
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
For the problem that the non-ground plane and dynamic object areas in surveillance videos have large deformation after geographic mapping, a new method for orthographic video map construction (OVMC) based on video and GIS is proposed. Firstly, the segmented video background (SegBG), dynamic object sub-image (SubObjPic) and its coordinates are extracted. Secondly, the homography matrix (H) is solved. An area (R) is set in a 2D map. based on H−1, the orthophoto map of the video background (OrviBG) is constructed. Finally, each SubObjPic are converted to geographic space and overlaid on OrviBG, then the ortho video map is generated. The results show that:(1) The accuracy of the semantic segmentation model for removing non-ground plane is 96.70%; (2) Compared with the traditional method, the amount of orthographic video is reduced by 22.9%; (3) The deformation of non-ground and dynamic object areas is eliminated. This method can promote the deep integration of surveillance video and GIS.
1. Introduction
With the rapid development of information technology, video surveillance is playing an increasingly important role in fields, such as smart city, public safety, and emergency relief (Sebe et al. Citation2003; Milosavljević et al. Citation2010). As an effective means of recording information, it can record the real-time change of geographical scene and show the interaction of people, vehicles and other objects. Currently, the number of video sensors is increasing, resulting in a massive amount of video data. Based on massive historical/real-time video data and high-precision geospatial data, video GIS technology has become one of the most commonly used technical means for monitoring geographic scene.
Due to the lack of geospatial reference information in the video, it is difficult for security personnel to determine the geographic location and direction of the moving objects, which makes the behavioural analysis of the objects more difficult. If video imagery and object trajectories are mapped directly to the map (Han et al. Citation2022; Luo et al. Citation2023; Zhang et al. Citation2023), we can analyze them in geospatial space, which facilitates a comprehensive analysis of the object’s behaviour. However, in terms of video image mapping, due to the lack of depth information, the direct mapping of the video image to the map results in severe deformation of its non-ground plane area and object area (Zhang et al. Citation2022). Therefore, the position of the mapping image is inconsistent with the map or remote sensing image. The visualization effect is poor, which is not conducive to video analysis in a map. This is because current research in video geographic mapping does not distinguish between foreground targets, backgrounds, and ground undulations in the monitored scene.
This paper adopts the method of separating the front and back scenes of the video and processing them separately to improve the visualization effect of geographic map-ping of the video image. The background part is semantically segmented to remove non ground plane areas, and the ortho background image is obtained after geographic mapping. Then, the foreground object is extracted without further geographic mapping, and directly covers the corresponding position of OrviBG. The specific process includes three major parts: video information extraction, video geographic mapping, orthophoto video generation and visualization. A detailed explanation of each section can be found in Section 3. The orthophoto video map in this article refers to a sequence of orthophoto images formed by orthophoto processing of video frames. Each pixel in the orthophoto image is consistent with the corresponding position in the remote sensing image or two-dimensional map. In practical applications, the video frames are first obtained and processed in real-time according to the method described in this article, which can be displayed in WebGIS.
The structure of this paper is as follows: Section 2 provides an overview of relevant work; Section 3 elaborates on the relevant technical details of OVMC; In Section 4, OVMC is discussed and analyzed according to the experimental results. Section 5 summarizes and discusses the paper.
2. Related work
Relying on massive historical/real-time video and high-precision geospatial data for comprehensive urban surveillance is currently one of the most widely used technologies. To solve the problem of severe dynamic object deformation in orthophoto video generation, this paper combines a video surveillance system with GIS. In this section, we introduce the progress of related research from three aspects: semantic segmentation, object detection and VideoGIS.
2.1. Semantic segmentation
Semantic segmentation is an important method in computer vision, which is aiming to assign semantic class labels to individual pixel in an image or video. Traditional methods mostly use machine learning technology, such as image processing, support vector machine, random forest, etc., which are commonly used to construct semantic classifier for image segmentation. These classifiers are trained on labeled data to achieve semantic segmentation. However, in recent years, deep learning technology has greatly improved the accuracy of semantic segmentation. Deep learning, especially convolutional neural network (CNN), as a powerful feature extraction tool, greatly improves the accuracy of classification or regression. These models can effectively capture multi-scale features, which provide more precise and detailed semantic segmentation results. With the development of deep learning technology, several segmentation models based on convolutional neural networks have emerged. In 2014, the first full convolutional neural network FCN (Arjovsky et al. Citation2017) for image semantic segmentation was proposed. It discards the end of the traditional convolutional neural network (fully-connected layer) and replaces it with deconvolution. The advantage of this improvement is that there is no limitation in the input size. Subsequently, a series of end-to-end semantic segmentation models were generated based on FCN, such as CRF-RNN (Zheng et al. Citation2015), U-Net (Ronneberger et al. Citation2015), SegNet (Badrinarayanan et al. Citation2017), DeepLab (Chen et al. Citation2015), etc. These algorithms have achieved good results in semantic segmentation. DeepLab series network can effectively reduce spatial resolution during low to medium sampling, and is a common pixel-by-pixel classification model for image semantic segmentation. DeepLab v1 aims to convert specific step parameters from the last or second pooling to 1. It can ensure that the perception field of the subsequent convolutional kernel does not change. The null convolution is designed and the actual feature extraction is maintained. DeepLab v2 (Chen et al. Citation2016) introduced the Atrous Spatial Pyramid Pooling (ASPP) module on the basis of previous methods. ASPP combines multiple scale convolutional kernels, which allows the model to capture contextual information effectively and improve the accuracy of semantic segmentation. DeepLab v3 (Chen et al. Citation2017) is based on DeepLab v2, which eliminates the corresponding cascading convolutions and further imports the corresponding 1 × 1 convolutions to obtain specific features of the same size as the actual input features. DeepLab v3+ (Chen et al. Citation2018) introduces a new encoding method based on DeepLab v3, and performs anti quadruple up-sampling operations around ASPP output, which obtain final features and improve the speed and accuracy of semantic segmentation. In 2020, Google released the Vision Transformer (VIT) model (Dosovitskiy et al. Citation2020), which does not rely on CNN at all but directly uses Transformer as an encoder to extract image features. Compared with advanced convolutional neural networks, VIT can consume less resources for training while obtaining more accurate results.In this article, in order to eliminate non ground area, we used semantic segmentation technology and constructed a semantic segmentation model for video geographic mapping.
2.2. Object detection
Object detection is a key technique for information extraction in computer vision. Its detection effect has a significant impact on the following work. There are three main categories of object detection: motion object detection, object detection based on pre-specified features, and object detection based on deep learning. Moving object detection is the extraction of moving objects in video. The background refers to the static area in the video, and the foreground is the dynamic target. Currently, the main methods include background subtraction (Bouwmans Citation2014; Sobral and Vacavant Citation2014), frame difference (Lipton et al. Citation1998), and optical flow method (Xu et al. Citation2012). The second category of methods mainly use manually designed features, which requires prespecified features, such as Haar (Viola and Jones Citation2001), HOG (Dalal and Triggs Citation2005). Due to the lack of more features, traditional object detection methods have complex feature design and low accuracy. Therefore, they have more limitations in the real-time application. The deep learning method automatically acquires object features through convolutional neural networks. Object detection can be divided into two categories: region-based object detection and regression-based object detection. Region-based object detection are two-stage algorithm, such as the R-CNN (Girshick et al. Citation2014) and Fast R-CNN (Girshick Citation2015), which introduce convolutional neural network into the field of object detection, resulting in an effective improvement in accuracy. Faster R-CNN (REN et al. Citation2015) forms an end-to-end object detection framework. Regression-based object detection is a single-stage detection algorithm. In recent years YOLO (Redmon et al. Citation2016; Redmon and Farhadi Citation2017, Citation2018) series algorithms introduce the idea of regression and the detection effect has been effectively improved. However, the detection effect is poor for small or group targets. The subsequent SSD (Liu et al. Citation2016) inherits YOLO's ideas of the bounding box regression and classification probability, while it uses the anchor mechanism in Faster R-CNN to improve the detection accuracy. Later, the YOLOv5 (Liu et al. Citation2020) was proposed by Ultralytics as an extension of the YOLO series, which adds the focus structure to the backbone network. Compared to algorithms such as Fast R-CNN, SSD and YOLOv4, it has a simple network structure, fast operation and higher detection accuracy, which can achieve real-time detection. Compared to traditional object detection methods, DETR (Carion et al. Citation2020) is a Transformer based object detection method. It treats the target detection task as a set prediction problem. By utilizing the sequence conversion capability of the Transformer, the image sequence is transformed into a positional encoding set. Then it achieves precise detection of the target object. In specific small object detection scenarios, YOLO-S (Betti and Tucci Citation2023) exhibits significant advantages. It is developed from the YOLO series of algorithms and is a simple and efficient detection network. In order to extract targets with high accuracy, this article constructs a target detection model using YOLOv5.
2.3. VideoGIS
VideoGIS is designed to fully utilize the advantage of video and GIS, which can provide real-time spatiotemporal information service. Monitoring video has the advantages of real-time, objective and high-definition, while GIS has the advantages of geographical positioning, measurement and map visualization. It is better at spatial analysis and visualization (Yoo and Kim Citation2004; Lewis et al. Citation2011). Geo-video is video data with temporal and spatial references. Compared to traditional video data, Geo-video has the advantages of maps and surveillance videos, which can display moving objects and their trajectories on a map. At the same time, we can comprehensively analyze the behavior of the target through real-time data and geospatial data (Zhang et al. Citation2021). Surveillance video is real-time and easily accessible, with rich spatiotemporal semantics, precise geographic location, intuitive representation, and clear spatial location relationships. The current research on video GIS mainly includes three aspects, namely the VideoGIS framework, geographic mutual mapping, and spatiotemporal information extraction. In terms of research on the VideoGIS framework, Lippman (Citation1980) first integrated video and spatial data in 1978, proposed a Hypermedia map system, which tried to integrate traditional video images into maps as spatial attribute data, and developed a dynamic update map service system with interactive function. Based on multimedia GIS, Kim et al. (Citation2009) first proposed a new concept of geographic video, which completed the design of a geographic video prototype system, using video streaming and dynamic image to achieve data browsing, spatial analysis and other functions. Han et al. (Citation2016, Citation2019) proposed a video data model and constructed a retrieval service framework using geographic information XIE (Xie et al. Citation2017) et al. integrated geographic information and dynamic objects, condensed and extracted video through information association to reduce redundant data in transmission, and built a prototype GIS-MOV system. This has led to a closer connection between surveillance video and geospatial. In terms of mutual mapping research, the models between video and map are mainly include the camera model-based method, line-of-sight intersection with the DEM method and homography matrix method (Sankaranarayanan and Davis Citation2008). In terms of spatiotemporal information extraction, the methods mainly include individual object extraction and crowd extraction. Sun et al. (Citation2022), Zhang et al. (Citation2015) designed a video and GIS collaborative crowd density estimation and mapping method for real-life scenarios where crowd counting often faces object occlusion and perspective problems. Compared with deep learning methods that only label heads, which combines homography matrix to achieve accurate extraction of crowd regions and fully utilizes the overall characteristics of the crowd. Luo et al. (Citation2022) proposed a complete moving object trajectory extraction algorithm (TraEA), which considered the multi-level semantic features of traffic scenes monitored by a single camera FOV, and achieved complete extraction of occluded trajectories in complex traffic scenes.
In this paper, we propose an orthographic video generation method, through video and GIS collaboration, which can solve the problem of video mapping deformation. The orthophoto video generated through this method provides a new perspective for urban regulation, which has better visualization effects and is more conducive to comprehensive analysis of geographical scenes.
3. Methodology
This section introduces the orthographic video generation method and elaborates the basic principle of each part. This methodology includes three parts: video information extraction, video geographic mapping and orthographic video generation. Firstly, based on sequence video frames, the video background is constructed by Gaussian background reconstruction and segmented by the semantic segmentation model. The object detection is performed on the extracted video image. Thereby the position and sub-image of the object in the video frame are obtained. Then, by selecting points at the same location in both video and high-definition remote sensing image, the homography matrix is solved. The video background and foreground dynamic objects can be mapped to geographic space, so then orthographic video is generated. Finally, Orthographic video generation and visualization include converting the coordinates of object sub-image, obtaining a new sub-image based on some size, generating orthographic video. shows the process of orthographic video generation.
Figure 1. Flowchart of the OVMC.
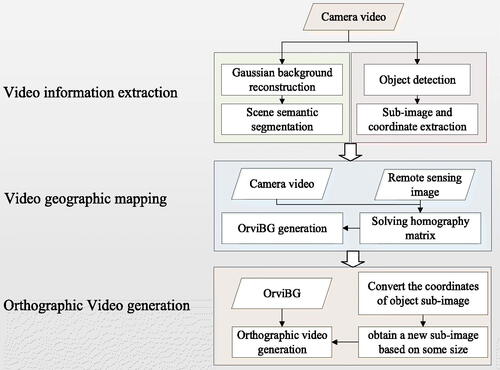
3.1. Video information extraction
3.1.1. Video background extraction
Video background extraction is the process of reconstructing the video background and extracting the ground area by a semantic segmentation model. This process can achieve high-precision extraction of the ground area in the surveillance video, which mainly includes two parts: Gaussian background reconstruction and semantic segmentation.
3.1.1.1. Gaussian background reconstruction
In order to obtain a high-precision video background, it is first necessary to collect adjacent sequence video frames of the experimental area. Then, a background reconstruction algorithm is used to construct the background. The Gaussian Mixture Model (GMM) is the most commonly used method.
GMM linearly combines individual Gaussian distribution, and it primarily uses a normal distribution to represent the change of pixel grey values. The pixels based Gaussian Mixture model have an obvious effect of background modeling and the method can meet the real-time requirement. In this paper, GMM is used for background modeling to achieve the information extraction of the video background. The Gaussian background reconstruction is shown in . Firstly, the Gaussian model is used to describe the characteristics of each pixel, which determine whether each pixel is foreground or background type.
Figure 2. Gaussian background reconstruction.
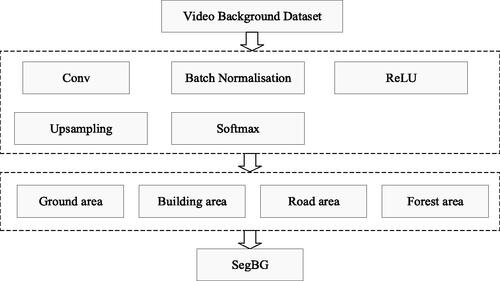
3.1.1.2 semantic segmentation
In video geographic mapping, non-ground areas such as buildings, trees, etc. They do not meet the homography matrix, resulting in severe deformation. In order to automatically extract non-ground areas from the video background, this paper constructs a semantic segmentation model. This model can divide the video background into two parts, namely the ground region and the non-ground region. In terms of semantic segmentation, DeepLab v3+ is currently the most commonly used semantic segmentation model.
The DeepLab v3+ model is suitable for constructing semantic segmentation. It has the advantages of high segmentation accuracy and fast running speed, which can im-prove model speed and usage performance. Based on the DeepLabv3+ model, this paper trains the scene semantic segmentation model through transfer learning. By collecting a lot of videos in experimental area with different status, a semantic segmentation dataset is created. Based on semantic information, the scene is divided into four categories: ground area, tree, building and road. Then, train the labeled samples and validate the model accuracy based on the trained model. Finally, the semantic segmentation model for the scene can be used, and the semantic category of each pixel is output. The pixels of the ground area class are preserved. The semantic segmentation process is completed and the background of the video (SegBG) is obtained. shows the semantic segmentation process of DeepLab v3+.
Figure 3. Semantic segmentation based on DeepLab v3+ model.
3.1.2. Foreground object extraction
Foreground object extraction uses object detection technology to detect objects, such as person and car in surveillance video. Then the image coordinates and corresponding picture of the object is obtained. Due to the complexity of geographical scenes, the object detection process may encounter various challenges, such as missed detection, false detection, and occlusion. This paper uses the YOLOv5 object detection method, which has high detection efficiency and fast speed for detection. The confidence level of the detected objects, object bounding boxes, and feature maps are the foundation for subsequent work, ultimately completing the end-to-end object detection task. YOLOv5 is highly robust and less affected by background, occlusion and lighting. This algorithm is designed to handle the vast amount of surveillance video data effectively. As a result, it can accurately detect dynamic objects in video frame. At the same time, it has the characteristics of continuity and real-time recognition, which can effectively extract object information from videos.
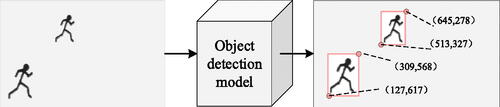
The process of foreground object extraction mainly includes three major processes, namely model training, object detection, location and sub-image recording. Firstly, we gather surveillance videos in the scene, which are captured at various times and different motion states of the objects. These videos are annotated to identify dynamic objects like people and cars, and an object detection model is trained based on YOLOv5; Then, the trained object detection model is used to detect the moving object in the scene and the position of the detected object is recorded; Finally, through the rectangle of the object, video frame is cut to obtain the sub-image (SubObjPic). At the same time, the coordinates of the lower left corner and upper right corner of the sub-image are recorded. is a Flow chart of foreground object extraction.
Figure 4. Flow chart of foreground object extraction.

In , we select some frame as an example, whose resolution is 1280 × 720. Within the framework, two objects are detected. For the object on the upper side, the pixel coordinate of the lower left corner is (513, 327) and the pixel coordinate of the upper right corner is (645, 278). Similarly, for the second object, the pixel coordinate of the lower left corner is (127, 617), and the pixel coordinate of the upper right corner is (309, 568).
Figure 5. Schematic diagram of foreground object extraction.
3.2. Video geographic mapping
Video geographic mapping refers to the process of mapping segmented back-ground and extracted dynamic objects to geographic space. The mutual mapping between surveillance video and 2D geospatial data aims to achieve the mutual conversion of image coordinates and 2D geographic coordinates, which contributes to the mutual data fusion and ultimately achieve mutually augment. The mutual mapping mainly includes two parts: the mapping from surveillance video to geospatial data and the mapping from geospatial data to surveillance video, which are based on the geometric mutual mapping model. Through the method of homography matrix, the mutual conversion between video image space and geographic space can be achieved. is a geographical mapping diagram.
Figure 6. Geographical mapping diagram.
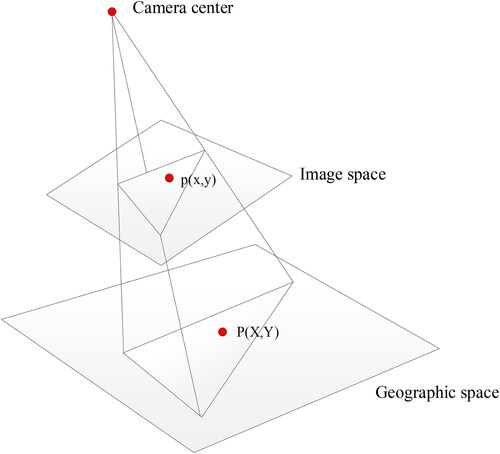
Set p (x, y) as a point in the image space, and P (X, Y) as the corresponding point in the geographic space. In order to map the video background and foreground objects to the geographic space, this paper uses the method of homography matrix to convert pixel coordinate into geographic coordinate, which ultimately achieves the mapping of video and geographic data. The matrix H is a homography matrix and H is a 3×3 matrix, which can be represented by formula (1). H is composed of where i is the number of the row and j is the number of the column.
(1)
(1)
When solving the homography matrix, it is necessary to predefine four or more pairs of p and P points in the image space and geographic space. Each pair of predefined p and P respectively represents the same location in image space and geographic space. They are used to calculate the parameters in H. Based on the calculated homography matrix, the mapping relationship between p and P can be determined. Finally, the Inverse matrix of the homography matrix can realize the transformation from geographical spatial coordinate to image spatial coordinate.
For a camera that has finished H calculation, through H p (
) can be converted to P (
), as shown formula (2). Obviously, through
P (
) can be converted to p (
).
(2)
(2)
3.3. Orthographic video generation
Orthographic video generation refers to the process of converting surveillance video into orthographic video in real time, which can intuitively express the association between geographic space and image space. This process mainly includes two aspects: orthographic video background generation and foreground object overlaying.
3.3.1. Orthographic video background generation
This paper designs a method for generating orthographic video background, specifically: Firstly, in the map, set the rectangular area R and the spatial resolution K. Secondly, the width and height of R is respectively a and b, and the number of coordinate points in R is The calculation formula for
is shown in formula (3). Solve the inverse matrix
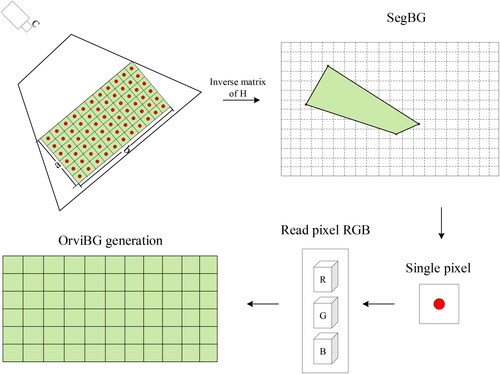
and convert the geographic coordinates of the points to pixel coordinates one by one. Finally, obtain the RGB values of the same pixel coordinate points in SegBG. Then generate a new image based on the obtained RGB values, which is the Orthographic Video Background (OrviBG). The flowchart of the orthophoto video background generation method is shown in .
(3)
(3)
Figure 7. Flow chart of orthographic video background generation.
3.3.2. Foreground object overlaying
If dynamic foreground objects in the video are directly extracted and mapped to geographic space through H, this can cause severe deformation of the object image. In order to eliminate the deformation, a new method of foreground object overlaying is proposed. Dynamic foreground object overlaying refers to overlaying the extracted dynamic object image to the orthographic background.
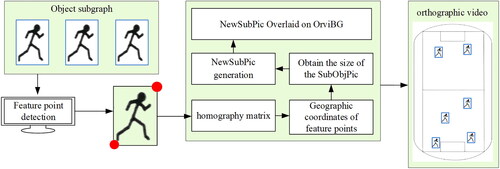
The process of this method is as follows: (1) Convert the lower left corner coordinate of the sub-image to the geographic coordinate (ObjPixCoor) based on H. (2) Obtain the size of SubObjPic and generate NewSubPic. Extract all SubObjPics detected by the object detection model and obtain their image height (SubH) and image width (SubW). Calculate the aspect ratio of the sub-image based on SubH and SubW. Then generate a new object sub-image (NewSubPic) with appropriate size and the same aspect ratio as SubObjPic. (3) NewSubPic overlaying. Locate the geographic coordinates of ObjPixCoor in OrviBG, and use this point as the bottom left boundary point of NewSubPic. Overlay NewSubPic on the corresponding position. Overlay all generated NewSubPics on OrviBG to generate the final orthographic video. shows the process of overlaying dynamic foreground objects.
Figure 8. Flow chart of foreground object overlaying.
4. Experiments and results
4.1. Experimental environment and data
The experimental environment of this paper is: Python 3.6, OpenCV4.0, MATLAB 2019b, Visual Studio 2012 C++ and C #. The hardware environment for training the object detection model is GPU GTX-1660Ti, CPU i7-10750H, memory 16GB. Hardware environment for semantic segmentation model training: GPU RTX 2080Ti, CPU i9-9820X, memory 32GB. This paper selected a school playground as the experimental area. At a height of approximately 33 meters, a high-resolution camera was deployed. shows the remote sensing image and fine electronic map of the playground. This chapter presents an experiment, using a camera to capture video footage of a play-ground. The experiment involves video background extraction, semantic segmentation, object detection, geographic mapping, and orthographic video generation. The results were compared to traditional method and analyzed.
Figure 9. The geospatial data of the experimental area.

4.2. Experimental analysis
4.2.1. Video background extraction
4.2.1.1. Gaussian mixture model and background reconstruction
In this paper, the separation experiment of video foreground and background was carried out based on Gaussian mixture model. The open-source code related to GMM in OpenCV was used in the experiment. shows the reconstruction effect. It can be seen from the figure that the method of Gaussian mixture model can extract the playground background. Objects such as person and crowd have been removed.
Figure 10. Effect of background reconstruction based on Gaussian Mixture model.

4.2.1.2. Semantic segmentation effect
In order to eliminate non-ground area in the image, this paper used image semantic segmentation, then constructed a semantic segmentation model. We conducted transfer learning on DeepLabv3+, and used MATLAB 2019b to train a semantic segmentation model.
In the experimental area, 3000 frames of video were collected, 2000 frames of which were used as the training dataset. They were divided into training and test sets in a ratio of 3:2. The semantics were divided into four categories, which is playground, forest, building and road. The training time was about 15 min, and the accuracy of the test set was 96.70%. Based on the model, playground and road belong to ground area, which were reserved. However, forest and building were removed. shows the semantic segmentation effect of the playground. The green area indicates the ground part. The blue area indicates the forest part. The yellow area indicates the building part and the cyan area indicates the road part. From the , it can be seen that the trained semantic segmentation model has a high accuracy and the semantic classification of the image is clear.
Figure 11. Semantic segmentation effect.

4.2.2. Video motion object extraction effect
A YOLOv5 pre-trained model based on the Pytorch framework was used for transfer learning and 8250 samples were collected in the experimental area. The dataset contained object sample in different weather conditions, such as day, night and cloudy. Firstly, the video images were extracted from the collected videos; Then, the video images were labeled using a label tool and the object type is mainly person; Finally, the labeled data were trained on the basis of the pre-trained model and the object detection model is obtained for playgrounds. The model only needed to be trained once and can be applied to similar scenarios. After collecting and labelling the sample data, the data was divided into a training set and a test set in a 4:1 ratio. The trained duration is 462 min and the step is 3000. The detection accuracy is 97%. shows the effect of object detection and shows the object sub-image extraction effect.
Figure 12. Object detection effect on the playground.

Figure 13. Object subgraph extraction effect.

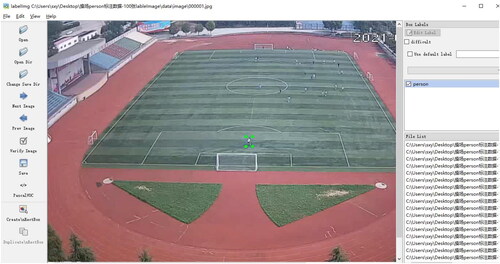
This paper used Labelme software to label different objects. It is an image annotation tool for obtaining the training dataset. The Labelme tool provides visual support for object detection work, allowing users to quickly determine the location using rectangular boxes and input the type of objects. The annotation results were saved in Pascal VOC label format, and the annotated labels were saved in an XML file. XML mainly included the image name and the coordinates of the bounding box for each target (the coordinates of the upper left corner and the lower right corner). The annotation interface is shown in .
Figure 14. Example of image annotation.
In order to verify the model accuracy for the playground video, 30 frames from the collected videos in different weather and object motion status were selected for accuracy evaluation. Set the number of objects, which were missed and wrongly detected in each frame was n, and the total number of objects in each frame was m. The accuracy rate of object detection for each video frame was The result of accuracy calculation for 30 frames was shown in . The result shows that the accuracy of object detection is above 85%, with a maximum of 100%. A few objects were missed and mis-detected because the playground was too large and the objects were too far away from the camera. shows the ObjPixCoor values of the SubObjPic extracted from a video frame. LL represents the coordinates of the lower left corner and UR is the coordinates of the upper right corner.
Figure 15. YOLO v5 algorithm object detection accuracy.
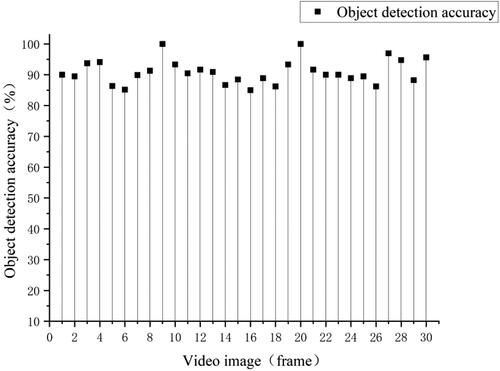
Table 1. Coordinate points of object subgraph.
4.2.3. Accuracy analysis of video geographic mapping
In order to analyze the accuracy of video geographic mapping, we randomly selected 8 pixels from a video frame as control points to solve the homography matrix(H), including C1 to C8 in . By selecting some pixels in the image, we calculated the distance between the true geographic coordinates and the geographic coordinates calculated through H. Then use the distance (Dis) between them as the accuracy evaluation indicator. The experimental results are shown in , and the distribution map of the points is shown in (the control points are green, and the test points are yellow). It shows that the mapping accuracy of the points including 1–11 is basically similar, which are on the ground. However, the points located on non-ground including 12–16 have larger mapping deviation than the ground points.
Figure 16. Point distribution map.

Table 2. Geographic mapping accuracy.
4.2.4. Analysis of orthographic video generation and visualization
In order to analyze the visualization effect of the generated orthographic video, we compared the traditional method with OVMC, as shown in .
Table 3. Comparison of visualization effects.
Adopting the traditional method, the video is directly mapped to geographic space as the whole through the homography matrix, which leads to a larger deformation of the object and poor visualization effect. From the experimental results of the traditional method, it can be seen that the deformation of the objects nearer to the camera was low, and the deformation of the objects farther away from the camera is large. OVMC used an electronic map of a playground as the base map, and overlaid the orthographic background and the non-mapping sub-image of the object. From the experimental results, it can be found that the orthographic video reduces the object deformation and the visualization effect is significantly improved.
In addition to improving the visualization effect, the data volume of orthophoto videos is smaller, as shown in . Set the data volume by the traditional method be n, the data volume by OVMC be m, and the data volume of the sub-image is W. Taking 5 frames of data as an example, the changes in the data volume of traditional methods, OVMC methods, and subgraphs were statistically analyzed. From the experimental results, it can be seen that the OVMC method generally has lower data volume than traditional methods, mainly due to the elimination of non- ground areas. At the same time, in GIS applications, sub-image can also be used to display geographic videos, which has a smaller data volume than the OVMC method.
Table 4. Test video frame parameters.
Set the total number of video frames be x and the reduced value of the data volume be PR, which is calculated as in EquationEquation (4)(4)
(4) .
(4)
(4)
In this experiment, 300 video frames generated by the traditional method are se-lected as the test set, and they were arranged in ascending order according to the data volume. The video frames in the test set were processed by the traditional method, OVMC, sub-image method. The three results were compared and analyzed frame by frame. As shown in , the x-axis represents the frame number, y-axis is the data volume.
Figure 17. Comparison of video frame data volume.
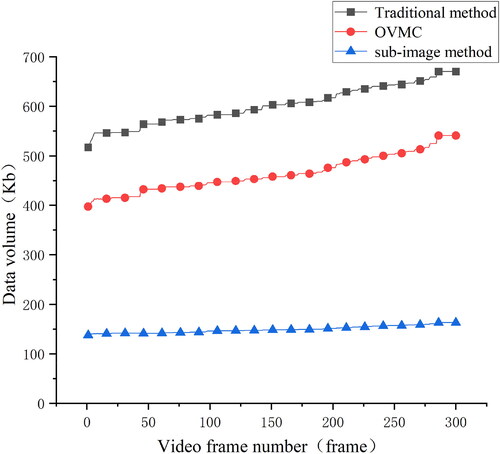
From the experimental results, it can be seen that the data volume of orthophoto videos using the OVMC method is generally lower than that of traditional methods, with a data reduction of 22.9%. The sub-image method has a smaller data volume, which is reduced by 75.1% and 67.7% respectively, compared to traditional methods and OVMC. Therefore, OVMC or sub-image methods have advantages in data network transmission and are more suitable for the in-depth application of video in WebGIS.
5. Conclusions and discussion
In this paper, video background and object sub-image are extracted, which are separately processed. A new method of orthographic video generation is proposed.
For video background processing, video background and ground area are separately obtained through the Gaussian Mixture model and semantic segmentation model. Then the segmented background is mapped to the geographic space through the homography matrix. In terms of object sub-image processing, based on the geographic coordinate of the object and the aspect ratio of the sub-image, the sub-image is overlaid to the orthographic background. This method effectively improves the effect of orthographic video and reduces the volume of transmitted data over the network. The research has shown that: (1) The accuracy of semantic segmentation model for removing non-ground area is 96.70%, which can perform high-precision extraction of ground area;(2) Compared with the traditional method, the data volume of orthographic video generated by OVMC is reduced by about 22.9%; (3) The deformation of non-ground and dynamic object areas in the orthographic video is eliminated by OVMC, and the visualization effect has been greatly improved.
This method has good results in generating orthographic video, which is suitable for cameras installed at high altitudes and has a wide monitoring range. It can be used in the field of comprehensive urban supervision and intelligent security prevention. However, due to the complexity of geographical scenes and the ‘near large, far small’ characteristics of surveillance video, it is less effective in indoor or small scenes. Especially in scenes with large terrain fluctuations, the mapping effect using this method is poor. Simultaneously, this study mainly focuses on single, fixed cameras. For PTZ camera and multi-camera, the method of orthographic video generation will be the focus of sub-sequent research. Currently, the GIS discipline pays less attention to real-time targets in geographic scenes, such as people and cars. However, the orthophoto videos generated in this study can provide real-time data sources for GIS, which can help its in-depth application in emergency relief, security and other fields.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The authors confirm that the data supporting the findings of this study are available within the article.
Additional information
Funding
References
- Arjovsky M, Chintala S, Bottou L. 2017. Wasserstein GAN. Proceedings of the 36th International Conference on Machine Learning (ICML). p. 214–223. doi: 10.48550/arXiv.1701.07875.
- Badrinarayanan V, Kendall A, Cipolla R. 2017. Segnet: a deep convolutional encoder-decoder architecture for image seg-mentation. IEEE Trans Pattern Anal Mach Intell. 39(12):2481–2495. doi: 10.1109/TPAMI.2016.2644615.
- Betti A, Tucci M. 2023. YOLO-S: a lightweight and accurate YOLO-like network for small target detection in aerial imagery. Sensors. 23(4):1865. doi: 10.3390/s23041865.
- Bouwmans T. 2014. Traditional and recent approaches in background modeling for foreground detection: an overview. Comp Sci Rev. 11:31–66. doi: 10.1016/j.cosrev.2014.04.001.
- Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. 2020. End-to-end object detection with transformers. European conference on computer vision. Cham: Springer International Publishing; p. 213–229. doi: 10.48550/arXiv.2005.12872.
- Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL. 2017. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans Pattern Anal Mach Intell. 40(4):834–848. doi: 10.1109/TPAMI.2017.2699184.
- Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL. 2016. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. PAMI. 2016:834–848. doi: 10.48550/arXiv.1606.00915.
- Chen LC, Papandreou G, Schroff F, Adam H. 2017. Rethinking atrous convolution for semantic image segmentation. arXiv. doi: 10.48550/arXiv.1706.05587.
- Chen LC, Zhu YK, Papandreou G, Schroff F, Adam H. 2018. Encoder-decoder with atrous separable convolution for semantic image segmentation. ECCV. 2018:833–851. doi: 10.48550/arXiv.1802.02611.
- Dalal N, Triggs B. 2005. Histograms of oriented gradients for human detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA: IEEE; p. 886–893. doi: 10.1109/CVPR.2005.177.
- Dosovitskiy A, Beyer L, Kolesnikov A, et al. 2020. An image is worth 16x16 words: transformers for image recognition at scale. arXiv Preprint. arXiv 2010119292020. doi: 10.48550/arXiv.2010.11929.
- Girshick R, Donahue J, Darrell T. 2014. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA: IEEE; p. 80–587. doi: 10.1109/CVPR.2014.81.
- Girshick R. 2015. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), 7–13 December 2015. Santiago, Chile: IEEE; p. S1440–S1448. doi: 10.1109/ICCV.2015.169.
- Han SJ, Dong XR, Hao XY, Miao SF. 2022. Extracting objects’ spatial-temporal information based on surveillance videos and the digital surface model. IJGI. 11(2):103. doi: 10.3390/ijgi11020103.
- Han Z, Cui C, Kong Y, Qin F, Fu P. 2016. Video data model and retrieval service framework using geographic information. Trans GIS. 20(5):701–717. 2016 doi: 10.1111/tgis.12175.
- Han Z, Li S, Cui C, Han D, Song H. 2019. Geosocial media as a proxy for security: a review. IEEE Access. 7:154224–154238. doi: 10.1109/ACCESS.2019.2949115.
- Kim K, Oh S, Lee J. 2009. Augmenting aerial earth maps with dynamic information. 8th IEEE International Symposium on Mixed & Augmented Reality (ISMAR). Orlando, FL, USA: IEEE: p. 35–38. doi: 10.1109/ISMAR.2009.5336505.
- Lewis P, Fotheringham S, Winstanley A. 2011. Spatial video and GIS. Int J Geogr Inf Sci. 25(5):697–716. doi: 10.1080/13658816.2010.505196.
- Liu W, Anguelov D, Erhan D. 2016. SSD: single shot multibox detector. European conference on computer vision. Cham, Switzerland: Springer International Publishing; p. 21–37. doi: 10.48550/arXiv.1512.02325.
- Liu YF, Lu BH, Peng JY. 2020. Research on the use of YOLOv5 object detection algorithm in mask wearing recognition. World Sci Res J. 6(11):38. doi: 10.6911/WSRJ.202011_6(11).0038.
- Lippman A. 1980. Movie-maps: an application of the optical videodisc to computer. SIGGRAPH Comput Graph. 14(3):32–42. doi: 10.1145/965105.807465.
- Lipton AJ, Fujiyoshi H, Patil R S. 1998. Moving object classification and tracking from real-time video. WACV '98: Proceedings of the 4th IEEE Workshop on Applications of Computer Vision, Princeton, NJ, USA: IEEE. doi: 10.1109/ACV.1998.732851.
- Luo X, Wang Y, Dong J, Li Z, Yang Y, Tang K, Huang T. 2022. Complete trajectory extraction for moving objects in traffic scenes that considers multi-level semantic features. Int J Geogr Inf Sci. 37(4):913–937. doi: 10.1080/13658816.2022.2158190.
- Luo X, Wang Y, Zhang X. 2023. A violation analysis method of traffic objects based on video and GIS. Geomat Inf Sci Wuhan Univ. 48(4):647–655. doi: 10.13203/j.whugis20200582.
- Milosavljević A, Dimitrijević A, Rančić D. 2010. GIS-augmented video surveillance. Int J Geogr Inf Sci. 24(9):1415–1433. doi: 10.1080/13658811003792213.
- Redmon J, Divvala S, Girshick R. 2016. You only look once: unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA: IEEE; p. 779–778. doi: 10.1109/CVPR.2016.91.
- Redmon J, Farhadi A. 2017. YOLO9000: better, faster, stronger. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA: IEEE; p. 6517–6525. doi: 10.48550/arXiv.1612.08242.
- Redmon J, Farhadi A. 2018. YOLOV3: An incremental improvement. Computer vision and pattern recognition. Berlin/Heidelberg, Germany: Springer. 1804:1–6. doi: 10.48550/arXiv.1804.02767.
- Ren S, He K, Girshick R, Sun J. 2015. Faster R-CNN: towards real-time object detection with region proposal net-works. IEEE Trans Pattern Anal Mach Intell. 39(6):1137–1149. doi: 10.1109/TPAMI.2016.2577031.
- Ronneberger O, Fischer P, Brox T. 2015. U-net: convolutional Networks for biomedical image segmentation. International Conference on Medical Image Computing and Computer-Assisted Intervention; p. 234–241. doi: 10.48550/arXiv.1505.04597.
- Sankaranarayanan K, Davis JW. 2008. A fast linear registration framework for multi-camera GIS coordination. In Proceedings of the fifth IEEE International Conference on Advanced Video and Signal Based Surveillance, AVSS 2008, Santa Fe, NM, USA: IEEE. doi: 10.1109/AVSS.2008.20.
- Sebe IO, Hu JH, You SY. 2003. 3D video surveillance with augmented virtual environments. In Proceedings of the First ACM SIGMM International Workshop on Video Surveillance, BerkeleyCAUSA. 2–8 November 2003; p. 107–112. doi: 10.1145/982452.982466.
- Sobral A, Vacavant A. 2014. A comprehensive review of background subtraction algorithms evaluated with synthetic and real videos. CVIU. 122:4–21. doi: 10.1016/j.cviu.2013.12.005.
- Sun Y, Zhang X, Shi X, Li Q. 2022. Crowd density estimation method considering video geographic mapping. J Geo-Inf Sci. 24(6):1130–1138. doi: 10.12082/dqxxkx.2022.210555.
- Viola P, Jones M. 2001. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA: IEEE; p. 511–518. doi: 10.1109/CVPR.2001.990517.
- Xie Y, Wang M, Liu X, Wu Y. 2017. Integration of GIS and moving objects in surveillance video. IJGI. 6(4):94. doi: 10.3390/ijgi6040094.
- Xu L, Jia JY, Matsushita Y. 2012. Motion detail preserving optical flow estimation. IEEE Trans Pattern Anal Mach Intell. 34(9):1744–1757. doi: 10.1109/TPAMI.2011.236.
- Yoo HH, Kim SS. 2004. Construction of facilities management system combining video and geographical information. KSCE J Civ Eng. 8(4):435–442. doi: 10.1007/BF02829167.
- Zhang X, Sun Y, Li Q, Li X, Shi X. 2023. Crowd density estimation and mapping method based on surveillance video and GIS. IJGI. 12(2):56. doi: 10.3390/ijgi12020056.
- Zhang X, Zhou Y, Luo X, Shi X, Wu C. 2022. An indoor real-time map construction method based on collaboration of multiple cameras. Sci Surv Mapp. 47(1):188–195. doi: 10.16251/j.cnki.1009-2307.2022.01.022.
- Zhang X, Shi X, Luo X, Sun Y, Zhou Y. 2021. Real-time web map construction based on multiple cameras and GIS. IJGI. 10(12):803. doi: 10.3390/ijgi10120803.
- Zhang X, Liu X, Wang S, Liu Y. 2015. Mutual mapping between surveillance video and 2D geospatial data. Geomat Inf Sci. 40(8):1130–1136. doi: 10.13203/j.whugis20130817.
- Zheng S, Jayasumana S, Romera-Paredes B, Vineet V, Su Z, Du D, Huang C, Torr PHS. 2015. Conditional random fields as recurrent neural networks. Proceedings of the IEEE International Conference on Computer Vision (ICCV). IEEE; p. 1529–1537. doi: 10.1109/ICCV.2015.179.