
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Transformer models boost building extraction accuracy by capturing global features from images. However, convolutional networks’ potential in local feature extraction remains underutilized in CNN + Transformer models, limiting performance. To harness convolutional networks for local feature extraction, we propose a feature attention large kernel (ALK) module and a dual encoder network for high-resolution image-building extraction. The model integrates an attention-based large kernel encoder, a ResNet50-Transformer encoder, a Channel Transformer (Ctrans) module and a decoder. Efficiently capturing local and global building features from both convolutional and positional perspectives, the dual encoder enhances performance. Moreover, replacing skip connections with the CTrans module mitigates semantic inconsistency during feature fusion, ensuring better multidimensional feature integration. Experimental results demonstrate superior extraction of local and global features compared to other models, showcasing the potential of enhancing local feature extraction in advancing CNN + Transformer models.
1. Introduction
With the rapid development of remote sensing technology and unmanned aerial vehicle photogrammetry, research on the efficient and precise automatic extraction of buildings from high-resolution images has attracted widespread attention from scholars domestically and internationally. This not only better supports urban planning and construction, land use management, disaster assessment and environmental monitoring (Li et al. Citation2018) but also brings great convenience to residential area management, urban and rural population statistics, as well as the maintenance and updating of geographic information data (Alshehhi et al. Citation2017). However, the swift expansion of cities and the increasing complexity and variability in building forms pose significant challenges to the performance and accuracy of large-scale automated building extraction studies.
At present, building extraction methods based on high-resolution remote sensing images can generally be divided into three categories: traditional, pattern recognition-based, and deep learning-based (Liao Citation2024).
Traditional methods rely on manual visual interpretation based on the spectral information and texture features of buildings to identify and extract them from images. This approach is highly dependent on the experiential knowledge of researchers, leading to variations in classification results due to individual experiences. The extraction efficiency of such methods is also relatively low (Zhou et al. Citation2021).
Pattern recognition-based methods involve directly obtaining shallow features, such as spectral channel numbers, pixel values, texture features, brightness and geometric information from images. These methods then use thresholds or machine learning algorithms based on these shallow feature values to extract buildings (Li et al. Citation2023). For instance, Liu, Lin, et al. (Citation2021), Liu, Liu, et al. (Citation2021) utilized classification and regression tree (CART) and random forest algorithms to extract buildings from remote sensing images. They differentiated between building and non-building classes by analyzing differences in spectral mean and variance and then trained the algorithms based on spectral and texture features. They found that the CART algorithm had poor extraction capabilities for high-rise buildings, whereas the random forest algorithm performed better. Similarly, Fan and Jiang (Citation2016) employed the random forest method to extract buildings from remote sensing images and assessed the importance of building features. They found that different combinations of the number of decision trees and the dimensionality of feature subsets in each decision tree node affected the accuracy of extraction, requiring manual selection through repeated experiments to achieve optimal results. Huang (Citation2022) proposed the use of the Extreme Random Trees algorithm and the Pearson correlation coefficient method to address the issues of high computational complexity and feature redundancy caused by the high spatial resolution image dimensions. They employed these techniques for feature dimensionality reduction and redundancy elimination, respectively, in order to conduct the extraction of building roofs using the Multi-scale Segmentation method. However, this method still suffers from insufficient automation and excessive manual intervention. These methods therefore tend to perform well only in the specific study area they were designed for, with lower generalization ability and applicability to other regions.
Deep learning-based methods (Zhou Citation2022; Yang Citation2022) involve using deep learning algorithms to form more abstract and semantic deep features of objects on the basis of shallow features in images through techniques, such as convolution and positional encoding (Hou Citation2023). These methods then combine deep and shallow features to create a more powerful representation of objects, enabling accurate identification and extraction of buildings. Three main research directions within this category are currently used: methods based on convolutional neural network (CNN) models, methods based on Vision Transformer (ViT) models, and methods based on a hybrid CNN + Transformer model for building extraction (Zhang et al. Citation2023).
Methods based on CNN models for building extraction construct deep features of buildings from shallow to deep using convolutional layers and pooling layers, ultimately extracting the buildings. Classic CNN models include U-Net (Ronneberger et al. Citation2015), SegNet (Kendall et al. Citation2017), PSPnet (Zhao et al. Citation2017), GAN (Goodfellow et al. Citation2014) and DeepLab (Chen et al. Citation2018). The U-Net model is particularly favored by scholars for its outstanding performance due to its unique upsampling, downsampling and skip connection structure (Ronneberger et al. Citation2015). Many researchers incorporate attention mechanisms into the U-Net model, allocating different weights to different parts of the input image, allowing the model to focus more on important features during data processing to further improve performance. For example, Michael et al.(2021) combined attention mechanisms with spectral channels and image deformation in the U-Net network, proposing channel attention mechanisms and spatial attention mechanisms to enhance the focus on image spectral channels and spatial deformation features, thereby improving the performance of the U-Net model. Although CNN models avoid redundant calculations through shared convolutional kernels, improving model performance, they face challenges, such as reduced image resolution and information loss during downsampling, as well as a smaller receptive field affected by convolutional kernel size. These challenges result in poor correlation between distant pixels and hinder the comprehensive use of contextual information for capturing global features of objects, limiting the accuracy of image classification. To address this, Wang P Q et al. (Citation2018) proposed the use of dilated convolutions to enlarge the receptive field in image classification tasks. He et al. (Citation2022) introduced dilated convolution modules in the E-Unet algorithm to improve the loss of detailed edge information in building extraction. Jia X et al. (Citation2022) further explored the local feature extraction capability of CNNs by introducing the large kernel module to increase the receptive field. These methods of expanding the receptive field can disrupt the operations of pooling layers, and the choice of dilation rate size can also impact the model’s performance. Moreover, the approach of continuously stacking deeper convolutional layers increases computational complexity, leading to reduced model efficiency. In summary, despite the numerous breakthroughs achieved by CNN-based methods, their weakness in capturing global features has limited further improvements in accuracy. This is because global features are crucial for detecting buildings in remote sensing images (Li et al. Citation2021; Yang et al. Citation2021).
Methods based on the ViT model for building extraction involve applying the Transformer (Vaswani et al. Citation2017) model, originally designed for natural language processing, to image classification. This approach was first proposed by Dosovitskiy et al. (Citation2021). The original image is divided into patches, which are then flattened into a sequence of tokens. After adding positional encoding and extra learnable classification tokens, the sequence is input into the encoder part of the Transformer model. Finally, a fully connected layer is added to classify and extract information from the image. Zheng et al. (Citation2021) transformed semantic segmentation into a sequence-to-sequence prediction task, abandoning the need for the model to learn local-to-global features by reducing resolution. Although this method yields good results, it also comes with a high computational complexity, making it less suitable for high-resolution images. Xie et al. (Citation2021) propose the SegFormer, which unifies Transformers with lightweight multilayer perceptron (MLP) decoders, this design removes positional encoding and complex decoder structures, making the Transformer lighter weight and improving model performance. Liu, Lin, et al. (Citation2021), Liu, Liu, et al. (Citation2021) proposed the Swin Transformer, which utilizes a hierarchical structure similar to CNNs to process images, enabling Transformer models to flexibly handle images of different scales. Han et al. (Citation2021) proposed a novel architecture called Transformer in Transformer, which divides patches into multiple smaller sub-patches, aggregating features of patches and sub-patches through linear transformations to enhance representational capacity. These methods effectively utilize the attention mechanism in the Transformer model to capture global context information, establishing long-range dependencies for the target, but their ability to extract local features still needs improvement.
Methods based on a hybrid CNN + Transformer model for building extraction simultaneously leverage the strengths of both models, attracting considerable attention from researchers in image segmentation (Zhou and Mao Citation2023). For example, Cao et al. (Citation2022) replaced the convolutional layers in U-Net with Swin modules, forming the SwinUNet model. Experimental results in image semantic segmentation demonstrated that a pure Transformer network in the U-shape architecture also possesses strong semantic segmentation capabilities. Chen et al. (Citation2021) proposed the TransUnet model by introducing Transformer modules into the encoder of the U-Net model. This transformation converts feature maps generated by CNN into sequences to enhance global contextual information, strengthening the model’s attention to the relationship between distant pixels. Wang et al. (Citation2021) identified a potential issue with semantic inconsistency leading to decreased performance when fusing feature maps during skip connections in the UNet model. To address this, they proposed the UCTransNet model, using channel Transformer (Ctrans) modules to guide feature fusion. Gong et al. (Citation2023) aimed to achieve a good balance between the accuracy and completeness of building extraction, propose a Context-Content Collaboration Network (C3Net) consisting of a Context-Content Aware Module (C2AM) and an Edge Residual Refinement Module (ER2M), they are respectively used to capture the long-range dependencies between the positions of each building and to refine the features output by the decoder. Considering the issue of insufficient preservation of spatial details in feature extraction by ViT, leading to the inability to perform fine-grained building segmentation, Wang et al. (Citation2022) proposed a novel visual transformer, BuildFormer, to encode spatial details and capture global dependencies.
Although these hybrid CNN + Transformer models have achieved good accuracy in building extraction, improving the Transformer module has often been the focus, and the enhancement of local feature extraction capabilities in the CNN module has been neglected. This oversight hinders further improvement in the performance and accuracy of image semantic segmentation.
In summary, traditional methods for building extraction suffer from low efficiency, while pattern recognition-based methods exhibit limitations in accuracy and subjective bias. CNN models, on the other hand, have significant advantages in extracting low-level features from images, which can focus on local regions, such as key points and subtle features of lines. However, CNNs often lack in capturing global features. Once these basic image elements are detected, higher-level semantic features tend to focus more on how these elements are related and combined to form a whole, as well as how the spatial relationships between different objects constitute a scene. Transformer models have a clear advantage in handling such global features. Although Transformers can capture long-range feature dependencies, they often overlook the details of local features. Therefore, combining the strengths of CNN models in handling local features with those of Transformer models in handling global features is a promising and potentially universal research direction.
The main objective of this study is to explore how to leverage a hybrid CNN + Transformer model to fully exploit the local feature extraction capability of CNNs and the global feature extraction capability of Transformers, thereby accurately extracting buildings from high-resolution images.
We designed a large kernel module with attention mechanism to enhance the model’s capability in extracting local features.
we designed a dual-encoder network structure that integrates the ResNet50-Transformer encoder and an encoder with feature attention large kernel (ALK) modules, while enhancing the capability to extract local features, it also considers capturing global contextual information, thereby efficiently extracting both global and local features of the images;
Introducing the CTrans module, it is connected to both the ALK encoder and decoder, thereby replacing the skip-connection part. This replacement is intended to better integrate the deep and shallow multidimensional features extracted from buildings, aiming to enhance the model’s accuracy and generalization capability in extracting complex buildings from high-resolution images.
2. Architecture of the model
The overall architecture of the proposed model in this article is illustrated in . It consists of three main components: a dual encoder comprising the ALK encoder and ResNet50-Transformer encoder, the CTrans module and the decoder.
Figure 1. Model overall framework diagram. ALK-Encoder: attention-based large kernel encoder; Ctrans: channel Transformer; CCT: channel-wise cross-fusion Transformer module; CCA: channel-wise cross-attention module.
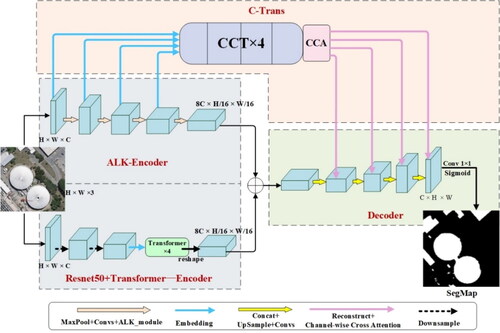
2.1. ResNet50-Transformer encoder
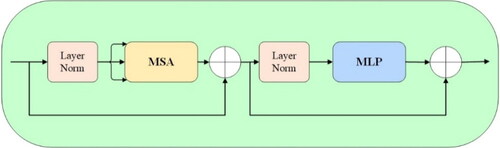
The ResNet50-Transformer encoder first undergoes three convolutional operations through the ResNet50 network. The output is then transformed into a one-dimensional vector through positional embedding operations. Subsequently, it enters four Transformer layers, aiming to enhance feature extraction and capture relationships between different positions in the image. The Transformer layers consist of multi-headed self-attention (MSA), multilayer perception (MLP) and two normalization layers (layer norm). The structure is illustrated in . This module captures global relationships and contextual information in the image through a positional sequence, thereby enhancing feature extraction capabilities.
Figure 2. Transformer module structure diagram.
2.2. ALK encoder
LK, which stands for large kernel, refers to the use of a large-sized convolutional kernel for convolution operations. However, directly increasing the size of the convolutional kernel would lead to an exponential growth in network parameters, resulting in a significant decline in network computational efficiency and potential overfitting issues.
To address this, we propose a feature attention-based large kernel (ALK) module. This module introduces three parallel sub-layers outside the K × K convolutional layer, including a 3 × 3 convolutional layer, a 1 × 1 convolutional layer, and an identity mapping layer. After concatenating the output feature maps of the K × K, 3 × 3 and 1 × 1 convolutional layers, the concatenated feature map is multiplied by the attention weights, and then concatenated with the identity mapping layer to obtain the output of the ALK layer. The ALK encoder output is obtained by iterating the ALK layer four times. By including the parallel sub-layers, such as the 1 × 1 × 1 convolutional layer and identity mapping layer, the number of parameters in the network can be effectively controlled (experimental calculations show that the ALK module reduces approximately half of the parameters compared to passing through a 7 × 7 convolutional layer). The structure of the ALK module is illustrated in .
Figure 3. Attention large kernel module structure diagram.
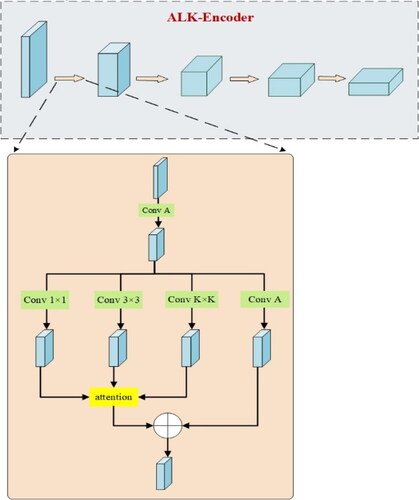
The results of each layer of the ALK encoder are used as input to the CTrans module for feature fusion. This module enhances the extraction of contextual information through convolution, thereby enhancing the feature extraction capability. After feature extraction is completed separately, the feature maps extracted by the two encoders are fused. The fused feature map serves as the input to the decoder during model upsampling.
2.3. CTrans module
During the process of skip connection, a problem may arise where the fusion of features from a certain layer leads to a decrease in accuracy. This is due to the occurrence of semantic inconsistency during feature fusion, which results in a decrease in model performance. To address this issue, we introduce the CTrans module to improve the quality of feature fusion.
The CTrans module consists of the channel-wise cross-fusion Transformer module (CCT) and the channel-wise cross-attention module (CCA) used to fuse the decoder features with enhanced CCT features. The structure is illustrated in . The CCT module is employed to enhance the features from different layers of the encoder using channel-wise Transformers. Subsequently, the CCA module is utilized to guide the effective fusion of multi-scale channel information with decoder information.
Figure 4. CTrans module structure diagram.
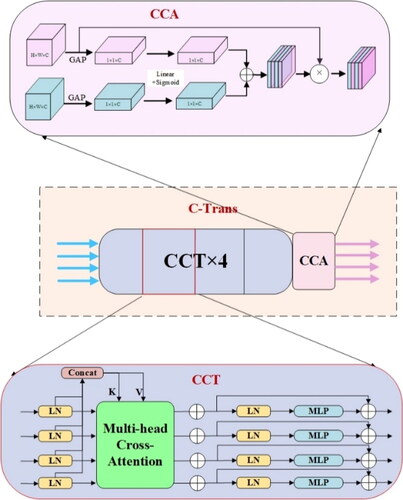
In this study, the model replaces the traditional skip connection with the CTrans module to enhance the fusion of features from different dimensions of the LK encoder with the decoder output.
2.4. Loss function
Due to the imbalanced distribution of positive and negative samples in the used dataset, the weighted Dice BCE loss function (Su et al. Citation2021) is chosen as the loss function in this article. This loss function combines weighted versions of binary cross-entropy (BCE) loss and Dice loss. BCE loss is typically used for binary classification problems, but its performance degrades in cases of imbalanced foreground-to-background ratios. The formula for BCE loss is given by EquationEquation (1)(1)
(1) :
(1)
(1)
where yn is the true label (0 or 1), indicating whether the sample belongs to the positive class (1) or the negative class (0), and xn is the predicted value of the model, representing the probability of the sample belonging to the positive class.
The Dice coefficient is a function used to evaluate the similarity between two samples, and its calculation formula is given by EquationEquation (2)(2)
(2) :
(2)
(2)
Dice loss is a loss function based on the Dice coefficient. Due to its consideration of pixel similarity in the segmentation results, it possesses robustness advantages for imbalanced data. Its calculation formula is given by EquationEquation (3)(3)
(3) :
(3)
(3)
The formula represents the intersection between two samples X and Y, where |X∩Y| denotes the size of the intersection. |X| and |Y| represent the number of elements in X and Y, respectively. The numerator coefficient is 2 because the denominator involves the double counting of common elements between X and Y.
The weighted Dice BCE loss function is calculated by combining the BCE loss and Dice loss values with a 1:1 ratio. The formula for the weighted Dice BCE loss is given by EquationEquation (4)(4)
(4) :
(4)
(4)
The effectiveness of this loss function is better observed when the data is relatively balanced. In situations of class imbalance, it helps the model capture detailed information in crucial regions, thereby improving the accuracy of image segmentation.
3. Experiment and result
3.1. Datasets and implementation
3.1.1. Configuring the environment
The experimental hardware configuration includes an NVIDIA RTX 3080 (10 GB) graphics card, 32 GB of RAM, Windows 10 operating system, and an Intel Core i9-10980XE @3.00 GHz processor. The PyTorch deep learning framework is utilized, with Python version 3.9 (Wilmington, United States) and CUDA version 11.7 (Santa Clara, California, United States).
3.1.2. Experimental data
The experimental training utilized the Chinese typical urban building instances dataset (Wu et al. Citation2021) and the WHU dataset (Ji and Wei Citation2019). Due to the presence of some images in the dataset that do not contain target buildings, the model may develop bias during training. To enhance the effectiveness of model training, we first performed data cleaning on the dataset, removing images that did not contain buildings.
Chinese typical urban building instances dataset
Chinese typical urban building instances dataset includes 7260 samples of image regions, with a total of 63,886 buildings distributed across four cities: Beijing, Shanghai, Shenzhen, and Wuhan. In this experiment, the dataset was divided into the training set (4356 images), validation set (1452 images), and test set (1452 images). After data cleaning, the training set of the Dataset consists of 4098 images, the validation set consists of 1367 images, and the test set consists of 1366 images. The ratio of the training set, validation set, and test set is 6:2:2.
WHU Dataset
The WHU dataset consists of aerial and satellite imagery. The aerial imagery dataset comprises around 220,000 buildings in New Zealand, with a spatial resolution of 0.3 m and covering an area of 450 km2. The satellite imagery dataset includes urban images of East Asia captured by remote sensing satellites, such as QuickBird, Worldview series, IKONOS and ZY-3, covering an area of 550 km2. For this experiment, high-resolution aerial imagery from the WHU dataset was used, consisting of approximately 4736 images in the training set, 1036 images in the validation set and 2416 images in the test set, totaling around 187,000 buildings. After data cleaning, the dataset consists of 4317 images in the training set, 737 images in the validation set and 1371 images in the test set. The ratio of the training set, validation set and test set is 6:1:2.
3.2. Hyperparameter settings
The experiment utilized the Adam optimizer and the Cosine Annealing Learning Rate Adjustment algorithm for training on the aforementioned datasets. The hyperparameter settings for training are presented in .
Table 1. Model training hyperparameter settings.
3.3. Accuracy evaluation metrics
To evaluate the accuracy of the model, this experiment uses four metrics: intersection over union (IoU), precision, recall and F1 score.
The IoU measures the ratio of the intersection to the union between the predicted segmentation mask and the ground truth segmentation mask. The formula is shown in EquationEquation (5)(5)
(5) :
(5)
(5)
In EquationEquation (5)(5)
(5) , the intersection area is the area of the intersection between the actual target region and the predicted region, and the union area is the area of the union between the actual target region and the predicted region. A higher IoU value indicates higher model accuracy.
Precision represents the proportion of true positive samples among all samples classified as positive. The calculation formula is given by EquationEquation (6)(6)
(6) :
(6)
(6)
In EquationEquation (6)(6)
(6) , TP represents the number of samples that the model correctly predicts as positive among the positive class samples, while FP represents the number of samples that the model incorrectly predicts as positive among the negative class samples.
Recall represents how many of the actual positive class samples are correctly predicted as positive by the model among all positive class samples. The calculation formula is shown in EquationEquation (7)(7)
(7) :
(7)
(7)
In EquationEquation (7)(7)
(7) , TN represents the number of samples where the model correctly predicts negative class samples as negative, and FN represents the number of samples where the model incorrectly predicts positive class samples as negative.
The F1 score is the harmonic mean of precision and recall, providing a balanced measure that considers precision and recall. The calculation formula is shown in EquationEquation (8)(8)
(8) :
(8)
(8)
3.4. Analysis of experimental results
3.4.1. Semantic segmentation ability analysis
To verify the semantic segmentation accuracy of the proposed model, four comparative experiments were conducted, comparing it with the UNet, SwinUNet, TransUNet, UCTransNet and C3Net models. illustrates the segmentation results of each model.
Figure 5. Comparison of segmentation results of Chinese typical urban building instances dataset.
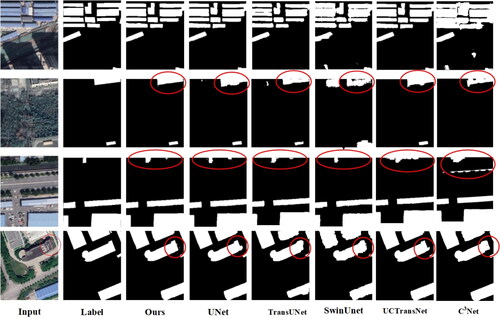
shows that the UNet and TransUNet models tend to misclassify the wall and ground parts with similar color textures as the roof of buildings, with some information loss in details. The SwinUNet model exhibits poor performance, showing jagged edges in building contours. The UCTransNet model has fewer instances of information loss but still misclassifies some walls as building roofs. The C3Net performs poorly on the Chinese typical urban building instances dataset, although the extracted building boundaries are relatively smooth, there are numerous misclassification occurrences. The proposed model demonstrates stable performance in extracting building details, achieving accurate building boundaries and outperforming other models in semantic segmentation of buildings.
Evaluation of building extraction accuracy on the Chinese typical urban building instances dataset includes precision, recall, F1 and IoU. The results obtained by different models are presented in .
Table 2. Comparison of average accuracy results of different models on the Chinese typical urban building instances dataset.
shows that our model achieved the best performance in recall, F1 and IoU. Compared with the TransUNet model, our model showed improvements of 6.04%, 1.71% and 2.02% in recall, F1 and IoU, respectively. Overall, the accuracy of our model surpasses other models, indicating that it performs more precisely in the segmentation task of buildings and non-buildings.
3.4.2. Generalization ability analysis
To test the generalization ability of our model, this study conducted comparative experiments using the WHU aerial image dataset. The experimental results are shown in .
Figure 6. Comparison of segmentation results of WHU data set.
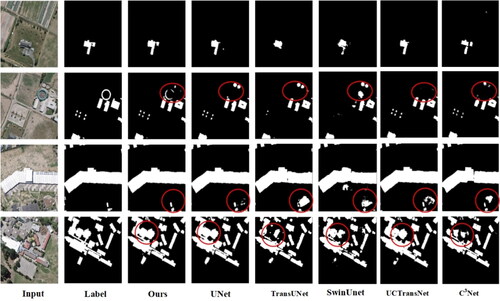
shows that compared with the other four models, our model performs more stably on some buildings with unique shapes and colors, showing fewer misclassifications and omissions. It also captures more details in the shape of the buildings compared with the ground truth labels.
The precision, recall, F1 and IoU results for building extraction on the WHU aerial dataset are presented in for different models.
Table 3. Comparison of average accuracy results of different models on the WHU data set.
Our model achieves the best results in terms of Recall, F1 score on the WHU aerial dataset, as shown in . Compared with the TransUNet model, our model exhibits improvements in recall, F1 score and IoU by 3.64%, 6.67% and 5.3%, respectively, demonstrating overall superior accuracy compared with other models. It is worth mentioning that although C3net performs well on the WHU dataset, it performs poorly on the Chinese typical urban building instances dataset, indicating that the network’s generalization capability is not very strong. Its outstanding performance in satellite and aerial imagery validates the excellent generalization capabilities of the proposed model.
3.4.3. Algorithm complexity comparison
To verify the complexity of the algorithm, we compared the Params, FLOPs and the time spent training for 100 epochs on the WHU dataset ().
Table 4. Time complexity comparison.
From the table, it can be seen that the proposed model has relatively high parameters due to the use of dual encoders. However, in the comparison of running time with other models, it can be observed that under the same hardware conditions, training for 100 epochs only increased the time by 4.32 h compared to the baseline TransUNet. Nevertheless, the experimental results are significantly better than those of TransUNet. In comparison with C3Net, although the experimental results are very close, due to the high FLOPs, C3Net’s running time is 11.16 h more than our model. This clearly indicates that the complexity of our model is within an acceptable range.
3.4.4. Ablation experiments
We conducted ablation experiments on the proposed algorithm, with the results shown in . It can be seen that when using Baseline + ALK, the accuracy is higher than when using only the Baseline for prediction. When the CTrans module is introduced, the accuracy is even higher than that of Baseline + ALK.
Table 5. Ablation experiments on dataset of typical urban buildings in Chinese typical urban building instances dataset and WHU datasets.
4. Discussion
4.1. Features
These experimental results indicate that the proposed model can more accurately extract information about buildings in high-resolution remote-sensing images. Our model adopts a dual encoder structure, consisting of ResNet50-Transformer and ALK, which combines the global feature extraction capabilities of a Transformer with powerful local feature extraction capabilities. Additionally, to address the potential issue of semantic inconsistency during feature fusion in skip connections, the skip connection part was replaced with the CTrans module, enhancing the fusion capability of multi-dimensional features.
4.2. Contributions
The segmentation of remote sensing images based on deep learning is currently a research hotspot. In recent years, due to the rapid development of the ViT method, the strong local feature extraction capability of CNN has gradually been overlooked. The model proposed in this article has been empirically validated: by enhancing the local feature extraction capability of CNN, the upper limit of CNN + Transformer models can be further improved. The model proposed in this article is applied to automatic building extraction in high-resolution images. While enhancing local feature extraction, it also focuses on capturing global features. It demonstrates good adaptability to the complex pixel distribution of buildings in high-resolution images, providing a new approach for automatic building extraction in high-resolution images based on deep learning methods.
The proposed model is designed for the automatic extraction of buildings in high-resolution imagery. It emphasizes enhancing local feature extraction while also focusing on capturing global features. The model exhibits good adaptability to the complex distribution of building pixels in high-resolution imagery, providing a new perspective for the automatic extraction of buildings in high-resolution imagery based on deep learning methods.
4.3. Outlook
In the model proposed in this article, we designed a pure convolutional ALK encoder to enhance the capability of local feature extraction, achieving favorable image segmentation results. In the future, the two encoders could be further integrated into a single encoder to reduce the model’s complexity. Additionally, experimenting with data augmentation techniques, such as rotation, translation and scaling could be explored to further improve the model’s accuracy.
5. Conclusion
In this study, we analyze the current application status of deep learning methods in the task of building image segmentation. Combining the respective strengths of CNN and Transformer models, the article proposes the dual-encoder model. The dual-encoder structure combining the ALK encoder and the ResNet50-Transformer encoder. This design enhances the extraction of local features in images and considers global context information. The model also replaces the skip-connection part with the CTrans module, improving the fusion capabilities of multi-dimensional features. Experimental results on the Chinese typical urban building instances dataset demonstrate that our model effectively enhances the extraction of building boundaries, with overall accuracy surpassing other models. Furthermore, its excellent performance on the WHU aerial dataset indicates the model’s strong generalization capabilities. In conclusion, our model is suitable for semantic segmentation tasks of building image data, achieving accurate building information extraction in satellite and aerial imagery.
Acknowledgements
We would like to thank the providers of the dataset used in this study, K. S. Wu and S. P. Ji, as well as the providers of the Chinese typical urban building instances dataset, WHU dataset. Additionally, we extend our gratitude to the editor and referees for their professional suggestions.
Disclosure statement
The authors declare no conflicts of interest.
Data availability statement
The data that support the findings of this study are openly available in [‘kaggle’ and ‘Science Data Bank’] at https://www.kaggle.com/datasets/sengulgs/whu-building-dataset and https://www.scidb.cn/en/detail?dataSetId=806674532768153600.
Additional information
Funding
References
- Alshehhi R, Marpu PR, Woon WL, Mura MD. 2017. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J Photogramm Remote Sens. 130:139–149. doi: 10.1016/j.isprsjprs.2017.05.002.
- Cao H, Wang Y, Chen J, Jiang D, Zhang X, Tian Q, Wang M. 2022. Swin-UNET: UNET-like pure Transformer for medical image segmentation//European conference on computer vision. Cham Switzerland: Springer Nature Switzerland; p. 205–218.
- Chen J, Lu Y, Yu Q, Luo X, Adeli E, Wang Y, Lu L,Yuille A, Zhou Y. 2021. Transunet: transformers make strong encoders for medical image segmentation. arXiv preprint arXiv:2102.04306.
- Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL. 2018. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans Pattern Anal Mach Intell. 40(4):834–848. doi: 10.1109/TPAMI.2017.2699184.
- Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai XH, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, et al. 2021. An image is worth 16 × 16words: transformers for image recognition at scale[2022-03-26]. https://arxiv.org/pdf/2010.11929.pdf.
- Fan C, Jiang H. 2016. Fine building extraction from world view-2 imagery using random forest. Geospat Inform. 14(01):58–62+5. https://kns.cnki.net/kcms/detail/42.1692.p.20160129.1533.034.html
- Gong M, Liu T, Zhang M, Zhang Q, Lu D, Zheng H, Jiang F. 2023. Context–content collaborative network for building extraction from high-resolution imagery. Knowledge-Based Systems. 263:110283. doi: 10.1016/j.knosys.2023.110283.
- Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y. 2014. Generative adversarial nets. Advances in Neural Information Processing Systems; Dec 8–13; Montreal, Quebec, Canada, 2014, 27.
- Han K, Xiao A, Wu E, Guo J, Xu C, Wang Y. 2021. Transformer in transformer. Advances in Neural Information Processing Systems; Dec 6–14; NeurIPS 2021 is a Virtual-only Conference, 2021, 34: 15908–15919.
- He Z, Ding H, An B. 2022. High-resolution remote sensing image building extraction with hole convolution e-UNET algorithm. Acta Geodaetic Cartograph Sin. 51 (03):457–467. https://link.cnki.net/urlid/11.2089.P.20211215.1136.012
- Hou F. 2023. Research on high-resolution remote sensing image retrieval technology based on deep learning. Beijing, China: Beijing University of Technology. doi: 10.26935/d.cnki.gbjgu.2021.000320.
- Huang Q. 2022. Extraction of building roofs from Remote Sensing Images Based on Extreme Random Trees. Ganzhou, China: Jiangxi University of Science and Technology. doi: 10.27176/d.cnki.gnfyc.2021.000169.
- Ji S, Wei S. 2019. Convolutional neural network and open-source dataset methods for extracting buildings from remote sensing images. Acta Geodaetic Cartograph Sin. 48(4):448–459. https://kns.cnki.net/kcms2/article/abstract?v=LeTZRn7a1NLSgYpy1cJzzWwyrdsSc__eDCzwQlm54CC4KYXFjPDeNrtIQ3TvN-SSgDMqUg7f3_blXI2jAuzI_s_dXHQU9V6v9n8PcbK_Hk7omjE9tpKGZhU8yaOyYACzpFp8szx4-xnhlsUqH-puEHBq_v97Vo5L&uniplatform=NZKPT&language=CHS
- Jia X, Bartlett J, Zhang T, Lu W, Qiu Z, Duan J. 2022. U-Net vs transformer: is u-net outdated in medical image registration? International Conference on Medical Image Computing and Computer Assisted Intervention - Workshop on Machine Learning in Medical Imaging (MICCAI-MLMI) Sep 18–22; Singapore, 2022:151–160.
- Kendall A, Gal Y, Cipolla R. 2017. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122.
- Li X, Huang L, Zhu J, Sun Y, Yang W. 2023. Edge-enhanced EDU-Net for building extraction in remote sensing images. Remote Sens Inform. 38(02):134–141. doi: 10.20091/j.cnki.1000-3177.2023.02.018.
- Li L, Liang J, Weng M, Zhu H. 2018. A multiple-feature reuse network to extract buildings from remote sensing imagery. Remote Sens. 10(9):1350. doi: 10.3390/rs10091350.
- Li R, Zheng S, Duan C, Su J, Wang L, Atkinson PM. 2021. Multi attention network for semantic segmentation of fine-resolution remote sensing images. IEEE Transactions on Geoscience and Remote Sensing, Town-Piscataway, United States, 2021, 60: 1–13.
- Liao WY. 2024. Extraction method of building roofs from high spatial resolution remote sensing images based on deep learning. Ganzhou, China: Jiangxi University of Science and Technology. doi: 10.27176/d.cnki.gnfyc.2023.000899.
- Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B. 2021. Swin transformer: hierarchical vision transformer using shifted windows. Proceedings of the IEEE. /CVF International Conference on Computer Vision, Oct 11–17; Montreal, BC, Canada. 2021:10012–10022.
- Liu J, Liu Z, Li F. 2021. Classification of urban building clusters based on remote sensing images. J Nat Dis. 30(06):61–66. doi: 10.13577/j.jnd.2021.0607.
- Ronneberger O, Fischer P, Brox T. 2015. U-Net: convolutional networks for biomedical image segmentation. International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI). 2015: 18th international conference, Oct 5–9, Munich, Germany, 2015, proceedings, part III 18. Springer International Publishing, 2015: 234–241.
- Su J, Liu Z, Zhang J, Sheng VS, Song Y, Zhu Y, Liu Y. 2021. DV-Net: accurate liver vessel segmentation via dense connection model with D-BCE loss function. Knowledge-Based Syst. 232:107471. doi: 10.1016/j.knosys.2021.107471.
- Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I. 2017. Attention is all you need. Advances in Neural Information Processing Systems, Dec 4–9; Long Beach, CA, USA, 2017, 30.
- Wang H, Cao P, Wang J, Zaiane O. 2021. UCtransnet: rethinking the skip connections in U-Net from a channel-wise perspective with Transformer. arXiv:2109.04335.
- Wang P, Chen P, Yuan Y, Liu D, Huang Z, Hou X, Cottrell G. 2018. Understanding convolution for semantic segmentation. 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2018: 1451–1460.
- Wang L, Fang S, Meng X, Li R. 2022. Building extraction with vision transformer. IEEE Trans Geosci Remote Sensing. 60:1–11. doi: 10.1109/TGRS.2022.3186634.
- Wu K, Zheng Y, Chen Y, Zeng L, Zhang J. 2021. Dataset of typical urban buildings in China. China Sci Data. 6(01):182–190.
- Xie E, Wang W, Yu Z, Anandkumar A, Alvarez JM, Luo P. 2021. Segformer: simple and efficient design for semantic segmentation with transformers[C]. Advances in Neural Information Processing Systems, Dec 6–14; NeurIPS 2021 is a Virtual-only Conference, 2021, 34:12077–12090.
- Yang H. 2022. Research on information extraction from high-resolution remote sensing images using a deep learning model with visual attention mechanism. Wuhan, China: Wuhan University. doi: 10.27379/d.cnki.gwhdu.2019.001342.
- Yang MY, Kumaar S, Lyu Y, Nex F. 2021. Real-time semantic segmentation with context aggregation network. ISPRS J Photogramm Remote Sens. 178:124–134. doi: 10.1016/j.isprsjprs.2021.06.006.
- Zhang Y, Guo W, Wu C. 2023. Fast building extraction in remote sensing images through fusion of CNN and transformer. Optics Precision Eng. 31(11):1700–1709. doi: 10.37188/OPE.20233111.1700.
- Zhao H, Shi J, Qi X, Wang X, Jia J. 2017. Pyramid scene parsing network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jul 21–26; Honolulu, HI, USA, 2017: 2881–2890.
- Zheng S, Lu J, Zhao H, Zhu X, Luo Z, Wang Y, Fu Y, Feng J, Xiang T, Torr PHS, et al. 2021. Rethinking semantic segmentation from a sequence-to-sequence perspective with Transformers. //Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. p. 6881–6890.
- Zhou K, Yang Y, Zhang Y, Miao R, Yang Y. 2021. Comprehensive review of land use classification methods for optical remote sensing images. Sci Technol Eng. 21 (32):13603–13613. https://kns.cnki.net/kcms2/article/abstract?v=LeTZRn7a1NJPJHVmv1Ptf4W6uZQeYbH3s2WBC1D7ACueebM4N3YP_s22x3WnqEkRz14wSD-VnW8RONU_VTABlDWwxjW-j8_VbMM8WkQjgn9ttnUOJqydE_QAZXgun9cPIMqR_rbfRqMc1bAQWNmZ9_xspz1byUvK&uniplatform=NZKPT&language=CHS
- Zhou W. 2022. Research on remote sensing image retrieval based on deep learning features. Wuhan, China: Wuhan University, doi: 10.27379/d.cnki.gwhdu.2019.002310.
- Zhou L, Mao N. 2023. Comprehensive review on visual transformer for recognition tasks. J Image Graph. 28 (10):2969–3003. https://kns.cnki.net/kcms2/article/abstract?v=LeTZRn7a1NKXxRqwB1PnFUcsb8iLX5lT_RD-rmA-OzJUm5_FVfHisn4zZc48eo0DSWxs3ffD-lxuTxVDqf0RAd1PGeZ8VBO3_D27ZkaVIEhceBm3BbSqNNy70VhfApwbNjk8wmovYTmja2X8de4BxiHXbzKn_Gl4&uniplatform=NZKPT&language=CHS