
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Recent advancements in satellite remote sensing technology and computer vision have enabled rapid extraction of road networks from massive, Very High-Resolution (VHR) satellite imagery. However, current road extraction methods face the following limitations: 1) Insufficient availability of accurate and diverse training datasets for global-scale road extraction; 2) Costly and time-consuming manual labeling of millions of road samples; and 3) Limited generalization ability of deep learning models across diverse global contexts, resulting in better performance for regions well-represented in the training dataset, but worse performance when faced with domain gaps. To address these challenges, a semi-supervised framework was developed in this study, which includes a global-scale benchmark dataset – termed GlobalRoadSet (GRSet) – and a pseudo-label guided semi-supervised road extraction network – termed GlobalRoadNetSF (GRNetSF). The GRSet dataset was constructed using high-resolution satellite imagery and open-source crowdsourced OpenStreetMap (OSM) data. It comprises 47,210 samples collected from 121 capital cities across six populated continents. The GRNetSF trains the network by generating pseudo-labels for unlabeled images, combined with a few labeled samples from the target region. To enhance the quality of the pseudo-labels, strong data augmentation perturbation and auxiliary feature perturbation techniques are employed to ensure model prediction consistency. The proposed GRNetSF_GRSet framework was implemented in over 30 cities worldwide, where most of the Intersection-over-Union (IoU) values increased by more than 10%. This outcome confirms its strong generalization ability.
1. Introduction
Rapid road expansion is currently underway and is expected to continue this century (Kleinschroth et al. Citation2019; Laurance et al. Citation2014), which is promoted by a multitude of factors, including urbanization and increased demand for travel and transportation. Accurate and up-to-date mapping and extraction of road networks are critical tasks to maintain the function of urbanicity and socioeconomic development, particularly in realizing smart transport and intelligent traffic management. Although there are some open-source datasets mapping roads globally, such as OpenStreetMap (OSM), they are typically outdated and spatially incomplete, with uneven accuracies. Moreover, the efficiency and accuracy of crowdsourced road mapping efforts cannot meet the requirement of real-world urban applications. Therefore, spatially explicit and complete global-scale road networks are urgently needed to improve our understanding of road network patterns, structure, and expansion across spatial-temporal scales and support a wide range of urban implications (Kleinschroth et al. Citation2019; Meijer et al. Citation2018).
Recently, with the rapid development of earth observation technology (D. Li et al. Citation2024), many advanced methods for road extraction from Very High Resolution (VHR) remote sensing imagery have been developed. Road extraction methods have developed from traditional methods (Shi, Miao, and Debayle Citation2013) based on manual features to deep learning methods (Mei et al. Citation2021) based on self-learning of features. Deep learning methods have become the mainstream methods for road extraction due to their high degree of automation and their ability to process massive remote sensing images (Z. Li et al. Citation2023; X. X. Zhu et al. Citation2017). However, supervised deep learning methods require numerous training samples for optimal performance. Thanks to the contributions of the scientific community, four typical road datasets are publicly available: Massachusetts (Mnih Citation2013), DeepGlobe (Demir et al. Citation2018), SpaceNet (Van Etten, Lindenbaum, and Bacastow Citation2018), and RoadTracer (Bastani et al. Citation2018).
Based on these four public datasets, some representative studies have been conducted. For example, Mnih (Citation2013) employed a multi-layer neural network for road extraction and released the Massachusetts road dataset. This was the first large-scale open-source dataset for road extraction, which was widely used in the following years (Saito, Yamashita, and Aoki Citation2016; M. Zhou et al. Citation2020). In the DeepGlobe Road Extraction Challenge, the D-LinkNet (Zhou et al. Citation2018) model won first place, which was built with LinkNet (Chaurasia and Culurciello Citation2017) and dilated convolution. For the SpaceNet Road Detection Challenge, the winning approach (Van Etten, Lindenbaum, and Bacastow Citation2018) used an ensemble of deep learning segmentation models. Differing from the previous segmentation-based methods, Bastani et al. (Citation2018) used Convolutional Neural Network (CNN)-guided iterative search to directly output the road graph. Undoubtedly, all these datasets and deep learning methods have promoted the progress of road extraction technology. However, these road datasets cover only a few countries, with limited data volumes and data diversity, and as deep learning models are heavily biased toward the data distribution of the training samples, the model performance will decline sharply when the data distributions of the training images and test images are different (Wang et al. Citation2022). Developing more diverse datasets will help improve model performance, but it requires expensive pixel-level annotation. Fortunately, differing from the ground objects in natural images, roads in remote sensing images already have many historical OSM road centerlines, which can be used as noisy supervised information.
As an alternative approach, many studies have attempted to improve the generalization ability of models by designing more advanced algorithms. For example, to improve the model performance on a target domain containing insufficient annotated data, domain adaptation techniques (Csurka Citation2017; Patel et al. Citation2015) emerged and have been successfully applied in many practical applications (Ghifary et al. Citation2016). Among these methods, Unsupervised Domain Adaptation (UDA) based on adversarial learning (Goodfellow et al. Citation2014) is the most widely used, which only needs labeled source domain samples and unlabeled target domain images to achieve domain adaptation. For instance, Lu et al. (Citation2021a) proposed the Global-lOcal Adversarial Learning (GOAL) approach, which can adaptively reweight the adversarial loss according to the road recognition difficulty; and Wang et al. (Citation2022) presented a feature transfer network to achieve cross-domain road extraction. But the UDA technique does not utilize target region samples at all, resulting in a limited model performance.
Similar to the UDA method, Semi-Supervised Learning (SSL) (H. Chen et al. Citation2022; X. Zhu and Goldberg Citation2009) is also a popular way to overcome the dependence on huge labeled datasets, and involves leveraging numerous unlabeled target images alongside a few labeled target samples. Consistency regularization and the pseudo-labeling learning framework predominantly drive the SSL methods, enabling effective learning on unlabeled data (Sohn et al. Citation2020). Consistency regularization refers to enforcing the model to maintain consistent predictions for inputs under different perturbations, thereby achieving supervised learning. Pseudo-labeling refers to incorporating high-confidence predictions of unlabeled images by the model into the training dataset. For instance, Cross-Consistency Training (CCT) (Ouali, Hudelot, and Tami Citation2020) and Mean Teacher (MT) (Tarvainen and Valpola Citation2017) were proposed for semi-supervised semantic segmentation based on consistency regularization. Chen et al. (Citation2023) employed rotation consistency constraints and adversarial learning to fully exploit the potential information from low-confidence pixels in pseudo labels for road extraction. Li et al. (Citation2022) proposed a multi-stage pseudo-label iteration framework for the land-cover mapping task of the 2022 IEEE GRSS Data Fusion Contest, which fuses the predictions of four models to generate pseudo-labels.
Based on the above analysis, although some road datasets and road extraction methods have been developed, the generalization ability of road extraction models is still limited. To alleviate this problem, a pseudo-label guided global-scale road extraction framework is introduced in this article. The contributions of this article can be summarized as follows:
A robust global-scale road benchmark dataset – GlobalRoadSet (GRSet) – was built in this study. Developing more diverse datasets can greatly improve model performance and help us understand how models perform in different regions of the world. However, manually labeling millions of road samples is labor-intensive. Thus, we leveraged massive VHR satellite imagery and crowdsourced OSM data to build the GRSet dataset, containing 47,210 samples from 121 capital cities across six continents in Europe, Africa, Asia, South America, Oceania, and North America, with a total area of 49,503 km2.
A pseudo-label guided global-scale road extraction method – GRNetSF—is proposed. In order to ensure that the model can adapt from GRSet to new imagery across different geographical regions worldwide, GRNetSF is first pre-trained on the GRSet dataset, to provide initialization parameters for the road extraction network. The pre-trained GRNetSF then produces pseudo-labels for the unlabeled images of the target region, along with the few labeled samples, to retrain the network. To improve the quality of the pseudo-labels and avoid the model overfitting on inaccurate pseudo-label annotated samples, strong data augmentations perturbation and auxiliary feature perturbation are adopted to constrain the consistency of the model predictions, which is based on the assumption that the model predictions should be similar when different perturbations are made to the same image.
The GRSet and GRNetSF were applied to the global-scale validation set, covering more than 30 cities in developed and developing countries across four continents: Europe, Africa, Asia, and North America. The global-scale validation set is made up of public road test sets and self-annotated large-scale samples. The experimental results show that GRSet and GRNetSF have strong robustness and a superior generalization ability, and can obtain the most complete and continuous roads, most of which improve the Intersection-over-Union (IoU) by more than 10%.
2. Related work
This section introduces the current research status from two aspects: the typical road datasets and the semi-supervised learning method applied in the remote sensing image processing field.
2.1. Representative road datasets
The most widely used road datasets are the Massachusetts (Mnih Citation2013), DeepGlobe (Demir et al. Citation2018), SpaceNet (Van Etten, Lindenbaum, and Bacastow Citation2018), and RoadTracer (Bastani et al. Citation2018) datasets. summarizes the resolution, width, data volume, and coverage area of the four public road datasets and the GRSet. Among them, the DeepGlobe dataset is precisely annotated with varying road widths. The remaining datasets are generated with OSM road centerlines with an equal width, and thus their road widths are fixed, and the road boundaries are not completely accurate. gives examples of the five road datasets. As can be seen, the road types in the Massachusetts and SpaceNet datasets are relatively simple, most of which are cement or asphalt roads. The RoadTracer and DeepGlobe road datasets are more diverse, with DeepGlobe in particular containing many rural dirt roads. Overall, GRSet is the most diverse.
Figure 1. Examples from the five road datasets (512 × 512 pixels).

Table 1. Details of the five road datasets.
2.2. Semi-supervised learning
Semi-supervised learning provides an effective means to improve model generalization performance using unlabeled data and it is dominated by pseudo-labeling and consistency regularization.
Pseudo-labeling is aimed at generating high-confidence pseudo-labels for unlabeled data using the model itself (Lee Citation2013). For the input unlabeled data , the predicted probability is
, the largest class probability is
, and the pseudo-label is
, which refers to the “hard” one-hot label. The pseudo-labeling loss can then be expressed as:
where is the threshold and
is an indicator function, which is used to filter out noisy unlabeled data with low prediction confidence;
is the cross entropy used to make the prediction
close to the pseudo-label
; B is the batch size of labeled data;
is the ratio of unlabeled data to labeled data; and
.
Consistency Regularization is a powerful technique that has been widely used in SSL algorithms (Sajjadi, Javanmardi, and Tasdizen Citation2016). To sum up the core idea, it enforces the consistency of the model predictions through various perturbations, for instance, input perturbation (Kim, Jang, and Park Citation2020), feature perturbation (Ouali, Hudelot, and Tami Citation2020) and network perturbation (Ke et al. Citation2019). Taking input interference as an example, the network output should be invariant when fed the same image with different data augmentations, such as the weak and strong data augmentations. The weak data augmentation usually includes random flip, crop and shift. For segmentation tasks, geometric transformation is not applicable due to the pursuit of pixel-level accuracy, and color jittering is generally used as strong data augmentation (T. Chen et al. Citation2020; Zou et al. Citation2020). To calculate the consistency loss, the L2-loss is commonly used, which can be expressed by EquationEquation (2)(2)
(2) :
where refers to unlabeled data;
and
represent different perturbations;
and
are the output probabilities.
3. GRSet dataset generation
The GRSet dataset was generated using VHR satellite imagery and OSM road data without any manual annotation. To ensure the quality of the OSM road data, only capital cities with abundant OSM data were selected, and only six categories of main roads were considered, to minimize the inclusion of narrow roads and inaccurate OSM data. The specific methodological steps were as follows:
Step 1: Satellite images with a spatial resolution of 1 m per pixel were acquired from the Google Earth Platform, and the OSM road centerline vector data were obtained using global city names as keywords. The capital cities were categorized based on administrative boundaries, encompassing both urban and rural regions. Notably, use of the Google Earth images must respect the “Google Earth” terms of use, and these images are exclusively intended for academic purposes, with any commercial usage strictly prohibited.
Step 2: The six main types of roads were retained based on the properties of the vector data, i.e. motorway, trunk, primary, secondary, tertiary, and residential. Referring to Van Etten et al. (Citation2018), the study retained the six main road types while disregarding other less significant road types to mitigate the impact of their inaccuracies.
Step 3: A 5-meter width label was assigned to each edge of the road vector through rasterization. It is important to emphasize that the annotation is rarely entirely accurate, and the principle of rasterization aims to maximize the number of positive samples.
Step 4: The images and labels were aligned based on their corresponding geographic coordinates, and subsequently, the images were cropped to a size of 1024 × 1024 pixels. Tiles that contained fewer than five roads were excluded from the dataset, as such tiles tend to exhibit a relatively high error rate.
The GRSet dataset was constructed based on the aforementioned steps and is publicly accessible at: https://github.com/xiaoyan07/GRNet_GRSet. As summarized in , GRSet is a geographically diverse road dataset with a substantial data volume, playing a critical role in enhancing the accuracy and generalizability of deep networks. Furthermore, the GRSet dataset is highly complex and diverse, encompassing roads with varying radiation levels, types, materials, and scales, as depicted in . However, GRSet is not a perfect dataset, as it includes certain instances of noise, such as missing roads and misregistration, as illustrated in .
Figure 2. Distribution of the geographical locations of the GRSet dataset.
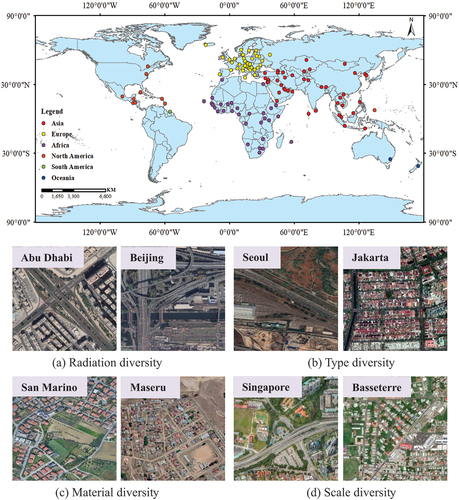
Figure 3. Annotation examples of the GRSet.

4. The pseudo-label guided global-scale road extraction framework
This section provides a comprehensive description of the proposed framework. As depicted in , the framework initially employs the GRSet dataset to pre-train the encoder and the main decoder (namely LinkNet50), which uses ResNet50 as the feature extractor. The sigmoid classifier is utilized to generate a one-layer prediction map. Specifically, LinkNet50 is the baseline model that won first prize in the DeepGlobe Road Extraction Challenge (L. Zhou, Zhang, and Ming Citation2018). In the second step, the encoder and the main decoder are initialized using the pre-trained model parameters from GRSet, and the auxiliary decoder is initialized using PyTorch’s default initialization (He et al. Citation2015), where linear layers are initialized with kaiming_uniform, and the weights and biases of convolutional layer are respectively initialized with kaiming_uniform and uniform. The network first produces pseudo-labels for the unlabeled target region images, and then is restrained with the few accurately labeled samples and the pseudo-label annotated samples from the target region. Nevertheless, the quality of the generated pseudo-labels cannot be guaranteed, potentially leading to overfitting of the model on incorrect samples. To alleviate this problem, different input data perturbations and auxiliary decoder feature perturbations are employed to enforce the consistency of model predictions, thereby mitigating the risk of overfitting to inaccurate pseudo-labels.
Figure 4. The flowchart of the proposed pseudo-label guided global-scale road extraction framework, which is composed of two parts: (a) GRSet generation, and (b) pseudo-label guided global-scale road extraction network.
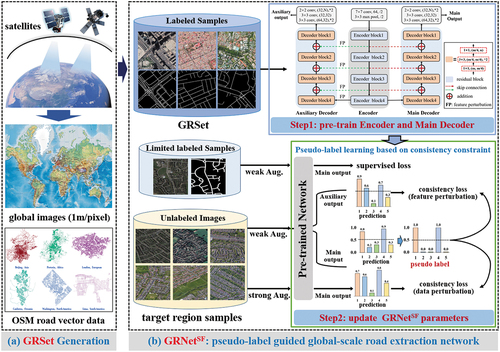
In essence, the fundamental concept of the second step is to achieve invariance in the model predictions when presented with the same image but subjected to various data and feature perturbations. The data augmentation perturbations encompass weak and strong approaches. The weak data augmentation comprises random horizontal flip, vertical flip, and rotation. And color jitter serves as the approach for strong data augmentation perturbations, encompassing adjustments in brightness, contrast, saturation, and hue. presents visualizations of both weak and strong data augmentations. In this study, the parameters for brightness, contrast, saturation, and hue were uniformly set to 0.5. Consequently, the brightness, contrast, and saturation of the image were randomly adjusted within a range of 50–150% relative to the original image’s levels, whereas the hue factor was randomly altered within the range of −0.5 to 0.5. The network main outputs for the weakly augmented data and strongly augmented data should share the same label. Regarding feature perturbations, we introduce a straightforward channel dropout technique with a 50% probability (implemented as nn.Dropout 2d (0.5) in PyTorch) into the auxiliary decoder. This dropout is applied to the extracted features of weakly perturbed images. The network main output and auxiliary output for the weakly perturbed images should share the same label. This study employs the consistency loss to enforce the consistency of the model predictions.
Figure 5. Visualizations of the weak and strong data augmentations.

Specifically, for the labeled samples input , they are transformed with weak data augmentation and propagated forward through the encoder and the main decoder (LinkNet50) to obtain the model prediction
, and the supervised loss between the predictions
and the ground truth
is calculated through EquationEquation (3)
(3)
(3) :
where and
respectively represent the binary cross-entropy (BCE) loss and dice coefficient loss, which are widely used for the road segmentation task.
For the unlabeled images input , in the branch generating the pseudo-labels,
is transformed with weak data augmentation, and as EquationEquation (4)
(4)
(4) shows, the model main output
is used to produce the pseudo-label
according to the threshold
, where
is set to 0.5, which is a default setting for binary segmentation tasks. In the data perturbation branch,
is transformed with weak data augmentation, which is followed by strong data augmentation, and the model main output is
, and then the consistency loss of data perturbation
is calculated between
and
through EquationEquation (5)
(5)
(5) :
where is set to 0.9 and
is set to 0.1 to filter out any noisy predictions with low confidence (the real label of road is 1, and 0 is for background).
In the feature perturbation branch, is transformed with weak data augmentation, and propagated forward through the encoder and the auxiliary decoder to obtain the auxiliary output
. Then, the consistency loss of feature perturbation
is calculated between
and
through EquationEquation (6)
(6)
(6) :
The whole optimization function is then .
To more clearly illustrate the training procedure for the pseudo-label guided global-local road extraction framework, the details are provided in Algorithm 1.
Table
5. Experiments and analyses
5.1. Experimental settings
Global-scale validation areas and data: the global-scale validation set was made up of the four test sets from the Massachusetts, RoadTracer, SpaceNet, and DeepGlobe road datasets, and the self-annotated test sets from the Boston, Birmingham, Helsinki, Kigali, Coast Province, Beijing, Shanghai, Wuhan, and LoveDA road datasets (Wang et al. Citation2021). The LoveDA dataset contains 2522 samples for training and 1669 samples for validation. displays the geographic distribution of the global-scale validation set, covering four continents – Europe, Africa, Asia, and North America – involving both developed and developing countries. The 1669 LoveDA test images cover the Chinese cities of Nanjing, Changzhou, and Wuhan, with 992 images from rural areas and 677 images from urban areas. The RoadTracer test set contains data from Boston and Paris, and the SpaceNet test set contains data from Paris and Shanghai. Therefore, the global- scale validation set covers more than 30 cities, with different spatial resolutions and different types of roads, and the details are given in .
Figure 6. Geographical locations of the validation sets. The validation set covers the four continents of Europe, Africa, Asia, and North America.
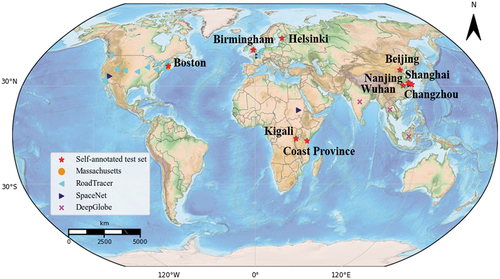
Table 2. The details of the validation set of global road networks.
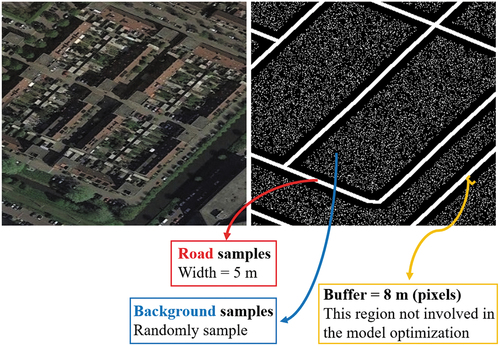
Implementation details: All the experiments were conducted on the PyTorch (Paszke et al. Citation2019) framework using an NVIDIA Titan RTX GPU accelerator with 24-GB memory. For the first step, random crops of 768 × 768 pixels with horizontal, vertical, and diagonal flipping were used. The training epochs were set to 12. The initial learning rate was set to 2e − 4, and was divided by 5 at epochs . The segmentation loss was the sum of the Binary Cross Entropy (BCE) loss and dice coefficient loss. In addition, to avoid the interference caused by inaccurate road boundaries, when taking the GRSet dataset as the training set, the regions within 8 m (8 pixels) from the left and right road boundaries were not involved in the model optimization. To ensure the balance of positive and negative samples, we randomly sample a number of negative samples close to the number of positive samples (roads) from the background to optimize the model together, as shown in .
Figure 7. Illustration of sampling of GRSet.
For the second step, the few labeled samples and unlabeled images from the target region were used to train the model for 40,000 steps, with both weak data augmentation and strong data augmentation. The model was trained using the Stochastic Gradient Descent (SGD) optimizer with the initial learning rate of 1e − 3, the weight decay was 5e − 4, and the crop size was set to 512. For the hyperparameter, τ was set to 0.9 and the initial value of
was set to 2, and thus the batch size was set to 4 for labeled samples and 8 for unlabeled images.
For model evaluation, four metrics are applied to calculate the road extraction accuracy: Precision (P), Recall (R), F1-score, and IoU.
Comparison methods: to demonstrate the superiority of GRSet over the other road datasets, four advanced road extraction models: LinkNet (Chaurasia and Culurciello Citation2017), D-LinkNet (L. Zhou, Zhang, and Ming Citation2018), FarSeg (Zheng et al. Citation2020) and GAMSNet (Lu, Zhong, Zheng, and Zhang Citation2021) were selected. Among them, LinkNet and D-LinkNet showed great advantages in the DeepGlobe Road Extraction Challenge. FarSeg is a remote sensing object segmentation network by foreground-scene relation modeling. GAMSNet improves the road recognition rate by using a global awareness operation to capture long-range information. All of these models used an ImageNet pre-trained ResNet50 network as the backbone, and are denoted as LinkNet50_IN, D-LinkNet_IN, FarSeg_IN, and GAMSNet_IN, respectively, consistent with the rest of this paper.
To evaluate the generalization ability of GRSet and GRNetSF, 14 comparison algorithms were used, with LinkNet50 used as the baseline model. As listed in , the comparison algorithms included UDA methods, semantic segmentation methods, and SSL methods, with different initialization approaches. For example, LinkNet50, LinkNet50_IN, and LinkNet50_GRSet respectively represent the LinkNet50 with PyTorch’s default initialization (P) (He et al. Citation2015), ImageNet pre-trained initialization (I) (Russakovsky et al. Citation2015), and GRSet pre-trained initialization (G).
Table 3. Initialization details of the comparison methods.
5.2. Experiment 1: the impact of different road training sets on model performance
This section aims to analysis the impact of different road training sets on model performance, and presents quantitative IoU comparisons among the five road datasets. Blue numbers indicate test results obtained when the training and test sets were sourced from the same dataset, while red numbers indicate the optimal test results achieved when training models on GRSet. The analysis of reveals the following findings:
Although the models trained on the Massachusetts, RoadTracer, SpaceNet, and DeepGlobe datasets obtain the best results when trained on their own training sets (blue numbers), they show a poor generalization ability when performing cross-region road extraction. Notably, the models trained on DeepGlobe demonstrate obvious advantages in terms of generalization capability. For the DeepGlobe→DeepGlobe and DeepGlobe→LoveDA tasks, D-LinkNet_IN (0.6662 and 0.3369), FarSeg_IN (0.6665 and 0.3613), and GAMSNet_IN (0.6826 and 0.3797) show a stable superiority, compared to the baseline, i.e. LinkNet50_IN (0.6630 and 0.3308). This is because the DeepGlobe dataset exhibits greater diversity, encompassing accurately annotated road pixels. However, the road labels in the Massachusetts, RoadTracer, SpaceNet, and GRSet datasets are derived from OSM road centerlines with uniform width, leading to a significant amount of contextual noise.
GRSet significantly enhances the model’s generalization ability and yields the most comprehensive and contiguous road extraction results. visualizes the results of LinkNet50_IN on the Birmingham image, providing a visual comparison of the effects of different road datasets. The models trained on the Massachusetts and SpaceNet training sets struggle to identify road areas, whereas those trained on the RoadTracer and DeepGlobe training sets yield a relatively comprehensive road network due to the greater diversity of these two training sets compared to Massachusetts and SpaceNet.
For the GRSet→DeepGlobe and GRSet→LoveDA tasks, FarSeg_IN (0.2047 and 0.2428) and GAMSNet_IN (0.2348 and 0.2668) obtain a lower accuracy compared to LinkNet50_IN (0.3392 and 0.4184) and D-LinkNet_IN (0.3930 and 0.4238). Since FarSeg_IN and GAMSNet_IN primarily concentrate on modeling the relationship between road objects and contextual information. Thus, the inclusion of noisy contextual information in GRSet leads to significantly lower accuracy. Additionally, the DeepGlobe and LoveDA road datasets encompass numerous narrow rural roads that are particularly susceptible to the interference caused by such noisy contextual information.
Figure 8. Quantitative IoU comparison of models trained on the different road datasets.
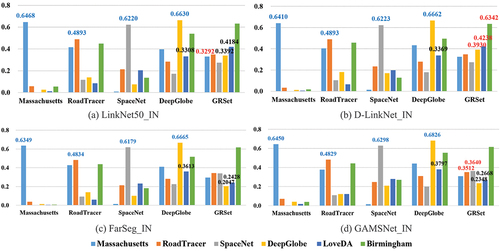
Figure 9. The visual outputs for the Birmingham image produced by LinkNet50_IN with different training sets.

5.3. Experiment 2: validation of the proposed GRNetSF_GRSet framework
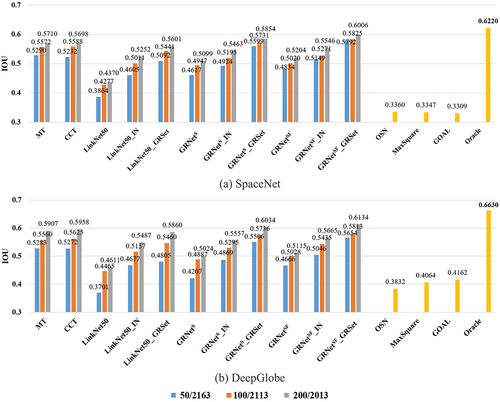
This section aims to verify the effectiveness of the proposed GRNetSF_GRSet framework, and the experiments are conducted on the SpaceNet and DeepGlobe datasets. For the semi-supervised training samples setting, 50, 100, and 200 labeled samples and the remaining unlabeled images were selected from the training set to train the model. gives the quantitative IoU accuracy, and the oracle setting was designed to test the upper limit of the accuracy, where the training set and test set were from the same dataset, and it is consistent with . From , there are three noticeable observations: 1) The UDA methods, namely OSN (0.3360 and 0.3832), MaxSquare (0.3347 and 0.4064), and GOAL (0.3309 and 0.4162), exhibit unsatisfactory performances primarily due to the noisy nature of the GRSet dataset, which contains missing and misregistered roads as depicted in . Hence, GRSet is not suitable for standalone use as a training set; instead, it is better suited for joint learning with precisely labeled samples from the target region. By leveraging these accurate samples, the semi-supervised GRNetSF_GRSet and GRNetS_GRSet can be guided toward improved accuracy. 2) In general, the performance of pre-trained models on GRSet surpasses that of the ImageNet pre-trained models. Since the GRSet dataset is specifically designed for road extraction, it can be effectively utilized for extracting roads in the target region through fine-tuning. 3) GRNetSF_GRSet (0.6006 and 0.6134) and GRNetS_GRSet (0.5854 and 0.6034) significantly enhances the model’s generalization ability, compared to other SSL methods like MT (0.5710 and 0.5907) and CCT (0.5698 and 0.5958), and supervised method: LinkNet50_GRSet (0.5601 and 0.5860), and its performance improves gradually as the number of labeled training samples increases. Notably, the accuracy of GRNetSF_GRSet is closest to the optimal performance achieved by the oracle setting (0.6220 and 0.6630), demonstrating the effectiveness of the proposed semi-supervised framework.
Figure 10. The histogram illustrates the quantitative results obtained on the SpaceNet and DeepGlobe dataset.
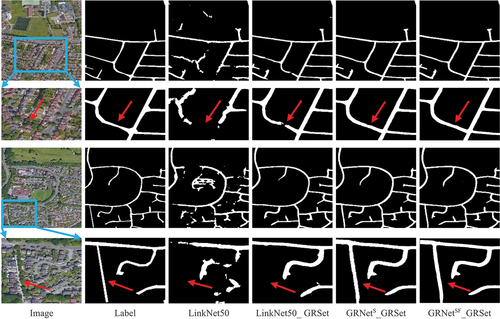
presents the visualization results of LinkNet50, LinkNet50_GRSet, GRNetS_GRSet and GRNetSF_GRSet on the 50/2163 training set division, along with the visualization results of the oracle setting. The visualization results align with the quantitative results, demonstrating that employing a GRSet pre-trained model can significantly enhance model performance. GRNetS and GRNetSF further refine the results, approaching the optimal performance of the oracle setting. In summary, the outputs of GRNetSF_GRSet exhibit the highest level of completeness and closest resemblance to the labeled data, even when utilizing only 50 annotated samples from the target region.
Figure 11. The visualization results of different road datasets, where the first and second rows respectively represent the results obtained on the SpaceNet and DeepGlobe datasets.
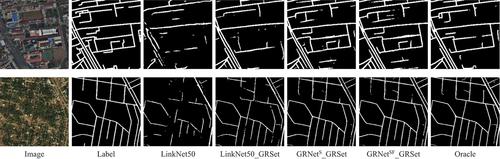
presents the visualization results of LinkNet50, LinkNet50_GRSet, GRNetS_GRSet and GRNetSF_GRSet on the 50/2163 training set division, along with the visualization results of the oracle setting. The visualization results align with the quantitative results, demonstrating that employing a GRSet pre-trained model can significantly enhance model performance. GRNetS and GRNetSF further refine the results, approaching the optimal performance of the oracle setting. In summary, the outputs of GRNetSF_GRSet exhibit the highest level of completeness and closest resemblance to the labeled data, even when utilizing only 50 annotated samples from the target region.
5.4. Experiment 3: global-scale road extraction applications
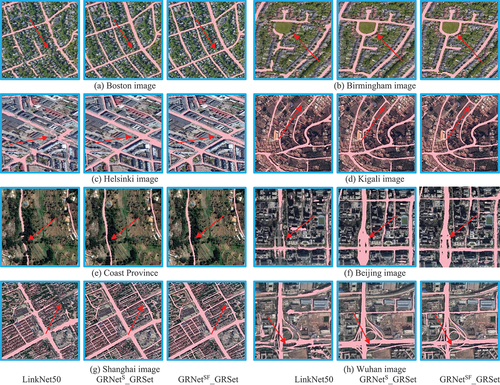
Due to space limitations, this section solely presents the qualitative and quantitative results of LinkNet50, GRNetS_GRSet and GRNetSF_GRSet for global-scale road extraction. lists the quantitative results for the large-scale images, revealing that GRNetSF_GRSet exhibits an IoU performance improvement of over 10% compared to LinkNet50, with the exception of the Kigali and Coast Province images. depicts the cross-region visualization results, revealing that LinkNet50 frequently generates fragmented roads due to the interference of trees, buildings, or surrounding objects with similar textures. In such case, GRNetS_GRSet and GRNetSF_GRSet can obtain continuous and smooth roads, confirming the superiority of the GRSet and the proposed framework. In some details, GRNetSF_GRSet is superior to GRNetS_GRSet, as shown in . Conversely, the Kigali and Coast Province images predominantly consist of mountain dirt roads, as depicted in , which represent a road type of lesser prevalence in the GRSet dataset, thereby diminishing the discernible advantages of GRNetSF_GRSet in these specific areas.
Figure 12. The Histogram illustrates the quantitative results of the large-scale images.
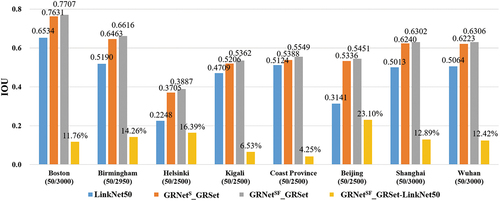
Figure 13. The local visualization results of the large-scale images.
Moreover, the performance of the GRNetSF_GRSet framework in urban and rural areas and in countries with different levels of development is analyzed and discussed below.
1) Performance of GRNetSF_GRSet in urban and rural areas: the LoveDA validation set, containing 1669 samples, of which 992 are from rural areas and 677 from urban areas, covering an area of 157.51 km2, was used to evaluate the model performance in urban and rural areas. For the semi-supervised training set, it contains 50 annotated samples (urban: 25, rural: 25) and 2472 unannotated images (urban: 1131, rural: 1341). lists the quantitative results obtained on the LoveDA validation set, which gives the urban, rural, and overall accuracy, respectively. It can be found that: 1) The accuracy for urban areas is always higher than that for rural areas, because rural roads are narrow and recognition is more challenging. 2) Pre-training can greatly improve the model performance, and pre-training with GRSet gains a greater improvement than pre-training with ImageNet in urban areas and overall accuracy. In rural areas, GRNetSF_GRSet is inferior to GRNetSF_IN, and GRNetS_GRSet is inferior to GRNetS_IN. One reason for this is that the GRSet dataset retains the six types of roads which mainly exist in urban areas, and another reason may be that the labels of the rural roads are not entirely accurate and cannot strictly reflect the accuracy of the model, as shown in . 3) In the case of a small number of samples, GRNetSF_GRSet can significantly improve the model performance, especially for rural roads. For instance, from LinkNet50 to GRNetSF_GRSet, the IoU performance is improved by 18.93% and 26.64% in urban and rural areas, respectively. This is because, in the GRNetSF_GRSet method, 2472 target region images are applied to generate pseudo-labels and participate in the model optimization, which significantly improves the model performance in the target region. In contrast, the UDA methods of OSN, MaxSquare, and GOAL perform poorly, and even worse than the baseline LinkNet50, which uses only 50 samples of the target region. This confirms that target region samples are crucial for model performance improvement, and the semi-supervised method provides the possibility for global-scale road extraction application.
Figure 14. The Histogram illustrates the quantitative results obtained on the LoveDA dataset.
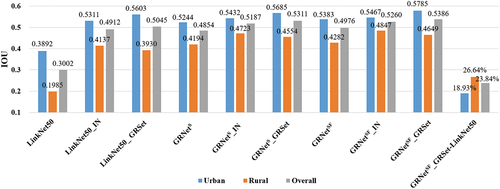
Figure 15. The visual urban and rural results obtained on the LoveDA road validation set.

shows the visualization results of LinkNet50, LinkNet50_GRSet, GRNetS_GRSet and GRNetSF_GRSet for urban and rural areas. The first urban image reflects the typical building style of a developing country such as China, which is dense and tall. As the magnified urban image shows, although there are no labels for the residential roads between buildings, the GRSet dataset retains residential road types, so that LinkNet50_GRSet, GRNetS_GRSet and GRNetSF_GRSet produce residential roads, and the prediction results of GRNetSF_GRSet are smoother and more continuous, and are the most consistent with the real image. Especially at intersections, GRNetSF_GRSet can successfully connect residential roads to main roads. In the rural image, there are mainly narrow roads in fields, for which the texture is very similar to that of the surrounding fields. In this case, as the magnified rural image shows, LinkNet50 produces badly fragmented roads, whereas the LinkNet50_GRSet results are improved, but there are still a lot of false positives. Meanwhile, the predictions of GRNetS_GRSet and GRNetSF_GRSet fit perfectly with the real image, even though the labels were not fully labeled. As shown in the red circle, the LinkNet50_GRSet predicted roads are broken due to the shadows caused by the surrounding trees, while GRNetS_GRSet and GRNetSF_GRSet obtain continuous roads by using the SSL technique. All the above results confirm the effectiveness of the proposed pseudo-label guided global-scale road extraction framework.
2) Performance of the GRNetSF_GRSet framework in countries with different levels of development: The LoveDA dataset represents the typical style of a developing country, with both urban asphalt and rural dirt roads, which are easily obscured by the surrounding tall buildings and trees. For developed countries, the Birmingham image, which covers an area of 66.29 km2, was chosen for the verification. The corresponding training set contains 3,000 samples of 1024 × 1024 pixels, the labels were generated by freely available OSM road centerlines, and the road width is fixed to 7 m, referring to (Lu, Zhong, and Zhang Citation2022). Thus, there are 50 labeled samples and 2,950 unlabeled images in the semi-supervised training set. The quantitative results are shown in gives the visual prediction results. Differing from developing countries, developed countries mainly feature asphalt roads, which are easier to identify, so that the IoU of GRNetSF_GRSet without pre-training reaches 0.5992. In addition, buildings in developed countries are mostly low and roads are often obscured by the surrounding trees, as the magnified images show. In this case, LinkNet50 obtains many fragmented roads, while the predicted roads of LinkNet50_GRSet are relatively complete, but not perfect in some details. Meanwhile, the road outputs of GRNetS_GRSet and GRNetSF_GRSet are complete and continuous, and the results most closely resemble the labels, which verifies the effectiveness of the proposed framework.
Figure 16. The histogram illustrates the quantitative results obtained on the Birmingham image.
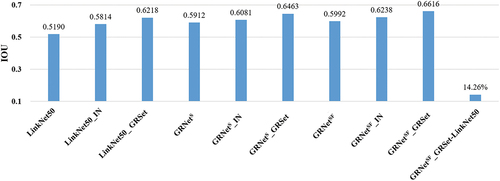
Figure 17. The visual results obtained on the Birmingham image.
Generally speaking, roads in developed countries are easier to recognize due to the reduced building shelter and more complete road facilities. Roads in developing countries are generally more difficult to identify because the buildings in urban areas are typically dense and tall, and can heavily obscure roads, while the rural roads are typically narrow. This situation is also consistent with the existing OSM road data. Developed countries typically feature completed urbanization, and their OSM road data are relatively complete and accurate, while there are still many roads in underdeveloped countries that need to be added to the existing OSM data, especially rural roads.
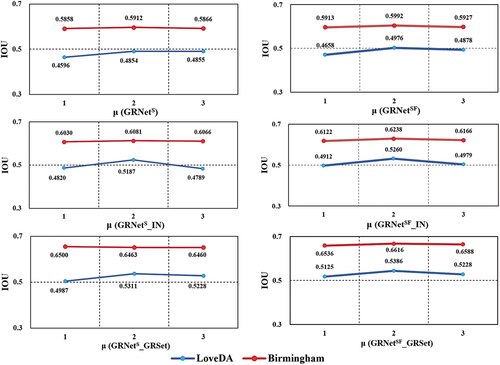
6. Sensitivity analysis
In the proposed GRNetSF, is the ratio of unlabeled to labeled data. In this section, we describe how parameter
was analyzed based on the LoveDA and Birmingham data. respectively gives the IoU performance variation of GRNetS, GRNetSF, GRNetS_IN, GRNetSF_IN, GRNetS_GRSet and GRNetSF_GRSet when
was set to 1, 2, and 3. From the trendline of the IoU, it can be seen that the value of
has a greater influence on the LoveDA data, but is relatively stable on the Birmingham data. Moreover, the IoU does not increase with the increase of
, but maintains a stable advantage when
= 2. Thus, in this study,
was set to 2, and the model input at each step consisted of four labeled samples and eight unlabeled images.
Figure 18. The IoU variation with different values of .
7. Conclusions
The primary objective of this study was to enhance the generalization capability of a deep road extraction network. To alleviate this problem, we introduced a pseudo-label guided global-scale road extraction framework called GRNetSF_GRSet. The GRNetSF_GRSet framework was constructed based on two key components. Firstly, a robust global-scale road benchmark dataset called GRSet was built, comprising 47,210 samples from 121 capital cities across six continents. This dataset provides valuable insights into the model’s performance across various regions worldwide. Secondly, a pseudo-label guided global-scale road extraction network named GRNetSF was developed to enable the model’s adaptation to new cross-region VHR satellite imagery globally. Experimental evaluations conducted in over 30 cities across four continents revealed that GRSet surpasses existing road datasets in terms of generalization capability. Additionally, the semi-supervised GRNetSF approach can further enhance the model’s generalization capability by employing strong data augmentation perturbations and feature perturbations strategy. We further explored and analyzed the performance of the proposed GRNetSF_GRSet framework across countries with varying levels of development, encompassing both urban and rural areas. Our findings reveal that identifying rural roads poses notably greater challenges due to their narrowness and the surrounding interference, particularly in developing nations. Therefore, future research could focus more on the recognition of roads in developing countries and rural areas.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are available at https://github.com/xiaoyan07/GRNet_GRSet from the author [X. Lu] and the corresponding author [Y. Zhong] ([email protected]), upon reasonable request.
Additional information
Funding
Notes on contributors
Xiaoyan Lu
Xiaoyan Lu is an IEEE member and a postdoctoral fellow at The Hong Kong Polytechnic University. She received the PhD degree from Wuhan University, in 2022. Her research interests include intelligent interpretation and application of remote sensing images and medical images. She was the recipient of the 2021 John I. Davidson President’s Award (First Place).
Yanfei Zhong
Yanfei Zhong is an IEEE senior member and a full professor with the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing (LIESMARS), Wuhan University. He organized the Intelligent Data Extraction, Analysis and Applications of Remote Sensing (RSIDEA) research group. His research interests include hyperspectral remote sensing information processing, high-resolution remote sensing image understanding, and geoscience interpretation for multisource remote sensing data and applications. Dr. Zhong is a Fellow of the Institution of Engineering and Technology (IET). He is currently serving as an Associate Editor for the IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, and the International Journal of Remote Sensing.
Zhuo Zheng
Zhuo Zheng is a postdoctoral fellow at Stanford University. He received the PhD degree from Wuhan University, in 2023. His major research interests remote sensing visual perception and Earth vision, especially multimodal and multitemporal remote sensing image analysis.
JunJue Wang
JunJue Wang is a PhD candidate at Wuhan University. His major research interests are high-resolution remote sensing imagery semantic segmentation and computer vision.
Dingyuan Chen
Dingyuan Chen is a PhD candidate at Wuhan University. His research interests include building extraction with multisource remote sensing imagery and deep learning-based object detection.
Yu Su
Yu Su received the PhD degree from Wuhan University, in 2023. Her major research interests include urban scene understanding for high-resolution remote sensing imagery and land use mapping based on multisource geographic data.
References
- Bastani, F., S. He, S. Abbar, M. Alizadeh, H. Balakrishnan, S. Chawla, S. Madden, and D. Dewitt. 2018. “RoadTracer: Automatic Extraction of Road Networks from Aerial Images.” In the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4720–4728. Salt Lake City, UT, USA, June 18–22.
- Chaurasia, A., and E. Culurciello. 2017. “LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation.” In the Proceedings of the IEEE Visual Communications and Image Processing, 1–4. Petersburg, FL, USA, December 10–13.
- Chen, T., S. Kornblith, M. Norouzi, and G. Hinton. 2020. “A Simple Framework for Contrastive Learning of Visual Representations.” In the International Conference on Machine Learning, 1597–1607. Online, July 12–18.
- Chen, H., Z. Li, J. Wu, W. Xiong, and C. Du. 2023. “SemiRoadexnet: A Semi-Supervised Network for Road Extraction from Remote Sensing Imagery via Adversarial Learning.” ISPRS Journal of Photogrammetry & Remote Sensing 198 (April): 169–183. https://doi.org/10.1016/j.isprsjprs.2023.03.012.
- Chen, H., S. Peng, C. Du, J. Li, and S. Wu. 2022. “SW-GAN: Road Extraction from Remote Sensing Imagery Using Semi-Weakly Supervised Adversarial Learning.” Remote Sensing 14 (17): 4145.
- Chen, M., H. Xue, and D. Cai. 2019. “Domain Adaptation for Semantic Segmentation with Maximum Squares Loss.” In the Proceedings of the IEEE/CVF International Conference on Computer Vision, 2090–2099. Seoul, Korea (South), October–November 27 2.
- Csurka, G. 2017. “A Comprehensive Survey on Domain Adaptation for Visual Applications.” Domain Adaptation in Computer Vision Applications (September): 1–35. https://doi.org/10.1007/978-3-319-58347-1_1.
- Demir, I., K. Koperski, D. Lindenbaum, G. Pang, J. Huang, S. Basu, F. Hughes, D. Tuia, and R. Raska. 2018. “DeepGlobe 2018: A Challenge to Parse the Earth Through Satellite Images.” In the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 172–181. Salt Lake City, UT, USA, June 18–22.
- Ghifary, M., W. B. Kleijn, M. Zhang, D. Balduzzi, and W. Li. 2016. “Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation.” In the European Conference on Computer Vision, 597–613. Amsterdam, The Netherlands, October 11–14.
- Goodfellow, I., J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. 2014. “Generative Adversarial Nets.” In the Advances in Neural Information Processing Systems, December 8–13, Montreal, Quebec, Canada.
- He, K., X. Zhang, S. Ren, and J. Sun. 2015. “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification.” In the Proceedings of the IEEE International Conference on Computer Vision, 1026–1034. Santiago, Chile, December 7–13.
- Ke, Z., D. Wang, Q. Yan, J. Ren, and R. W. Lau. 2019. “Dual Student: Breaking the Limits of the Teacher in Semi-Supervised Learning.” In the Proceedings of the IEEE/CVF International Conference on Computer Vision, 6728–6736. Seoul, Korea (South), October–November 27 2.
- Kim, J., J. Jang, and H. Park. 2020. “Structured Consistency Loss for Semi-Supervised Semantic Segmentation.” https://doi.org/10.48550/arXiv.2001.04647.
- Kleinschroth, F., N. Laporte, W. F. Laurance, S. J. Goetz, and J. Ghazoul. 2019. “Road Expansion and Persistence in Forests of the Congo Basin.” Nature Sustainability 2 (7): 628–634.
- Laurance, W. F., G. R. Clements, S. Sloan, C. S. O’connell, N. D. Mueller, M. Goosem, O. Venter, D. P. Edwards, B. Phalan, and A. Balmford. 2014. “A Global Strategy for Road Building.” Nature 513 (7517): 229–232.
- Lee, D.-H. 2013. “Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks.” In the International Conference on Machine Learning, 896. Atlanta, GA, USA, June 16–21.
- Li, Z., H. Chen, N. Jing, and J. Li. 2023. “RemainNet: Explore Road Extraction from Remote Sensing Image Using Mask Image Modeling.” Remote Sensing 15 (17): 4215.
- Li, D., M. Wang, H. Guo, and W. Jin. 2024. “On china’s Earth Observation System: Mission, Vision and Application.” Geo-Spatial Information Science (April): 1–19. https://doi.org/10.1080/10095020.2024.2328100.
- Li, Z., J. Zou, F. Lu, and H. Zhang. 2022. “Multi-Stage Pseudo-Label Iteration Framework for Semi-Supervised Land-Cover Mapping.” In the Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, 4607–4610. Kuala Lumpur, Malaysia, July 17–22.
- Lu, X., Y. Zhong, and L. Zhang. 2022. “Open-Source Data-Driven Cross-Domain Road Detection from Very High Resolution Remote Sensing Imagery.” IEEE Transactions on Image Processing 31 (October): 6847–6862. https://doi.org/10.1109/TIP.2022.3216481.
- Lu, X., Y. Zhong, Z. Zheng, and J. Wang. 2021. “Cross-Domain Road Detection Based on Global-Local Adversarial Learning Framework from Very High Resolution Satellite Imagery.” Isprs Journal of Photogrammetry & Remote Sensing 180:296–312.
- Lu, X., Y. Zhong, Z. Zheng, and L. Zhang. 2021. “GAMSNet: Globally Aware Road Detection Network with Multi-Scale Residual Learning.” Isprs Journal of Photogrammetry & Remote Sensing 175 (May): 340–352. https://doi.org/10.1016/j.isprsjprs.2021.03.008.
- Meijer, J. R., M. A. Huijbregts, K. C. Schotten, and A. M. Schipper. 2018. “Global Patterns of Current and Future Road Infrastructure.” Environmental Research Letters 13 (6): 064006.
- Mei, J., R.-J. Li, W. Gao, and M.-M. Cheng. 2021. “CoAnet: Connectivity Attention Network for Road Extraction from Satellite Imagery.” IEEE Transactions on Image Processing 30 (October): 8540–8552. https://doi.org/10.1109/TIP.2021.3117076.
- Mnih, V. 2013. Machine Learning for Aerial Image labeling. Canada: University of Toronto.
- Ouali, Y., C. Hudelot, and M. Tami. 2020. “Semi-Supervised Semantic Segmentation with Cross-Consistency Training.” In the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, June 14–19, pp. 12674–12684.
- Paszke, A., S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, and L. Antiga. 2019. “Pytorch: An Imperative Style, High-Performance Deep Learning Library.” In the Advances in Neural Information Processing Systems, December 8–14, Vancouver, Canada.
- Patel, V. M., R. Gopalan, R. Li, and R. Chellappa. 2015. “Visual Domain Adaptation: A Survey of Recent Advances.” IEEE Signal Processing Magazine 32 (3): 53–69.
- Russakovsky, O., J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, and M. Bernstein. 2015. “ImageNet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision 115 (3): 211–252.
- Saito, S., T. Yamashita, and Y. Aoki. 2016. “Multiple Object Extraction from Aerial Imagery with Convolutional Neural Networks.” Electronic Imaging 28 (February): 1–9. https://doi.org/10.2352/issn.2470-1173.2016.10.robvis-392.
- Sajjadi, M., M. Javanmardi, and T. Tasdizen. 2016. “Regularization with Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning.” In The Advances in Neural Information Processing Systems, December 5–10, Barcelona, Spain.
- Shi, W., Z. Miao, and J. Debayle. 2013. “An Integrated Method for Urban Main-Road Centerline Extraction from Optical Remotely Sensed Imagery.” IEEE Transactions on Geoscience & Remote Sensing 52 (6): 3359–3372.
- Sohn, K., D. Berthelot, N. Carlini, Z. Zhang, H. Zhang, C. A. Raffel, E. D. Cubuk, A. Kurakin, and C.-L. Li. 2020. “Fixmatch: Simplifying Semi-Supervised Learning with Consistency and Confidence.” In The Advances in Neural Information Processing Systems, December 6–12, Online, pp. 596–608.
- Tarvainen, A., and H. Valpola. 2017. “Mean Teachers Are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results.” In the Advances in Neural Information Processing Systems, December 4–9, Long Beach, CA, USA.
- Tsai, Y.-H., W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker. 2018. “Learning to Adapt Structured Output Space for Semantic Segmentation.” In the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7472–7481. Salt Lake City, UT, USA, June 18–22.
- Van Etten, A., D. Lindenbaum, and T. M. Bacastow. 2018. “SpacenNet: A Remote Sensing Dataset and Challenge Series.” https://doi.org/10.48550/arXiv.1807.01232.
- Wang, J., A. Ma, Y. Zhong, Z. Zheng, and L. Zhang. 2022. “Cross-Sensor Domain Adaptation for High Spatial Resolution Urban Land-Cover Mapping: From Airborne to Spaceborne Imagery.” Remote Sensing of Environment 277 (August): 113058. https://doi.org/10.1016/j.rse.2022.113058.
- Wang, J., Z. Zheng, A. Ma, X. Lu, and Y. Zhong. 2021. “LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation.” NeurIPS 2021 Datasets and Benchmarks Track 1 (May). https://doi.org/10.48550/arXiv.2110.08733.
- Zheng, Z., Y. Zhong, J. Wang, and A. Ma. 2020. “Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery.” In the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4096–4105. Online, June 14–19.
- Zhou, M., H. Sui, S. Chen, J. Wang, and X. Chen. 2020. “BT-Roadnet: A Boundary and Topologically-Aware Neural Network for Road Extraction from High-Resolution Remote Sensing Imagery.” Isprs Journal of Photogrammetry & Remote Sensing 168 (October): 288–306. https://doi.org/10.1016/j.isprsjprs.2020.08.019.
- Zhou, L., C. Zhang, and W. Ming. 2018. “D-Linknet: Linknet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction.” In the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 182–186. Salt Lake City, UT, USA, June 18–22.
- Zhu, X., and A. B. Goldberg. 2009. “Introduction to Semi-Supervised Learning.” Synthesis Lectures on Artificial Intelligence and Machine Learning 3 (1): 1–130.
- Zhu, X. X., D. Tuia, L. Mou, G.-S. Xia, L. Zhang, F. Xu, and F. Fraundorfer. 2017. “Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources.” IEEE Geoscience and Remote Sensing Magazine 5 (4): 8–36.
- Zou, Y., Z. Zhang, H. Zhang, C.-L. Li, X. Bian, J.-B. Huang, and T. Pfister. 2020. “Pseudoseg: Designing Pseudo Labels for Semantic Segmentation.” https://doi.org/10.48550/arXiv.2010.09713.