
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This article addresses the class imbalance problem in urban gain modelling (UGM) of Tabriz and Isfahan megacities in Iran by proposing novel cost-sensitive machine learning models, namely cost-sensitive support vector machine (CSVM), random forest (CRF) and artificial neural network (CANN). Random sampling, a frequently utilized method, fails to effectively tackle this issue by biasing models towards no change samples, which outnumber change samples. The results showed that CRF exhibited the highest accuracy (AUC = 0.560), followed by CANN (AUC = 0.557) and CSVM (AUC = 0.448) in Isfahan. In Tabriz, CRF (AUC = 0.809) and CANN (AUC = 0.818) excelled, outperforming balanced sampling models constructed with ANN, RF and SVM with the AUROC of ANN and RF boosted by 15% and 2% in validation. By emphasizing the significance of addressing class imbalance appropriately, this research highlights the improvement in modelling outcomes achievable through the cost-sensitive models especially in Tabriz case.
1. Introduction
In the past two centuries, the excessive migration from rural to urban areas has led to the physical development of urban settlements and changed the land use and cover (Rogers and Williamson Citation1982; Bhagat and Mohanty Citation2009). Urban growth can bring economic benefits and improve communities, but they can also lead to significant environmental problems (Ayedun et al. Citation2011; El Garouani et al. Citation2017). So, it’s crucial to analyse and simulate urban developments, especially in large cities, to understand how they may impact the future state of cities, identify influential factors in urban development and assess environmental consequences (Falah et al. Citation2020; Tong and Feng Citation2020).
Urban growth in Iranian cities like Tabriz and Isfahan presents a myriad of socio-economic and environmental implications that deserve attention. From a socio-economic perspective, the rapid urbanization in these cities can lead to increased demand for housing, infrastructure and services, putting pressure on existing resources and potentially leading to social inequalities (Bagheri and Soltani Citation2023). As populations swell due to rural-to-urban migration and natural population growth, issues such as inadequate housing, traffic congestion, strain on public services and unemployment may arise (Dadashpoor et al. Citation2019). This can affect the quality of life for residents and challenge the capacity of local governments to provide essential services efficiently. By considering the socio-economic and environmental dimensions of urban growth in Tabriz and Isfahan, policymakers, urban planners and stakeholders can implement sustainable strategies that promote inclusive growth, environmental conservation and the well-being of present and future generations. Urban growth modelling (UGM) is an essential tool for effective urban management. In recent years, researchers and modellers have been working on creating models that can accurately simulate the complex and nonlinear nature of urban expansion (Liu et al. Citation2021; Lv et al. Citation2021). Previous studies have primarily focused on novel models and overlooked the inherent imbalance in urban growth data (Ahmadlou et al. Citation2022). The nature of urban growth data itself is characterized by this imbalance, with certain areas experiencing rapid development while others lag behind (Ahmadlou et al. Citation2022). Existing studies have often failed to adequately account for this imbalance, leading to potential biases in modelling and a limited understanding of the dynamics of urban growth.
The common approach for UGM involves considering the data in two time intervals (Verburg et al. Citation2019). The data from the first interval is used to develop models, while the data from the second interval is used for model validation. However, an important challenge in UGM is the class imbalance problem, where there are far fewer urban gain samples in the first interval compared to no change samples (Conway and Wellen Citation2011; Ahmadlou et al. Citation2022, Citation2023). Researchers have traditionally used random sampling and balanced sampling methods for modelling (Xu et al. Citation2019; Mansour et al. Citation2020). In random sampling, approximately 70% of the whole data from the first interval is used for modelling (Moghadam and Helbich Citation2013; Shafizadeh-Moghadam et al. Citation2021). This approach is not appropriate because it exacerbates the class imbalance issue, allowing more no change samples to enter the modelling process (Ahmadlou et al. Citation2022). As a result, the computational load and execution time of the models increases. Balanced sampling, on the other hand, selects no change samples in the same quantity as the change samples from the first interval (Karimi et al. Citation2019). However, this method has a major drawback (Ahmadlou et al. Citation2022, Citation2023). The selected no change samples may have significant potential for urban gain but may not have experienced it in the first interval (Ahmadlou et al. Citation2023). It is possible that these samples will undergo urban gain in the future. Including such samples in the training dataset can confuse the models and reduce their efficiency (Ahmadlou et al. Citation2022). In summary, the existing sampling methods for UGM have limitations. Random sampling introduces imbalance and computational burden, while balanced sampling may misrepresent samples that have the potential for urban gain in the future. Consequently, the models face challenges in distinguishing between samples that have experienced growth and those that are likely to experience growth in subsequent intervals.
The class imbalance problem is one of the major challenges in datasets of different fields (Rendón et al. Citation2020; Soltanzadeh and Hashemzadeh Citation2021; Muslim et al. Citation2023; Ren et al. Citation2023). This problem can be dealt with in two approaches: data-level and algorithm-level approaches. In data-level approaches, under-sampling and over-sampling methods are employed to balance the training dataset (Chen et al. Citation2021; Ding et al. Citation2023). However, cost-sensitive algorithms are adopted in algorithm-level approaches (Gan et al. Citation2020; He et al. Citation2023; Wang et al. Citation2023).
In an over-sampling approach, artificial samples are generated from the urban gain samples in the first interval (Tao et al. Citation2019). Due to the spatial nature of samples in urban gain, creating the artificial samples of urban gain may lead to the elimination of no change samples in a study area. Hence, this UGM approach cannot provide the necessary efficiency. In an under-sampling approach, the urban gain samples are retained in the first interval, and the non-chance samples that exist in a much larger number than change samples are deleted so that there will be an equal number of both samples (Ahmadlou et al. Citation2023). This approach may lose a large amount of information due to the illogical elimination of no change samples. A few recent studies have implemented innovative sampling techniques that demonstrated effective outcomes in modelling. For instance, Ahmadlou et al. (Citation2023) developed a well-balanced sampling strategy utilizing maximum entropy and the ecological niche factor analysis (ENFA) model. These approaches yielded satisfactory outcomes when contrasted with conventional sampling techniques (Ahmadlou et al. Citation2023). In algorithm-level solutions, researchers try to change the structures of traditional machine learning and data mining algorithms, in which various weights are considered for each class in the algorithm structure to achieve the favourable accuracy. It is pertinent to explore and assess various approaches at both the data and algorithm levels to effectively address the imbalance problem in UGM. Different approaches may exhibit strengths in distinct domains, underscoring the importance of thorough investigation and evaluation to leverage the diverse capabilities across different areas.
Using the random sampling approach, which is the most common method in previous studies, is not a suitable approach to deal with the class imbalance problem due to the skewness of the models towards the majority samples. Using advanced machine learning algorithms that are specifically designed to handle imbalanced data can help improve the performance of the models. It is important to carefully evaluate and compare different approaches in order to determine the most effective model for dealing with imbalance data in a particular study. This study aims to address the class imbalance problem in UGM of Tabriz and Isfahan in Iran by developing three novel cost-sensitive algorithms: cost-sensitive artificial neural network (CANN), cost-sensitive random forest (CRF) and cost-sensitive support vector machine (CSVM). In other words, the primary objective of this study is to compare the performance of these cost-sensitive models against traditional machine learning models commonly used in UGM. Through a comprehensive analysis and evaluation, this research aims to provide insights into the effectiveness and applicability of cost-sensitive algorithms in enhancing the accuracy and reliability of urban growth predictions in Tabriz and Isfahan cities in Iran. The research emphasizes the importance of accurate and detailed models in predicting future urban growth with precision, highlighting the potential of cost-sensitive approaches in UGM. The following section reviews the research literature on the class imbalance problem in UGM. The study areas and research data will then be described in Section 3. Section 4 presents the details of the adopted models and their evaluation indices. Section 5 reports the modelling results, whereas Section 6 discusses the results. Finally, Section 7 draws a general conclusion.
2. Review of literature on class imbalance in urban gain modelling
There are two types of land use change models based on the data type used in modelling: (1) raster-based LUC models (Gounaridis et al. Citation2019; Xing et al. Citation2020), and (2) vector-based LUC models (Tepe and Guldmann Citation2017, Citation2020; Zhai et al. Citation2020). This study focuses on raster-based LUC models.
Imbalance problem is a common challenge in the field of machine learning and can significantly affect the performance of machine learning and statistical models. Imbalanced data occurs when the distribution of classes in a dataset is heavily skewed, with one or more classes being significantly more prevalent than others. This scenario can be seen in various real-world applications such as fraud detection, medical diagnosis and anomaly detection. Addressing imbalanced data is crucial in machine learning as it can lead to biased models that prioritize accuracy on the majority class while ignoring the minority class. According to the review of studies on land use change modelling and class imbalance, feasible solutions can be classified as two general categories: data-level approaches (sampling) and algorithm-level approaches. Huang et al. (Citation2010) conducted the first study to model imbalanced urban gain (Huang et al. Citation2010). They employed an SVM to address the imbalance problem by considering different costs of errors made by the incorrect modelling of urban change and no change cells. In fact, they utilized an algorithm-based method to model urban gain in New Castle County, Delaware between 1984 and 1992, 1992 and 1997 and 1997 and 2002 periods. Although the imbalanced SVM yielded reliable results of acceptable accuracy, it was considered separately for each time interval without evaluating its generalizability for other intervals, something which may lead to exaggerative results. In other words, there will be no guarantee to reach a favourable accuracy in the intervals other than the modelled ones. Furthermore, Samardži’c-Petrovi’c et al. (2015, 2016) utilized the balanced sampling method to handle imbalance in the land use change data (Samardžić-Petrović et al. Citation2015, 2016). These two studies were among the early research works in which data-level solutions were employed to model the imbalanced land use change. Although an SVM model was used and validated along with balanced sampling in two separate intervals, considering an equal number of samples randomly for modelling when there are far more no change samples than change samples will lead to the loss of data on the high-quantity samples. Therefore, the resultant model may not have acceptable efficiency on no change cells. Karimi et al. (Citation2019) evaluated three sampling methods to deal with the imbalance problem for UGM in Gliford, USA (Karimi et al. Citation2019). The first strategy was to select 5%, 10% and 20% of all urban gain and no change samples, whereas the second strategy was to select all urban gain samples. Finally, the third strategy was to select the same number of no change samples as urban gain samples. Considering these three strategies can be an effective step in dealing with the imbalance problem. Nevertheless, the first strategy does not suit the imbalanced data because it will drive models towards overfitting on no change samples which are more abundant than urban gain samples. In the second strategy, models are driven to learn urban gain samples, and no change samples are disregarded. As mentioned previously, despite the balance of training samples, a large amount of information on no change samples will be lost in the third strategy. The reason can be attributed to the very large number of no change samples and the absence of some no change samples in modelling. In addition, most of the foregoing studies adopted SVMs for modelling. Despite all of its unique properties, the use of an SVM is very time-consuming in UGM and will cause difficulty in testing further states to develop a reliable model with a high accuracy (Shafizadeh-Moghadam, Asghari, et al. Citation2017; Shafizadeh-Moghadam, Tayyebi, et al. Citation2017). In many studies, this model also failed to yield acceptable results in the imbalance urban gain data (Ahmadlou et al. Citation2022, Citation2023).
3. Study area and data
This study focused on the modelling of the imbalanced urban gain data for two major cities in Iran: Tabriz and Isfahan ().
Figure 1. Study area: (a) Iran map, (b) the location map of Tabriz and (c) the location map of Isfahan.
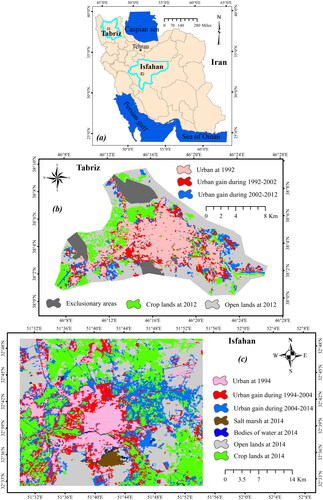
3.1. Study area
Tabriz, situated in the northwestern part of Iran, is a bustling city with a population of over 1.8 million individuals. It holds significant importance as an economic, political and cultural centre in the region. Serving as the capital city of East Azerbaijan Province, Tabriz boasts an average elevation of approximately 1500 meters. Bordered by mountains to the north, south and east, Tabriz encompasses the flatlands of the Tabriz Plain and the Aji Chay Saltmarshes to the west. The study focused on examining the urban gain of Tabriz throughout two distinct periods: 1992–2002 for modelling and 2002–2012 for validation. Isfahan, located in central Iran, is a city steeped in history. Its population exceeded 1.96 million residents in 2016, making it the third-largest city in Iran after Tehran and Mashhad. Isfahan is renowned for its abundance of historical landmarks and holds a significant position as an industrial hub within the country. With an average elevation of 1500 meters, the city is traversed by the Zayandeh Rud river, which historically served as a crucial water source for agricultural purposes and continues to play a vital role in urban development.
3.2. Data set
The United States Geological Survey (USGS) provided Landsat images of Isfahan in 1994 (TM), 2004 (TM) and 2014 (Landsat 8). All radiometric and geometric corrections were performed on these satellite images. These images were used to create maps showing how the land was used and to identify areas where urban development had taken place. The different land use categories included croplands, open lands, built-up areas, water bodies and salt marshes. The maximum likelihood classification (MLC) method was used, resulting in overall accuracy rates of 84%, 86% and 87% for the corresponding land use maps of each year when comparing with the ground truth points. Urban gain maps were created by comparing the land use maps of 1994 with 2004 and 2004 with 2014 to analyse the periods of 1994–2004 and 2004–2014. The process of UGM in Isfahan involved considering nine significant factors as indicated in . For the elevation map, the Advanced Spaceborne Thermal Emission and Reflection Radiometer (ASTER)’s 30 m digital elevation model (DEM) was utilized. Additionally, slope maps were generated from the elevation map using slope analysis in a geographical information system (GIS) environment. Distance-related factors were determined using Euclidean distance analysis within the GIS framework. Similar approaches were applied to Tabriz, using Landsat images from 1992 (TM), 2002 (TM) and 2012 (TM). For the urban development modelling of Tabriz, a total of 14 factors were taken into account. The elevation and slope maps for Tabriz were derived from the ASTER DEM. The selection of specific drivers of urban gain differed between the two cities, based on expert opinions and existing studies.
Table 1. Urban gain drivers for Tabriz in 1994–2004 and Isfahan in 1992–2002.
4. Methodology
The dataset of Tabriz includes 14 effective factors of urban gain for the 1990–2000 and 2000–2010 periods, whereas the dataset of Isfahan includes nine effective factors of urban gain for the 1994–2004 and 2004–2014 periods. The first intervals were considered in each of the two datasets to develop cost-sensitive models, whereas the second intervals were used to validate the models. After the preparation of datasets, the imbalanced data of the first interval of each city were entered separately into the CANN, CRF and CSVM. After the development of cost-sensitive models, they were validated on the imbalanced data of the second intervals. The following subsections describe the traditional and cost-sensitive models and present their evaluation criteria.
4.1. ANN, RF and SVM models
ANN, RF and SVM are well-known machine learning models (Chinthamu and Karukuri Citation2023) and have been widely used and applied in UGM (Jun Citation2021). ANNs are one of the most well-known and successful machine learning models inspired by the human brain’s neural networks. They consist of neurons that process input data through weighted connections. RF is an ensemble learning model that combines multiple decision trees to enhance prediction accuracy and reduce overfitting. Each tree in the forest is trained on a subset of the training data and a random subset of features. During prediction, the results from individual trees are aggregated to provide a final prediction. Random Forest models are known for their robustness, scalability and ability to handle high-dimensional data (Kamusoko and Gamba Citation2015). They are effective for classification and regression tasks and can handle missing data well. Random Forests are less prone to overfitting compared to individual decision trees. SVM is a supervised machine learning model used for classification and regression tasks (Huang et al. Citation2010). SVM finds the optimal hyperplane that separates classes in the feature space by maximizing the margin between classes. It is effective in high-dimensional spaces and is versatile due to its ability to use different kernel functions to transform input data.
4.2. Cost-sensitive RF
Chen et al. (Citation2004) initially introduced the CRF and offered two approaches for incorporating weights: (1) incorporating weights in the model development process, and (2) assigning weights to different classes at the leaf nodes (Chen et al. Citation2004). In their research, the weights were implemented in two modes using the splitting criterion, which is the Gini index. This first mode can be viewed as a manipulation within the structure of the RF algorithm, also known as the algorithm-based method. Within thr RF model, a subset of the training dataset is randomly chosen to construct a tree. This chosen subset is placed at the root node, and various splitting criteria are used to divide the samples into child nodes, with the Gini index being a renowned criterion. The Gini index was initially introduced by Italian statistician Corrado Gini in 1912 and was later employed by Breiman et al. (Citation1984) in the development of decision trees and regression models (Breiman et al. Citation1984). EquationEquation (1)(1)
(1) outlines the definition of the Gini index:
(1)
(1)
In EquationEquation (1)(1)
(1) , the c, k and H indices correspond to the child nodes, the number of classes, the number of observations for the ith class, and n is the number of child nodes resulting from the division of each node, respectively. To incorporate the appropriate weights into EquationEquation (1)
(1)
(1) , the following equations are utilized (Chen et al. Citation2004):
(2)
(2)
(3)
(3)
(4)
(4)
(5)
(5)
Impurity refers to the overall impurity, and the objective is to minimize the impurity when solving the modelling problem. When there are only two classes (urban gain and no change classes) and each node is divided into two child nodes, EquationEquations (2)–(5) are transformed into EquationEquation (6)(6)
(6) :
(6)
(6)
Determining the relevant weights is of utmost importance. In order to achieve this objective, several methods have been put forward, one of which is the grid search.
4.3. Cost-sensitive SVM
In a CSVM algorithm, there is a parameter called C that plays a crucial role in controlling both the model error on the training data and the resulting margin, which needs to be maximized (Iranmehr et al. Citation2019). With regard to the errors of each class, this parameter is treated individually, and different values are assigned in such a manner that it prioritizes the minority data (Kim and Sohn Citation2020). EquationEquation (7)(7)
(7) illustrates the optimization process of the traditional SVM algorithm:
(7)
(7)
In EquationEquation (7)(7)
(7) , w is the direction of the hyperplane in the SVM model. Additionally, the errors of minority and majority samples, denoted as
and
respectively, are positioned within the margin of the SVM model. In EquationEquation (7)
(7)
(7) , assigning a value of zero to the parameter C violates the equation’s conditions arbitrarily and results in a weak classifier. Choosing large values for C causes the margin in the model to become very narrow, transforming the problem into a hard-margin scenario. Conversely, selecting small values widens the margin and consequently increases the errors
and
EquationEquation (7)
(7)
(7) assumes the same value of C for both modelling errors of samples labelled as zero or one. However, in the case of an imbalanced dataset, different values are allocated to the errors of both classes to emphasize the minority urban gain samples and make the model sensitive to the cost imbalance. EquationEquation (8)
(8)
(8) presents the modified optimization equation for a CSVM:
(8)
(8)
EquationEquation (8)(8)
(8) possesses a quadratic structure and can be resolved by converting it into a Lagrangian equation (Kim and Sohn Citation2020). Consequently, the coefficients associated with minority samples are intentionally assigned smaller values compared to those of majority samples in the equation. This adjustment aims to prioritize the focus on minority samples. Similar to the CRF model, the coefficients or weights that result in more accurate predictions for both relevant classes are favoured.
4.4. Cost-sensitive ANN
In this research, a CANN utilizes a multilayer perceptron neural network as its baseline algorithm. In a regular feedforward neural network, each neuron in the hidden layers and the output layer has two main components (Ojha et al. Citation2017). The first component is a sigma operator, which involves multiplying the connection weights of neurons by their outputs and adding up the results. The second component is an activation function, such as the sigmoid activation function, which takes the sigma value and transforms it into a value between 0 and 1 or between −1 and 1. Typically, the mean squared error or the cross-entropy is employed as a loss function to optimize the network’s parameters (Kline and Berardi Citation2005). Considering the categorical nature of land use change modelling, the cross-entropy is chosen as the loss function. In a CANN, a softmax layer is added after the output layer (Zhang et al. Citation2020). The softmax layer’s output is calculated using the EquationEquation (9)(9)
(9) , assuming a target variable with two values and considering two outputs (t1 and t2) from the multilayer perceptron neural network, obtained by evaluating sigma values and activation functions in the hidden layers and the output layer:
(9)
(9)
The equation of the loss function after the softmax layer is defined as EquationEquation (10)(10)
(10) :
(10)
(10)
In EquationEquation (10)(10)
(10) , x represents an input vector sample, while
and
represent the actual outputs within {0, 1}. As mentioned in EquationEquation (9)
(9)
(9) ,
and
have significant influence on the loss function. Additionally, EquationEquations (11)
(11)
(11) and Equation(12)
(12)
(12) demonstrate the overall error for the negative (or zero) class and the positive (or one) class, respectively:
(11)
(11)
(12)
(12)
When there is a substantial difference between the number of one and zero samples in a dataset, the value of will be very high. In this case, the network tends greatly to improve the accuracy of majority samples by minimizing
Therefore, the standard neural network for such problems will not be adequately efficient in the minority class (Zhang et al. Citation2020). According to EquationEquations (10–12), a cost matrix is designed to solve the problem and correct the softmax outputs. Therefore, the following equations will be used in the loss function formula:
(13)
(13)
(14)
(14)
Where and
refer the thresholds of one and zero classes; moreover, a and b are used to adjust the errors of the two classes (which should be greater than 1). Therefore, the loss function equation is written as below for a given sample like x:
(15)
(15)
If appropriate coefficients are selected for a and b, the model can be driven to focus further on the minority training samples. Like the CRF and CSVM models, the search methods can be adopted to find these two coefficients.
4.5. Evaluation of UGMs
The assessment of the proposed models and the comparison of their results with other studies in both cities involved the use of four metrics: figure of merit (FoM), producer accuracy (PA), overall accuracy (OA) and area under the receiver operating characteristic curve (AUROC). These metrics were utilized to evaluate the models’ performance and enable meaningful comparisons with previous research (Chintalapudi et al. Citation2023). User accuracy (UA) measures the proportion of correctly classified samples among those predicted as urban gain by the model. FoM offers a comprehensive measure that combines both PA and UA to assess the overall performance of a model (Shafizadeh-Moghadam Citation2019). It takes into account the correct classification of change samples (hits or true positive [TP]) and the correct identification of no change samples (correct rejection or true negative [TN]), as well as the misclassification of no change samples as change (false alarm or false positive [FP]) and vice versa (misses or false negative [FN]) according to EquationEquation (16)(16)
(16) . PA or true positive rate (TPR) evaluates the model’s ability to correctly identify change samples (EquationEquation 17
(17)
(17) ), while UA assesses the accuracy of the model in identifying no change samples. Total operating characteristics (TOC) is a metric that provides a comprehensive assessment of classification performance by considering multiple thresholds for modelling urban gain (Liu and Pontius Jr, 2021). It incorporates measures such as TPR and false positive rate (FPR; EquationEquation (18)
(18)
(18) ) to offer a more detailed evaluation of the model’s performance across different decision thresholds. These evaluation metrics are crucial in quantitatively assessing the quality and reliability of urban gain models.
(16)
(16)
(17)
(17)
(18)
(18)
5. Results
The predictor variables in the study included the factors that drove urban gain in Isfahan in 1994 and Tabriz in 1992, while the target variables were the real urban gain observed between 1994 and 2004 for Isfahan and between 1992 and 2002 for Tabriz. After preparing the data, the training dataset was created using the urban gain cells of the first time period along with the drivers of urban gain during that period. The number of urban gain cells obtained for Isfahan from 1994 to 2004 was 160,769, while for Tabriz it was 28,051. Similarly, the number of no change cells for Isfahan during the same period was 895,276, and for Tabriz it was 184,519. As a result, the rate of class imbalance for Isfahan was about 1–6, meaning that the number of urban gain cells was six times higher than the number of no change samples. For Tabriz, the rate of class imbalance was about 1–7, meaning that the number of urban gain cells was about seven times higher than the number of no change samples. Higher imbalance ratios can lead to biased model performance, reduced prediction accuracy, increased false positives/negatives, difficulty in learning minority class patterns and overfitting to the majority class.
5.1. The suitability, simulated and error maps of three cost-sensitive models
Three cost-sensitive models produce suitability maps with values ranging from zero to one. For example, shows the suitability maps produced by CRF and CANN models for Tabriz in 2012. Values closer to one indicate a high potential for urban change, while values closer to zero suggest a tendency to maintain their previous use. To convert the suitability maps into simulated maps with binary values of zero and one, the cells with the highest potential in the first interval are converted to one, ensuring that this count matches the number of urban gain samples in the initial time period, while the remaining cells are assigned as zero. For example, in the Isfahan city, in suitability map generated by three cost-sensitive models, the cells with the highest probability values are converted to one, ensuring that this count matches the number of urban gain samples in the 2004–2014 (227,094), while the remaining cells are assigned as zero. In the simulated maps, zero value means simulated no change samples, and one represents simulated urban gain samples. The simulated maps of the second time interval were compared with the real urban gain map of the same period, resulting in the creation of the error map.
Figure 2. The suitability maps of (a) CRF and (b) CANN for Tabriz in 2012.
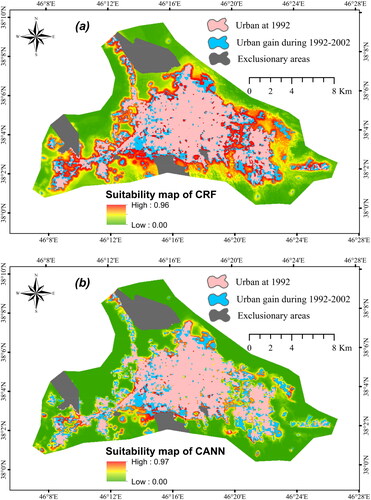
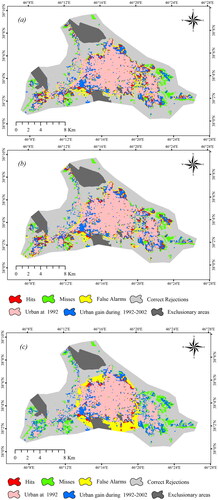
and illustrate the error maps for three cost-sensitive models for Isfahan and Tabriz in the second time intervals of 2004–2014 and 2000–2012, respectively. The majority of the misclassifications errors were concentrated in the northeast of Isfahan city, while in Tabriz, these errors were observed away from the urban areas. The variation in the predictive factors of this particular areas compared to others could be a potential reason for this.
Figure 3. The error maps of the (a) CANN, (b) CRF and (c) CSVM cost-sensitive model’s urban gain predictions for Isfahan city in 2004–2014.
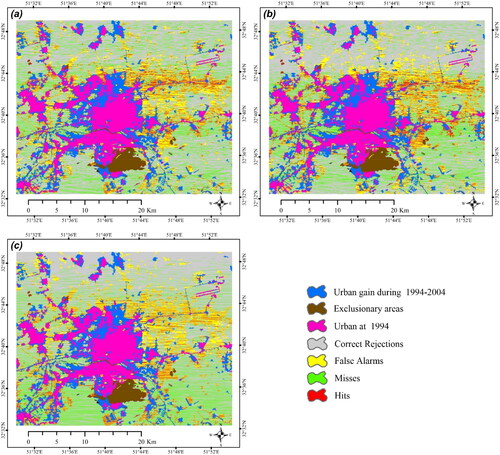
Figure 4. The error maps of the (a) CANN, (b) CRF and (c) CSVM cost-sensitive model’s urban gain predictions for Tabriz in 2002–2012.
5.2. Evaluation of cost-sensitive based models
and display the TOC curve of three cost-sensitive models, which are CANN, CRF and CSVM. In the case of Isfahan, the three proposed cost-sensitive models did not achieve satisfactory performance. For Isfahan, indicates that the CRF model had the highest accuracy with an AUC of 0.560, followed by CANN (AUC = 0.557) and CSVM (AUC = 0.448) models. It should be noted that the SVM-based models were overfitted. For Isfahan, the performance of the proposed cost-sensitive models was not impressive when compared to the ANN (AUC = 0.682), SVM (AUC = 0.481) and RF(AUC = 0.661) created by balance sampling, which did not take into account the different costs associated with misclassification of urban gain samples and no change samples. For Tabriz, the proposed CRF and CANN performed well and achieved impressive performance. illustrates that the CANN model had the highest accuracy with an AUC of 0.818, followed by CRF (AUC = 0.809) and CSVM (AUC = 0.512) models. Again, the CSVM model was overfitted. For Tabriz, compared to ANN (AUC = 0.71), SVM (AUC = 0.521) and RF (AUC = 0.791) models created by balanced sampling, the proposed CANN (AUC = 0.818) and CRF (AUC = 0.809) increased the AUROC of ANN and RF models by 15% and 2% during the validation phase, respectively. provides the PA, OA and FoM values for all the cost-sensitive models. It can be observed that the PA, OA and FoM of the CRF and CANN models were higher than those of the other models. In Isfahan, models developed using traditional balance sampling outperformed cost-sensitive models in terms of accuracy. Even though the accuracy of the balanced sampling method is not exceptionally high, these findings indicate that simple balanced sampling produced better results compared to the algorithm-level approaches. Conversely, in Tabriz, cost-sensitive models demonstrate higher FoM, OA and PA than models created using balanced sampling.
Figure 5. The TOC and AUC of the cost-sensitive models for Isfahan city in the second time interval.
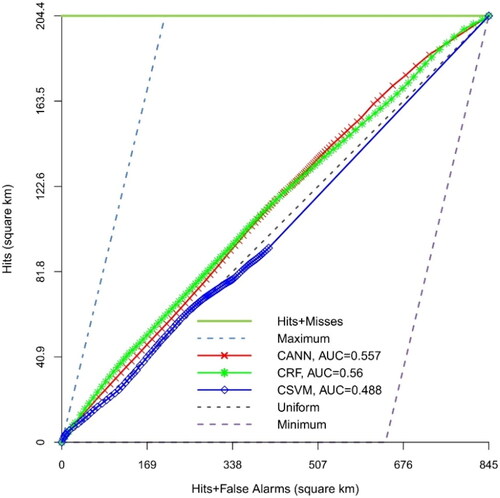
Figure 6. The TOC and AUC of the cost-sensitive models for Isfahan city in the second time interval.
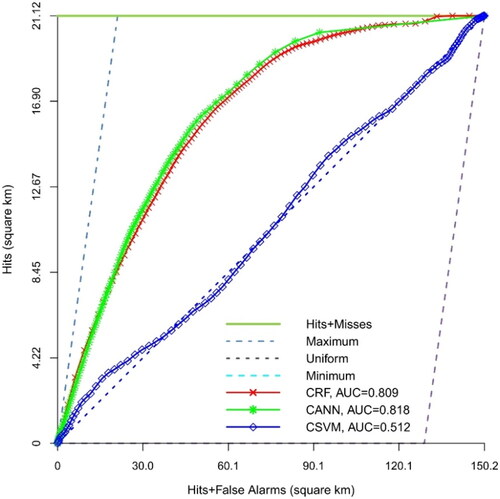
Table 2. The validation of three cost-sensitive models using FOM, OA and PA.
6. Discussion
Urban gain has numerous implications, ranging from environmental concerns to socio-economic impacts. Recognizing the significance of urban gain and its potential consequences, there is an increasing need for UGM. However, UGM is not without its challenges, particularly in dealing with various uncertainties. The urban gain data exhibits an imbalance, indicating a significant disparity between the abundance of unchanged samples and the scarcity of urban gain samples. The objective of this research was to assess three cost-sensitive machine learning models – CANN, CRF and CSVM – in addressing the issue of class imbalance in UGM.
Isfahan and Tabriz, two cities, were selected as the study areas to assess proposed cost-sensitive models. The decision to choose these cities and related drivers was based on several factors: (1) the varying level of class imbalance between urban gain and no change samples, (2) the complex and non-linear behaviour of urban gain in these cities and (3) the availability of prior studies on Isfahan and Tabriz, which allowed for result comparisons. This study benefited from the existing research conducted on these cities to enhance its findings.
Previous studies have commonly employed random sampling to select change and no change samples for training datasets. However, since urban gain datasets typically have fewer change samples compared to no change samples, random sampling tends to result in training datasets that are skewed towards no change samples. This bias can influence the model’s predictions. Therefore, two strategies can be utilized to tackle the class imbalance problem: data level strategies and algorithm level strategies. In this study, we employed the latter strategy to address the class imbalance issue in training datasets of UGMs.
Previous studies on UGM in Isfahan and Tabriz have explored different approaches to model the urban gain of Tabriz and Isfahan cities. (Parvinnezhad et al. Citation2021; Shafizadeh-Moghadam, Asghari, et al. Citation2017; Shafizadeh-Moghadam, Tayyebi, et al. Citation2017) have developed hybrid models using random sampling without considering the imbalance issue. For example, Parvinnezhad et al. (Citation2021) used fuzzy rough set theory-based feature selection integrated with a support vector regression for UGM of Tabriz. Also, Shafizadeh-Moghadam, Asghari, et al. (Citation2017) and Shafizadeh-Moghadam, Tayyebi, et al. (Citation2017) used CA-based land transformation model (LTM) for UGM of Isfahan. However, due to the imbalanced nature of urban gain data, the use of data mining and machine learning models in these studies has not been effective. Other studies, such as (Ahmadlou et al. Citation2023) have focused on resolving the imbalance problem through data-level approaches. They developed a sampling logic using two approaches, namely maximum entropy and ENFA models, to tackle the imbalance issue. In this study, a different approach was taken by utilizing cost-sensitive algorithms to model urban gain in Isfahan and Tabriz. By comparing the results of this study to the findings of Ahmadlou et al. (Citation2023), it was found that using data-level approaches for addressing the imbalance problem in UGM of Isfahan produced better results compared to the algorithm-level approaches in terms of accuracy and goodness of fit. On the other hand, the results obtained in Tabriz showed that algorithm-level approaches were more effective in handling the imbalance problem. Specifically, CANN and CRF models outperformed the maximum entropy-based ANN and RF models. Therefore, it can be concluded that both algorithm-level and data-level approaches should be considered and evaluated for each specific study area. The differences in the effectiveness of the cost-sensitive models between the two cities are indeed intriguing. The reasons for these variations could be attributed to the urban characteristics specific to Isfahan and Tabriz, as well as the selected factors used in the modelling. The unique urban landscapes, infrastructure and developmental patterns of each city could significantly affect the performance of the models. Additionally, differences in the nature and quality of the available data for the two cities may also contribute to contrasting results. Exploring these factors further would provide valuable insights into the nuances of UGM in different contexts. Furthermore, the findings of this study align with the research conducted by Ahmadlou et al. (Citation2023), as they indicated that SVM-based models do not yield satisfactory results in UGM. The overfitting of the SVM-based models may arise from the kernel selection, hyper-parameter tuning or the high-dimensional feature space. To address this concern effectively in future studies, it is essential to not only describe but also evaluate the impact of overfitting. This evaluation can be achieved by implementing rigorous testing procedures focusing on model performance on unseen data. Moreover, utilizing diverse hyper-parameter tuning, feature selection techniques and dimensionality reduction methods can play a crucial role in preventing overfitting and enhancing the generalization capabilities of the models. The outcomes from implementing the CRF model in Tabriz align with the findings of Mienye and Sun (Citation2021), who evaluated the CRF model against the standard RF model across four imbalanced medical datasets. The CRF model demonstrated superior performance over the standard RF model in all four datasets. Similarly, in our research, utilizing CANN in Tabriz showed better performance than the standard ANN, consistent with the results of Yotsawat et al. (Citation2021). Their study introduced a novel cost-sensitive neural network model for credit scoring, revealing that CANN enhances predictive accuracy compared to a traditional neural network.
Accurate and detailed models play a crucial role in predicting future urban growth with a high level of precision, closely aligning with reality. By effectively capturing various factors influencing urban expansion such as population trends, infrastructure development, economic dynamics and environmental considerations, these advanced models can provide insightful predictions that closely depict the actual growth patterns within cities. Through their comprehensive analysis and incorporation of relevant data points, these models offer valuable insights that enable urban planners and policymakers to make informed decisions and strategic interventions in urban development processes. As a result, the utilization of such sophisticated models enhances the capability to anticipate and adapt to the evolving urban landscape, fostering more sustainable and resilient cities for the future.
7. Conclusion
The objective of this study was to create three novel cost-sensitive algorithms, called CANN, CRF and CSVM, to tackle the class imbalance problem in urban gain modelling. These algorithms were then assessed using urban gain data from Isfahan and Tabriz, two cities in Iran, over two different time intervals, respectively: 1994–2004, 2004–2014, 1992–2002 and 2002–2012. The first time intervals were utilized for building the models, while the second one was used for validation purposes. Nine and 14 variables were utilized in the UGM of two cities, respectively. Based on the findings, the performance of the proposed cost-sensitive models varied across different cities.
In the case of Isfahan, the three cost-sensitive models did not achieve satisfactory results. The CRF model showed the highest accuracy with an AUC of 0.560, followed by CANN (AUC = 0.557) and CSVM (AUC = 0.448), indicating that the SVM-based models were overfitted. However, when compared to the models created by balance sampling (ANN, SVM and RF) without considering different costs, the performance of the proposed cost-sensitive models in Isfahan was not impressive. On the other hand, in the case of Tabriz, the proposed CRF and CANN models performed well and showed impressive results. The CANN model demonstrated the highest accuracy with an AUC of 0.818, followed by CRF (AUC = 0.809) and CSVM (AUC = 0.512). Similarly, the CSVM model was found to be overfitted. In Tabriz, the CANN and CRF models outperformed the models created by balanced sampling (ANN, SVM and RF) in terms of AUROC, increasing the AUROC of ANN and RF models by 15% and 2%, respectively, during the validation phase. Overall, the results highlight the importance of considering cost-sensitive approaches, particularly in urban gain modelling. The proposed CRF and CANN models showed promising outcomes in Tabriz, while further improvements are necessary for the Isfahan case. Future research could focus on refining the cost-sensitive models to enhance their performance in different settings and explore additional factors that contribute to their effectiveness. In addition, these studies may integrate data-level approaches with algorithm-level approaches to tackle the imbalance problem in urban gain models to achieve better results.
Disclosure statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this article.
Data availability statement
The data presented in this study are available on request from the corresponding author.
References
- Ahmadlou M, Karimi M, Al-Ansari N. 2023. The use of maximum entropy and ecological niche factor analysis to decrease uncertainties in samples for urban gain models. GISci Remote Sens. 60(1):2222980. doi: 10.1080/15481603.2023.2222980.
- Ahmadlou M, Karimi M, Pontius RG. Jr, 2022. A new framework to deal with the class imbalance problem in urban gain modeling based on clustering and ensemble models. Geocarto Int. 37(19):5669–5692. doi: 10.1080/10106049.2021.1923826.
- Ayedun C, Durodola O, Akinjare O. 2011. Towards ensuring sustainable urban growth and development in Nigeria: challenges and strategies. Business Manag Dynm. 1(2):99. https://core.ac.uk/download/pdf/20075149.pdf
- Bagheri B, Soltani A. 2023. The spatio-temporal dynamics of urban growth and population in metropolitan regions of Iran. Habitat Int. 136:102797. doi: 10.1016/j.habitatint.2023.102797.
- Bhagat R, Mohanty S. 2009. Emerging pattern of urbanization and the contribution of migration in urban growth in India. Asian Popul Stud. 5(1):5–20. doi: 10.1080/17441730902790024.
- Breiman L, Friedman J, Olshen R, Stone C. 1984. Classification and regression trees. Belmont (CA): Wadsworth; p. 978–0412048418.
- Chen C, Liaw A, Breiman L. 2004. Using random forest to learn imbalanced data. Vol. 110. Berkeley (CA): University of California; p. 24.
- Chen Z, Duan J, Kang L, Qiu G. 2021. A hybrid data-level ensemble to enable learning from highly imbalanced dataset. Inf Sci. 554:157–176. doi: 10.1016/j.ins.2020.12.023.
- Chintalapudi N, Dhulipalla VR, Battineni G, Rucco C, Amenta F. 2023. Voice biomarkers for Parkinson’s disease prediction using machine learning models with improved feature reduction techniques. JDSIS. 1(2):92–98. doi: 10.47852/bonviewJDSIS3202831.
- Chinthamu N, Karukuri M. 2023. Data science and applications. JDSIS. 1(2):83–91. doi: 10.47852/bonviewJDSIS3202837.
- Conway TM, Wellen CC. 2011. Not developed yet? Alternative ways to include locations without changes in land use change models. Int J Geograph Inform Sci. 25(10):1613–1631. doi: 10.1080/13658816.2010.534738.
- Dadashpoor H, Azizi P, Moghadasi M. 2019. Analyzing spatial patterns, driving forces and predicting future growth scenarios for supporting sustainable urban growth: evidence from Tabriz metropolitan area, Iran. Sustain Cities Soc. 47:101502. doi: 10.1016/j.scs.2019.101502.
- Ding H, Sun Y, Wang Z, Huang N, Shen Z, Cui X. 2023. RGAN-EL: a GAN and ensemble learning-based hybrid approach for imbalanced data classification. Inform Proc Manag. 60(2):103235. doi: 10.1016/j.ipm.2022.103235.
- El Garouani A, Mulla DJ, El Garouani S, Knight J. 2017. Analysis of urban growth and sprawl from remote sensing data: case of Fez, Morocco. Int J Sustain Built Environ. 6(1):160–169. doi: 10.1016/j.ijsbe.2017.02.003.
- Falah N, Karimi A, Harandi AT. 2020. Urban growth modeling using cellular automata model and AHP (case study: qazvin city). Model Earth Syst Environ. 6(1):235–248. doi: 10.1007/s40808-019-00674-z.
- Gan D, Shen J, An B, Xu M, Liu N. 2020. Integrating TANBN with cost sensitive classification algorithm for imbalanced data in medical diagnosis. Comput Ind Eng. 140:106266. doi: 10.1016/j.cie.2019.106266.
- Gounaridis D, Chorianopoulos I, Symeonakis E, Koukoulas S. 2019. A Random Forest-Cellular Automata modelling approach to explore future land use/cover change in Attica (Greece), under different socio-economic realities and scales. Sci Total Environ. 646:320–335. doi: 10.1016/j.scitotenv.2018.07.302.
- He Y, Li X, Fournier‐Viger P, Huang JZ, Li M, Salloum S. 2023. Observation points classifier ensemble for high‐dimensional imbalanced classification. CAAI Trans Intel Tech. 8(2):500–517. doi: 10.1049/cit2.12100.
- Huang B, Xie C, Tay R. 2010. Support vector machines for urban growth modeling. Geoinformatica. 14(1):83–99. doi: 10.1007/s10707-009-0077-4.
- Iranmehr A, Masnadi-Shirazi H, Vasconcelos N. 2019. Cost-sensitive support vector machines. Neurocomputing. 343:50–64. doi: 10.1016/j.neucom.2018.11.099.
- Jun MJ. 2021. A comparison of a gradient boosting decision tree, random forests, and artificial neural networks to model urban land use changes: the case of the Seoul metropolitan area. Int J Geograph Inform Sci. 35(11):2149–2167. doi: 10.1080/13658816.2021.1887490.
- Kamusoko C, Gamba J. 2015. Simulating urban growth using a random forest-cellular automata (RF-CA) model. IJGI. 4(2):447–470. doi: 10.3390/ijgi4020447.
- Karimi F, Sultana S, Babakan AS, Suthaharan S. 2019. An enhanced support vector machine model for urban expansion prediction. Comput Environ Urban Syst. 75:61–75. doi: 10.1016/j.compenvurbsys.2019.01.001.
- Kim KH, Sohn SY. 2020. Hybrid neural network with cost-sensitive support vector machine for class-imbalanced multimodal data. Neural Netw. 130:176–184. doi: 10.1016/j.neunet.2020.06.026.
- Kline DM, Berardi VL. 2005. Revisiting squared-error and cross-entropy functions for training neural network classifiers. Neural Comput Appl. 14(4):310–318. doi: 10.1007/s00521-005-0467-y.
- Liu J, Xiao B, Li Y, Wang X, Bie Q, Jiao J. 2021. Simulation of dynamic urban expansion under ecological constraints using a long short term memory network model and cellular automata. Remote Sens. 13(8):1499. doi: 10.3390/rs13081499.
- Liu Z, Pontius RG. Jr, 2021. The total operating characteristic from stratified random sampling with an application to flood mapping. Remote Sens. 13(19):3922. doi: 10.3390/rs13193922.
- Lv J, Wang Y, Liang X, Yao Y, Ma T, Guan Q. 2021. Simulating urban expansion by incorporating an integrated gravitational field model into a demand-driven random forest-cellular automata model. Cities. 109:103044. doi: 10.1016/j.cities.2020.103044.
- Mansour S, Al-Belushi M, Al-Awadhi T. 2020. Monitoring land use and land cover changes in the mountainous cities of Oman using GIS and CA-Markov modelling techniques. Land Use Policy. 91:104414. doi: 10.1016/j.landusepol.2019.104414.
- Mienye ID, Sun Y. 2021. Performance analysis of cost-sensitive learning methods with application to imbalanced medical data. Inf Med Unlocked. 25:100690. doi: 10.1016/j.imu.2021.100690.
- Moghadam HS, Helbich M. 2013. Spatiotemporal urbanization processes in the megacity of Mumbai, India: a Markov chains-cellular automata urban growth model. Appl Geogr. 40:140–149. doi: 10.1016/j.apgeog.2013.01.009.
- Muslim MA, Dasril Y, Javed H, Abror WF, Pertiwi DAA, Mustaqim T, Alamsyah, Jumanto. (2023). An ensemble stacking algorithm to improve model accuracy in bankruptcy prediction. JDSIS 2( 2):79–86. doi: 10.47852/bonviewJDSIS3202655.
- Ojha VK, Abraham A, Snášel V. 2017. Metaheuristic design of feedforward neural networks: a review of two decades of research. Eng Appl Artif Intell. 60:97–116. doi: 10.1016/j.engappai.2017.01.013.
- Parvinnezhad D, Delavar MR, Pijanowski BC, Claramunt C. 2021. Integration of adaptive neural fuzzy inference system and fuzzy rough set theory with support vector regression to urban growth modelling. Earth Sci Inform. 14(1):17–36. doi: 10.1007/s12145-020-00522-0.
- Ren Z, Wang S, Zhang Y. 2023. Weakly supervised machine learning. CAAI Trans Intel Tech. 8(3):549–580. doi: 10.1049/cit2.12216.
- Rendón E, Alejo R, Castorena C, Isidro-Ortega FJ, Granda-Gutiérrez EE. 2020. Data sampling methods to deal with the big data multi-class imbalance problem. Appl Sci. 10(4):1276. doi: 10.3390/app10041276.
- Rogers A, Williamson JG. 1982. Migration, urbanization, and third world development: an overview. Econ Dev Cultural Change. 30(3):463–482. doi: 10.1086/452572.
- Samardžić-Petrović M, Dragićević S, Bajat B, Kovačević M. 2015. Exploring the decision tree method for modelling urban land use change. Geomatica. 69(3):313–325. doi: 10.5623/cig2015-305.
- Samardžić‐Petrović M, Dragićević S, Kovačević M, Bajat B. 2016. Modeling urban land use changes using support vector machines. Trans GIS. 20(5):718–734. doi: 10.1111/tgis.12174.
- Shafizadeh-Moghadam H. 2019. Improving spatial accuracy of urban growth simulation models using ensemble forecasting approaches. Comput Environ Urban Syst. 76:91–100. doi: 10.1016/j.compenvurbsys.2019.04.005.
- Shafizadeh-Moghadam H, Asghari A, Taleai M, Helbich M, Tayyebi A. 2017. Sensitivity analysis and accuracy assessment of the land transformation model using cellular automata. GISci Remote Sens. 54(5):639–656. doi: 10.1080/15481603.2017.1309125.
- Shafizadeh-Moghadam H, Minaei M, Pontius RG, Jr, Asghari A, Dadashpoor H. 2021. Integrating a forward feature selection algorithm, random forest, and cellular automata to extrapolate urban growth in the Tehran-Karaj Region of Iran. Comput Environ Urban Syst. 87:101595. doi: 10.1016/j.compenvurbsys.2021.101595.
- Shafizadeh-Moghadam H, Tayyebi A, Ahmadlou M, Delavar MR, Hasanlou M. 2017. Integration of genetic algorithm and multiple kernel support vector regression for modeling urban growth. Comput Environ Urban Syst. 65:28–40. doi: 10.1016/j.compenvurbsys.2017.04.011.
- Soltanzadeh P, Hashemzadeh M. 2021. RCSMOTE: range-Controlled synthetic minority over-sampling technique for handling the class imbalance problem. Inf Sci. 542:92–111. doi: 10.1016/j.ins.2020.07.014.
- Tao X, Li Q, Ren C, Guo W, Li C, He Q, Liu R, Zou J. 2019. Real-value negative selection over-sampling for imbalanced data set learning. Expert Syst Appl. 129:118–134. doi: 10.1016/j.eswa.2019.04.011.
- Tepe E, Guldmann JM. 2017. Spatial and temporal modeling of parcel-level land dynamics. Comput Environ Urban Syst. 64:204–214. doi: 10.1016/j.compenvurbsys.2017.02.005.
- Tepe E, Guldmann JM. 2020. Spatio-temporal multinomial autologistic modeling of land-use change: A parcel-level approach. Environ Plann B urban Anal City Sci. 47(3):473–488. doi: 10.1177/2399808318786511.
- Tong X, Feng Y. 2020. A review of assessment methods for cellular automata models of land-use change and urban growth. Int J Geograph Inform Sci. 34(5):866–898. doi: 10.1080/13658816.2019.1684499.
- Verburg PH, Alexander P, Evans T, Magliocca NR, Malek Z, Rounsevell MD, van Vliet J. 2019. Beyond land cover change: towards a new generation of land use models. Curr Opin Environ Sustain. 38:77–85. doi: 10.1016/j.cosust.2019.05.002.
- Wang W, Sun Y, Li K, Wang J, He C, Sun D. 2023. Fully Bayesian analysis of the relevance vector machine classification for imbalanced data problem. CAAI Trans Intel Tech. 8(1):192–205. doi: 10.1049/cit2.12111.
- Xing W, Qian Y, Guan X, Yang T, Wu H. 2020. A novel cellular automata model integrated with deep learning for dynamic spatio-temporal land use change simulation. Comput Geosci. 137:104430. doi: 10.1016/j.cageo.2020.104430.
- Xu T, Gao J, Coco G. 2019. Simulation of urban expansion via integrating artificial neural network with Markov chain–cellular automata. Int J Geograph Inform Sci. 33(10):1960–1983. doi: 10.1080/13658816.2019.1600701.
- Yotsawat W, Wattuya P, Srivihok A. 2021. A novel method for credit scoring based on cost-sensitive neural network ensemble. IEEE Access. 9:78521–78537. doi: 10.1109/ACCESS.2021.3083490.
- Zhai Y, Yao Y, Guan Q, Liang X, Li X, Pan Y, Yue H, Yuan Z, Zhou J. 2020. Simulating urban land use change by integrating a convolutional neural network with vector-based cellular automata. Int J Geograph Inform Sci. 34(7):1475–1499. doi: 10.1080/13658816.2020.1711915.
- Zhang L, Sheng G, Hou H, Jiang X. 2020. A fault diagnosis method of power transformer based on cost sensitive one-dimensional convolution neural network. Paper presented at the 2020 5th Asia Conference on Power and Electrical Engineering (ACPEE), Chengdu, China. New York: IEEE. pp. 1824–1828. doi: 10.1109/ACPEE48638.2020.9136223.