed other state-of-the-art algorithms on the two datasets in IoU and F1 metrics. The efficiency analysis reveals that the proposed CFF-Net achieves a great balance between building extraction performance and complexity/efficiency, with faster convergence and higher robustness.
1. Introduction
Building extraction from remote sensing images is an important application, which has an important role in urban planning, smart city construction, and disaster management (Cai et al. Citation2023; Chen et al. Citation2020; Ding et al. Citation2022; Dong and Shan Citation2013; Shao et al. Citation2021; Trinder and Liu Citation2020). In recent decades, the development of Very High Resolution (VHR) remote sensing satellites and unmanned aerial vehicles, which can generate meter- and submeter-level remote sensing images easily, has further promoted the development of building extraction techniques (Li, Huang, et al. Citation2022). VHR remote sensing images include more detailed feature information, from which the finer results of building extraction can be achieved. And the obtained products have wider applications (Huang et al. Citation2019). However, the VHR remote sensing images also make the homogeneous and heterogeneous effects more obvious and introduce more noise, for example, houses and roads are very similar, making it difficult to extract the fine building results (Guo et al. Citation2022).
The current methods of extracting buildings based on optical remote sensing images mainly include the traditional hand-craft feature – methods and deep-learning-based methods. The traditional methods extract hand-craft features from remote sensing images, including color, spectrum, and texture, and apply traditional machine learning methods to recognize buildings (Dornaika et al. Citation2016; Zhang Citation1999). For example, Huang et al. (Citation2016) took advantage of the difference in morphological profiles for building extraction from remote sensing images. Hossain and Chen (Citation2022) used spectral features of VHR remote sensing images for the image segmentation task to finally achieve building extraction. However, traditional hand-craft features are often designed relying on experience, and these features vary in different weather conditions and sensors, which have little robustness (Zhu et al. Citation2021). In recent years, deep learning has been a mainstream approach to learning features autonomously. Semantic segmentation, where the goal is to classify each pixel into a fixed set of categories without differentiating object instances (He et al. Citation2017), is a main task of computer vision and is widely used for building extraction from remote sensing images (Heipke and Rottensteiner Citation2020). Convolutional Neural Network (CNN) is currently the main deep learning approach for building extraction, which can automatically learn various types of information through convolutional layers, including textures, spectrums, spatial context, and the interactions among geo-objects (Bai et al. Citation2023; Li, Zheng, et al. Citation2022; Wang et al. Citation2023).
A Fully Convolutional Network (FCN) derived from CNNs can achieve pixel-level category prediction on images (Long, Shelhamer, and Darrell Citation2015), which is widely used in the satellite building extraction task. Ronneberger, Fischer, and Brox (Citation2015) proposed U-Net, which downsamples the images to extract the feature first, and then upsamples the image to the original size while obtaining the extraction results. SegNet adds the pooling index for upsampling based on U-Net (Badrinarayanan, Kendall, and Cipolla Citation2017). Deeplab-v3 uses atrous separable convolution for feature extraction to obtain the information of different receptive fields (Chen et al. Citation2017). HRNet extracts the feature through parallel branches simultaneously and integrates to achieve the segmentation task (Sun, Xiao, et al. Citation2019). In recent years, there have been many researches focused on building extraction in the remote sensing field, Z. Zhang et al. (Citation2018) proposed a Siamese U-Net with shared weights in two branches, SiU-Net, for building extraction. Chen, Zhang, et al. (Citation2022) designed CLNet, which improves the final accuracy by enhancing the features extracted in the network. The transformer was first used in the field of Natural Language Processing (NLP) (Vaswani et al. Citation2017) and has now been applied to the field of computer vision, Vision Transformer (ViT) (Dosovitskiy et al. Citation2020) and DEtection TRansformer (DETR) (Carion et al. Citation2020). BuildFormer uses ViT and CNN dual path for information extraction to finally achieve building extraction for remote sensing images (Wang et al. Citation2022).
The key to the deep learning-based methods to extract building consists of acquiring the semantic information of the remote sensing images and applying the extracted features appropriately for the final prediction results. The deep learning network normally includes several stages, which produce feature maps containing different feature information, respectively (Xu et al. Citation2022). Low-level feature maps have more detailed spatial information but are less capable of global perception while high-level feature maps are able to have a clearer understanding of semantic information (Zhu et al. Citation2020). The proper fusion of low-level and high-level is the key to extracting buildings accurately. The texture details contained in the feature maps weaken as the network deepens. In contemporary deep learning methodologies, efforts have been made to integrate intricate low-level details into high-level feature maps. For instance, U-Net employs skip connections to fuse feature maps from the encoder, which contain finer spatial details, into the decoder. Furthermore, feature fusion techniques have found application in the domain of building extraction (Ronneberger, Fischer, and Brox Citation2015). BMFR-Net adopts a multi-stage approach within the decoder for result prediction, where results from different stages are fused (Ran et al. Citation2021). Sun et al. (Citation2019) proposed a fusion strategy based on parallel Support Vector Mechanism (SVM) to utilize the deep features extracted from multi-scale CNN structures at different scales. Additionally, Chen et al. (Citation2022) employed transformer architectures for multi-scale feature extraction, fusing these features to facilitate building extraction. However, the ways are too simple to make full use of the information in high-level feature maps, which exhibit major limitations in difficult identification of buildings at image boundaries, confusion between buildings and non-buildings, and blurred boundaries of complex buildings.
In order to solve the above problems, we proposed a Cross-stage Feature Fusion network (CFF-Net) for building extraction from VHR remote-sensing images. The proposed CFF-Net is able to fuse features from multiple feature maps generated in different stages and make full use of the global semantic and spatially local information through the attention mechanism. Moreover, the CFF-Net is capable of utilizing more information during the prediction by prediction enhancement. We took the feature maps generated in the intermediate stage for the prediction to enhance the prediction results of the final convolutional layer, which is capable of obtaining more accurate extraction results. The main contributions of this study are as follows:
We proposed a CFF-Net, a novel cross-stage feature fusion network designed for precise building extraction from VHR remote sensing images. This network adeptly amalgamates cross-stage semantic features derived from multiple processing stages, demonstrating exceptional proficiency across various scales, ensuring accurate predictions for buildings of diverse sizes. Specifically, the network leverages intermediate-stage feature maps to refine predictions generated by the final convolutional layer, significantly enhancing prediction accuracy. And the CFF-Net obtained the best building extraction results on two public data sets compared with the traditional methods.
The cross-stage feature fusion module is proposed to fuse the feature information generated in multiple stages. In contrast to conventional methods, which integrate feature via skip connections simply, the CFF module employs the attention mechanism to amalgamate features extracted from different stages within the encoder and pass them into the decoder. This mechanism facilitates the integration of low-level spatial details and high-level semantic information, enriching the ability of network to comprehend multiple scales. The embedded attention mechanism makes the network pay more attention to building areas, improving its capacity to discriminate between building and non-building regions. Notably, the network exhibits superior performance in extracting buildings located at the image peripheries, which are often ignored.
To effectively leverage the details information extracted from the intermediate process of network for refining final predictions, we designed a prediction enhancement module in CFF-Net. Diverging from conventional deep learning methodologies that solely rely on the last convolutional layer of the FCN for final predictions, our prediction enhancement module leverages predictions from the intermediate layer of network. This strategic integration enhances the predictions generated by the final layer, leading to more accurate building extraction. Compared to the last convolutional layer, the feature maps in the intermediate stage bring more detailed information. Consequently, this finer level of information empowers the final predictions, ensuring superior accuracy in delineating complex-shaped buildings and small-scale structures.
We organize the rest of this article as follows. We describe the related work involving attention mechanisms and feature fusion in Section 2. The structure and components of CFF-Net are presented in Section 3. Then we give the experiments and result analysis in Section 4, and the conclusions are presented in Section 5.
2. Related work
2.1. Attention mechanisms
Attention mechanisms introduced into computer vision is aiming at imitating people, who can naturally and effectively find salient regions in complex scenes (Guo et al. Citation2022). Such an attention mechanism can be regarded as a dynamic weight adjustment process based on features of the input image. The process of attention mechanisms working can be formulated as:
where represents to generate attention on the whole image;
means processing input
based on the attention
.
In recent years, many studies have been put into attention mechanisms and have made some progress in computer vision tasks. SENet is a novel channel-attention network that implicitly and adaptively predicts the potential key features (Jie, Shen, and Sun Citation2018). The network learns the relationship between channels and the importance of each channel in a set of feature maps, and the features of the channels are weighted and fused to improve the representing capacity of the network. Similar to the channel attention mechanism, which aims to capture the important channels, the spatial attention mechanism aims to enable the model to adaptively learn the attention weights of different regions by introducing an attention module (Zhu et al. Citation2019). The model pays more attention to the important image regions and ignore the unimportant ones. The self-attention mechanism is one type of spatial attention mechanism that captures long-range dependencies between elements adaptively by computing the relative importance between elements, with some popular models being Non-local (Wang et al. Citation2018), GCNet (Cao et al. Citation2019), and ViT (Dosovitskiy et al. Citation2020). Convolutional Block Attention Module (CBAM) (Woo et al. Citation2018) is an attention mechanism that combines the channel attention mechanism and spatial attention mechanism. The coordinate attention mechanism considers both inter-channel relationships and long-distance location information with only a small increase in computational effort, which can effectively improve the accuracy of the model (Hou, Zhou, and Feng Citation2021). In the field of remote sensing, numerous studies have introduced attention mechanisms tailored to remote sensing tasks. Zhao et al. (Citation2023) proposed a multiple attention network, including a plug-and-play attention module, for spartina alterniflora segmentation using multitemporal remote sensing images. Y. Gao et al. (Citation2023) introduced a cross-scale mixing attention mechanism to facilitate the fusion and classification of multisource remote sensing data. Li et al. (Citation2022) used the self-attention mechanism for Hyperspectral and SAR Image Classification in AsyFFNet. In SOT-Net (M. Zhang et al. Citation2022), a cross-attention module was employed to enhance the spectral information of HyperSpectral Imagery (HSI). Additionally, the DFINet featured a depth-wise cross-attention module meticulously crafted to extract both self-correlation and cross-correlation patterns from multisource feature pairs (Y. Gao et al. Citation2021).
2.2. Feature fusion
Efficient fusion of features during the network, absorbing what is good and rejecting what is bad, is the key to improving the extraction accuracy of the model. Many studies have been conducted on how to better fuse the features of multiple channel feature maps at a single stage, where the feature maps have the same size, to fully exploit the extracted to information (Pan et al. Citation2023; Yuan et al. Citation2023). SENet recalibrates channel-wise feature responses by explicitly modeling interdependencies between channels (Jie, Shen, and Sun Citation2018). GCNet captures global contextual information through the global average pooling layer, and fuses global contextual information with local features when fusing multiple feature maps (Cao et al. Citation2019). DANet uses dual-attention paths of spatial attention mechanism and channel attention mechanism for the acquisition of important information and integrates local features with their global dependencies in the feature fusion process adaptively (Fu et al. Citation2019).
The improvement of the feature fusion method in single-stage channels can obtain useful information. The size of the feature maps differ in multiple stages, and the scales of the contained features vary more. The fusion of the feature maps of multiple stages can provide better knowledge of the details and global information. Feature Pyramid Network (FPN) enables the upper-level features to receive high-resolution information from the lower level and maintain high-quality semantic information during feature fusion by adding lateral connections in the feature pyramid at different levels (Lin et al. Citation2017). Atrous Spatial Pyramid Pooling (ASPP) is a pyramid fusion method using atrous convolution, where atrous convolution operations are performed at different atrous rates to obtain features with different scales, which are then fused together (Chen et al. Citation2017). ExFuse introduces semantic information into low-level features and high-resolution details into high-level features to achieve the integration of multi-stage features (Zhang et al. Citation2018).
The above attention mechanisms and feature fusion approaches have good results in semantic segmentation tasks. Unlike natural images, remote sensing images cover a wider range and contain more complex feature information. These methods may not necessarily achieve good results when applied directly to building extraction from remote sensing images. Therefore, for building extraction of remote sensing images, the features fusion methods deserve further exploration.
3. The proposed method
3.1. Overview
To make full use of the spatial details and global semantic information of the feature maps to extract buildings from remote sensing images, we proposed a Cross-stage Feature Fusion Network (CFF-Net). The proposed network fuses cross-stage features in an optimal manner (). The image feature extraction component extracts multi-level features from the input image; the feature fusion component fuses these cross-stage features obtained from the previous stage.
Figure 1. The structure of the proposed CFF-Net.
3.2. CFF network
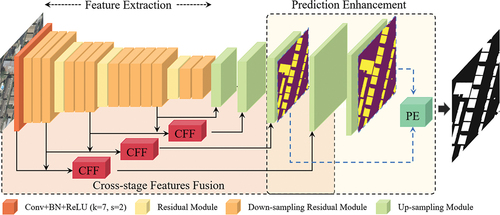
CFF-Net was designed based on the U-net (Ronneberger, Fischer, and Brox Citation2015), which has been demonstrated to perform well in building extraction. The U-Net contains an encoder, decoder, and skip connection components. In CFF-Net, Resnet-34 was chosen as the feature extraction network (He et al. Citation2016). Deep-residual networks have been demonstrated to reduce gradient degradation problems in model training and have the ability to locate the building features accurately (Audebert, Saux, and Lefèvre Citation2018). As shown in , the feature extraction stage contains one down-sampling convolutional layer and four residual layers, where five feature maps are obtained. The width and height of each level are 1/2 of the upper level. The size of the convolution kernel of the first convolutional layer is 7 × 7, and the strider is 2. The residual layer consists of residual blocks (), and the number of residual blocks in the four residual layers is 3, 4, 6, 3, respectively. A maxpool layer is included between the convolutional layer and the first residual layer to down-sample the feature map. The first residual block of the remaining residual layers is the down-sampling residual module, and the rest of the residual blocks are normal residual blocks. Decoder, whose function is to fuse the current feature maps and the feature maps in the skip connection and upsample, includes four up-sampling modules (). We obtain the feature map with the same size as the input image through the decoder. Note that each up-sampling operation changes the width and height of the feature map to twice of the previous one by linear interpolation.
Figure 2. The structure of the residual module. (a) Down-sampling residual module. (b) Normal residual module.
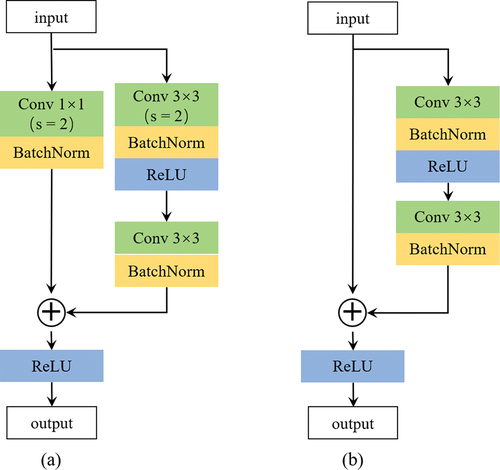
Figure 3. The structure of the up-sampling module.
3.3. Cross-stage feature fusion module
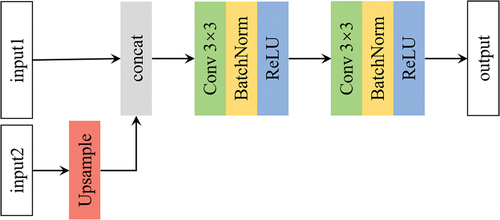
To make full use of features extracted during the feature extraction stage, we proposed a Cross-stage Feature Fusion (CFF) module, which fuses cross-stage lateral encoder features (). Inspired by Zhang et al. (Citation2018), CFF – Net fuses the two adjacent features, which can take advantage of the spatial detail and global semantic information. The fused feature map is passed into a decoder with the skip connection to transmit feature information.
Figure 4. The structure of the cross-level feature fusion module.
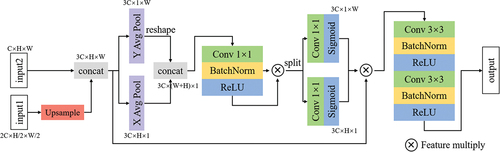
Cross-stage feature fusion is the process of fusing the feature maps generated by two stages to obtain their respective useful information. The feature maps generated in each stage own different sizes. The features are first interpolated to the same size and fused by concat operation. To capture the exact precise positional information and dependency, we draw on the operation proposed by Hou, Zhou, and Feng (Citation2021). As shown in , two adjacent feature maps are linearly interpolated to the same size and then concatenated. In order to obtain the relative positional relationships of the features, the features concatenated are averaged pooled in the both horizontal direction and vertical direction, respectively. For the feature map , we use the pooling kernel
for horizontal pooling operations. And the output of the c-th channel at height h can be formulated as:
Similarly, the pooling kernel is used to perform vertical pooling operations. And the output of the c-th channel at width w can be written as:
Two attention maps obtained by pooling horizontally and pooling vertically are concatenated and switched through the non-linear operation. The concatenation of two attention maps enables the network to learn the interconnections between the horizontal and vertical directions of the feature maps. After that, the maps are split and two attention weighed maps are obtained by two 1 1 convolution, each element in which reflects whether the object of interest exists in the corresponding row and column. The features concatenated are weighted with the two attention maps and two 3
3 convolutional transformations are utilized to obtain the output.
There are five stages in the decoder and encoder of the network respectively. Let denotes the feature map input into the
stage of decoder, then we have:
where indicates the skip connection operation,
represents the processed feature by Up-sampling module,
represents the processed feature by the CFF module, and
denotes the feature map generated from
layer during the decoder process.
3.4. Predication enhancement module
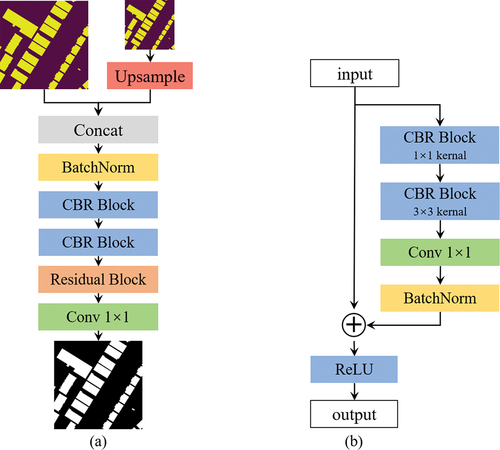
To make full use of the feature detail obtained from the hidden layers for the final result, inspired by the Deeply-Supervised (Li, Huang, et al. Citation2022), we proposed the prediction enhancement module (). Rather than obtaining the result from the only last convolutional layer, we also predict the extraction result using the feature map with the 1/4 size of the original image generated in third stage during the encoder process. The prediction results of the two stages are fed into the PE module to obtain the final building extraction results. Furthermore, the prediction enhancement module can directly supervise the hidden layer to ensure the network can converge more quickly. The feature map generated in third stage of a decoder is chosen to balance the global semantic and spatial detail information. depicts the prediction enhancement module and Residual Block. The prediction results from the two stages are fed into the PE module, and linear interpolation is operated to make the feature maps have the same size. Then the feature maps concatenated are normalized by BN operation, further fused by two sets of Conv-BN-ReLU operation and residual block operation. The final building extraction result is obtained by a 1 × 1 convolution.
Figure 5. The structure of the prediction enhancement (PE) module. (a) Prediction enhancement module. (b) Residual block.
3.5. Model implementation and loss function
All experiments run on NVIDIA GeoForce RTX 3090 GPUs. The operating system is Ubuntu 20.04. And all programs were implemented using Pytorch library. We used Adam as the optimizer. The initial learning rate is 0.001 and is decreased to 0.7 of the current learning rate if the accuracy does not increase on the validation set. The training process stops when the epoch reaches 100 or the learning rate is lower than 1e-7. During the training, random horizontal and vertical flipping were selected as data augmentation strategies. The sigmoid binary cross-entropy loss was selected as the loss function of CFF-Net, considering the task of the pixel-wise binary classification. For the position , the loss can be computed as:
where represents the predicted result, and
indicates the ground truth. The sigmoid function was applied to logits to ensure that
. The loss value is the average of
at all positions for an input image.
4. Experimental and analysis
4.1 datasets
To evaluate the performance of the proposed CFF-Net, we conducted a comprehensive experiment on two publicly available building datasets, including the WHU building dataset (Shunping, Wei, and Lu Citation2018) and the Inria aerial image dataset (Maggiori et al. Citation2017).
The WHU building dataset includes aerial and satellite subsets. In our experiment, we selected the aerial subset, which overs over a 450 km2 area with about 22,000 buildings. The buildings with various appearances and scales can evaluate the robustness of the proposed algorithm. Each image has three bands, corresponding to Red (R), Green (G), and Blue (B) wavelengths, with each image size of 512 × 512 pixels. And the spatial resolution of the R-G-B composite aerial images is 0.3 m. There are a total of 8188 tiles of images, including 4736, 2416, and 1036 tiles as training, test, and validation data sets, respectively. We conducted our experiment at its original provided data set partitioning.
The Inria aerial image dataset includes 360 aerial images with 5000 × 5000 pixels from 5 cities (Austin, Chicago, Kitsap, Tyrol, and Vienna). The images cover dissimilar urban buildings, ranging from dense urban villages to alpine towns. Only 180 training images have labels, and we cropped them into the images with 512 × 512 pixels. We got a total of 12,095 tiles, and these images were randomly assigned to the training set and the test machine in an 8:2 ratio. Finally, there are 9676 and 2419 tiles as training and validation data sets.
4.2. Evaluation metrics
The building extraction is the classification result of each pixel, so we apply the pixel-level metrics to assess the performance of the methods, including precision, recall, the F1-score, and the Intersection-Over-Union (IoU). Precision represents the percentage of the correct areas that are predicted as buildings, while recall indicates the proportion of the correct predictions in the building ground truths. The F1-score is the harmonic mean of precision and recall; the IoU represents the ratio of the intersection areas over the union areas between the building predictions and the ground truths. There are four classifying conditions: True prediction on a Positive sample (TP), False prediction on a Positive sample (FP), True prediction on a Negative sample (TN), and False prediction on a Negative sample (FN). Equations are given as follows:
4.3. Performance evaluation
4.3.1. Comparison methods
We selected five state-of-the-art methods, including U-net, BiSeNet v2, Deeplab v3, HRNet, and SegNet, and four recent methods, including SiU-Net, BuildFormer, CLNet, and BalNet, for comparison. We will introduce them briefly.
U-net was proposed at 2015 for Biomedical Image Segmentation (Ronneberger, Fischer, and Brox Citation2015), which includes an encoder, decoder, and skip connection. It won the ISBI cell tracking challenge 2015 and has good performance in semantic segmentation and building extraction tasks. BiseNet v2 (Yu et al. Citation2021) is a lightweight semantic segmentation network that improved on BiseNet. BiSeNet v2 processes these spatial details and classification semantics separately to achieve highly accurate and efficient semantic segmentation in real-time. Deeplab v3 (Chen et al. Citation2017) used the Multi-Grid strategy based on the previous model and adds batch normalization to the ASPP module. The ASPP module with different atrous rates can effectively capture multi-scale information. The method obtained the SOTA performance at VOC2012 at that time. HRNet (Sun et al. Citation2019) is a high-resolution network that maintains high-resolution representations throughout the processing of the network. SegNet (Badrinarayanan, Kendall, and Cipolla Citation2017) explicitly proposes the encoder-decoder architecture and proposed the maxpool index to decode, which can save memory.
SiU-Net (Shunping, Wei, and Lu Citation2018) is a Siamese U-Net with shared weights in two branches and original images and their down-sampled counterparts as inputs, which significantly improves the segmentation accuracy, especially for large buildings. BuildFormer (Wang et al. Citation2022) is a novel ViT with a dual-path structure, including a spatial-detailed context path to encode rich spatial details and a global context path to capture global dependencies. CLNet (Chen et al. Citation2022) is fully convolutional neural network consisting of the spatial fusion module, the focus enhancement module, and the feature decoder module. BalNet (He and Jiang Citation2021) is a fully convolutional network which embeds a boundary learning task and the spatial variation fusion module, adopts separable convolution with a larger kernel, and utilizes the convolutional block attention module.
4.3.2. Quantitative comparison
The quantitative evaluations of our proposed CFF-Net and the comparison methods on the Inria aerial dataset are shown in , and the evaluations of the WHU building dataset are shown in . Our proposed CFF-Net outperformed the comparative methods on the two datasets, which demonstrates the effectiveness of our proposed method. CFF-Net reached the highest IoU and F1 for both two datasets. Compared with BuildFormer proposed recently, CFF-Net increased the IoU by 0.12% and 0.43%, respectively. CFF-Net reached the highest and second highest Recall on the Inria Dataset and WHU building dataset, respectively. The higher Recall means that the more buildings could be extracted. We noticed that CLNet had a poor IoU, but reached the highest Precision on both datasets, indicating that it had more omissions in the process of building extraction. In terms of Precision, for the WHU dataset, CFF-Net achieved the second highest Precision after CLNet, which comes at the cost of missing many buildings. For the Inria dataset, there is the same phenomenon that Bal-Net and CLNet have the highest Precision but the low IOU. CFF-Net has a high Precision while having the highest IOU and F1. On the other hand, the proposed CFF-Net algorithm is able to maintain a high level of identifying the buildings and non-buildings in the process of building extraction. BuildFormer, obtaining multi-scale semantic information from the dual-path structure of ViT and CNN, reached the second highest IoU and F1 on the both datasets, which demonstrates it is crucial for building extraction to acquire and fuse multi-scale feature.
Table 1. Quantitative comparison with SOTA methods on the Inria dataset.
Table 2. Quantitative comparison with SOTA methods on the WHU dataset.
4.3.3. Qualitative comparison
To further analyze the limitations and advantages of the compared methods, we visualized some prediction examples of the top five IoU methods on the two publicly available datasets. As shown in , consistent with the quantitative metrics, our proposed CFF-Net can obtain more precise building extraction results than the other competing methods.
Figure 6. Examples of building extraction results of the proposed CFF-Net and other comparison methods on the inria dataset.

Figure 7. Examples of building extraction results of the proposed CFF-Net and other comparison methods on the WHU dataset.
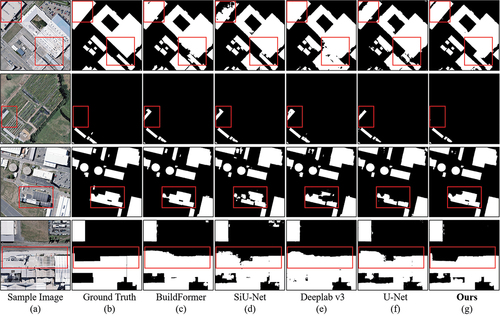
In row 3 and row 2, there are surface features with similar characteristics to buildings in the remote sensing images of the two datasets, and the comparison methods all incorrectly recognize them as buildings. Our proposed CFF-Net in this paper is able to distinguish the heterogeneity of different features well through the fusion of multi-stage information and identify the real buildings. In (row 1 and row 3), there are small holes in the building extraction results of Deeplab-v3 and U-Net, but the CFF-Net proposed is able to extract the whole building more successfully. For buildings with complex shapes, CFF-Net proposed can present their complex boundaries completely, as shown in (row 1, row 4) and (row 4), and the results obtained by other comparative algorithms are quite different from the ground truth. Moreover, in (row 2), CFF-Net is capable to detect small buildings accurately and obtain the complete boundaries, while other comparative methods occur omission or get broken buildings.
4.4. Ablation studies
To examine the functionality of the CFF module and PE module proposed in our CFF-Net, we set up a series of ablation experiments. We tested baseline, baseline plus CFF module, baseline plus CFF module, and PE module, which is CFF-Net, on the Inria and WHU datasets. The results of the ablation experiments on the two datasets are shown in , respectively.
Table 3. Ablation experimental results on the Inria dataset.
Table 4. Ablation experimental results on the WHU dataset.
As shown in , the baseline obtained 79.37% IoU on the Inria dataset. Adding the CFF module achieved a 0.61% improvement in IoU. And the Precision increased from 88.69% to 89.80%, indicating that the fusion of multi-scale feature information can reduce the false identification of buildings. Furthermore, the addition of PE module for baseline and baseline plus CFF module increases the IoU by 0.42%, 0.43% respectively, which indicates that the combined effect of multi-stage prediction results can extract buildings more accurately. As shown in , for the WHU dataset, the addition of CFF module and PE module also obtain an increase of IoU by 0.43%, 0.39% and the combination of the two modules gets an increase of IoU by 0.85%, which illustrates the effectiveness of our proposed method.
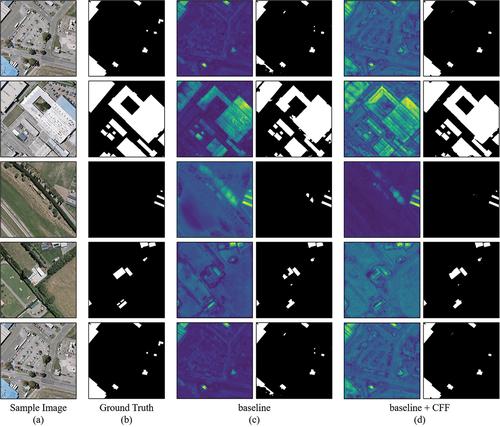
To further illustrate the contribution of the proposed CFF module, which fuses the cross-scale information for the final building extraction, as shown in , we visualized the feature maps of baseline and baseline with the CFF module in the process of building extraction on the WHU dataset. The fusion of multi-scale features enables the network to have a more accurate perception at any scale. As shown in (row 2, row 3, and row 4), the CFF module is able to suppress non-building regions while having better attention to complex buildings. In addition, the fusion of multi-scale information enables the network to have more accurate judgments on regions that are easily ignored. As illustrated in (row 1 and row 5), the network is able to focus more on the buildings at the image boundaries, making the final results more accurate.
Figure 8. Feature visualization from baseline and baseline with CFF module on the WHU dataset. The first column presents feature visualization and the second column presents the prediction result of baseline and baseline with CFF module in (c) and (d).
4.5. Complexity of CFF-Net
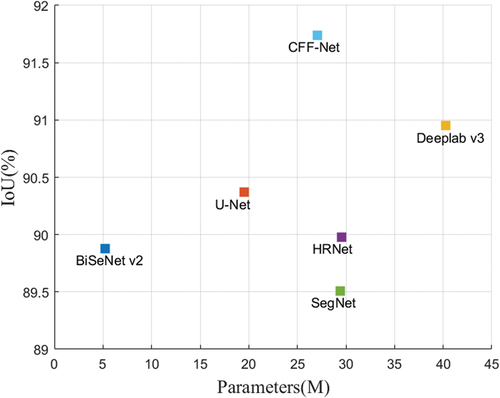
To validate the efficiency and accuracy of the proposed CFF-Net algorithm, as shown in , we visualized the IoU, parameters, and model size of the CFF-Net with the compared SOTA methods. As shown in , CFF-Net with 27.08 M parameters achieved the highest IoU, 91.74%. Deeplab-v3 obtains 90.95% IoU with 40.29 M parameters, which has much more parameters than CFF-Net. In summary, our proposed CFF-Net achieves higher accuracy and owns lower complexity compared to the competing SOTA methods.
Figure 9. Comparison of complexity and accuracy of CFF-Net and the comparison methods.
5. Conclusions
The difficult identification of buildings at the boundary of images and confusion between buildings and non-buildings are the main challenges in building extraction from remote sensing. To address the above challenges, we proposed a Cross-stage Feature Fusion Network (CFF-Net) for building extraction. The Cross-stage Feature Fusion (CFF) module was proposed to fuse the feature maps generated in different stages, making the network a better grasp of both detailed features and global information, and accurately identifying buildings in complex areas. Furthermore, the results are predicted using the feature map generated in the intermediate stages and the last convolutional layer. We fused the two prediction results to improve the final extraction results through the Prediction Enhancement (PE) module.
Experiments on the Inria and WHU datasets demonstrate the effectiveness and robustness of the proposed method for building extraction from remote sensing images. CFF-Net achieves the highest IoU, 80.41% and 91.74%, on the two datasets, respectively, and has the best extraction results. The ablation experiments confirm the effectiveness of the proposed CFF module and PE module, where the CFF module can accurately guide the network to focus on important regions. In addition, CFF-Net achieves a better balance between building extraction performance and network complexity/efficiency. The Precision of our method does not achieve the highest value, which indicates that our algorithm can misjudge when recognizing buildings, which deserves further research. Moreover, further work will improve the network’s performance while simplifying the structure, and apply CFF-Net to other remote sensing tasks.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are available from the corresponding author, upon reasonable request.
Additional information
Funding
Notes on contributors
Xiaolong Zuo
Xiaolong Zuo received the B.S. degree in spatial information and digital technology from Wuhan University, Wuhan, China, in 2022. He is currently working toward the Ph.D. degree in the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing (LIESMARS), Wuhan University. His research field includes image processing and the applications of deep learning in remote sensing.
Zhenfeng Shao
Zhenfeng Shao received the Ph.D. degree in photogrammetry and remote sensing from the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing (LIESMARS), Wuhan University, Wuhan, China, in 2004. Since 2009, he has been a Full Professor with LIESMARS, Wuhan University. He has authored or coauthored over 50 peer-reviewed articles in international journals. His research interests include high-resolution image processing, pattern recognition, and urban remote sensing applications.
Jiaming Wang
Jiaming Wang received his B.S. degree from Wuhan University, Wuhan, China, in 2015, M.S. degree from the Geographic Information Science and Technology, Georgia Institution of Technology, Atlanta, GA, USA, in 2016, and Ph.D. degree in Geography from the University of South Carolina, Columbia, SC, USA, in 2020. He is currently an Assistant Professor with the Department of Environmental Sciences at Emory University. His research interests cover GeoAI, deep learning, and human-environmental interactions.
Xiao Huang
Xiao Huang received the Ph.D. degree from the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, Wuhan, in 2022. He is currently working at the School of Computer Science and Engineering, Wuhan Institute of Technology. His research interests include image/video processing, computer vision, and artificial intelligence.
Yu Wang
Yu Wang received a master’s degree in engineering from Wuhan Institute of Technology, Wuhan, China, in 2021. He is currently pursuing the Ph.D. degree under the supervision of Prof. Zhenfeng Shao with the State Key Laboratory for Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, Wuhan. His research field includes image/video processing and computer vision.
References
- Audebert, N., B. L. Saux, and S. Lefèvre. 2018. “Beyond RGB: Very High Resolution Urban Remote Sensing with Multimodal Deep Networks.” ISPRS Journal of Photogrammetry and Remote Sensing 140: 20–32. https://doi.org/10.1016/j.isprsjprs.2017.11.011.
- Badrinarayanan, V., A. Kendall, and R. Cipolla. 2017. “Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (12): 2481–2495. https://doi.org/10.1109/TPAMI.2016.2644615.
- Bai, T., L. Wang, D. Yin, K. Sun, Y. Chen, W. Li, and D. Li. 2023. “Deep Learning for Change Detection in Remote Sensing: A Review.” Geo-Spatial Information Science 26 (3): 262–288.
- Cai, B., Z. Shao, X. Huang, X. Zhou, and S. Fang. 2023. “Deep Learning-Based Building Height Mapping Using Sentinel-1 and Sentienl-2 Data.” International Journal of Applied Earth Observation and Geoinformation 122: 103399. https://doi.org/10.1016/j.jag.2023.103399.
- Cao, Y., J. Xu, S. Lin, F. Wei, and H. Hu. 2019. “Gcnet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond.” In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. Seoul, South Korea: IEEE Computer Society.
- Carion, N., F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko. 2020. “End-to-End Object Detection with Transformers.” In European Conference on Computer Vision, 213–229. Glasgow, UK: Springer.
- Chen, L.-C., G. Papandreou, F. Schroff, and H. Adam. 2017. “Rethinking Atrous Convolution for Semantic Image Segmentation.” arXiv Preprint arXiv: 170605587. https://doi.org/10.48550/arXiv.1706.05587.
- Chen, Q., L. Wang, S. L. Waslander, and X. Liu. 2020. “An End-To-End Shape Modeling Framework for Vectorized Building Outline Generation from Aerial Images.” ISPRS Journal of Photogrammetry & Remote Sensing 170: 114–126. https://doi.org/10.1016/j.isprsjprs.2020.10.008.
- Chen, J., D. Zhang, Y. Wu, Y. Chen, and X. Yan. 2022. “A Context Feature Enhancement Network for Building Extraction from High-Resolution Remote Sensing Imagery.” Remote Sensing 14 (9): 2276.
- Chen, X., C. Qiu, W. Guo, A. Yu, X. Tong, and M. Schmitt. 2022. “Multiscale Feature Learning by Transformer for Building Extraction from Satellite Images.” IEEE Geoscience & Remote Sensing Letters 19: 1–5. https://doi.org/10.1109/LGRS.2022.3142279.
- Ding, Q., Z. Shao, X. Huang, O. Altan, and B. Hu. 2022. “Time-Series Land Cover Mapping and Urban Expansion Analysis Using OpenStreetmap Data and Remote Sensing Big Data: A Case Study of Guangdong-Hong Kong-Macao Greater Bay Area, China.” International Journal of Applied Earth Observation and Geoinformation 113: 103001. https://doi.org/10.1016/j.jag.2022.103001.
- Dong, L., and J. Shan. 2013. “A Comprehensive Review of Earthquake-Induced Building Damage Detection with Remote Sensing Techniques.” ISPRS Journal of Photogrammetry and Remote Sensing 84: 85–99. https://doi.org/10.1016/j.isprsjprs.2013.06.011.
- Dornaika, F., A. Moujahid, Y. E. Merabet, and Y. Ruichek. 2016. “Building Detection from Orthophotos Using a Machine Learning Approach: An Empirical Study on Image Segmentation and Descriptors.” Expert Systems with Applications 58: 130–142. https://doi.org/10.1016/j.eswa.2016.03.024.
- Dosovitskiy, A., L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, et al. 2020. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” arXiv Preprint arXiv: 201011929. https://doi.org/10.48550/arXiv.2010.11929.
- Fu, J., J. Liu, H. Tian, Y. Li, Y. Bao, Z. Fang, and H. Lu. 2019. “Dual Attention Network for Scene Segmentation.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3146–3154. Long Beach, California: IEEE Computer Society.
- Gao, Y., W. Li, M. Zhang, J. Wang, W. Sun, R. Tao, and Q. Du. 2021. “Hyperspectral and Multispectral Classification for Coastal Wetland Using Depthwise Feature Interaction Network.” IEEE Transactions on Geoscience & Remote Sensing 60: 1–15. https://doi.org/10.1109/TGRS.2021.3097093.
- Gao, Y., M. Zhang, J. Wang, and W. Li. 2023. “Cross-Scale Mixing Attention for Multisource Remote Sensing Data Fusion and Classification.” IEEE Transactions on Geoscience & Remote Sensing 61: 1–15. https://doi.org/10.1109/TGRS.2023.3263362.
- Guo, H., B. Du, L. Zhang, and X. Su. 2022. “A Coarse-To-Fine Boundary Refinement Network for Building Footprint Extraction from Remote Sensing Imagery.” ISPRS Journal of Photogrammetry & Remote Sensing 183: 240–252. https://doi.org/10.1016/j.isprsjprs.2021.11.005.
- Guo, M.-H., T. Xu, J. Liu, Z. Liu, P. Jiang, T. Mu, S. Zhang, R. R. Martin, M. Cheng, and S. Hu. 2022. “Attention Mechanisms in Computer Vision: A Survey.” Computational Visual Media 8 (3): 331–368. https://doi.org/10.1007/s41095-022-0271-y.
- He, K., G. Gkioxari, P. Dollár, and R. Girshick. 2017. “Mask r-cnn.” In Proceedings of the IEEE International Conference on Computer Vision, 2961–2969. Venice, Italy: IEEE Computer Society.
- He, K., X. Zhang, S. Ren, and J. Sun. 2016. “Identity Mappings in Deep Residual Networks.” In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, 630–645. Amsterdam, Netherlands: Springer.
- He, S., and W. Jiang. 2021. “Boundary-Assisted Learning for Building Extraction from Optical Remote Sensing Imagery.” Remote Sensing 13 (4): 760. https://doi.org/10.3390/rs13040760.
- Heipke, C., and F. Rottensteiner. 2020. “Deep Learning for Geometric and Semantic Tasks in Photogrammetry and Remote Sensing.” Geo-Spatial Information Science 23 (1): 10–19. https://doi.org/10.1080/10095020.2020.1718003.
- Hossain, M. D., and D. Chen. 2022. “A Hybrid Image Segmentation Method for Building Extraction from High-Resolution RGB Images.” ISPRS Journal of Photogrammetry and Remote Sensing 192: 299–314. https://doi.org/10.1016/j.isprsjprs.2022.08.024.
- Hou, Q., D. Zhou, and J. Feng. 2021. “Coordinate Attention for Efficient Mobile Network Design.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13713–13722. IEEE Computer Society.
- Huang, J., X. Zhang, Q. Xin, Y. Sun, and P. Zhang. 2019. “Automatic Building Extraction from High-Resolution Aerial Images and LiDAR Data Using Gated Residual Refinement Network.” ISPRS Journal of Photogrammetry & Remote Sensing 151: 91–105. https://doi.org/10.1016/j.isprsjprs.2019.02.019.
- Huang, X., X. Han, L. Zhang, J. Gong, W. Liao, and J. A. Benediktsson. 2016. “Generalized Differential Morphological Profiles for Remote Sensing Image Classification.” IEEE Journal of Selected Topics in Applied Earth Observations & Remote Sensing 9 (4): 1736–1751.
- Jie, H., L. Shen, and G. Sun. 2018. “Squeeze-And-Excitation Networks.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7132–7141. Salt Lake City, Utah: IEEE Computer Society.
- Li, J., X. Huang, L. Tu, T. Zhang, and L. Wang. 2022. “A Review of Building Detection from Very High Resolution Optical Remote Sensing Images.” GIScience & Remote Sensing 59 (1): 1199–1225. https://doi.org/10.1080/15481603.2022.2101727.
- Li, R., S. Zheng, C. Duan, L. Wang, and C. Zhang. 2022. “Land Cover Classification from Remote Sensing Images Based on Multi-Scale Fully Convolutional Network.” Geo-Spatial Information Science 25 (2): 278–294.
- Li, W., Y. Gao, M. Zhang, R. Tao, and Q. Du. 2022. “Asymmetric Feature Fusion Network for Hyperspectral and SAR Image Classification.” IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2022.3149394.
- Lin, T.-Y., P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie. 2017. “Feature Pyramid Networks for Object Detection.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2117–2125. Honolulu, Hawaii: IEEE Computer Society.
- Long, J., E. Shelhamer, and T. Darrell. 2015. “Fully Convolutional Networks for Semantic Segmentation.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3431–3440. Boston, Massachusetts: IEEE Computer Society.
- Maggiori, E., Y. Tarabalka, G. Charpiat, and P. Alliez. 2017. “Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark.” In 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), 3226–3229. Fort Worth, Texas: IEEE.
- Pan, J., L. Chen, Q. Shu, Q. Zhao, J. Yang, and S. Jin. 2023. “Spatiotemporal Imagery Selection for Full Coverage Image Generation Over a Large Area with HFA-Net Based Quality Grading.” Geo-Spatial Information Science 1–18. https://doi.org/10.1080/10095020.2023.2270641.
- Ran, S., X. Gao, Y. Yang, S. Li, G. Zhang, and P. Wang. 2021. “Building Multi-Feature Fusion Refined Network for Building Extraction from High-Resolution Remote Sensing Images.” Remote Sensing 13 (14): 2794. https://doi.org/10.3390/rs13142794.
- Ronneberger, O., P. Fischer, and T. Brox. 2015. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III 18, 234–241. Munich, Germany: Springer.
- Shao, Z., N. S. Sumari, A. Portnov, F. Ujoh, W. Musakwa, and P. J. Mandela. 2021. “Urban Sprawl and Its Impact on Sustainable Urban Development: A Combination of Remote Sensing and Social Media Data.” Geo-Spatial Information Science 24 (2): 241–255.
- Shunping, J., S. Wei, and M. Lu. 2018. “Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set.” IEEE Transactions on Geoscience and Remote Sensing 57 (1): 574–586.
- Sun, G., H. Huang, A. Zhang, F. Li, H. Zhao, and H. Fu. 2019. “Fusion of Multiscale Convolutional Neural Networks for Building Extraction in Very High-Resolution Images.” Remote Sensing 11 (3): 227.
- Sun, K., B. Xiao, D. Liu, and J. Wang. 2019. “Deep High-Resolution Representation Learning for Human Pose Estimation.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5693–5703. Long Beach, California: IEEE Computer Society.
- Trinder, J., and Q. Liu. 2020. “Assessing Environmental Impacts of Urban Growth Using Remote Sensing.” Geo-Spatial Information Science 23 (1): 20–39. https://doi.org/10.1080/10095020.2019.1710438.
- Vaswani, A., N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. 2017. “Attention is All You Need.” In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), 6000–6010. Red Hook, NY: Curran Associates Inc.
- Wang, L., S. Fang, X. Meng, and R. Li. 2022. “Building Extraction with Vision Transformer.” IEEE Transactions on Geoscience & Remote Sensing 60: 1–11. https://doi.org/10.1109/TGRS.2022.3186634.
- Wang, X., R. Girshick, A. Gupta, and K. He. 2018. “Non-Local Neural Networks.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7794–7803. Salt Lake City, Utah: IEEE Computer Society.
- Wang, Y., Z. Shao, T. Lu, C. Wu, and J. Wang. 2023. “Remote Sensing Image Super-Resolution via Multiscale Enhancement Network.” IEEE Geoscience & Remote Sensing Letters 20: 1–5. https://doi.org/10.1109/LGRS.2023.3248069.
- Woo, S., J. Park, J. Lee, and I. S. Kweon. 2018. “Cbam: Convolutional Block Attention Module.” In Proceedings of the European Conference on Computer vision (ECCV), 3–19. Munich, Germany: Springer.
- Xu, C., S. Zhang, B. Zhao, C. Liu, H. Sui, W. Yang, and L. Mei. 2022. “SAR Image Water Extraction Using the Attention U-Net and Multi-Scale Level Set Method: Flood Monitoring in South China in 2020 as a Test Case.” Geo-Spatial Information Science 25 (2): 155–168. https://doi.org/10.1080/10095020.2021.1978275.
- Yuan, J., X. Ma, Z. Zhang, Q. Xu, G. Han, S. Li, W. Gong, F. Liu, and X. Cai. 2023. “EFFC-Net: Lightweight Fully Convolutional Neural Networks in Remote Sensing Disaster Images.” Geo-Spatial Information Science 1–12. https://doi.org/10.1080/10095020.2023.2183145.
- Yu, C., C. Gao, J. Wang, G. Yu, C. Shen, and N. Sang. 2021. “Bisenet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation.” International Journal of Computer Vision 129: 3051–3068. https://doi.org/10.1007/s11263-021-01515-2.
- Zhang, Y. 1999. “Optimisation of Building Detection in Satellite Images by Combining Multispectral Classification and Texture Filtering.” ISPRS Journal of Photogrammetry and Remote Sensing 54 (1): 50–60. https://doi.org/10.1016/S0924-2716(98)00027-6.
- Zhang, M., W. Li, Y. Zhang, R. Tao, and Q. Du. 2022. “Hyperspectral and LiDAR Data Classification Based on Structural Optimization Transmission.” IEEE Transactions on Cybernetics 53 (5): 3153–3164. https://doi.org/10.1109/TCYB.2022.3169773.
- Zhang, Z., X. Zhang, C. Peng, X. Xue, and J. Sun. 2018. “Exfuse: Enhancing Feature Fusion for Semantic Segmentation.” In Proceedings of the European Conference on Computer Vision (ECCV), 269–284. Munich, Germany: Springer.
- Zhao, B., M. Zhang, J. Wang, X. Song, Y. Gui, Y. Zhang, and W. Li. 2023. “Multiple Attention Network for Spartina Alterniflora Segmentation Using Multi-Temporal Remote Sensing Images.” IEEE Transactions on Geoscience & Remote Sensing 61: 1–15. https://doi.org/10.1109/TGRS.2023.3272978.
- Zhu, Q., C. Liao, H. Hu, X. Mei, and H. Li. 2020. “MAP-Net: Multiple Attending Path Neural Network for Building Footprint Extraction from Remote Sensed Imagery.” IEEE Transactions on Geoscience & Remote Sensing 59 (7): 6169–6181. https://doi.org/10.1109/TGRS.2020.3026051.
- Zhu, X., D. Cheng, Z. Zhang, S. Lin, and J. Dai. 2019. “An Empirical Study of Spatial Attention Mechanisms in Deep Networks.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, 6688–6697. Seoul, South Korea: IEEE Computer Society.
- Zhu, Y., B. Huang, J. Gao, E. Huang, and H. Chen. 2021. “Adaptive Polygon Generation Algorithm for Automatic Building Extraction.” IEEE Transactions on Geoscience & Remote Sensing 60: 1–14. https://doi.org/10.1109/TGRS.2021.3081582.